ComfyUI Tutorial Series 61-73
I learned ComfyUI from these tutorials ComfyUI Tutorial Series
Ep01 - Introduction and Installation
Ep02 - Nodes and Workflow Basics
Ep03 - TXT2IMG Basics
Ep04 - IMG2IMG and LoRA Basics
Ep05 - Stable Diffusion 3 Medium
Ep06 - Get 300 Free Art Styles
Ep07 - Working With Text - Art Styles Update
Ep08 - Flux 1: Schnell and Dev Installation Guide
Ep09 - How to Use SDXL ControlNet Union
Ep10 - Flux GGUF and Custom Nodes
Ep11 - LLM, Prompt Generation, img2txt, txt2txt Overview
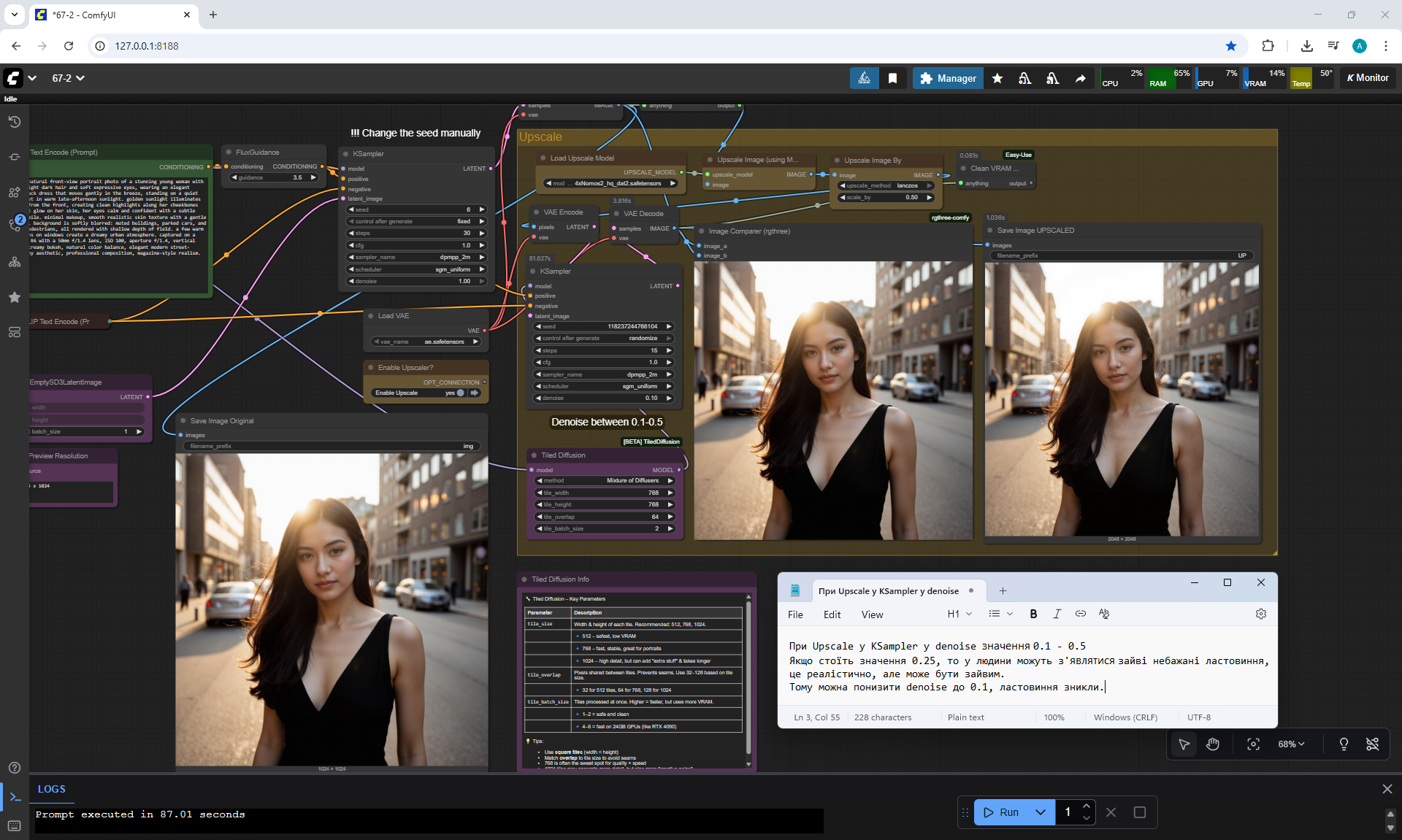
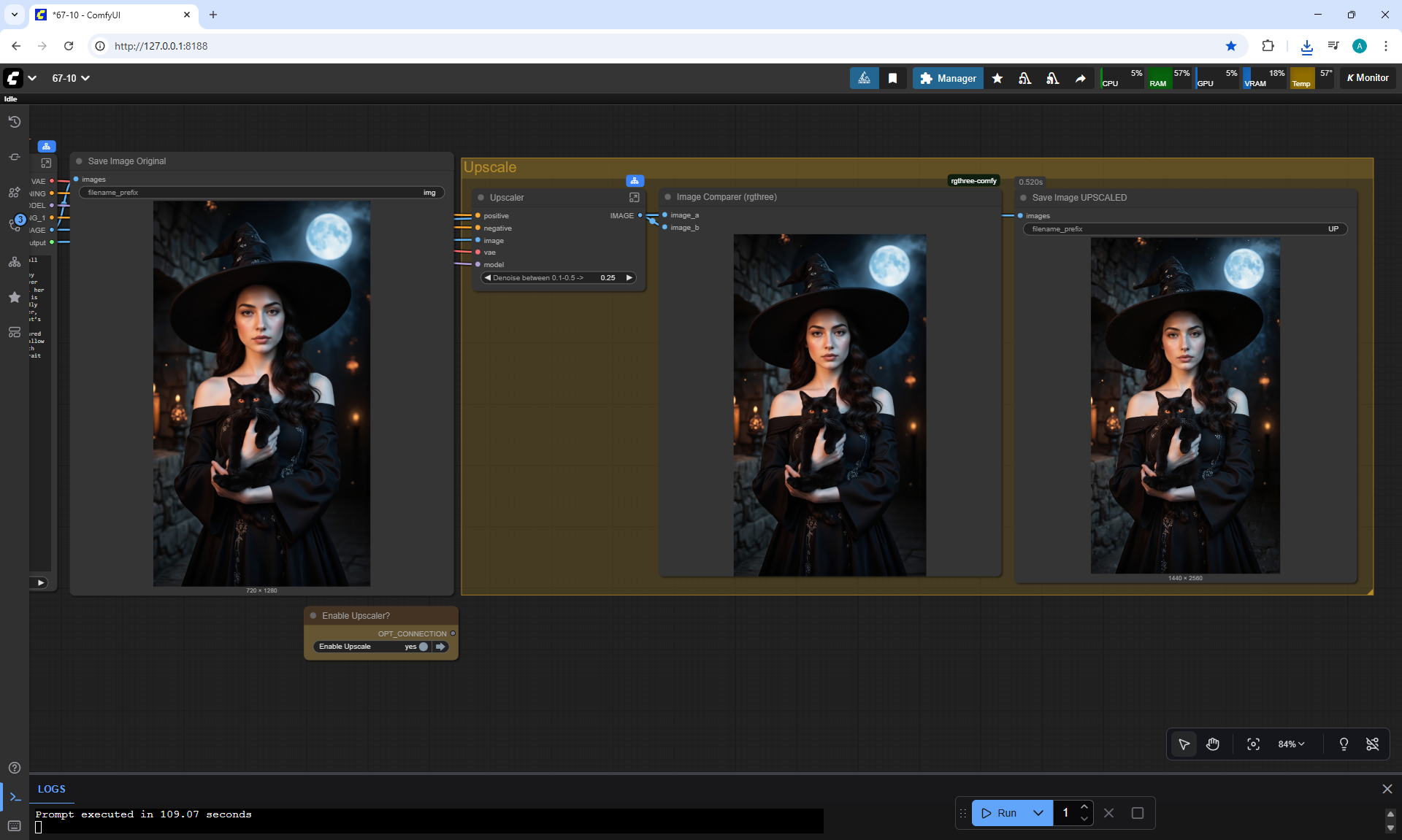
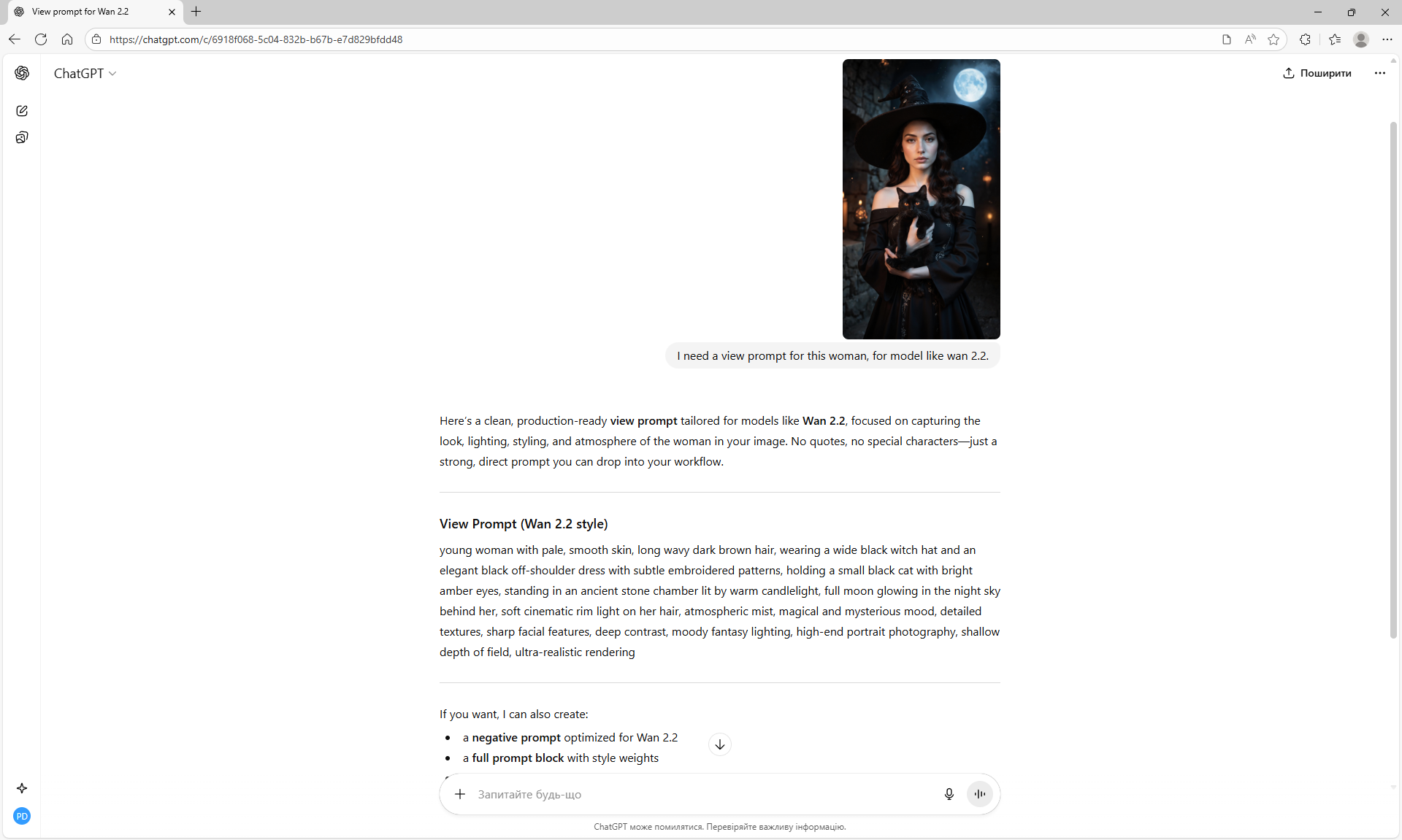
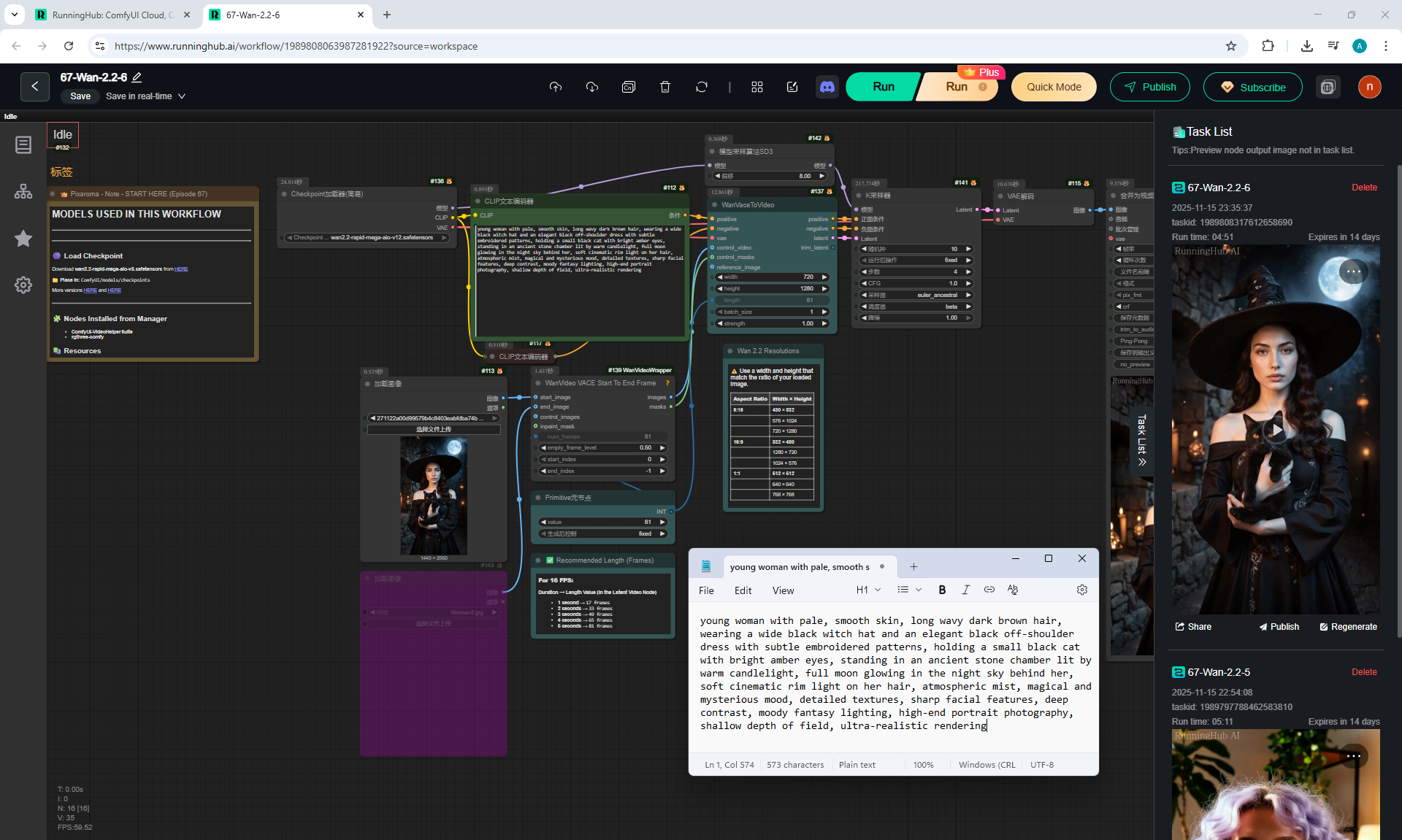
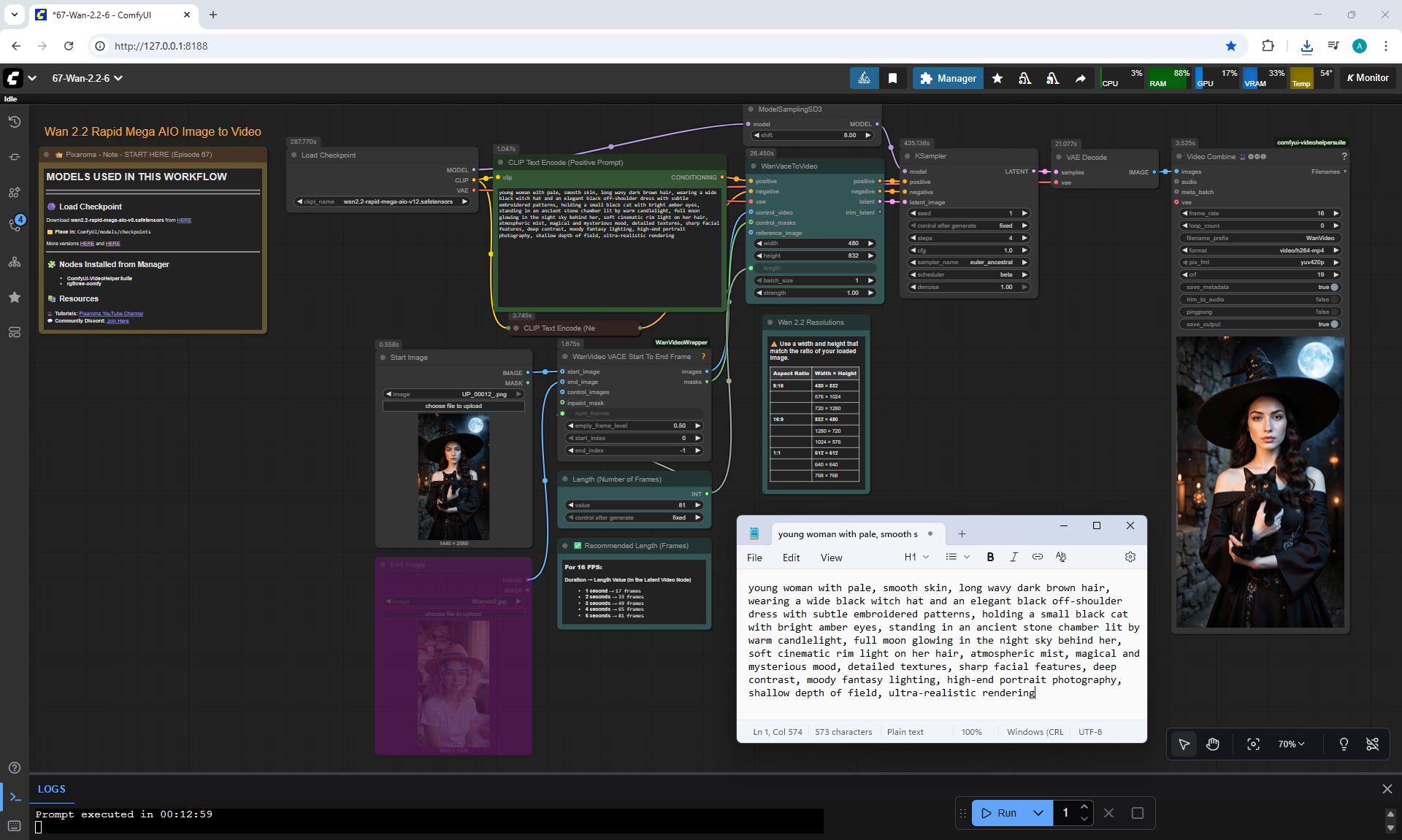
Ep12 - How to Upscale Your AI Images
Ep13 - Exploring Ollama, LLaVA, Gemma Models
Ep14 - How to Use Flux ControlNet Union Pro
Ep15 - Styles Update, Prompts from File & Batch Images
Ep16 - How to Create Seamless Patterns & Tileable Textures
Ep17 - Flux LoRA Explained! Best Settings & New UI
Ep18 - Easy Photo to Cartoon Transformation!
Ep19 - SDXL & Flux Inpainting Tips with ComfyUI
Ep20 - Sketch to Image Workflow with SDXL or Flux!
Ep21 - How to Use OmniGen in ComfyUI
Ep22 - Remove Image Backgrounds with ComfyUI or Photoshop
Ep23 - How to Install & Use Flux Tools, Fill, Redux, Depth, Canny
Ep24 - Unlock Flux Redux & Inpainting with LoRA
Ep25 - LTX Video – Fast AI Video Generator Model
Ep26 - Live Portrait & Face Expressions
Ep27 - Photo to Watercolor, Oil & Digital Paintings – Workflow
Ep28 - Create Flux Consistent Characters + Train Loras Online
Ep29 - How to Replace Backgrounds with AI
Ep30 - Game Design with AI and Photoshop
Ep31 - ComfyUI Tips & Tricks You Need to Know
Ep32 - How to Create Vector SVG Files with AI
Ep33 - How to Use Free, Local Text-to-Speech for AI Voiceovers
Ep34 - Turn Images into Prompts Using DeepSeek Janus Pro
Ep35 - How to Run ComfyUI in the Cloud
Ep36 - WAN 2.1 Installation – Turn Text & Images into Video!
Ep37 - LTX 0.9.5 Installation, Images to Video Faster Than Ever!
Ep38 - Bring Portraits to Life! Talking Avatar with Sonic
Ep39 - Using WAN 2.1 with LoRAs for Wild Effects: Squish, more
Ep40 - TeaCache: Speed Up Your Workflows with Smart Caching
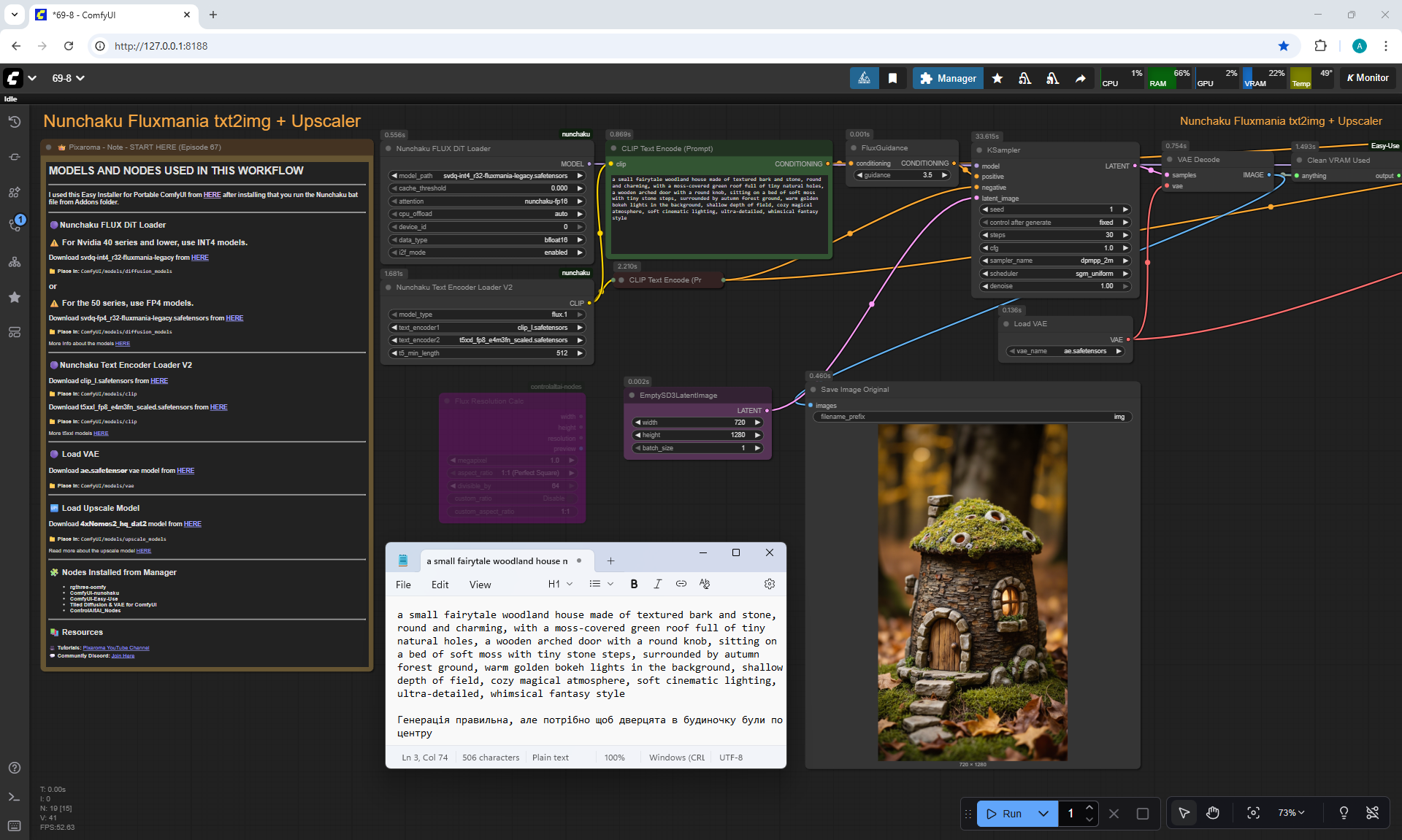
Ep41 - How to Generate Photorealistic Images - Fluxmania
Ep42 - Inpaint & Outpaint Update + Tips for Better Results
Ep43 - KayTool – Align Nodes, Tweak Image Colors, Monitor
Ep44 - HiDream AI – How to Set Up & Choose the Best Model
Ep45 - Unlocking Flux Dev ControlNet Union Pro 2.0 Features
Ep46 - How to Upscale Your AI Images (Update)
Ep47 - Make Free AI Music with ACE-Step V1
Ep48 - LTX 0.9.7 – Turn Images into Video at Lightning Speed!
Ep49 - txt2video, img2video & video2video with Wan 2.1 VACE
Ep50 - Generate Stunning AI Images for Social Media, 50+ Free
Ep51 - Nvidia Cosmos Predict2 Image & Video
Ep52 - Master Flux Kontext – Inpainting, Editing & Character ..
Ep Nunchaku - Speed Up Flux Dev & Kontext with This Trick
Ep53 - Flux Kontext LoRA Training with Fal AI - Tips & Tricks
Ep54 - Create Vector SVG Designs with Flux Dev & Kontext
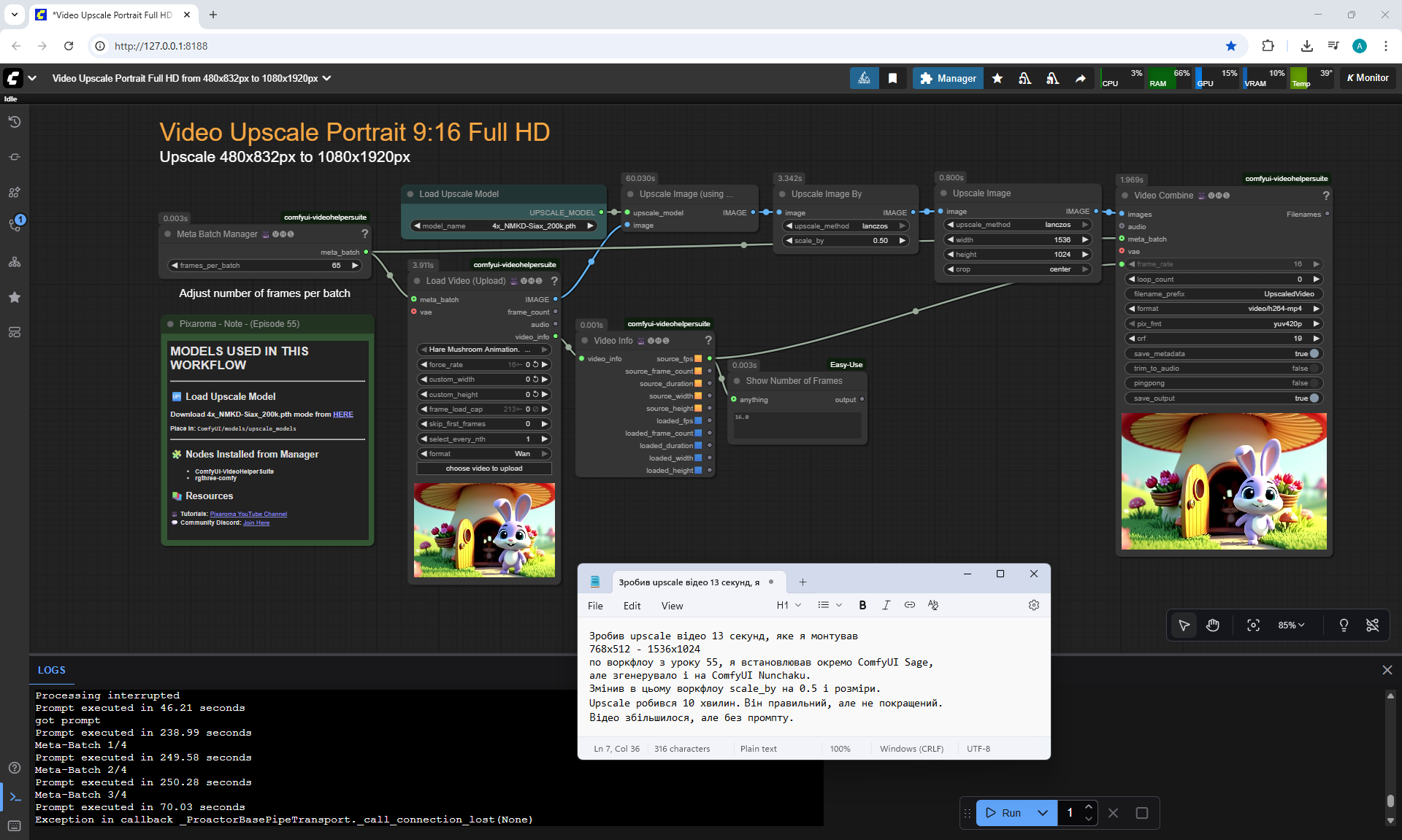
Ep55 - Sage Attention, Wan Fusion X, Wan 2.2 & Video Upscale ..
Ep56 - Flux Krea & Shuttle Jaguar Workflows
Ep57 - Qwen Image Generation Workflow for Stunning Results
Ep58 - Wan 2.2 Image Generation Workflows
Ep59 - Qwen Edit Workflows for Smarter Image Edits
Ep60 - Infinite Talk (Audio-Driven Talking AI Characters)
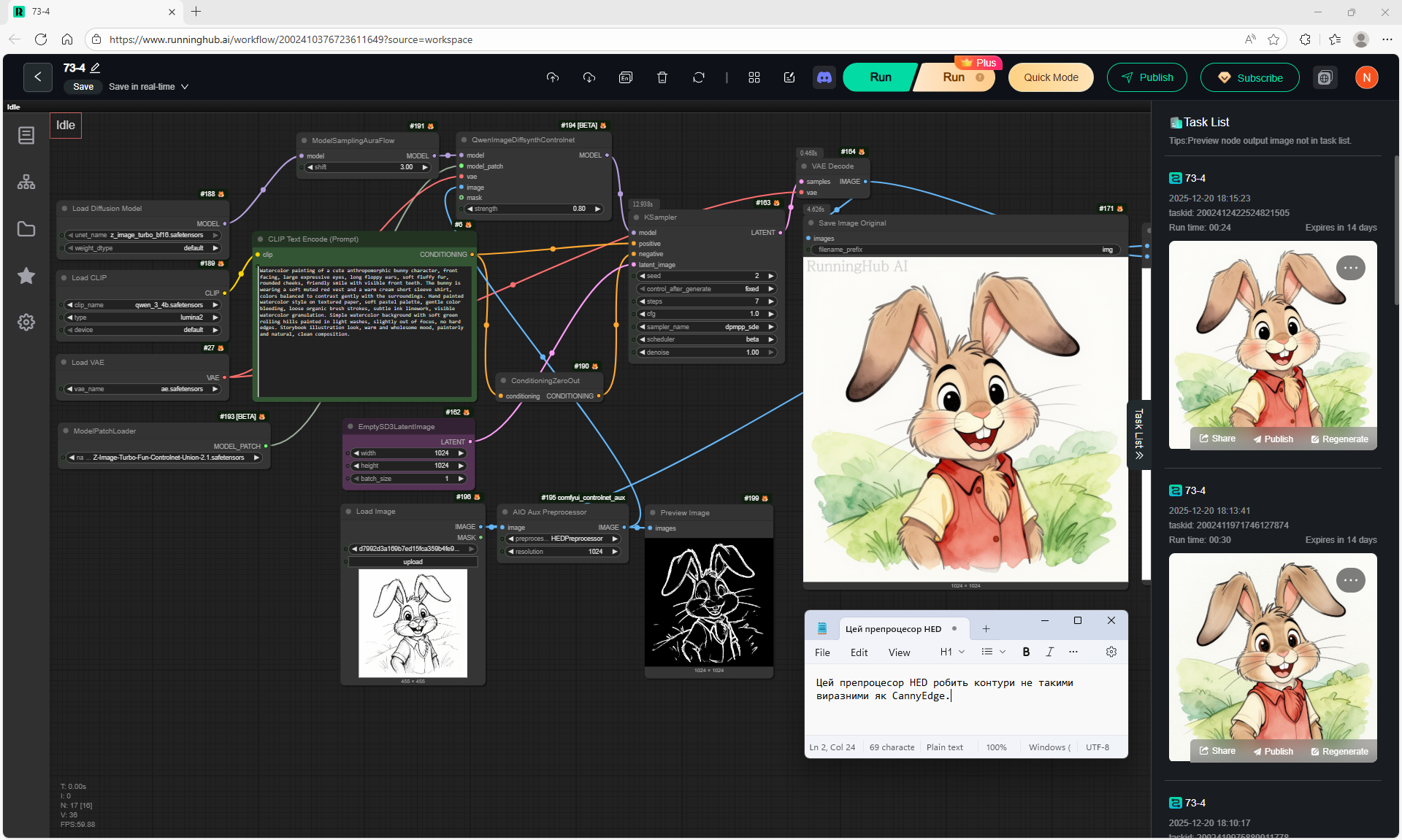
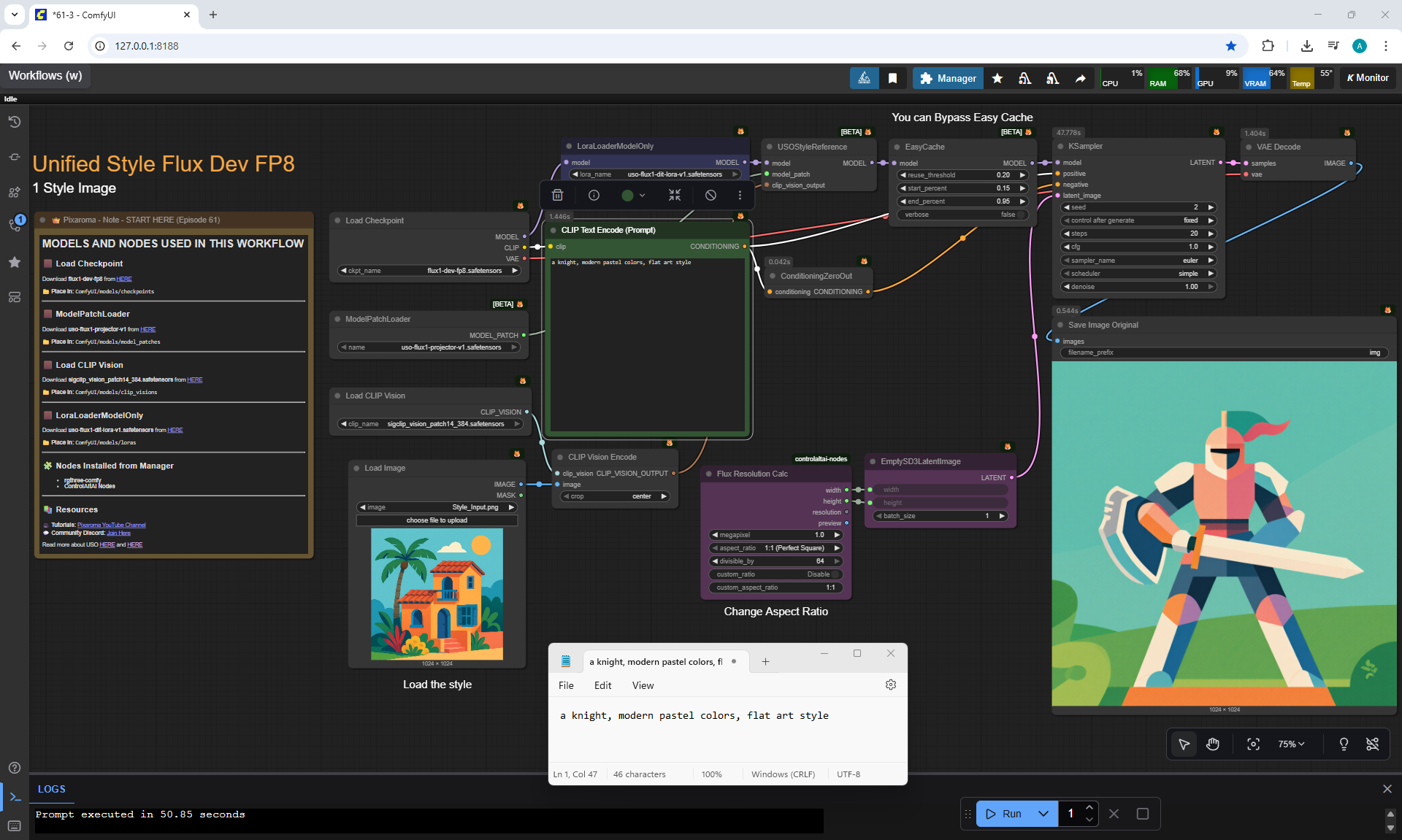
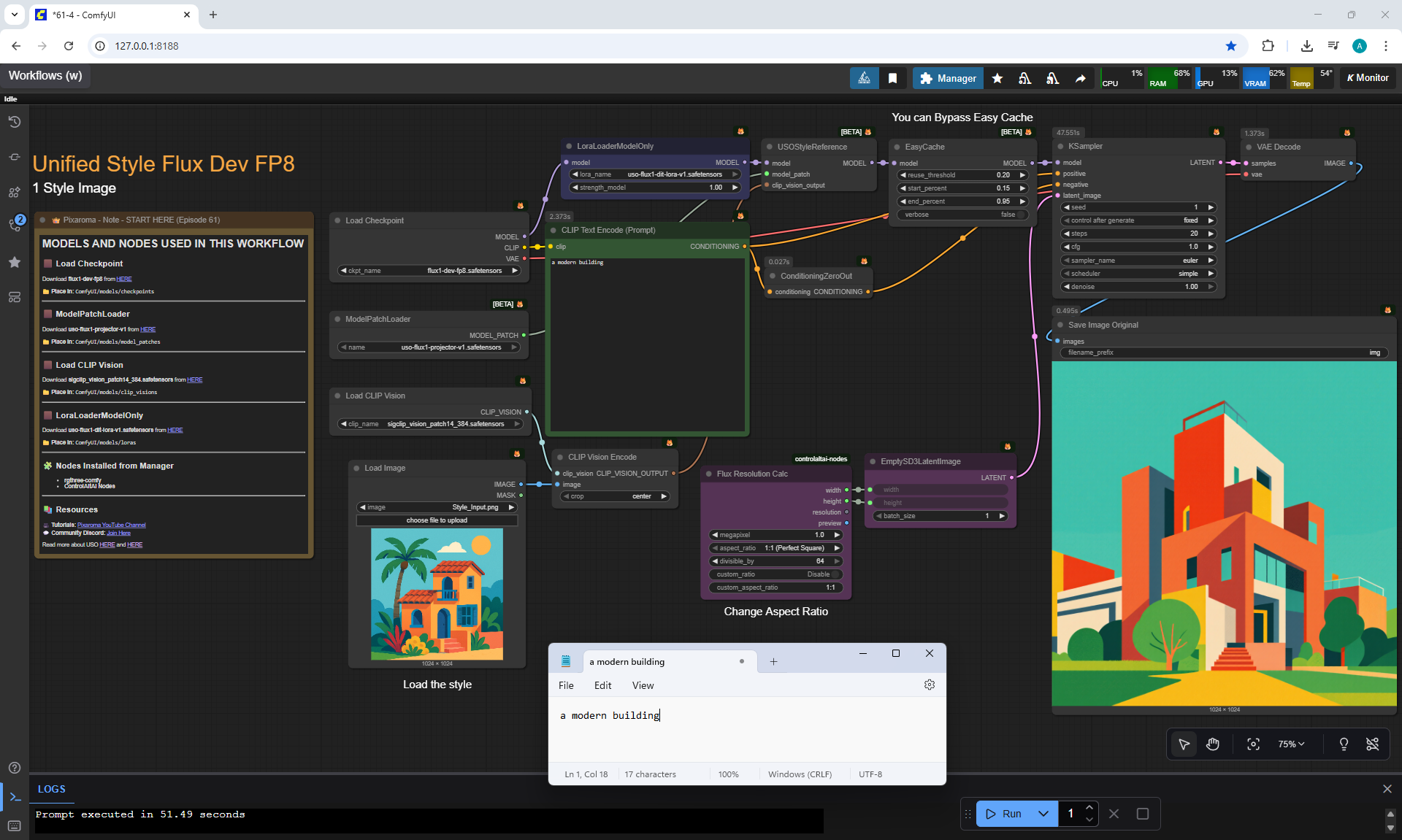
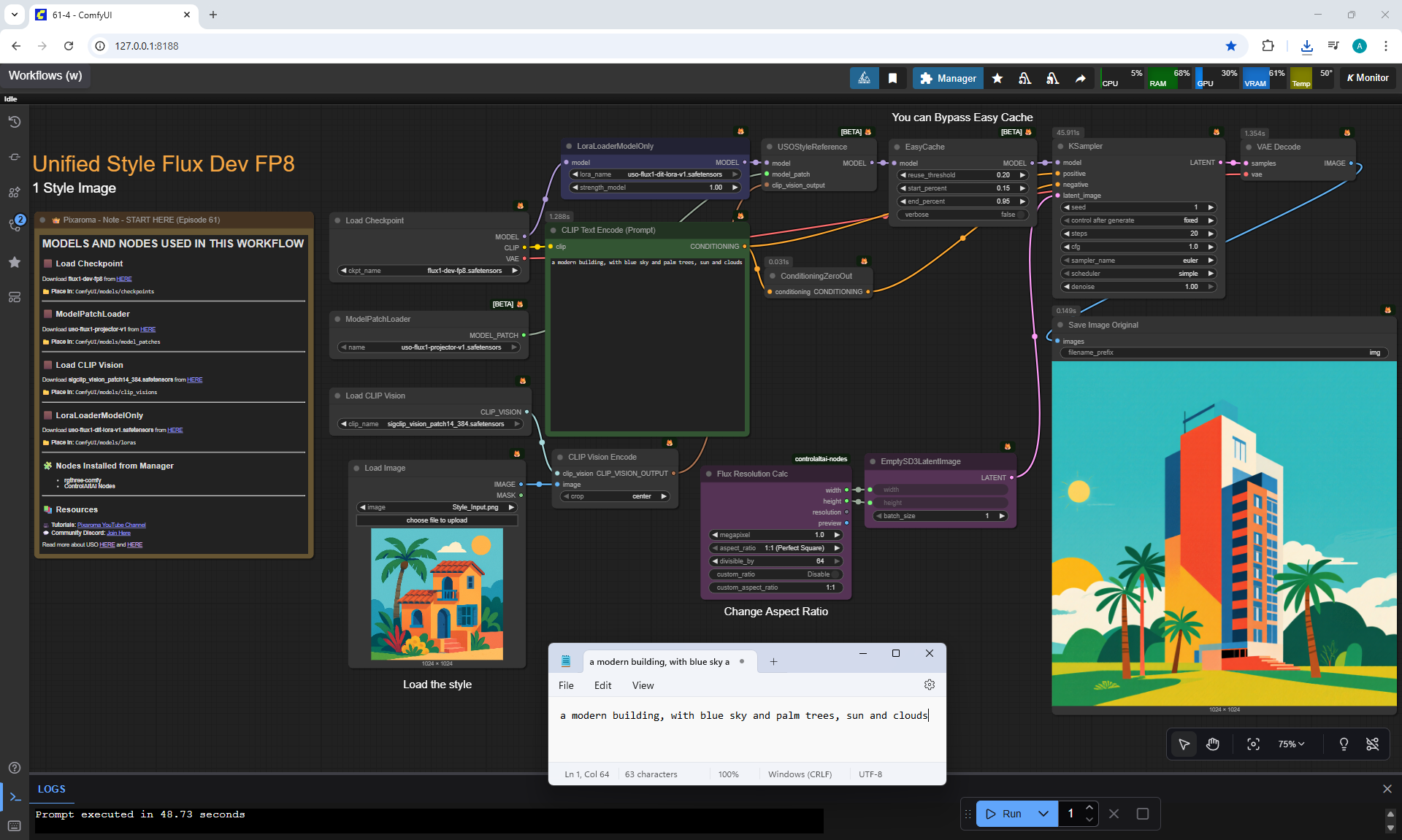
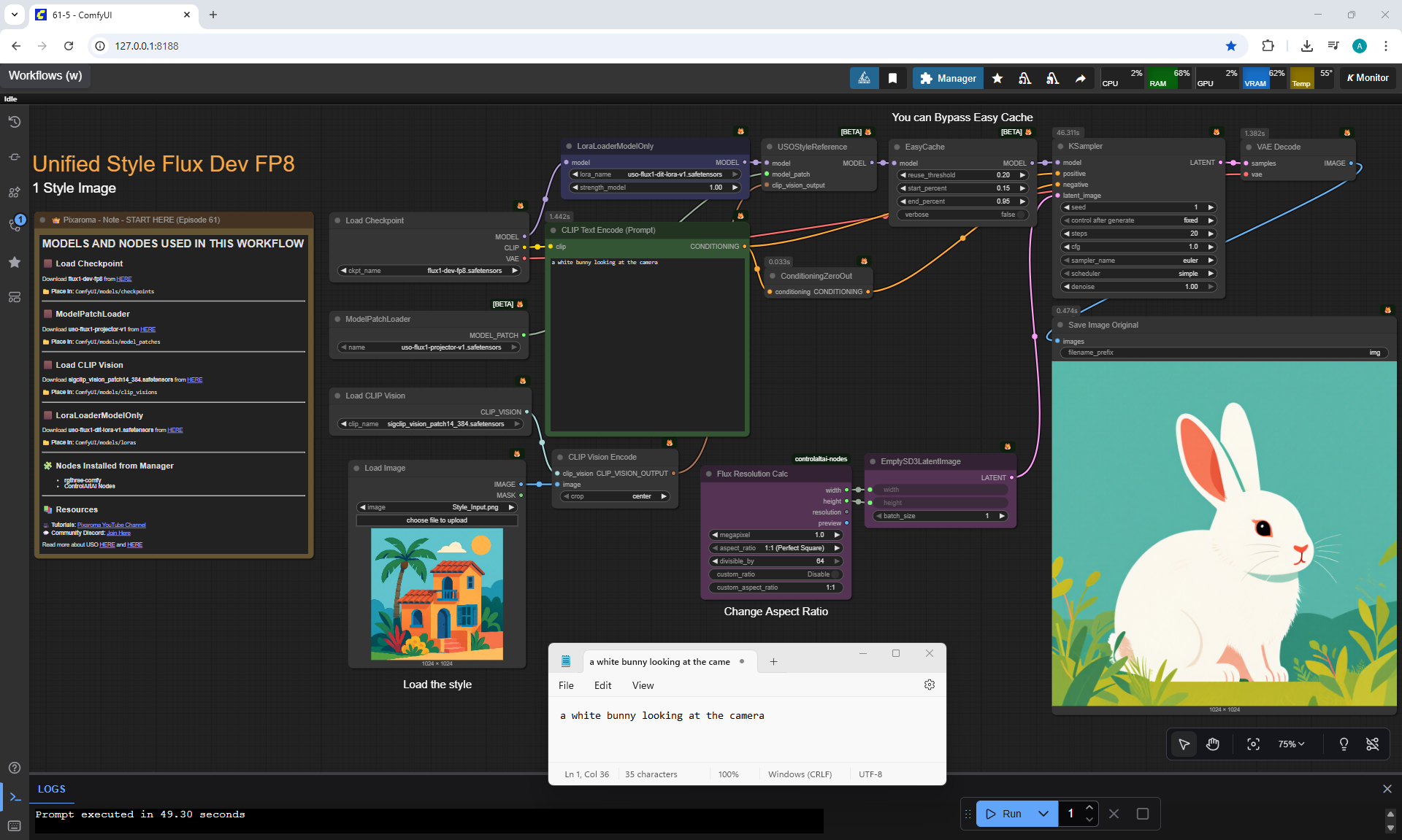
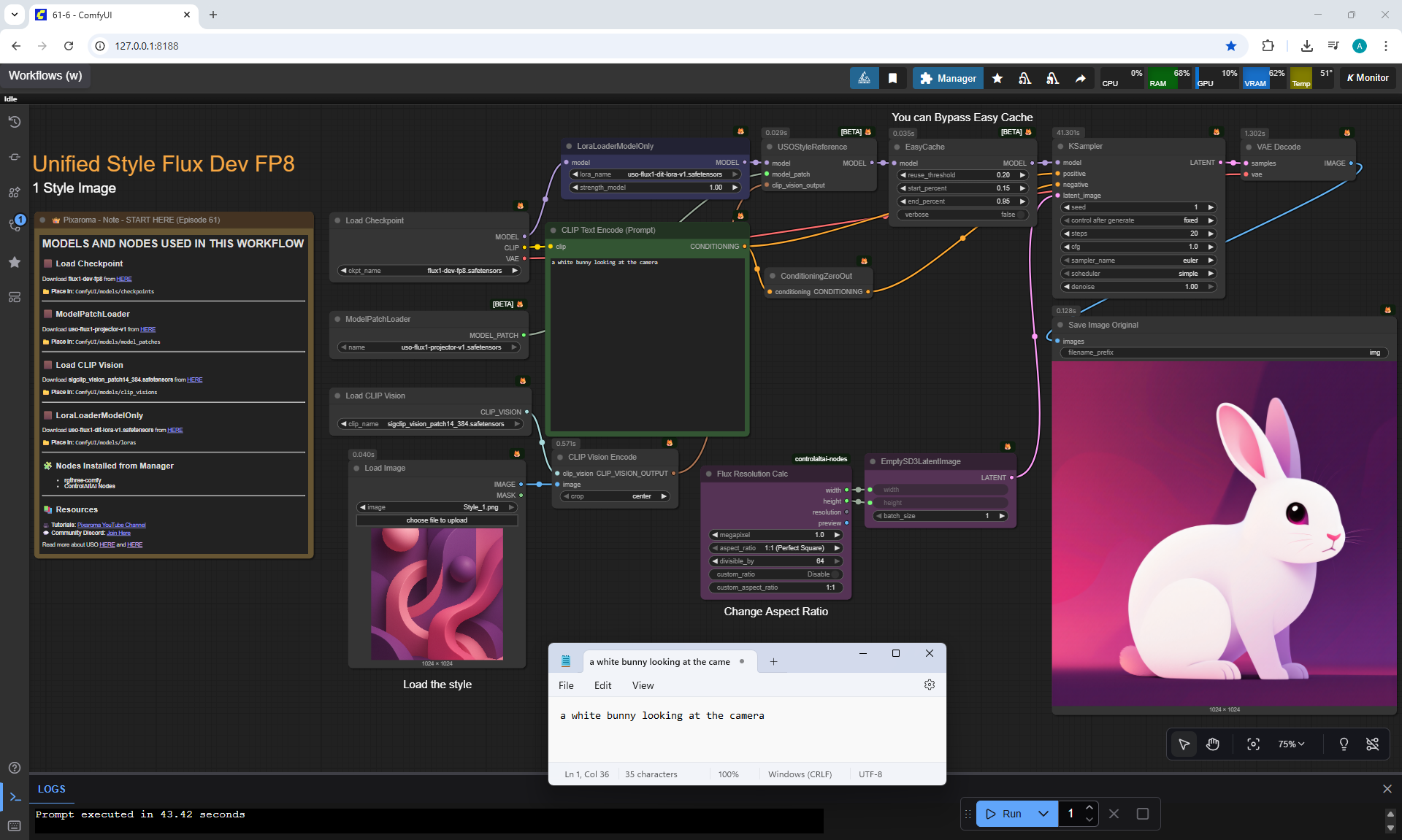
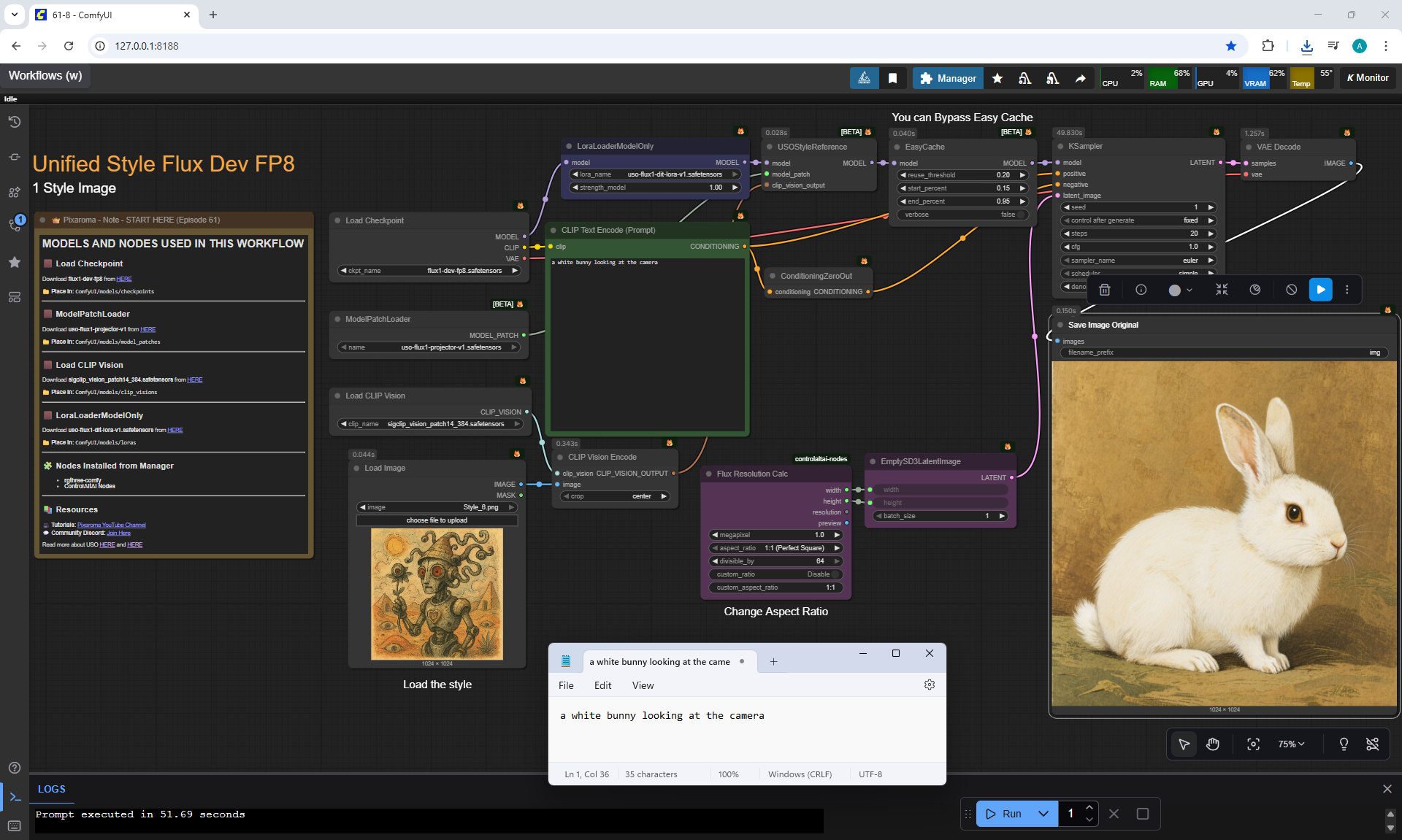
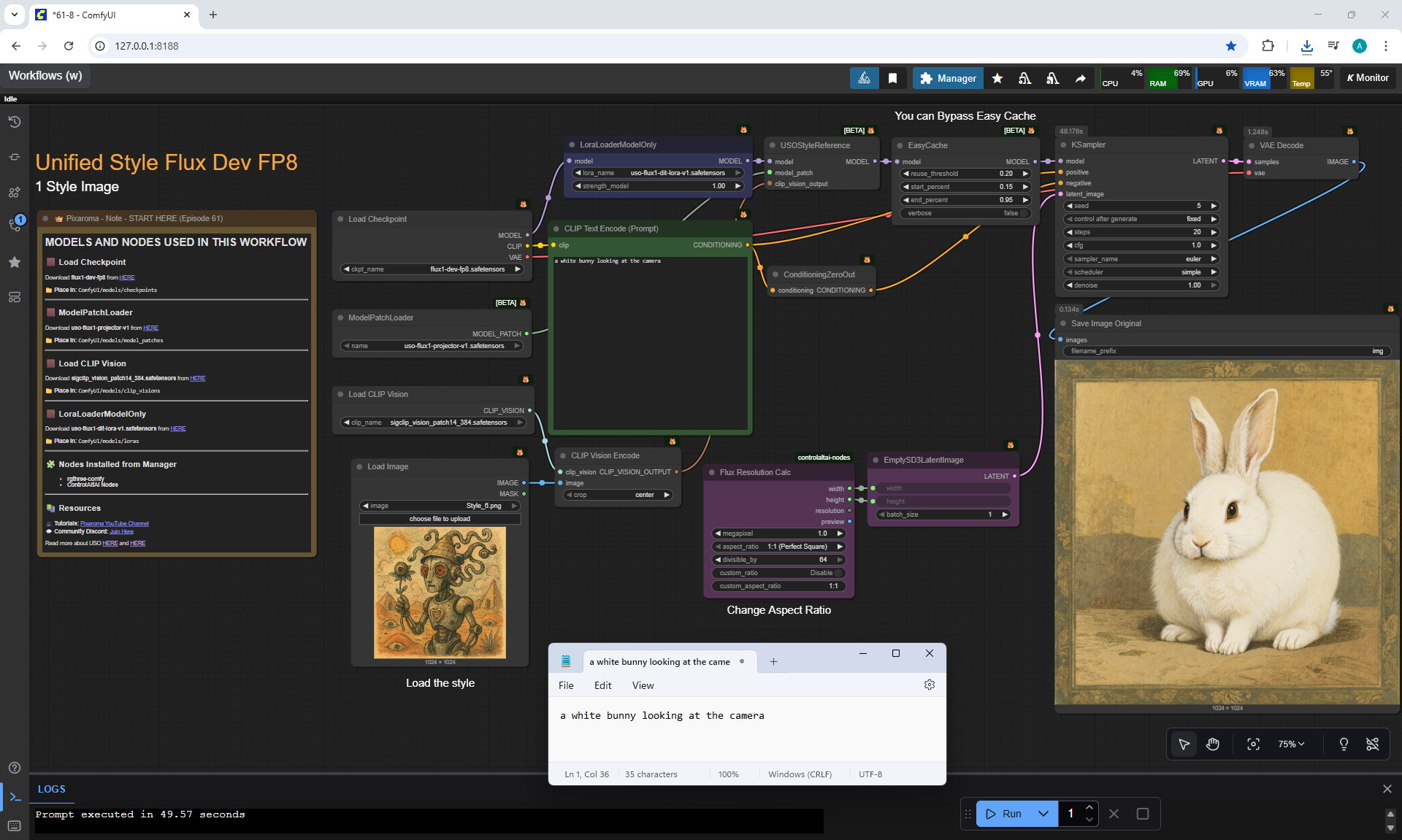
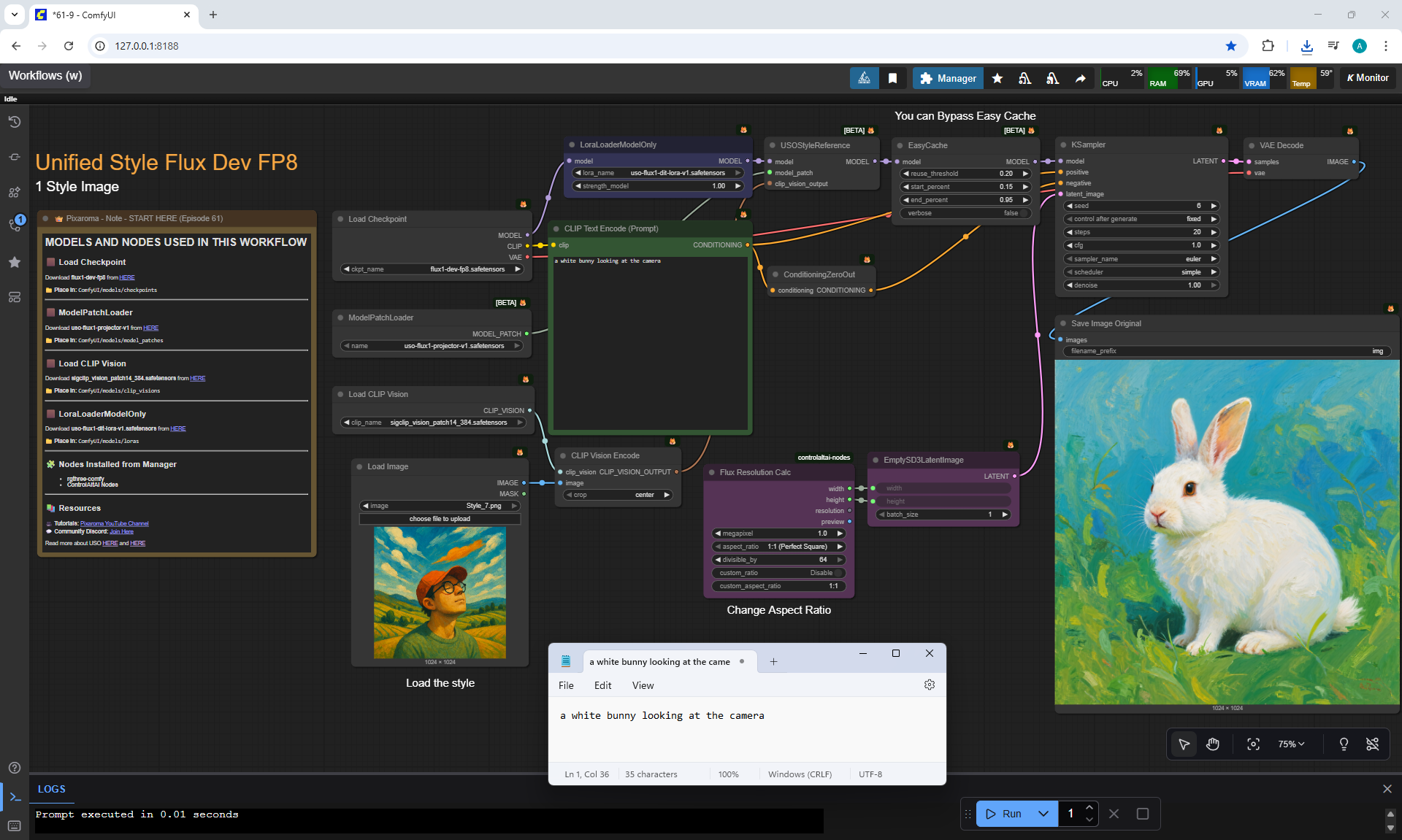
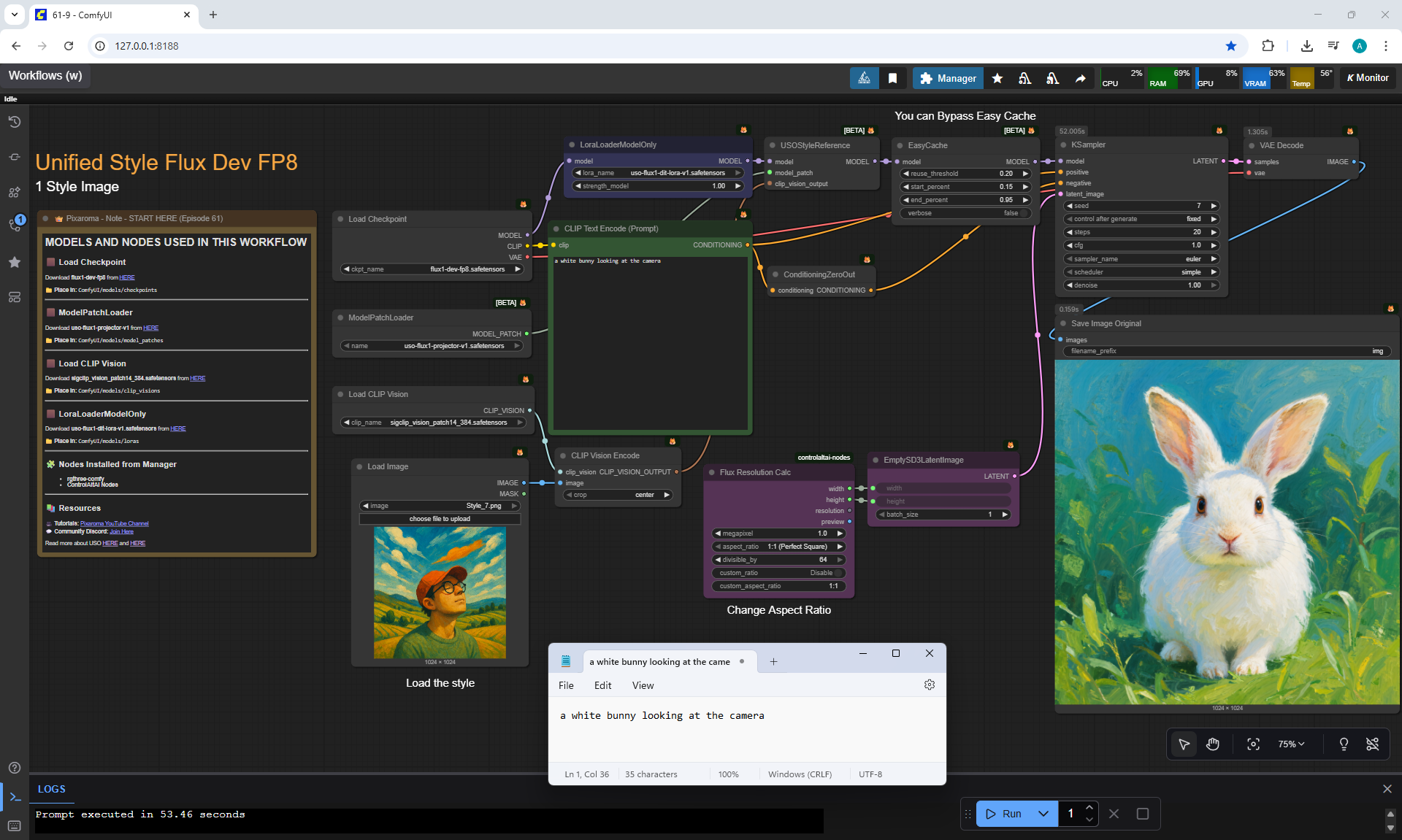
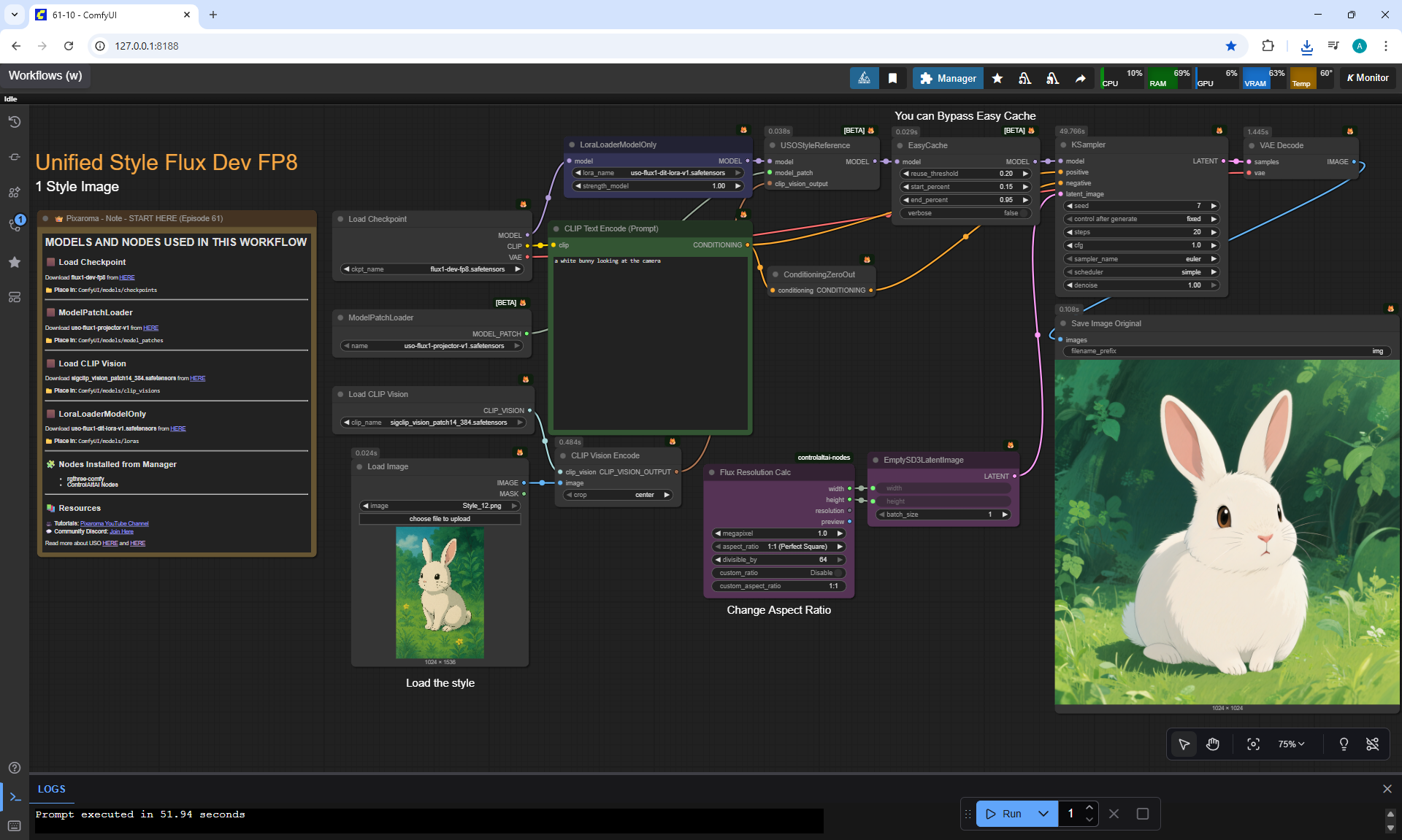
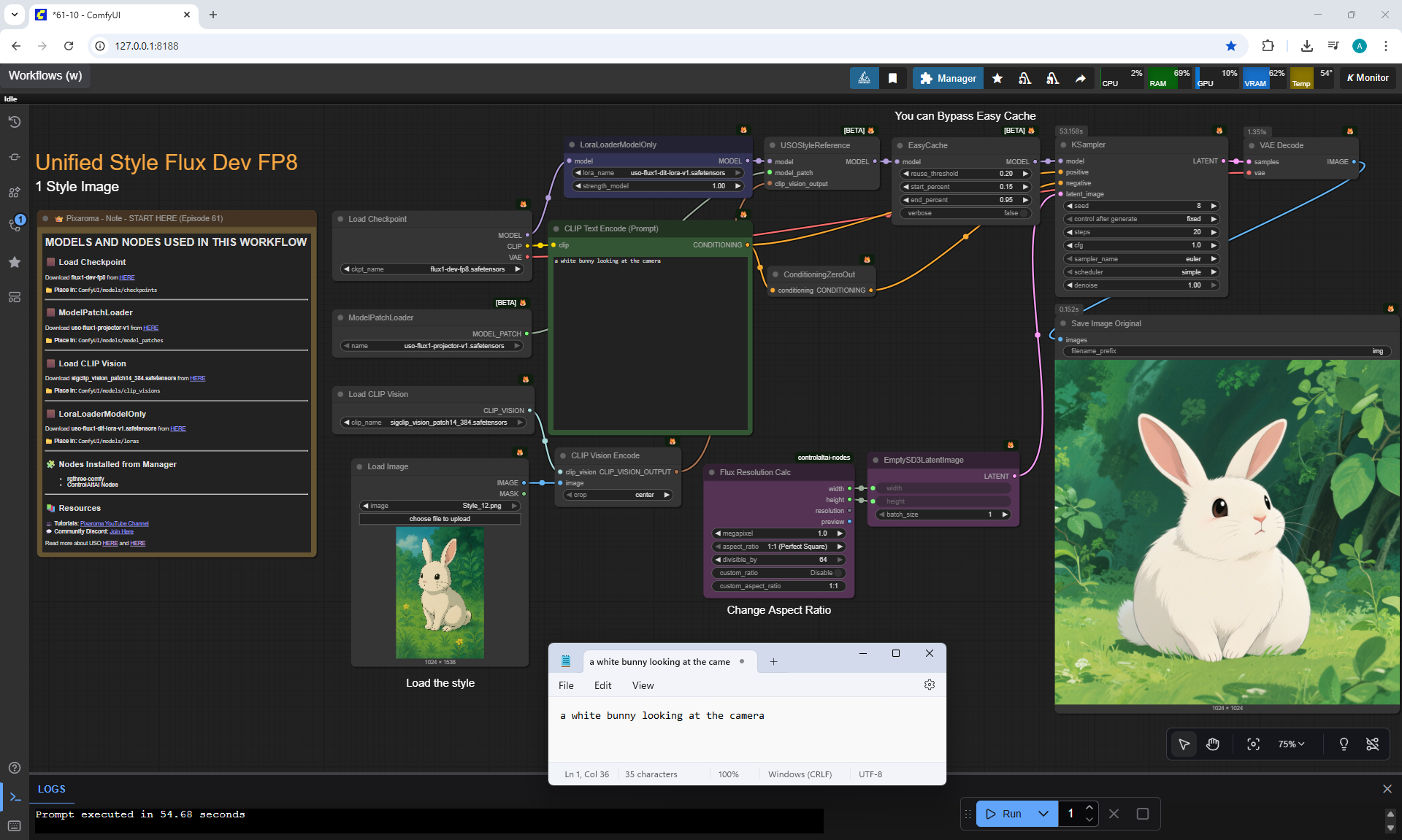
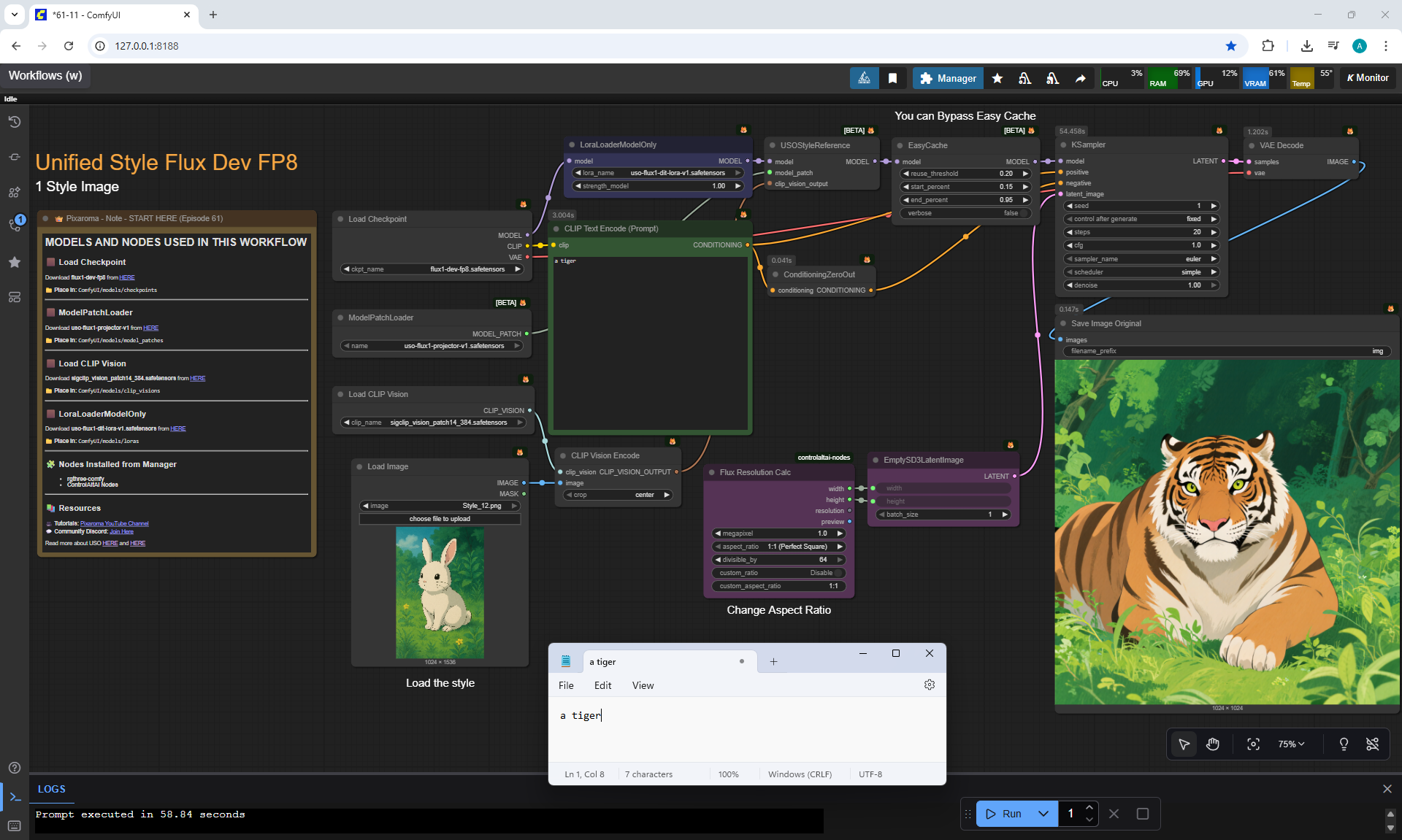
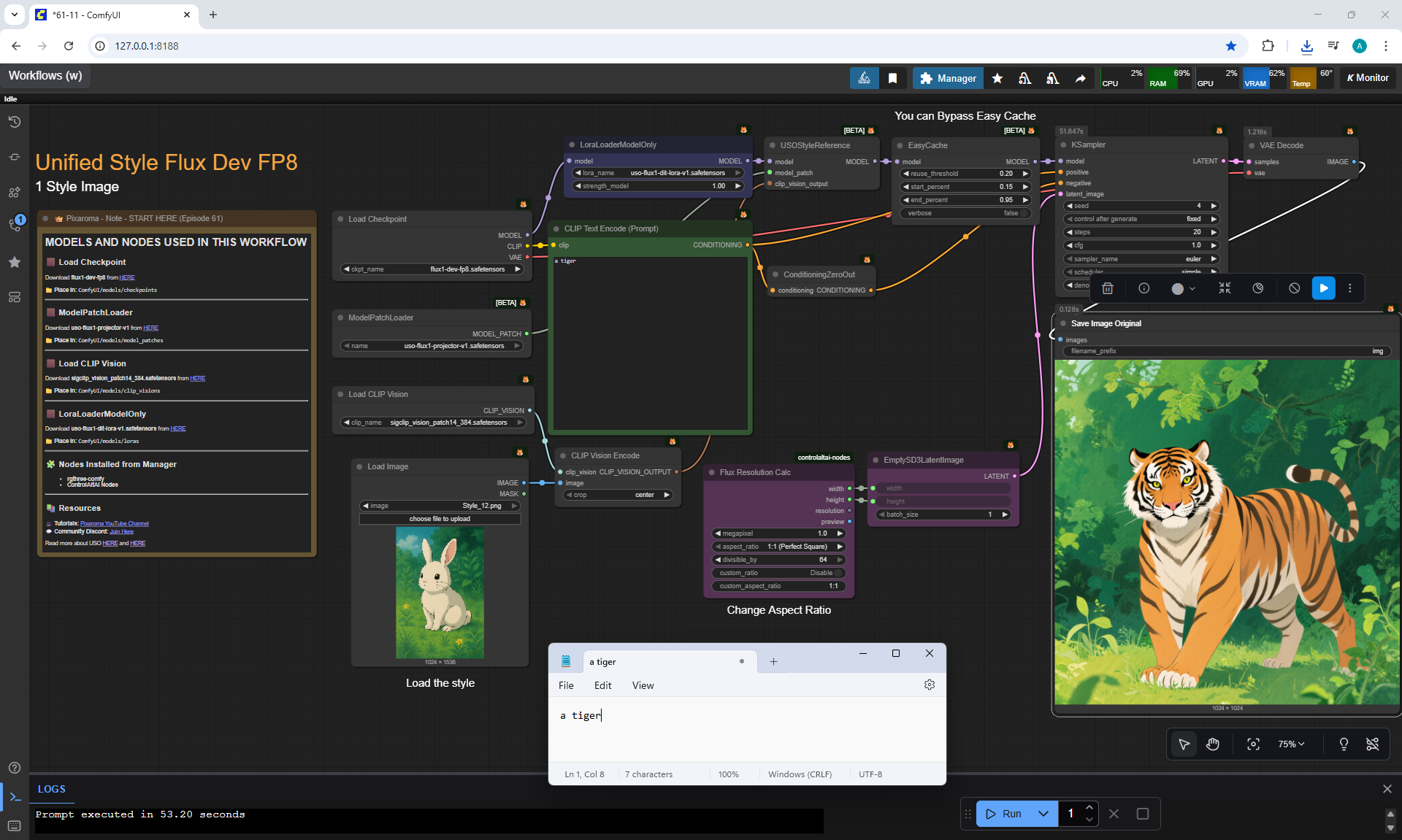
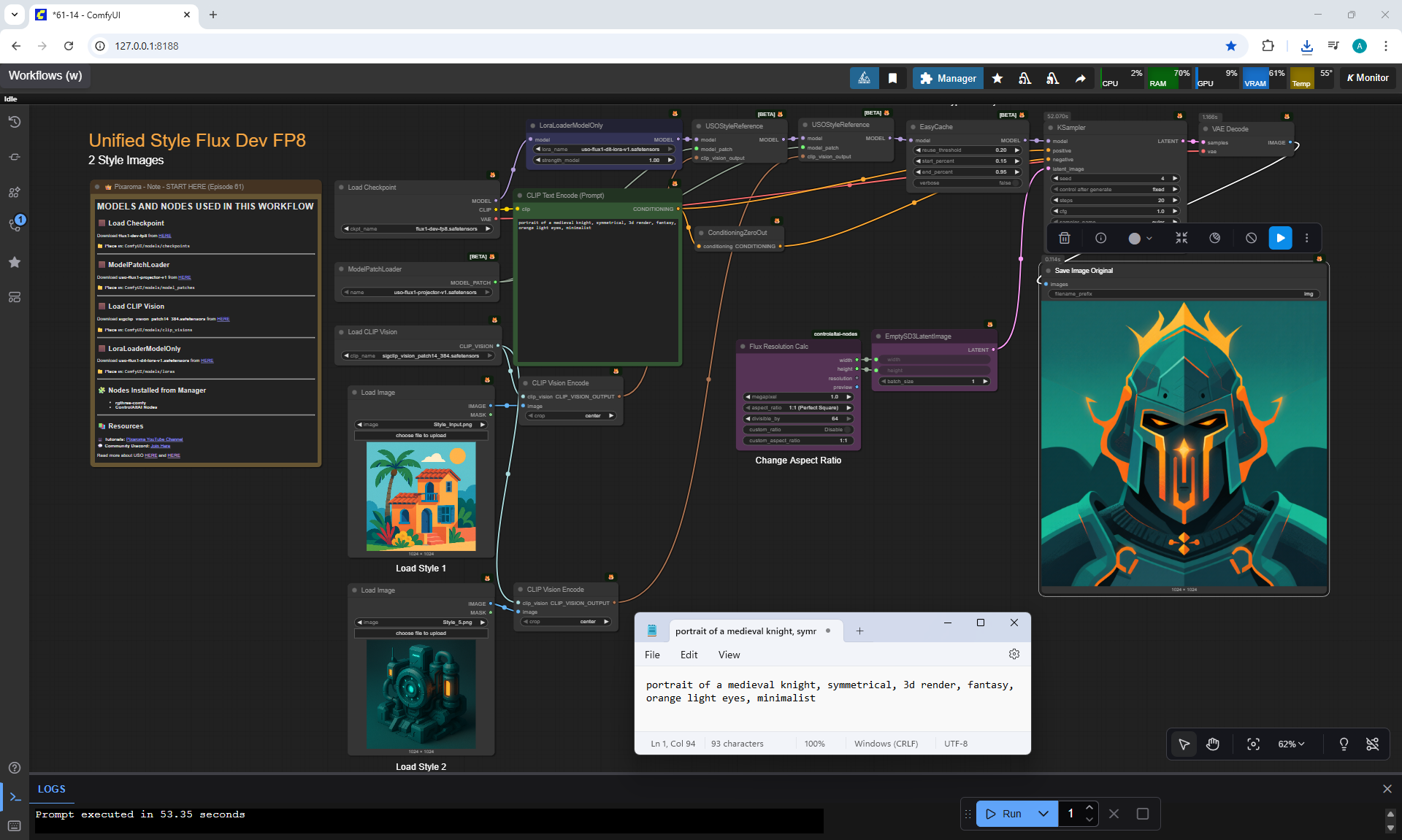
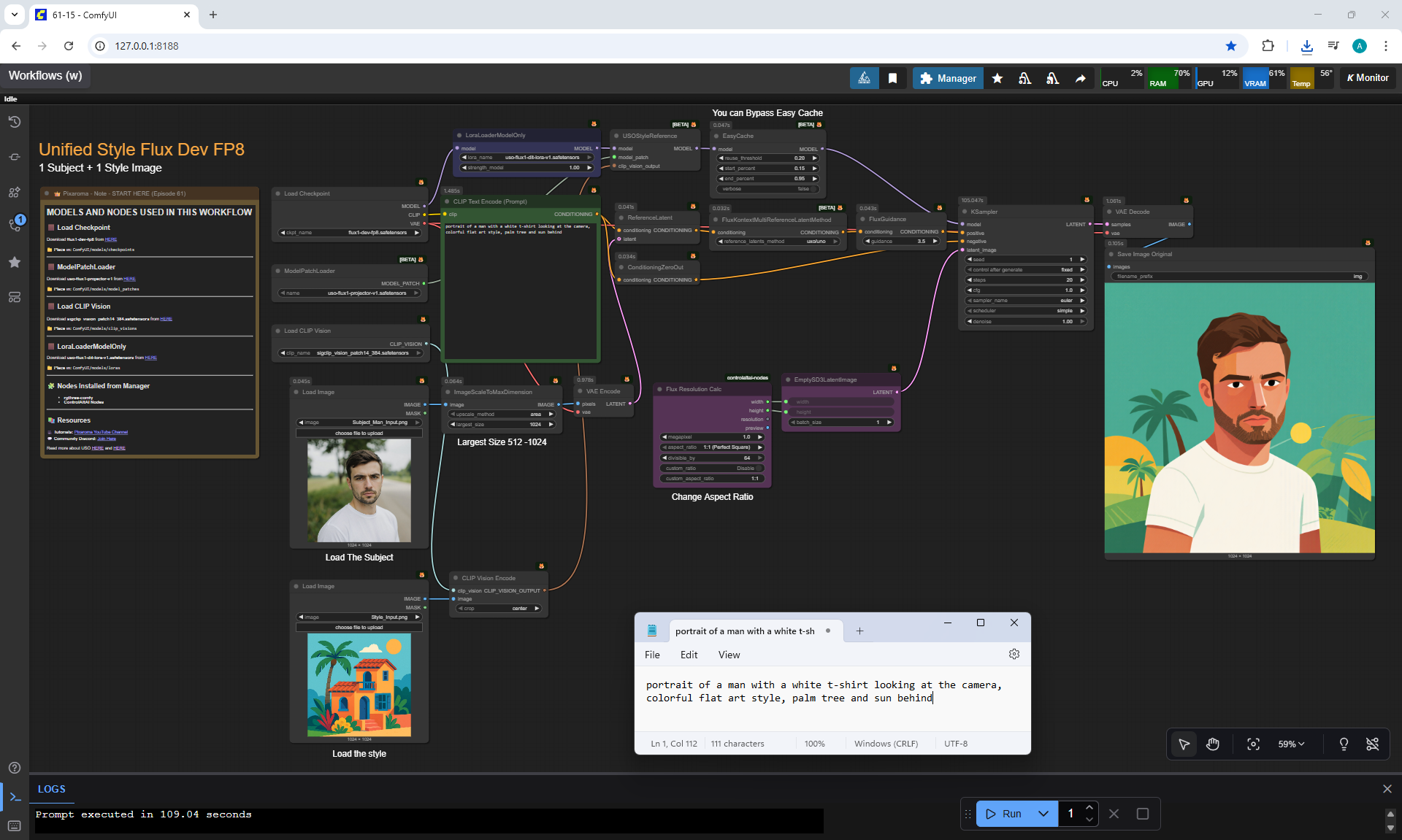
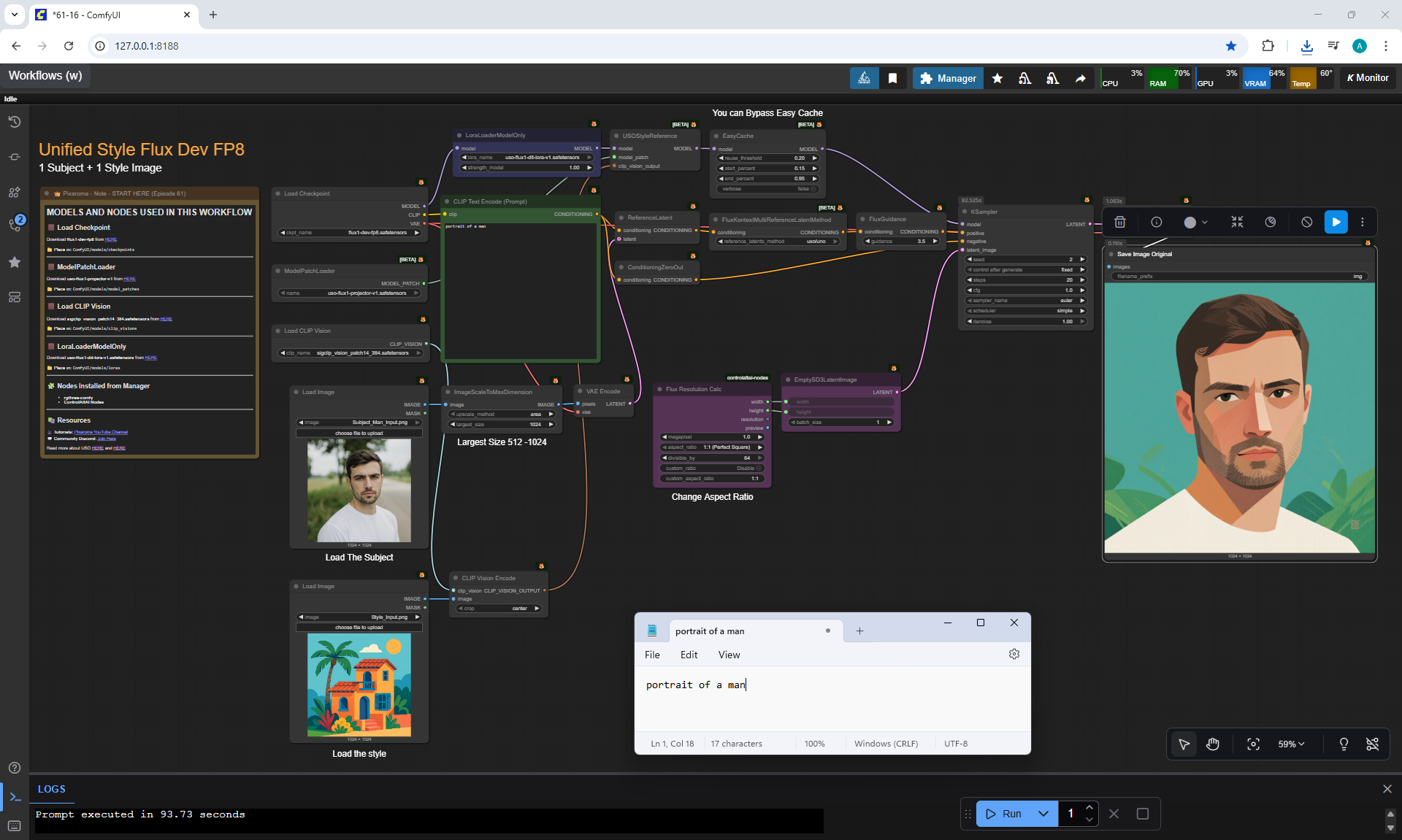
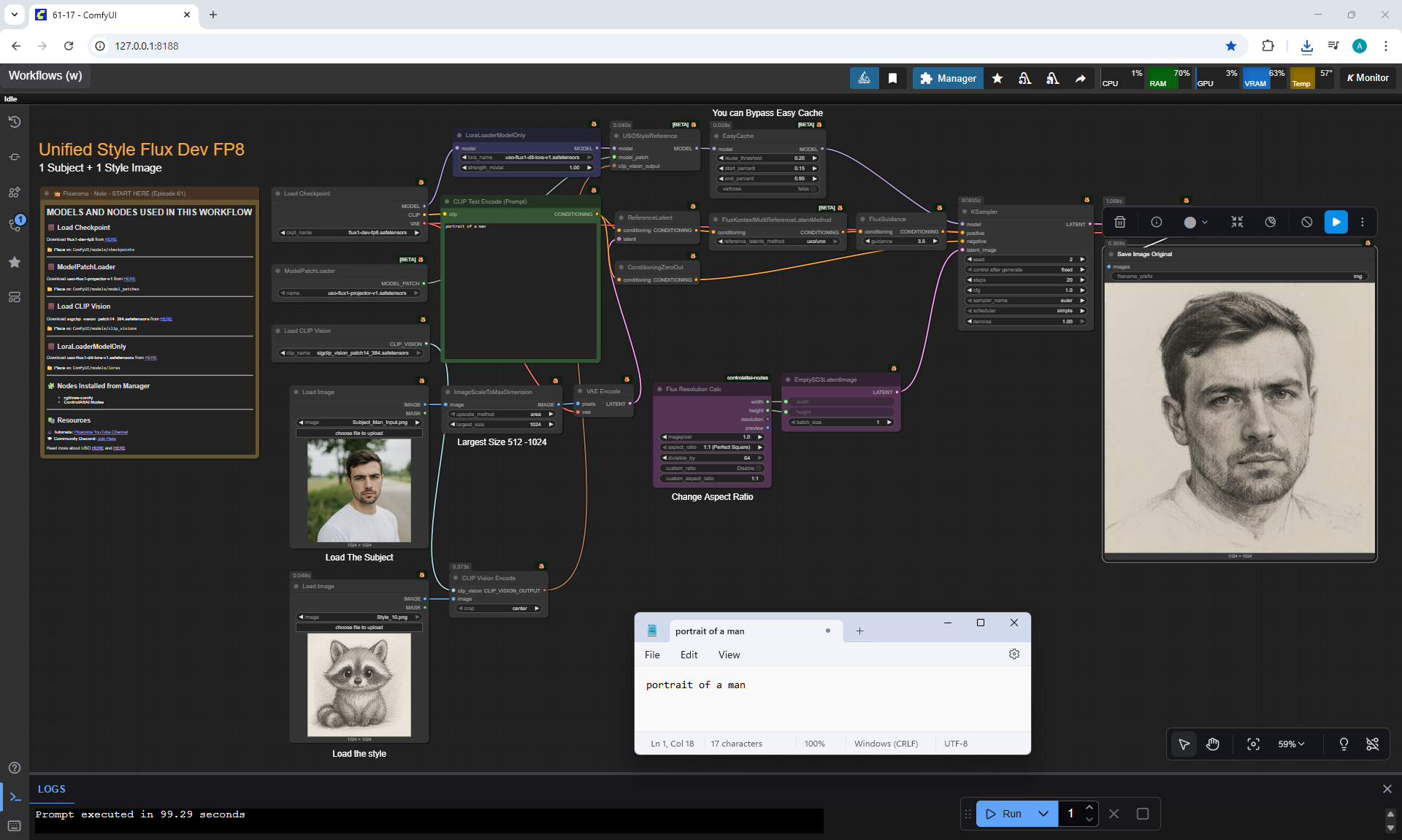
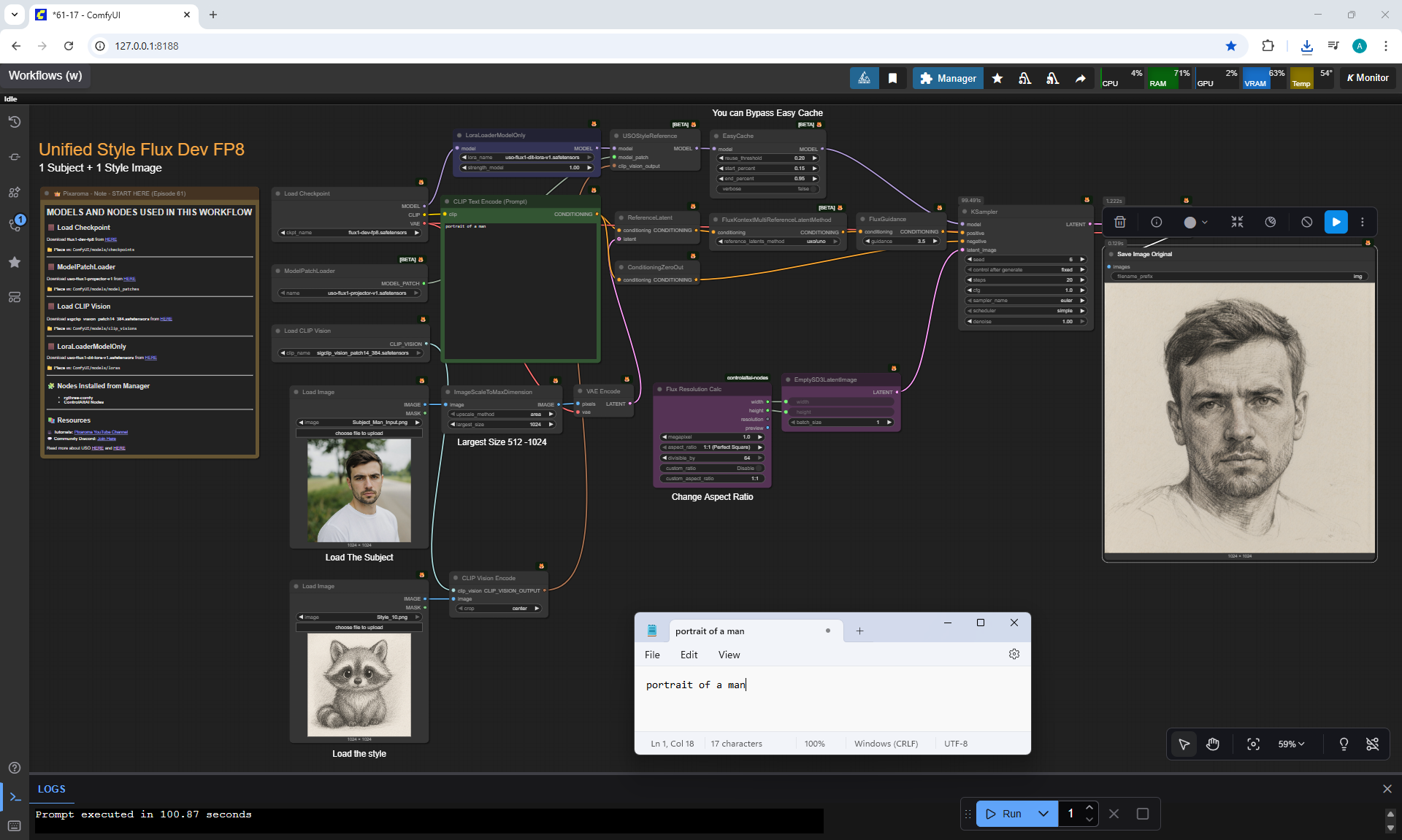
Ep61 - USO - Unified Style and Subject-Driven Generation
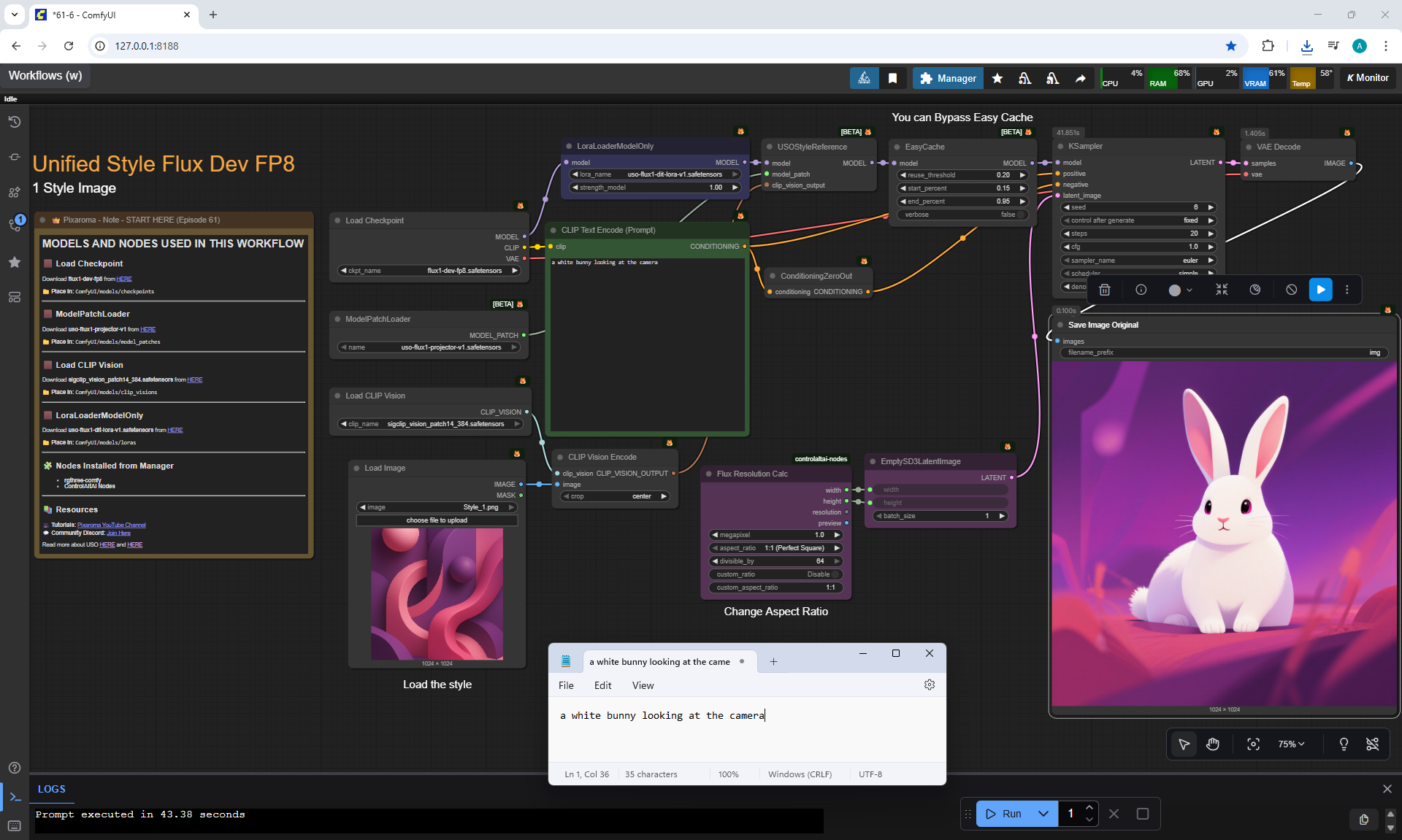
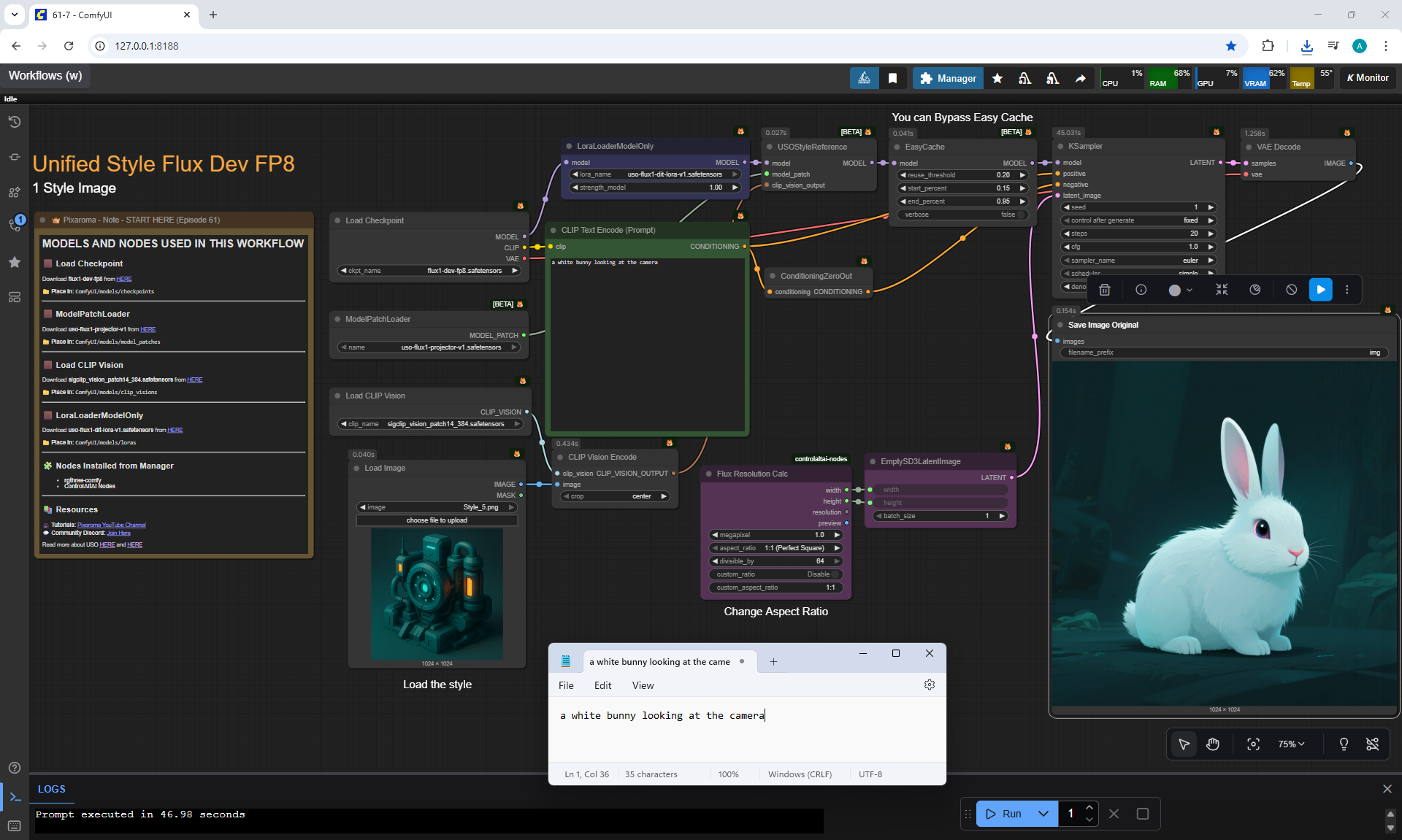
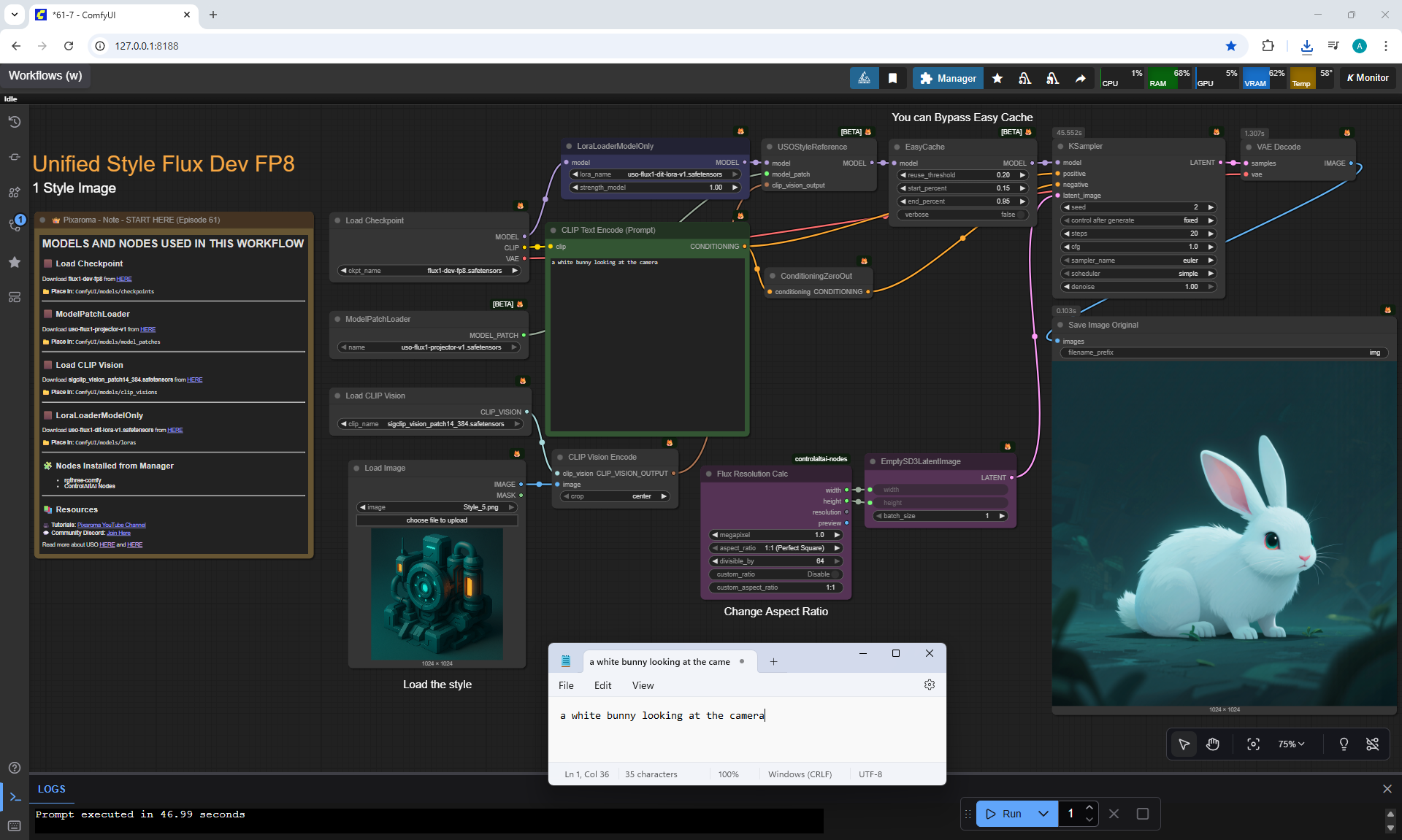
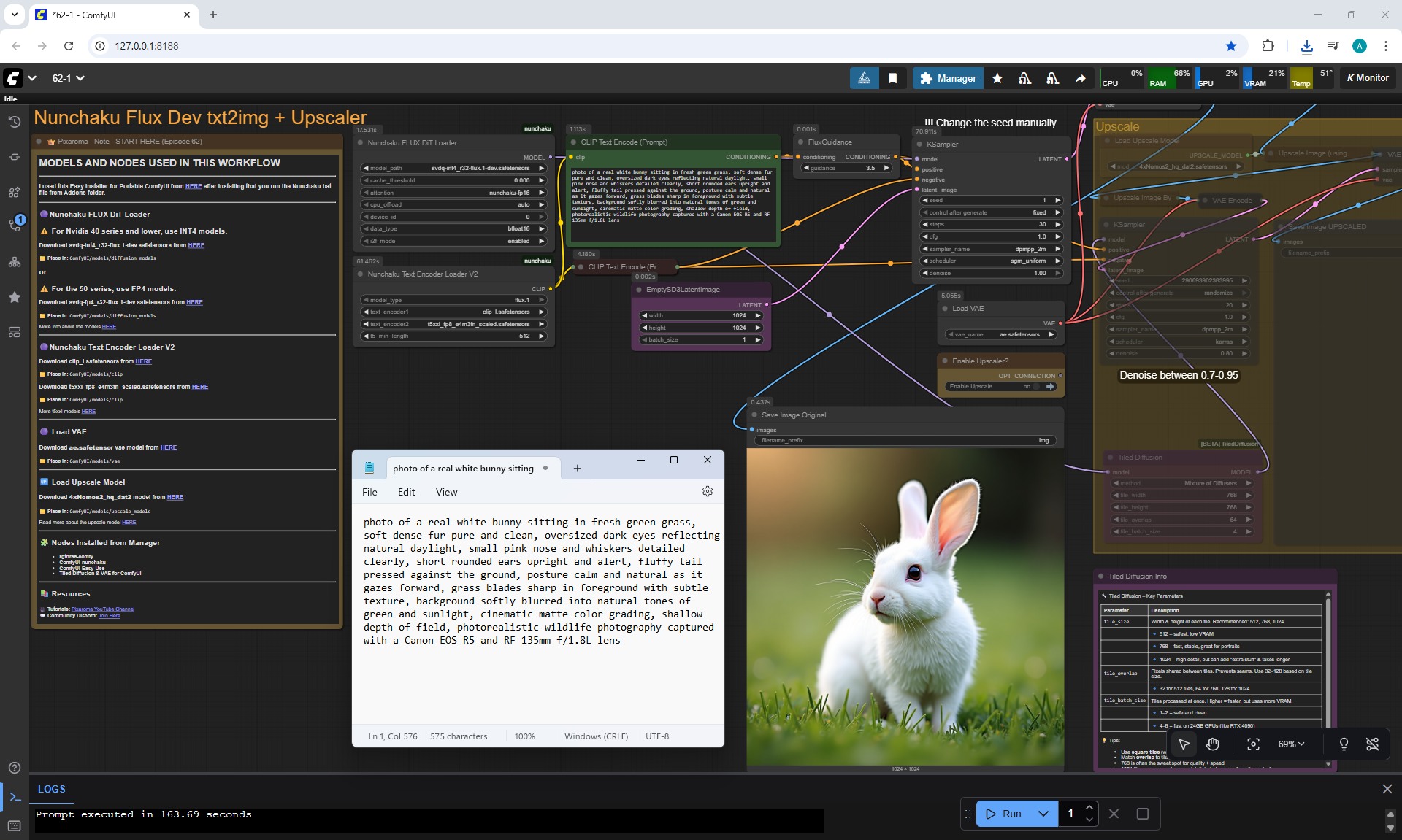
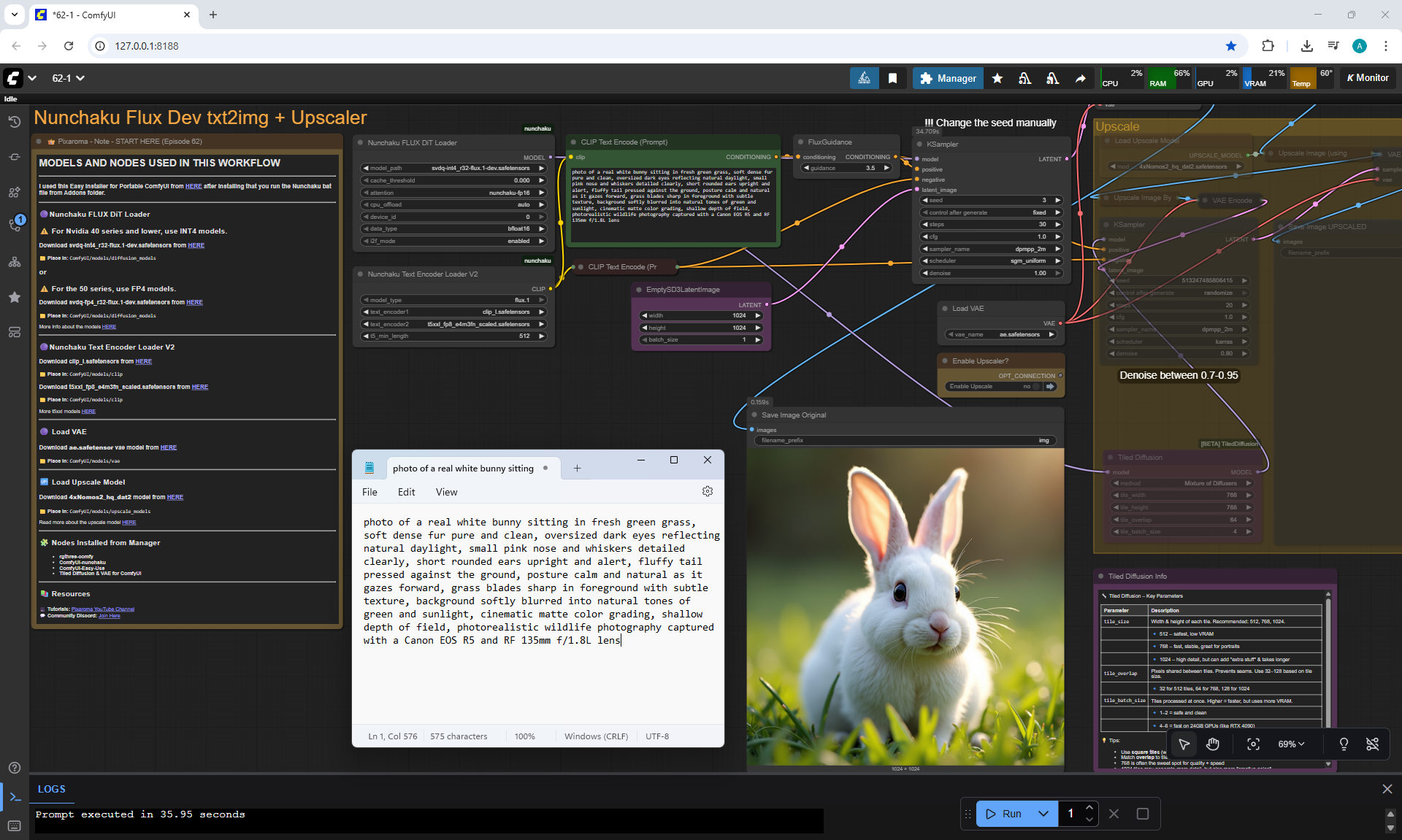
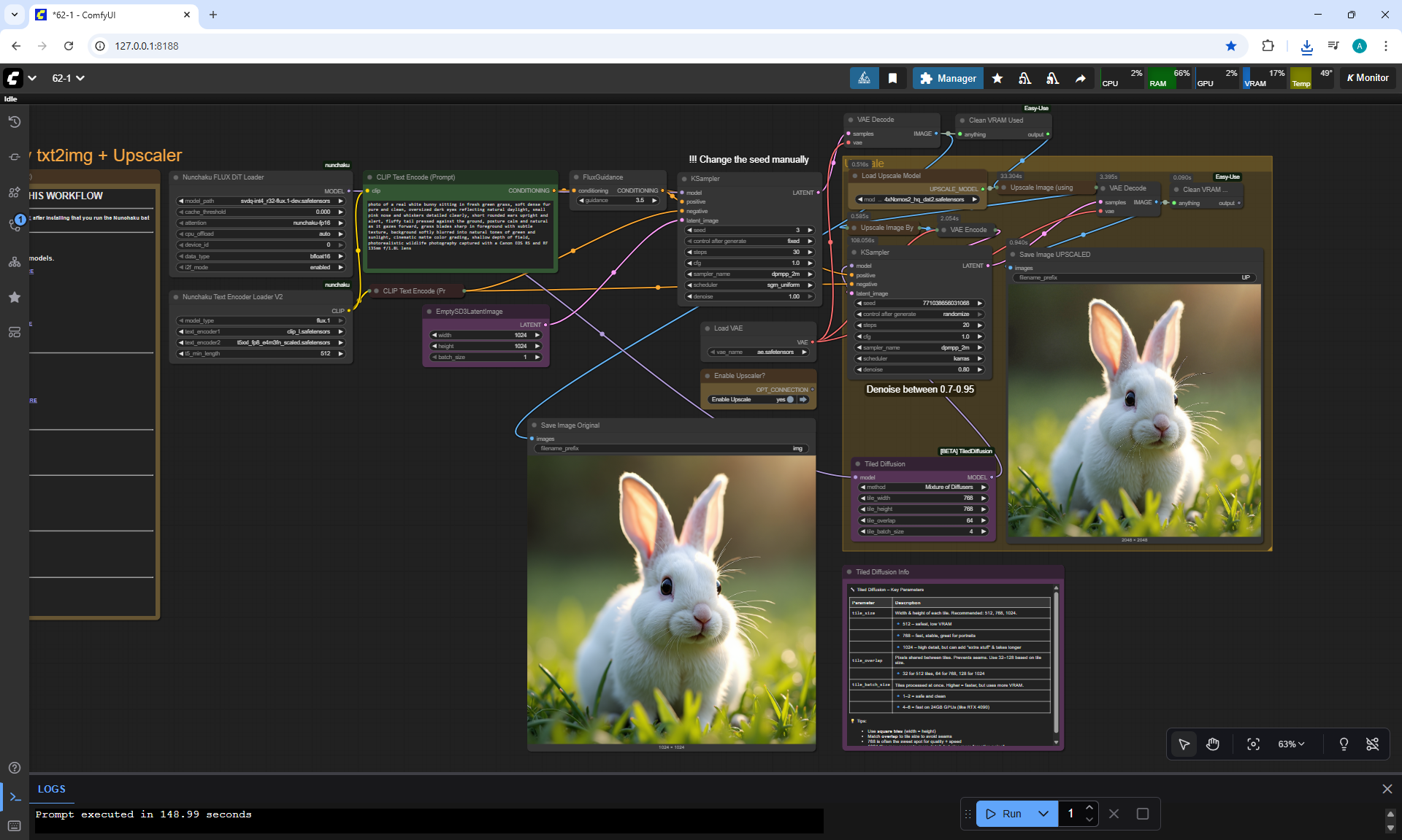
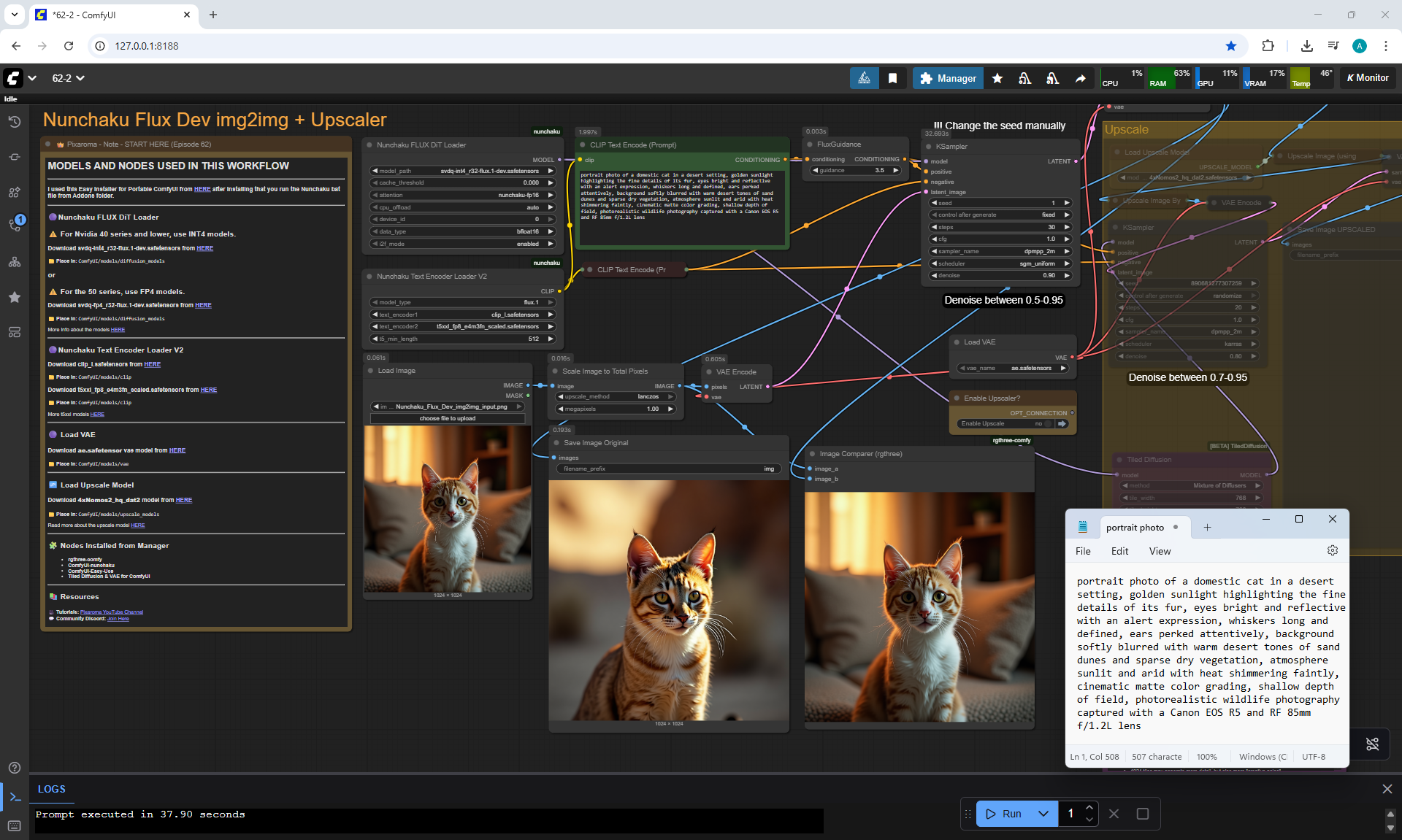
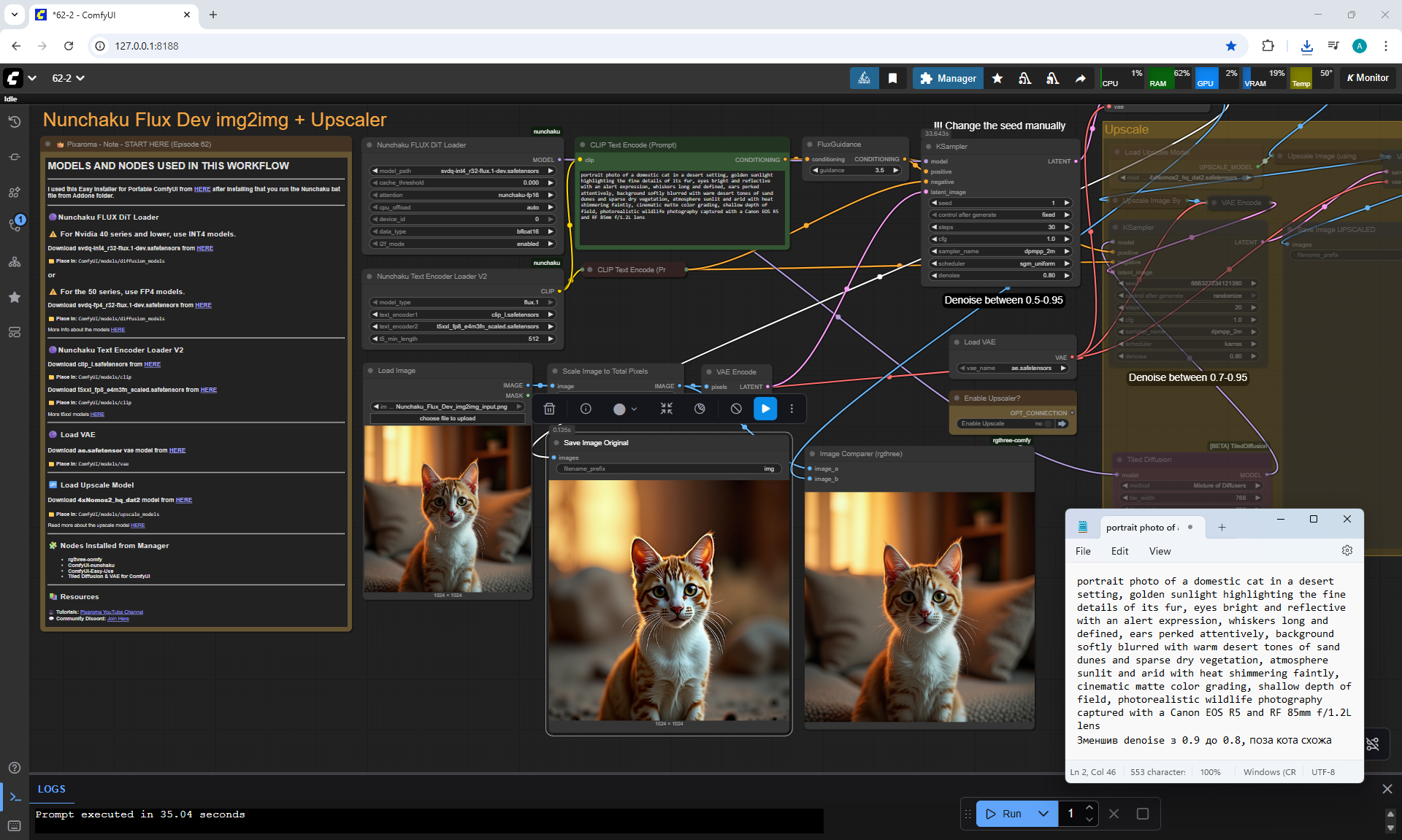
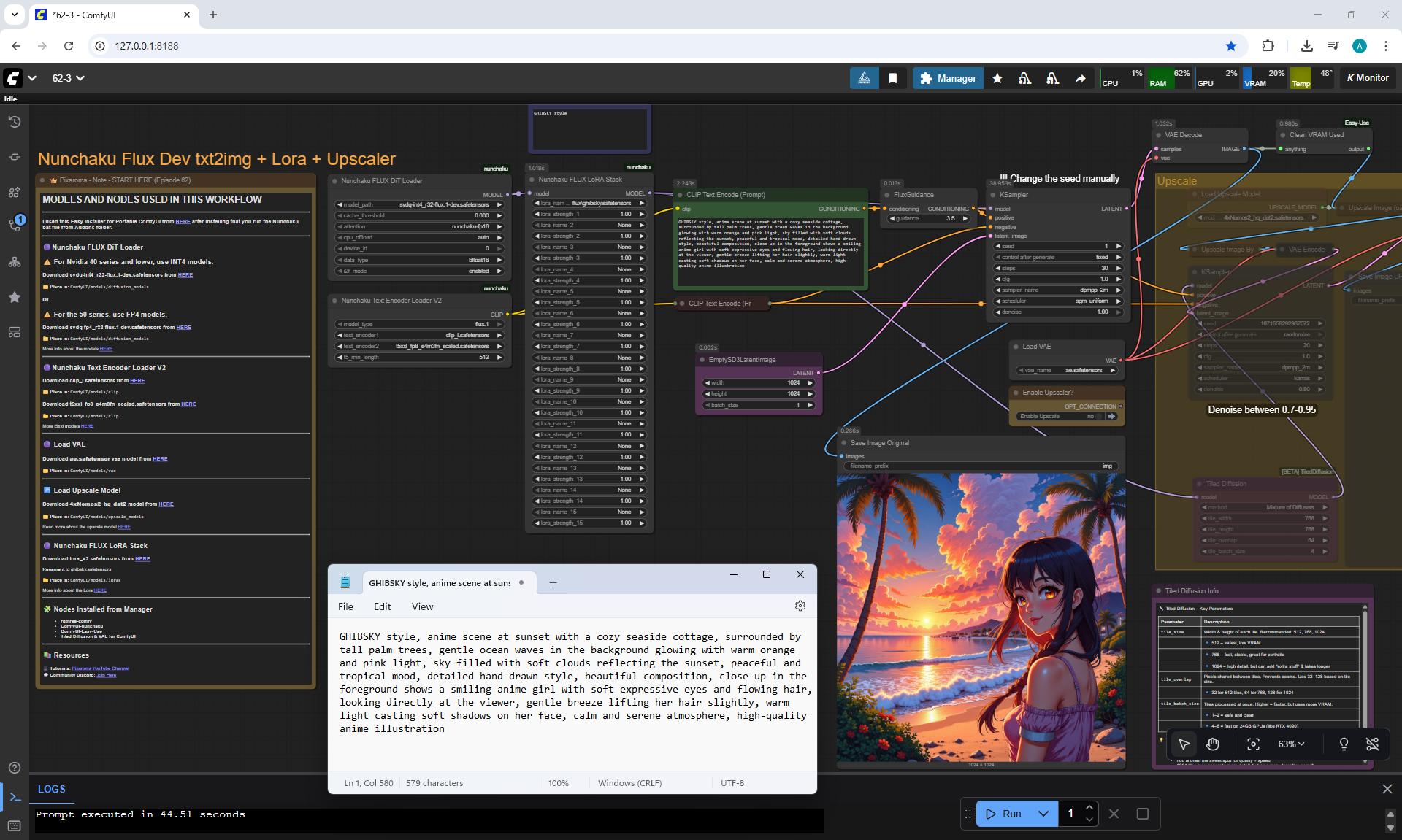
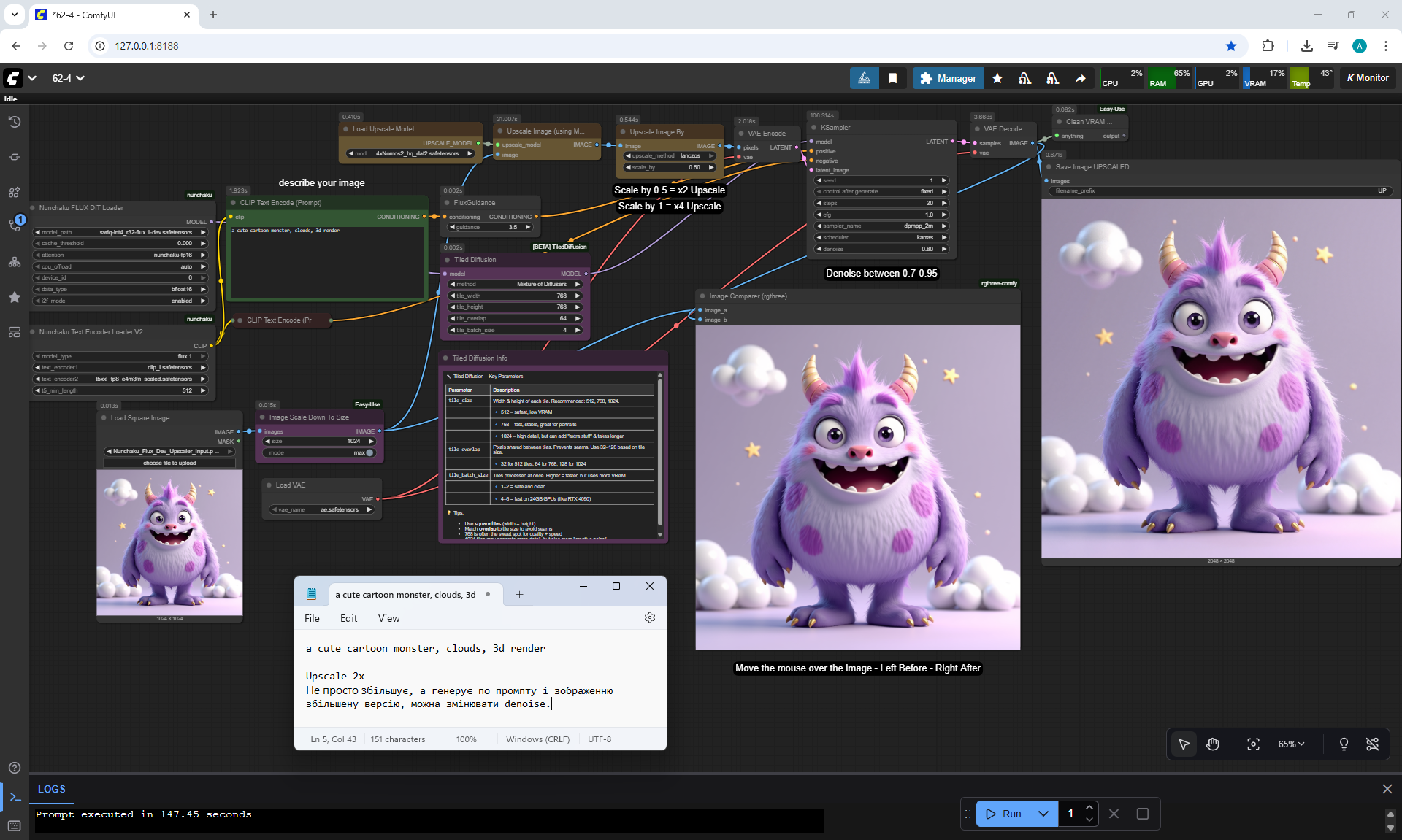
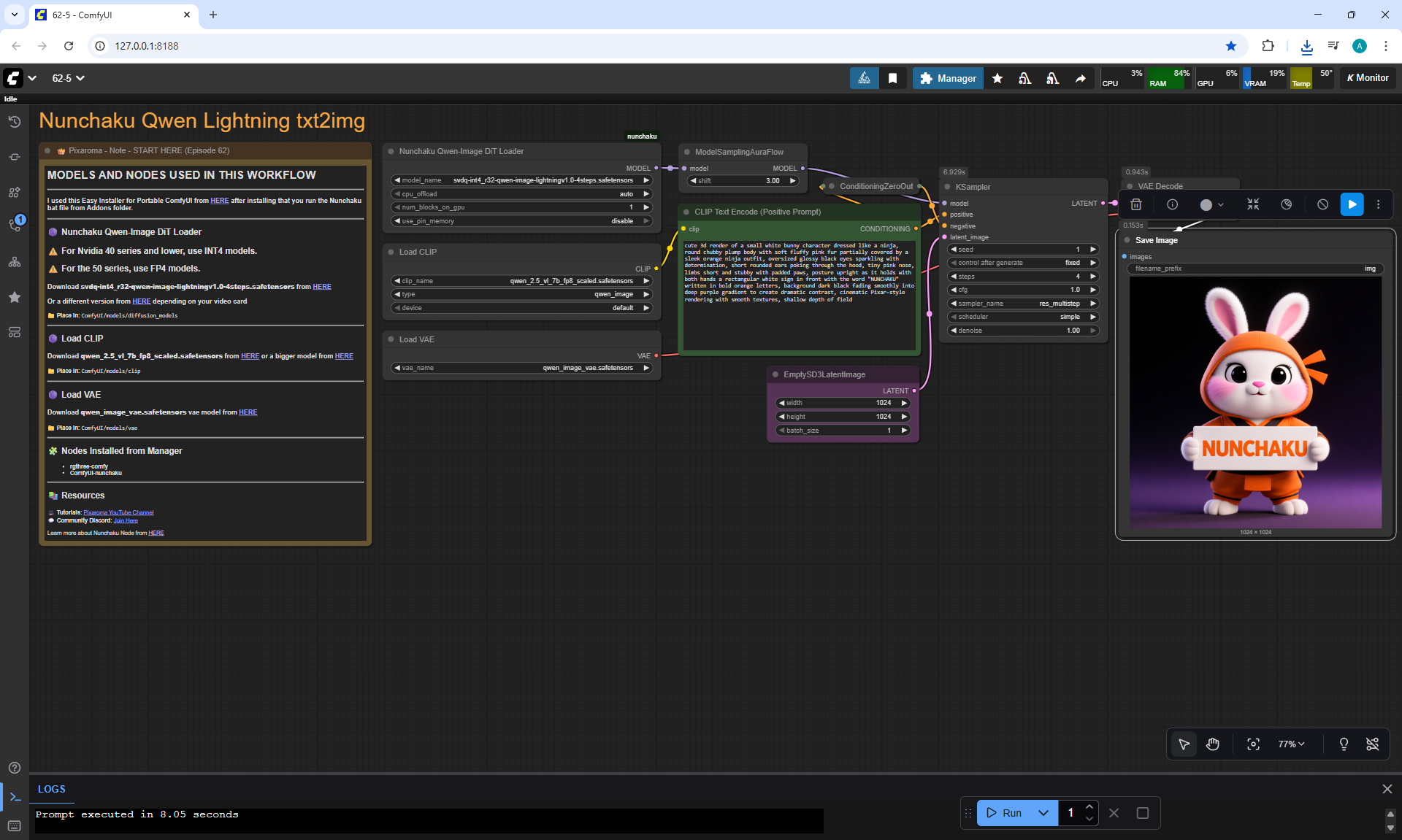
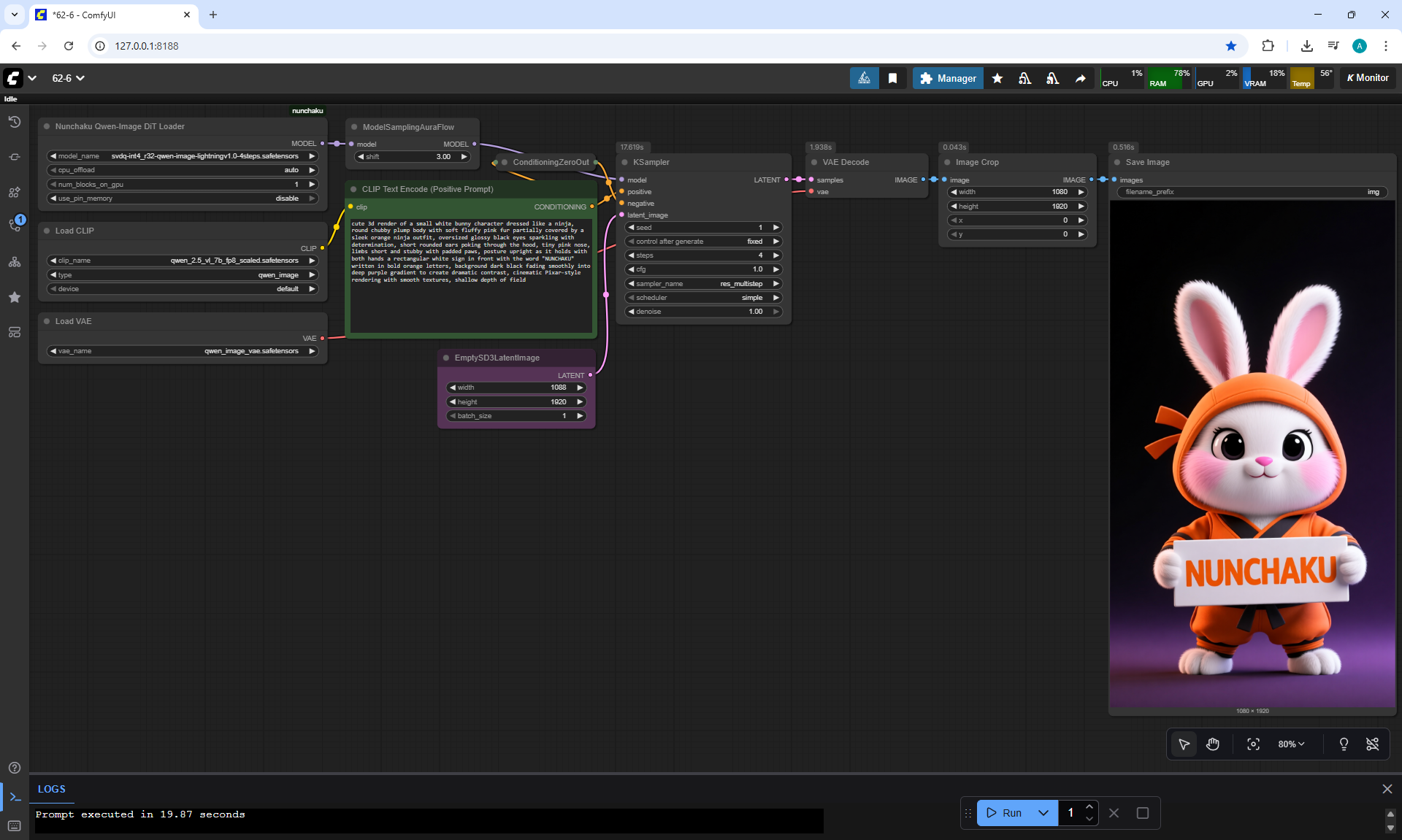
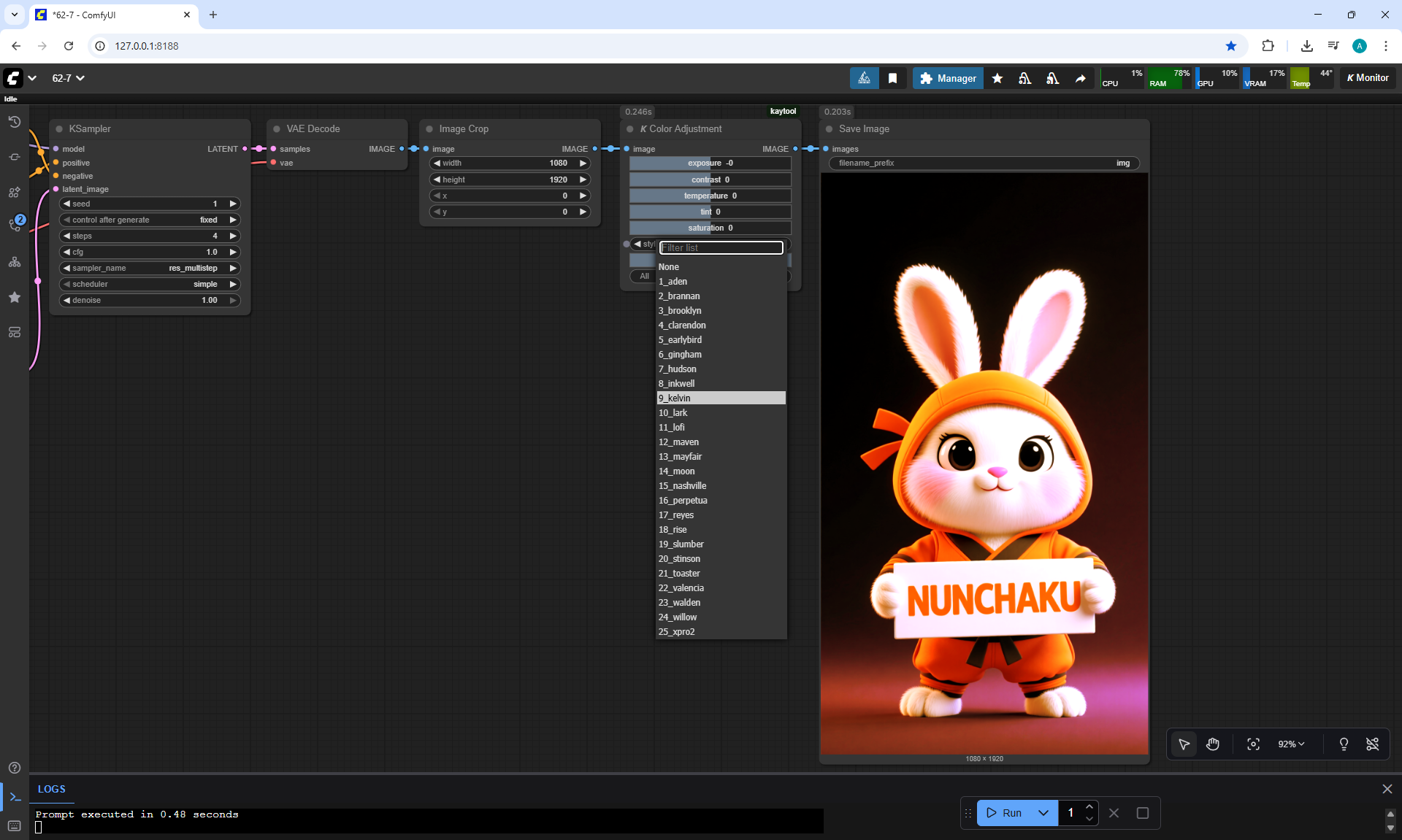
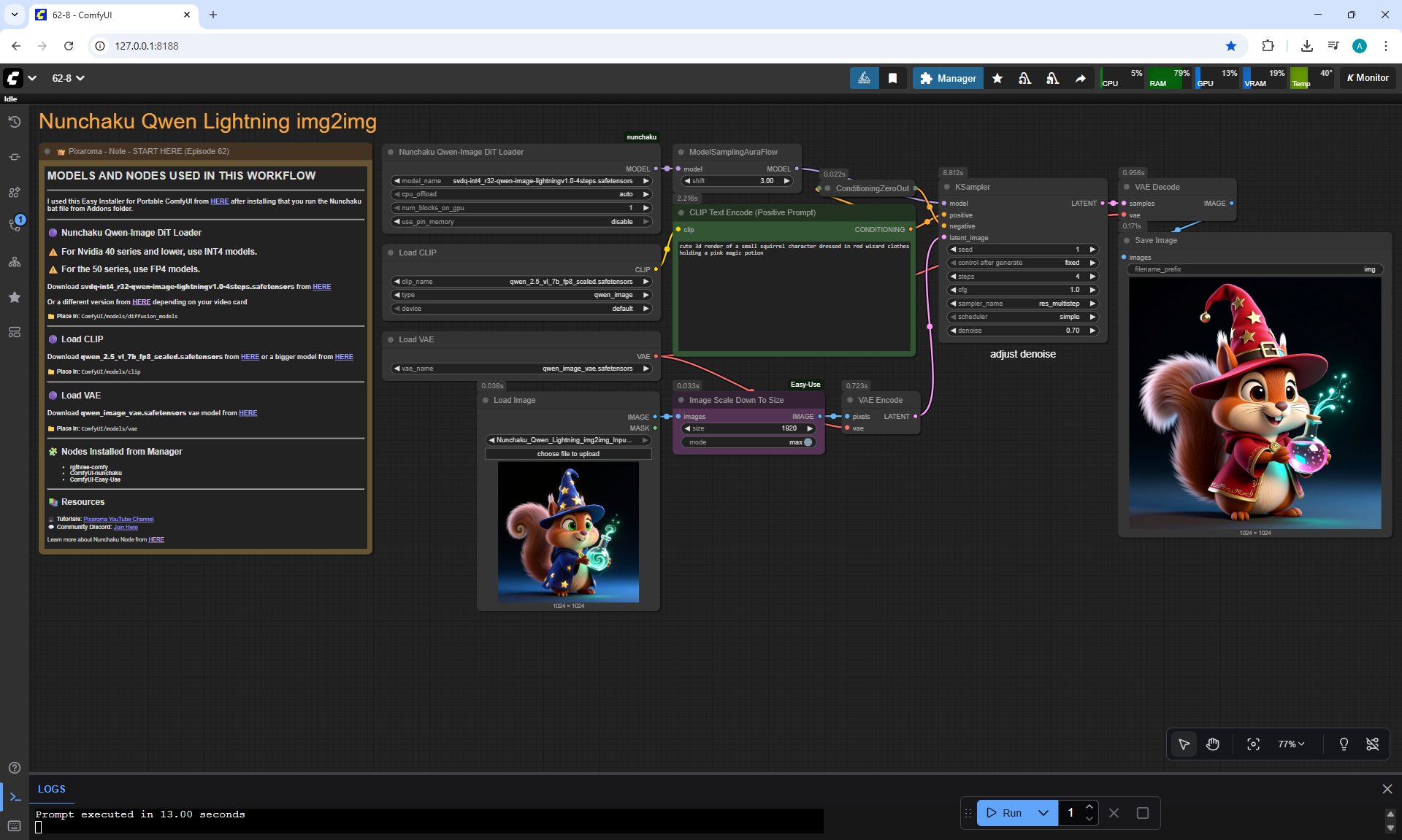
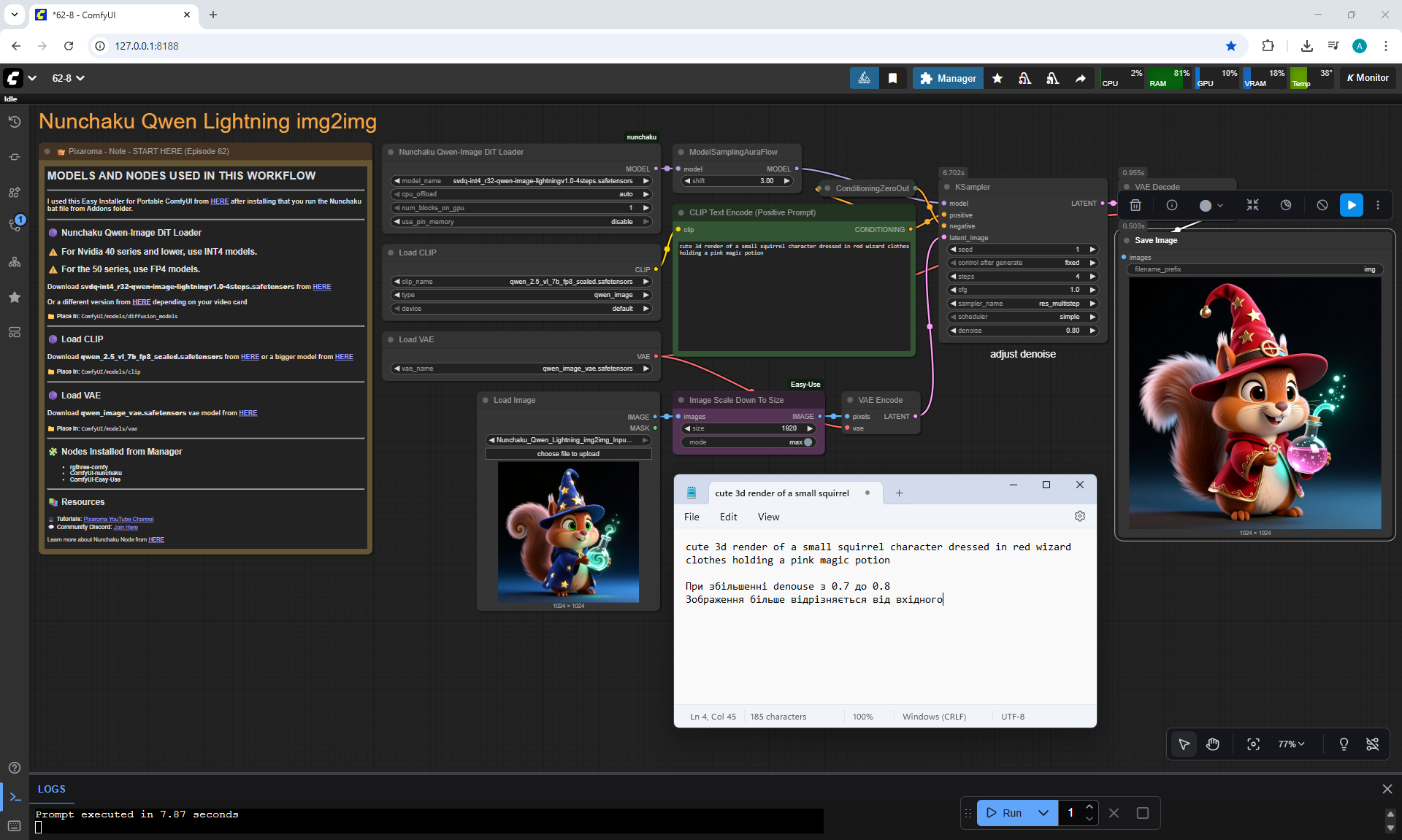
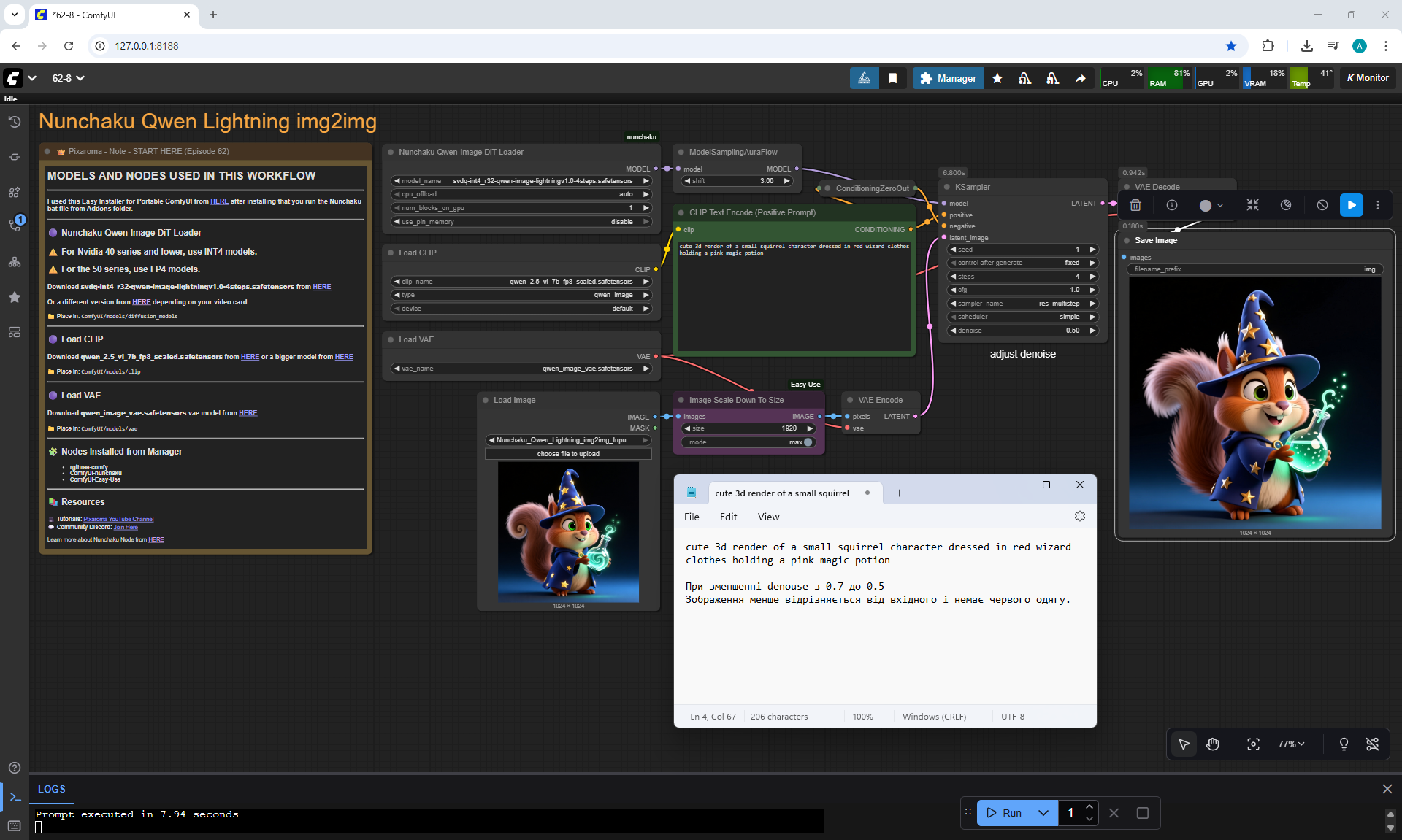
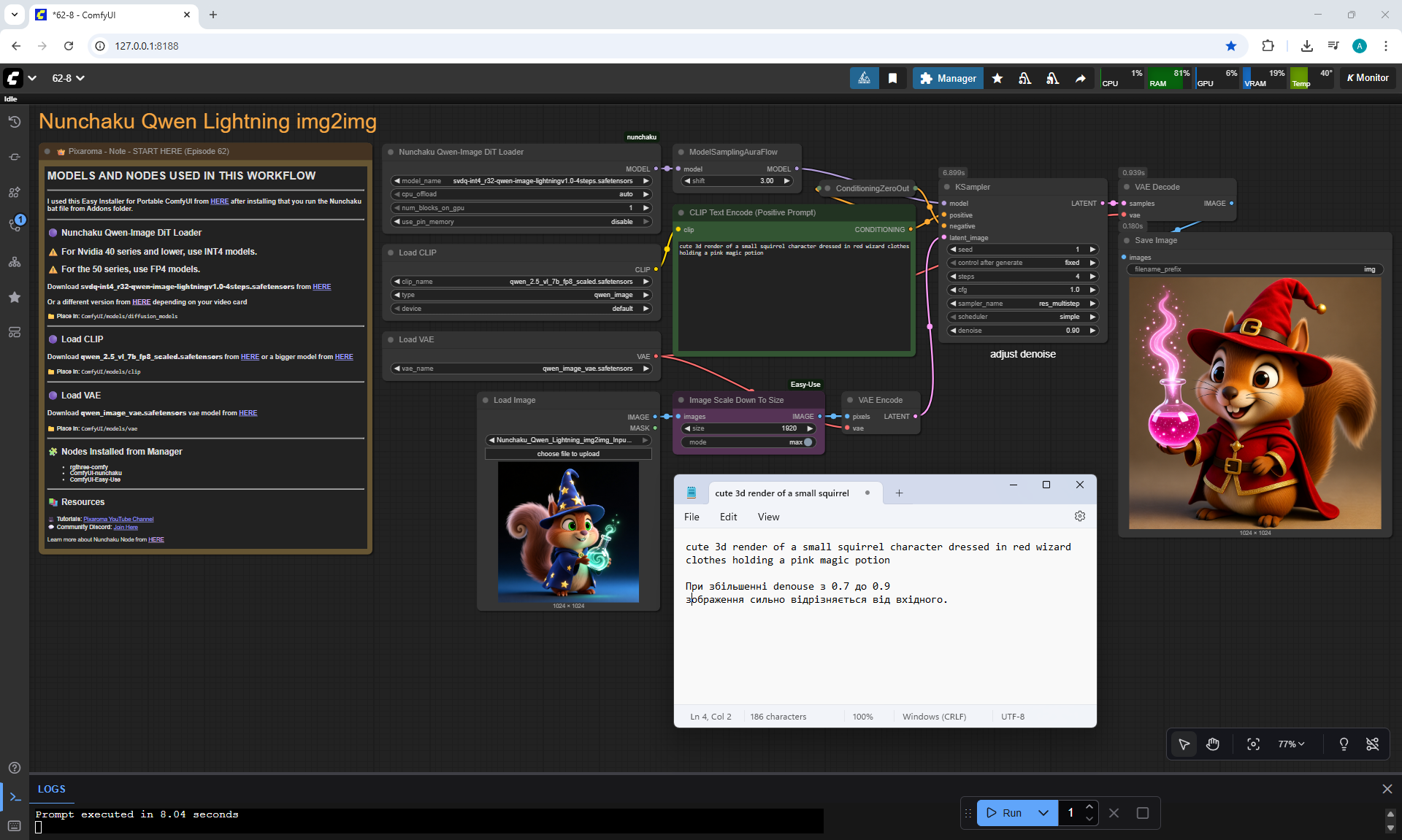
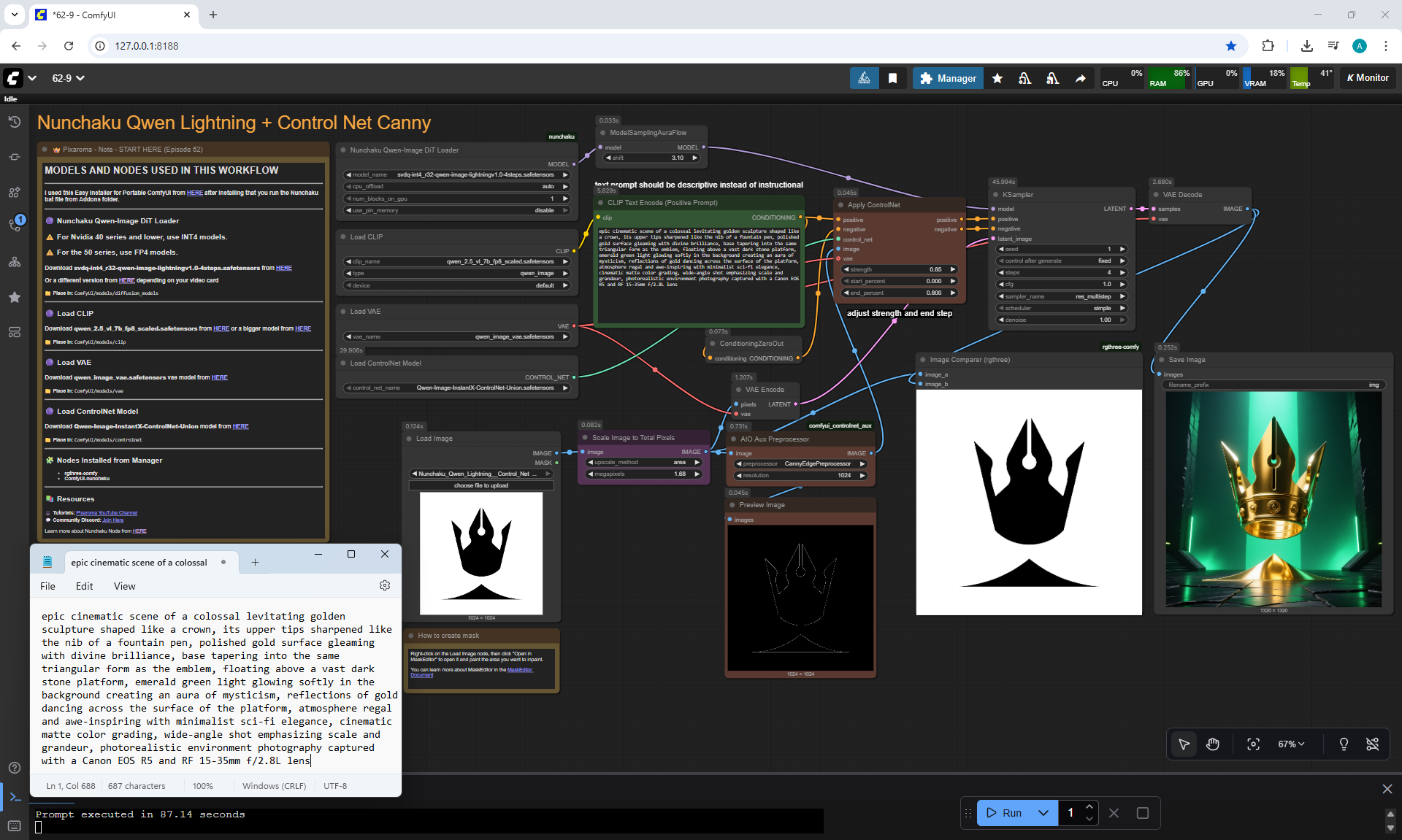
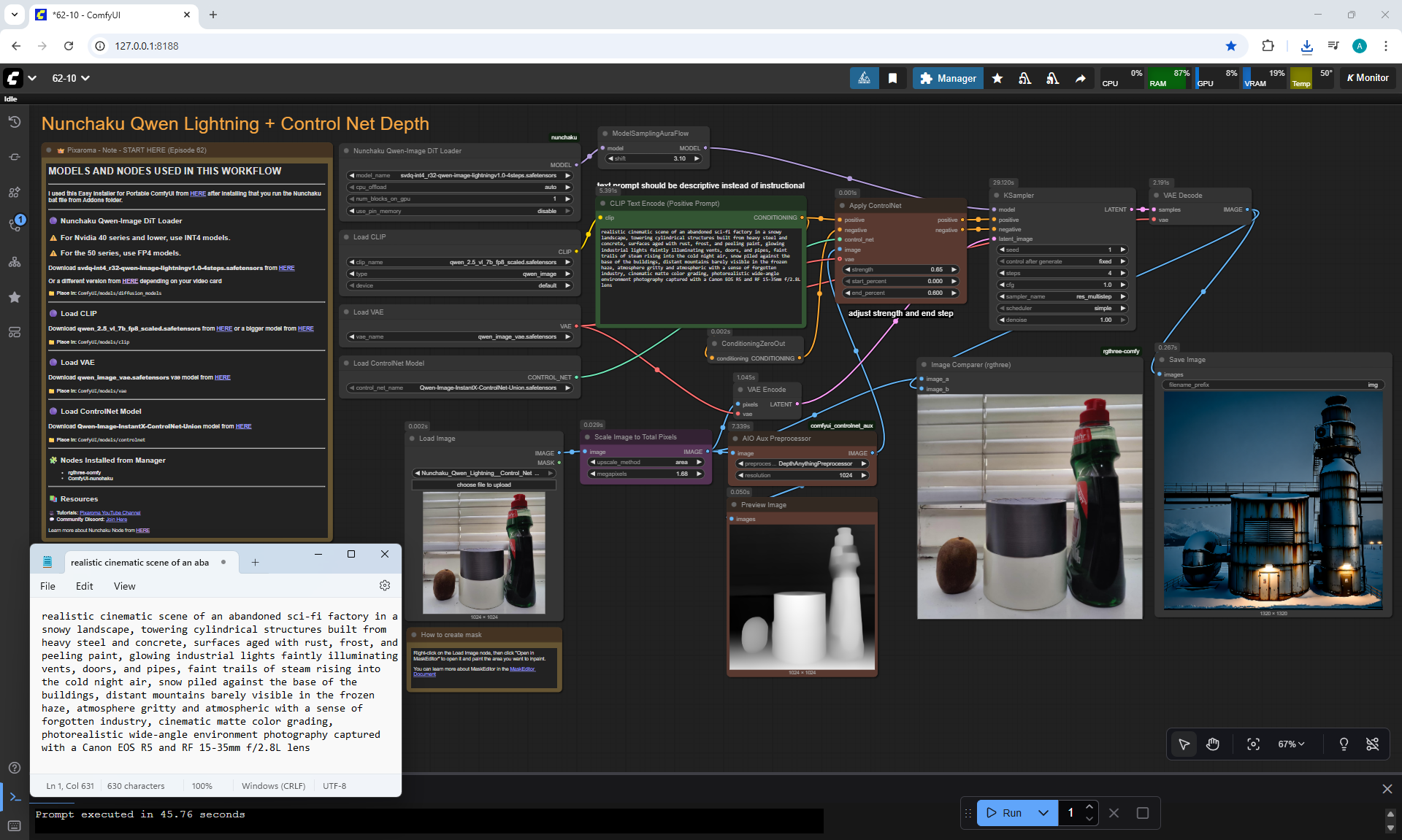
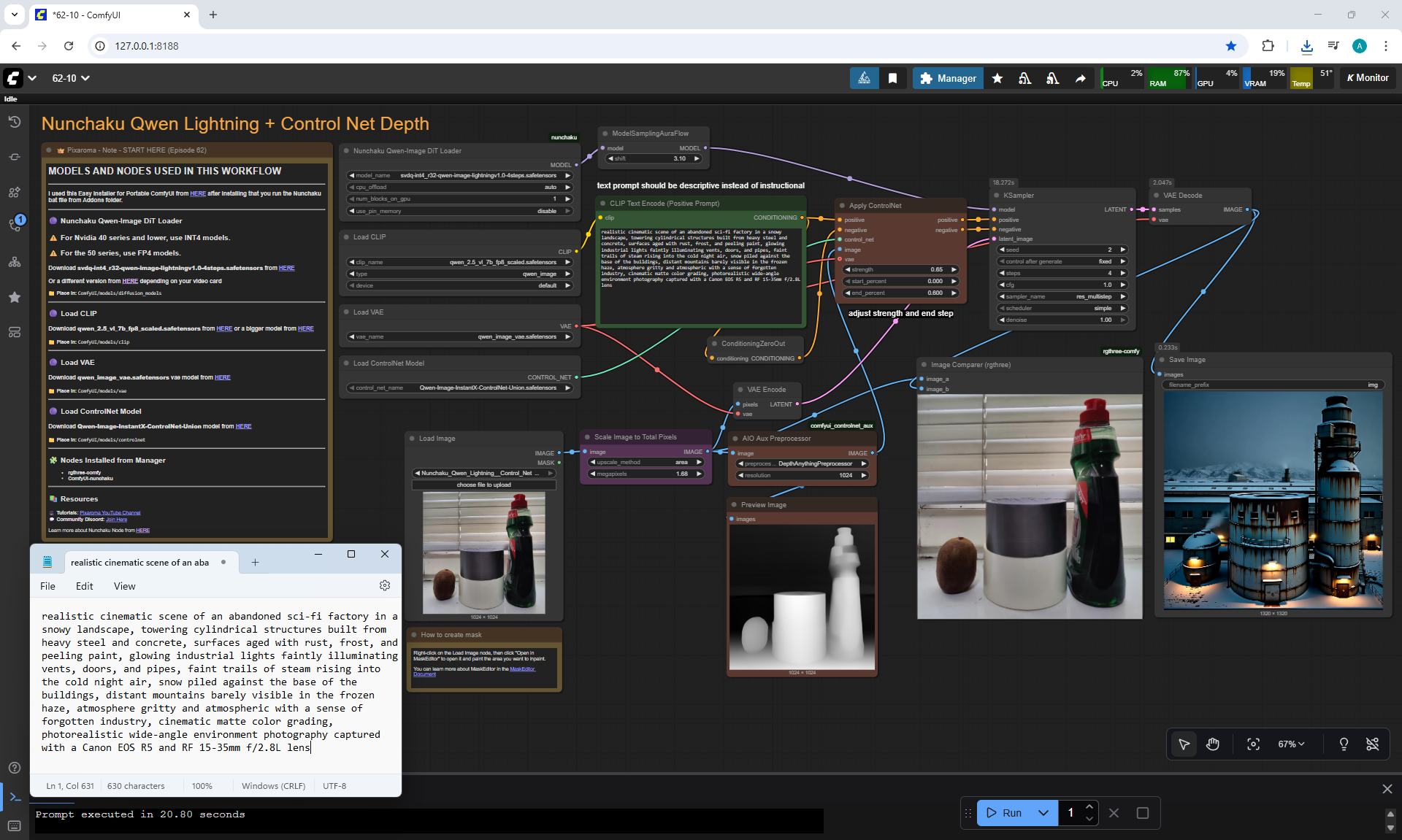
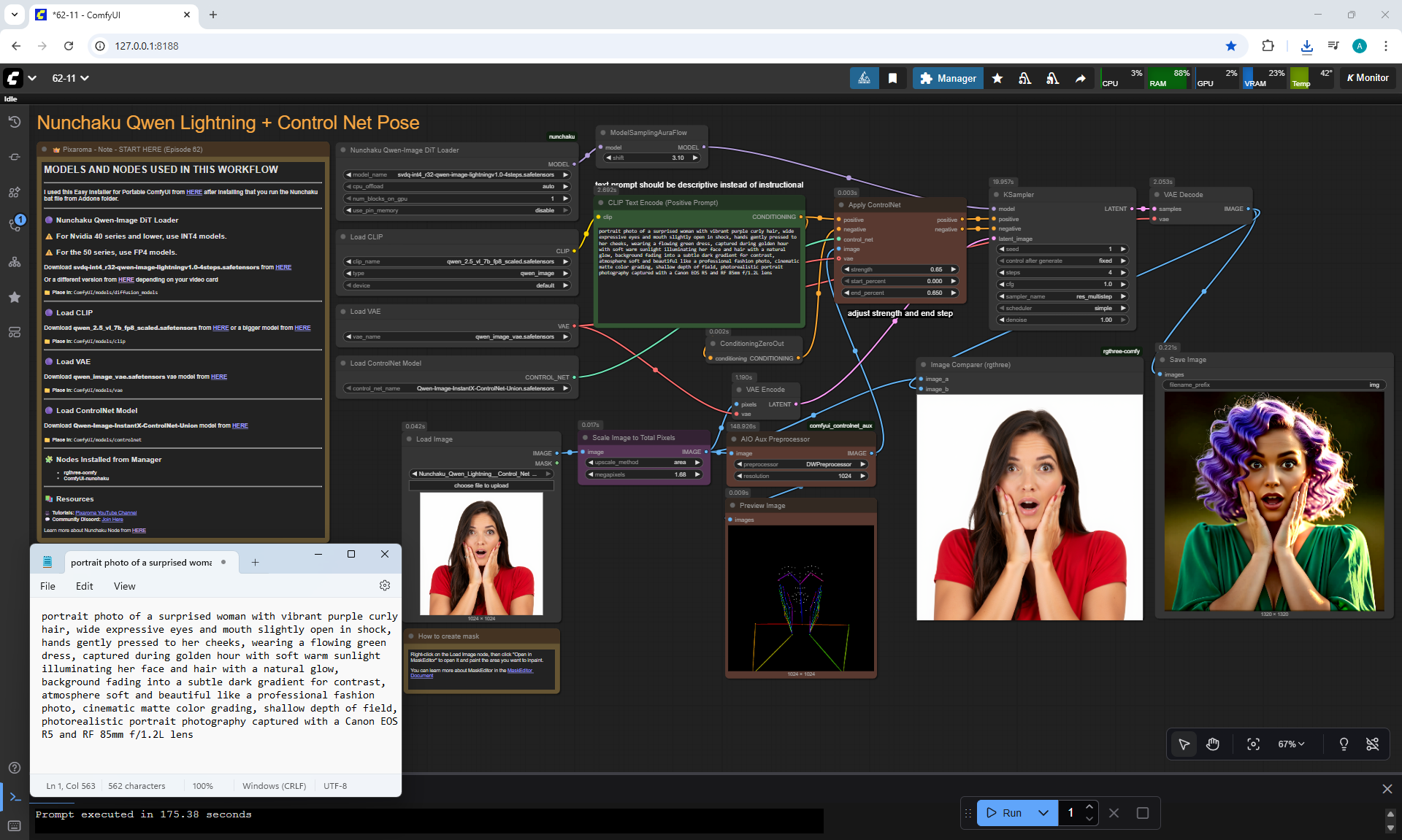
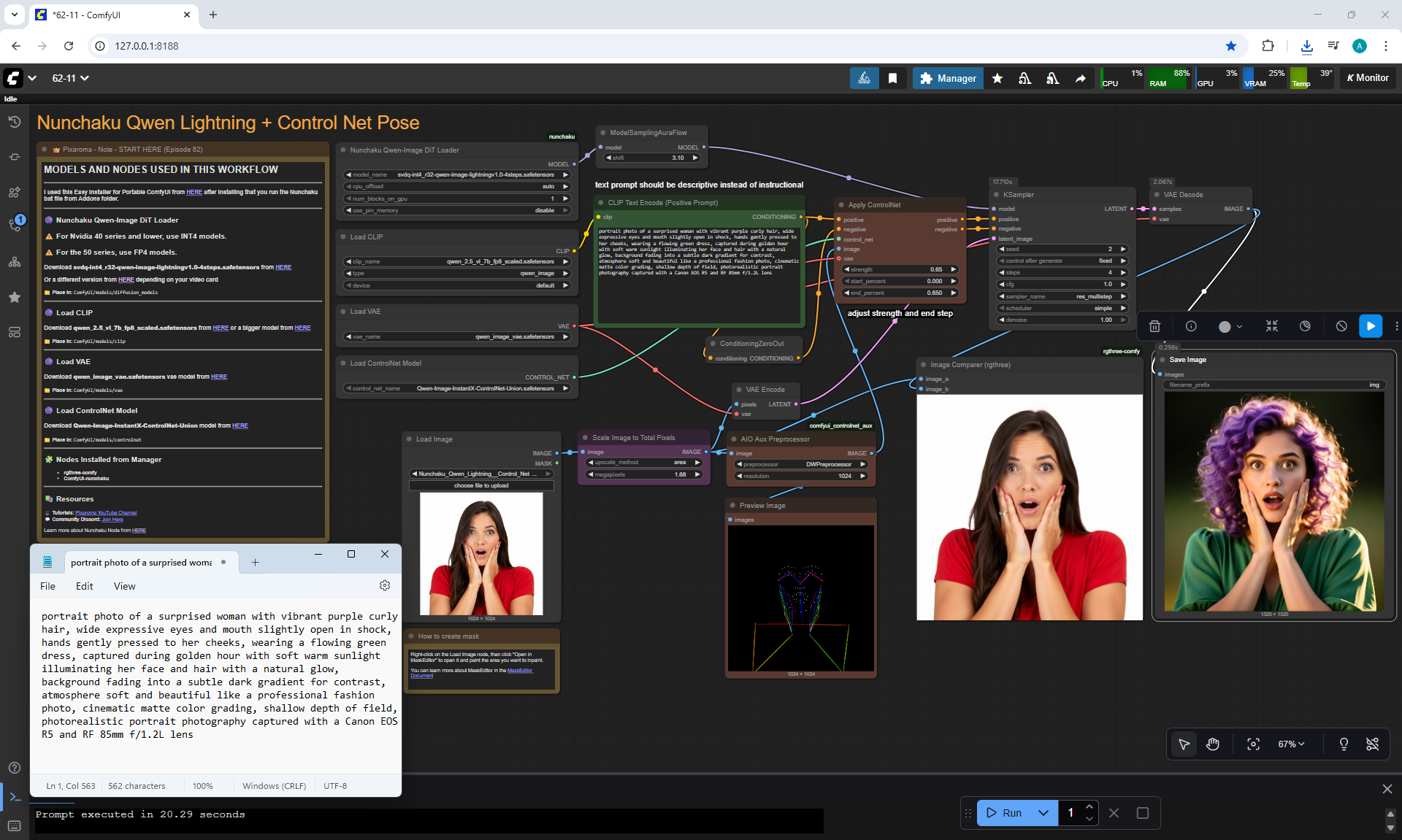
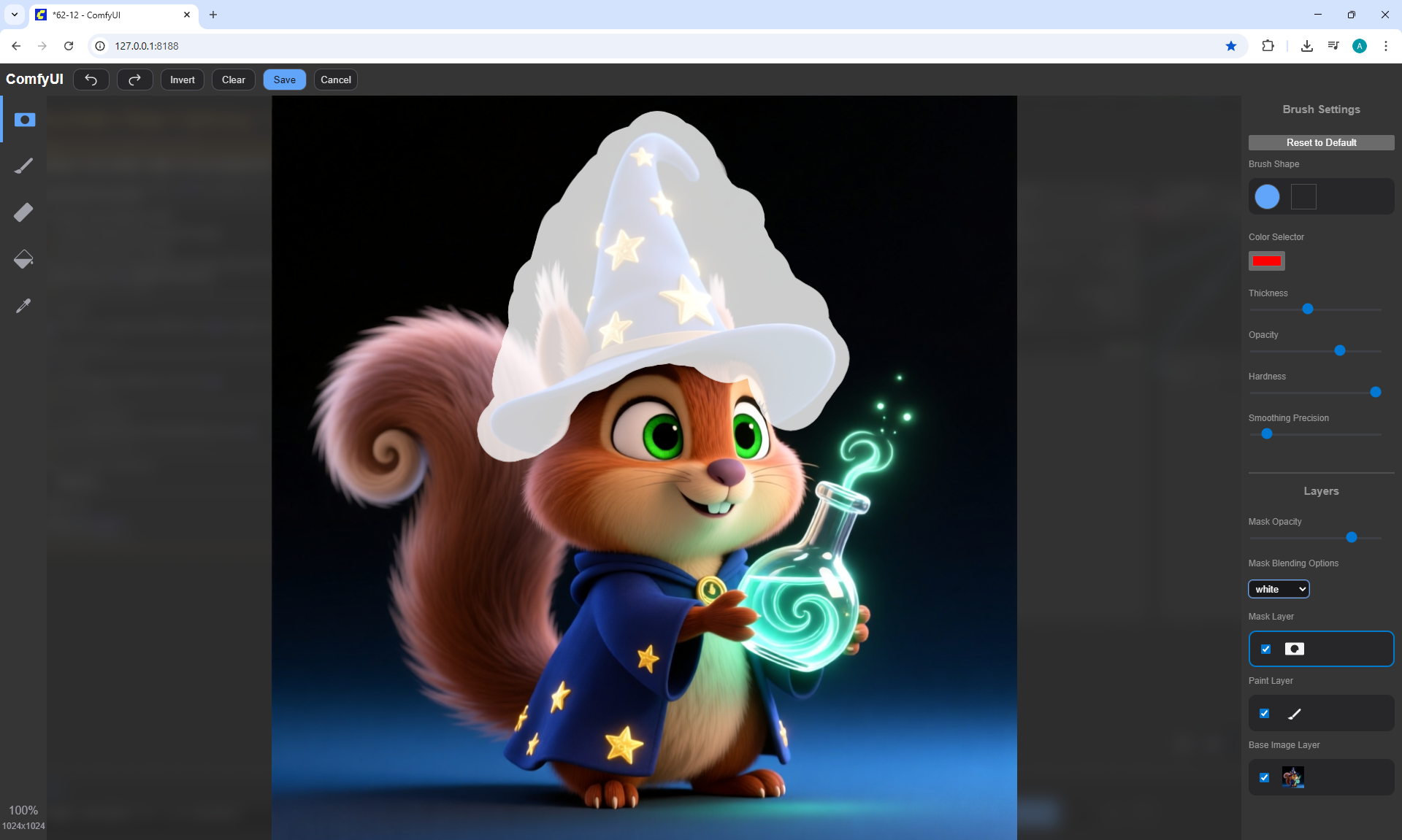
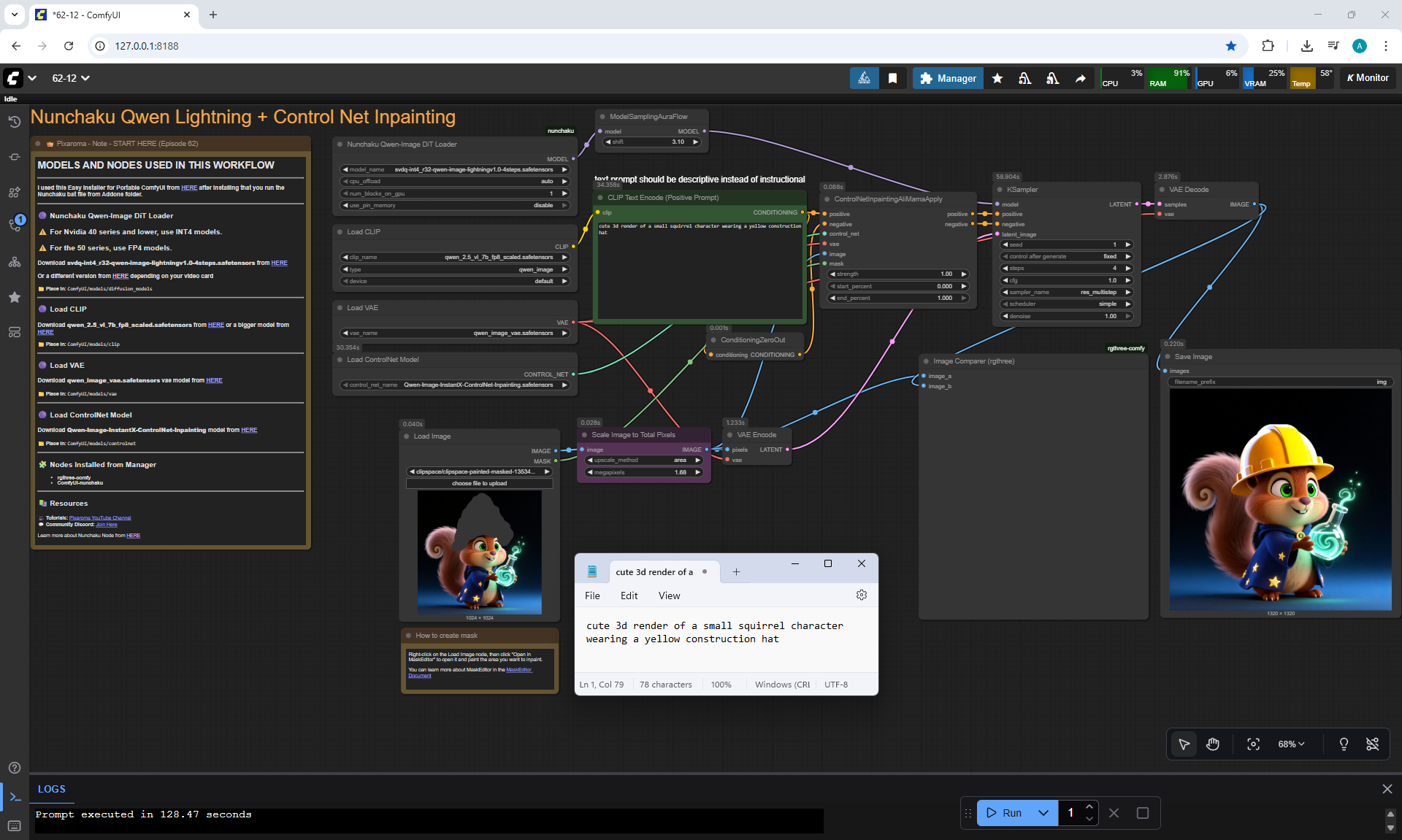
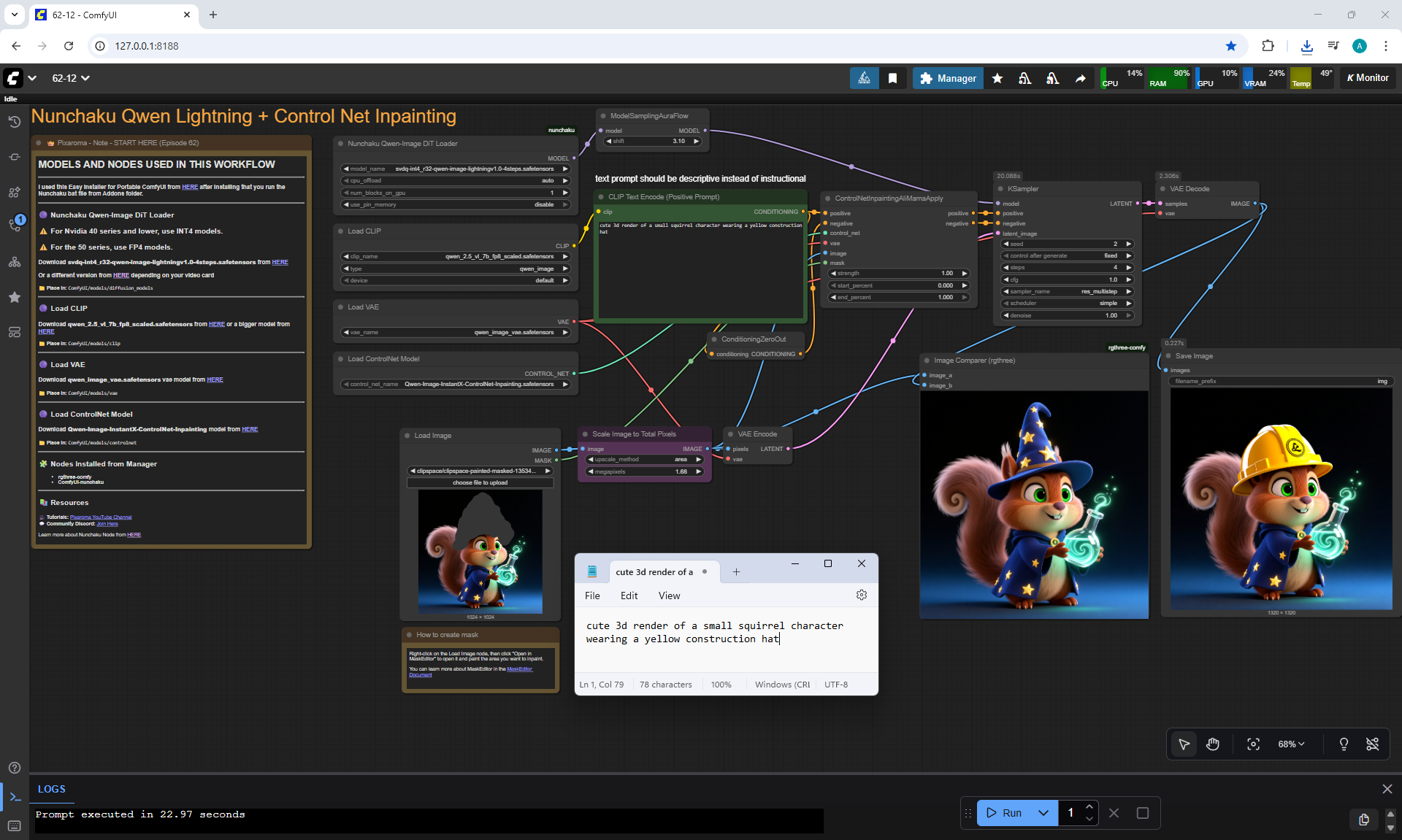
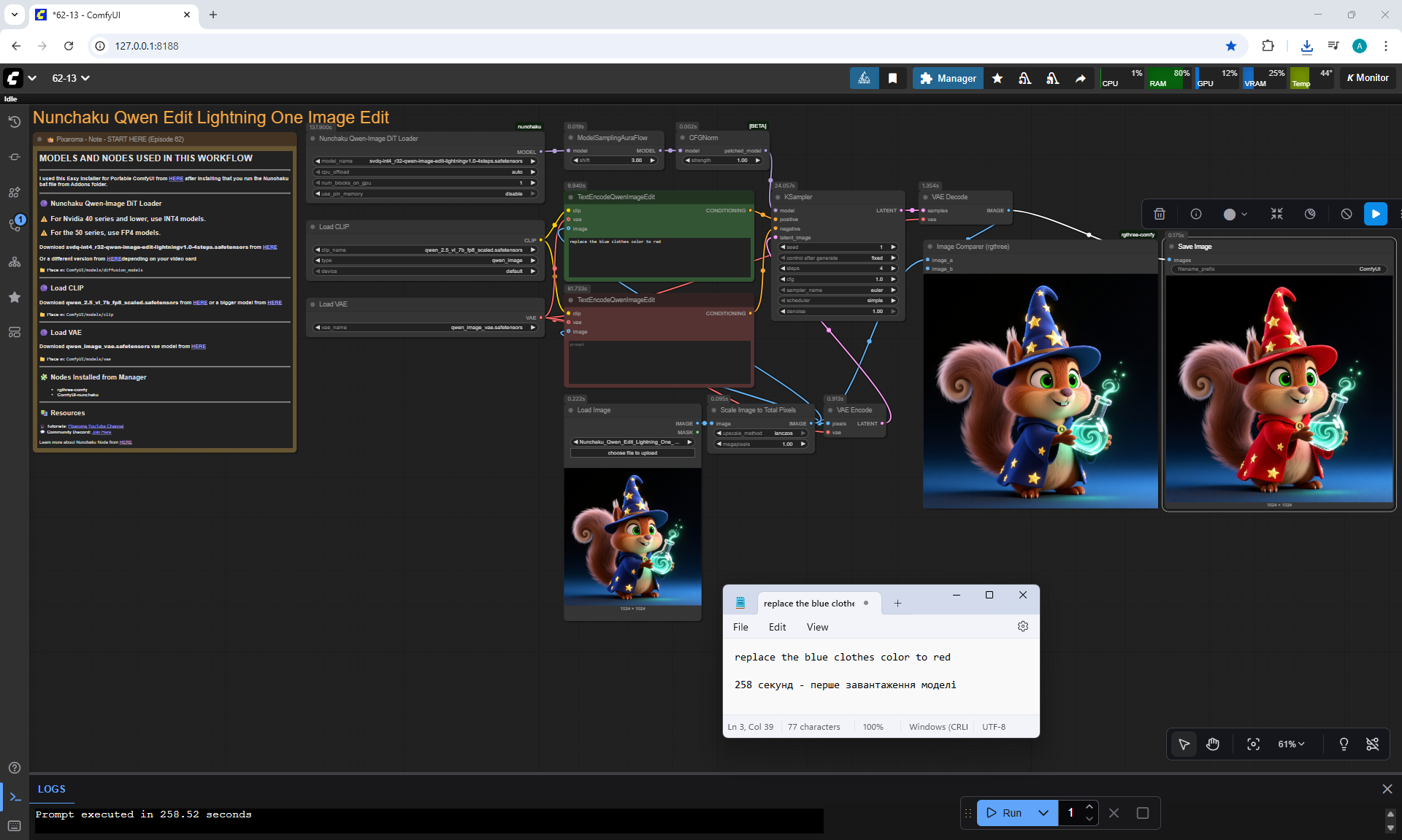
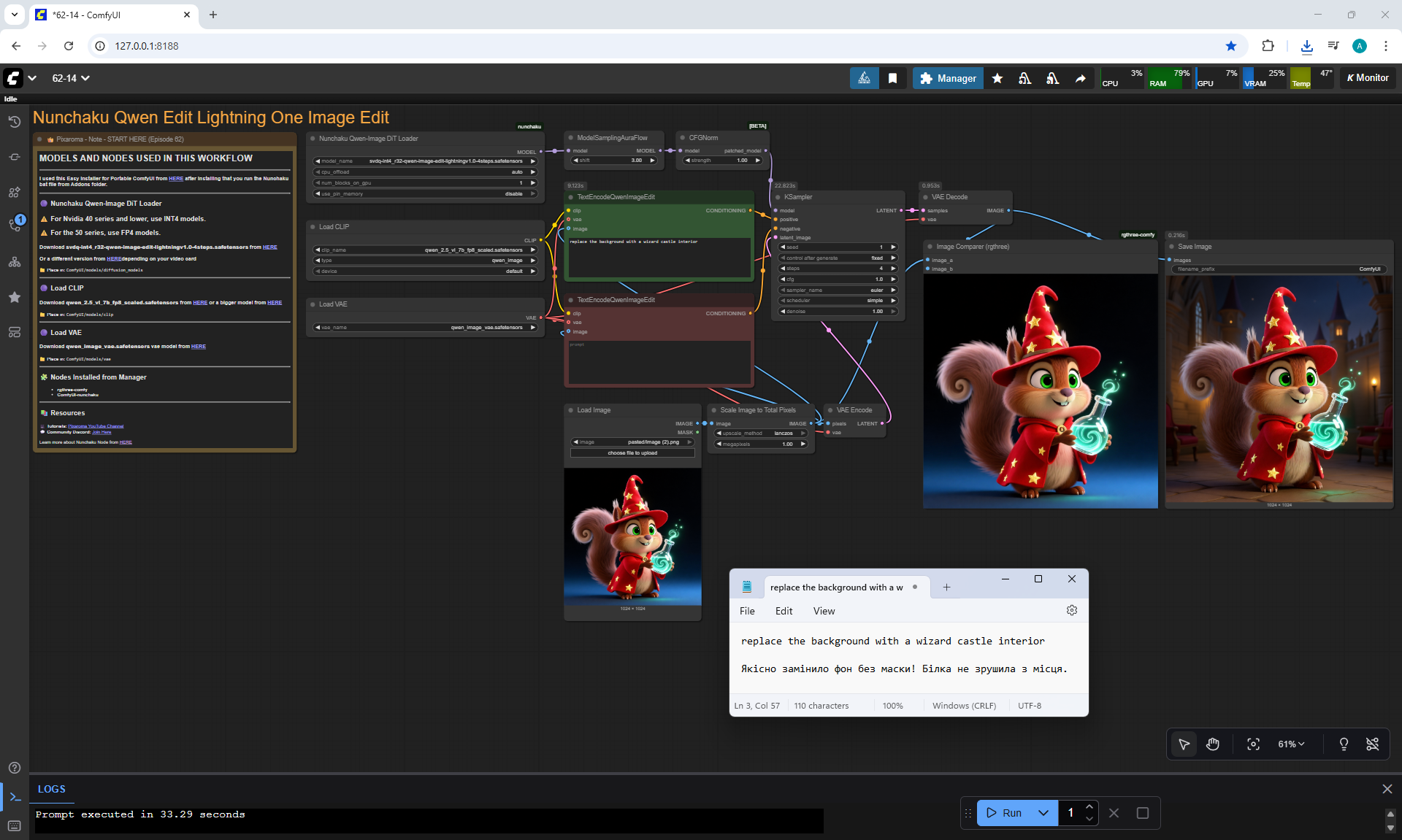
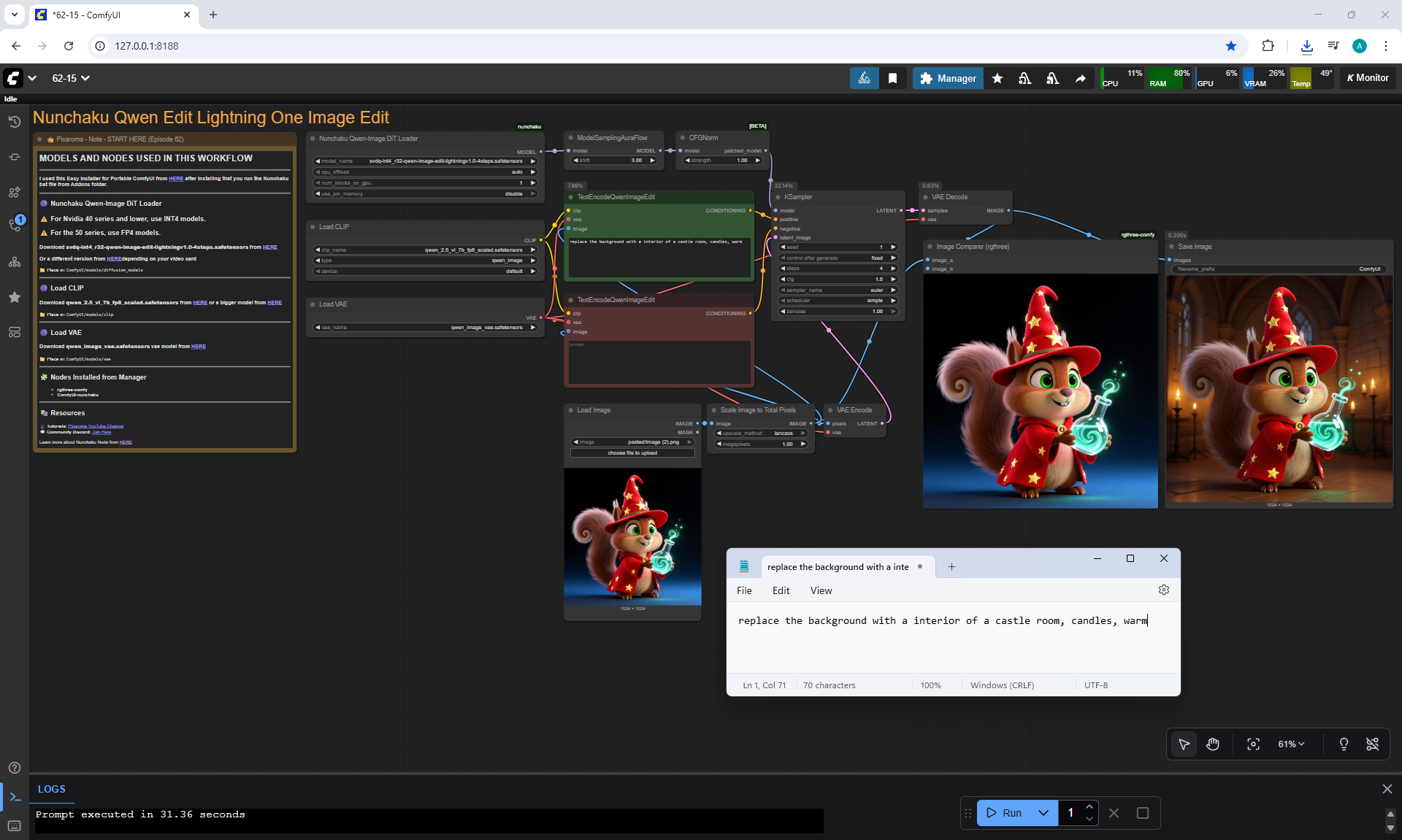
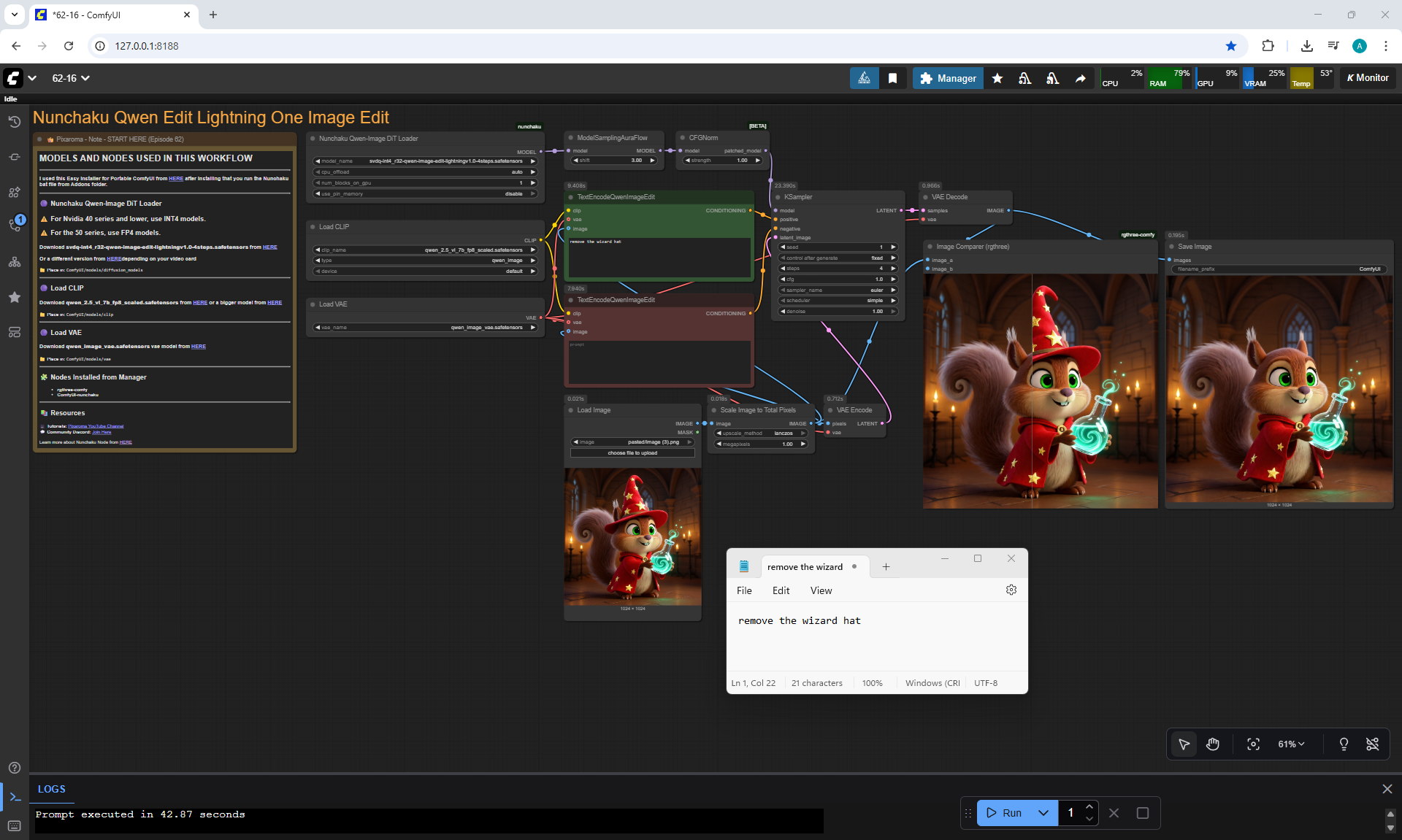
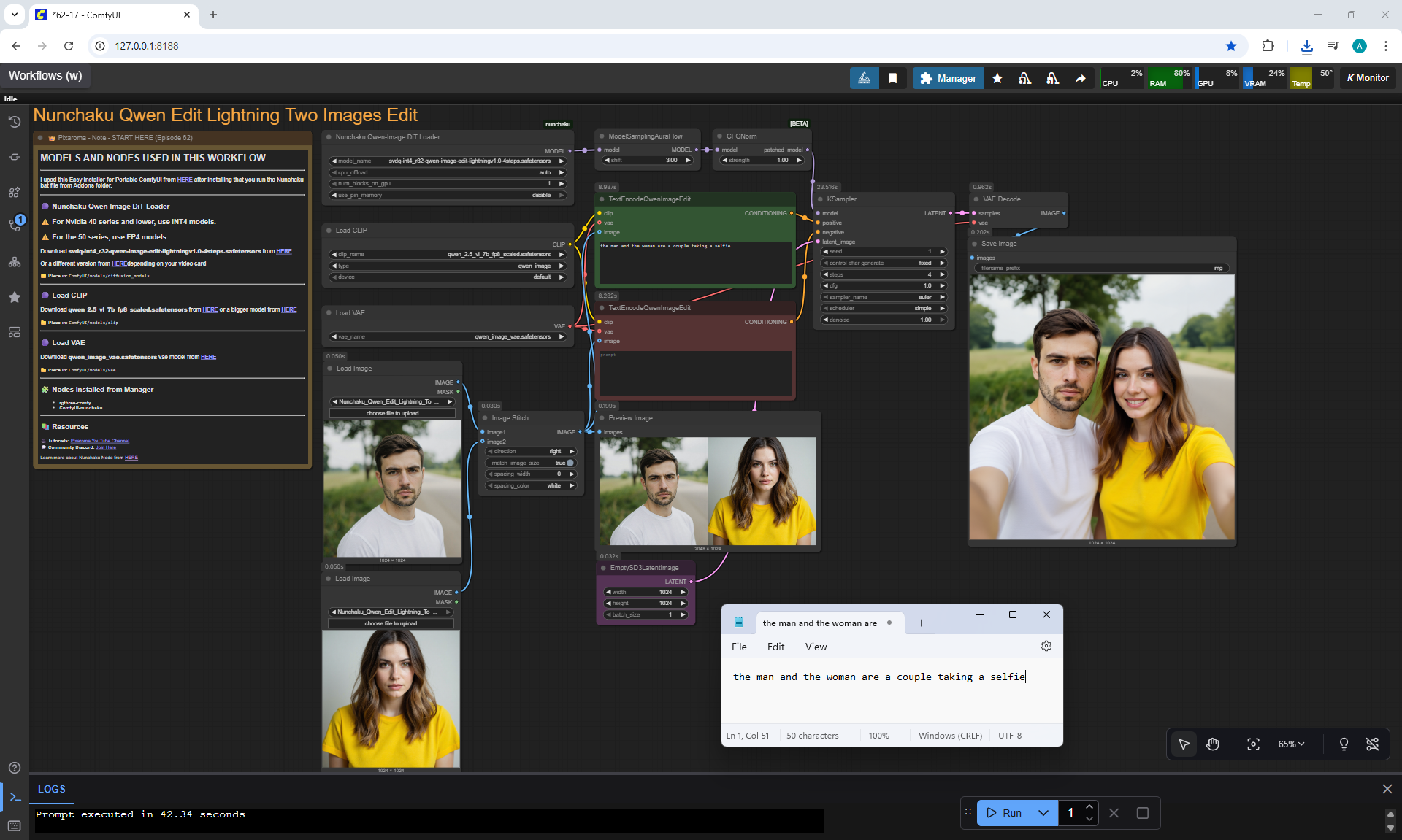
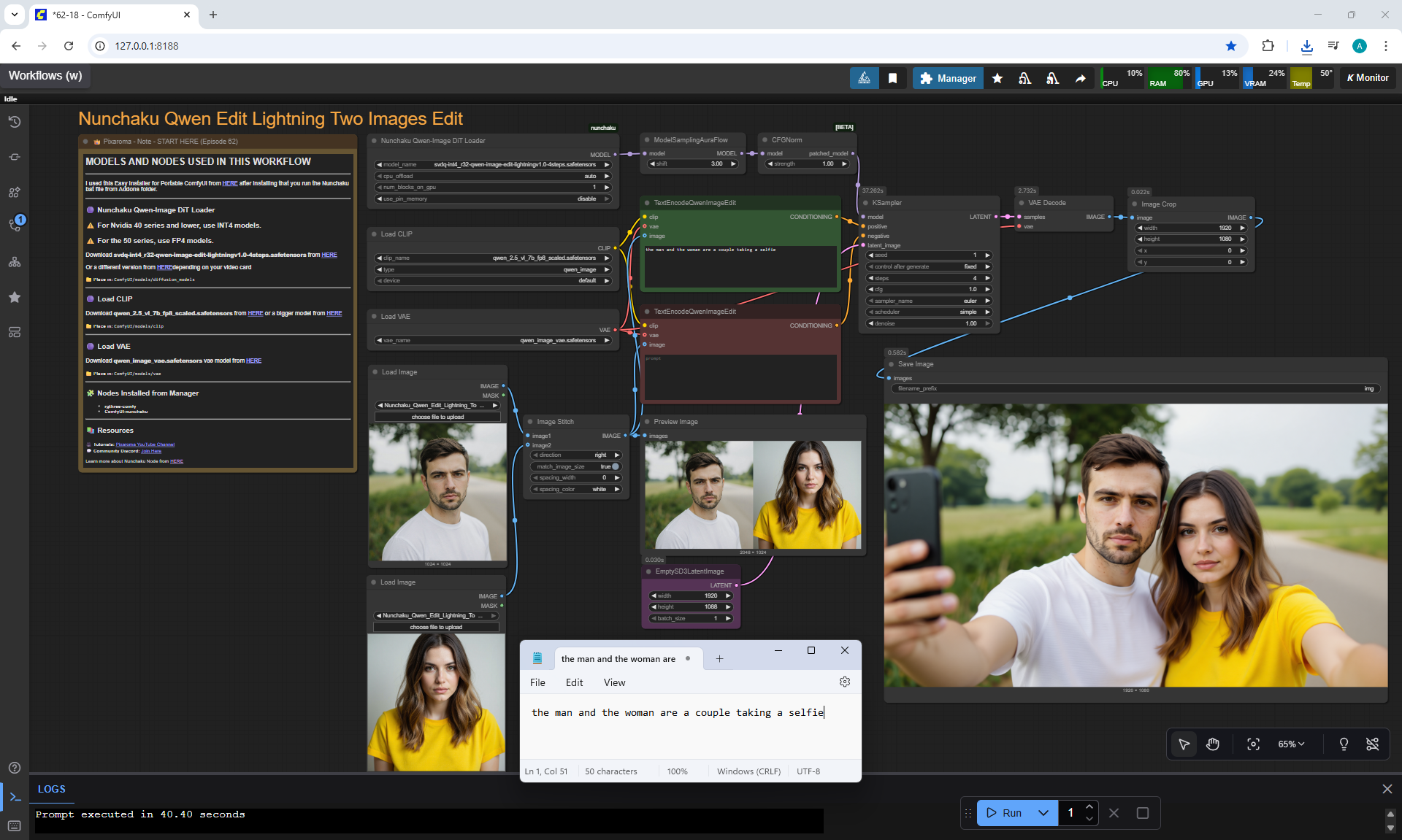
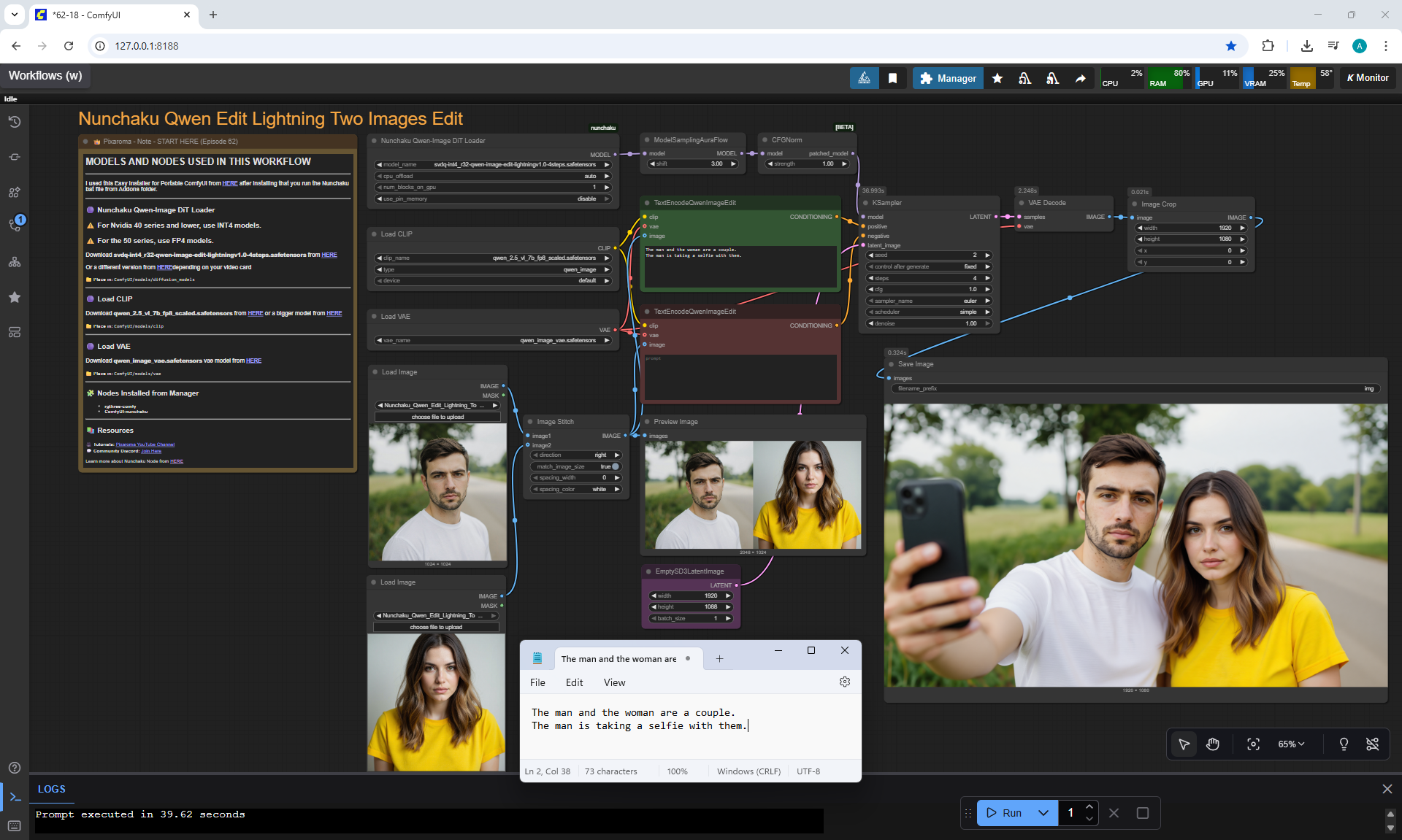
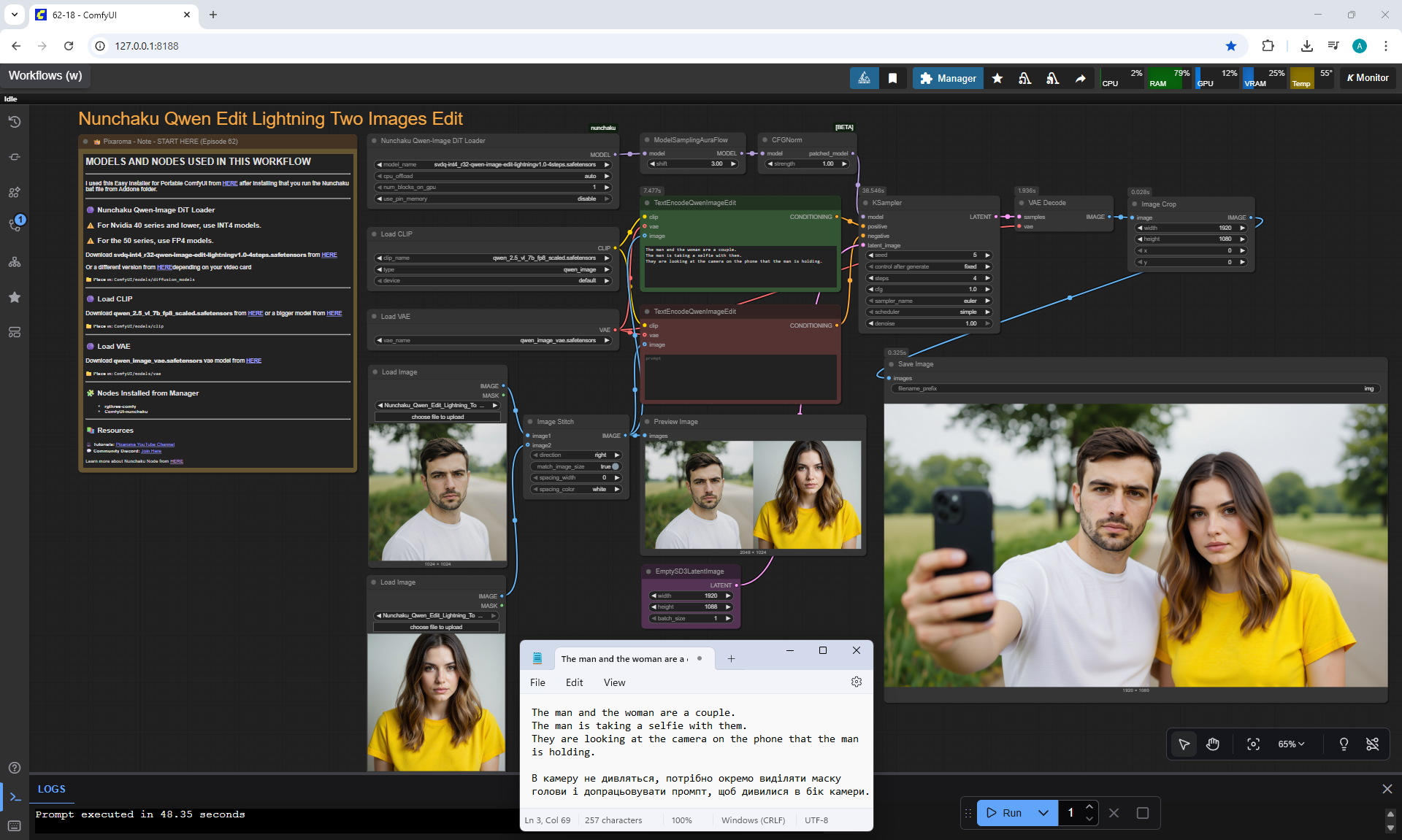
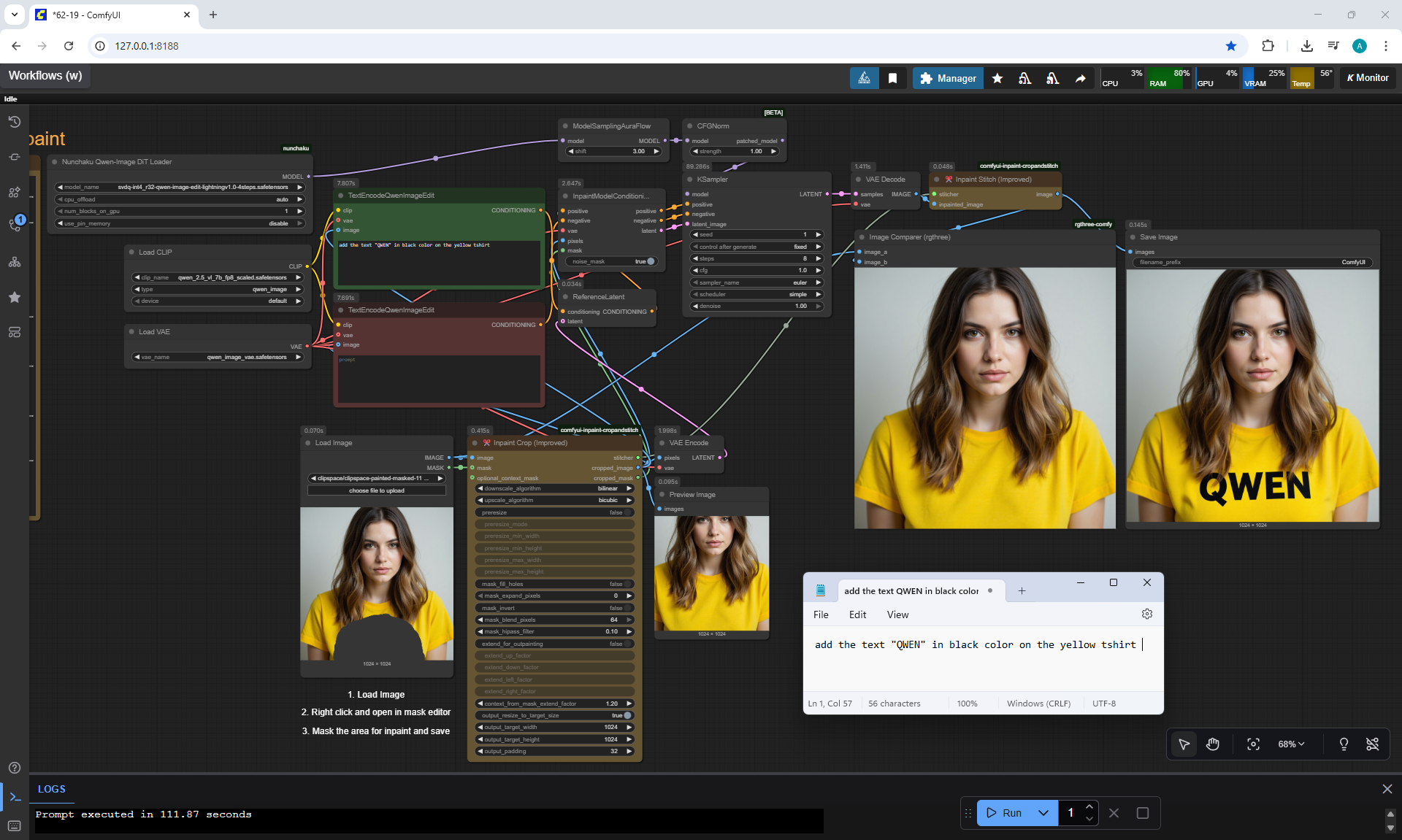
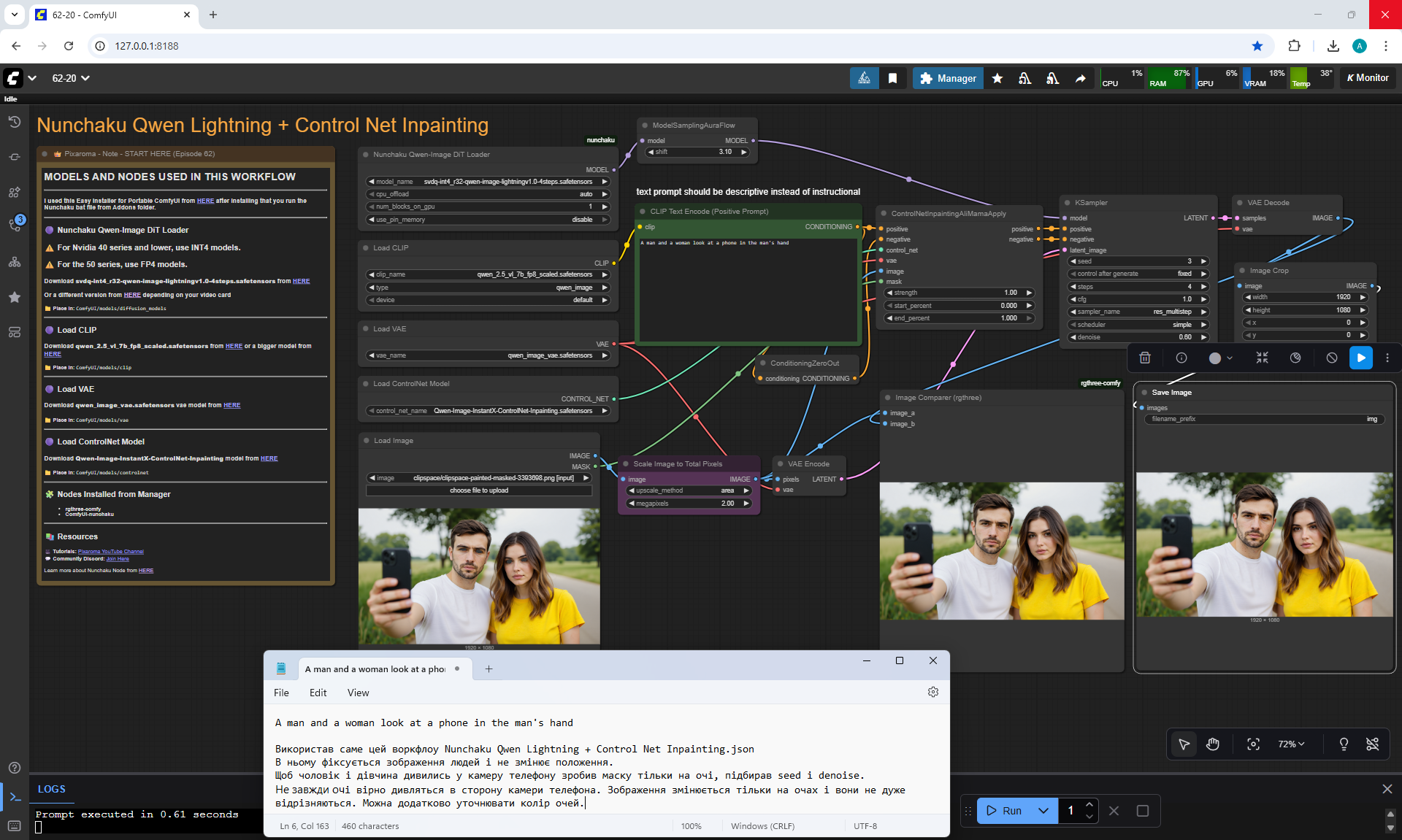
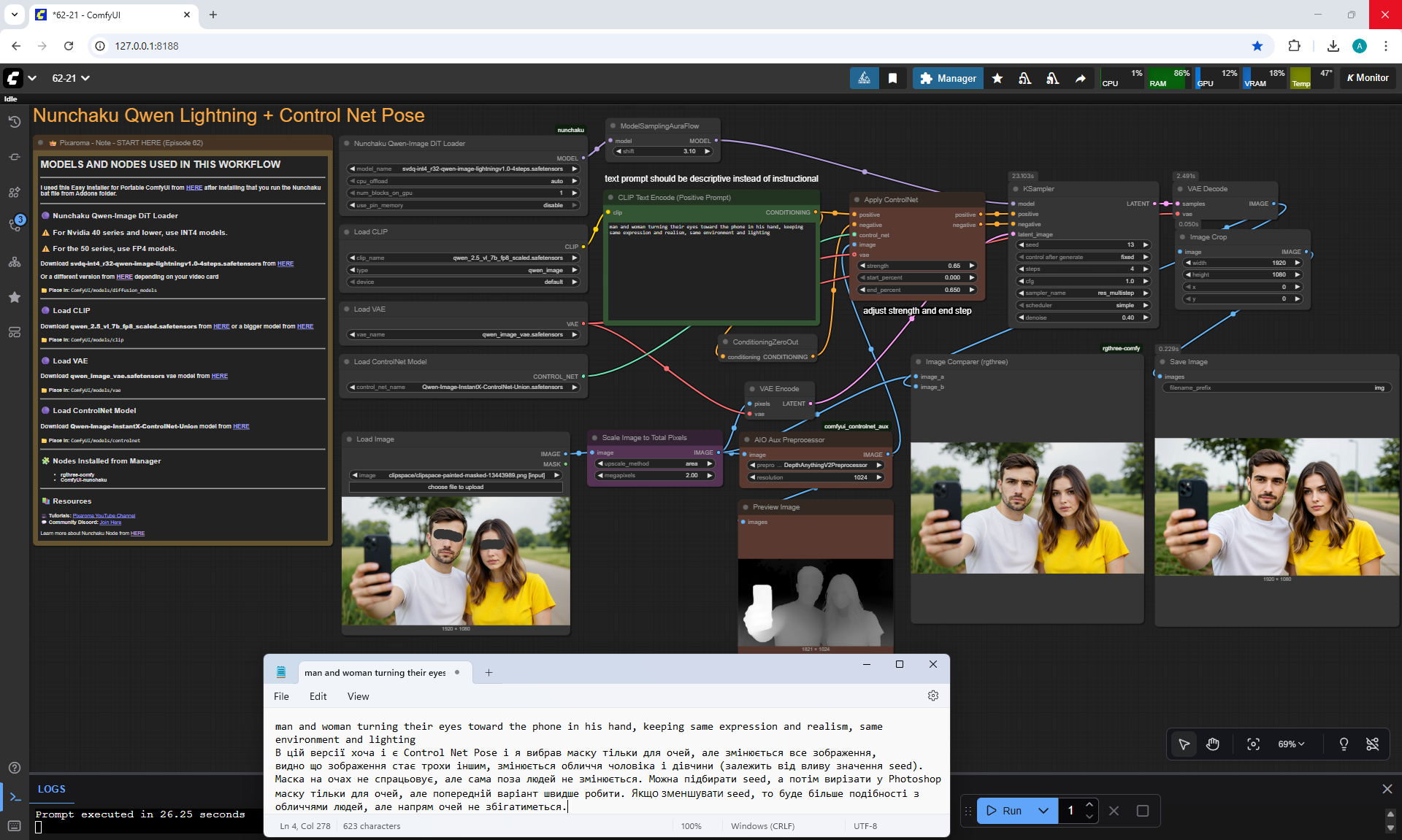
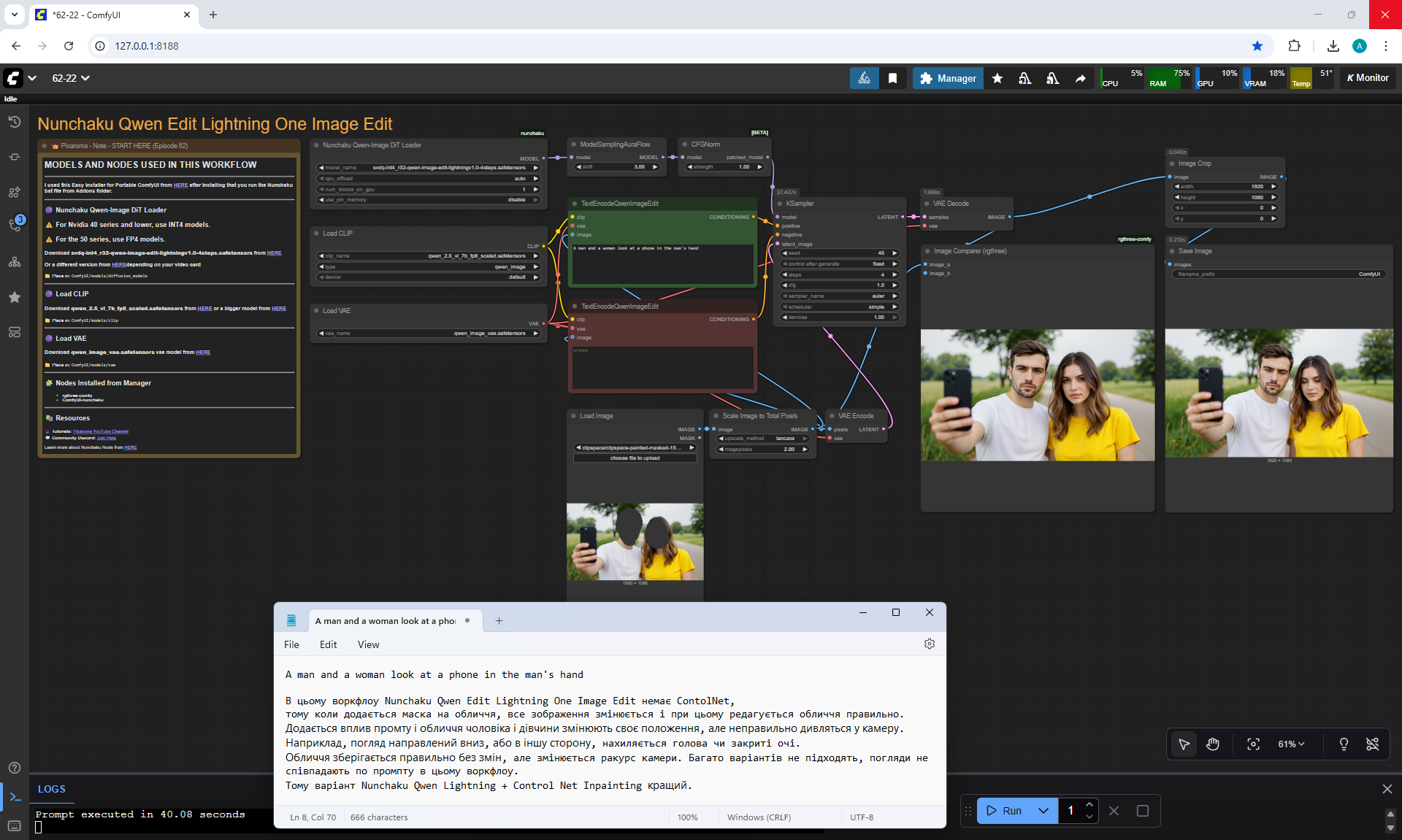
Ep62 - Nunchaku Update | Qwen Control Net, Qwen Edit & Inpa..
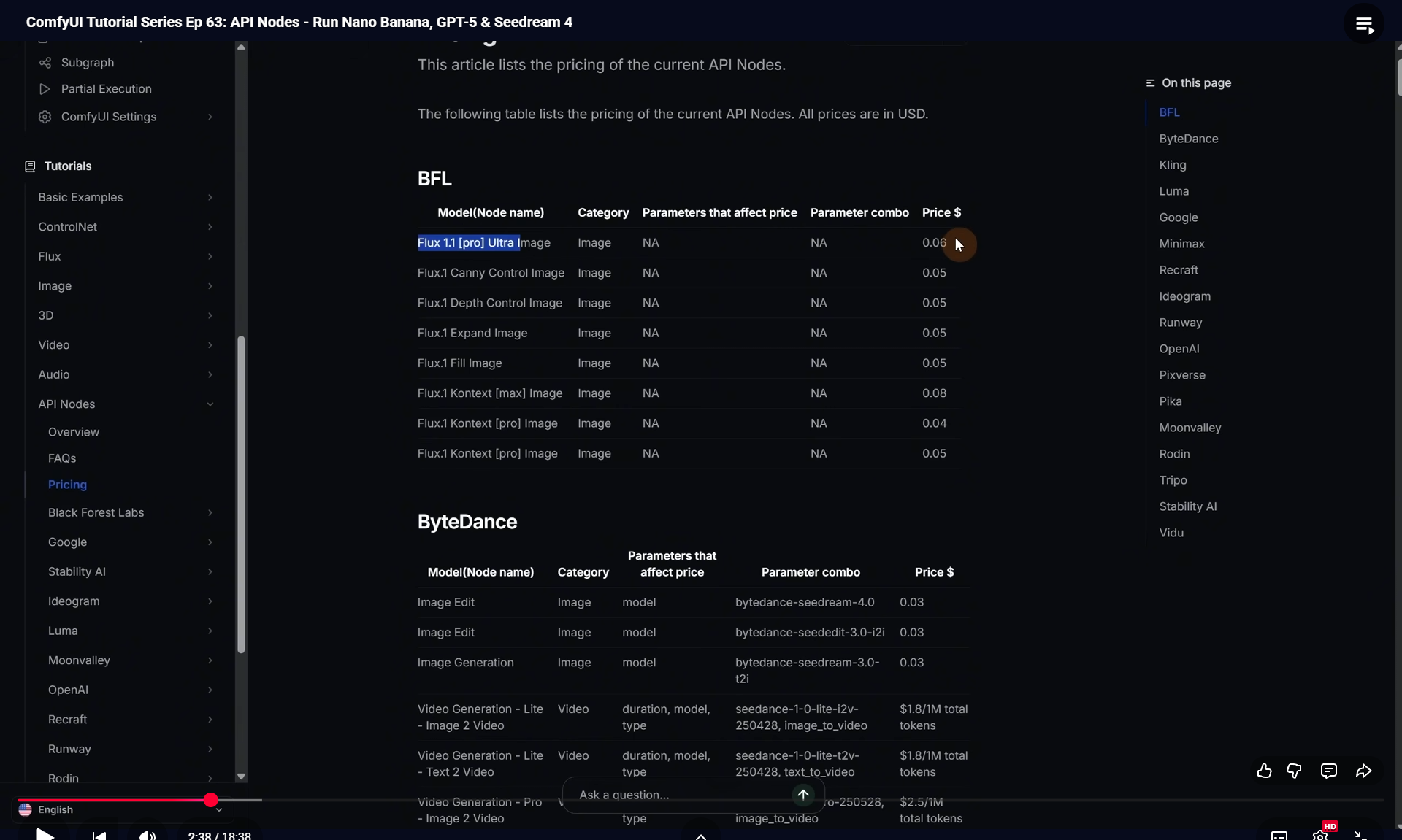
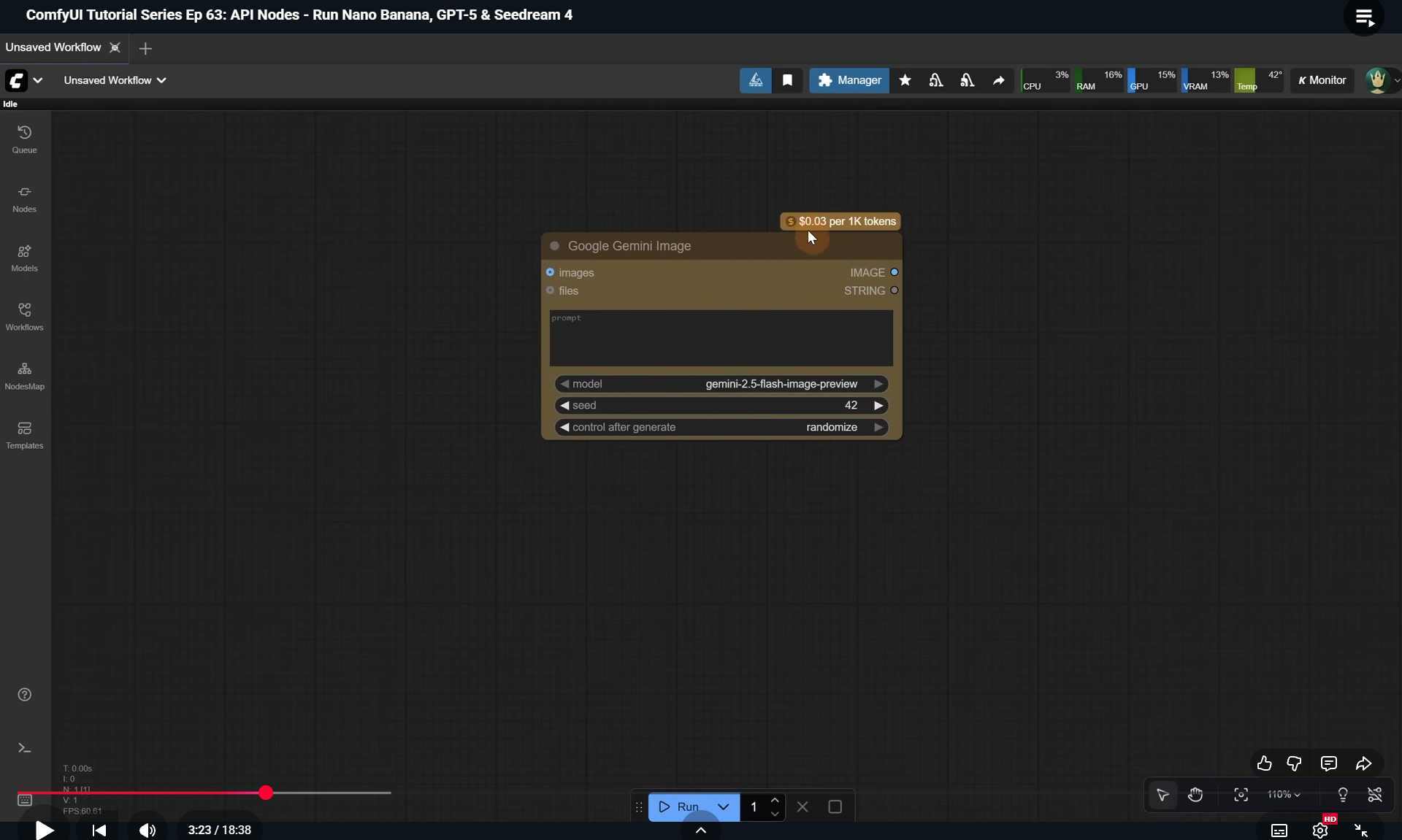
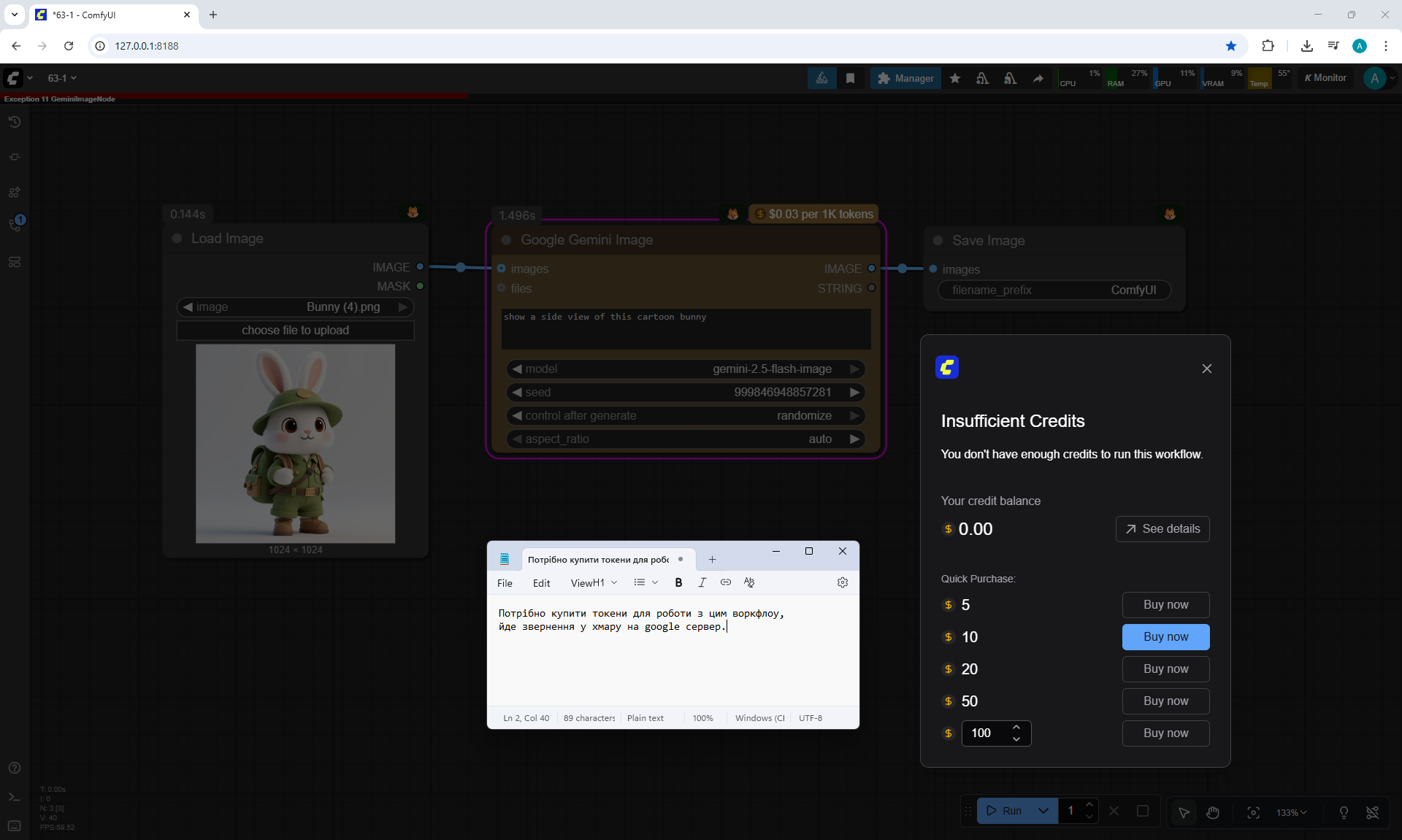
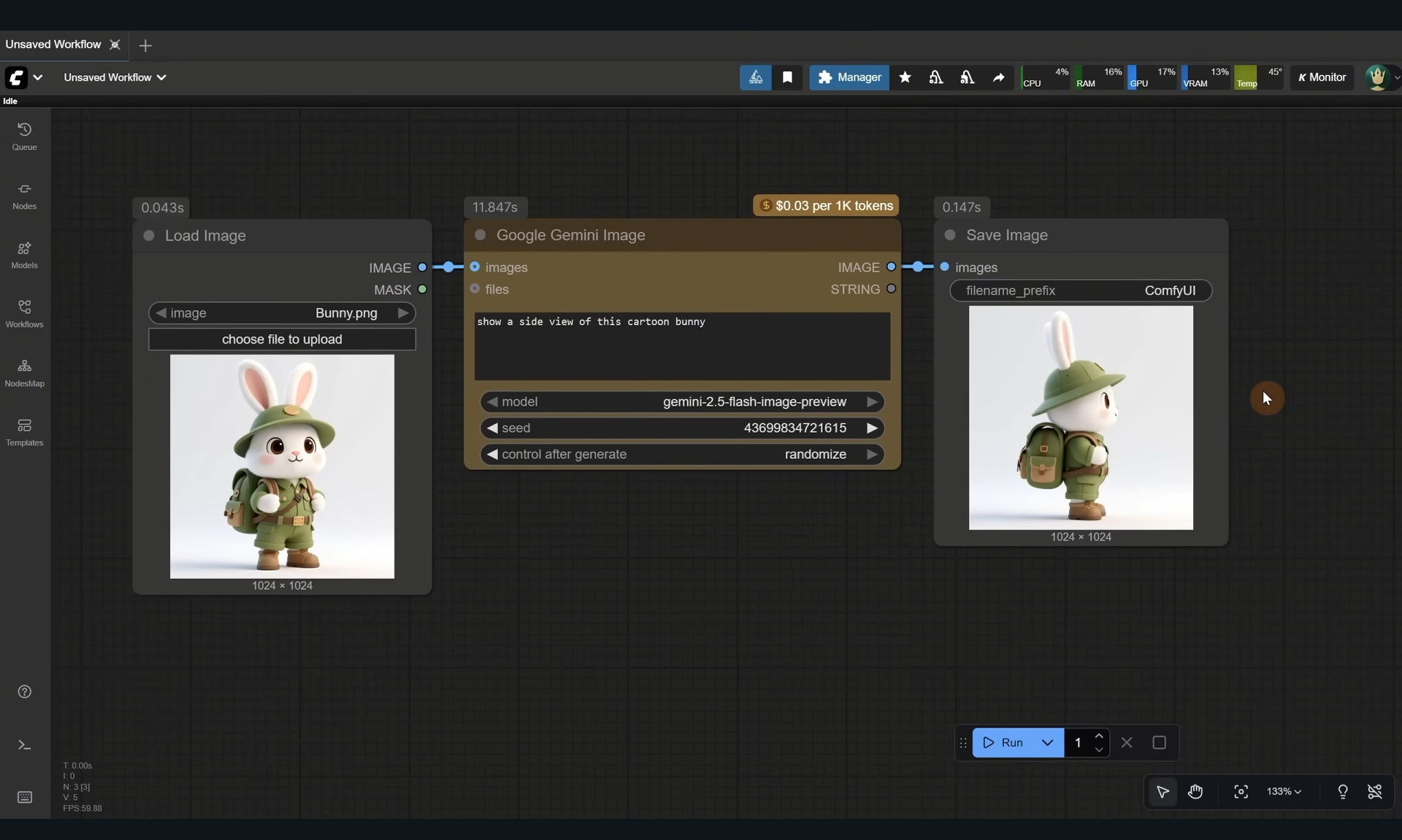
Ep63 - API Nodes - Run Nano Banana, GPT-5 & Seedream 4
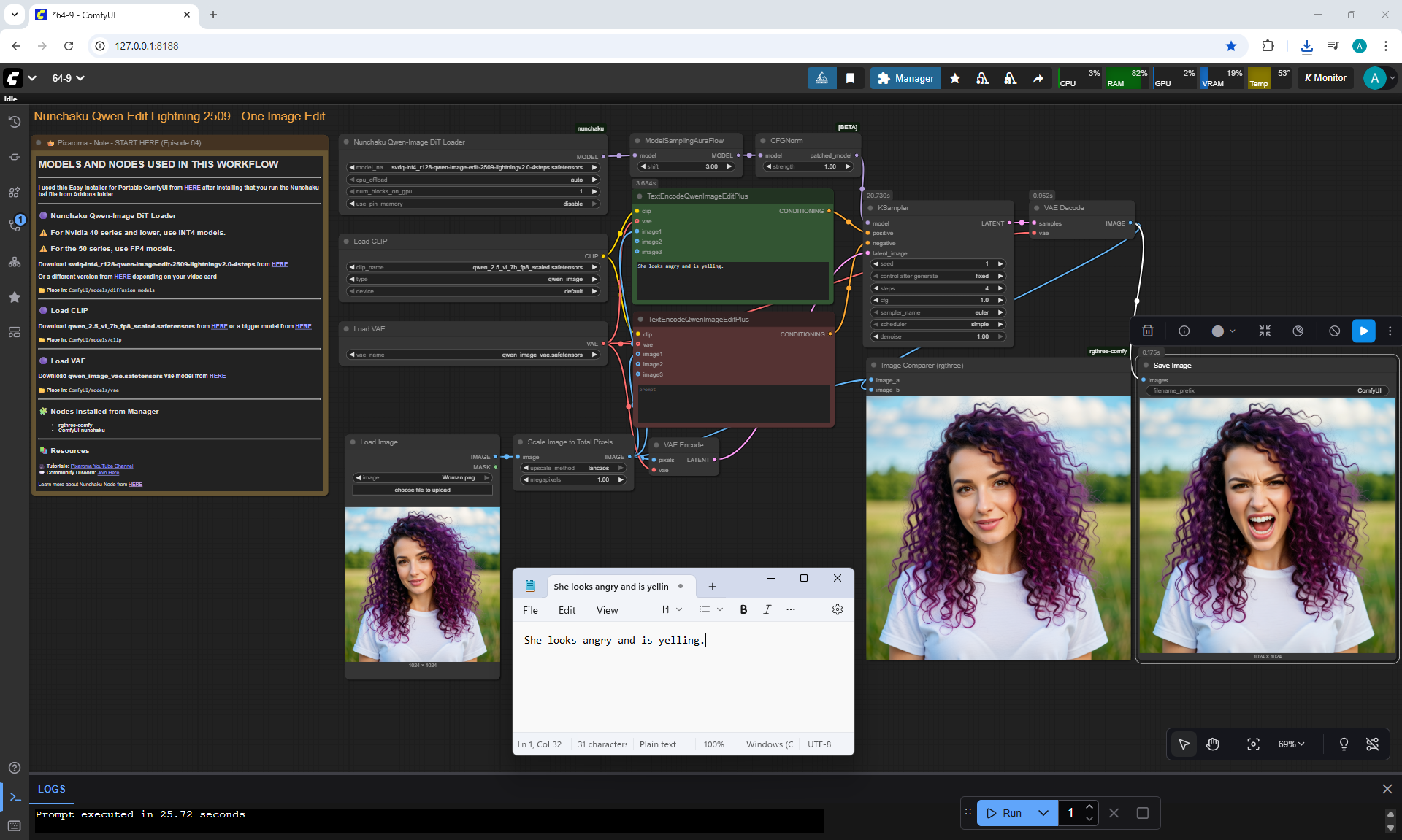
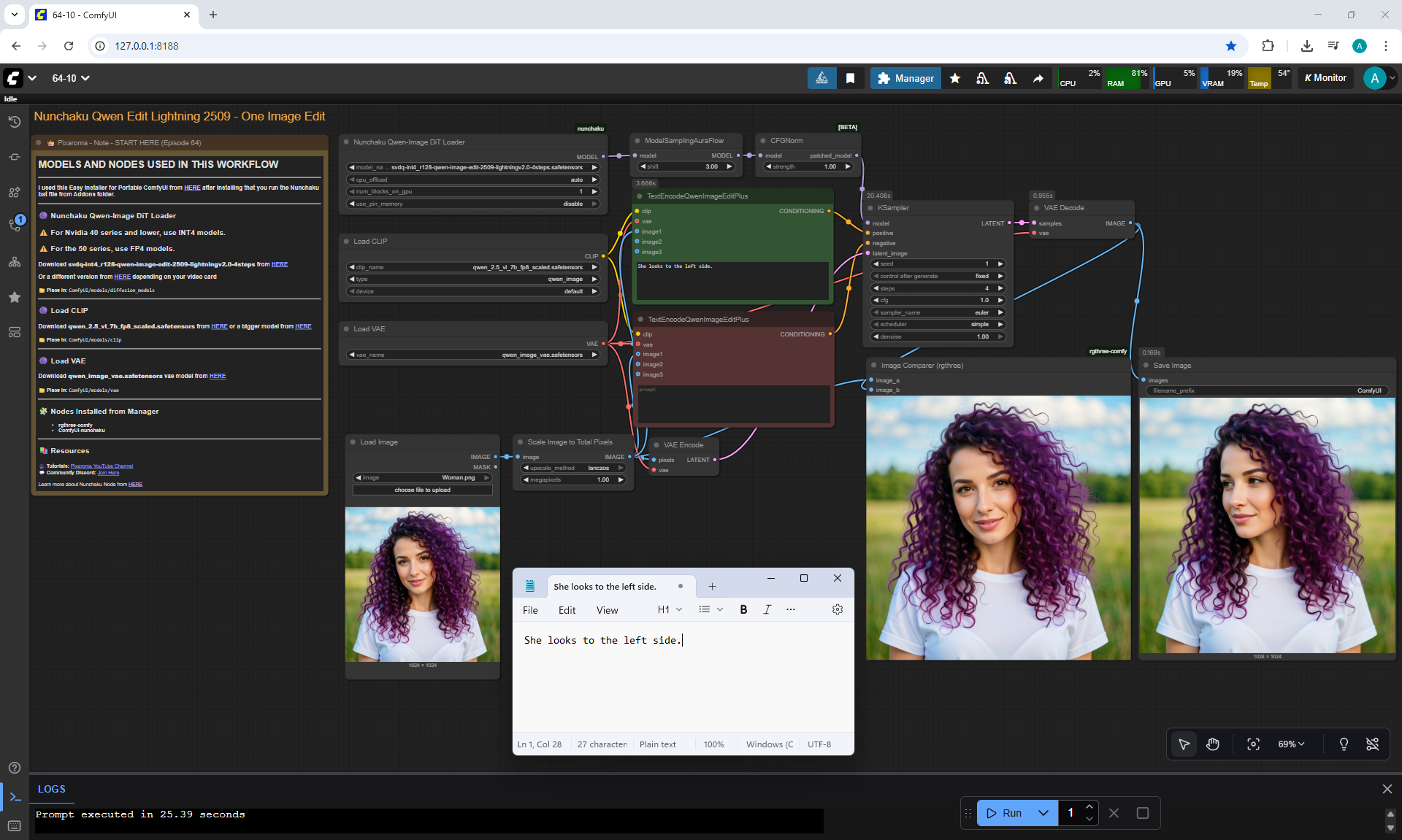
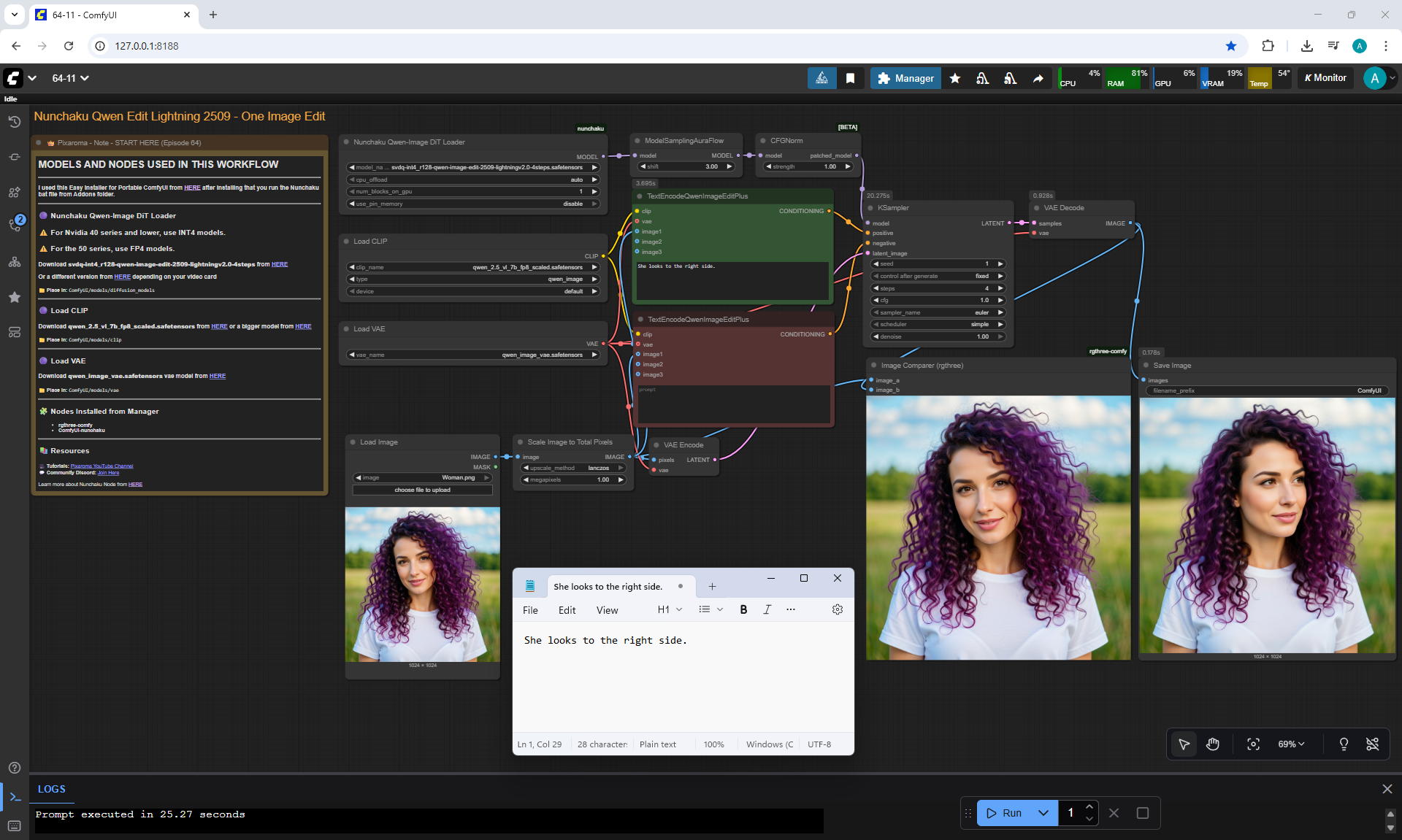
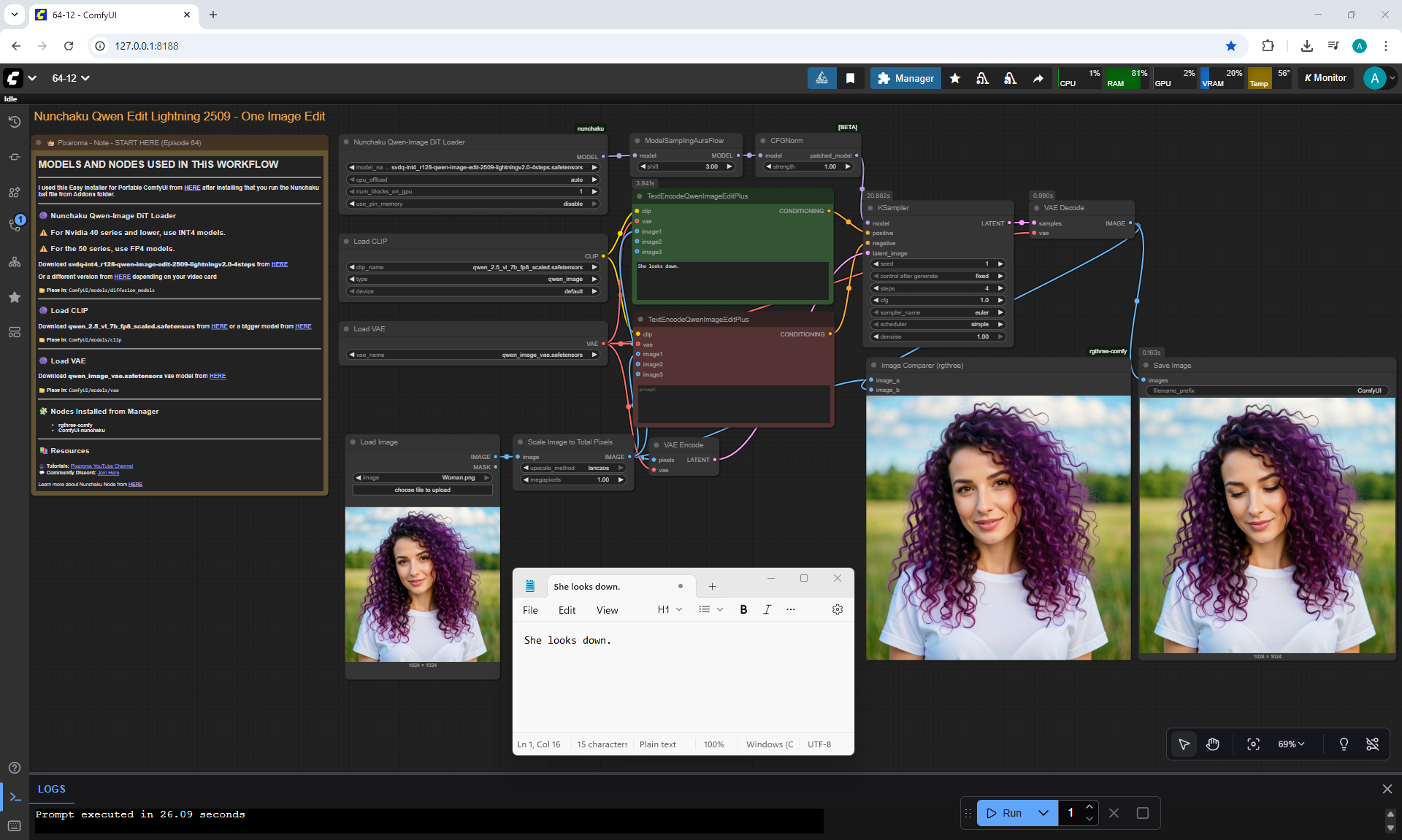
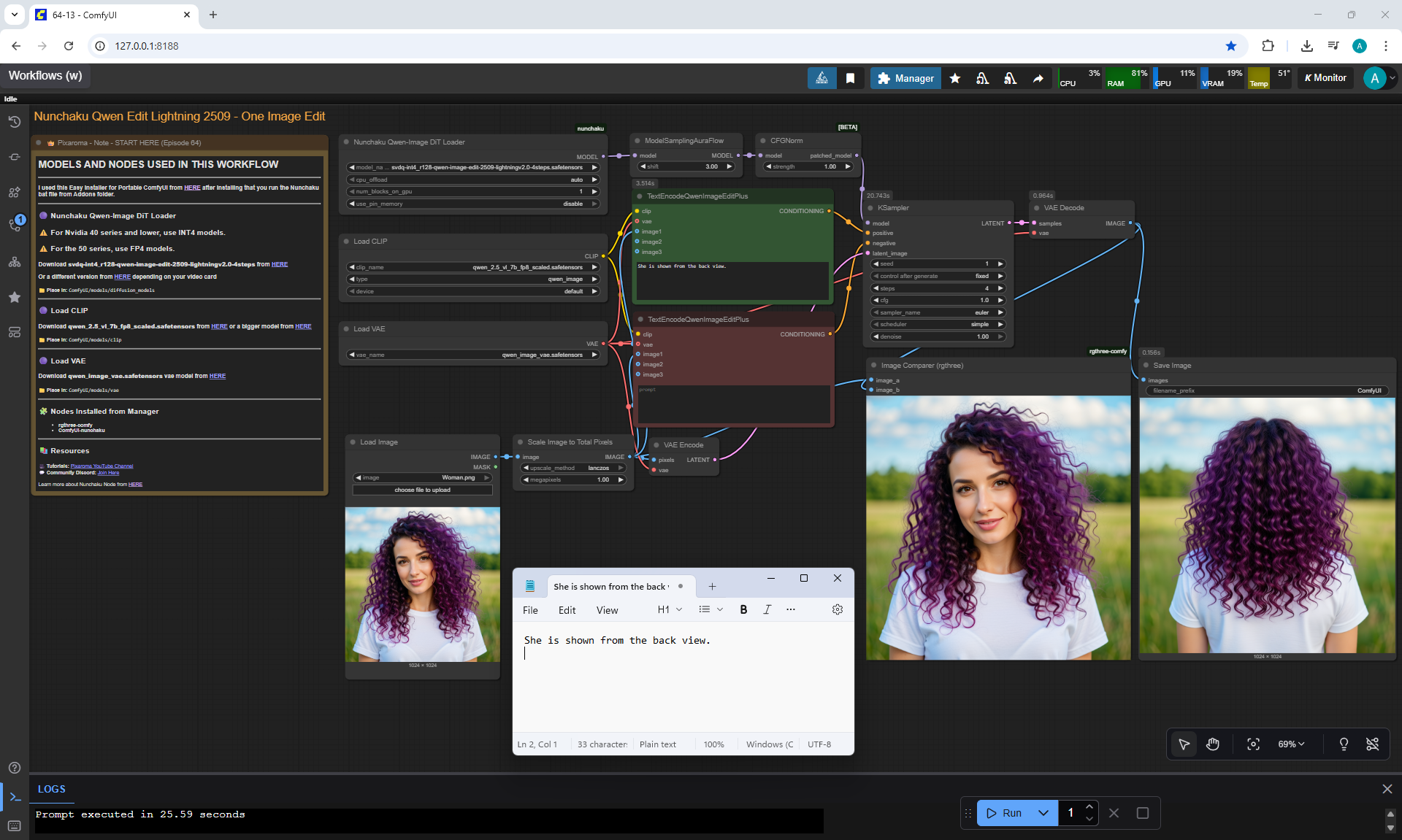
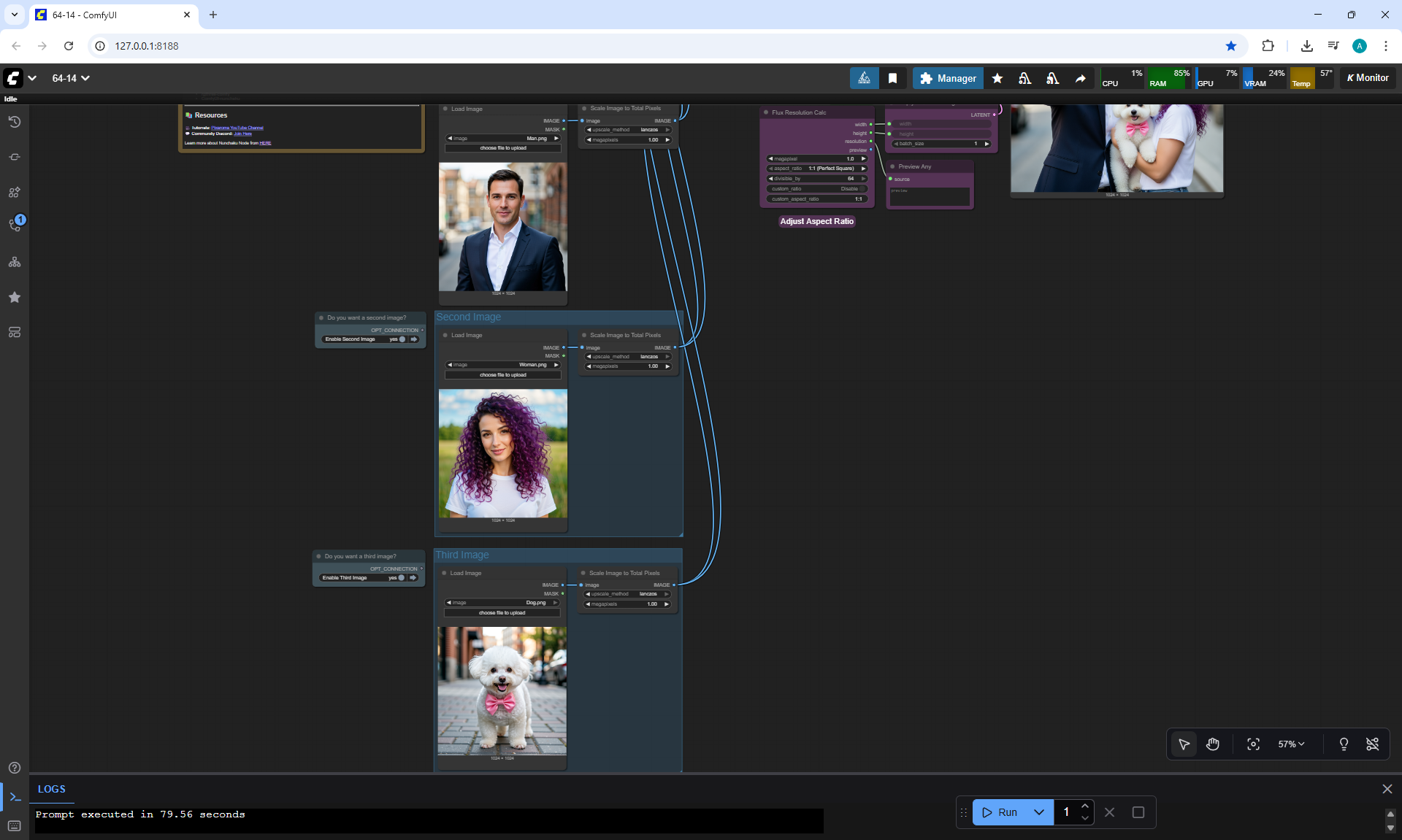
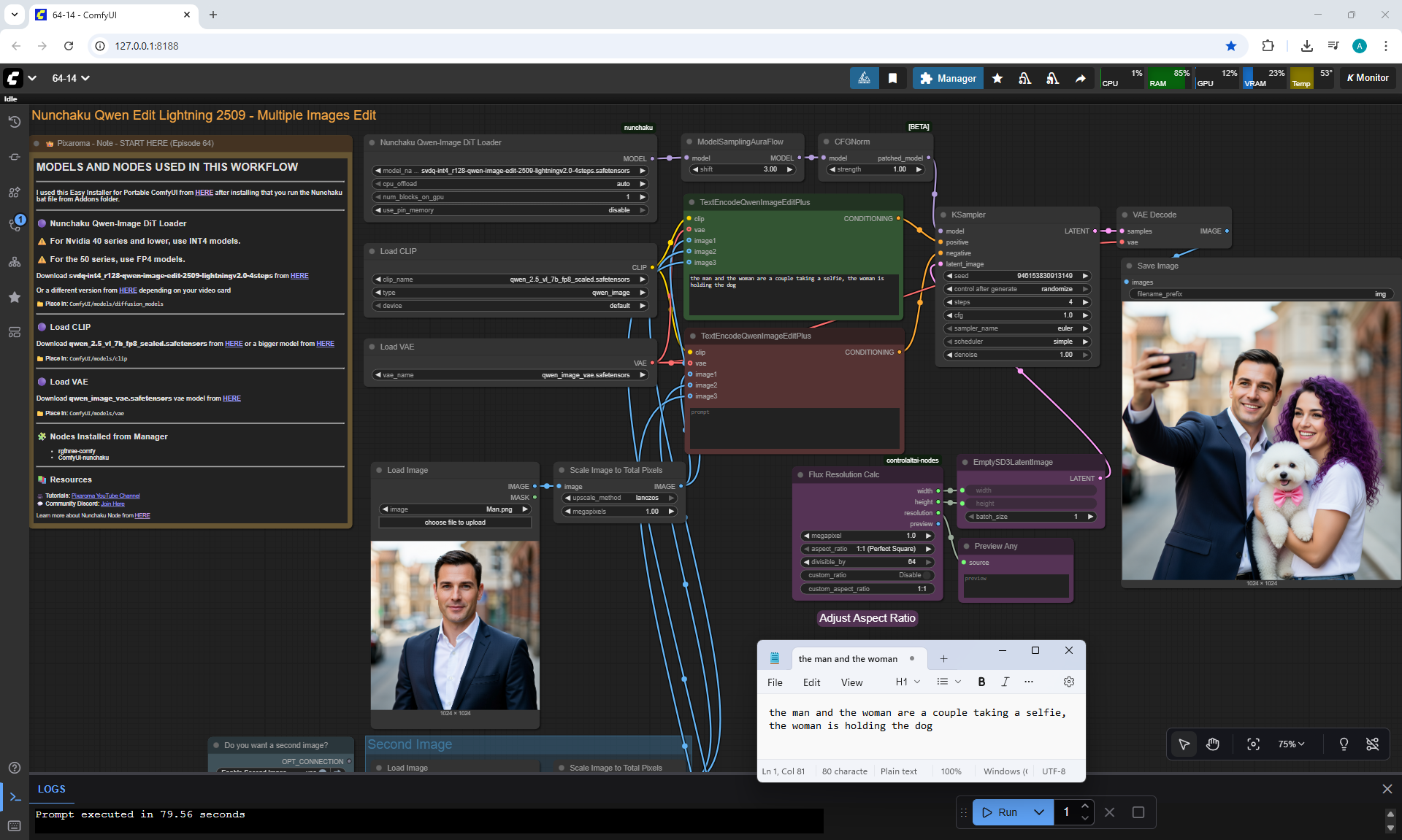
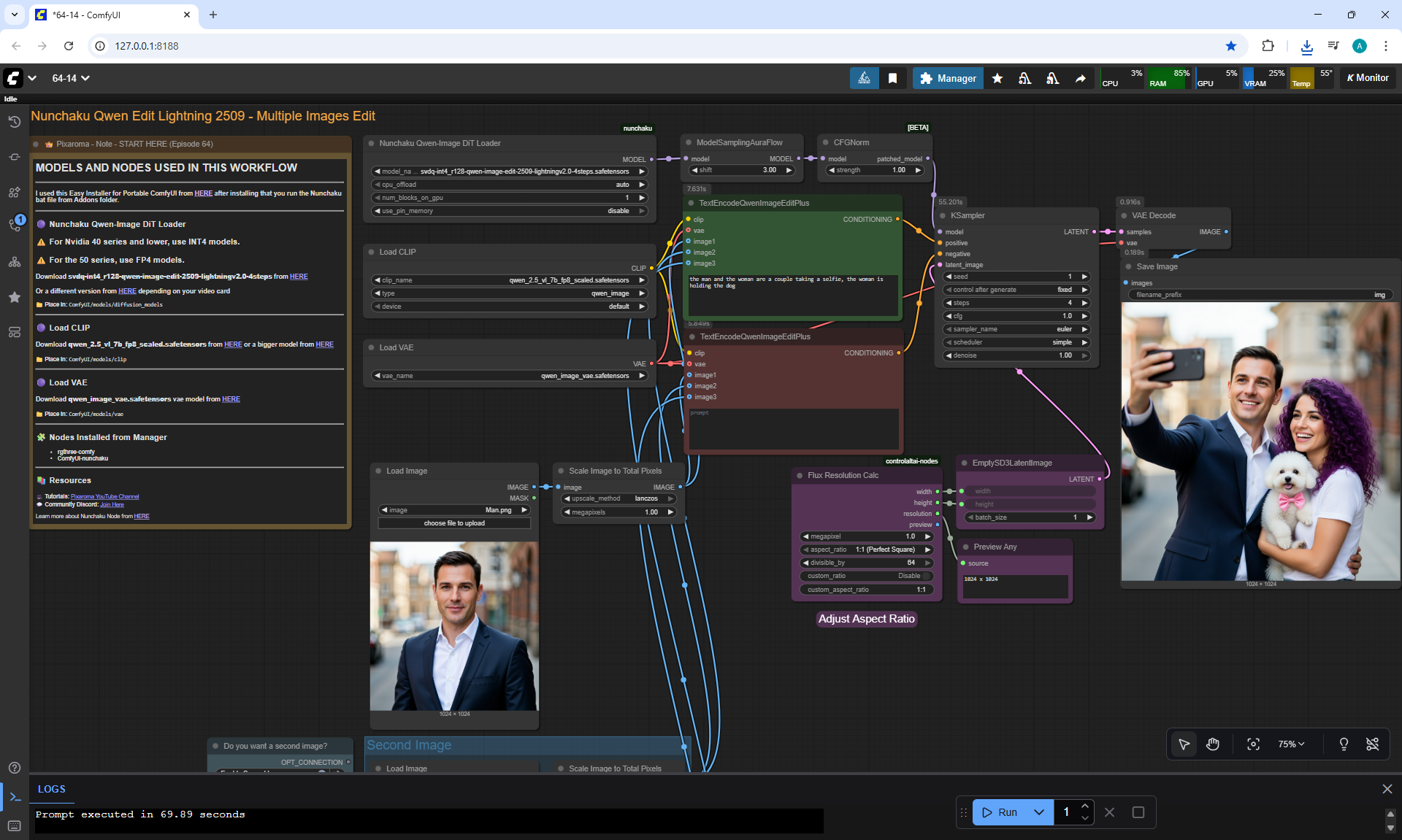
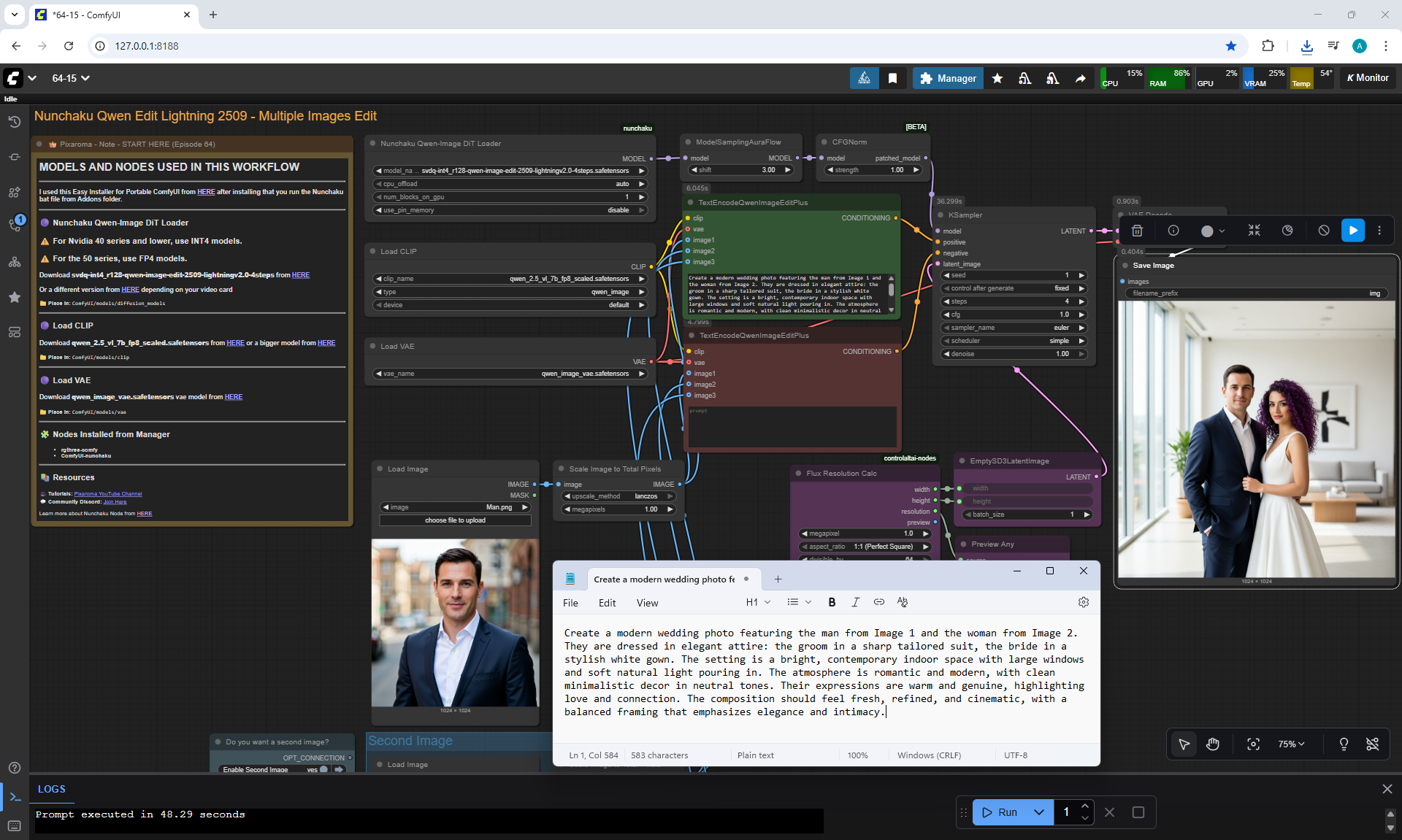
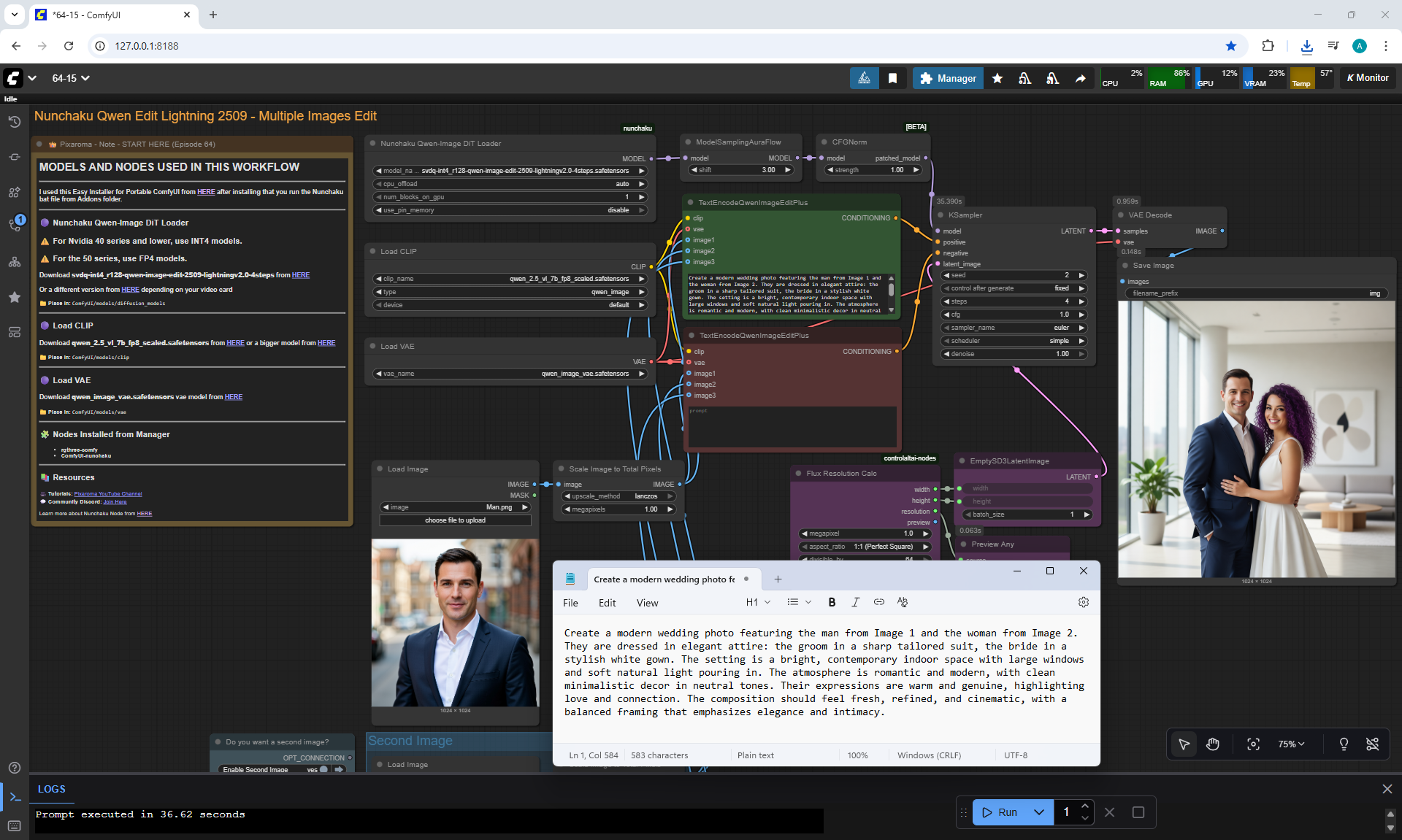
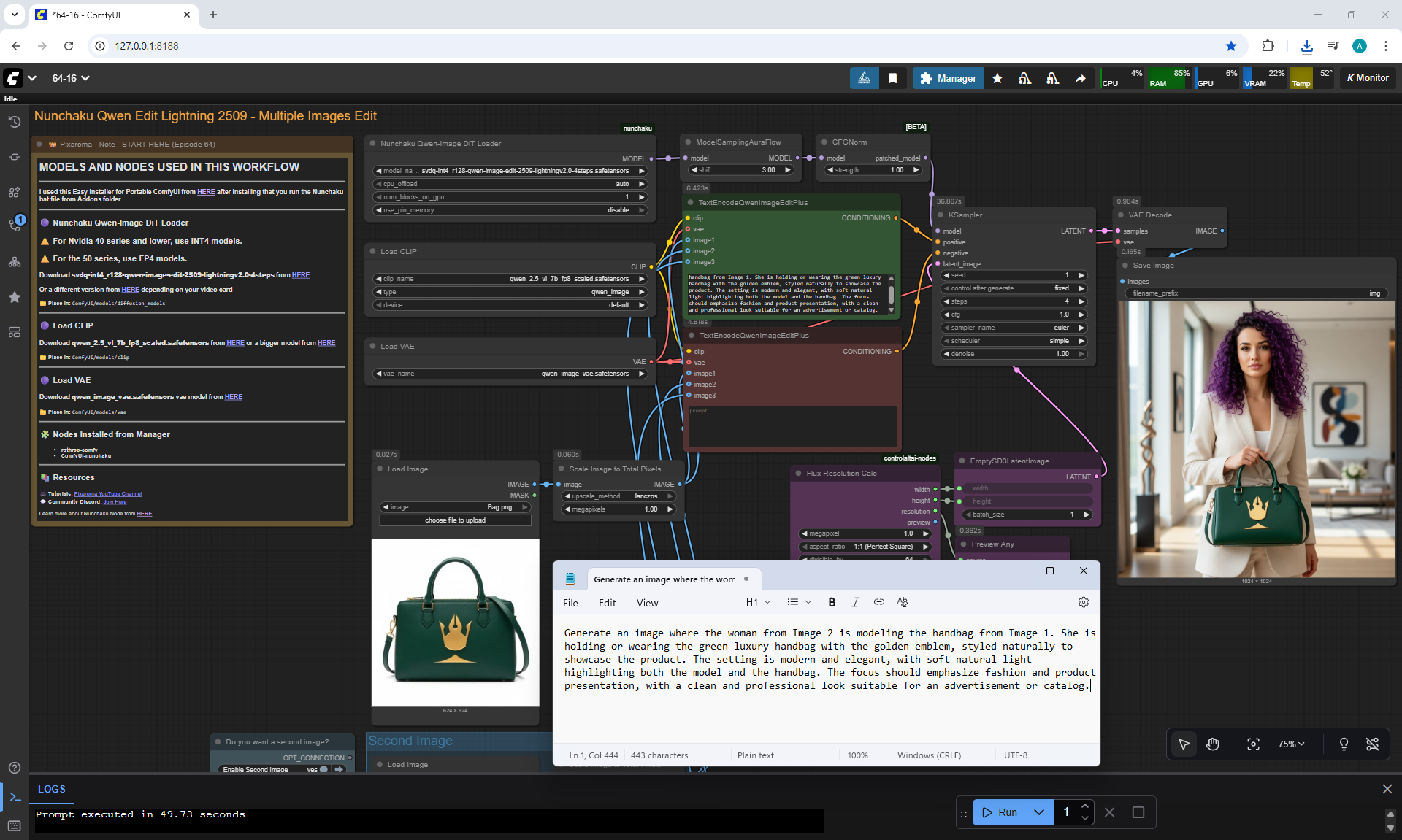
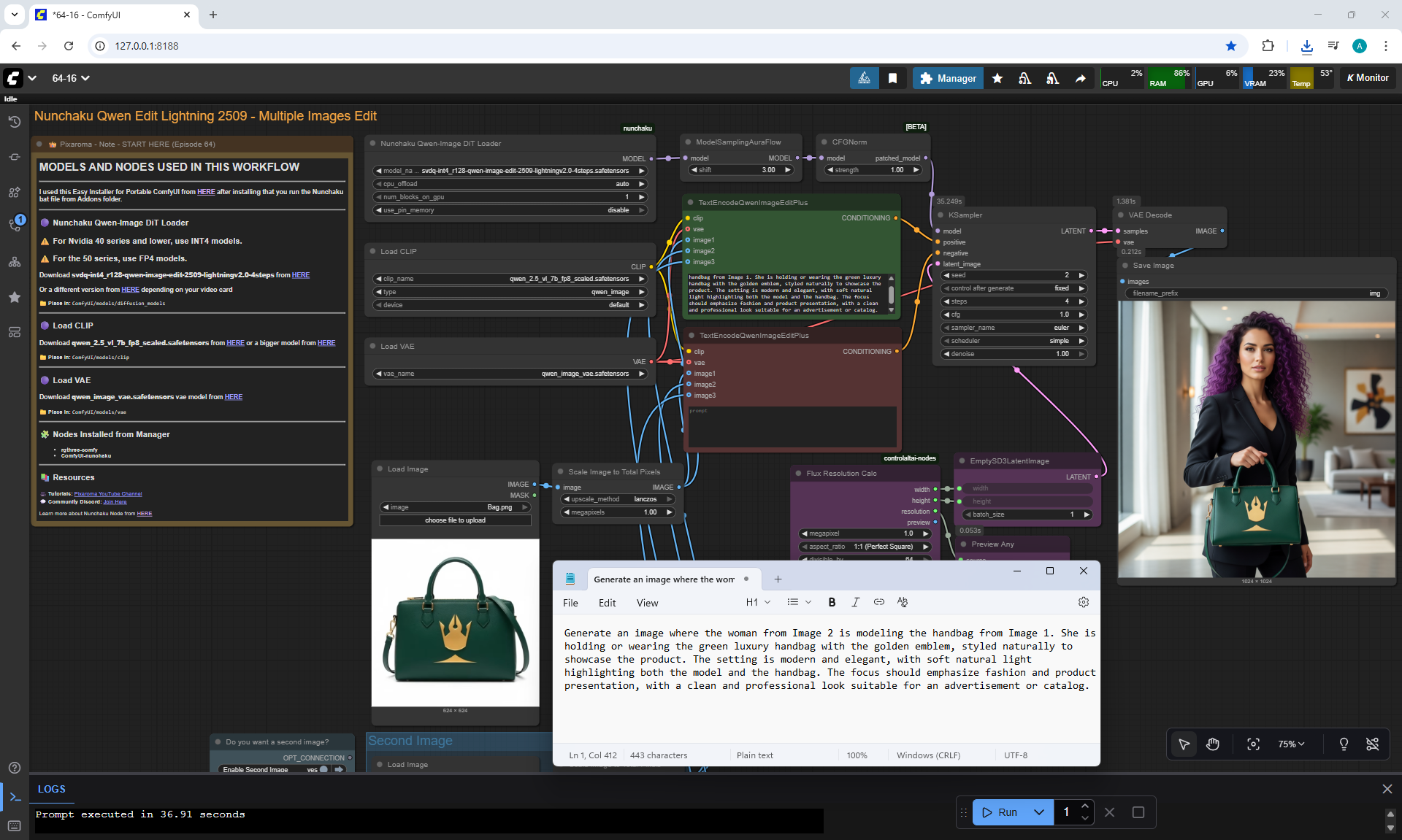
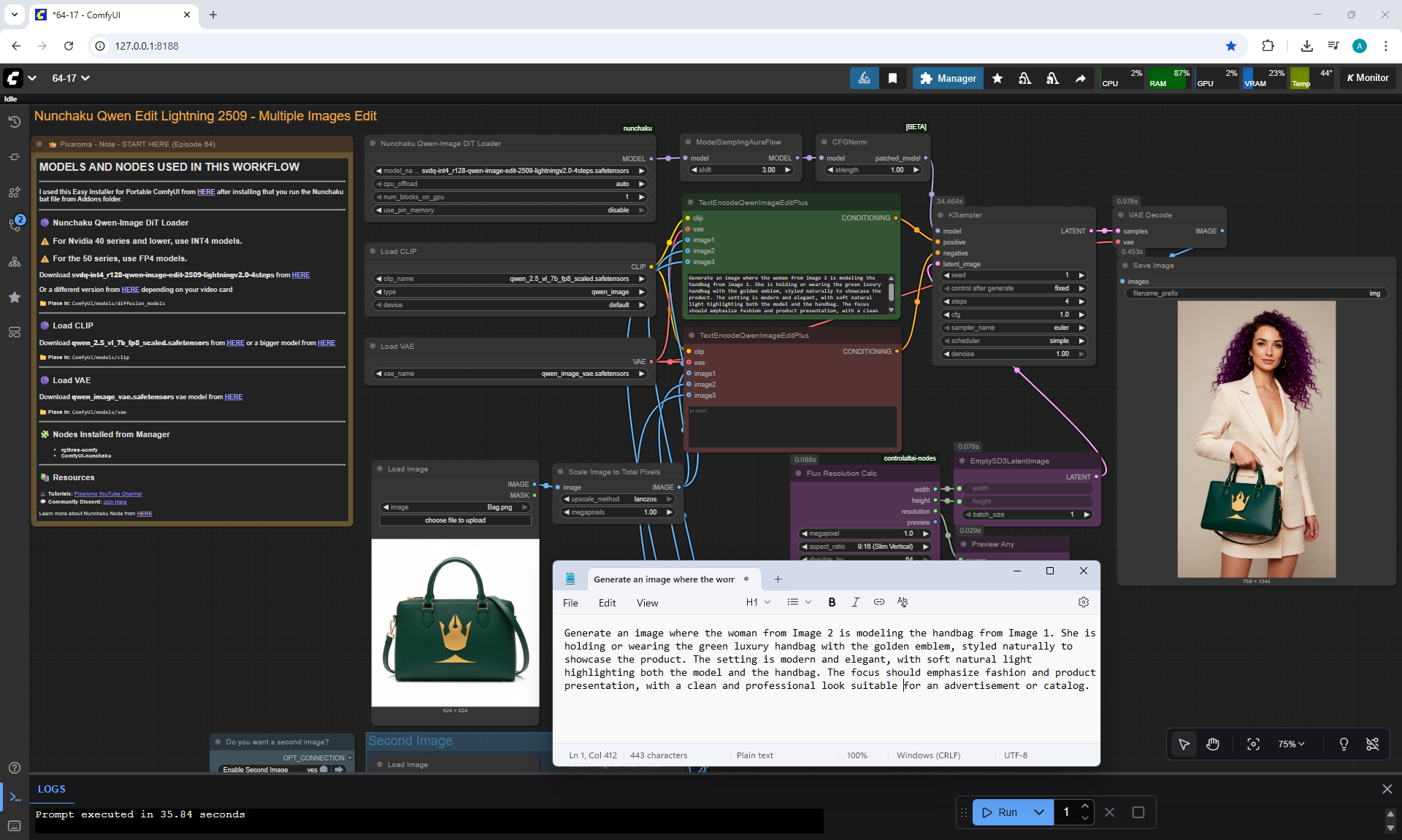
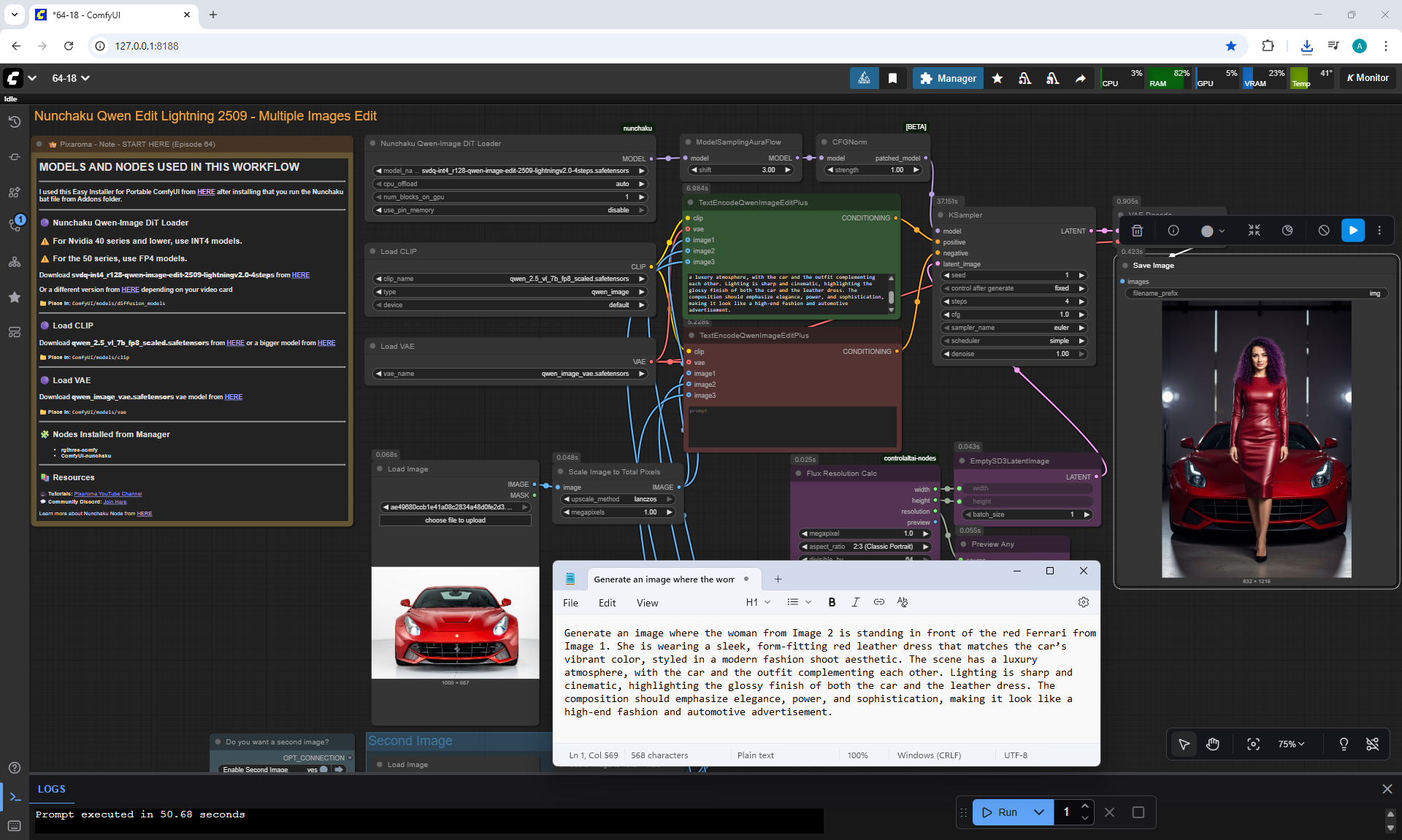
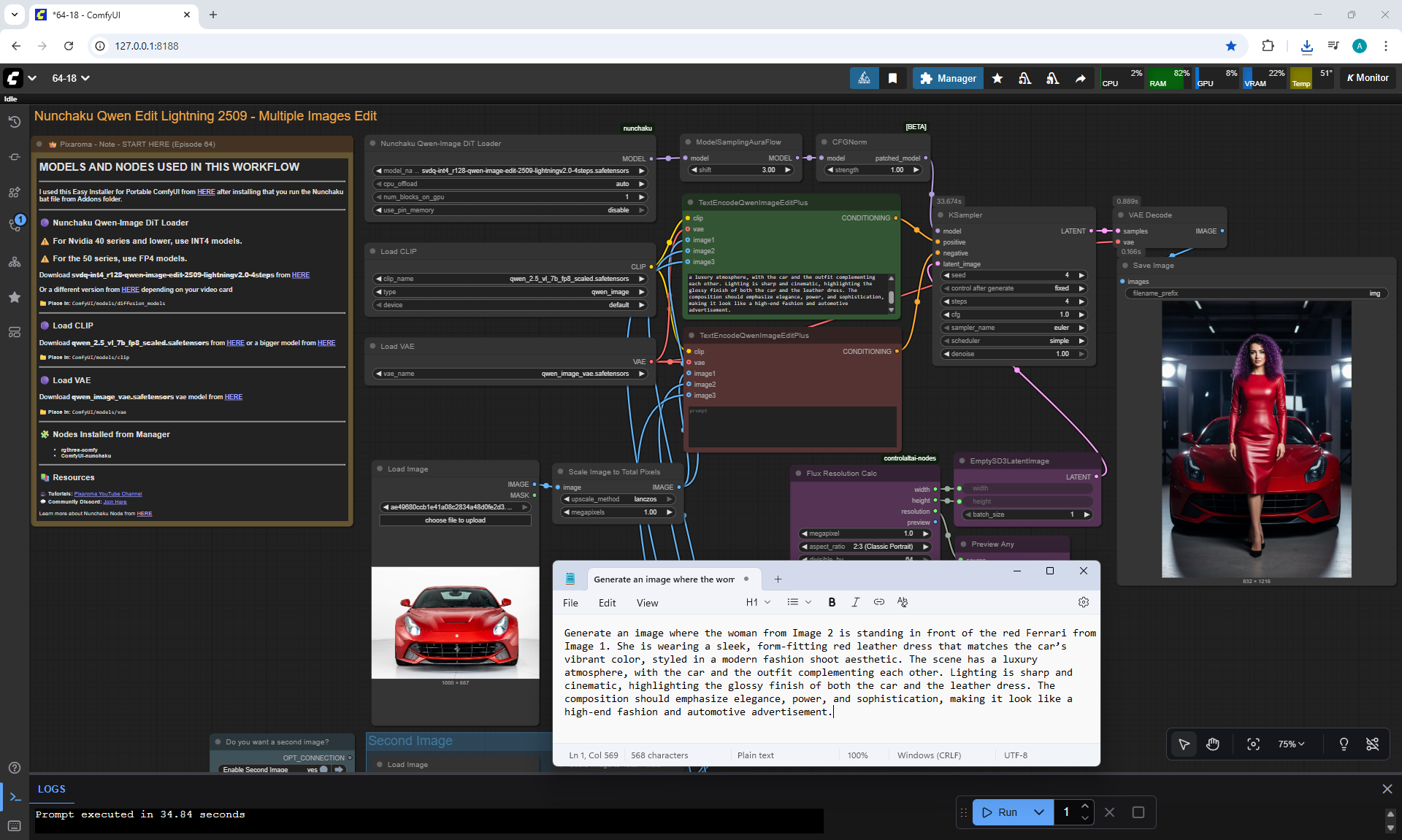
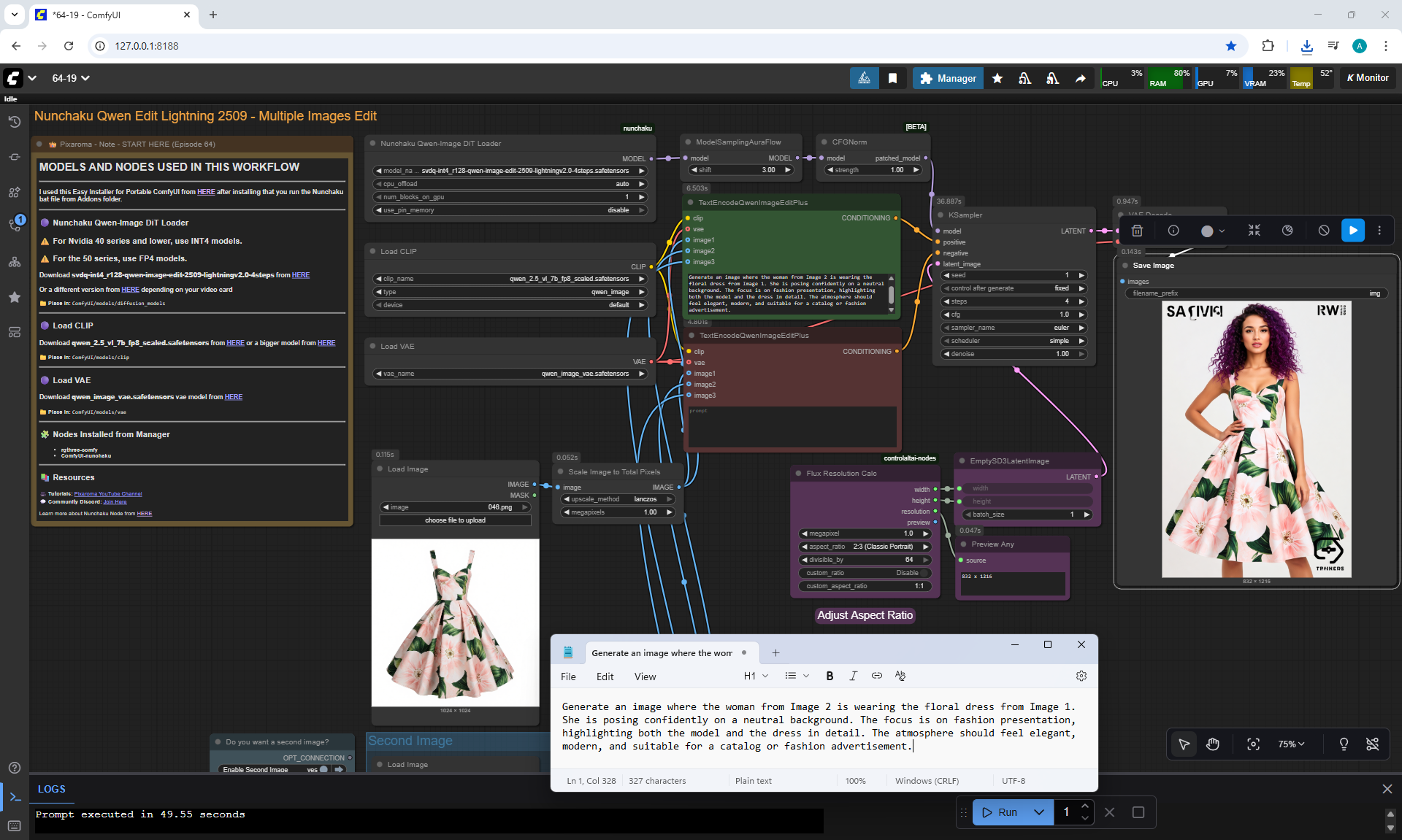
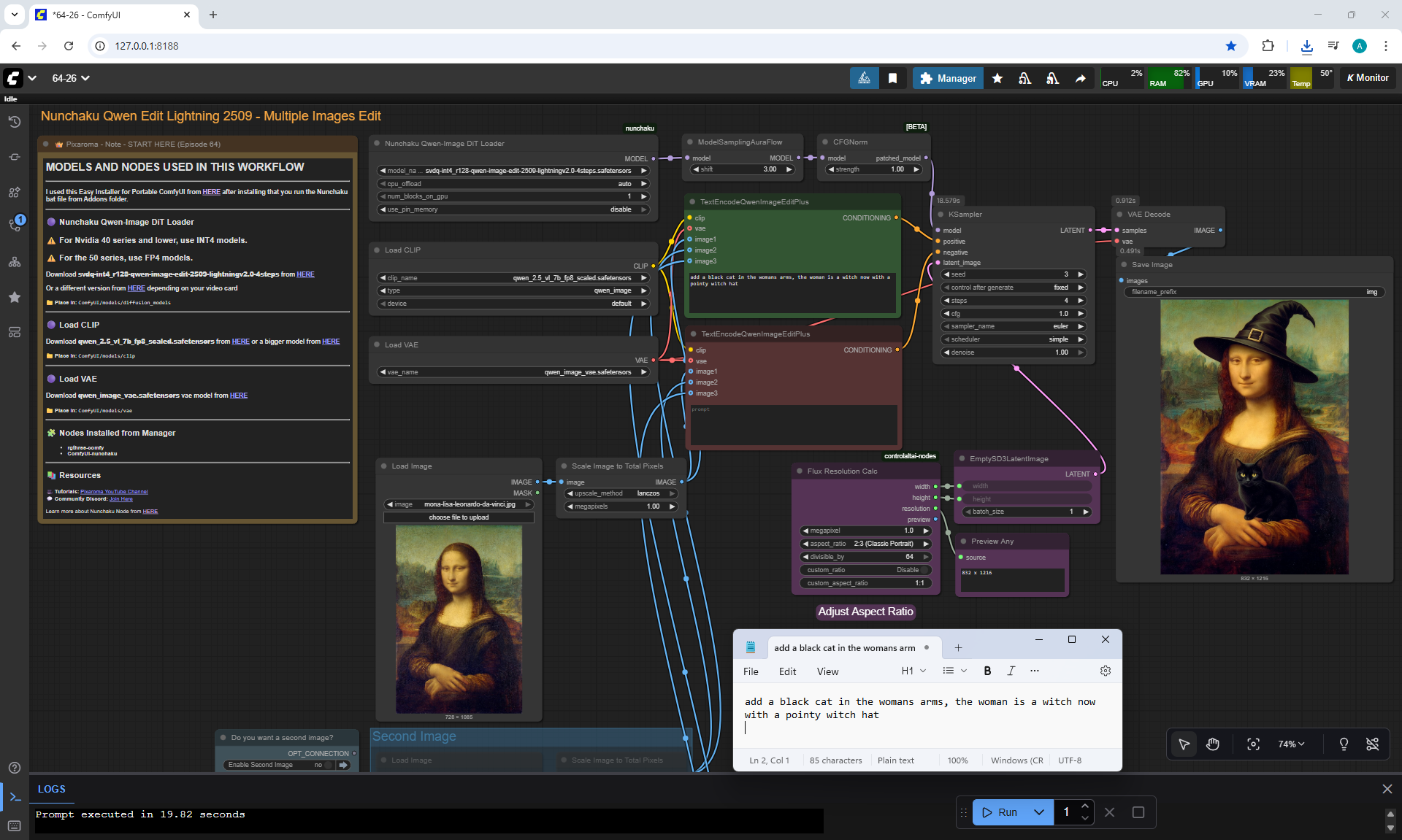
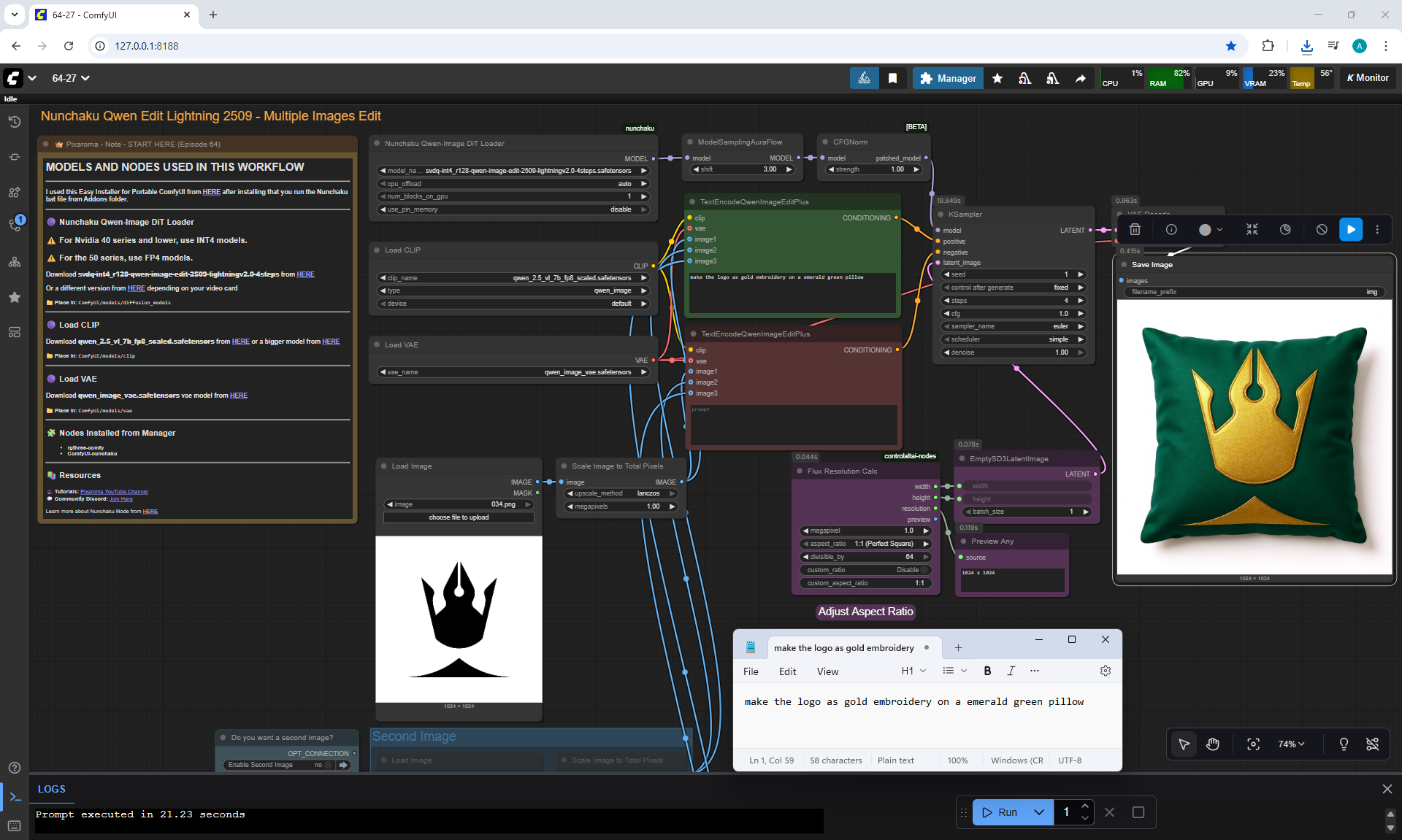
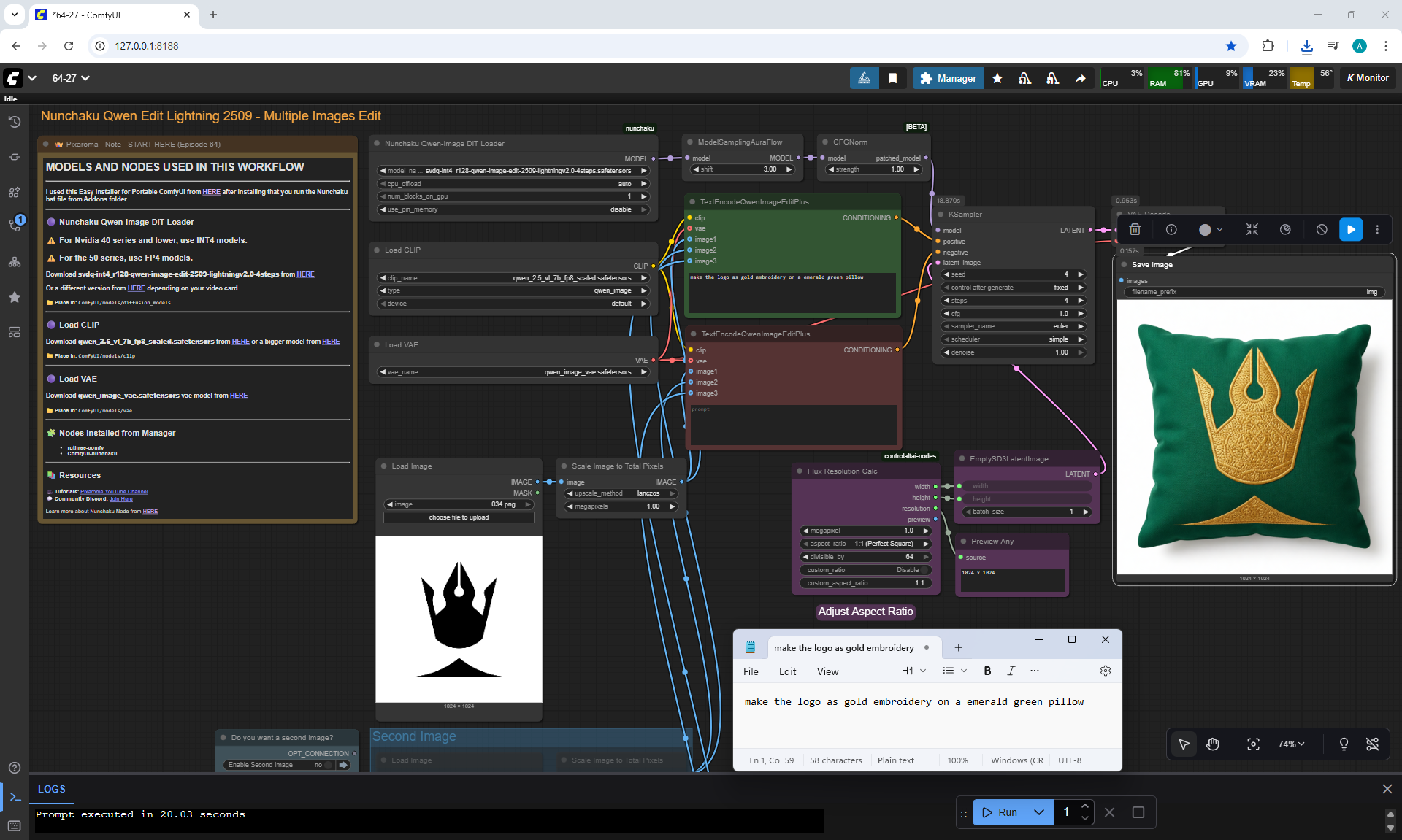
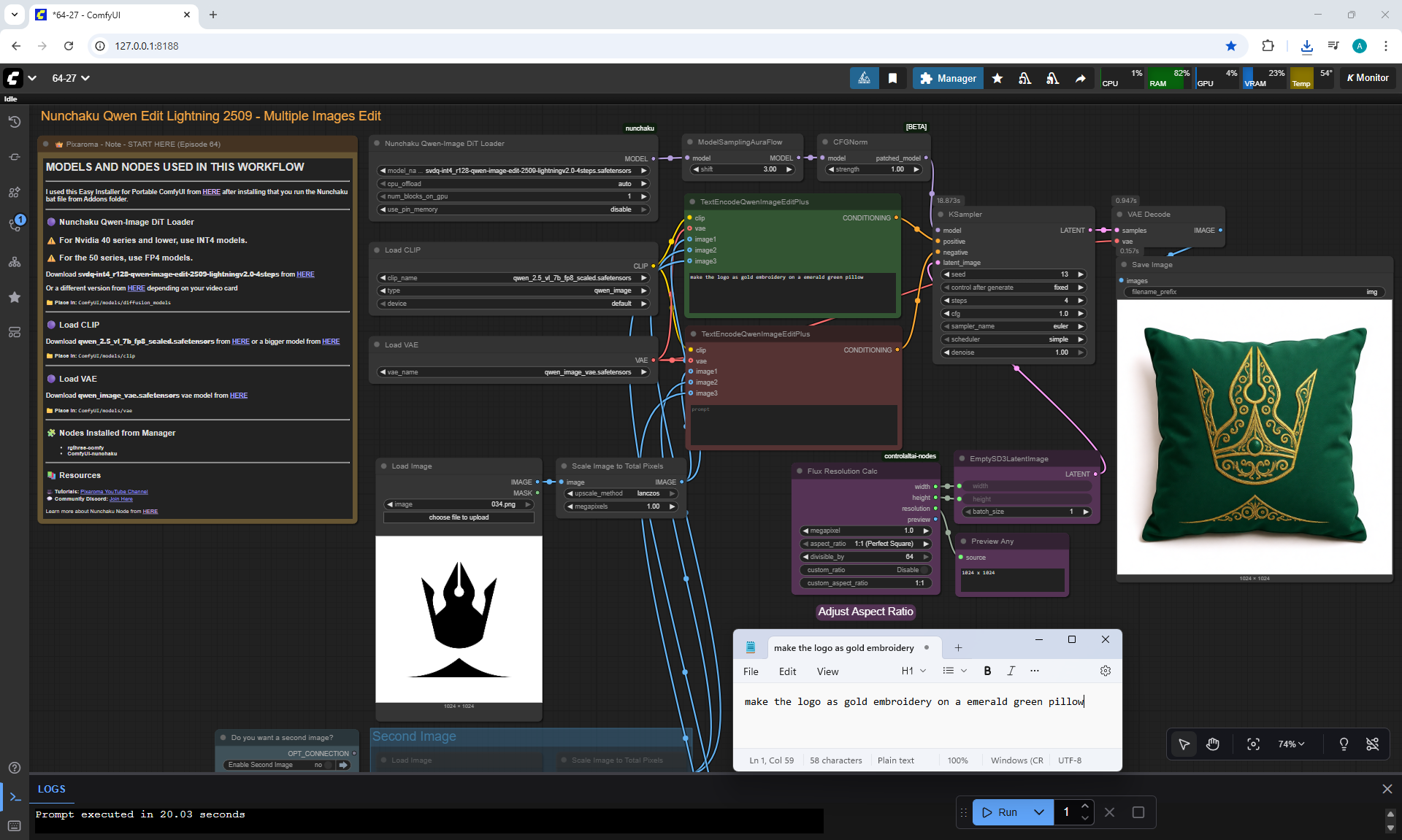
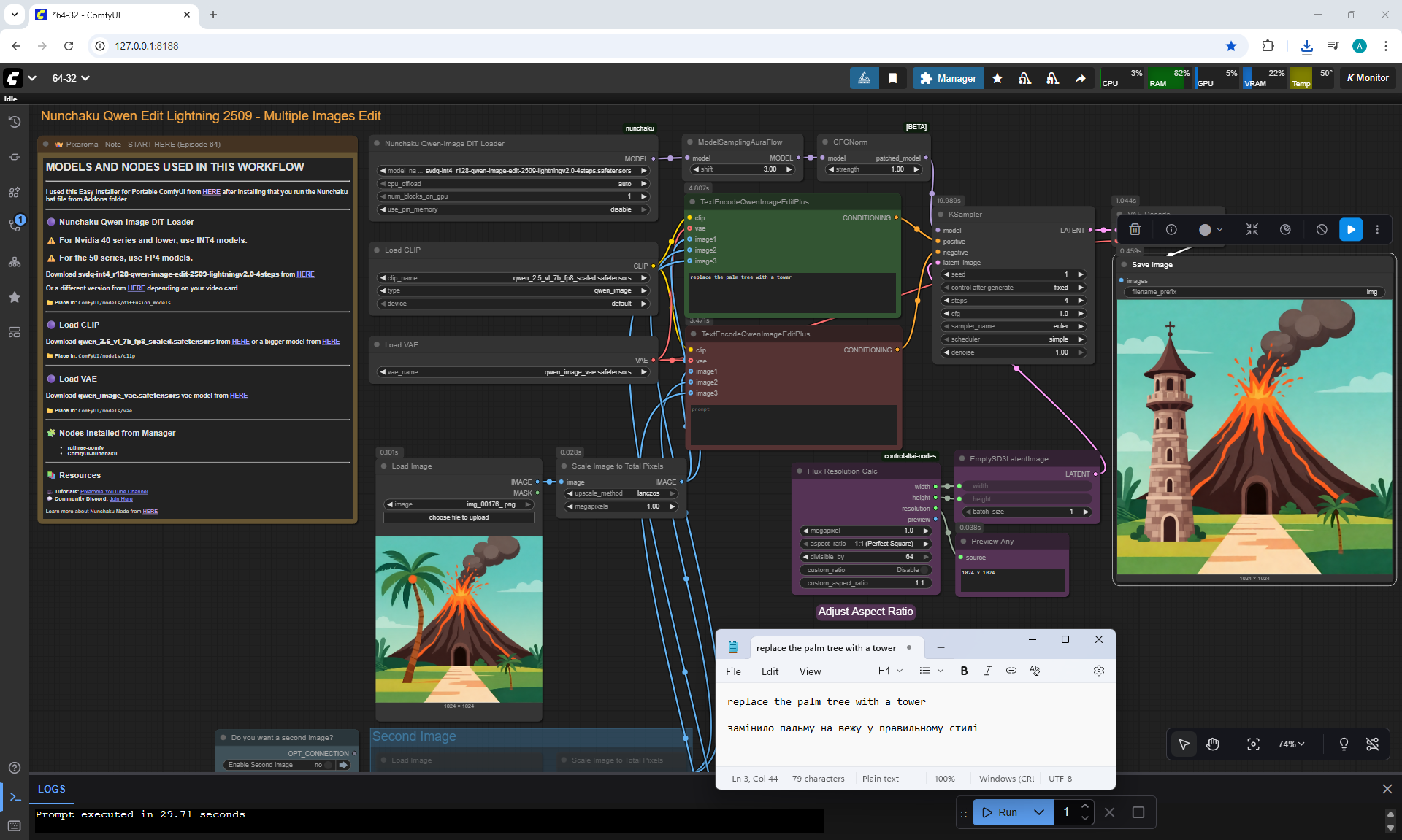
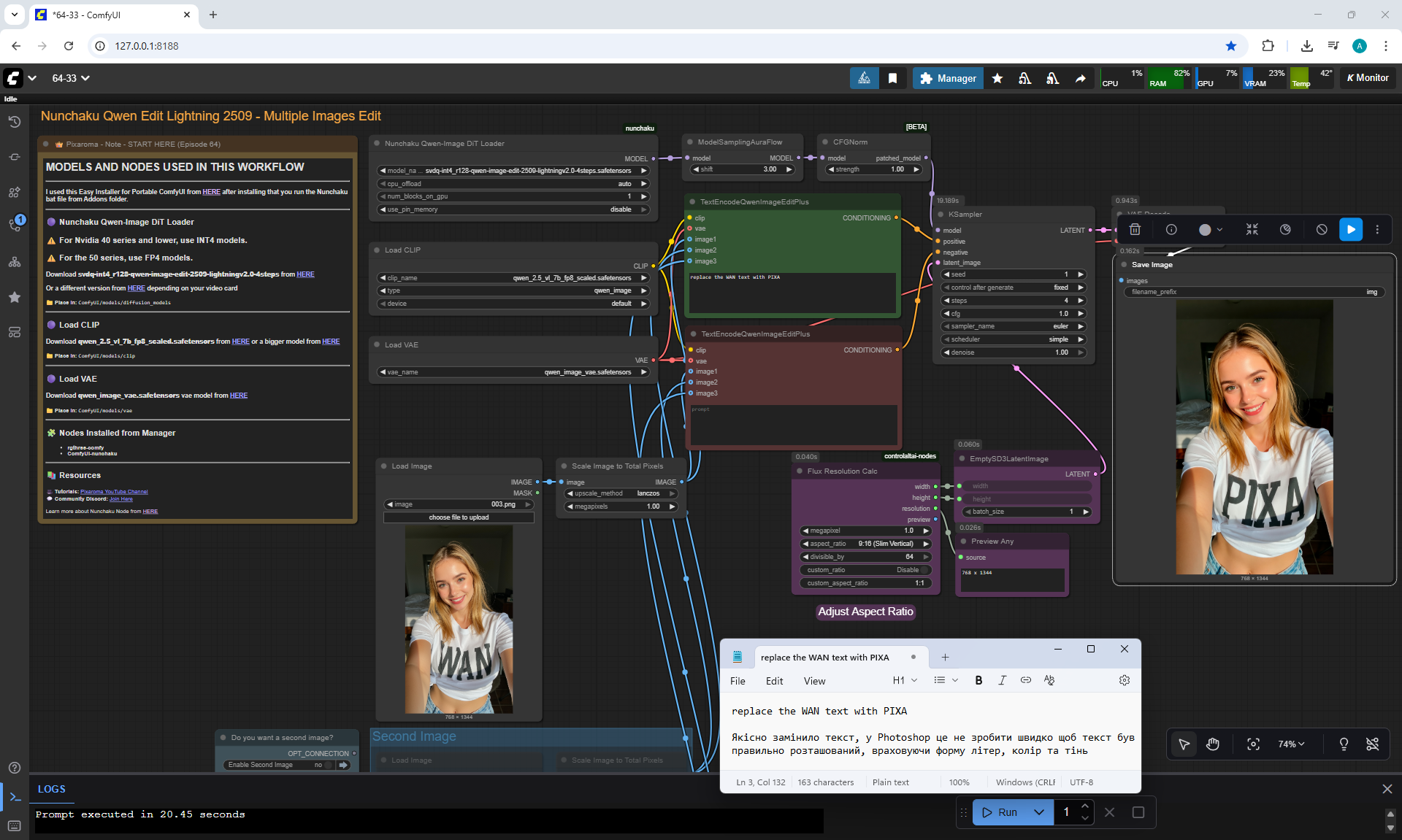
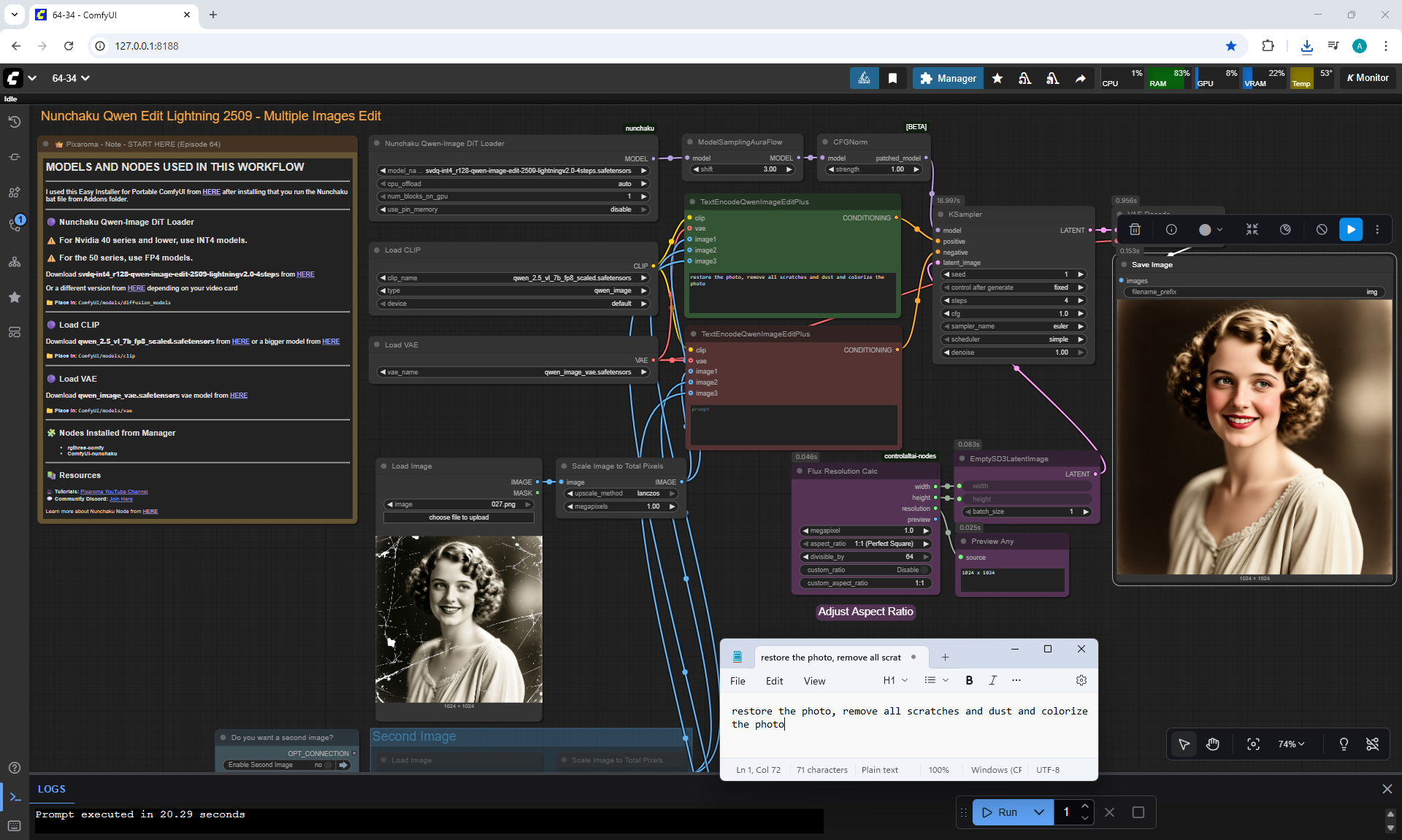
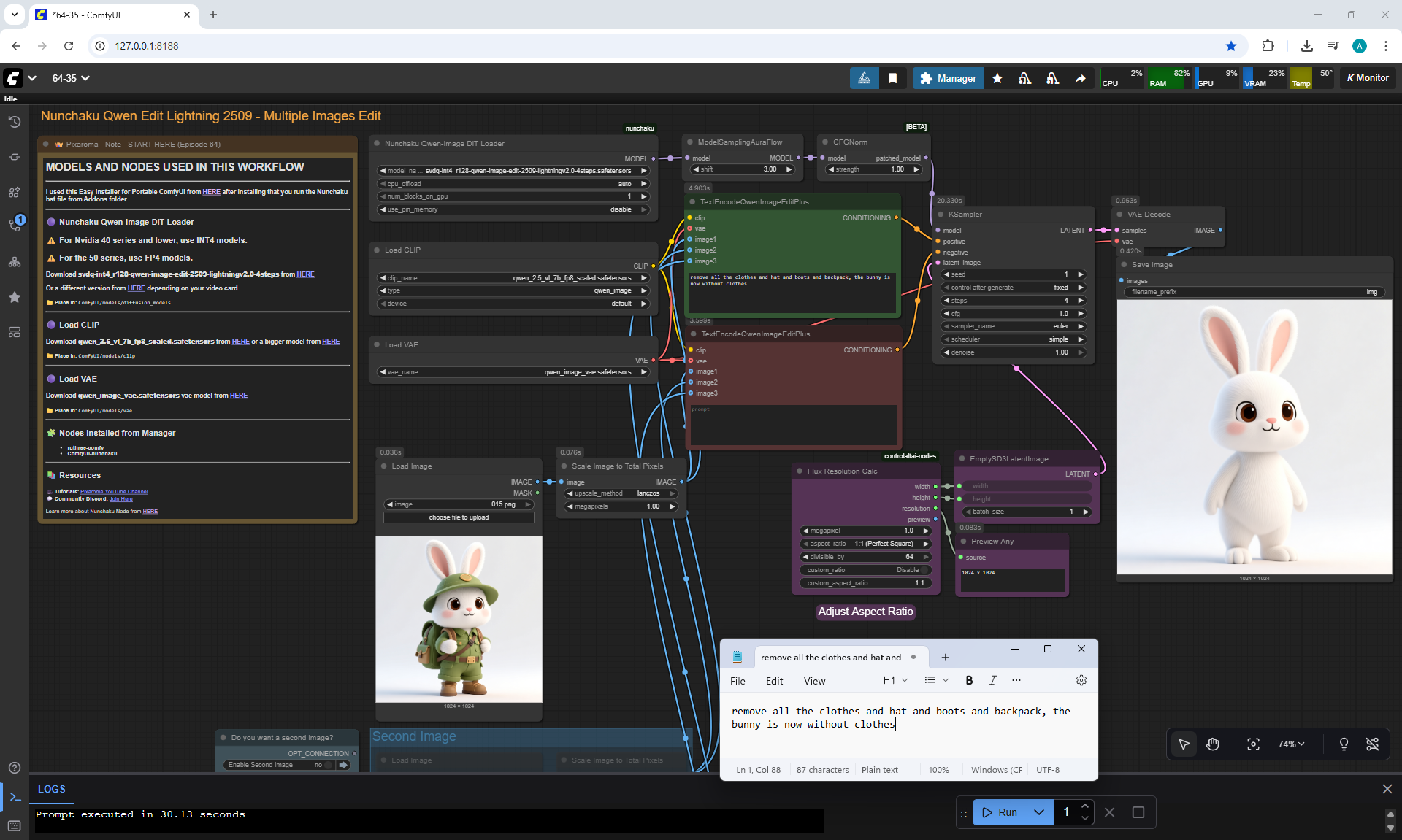
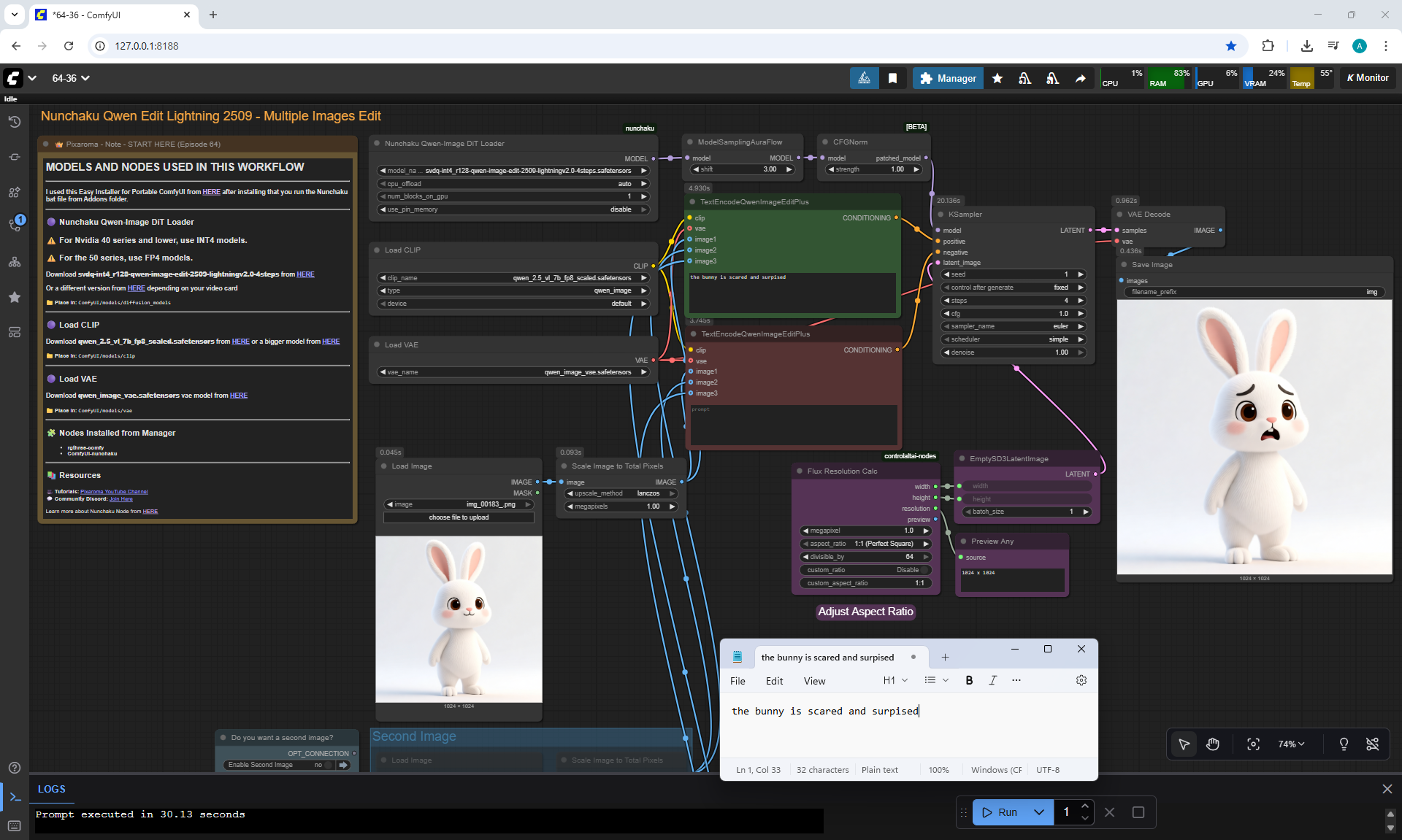
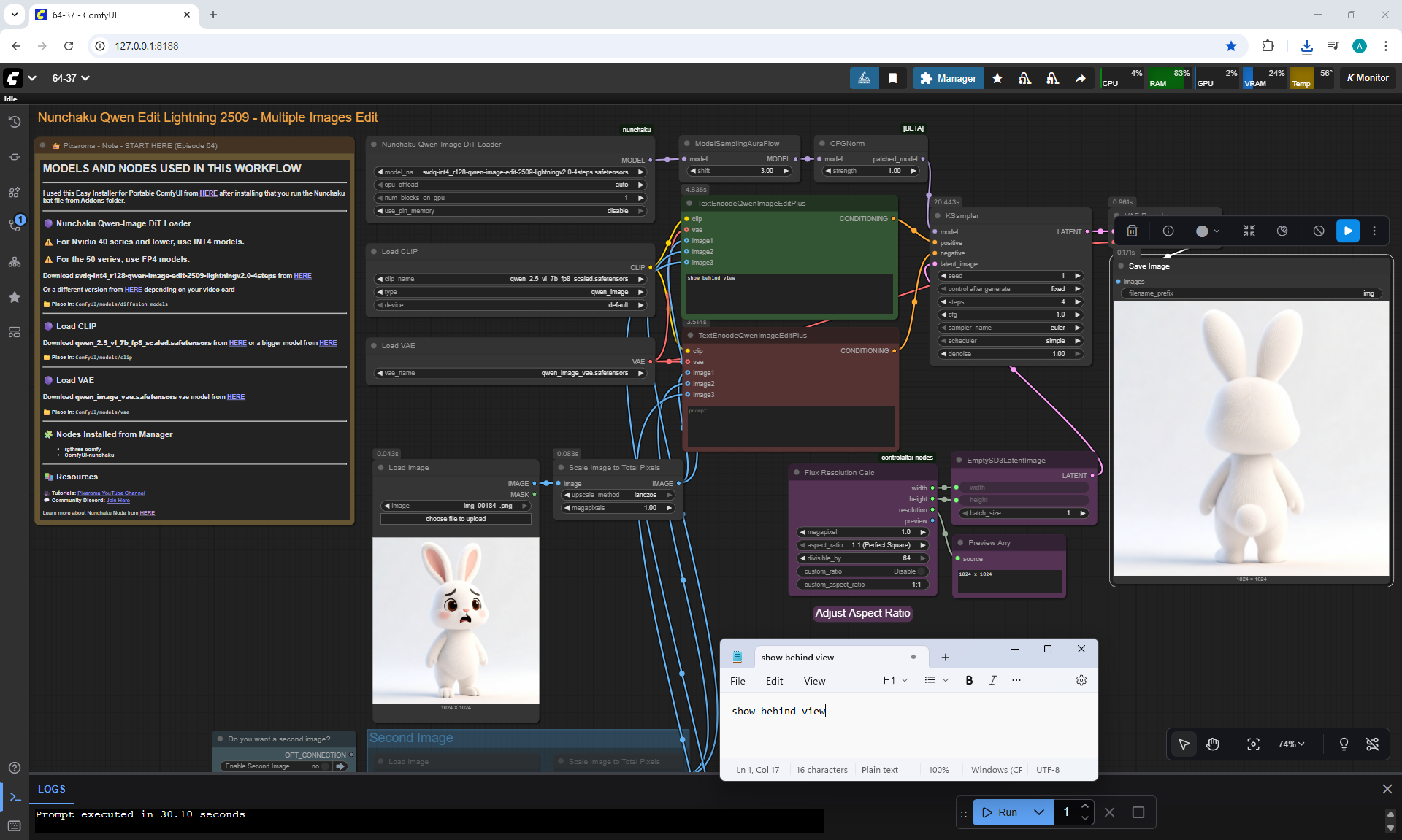
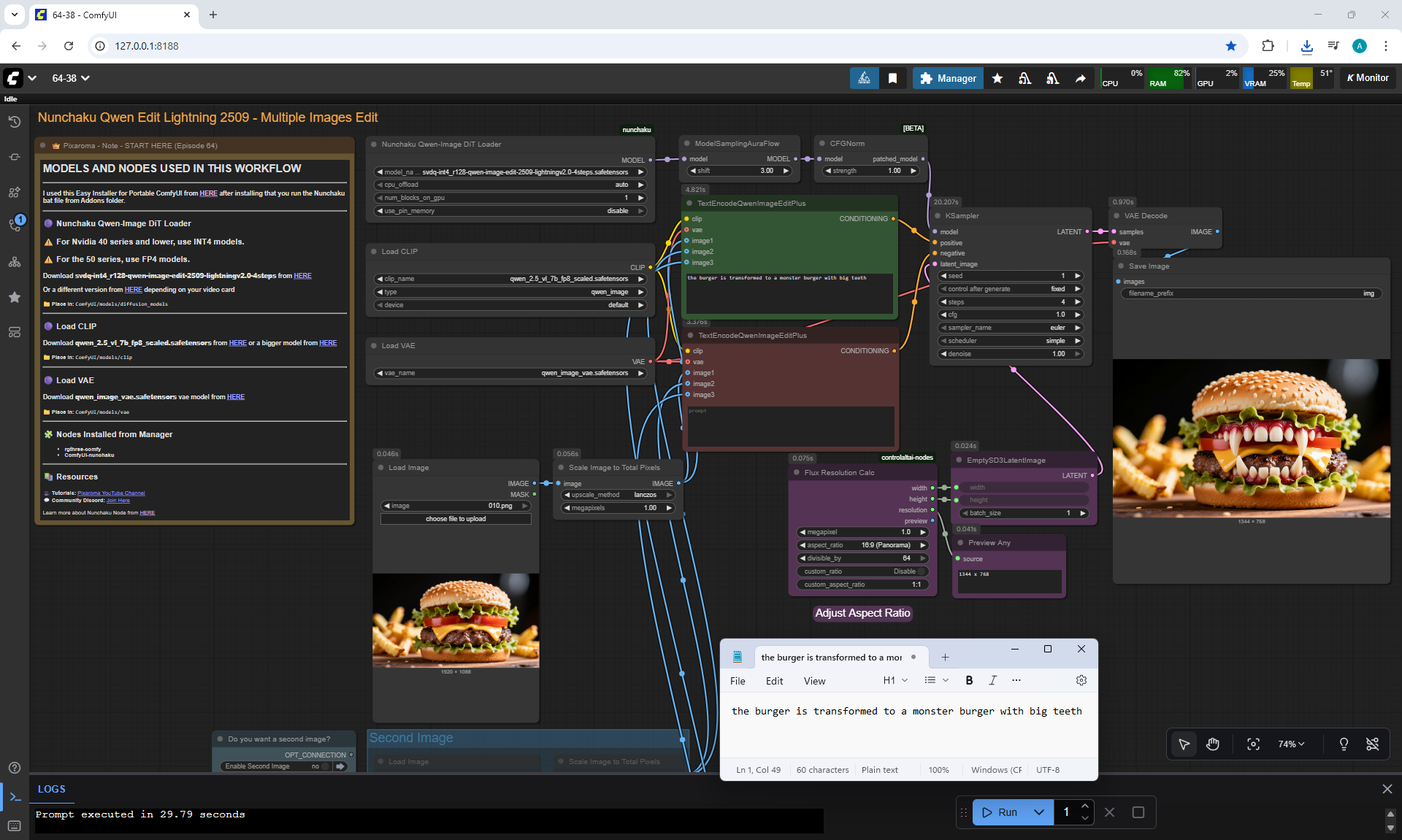
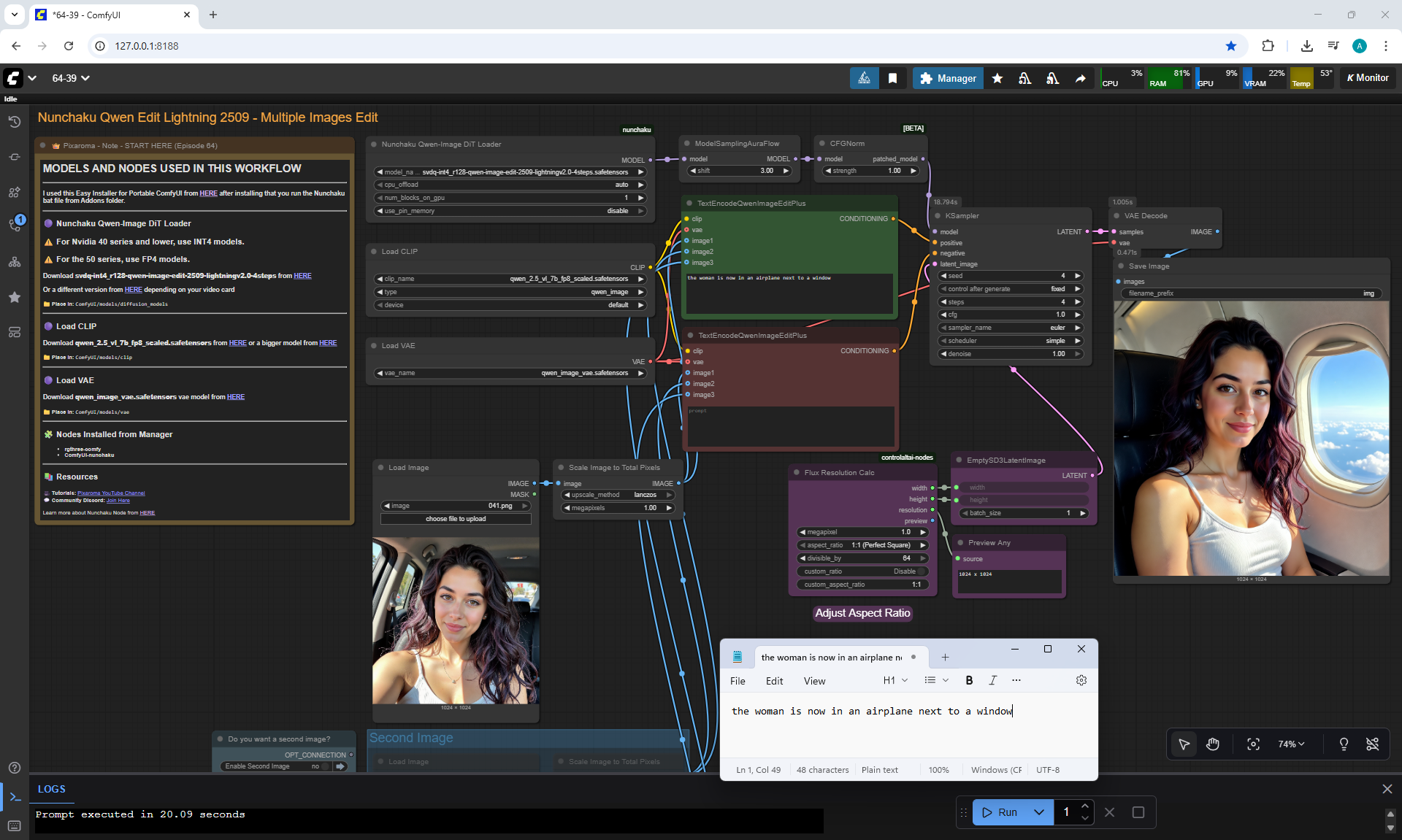
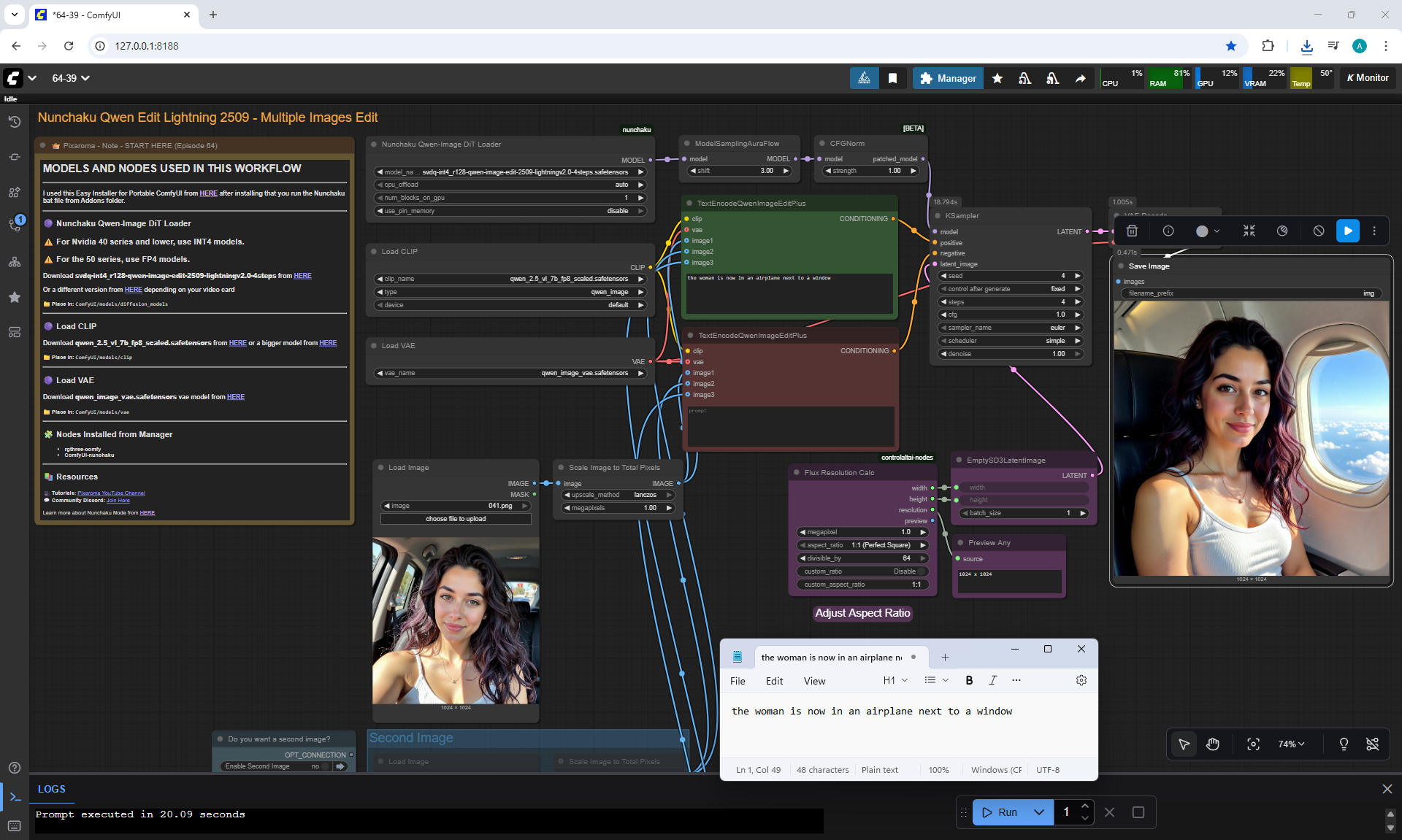
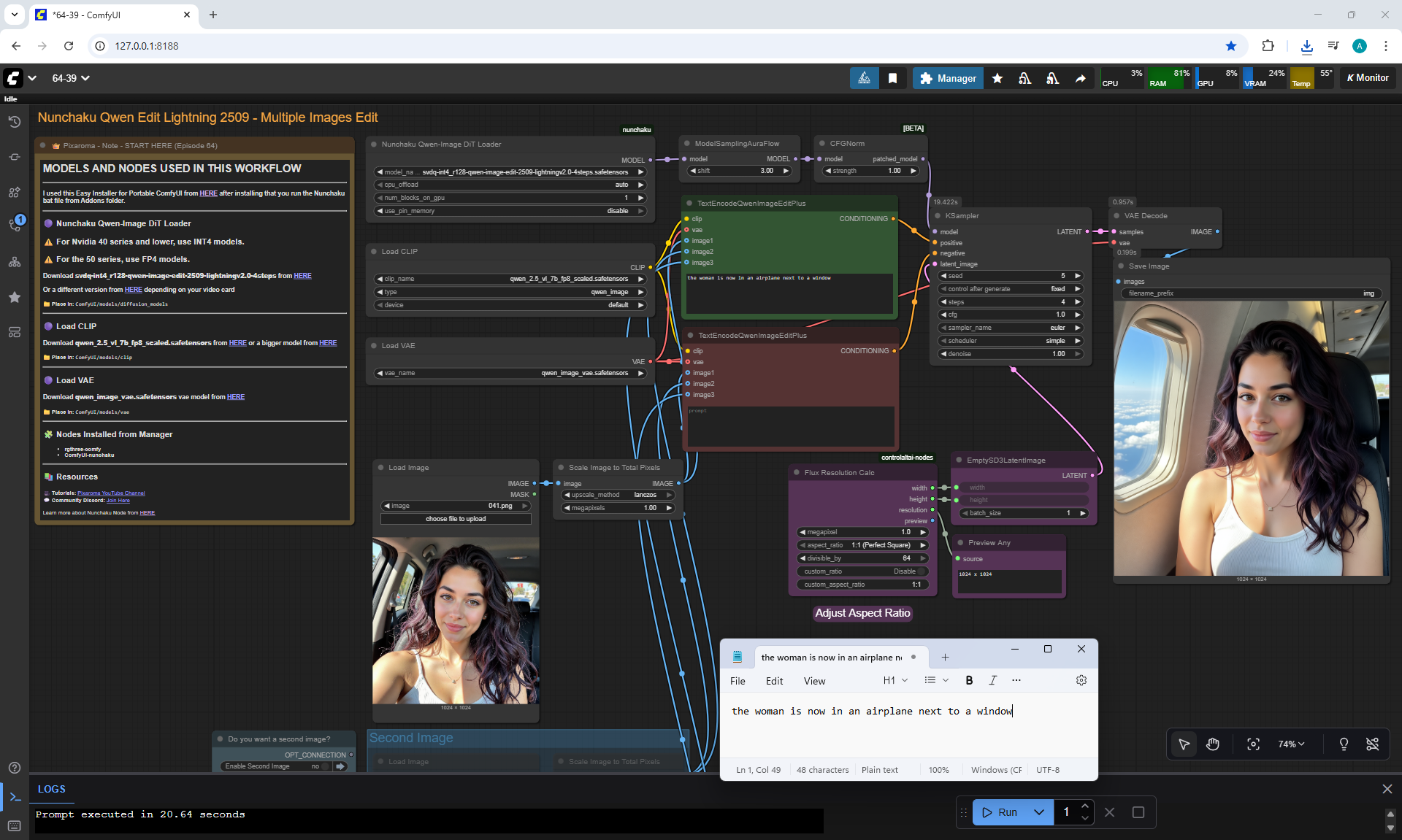
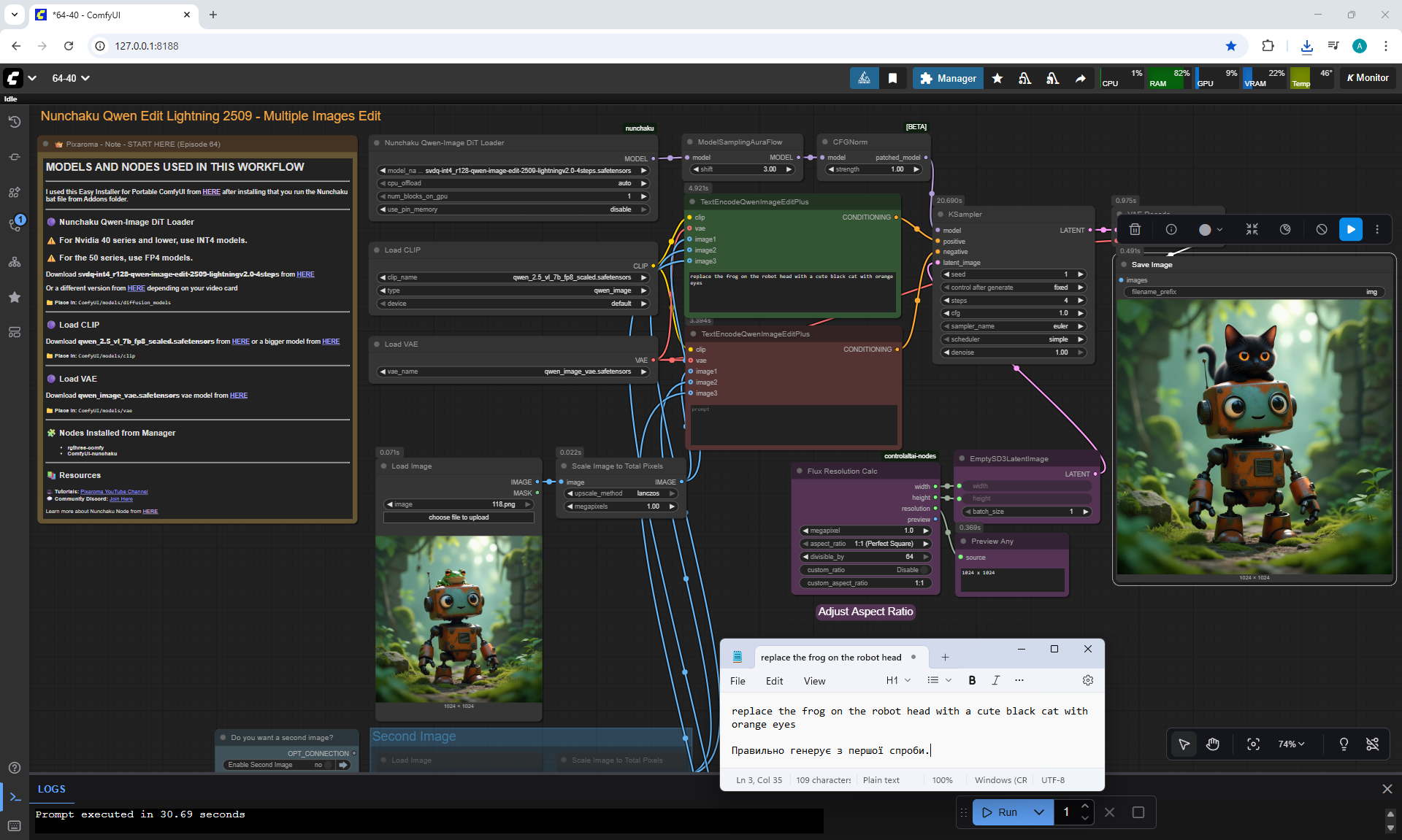
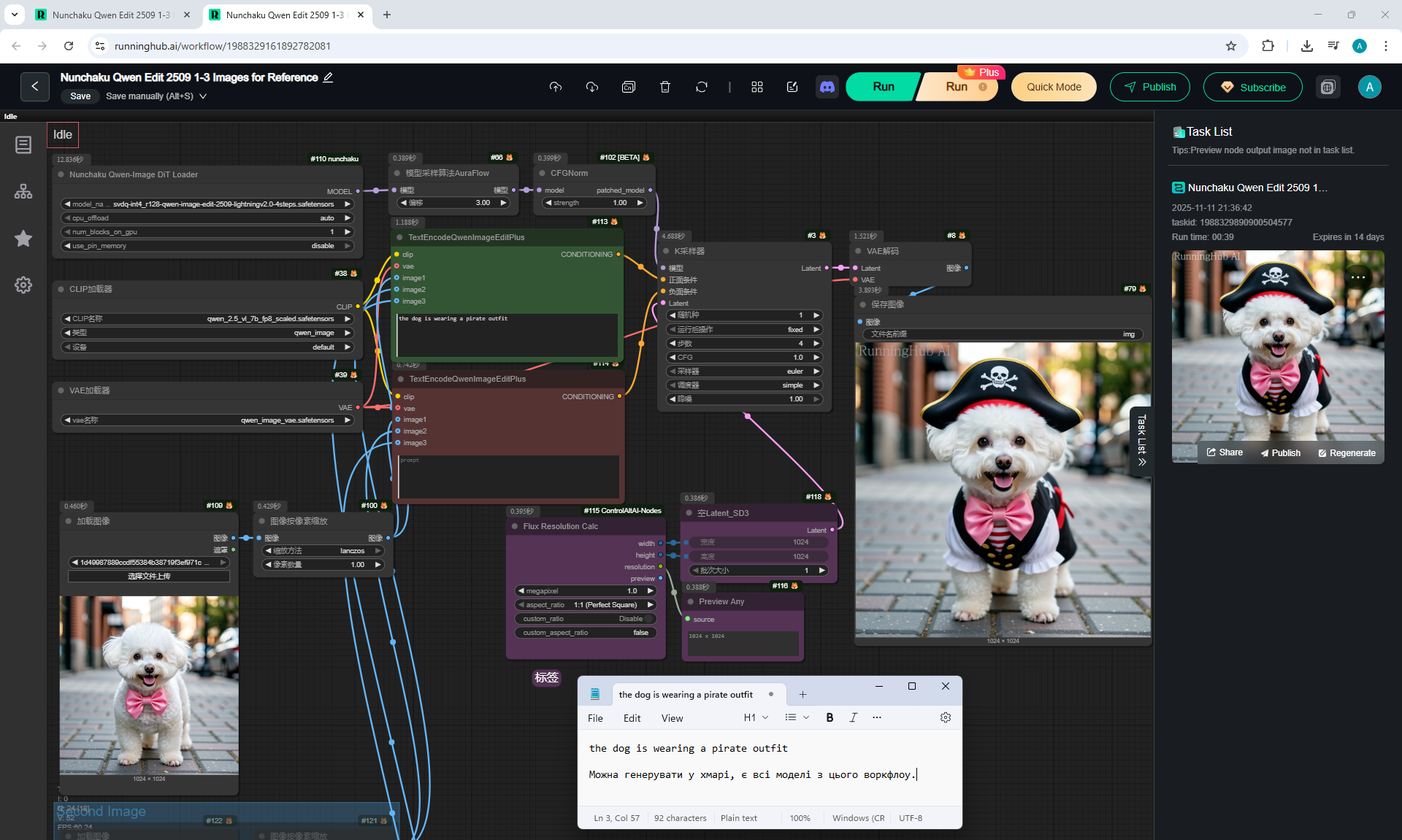
Ep64 - Nunchaku Qwen Image Edit 2509
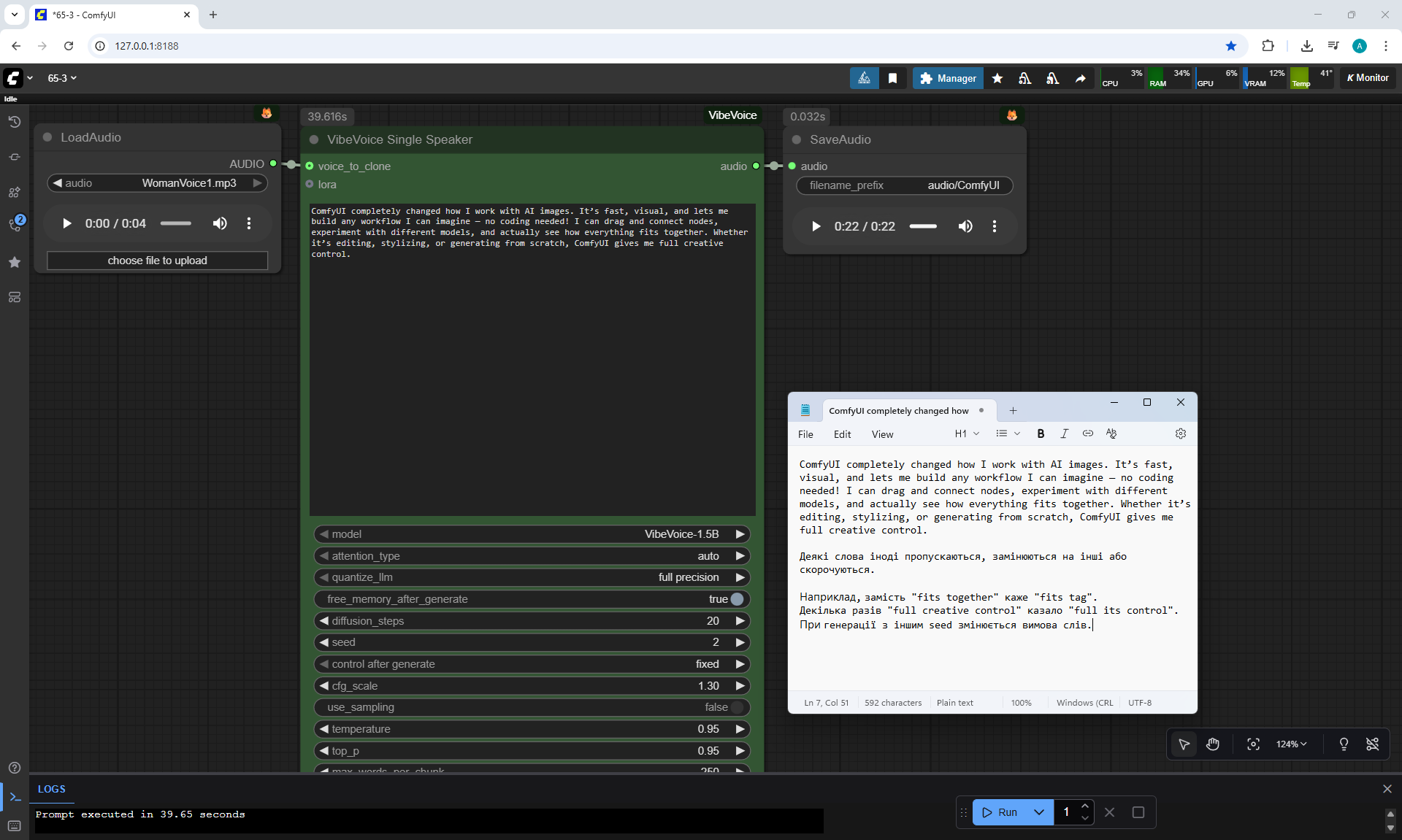
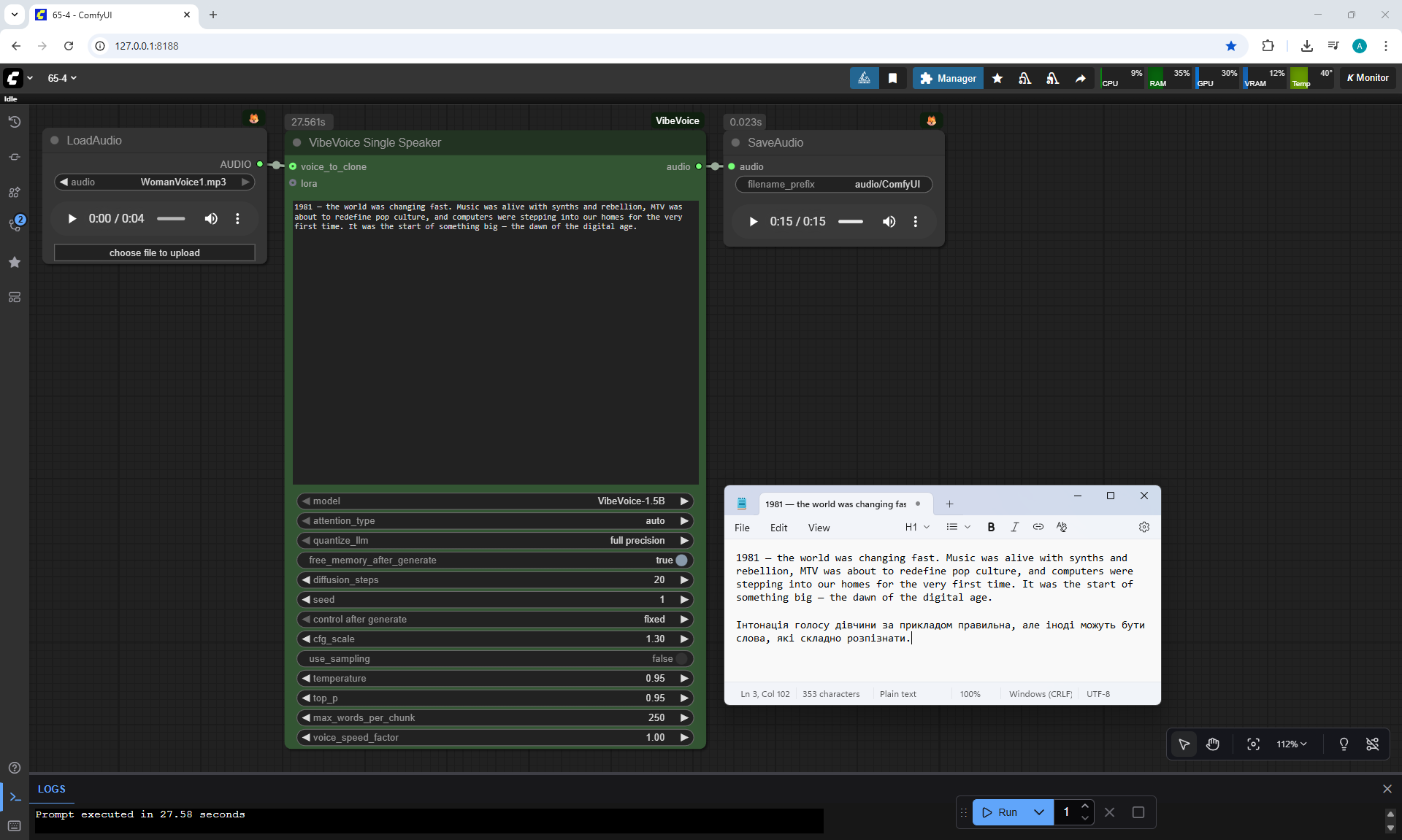
Ep65 - VibeVoice Free Text to Speech Workflow
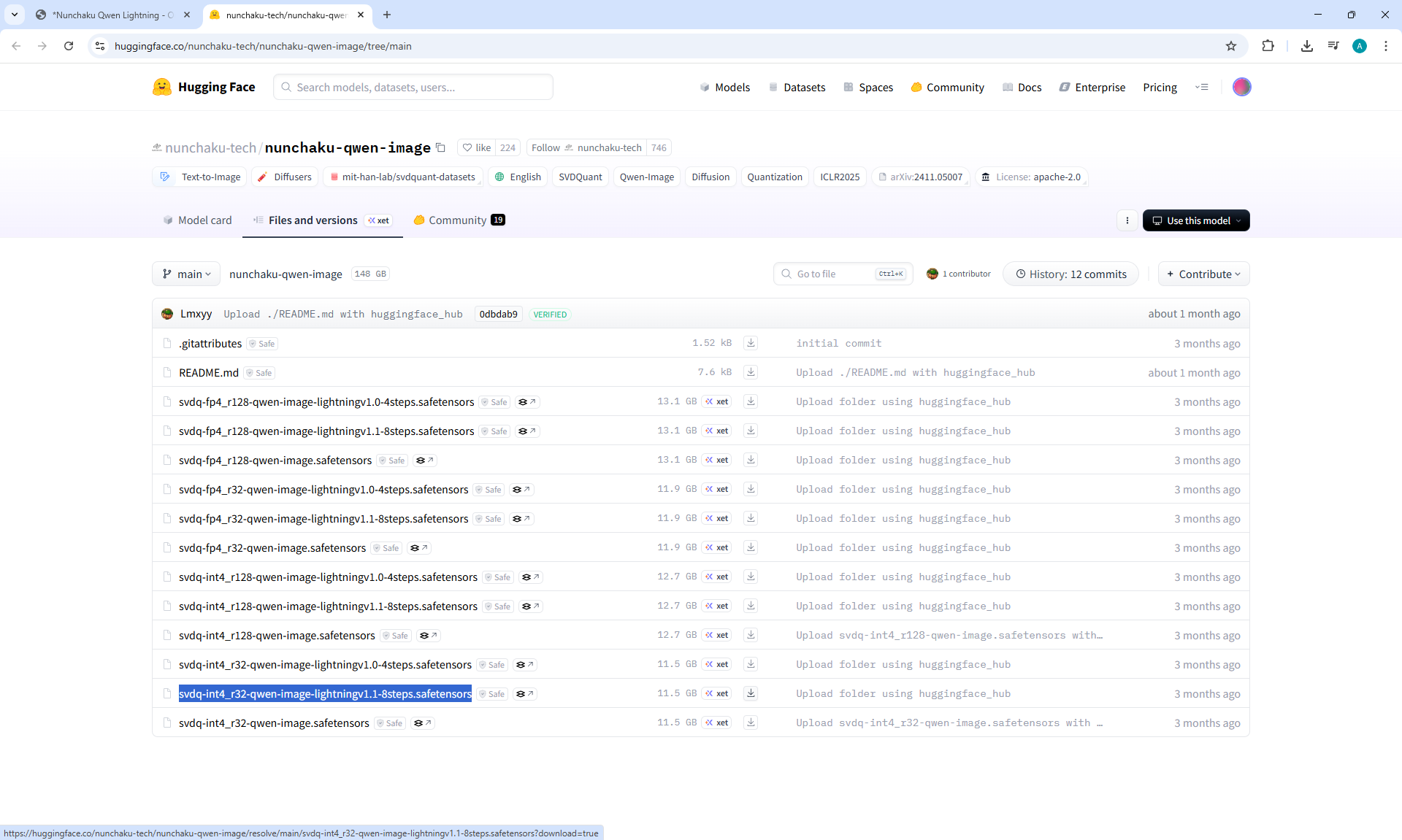
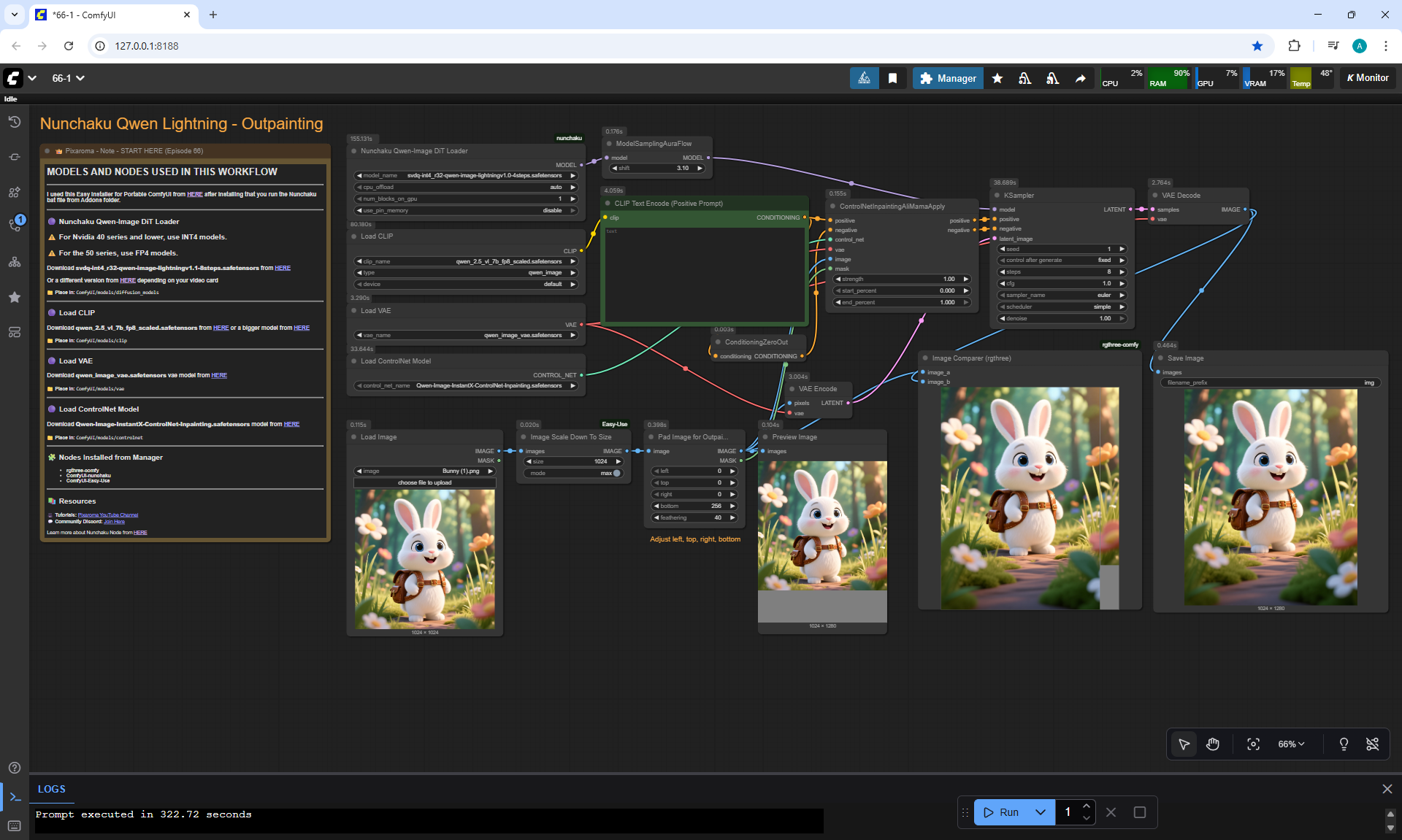
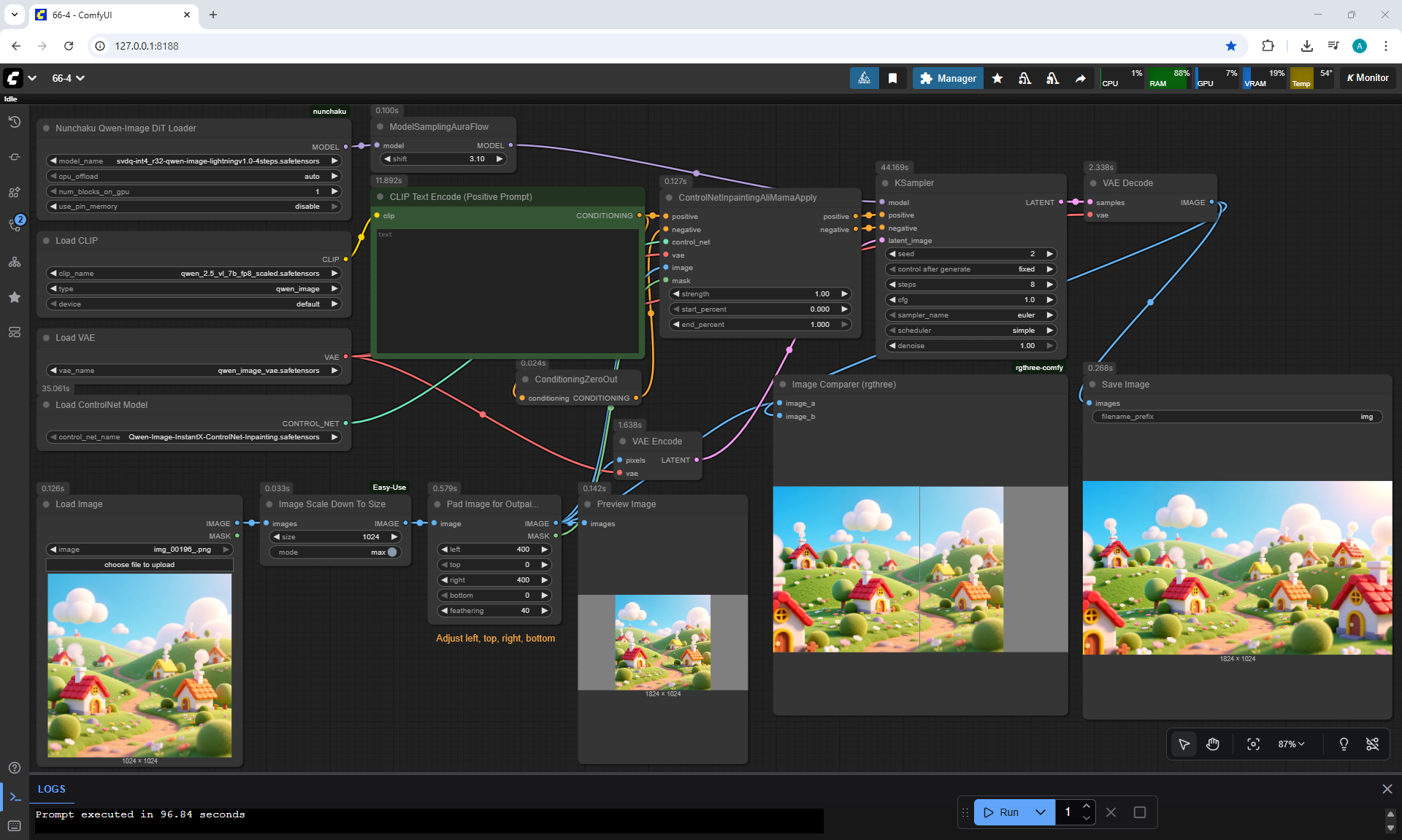
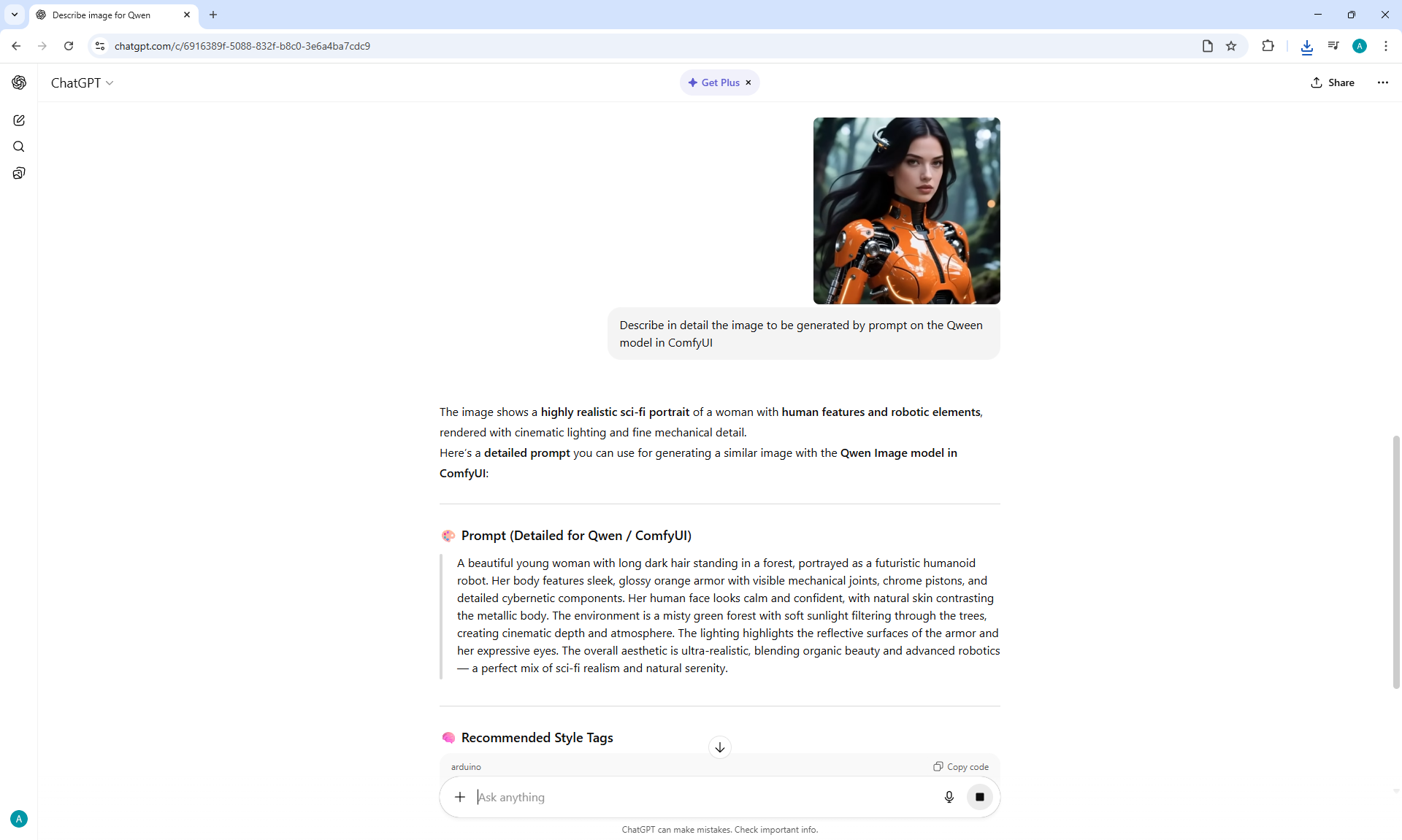
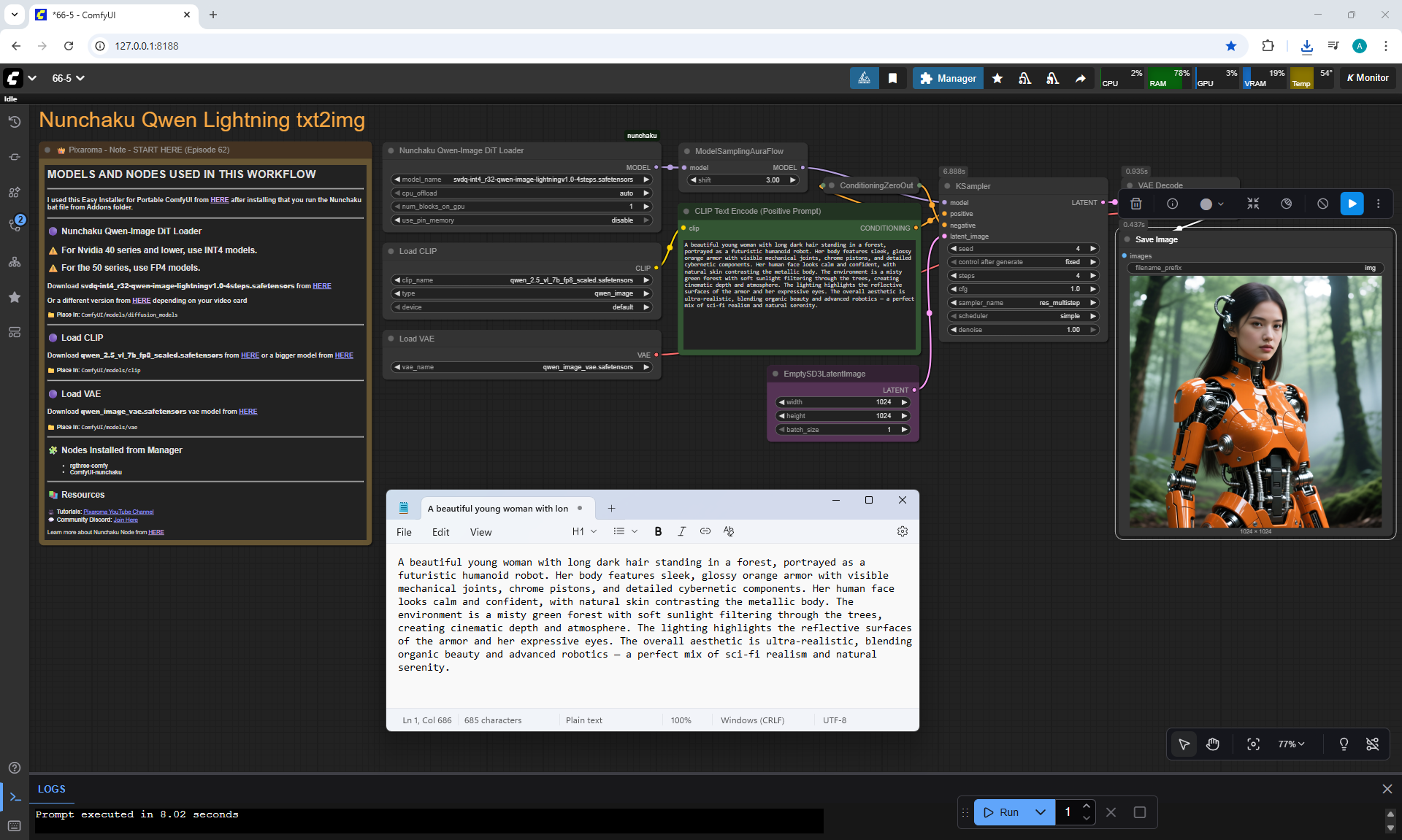
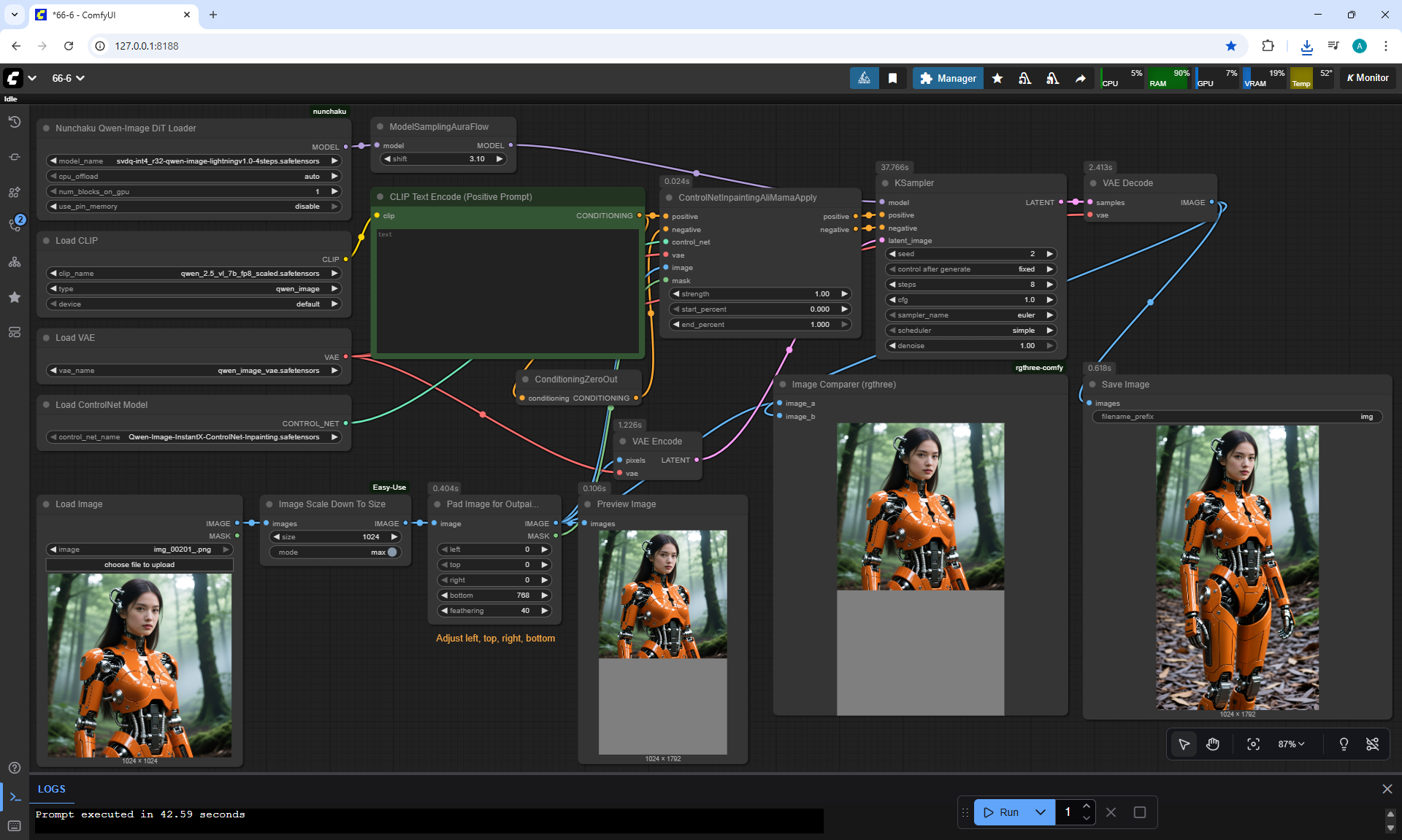
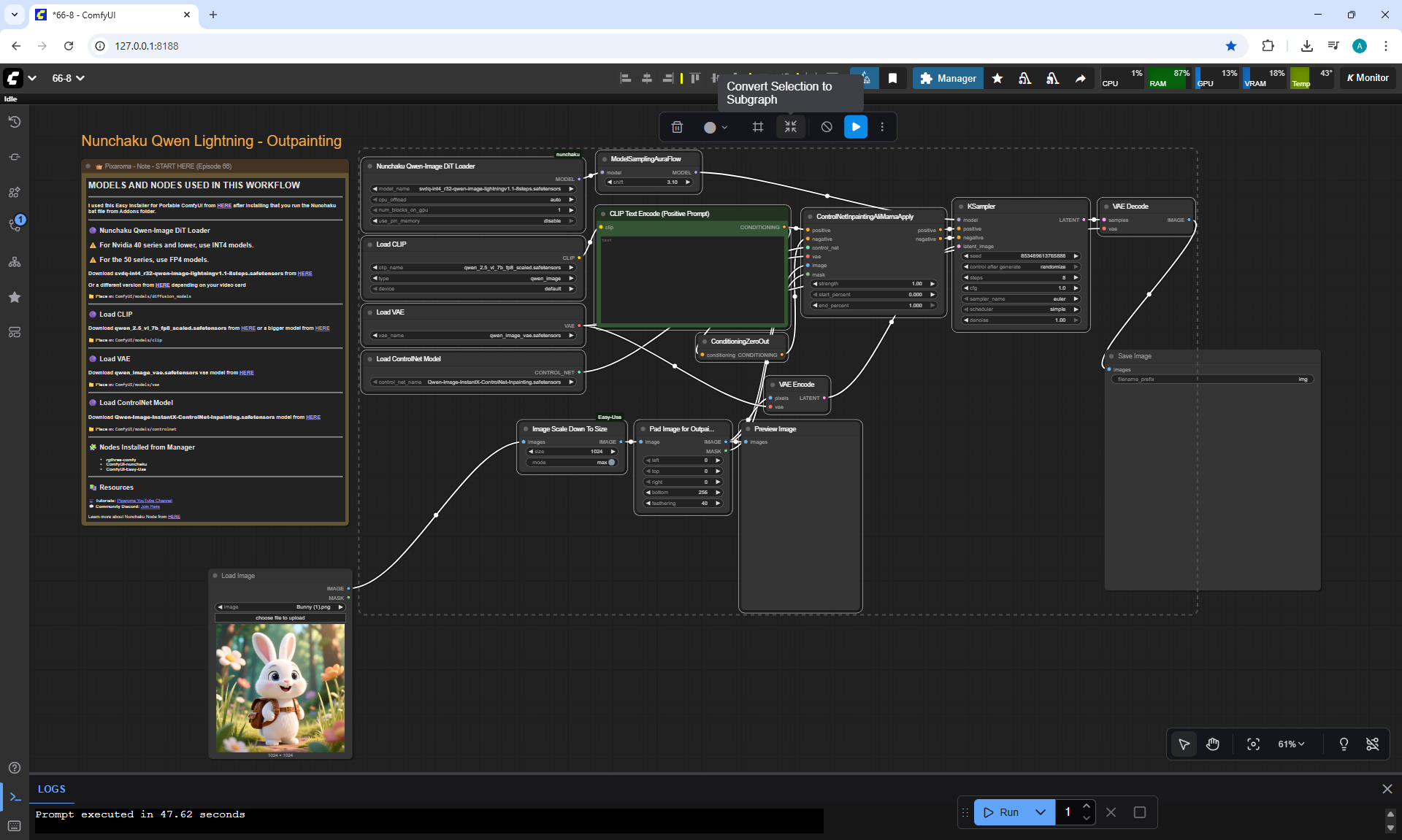
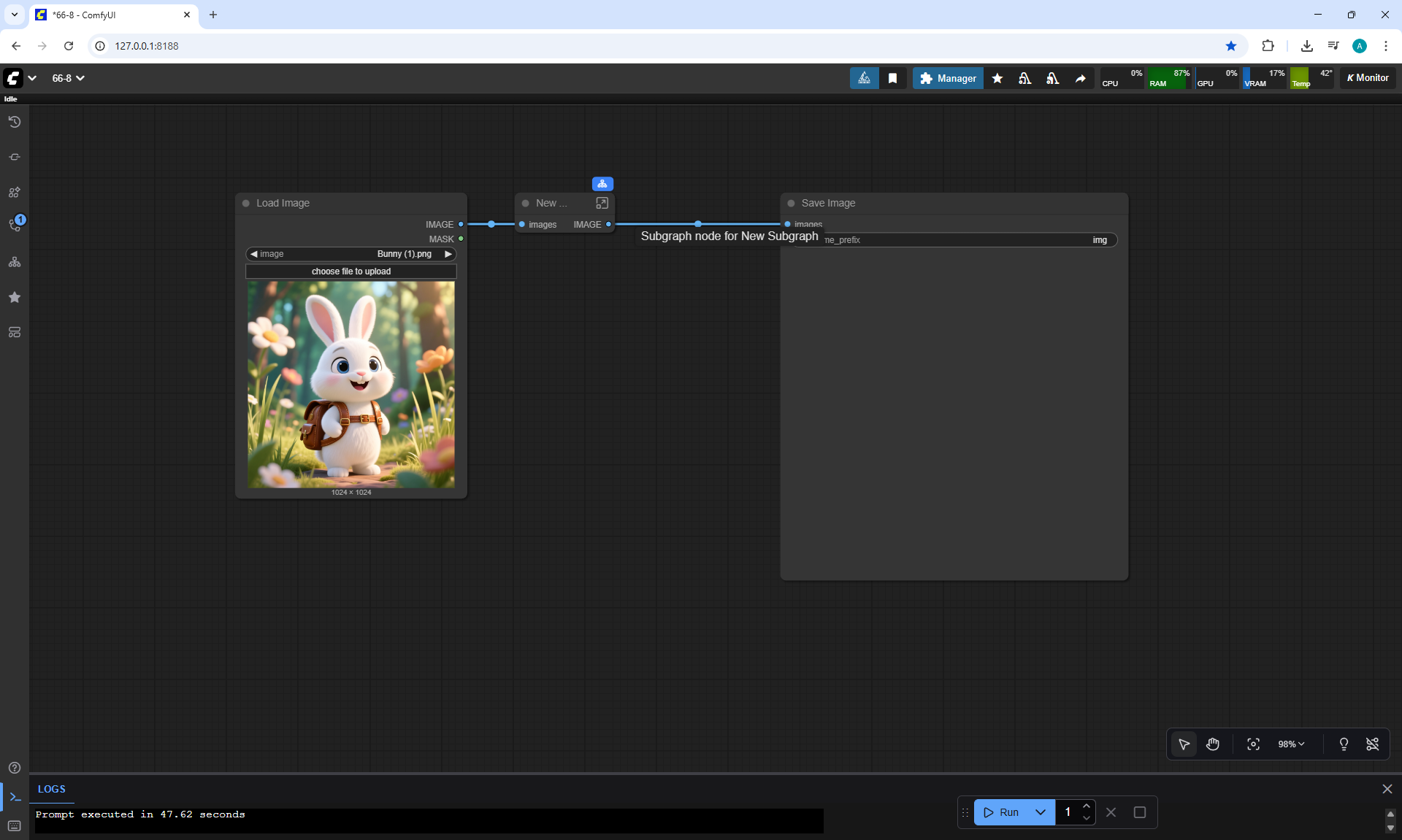
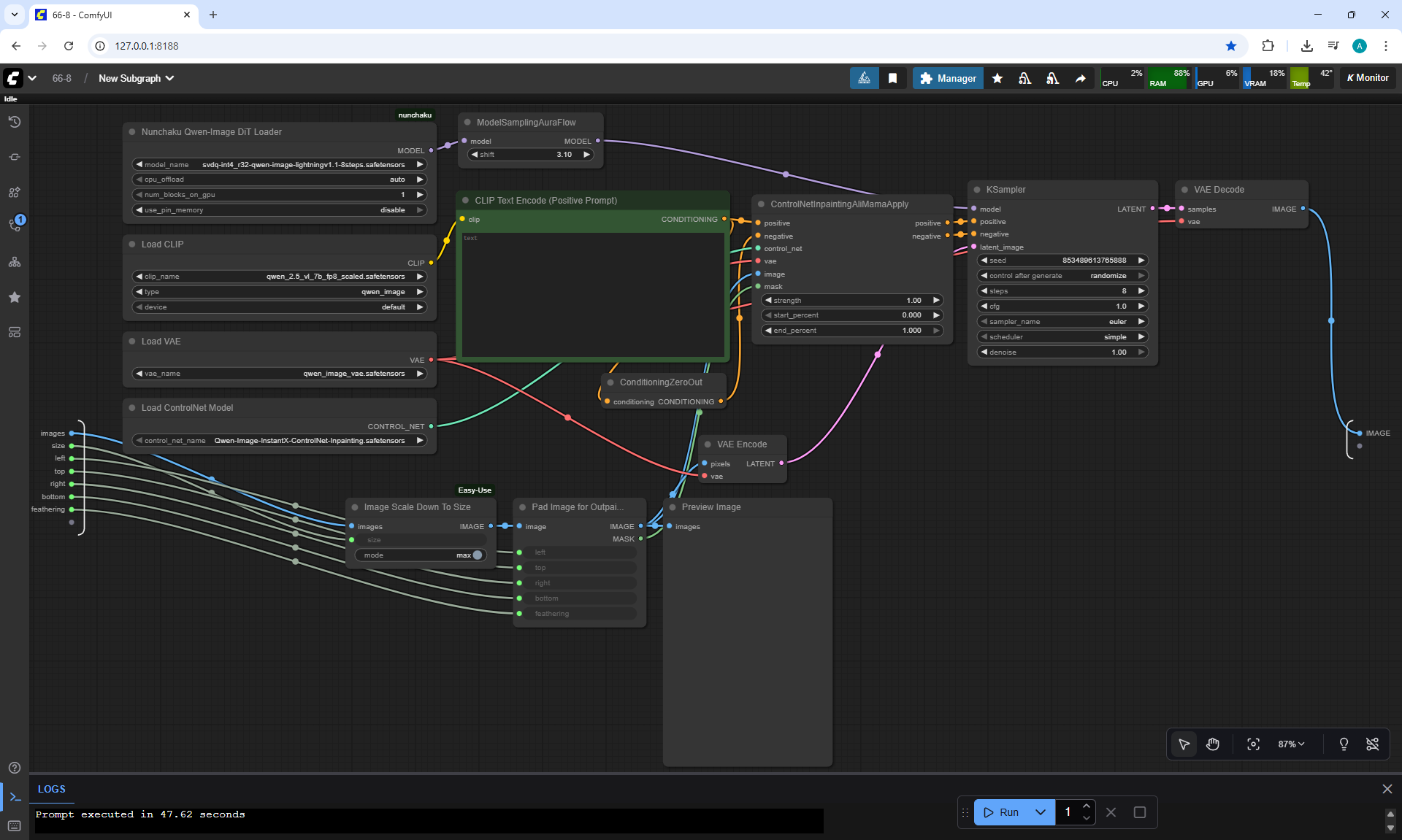
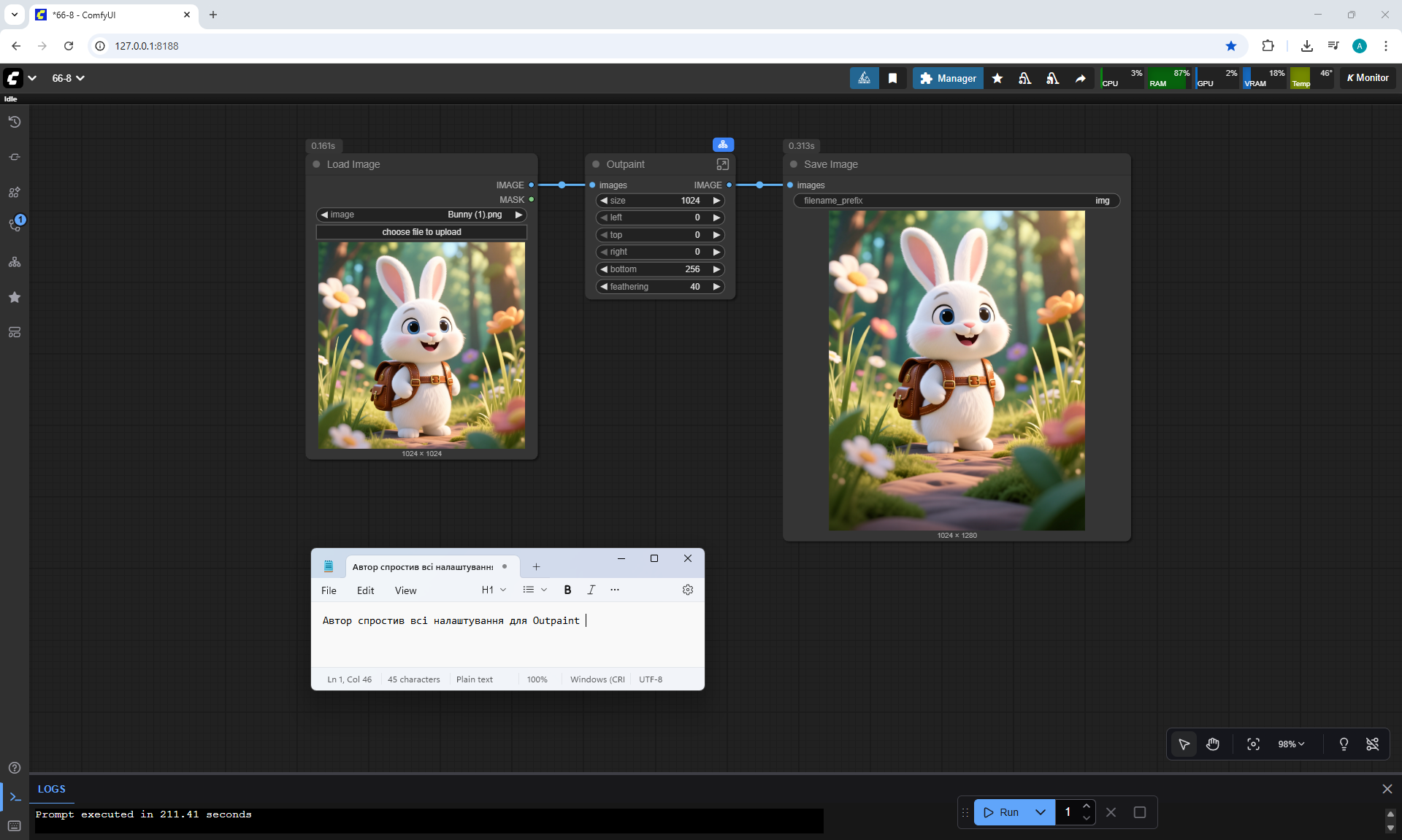
Ep66 - Qwen Outpainting Workflow + Subgraph Tips
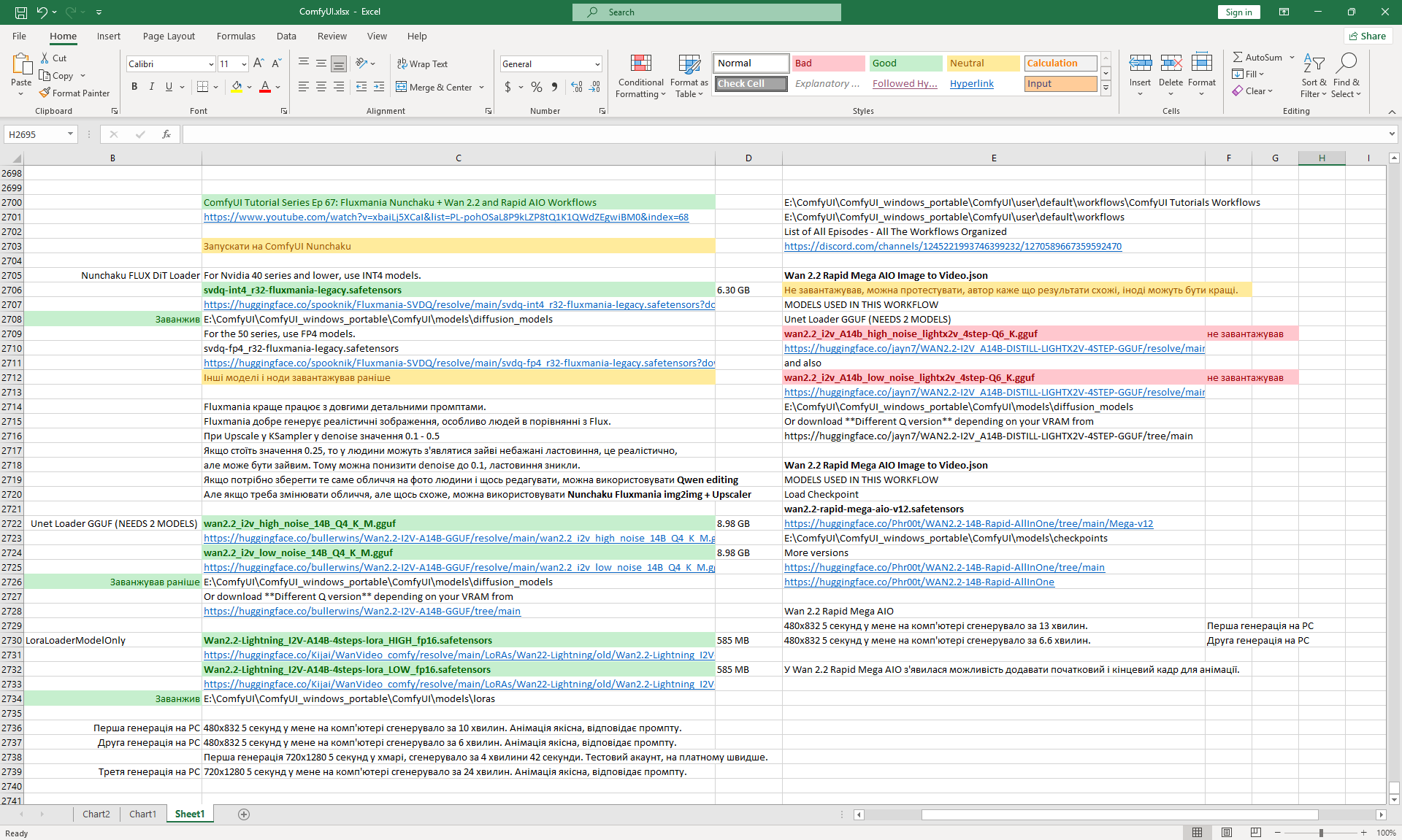
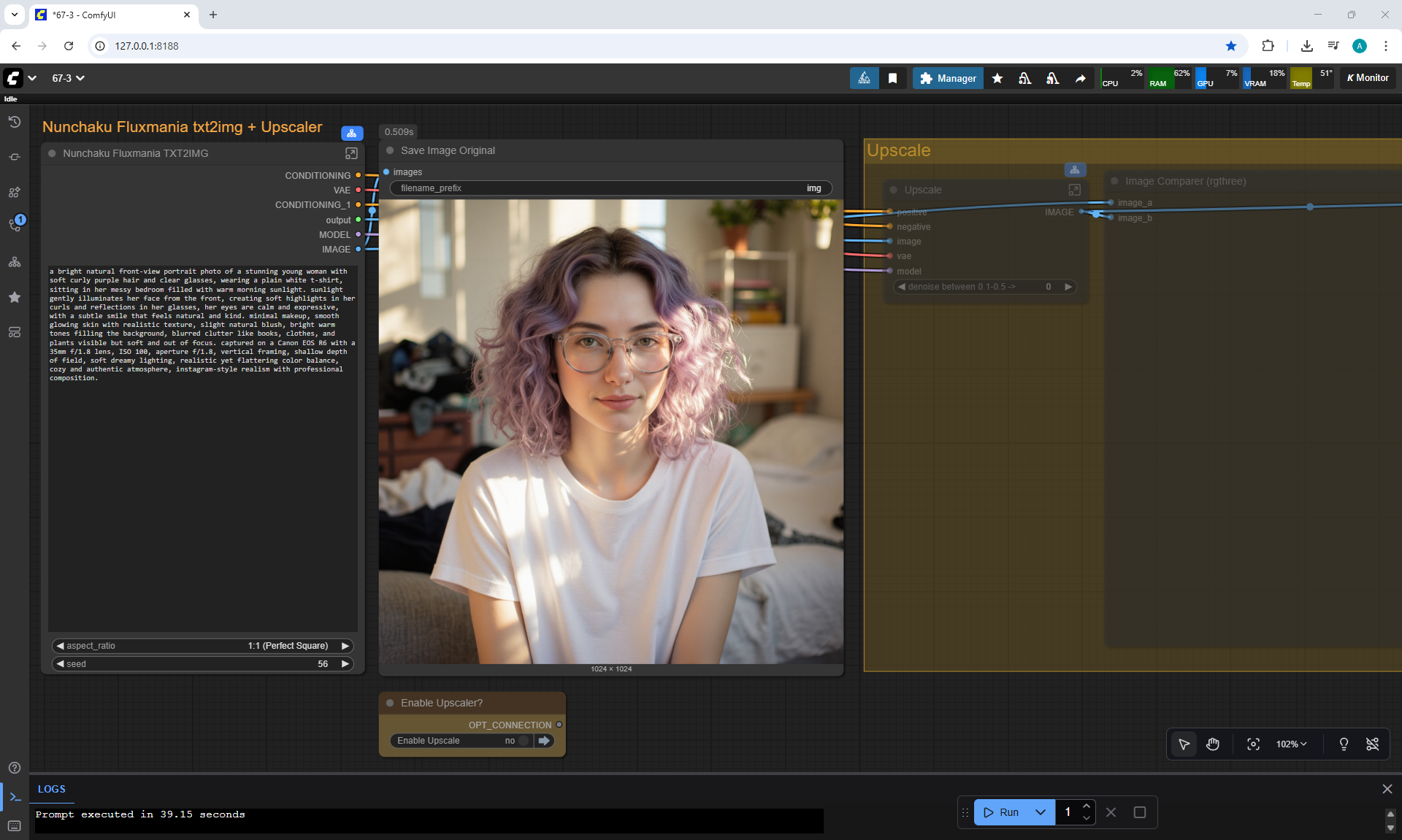
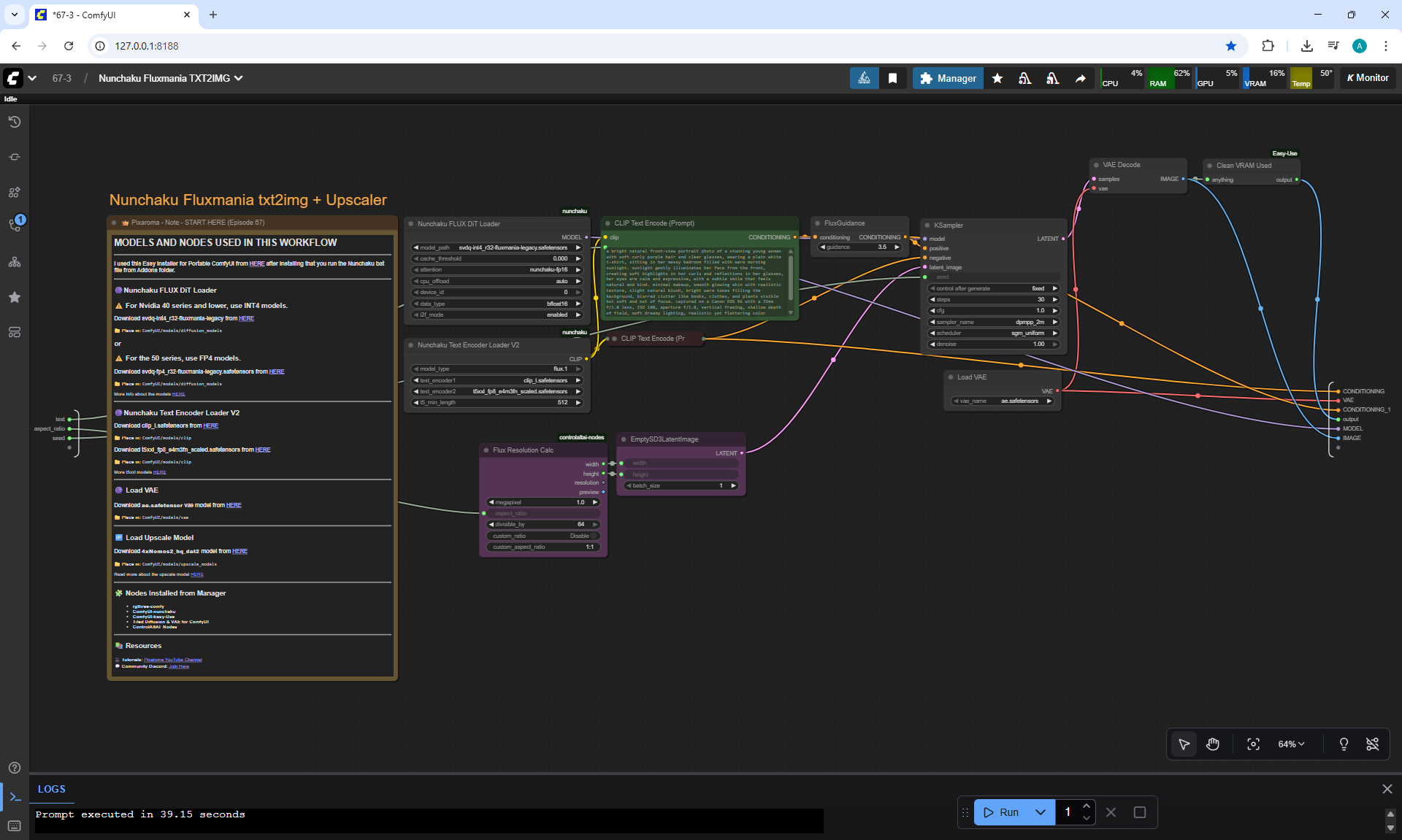
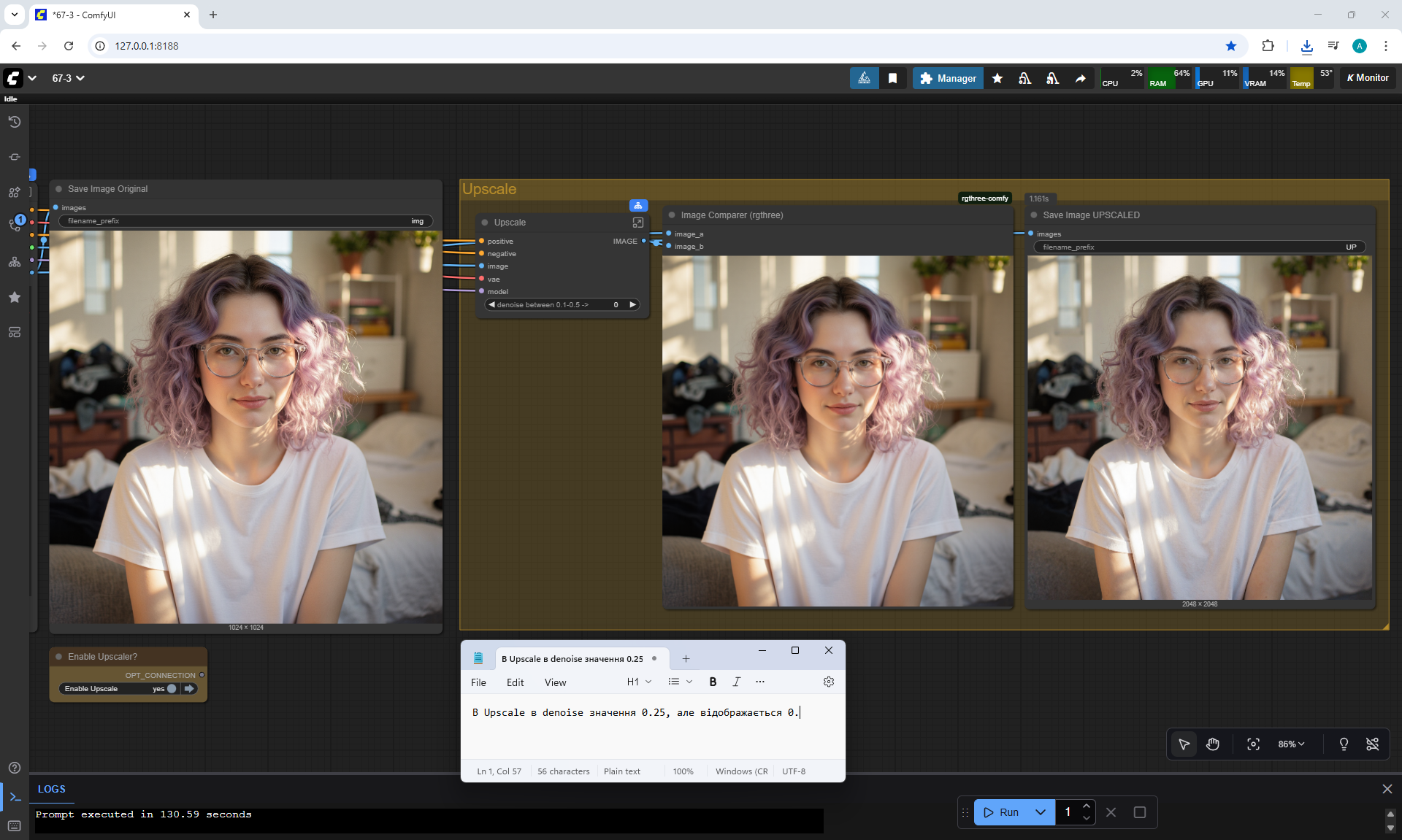
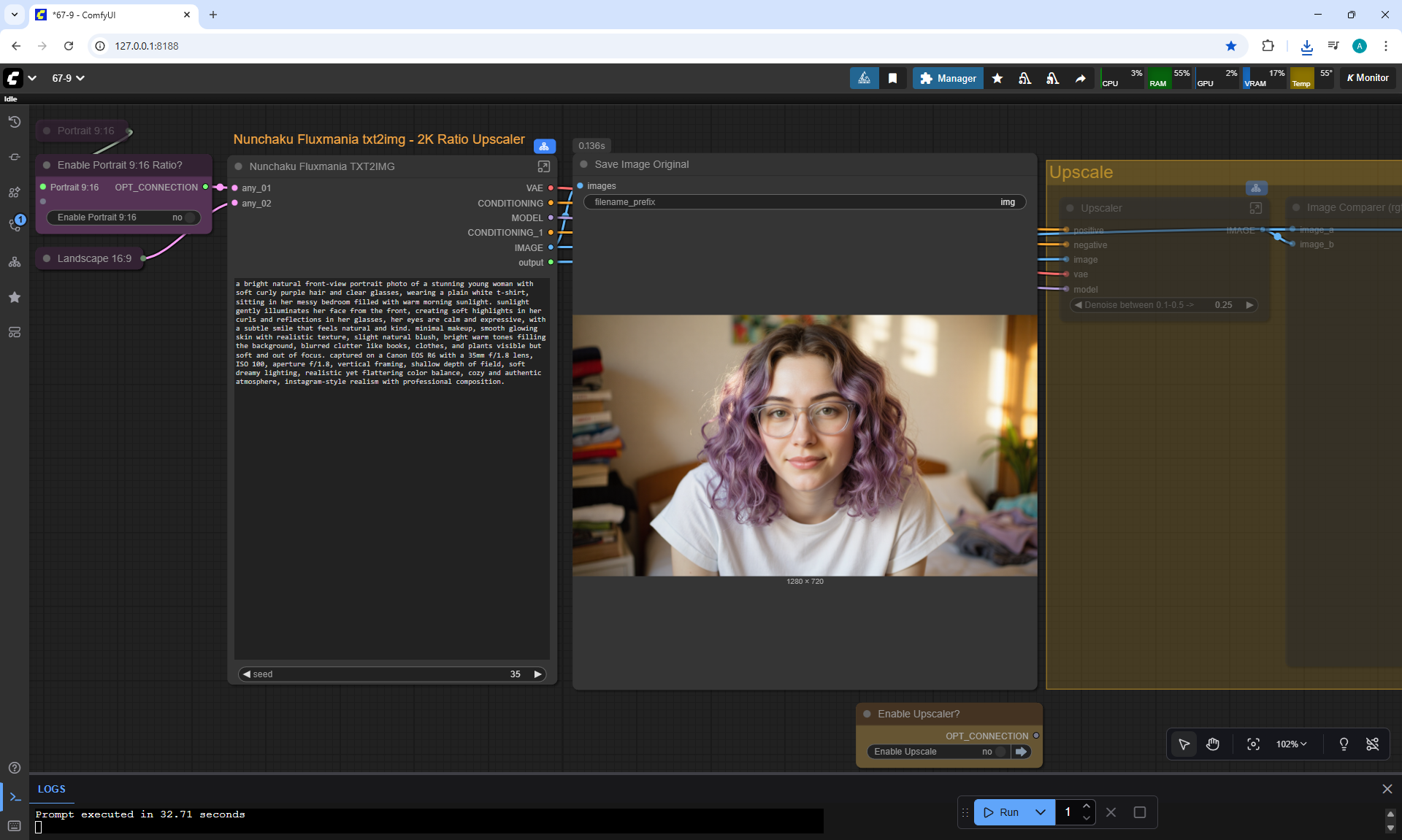
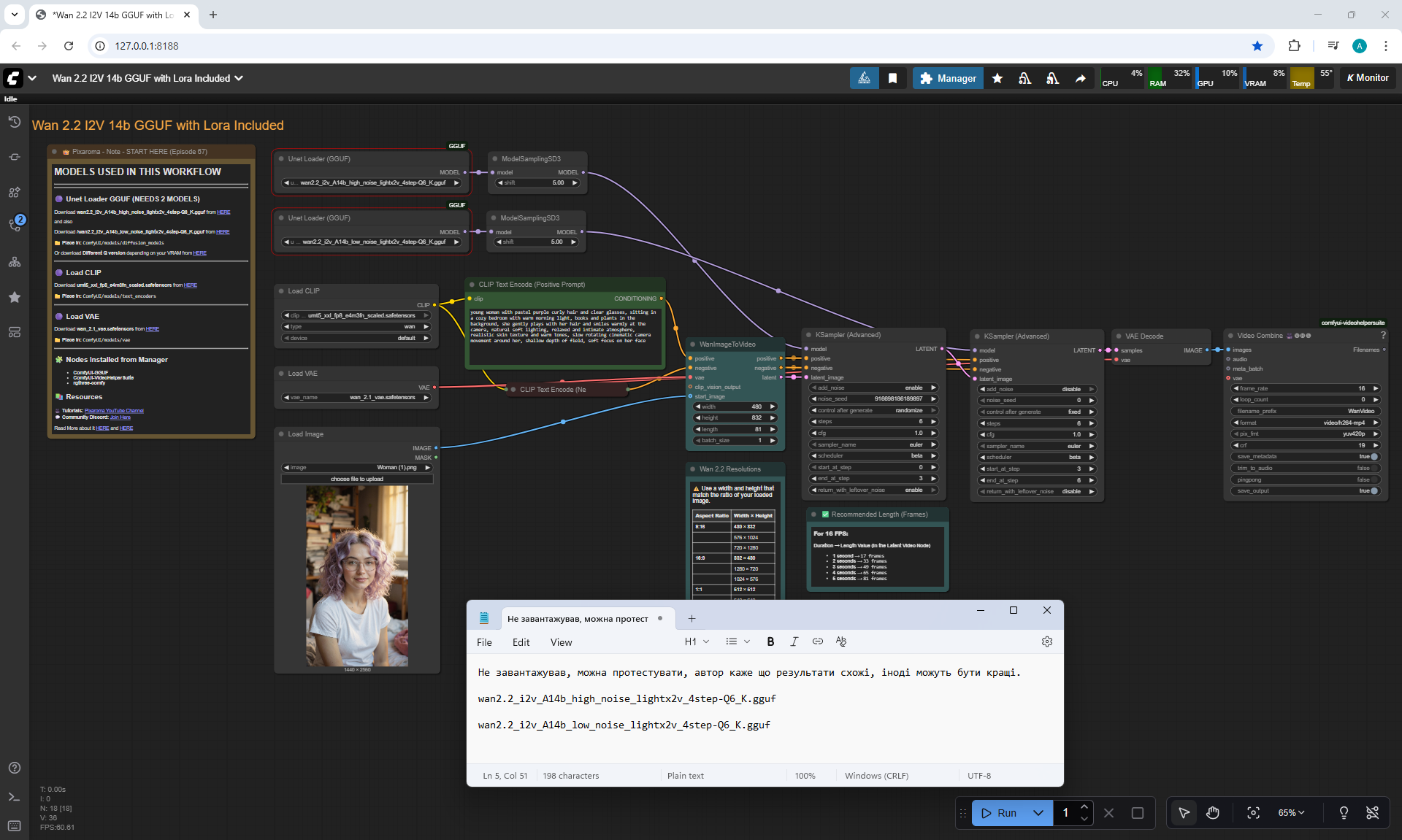
Ep67 - Fluxmania Nunchaku + Wan2.2 and Rapid AIO Workflows
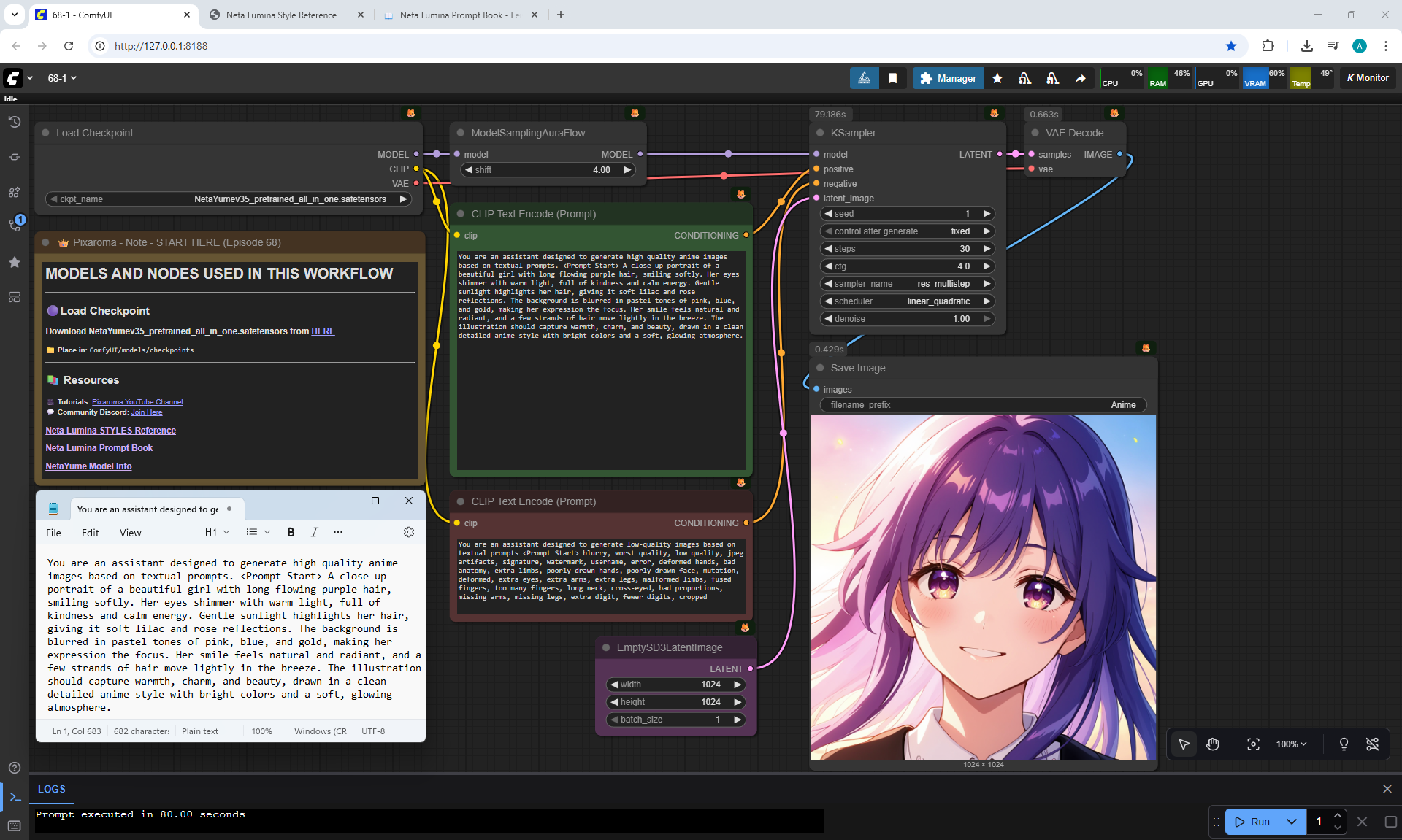
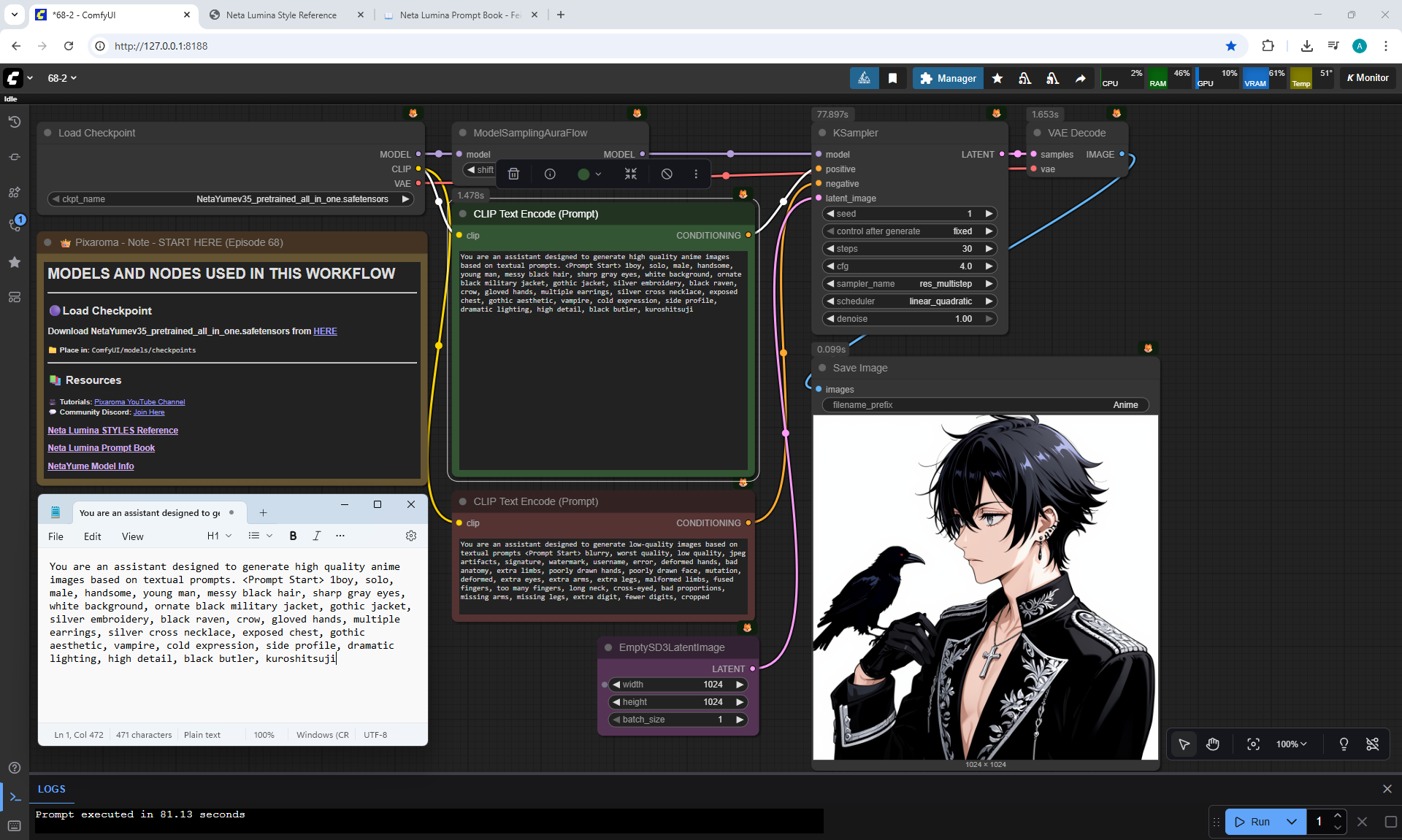
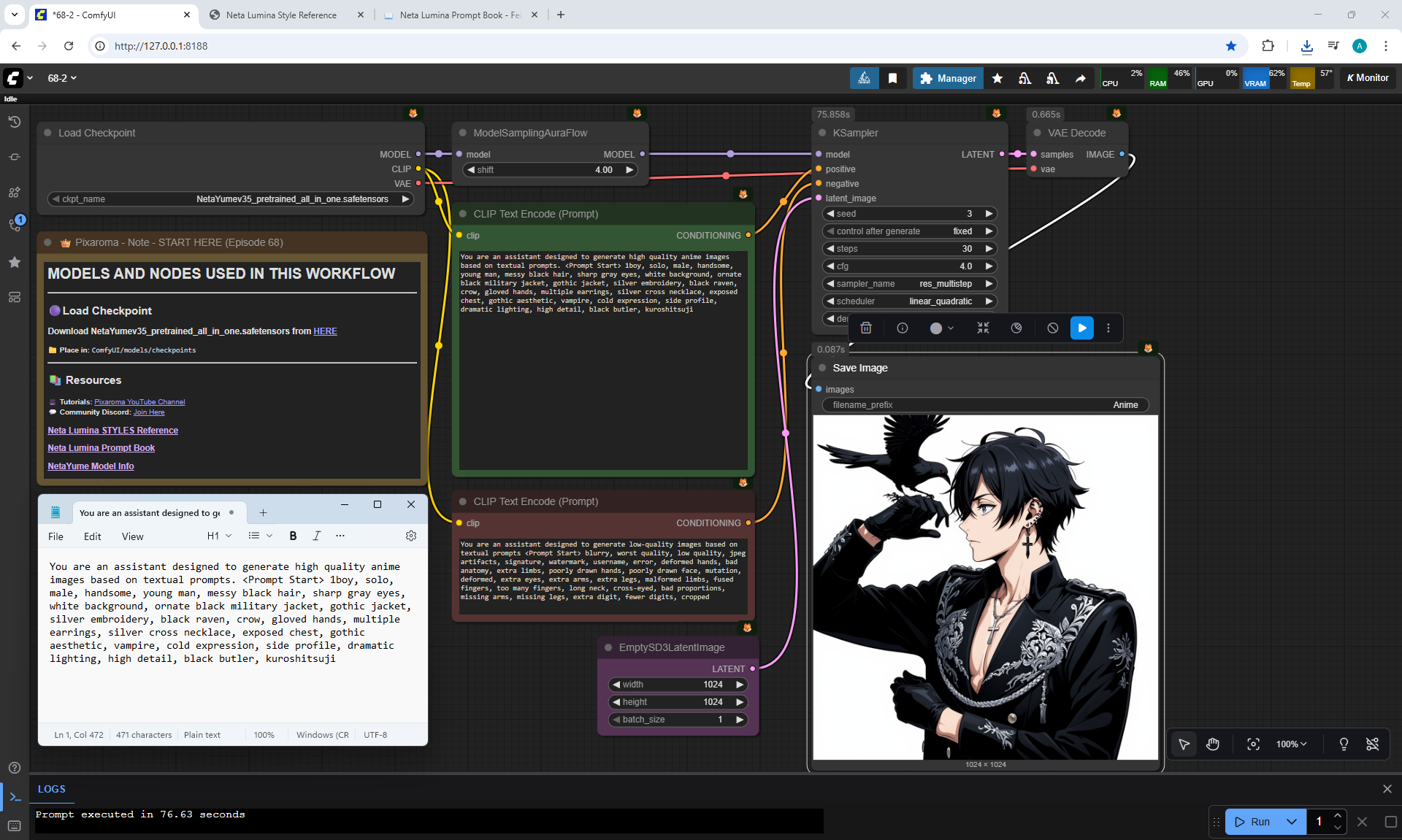
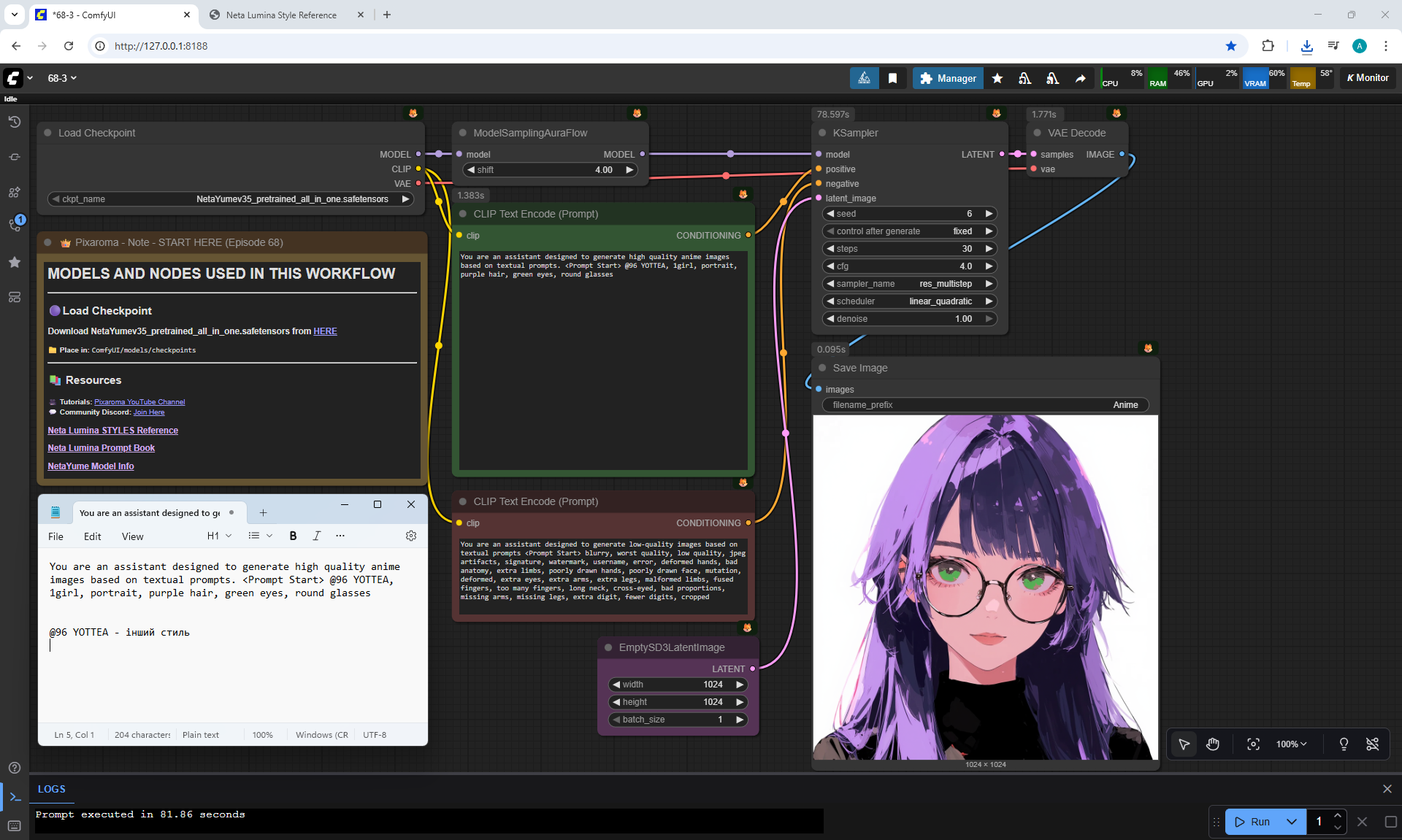
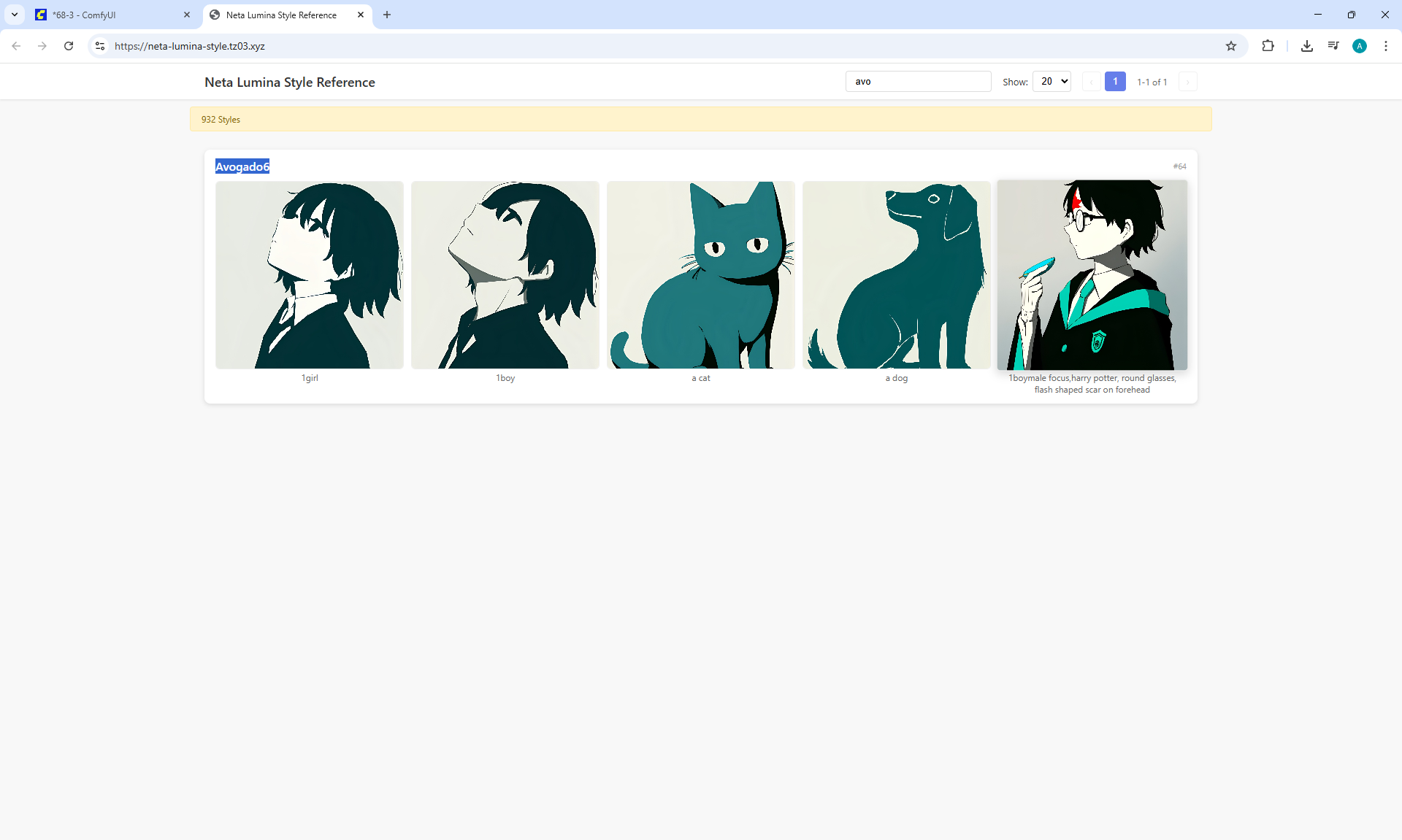
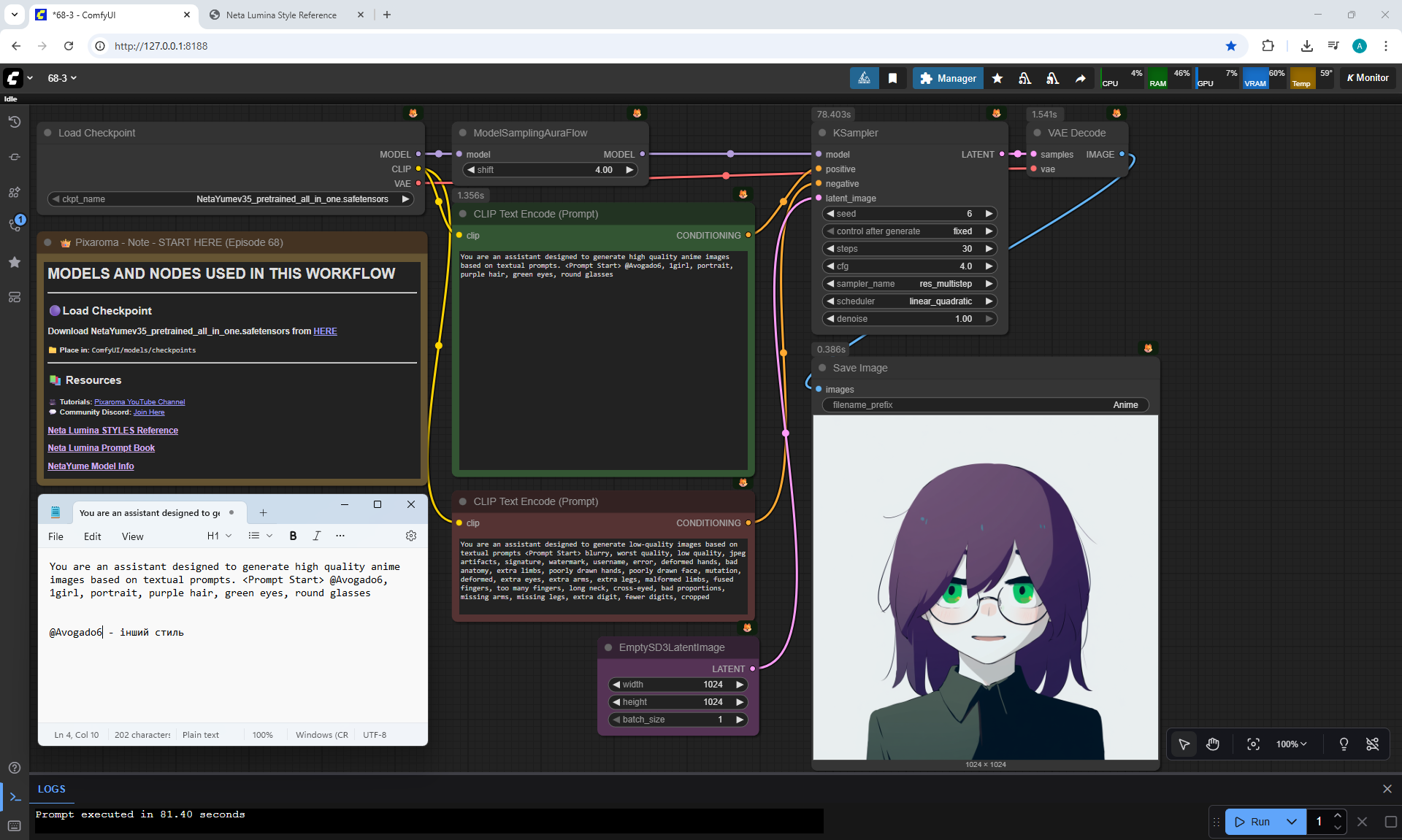
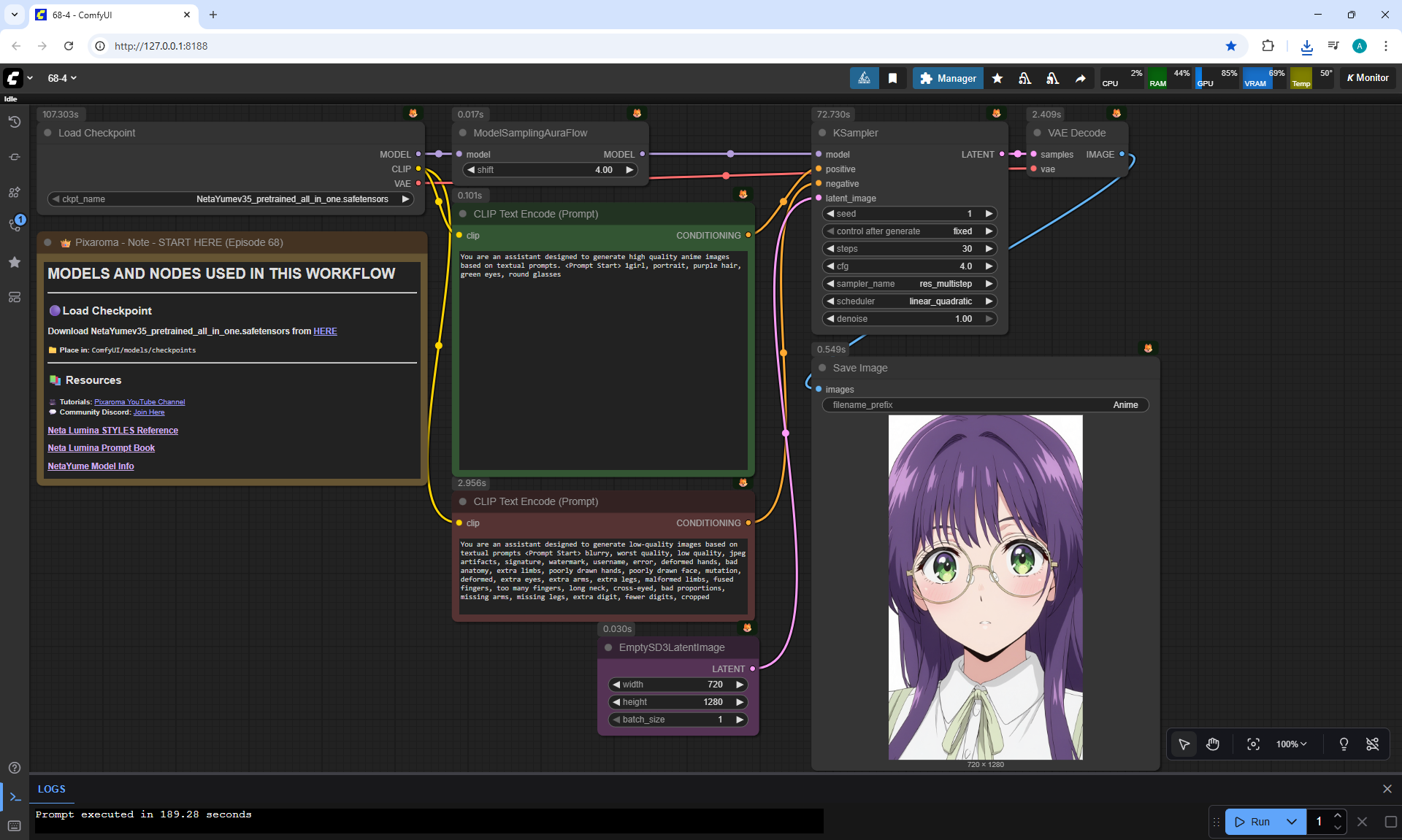
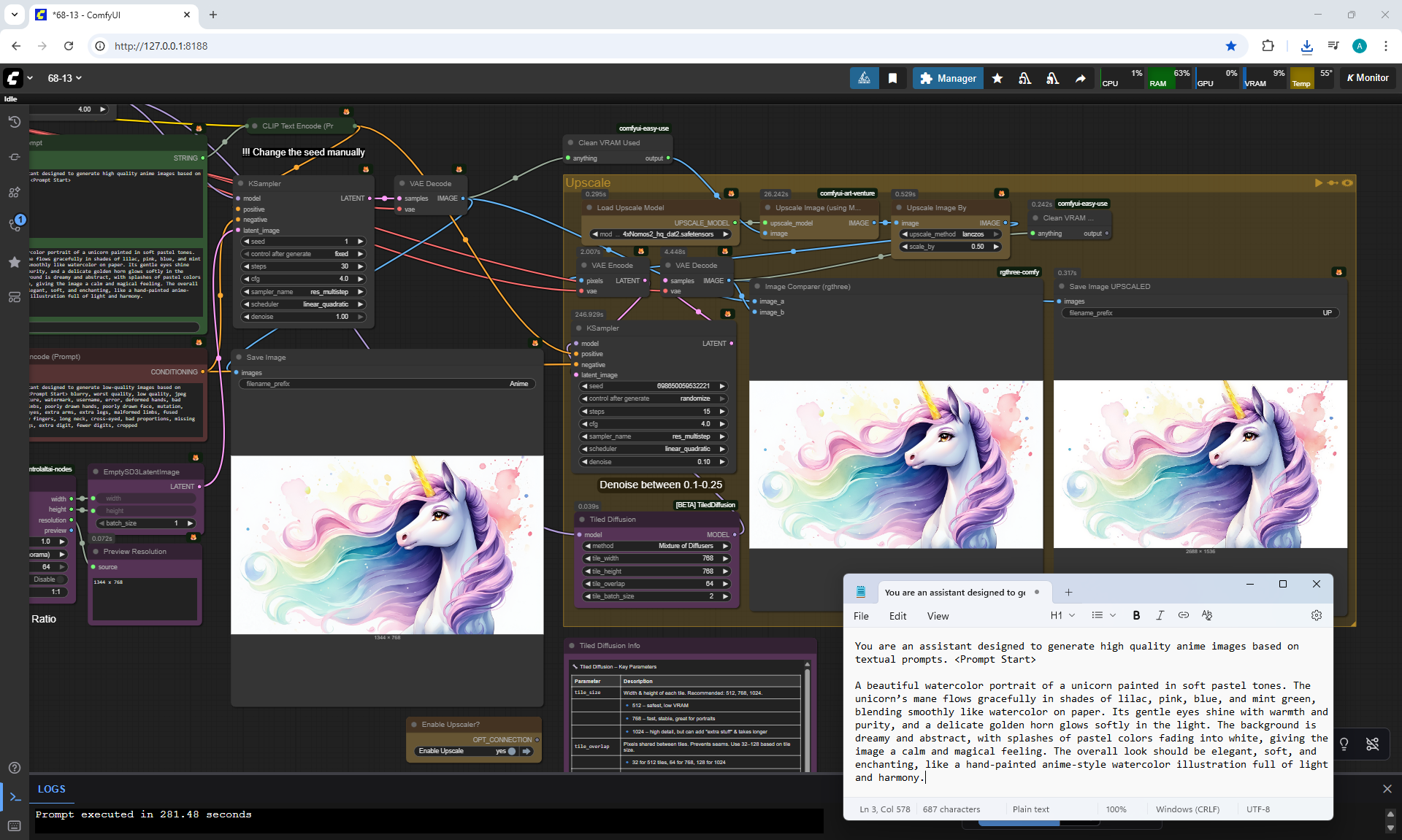
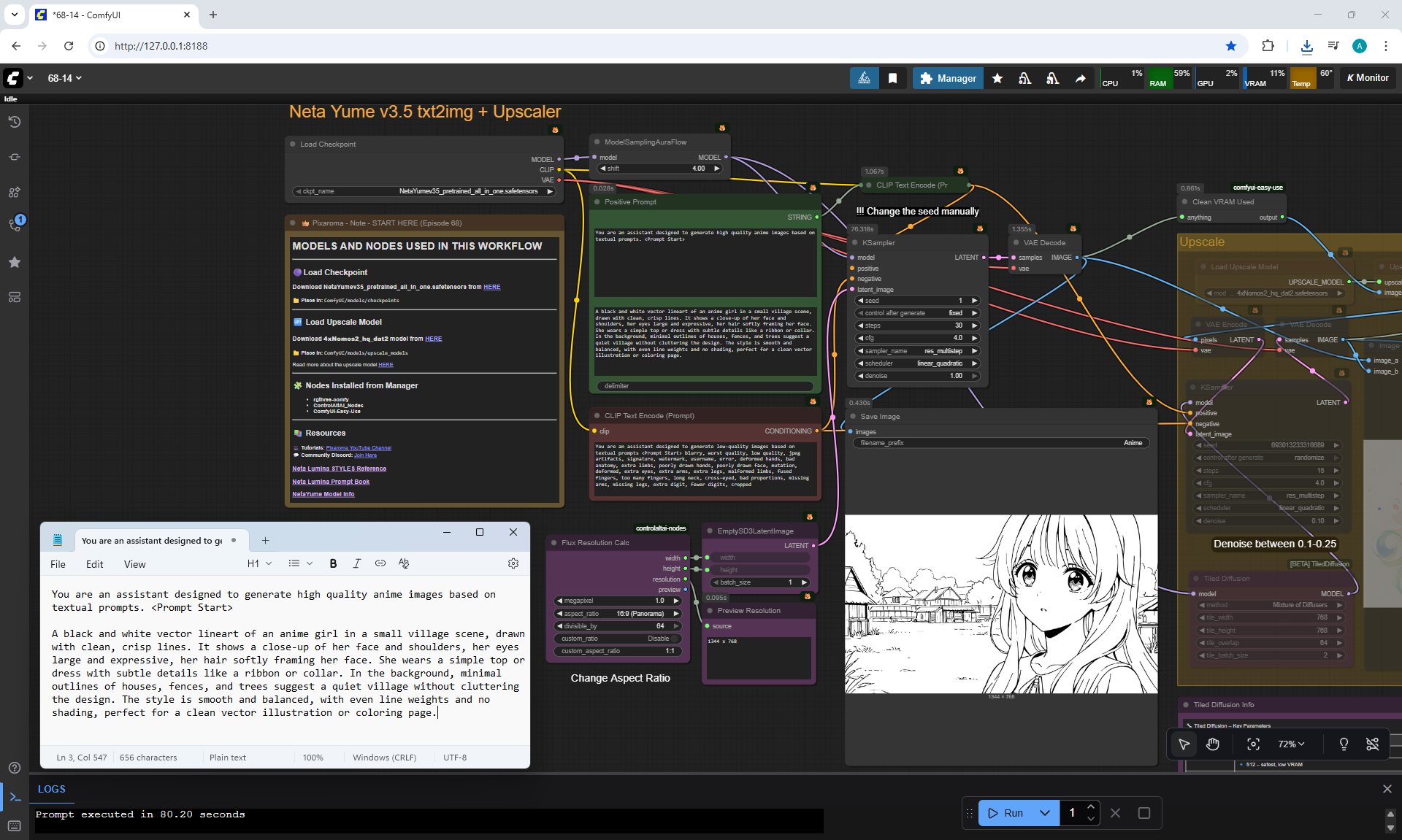
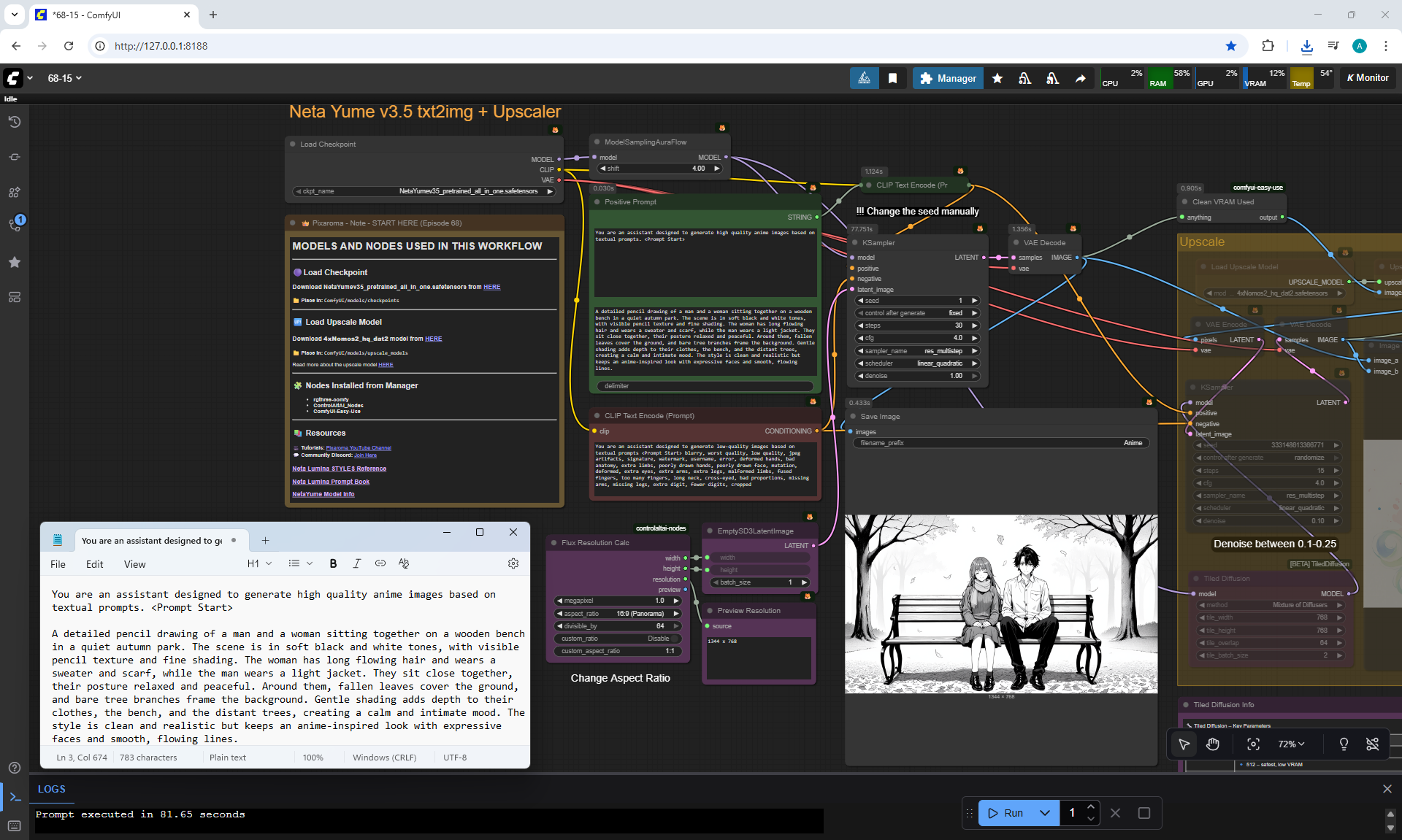
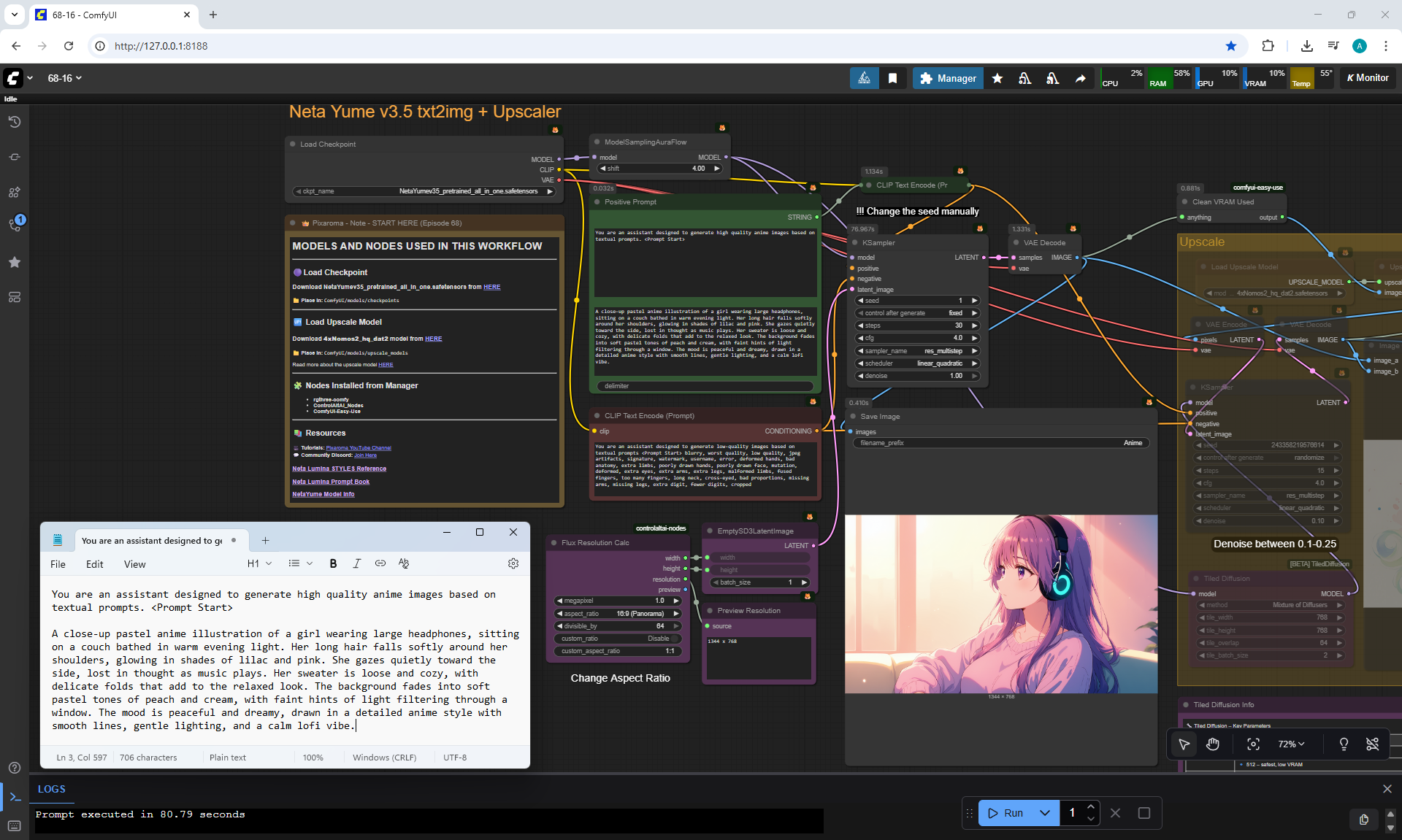
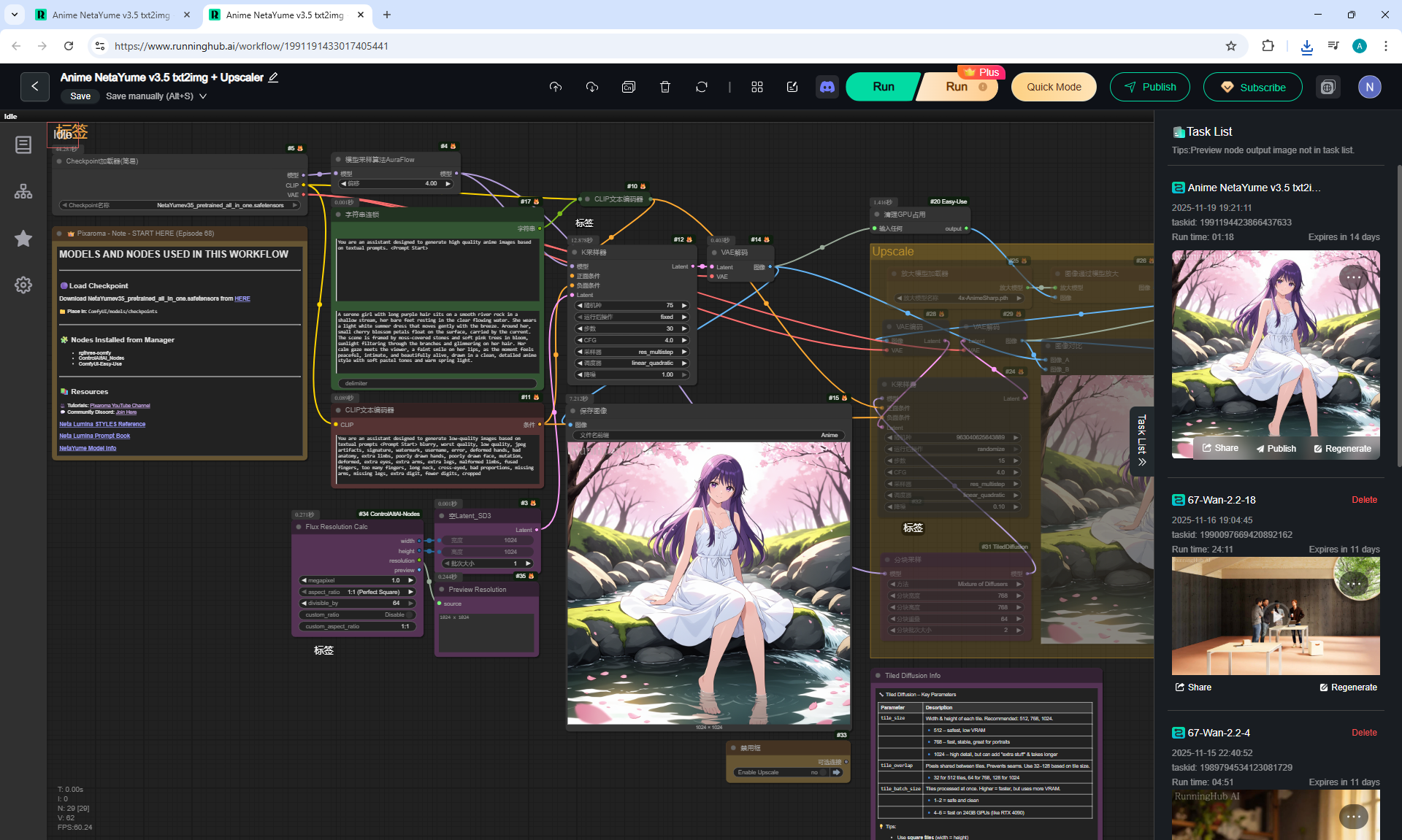
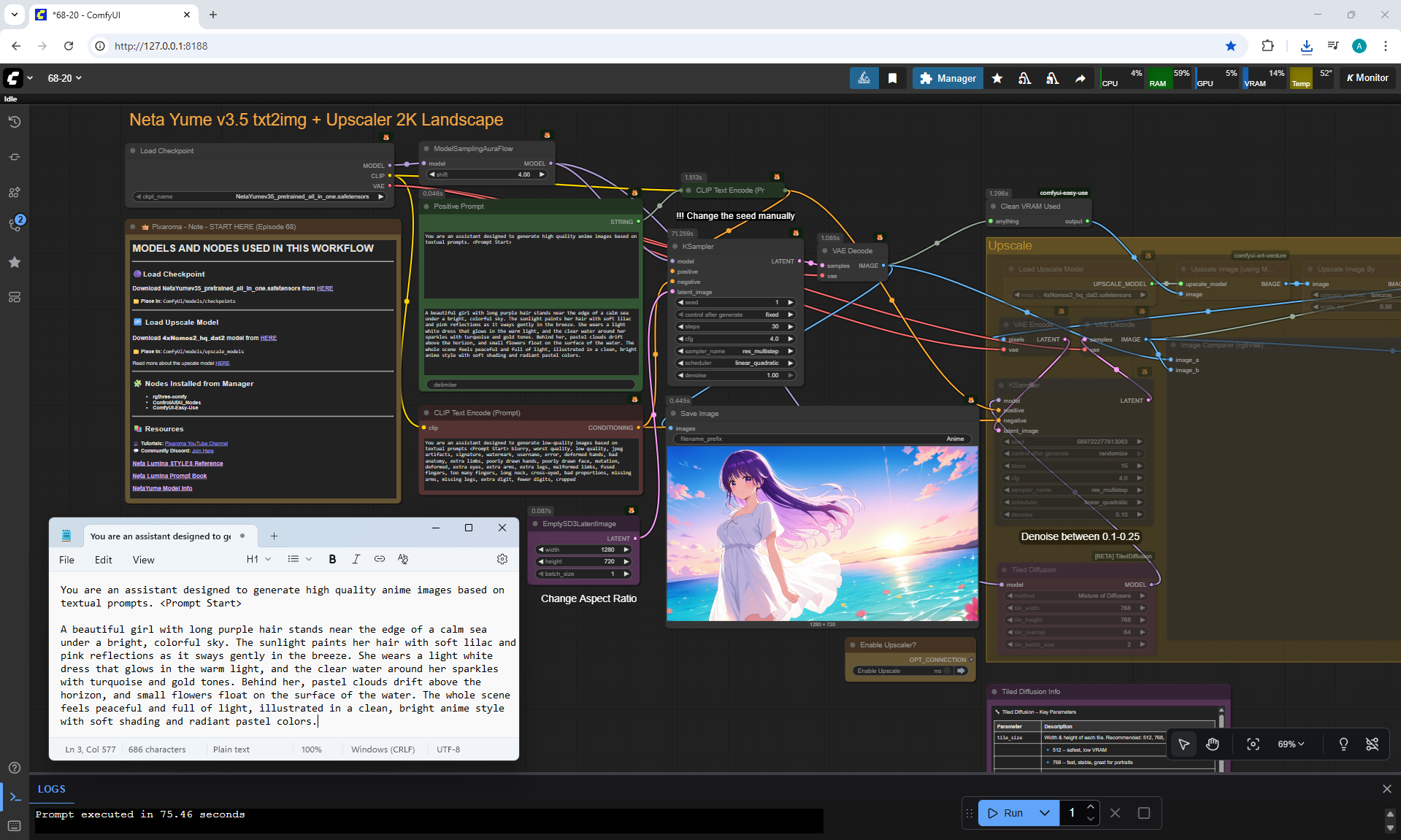
Ep68 - How to Create Anime Illustrations - NetaYume v3.5
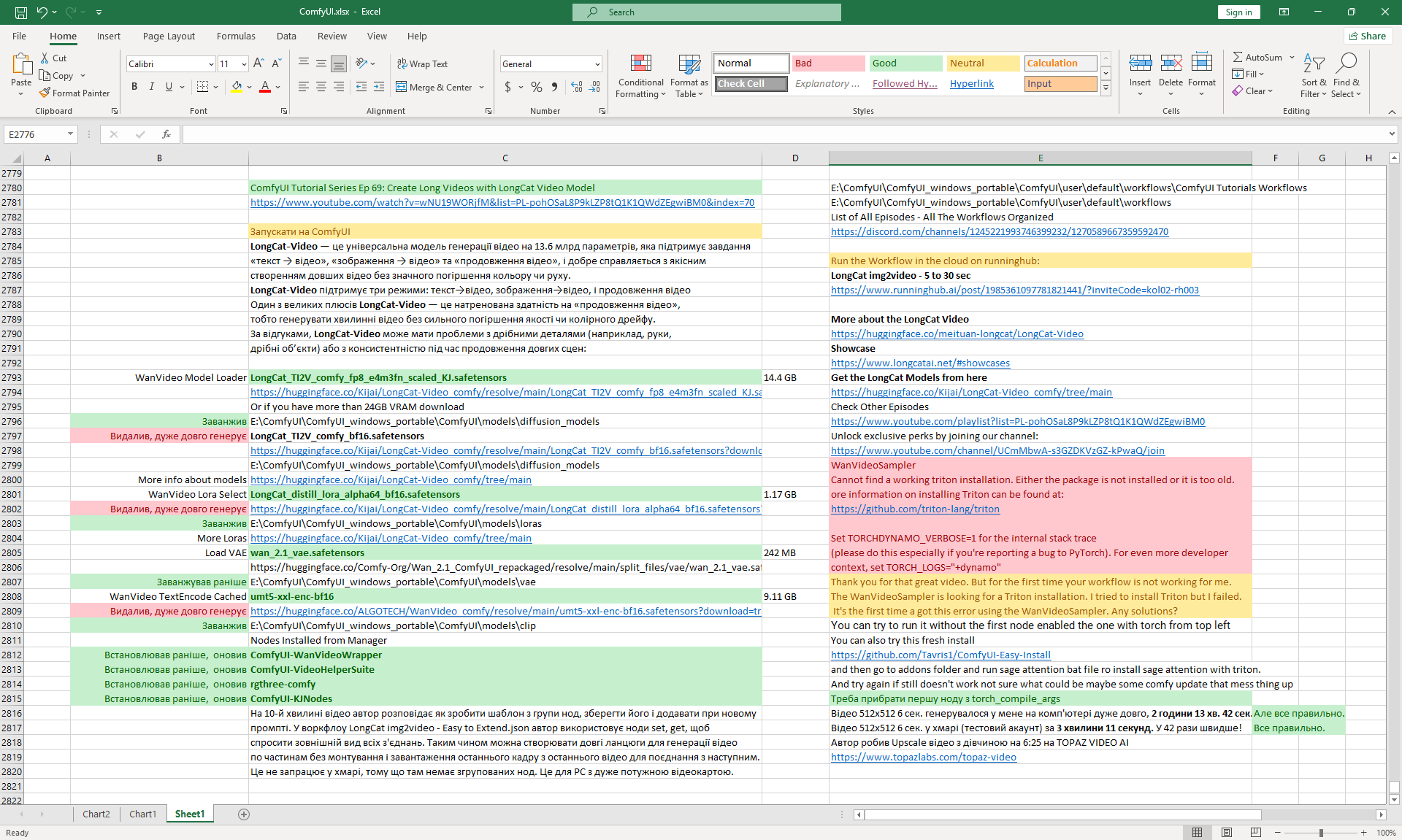
Ep69 - Create Long Videos with LongCat Video Model
Ep70 - Nunchaku Qwen Loras - Relight, Camera Angle & Scene..
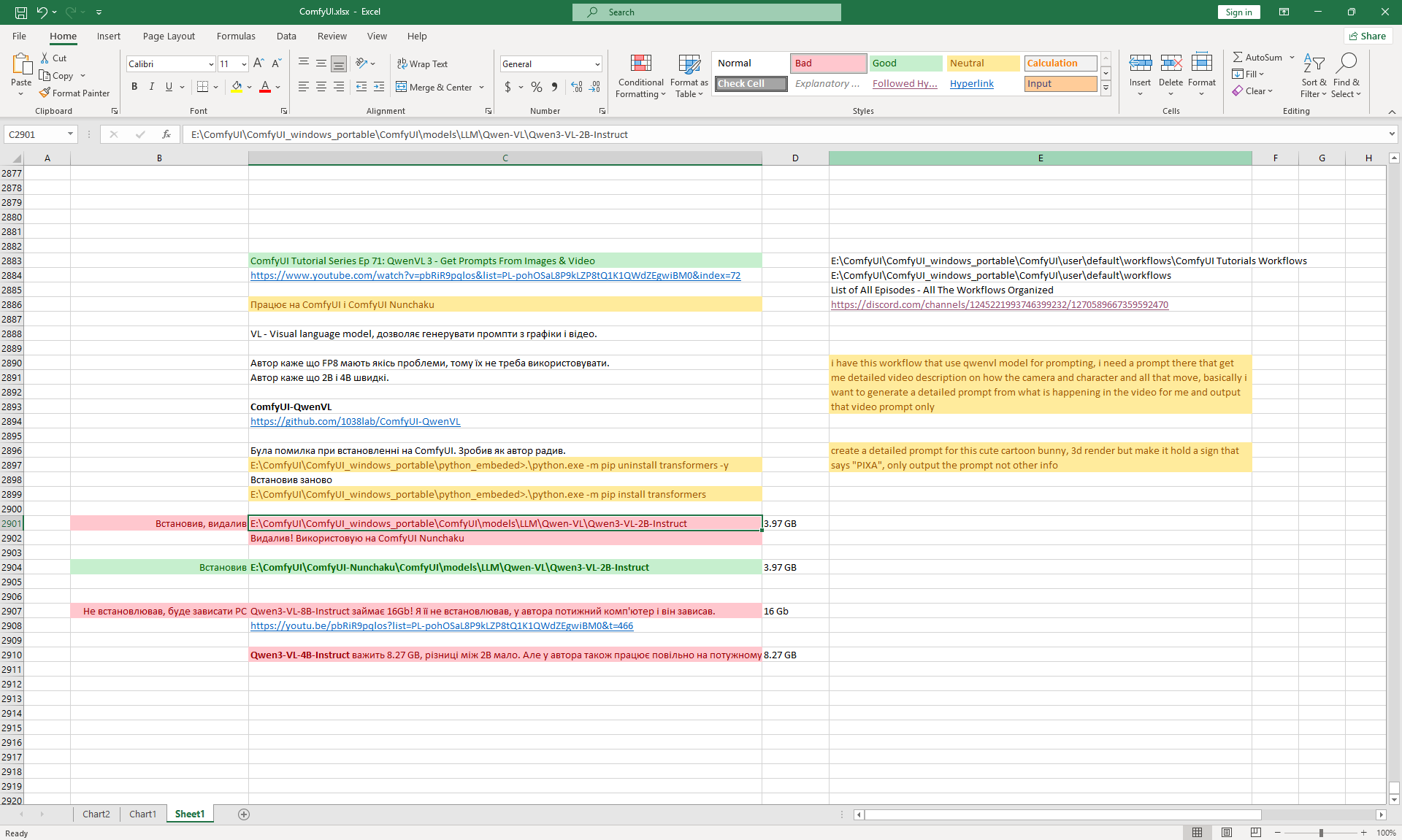
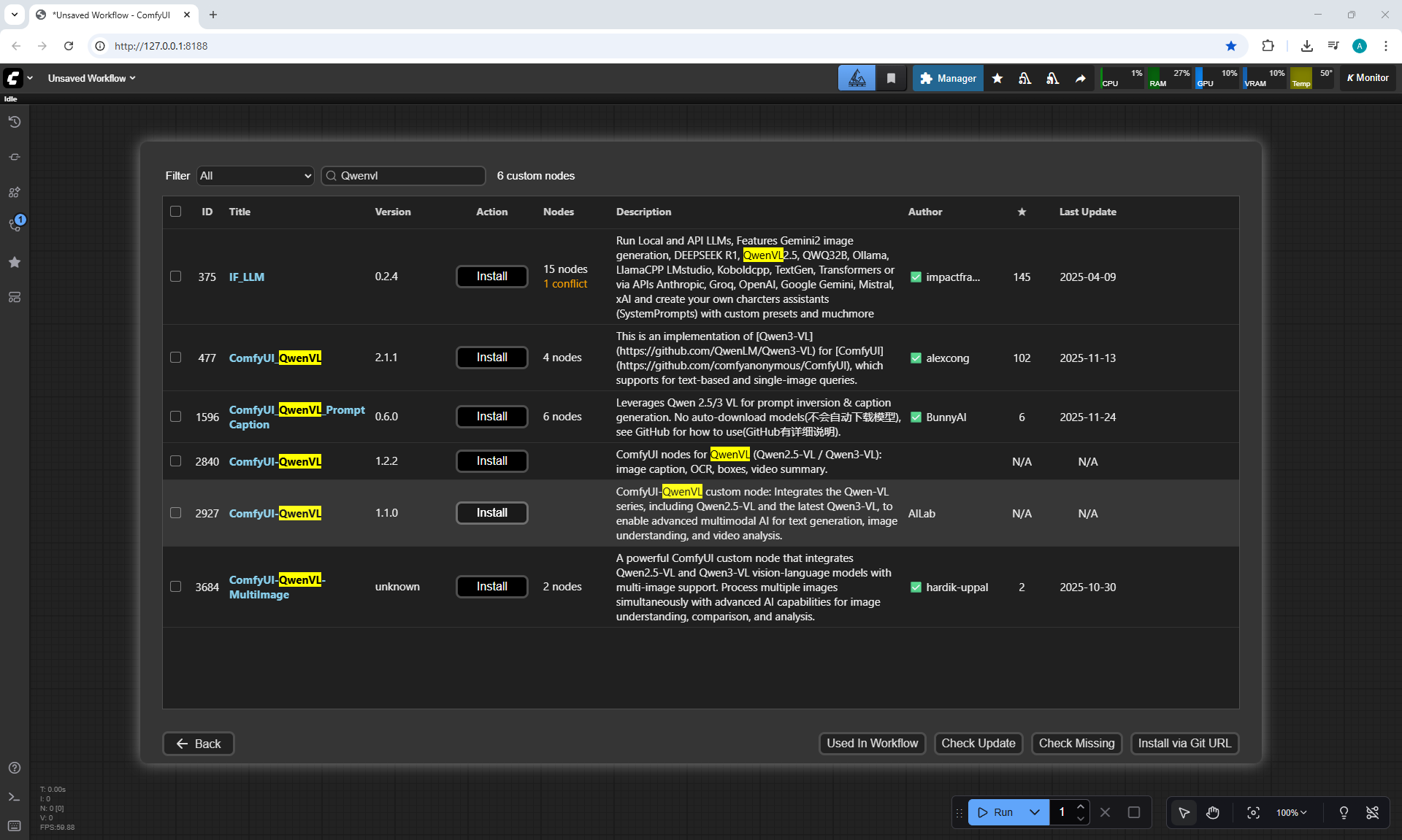
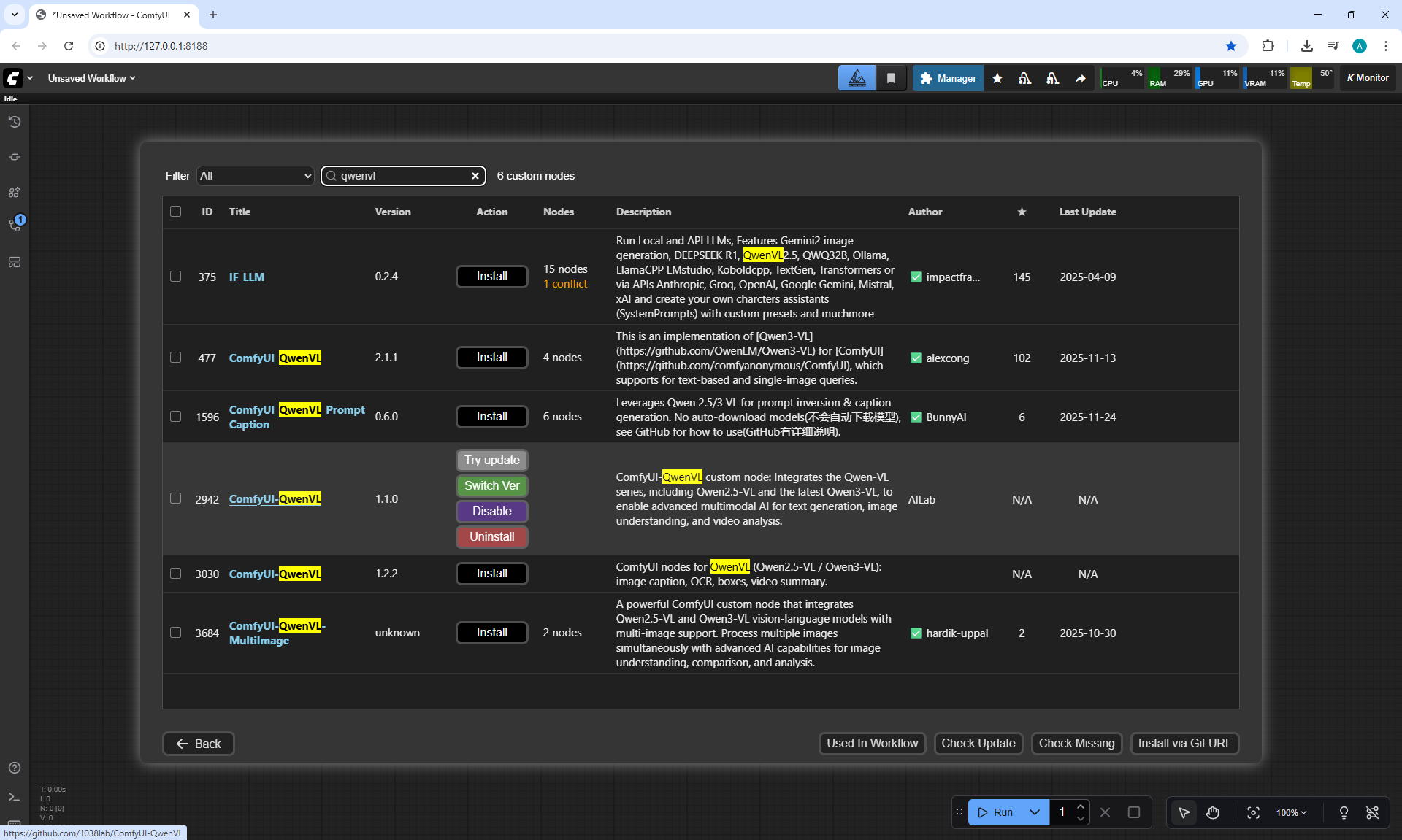
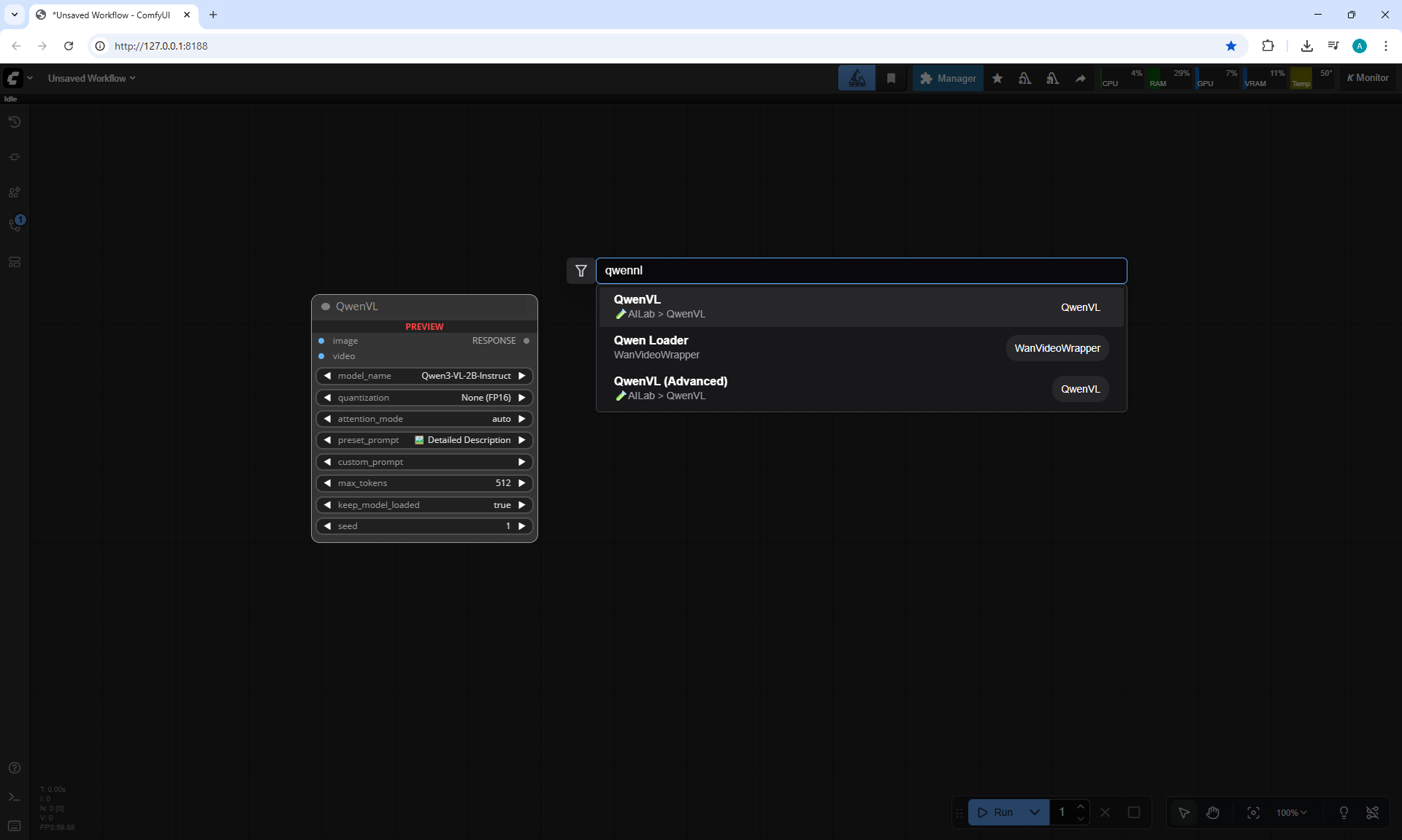
Ep71 - QwenVL 3 - Get Prompts From Images & Video
Ep72 - Z-Image Turbo Workflows, ControlNet Esse.. & LoRA Trai..
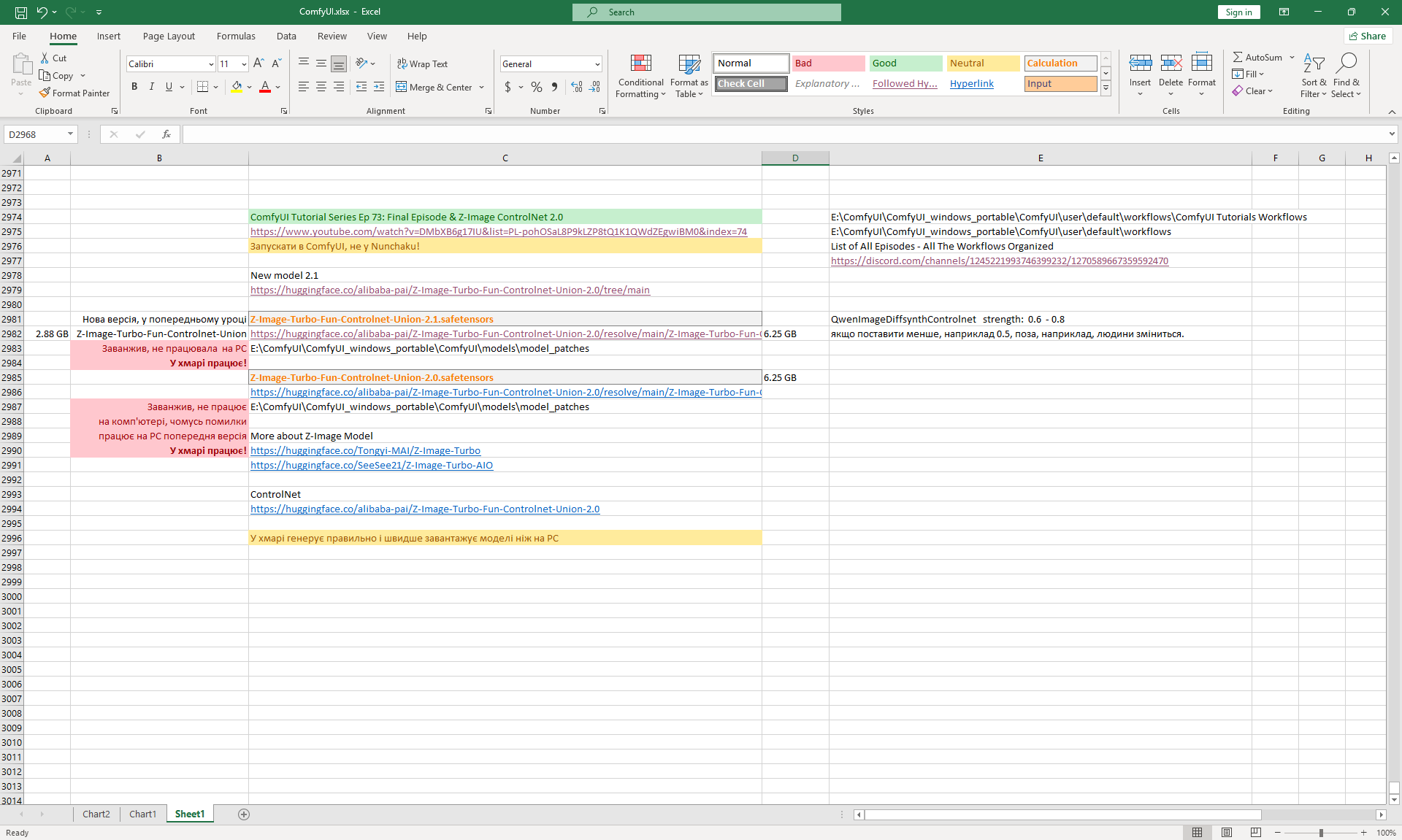
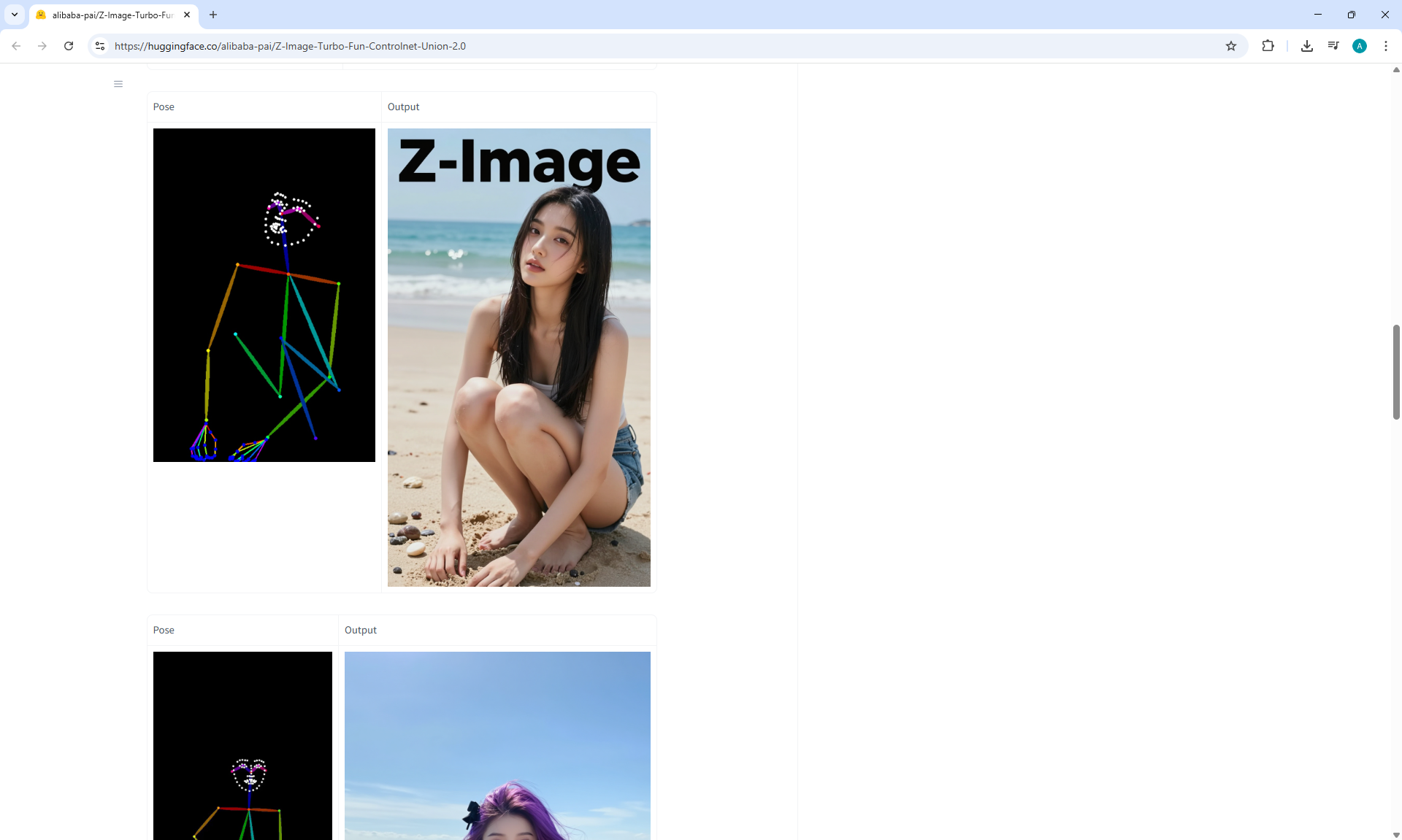
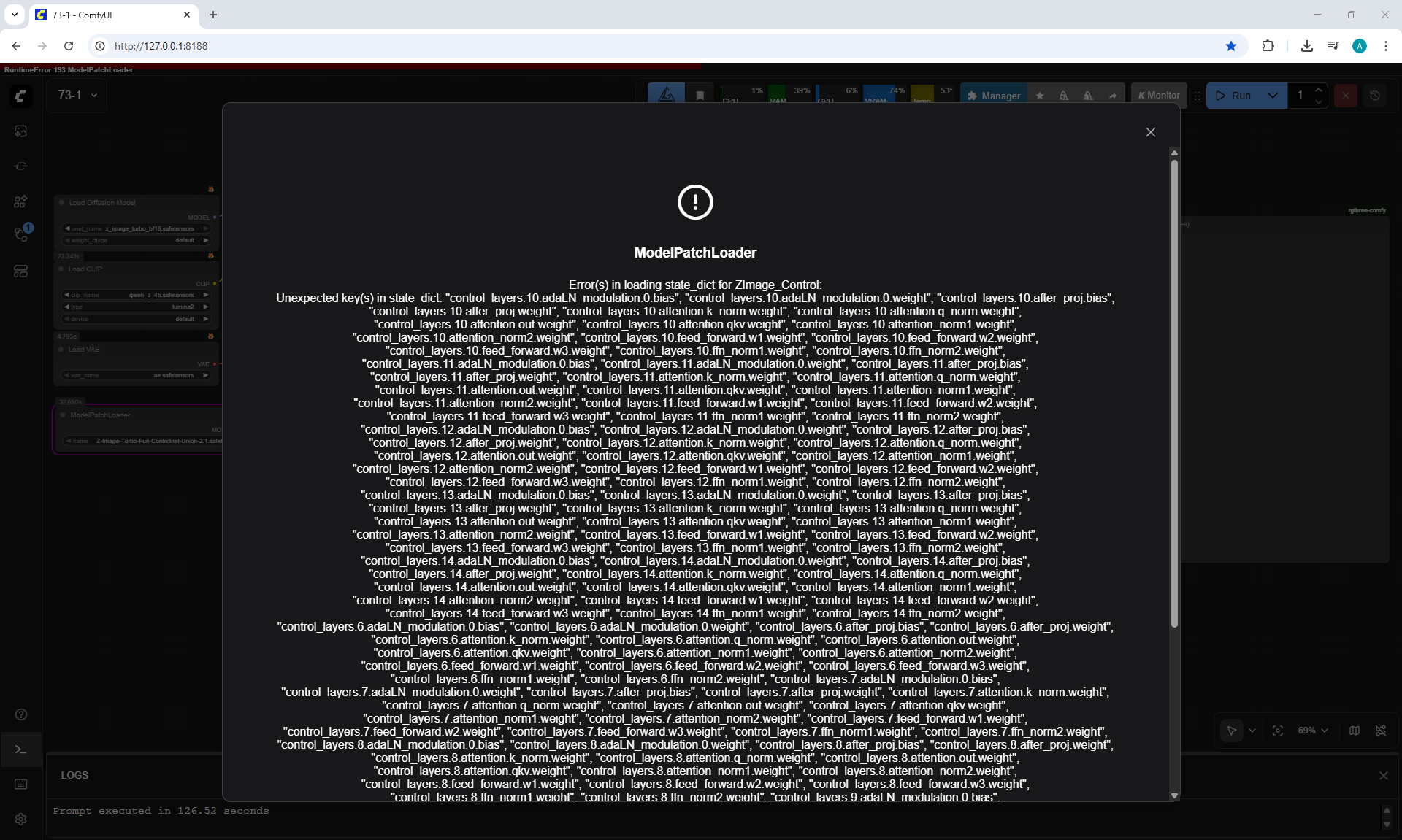
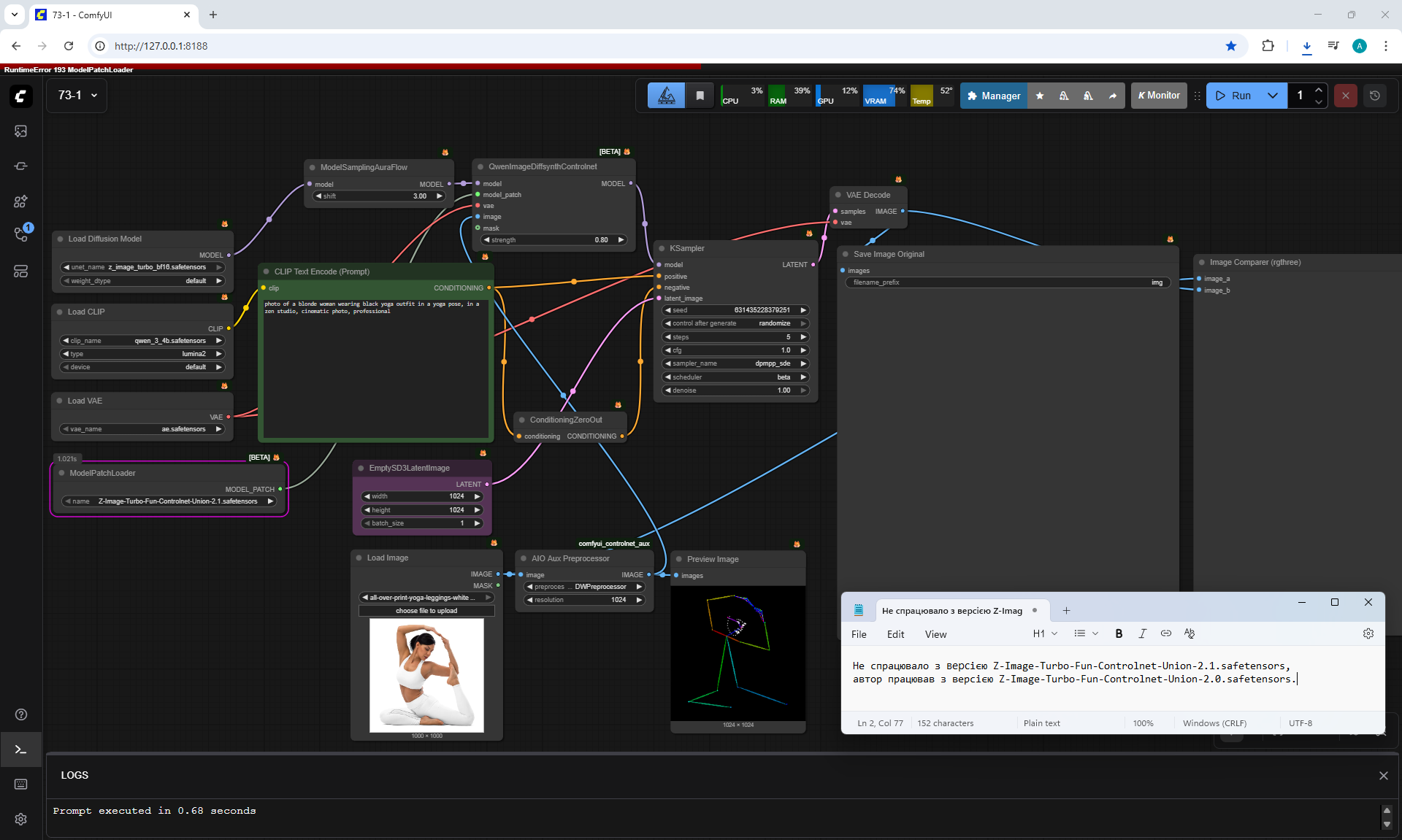
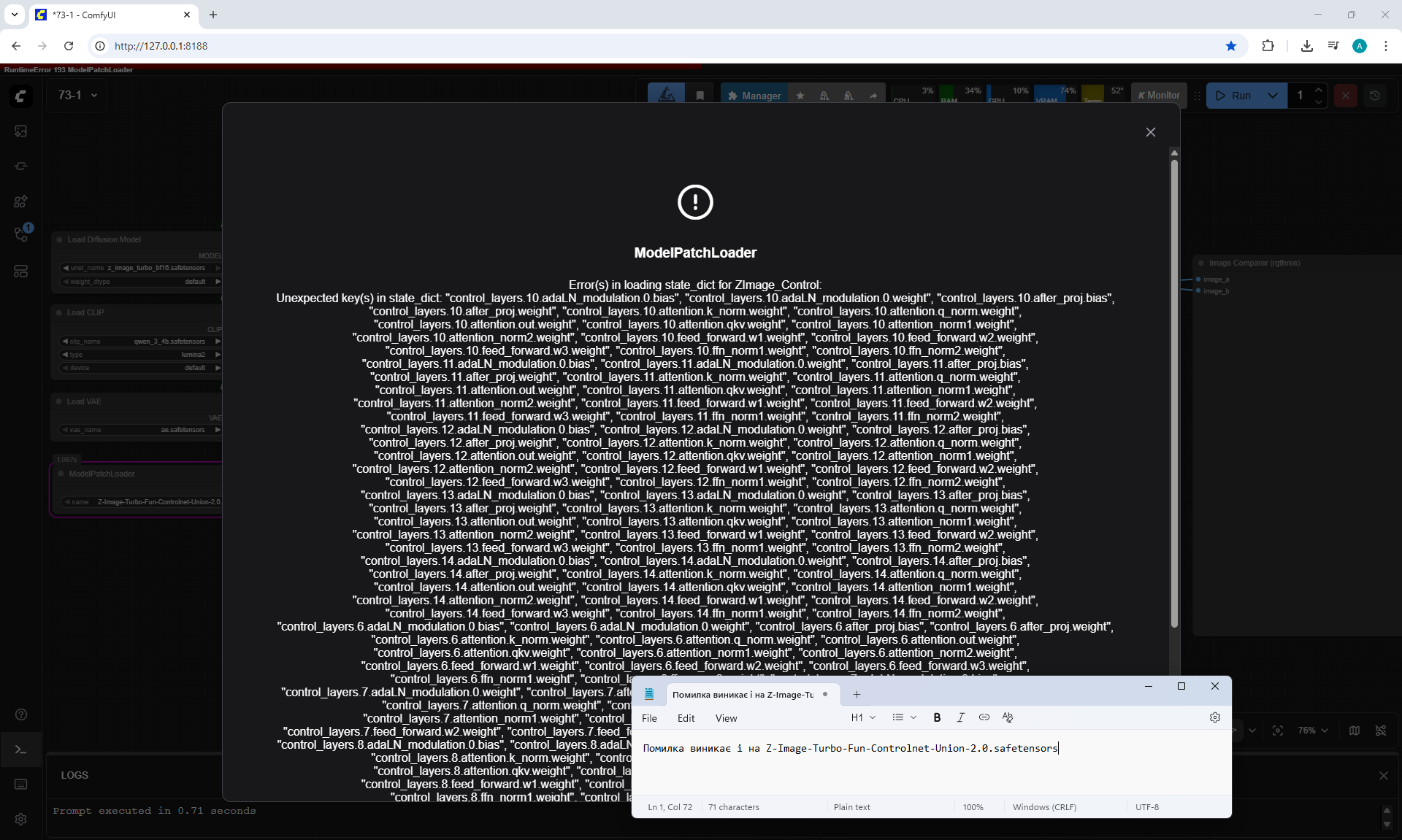
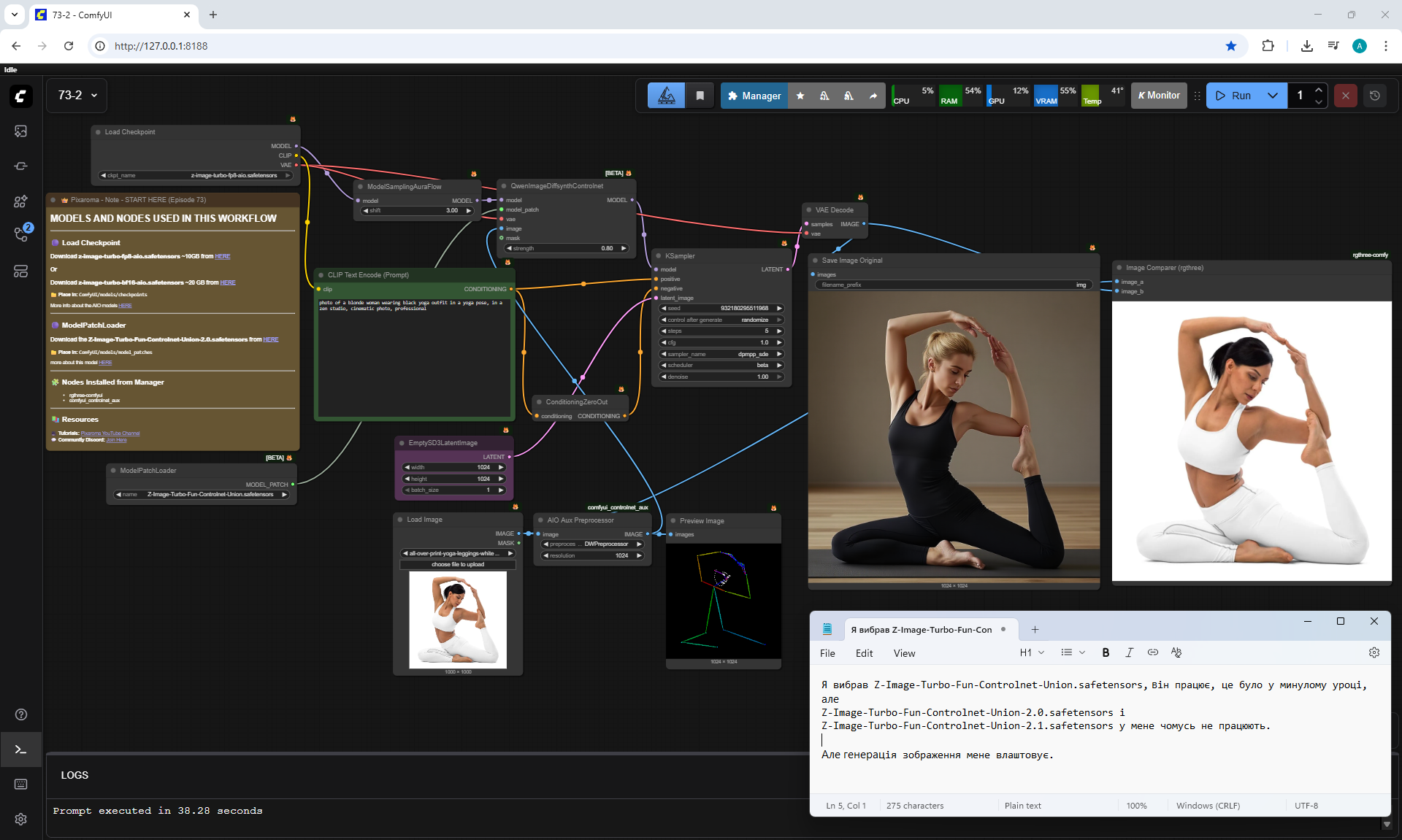
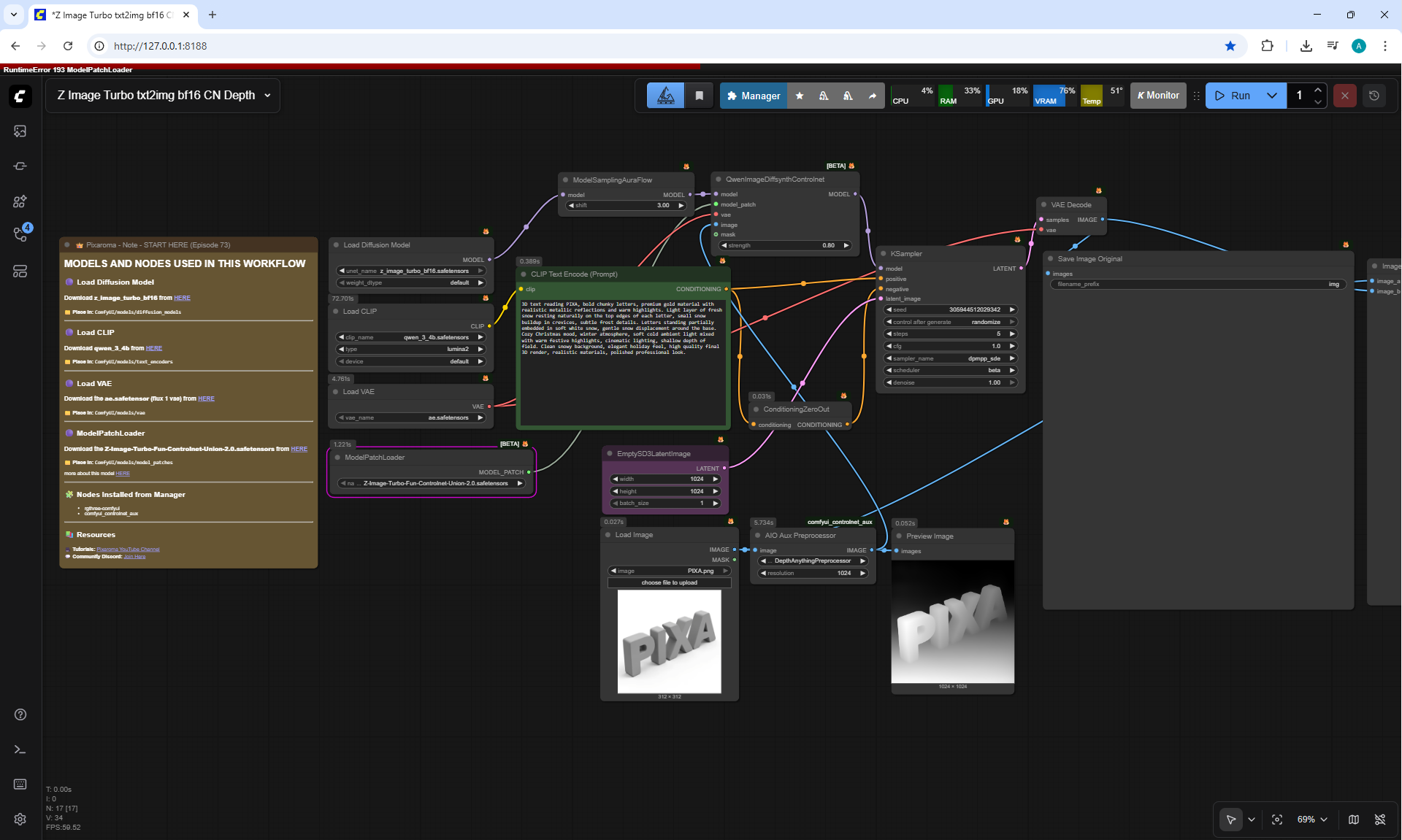
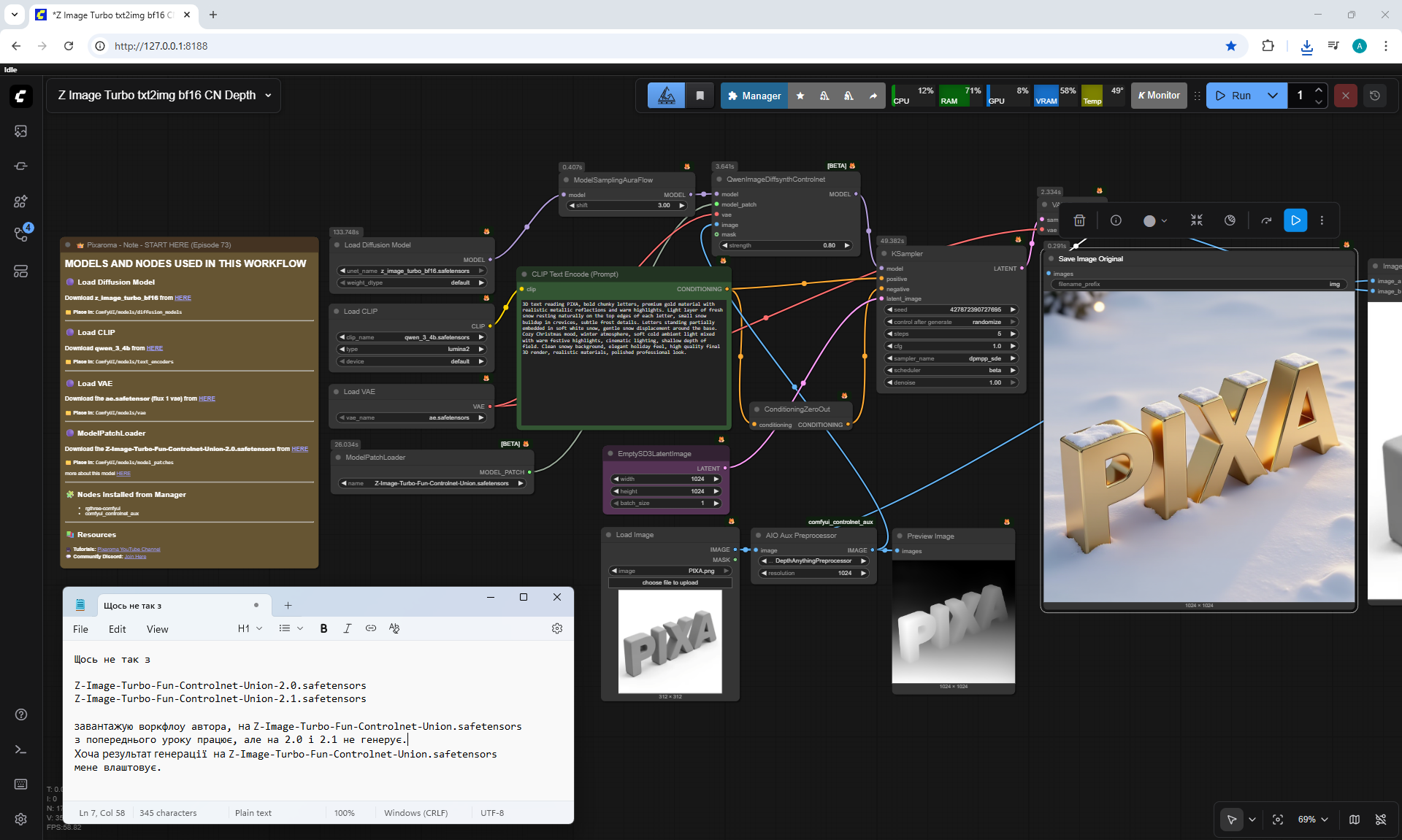
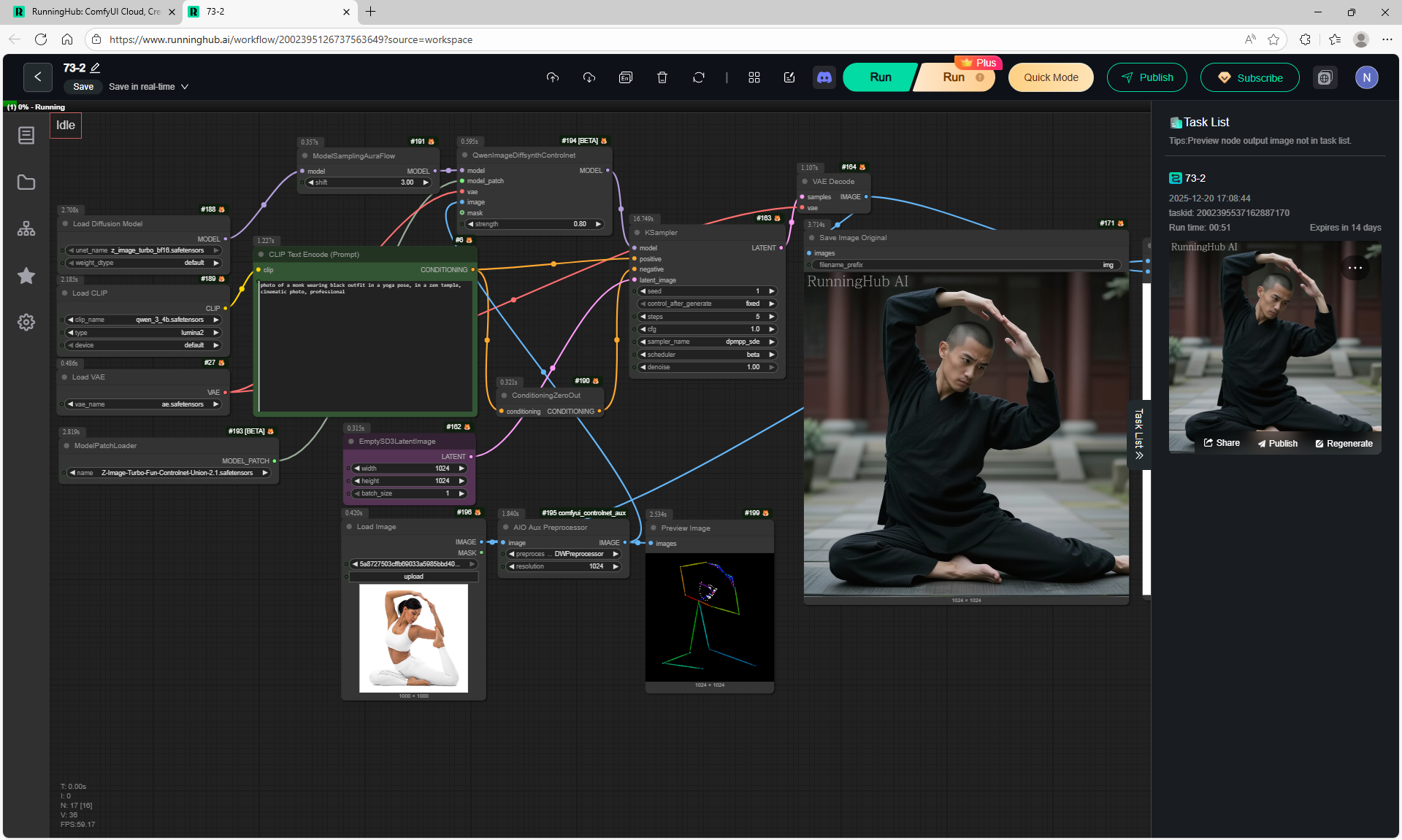
Ep73 - Final Episode & Z-Image ControlNet 2.0
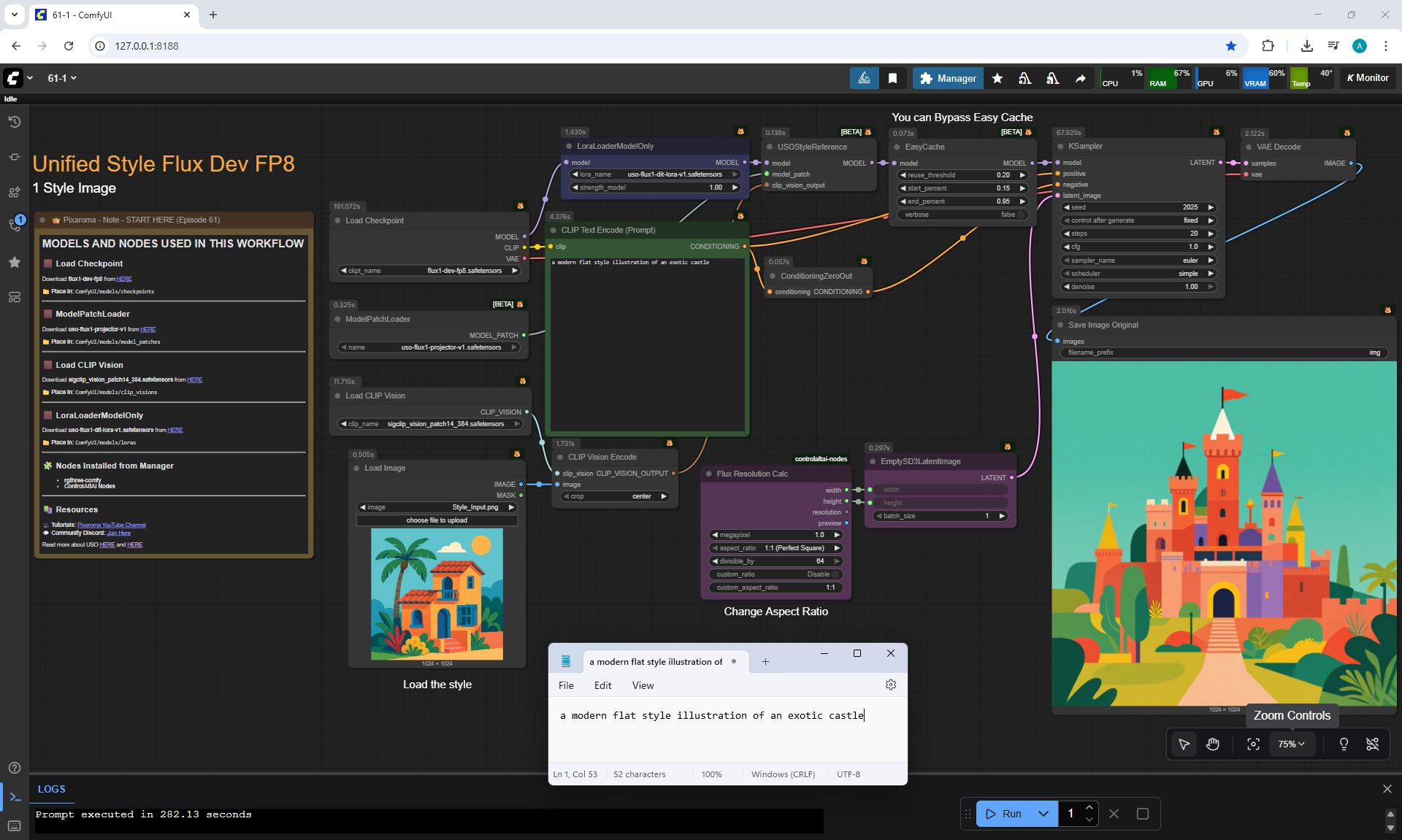
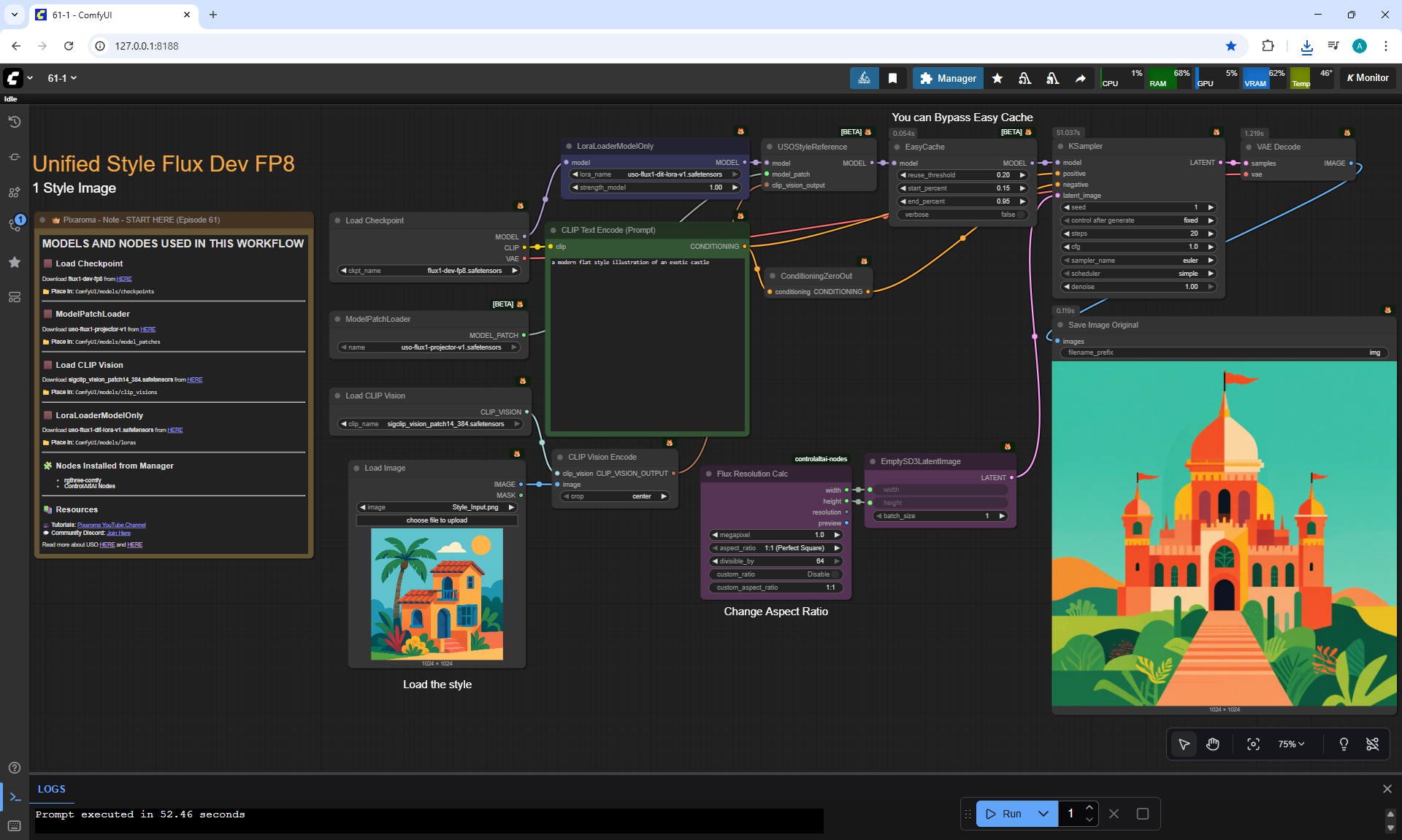
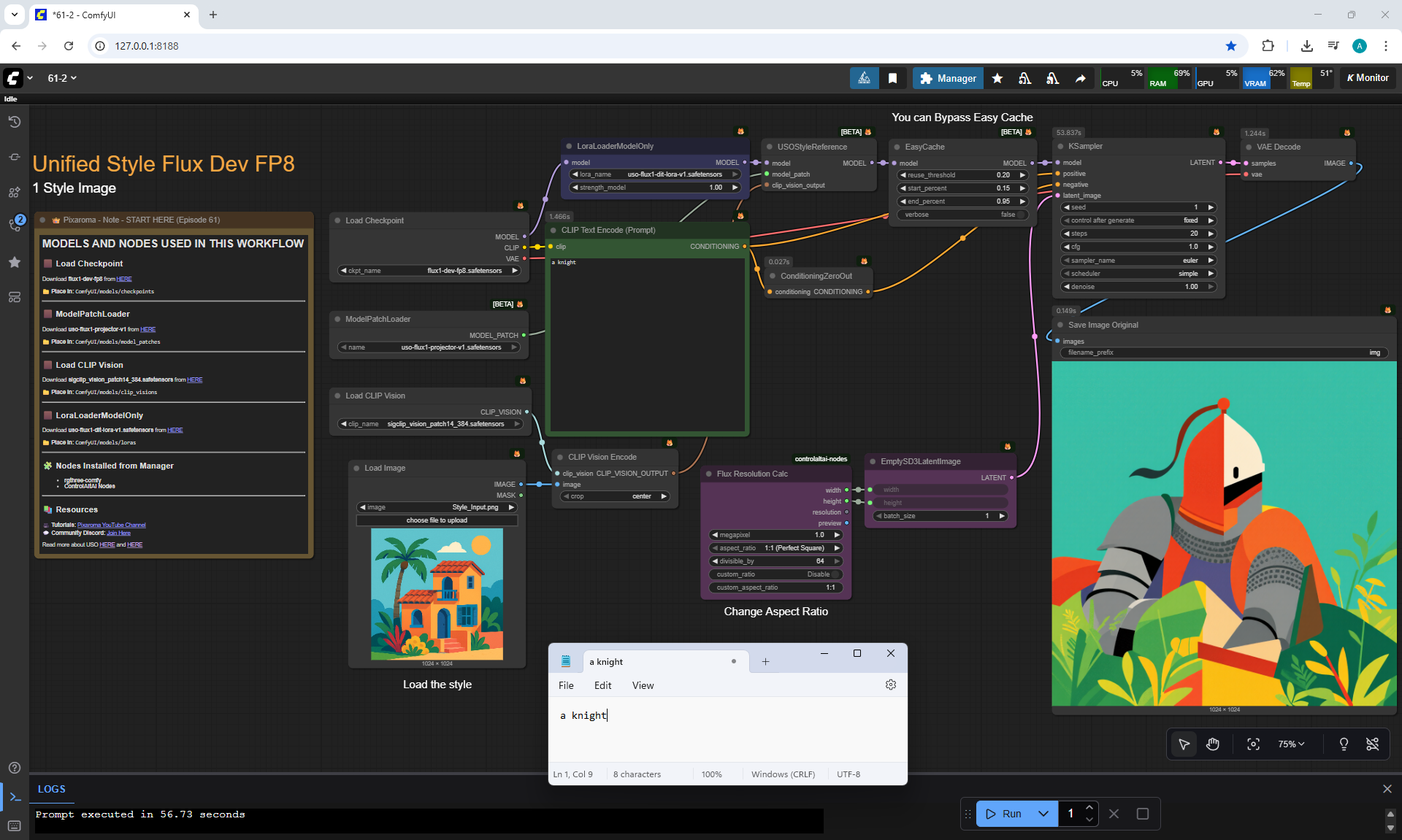
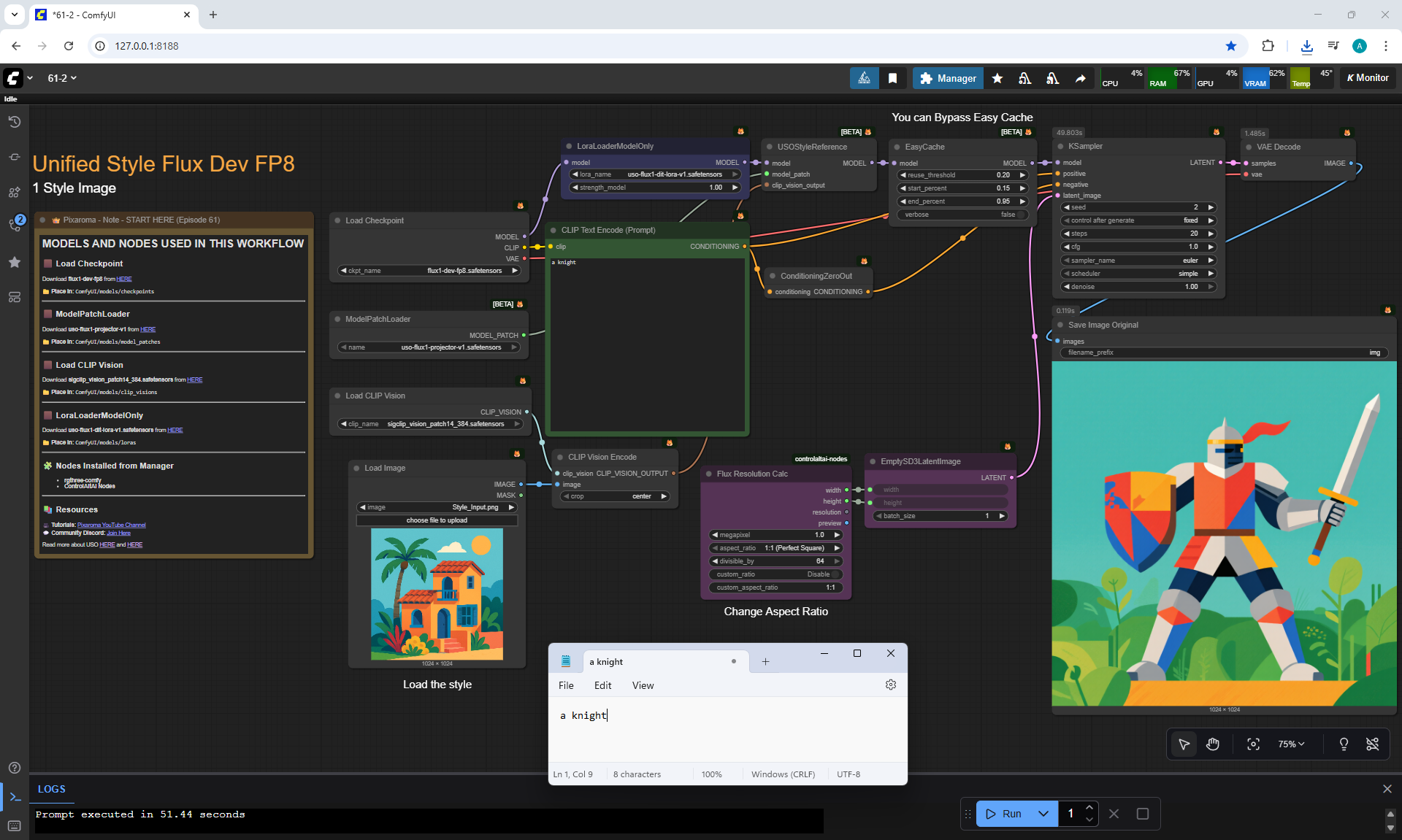
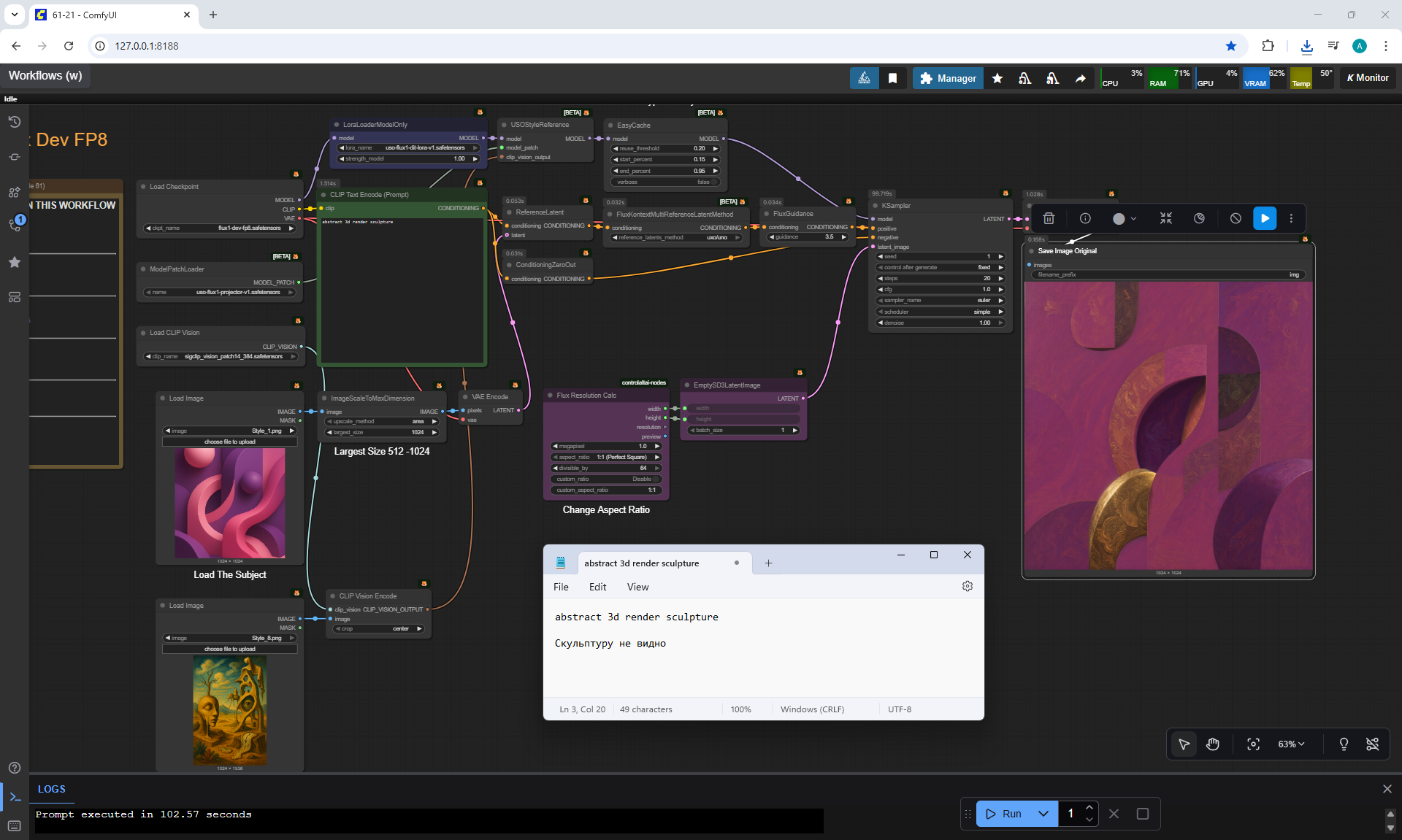
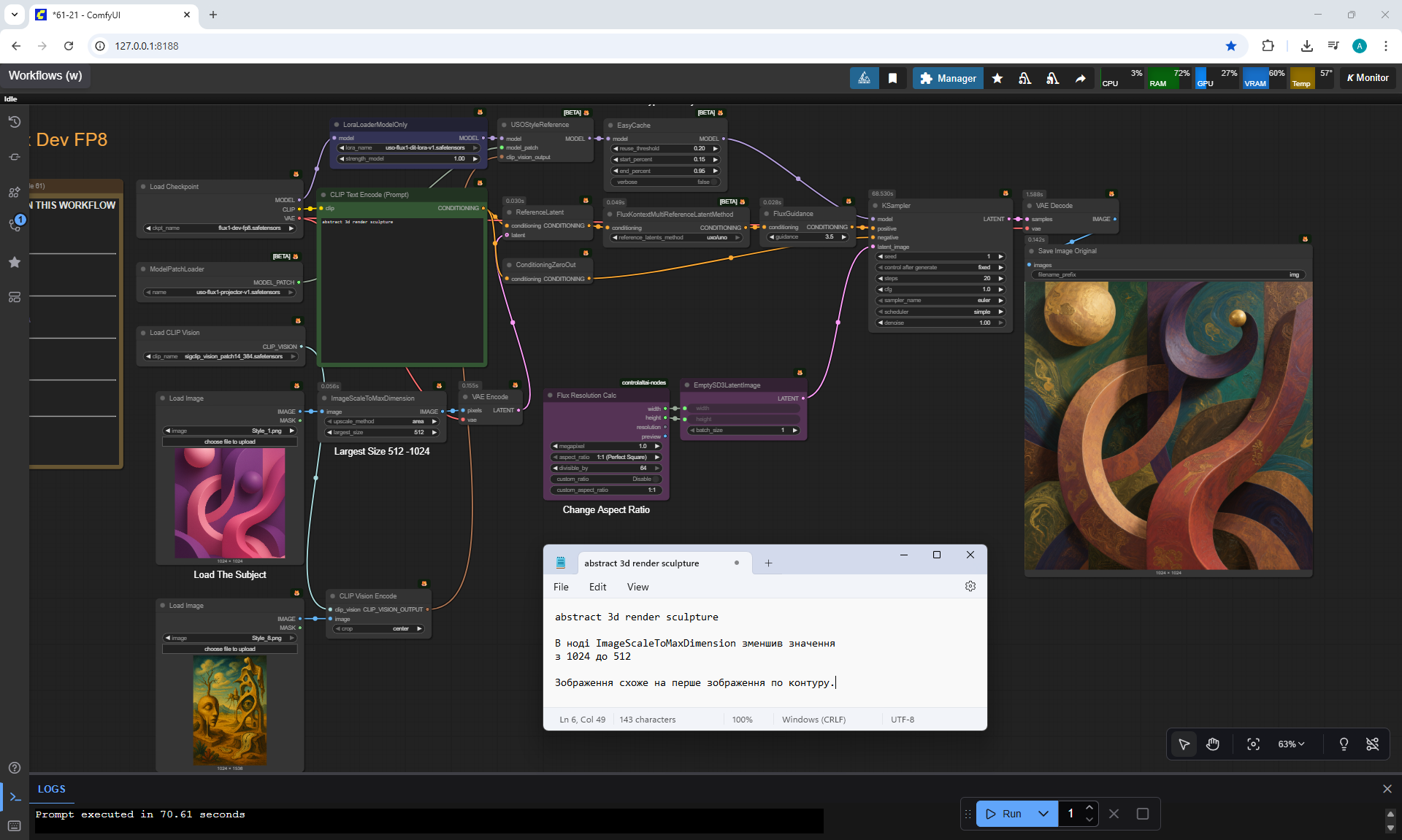
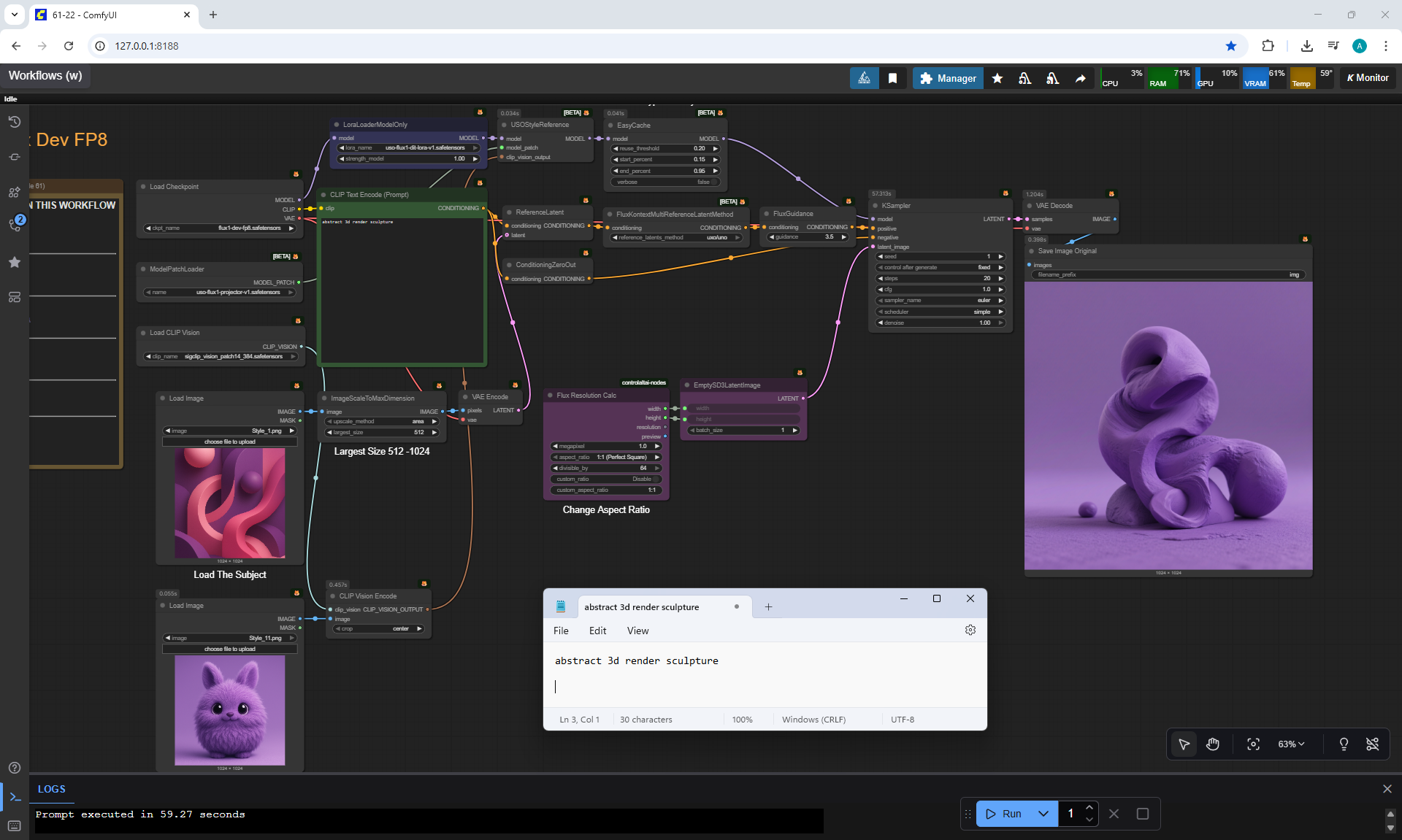
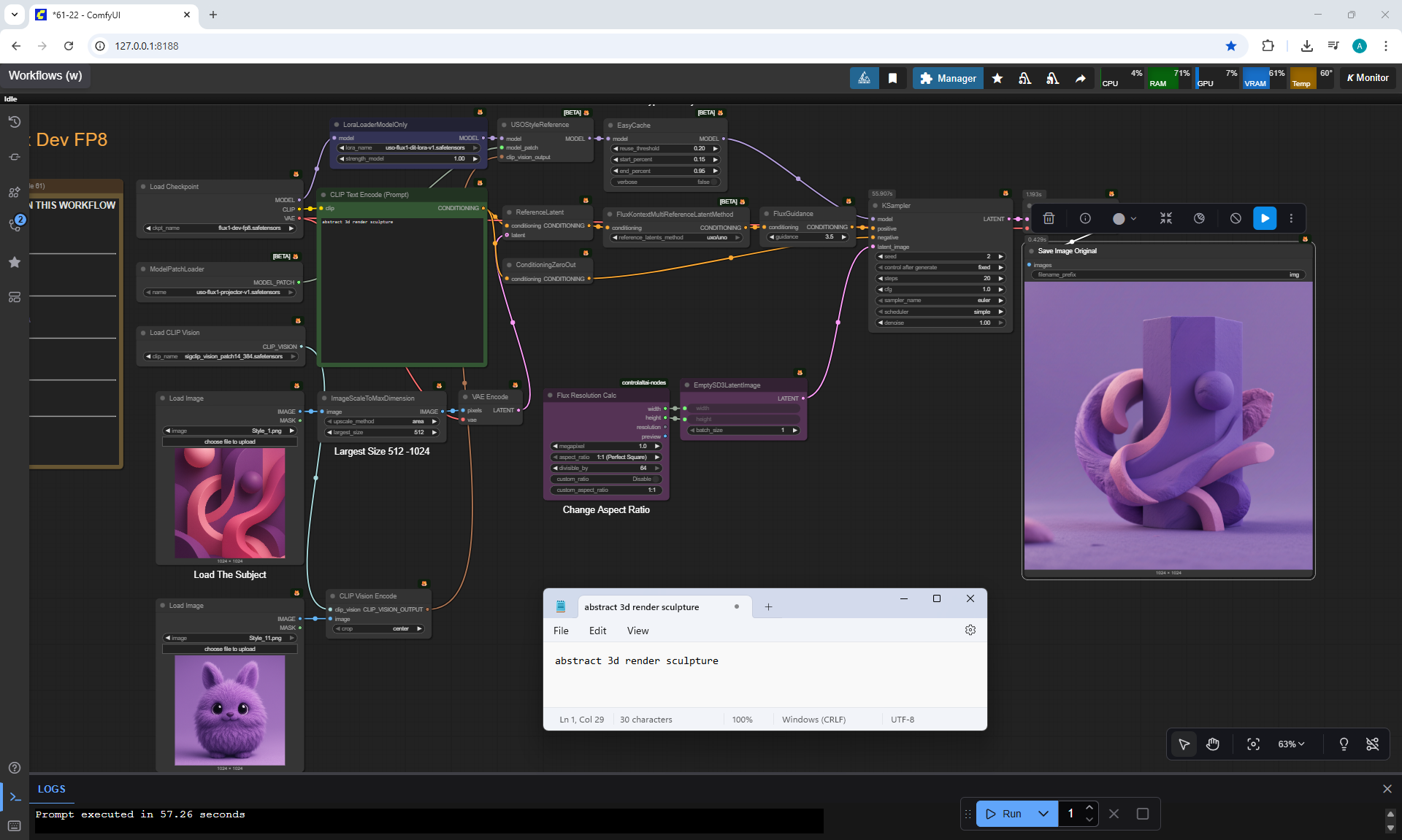
ComfyUI Tutorial Series Ep 61: USO - Unified Style and Subject-Driven Generation



















































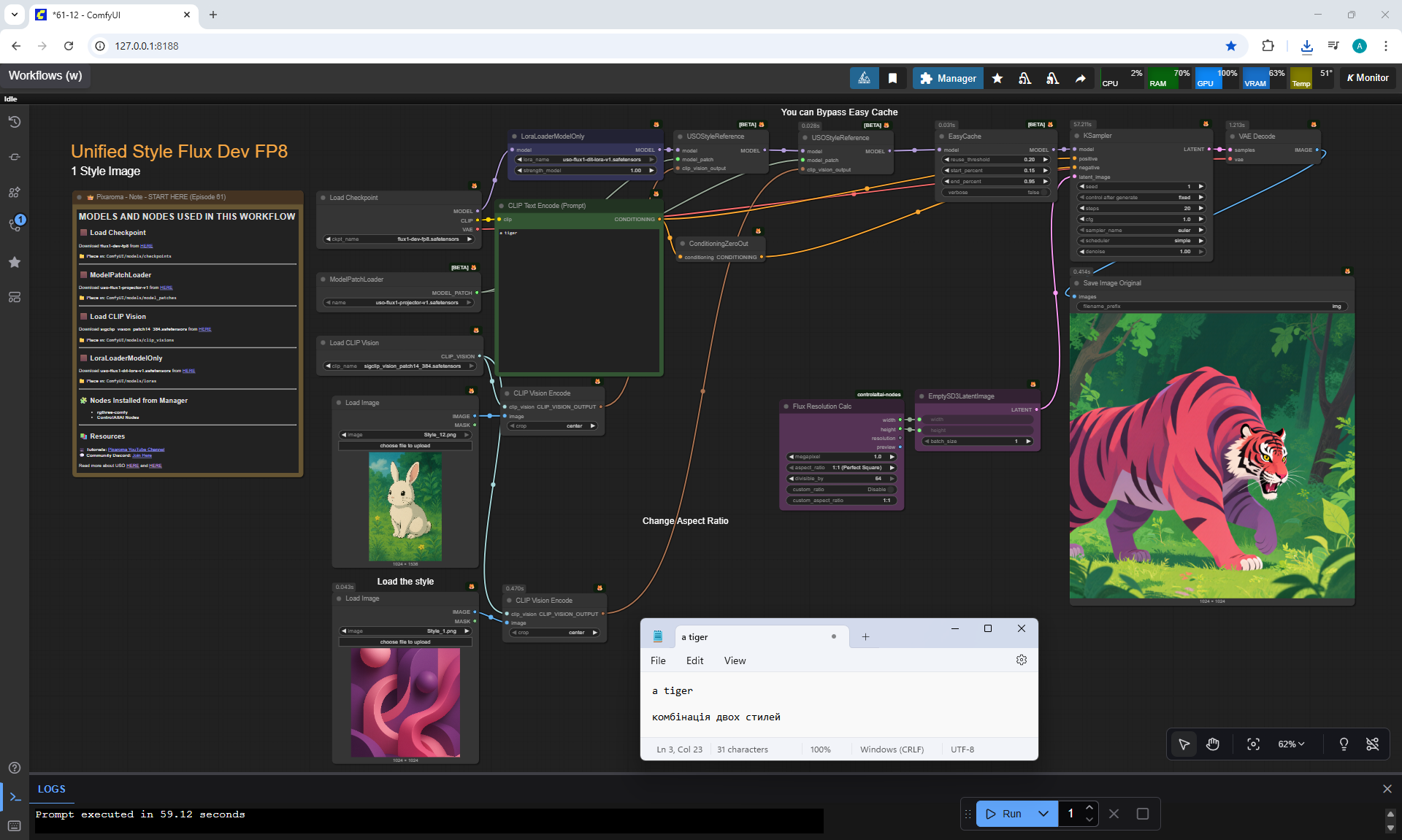
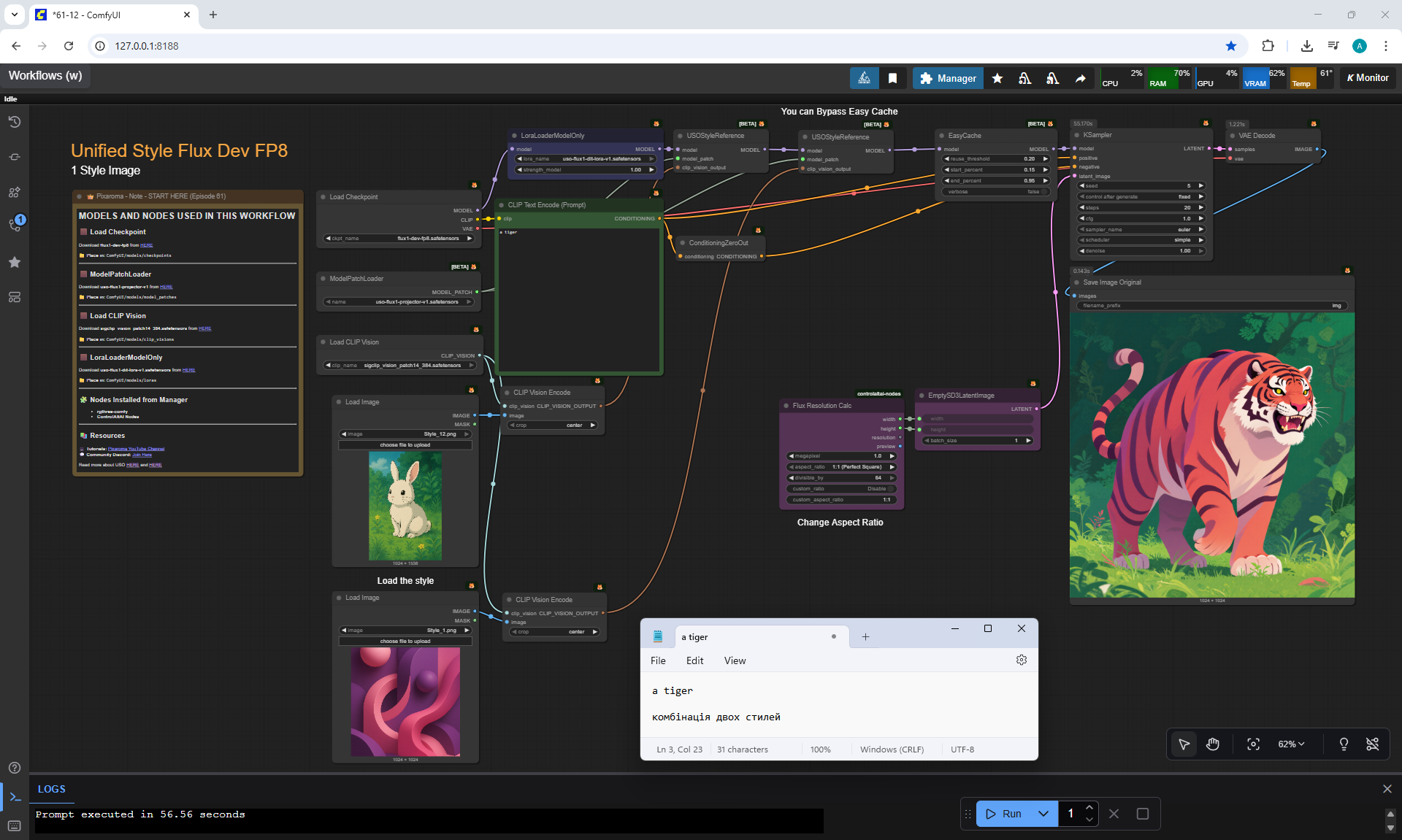
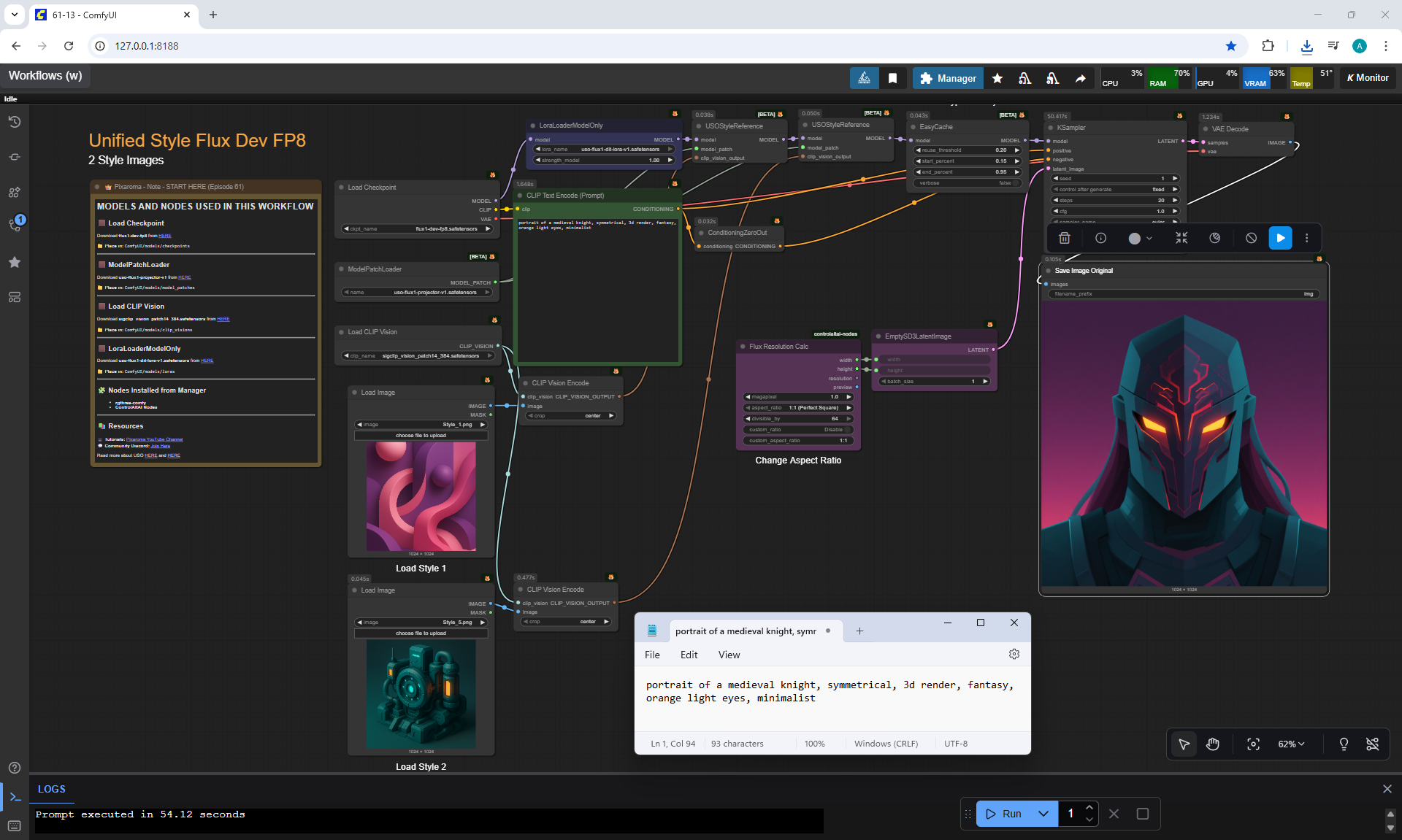
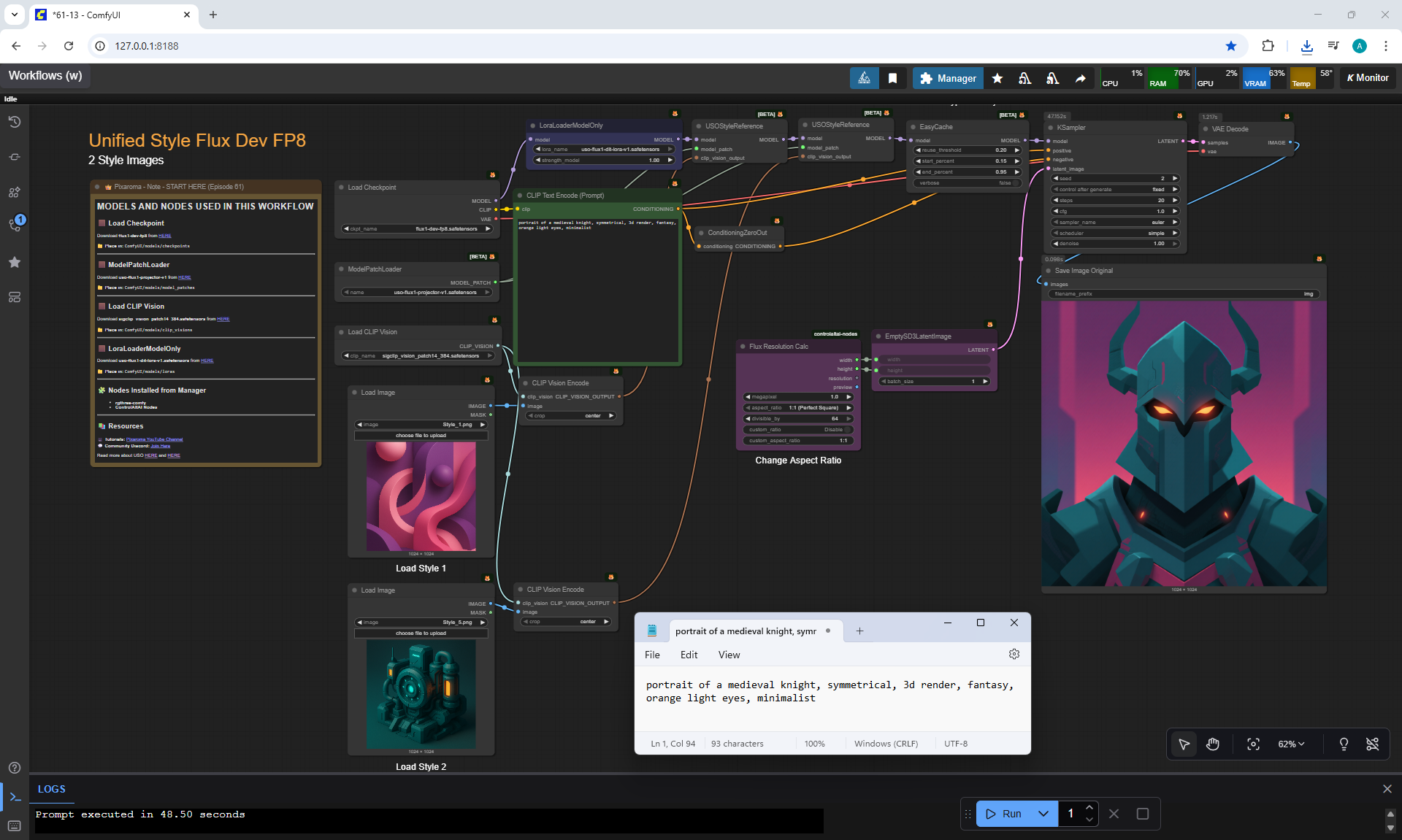
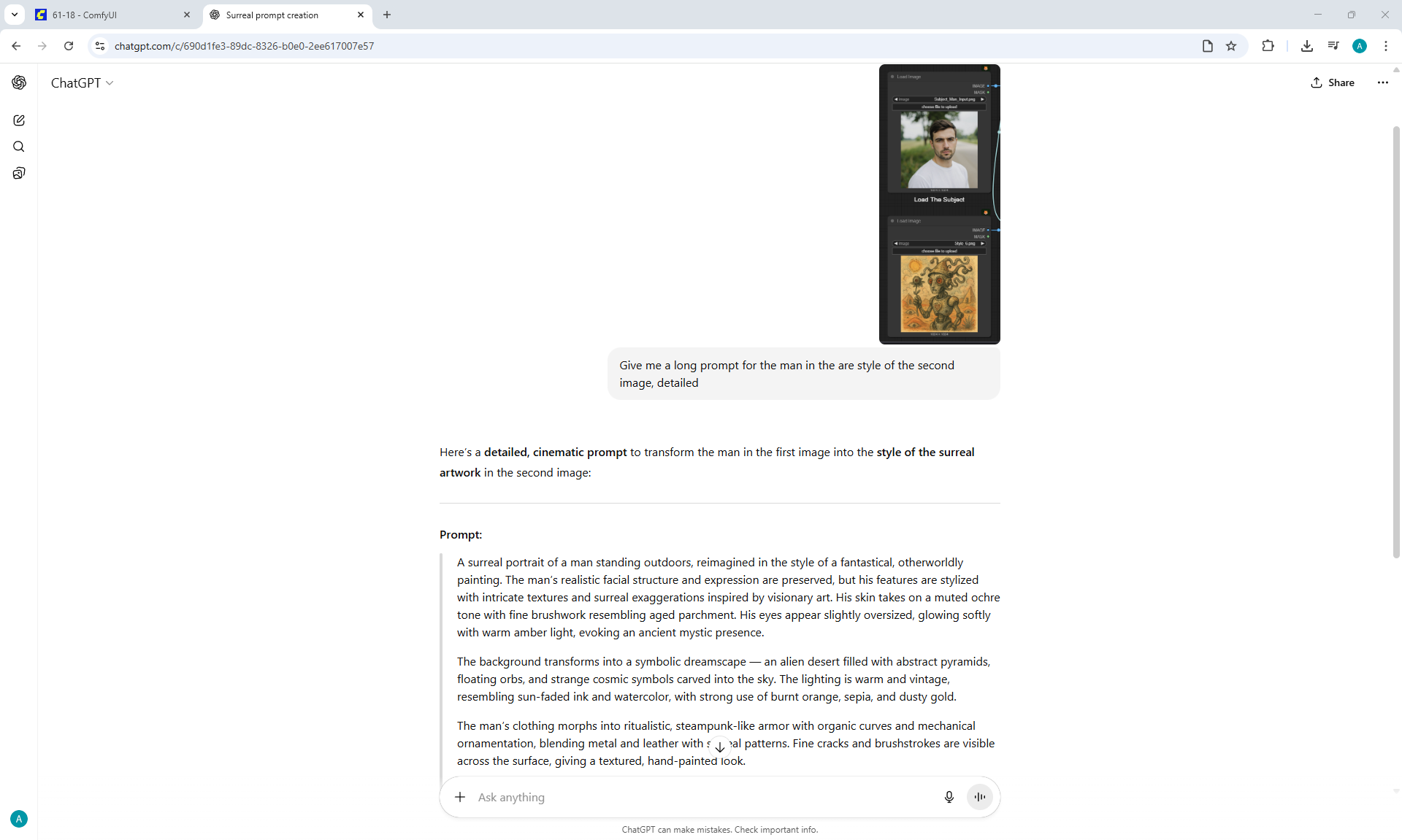
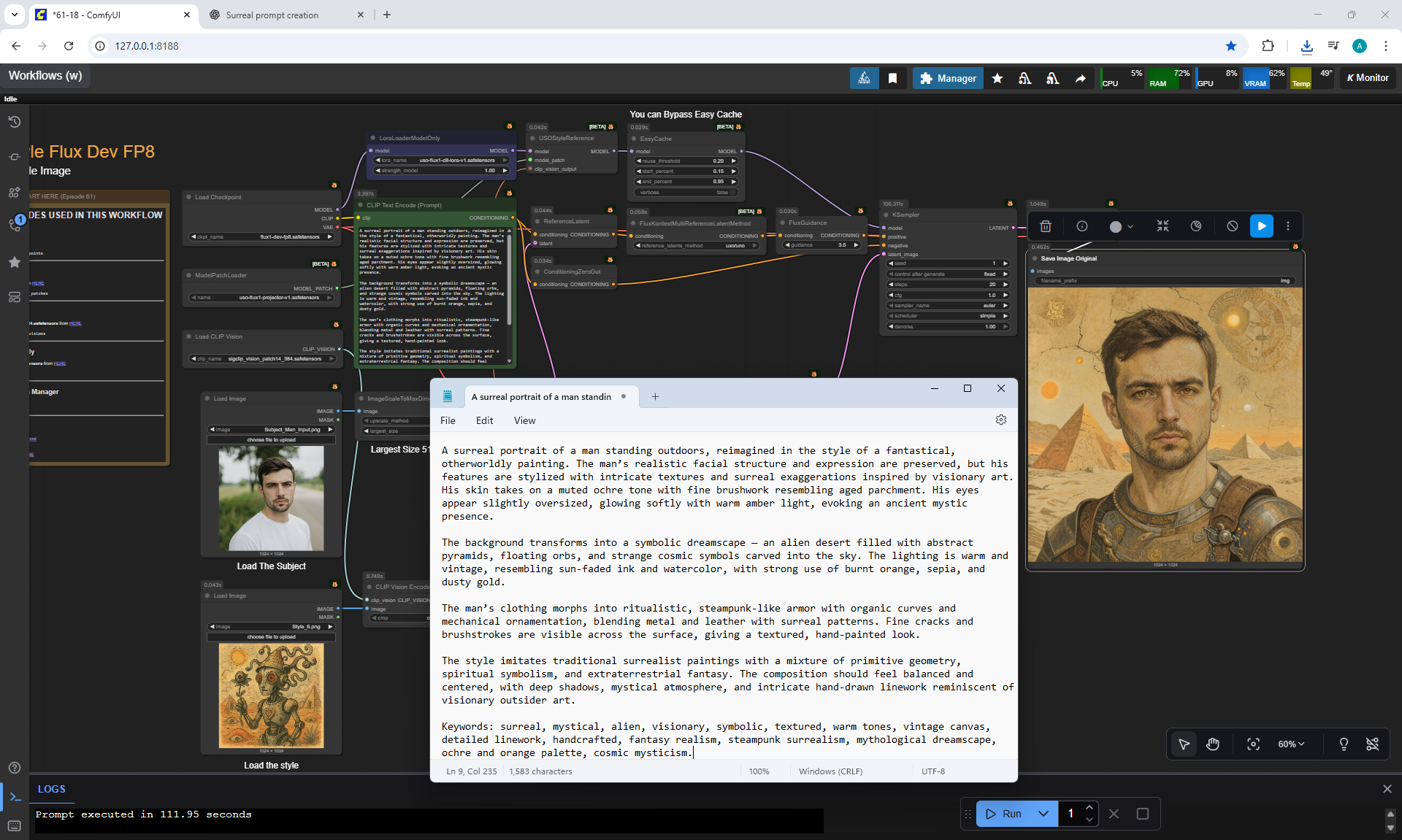
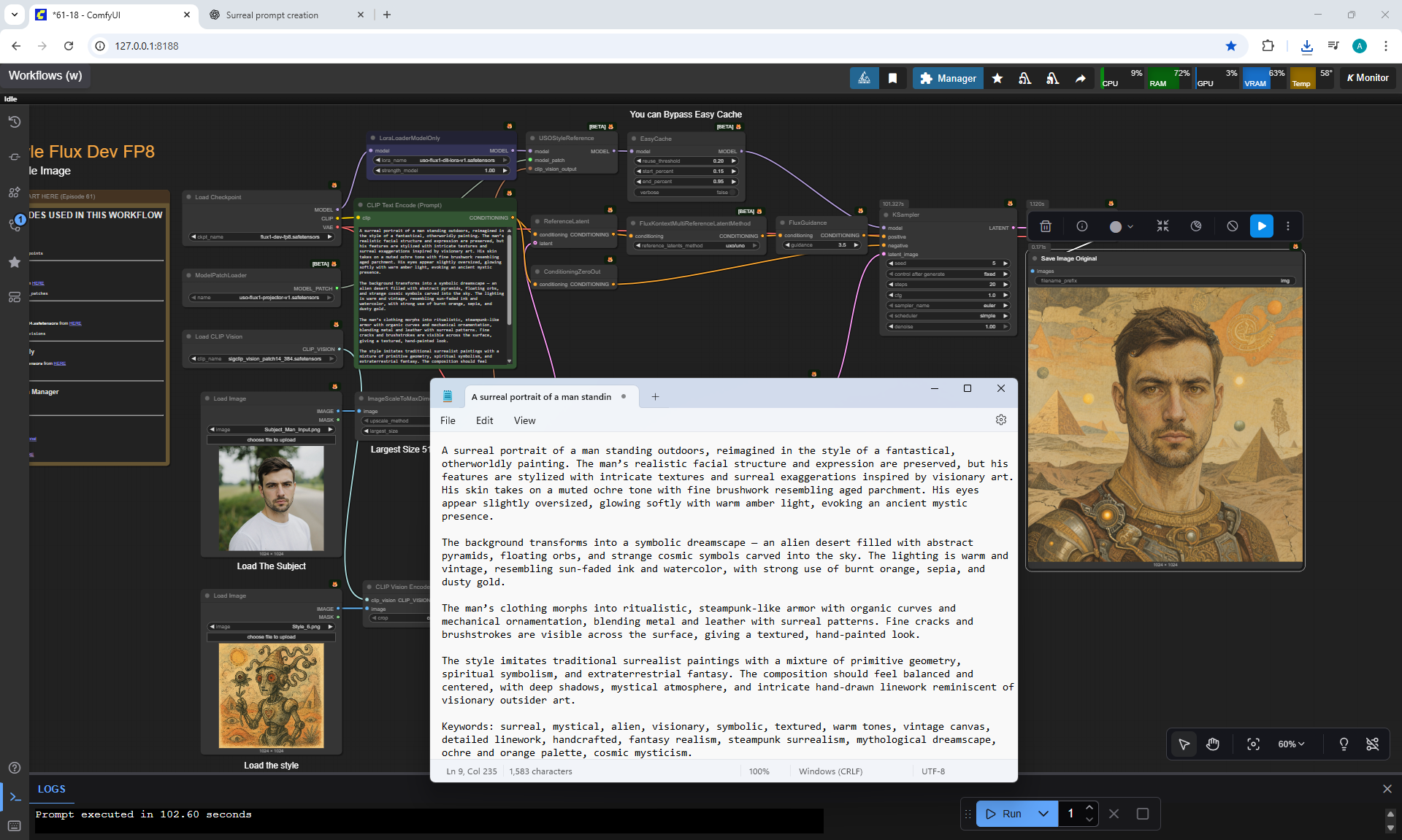
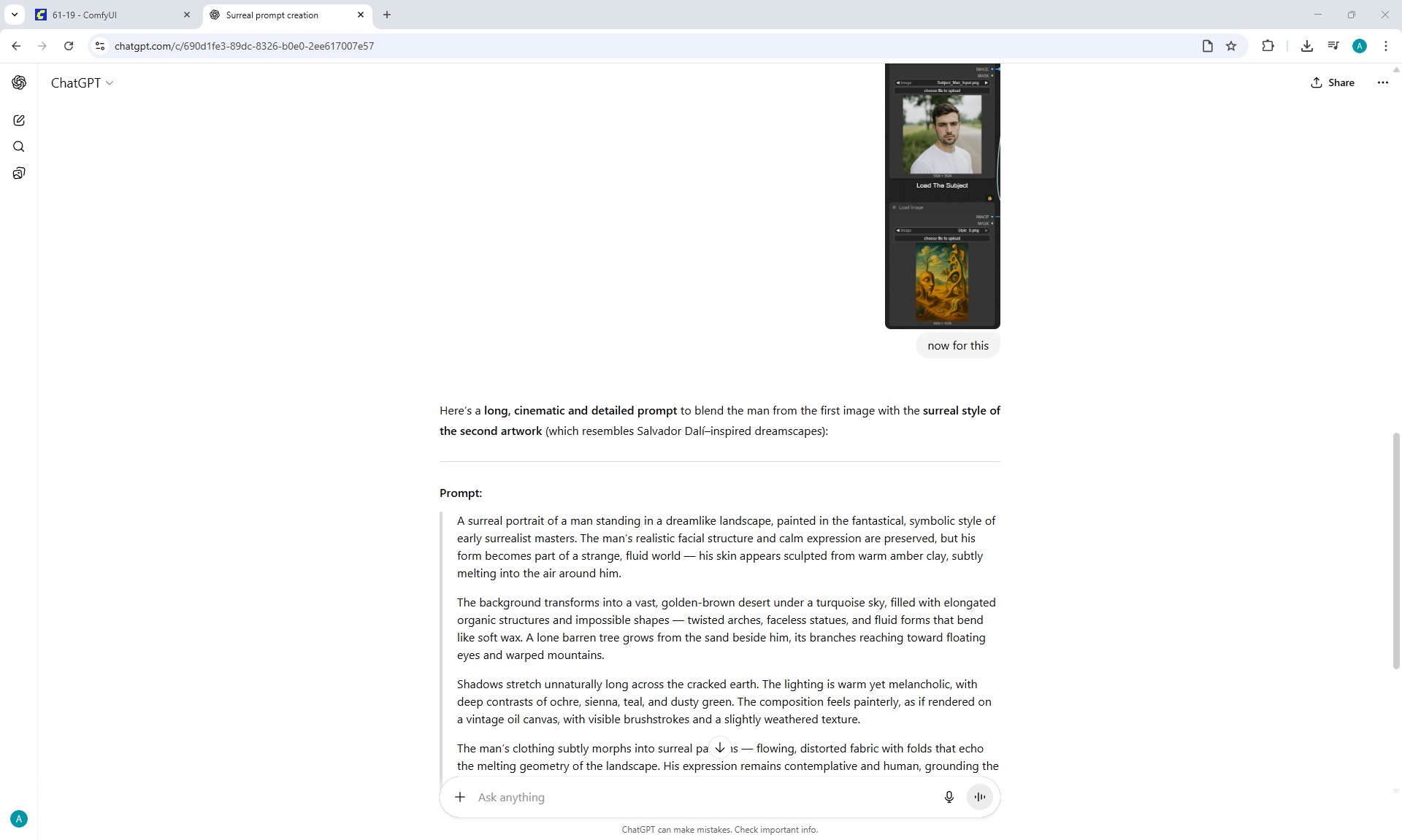
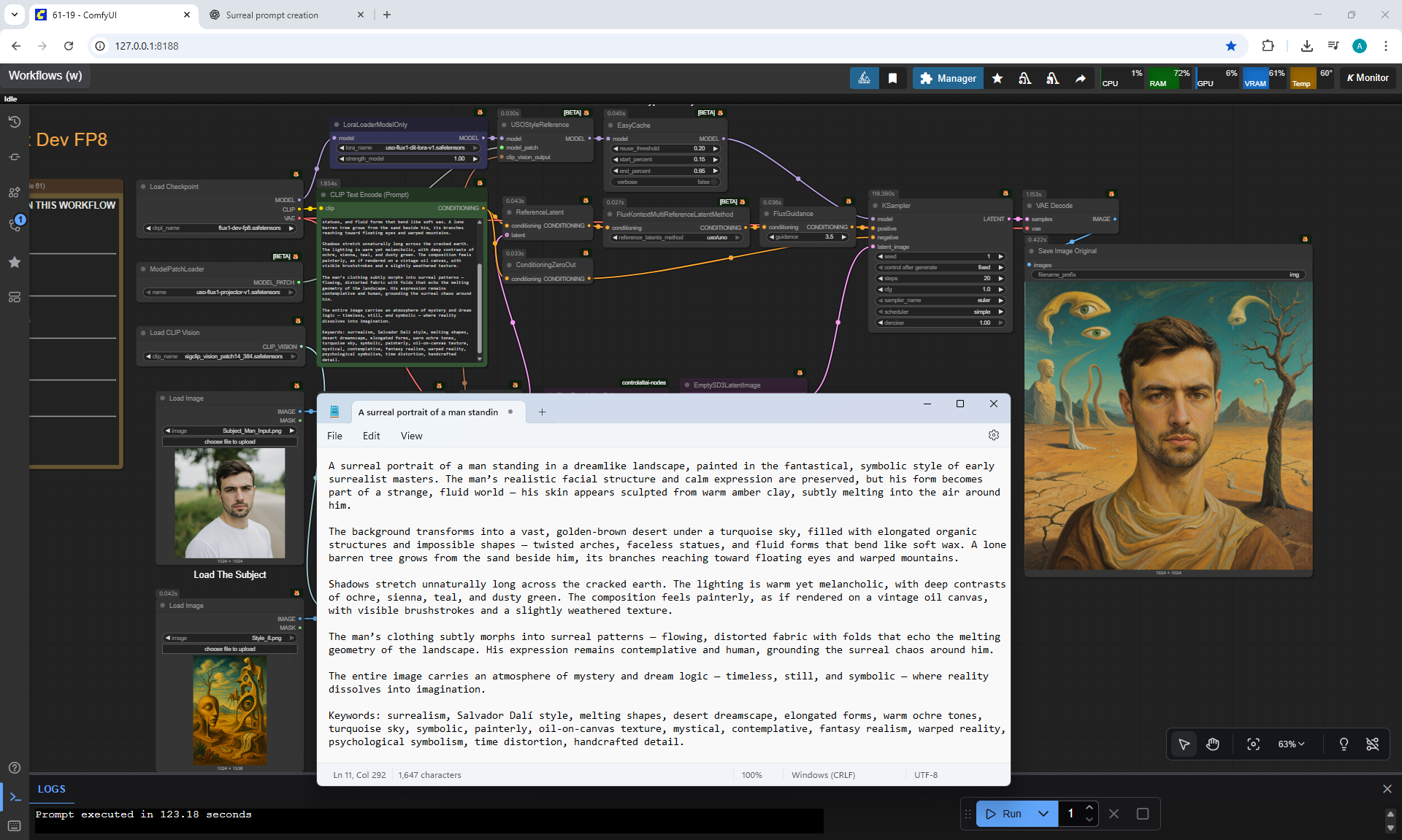
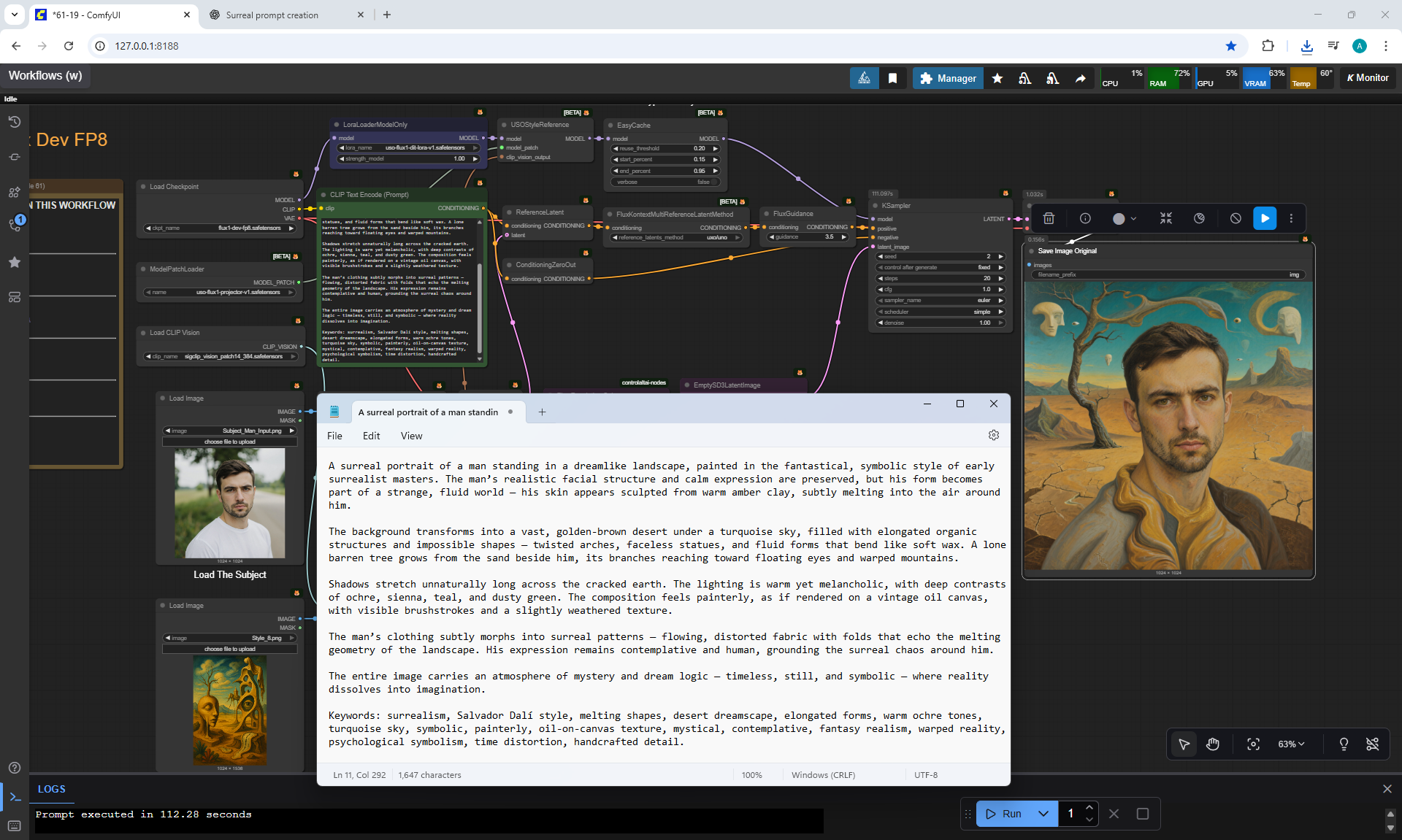
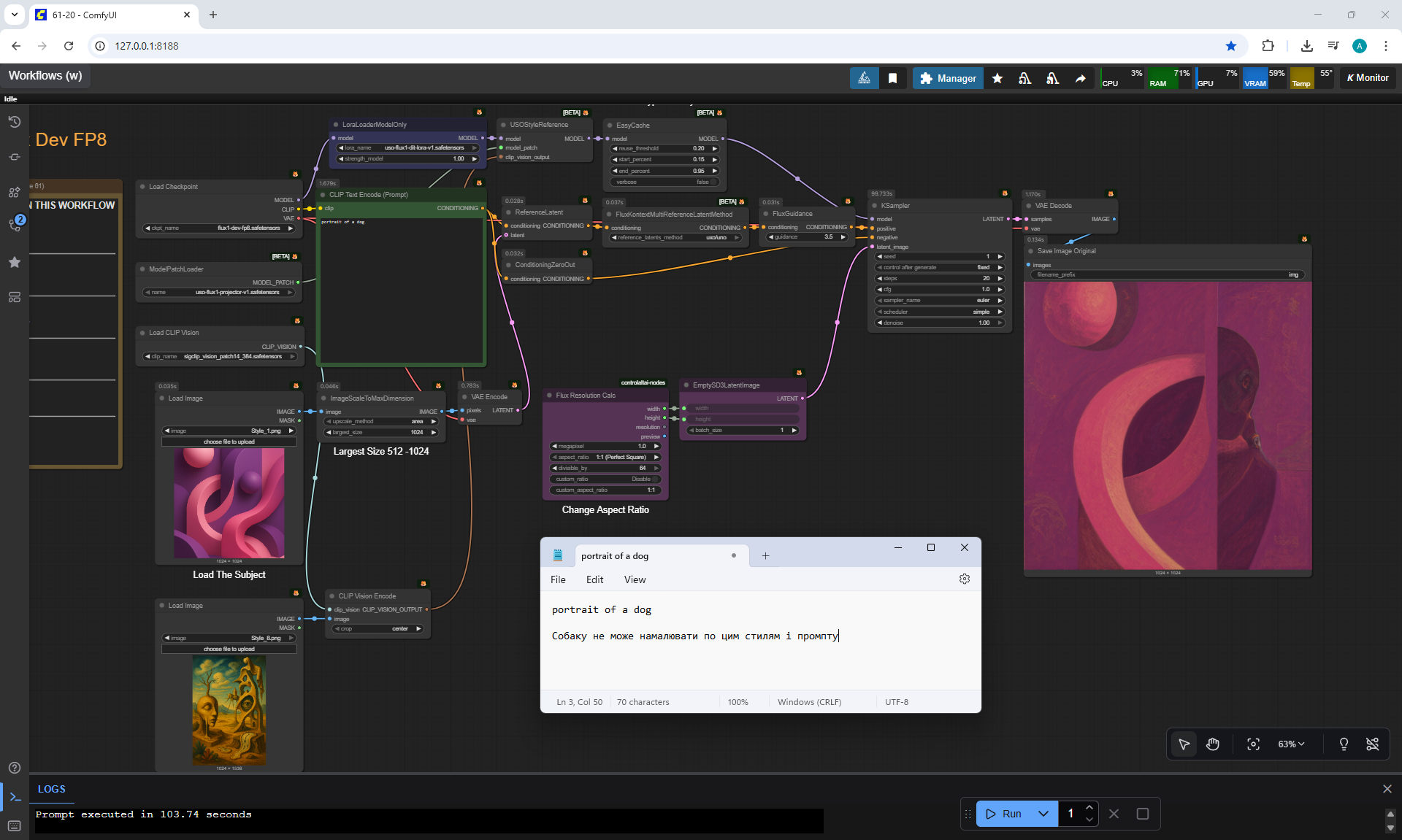
ComfyUI Tutorial Series Ep 62: Nunchaku Update | Qwen Control Net, Qwen Edit & Inpaint








































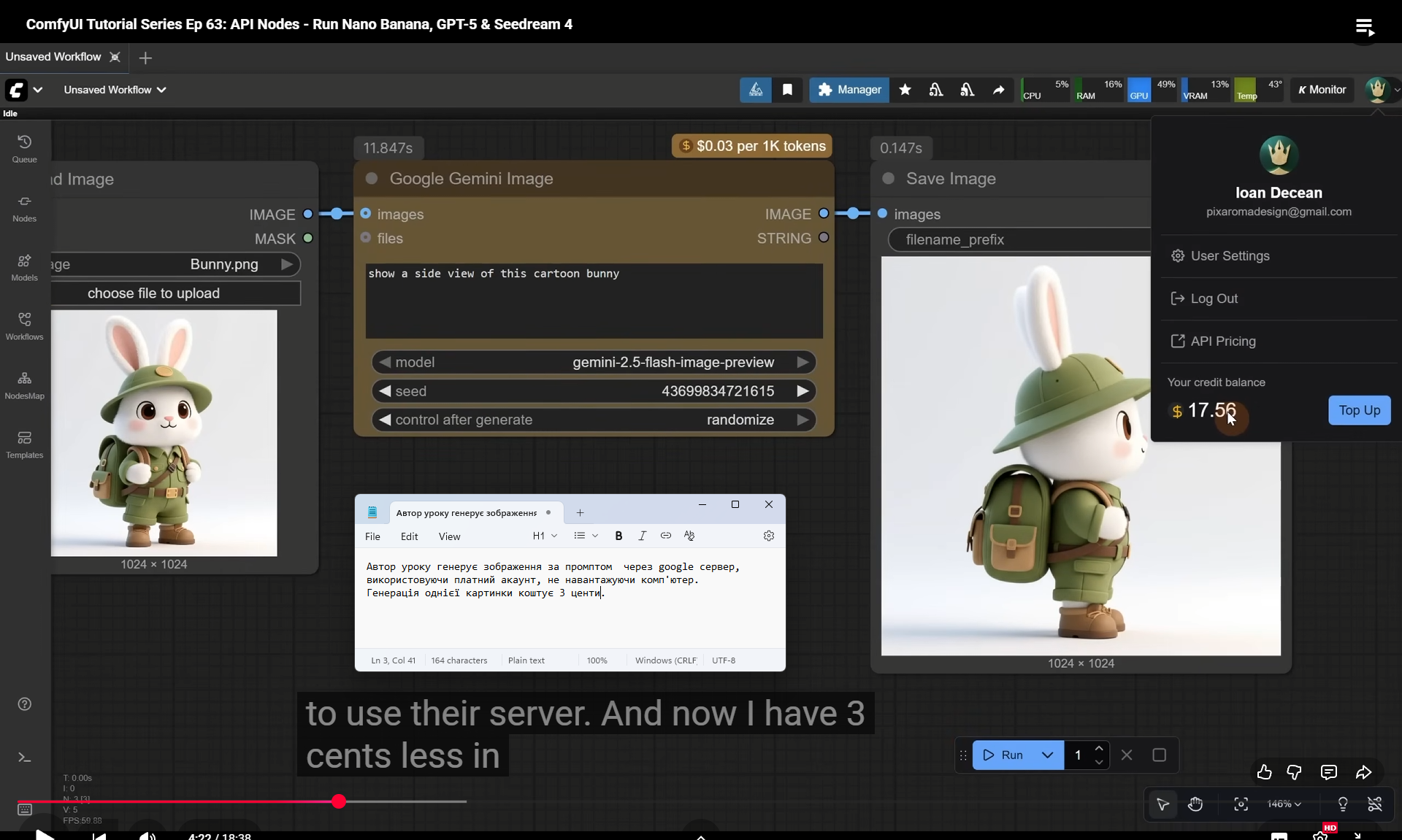
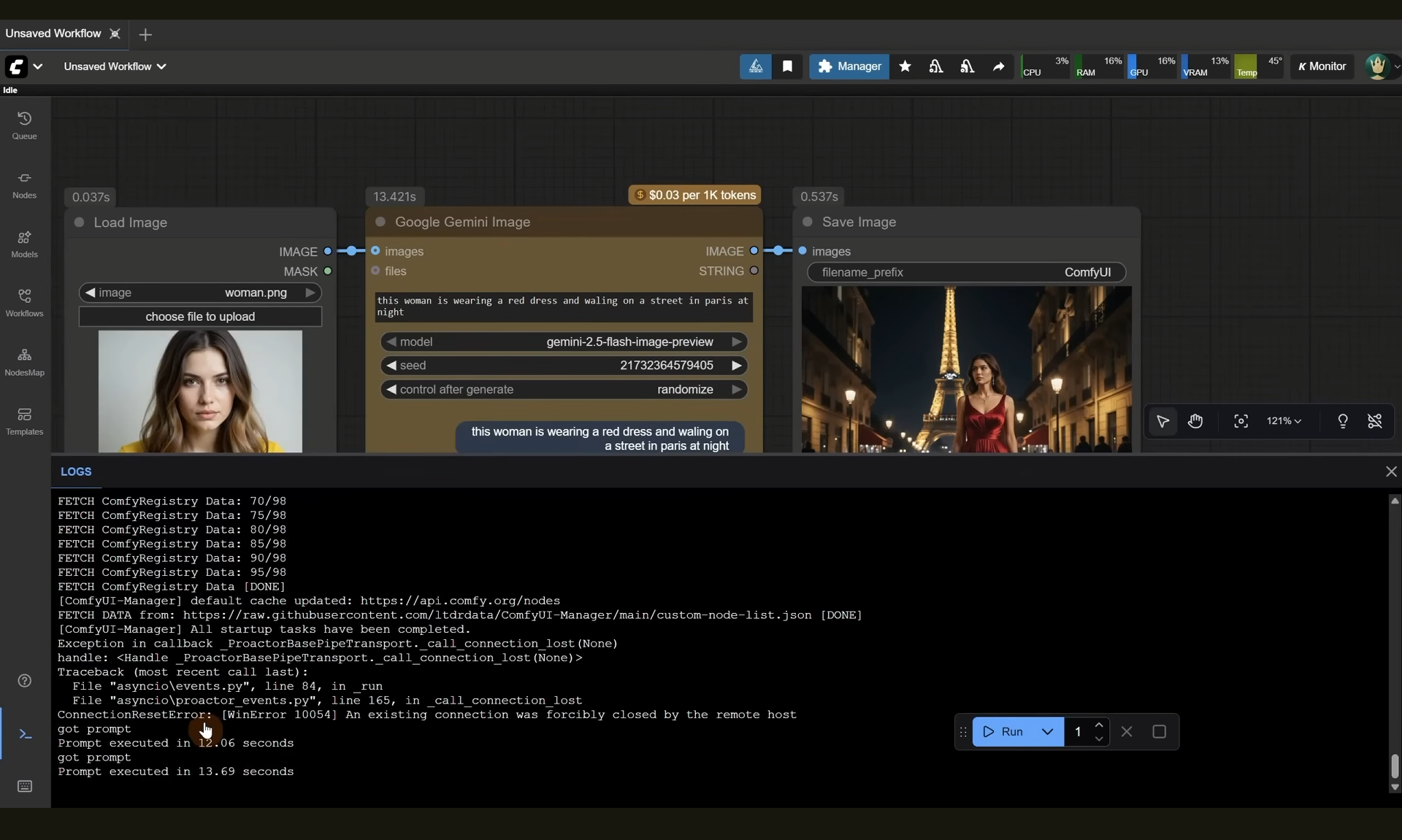
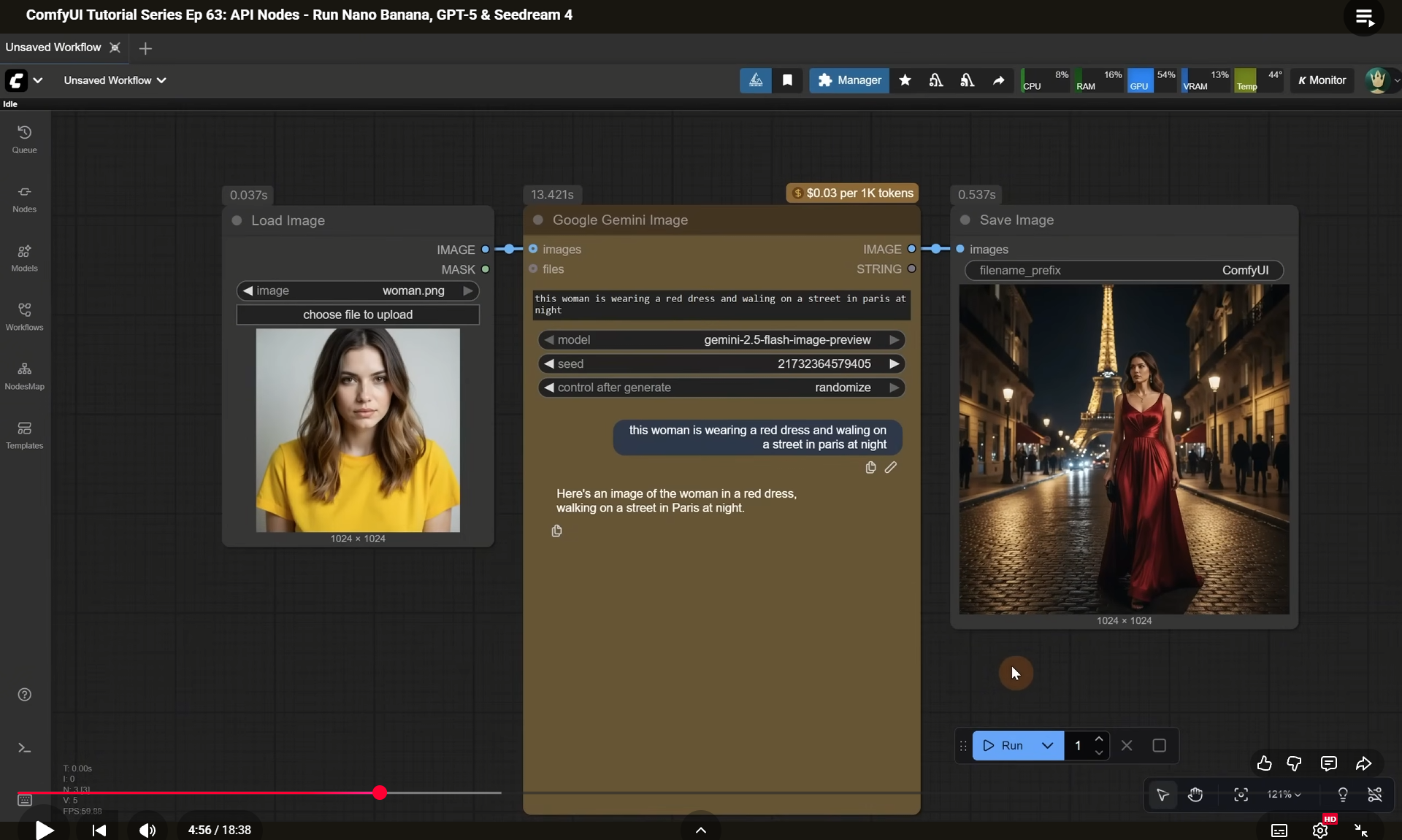
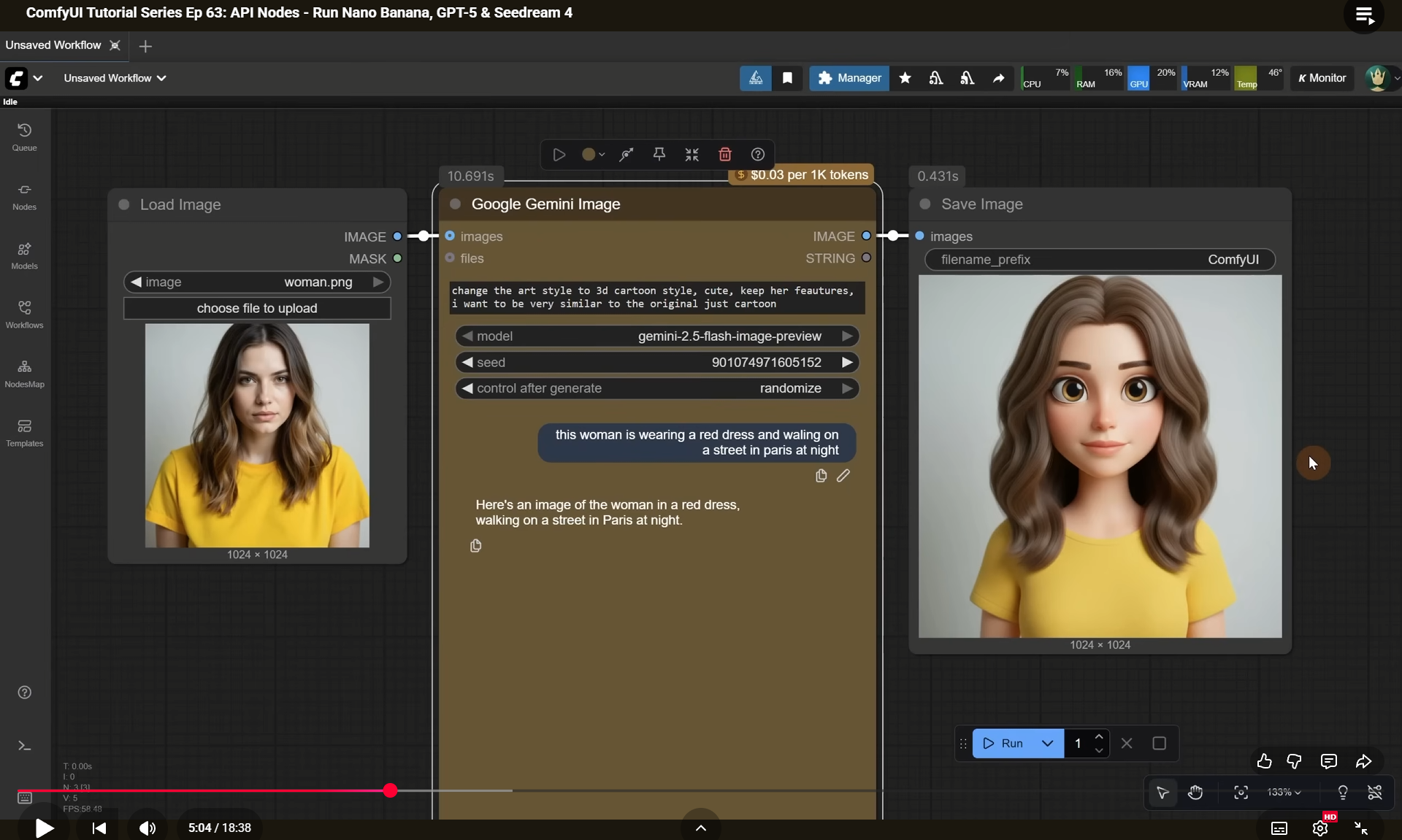
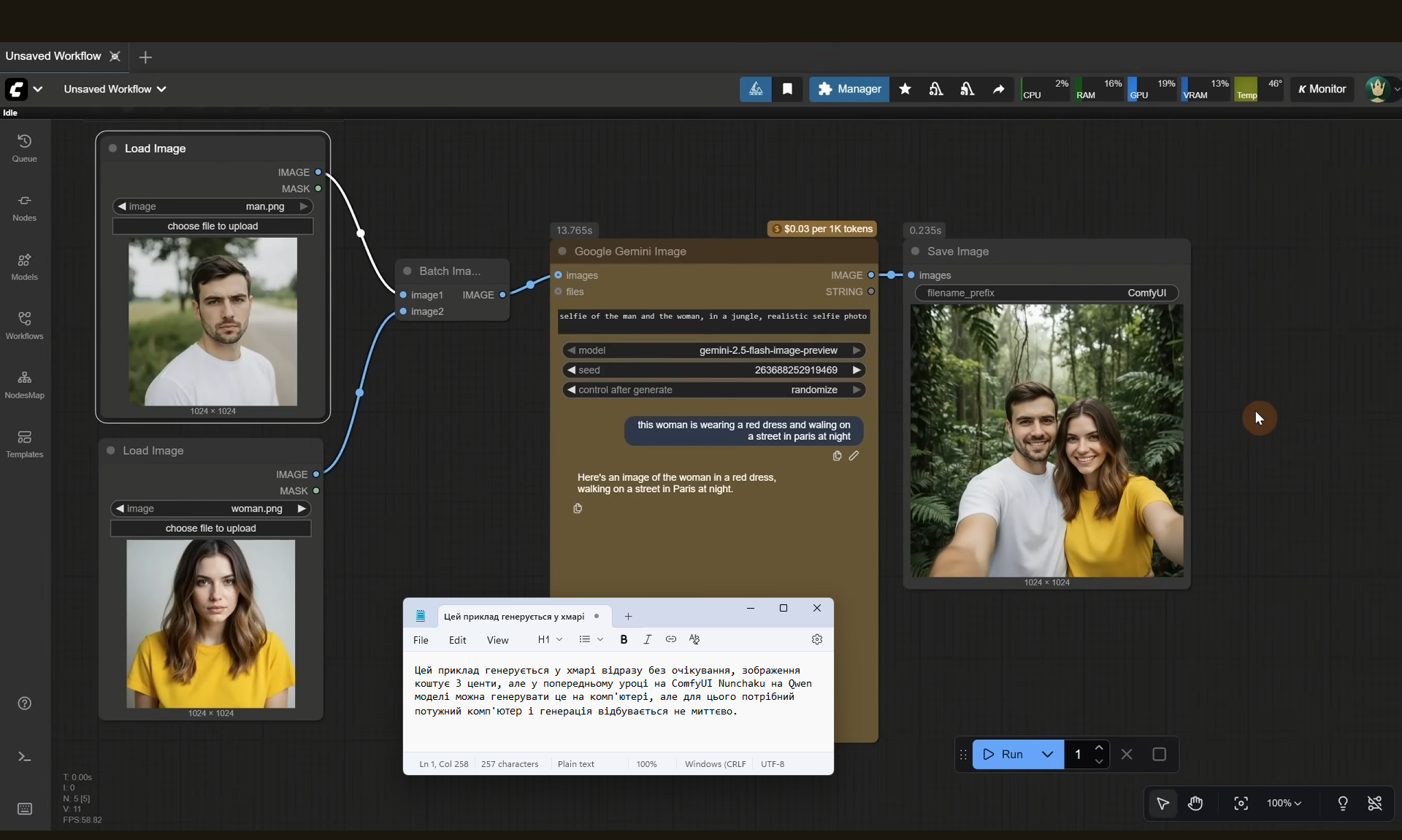
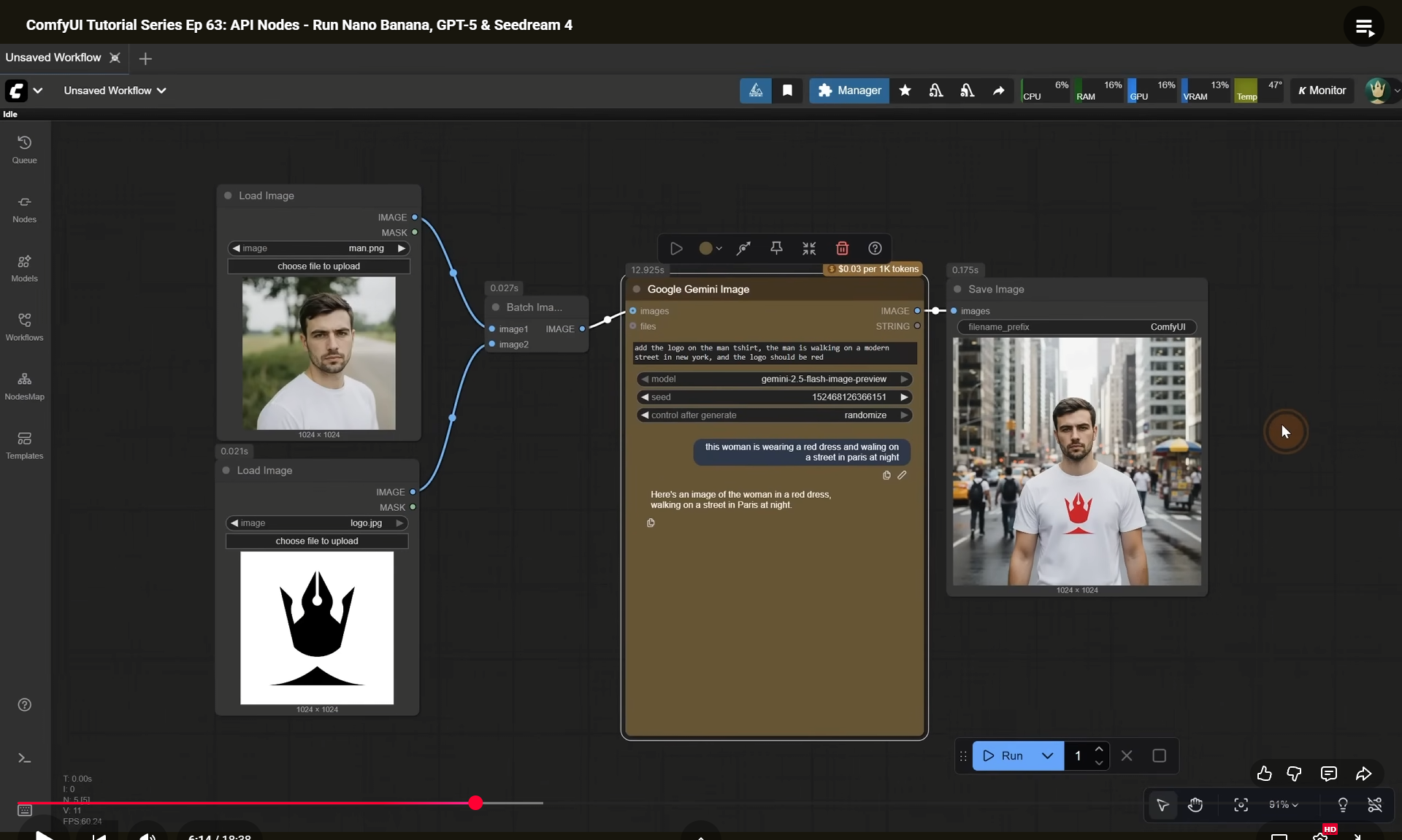
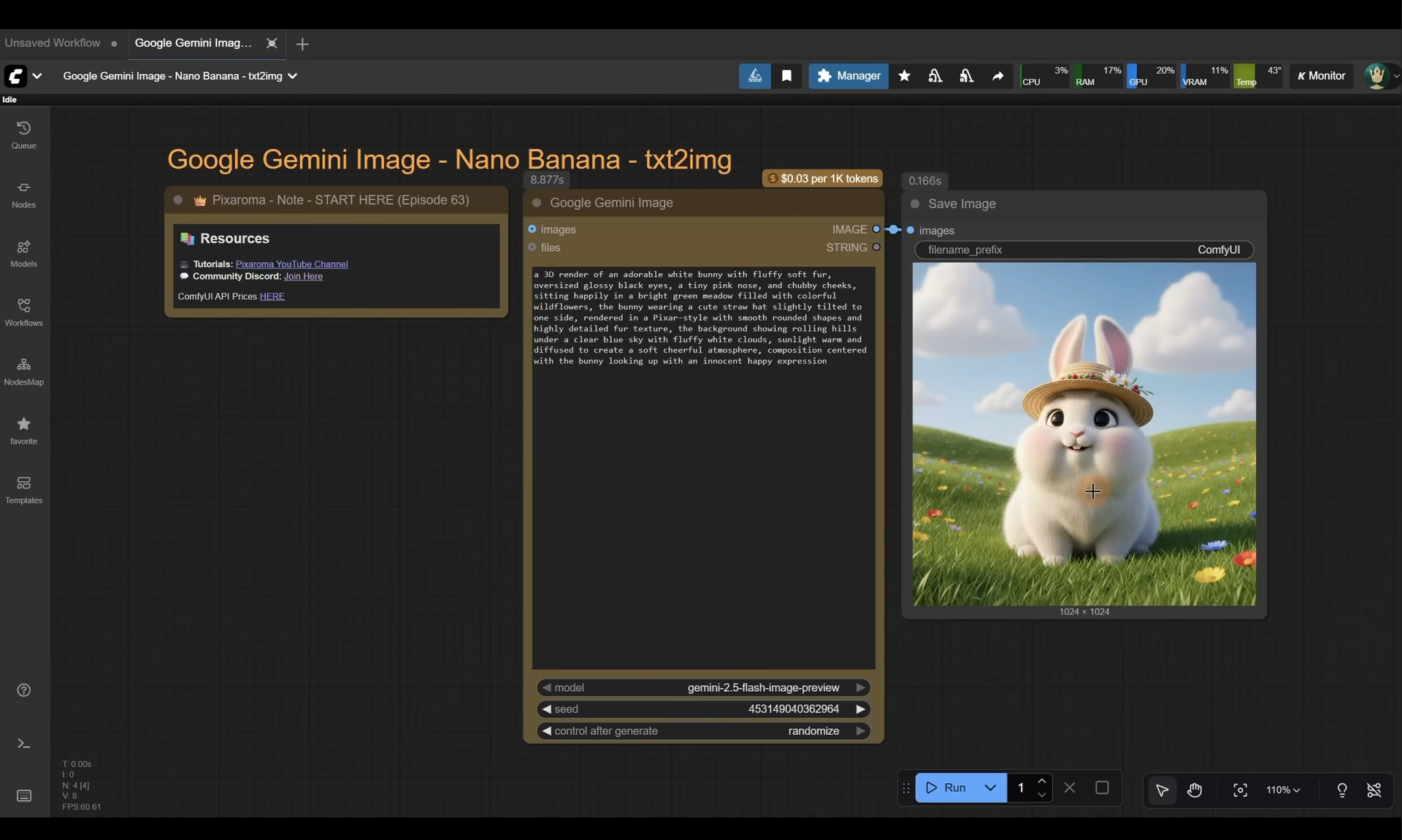
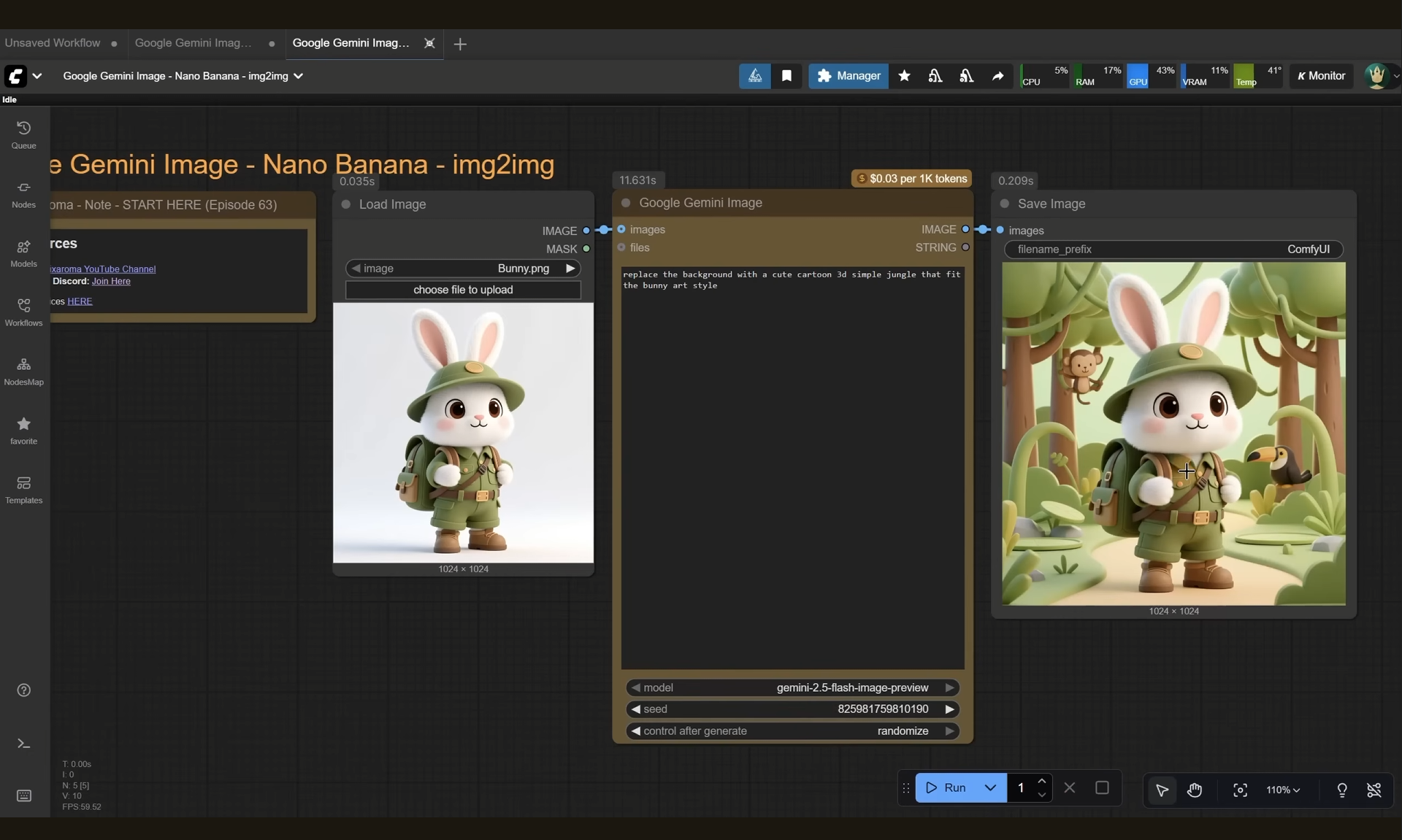
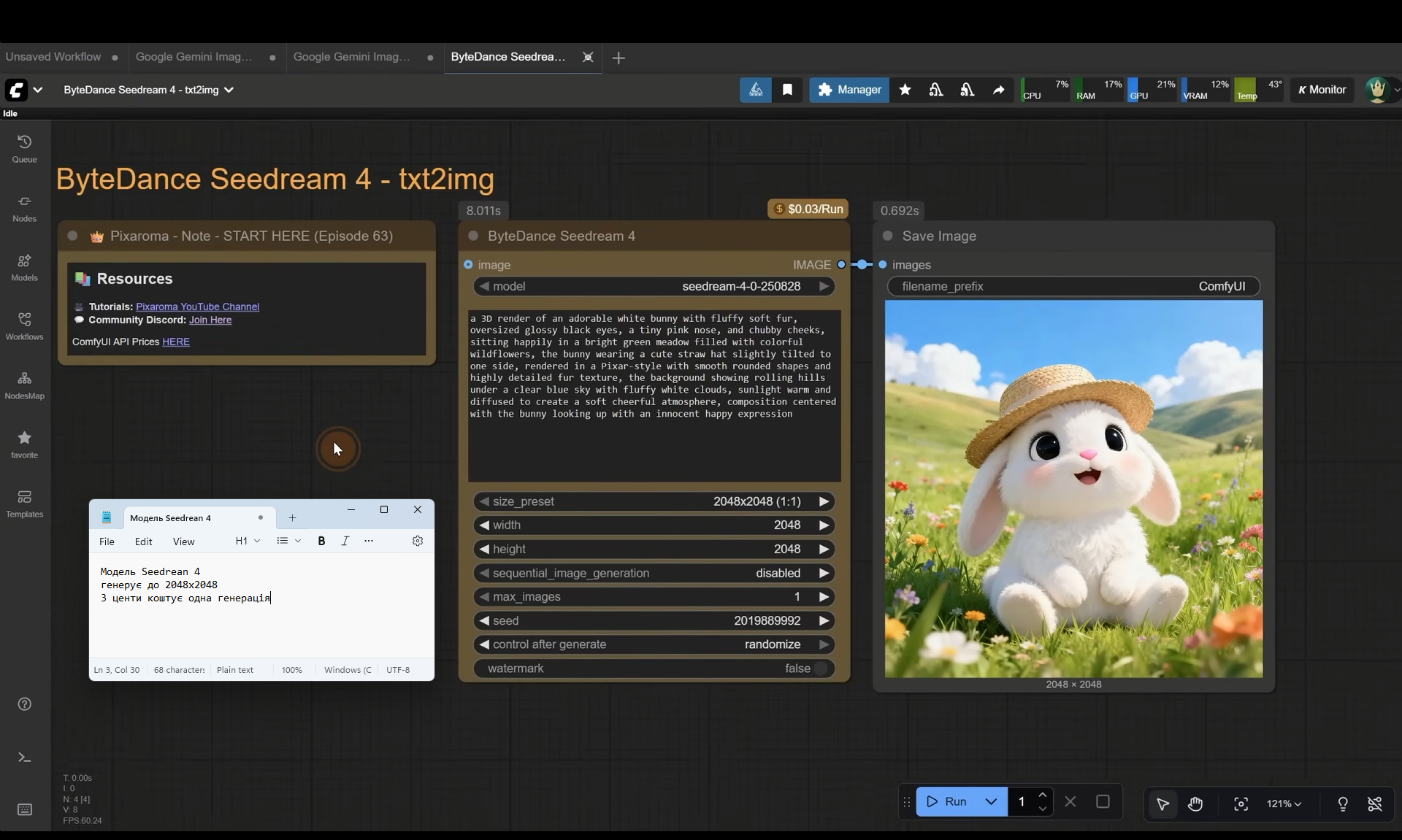
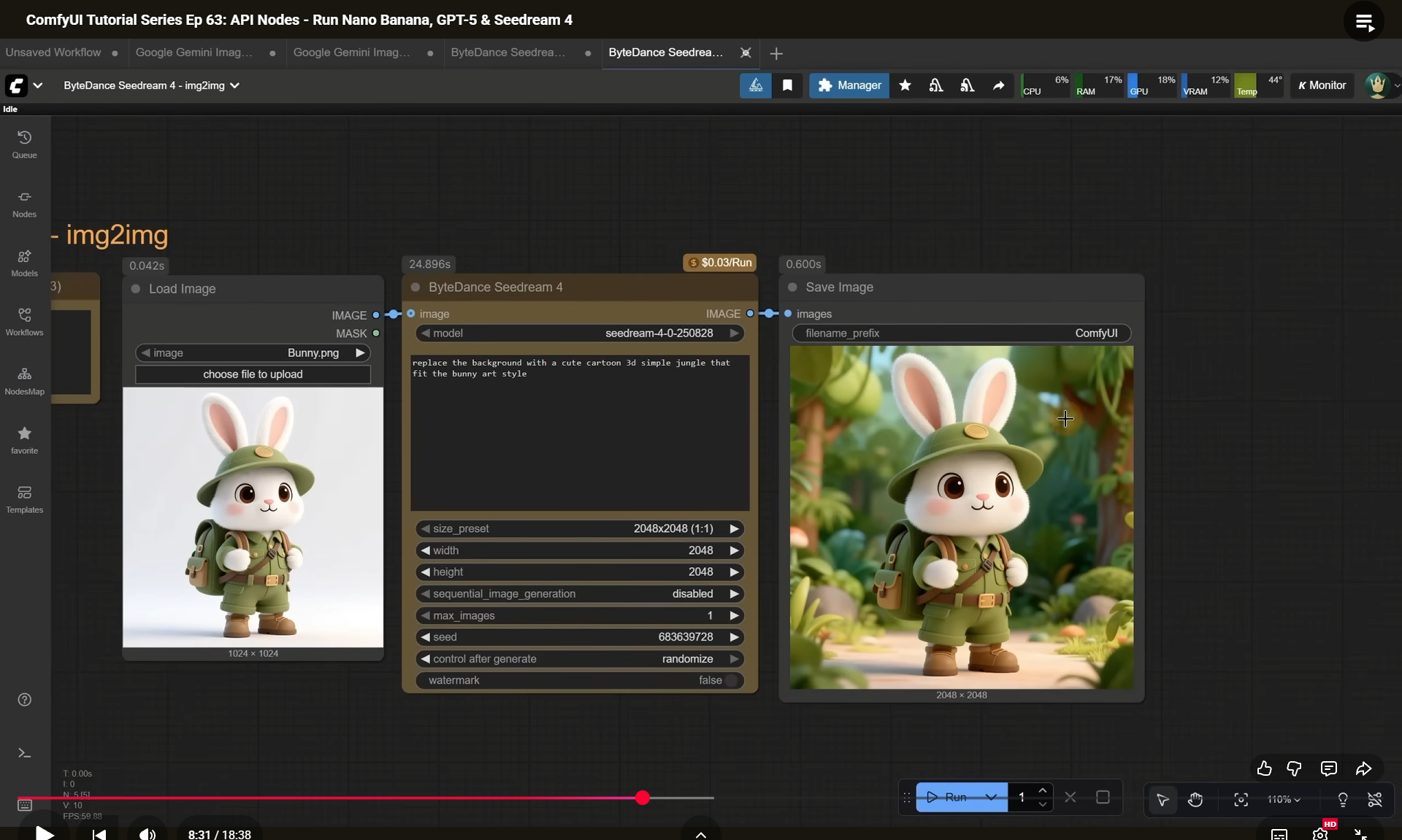
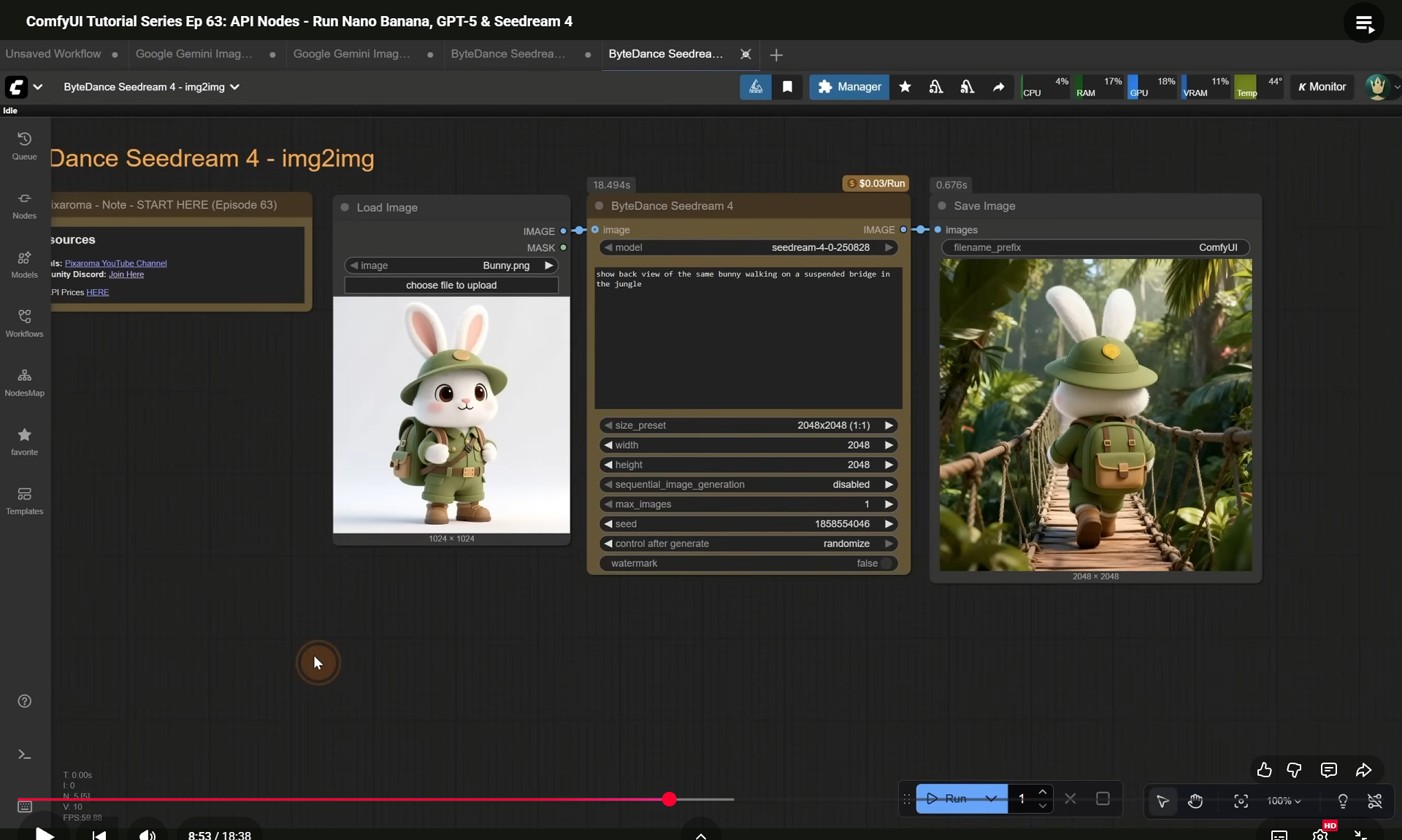
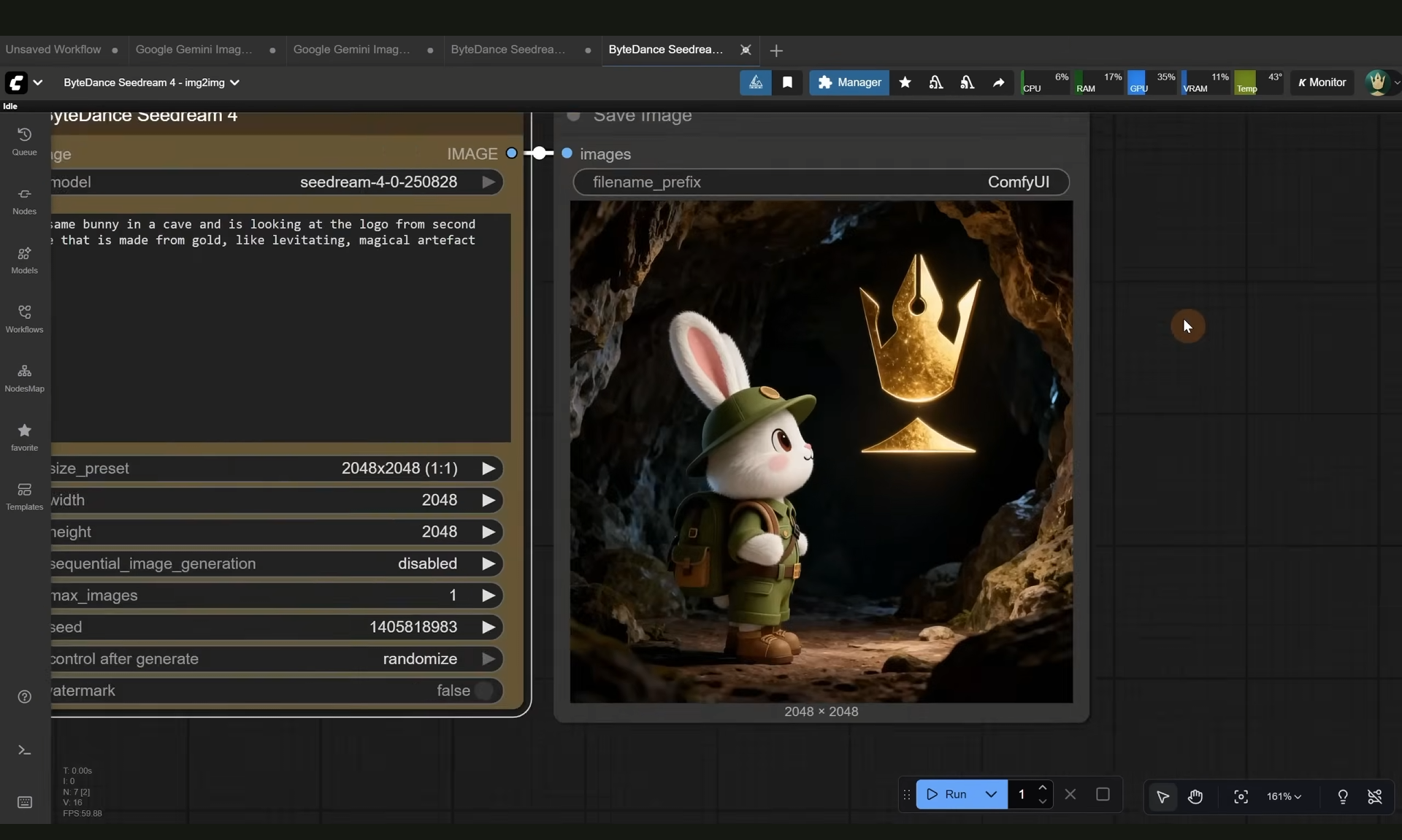
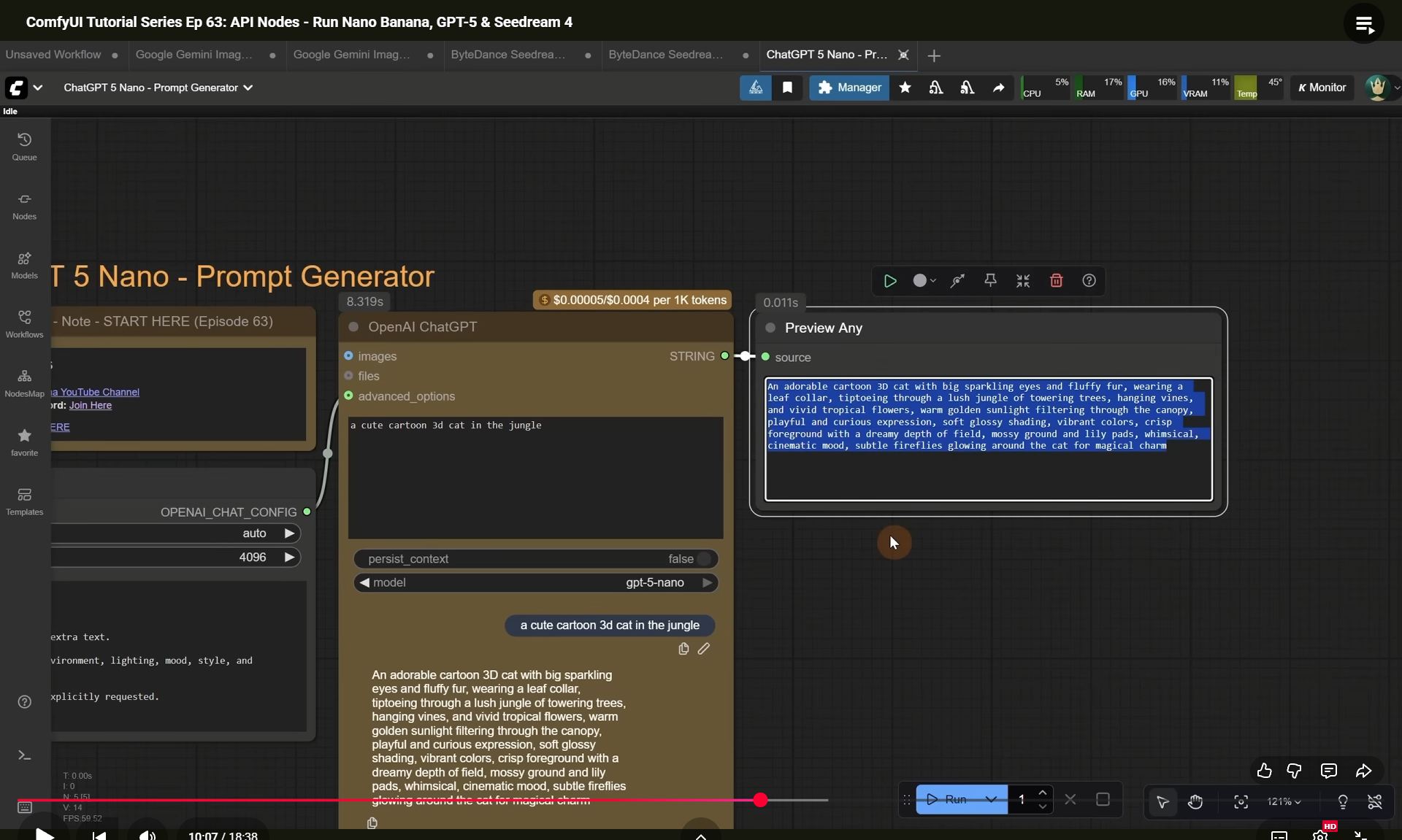
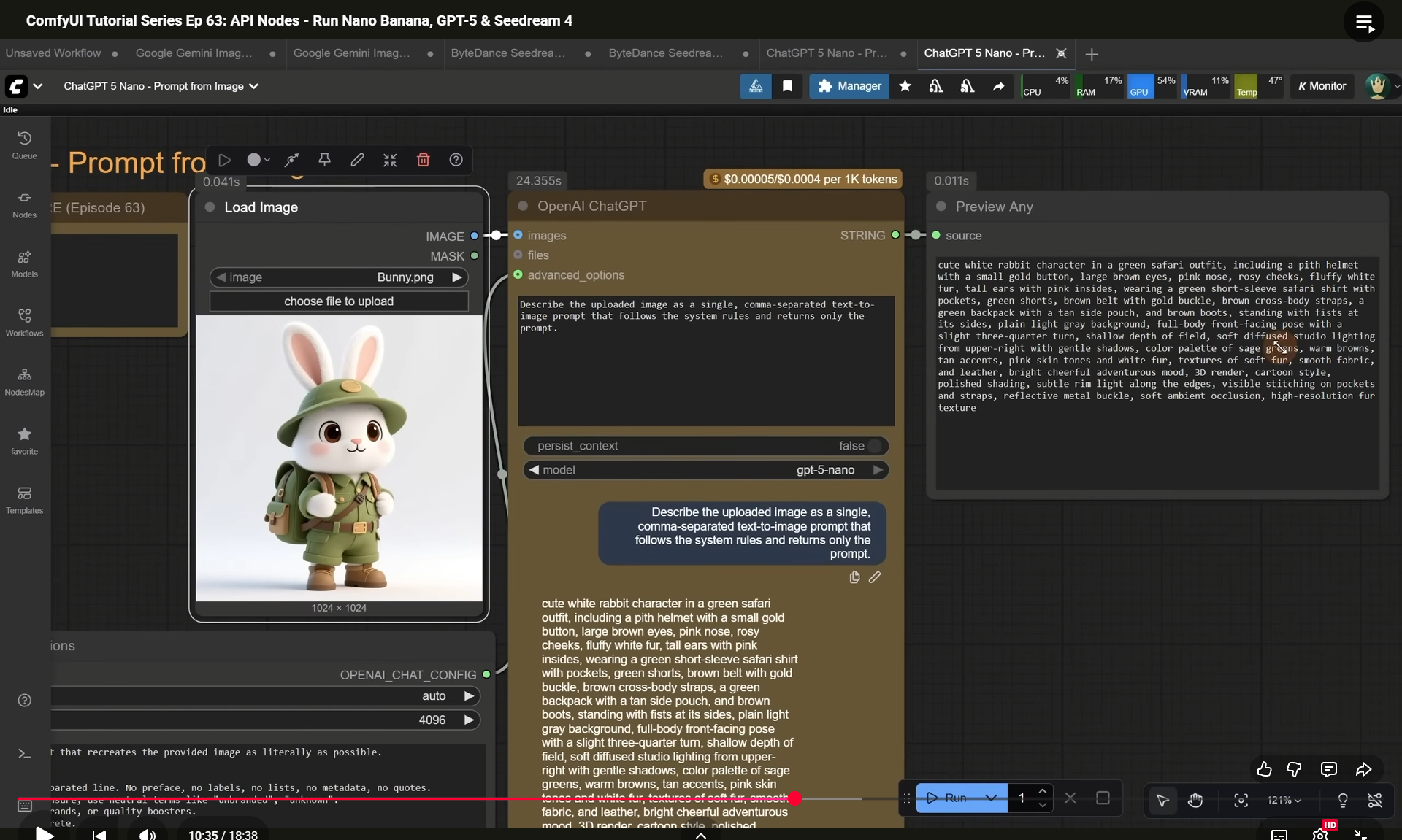
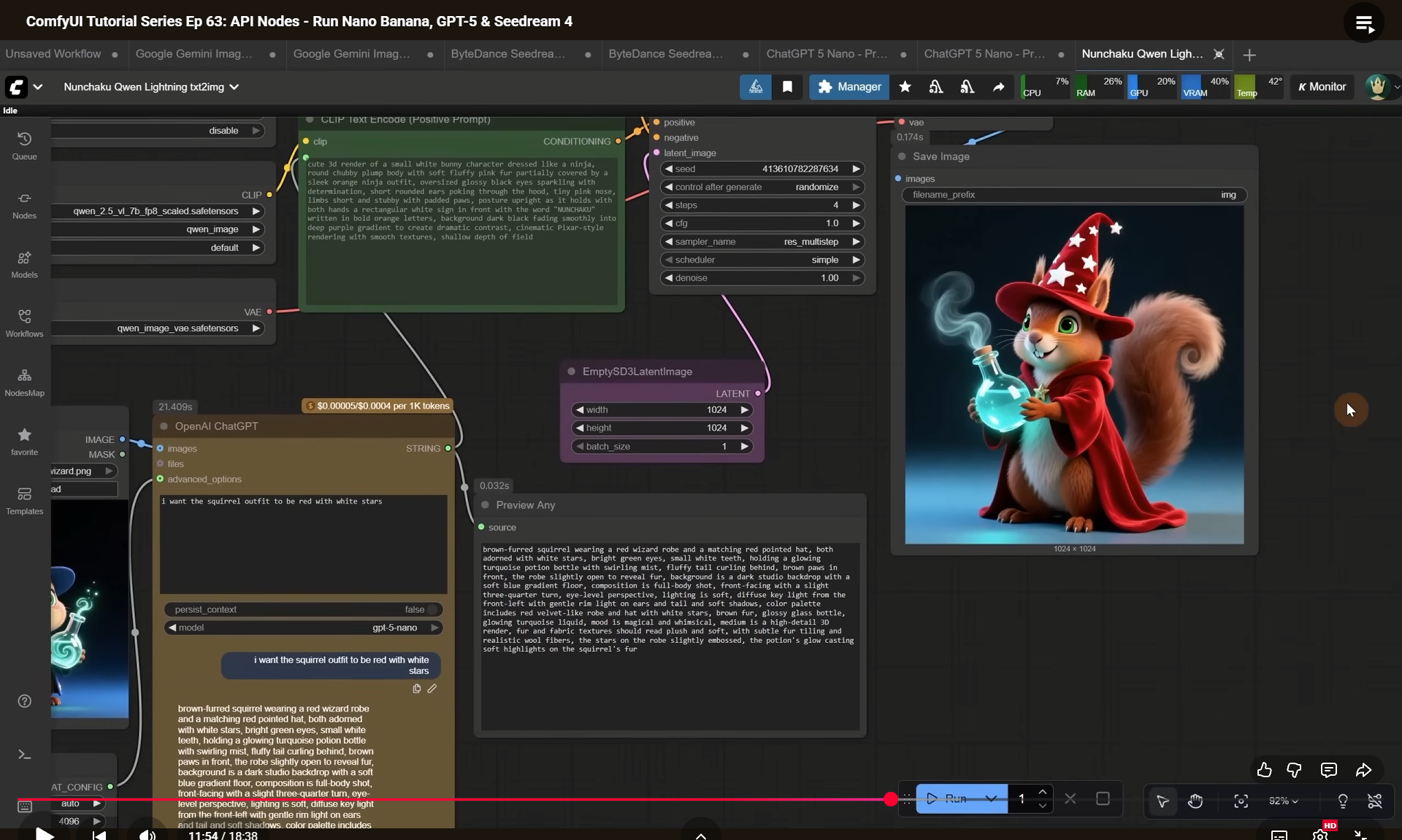
ComfyUI Tutorial Series Ep 63: API Nodes - Run Nano Banana, GPT-5 & Seedream 4








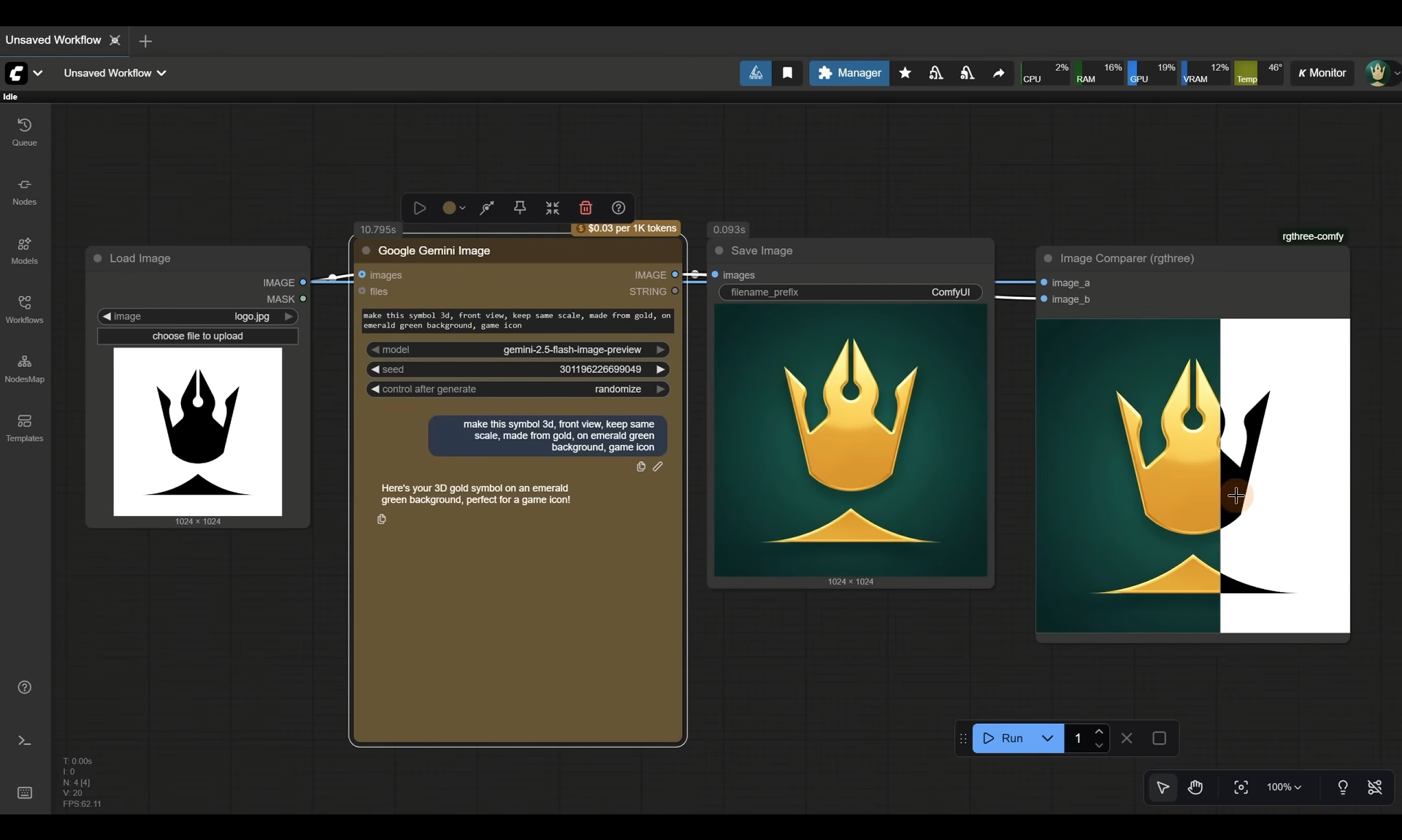
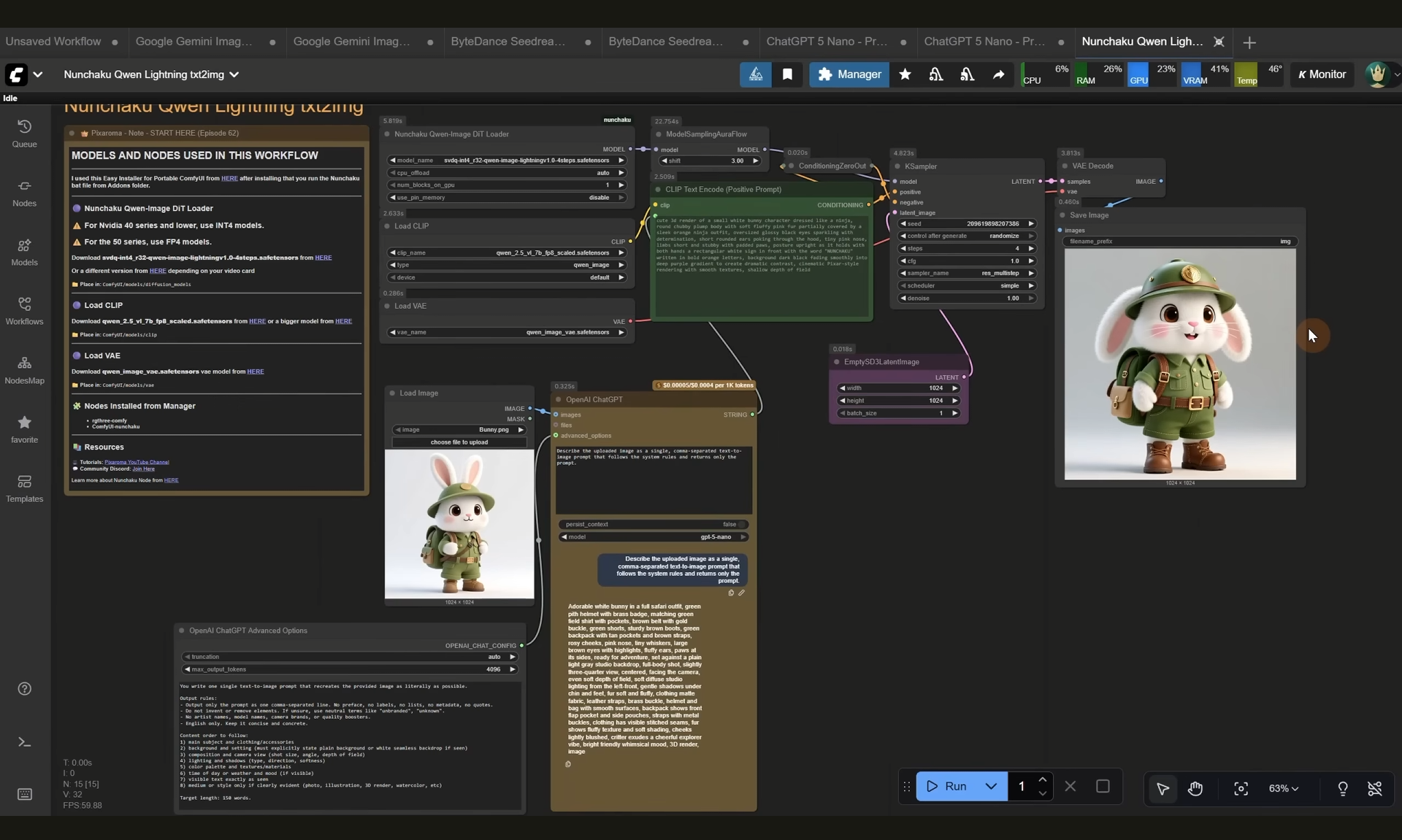
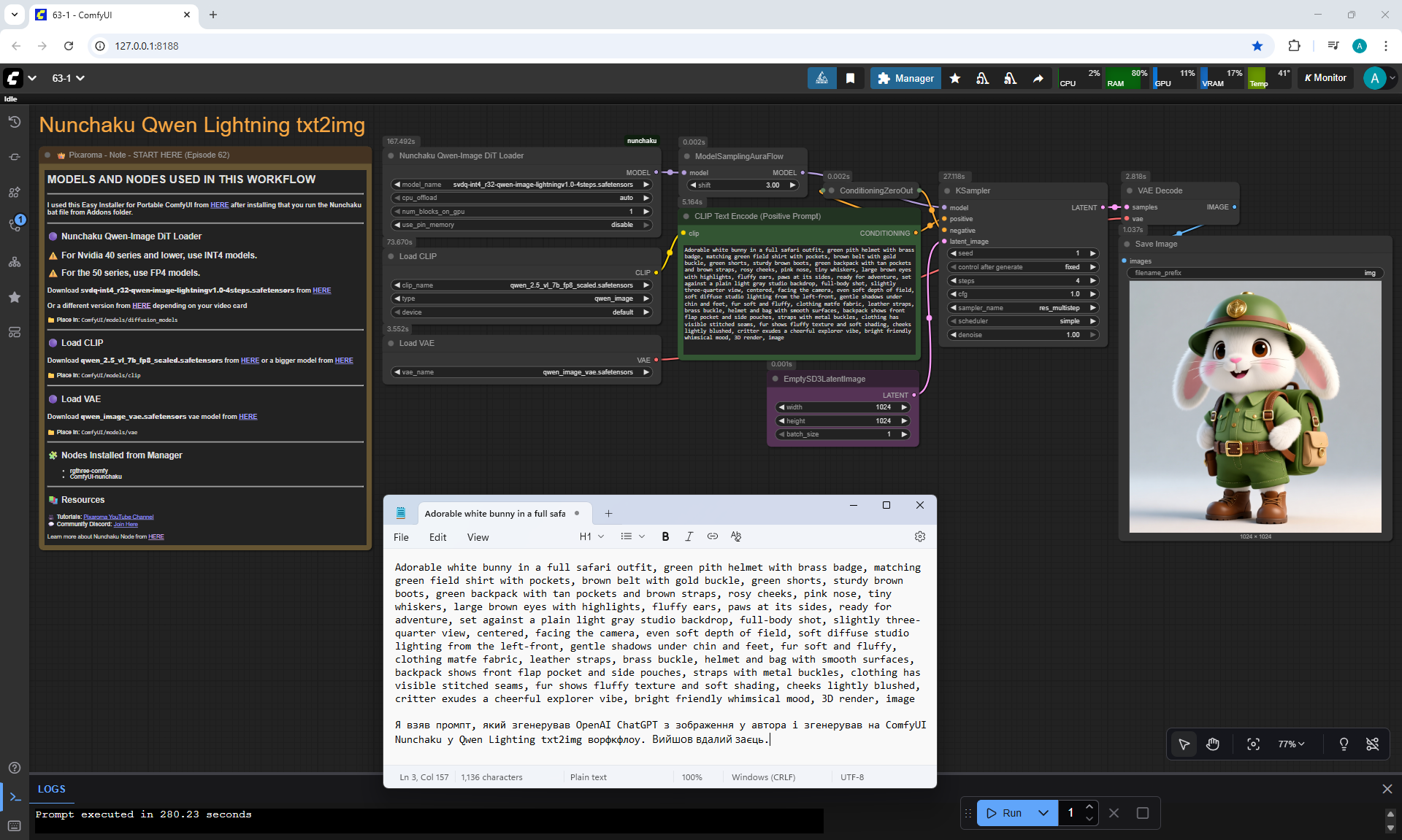
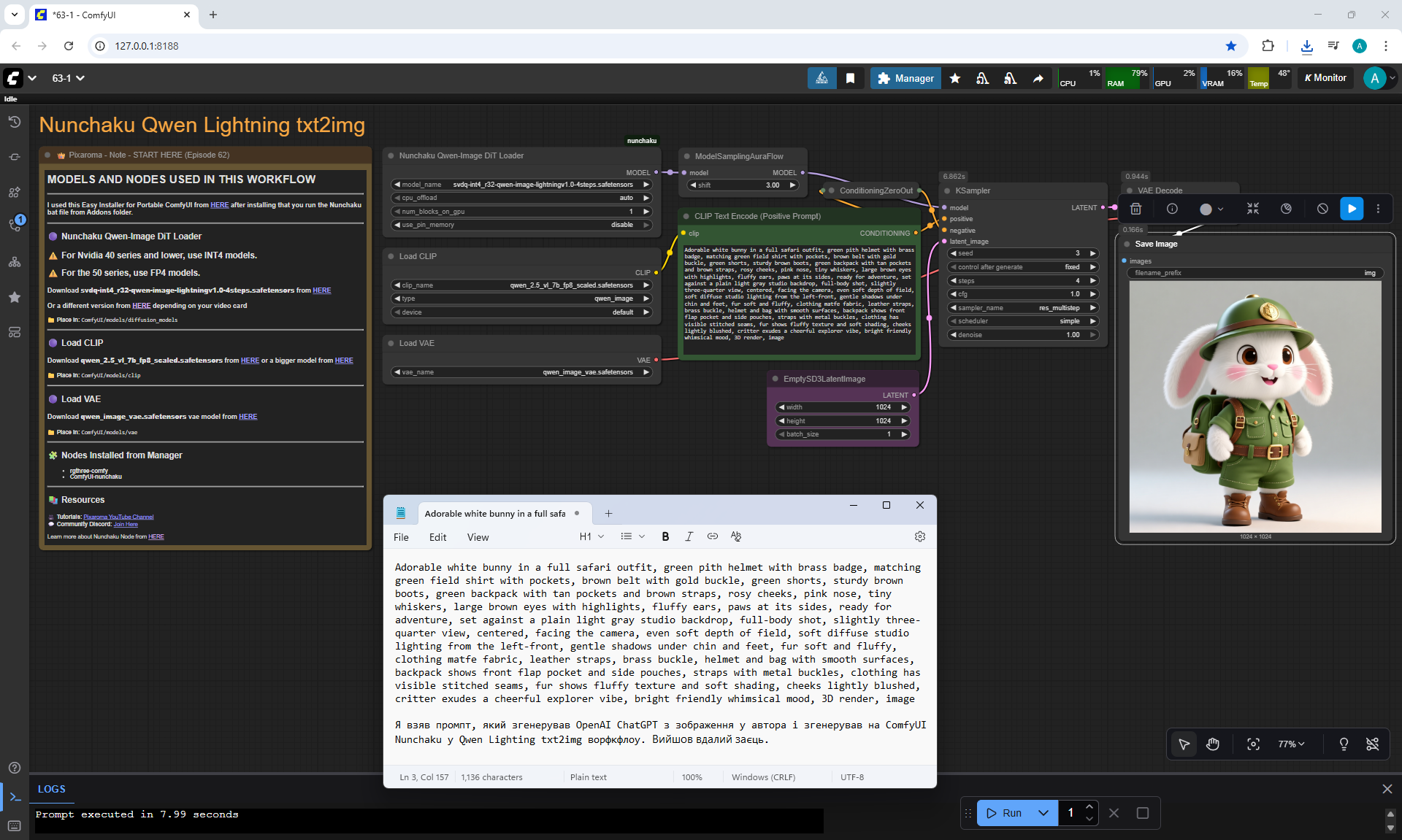
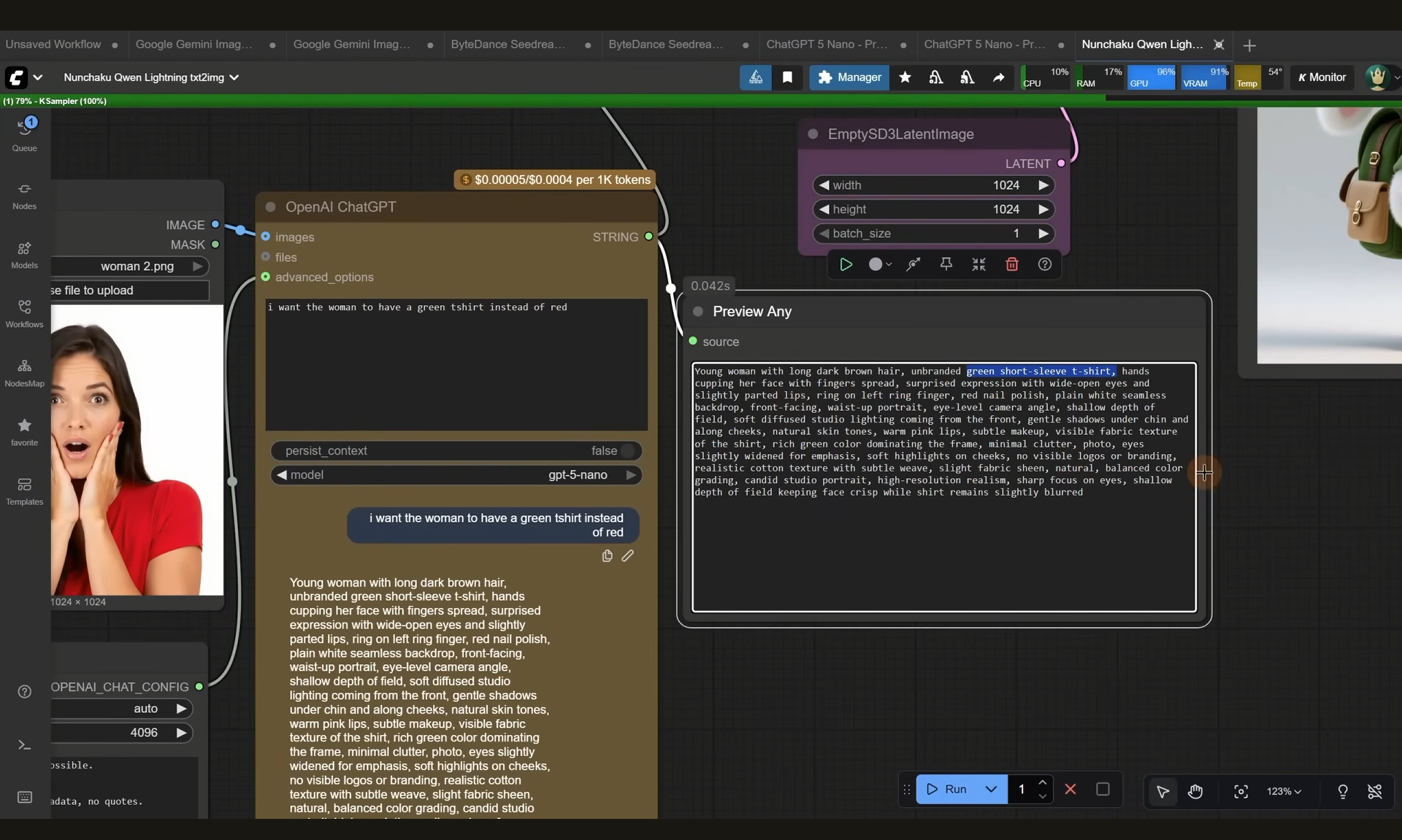
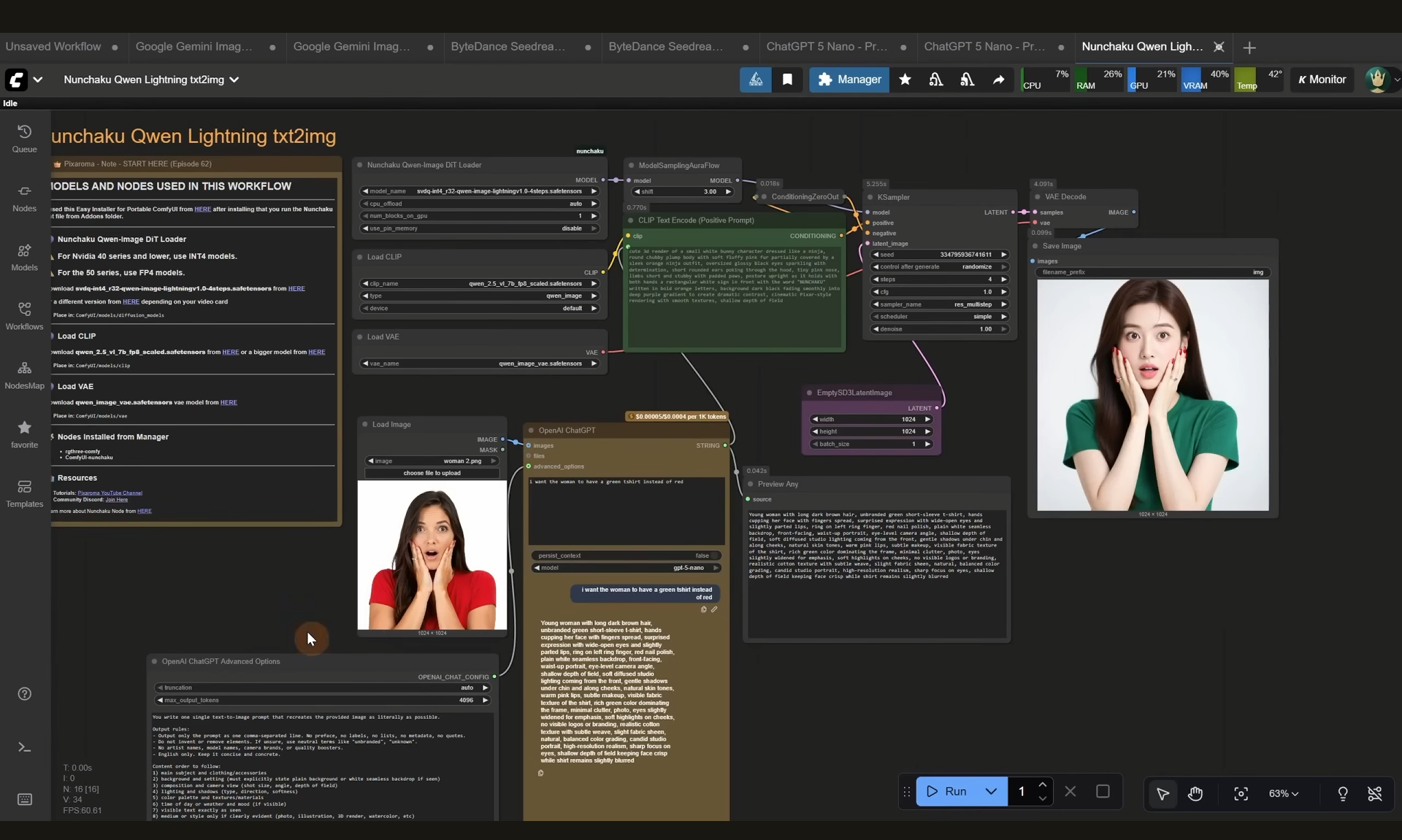
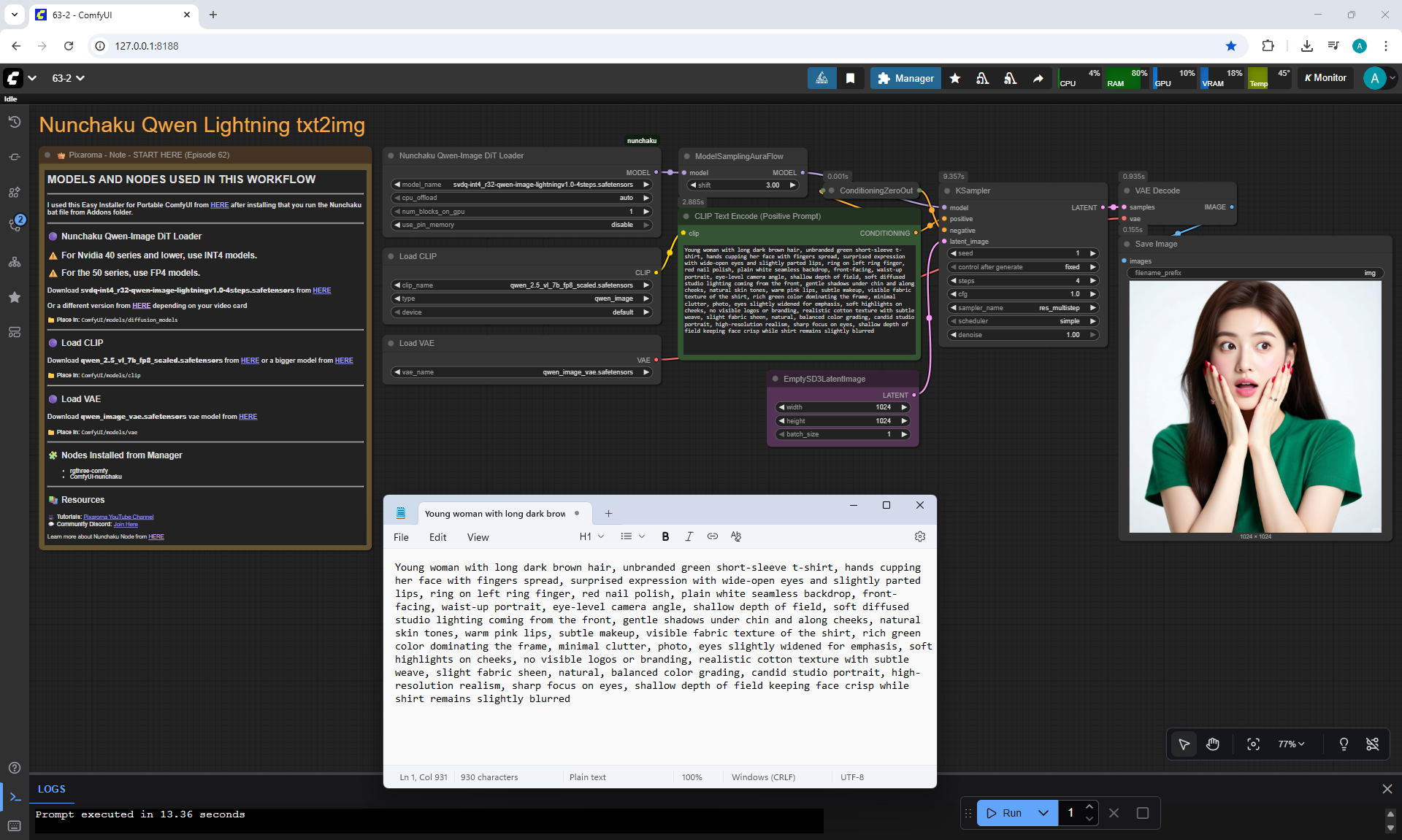
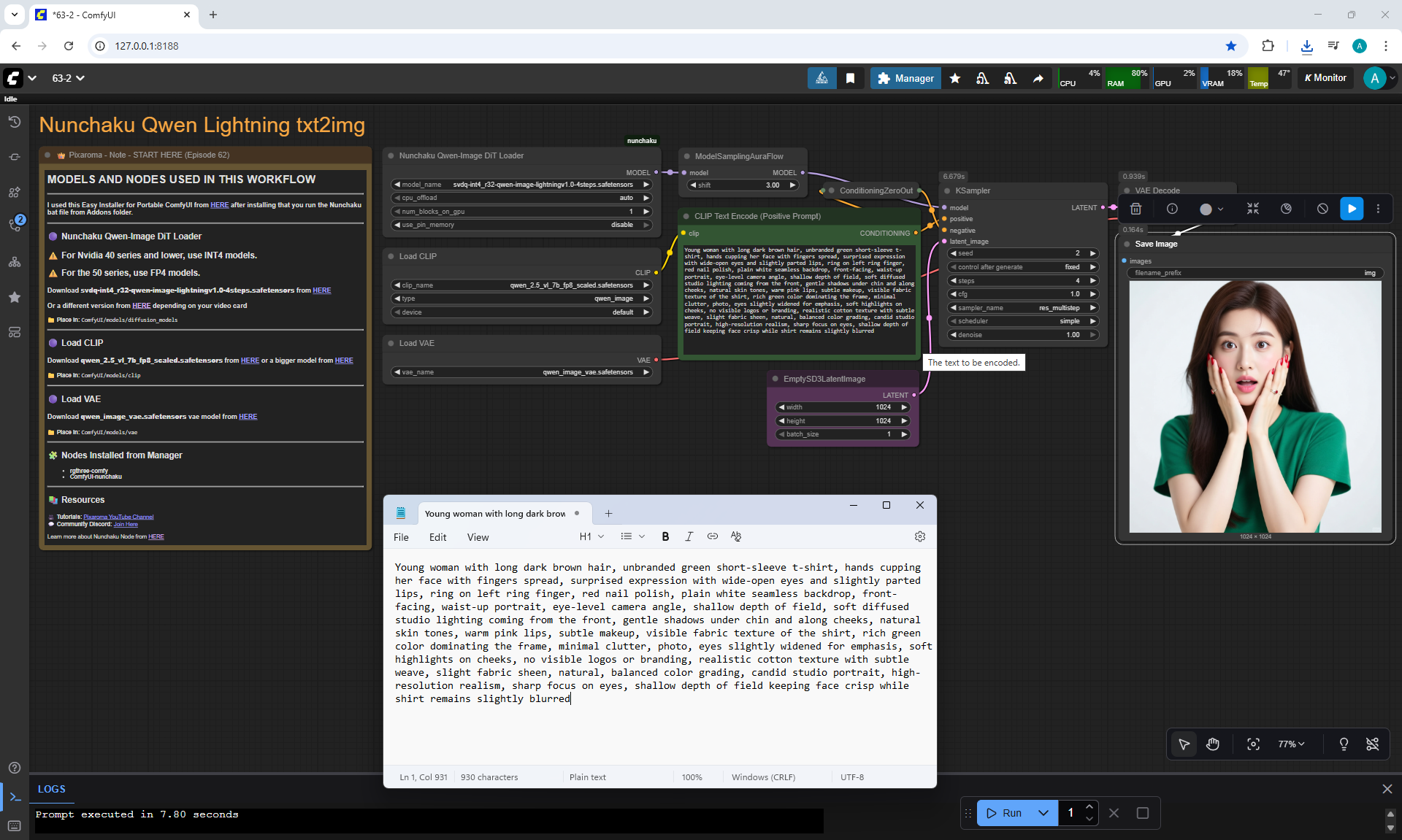
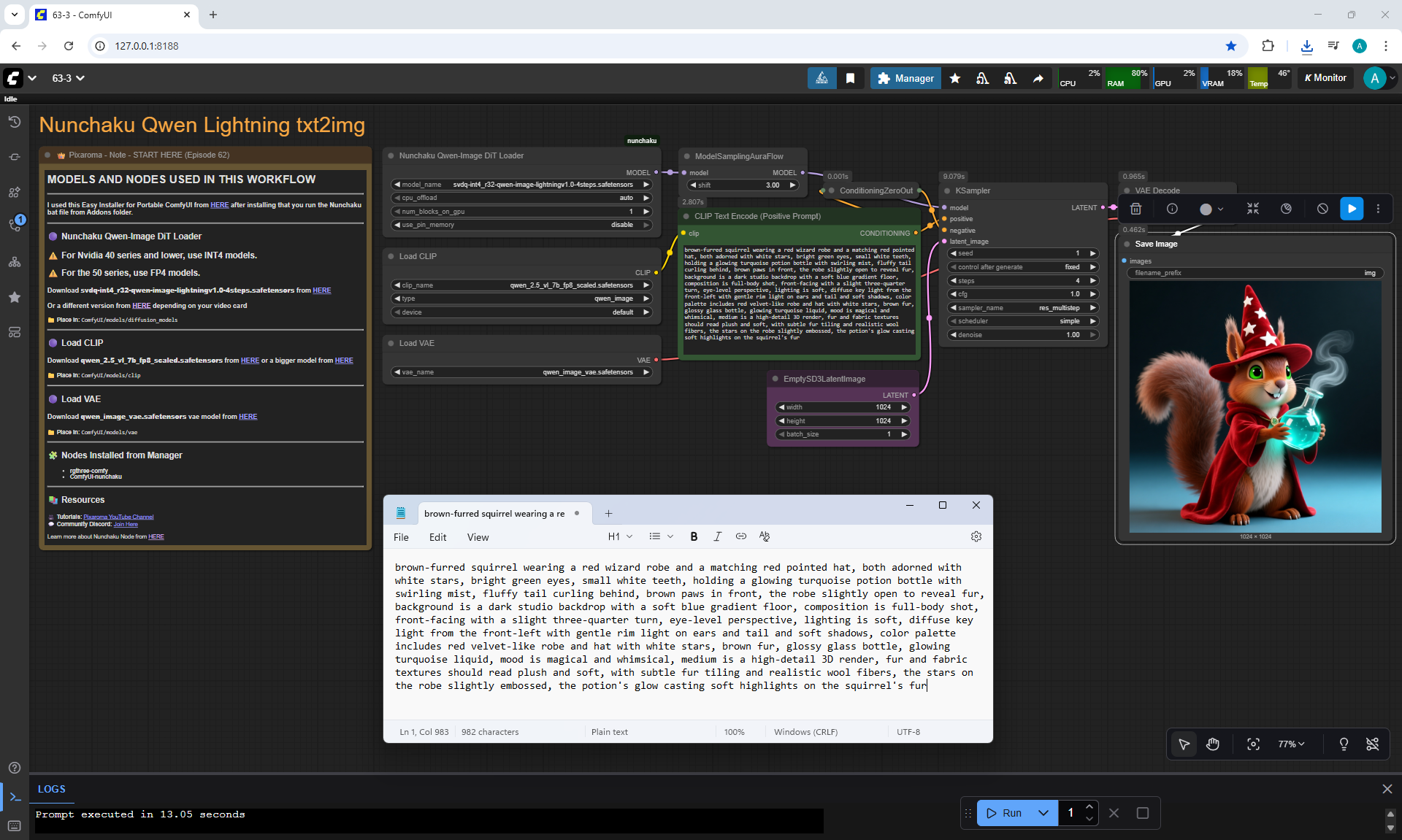
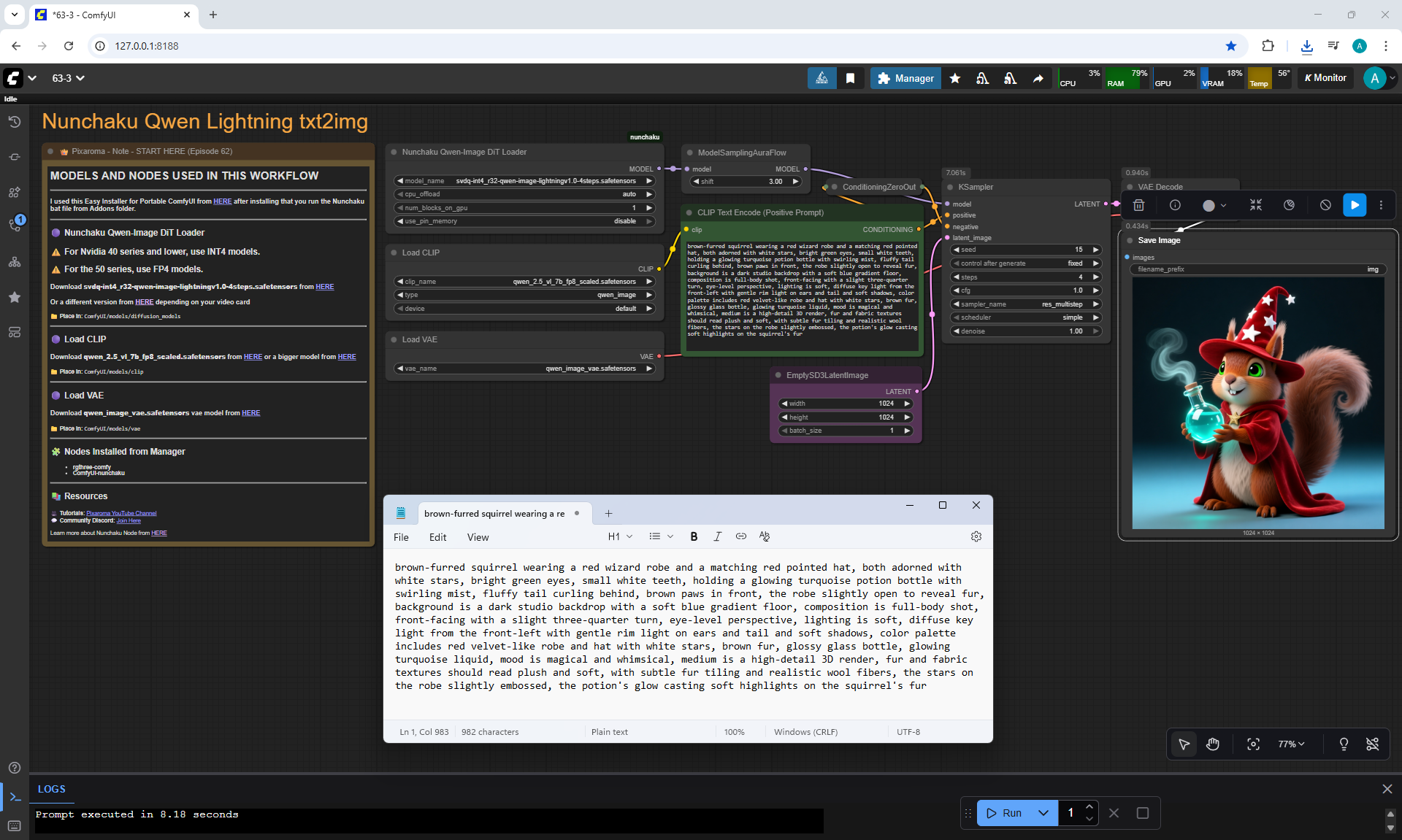
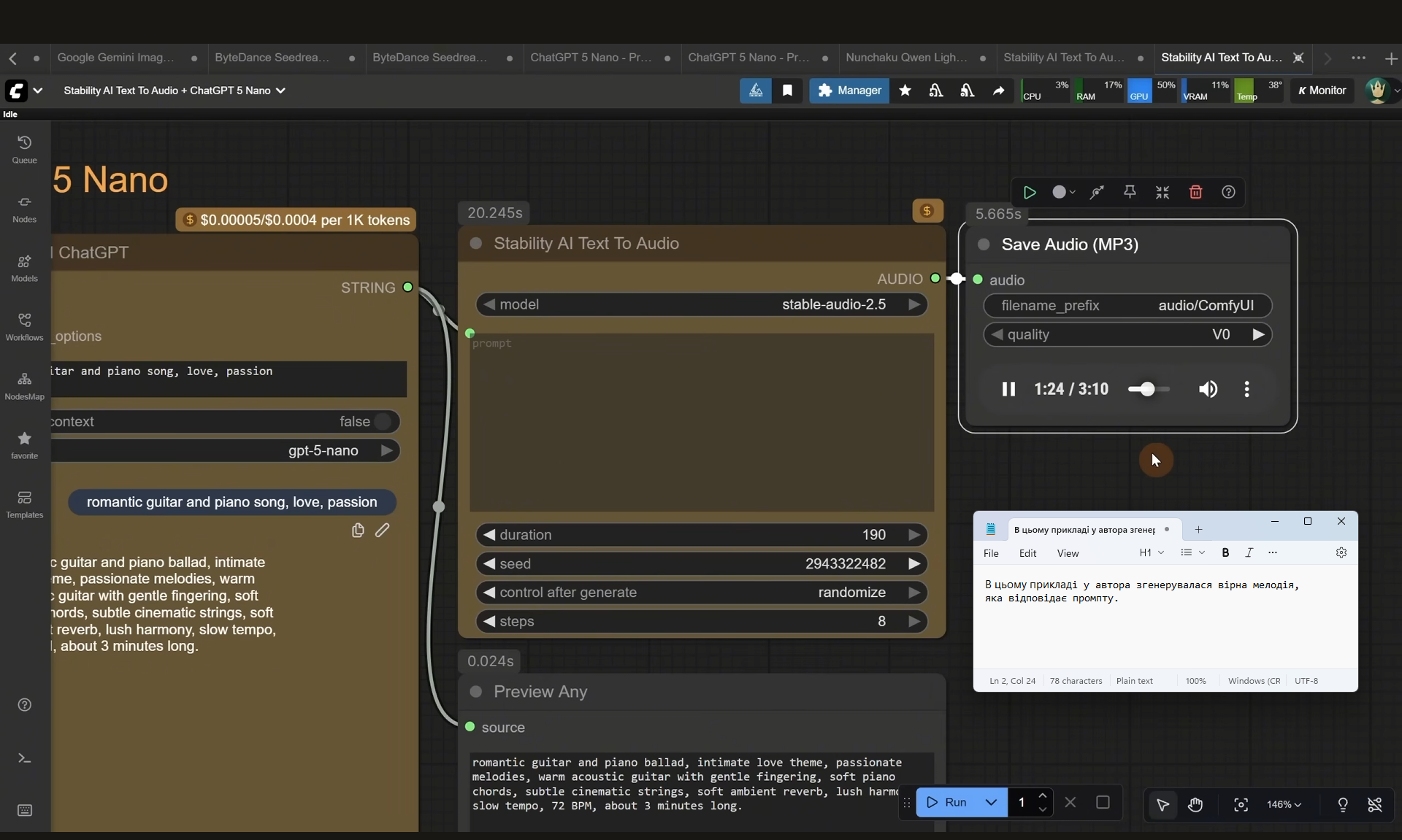
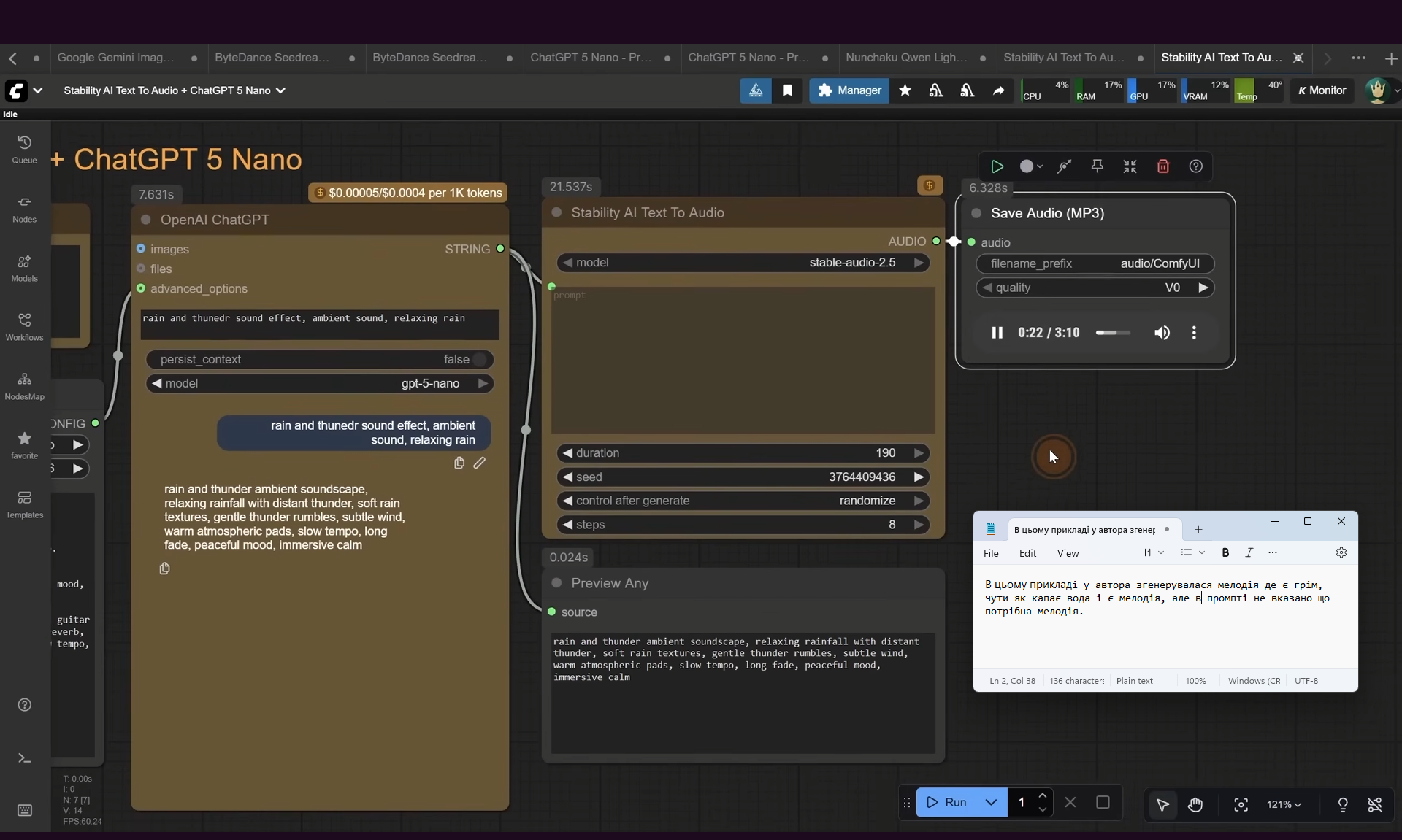
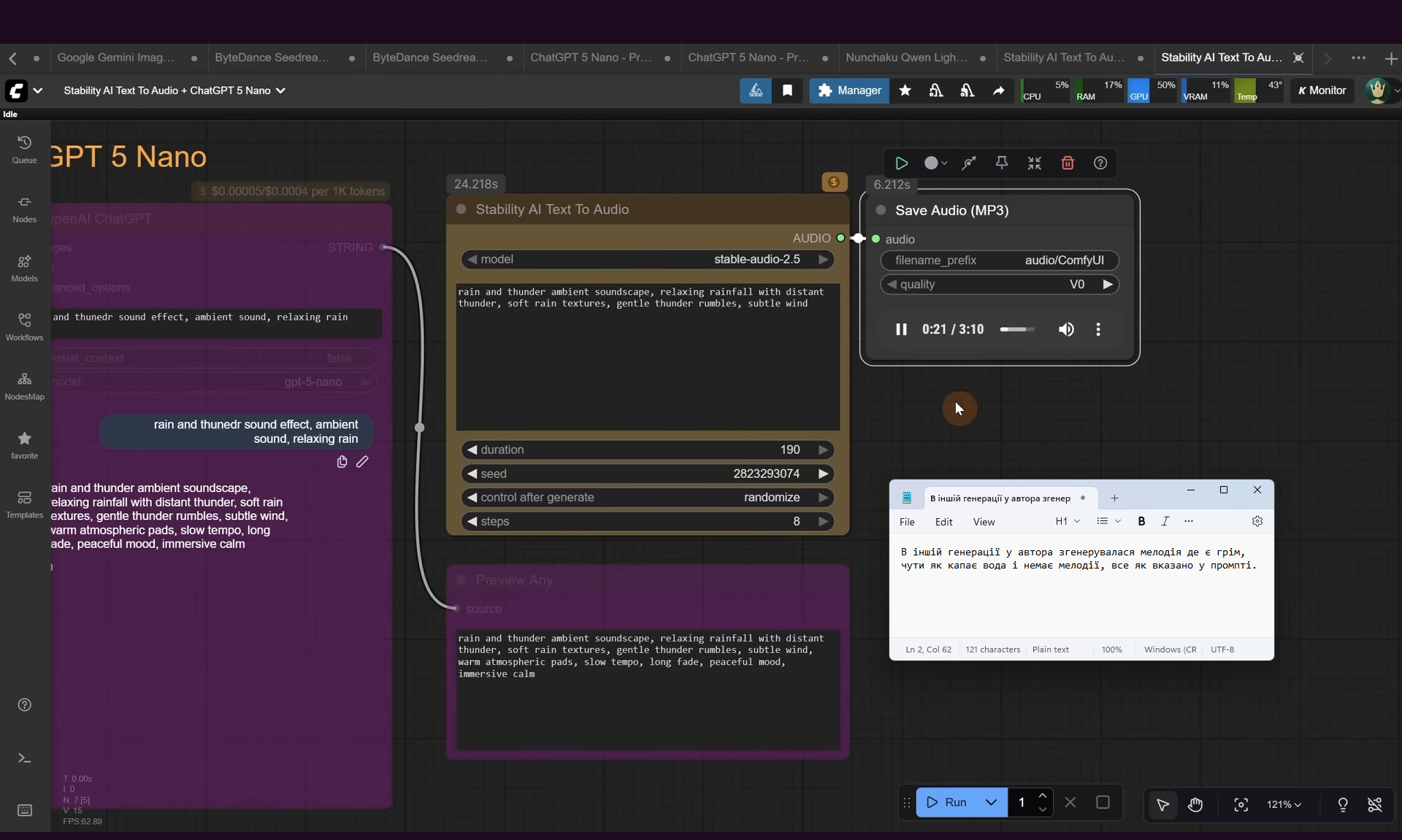
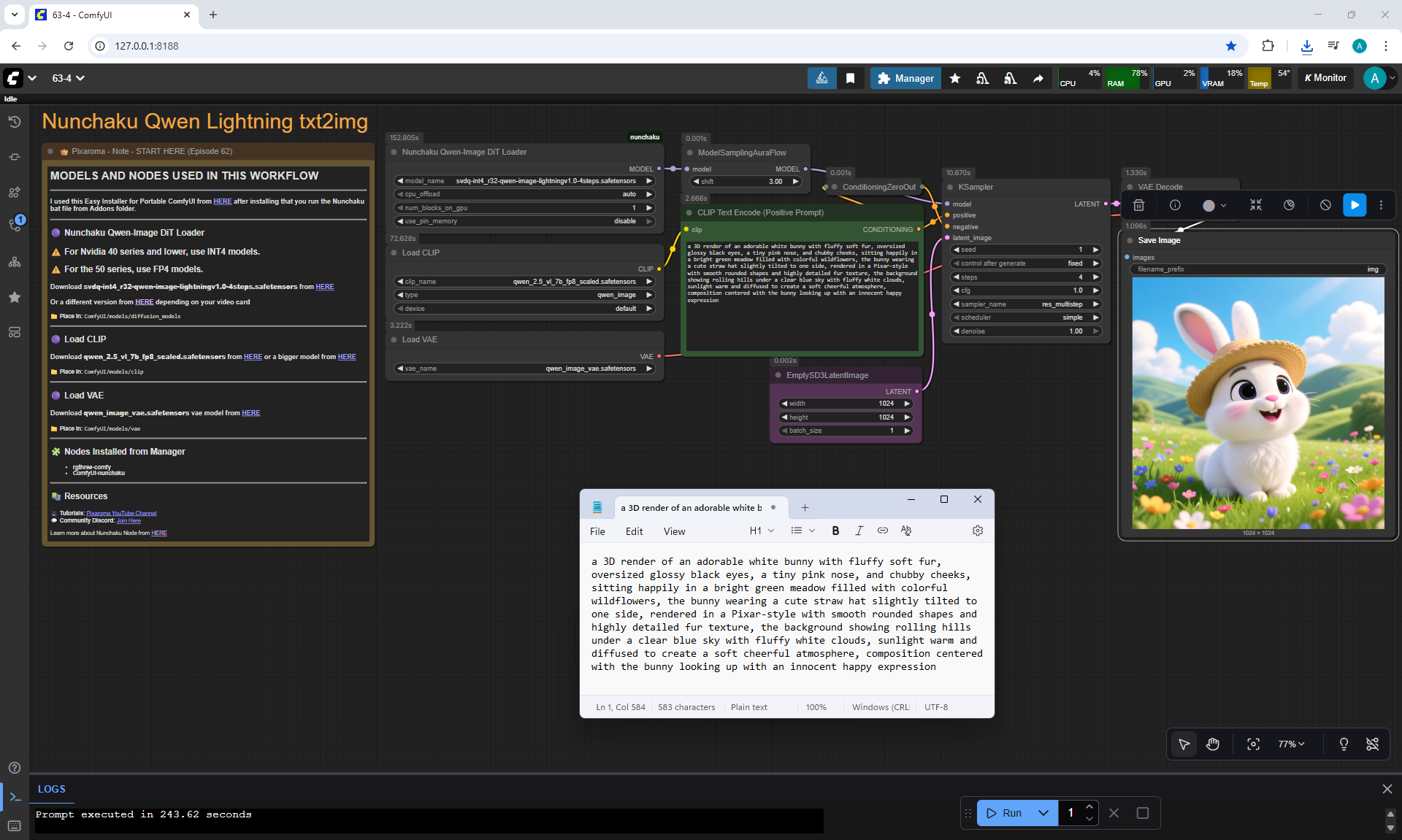
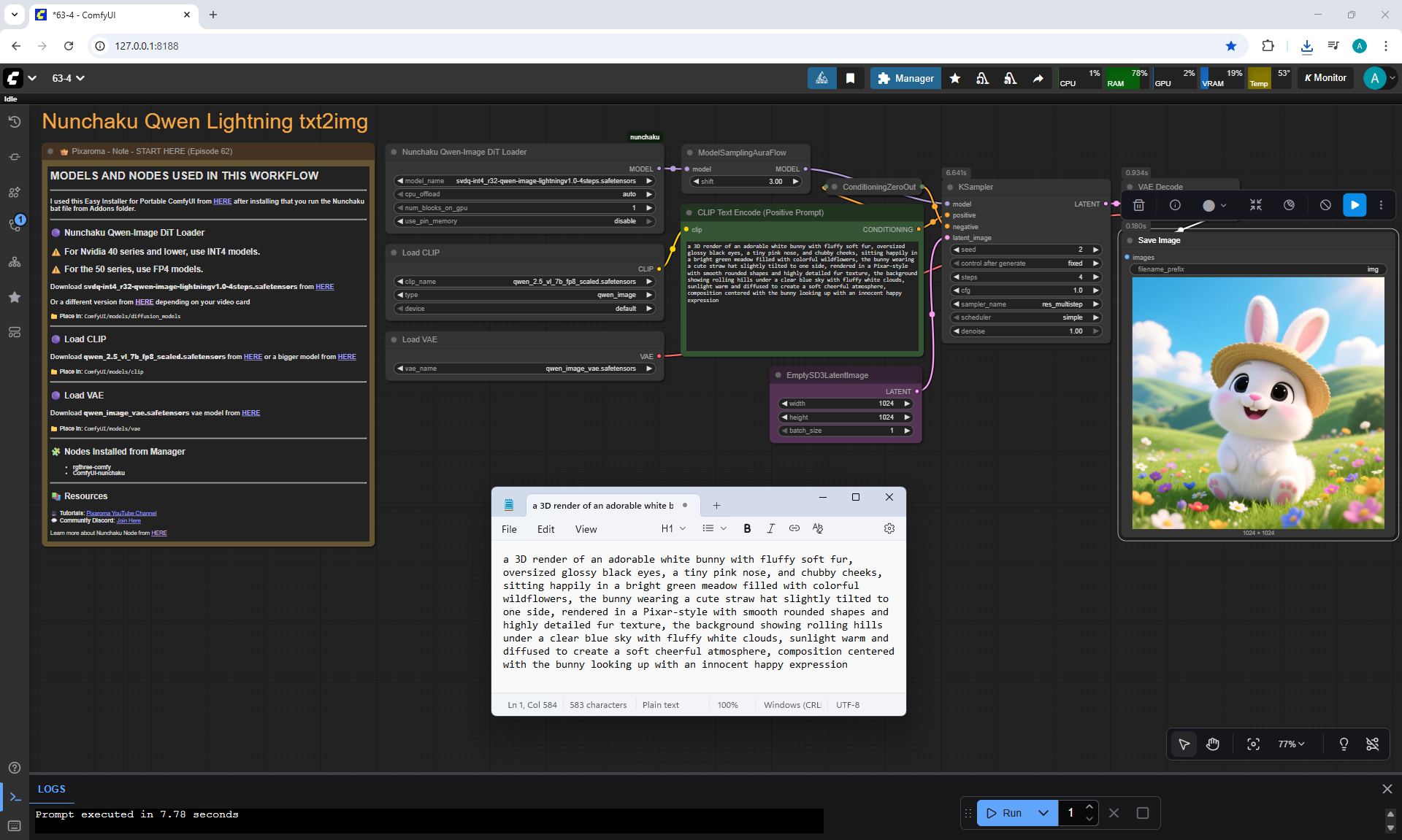
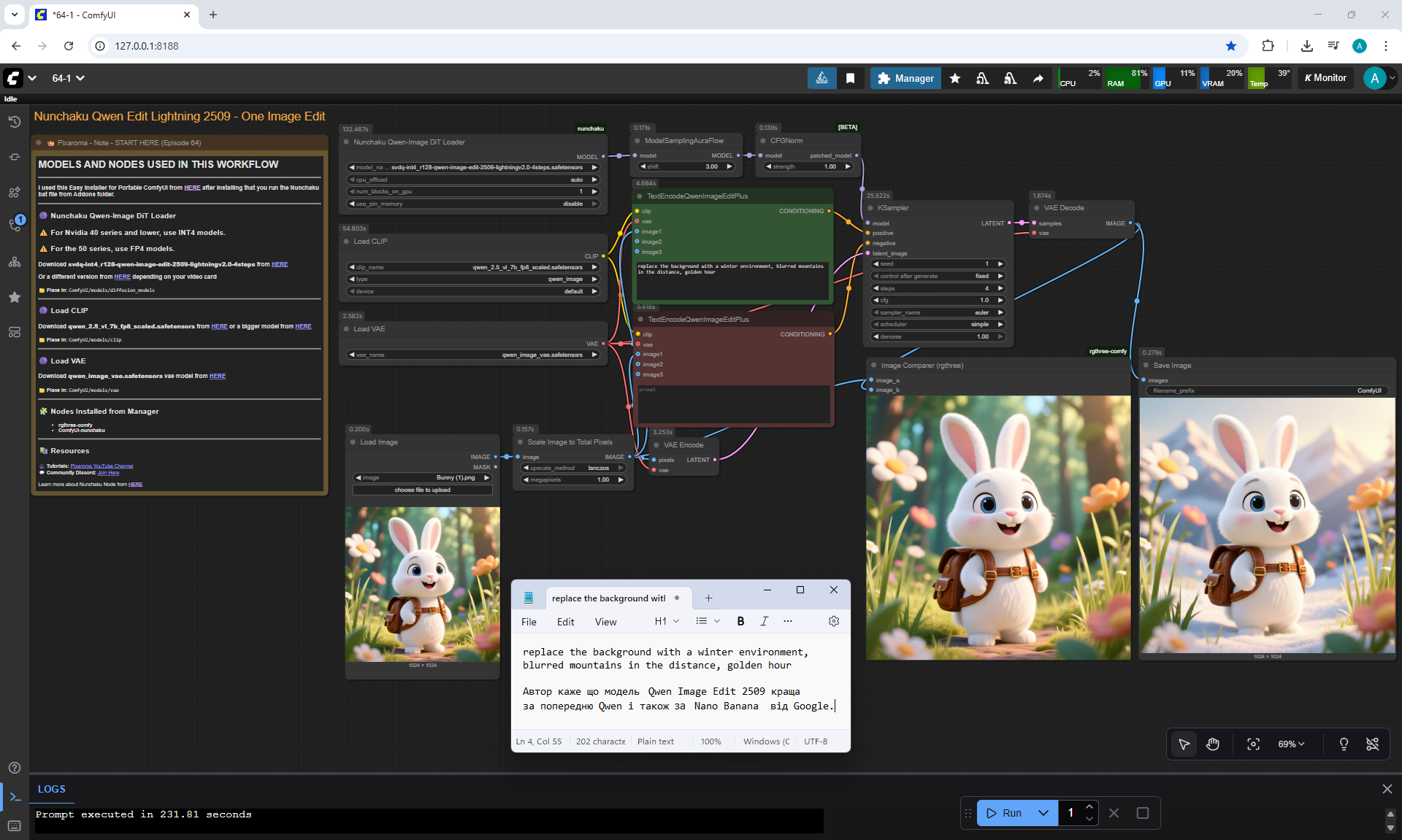
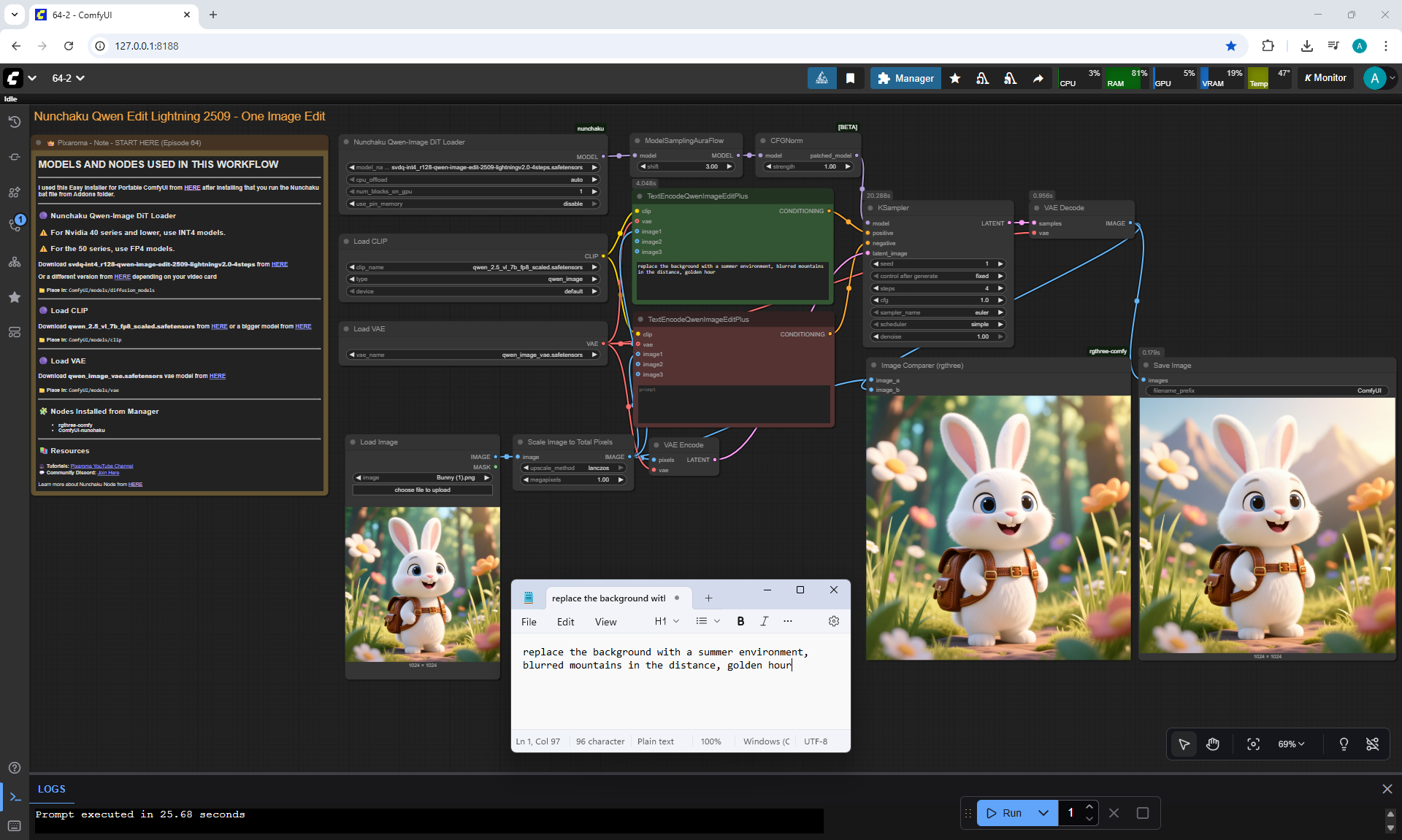
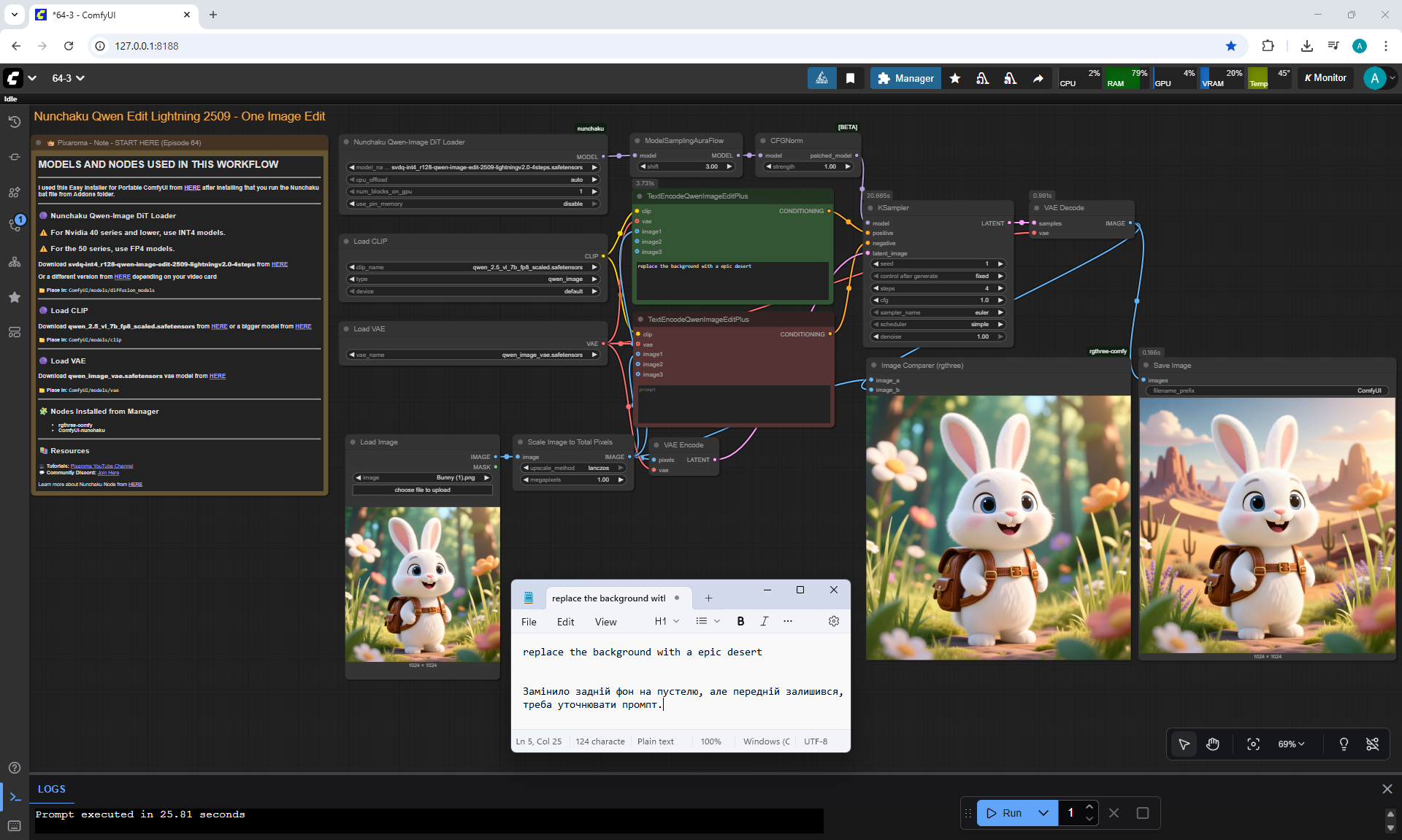
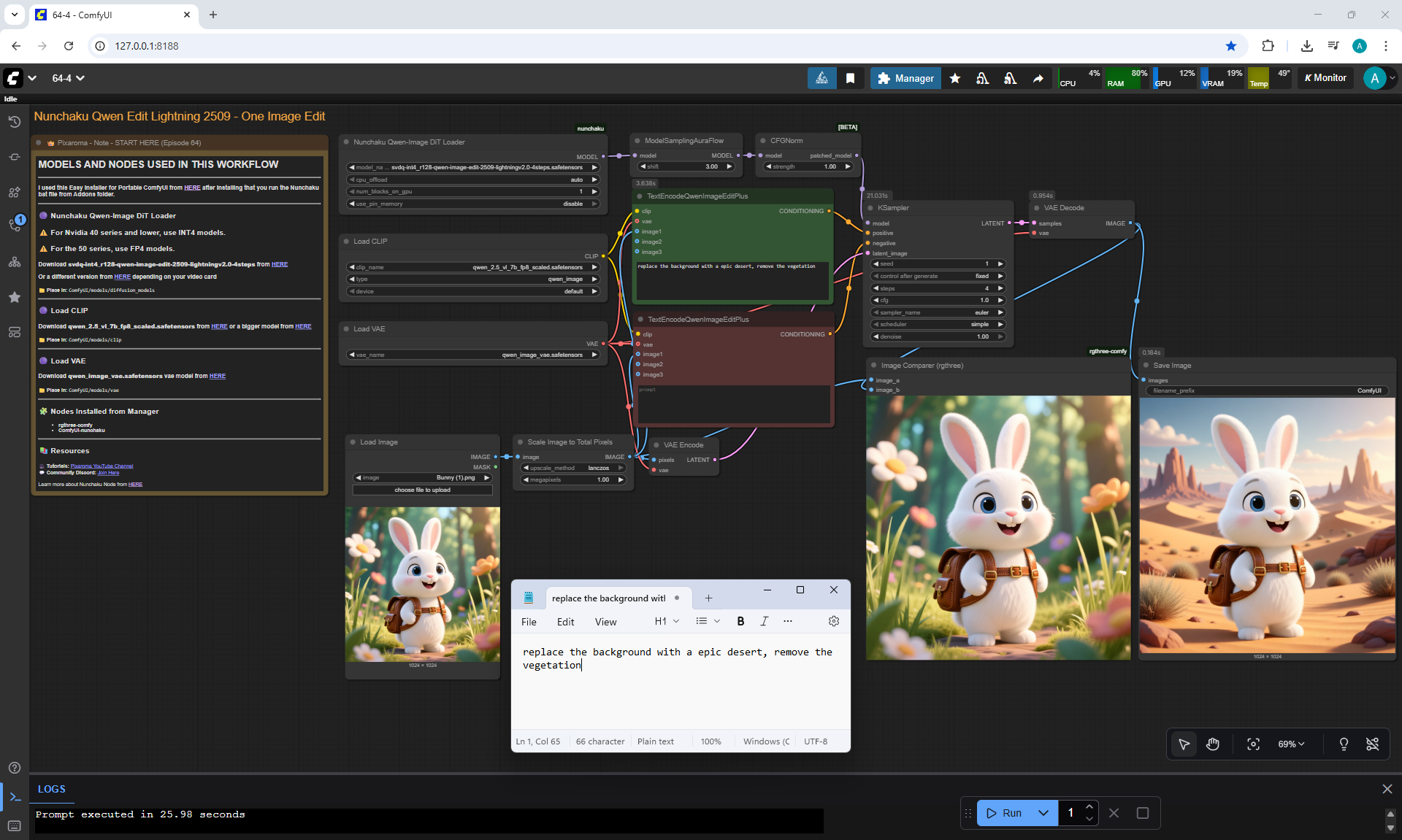
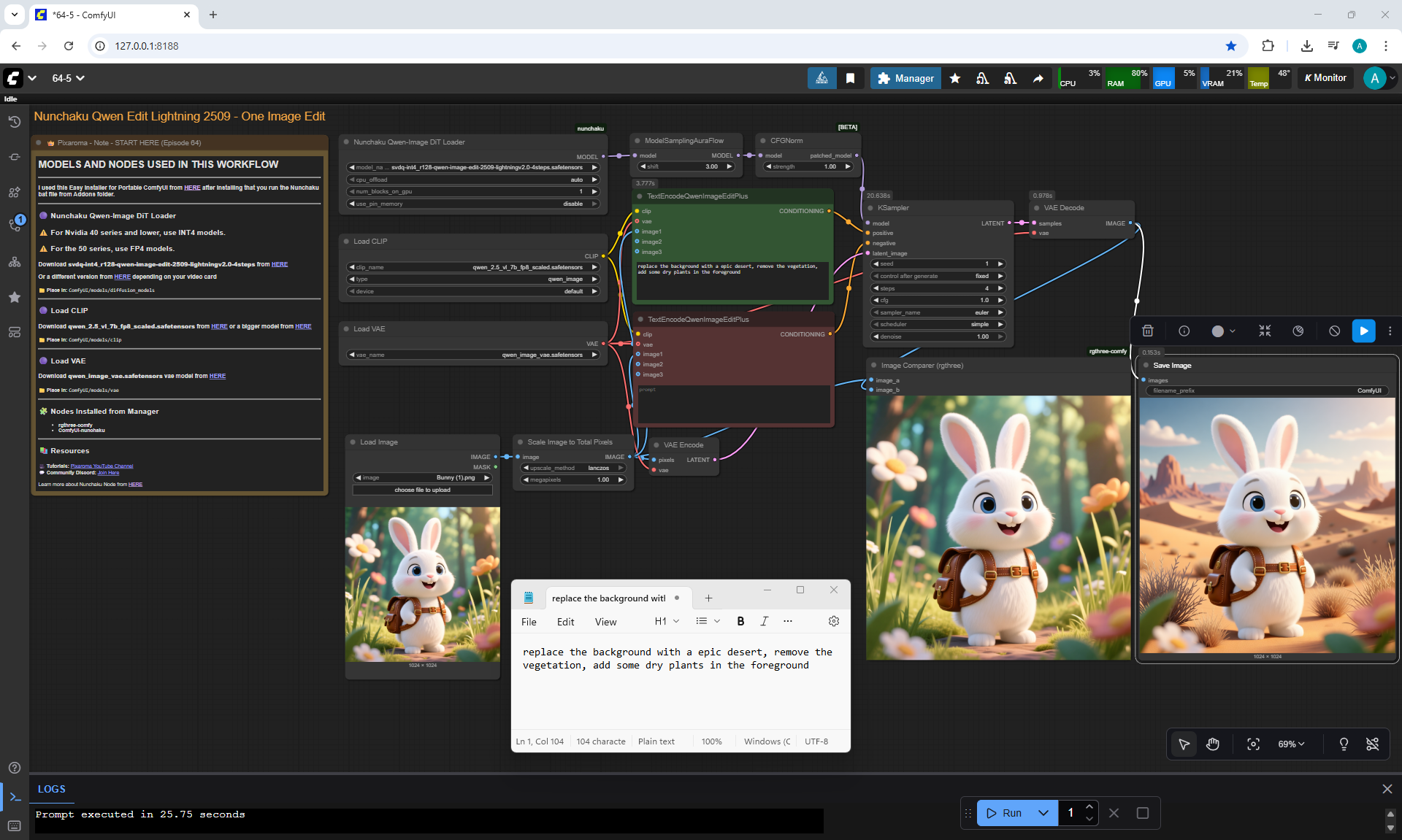
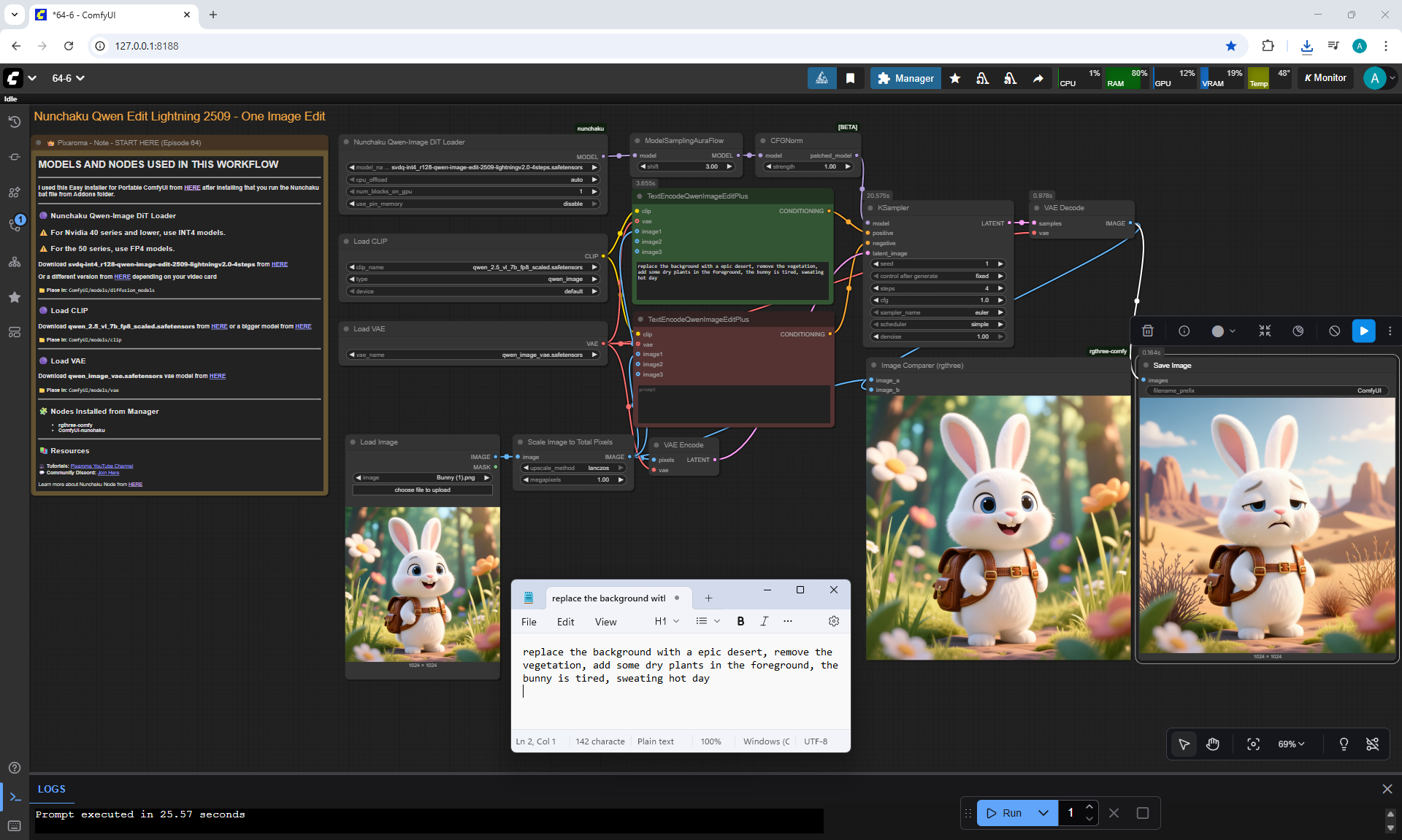
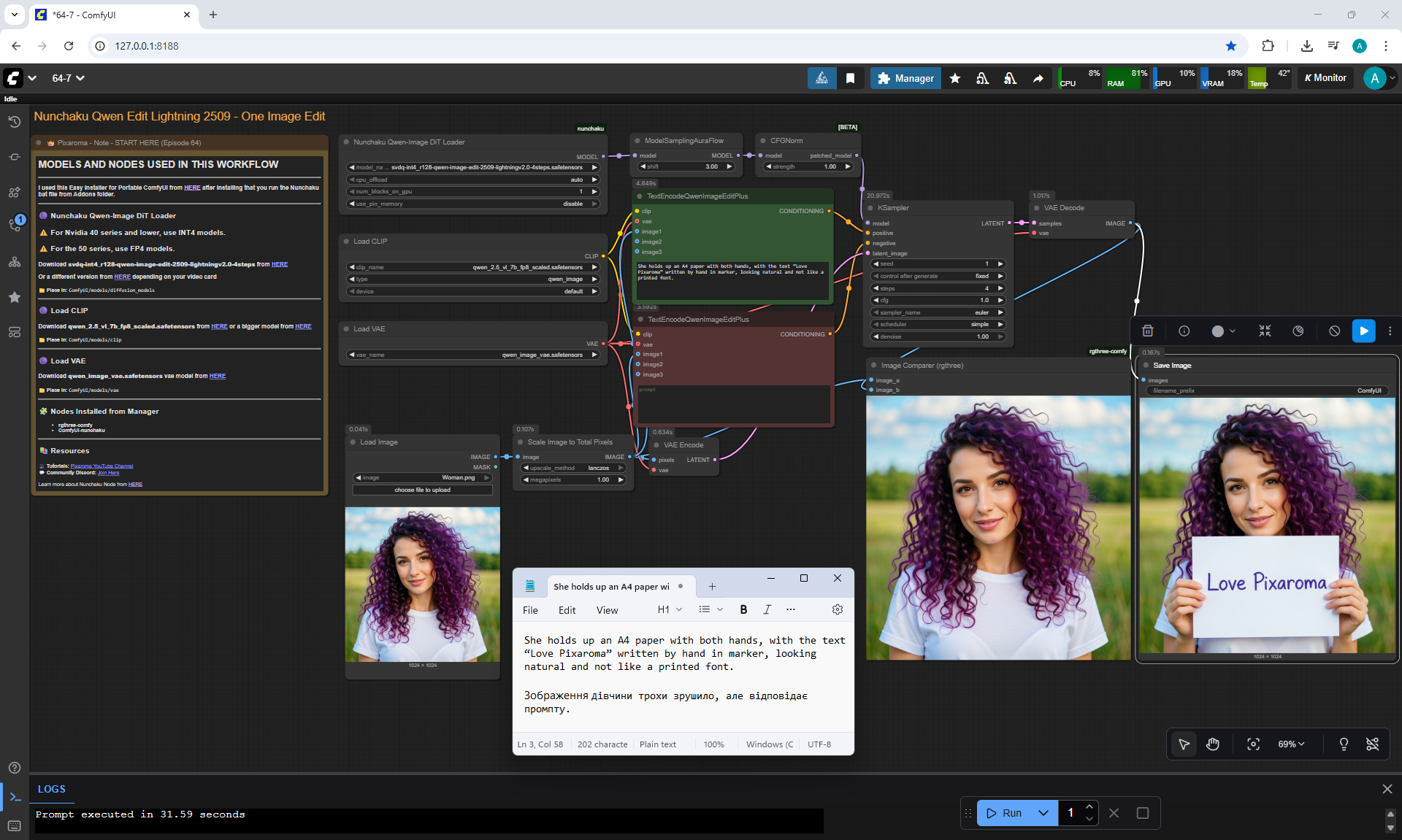
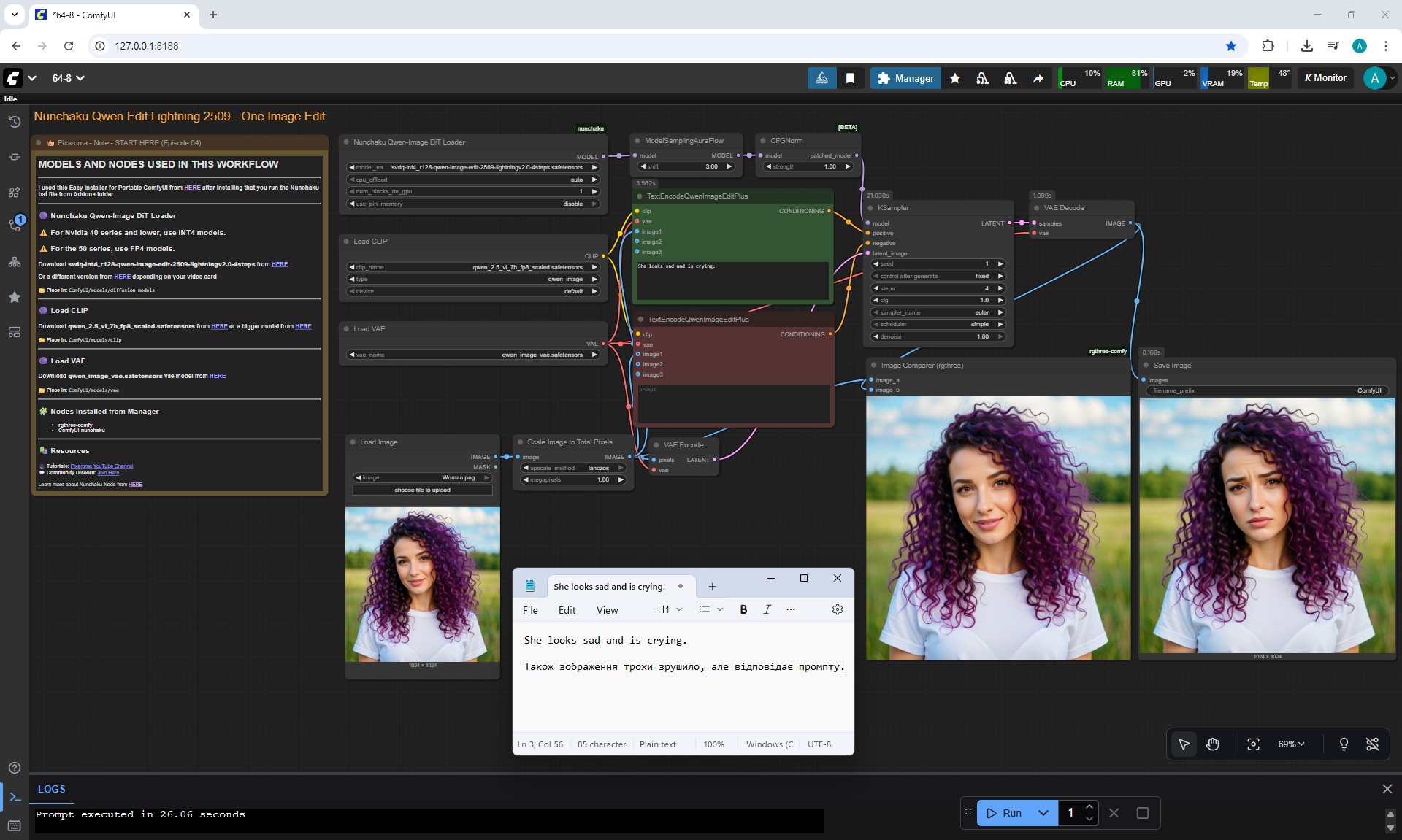
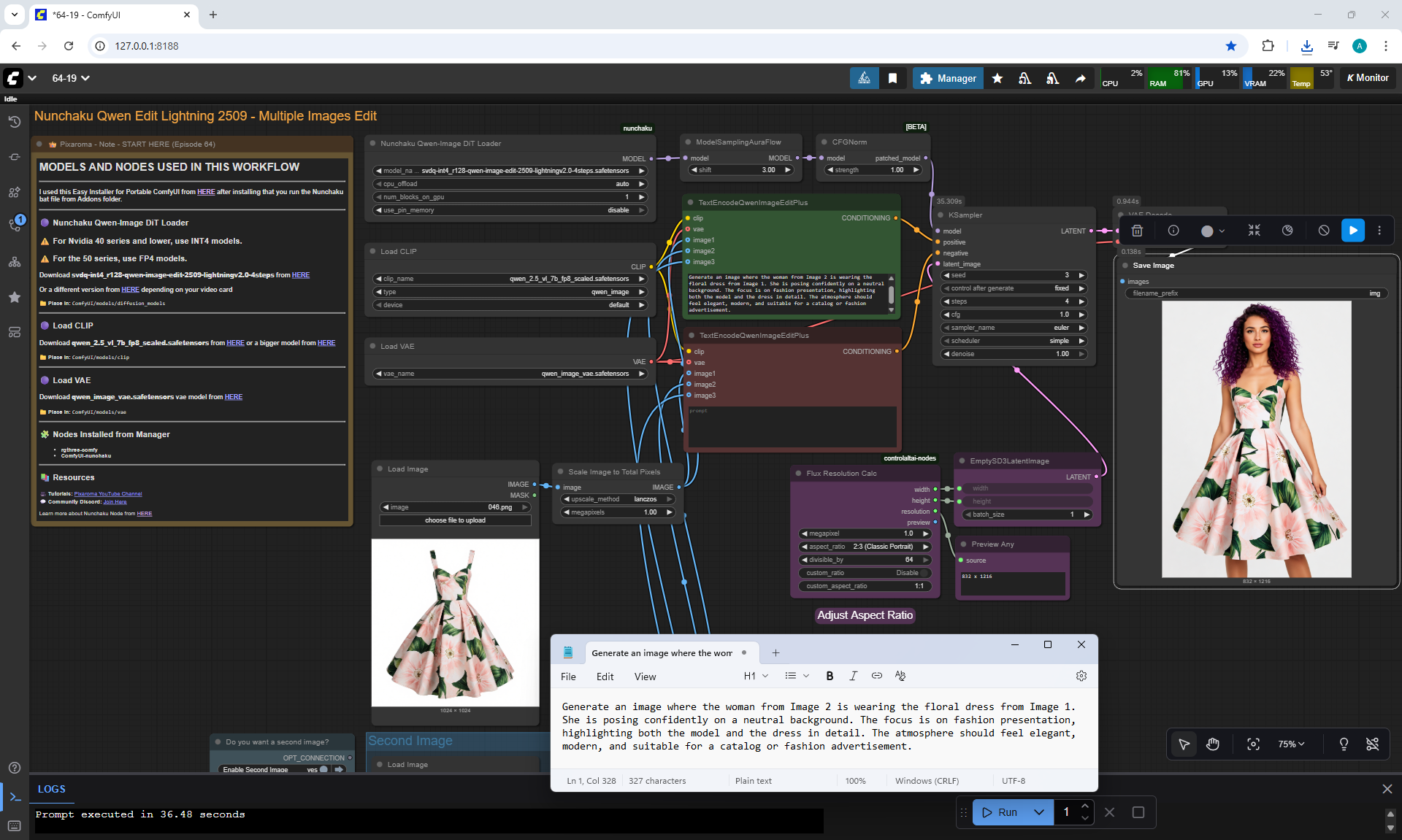
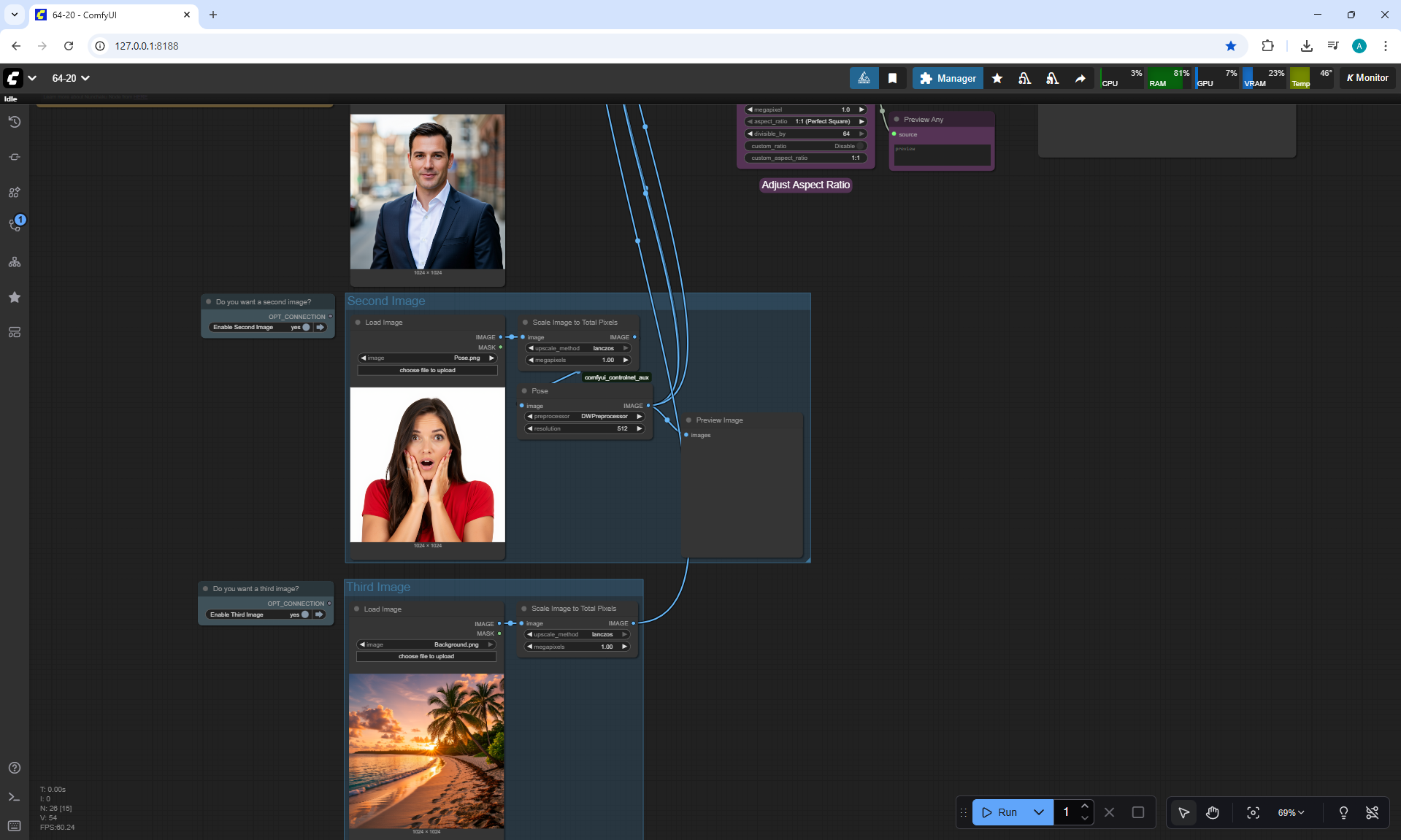
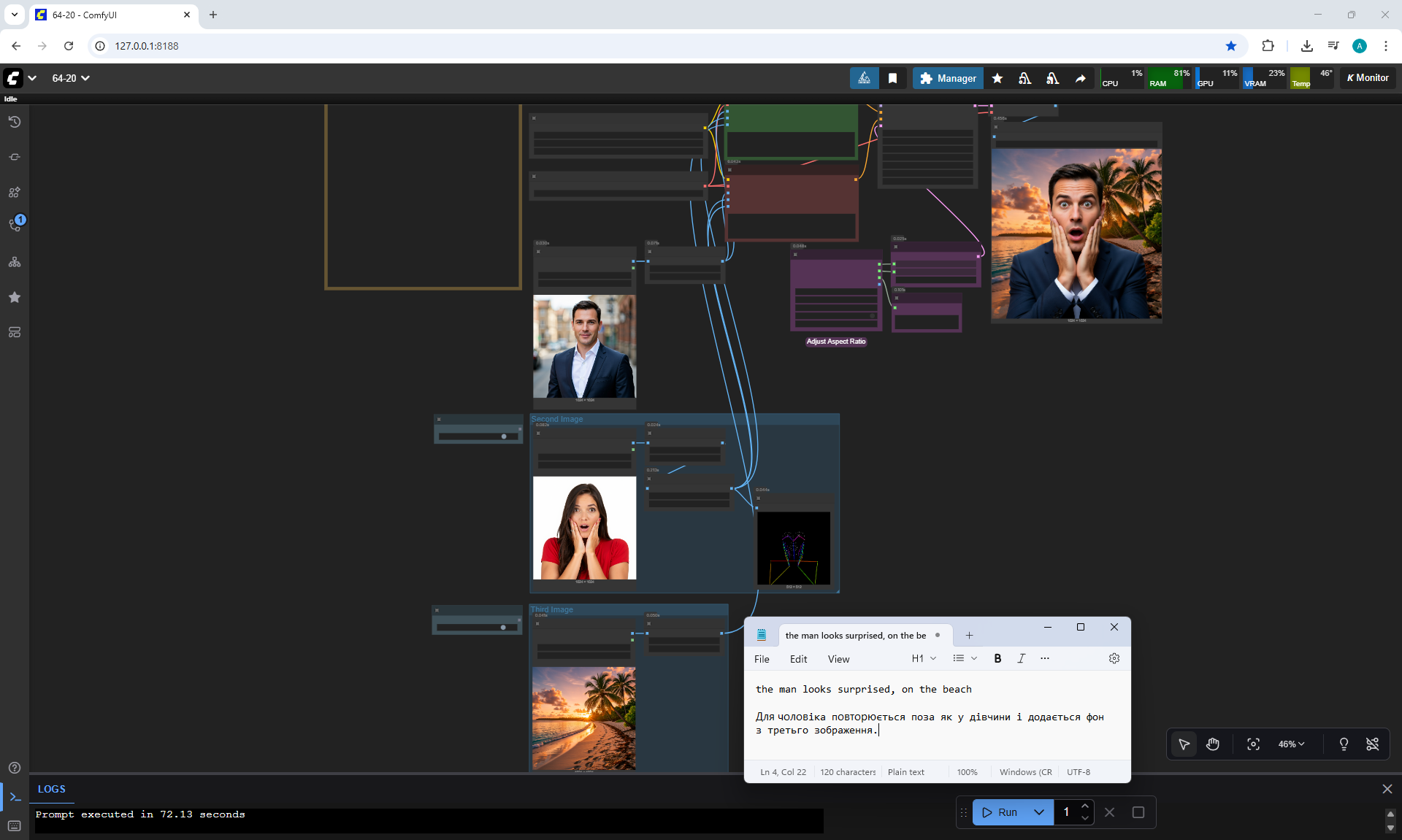
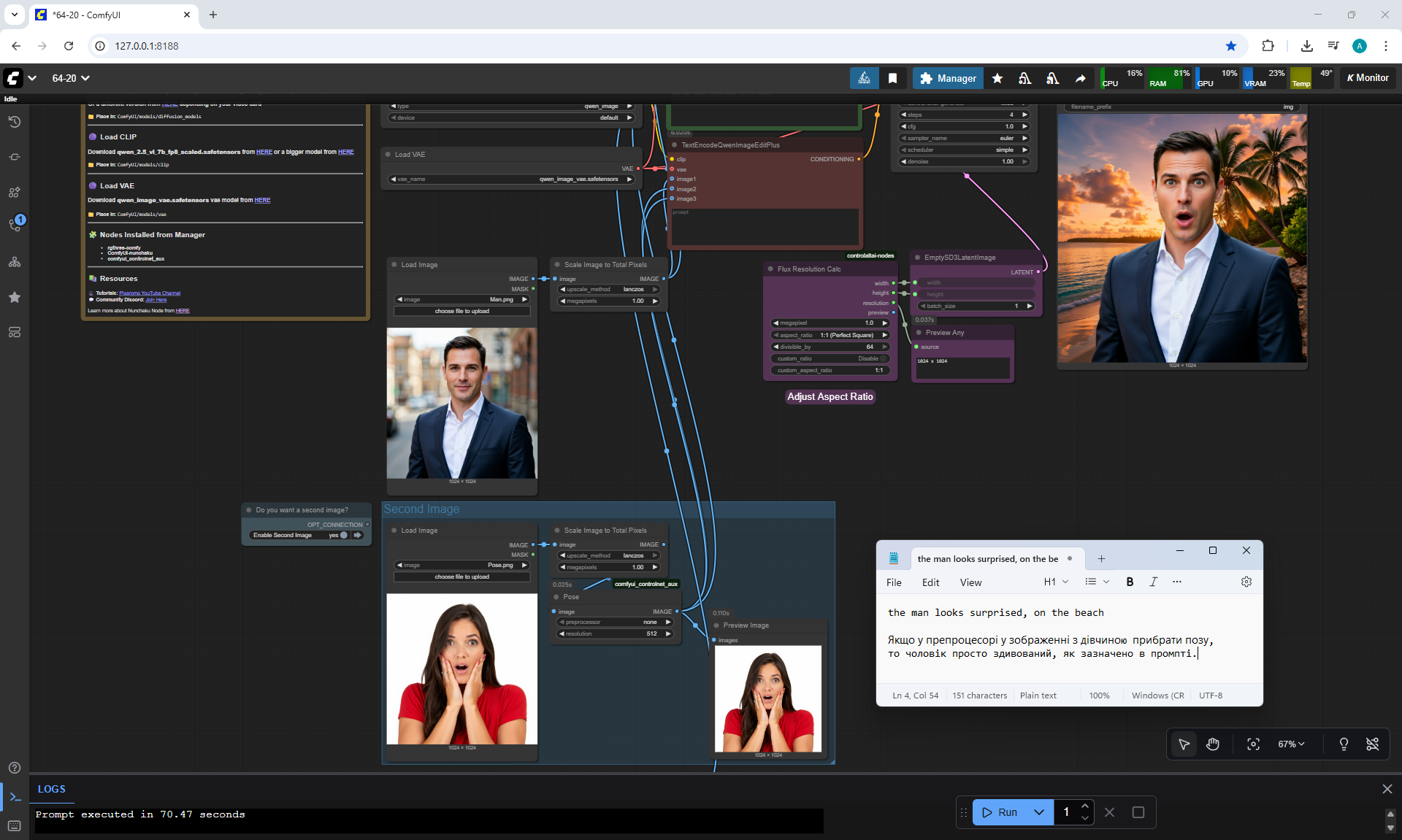
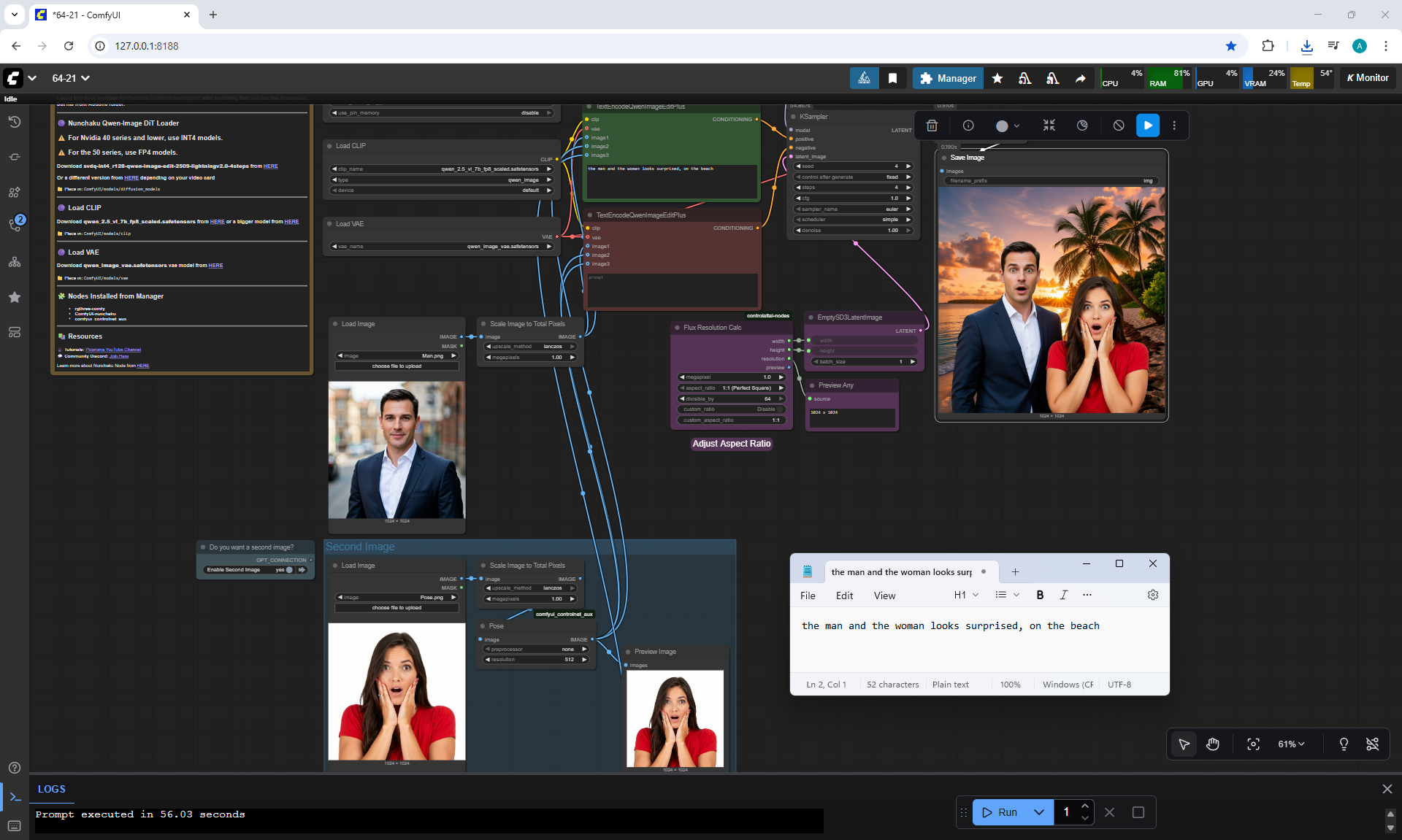
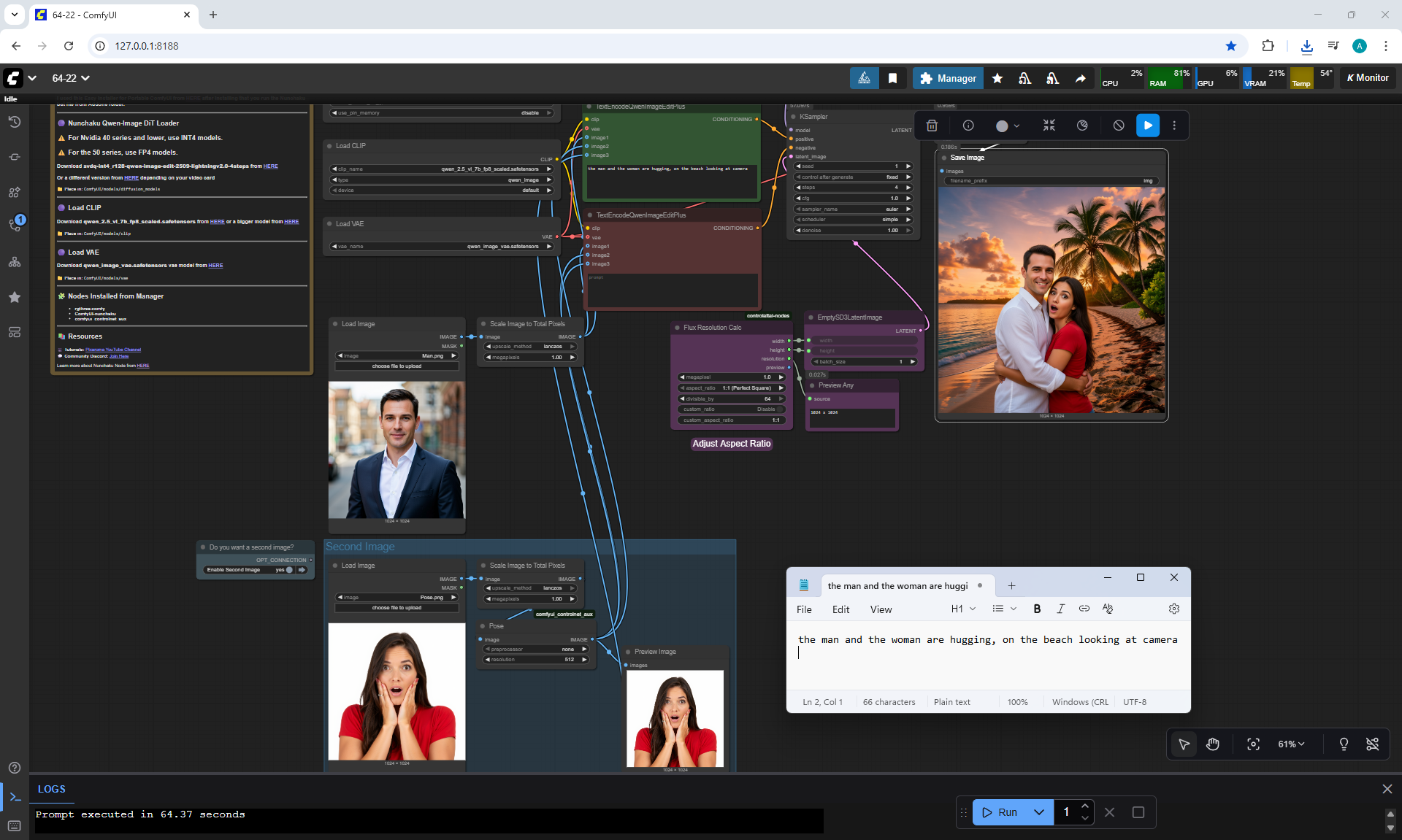
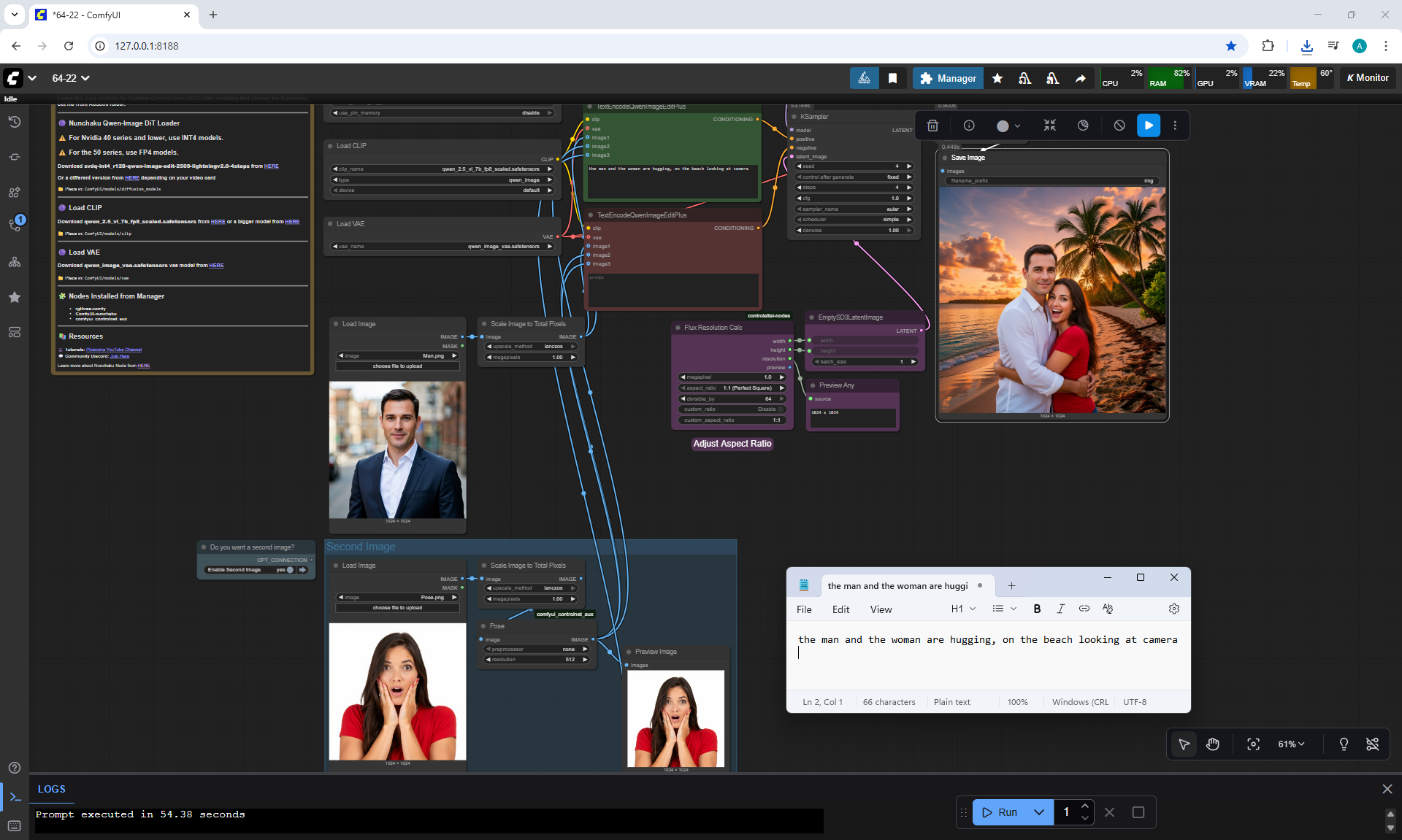
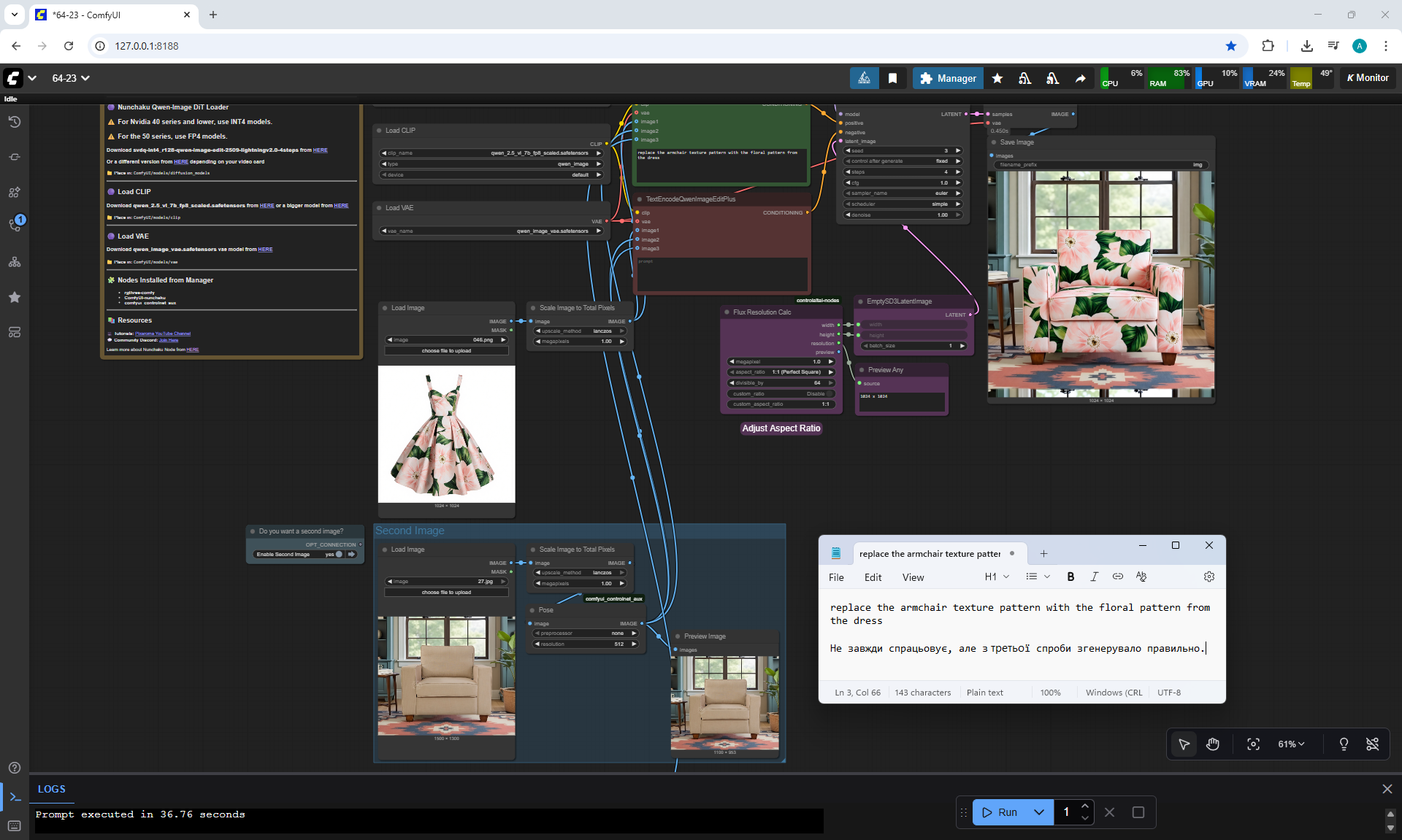
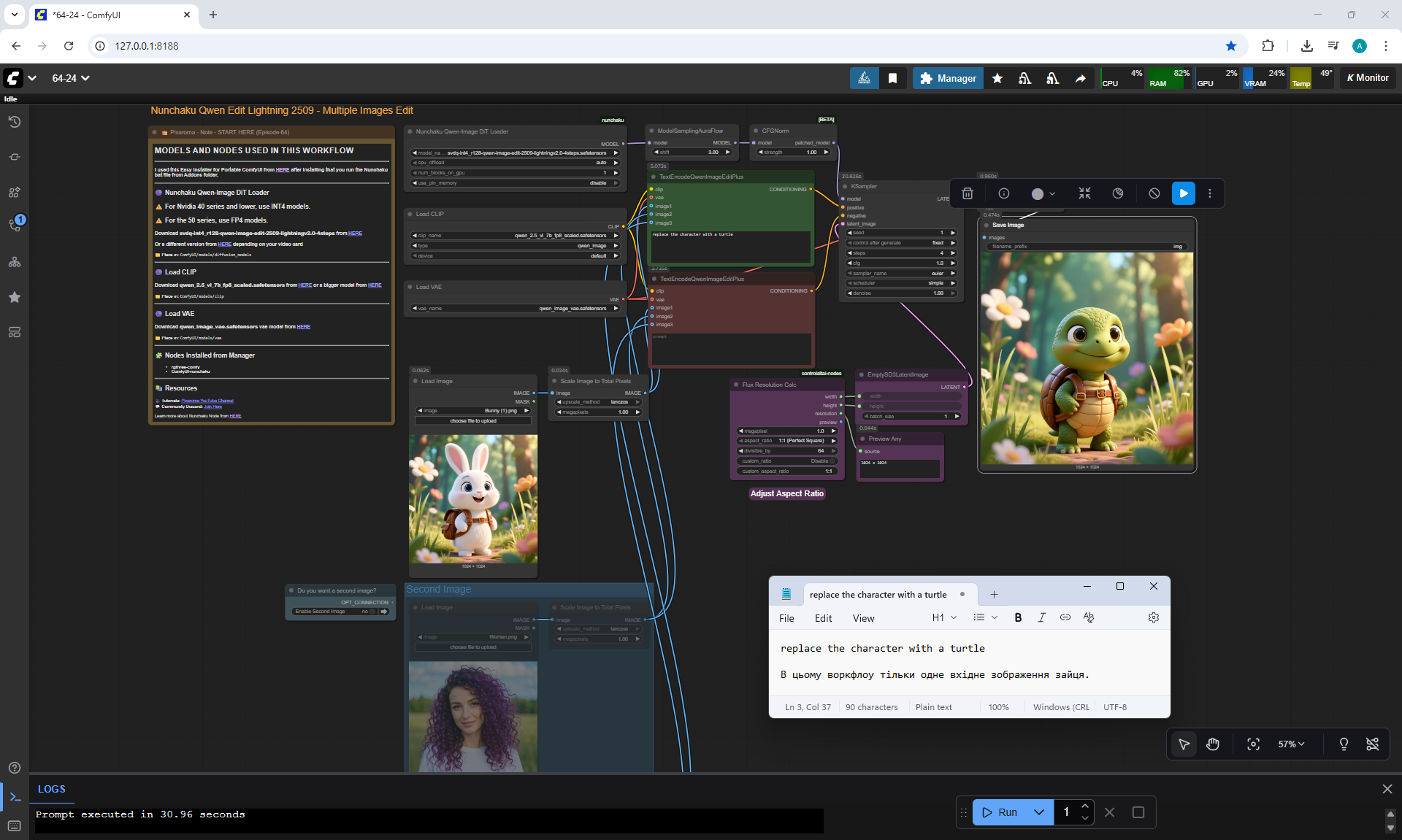
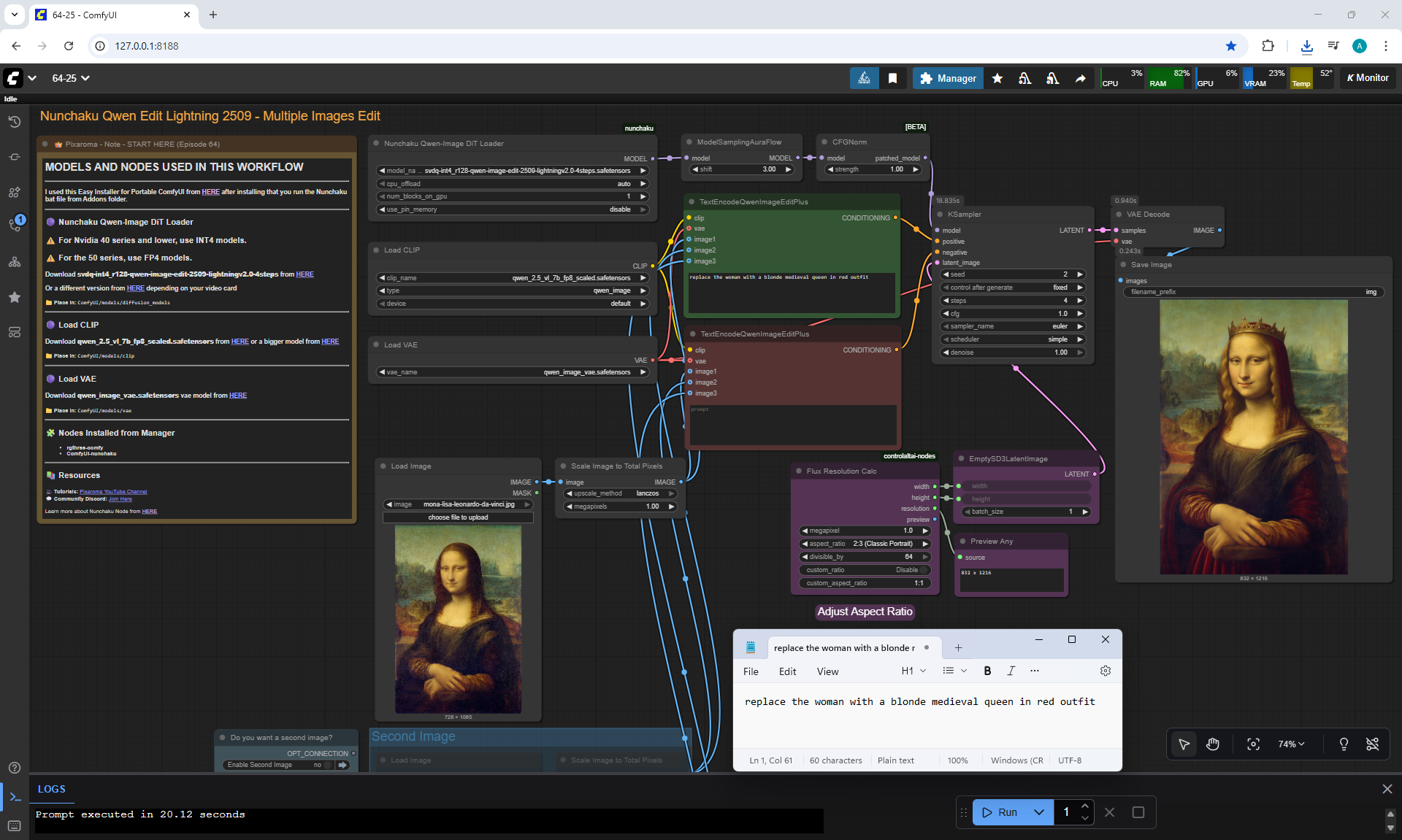
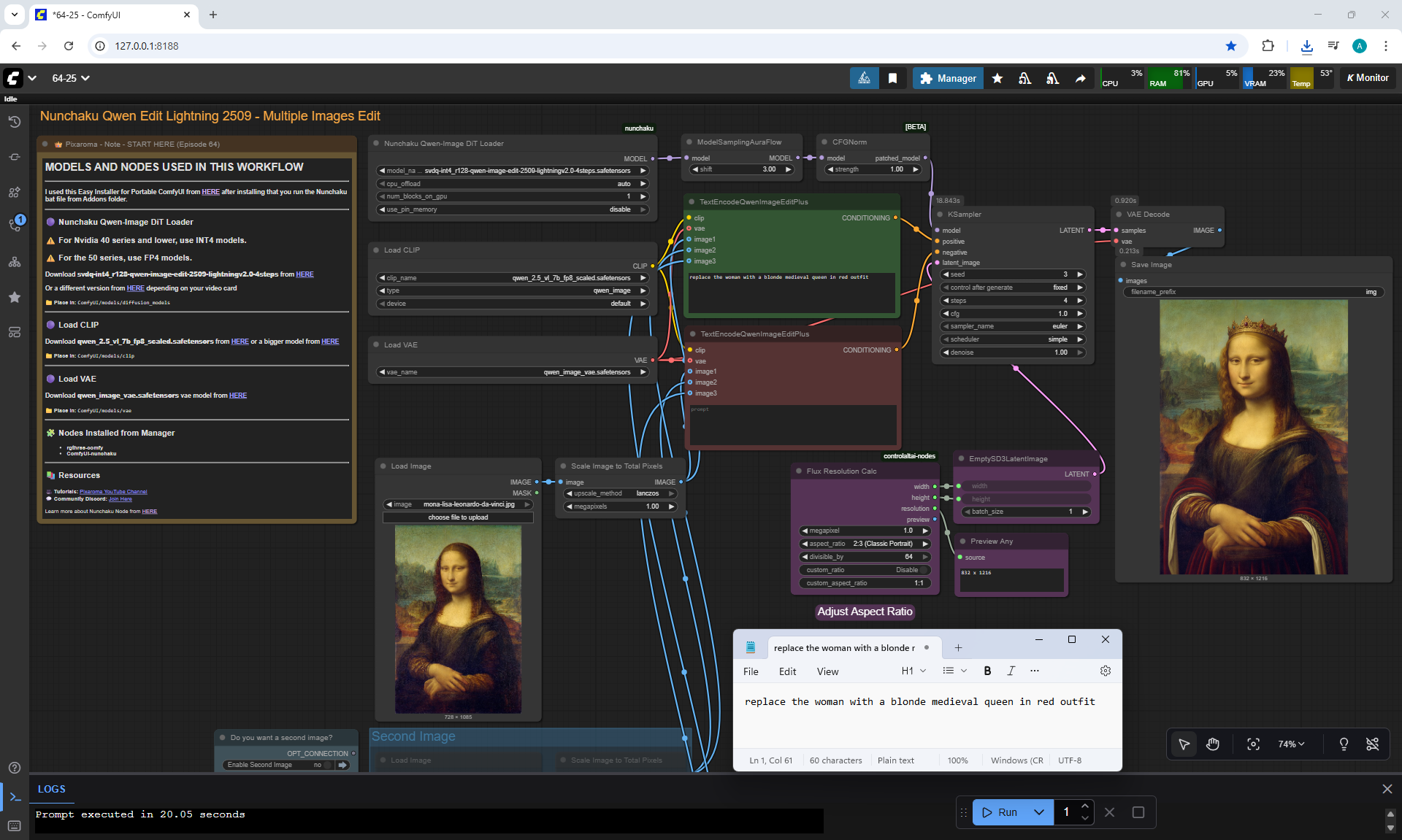
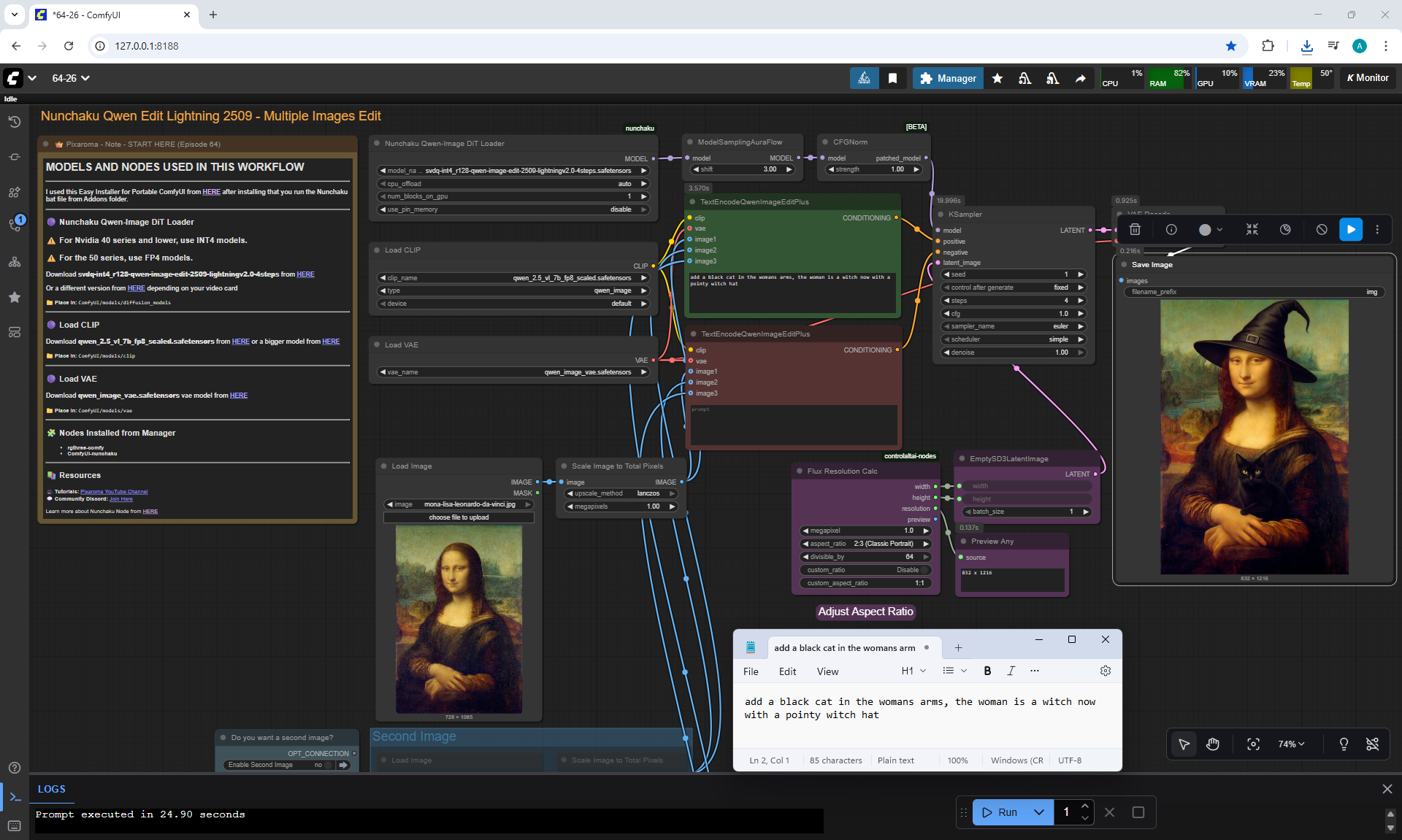
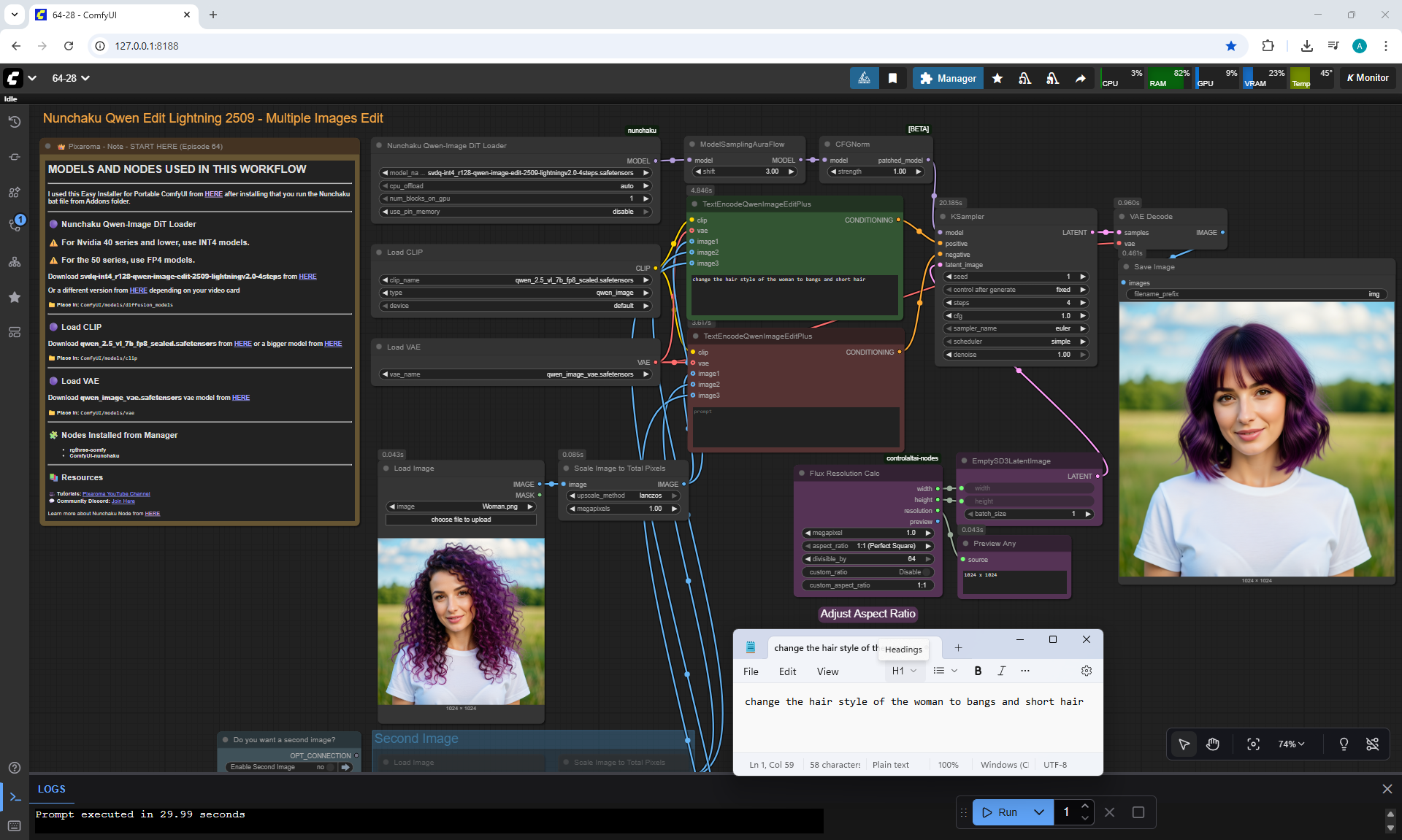
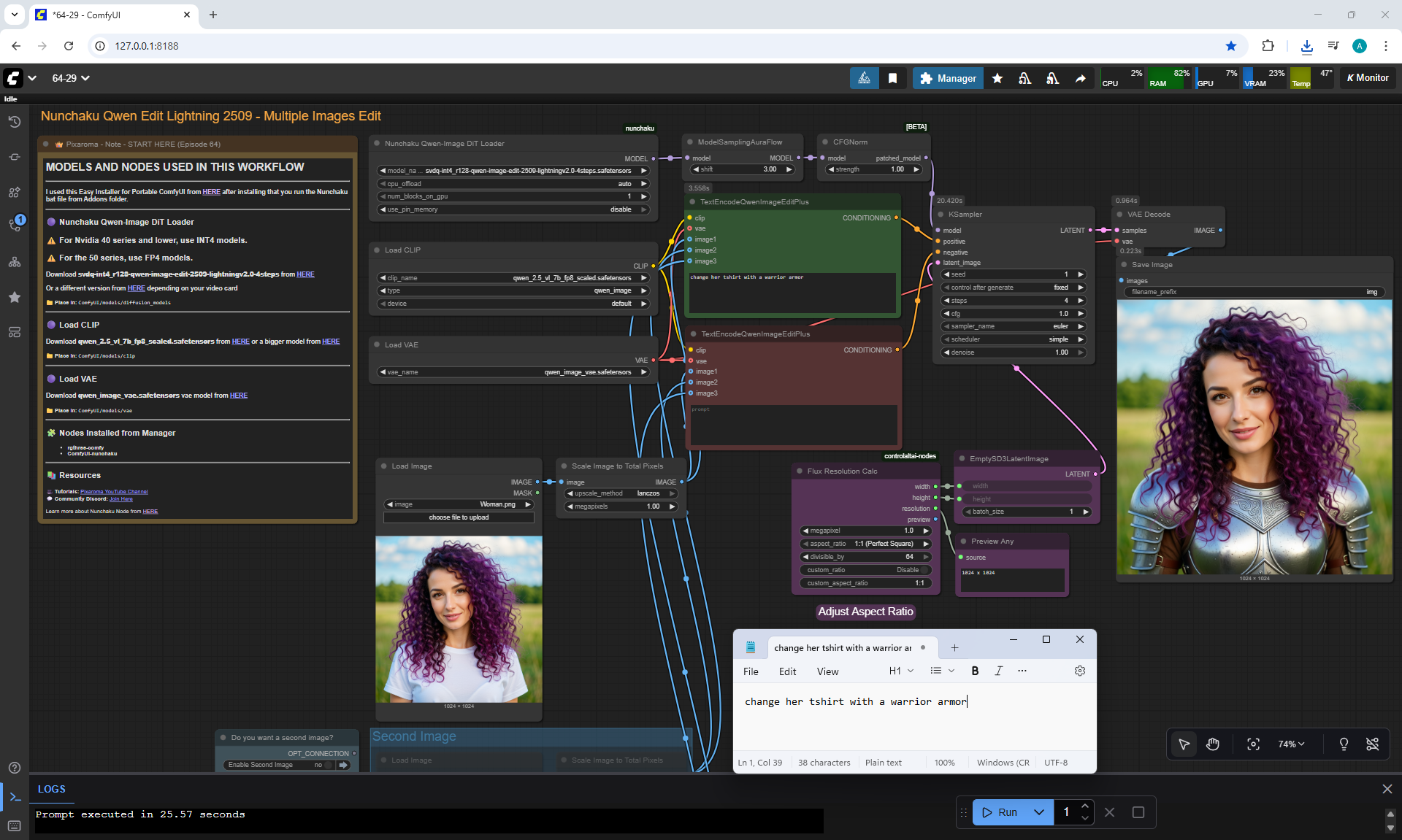
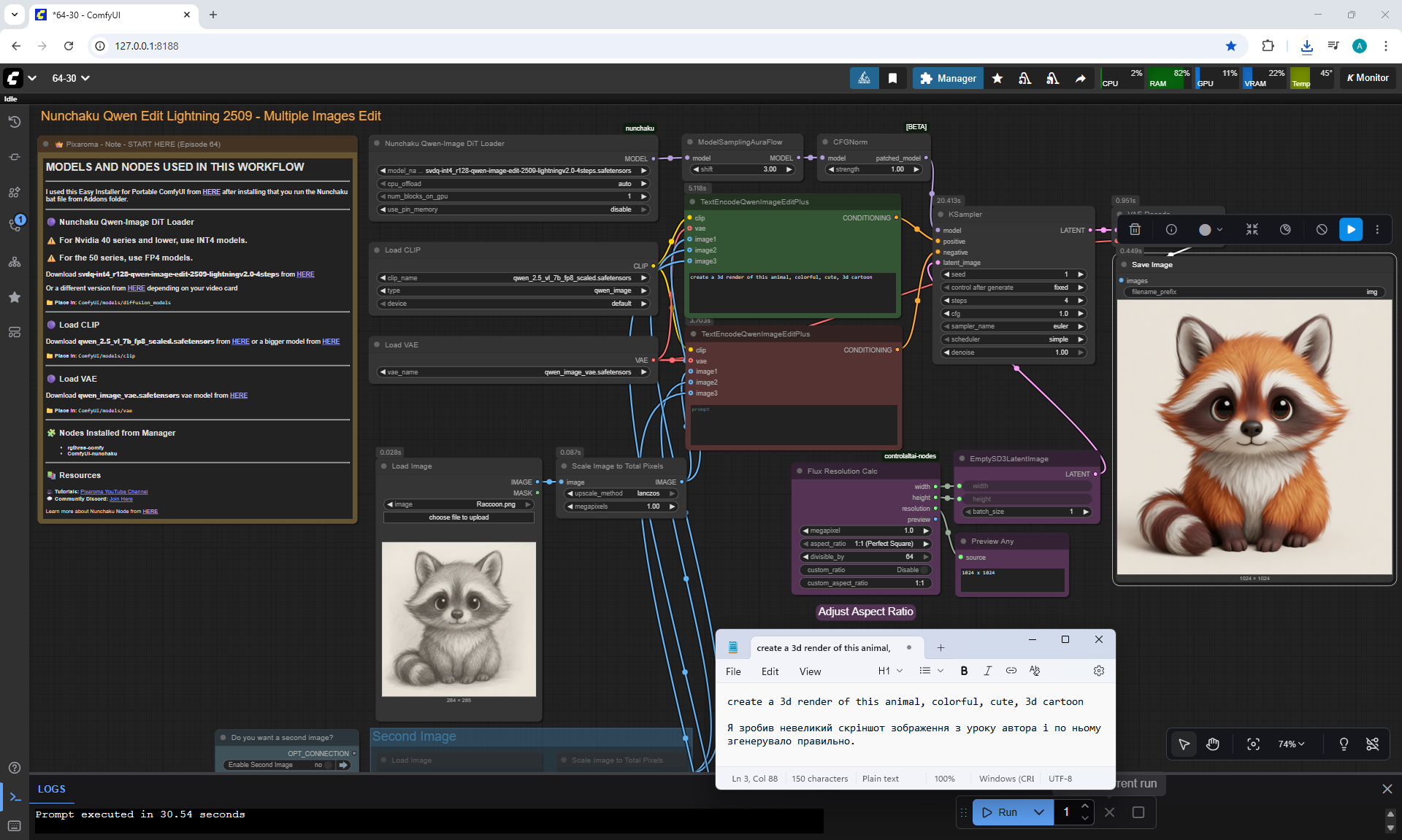
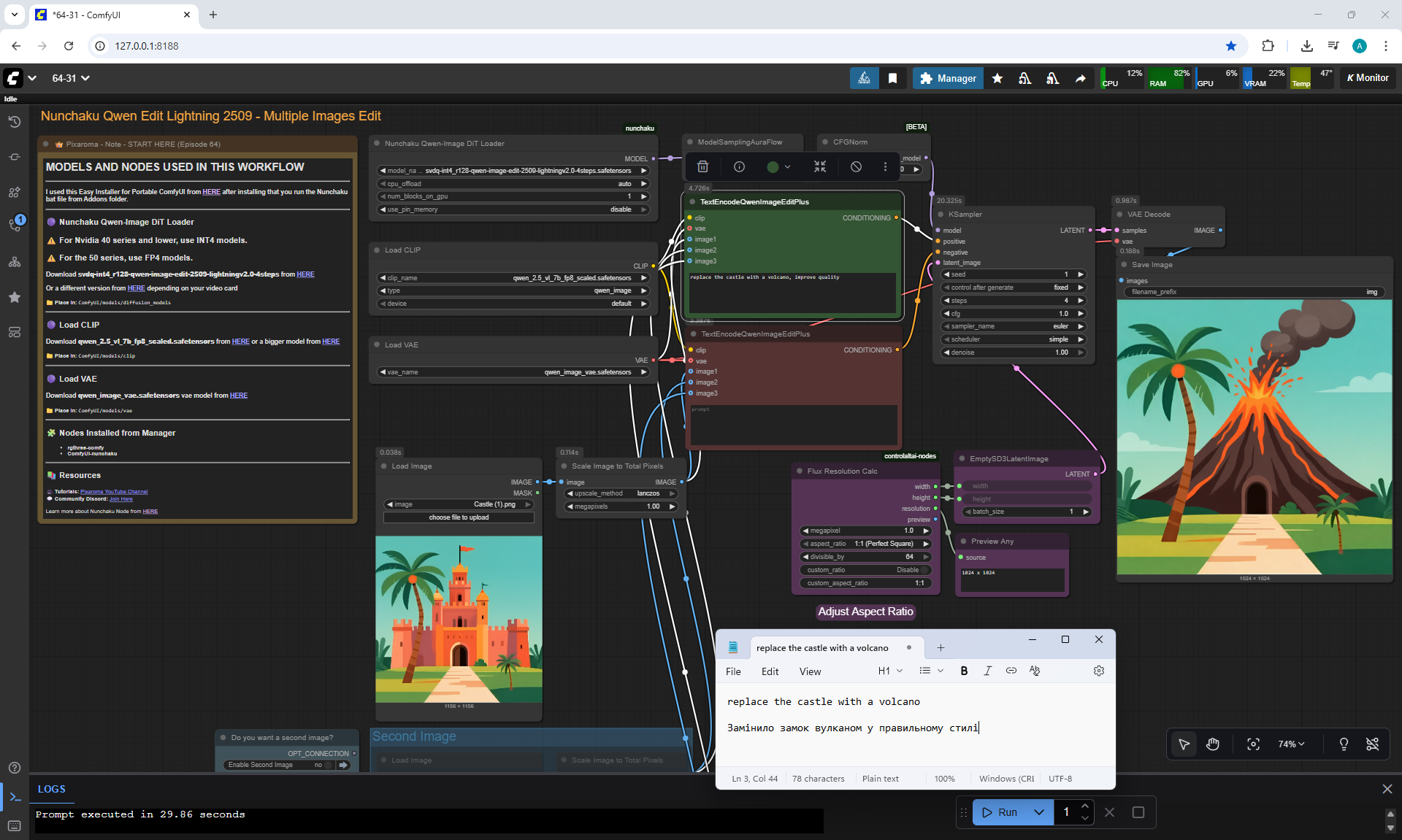
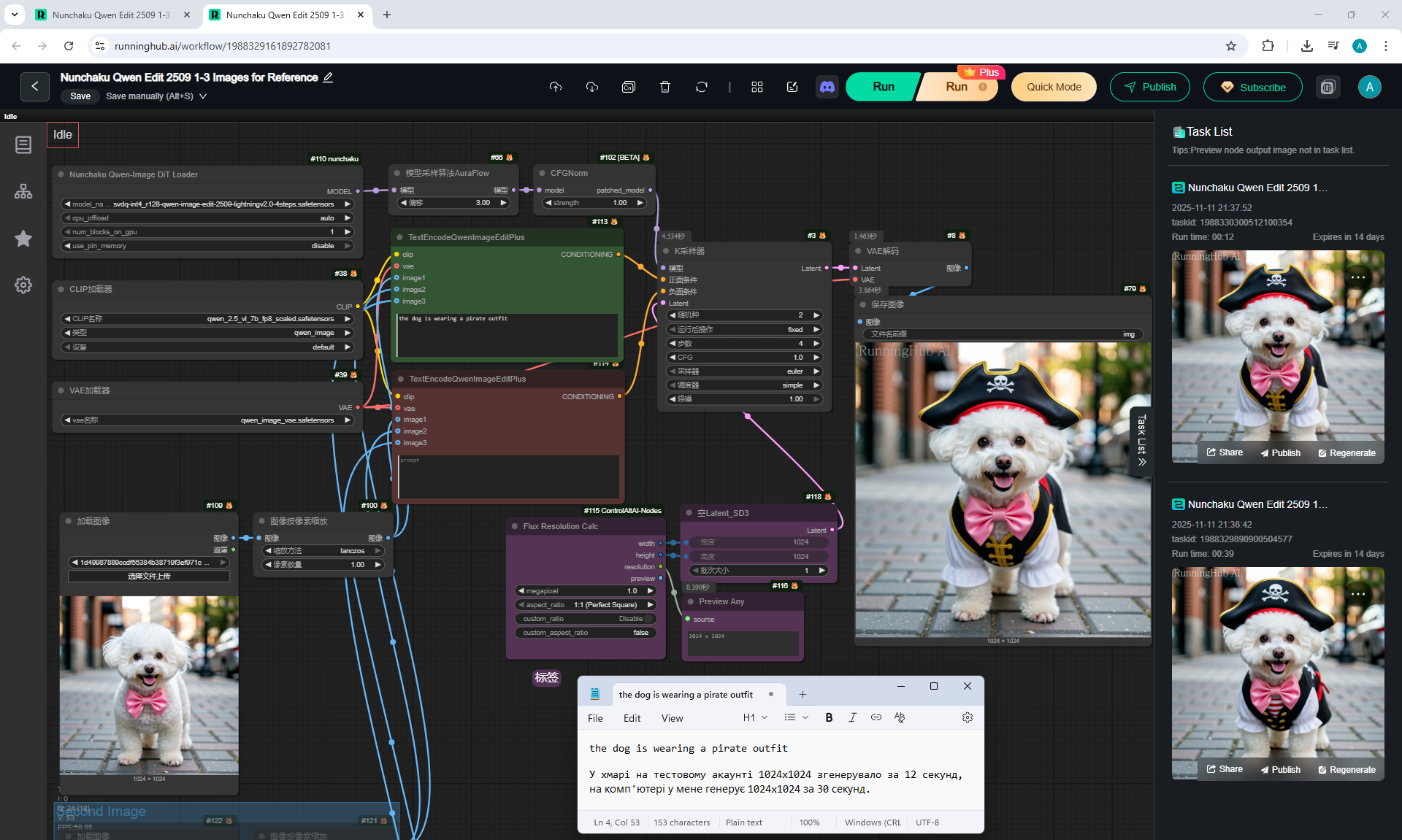
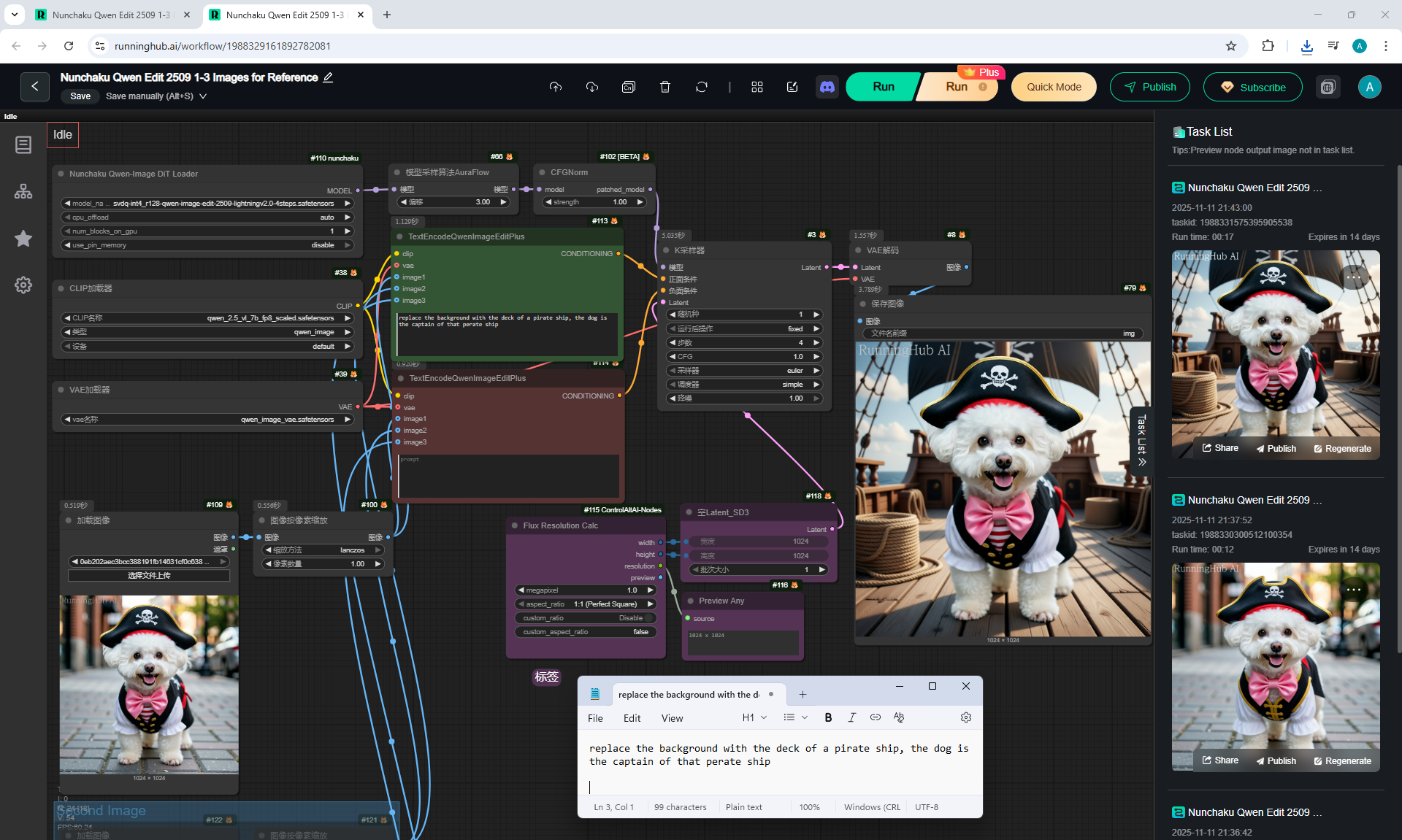
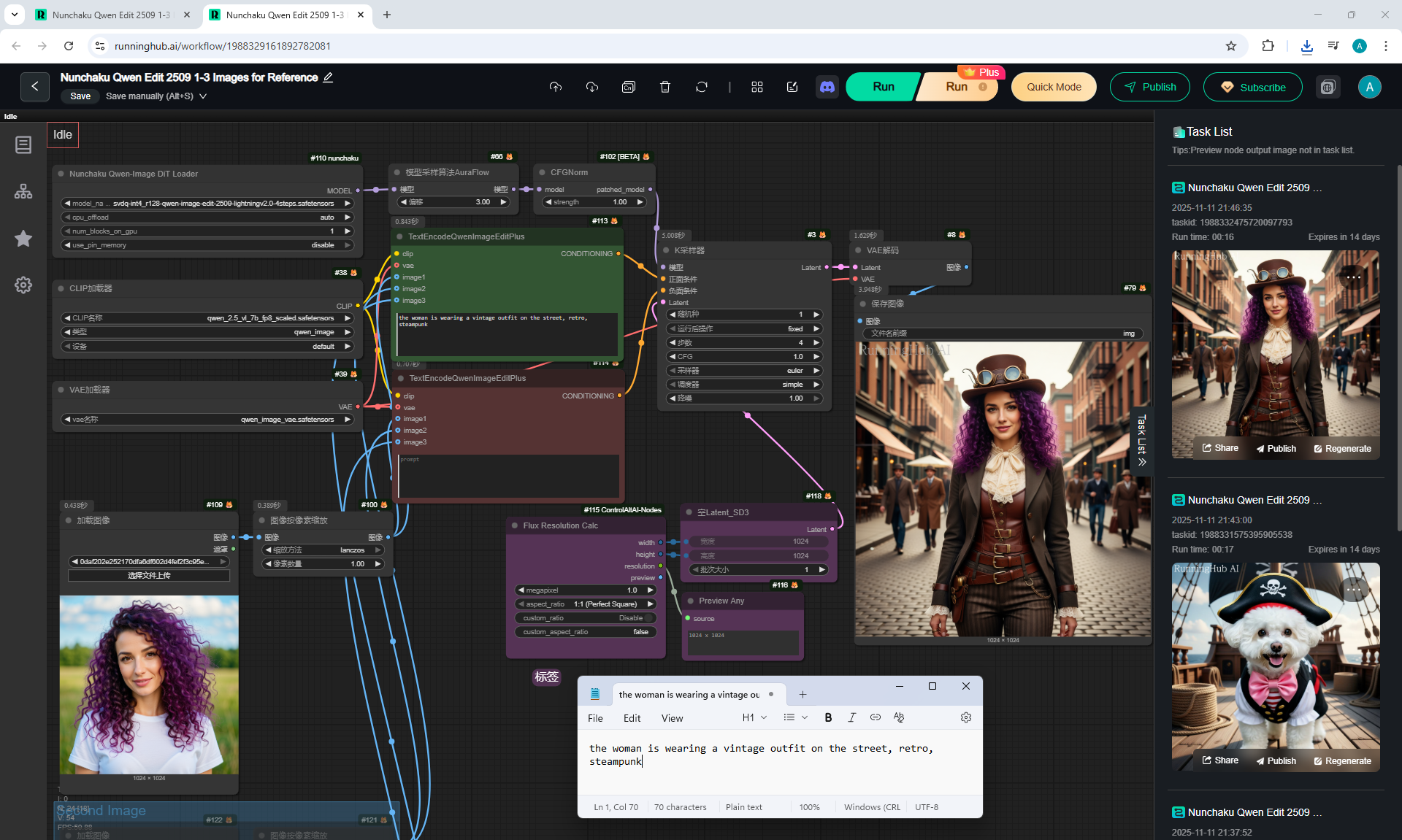
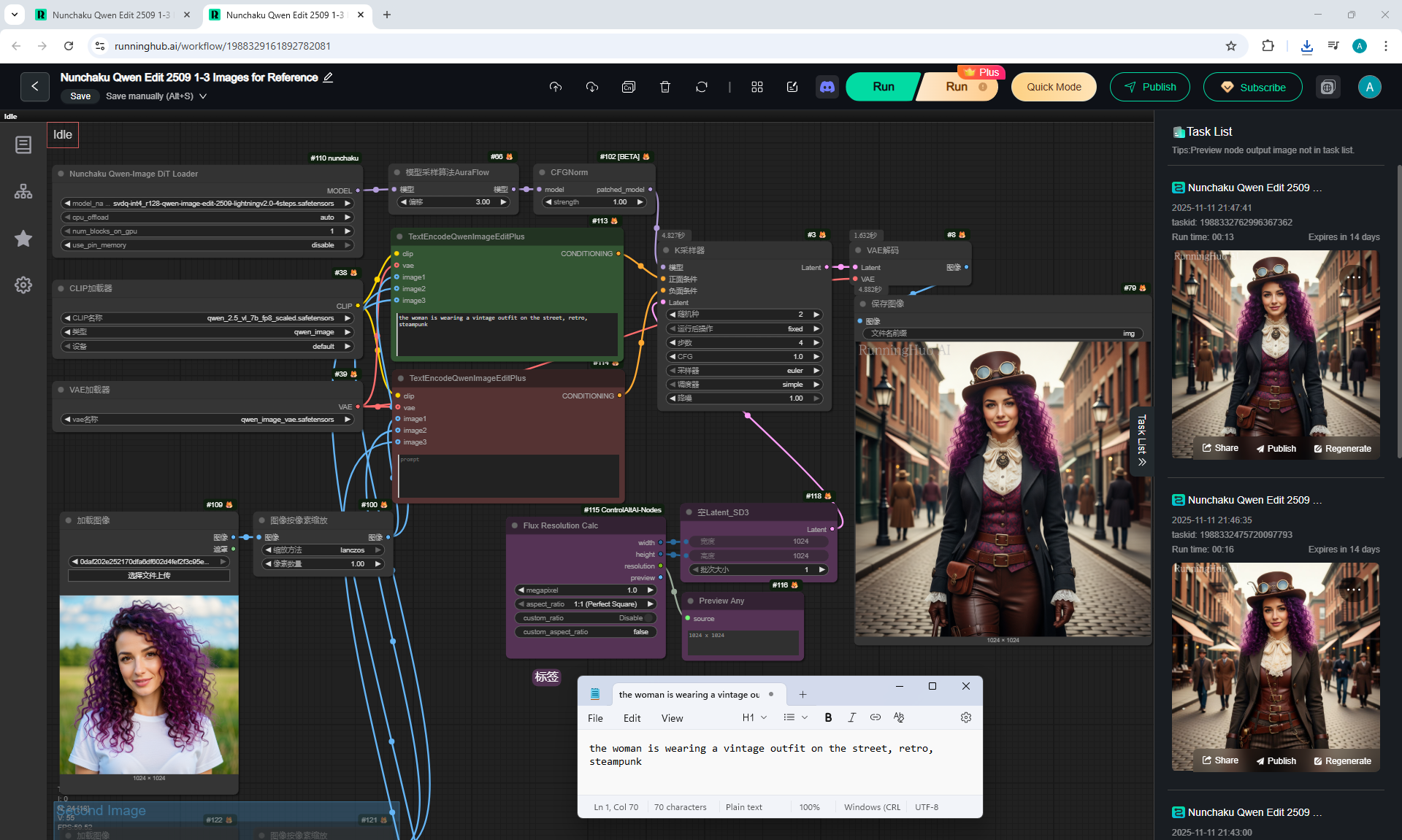
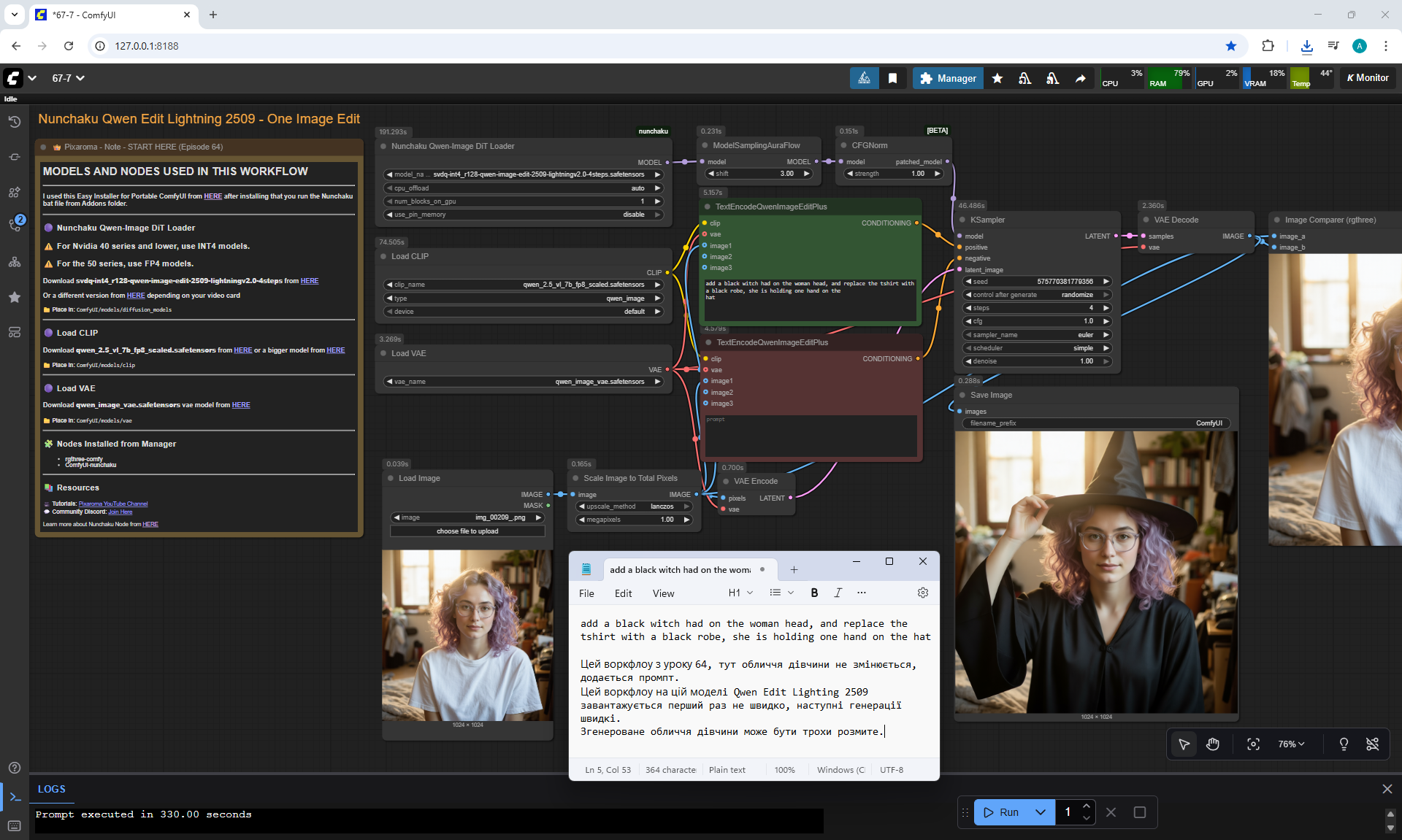
ComfyUI Tutorial Series Ep 64 Nunchaku Qwen Image Edit 2509














































































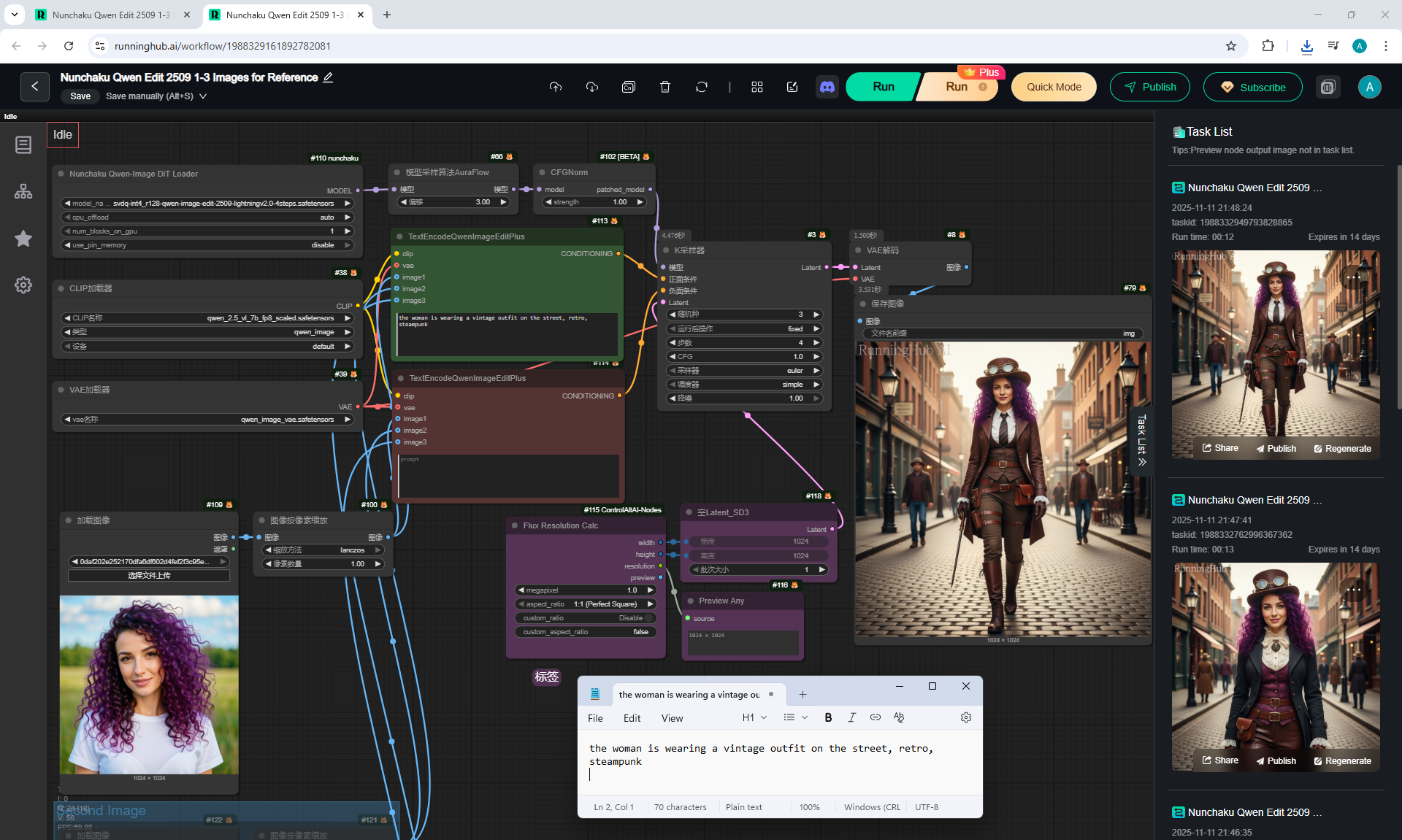
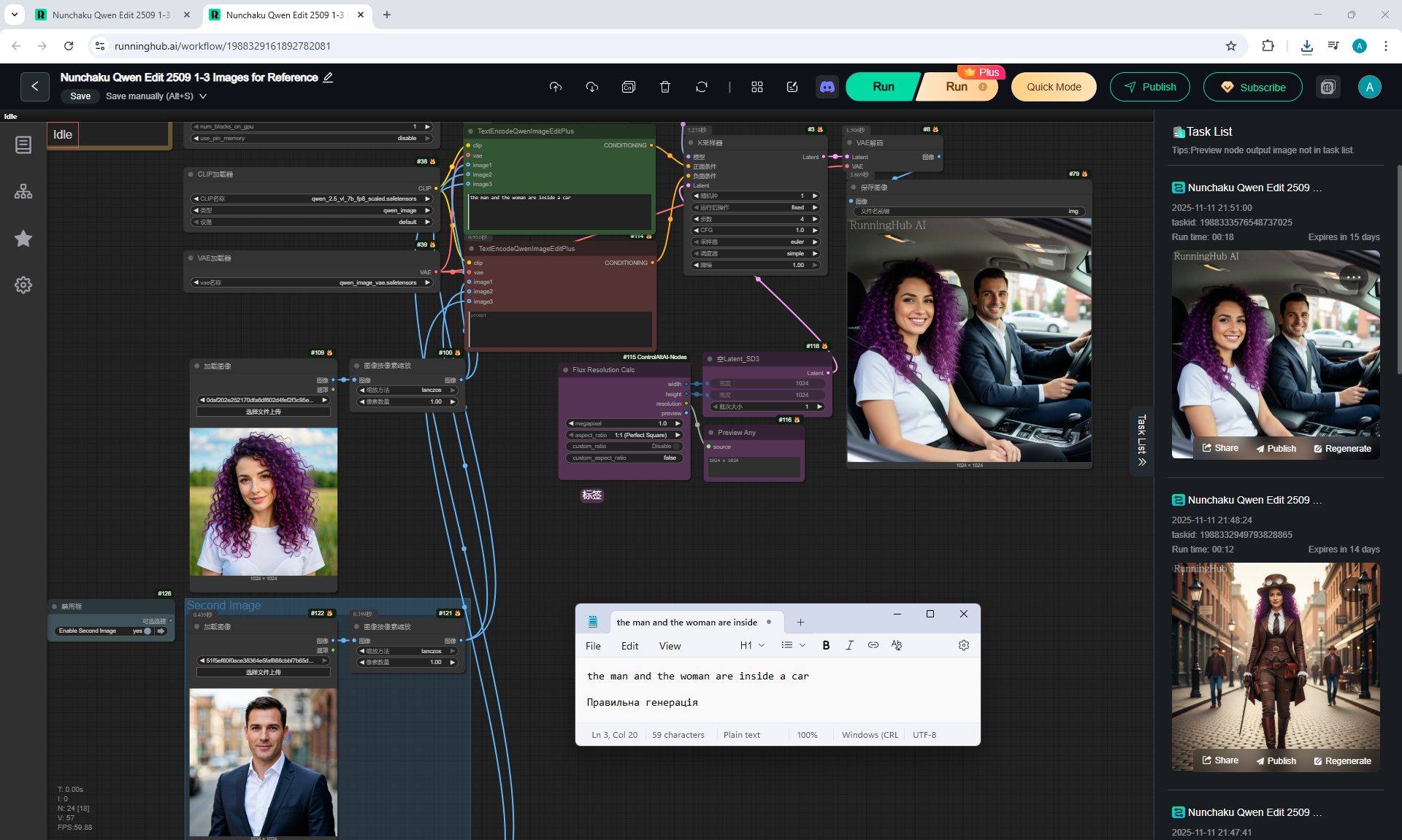
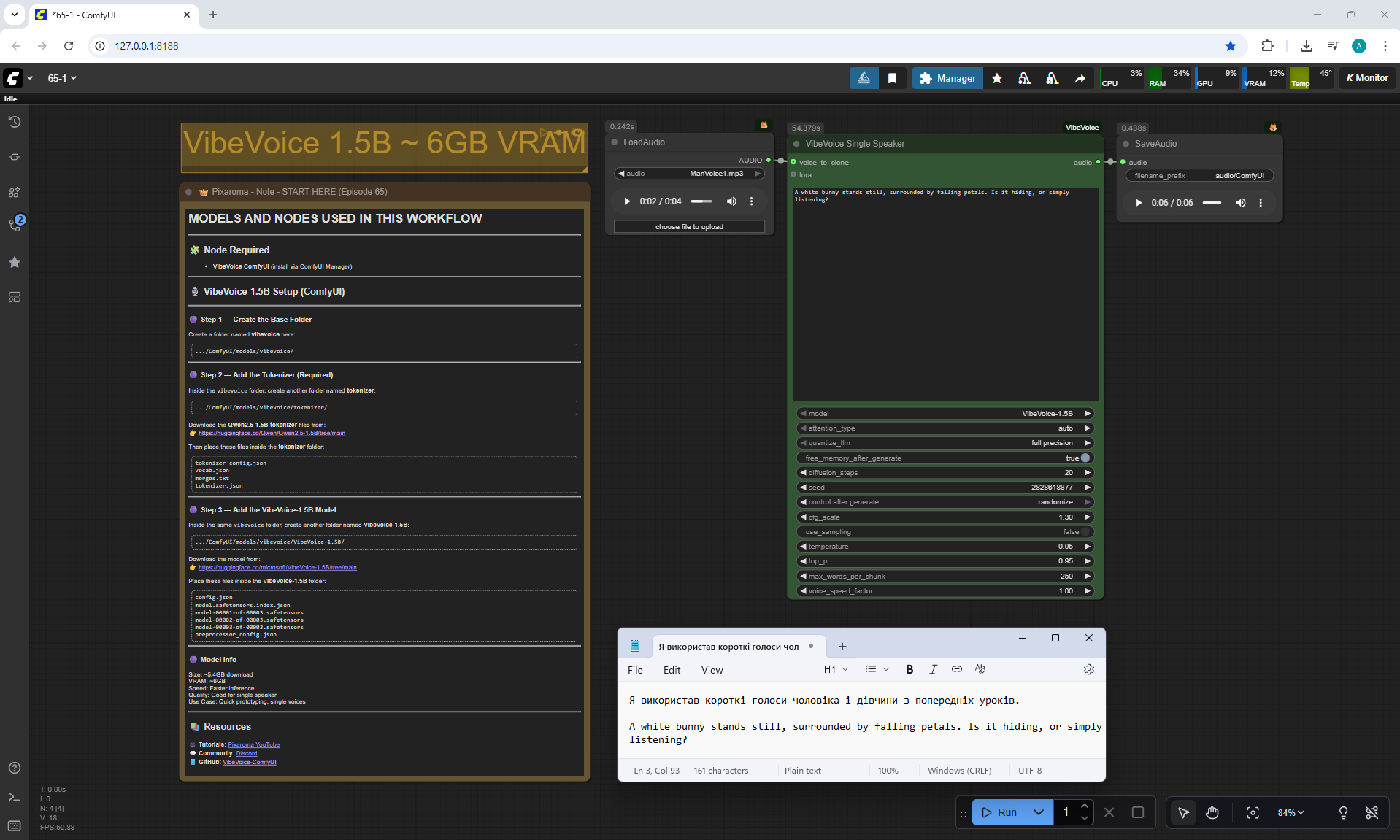
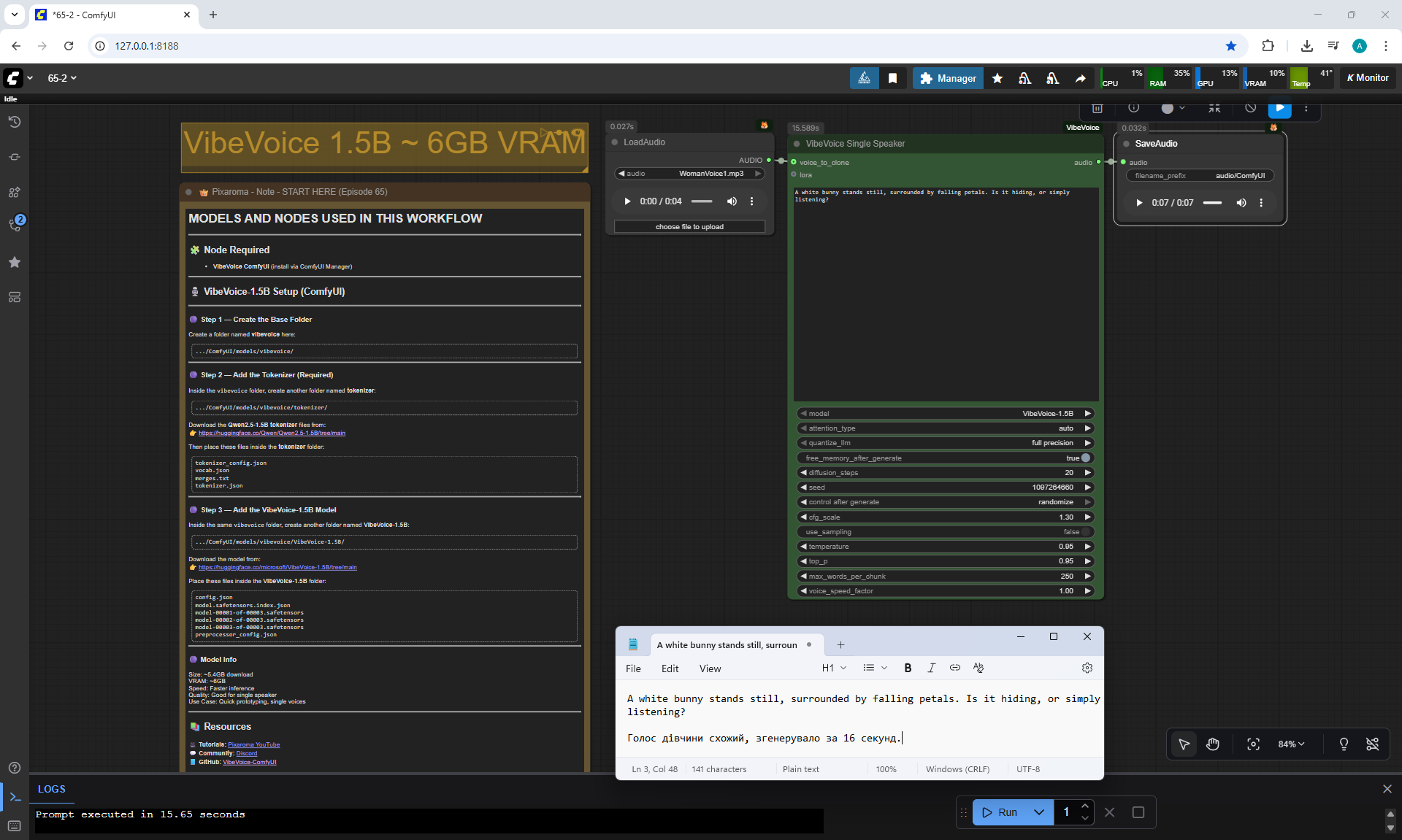
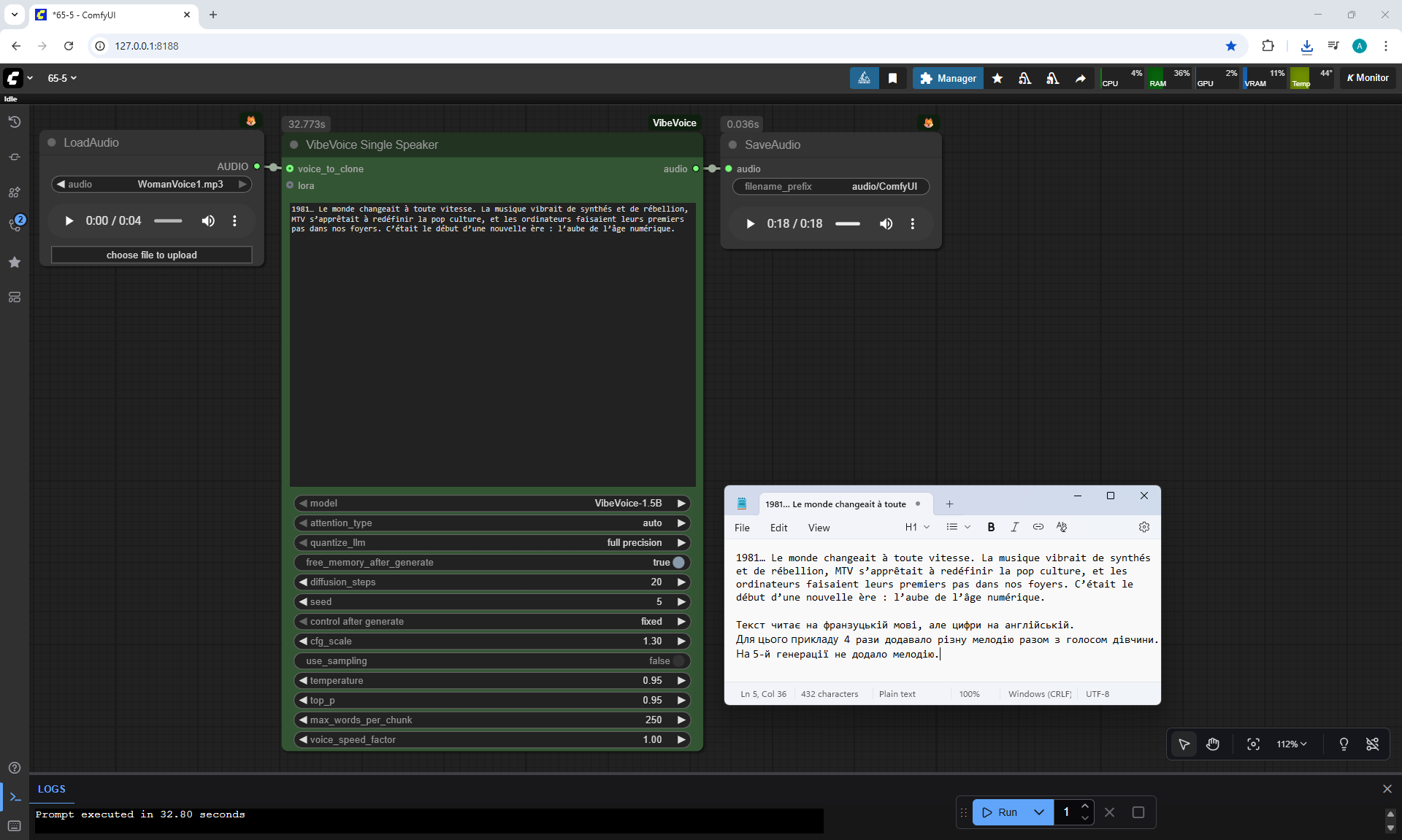
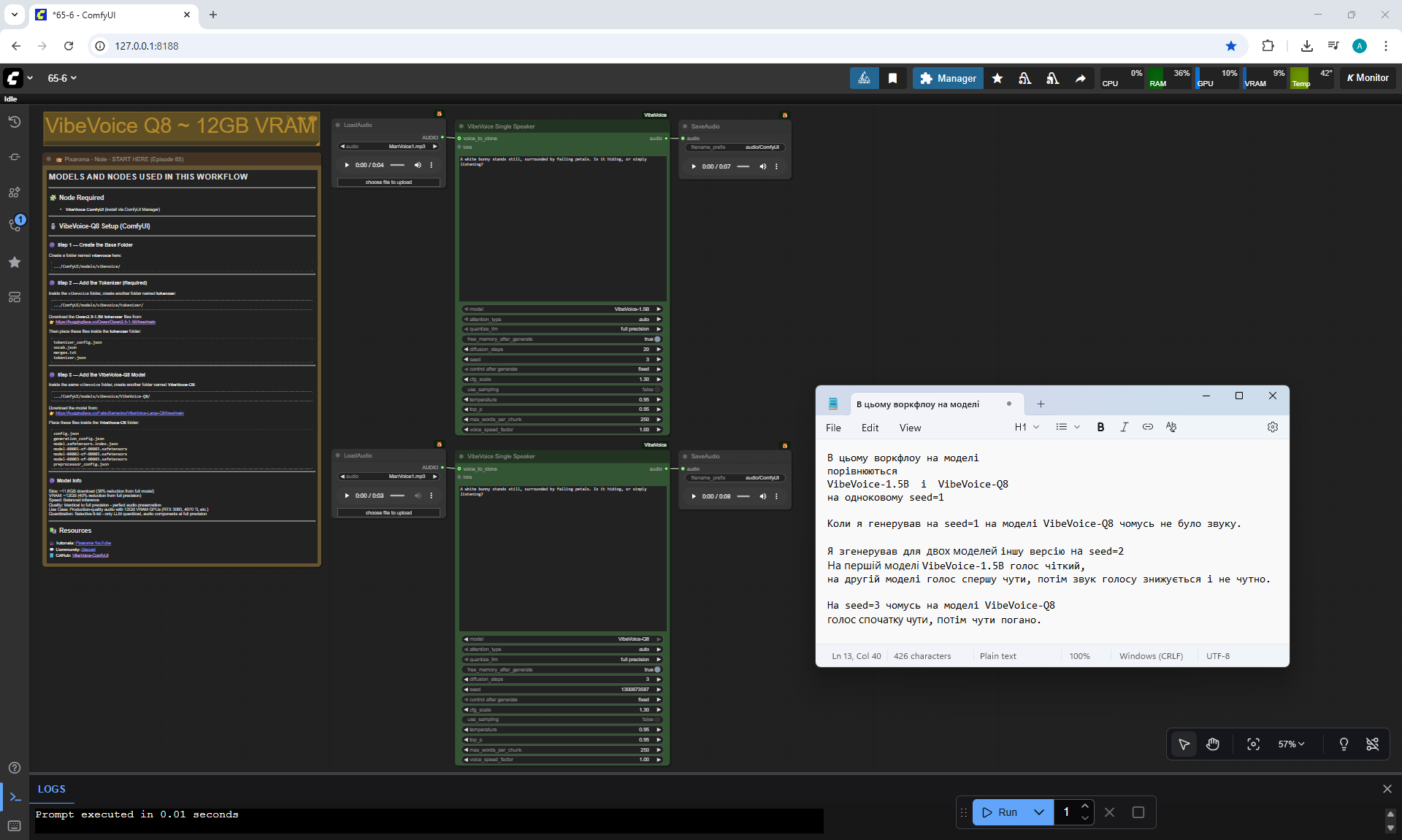
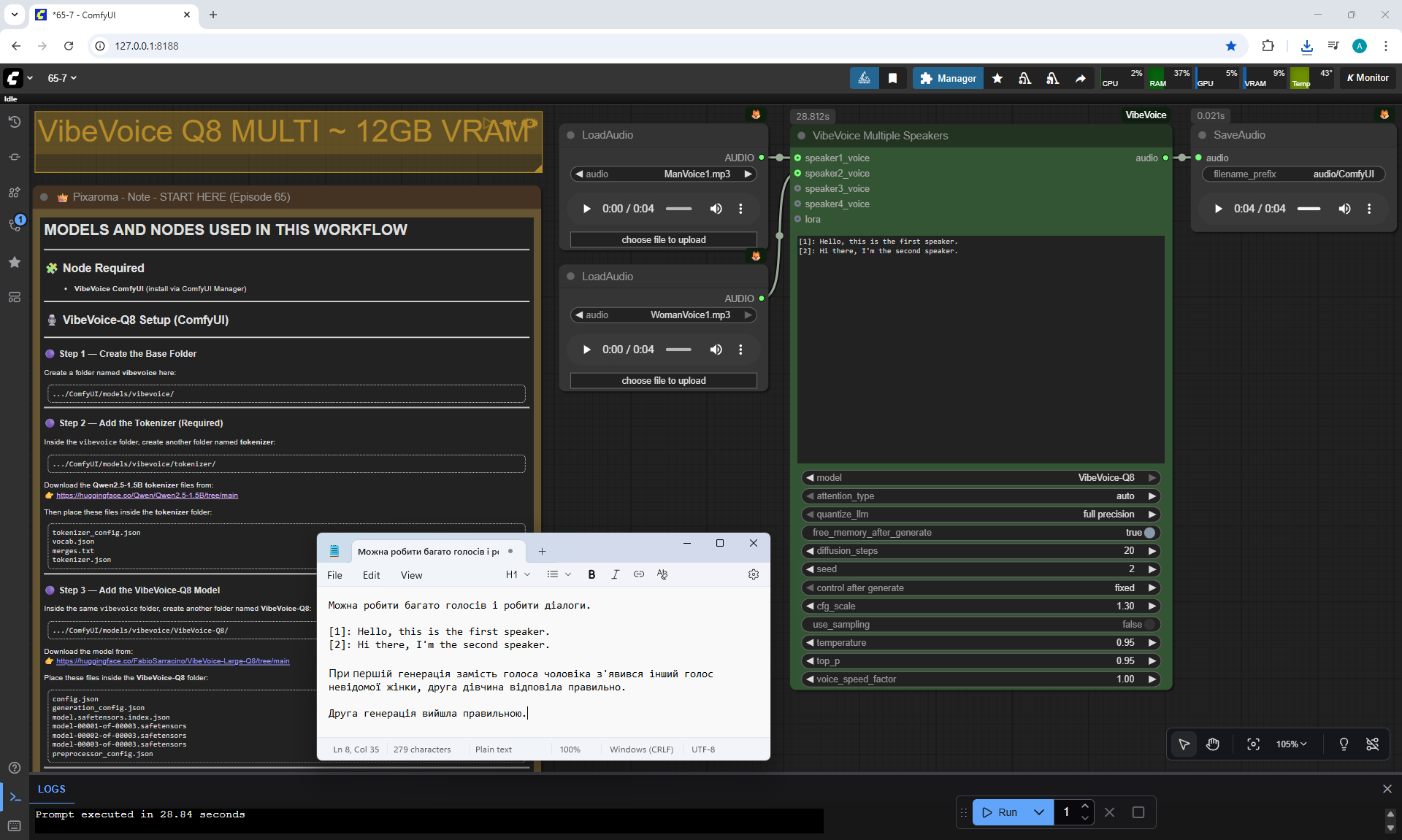
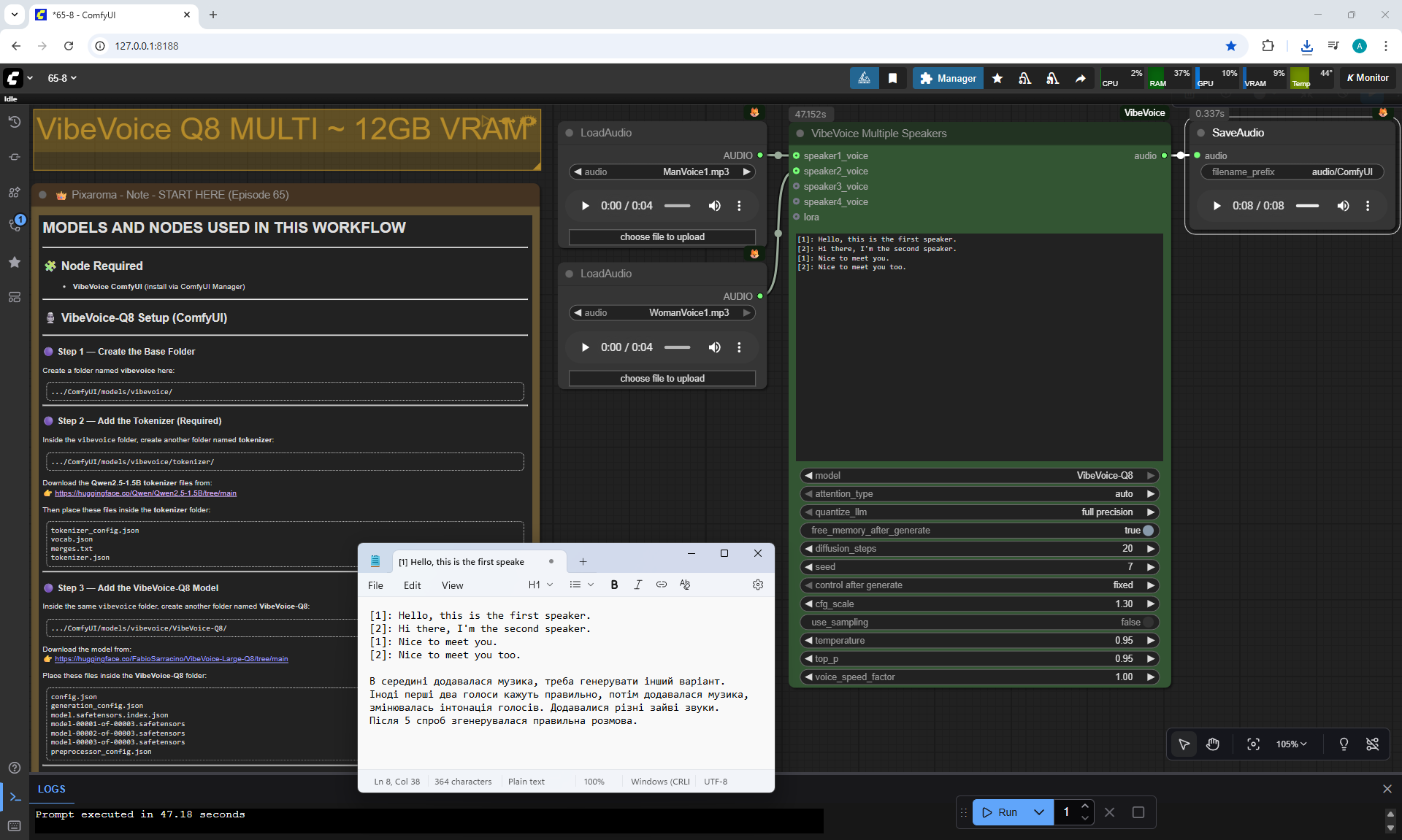
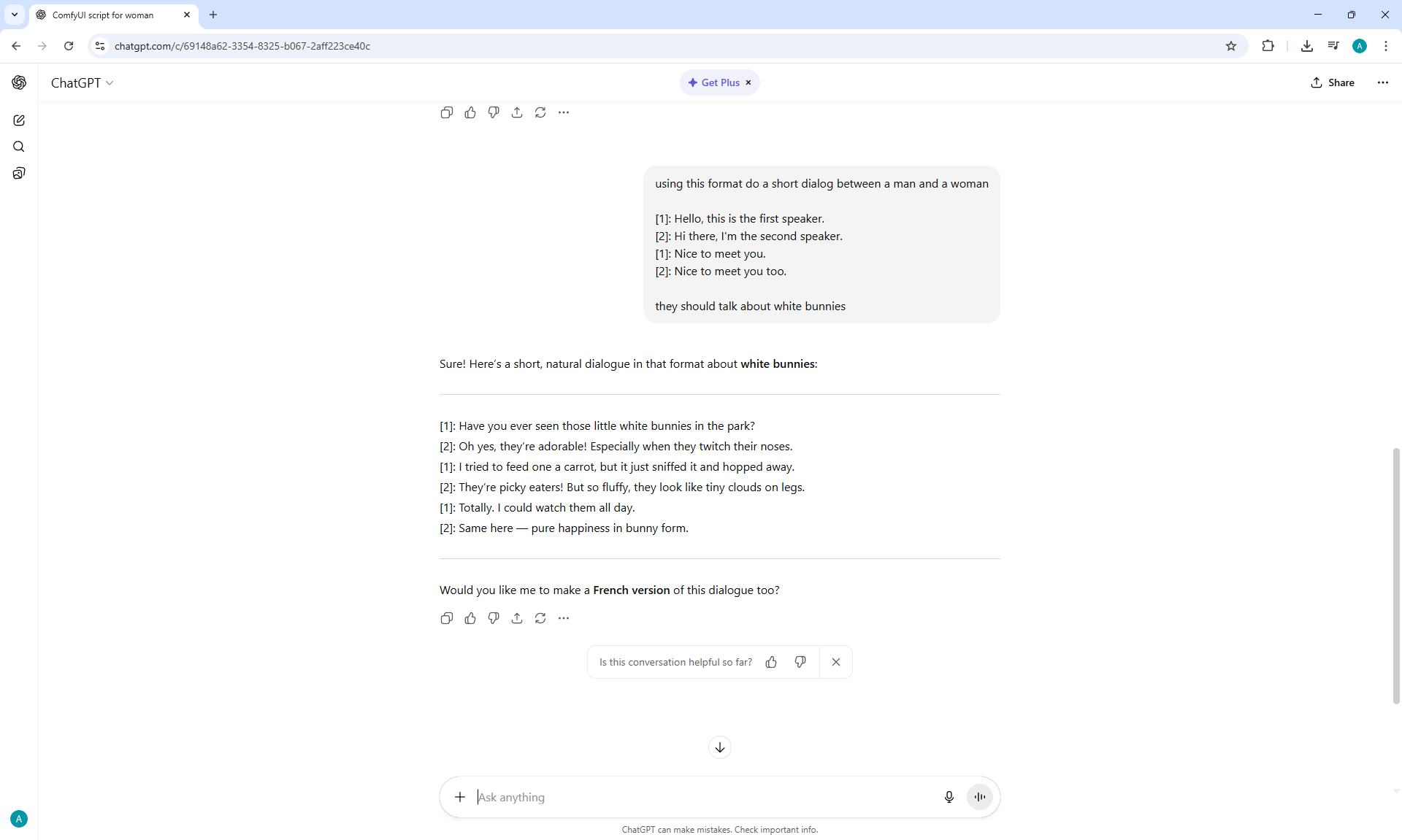
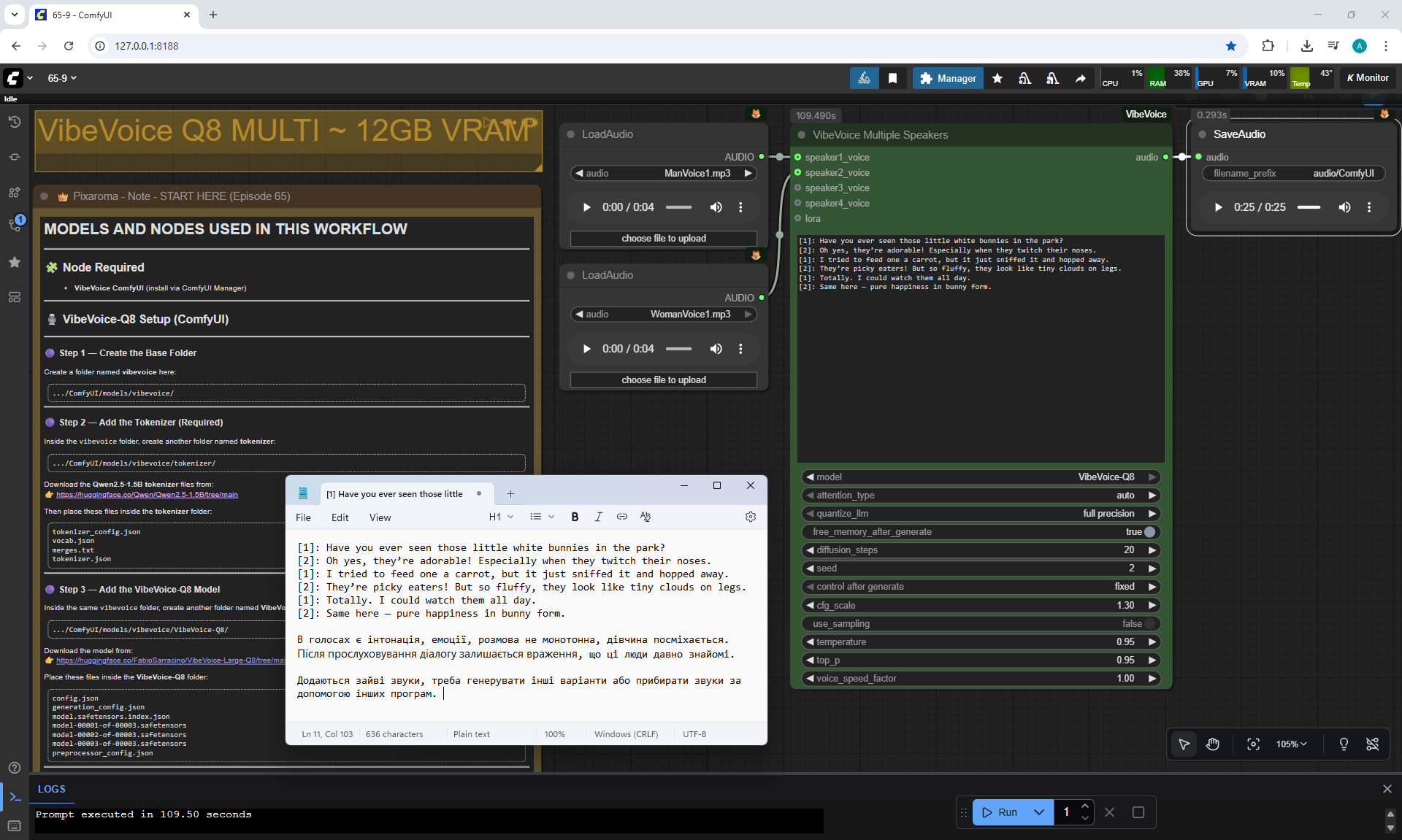
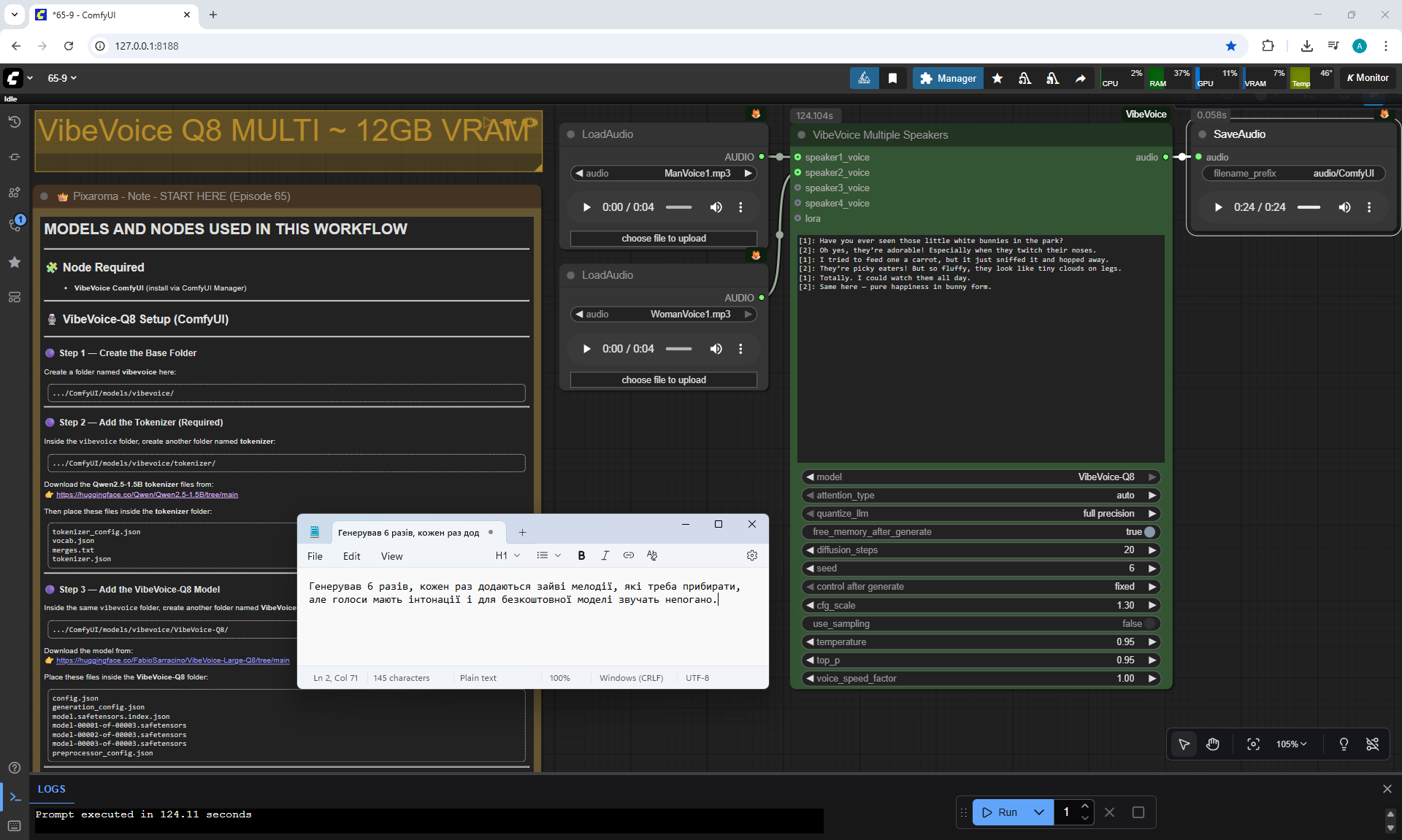
ComfyUI Tutorial Series Ep 65: VibeVoice Free Text to Speech Workflow
ManVoice.mp3
WomanVoice.mp3
001.flac
002.flac
003.flac
004.flac
005.flac
006.flac
007.flac
008.flac
009.flac
010.flac
011.flac
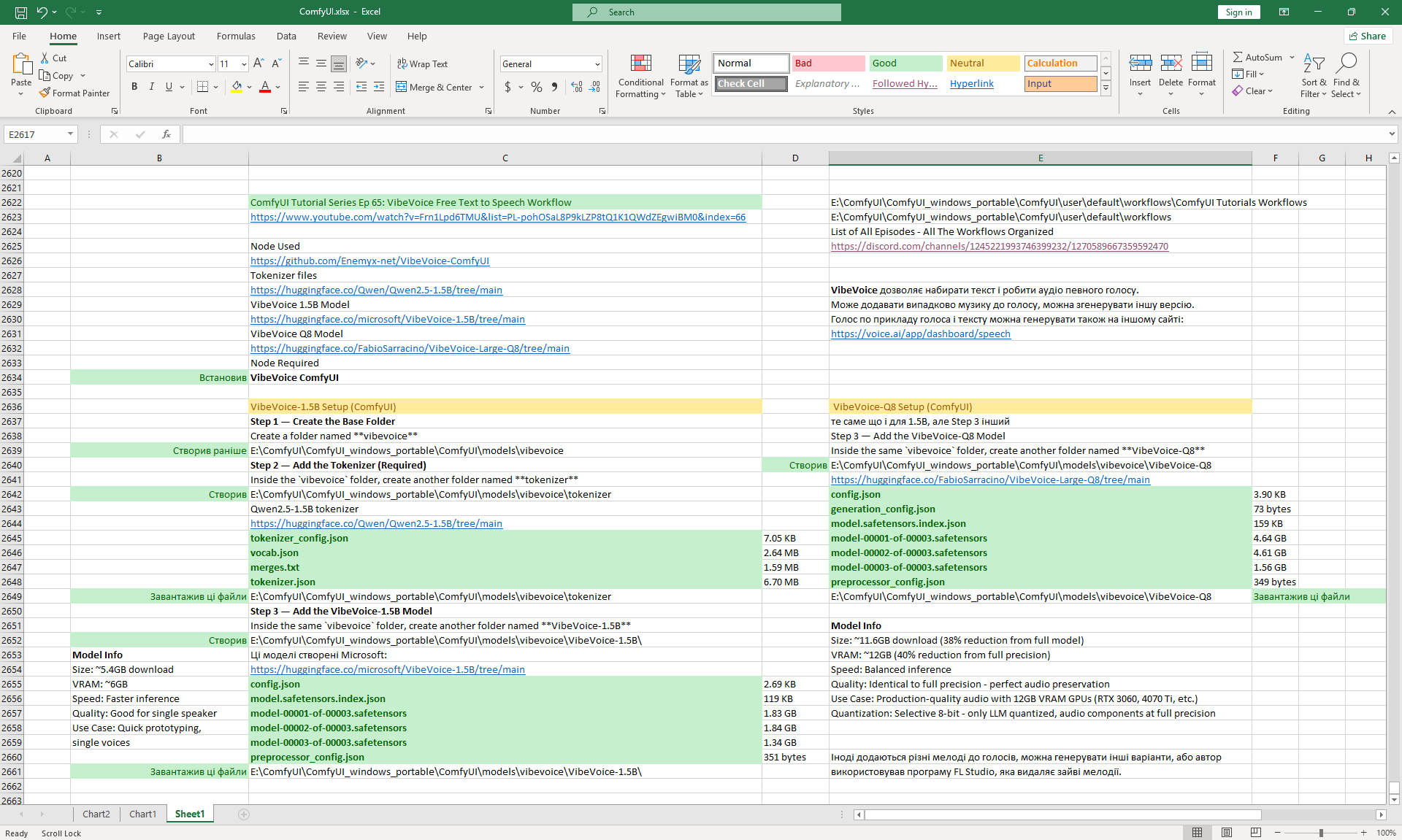
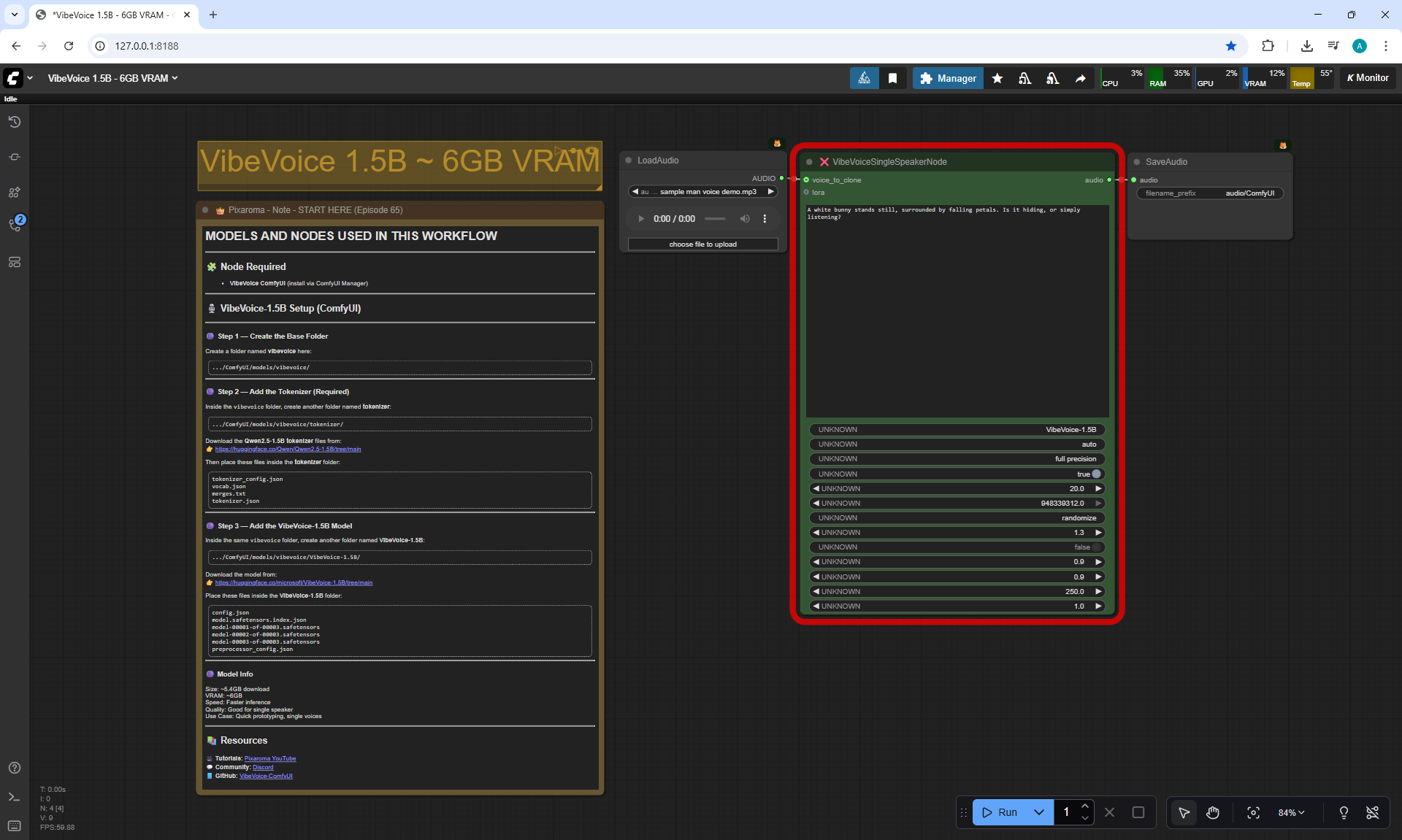
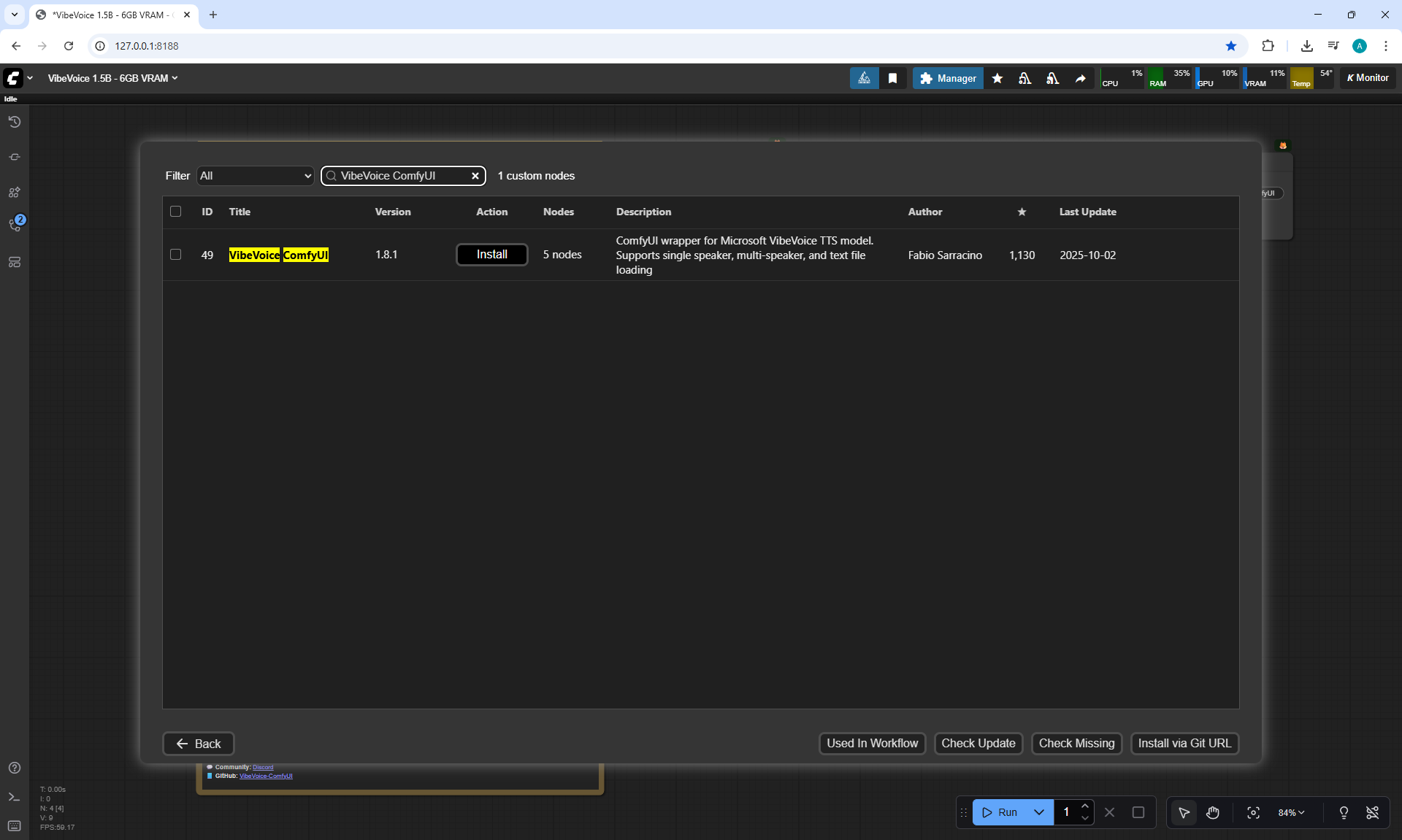
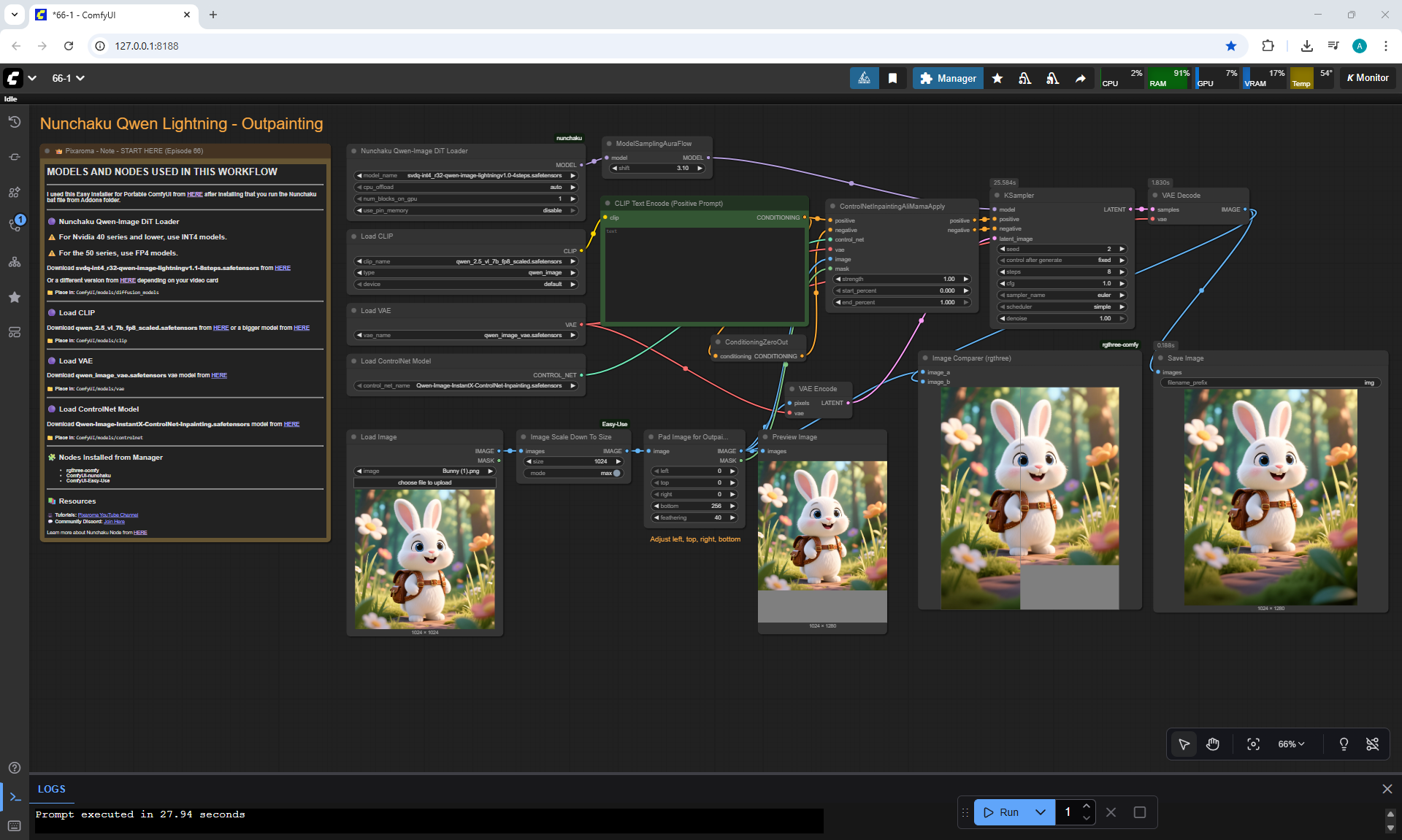
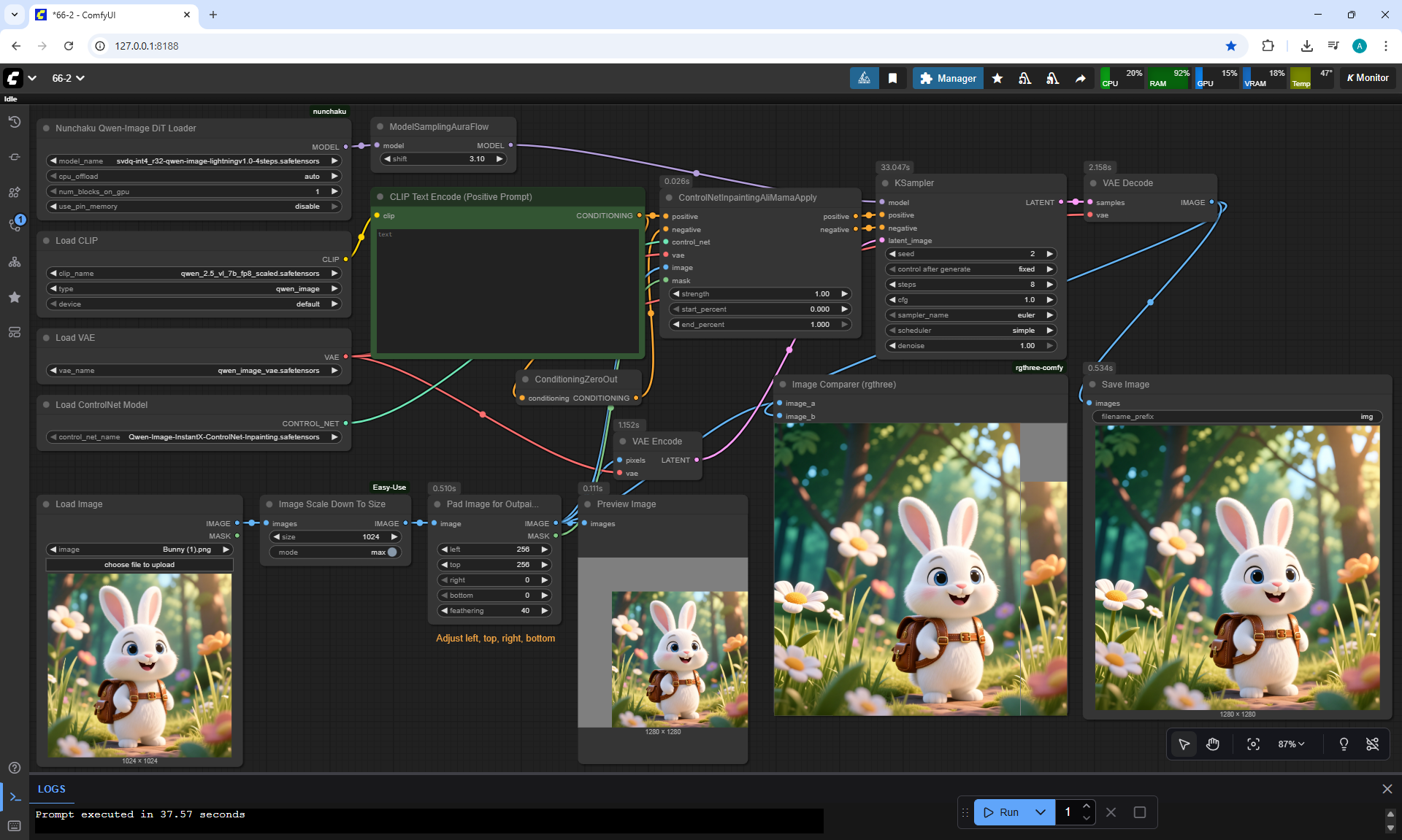
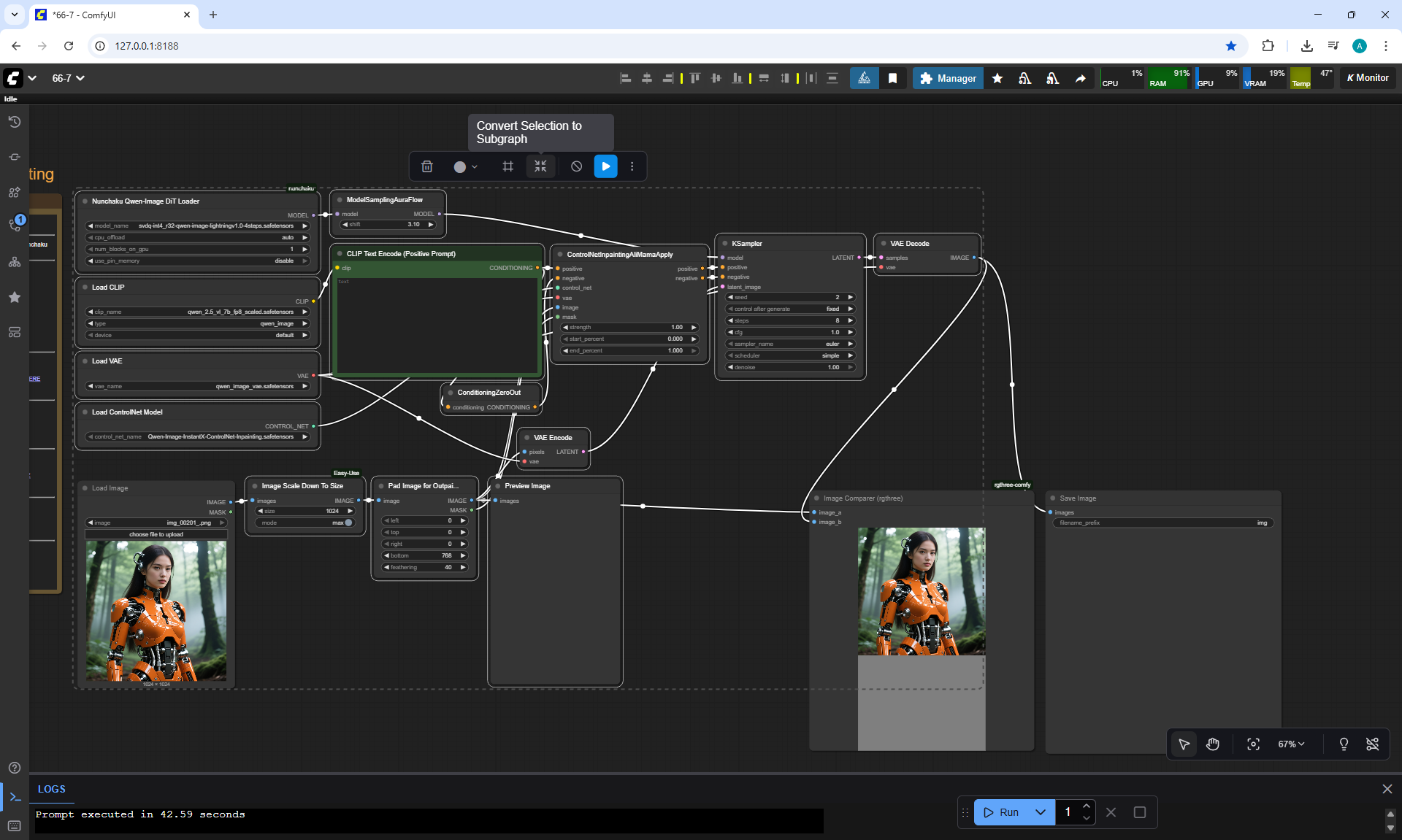
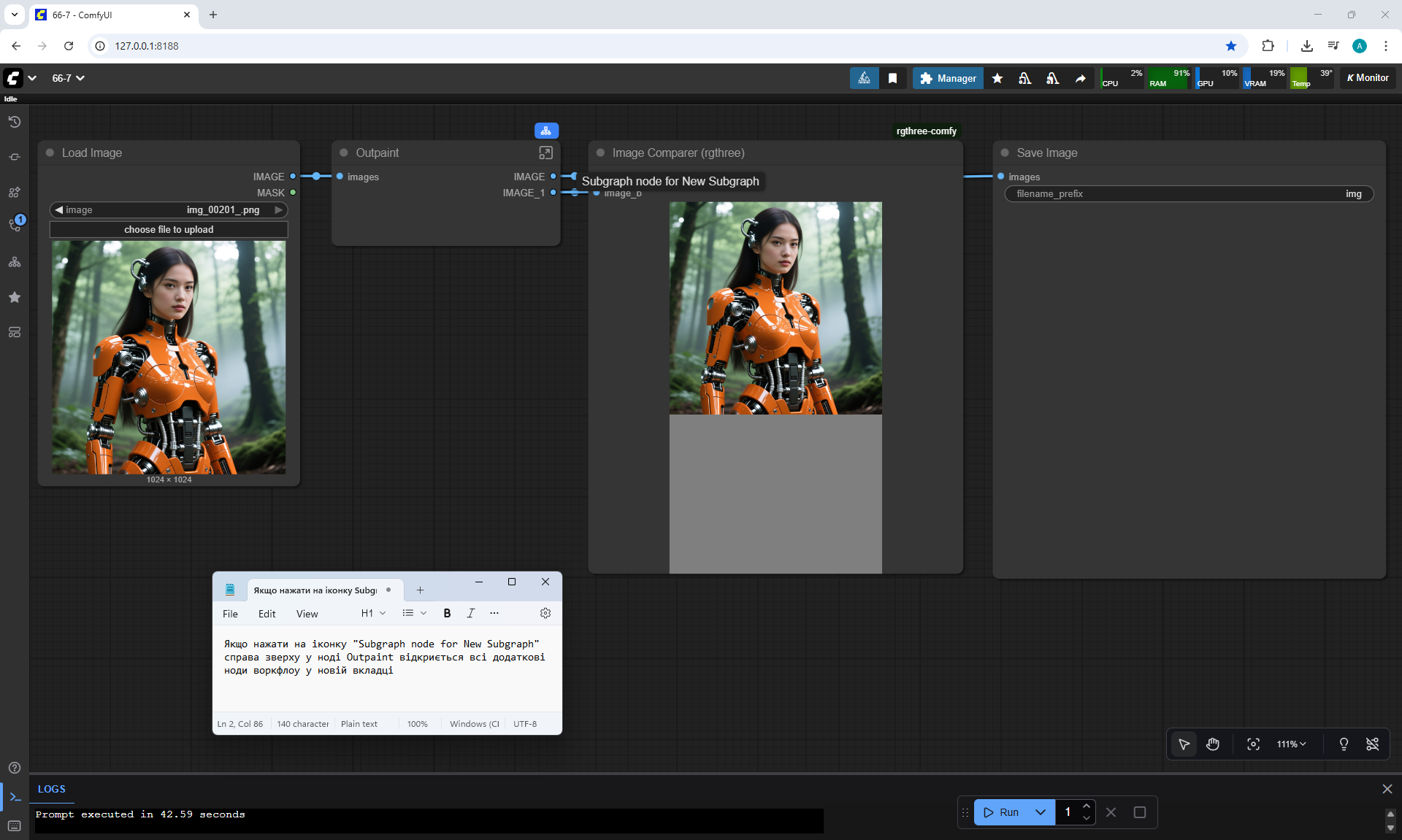
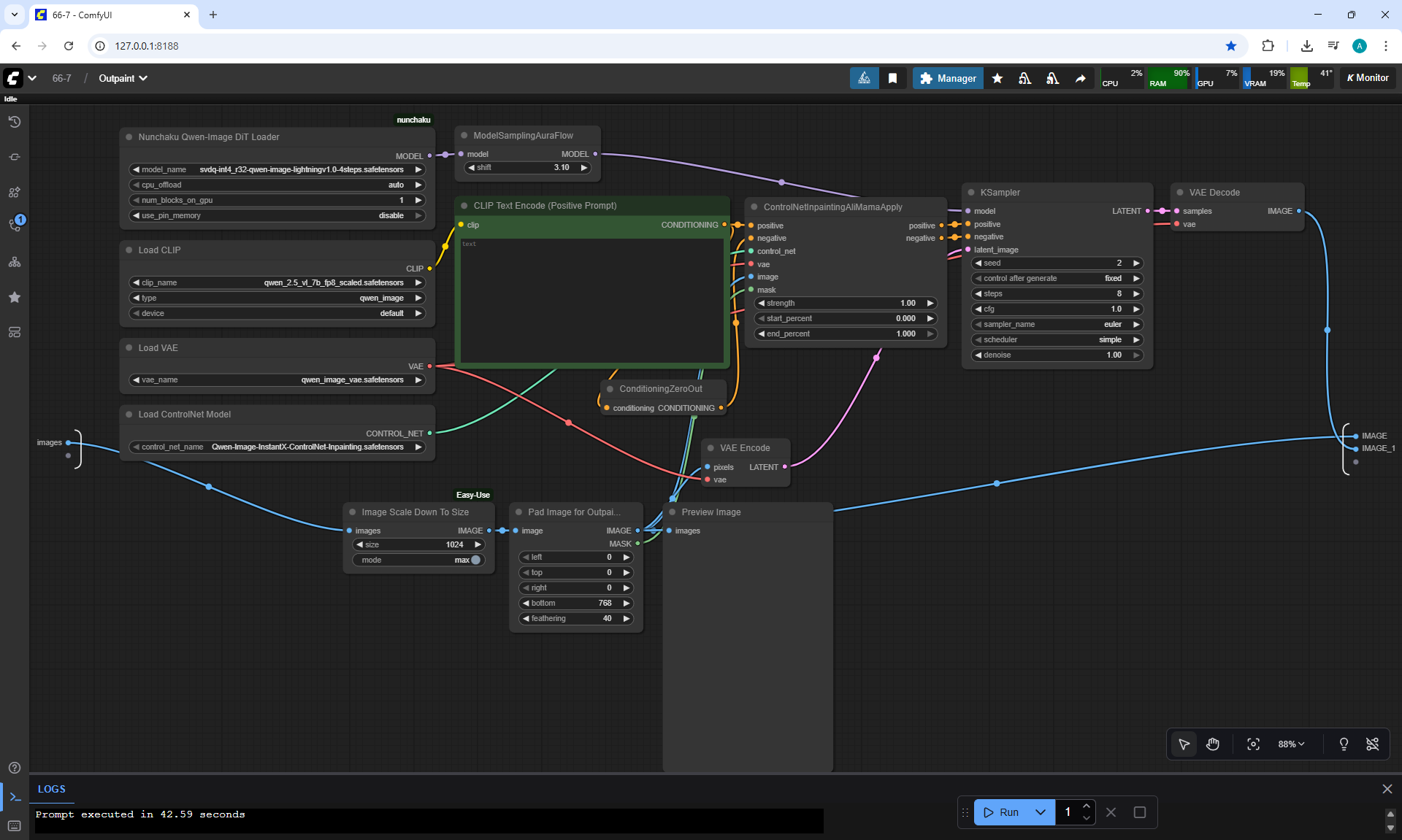
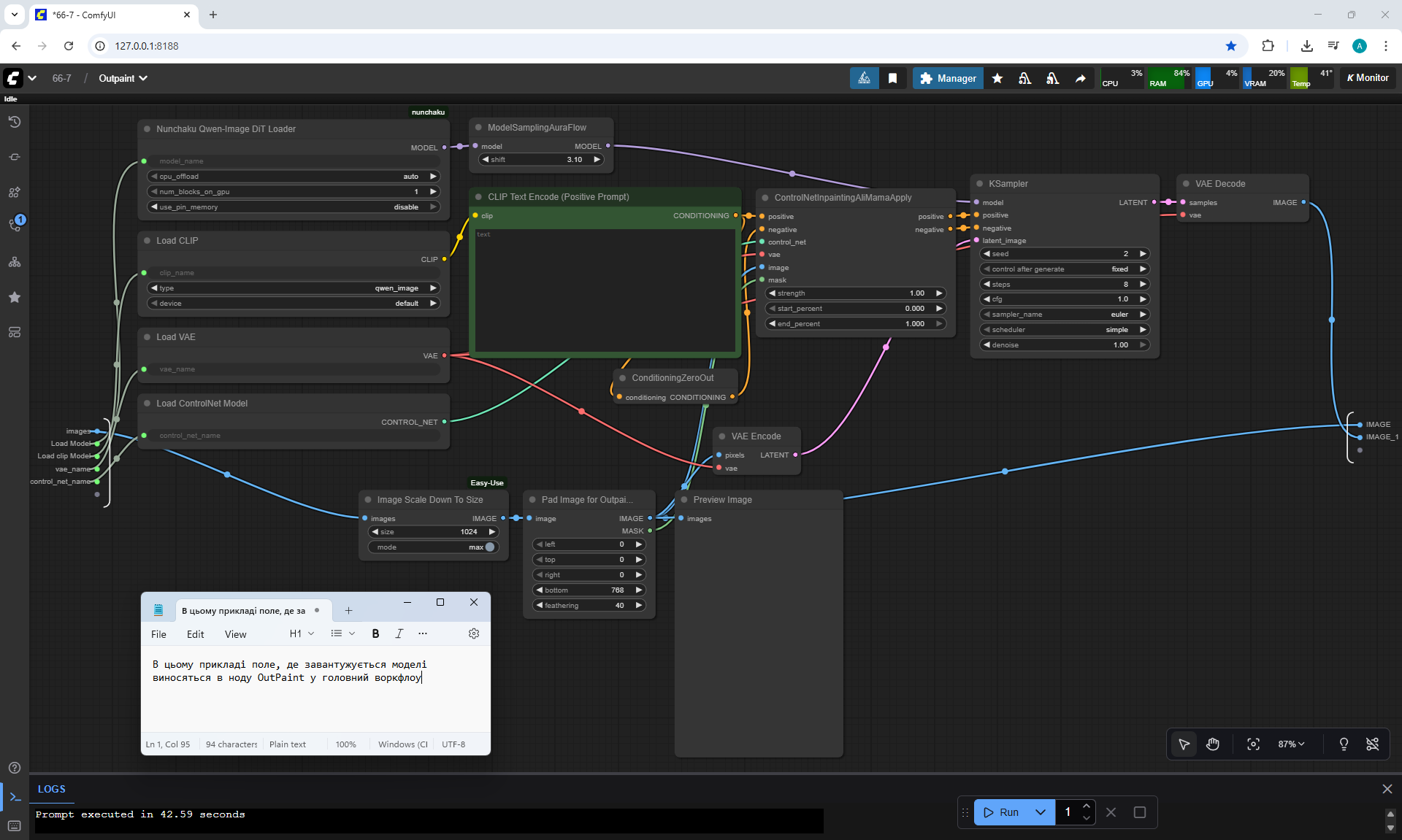
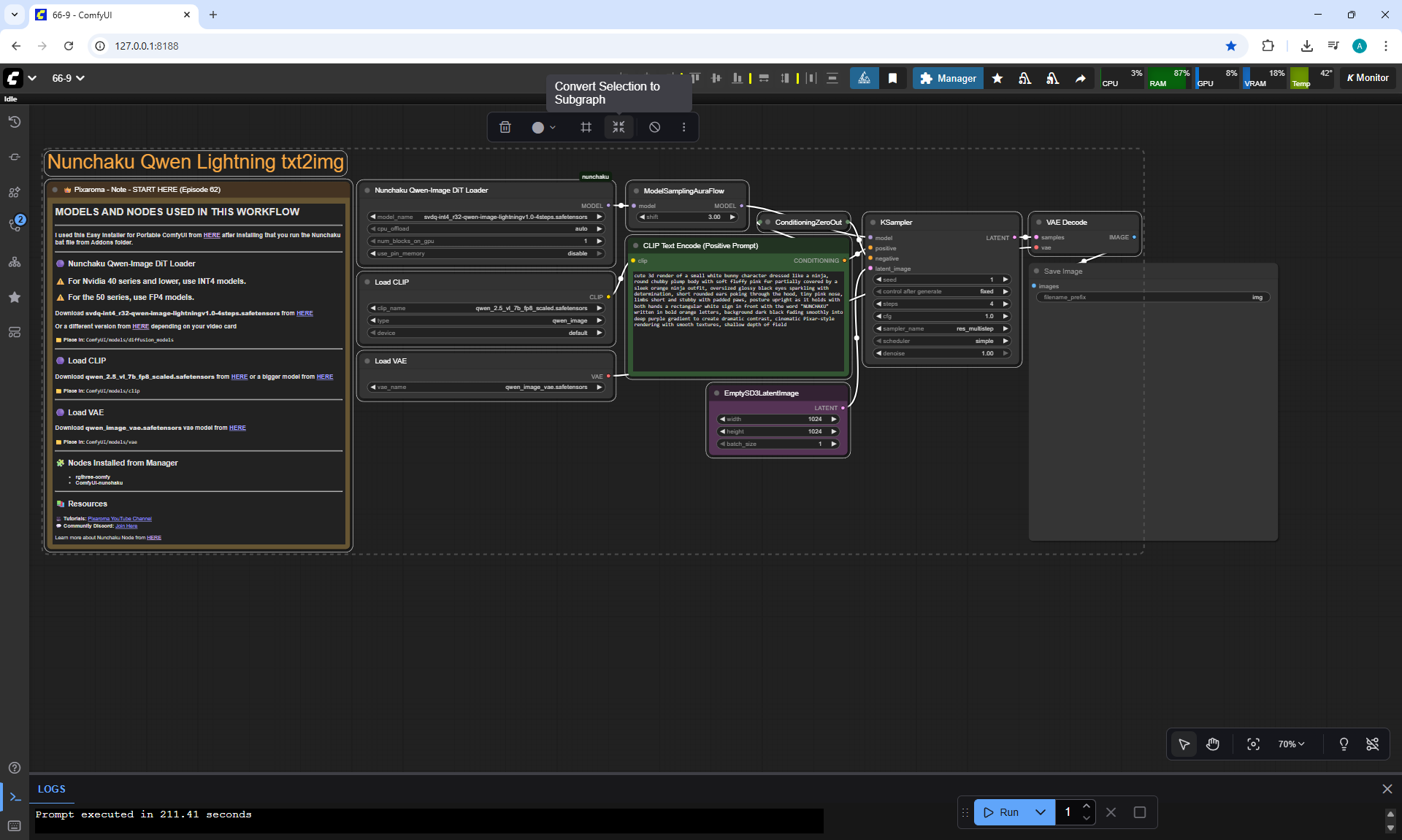
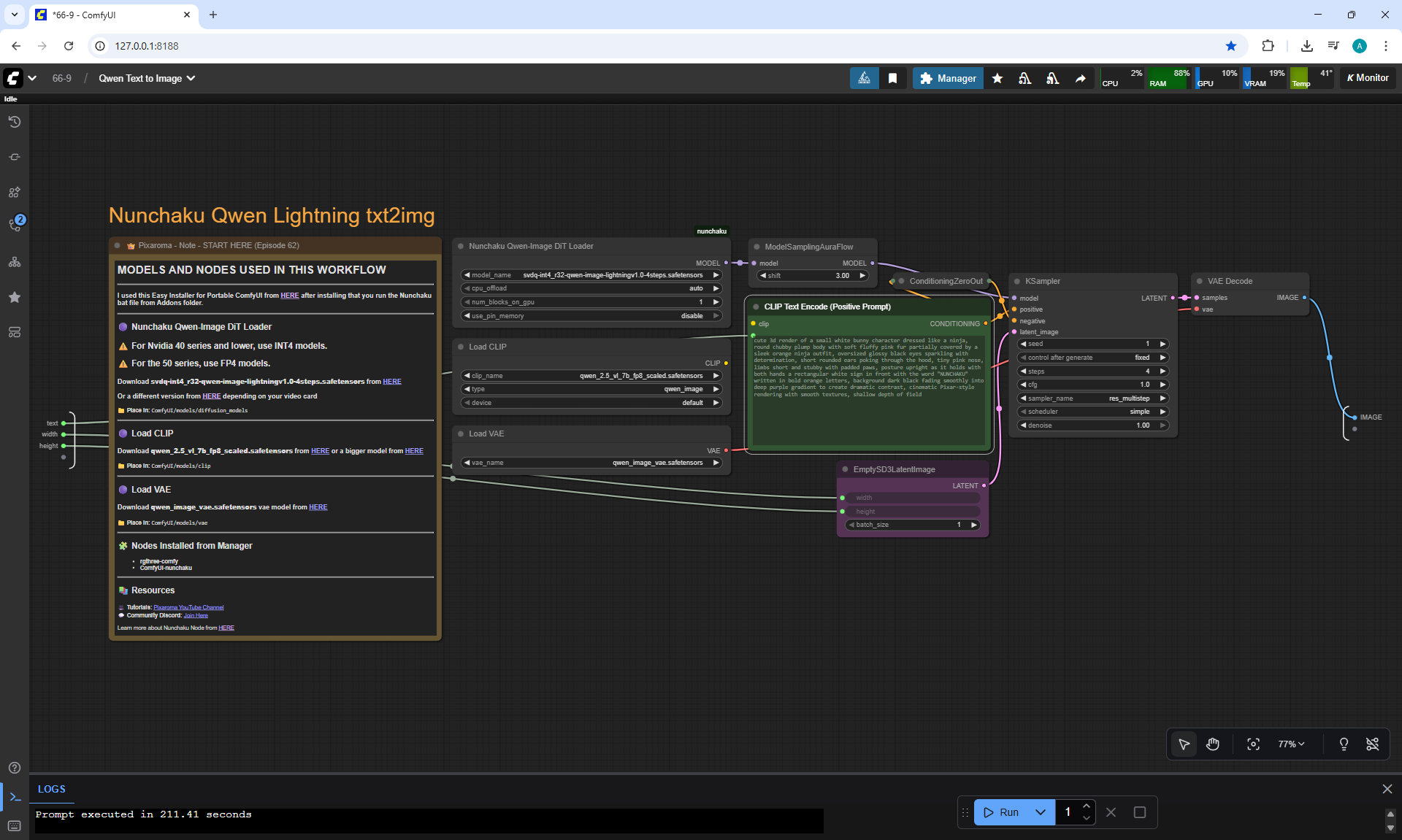
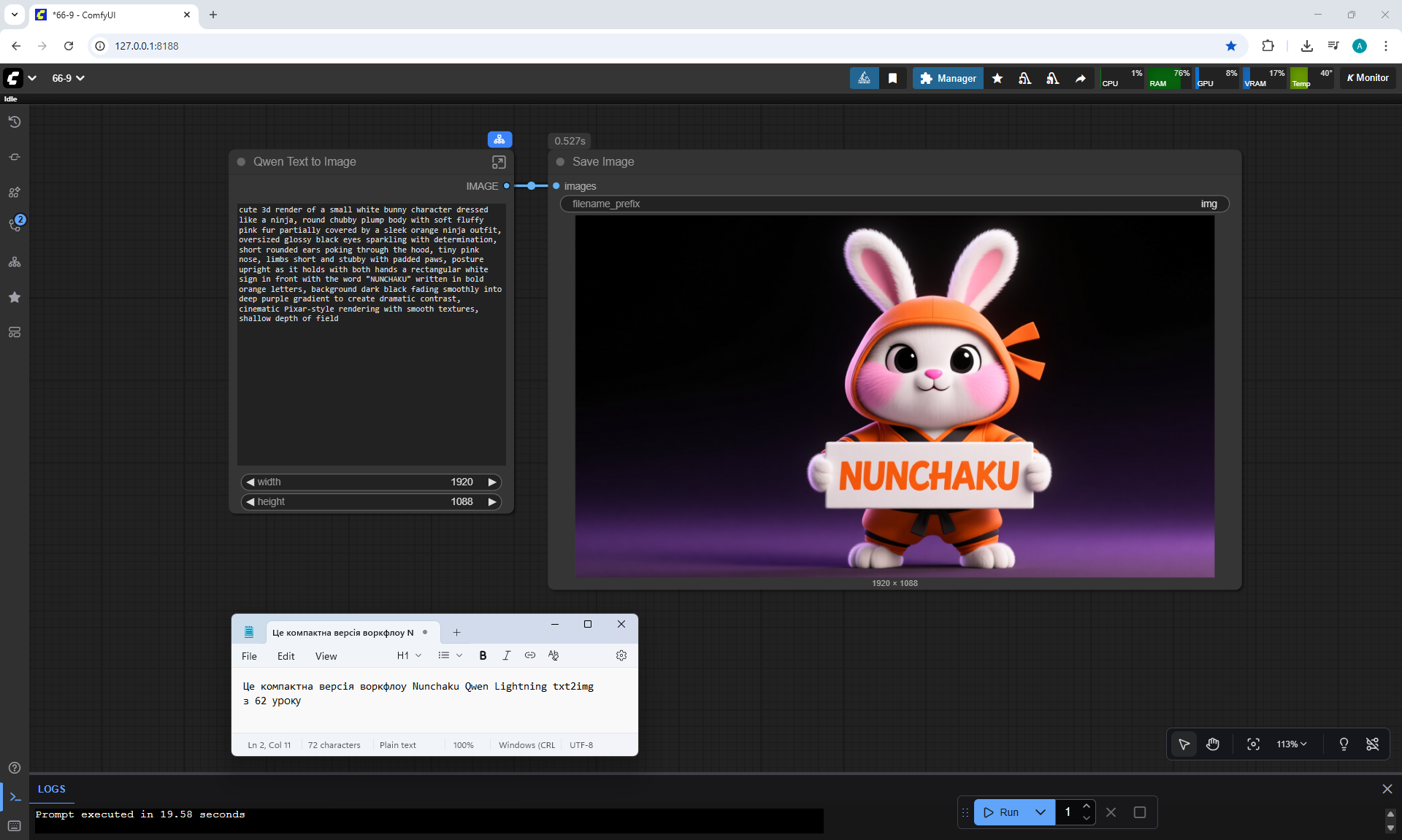
ComfyUI Tutorial Series Ep 66: Qwen Outpainting Workflow + Subgraph Tips










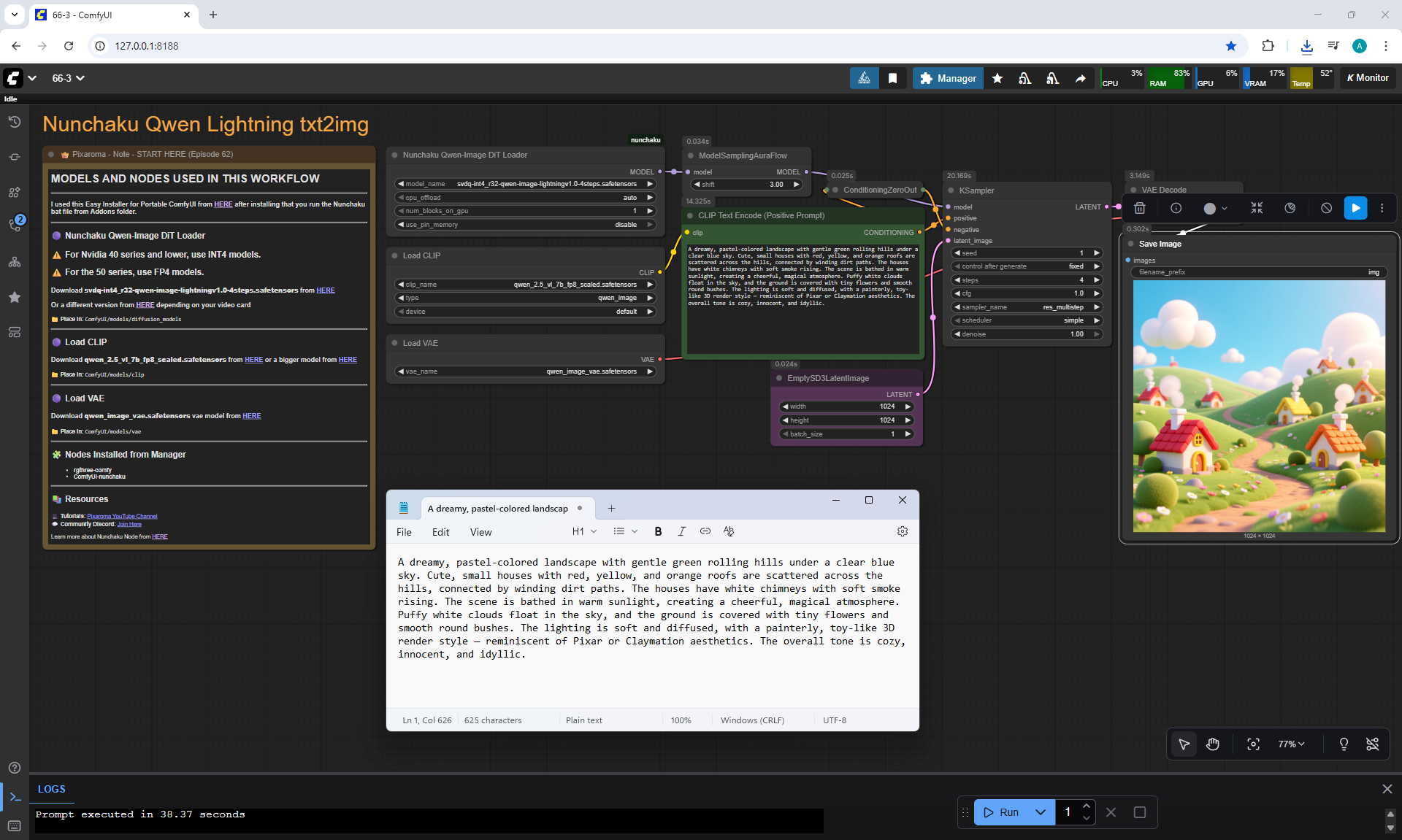
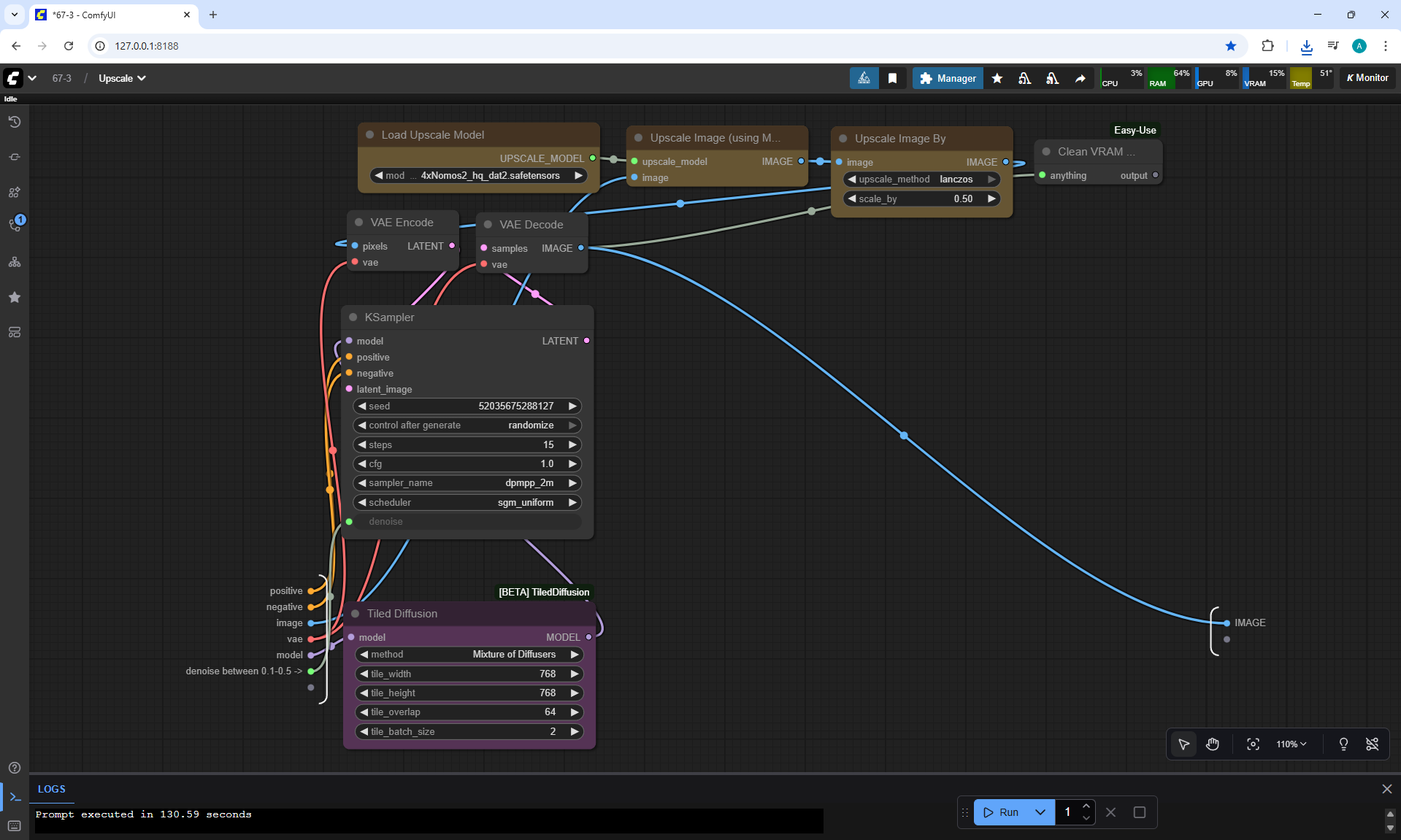
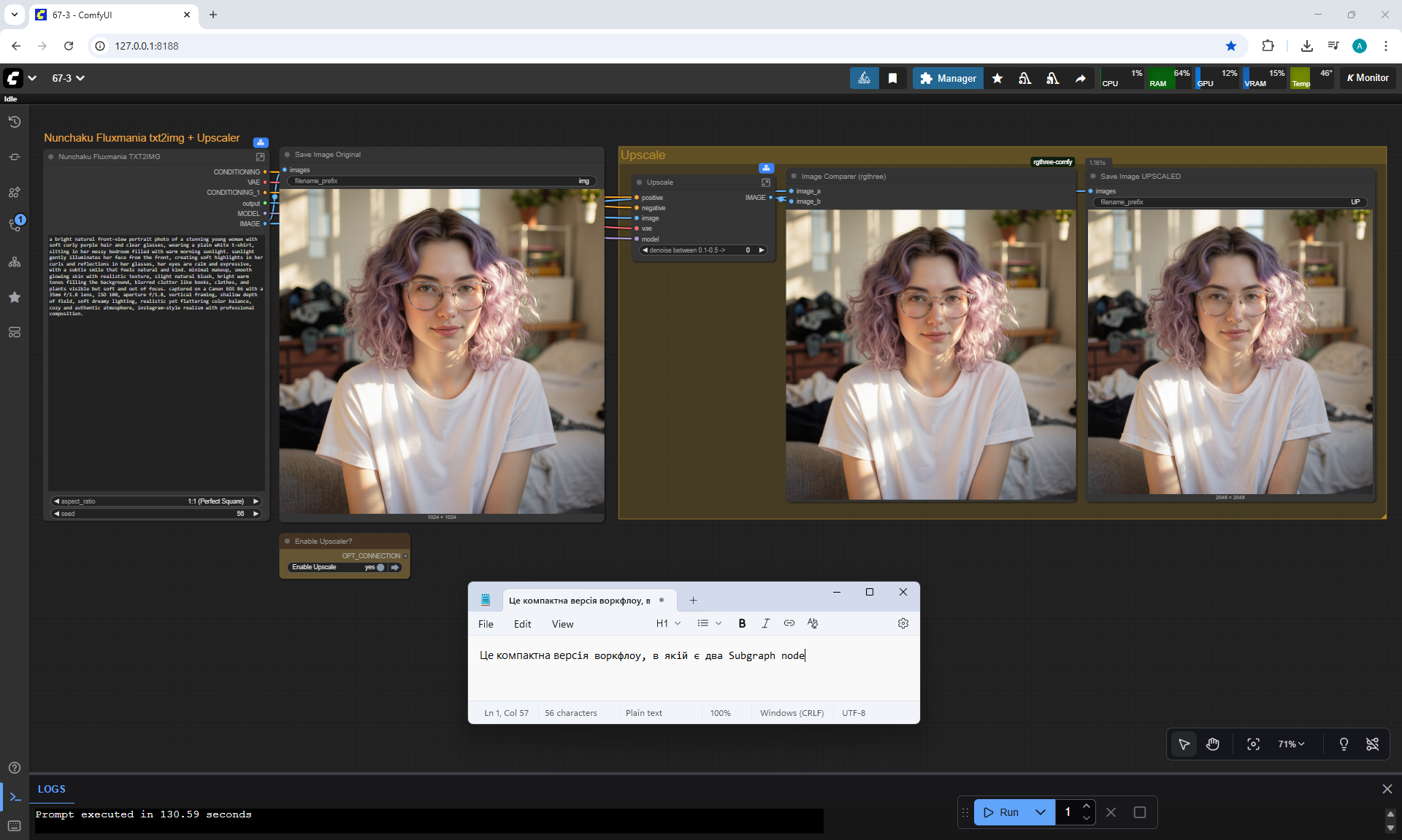
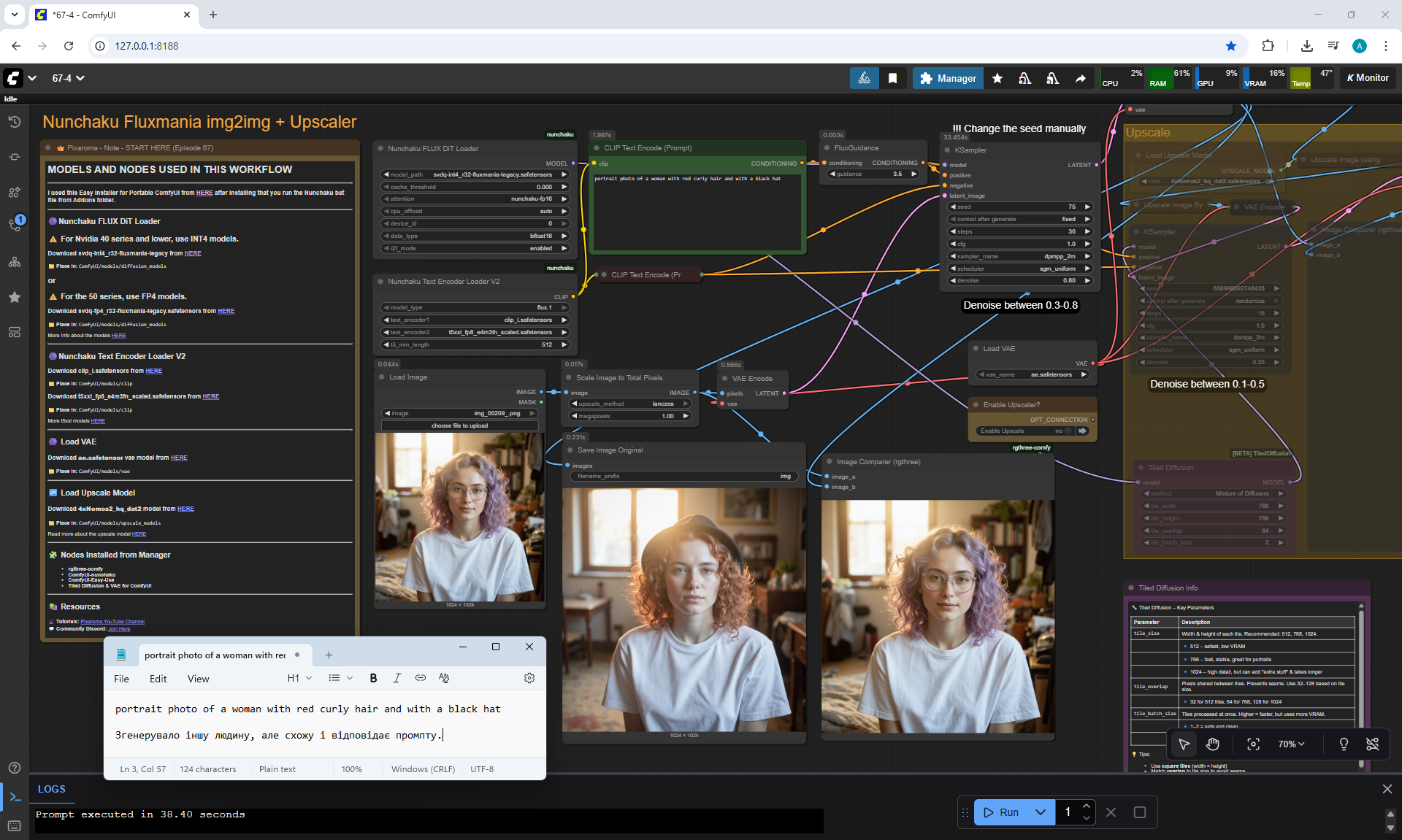
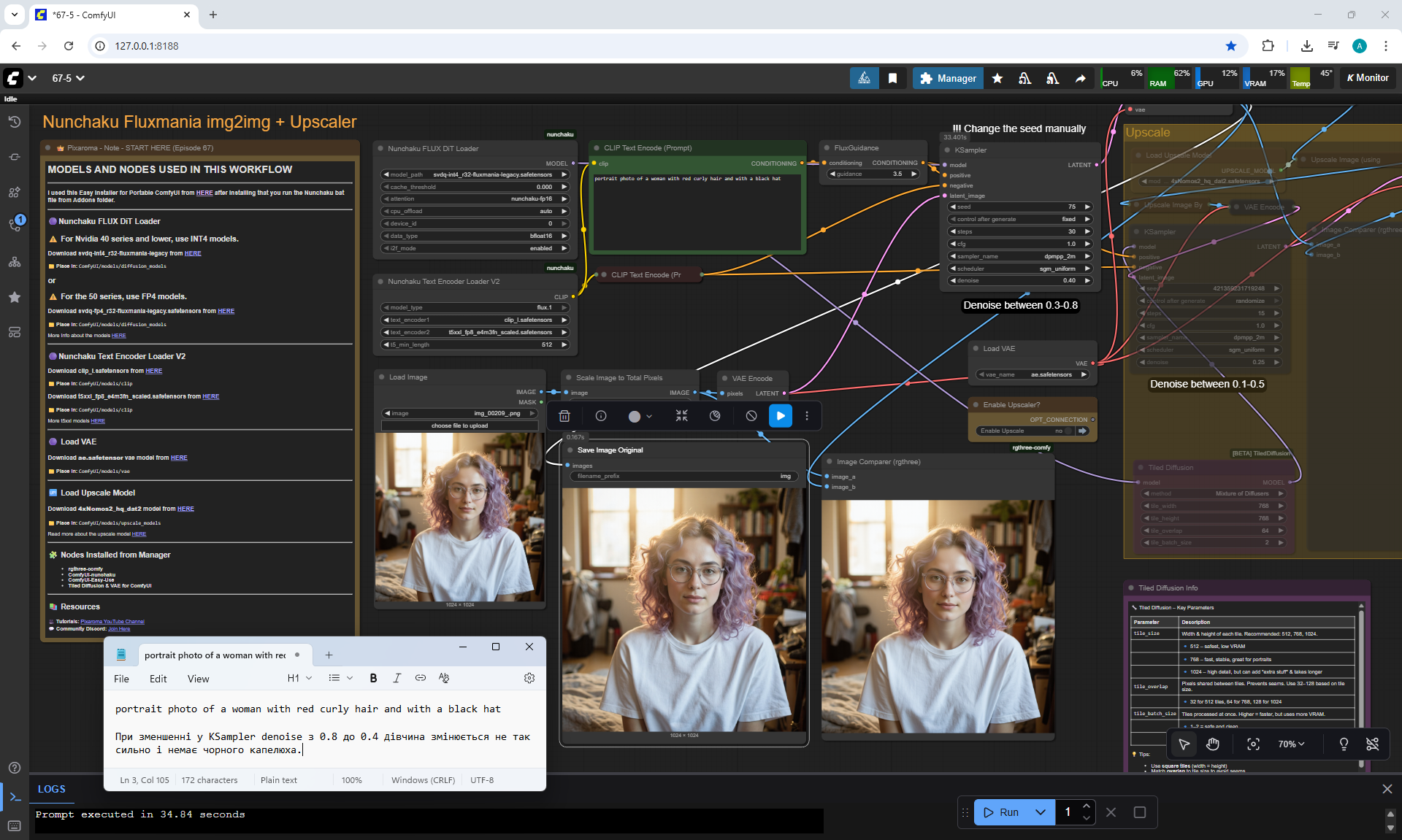
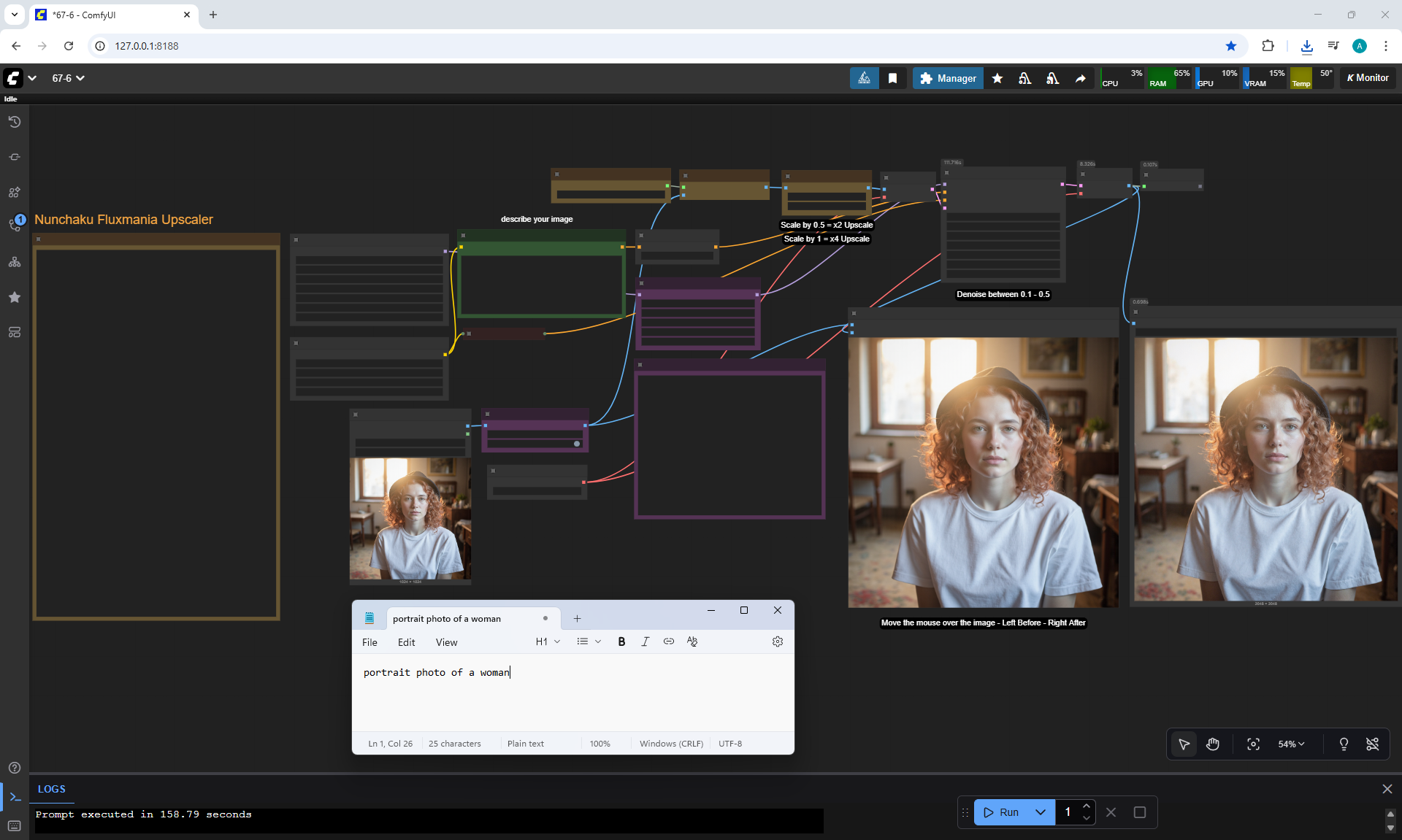
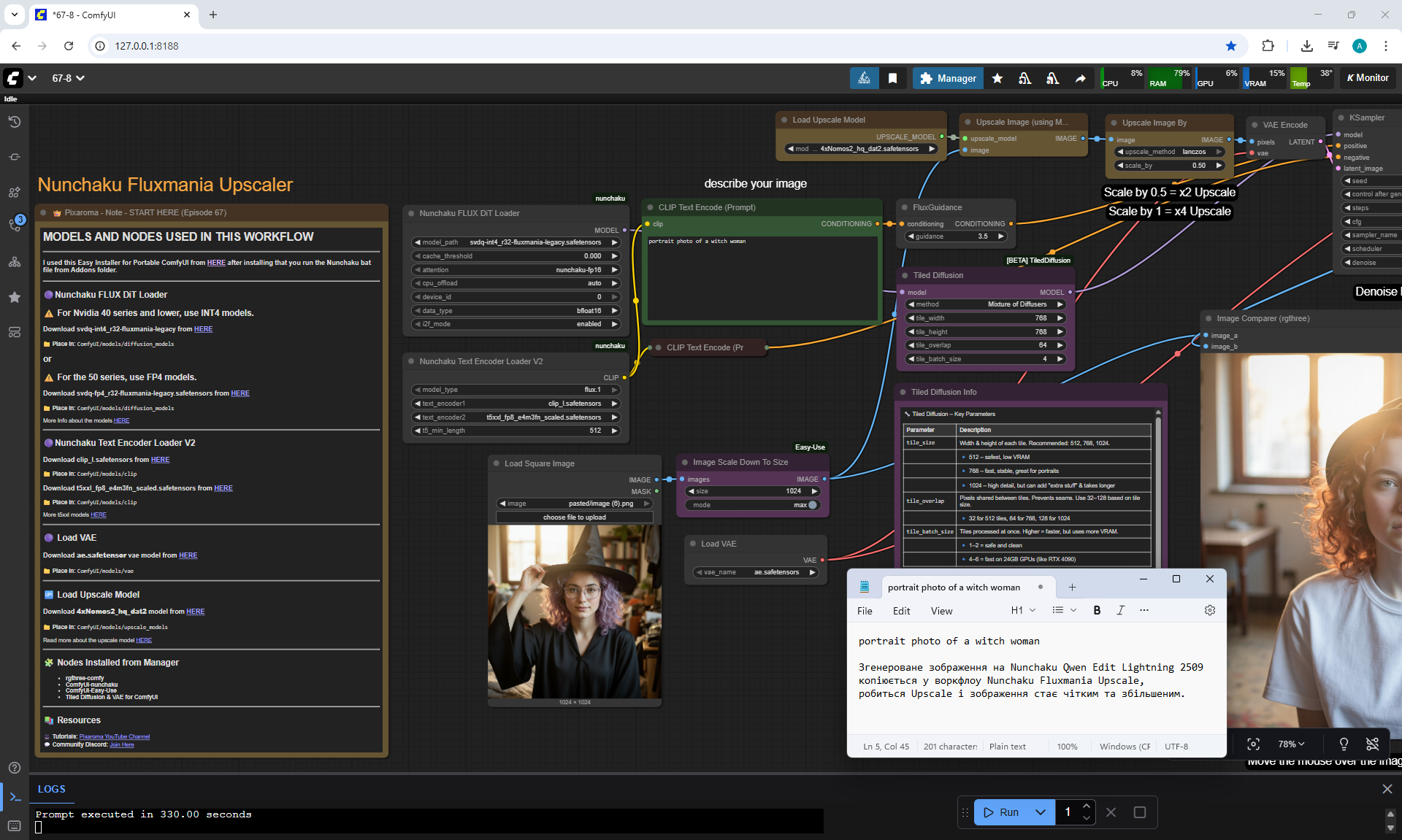
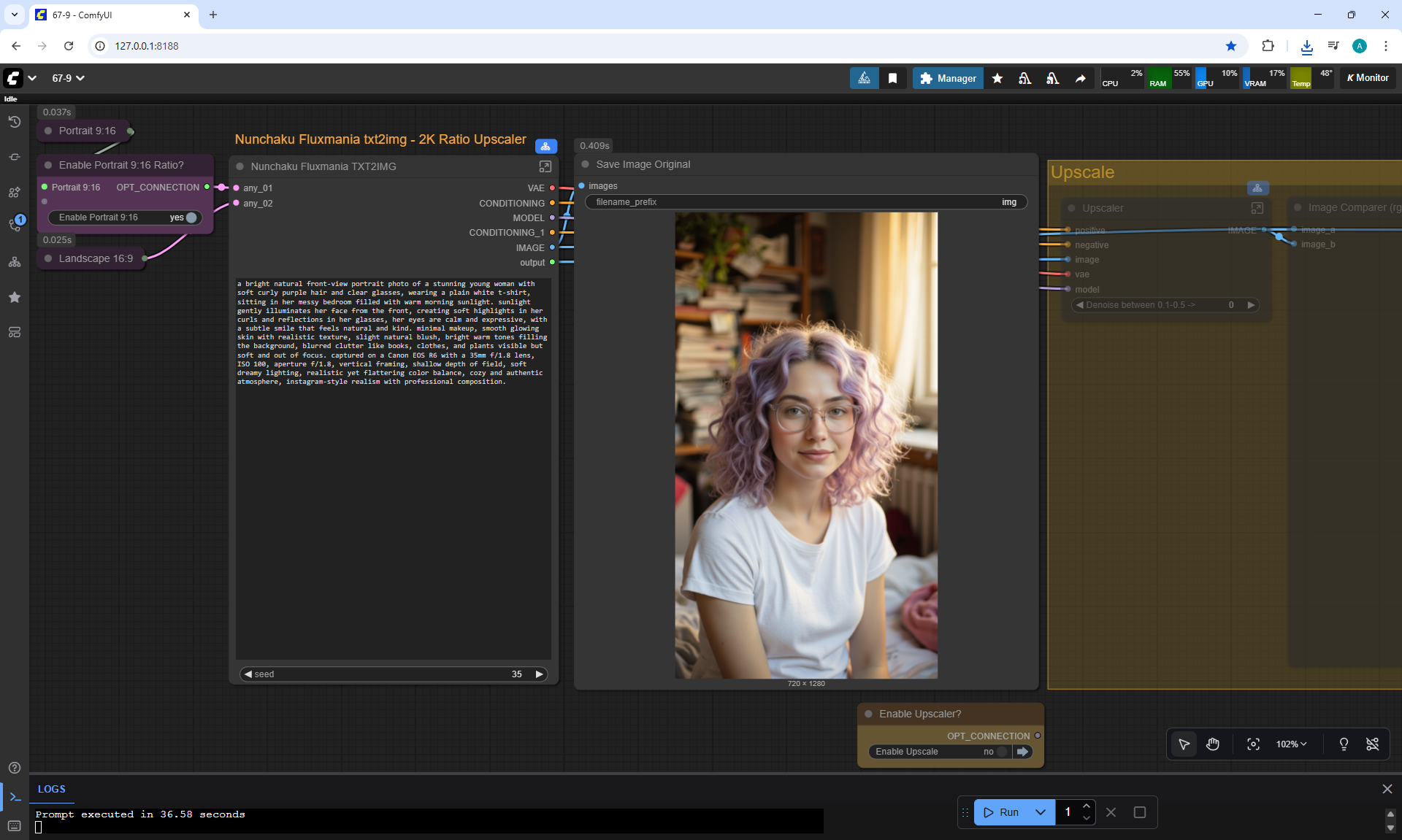
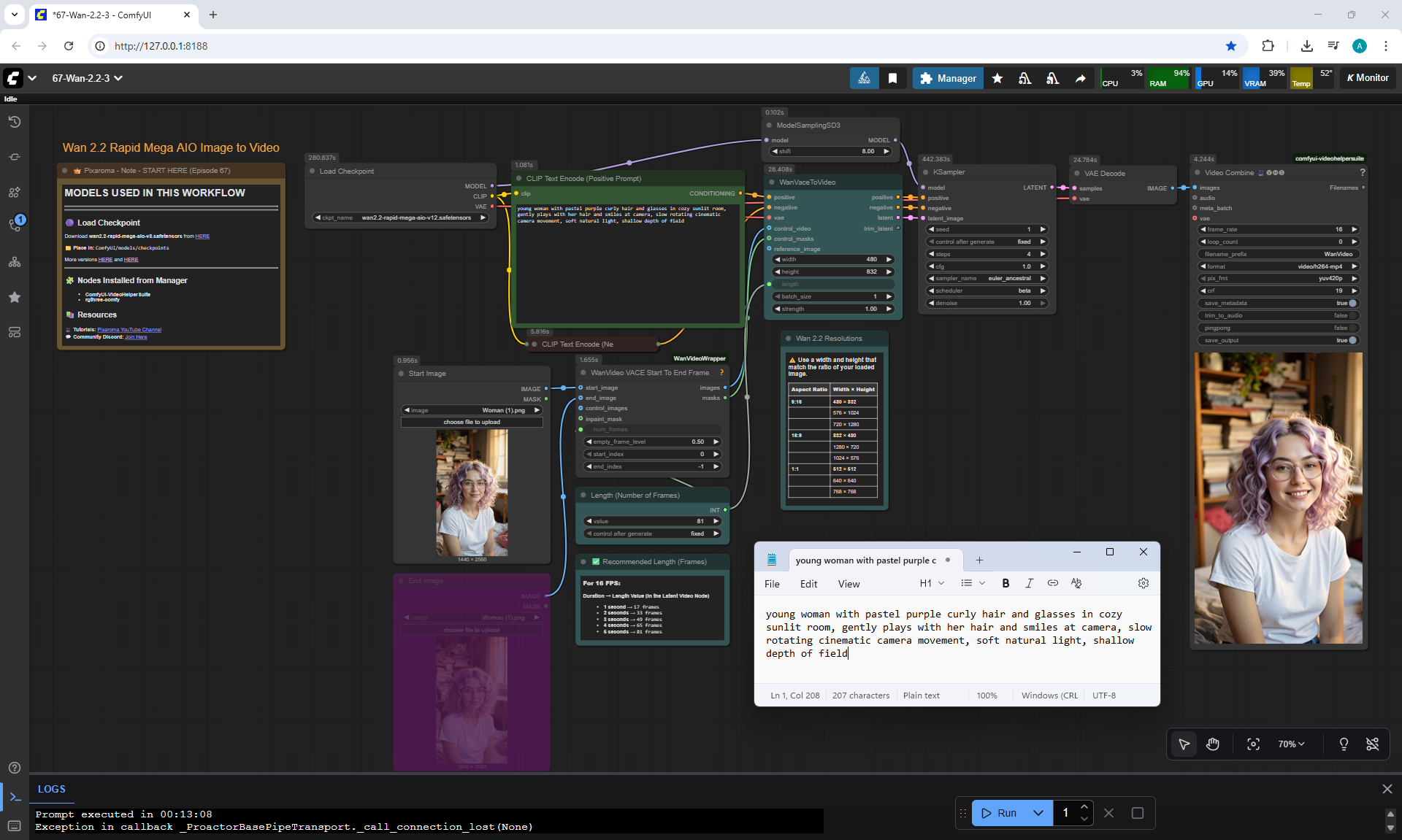
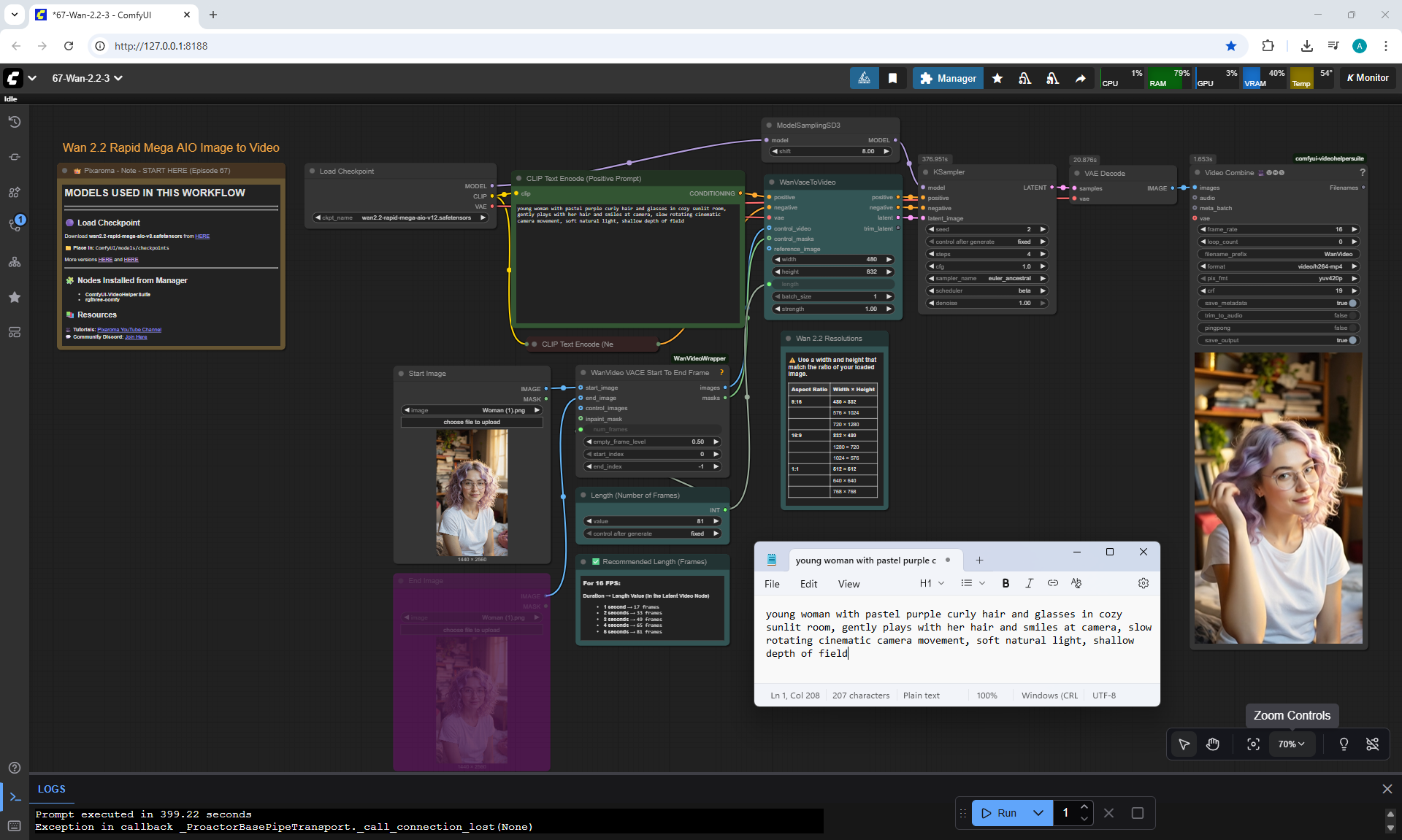
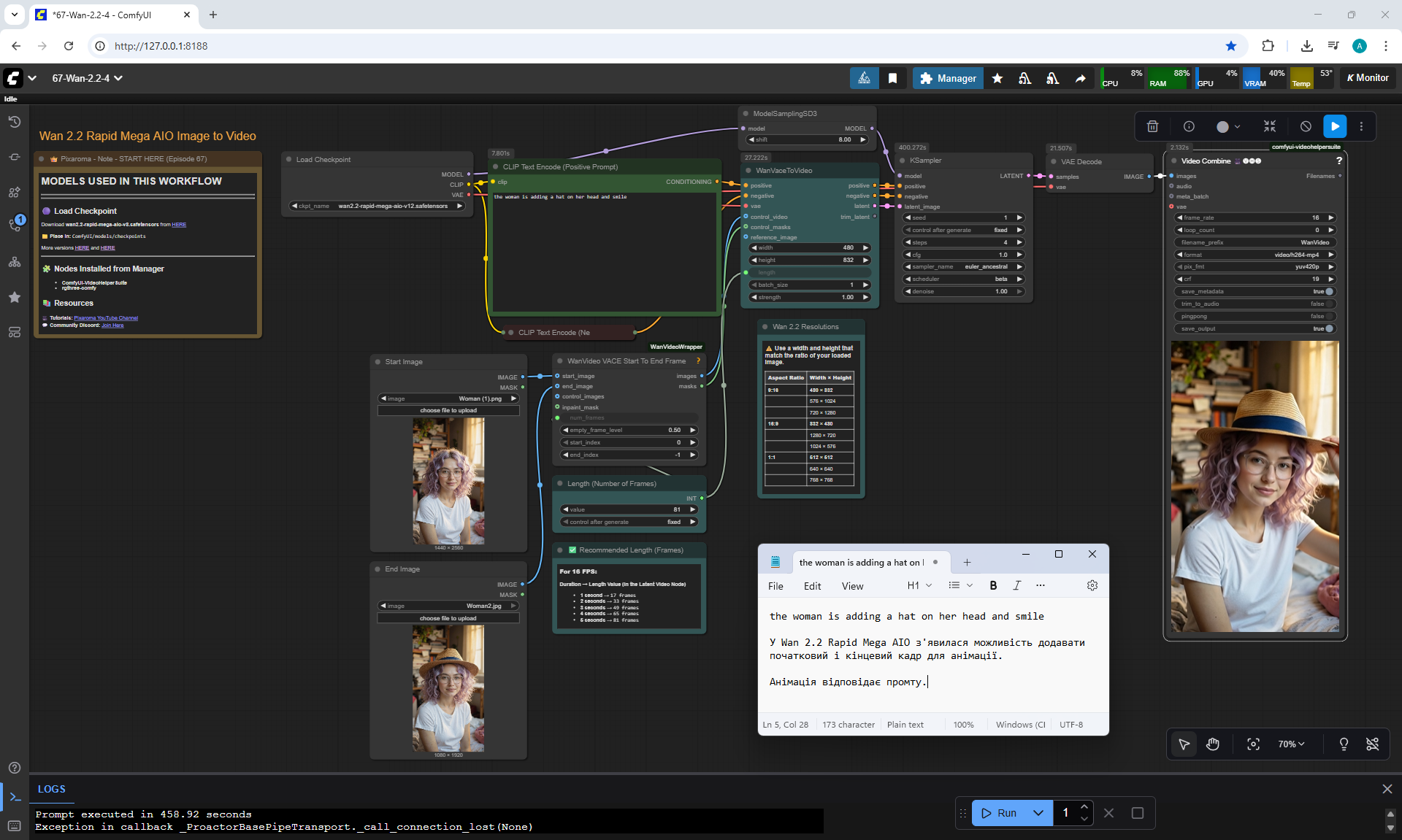
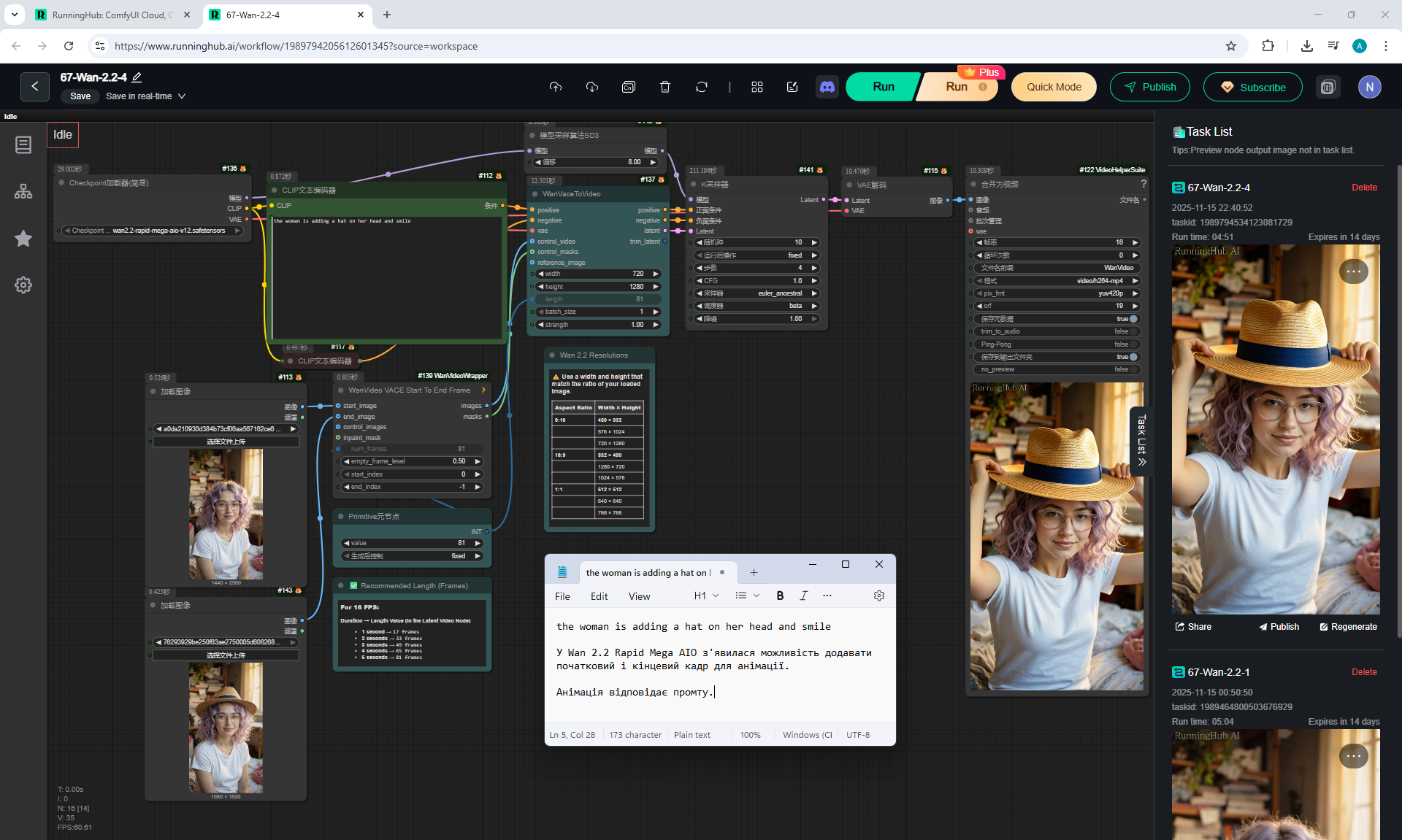
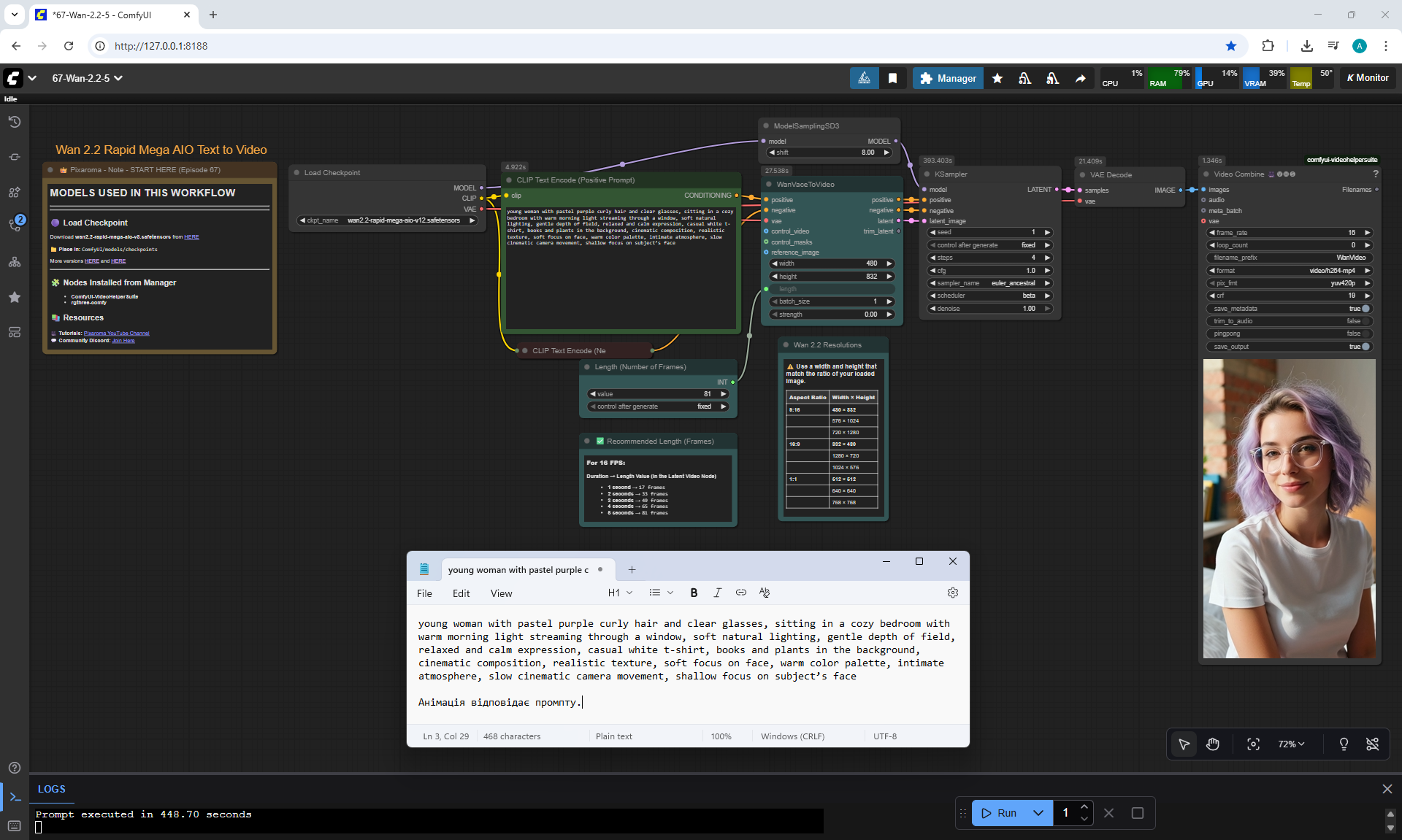
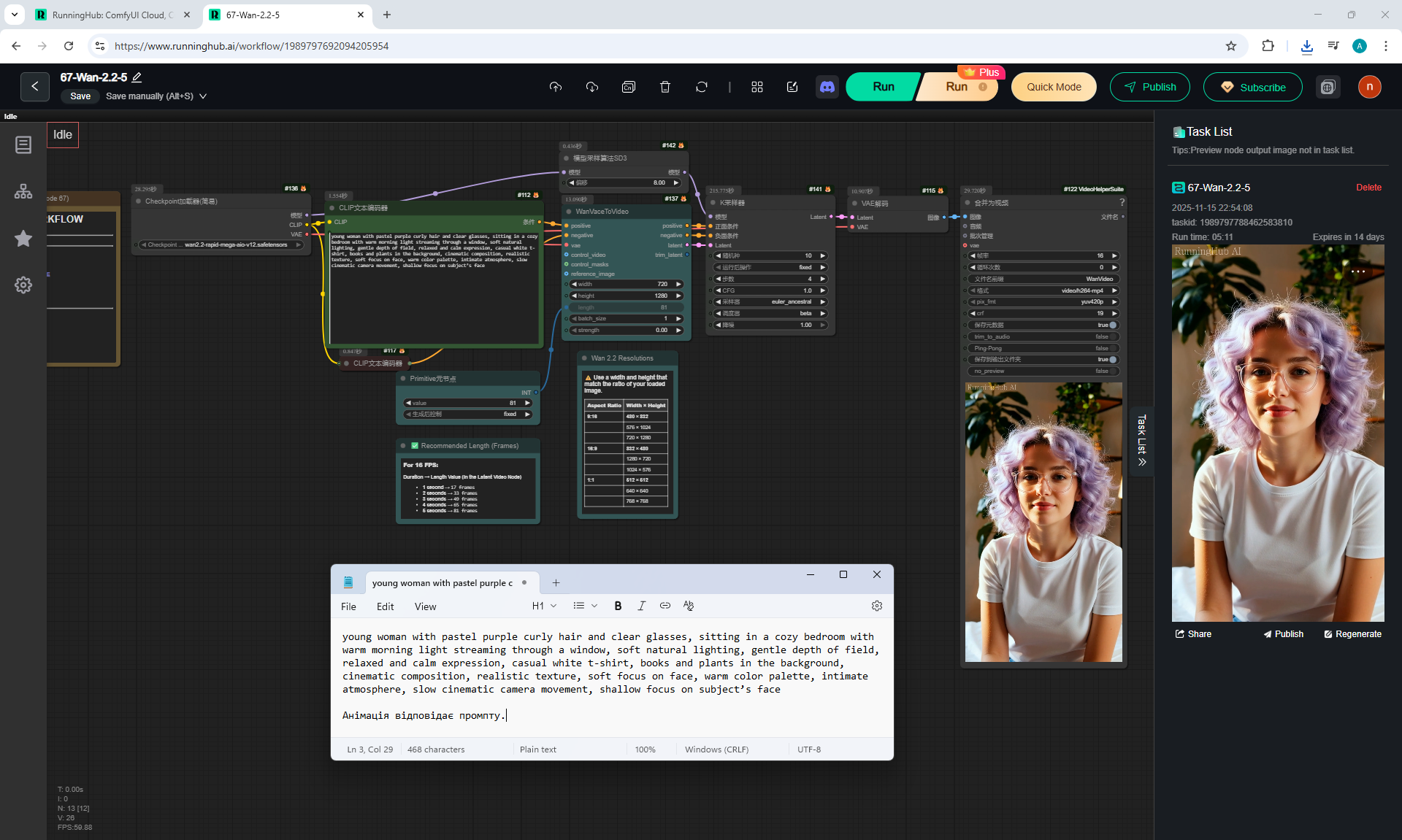
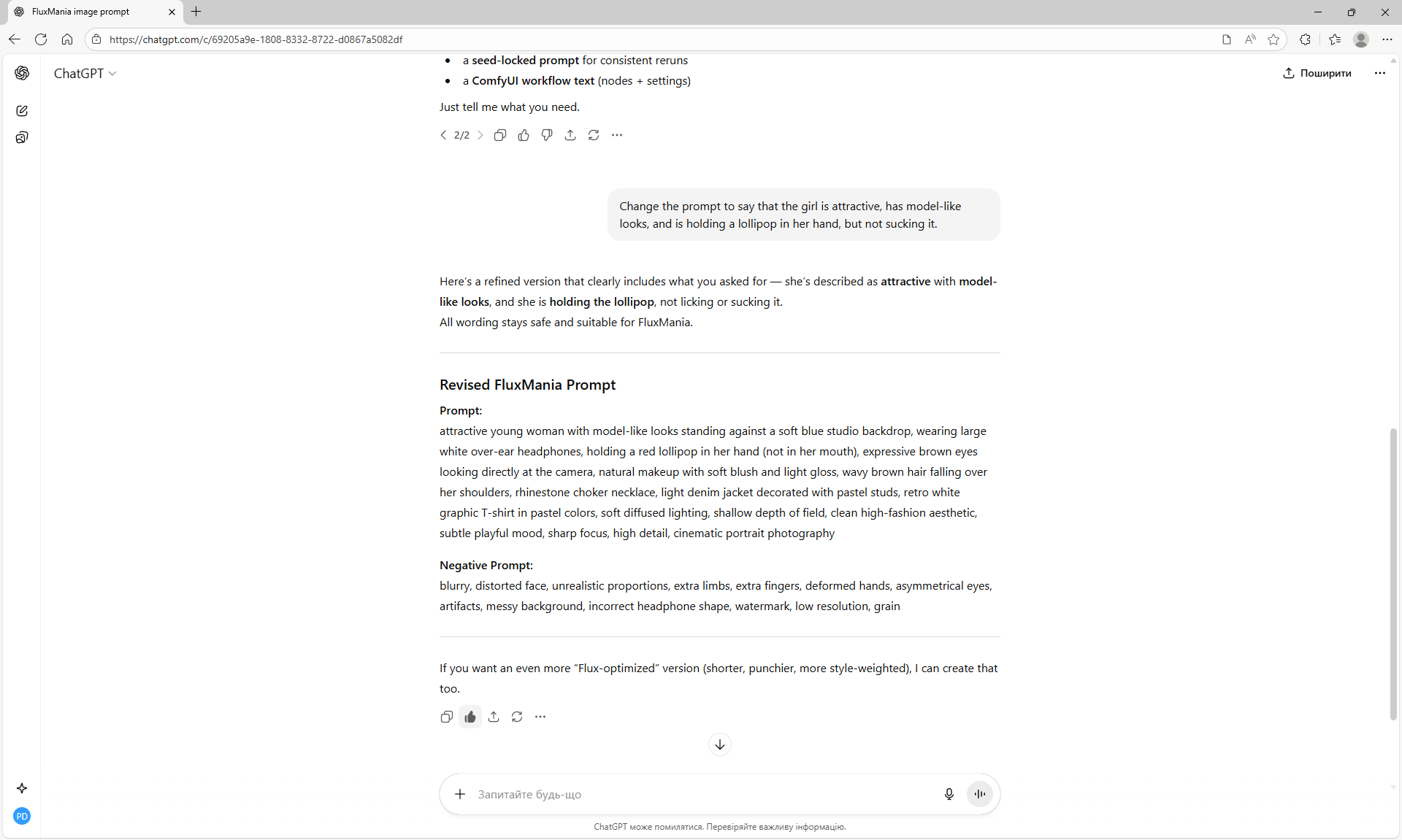
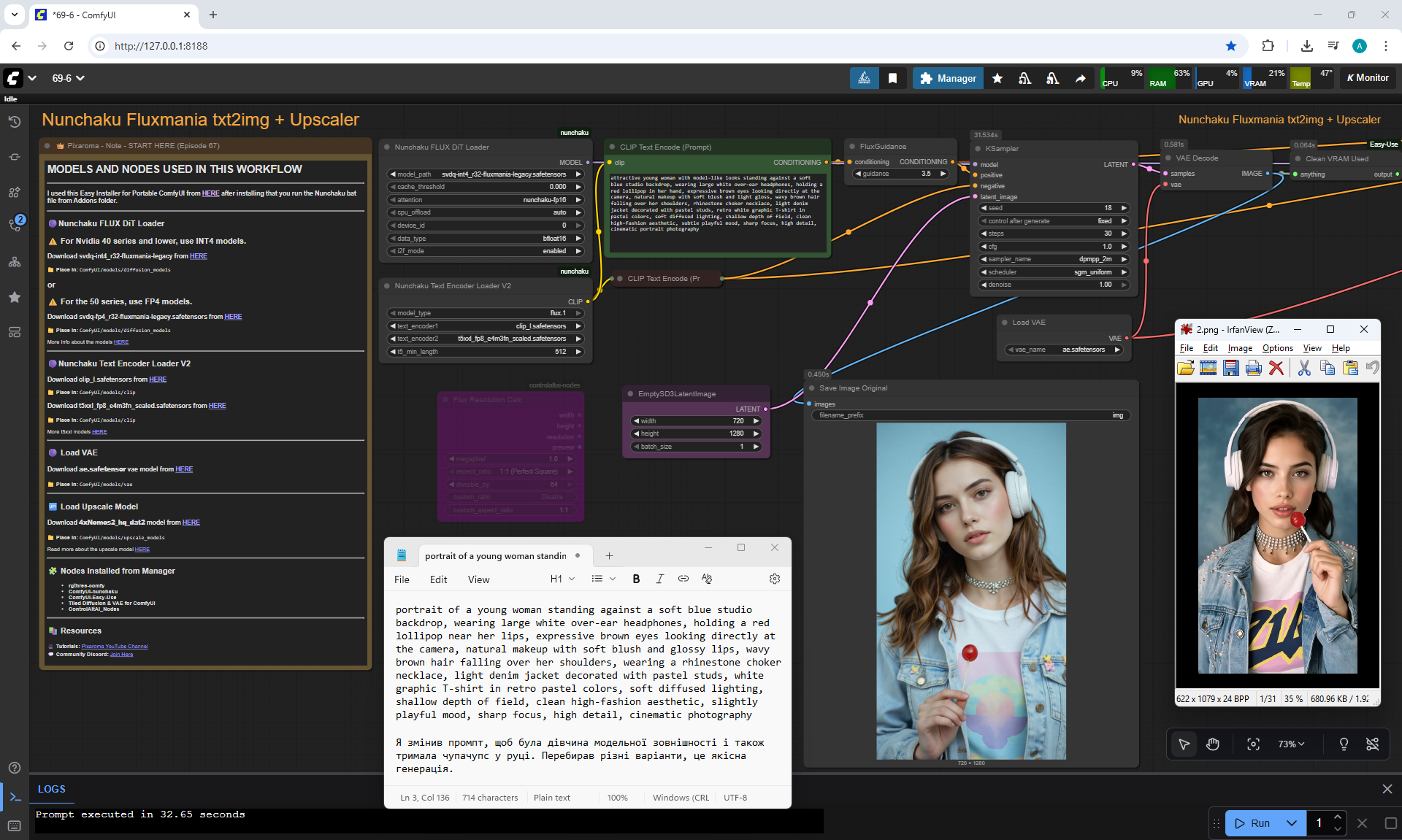
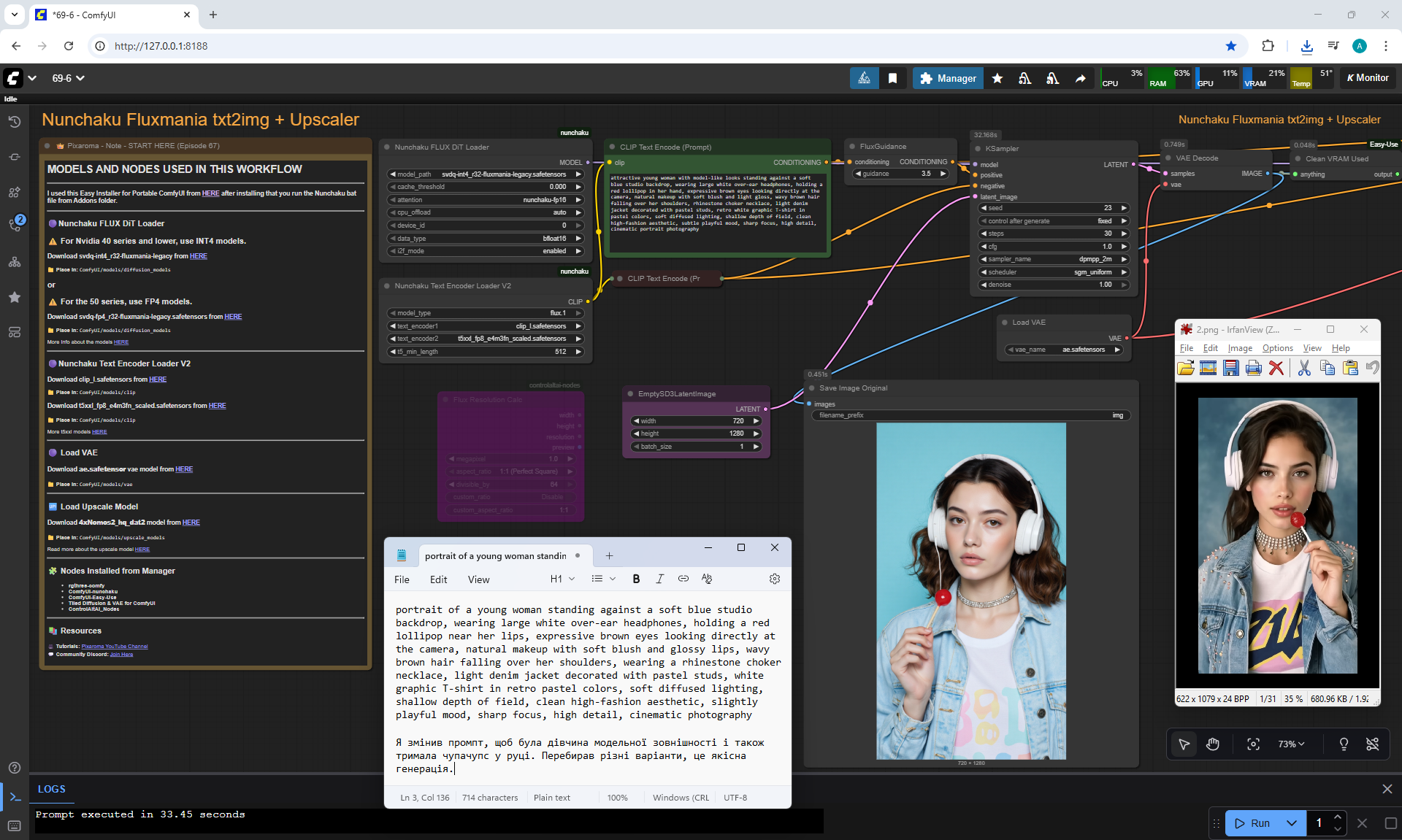
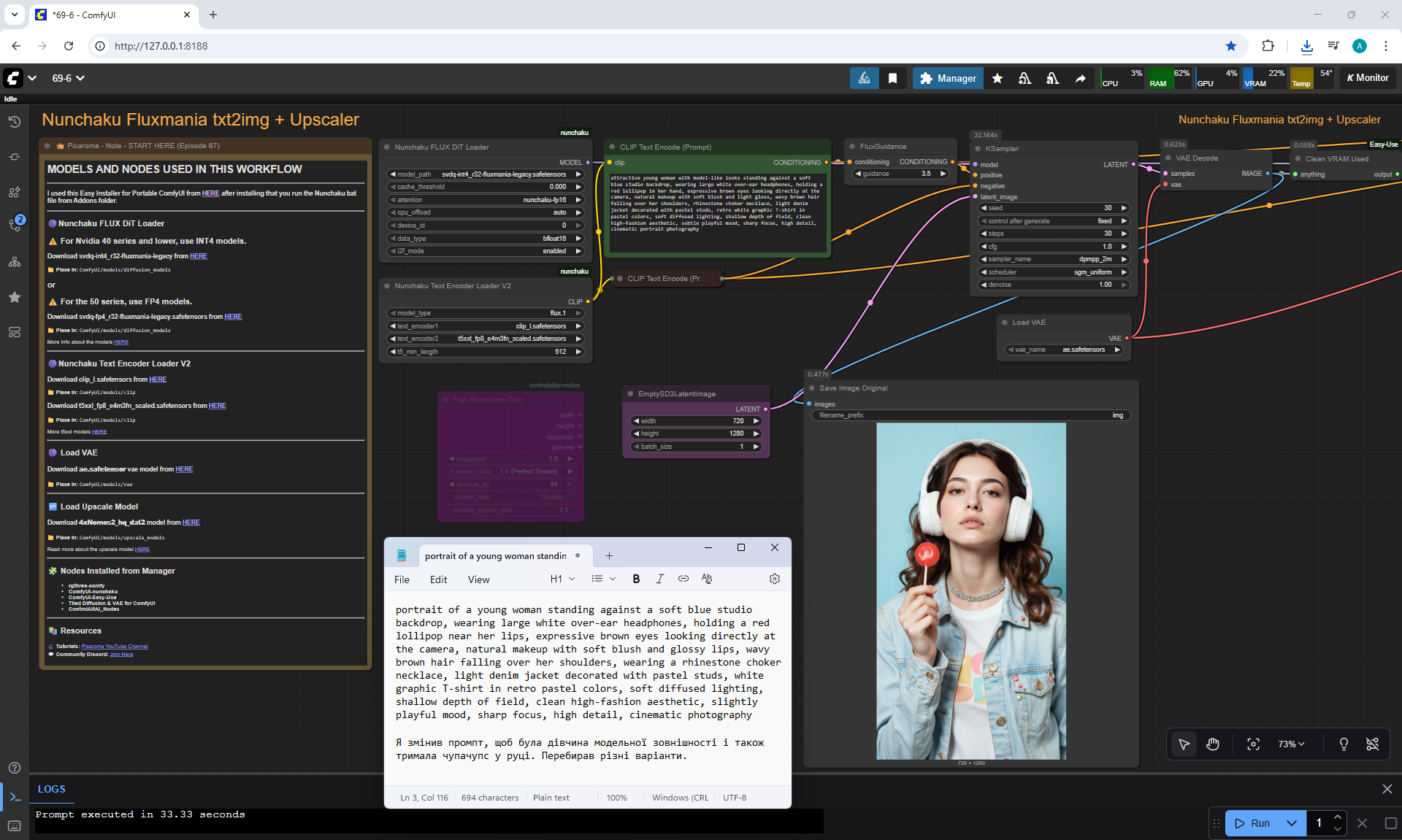
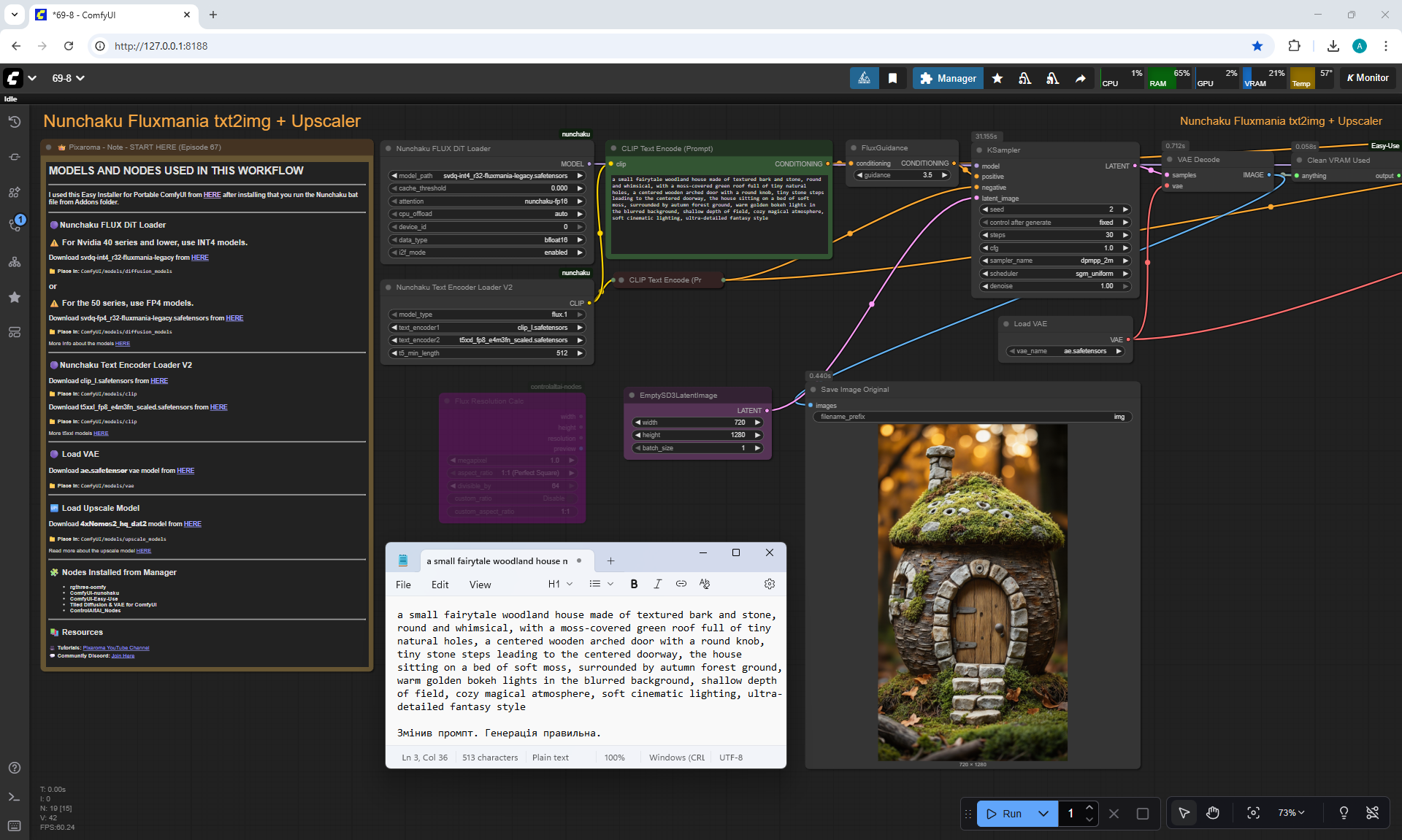
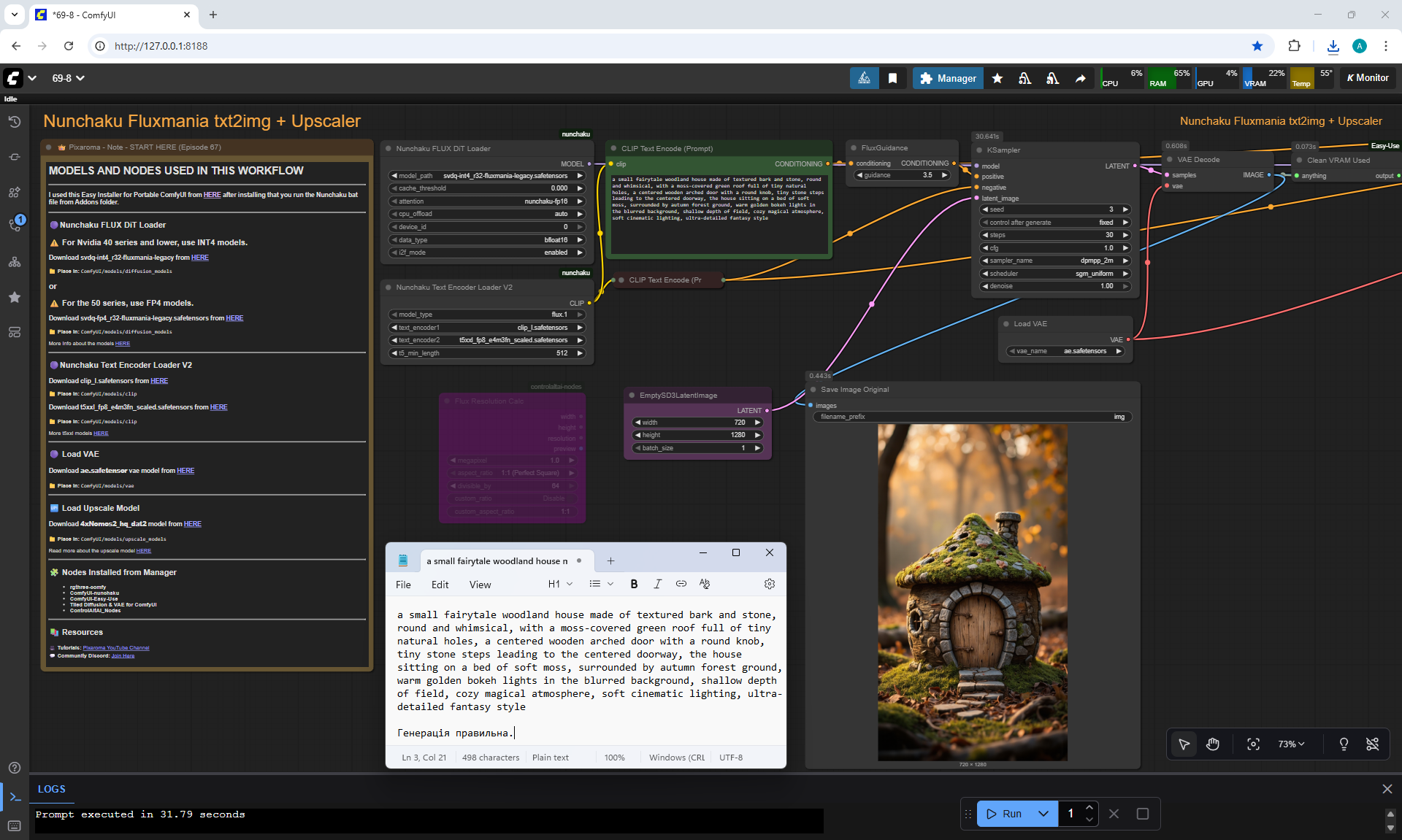
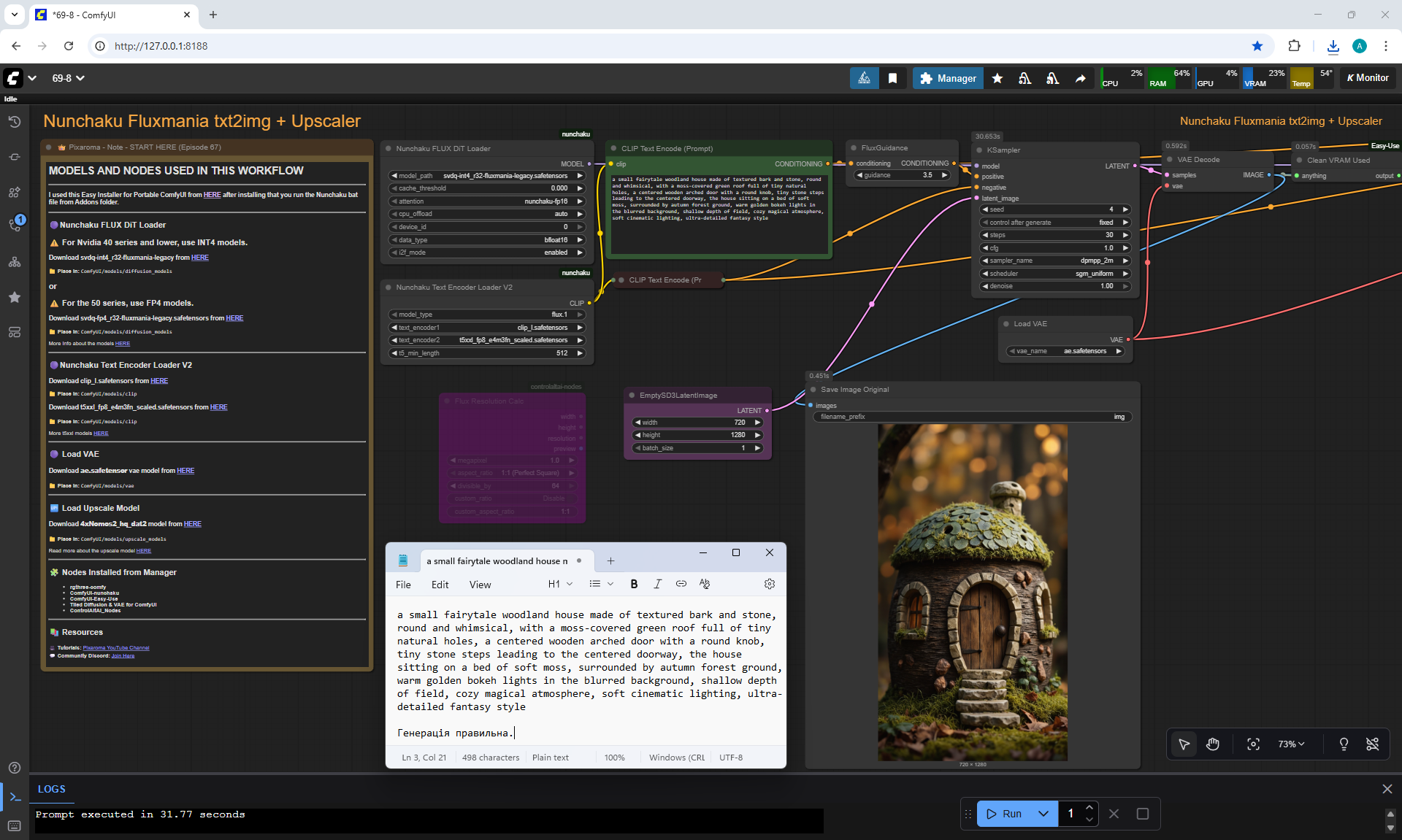
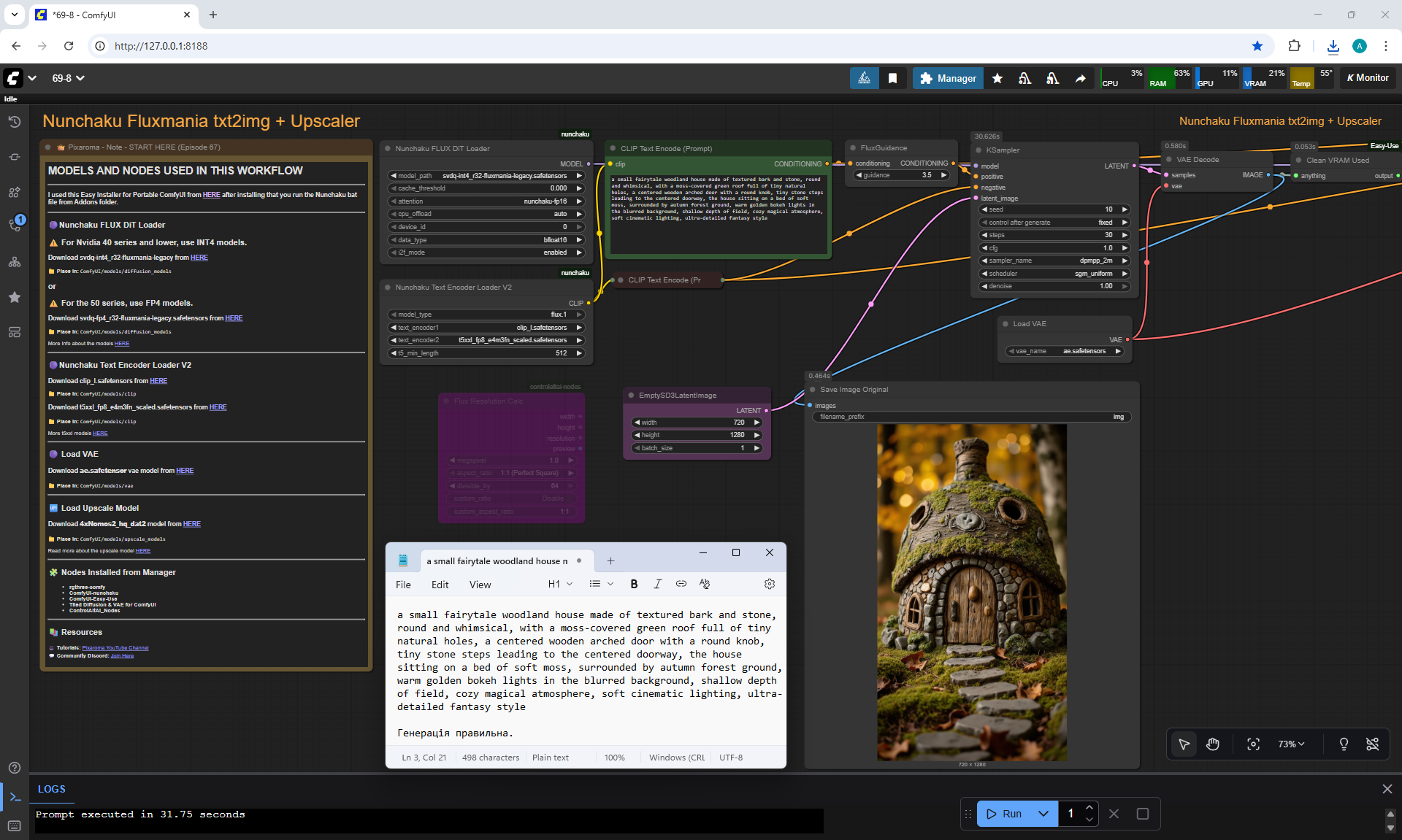
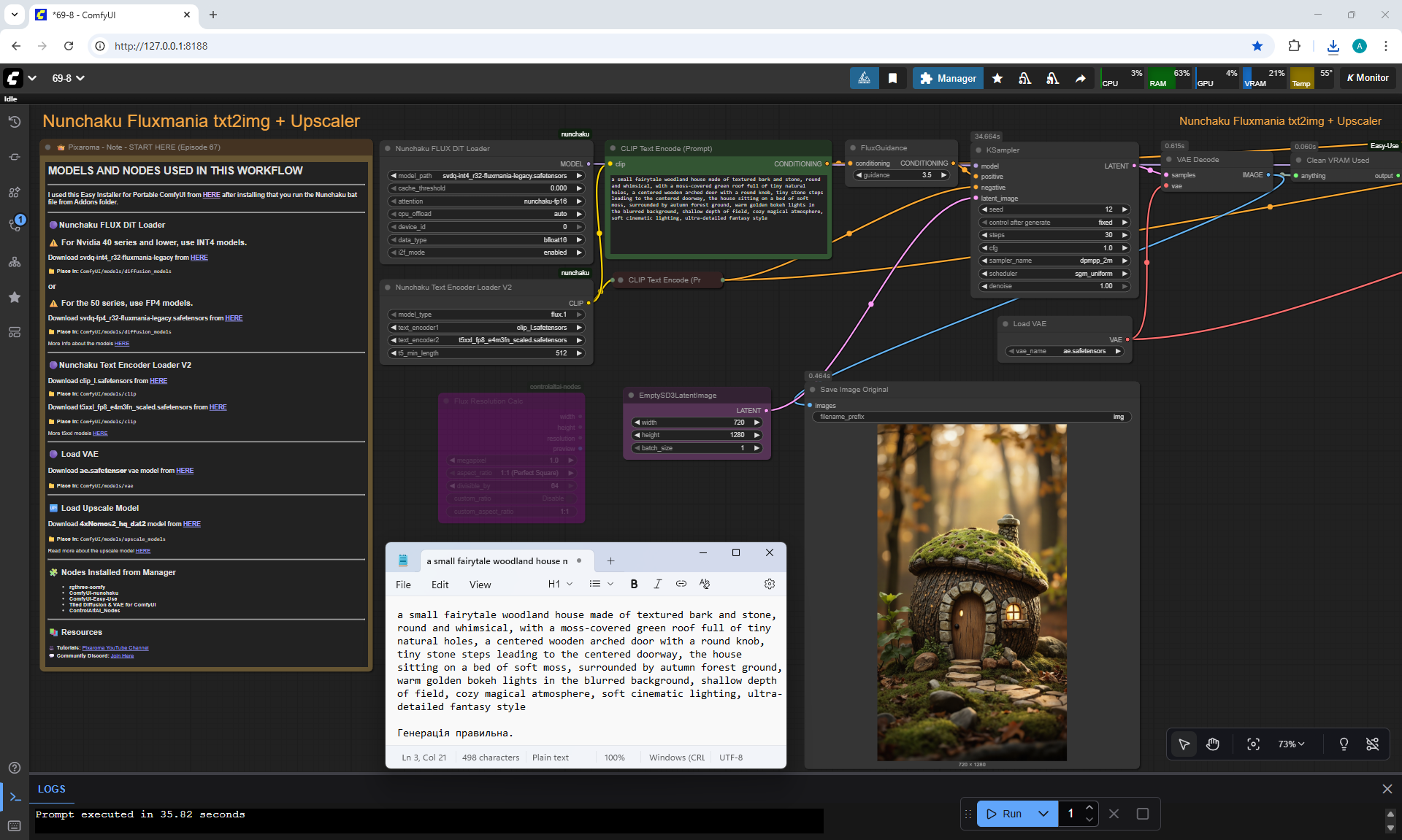
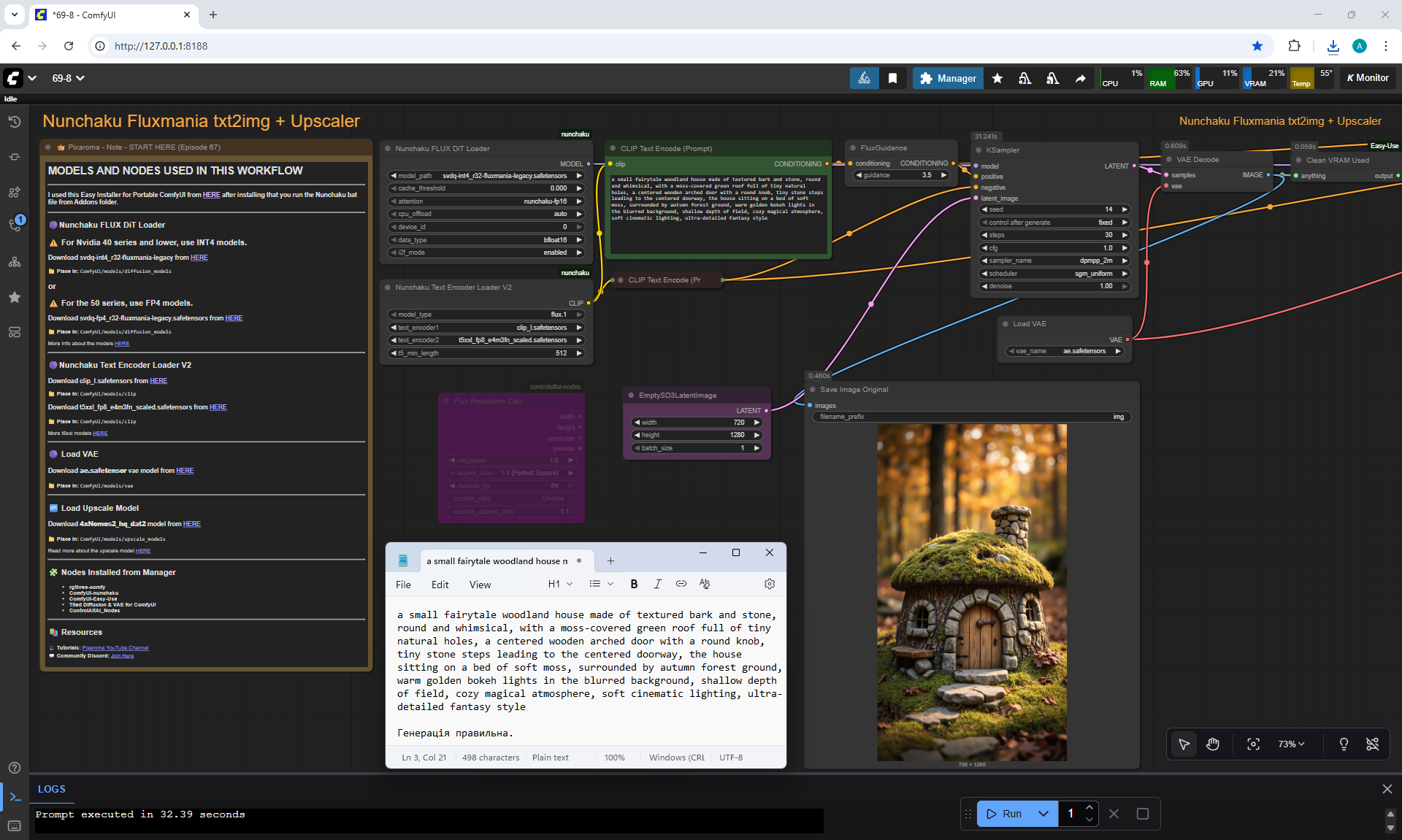
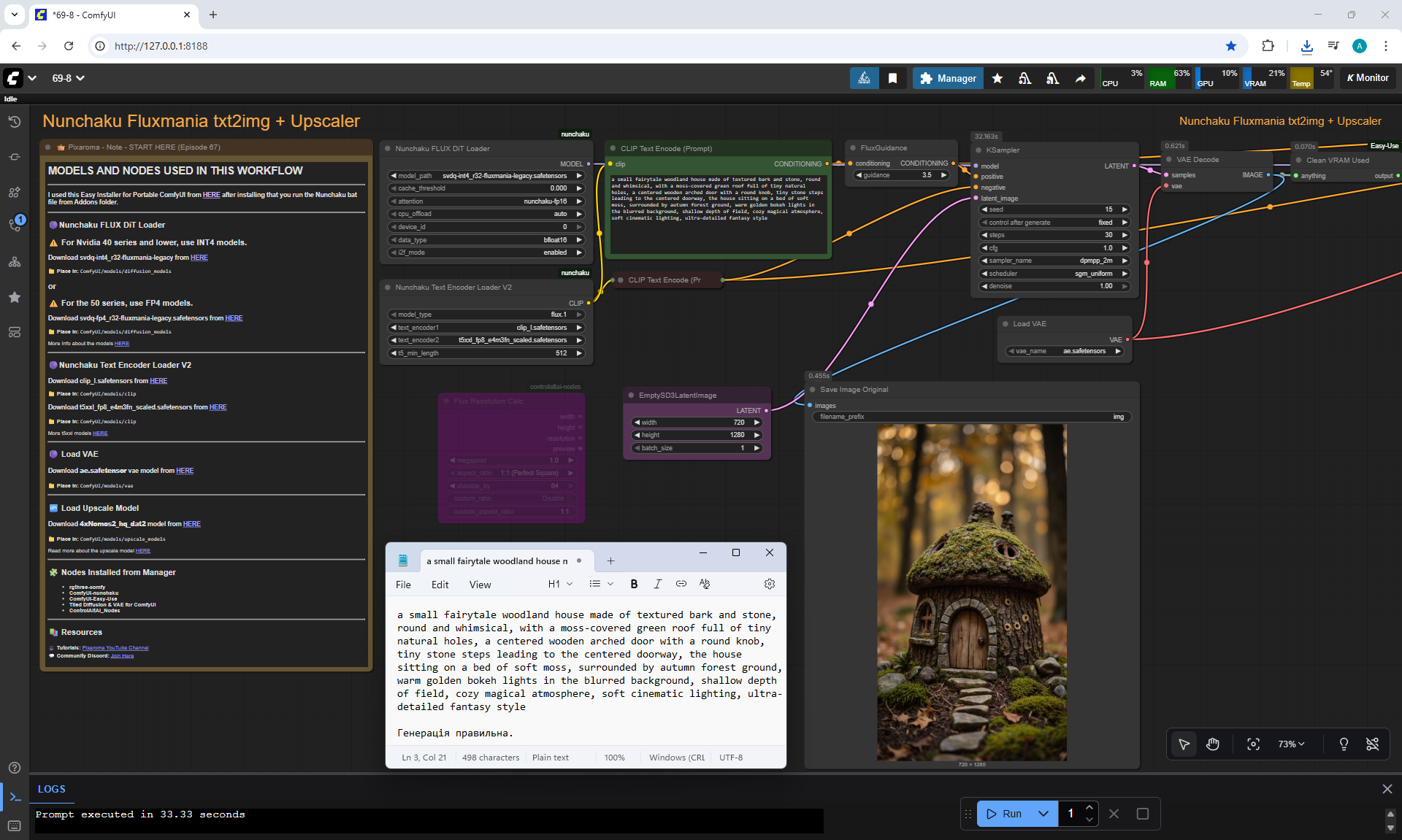
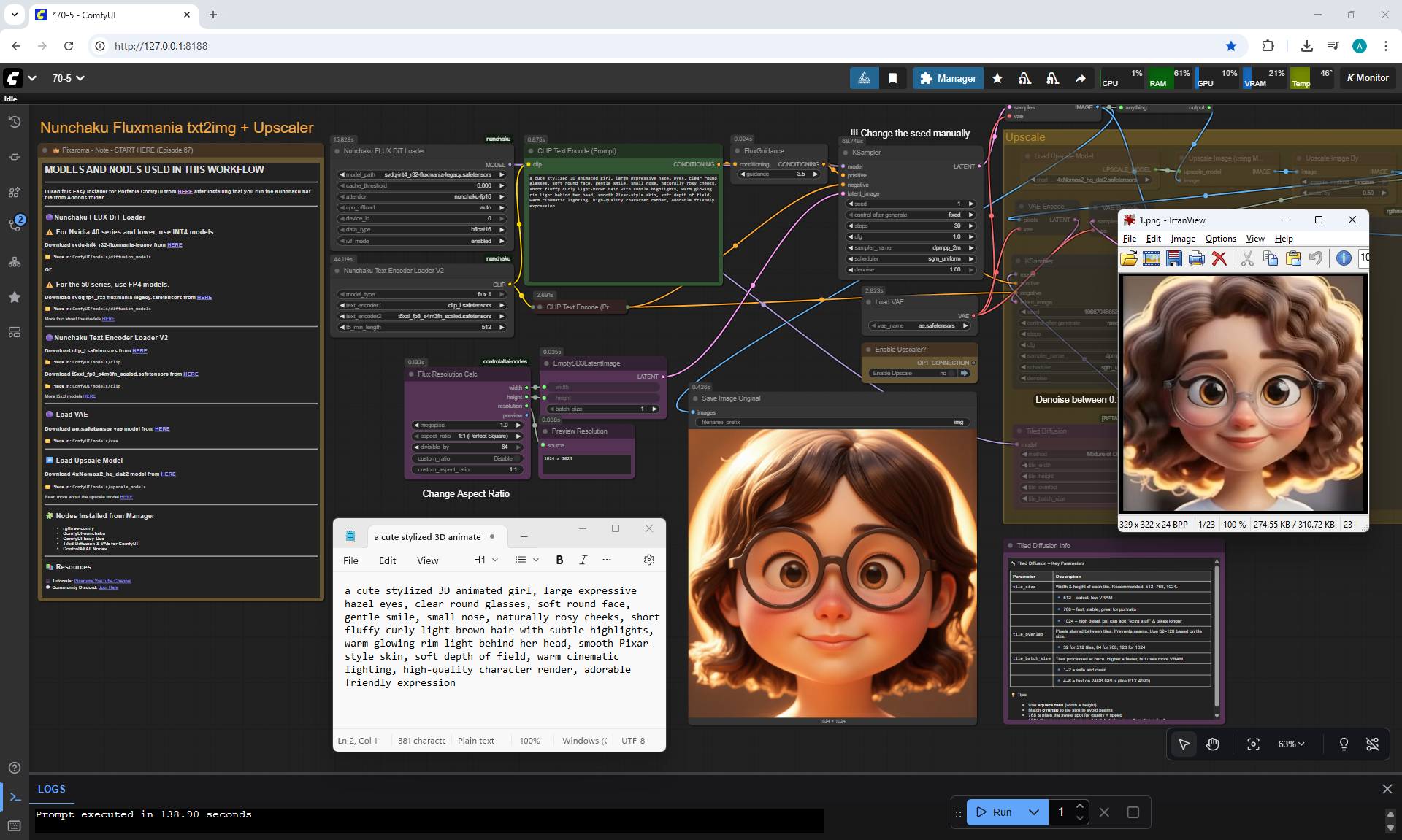
ComfyUI Tutorial Series Ep 67: Fluxmania Nunchaku + Wan 2.2 and Rapid AIO Workflows


















































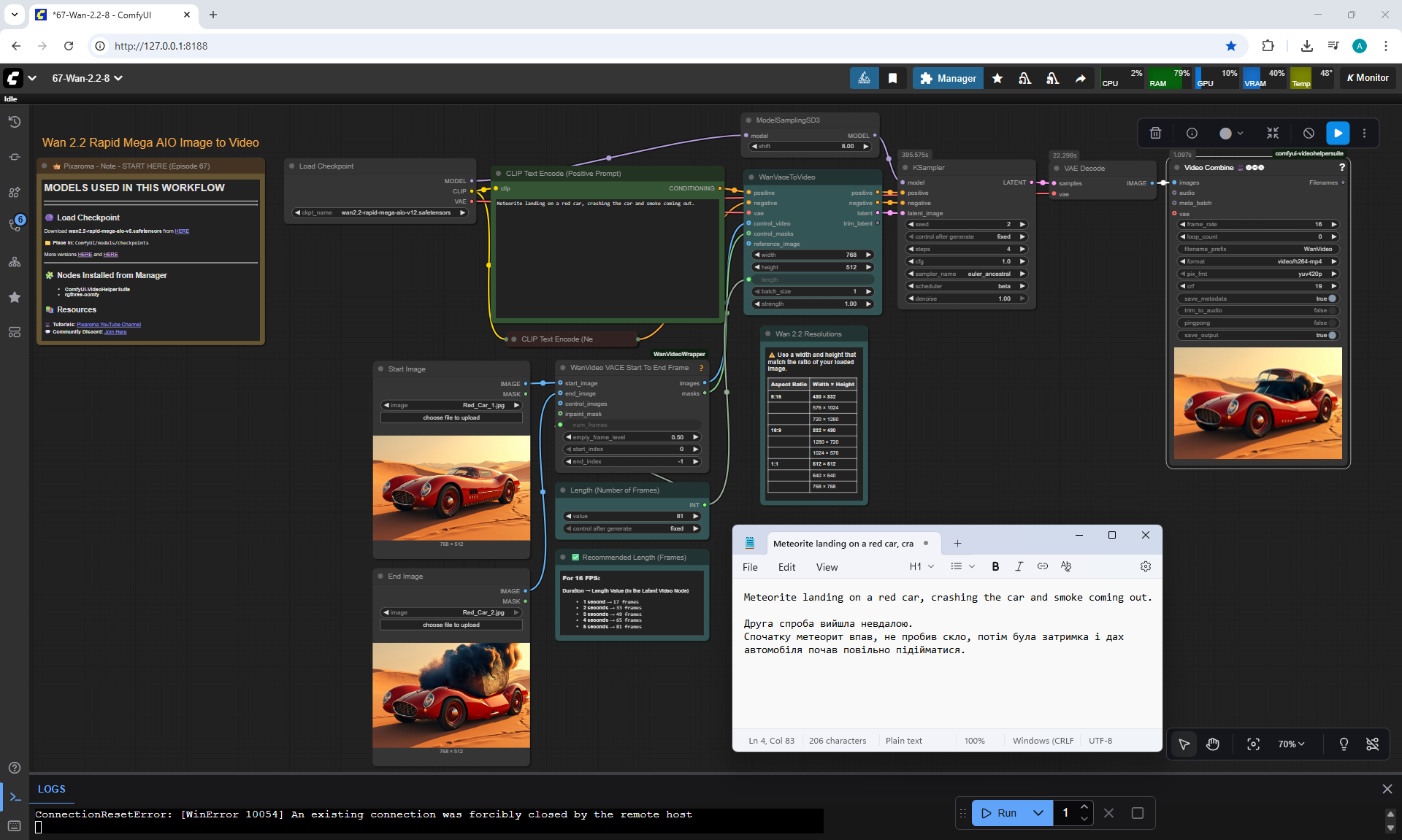
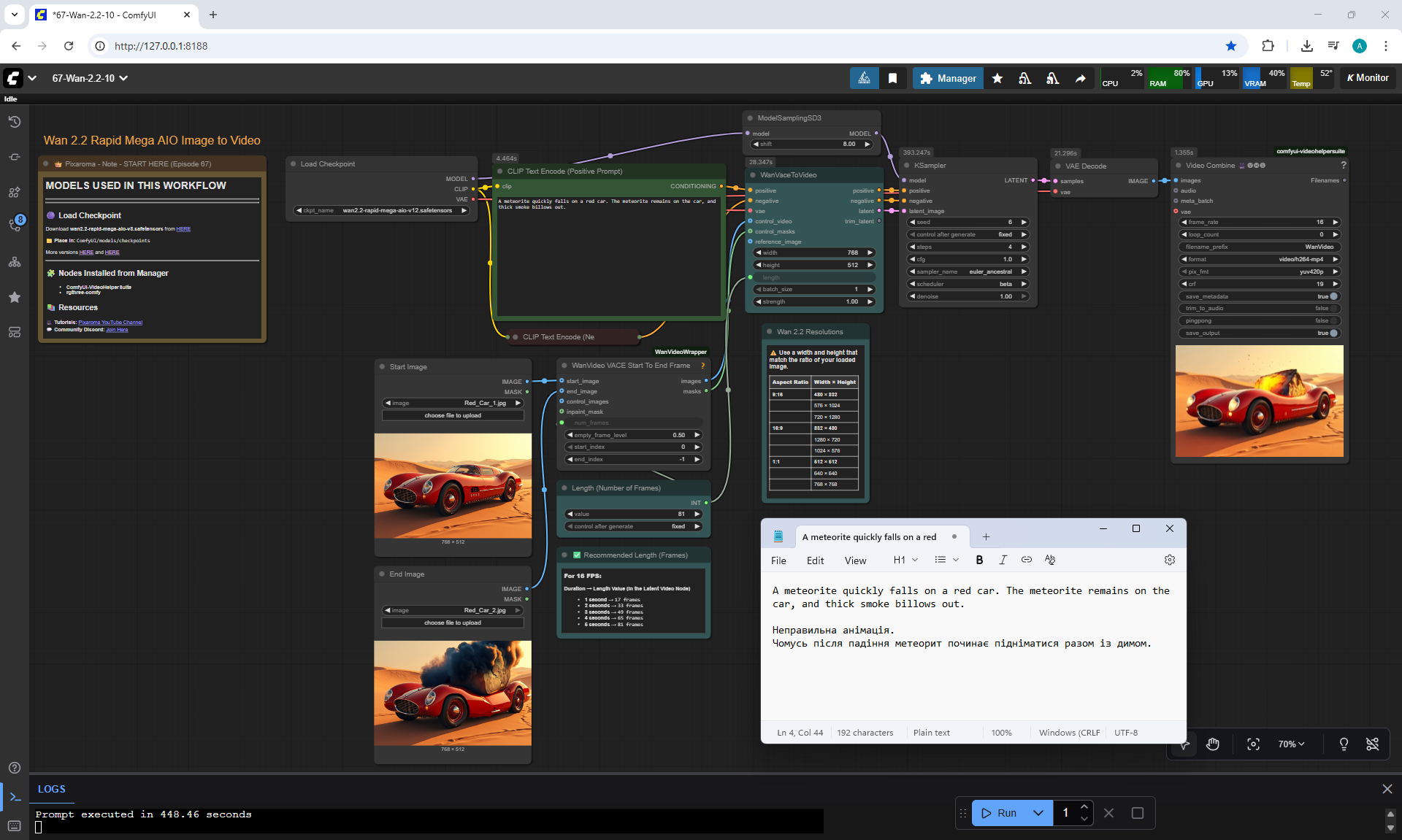
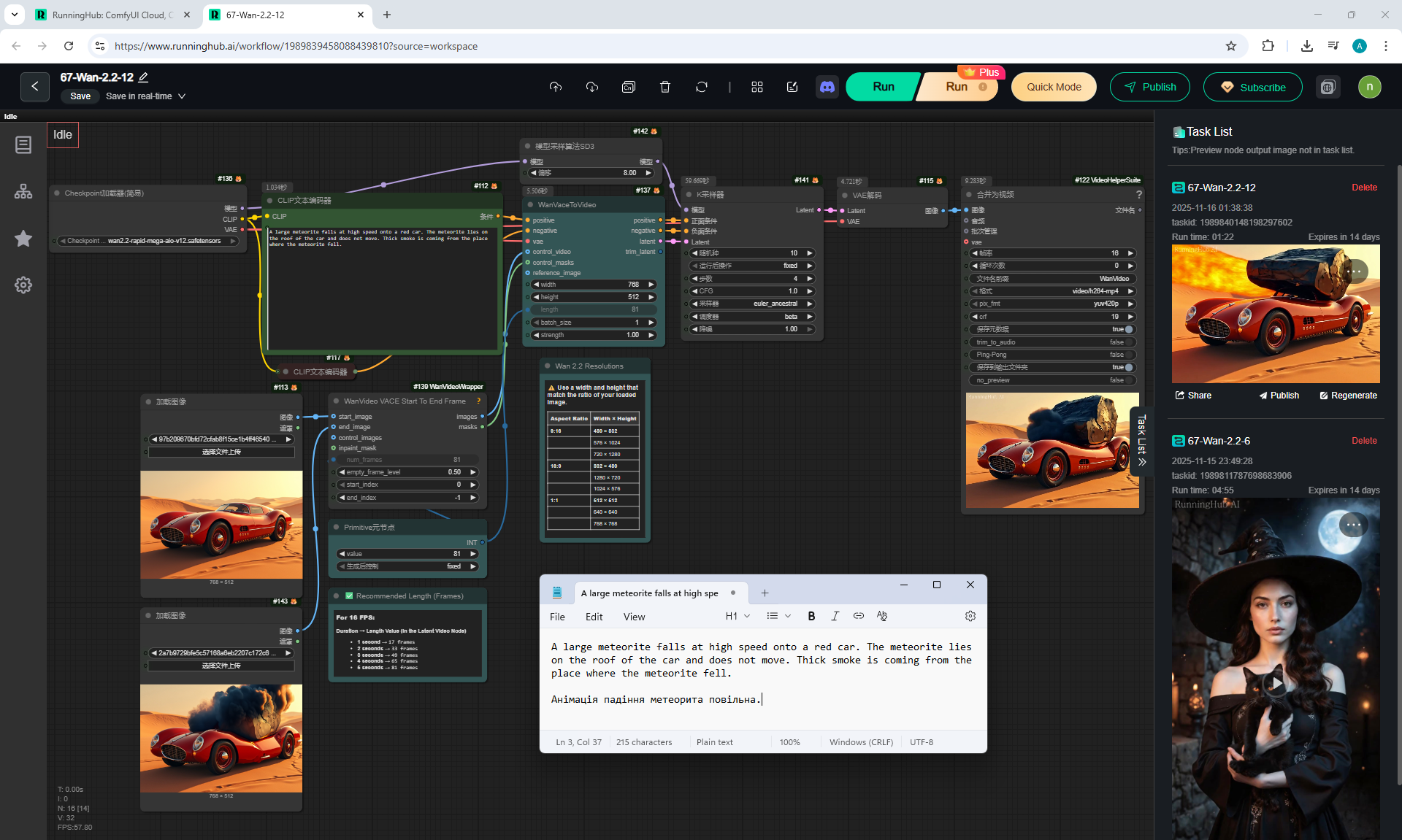
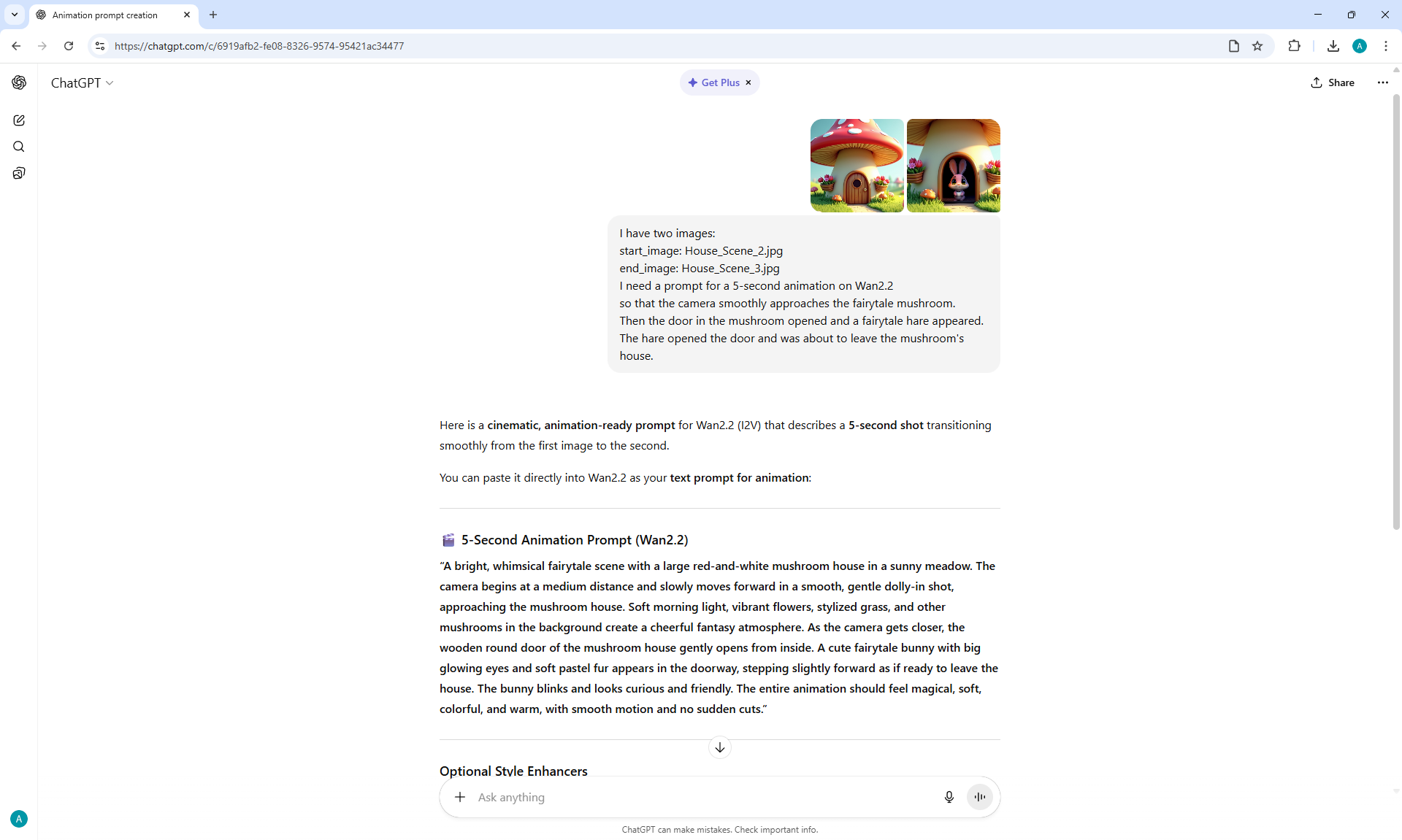
I tested this animation in the previous
lesspn 48 LTX 0.9.7
In LTX, it is possible to add two frames between which the animation takes place.
In Wan2.2, this version also has the ability to add a start and end image for the animation.
This version of Wan2.2 generates animations better, more detailed than LTX 0.9.7.
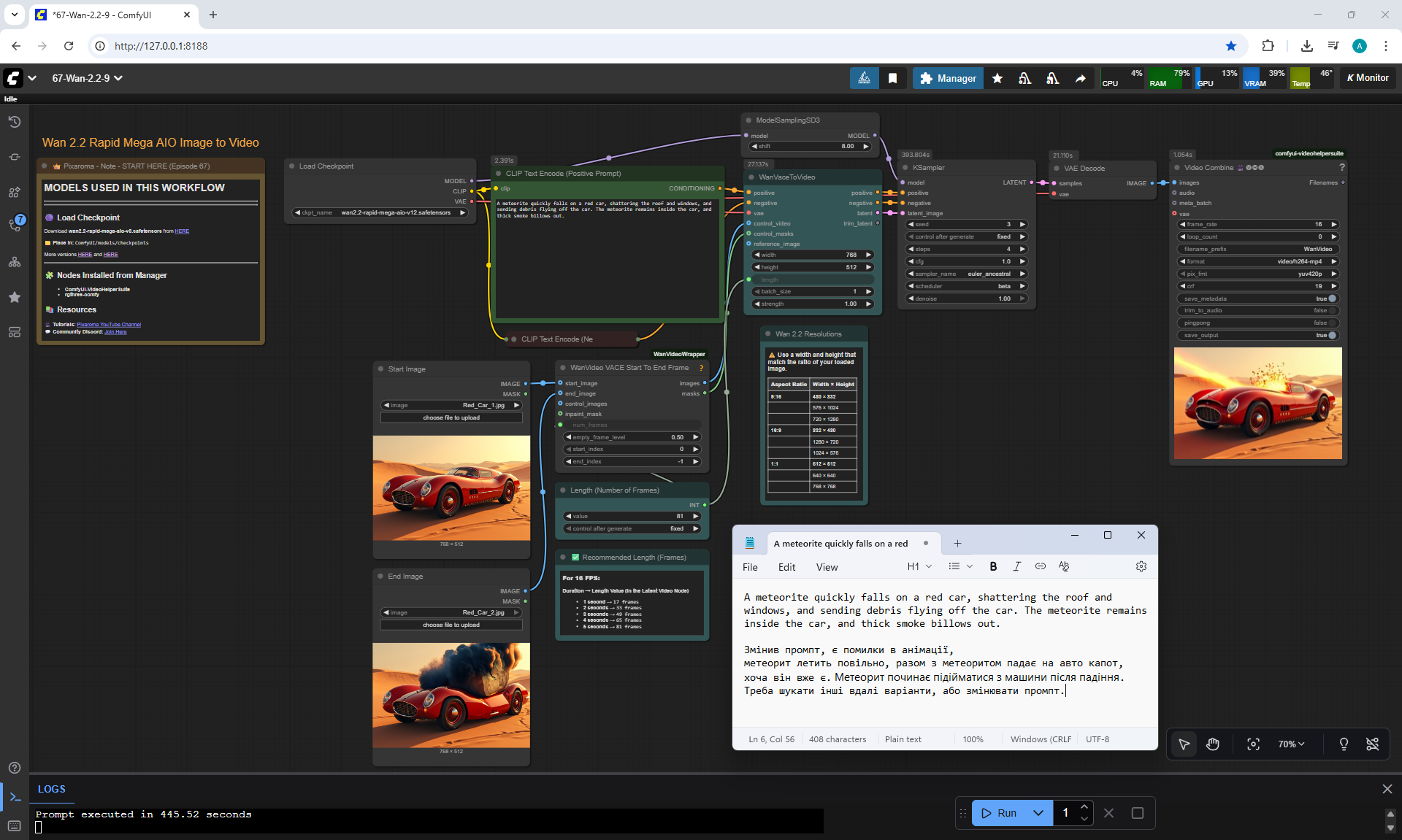
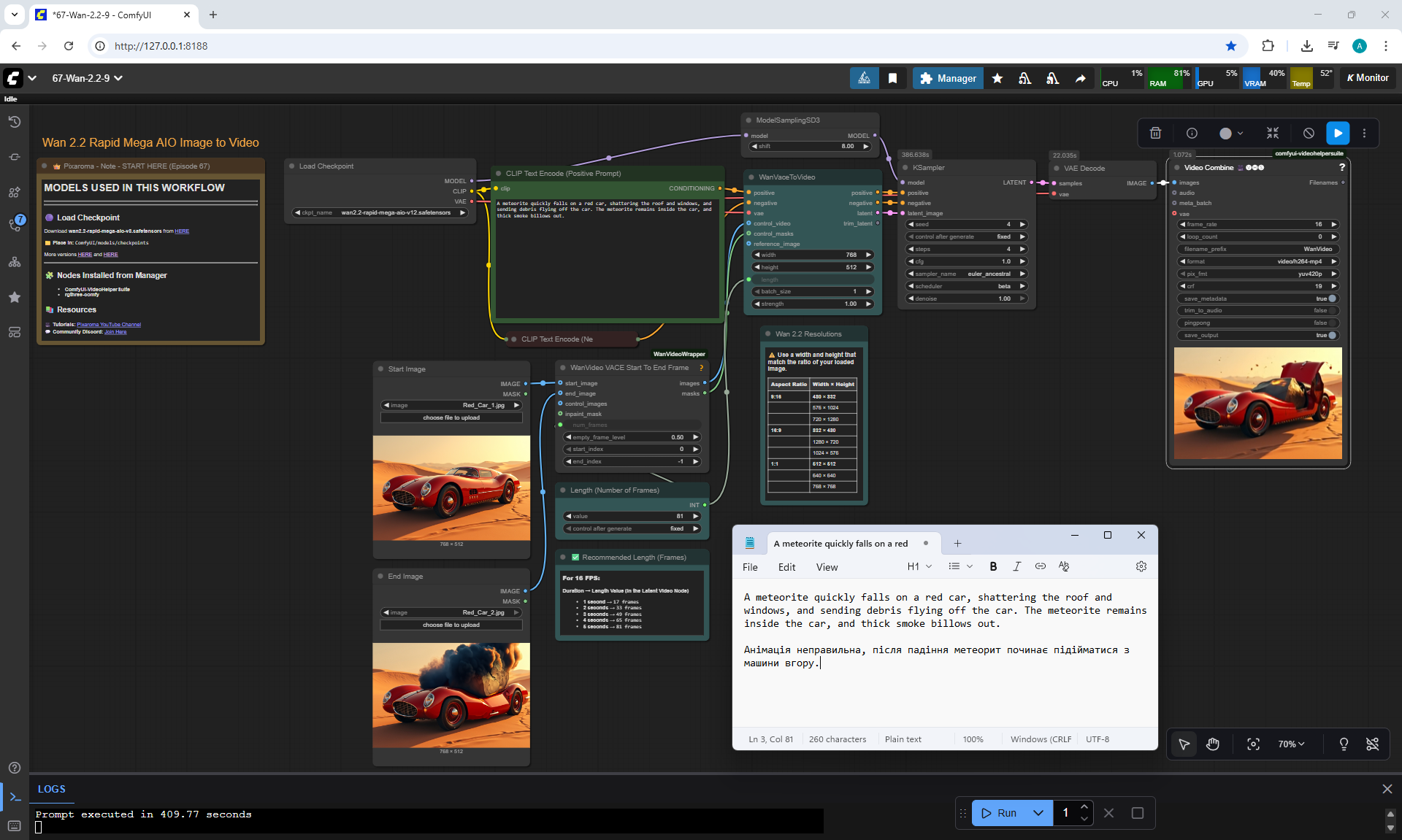
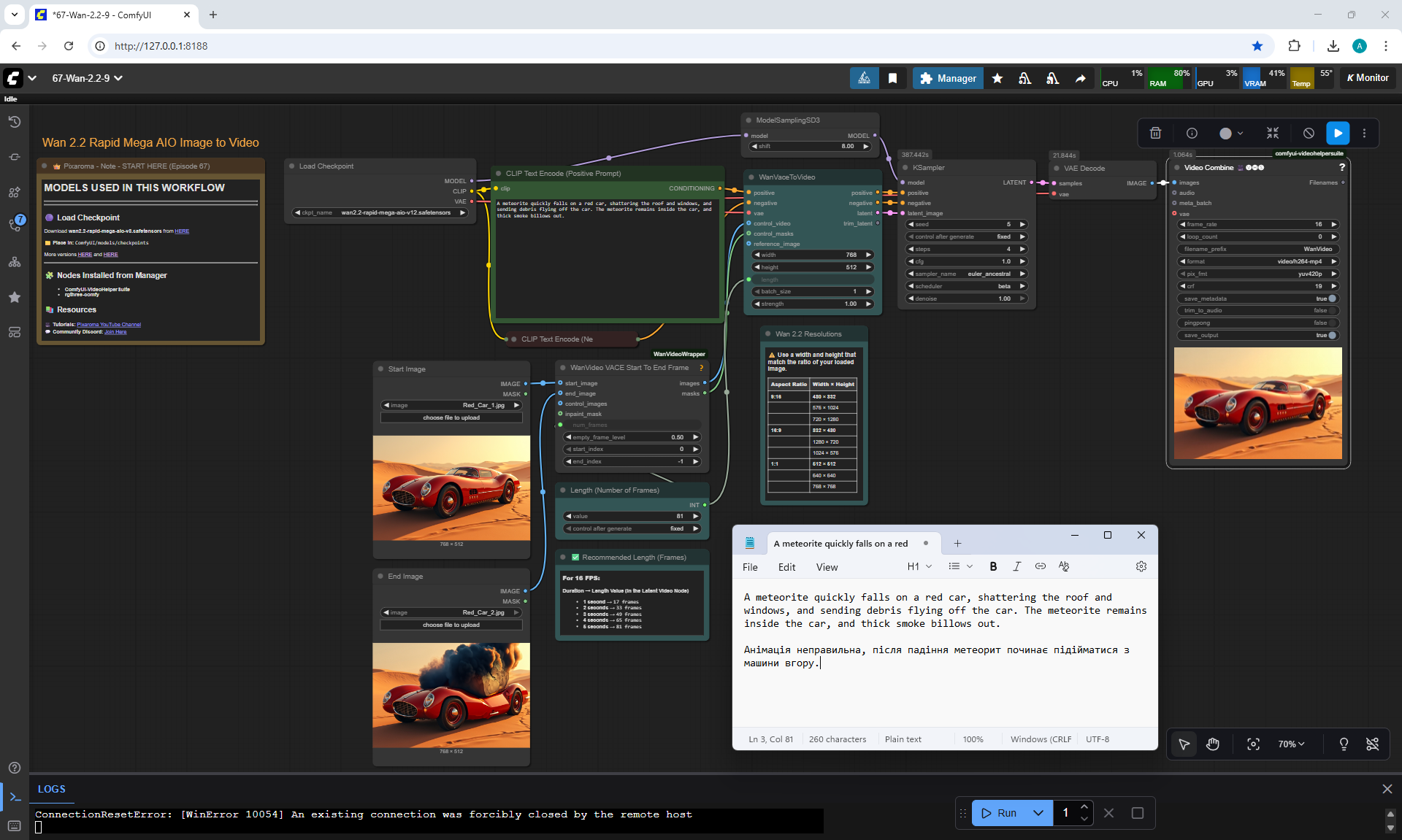
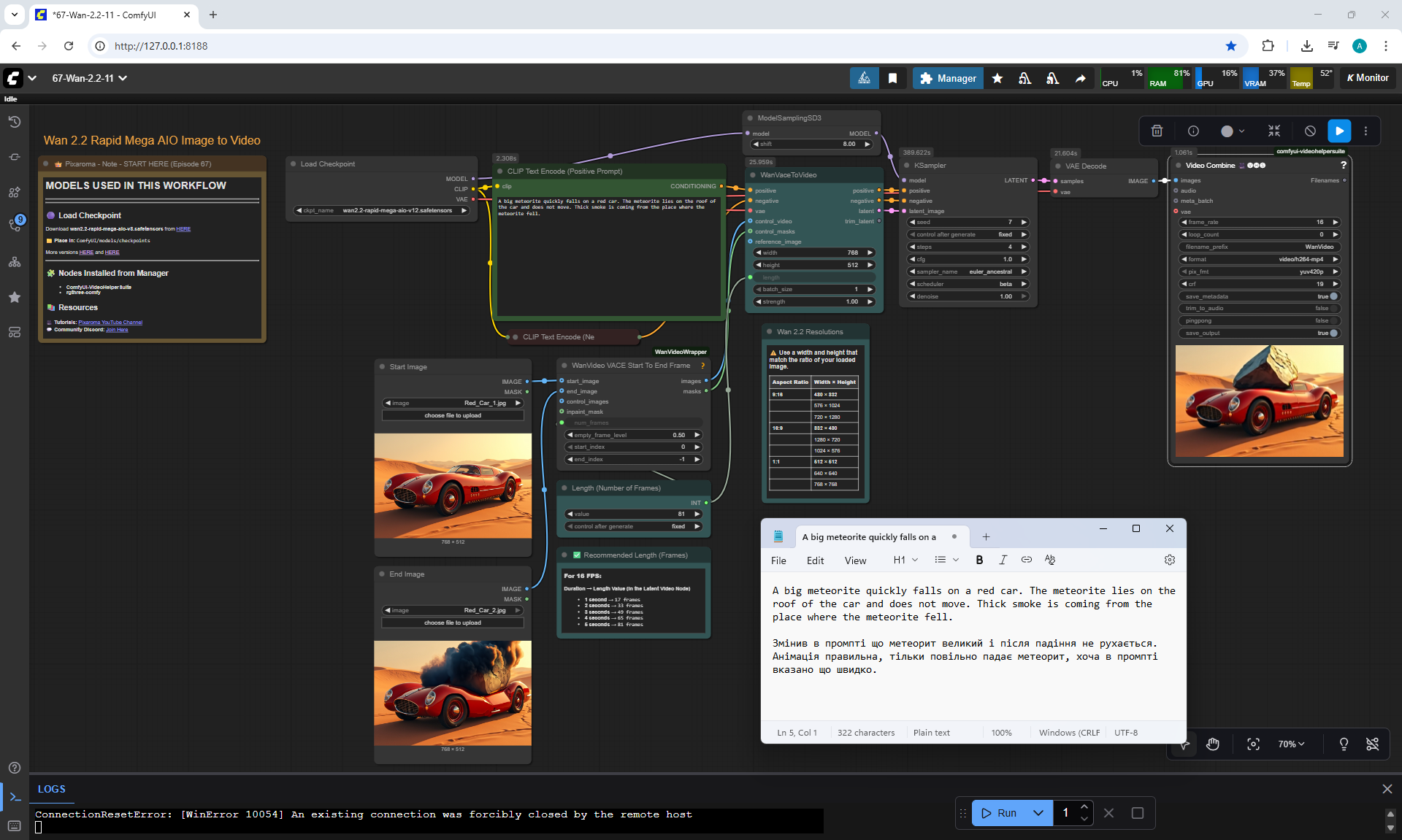
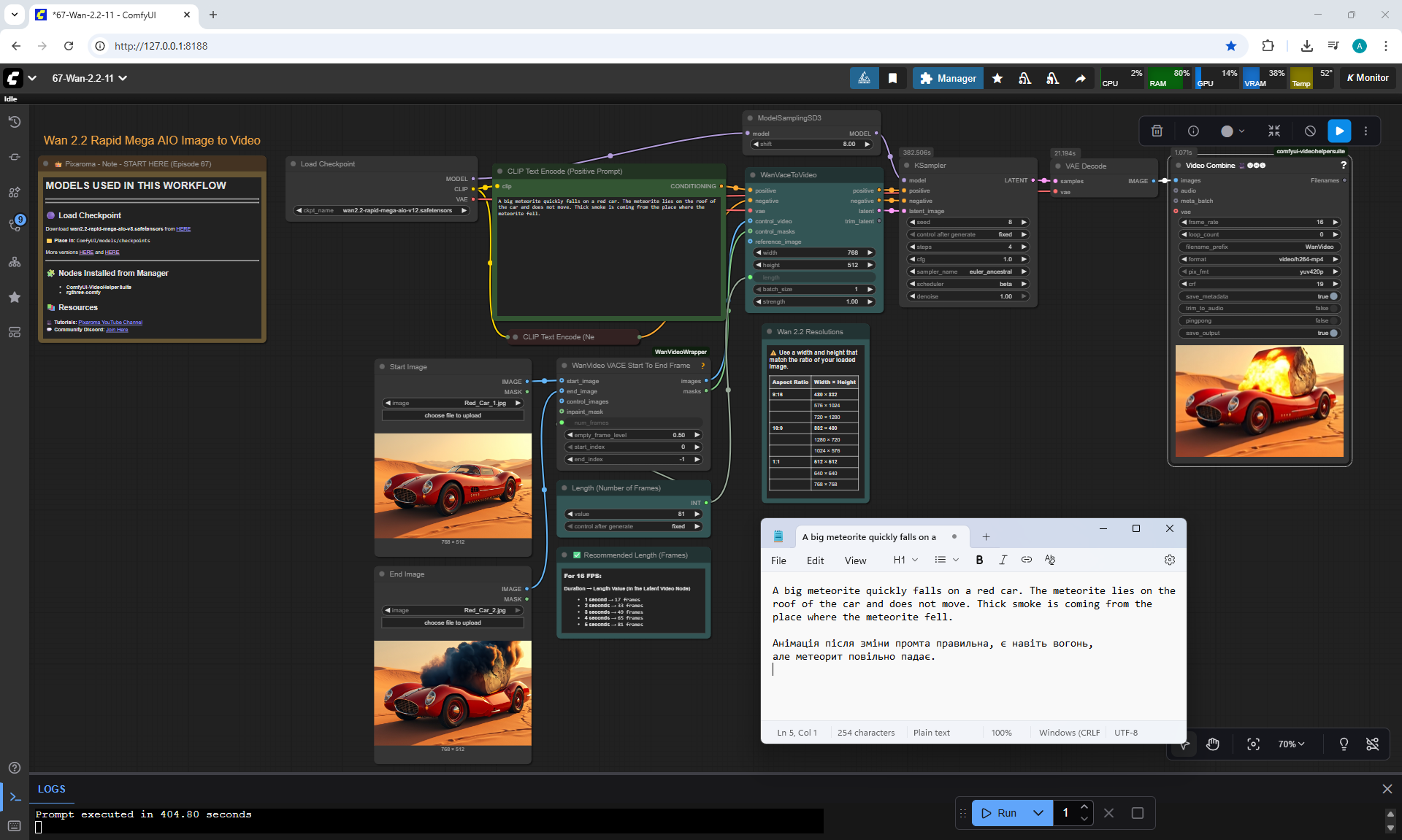
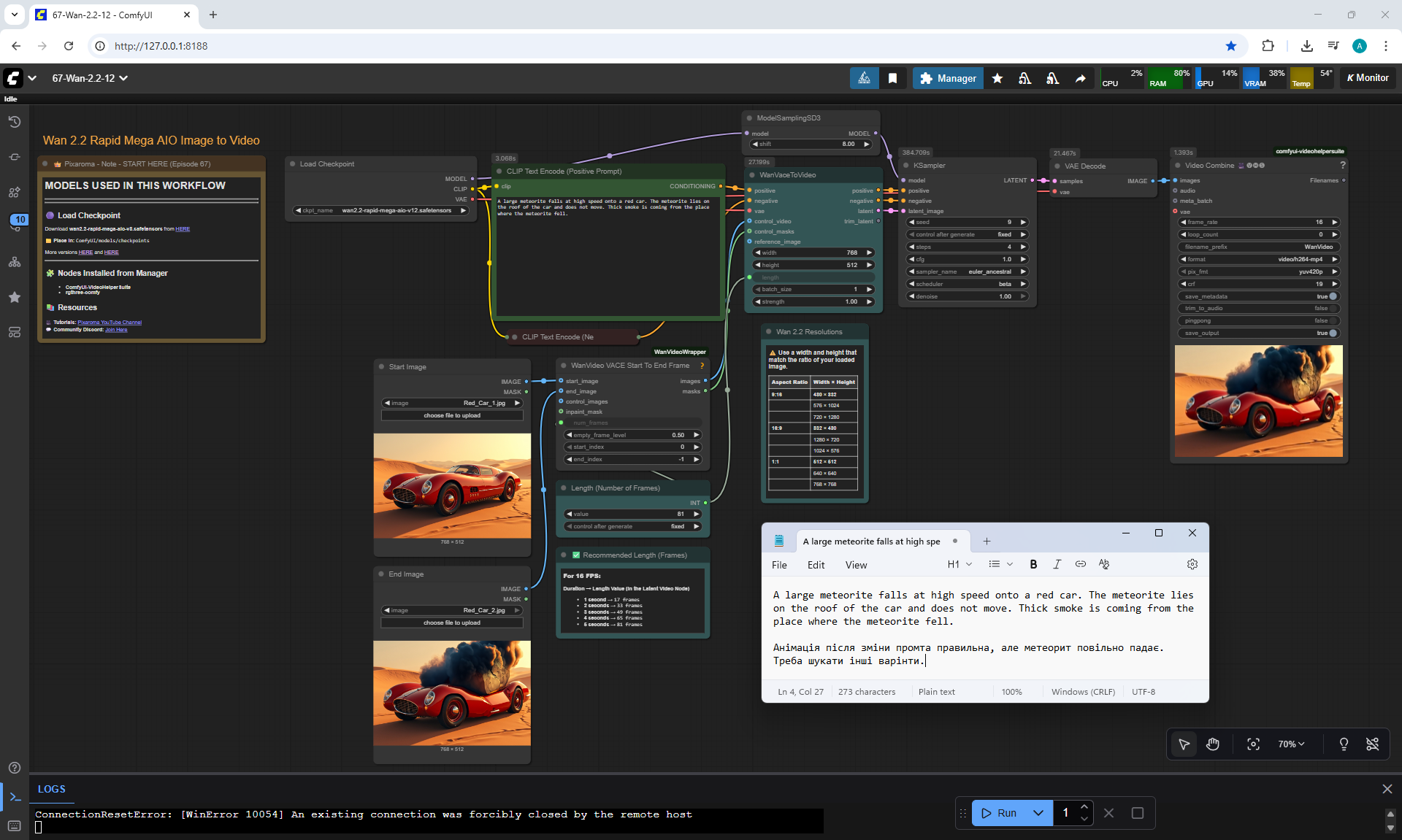
But there are errors in the animation.
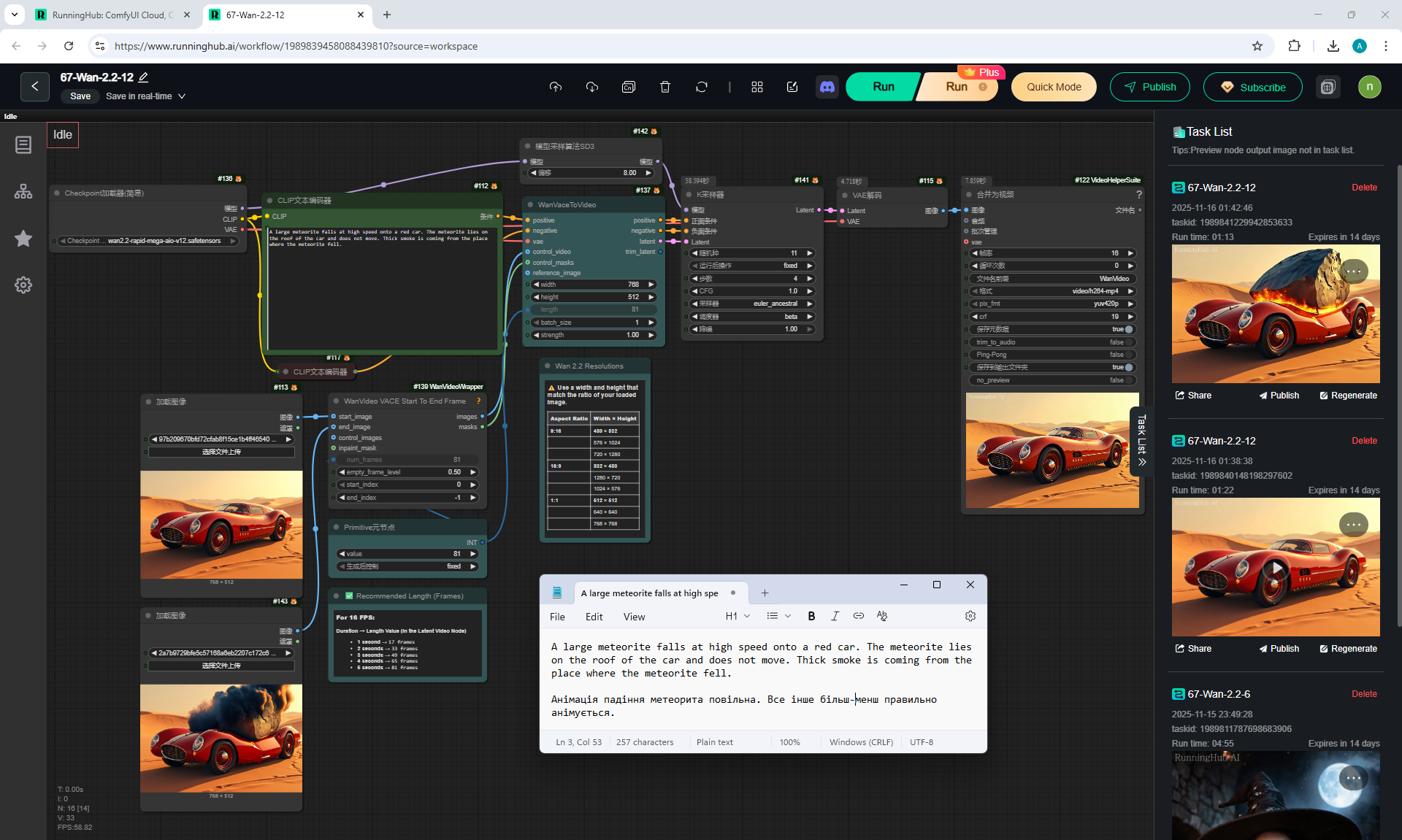
For example, a meteorite can fall slowly, can fly from different directions, even flew from the ground once, if you do not specify where the meteorite is flying from. The speed of the meteorite is not set, even if you specify that it falls quickly.
When a meteorite falls into a car, incorrect animations may occur. The meteorite may fall, lie down, start to rise up, then smoke will come out or a second hood may rise from the car, the first hood of the car does not move.













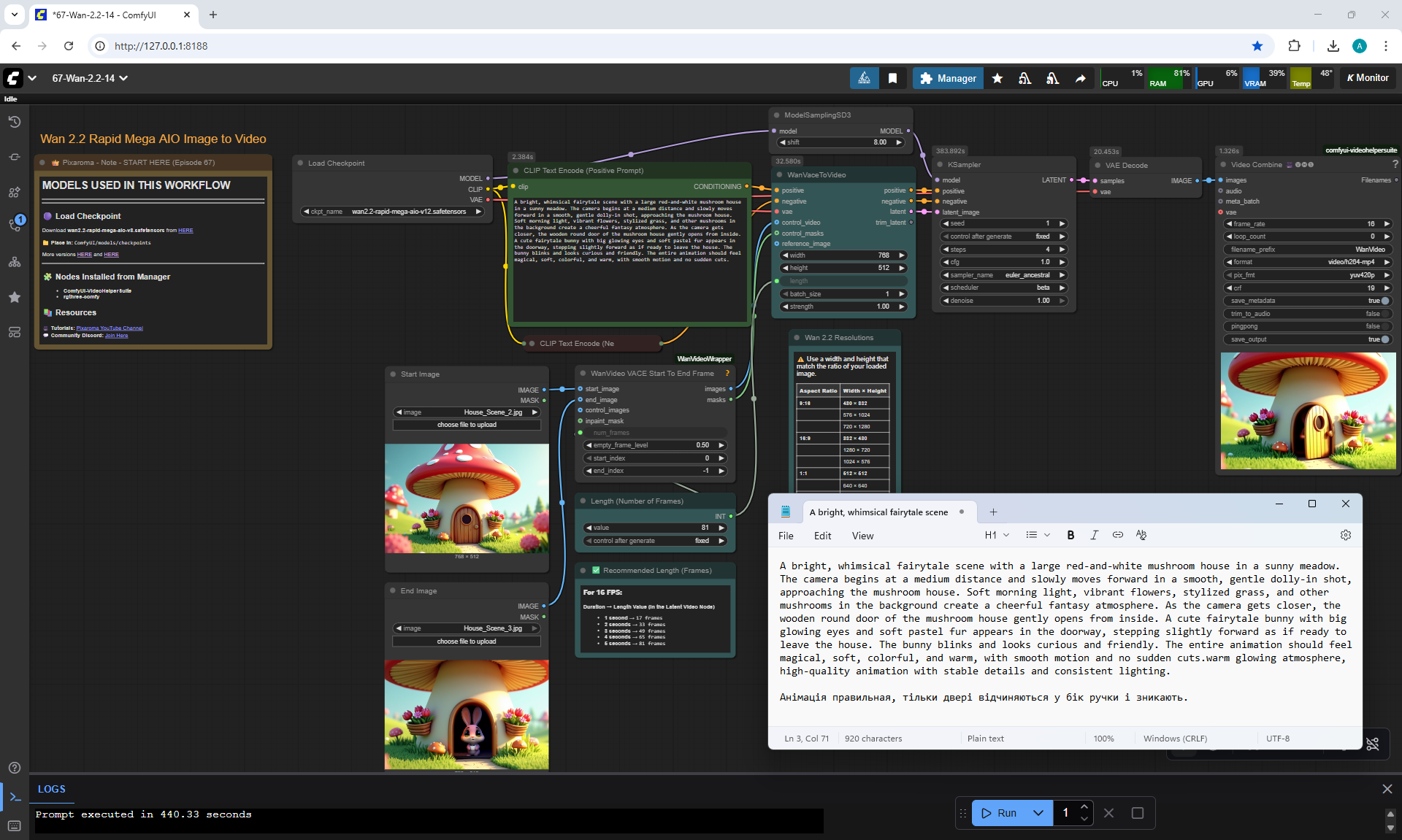
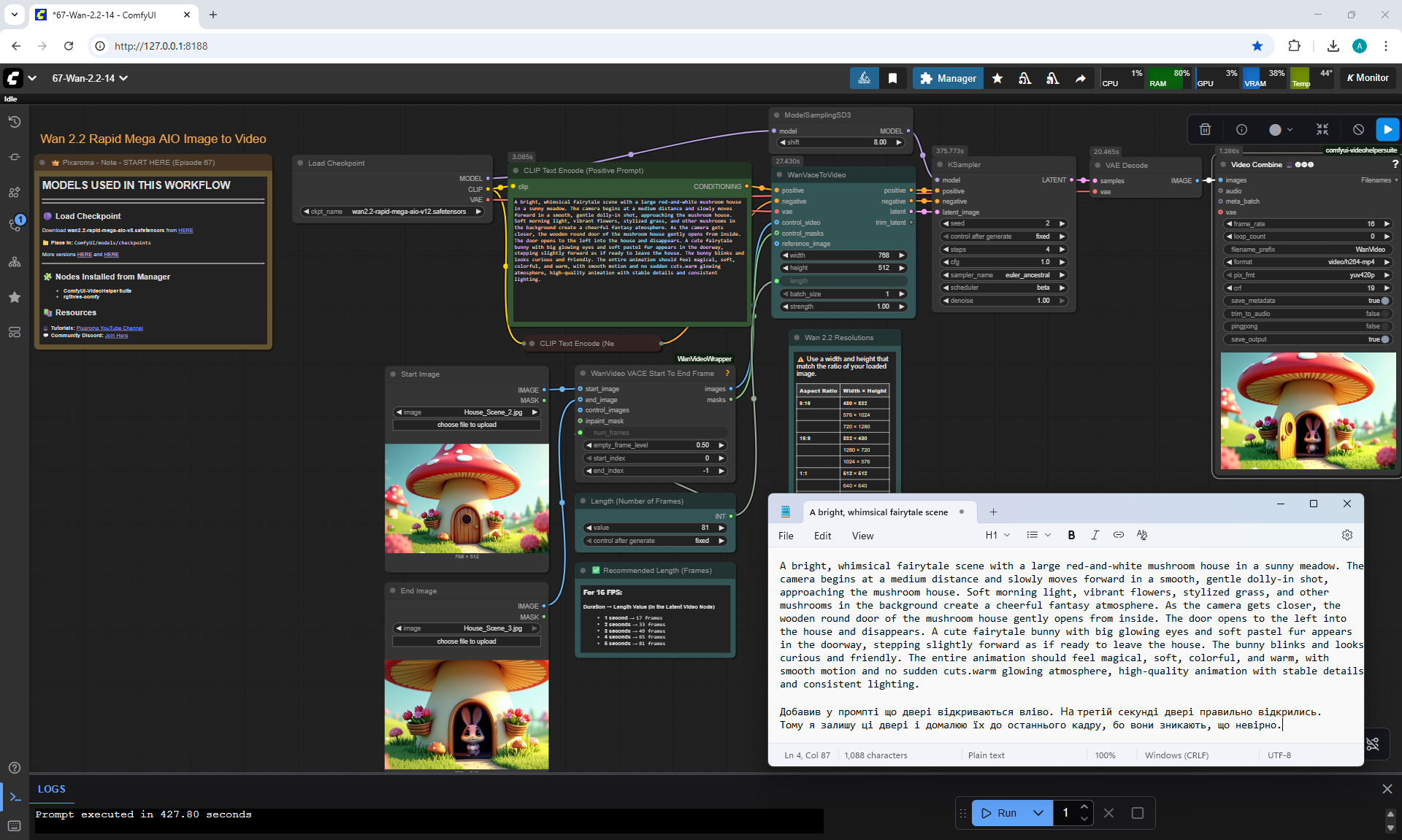
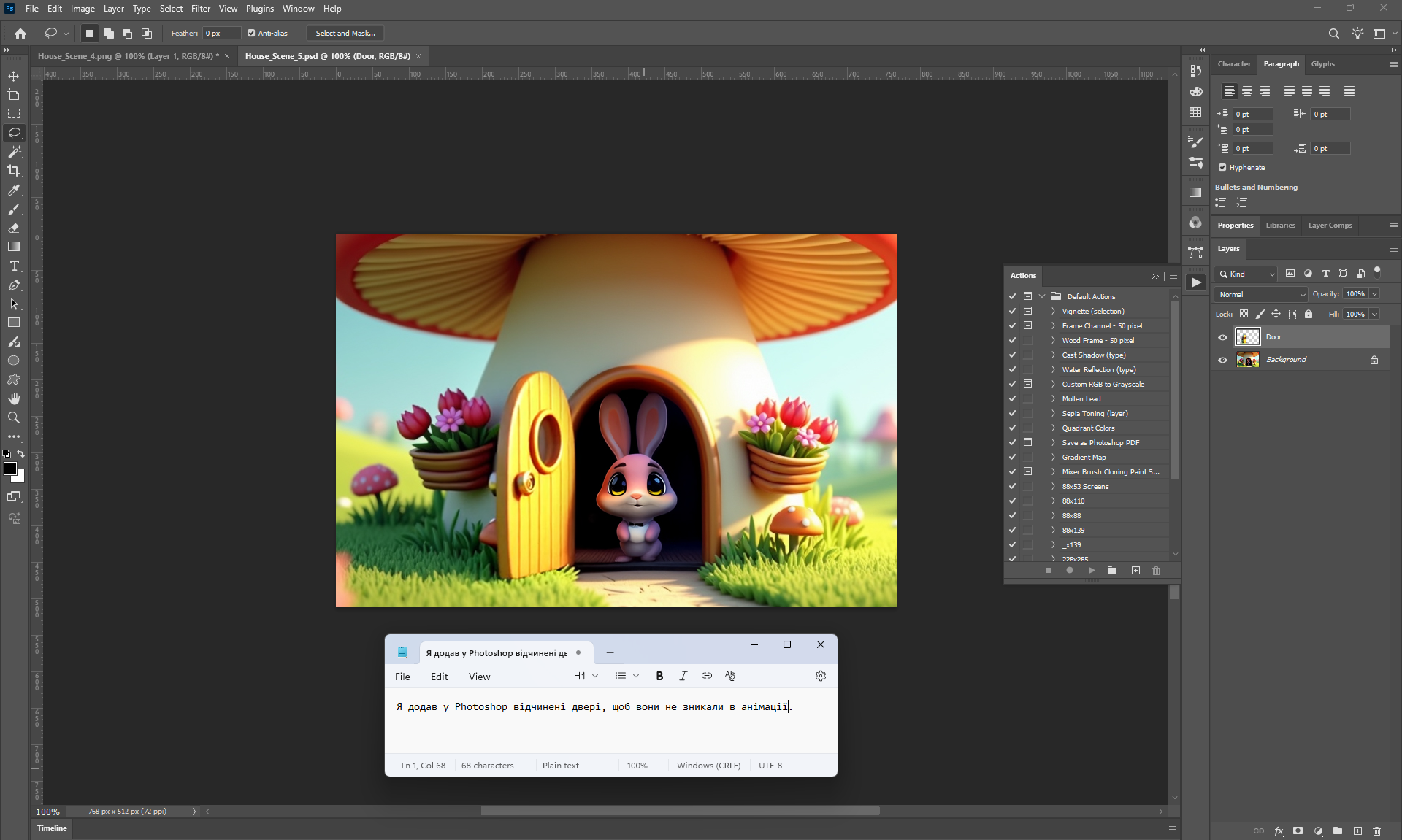
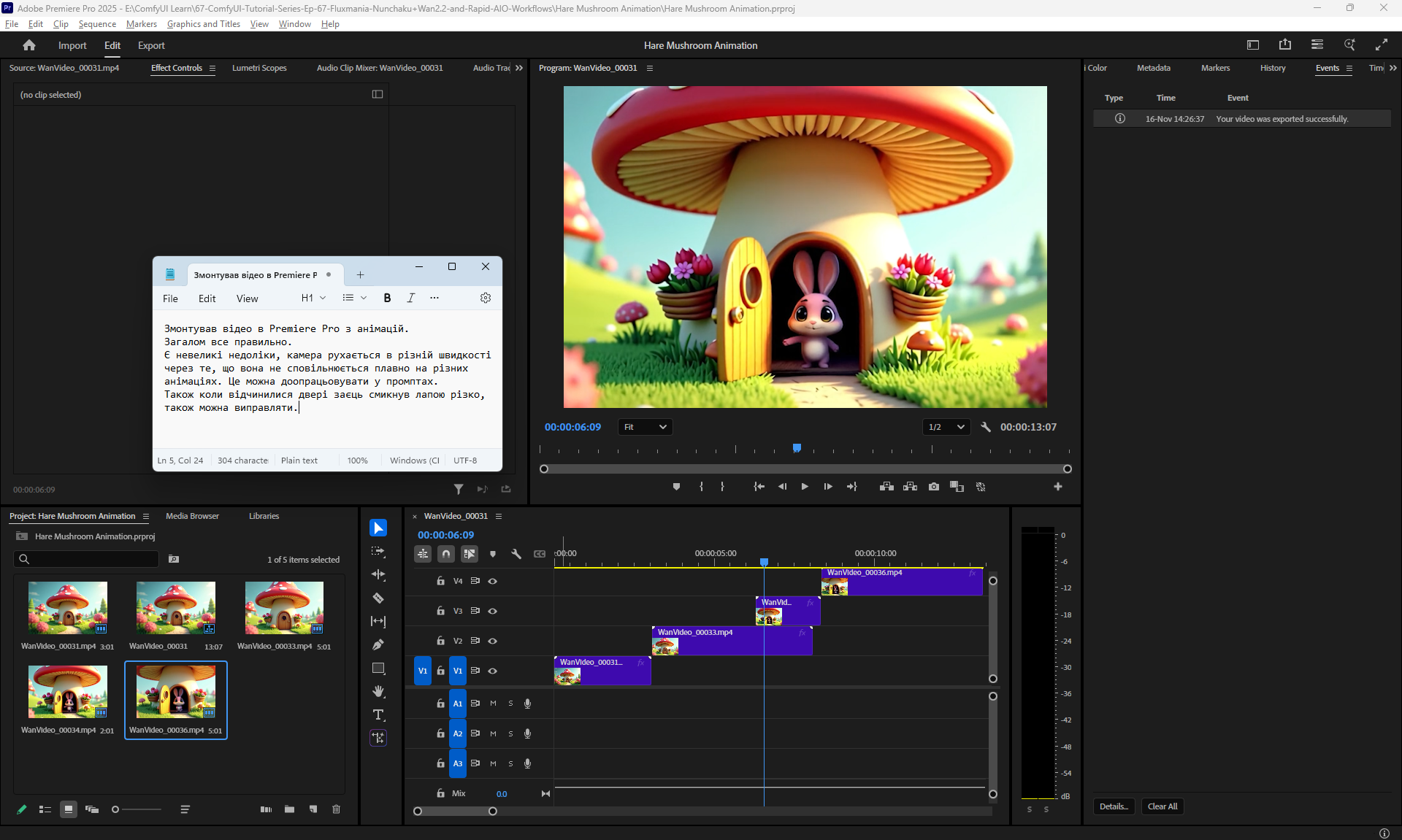
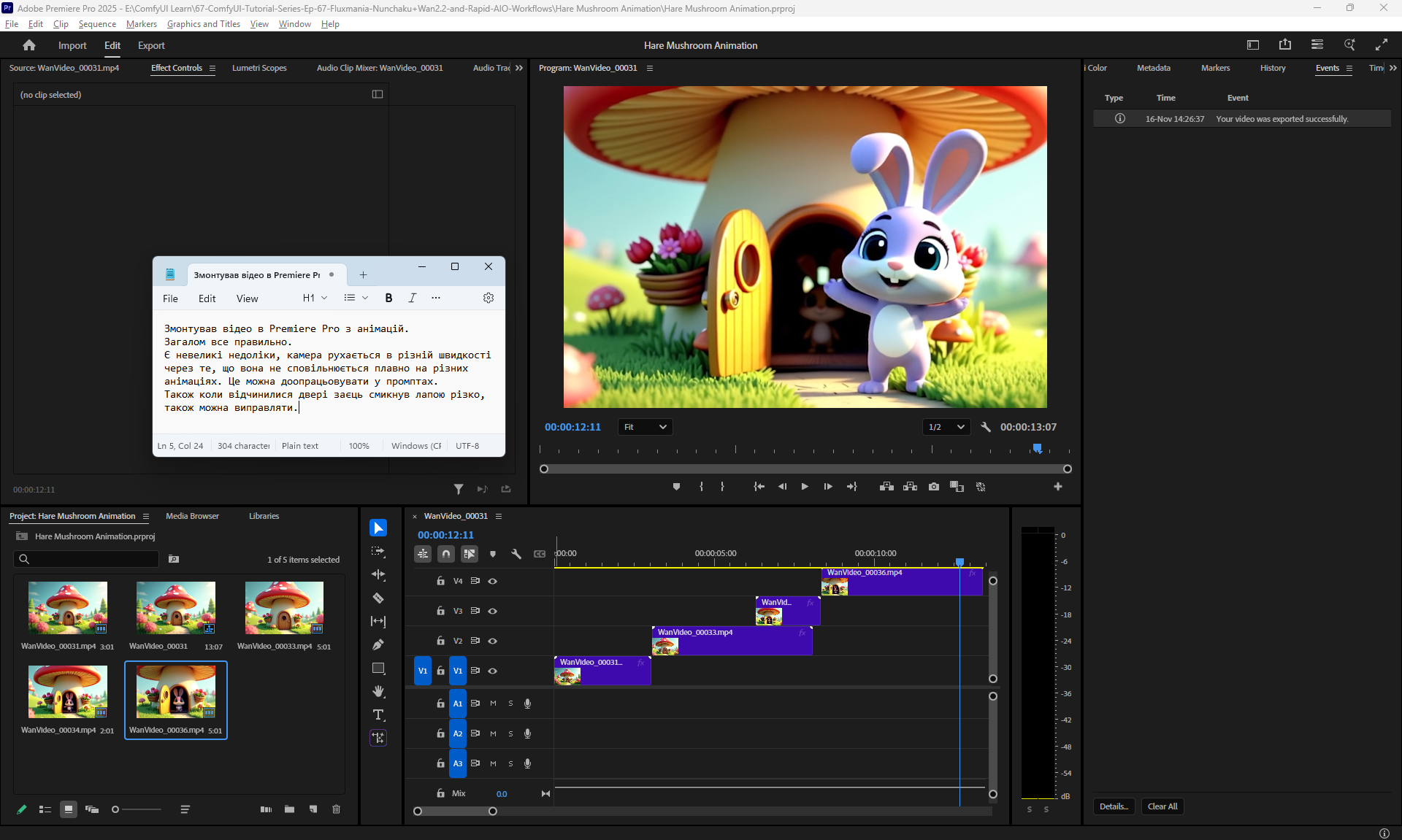
I did this animation in parts: first the camera approaches, then the door opens, the hare appears, then he comes out and says hello. Here I didn't have a frame in which the door is open, so during the animation the door should disappear, because when the hare appears there is no door. I made an animation of the door opening and added the door to the frame when the hare appears.
There are small inconsistencies with the speed of the camera movement, because when approaching the speed is one, then in the next animation the camera approaches at a different speed and this transition is not smooth.
I edited these videos in parts.
I made an upscale video, but when upscaled, the video is not detailed by the prompt and is not corrected if there are errors, as was done in ltx.
In the next lesson 69 there will be LongCat video, there is an opportunity to create a whole chain of prompts for one image and set complex scenarios for animation. This allows you you not to edit video pieces in parts.



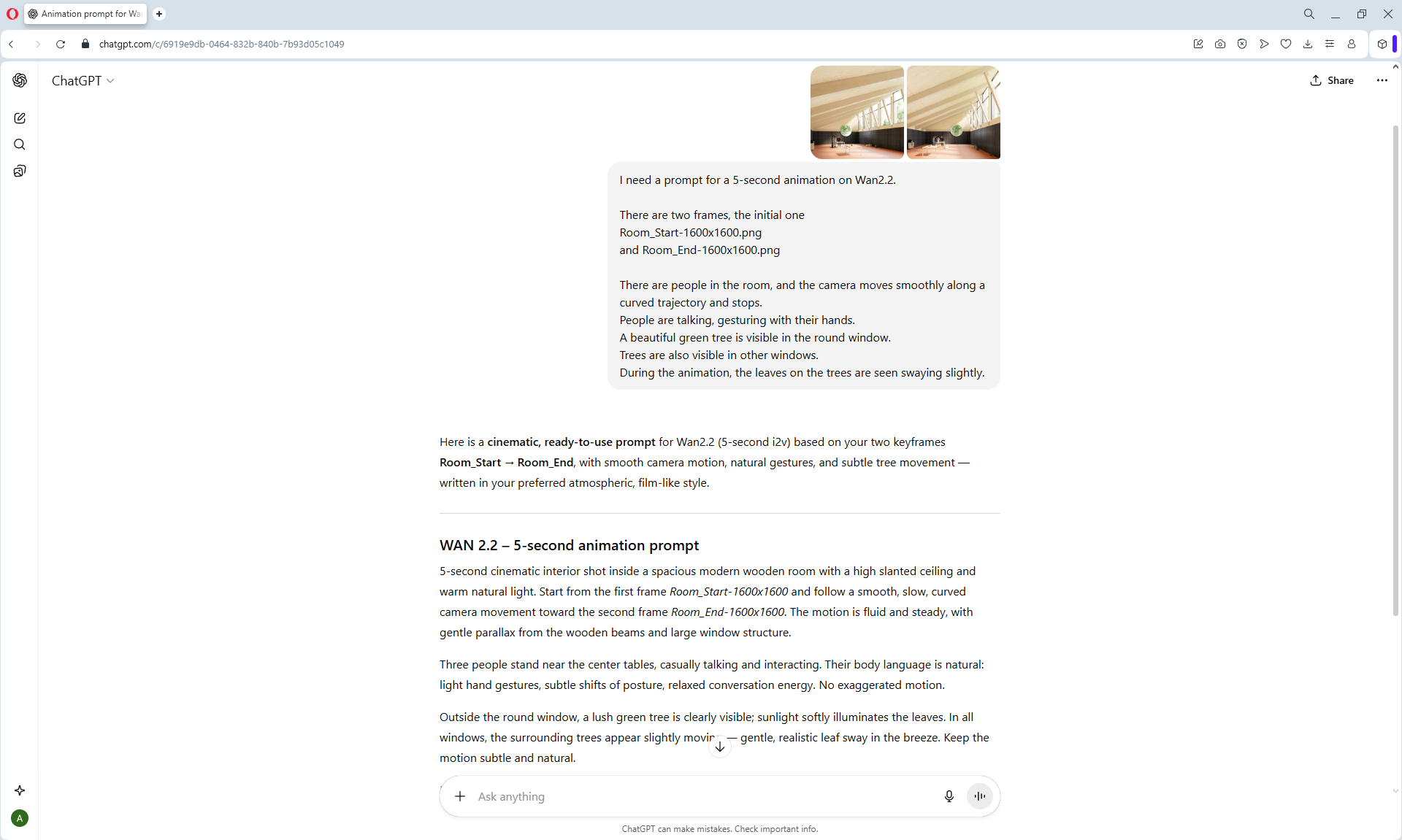
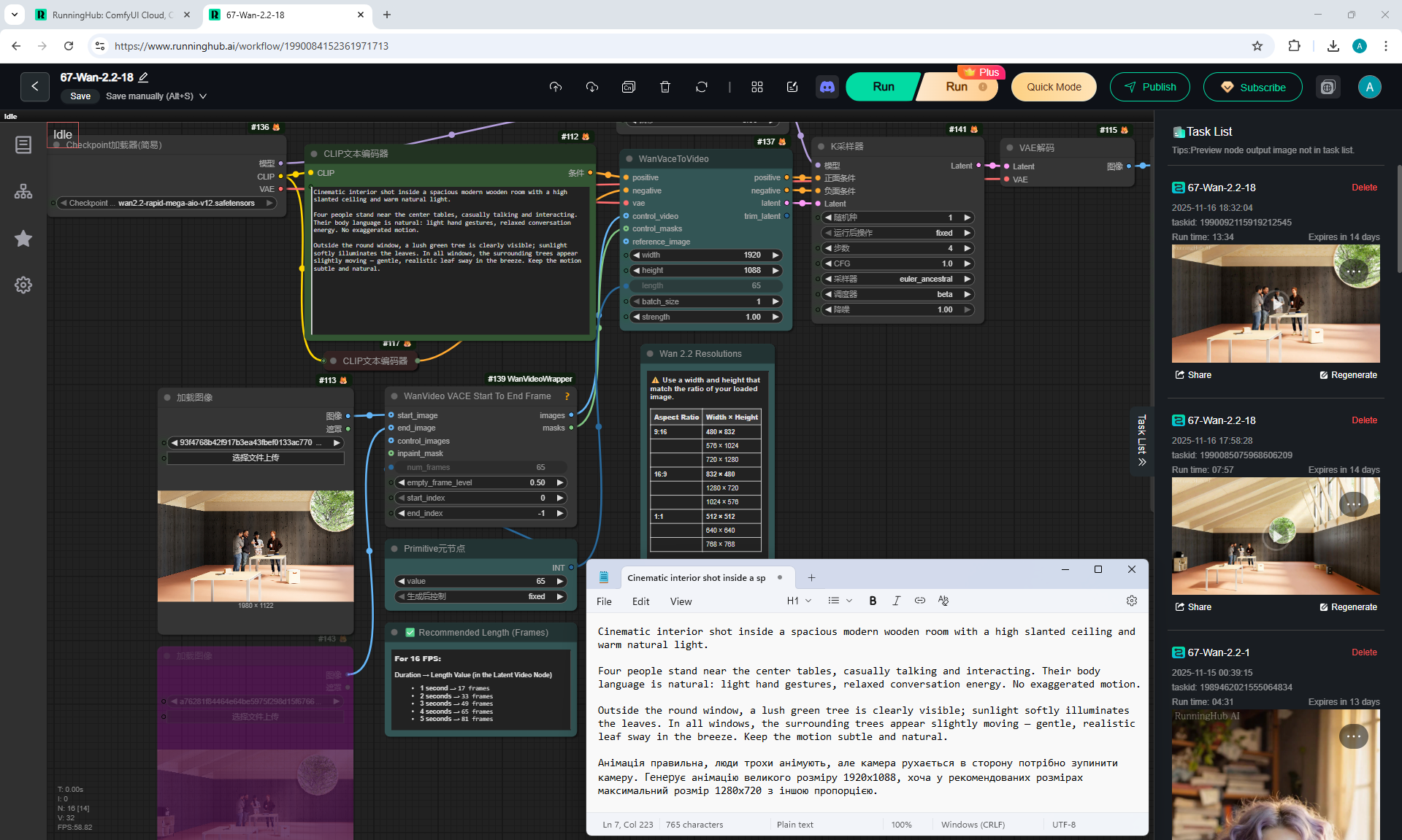
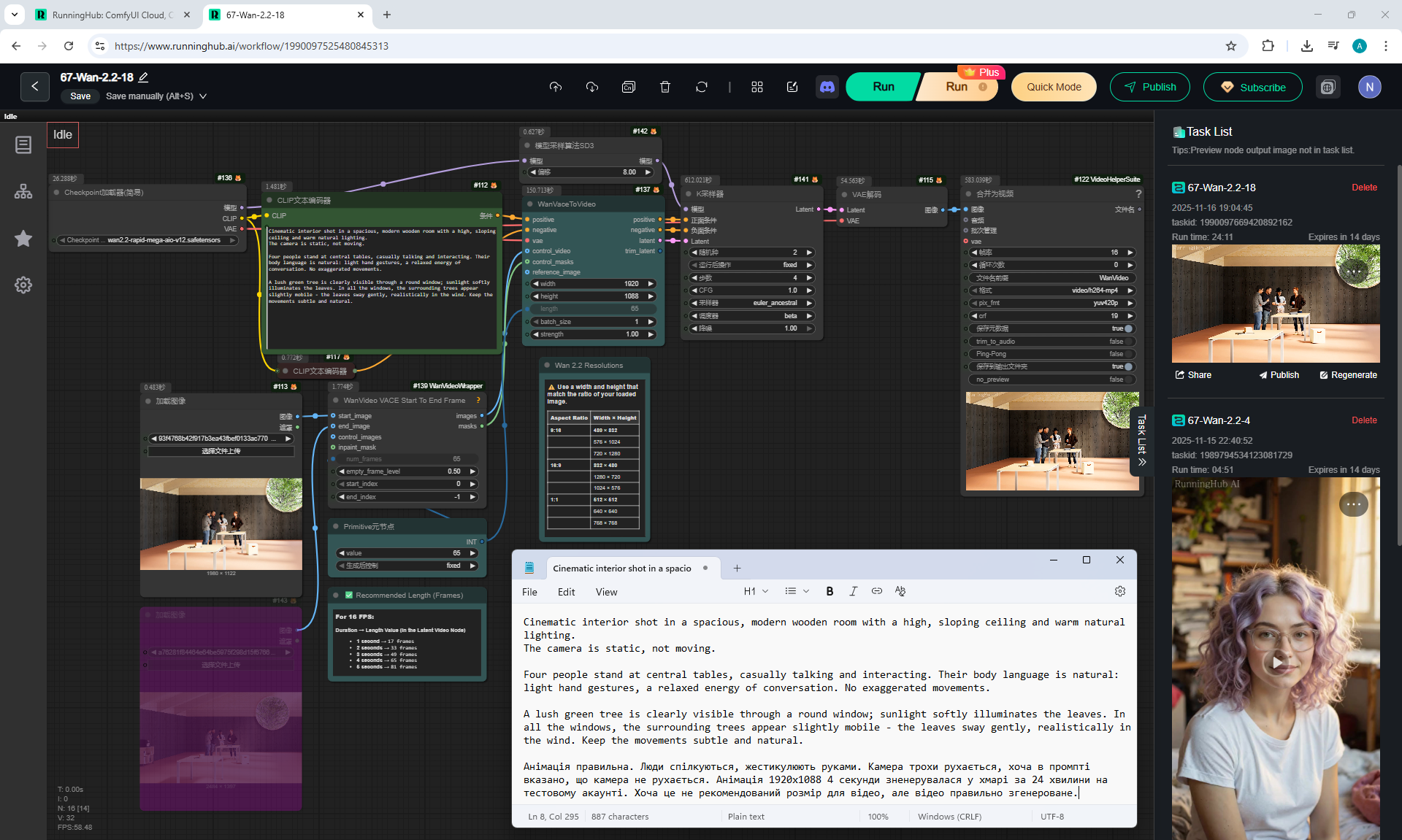
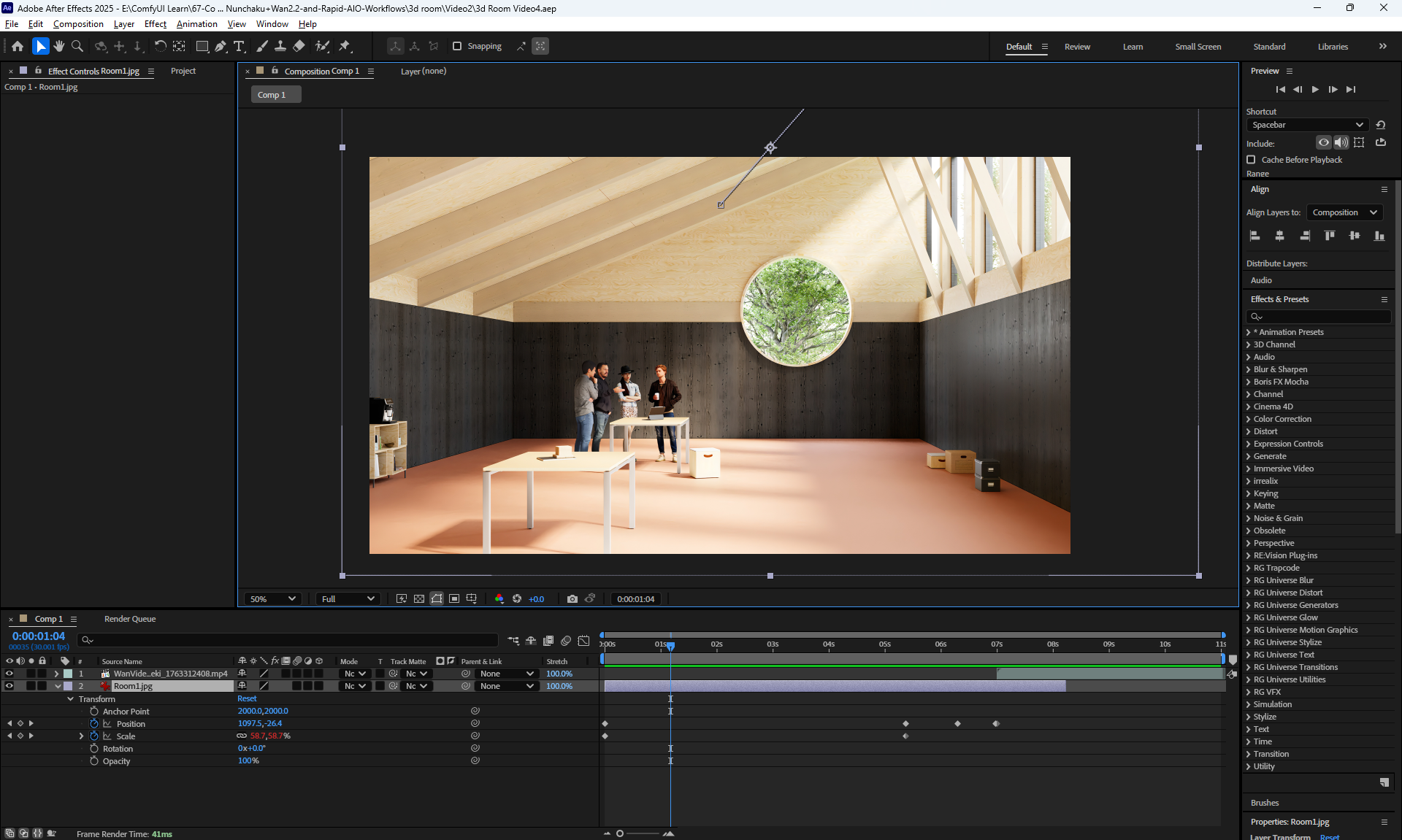
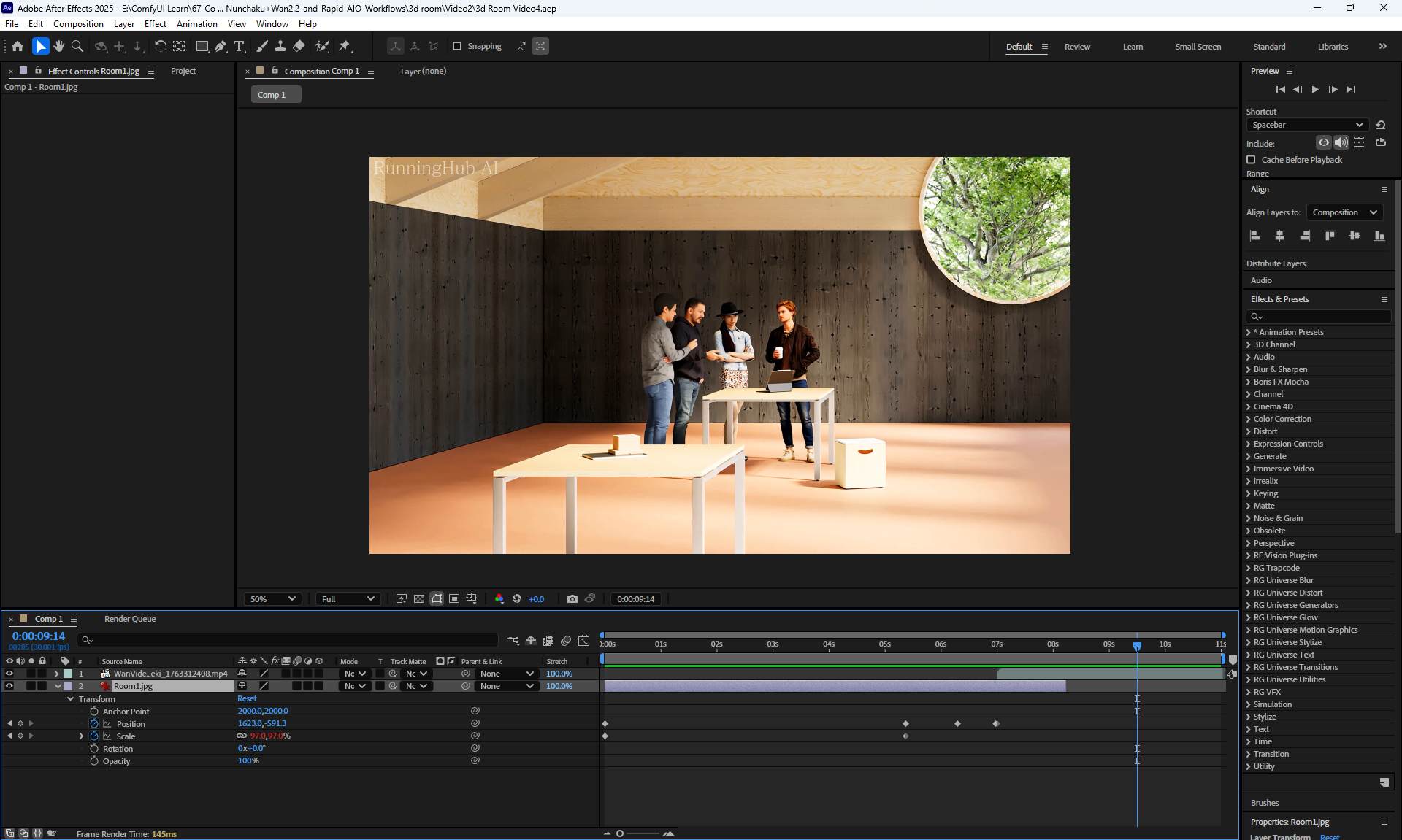
I modeled this room in
Cinema 4d lesson, Corona render.
I tested the motion animation in Wan2.2 on frames that I modeled in Cinema4d.
The camera motion animation is almost correct, except for the glitches in the movement of the beams on the top right, because the AI is confused about which beams should move where. You can test other generations, add clarifications in the prompt and test how to fix it. Such an animation should be run correctly in Cinema4d, and there will be a higher quality correct animation with the detail of the tree and other objects, but it will take more time to generate all the frames.
I added a prompt in this animation for people to gesture, but because the people are small, the AI does not animate them.





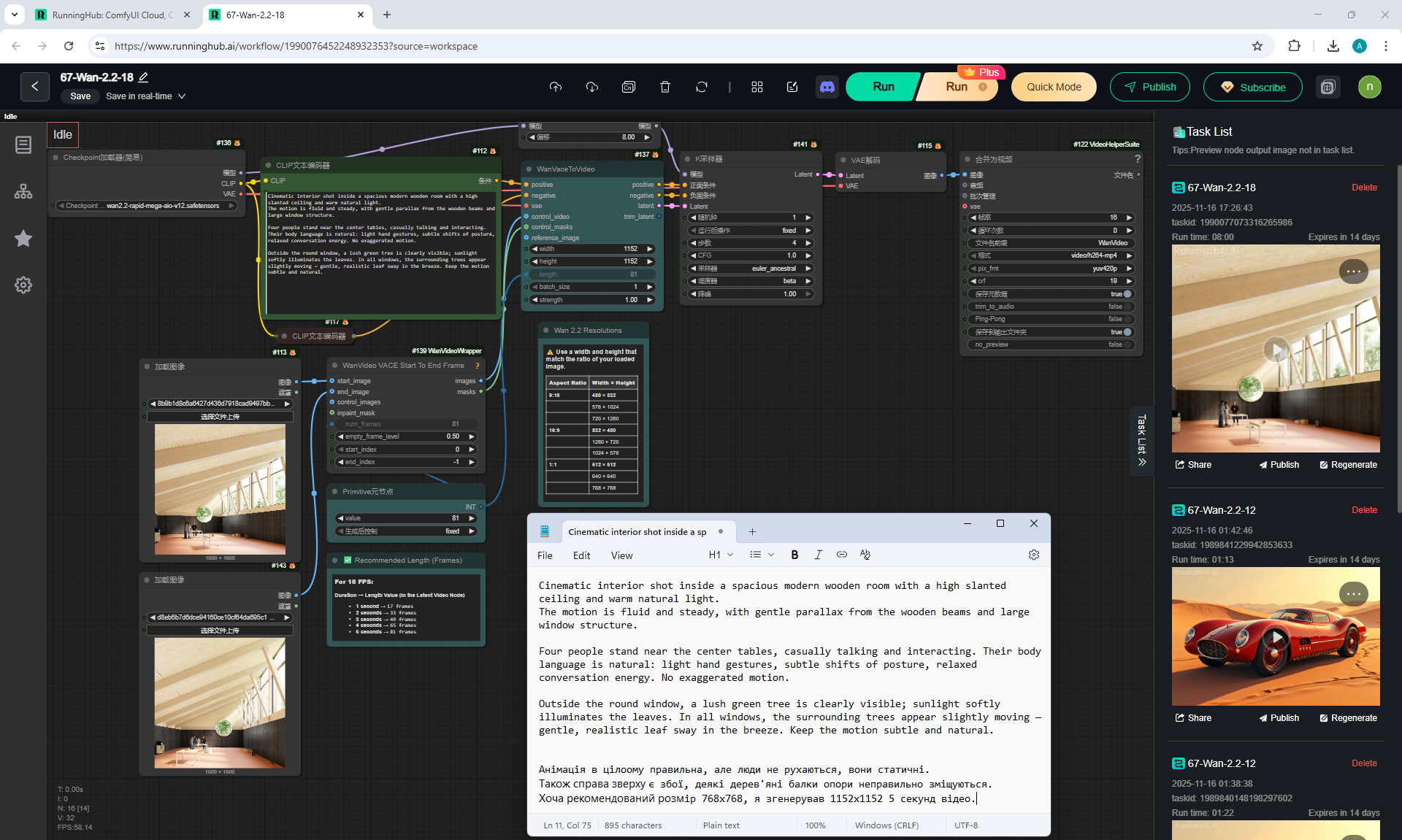
I generated animation
in Wan2.2 horizontal video with an enlarged angle of people.
I made a camera zoom animation (Image scaling) and added a generated animation with people gesturing.
At a distance, people are poorly recognized by AI and do not animate, so they are initially static.
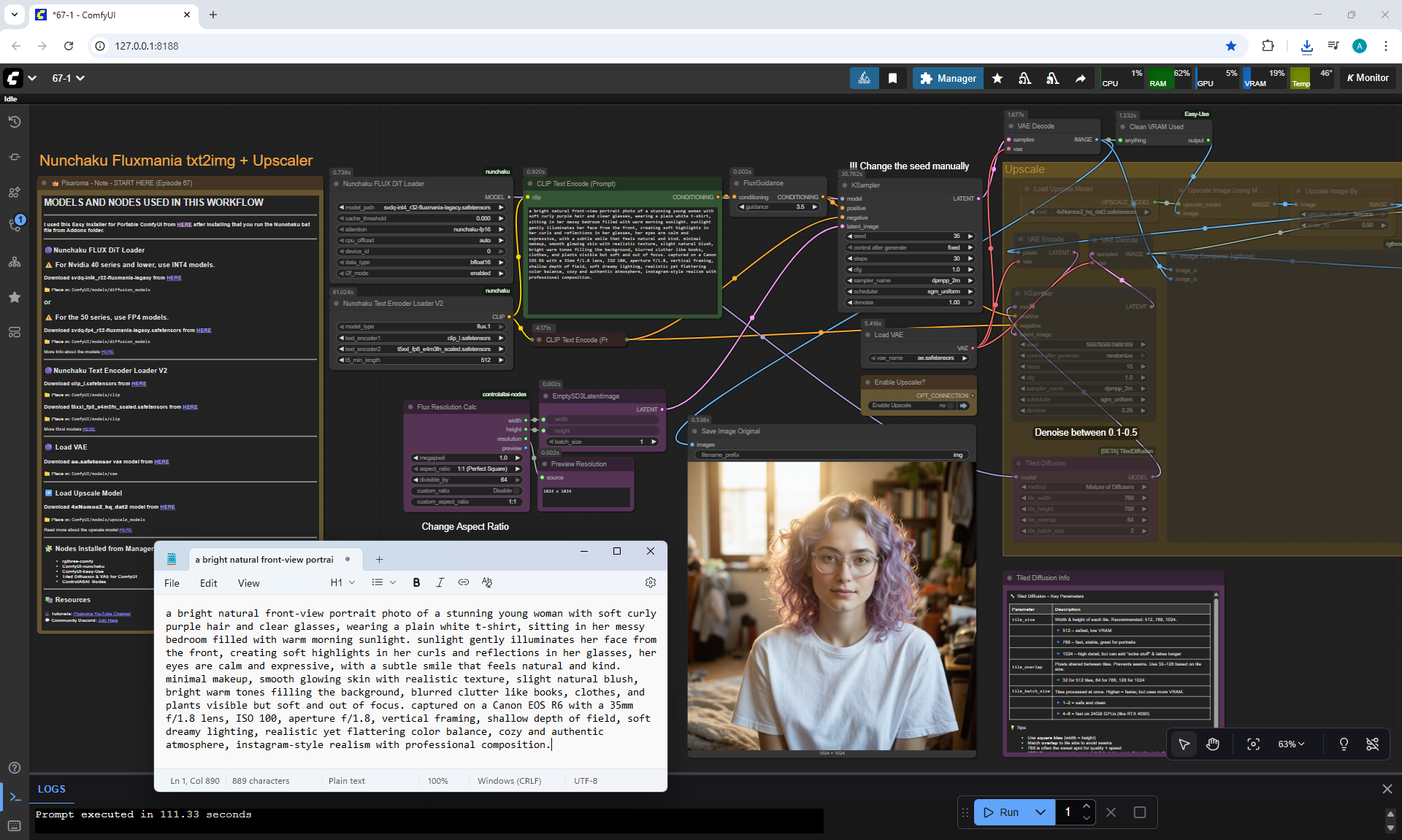
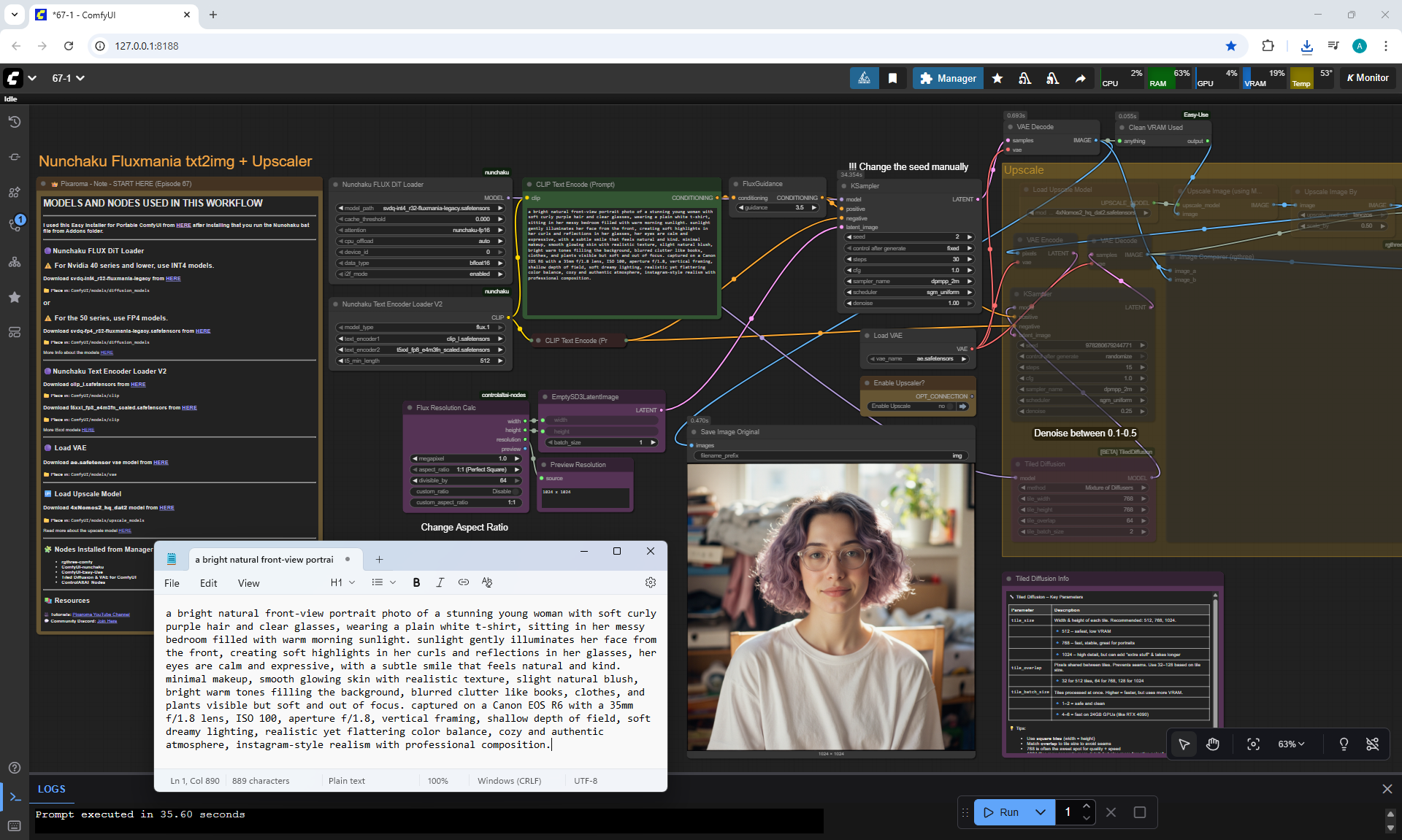
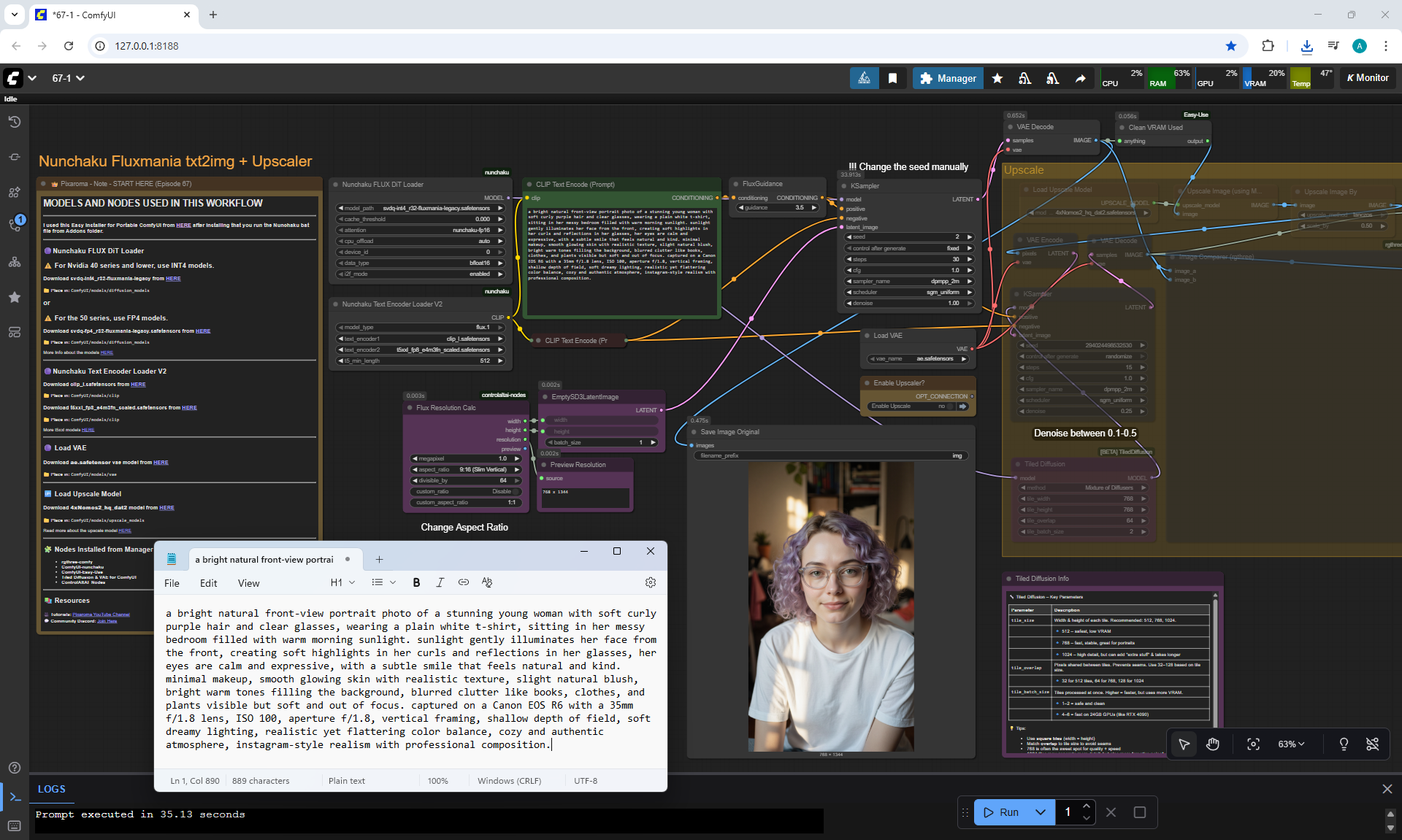
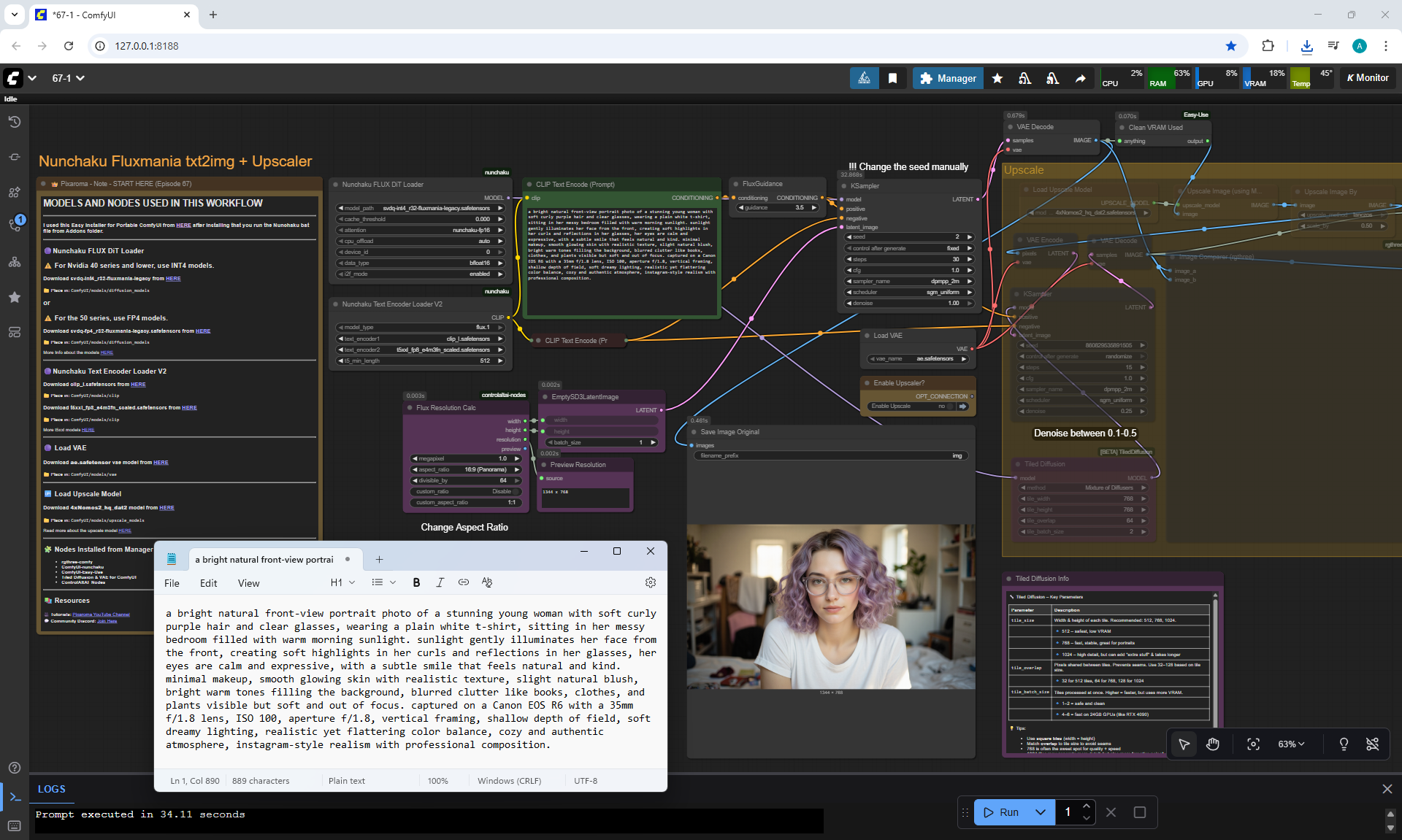
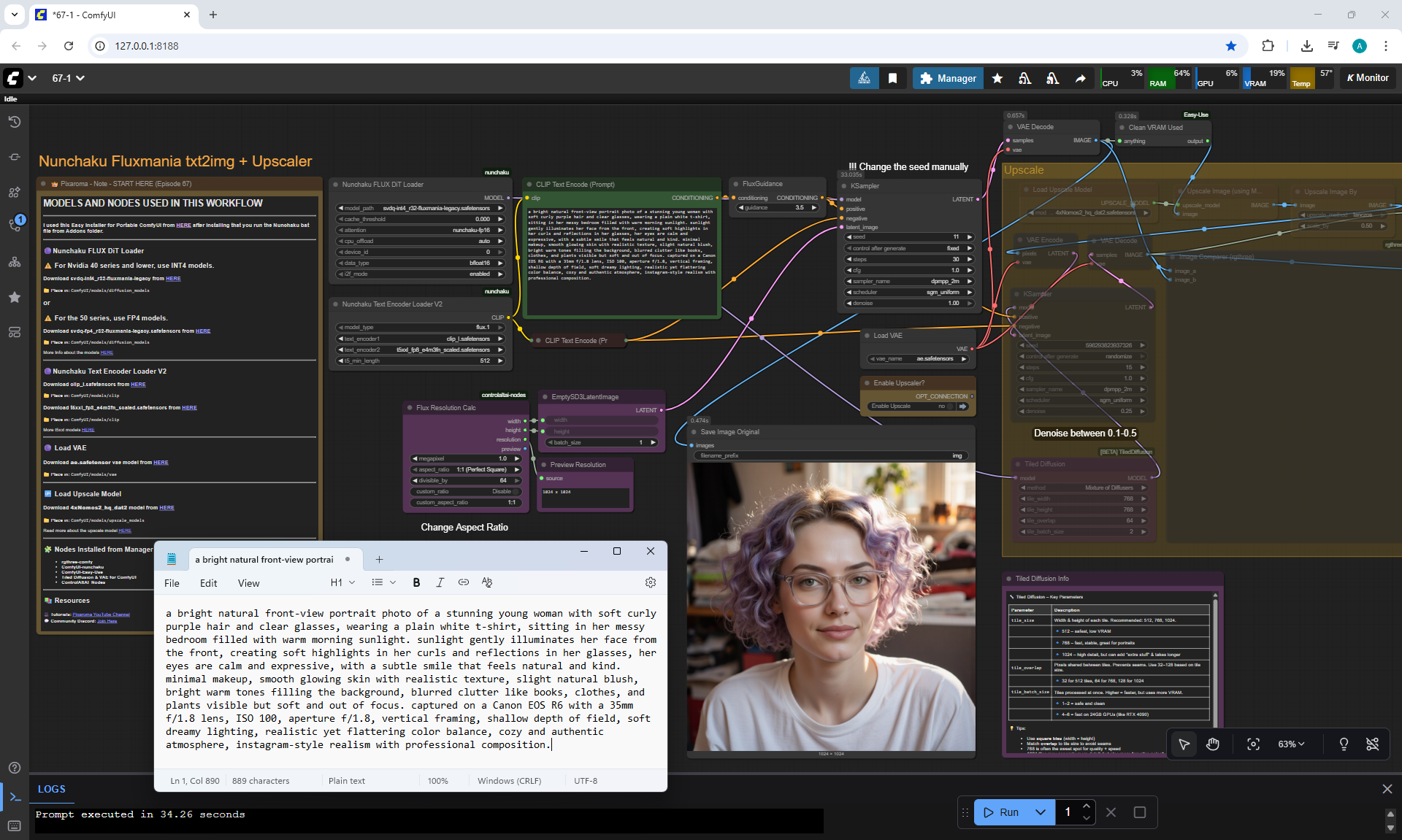
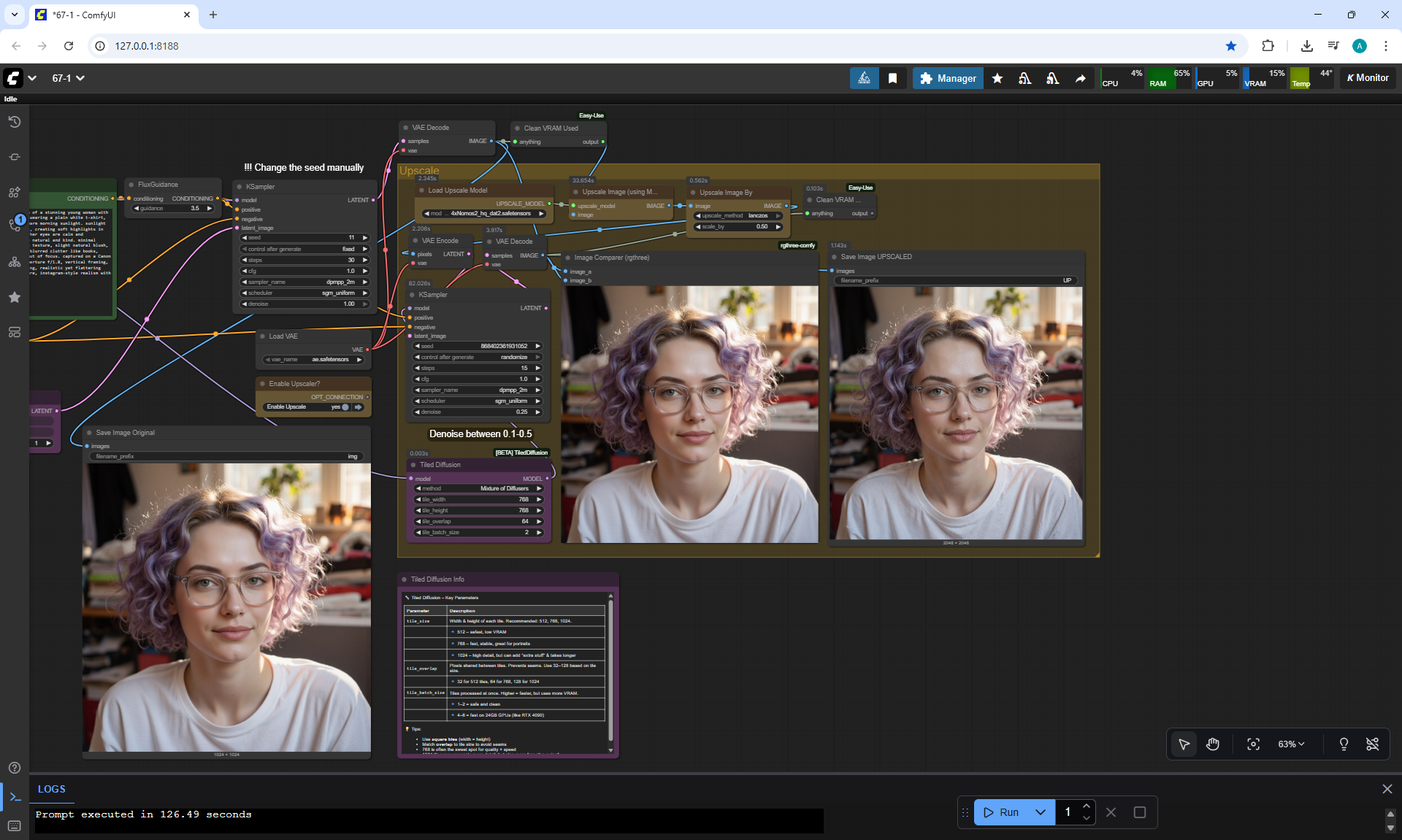
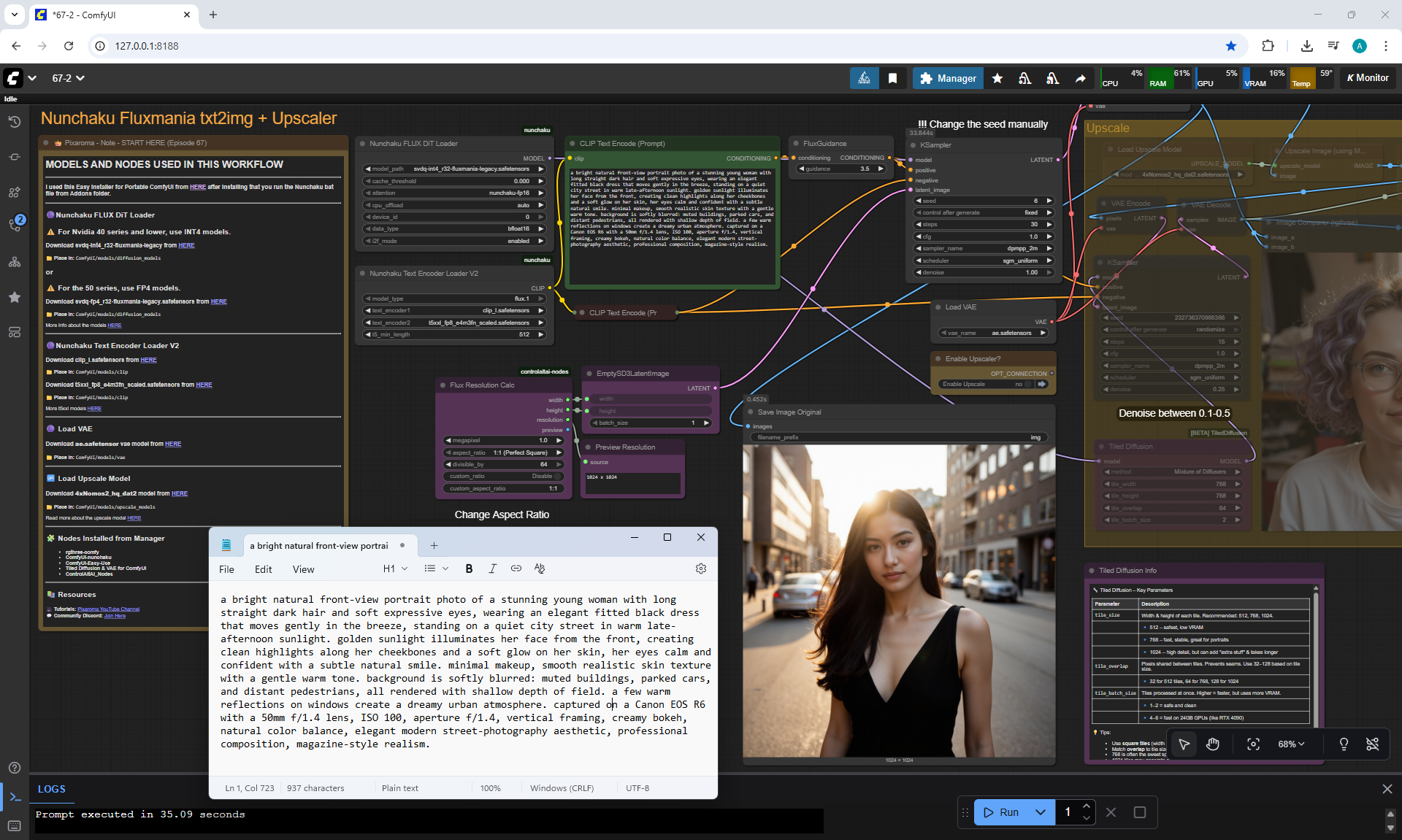
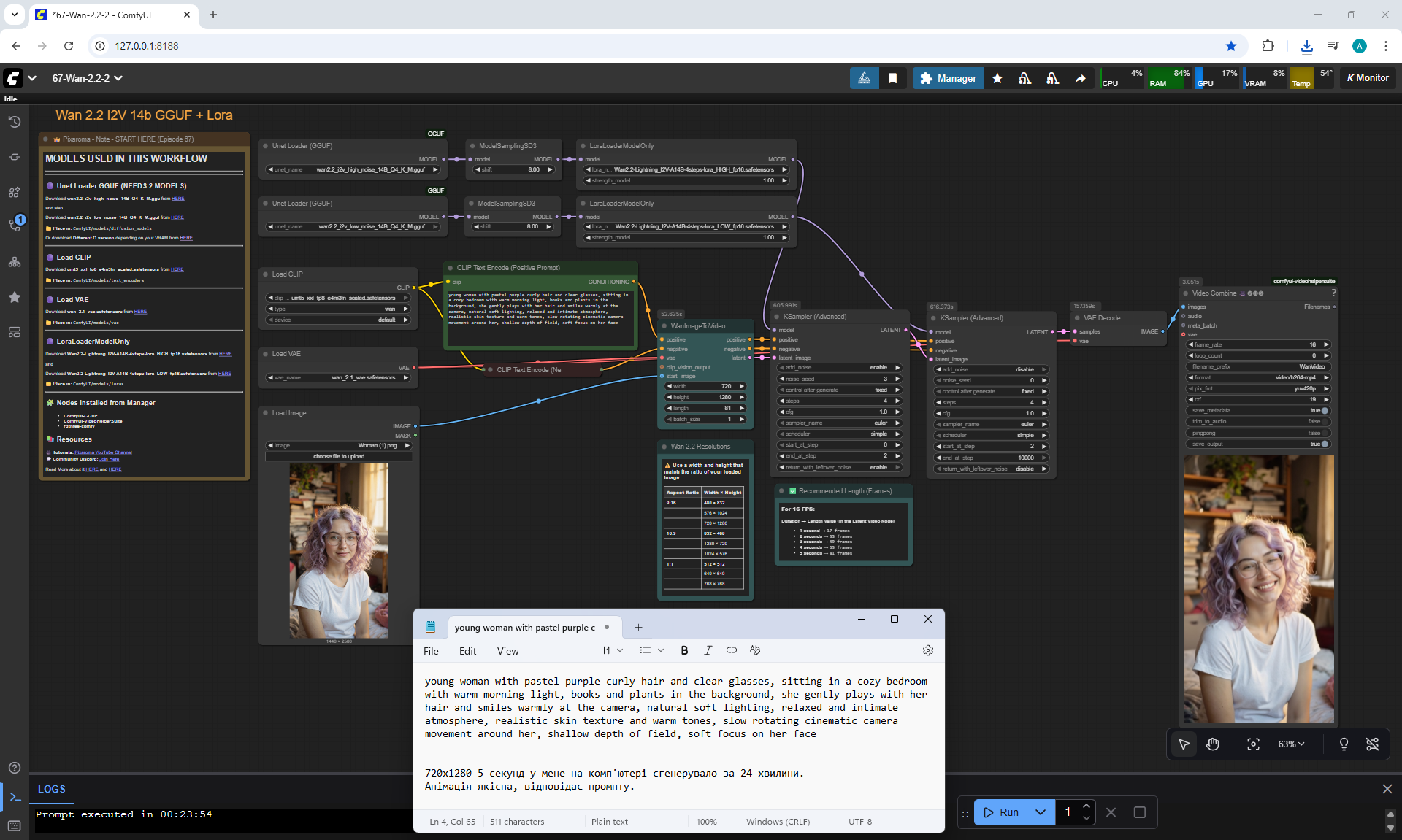
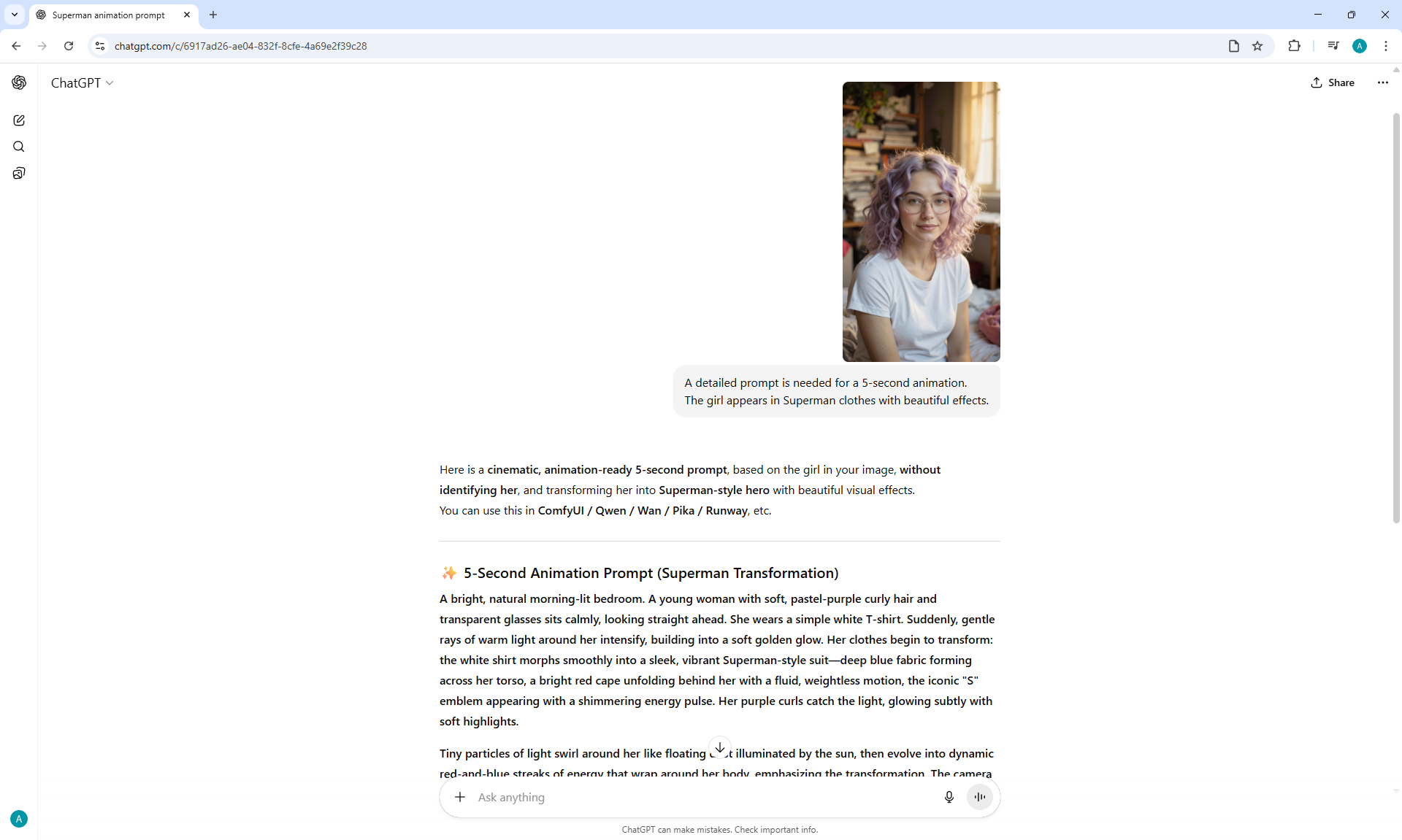
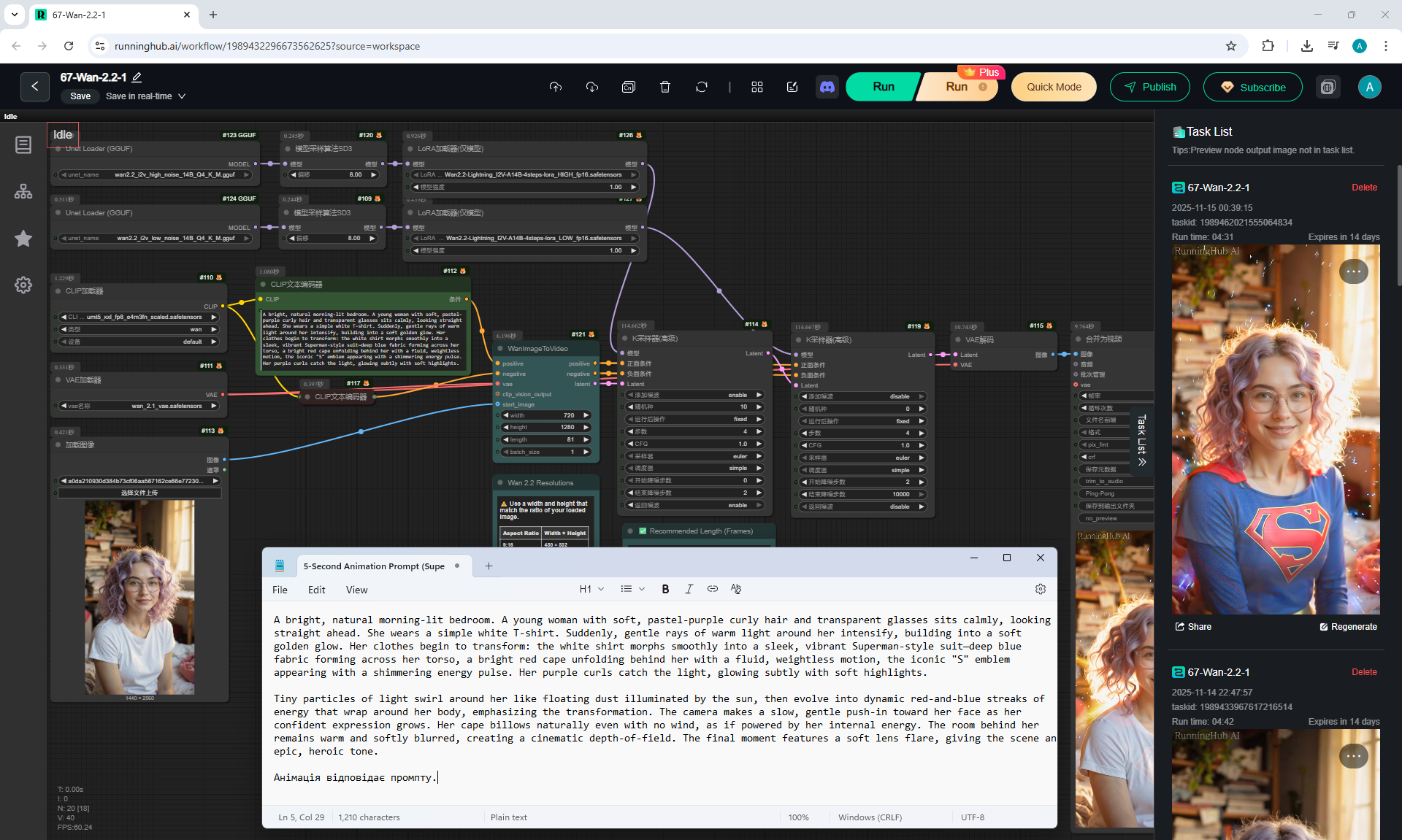
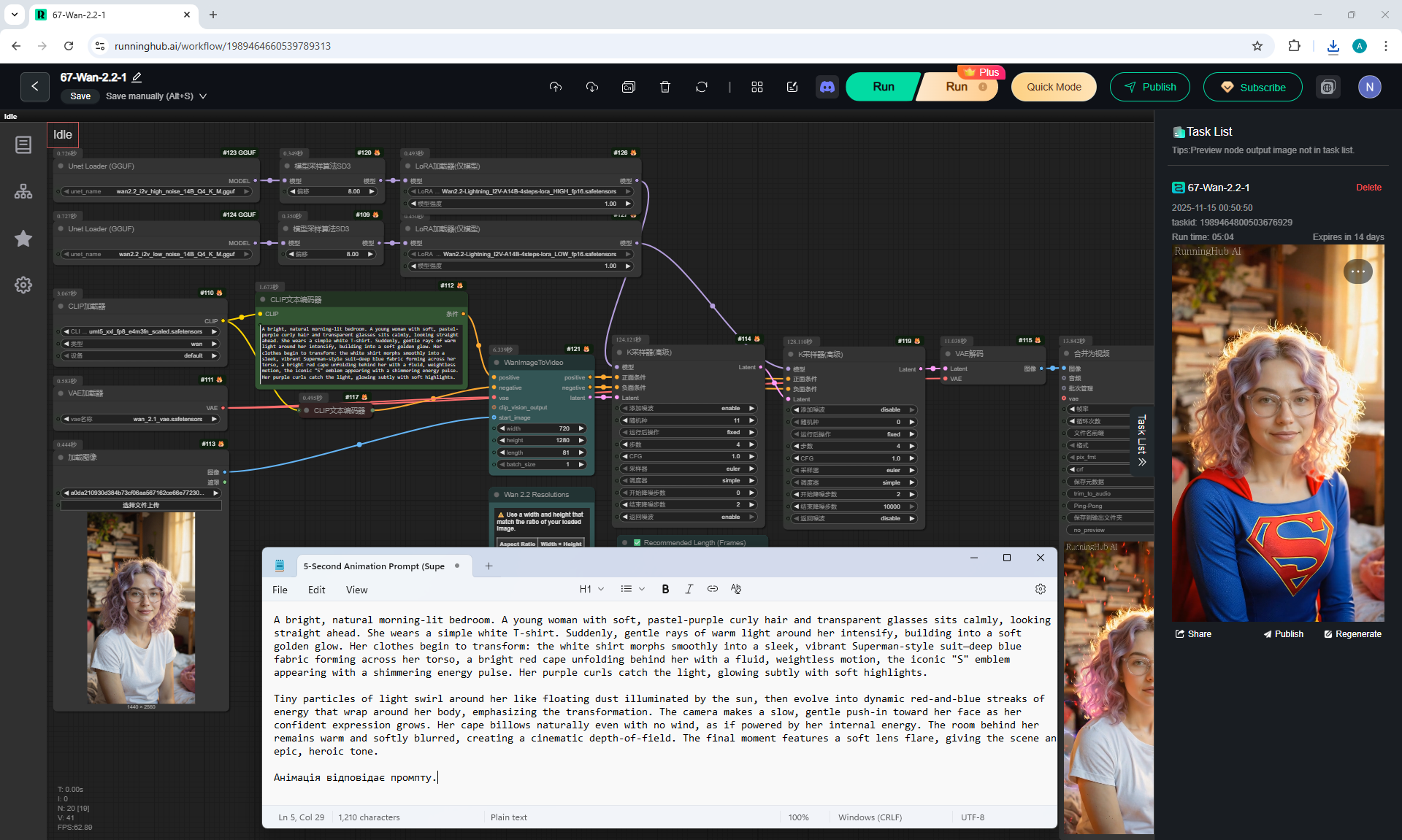
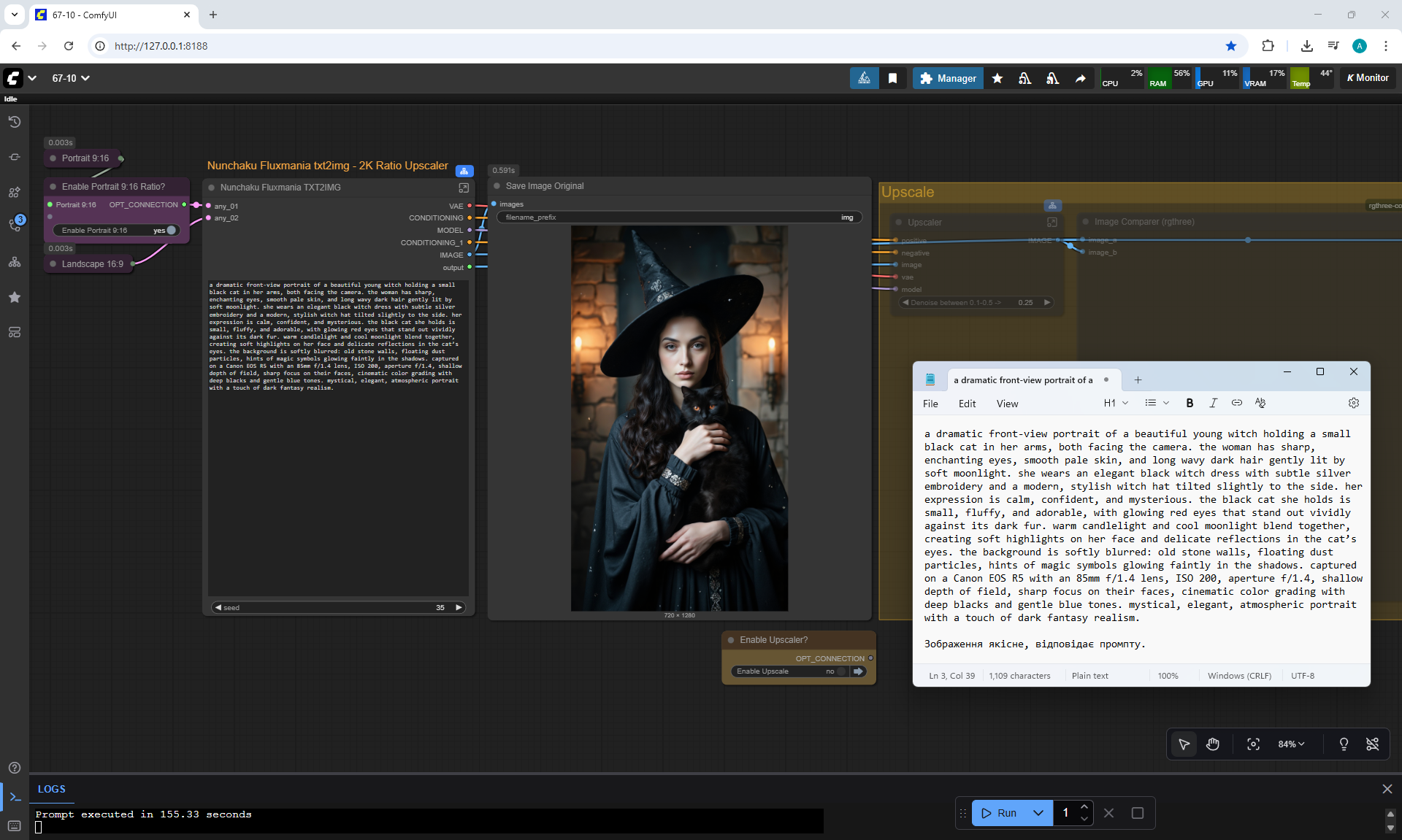
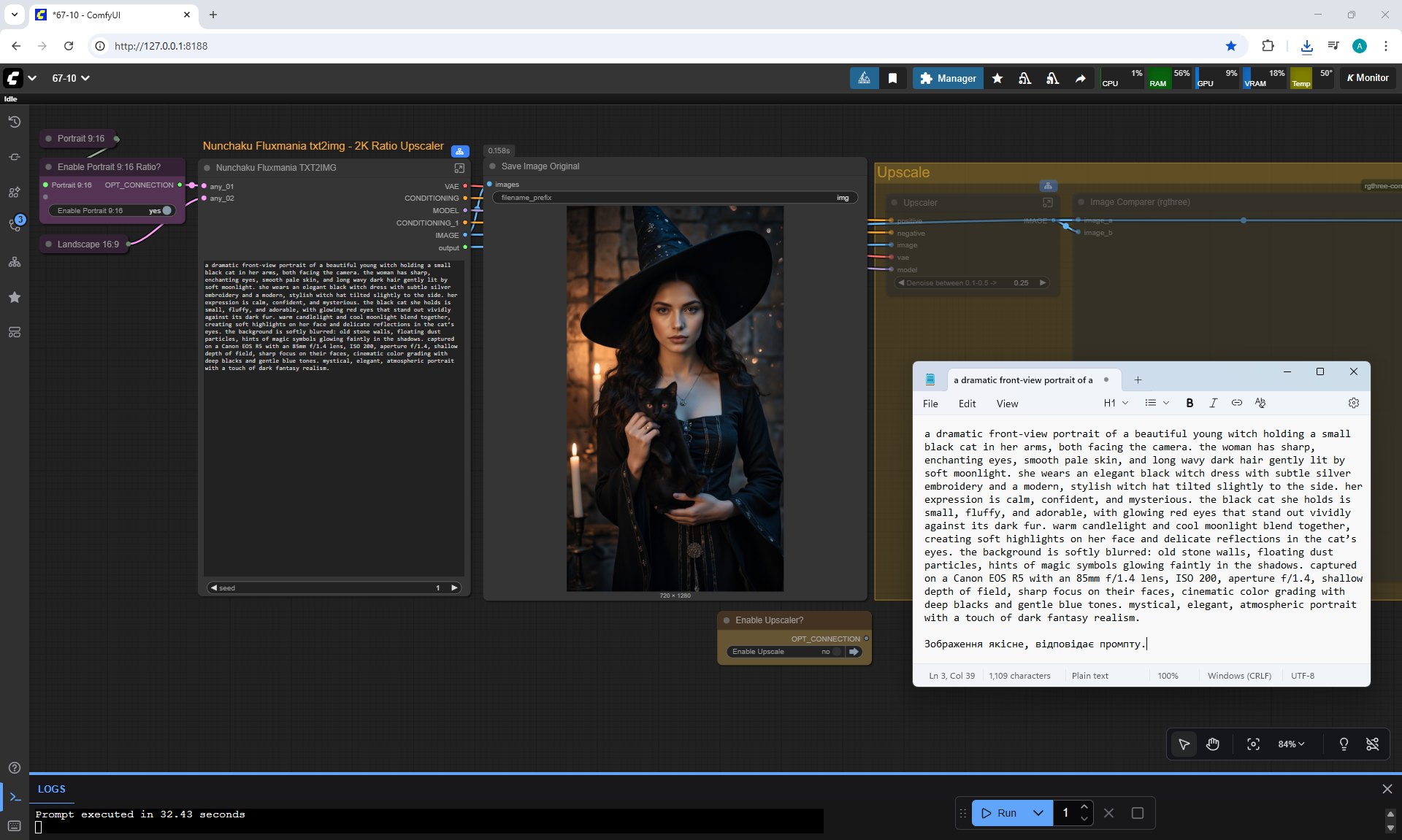
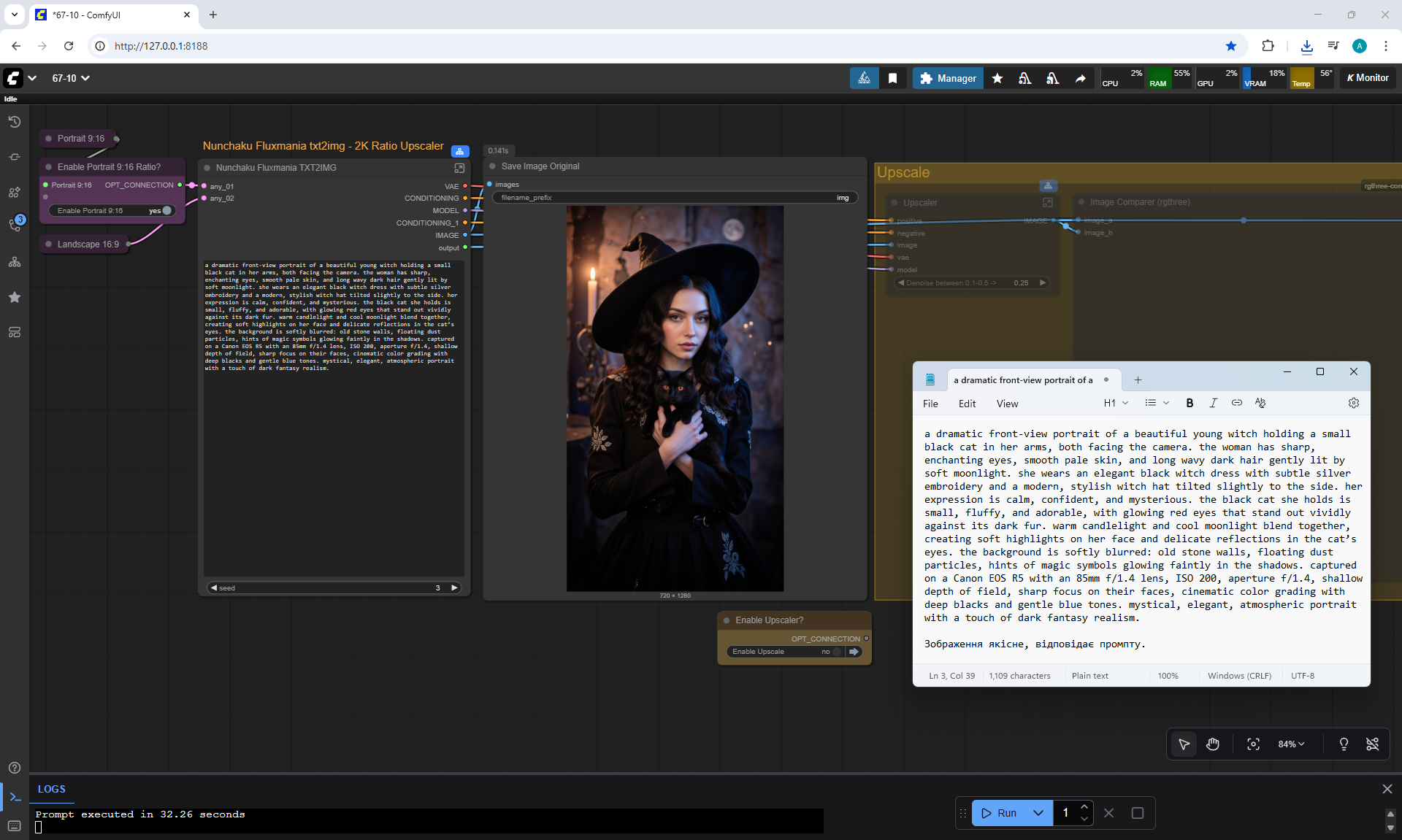
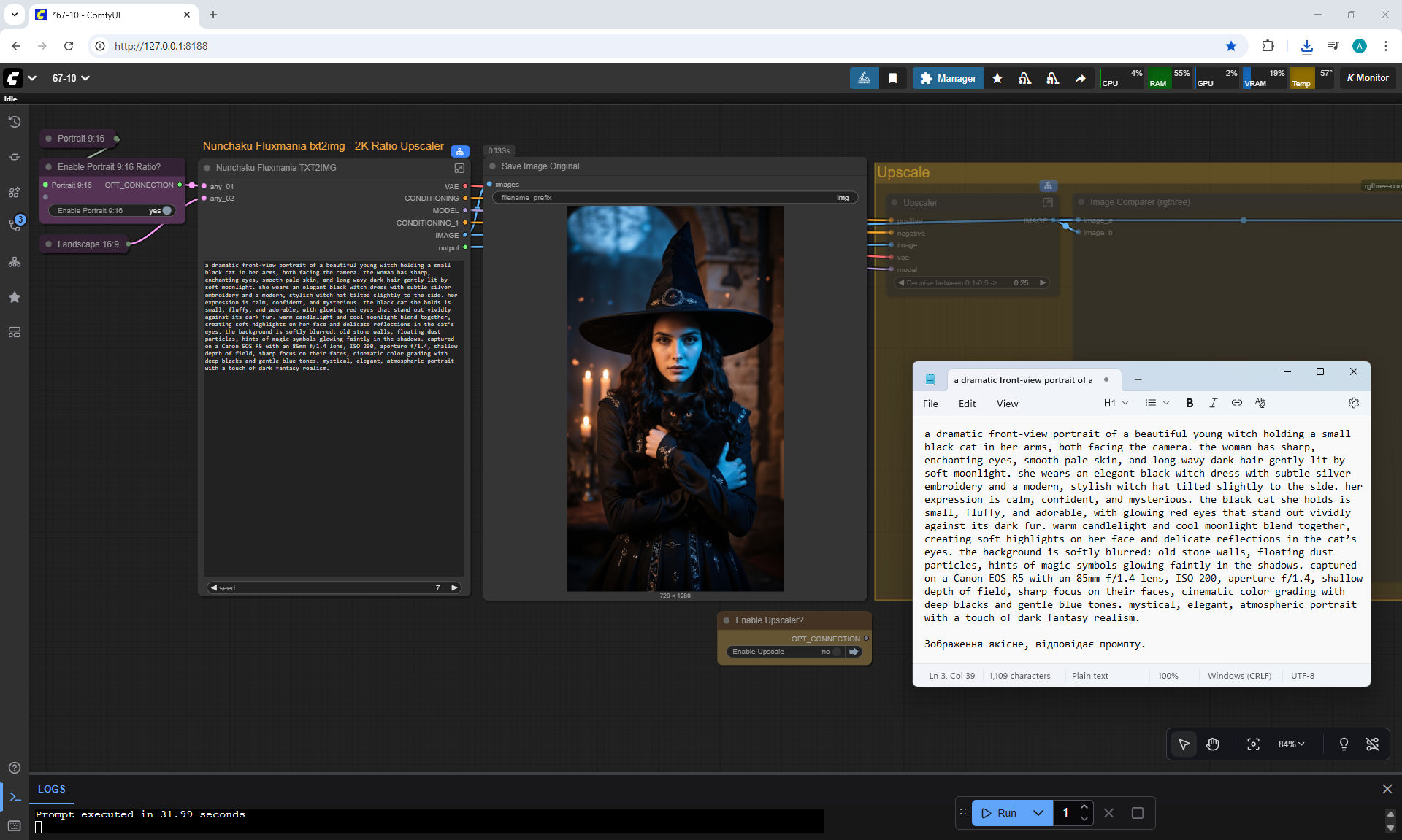
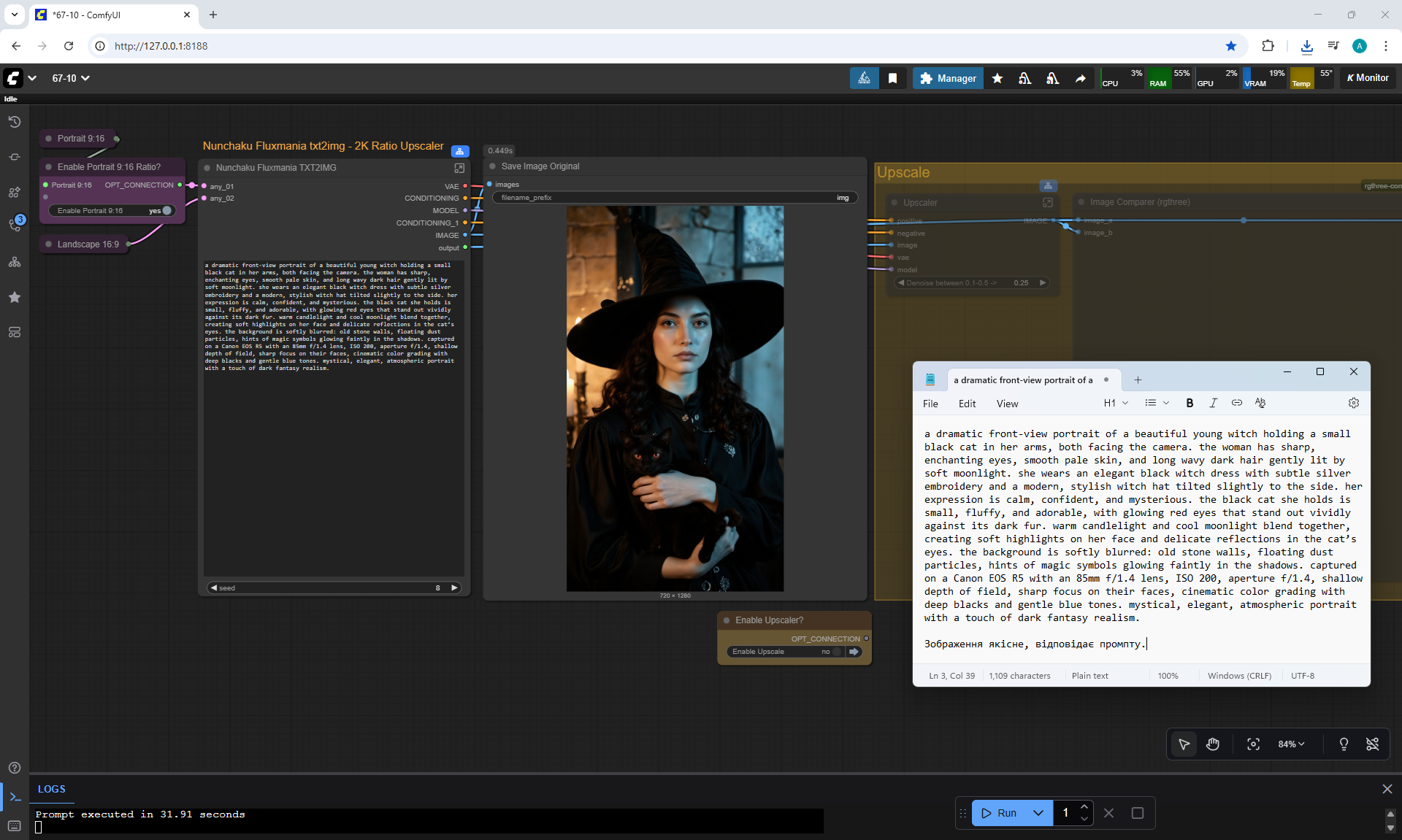
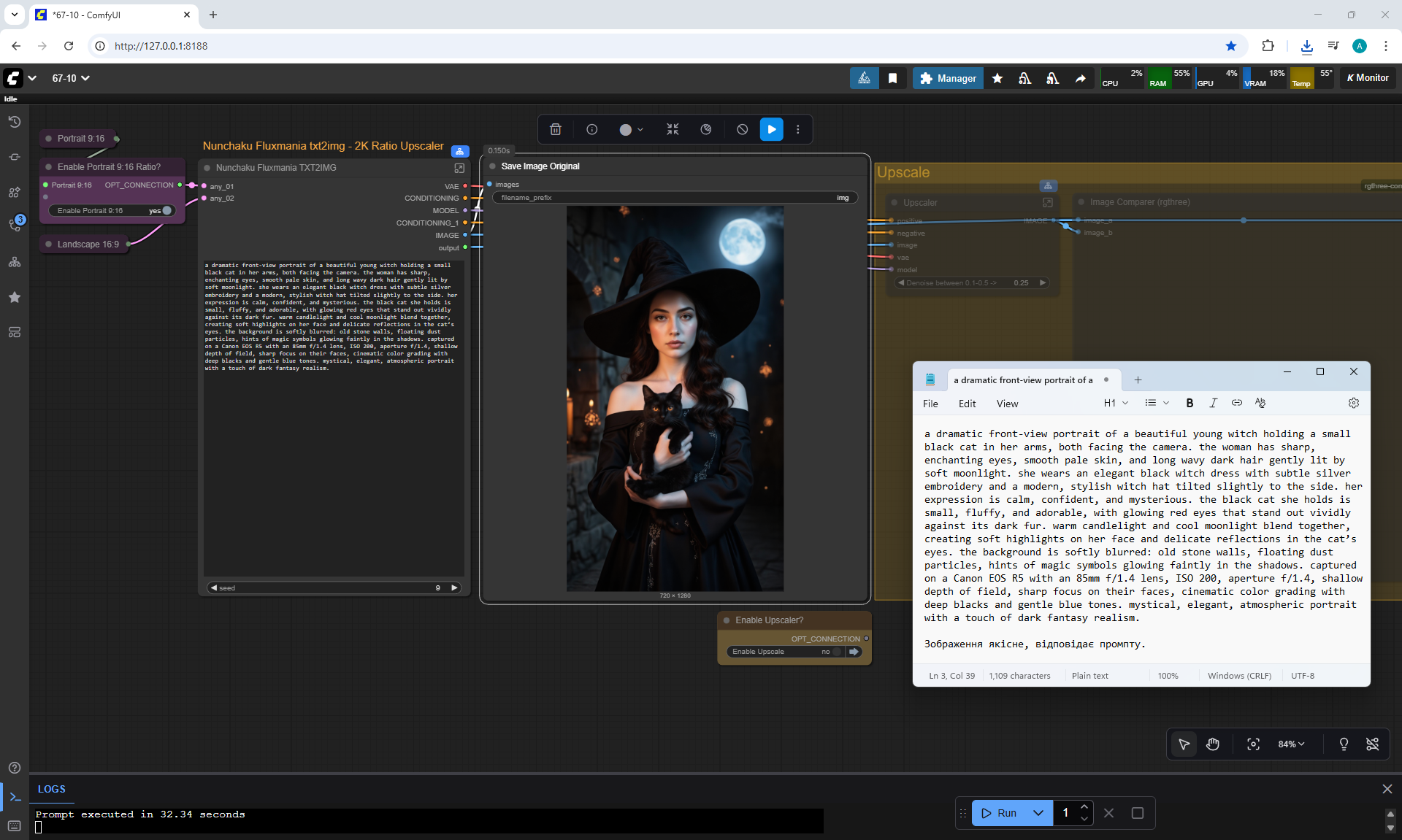
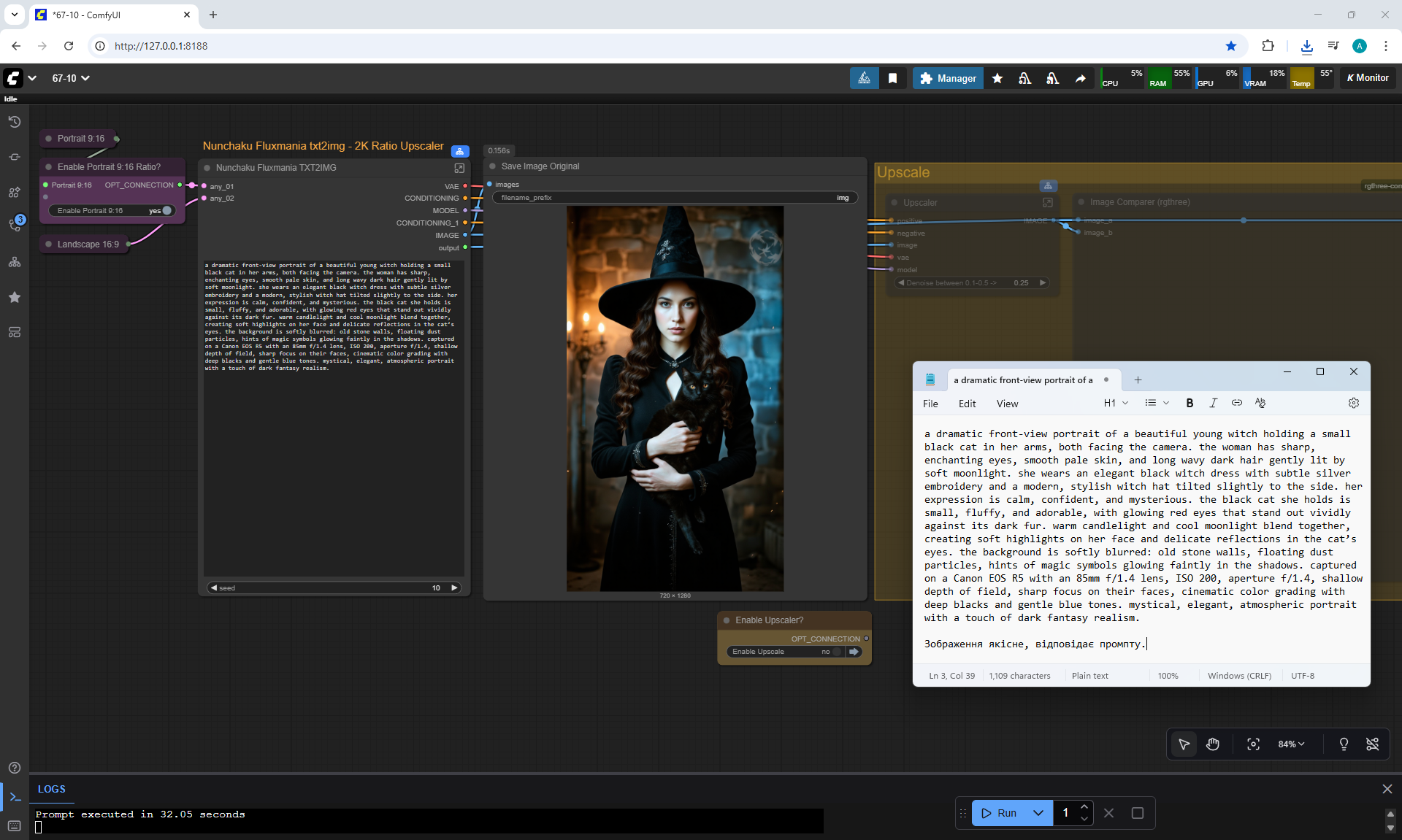
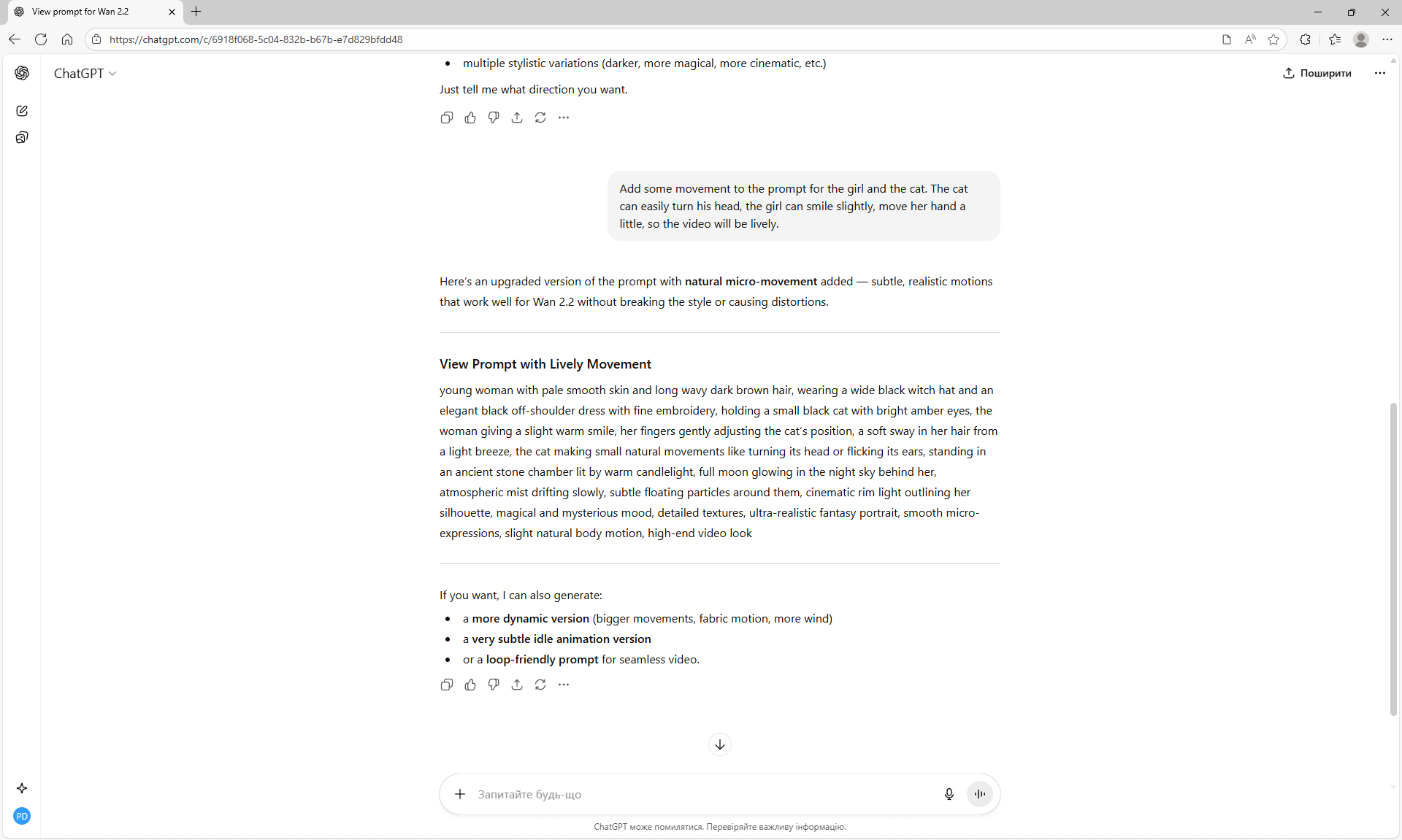
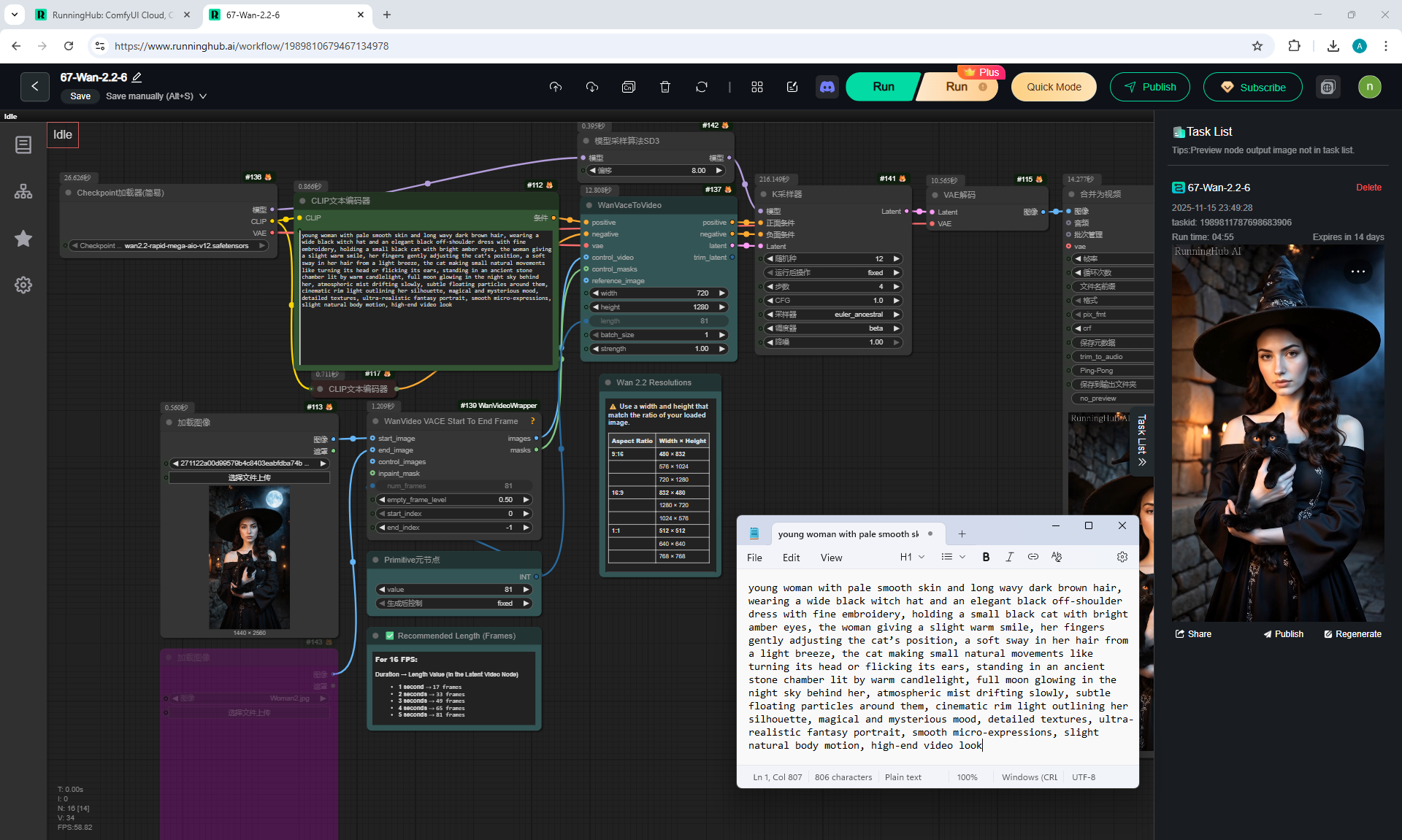
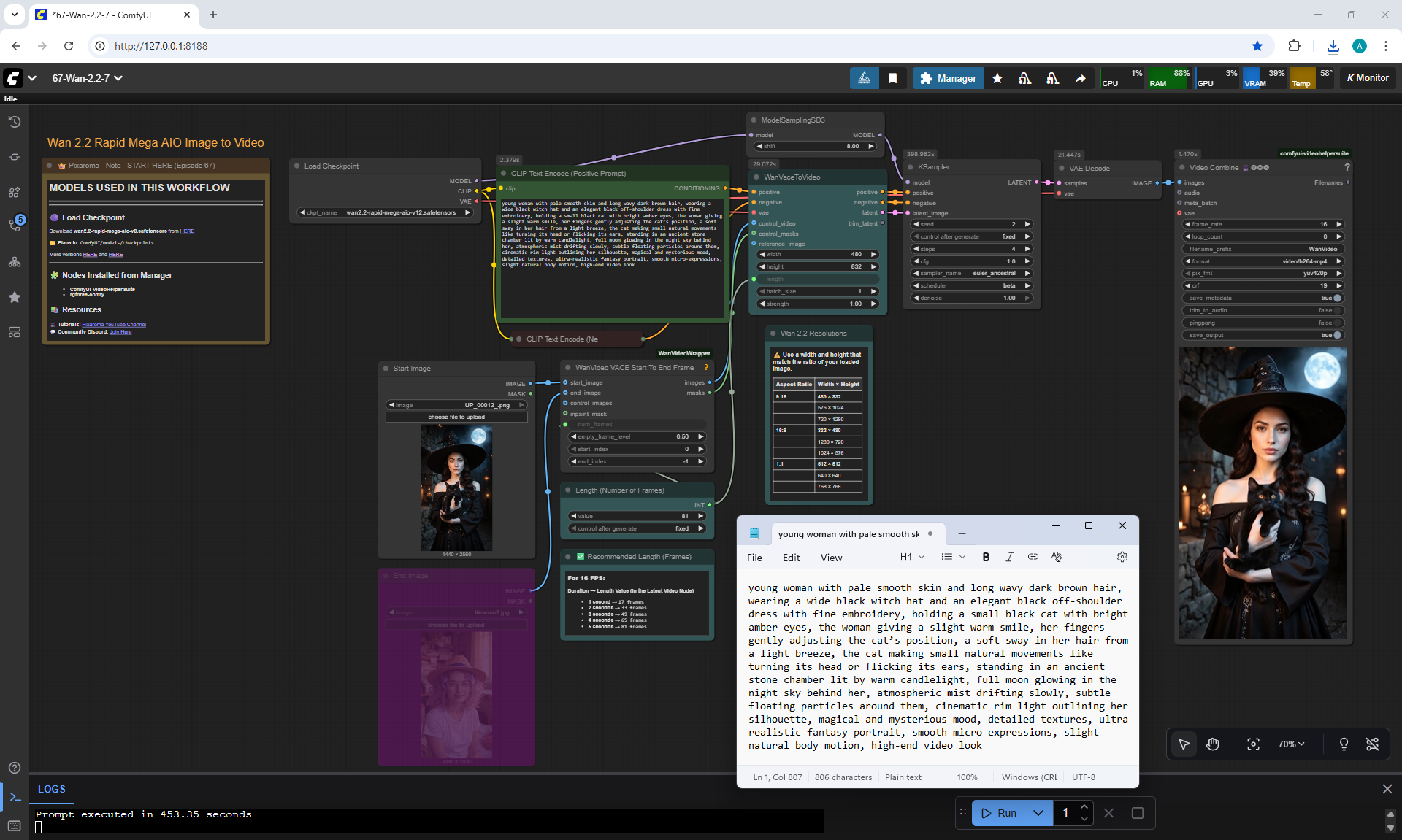
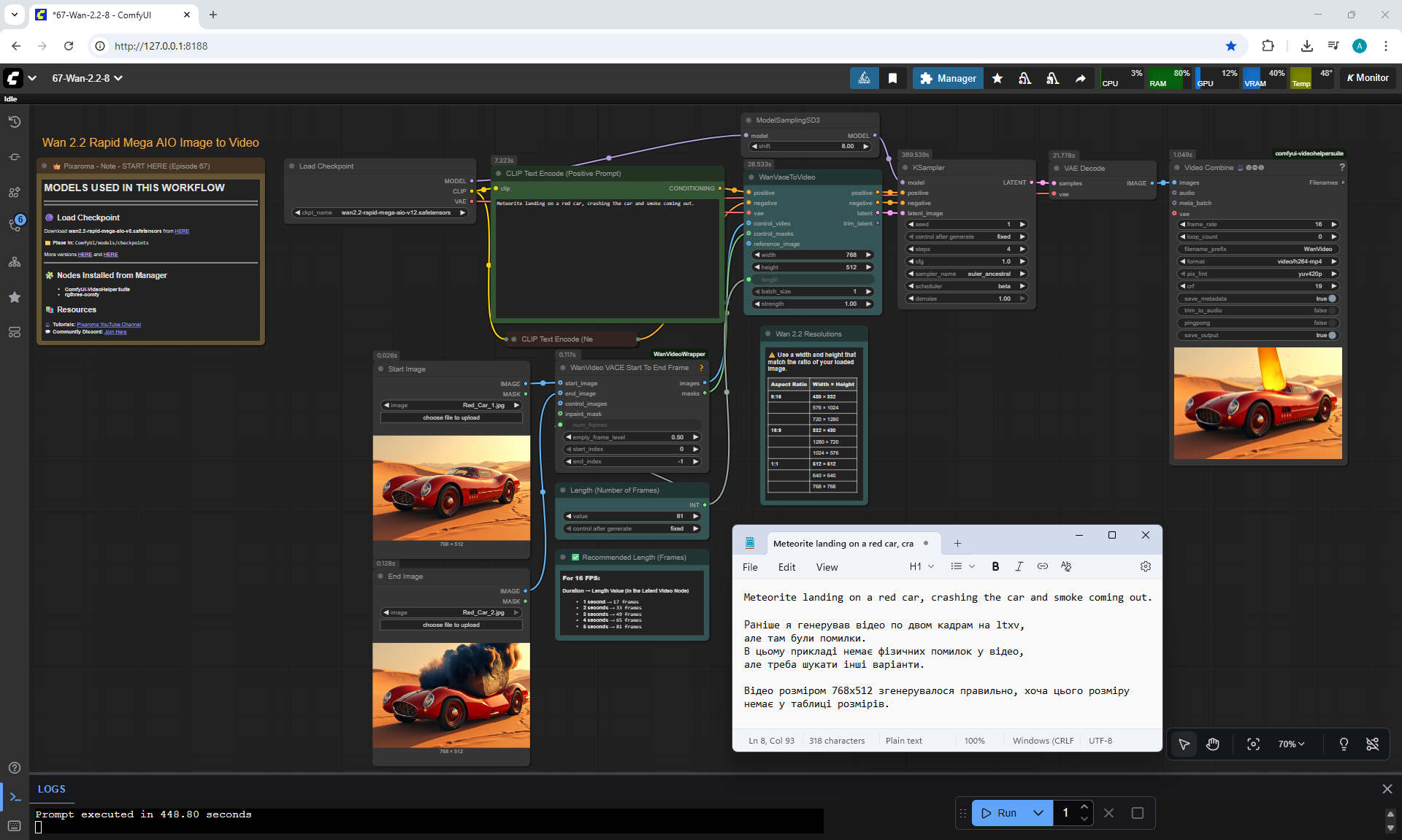
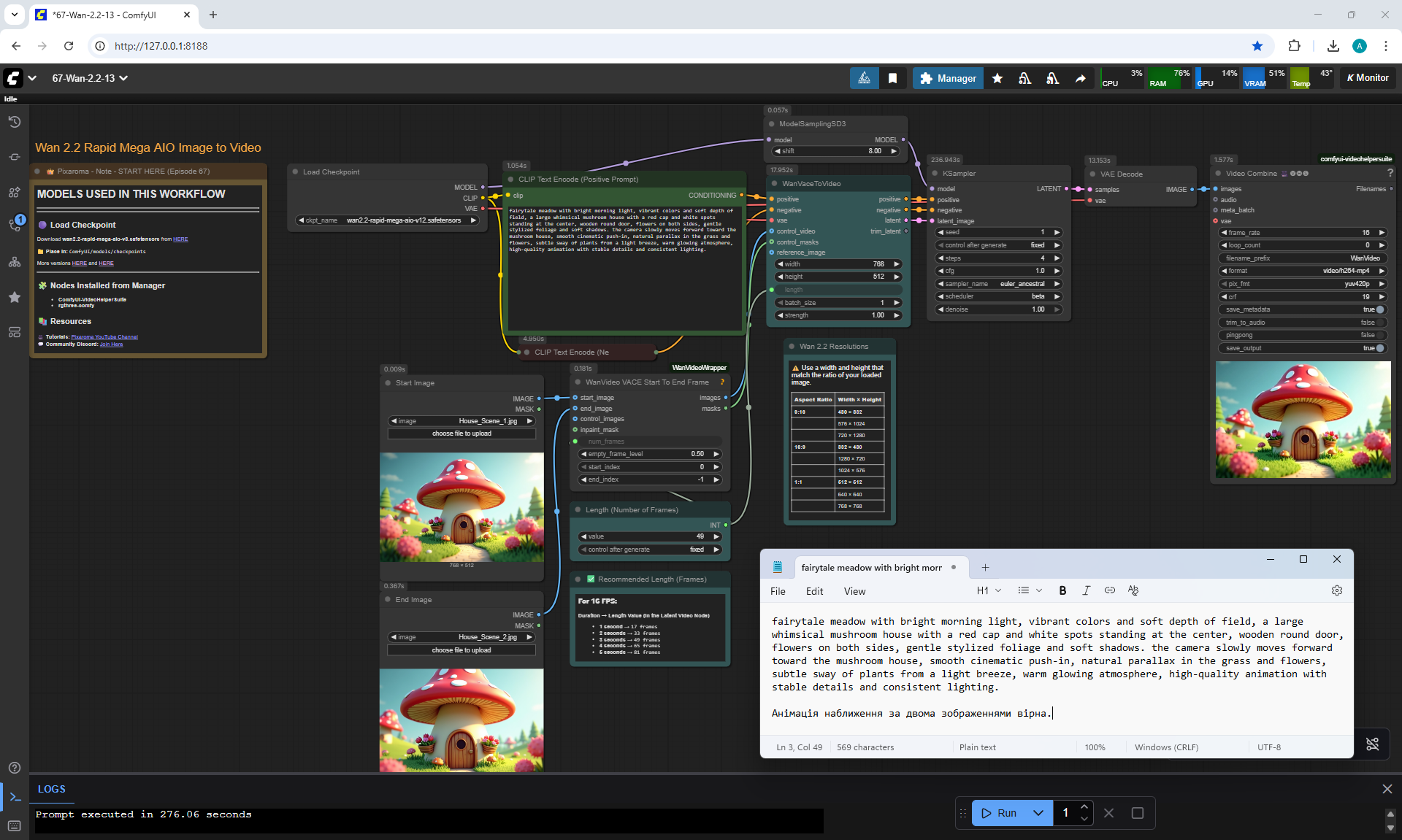
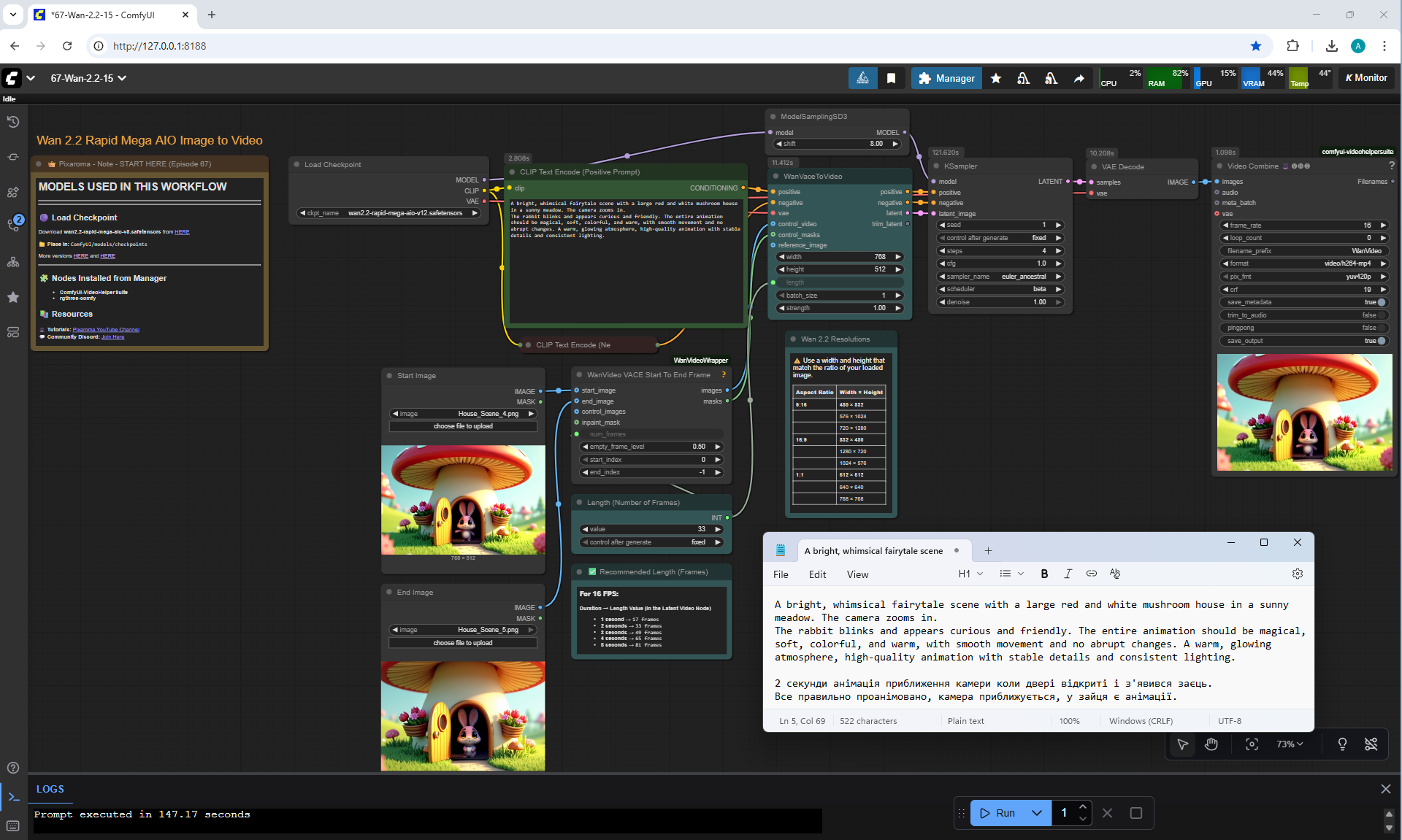
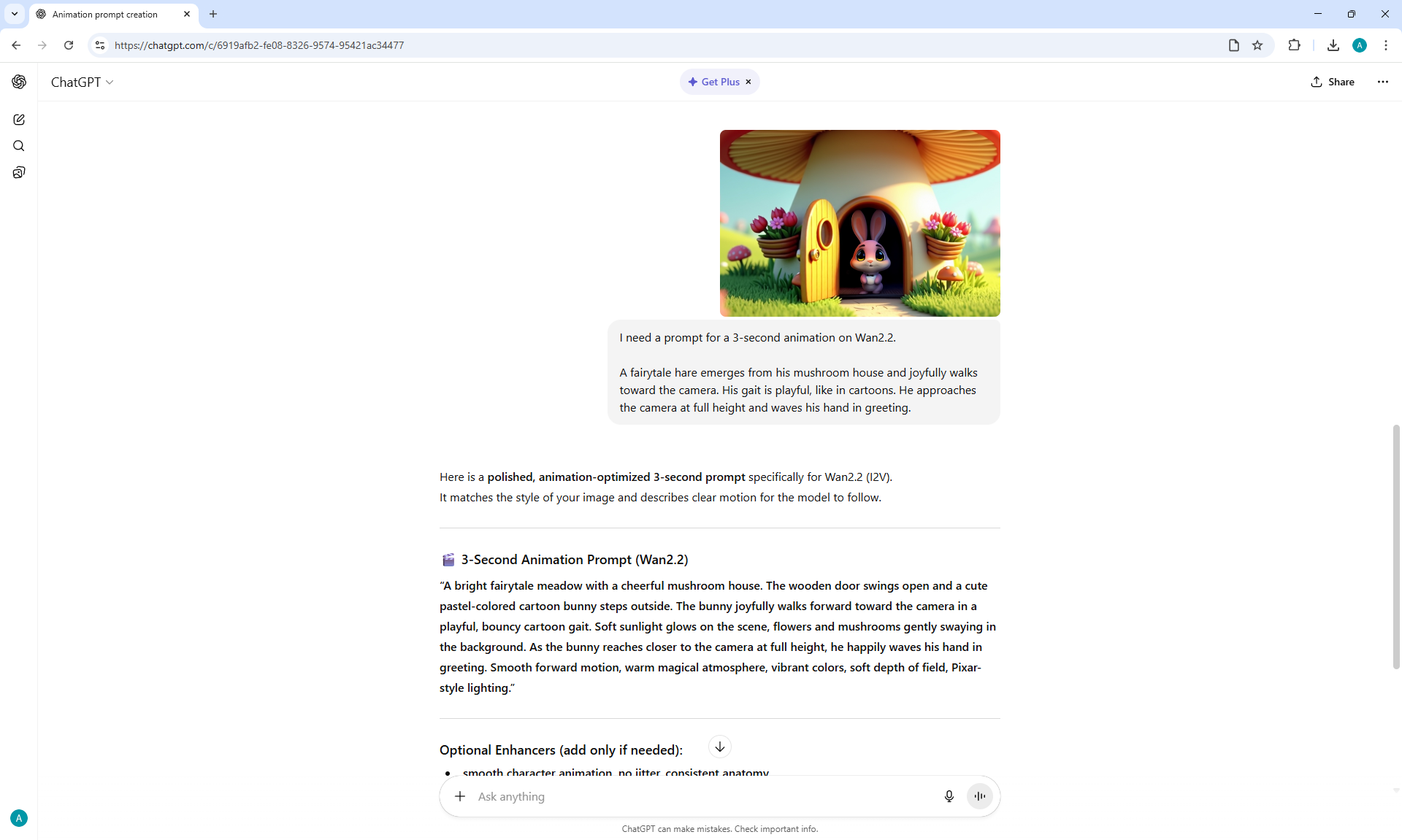
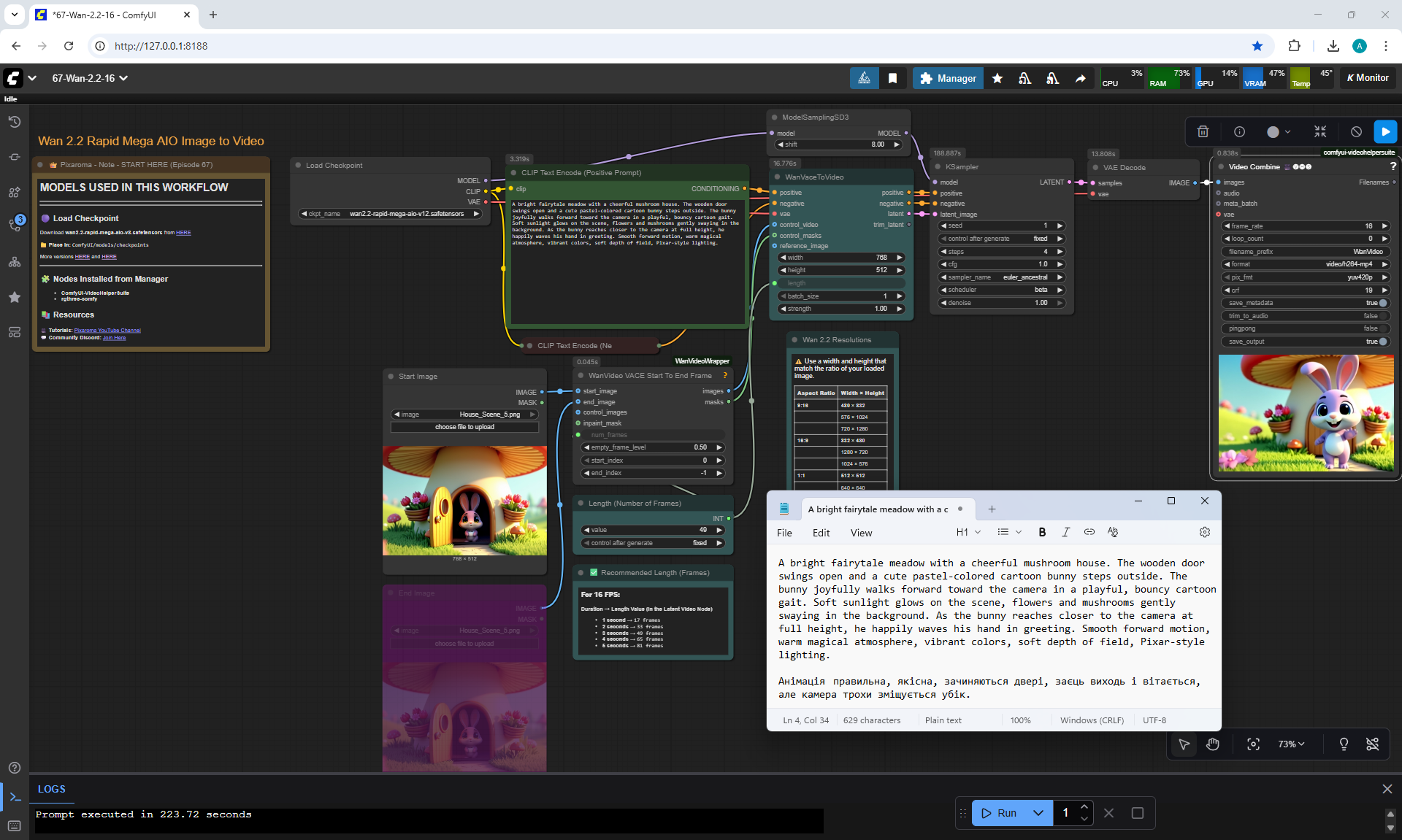
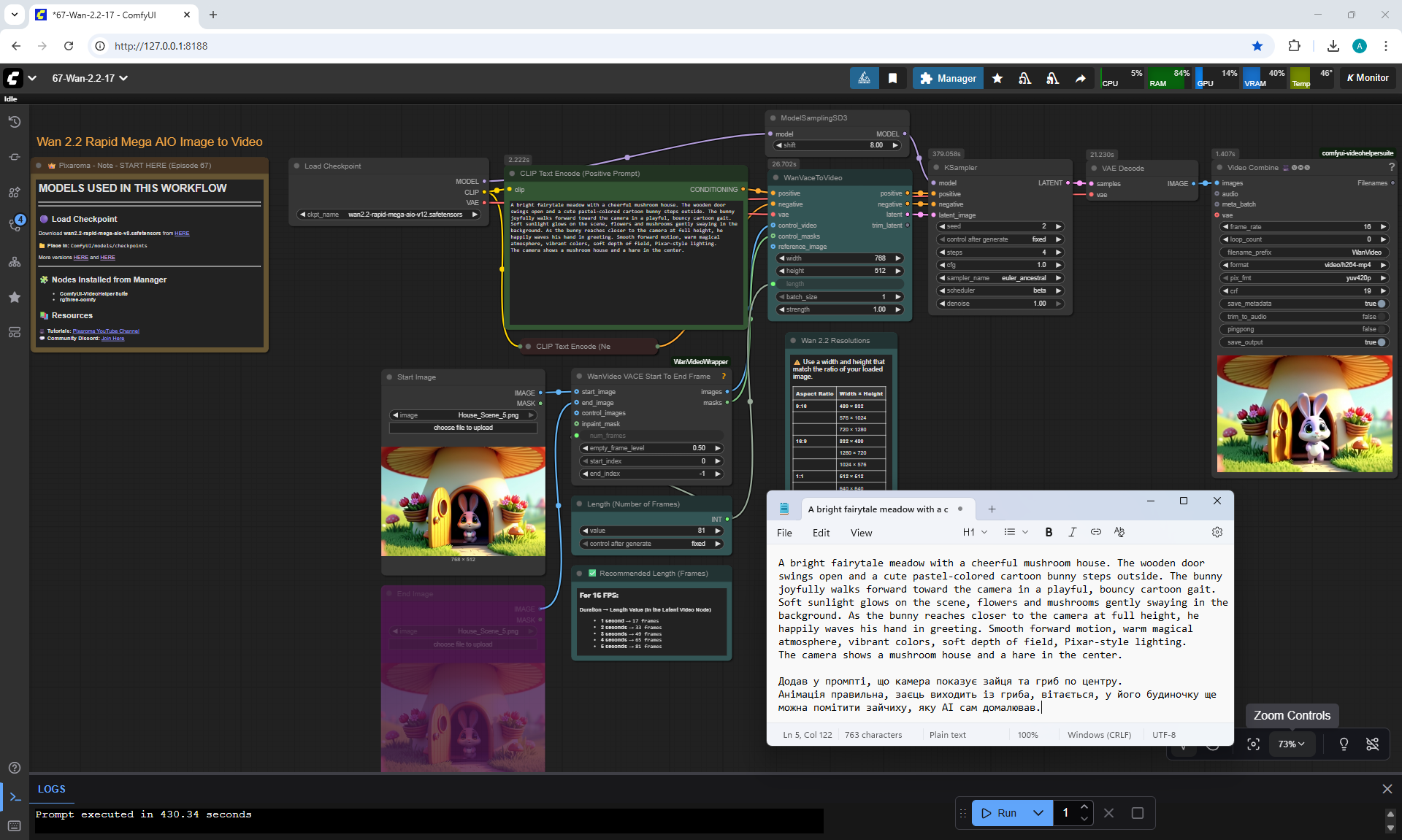
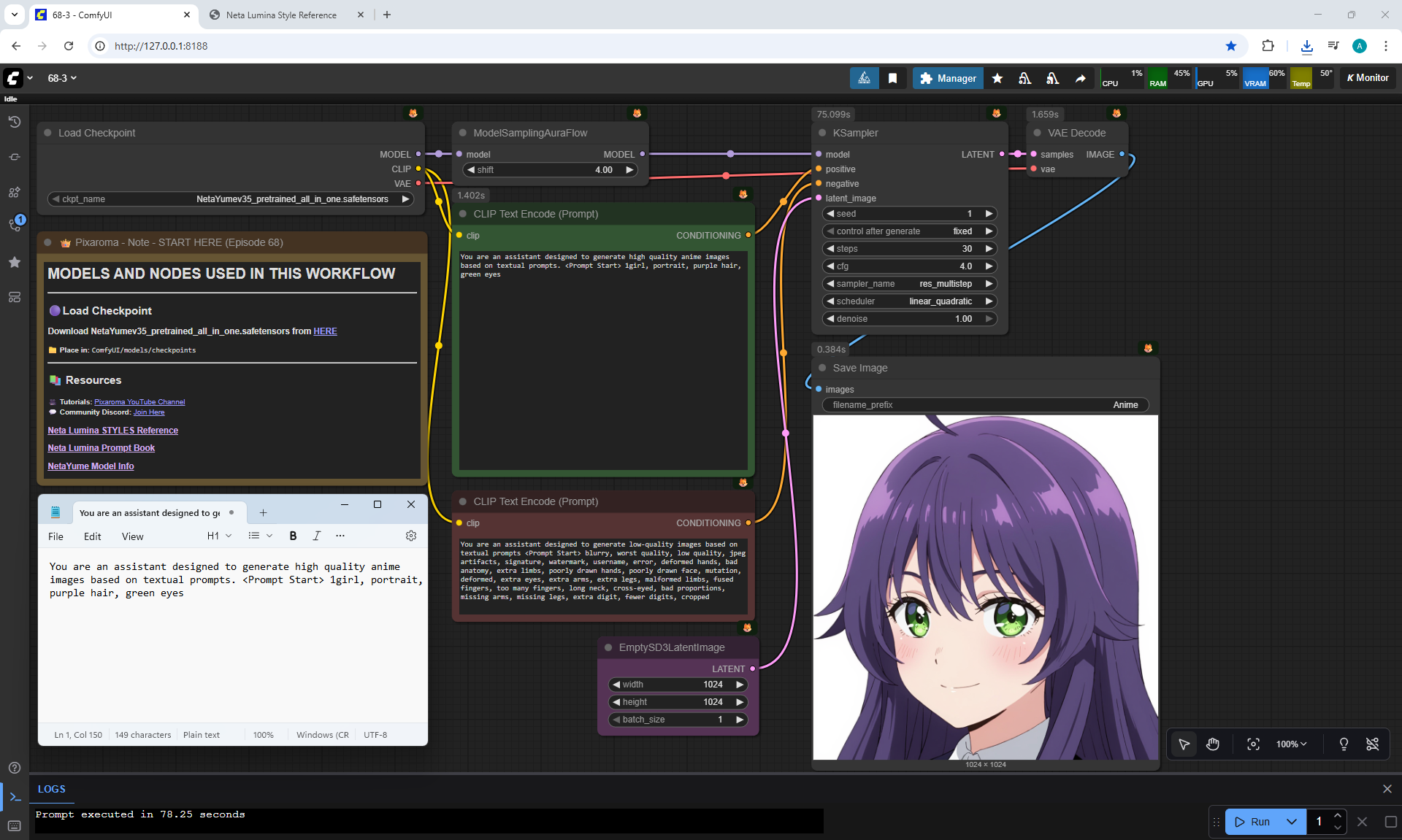
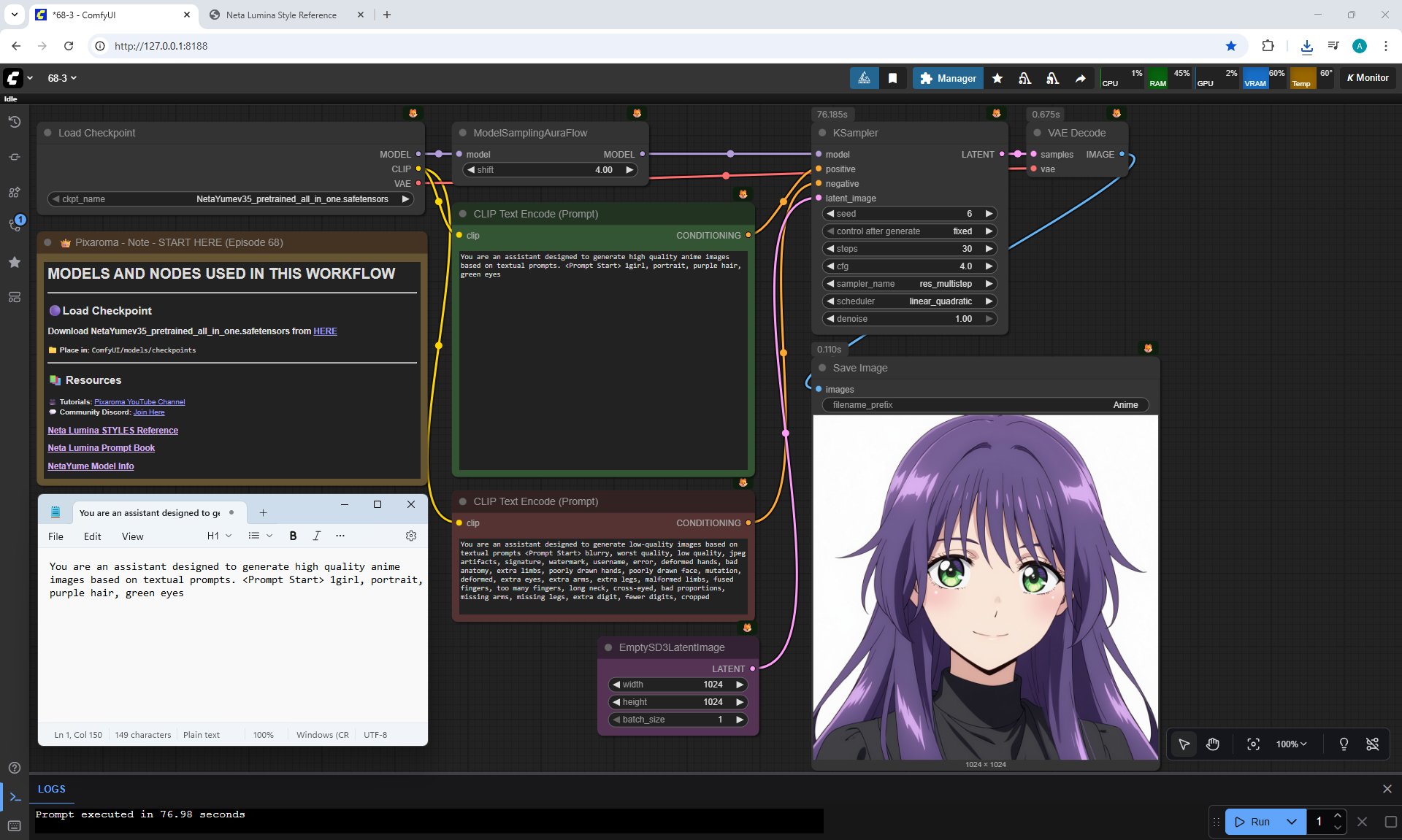
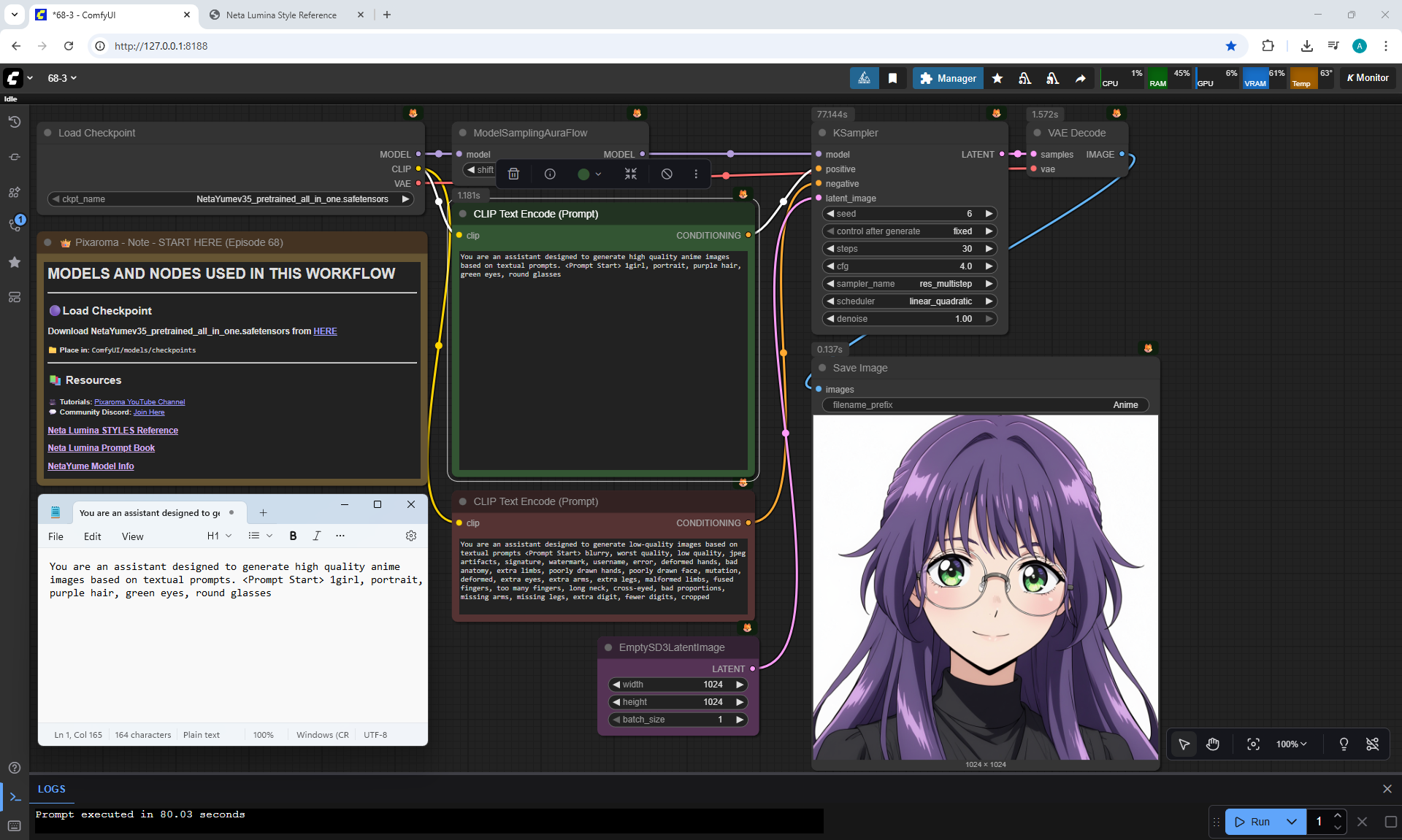
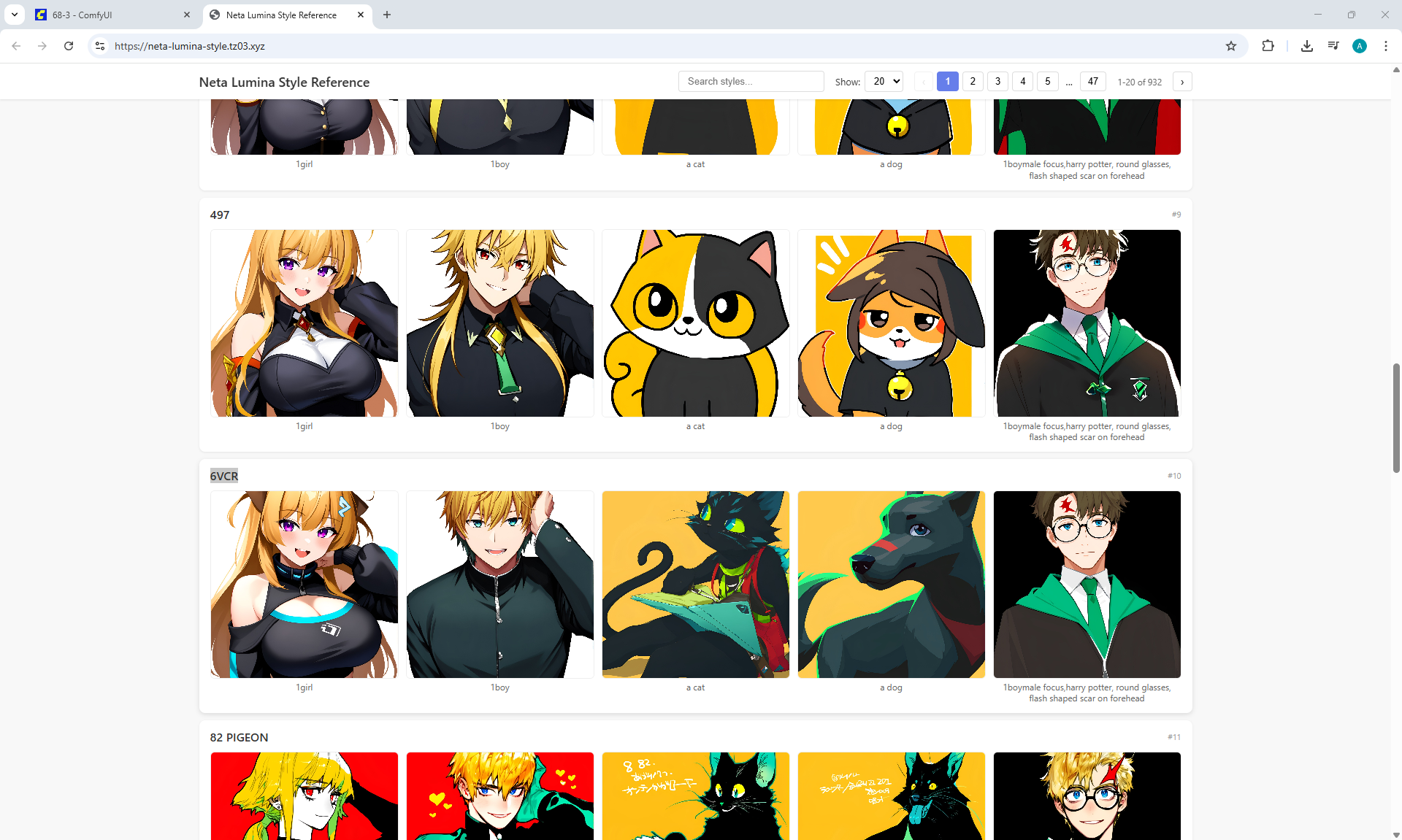
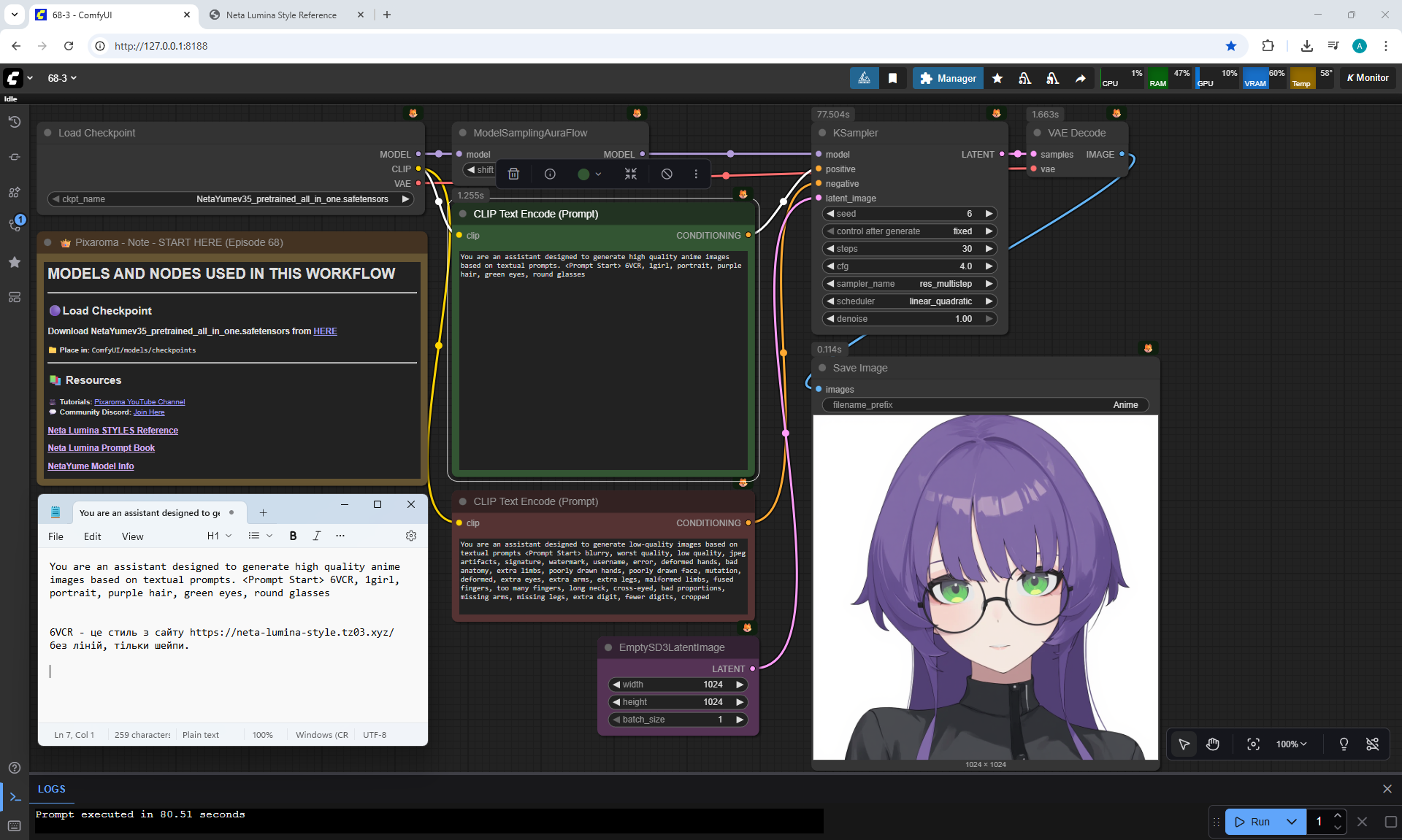
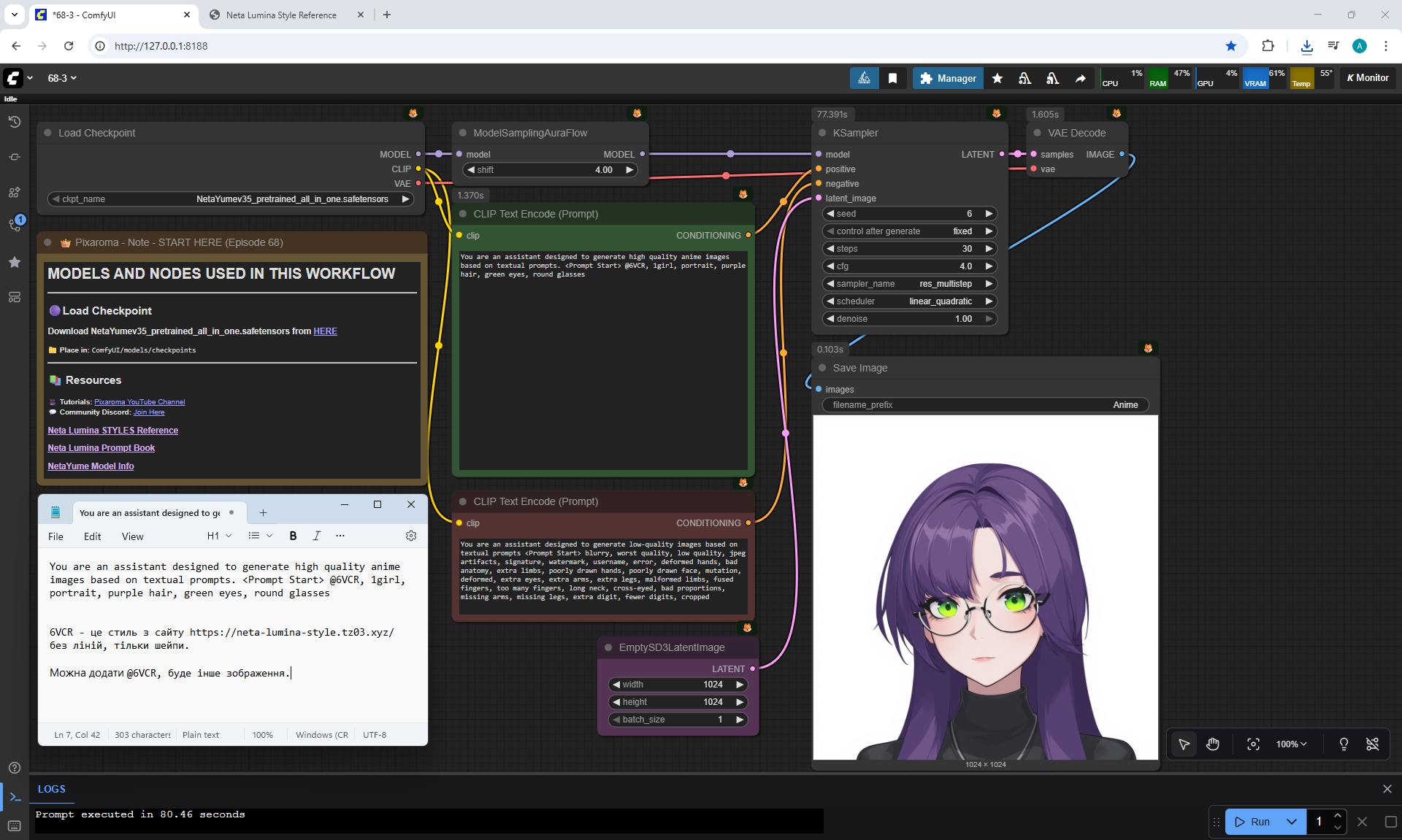
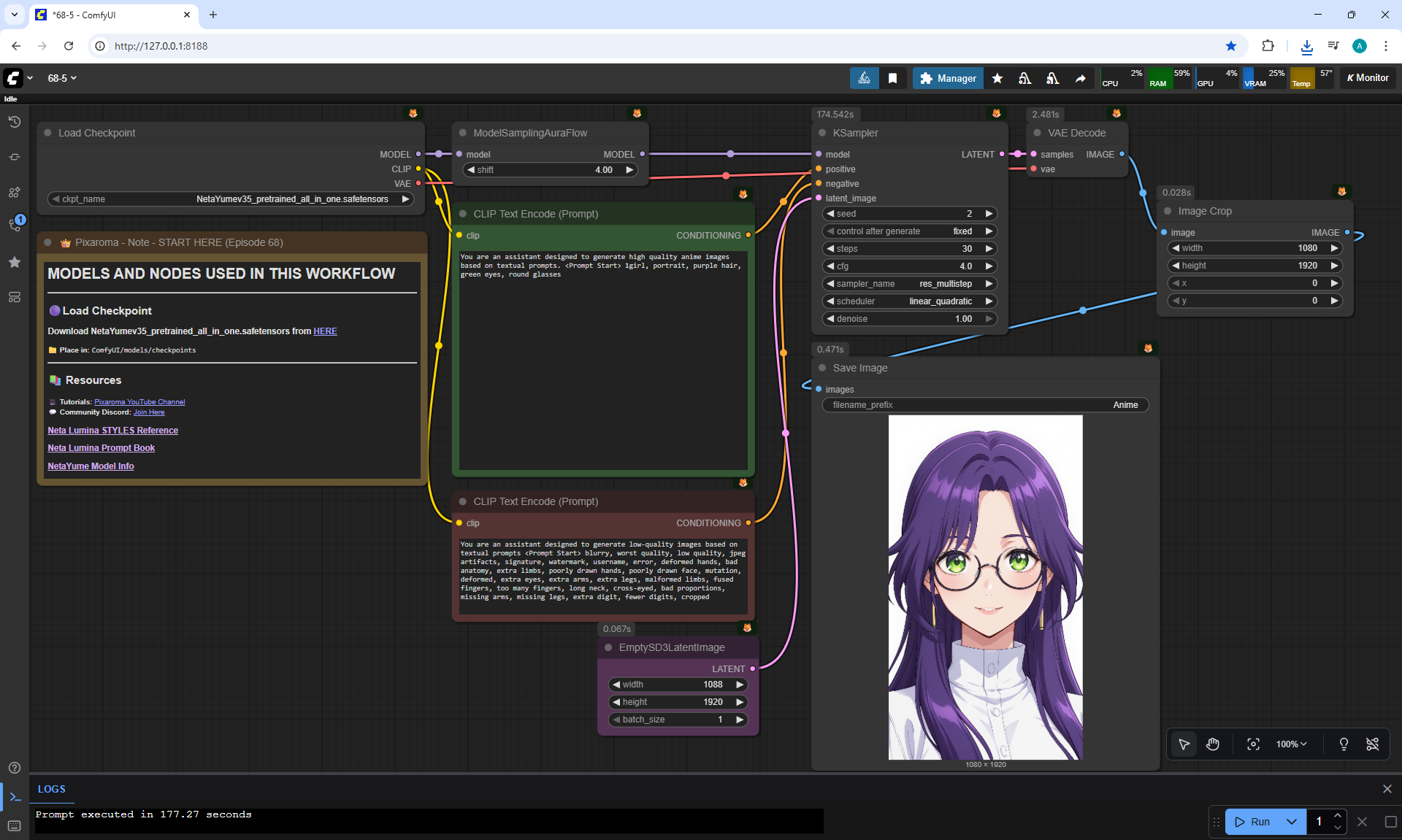
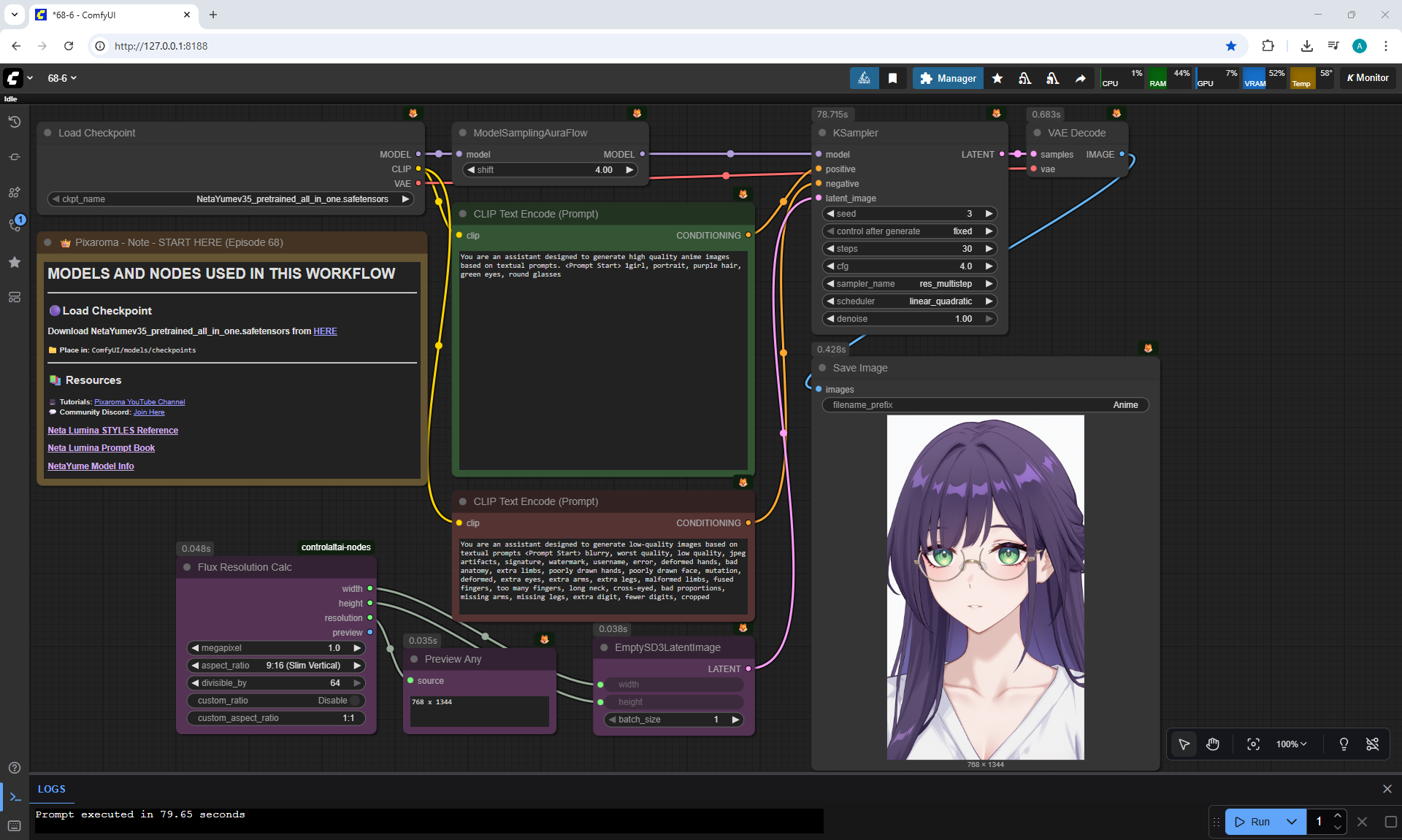
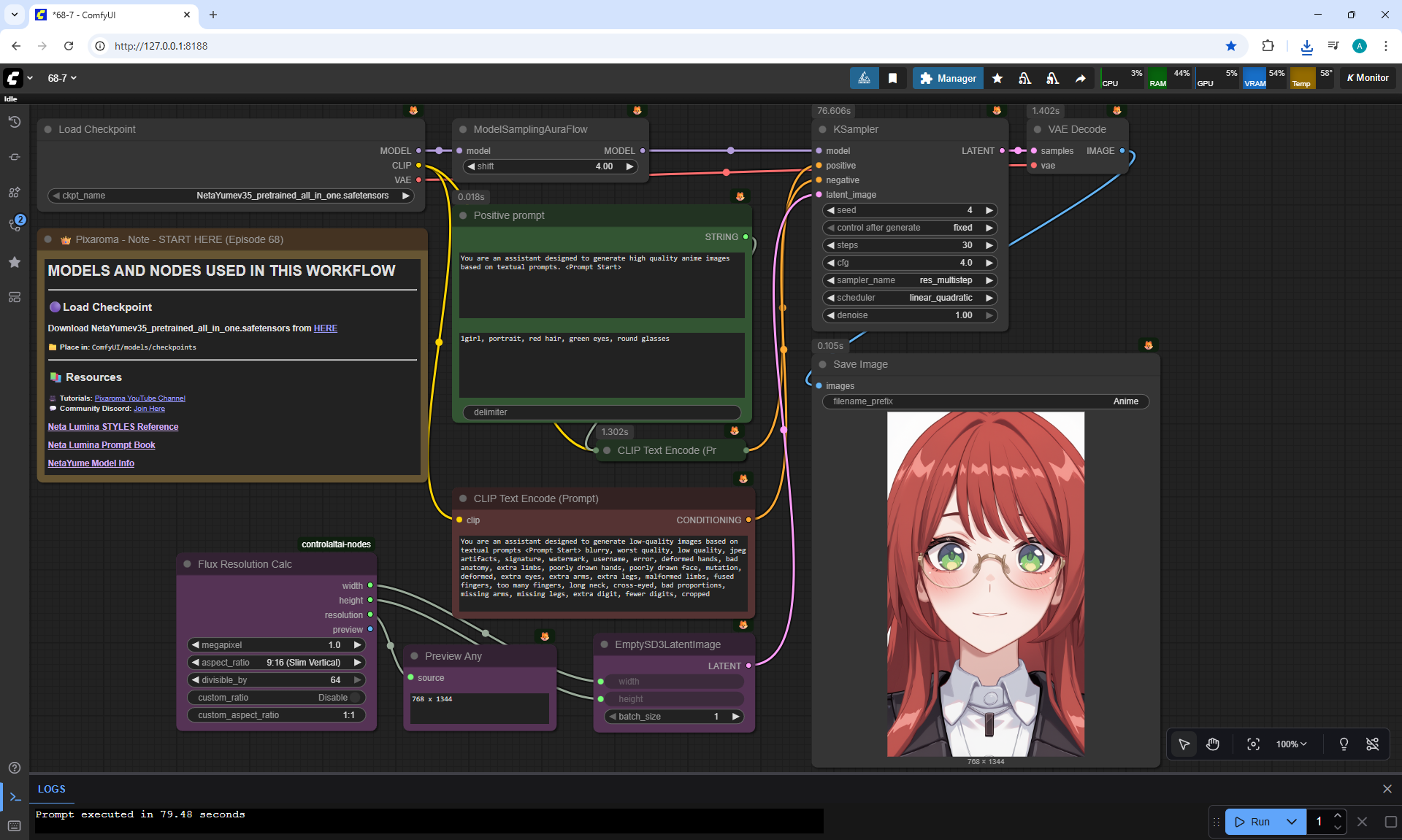
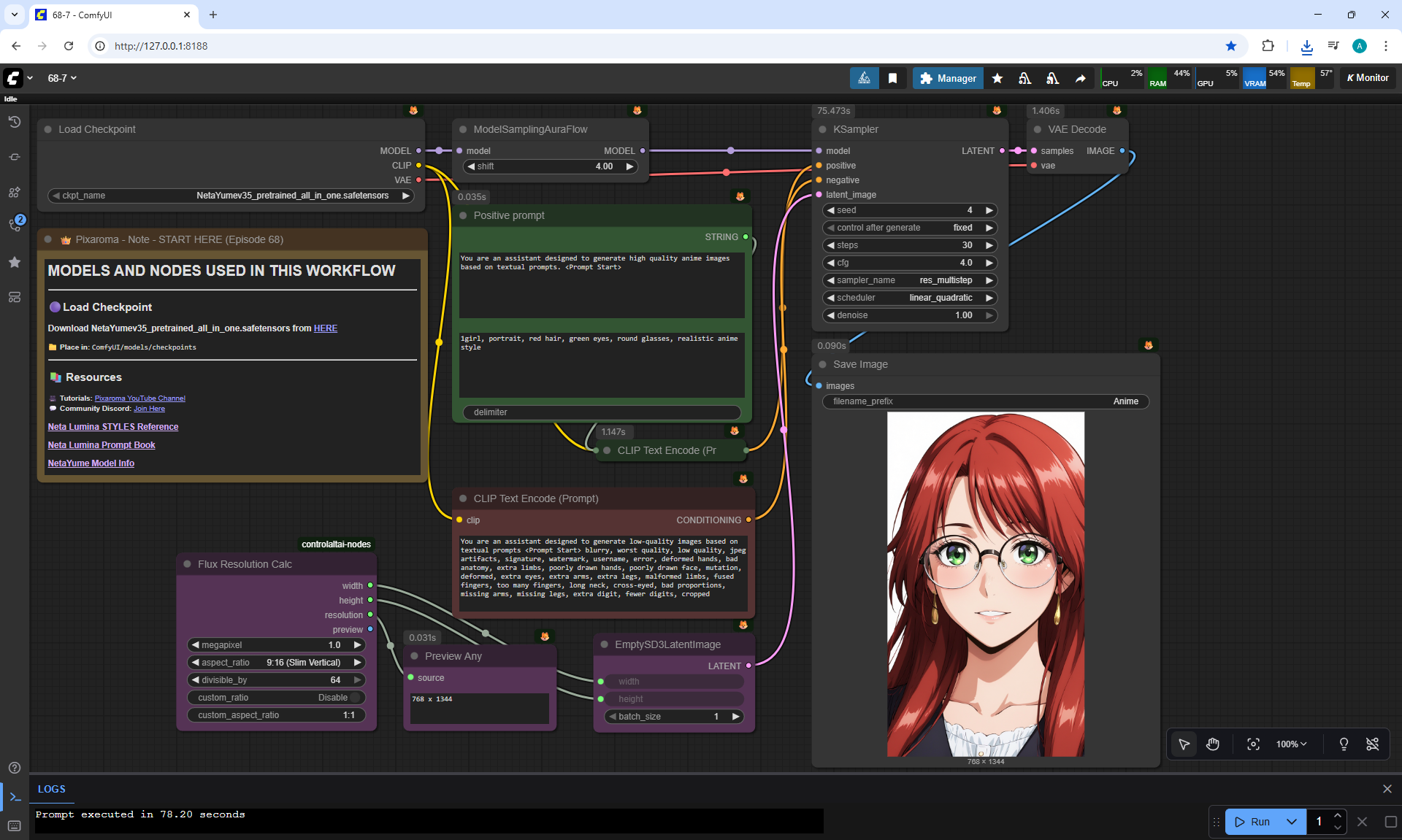
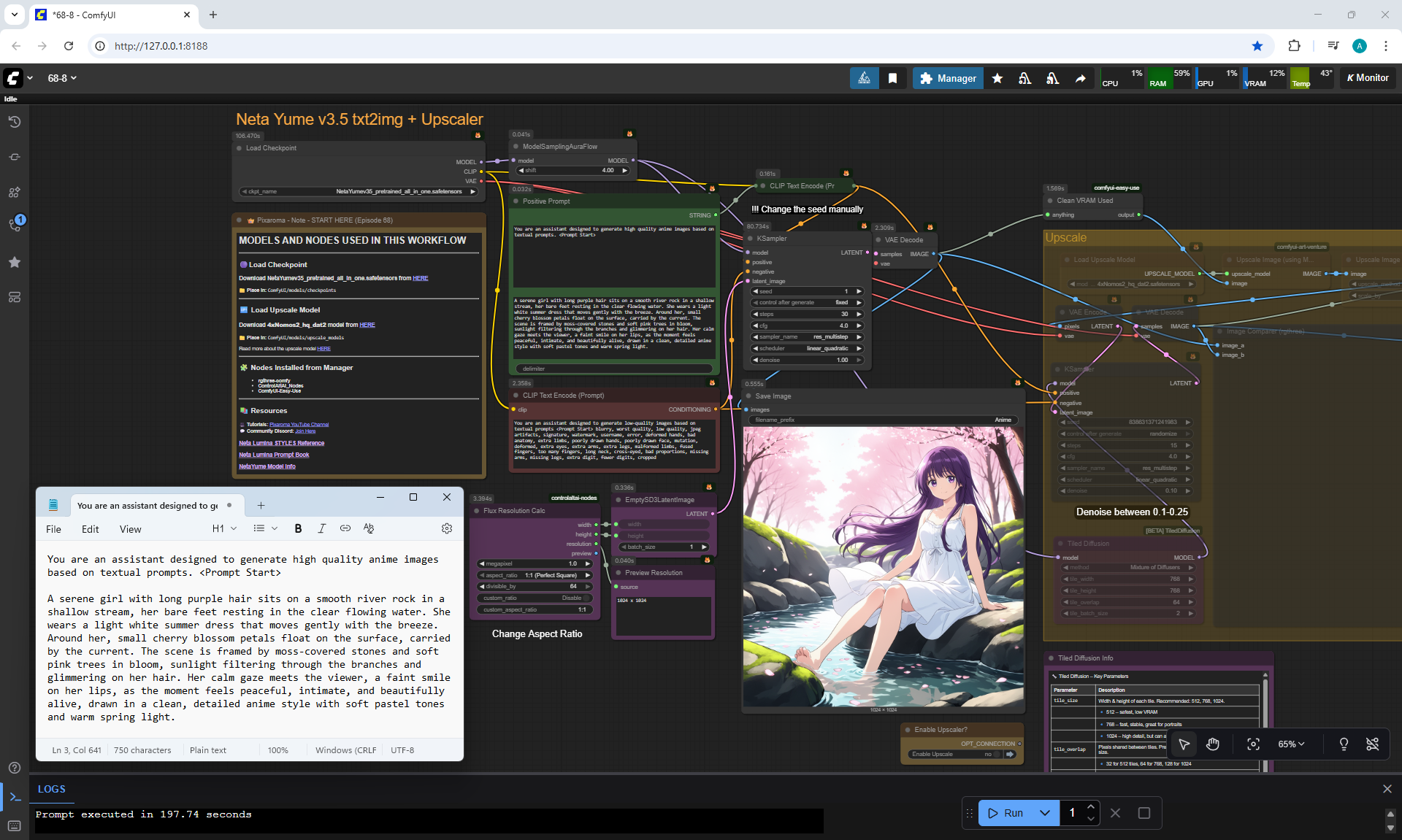
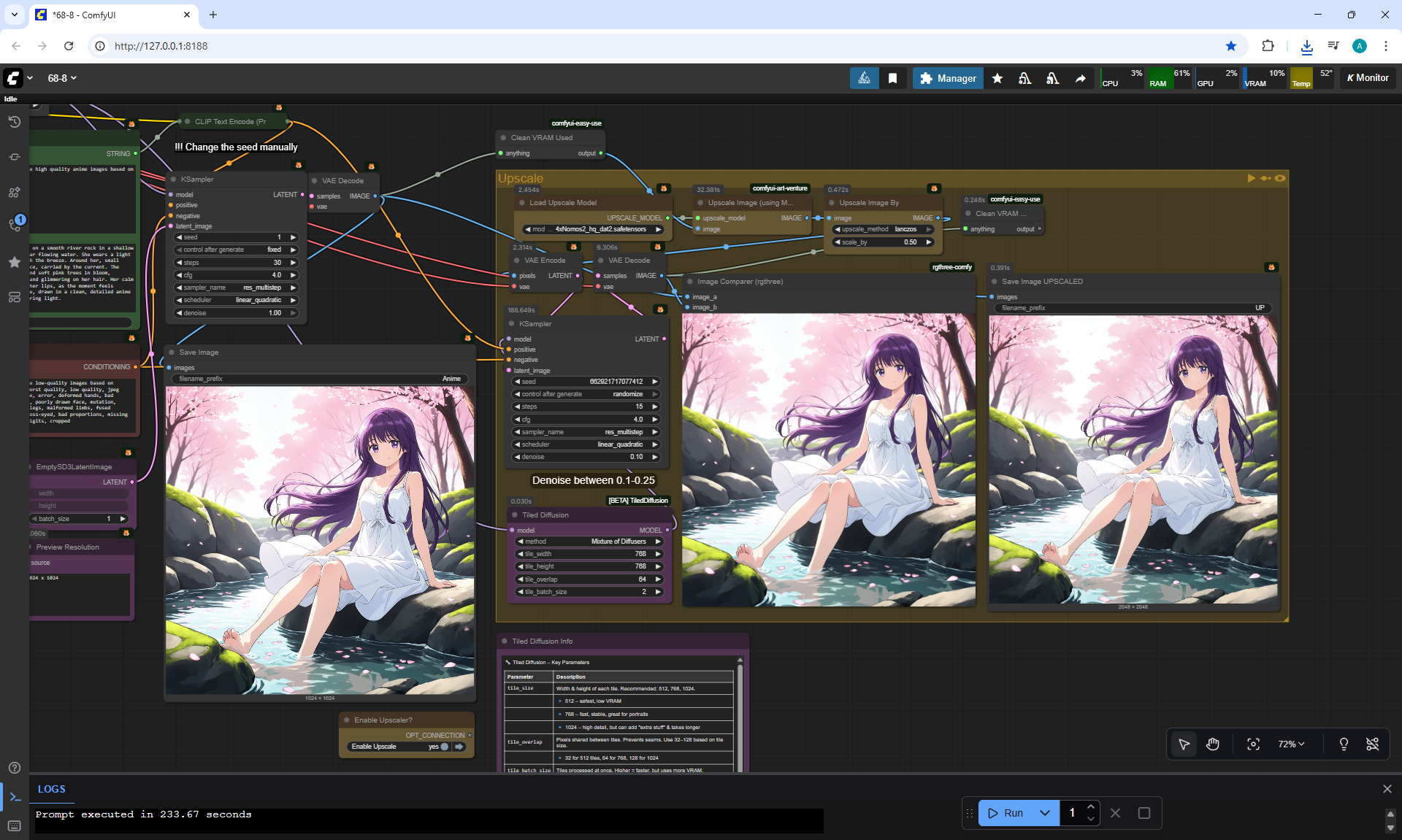
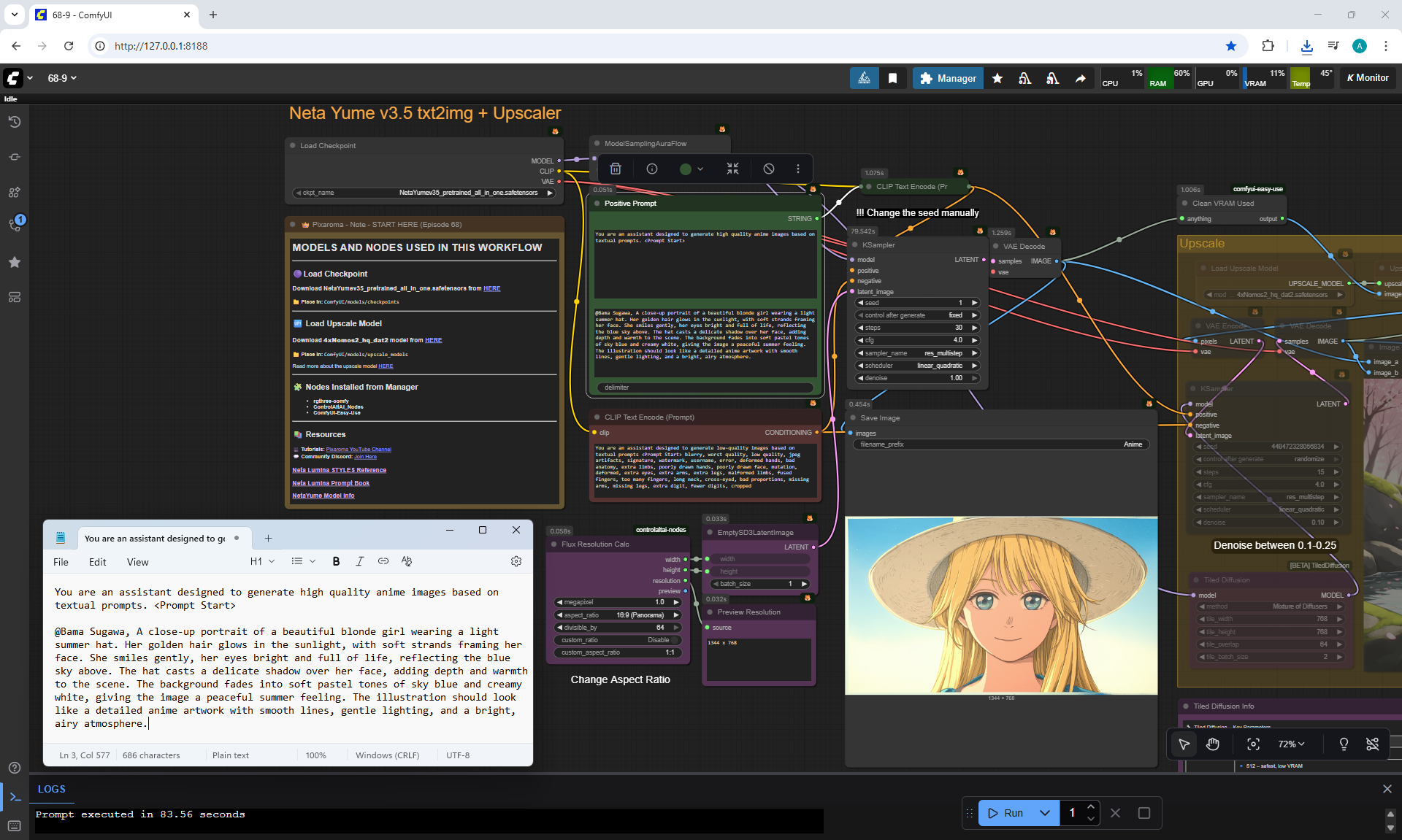
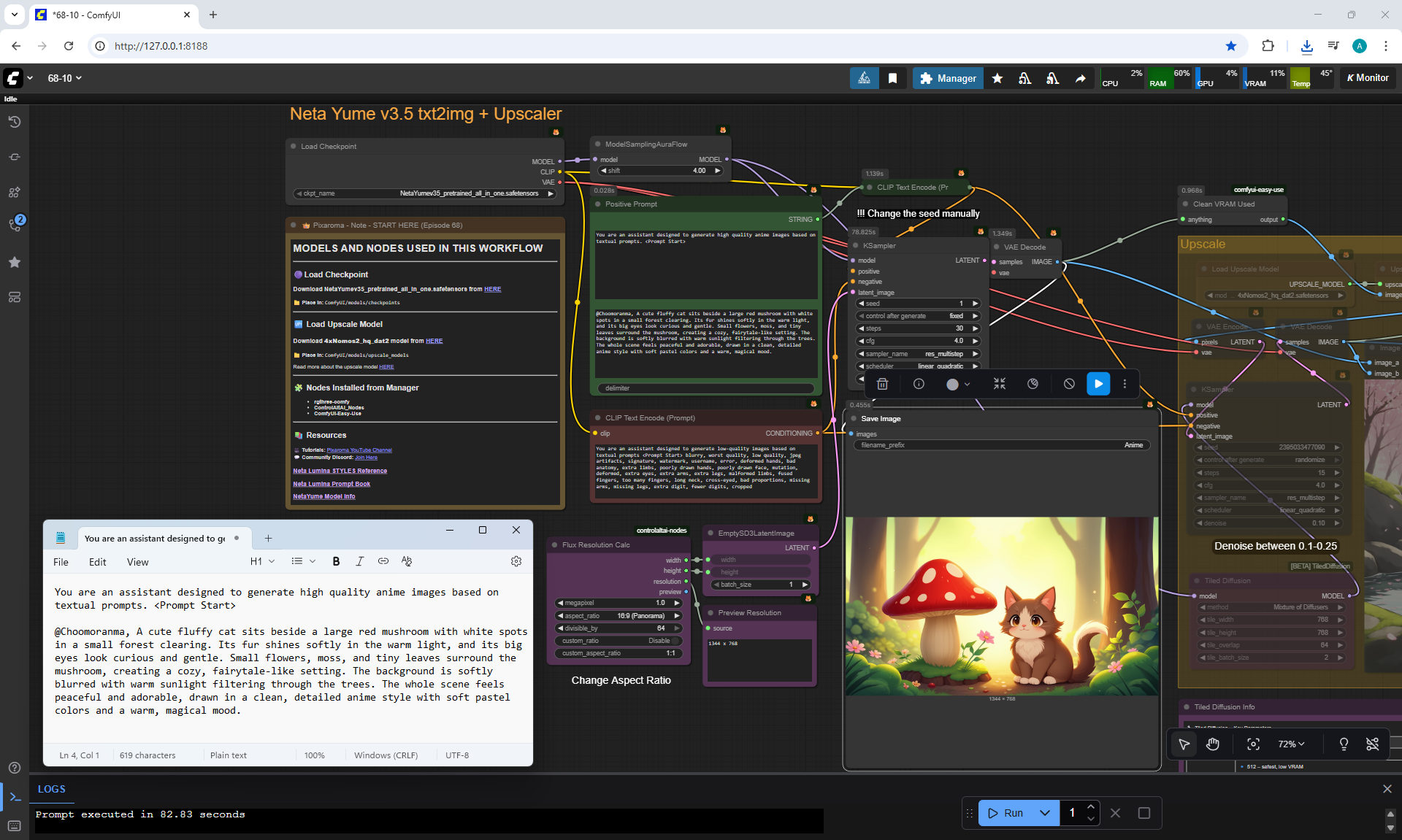
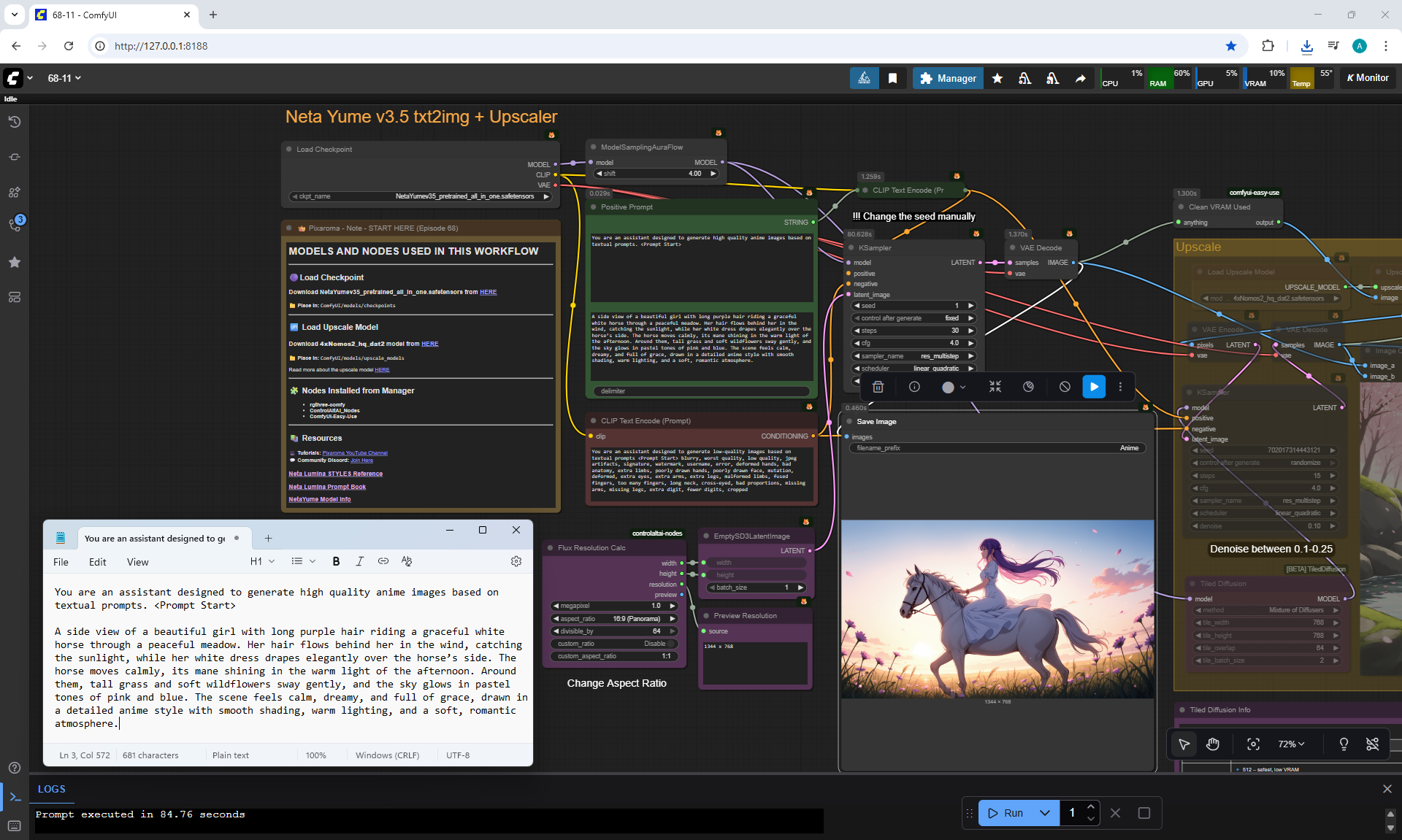
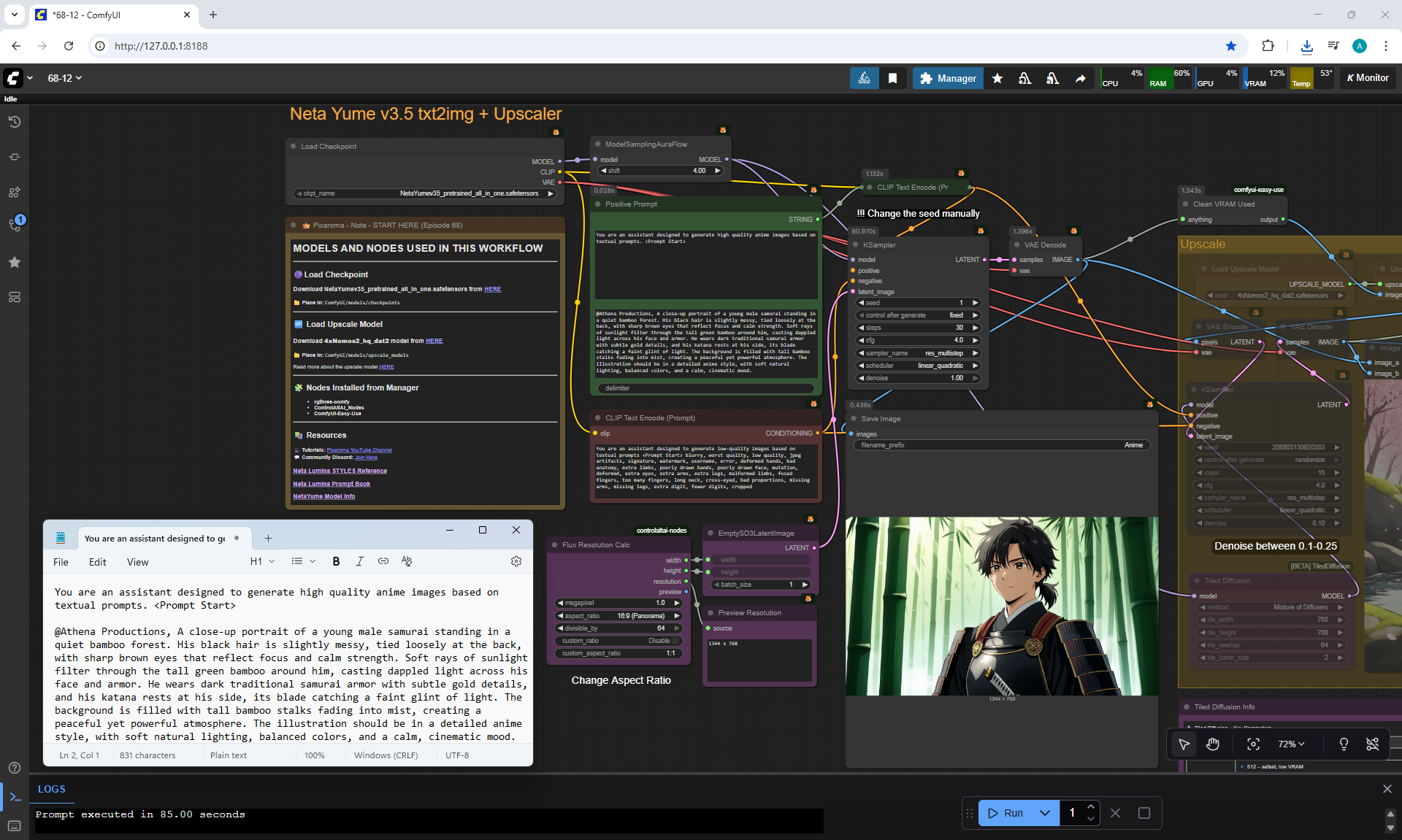
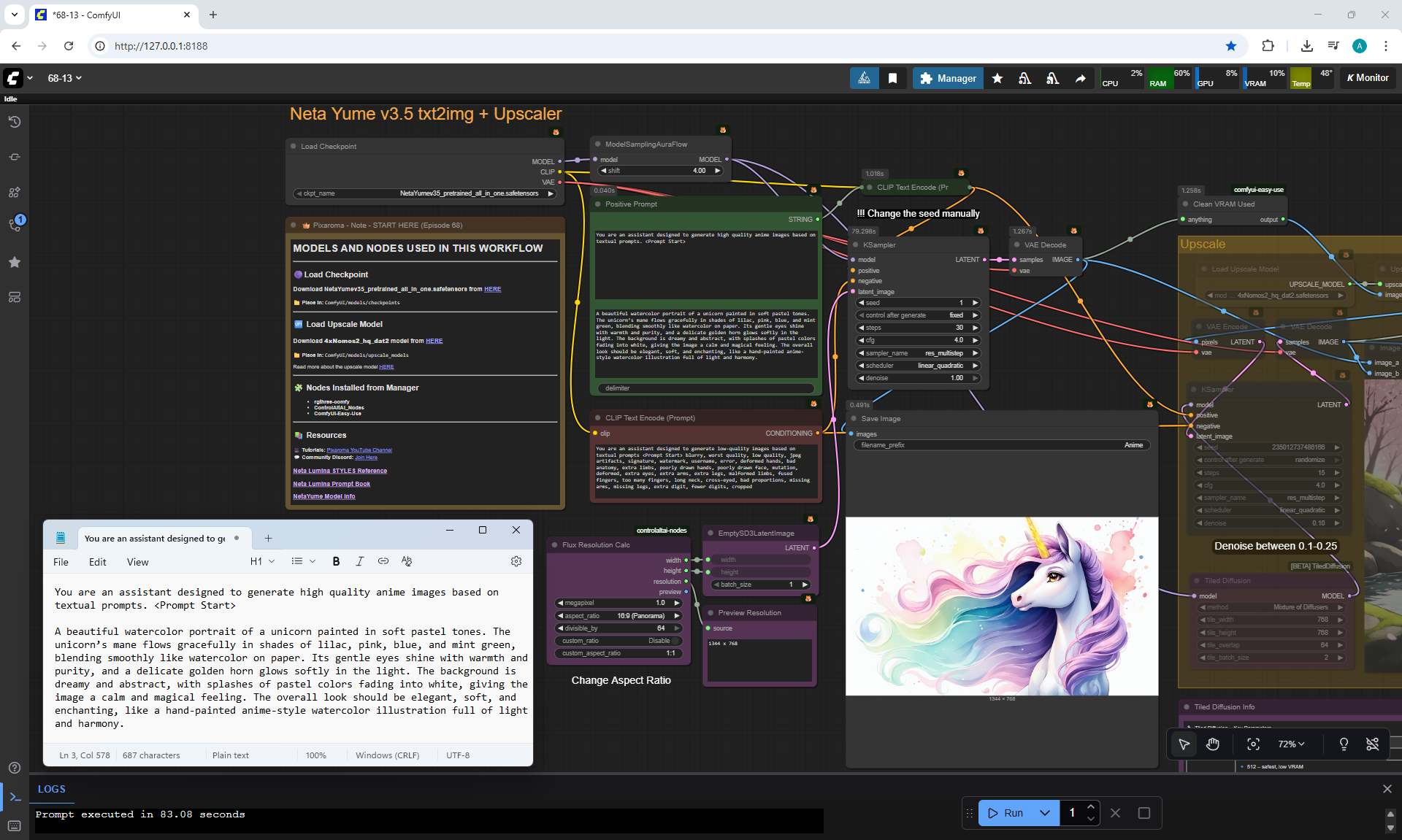
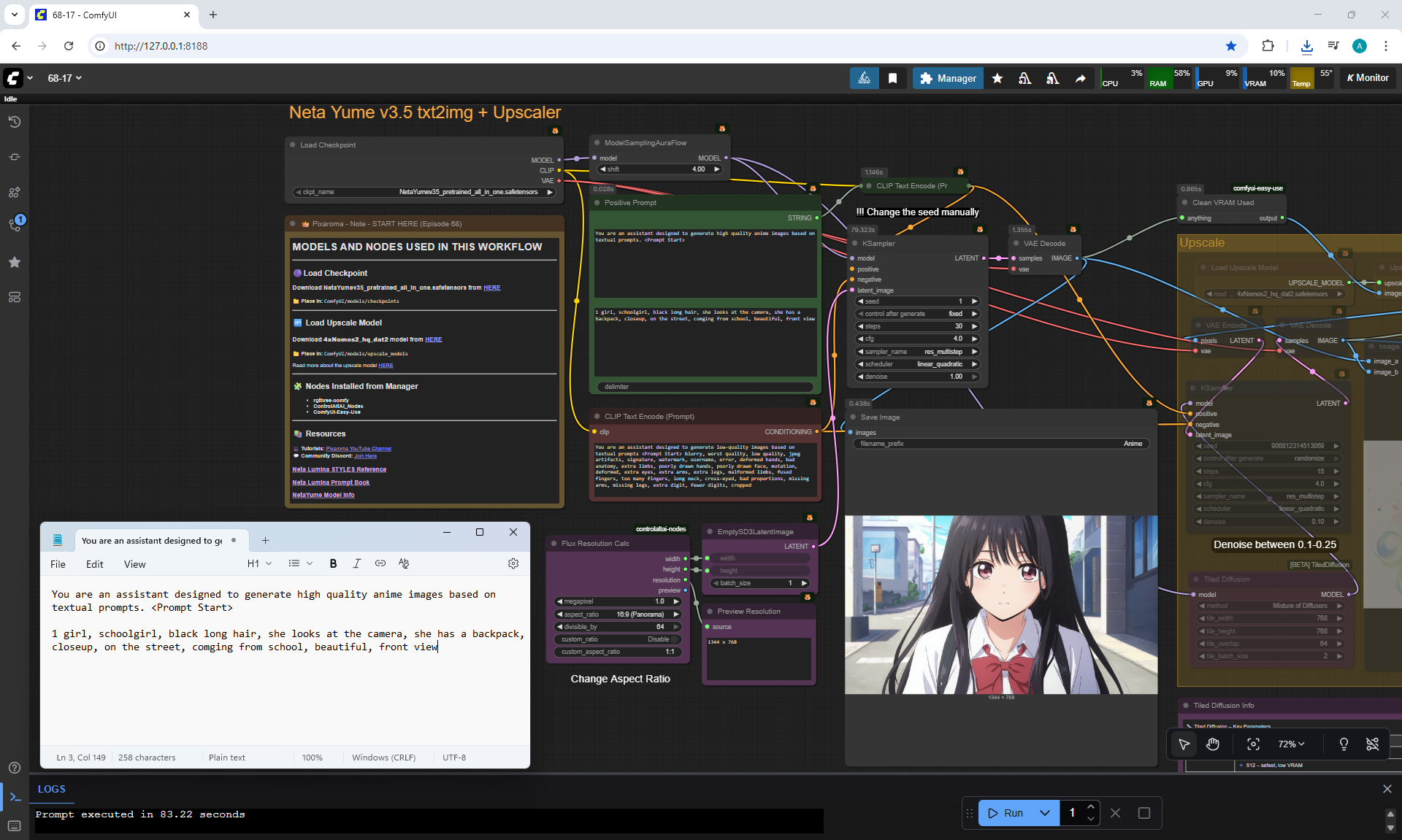
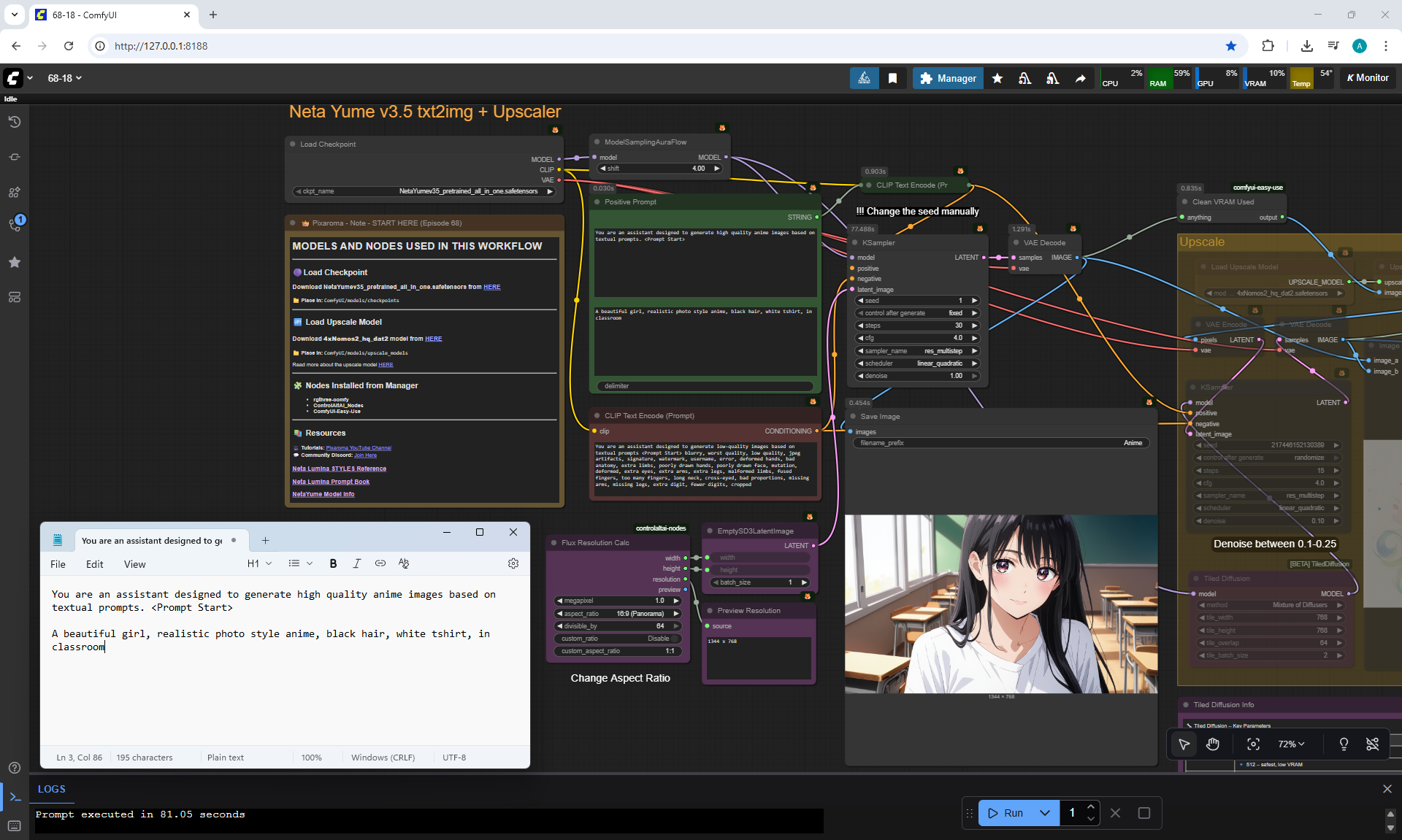
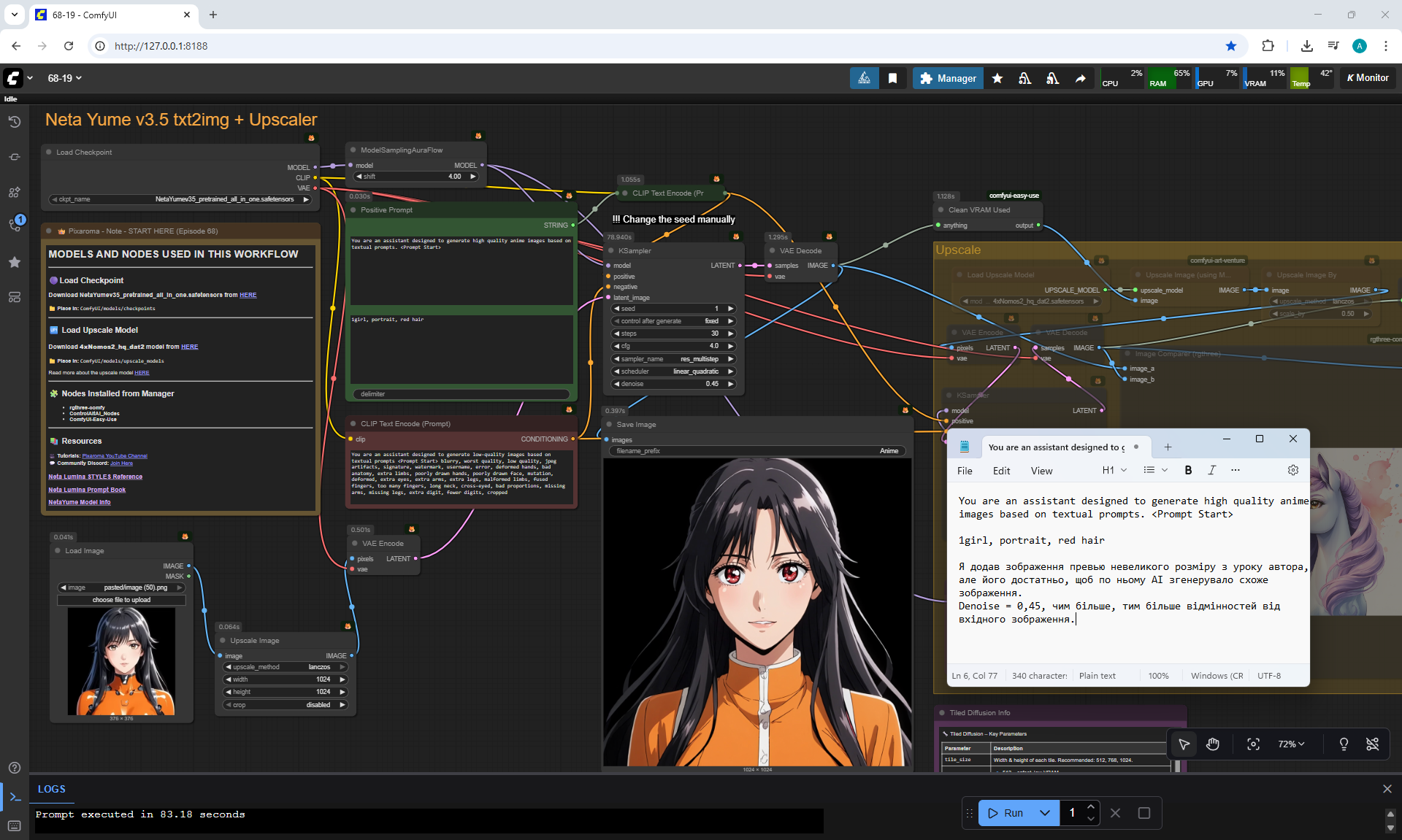
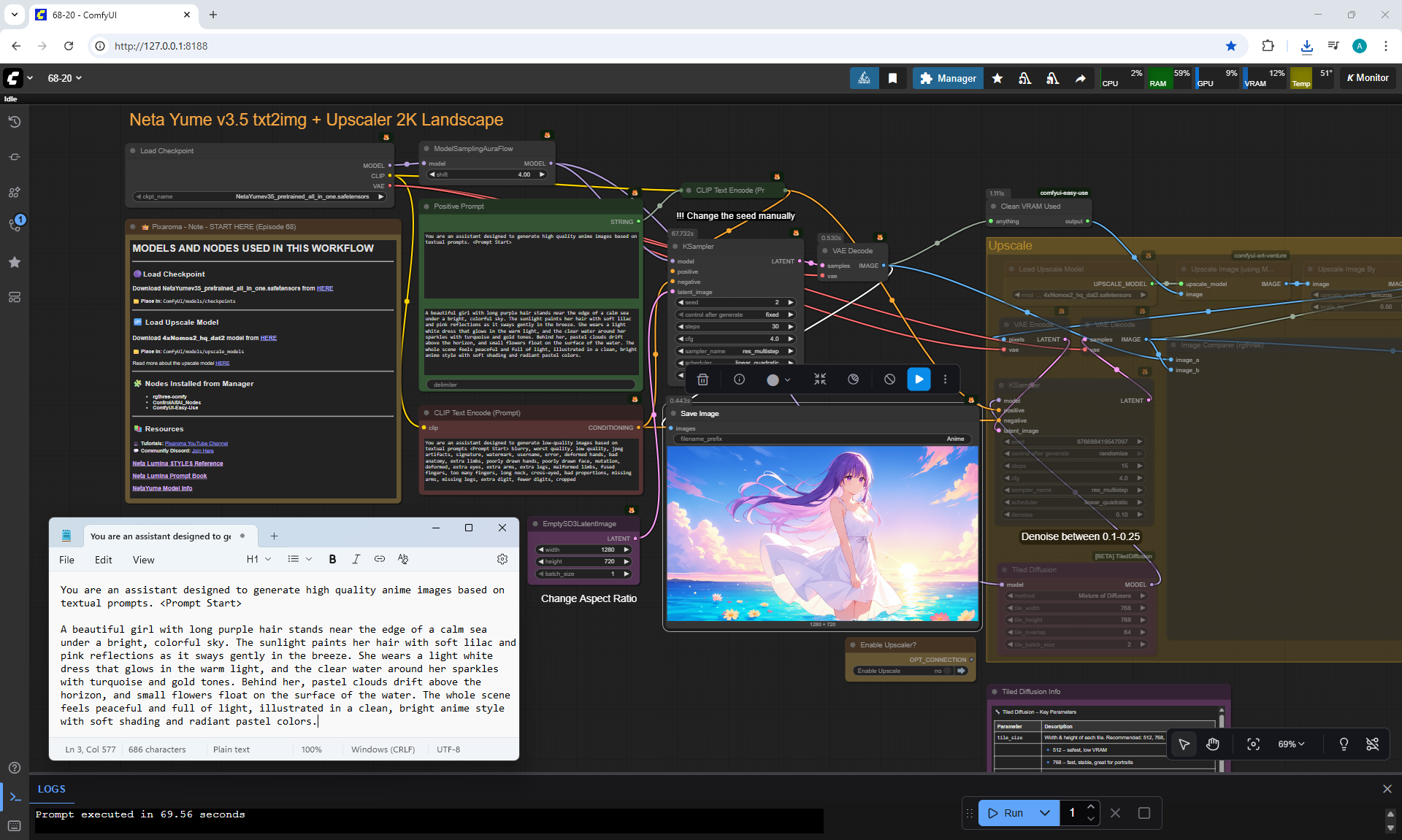
ComfyUI Tutorial Series Ep 68: How to Create Anime Illustrations - NetaYume v3.5








































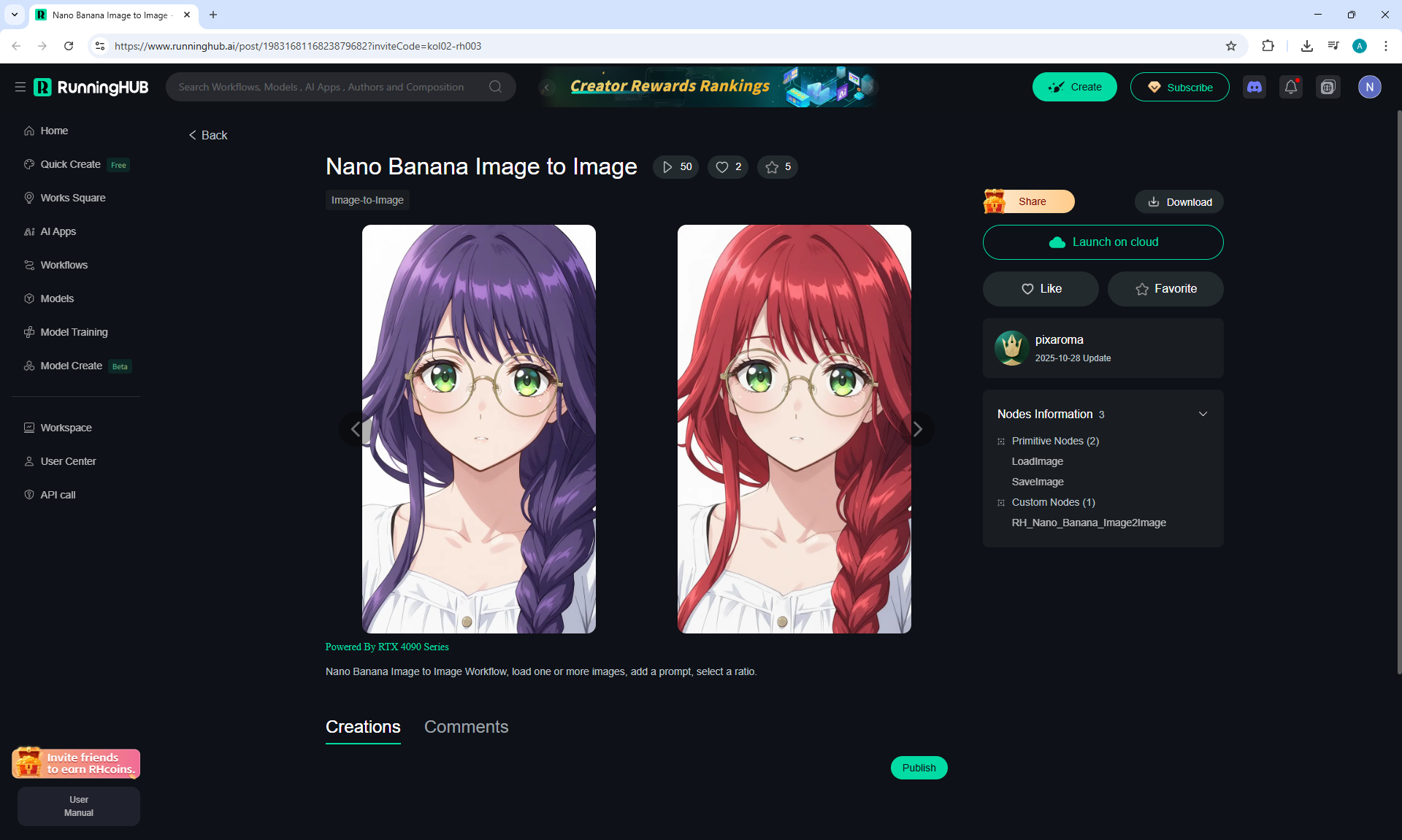
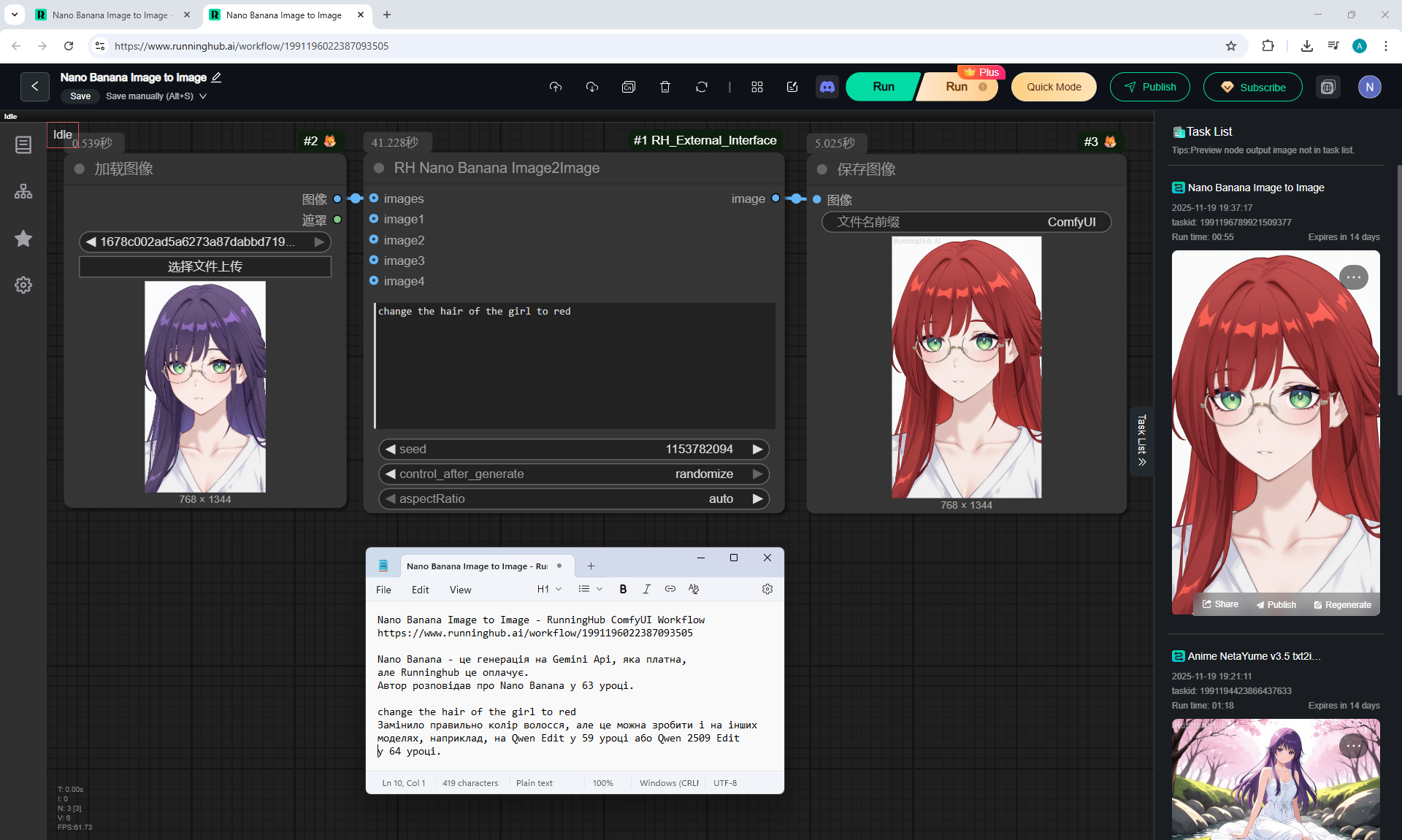
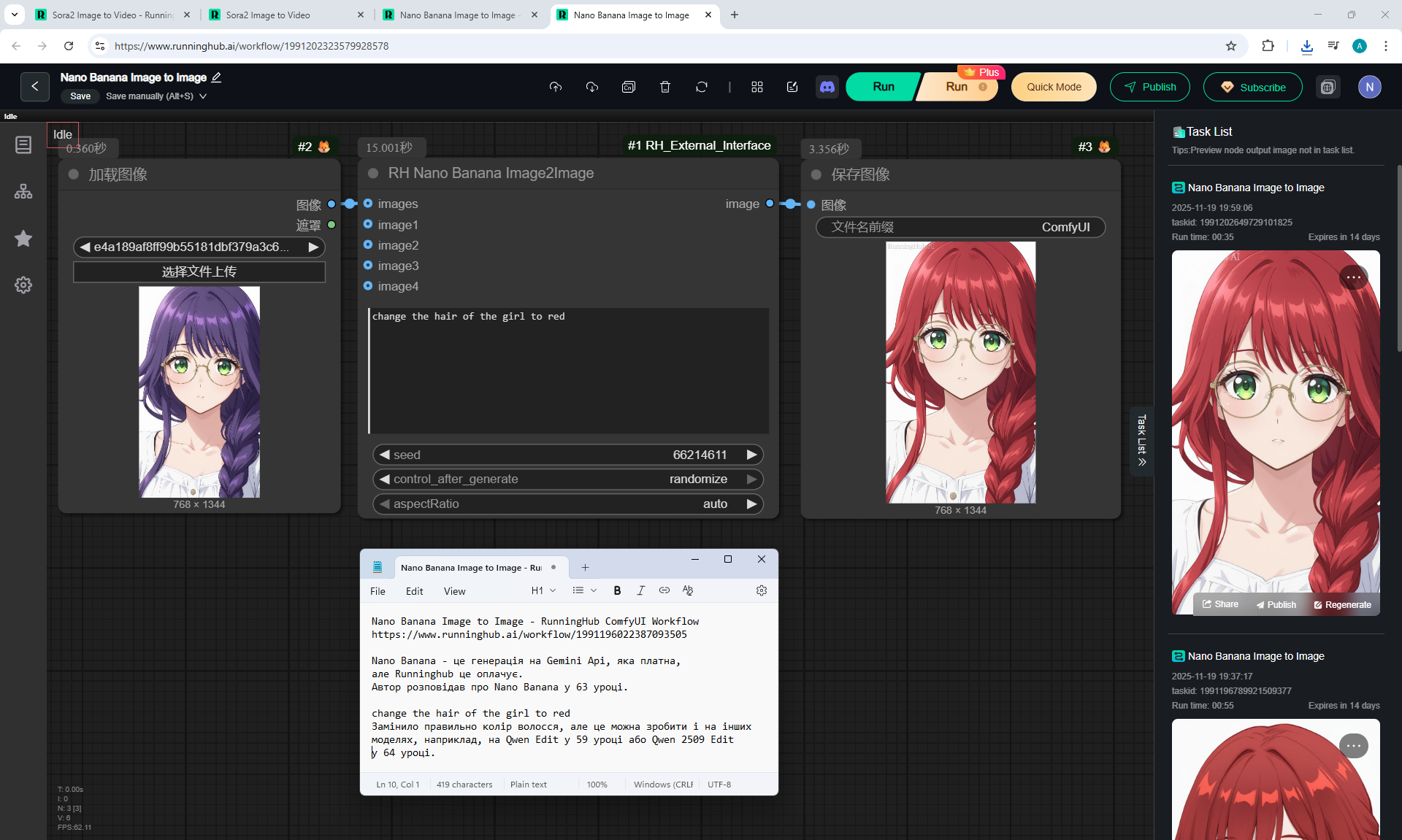
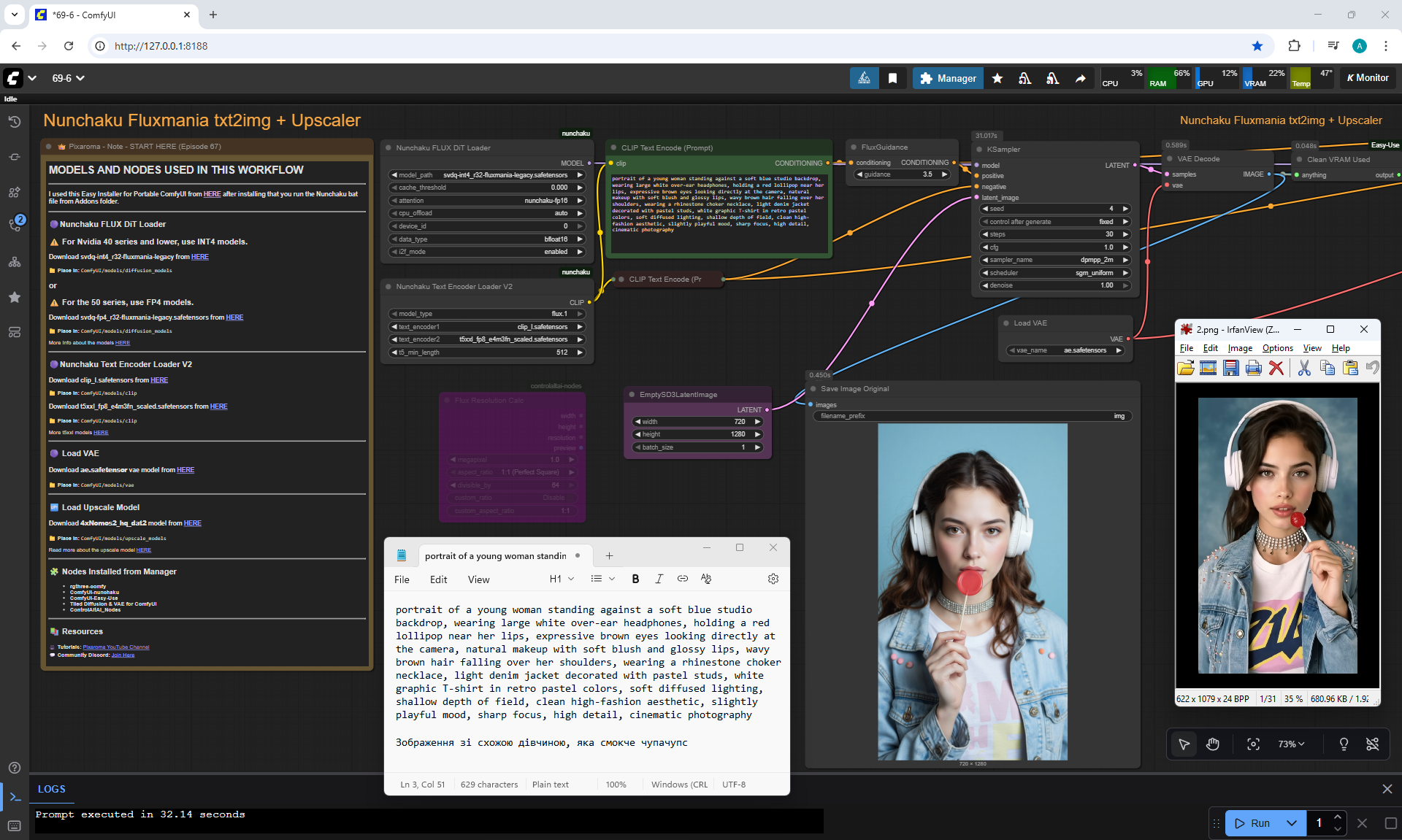
Here the author shows how to generate in the cloud Image2Image on Nano Banana






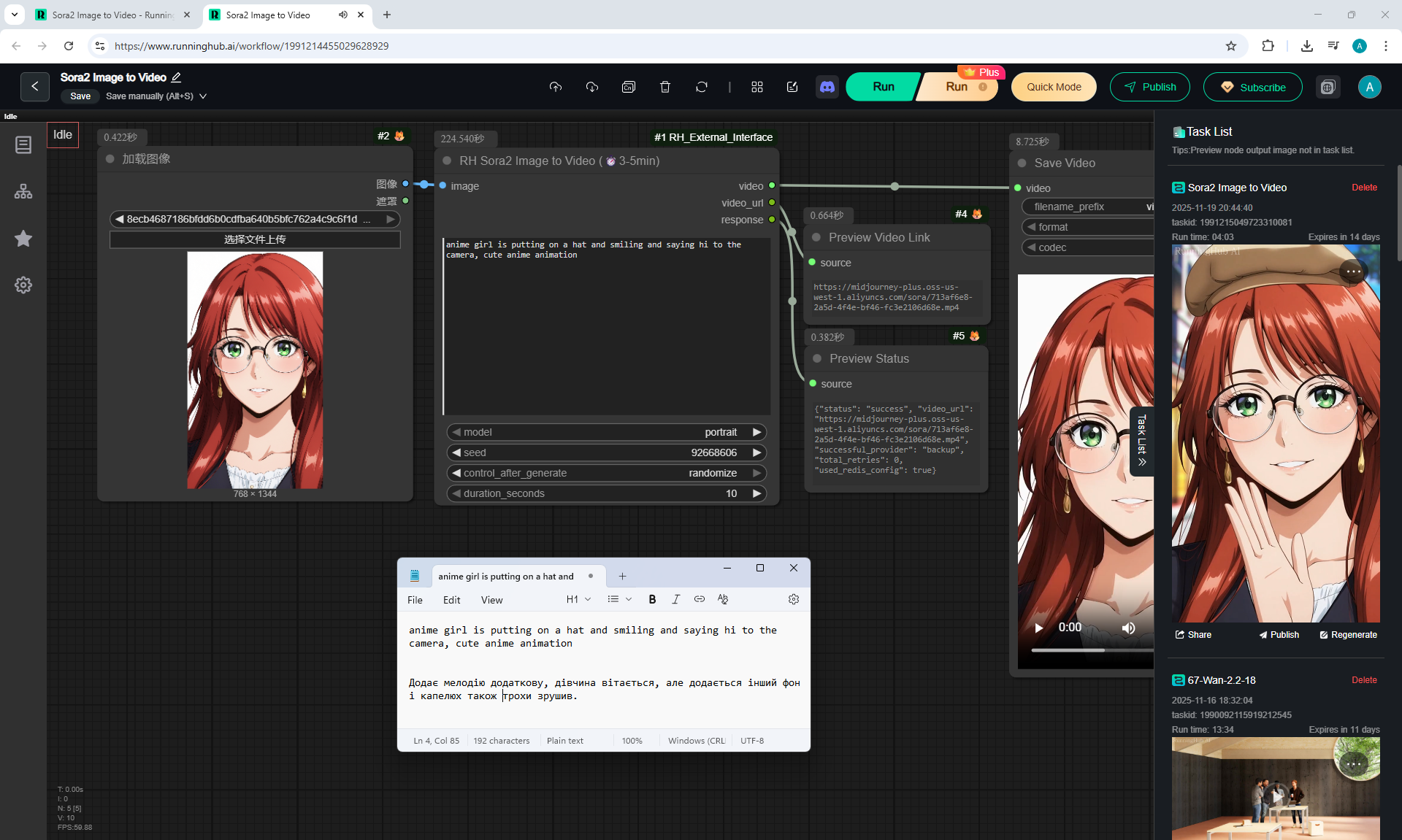
Anime animations on the NetaYume v3.5 model are generated with sounds, and melodies are added to the background.
But sometimes melodies get in the way and are added even when the prompt says that melodies are not needed.
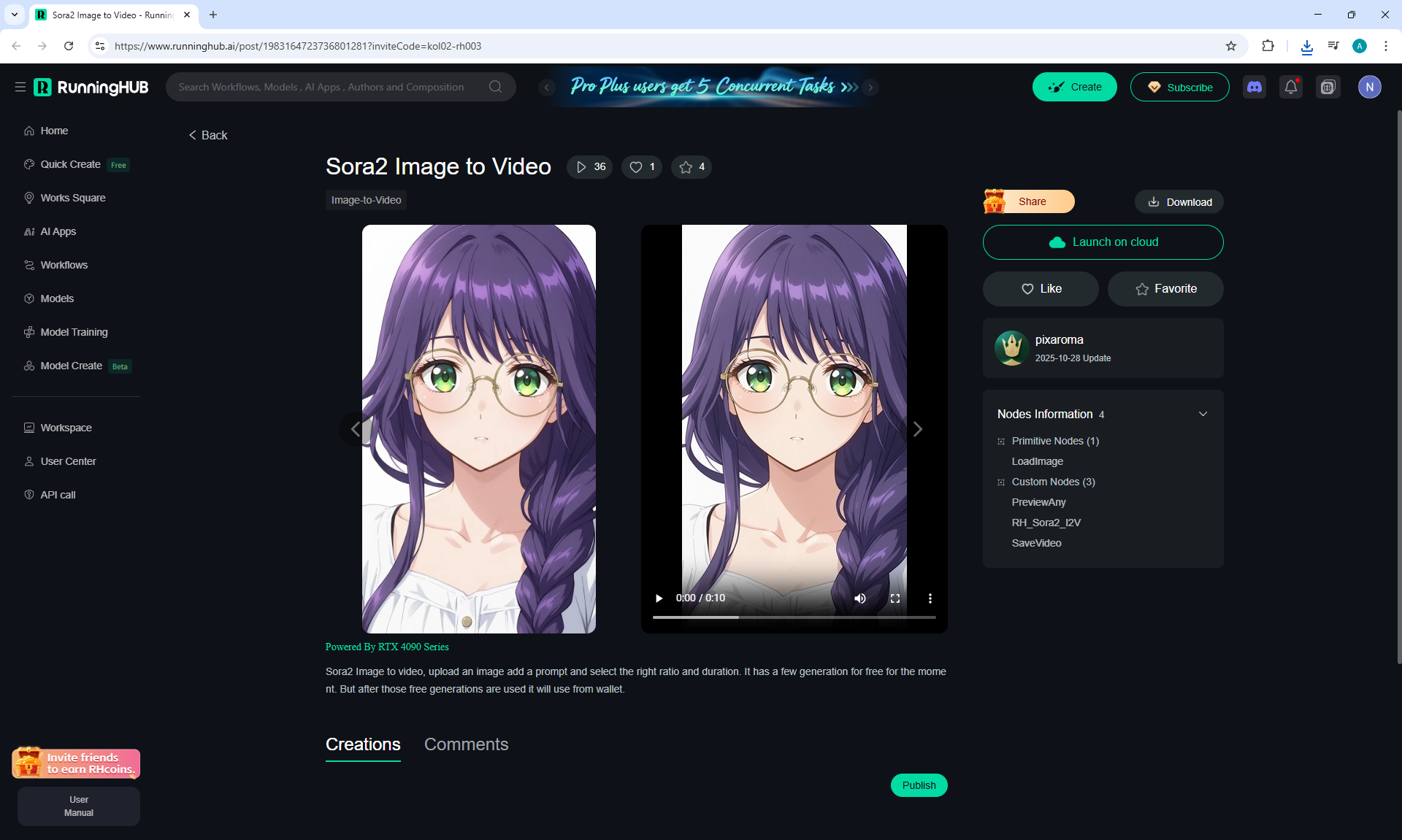
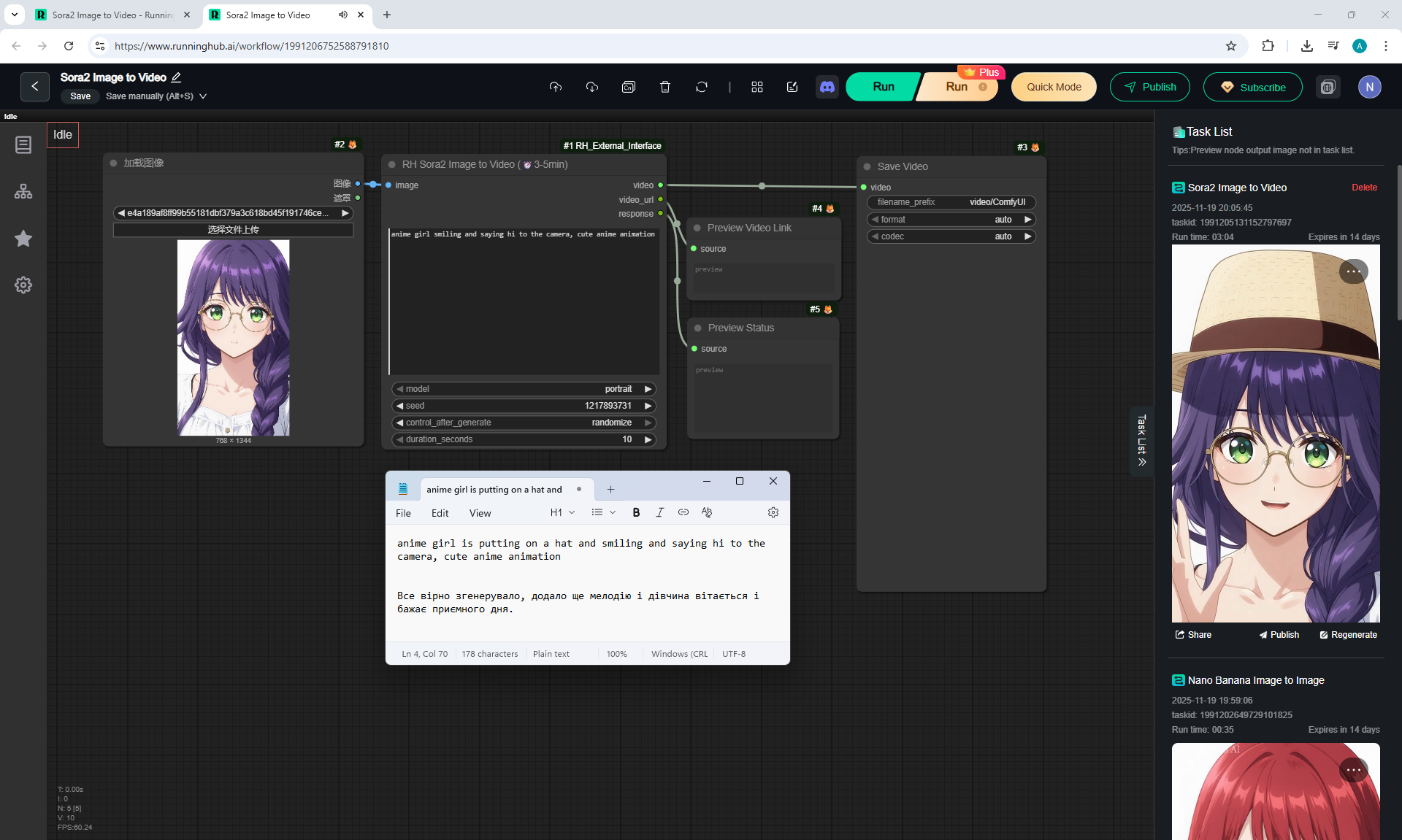
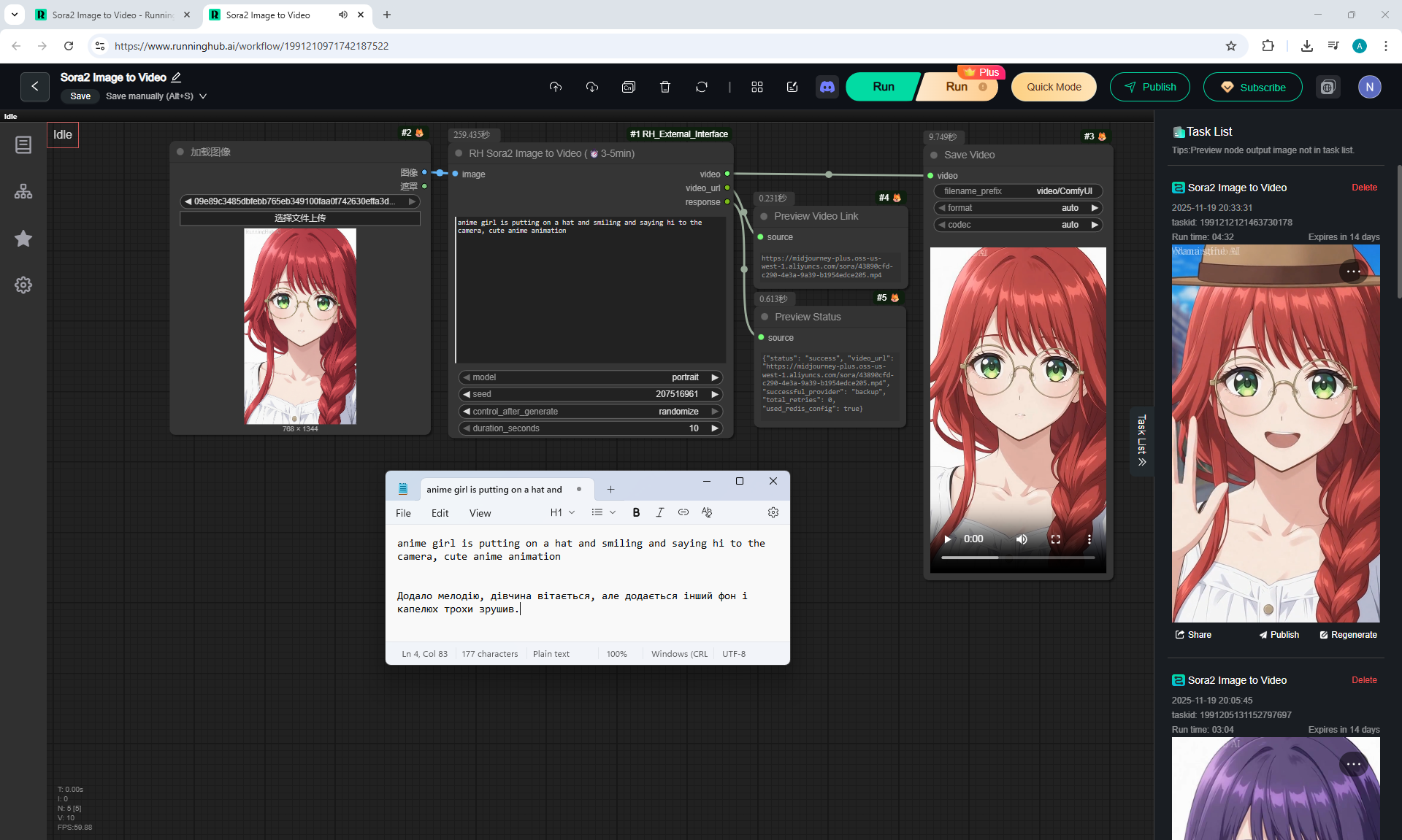
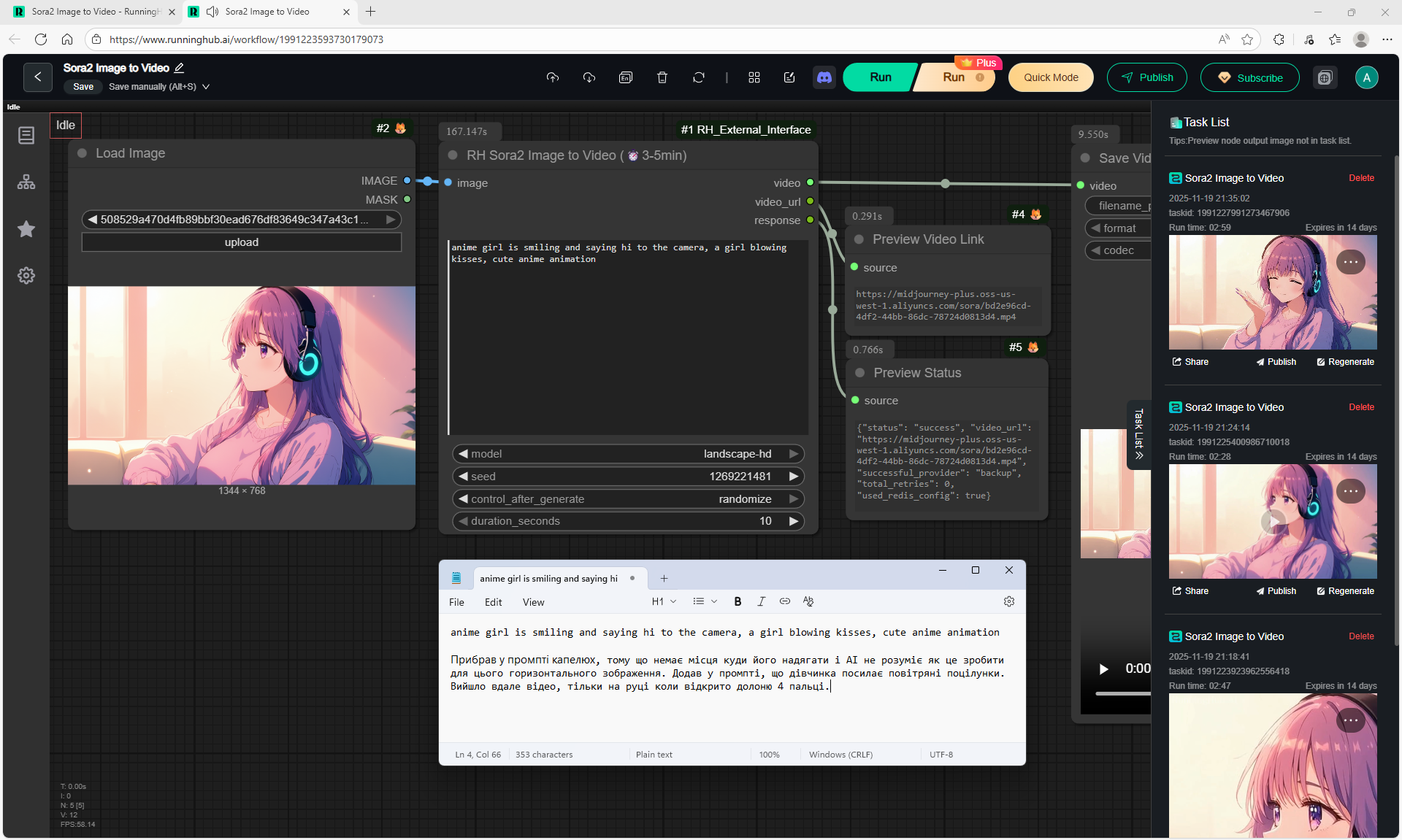
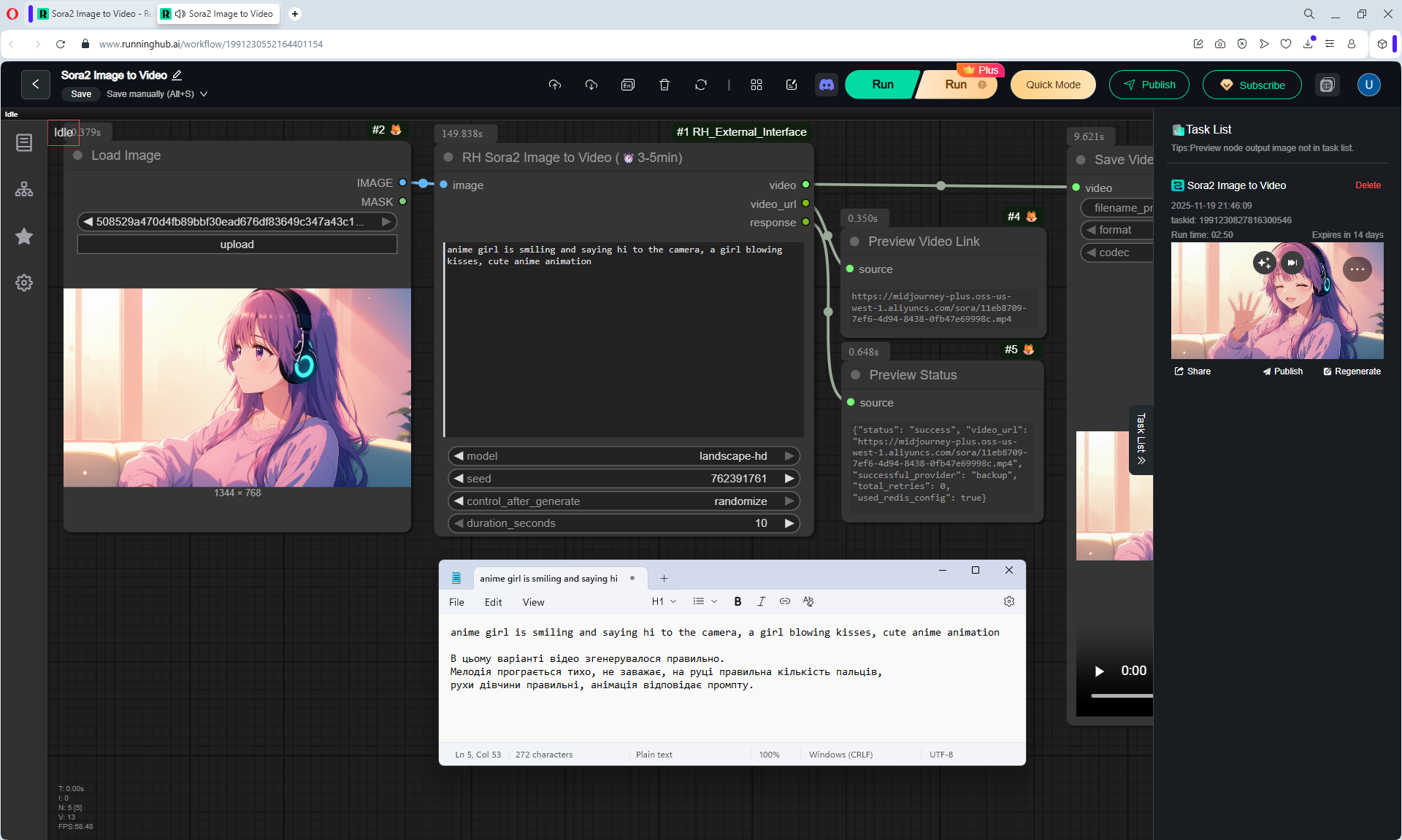
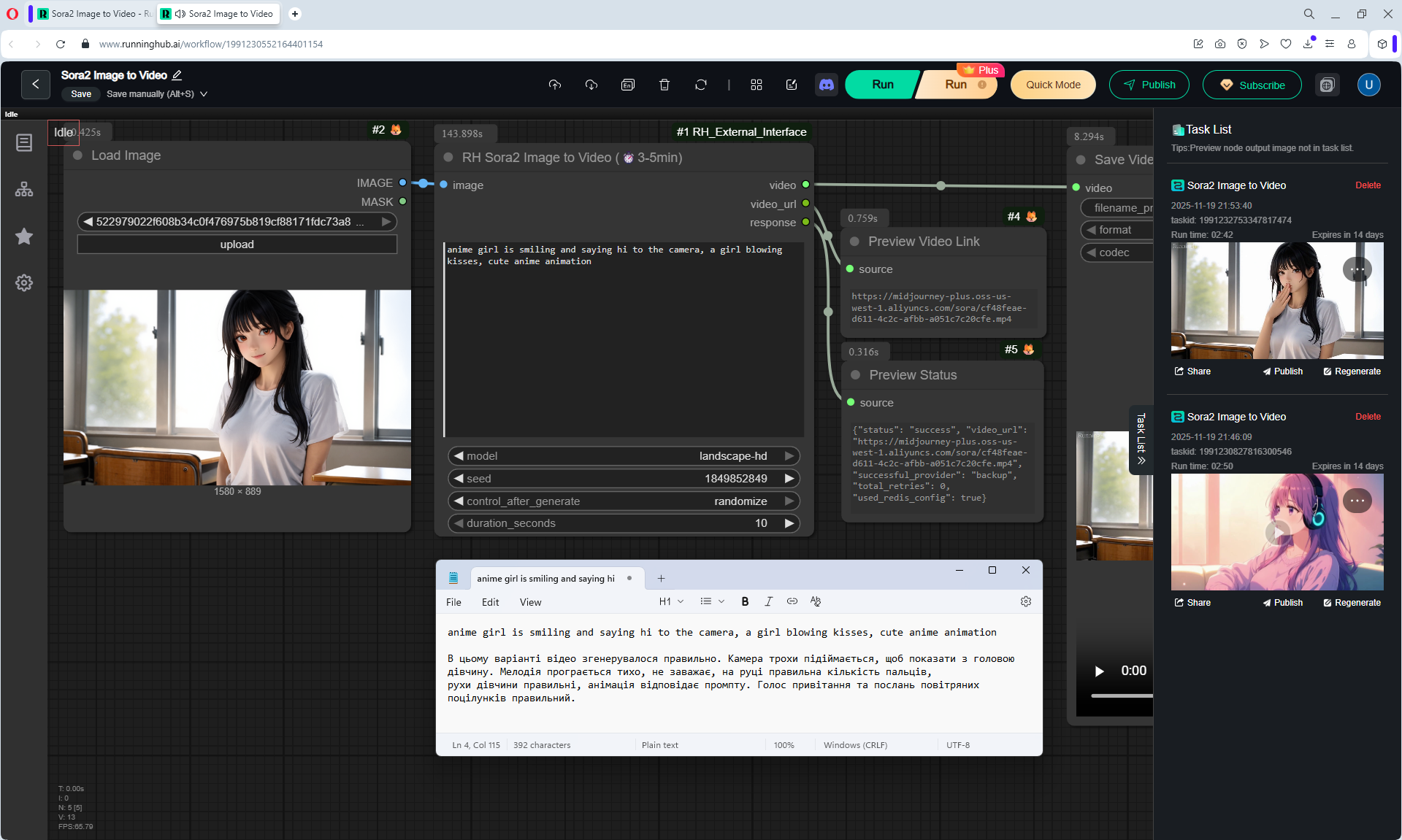
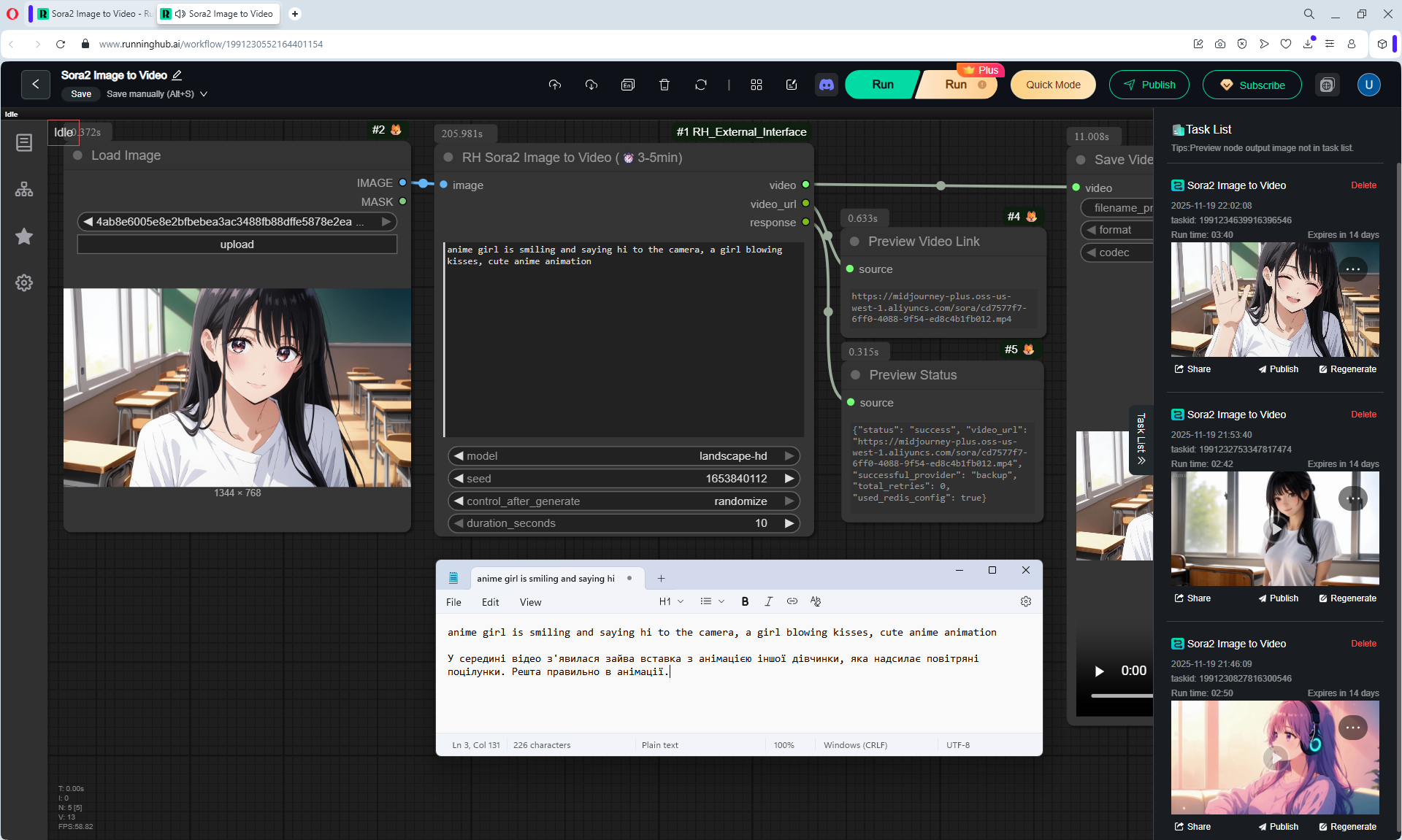
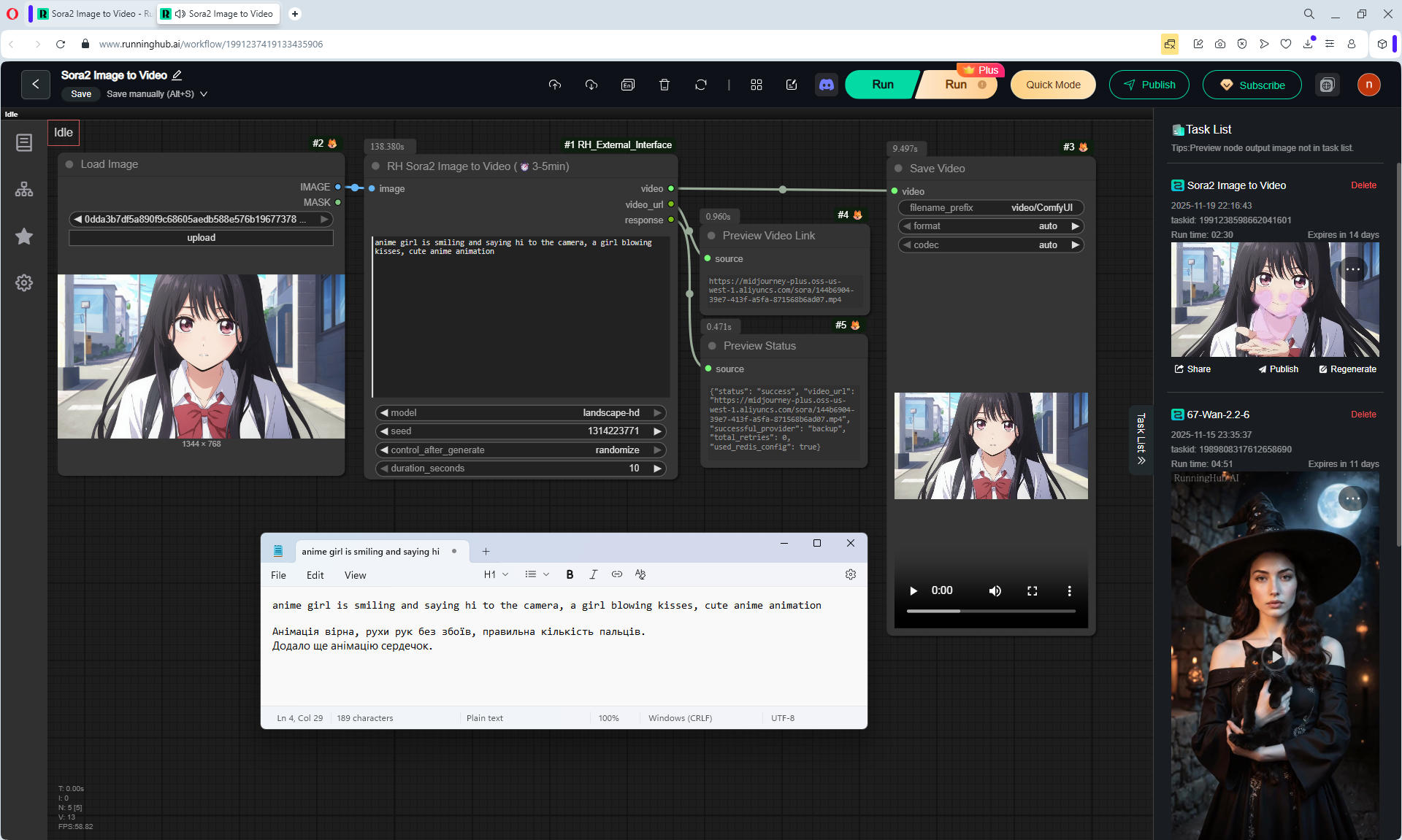
Here the author shows how to generate in the cloud Image2Video на Sora2,
there is a link from midjorney-plus.oss-west-1.aliyuncs.com/sora to an mp4 that is downloaded without compression, this link can be downloaded, then it is deleted there.


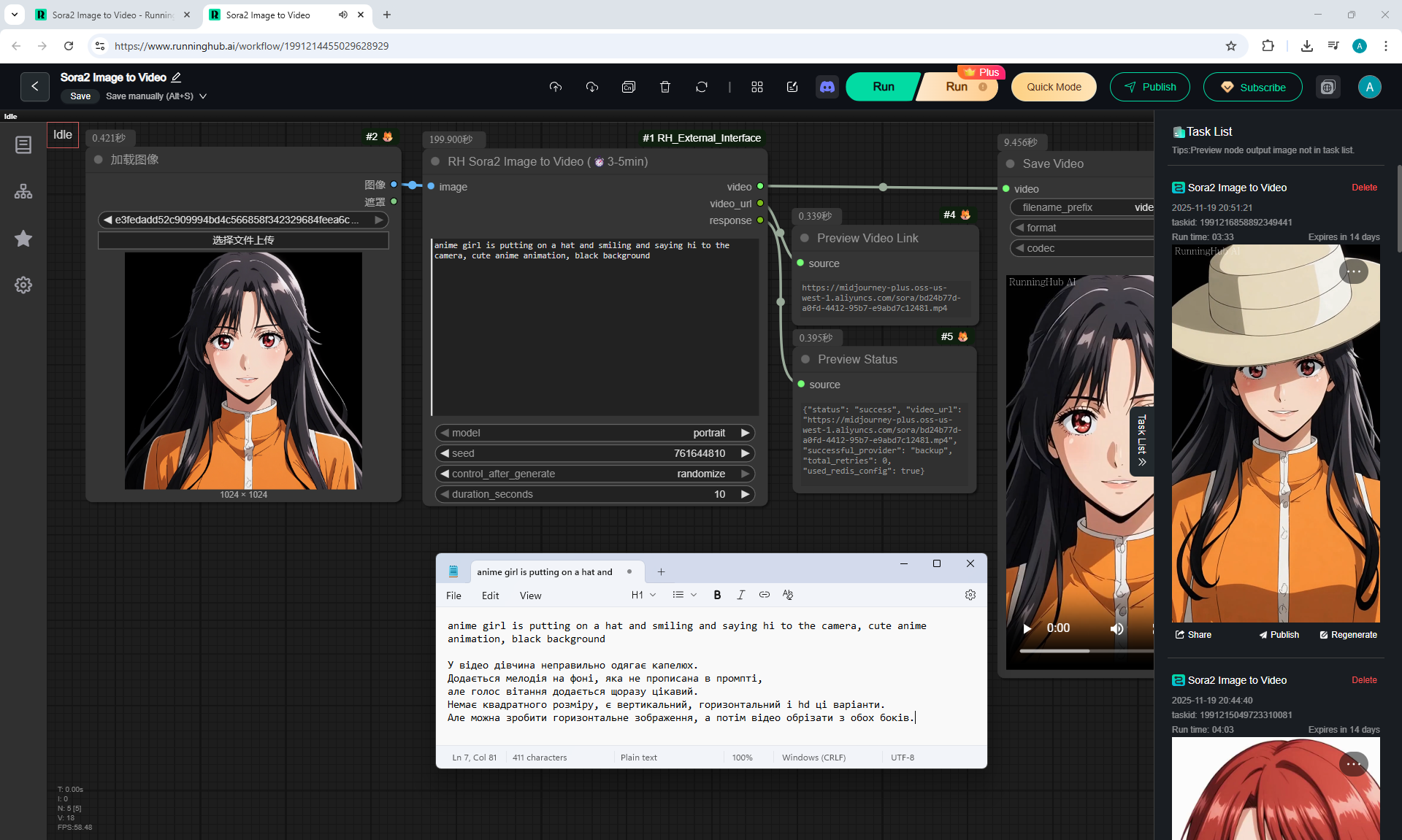
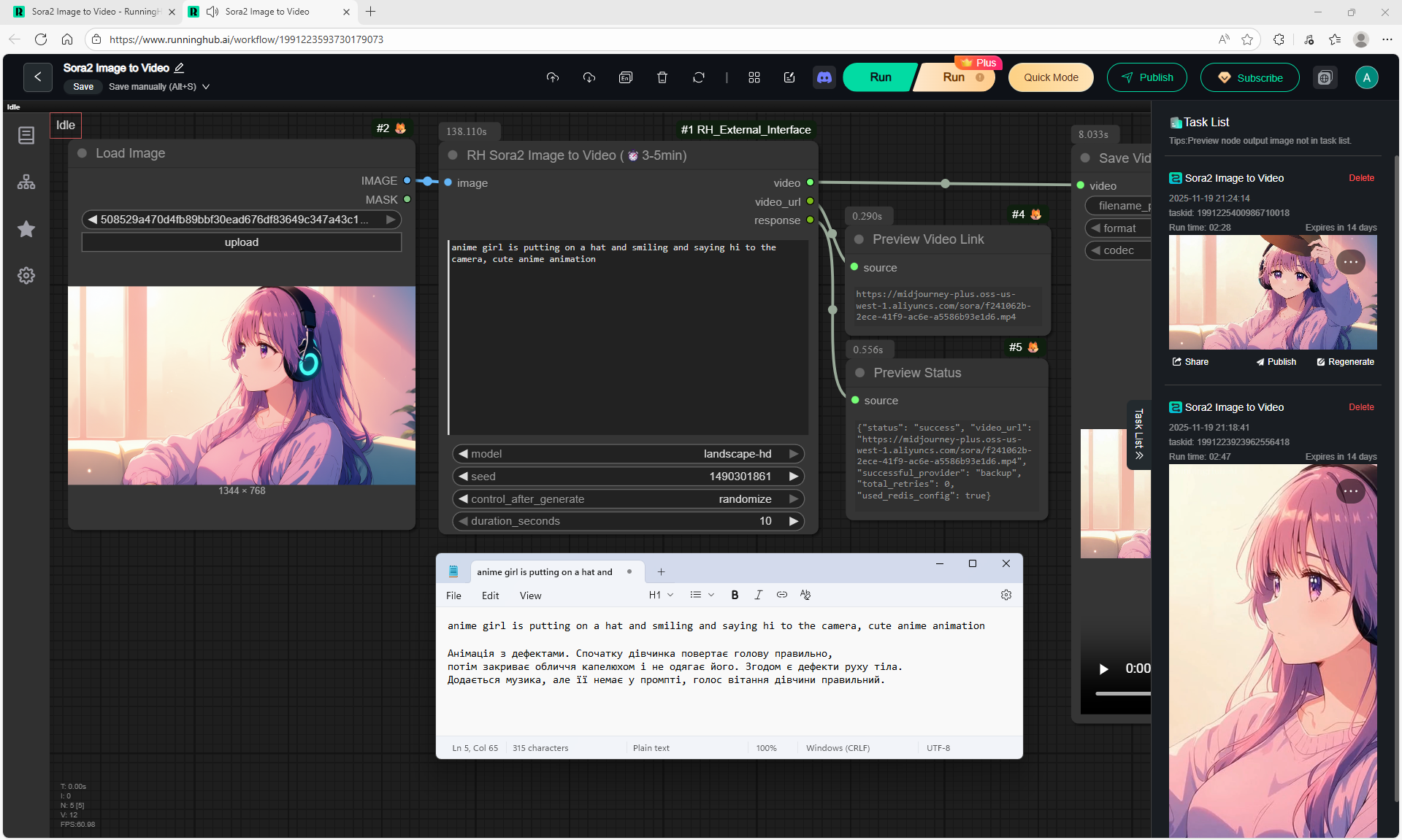
I tested in in the cloud on the Sora2 Image to Video model, the video is not fully animated, this is a complex prompt for this image.
The hare does not walk, but loops, perhaps it is worth testing this generation model more.
Sparks fly well in the animation, sounds are added in the forest, birds sing.
In previous lessons I tested a lot of animation generation on different models with this hare.
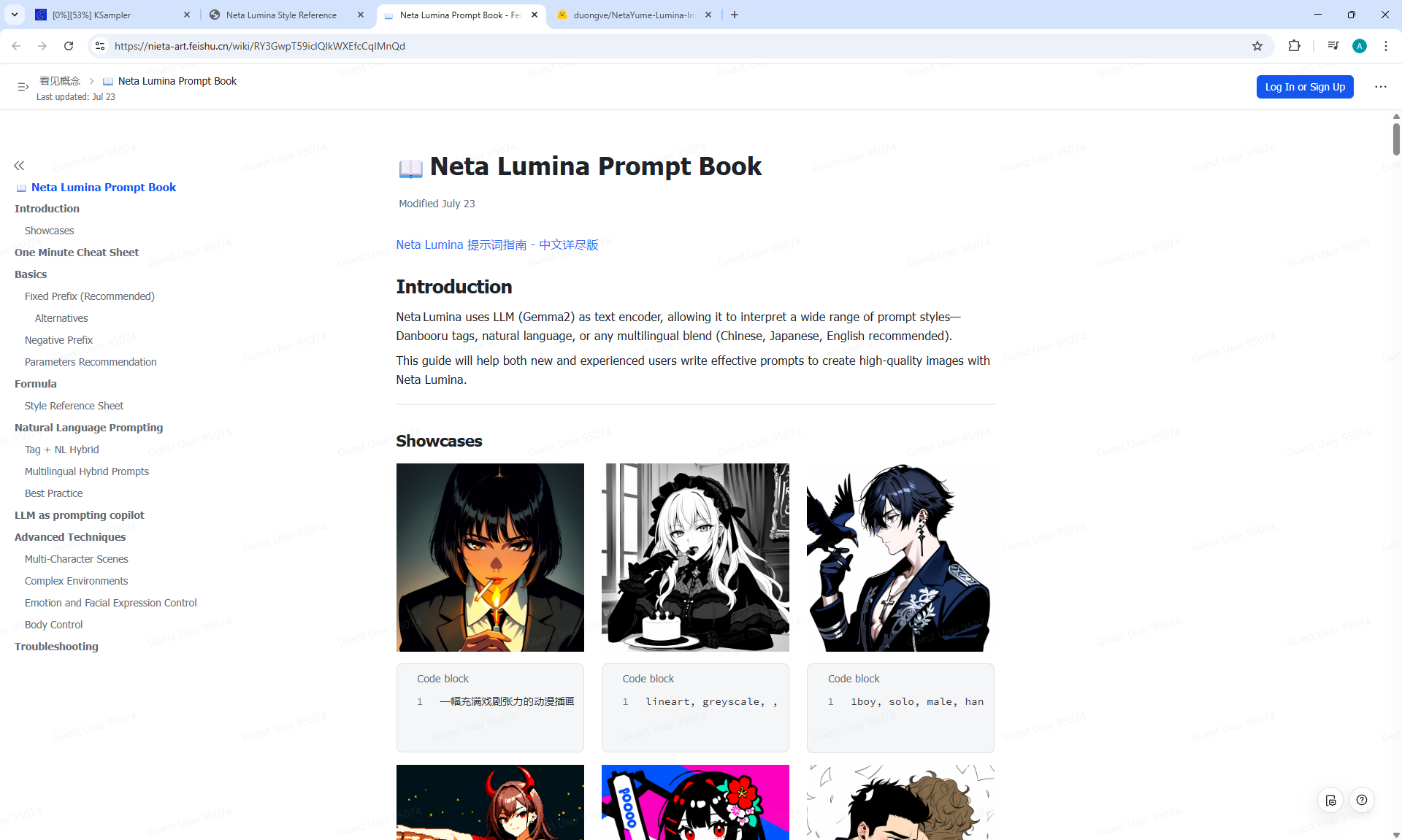
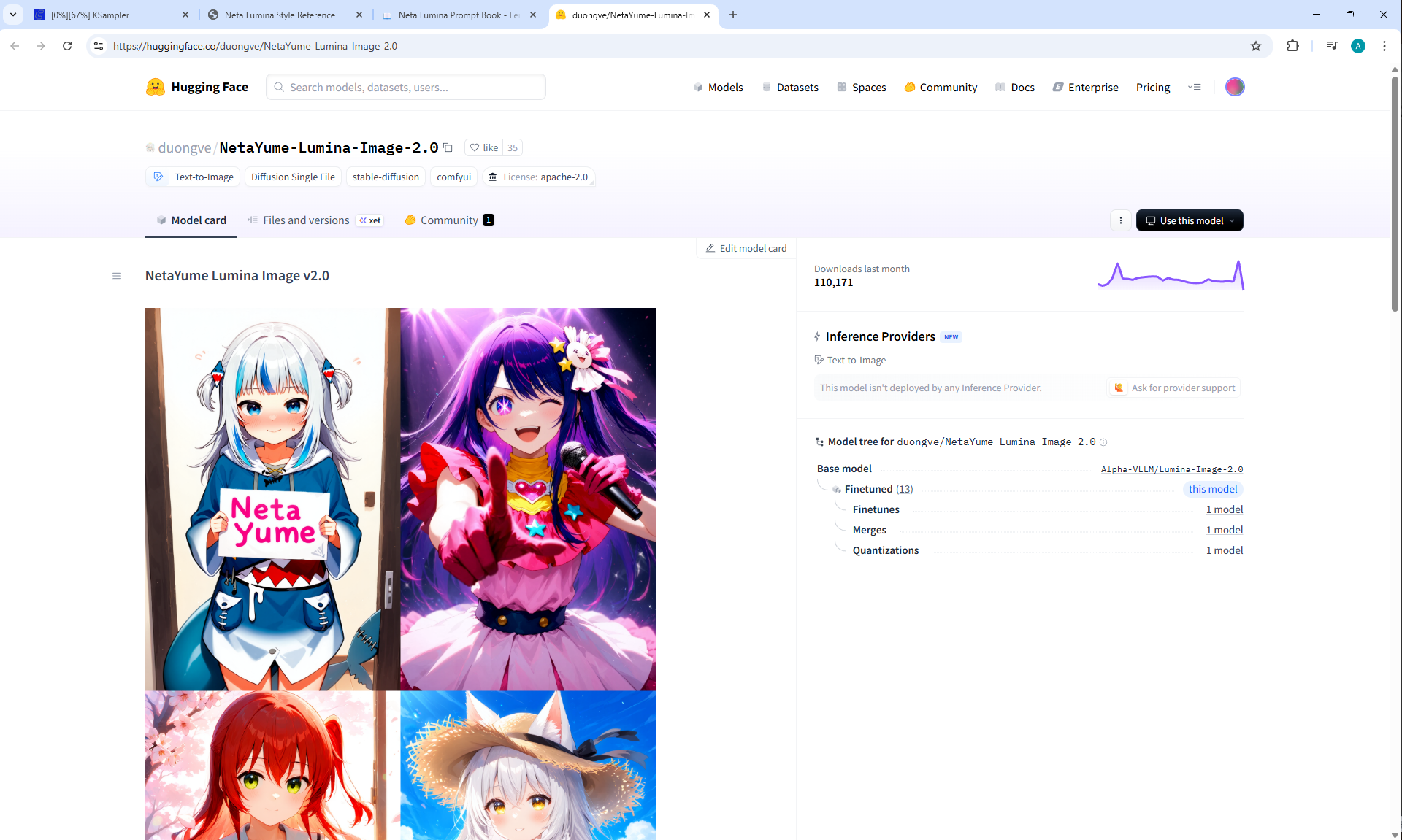
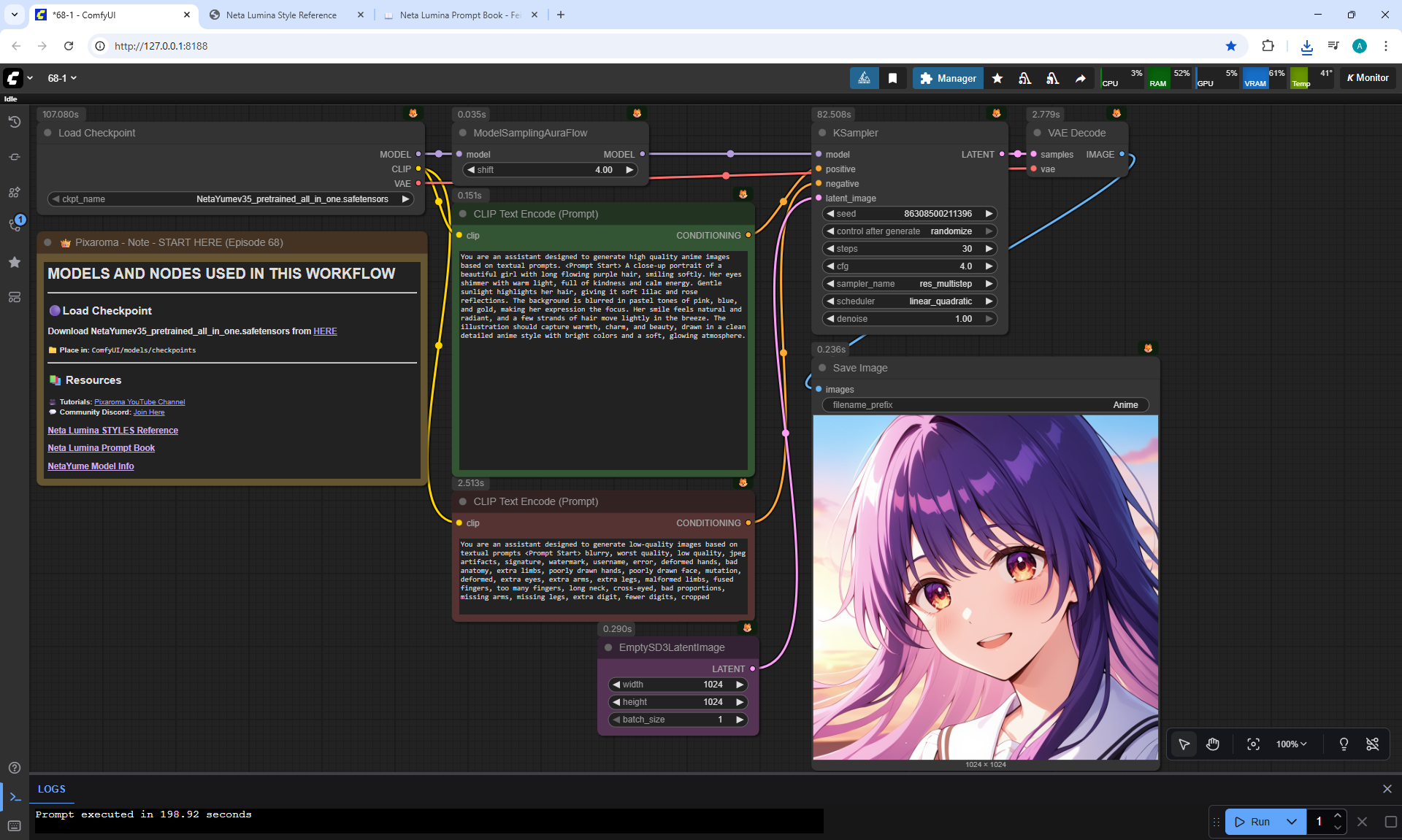
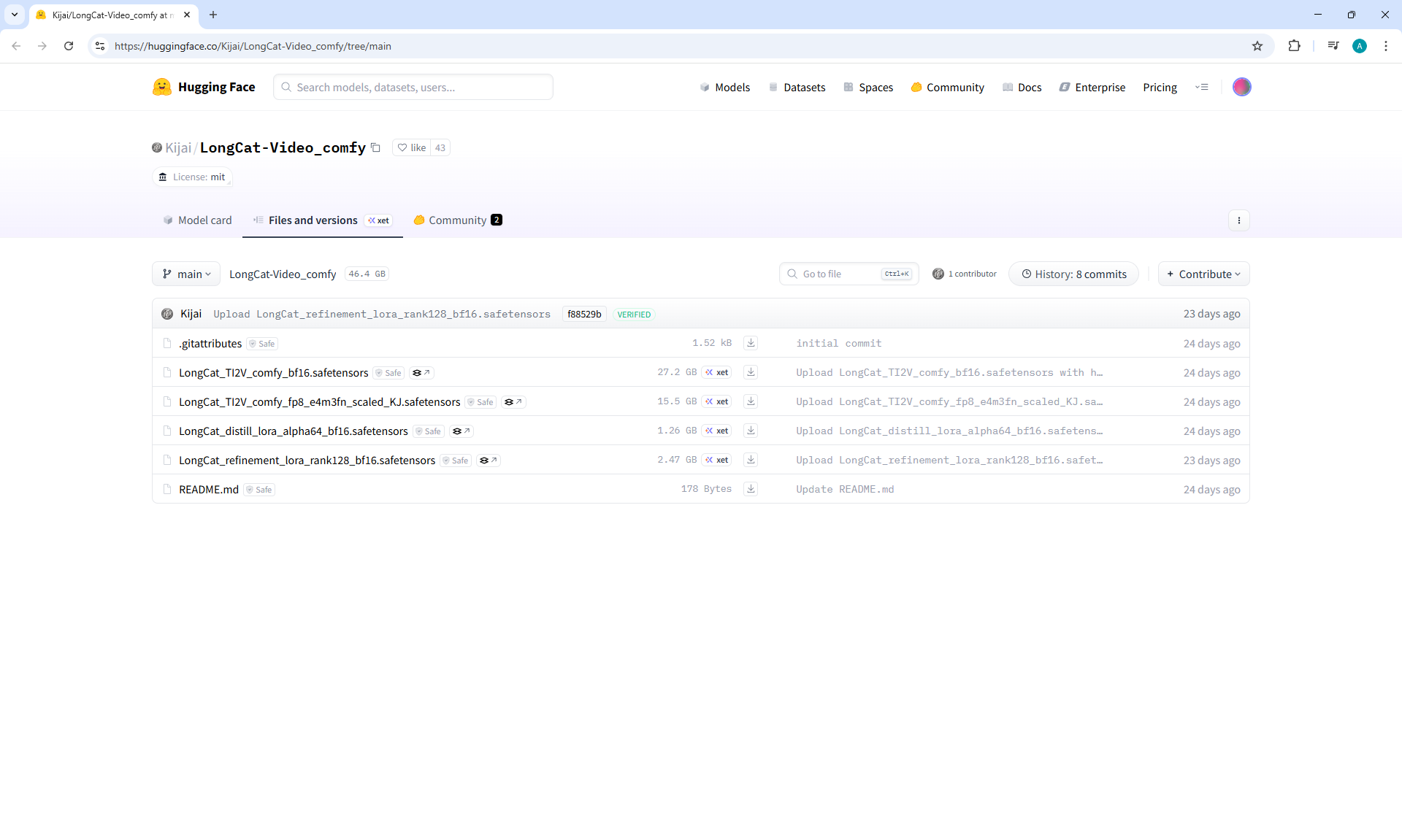
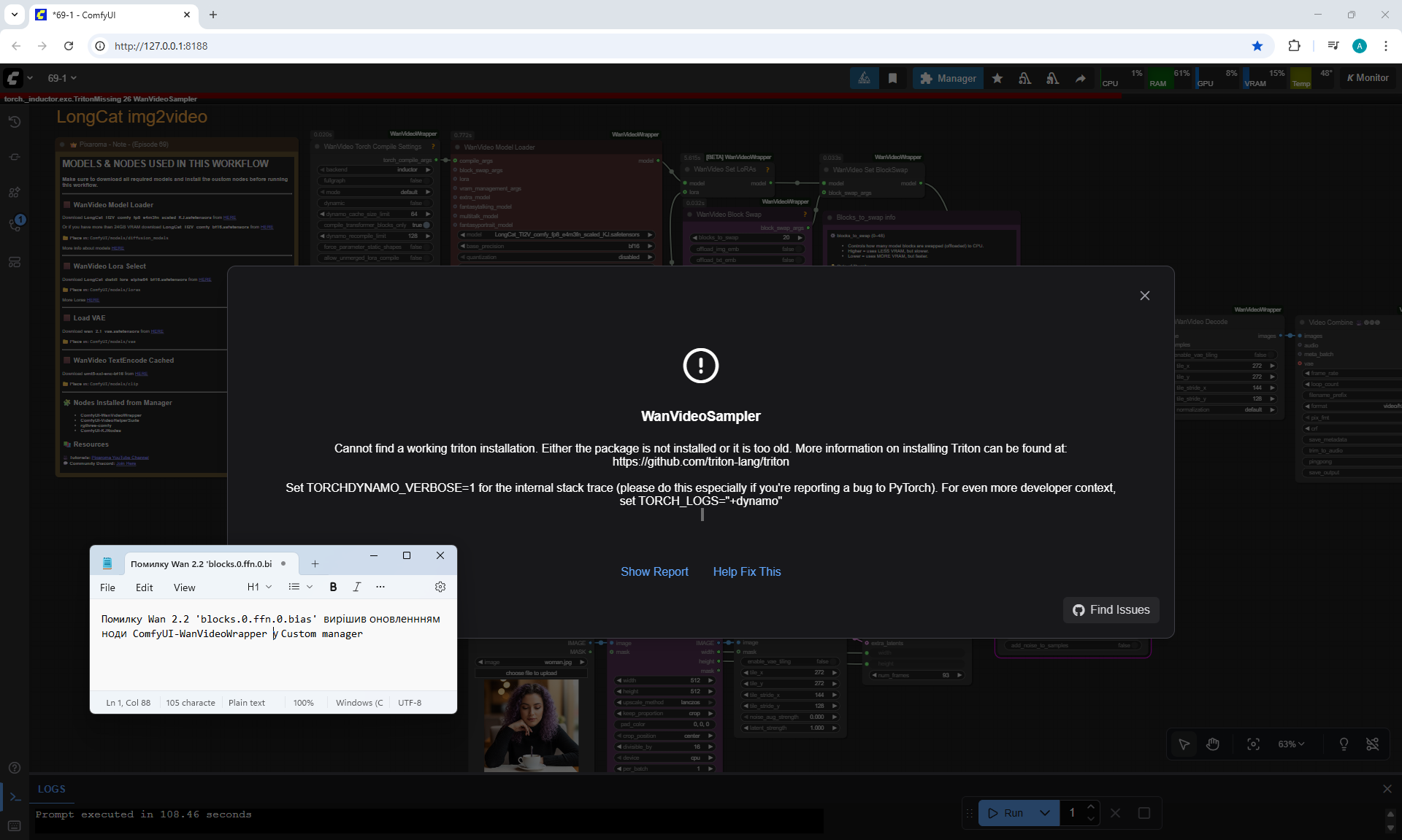
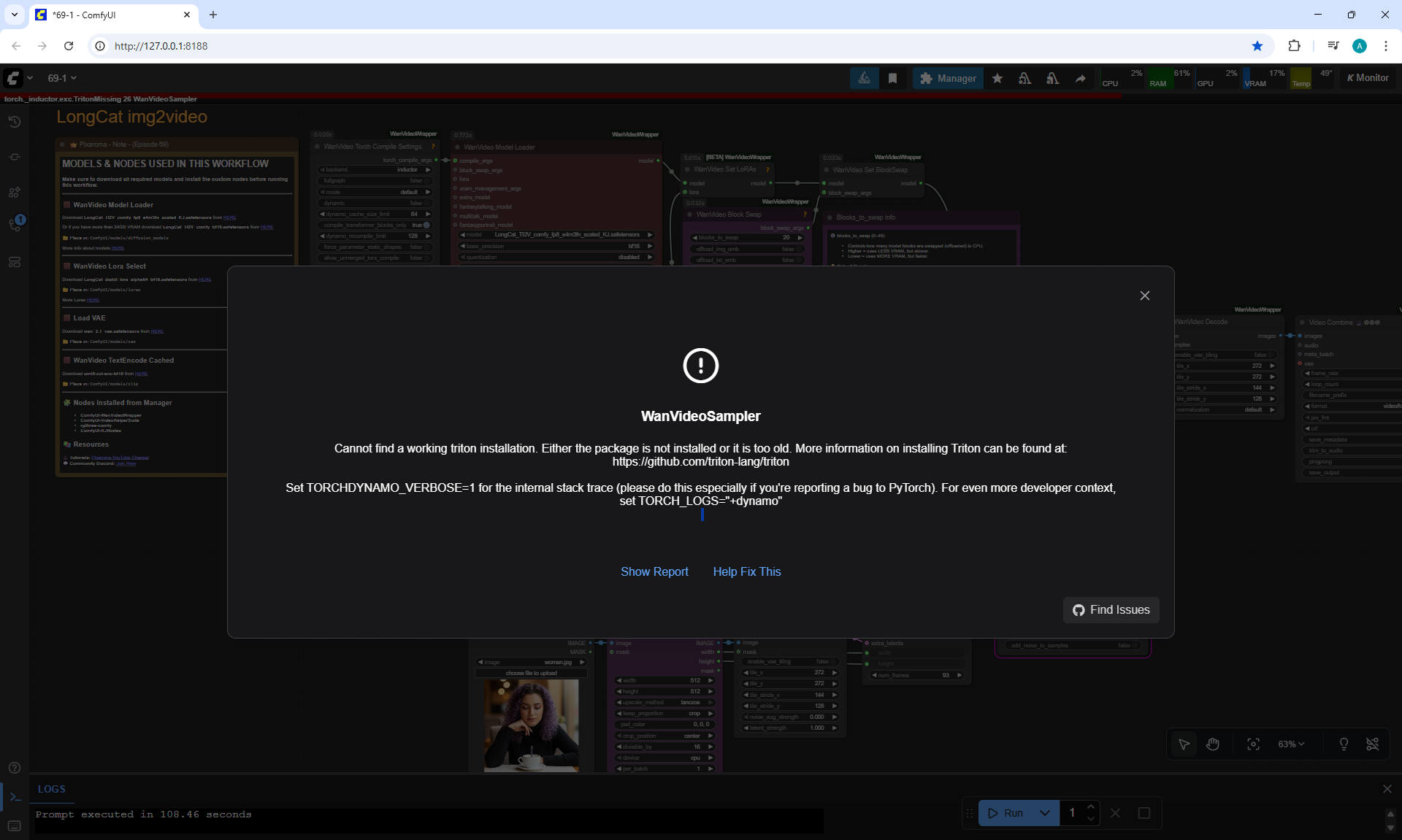
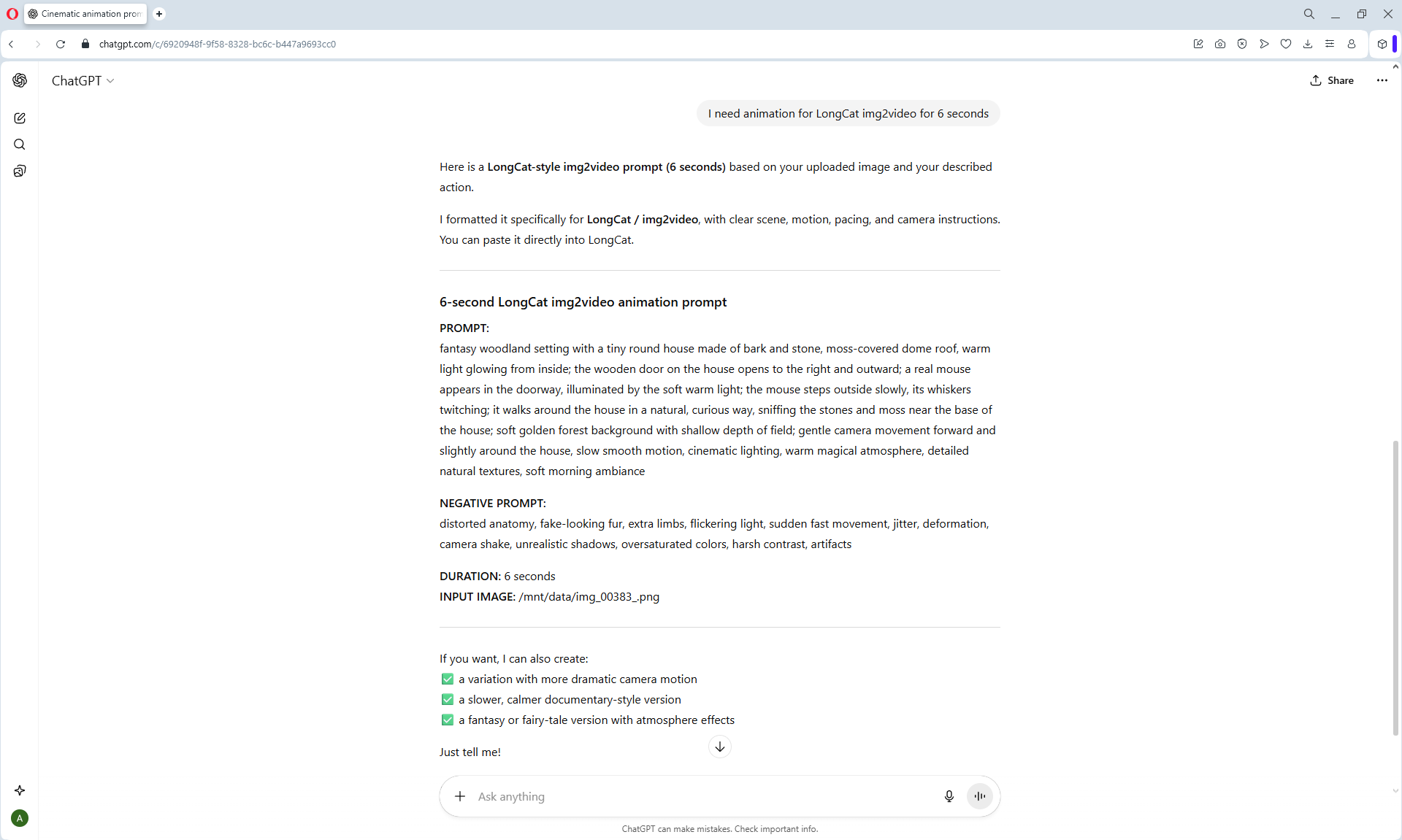
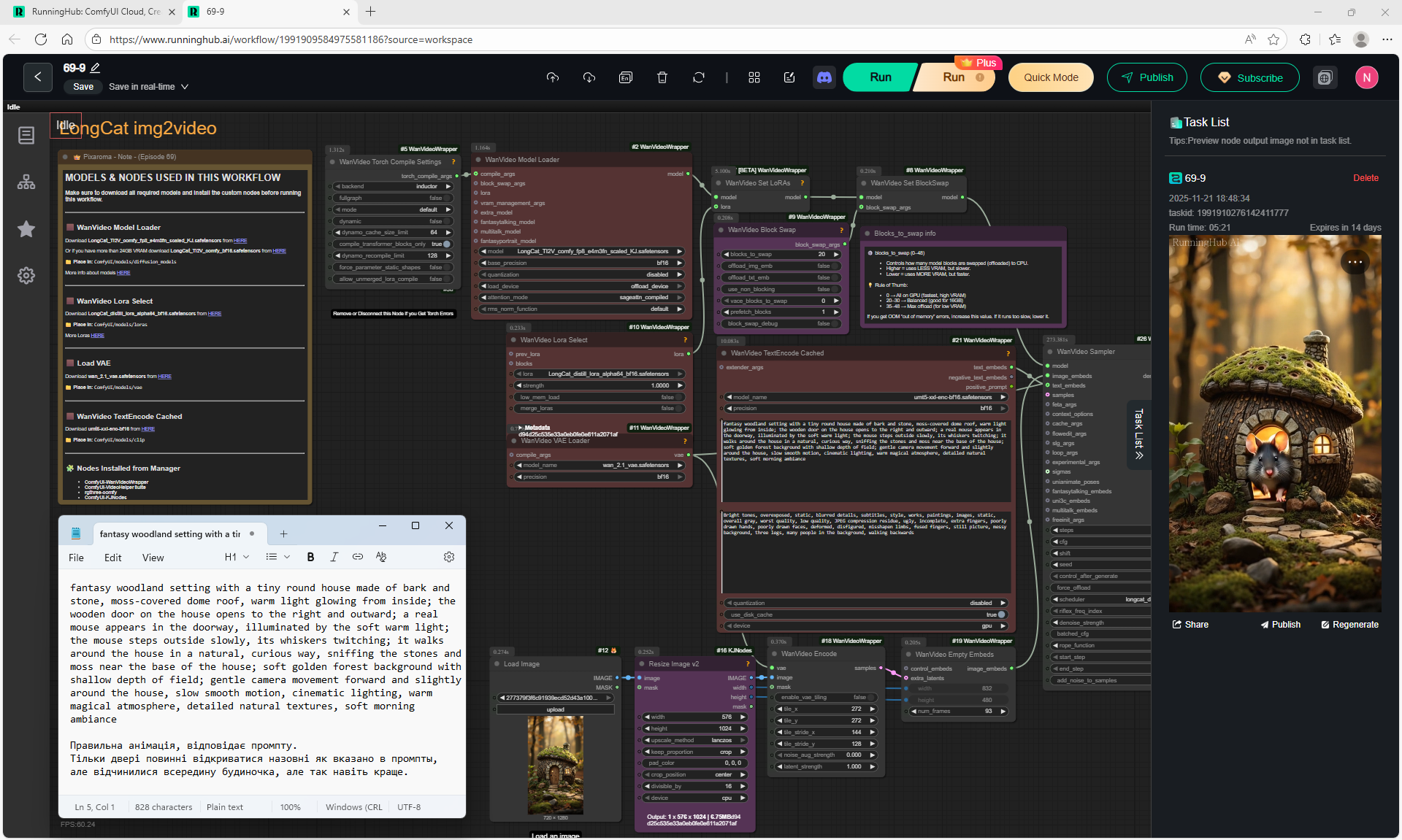
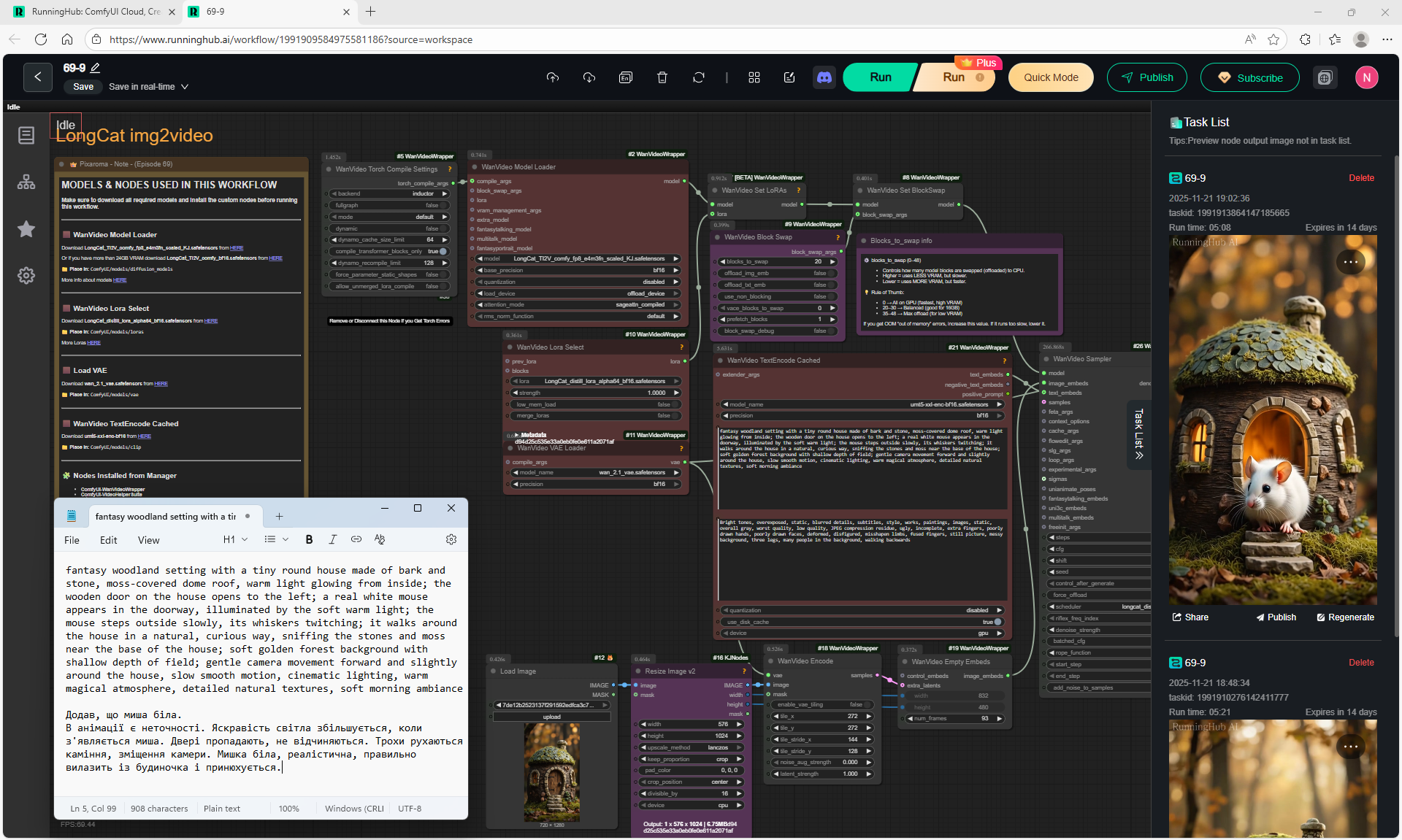
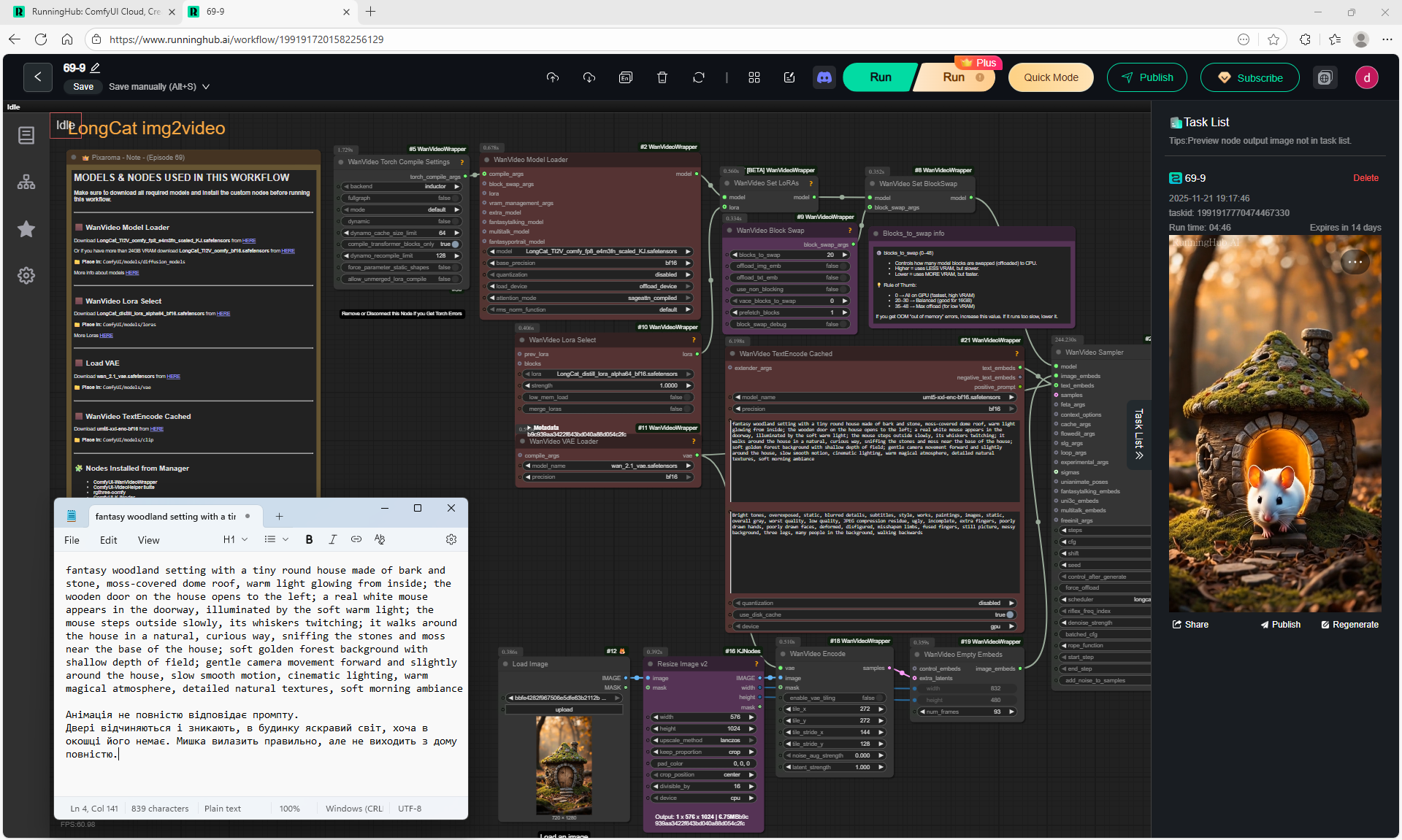
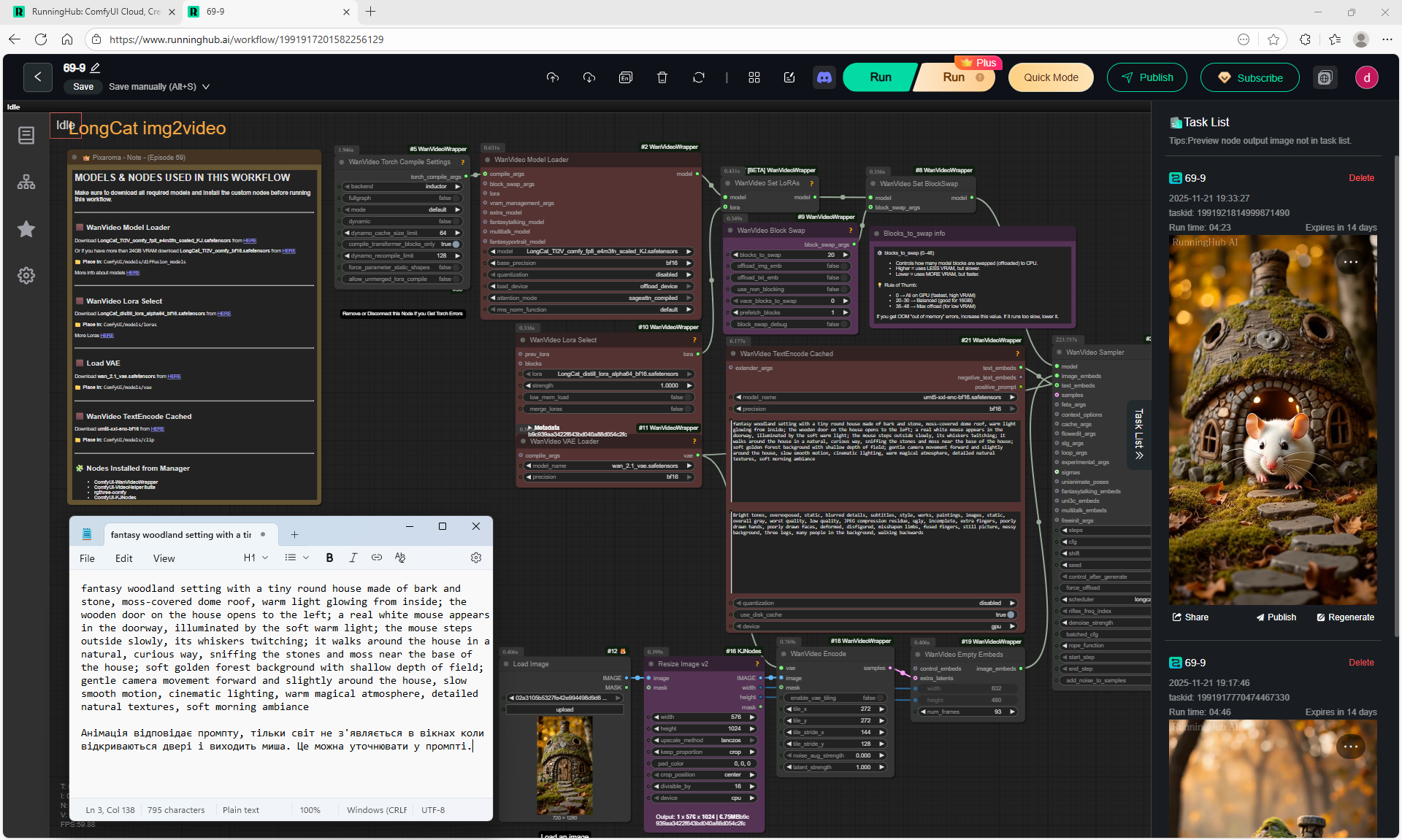
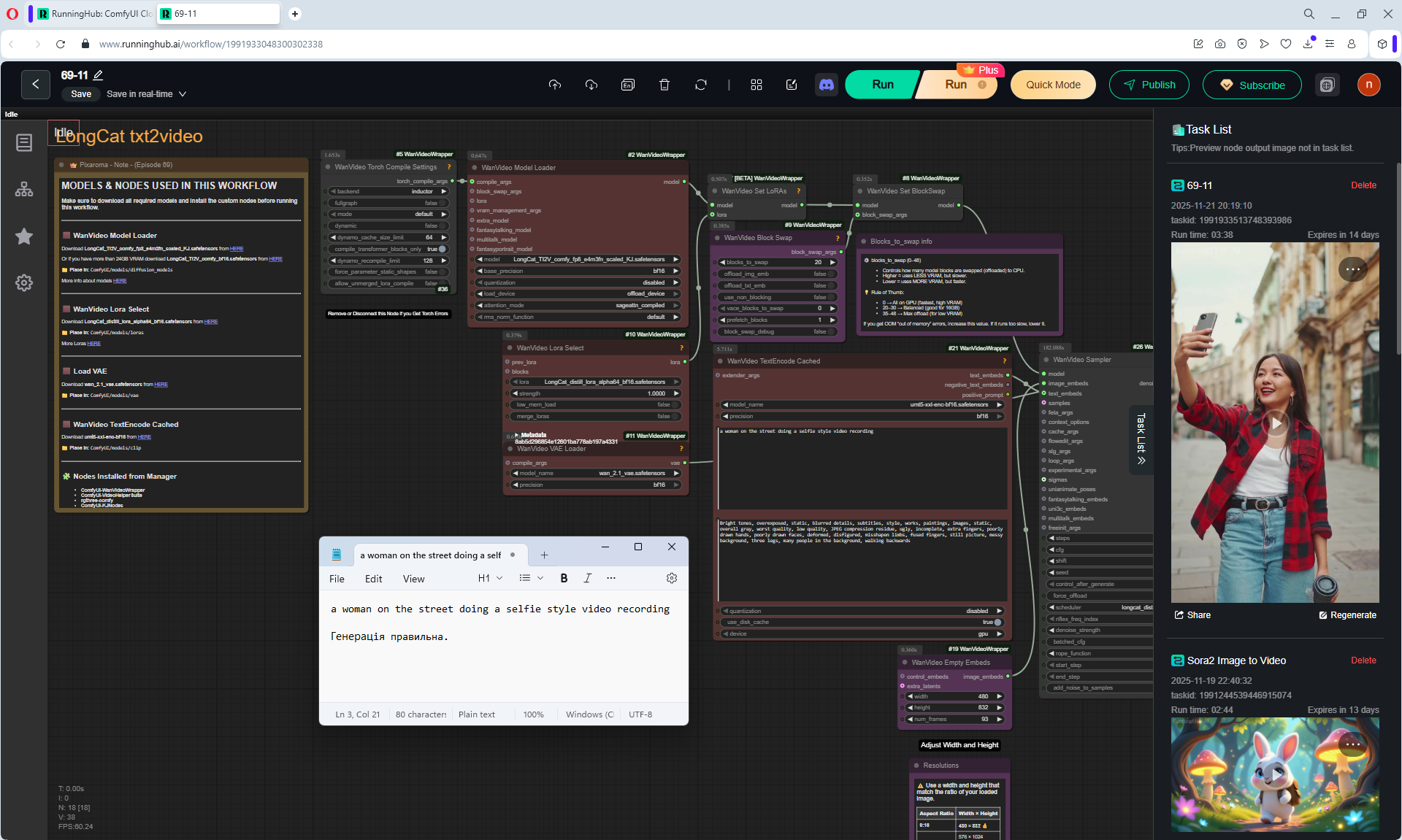
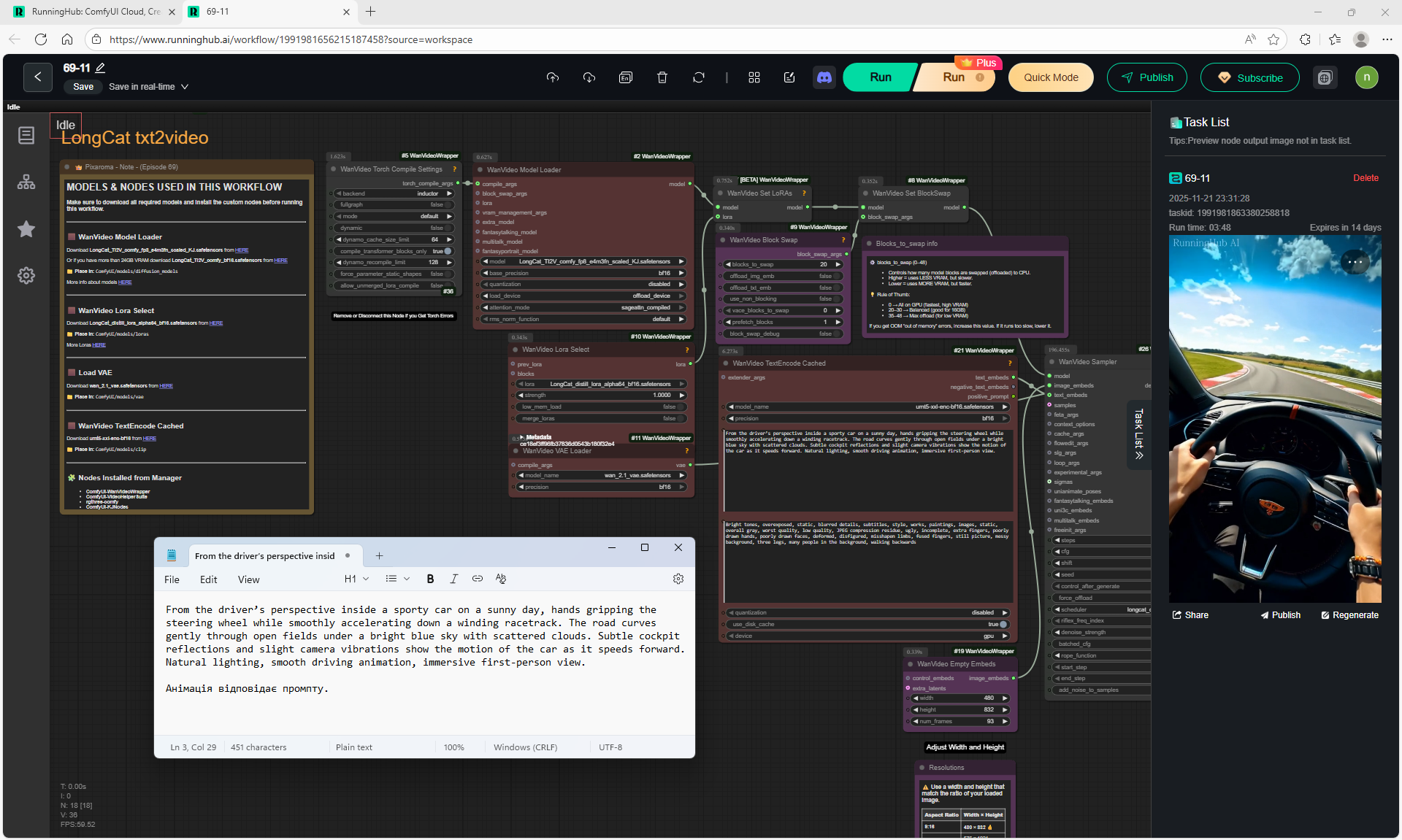
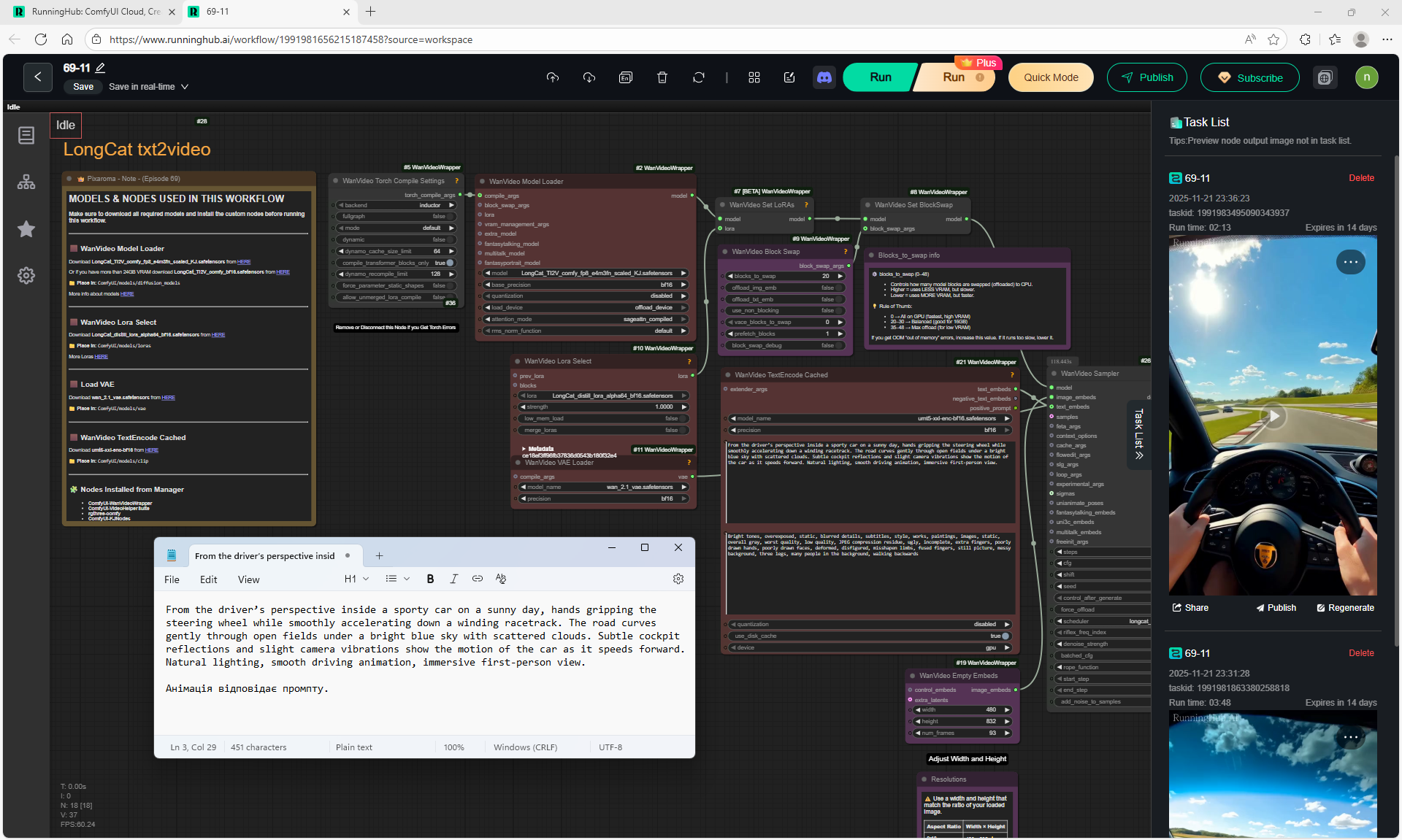
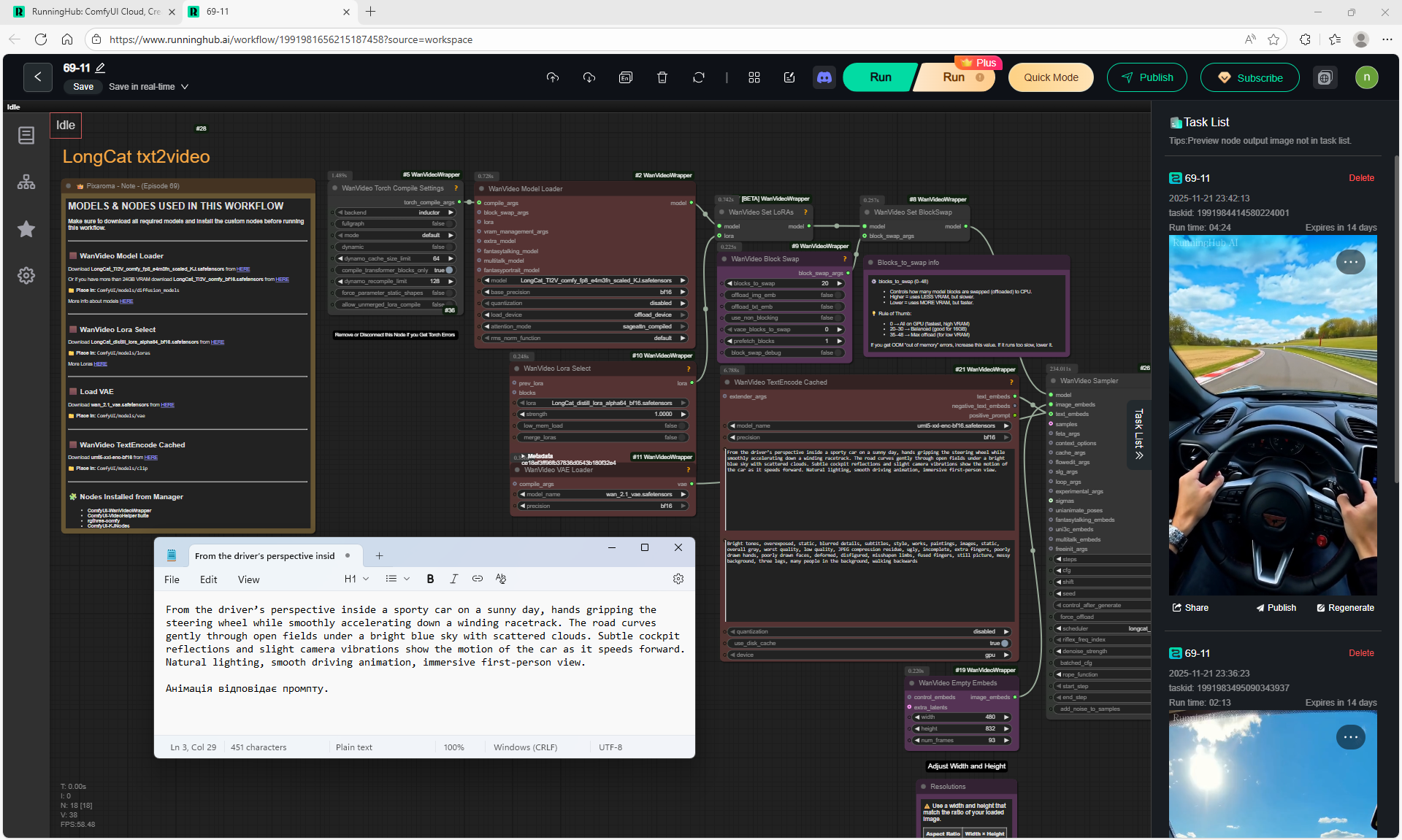
ComfyUI Tutorial Series Ep 69: Create Long Videos with LongCat Video Model






















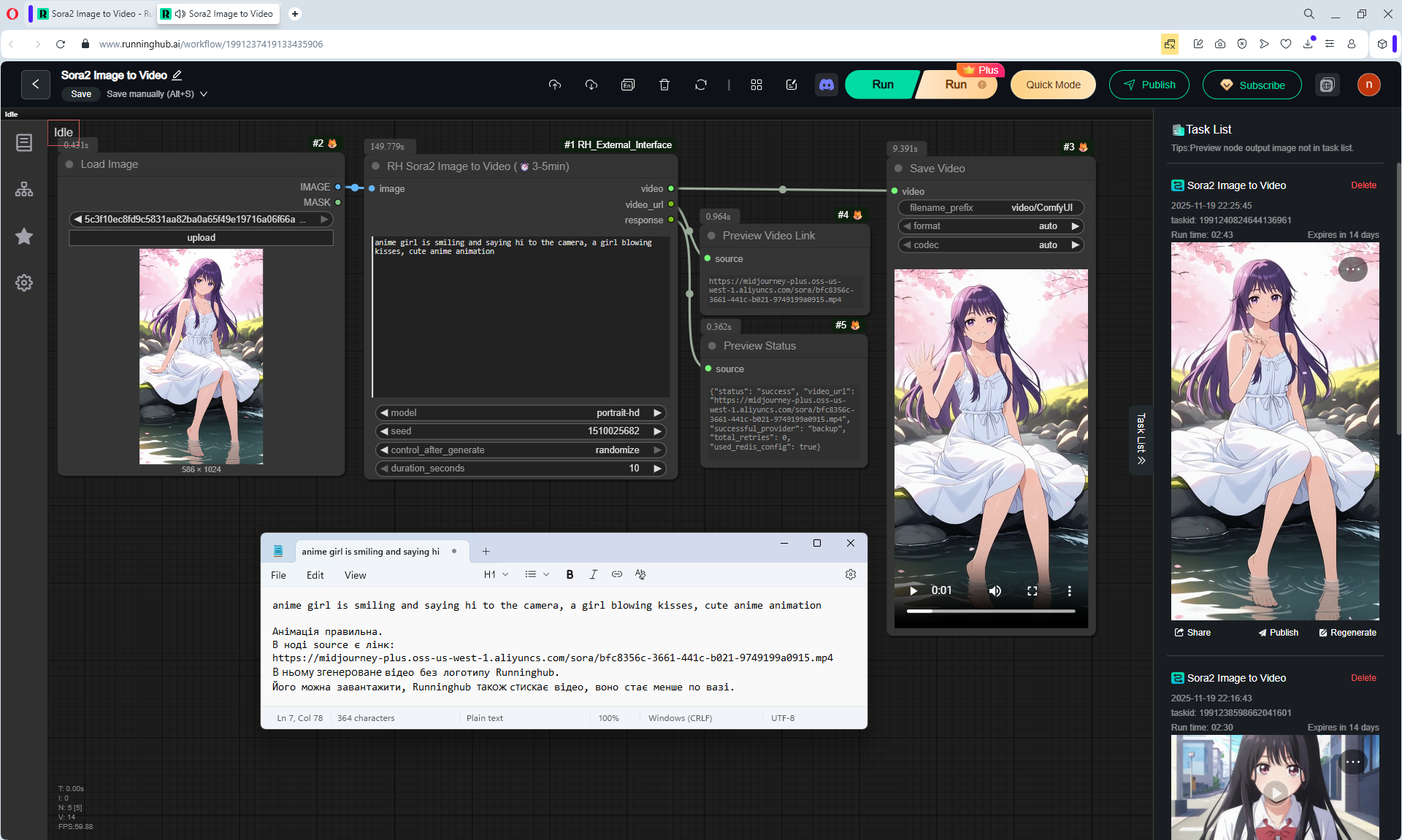
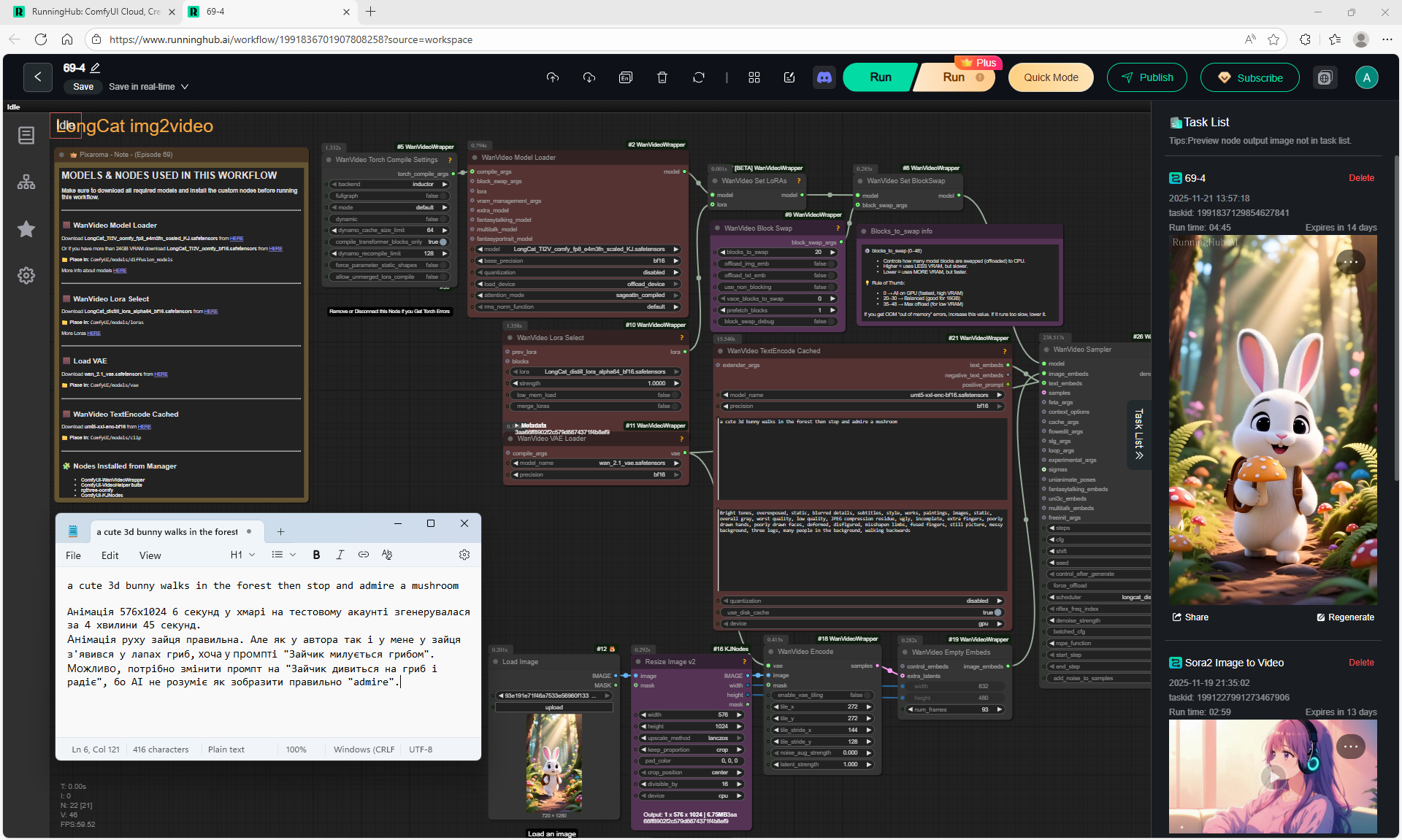
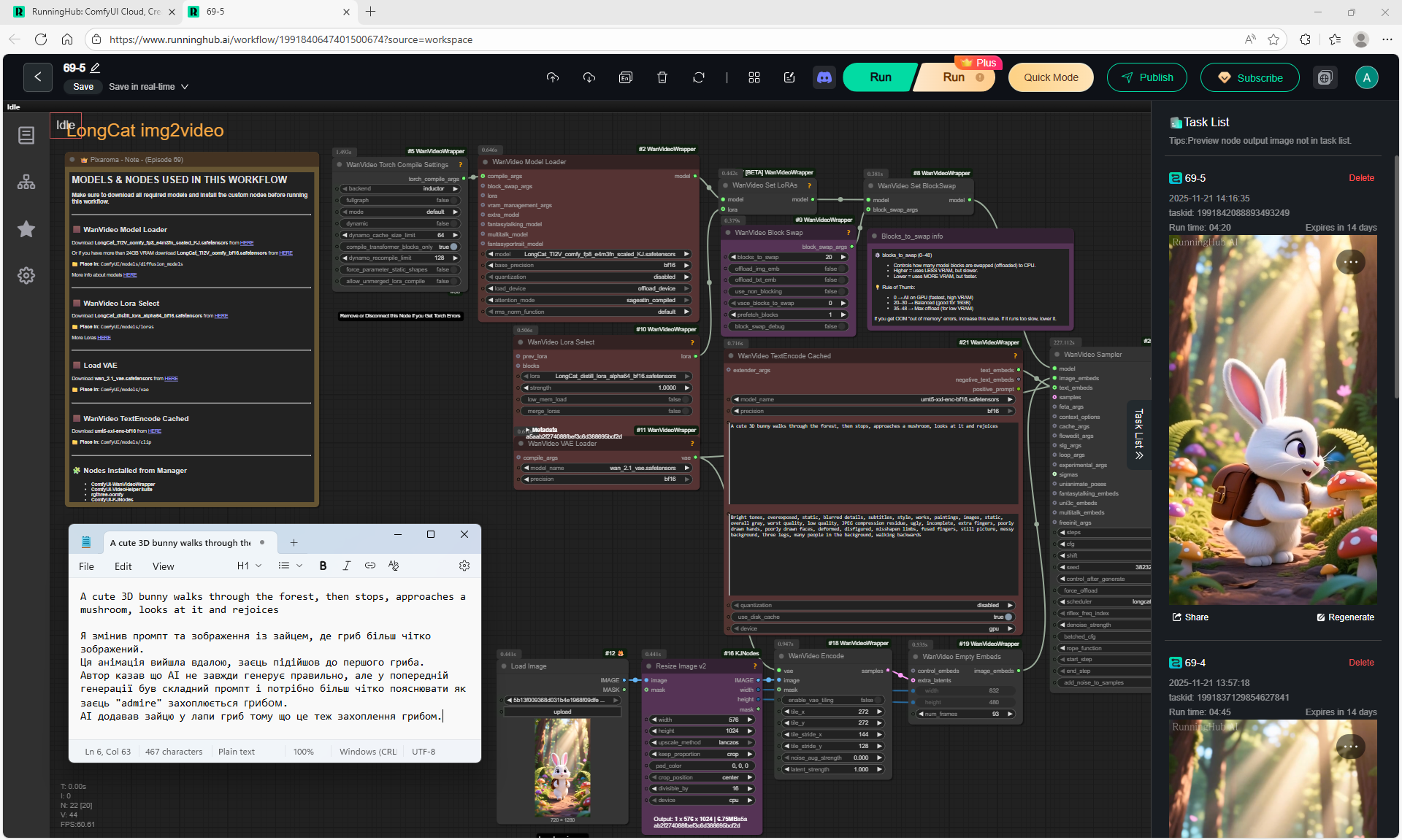
This is an animation of a hare in the forest sniffing mushrooms on the LongCat model.
First, the hare had a mushroom in its paw, I made a more detailed prompt, that the hare approaches the mushroom, stops, rejoices.
In the animation, the hare is not just rejoiced, he takes the mushroom, although this is not indicated in the prompt, you can further test the prompt.
The animation of the hare's movement is high-quality, although in the second video the mushrooms in the foreground rise slightly during the hare's movement.








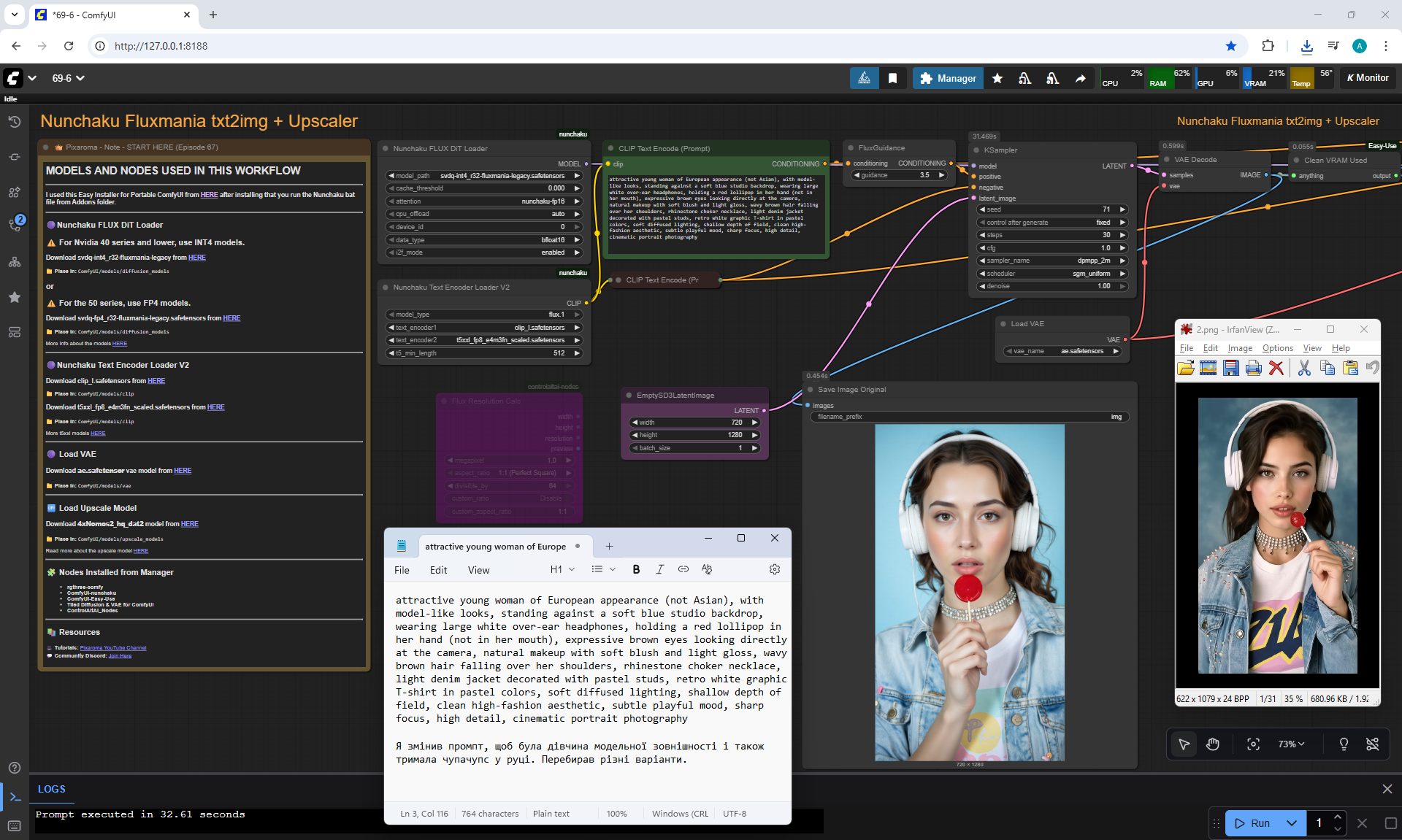
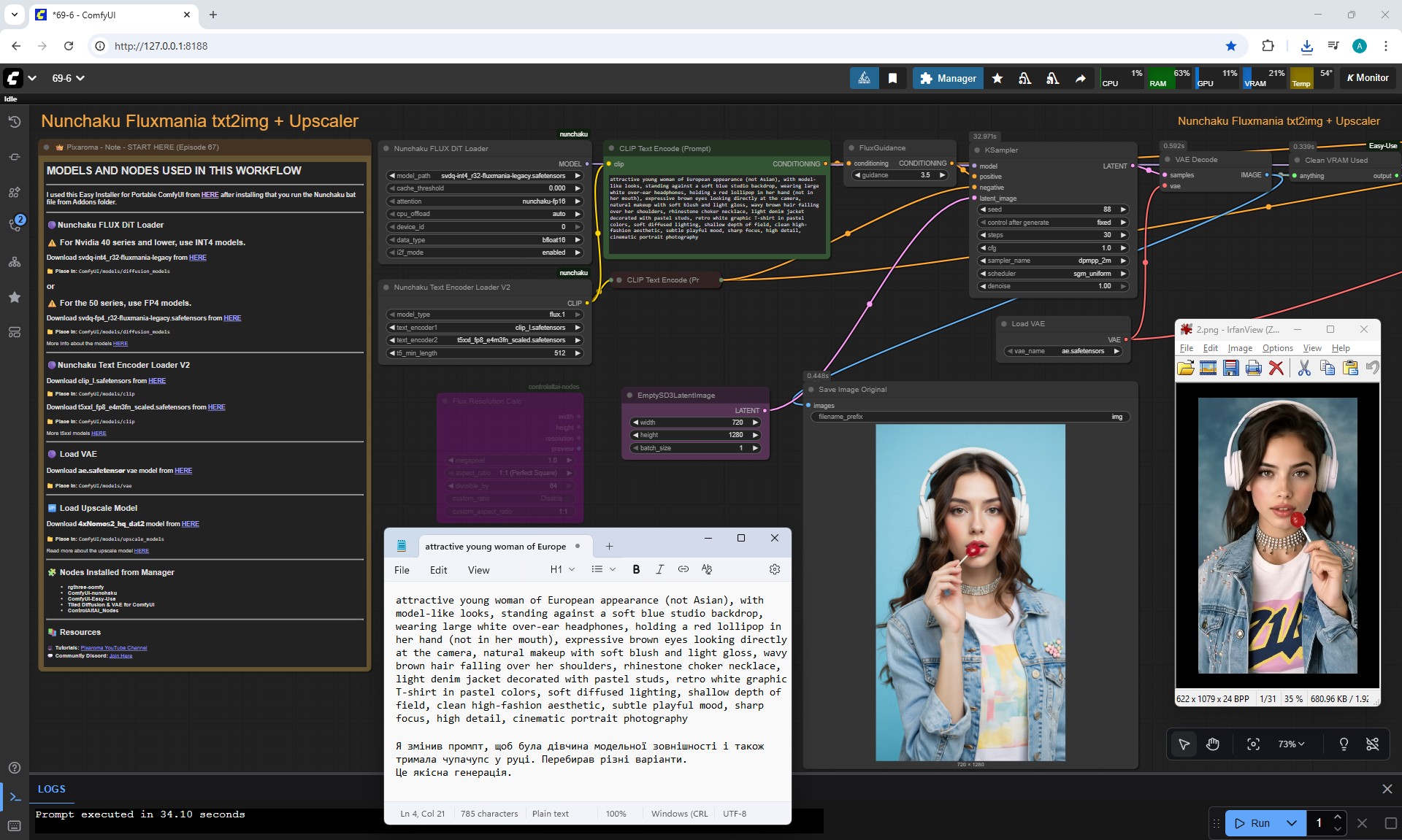
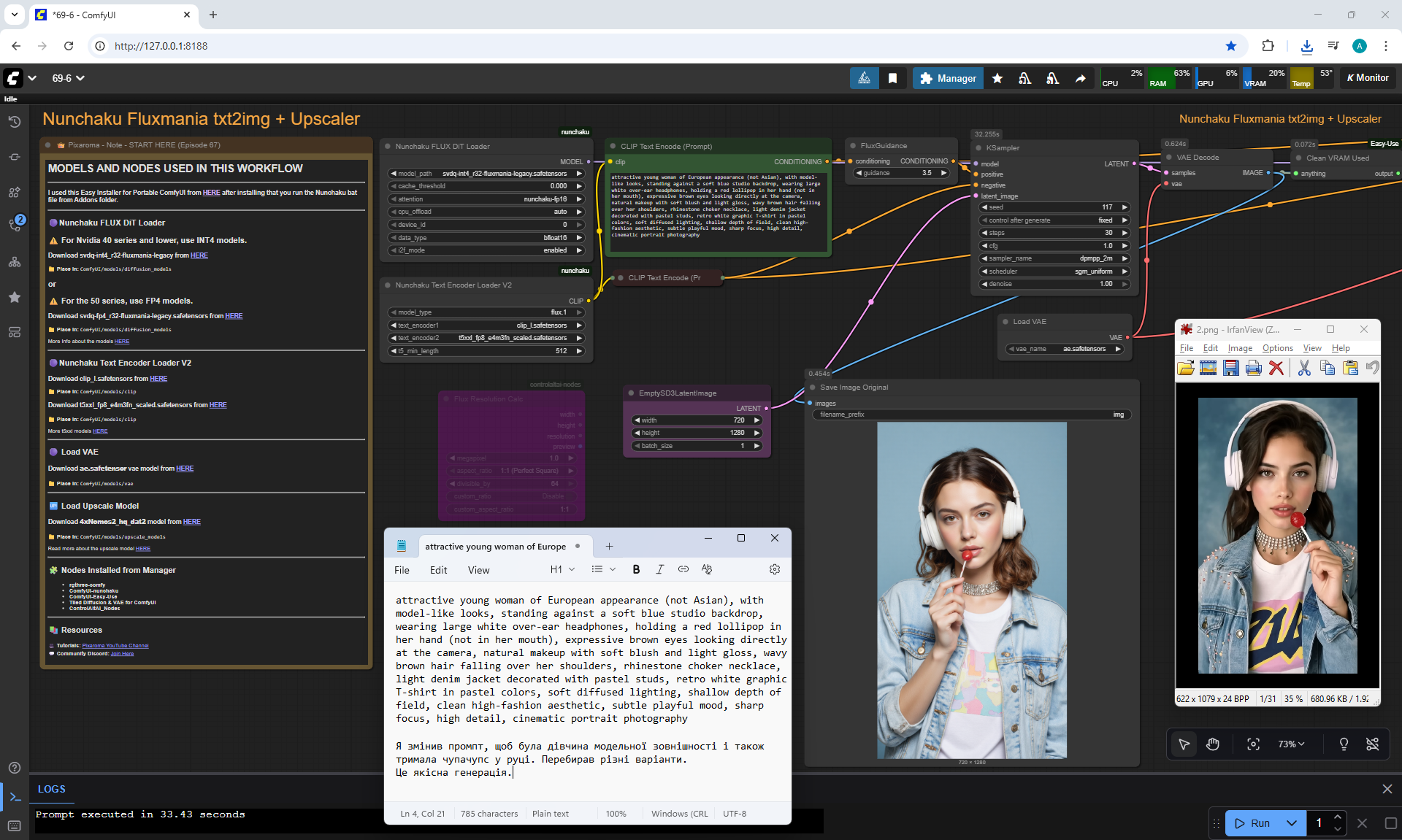
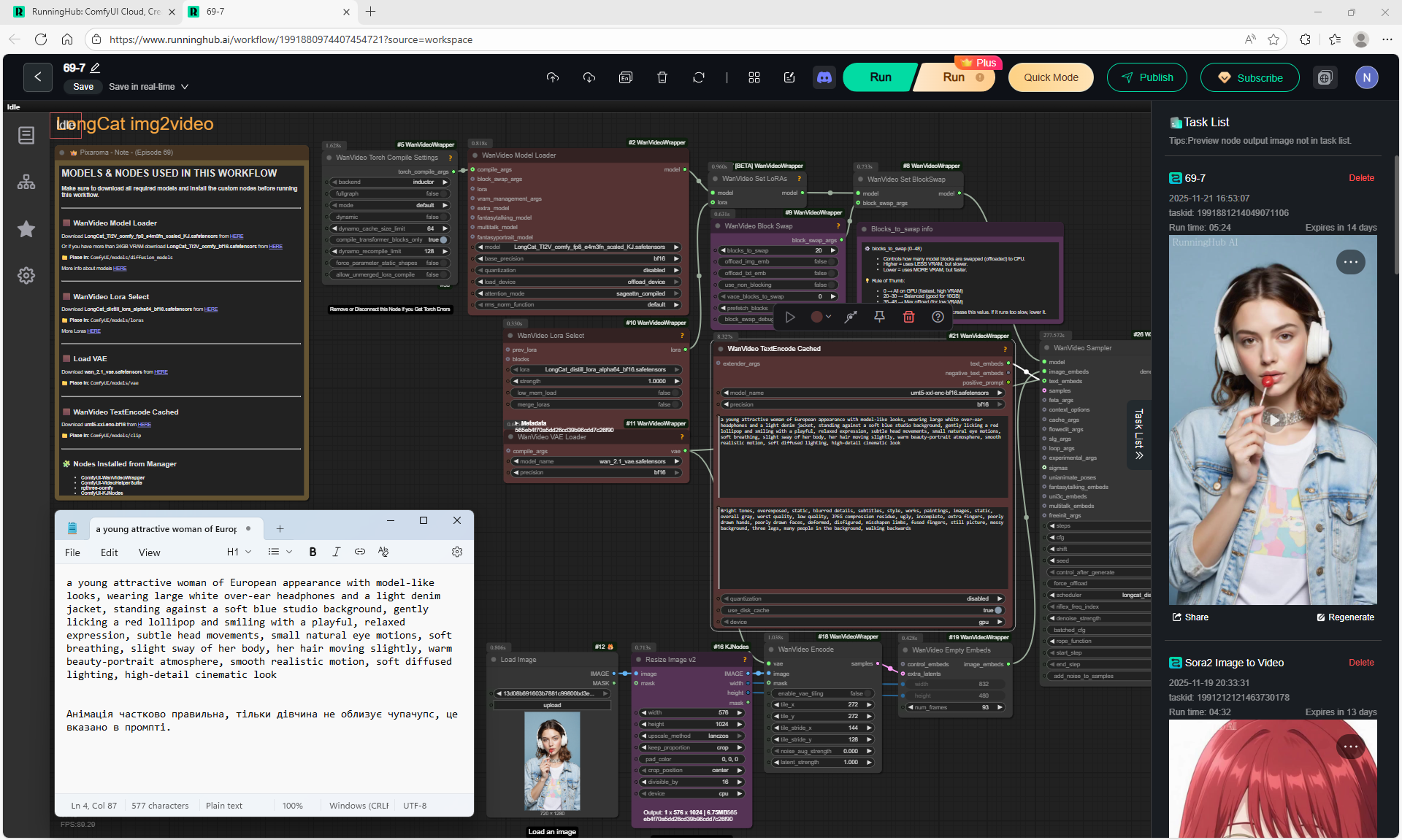
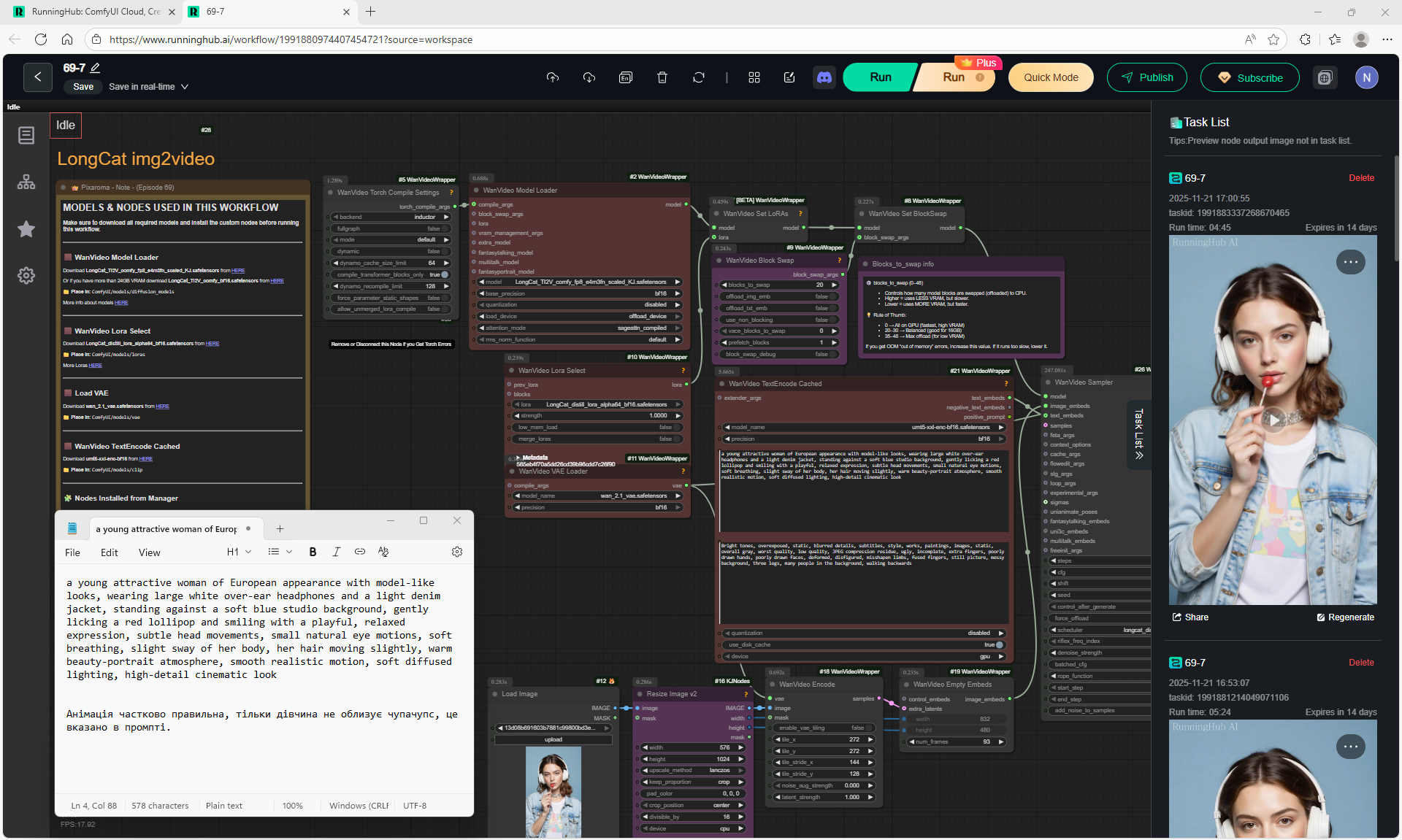
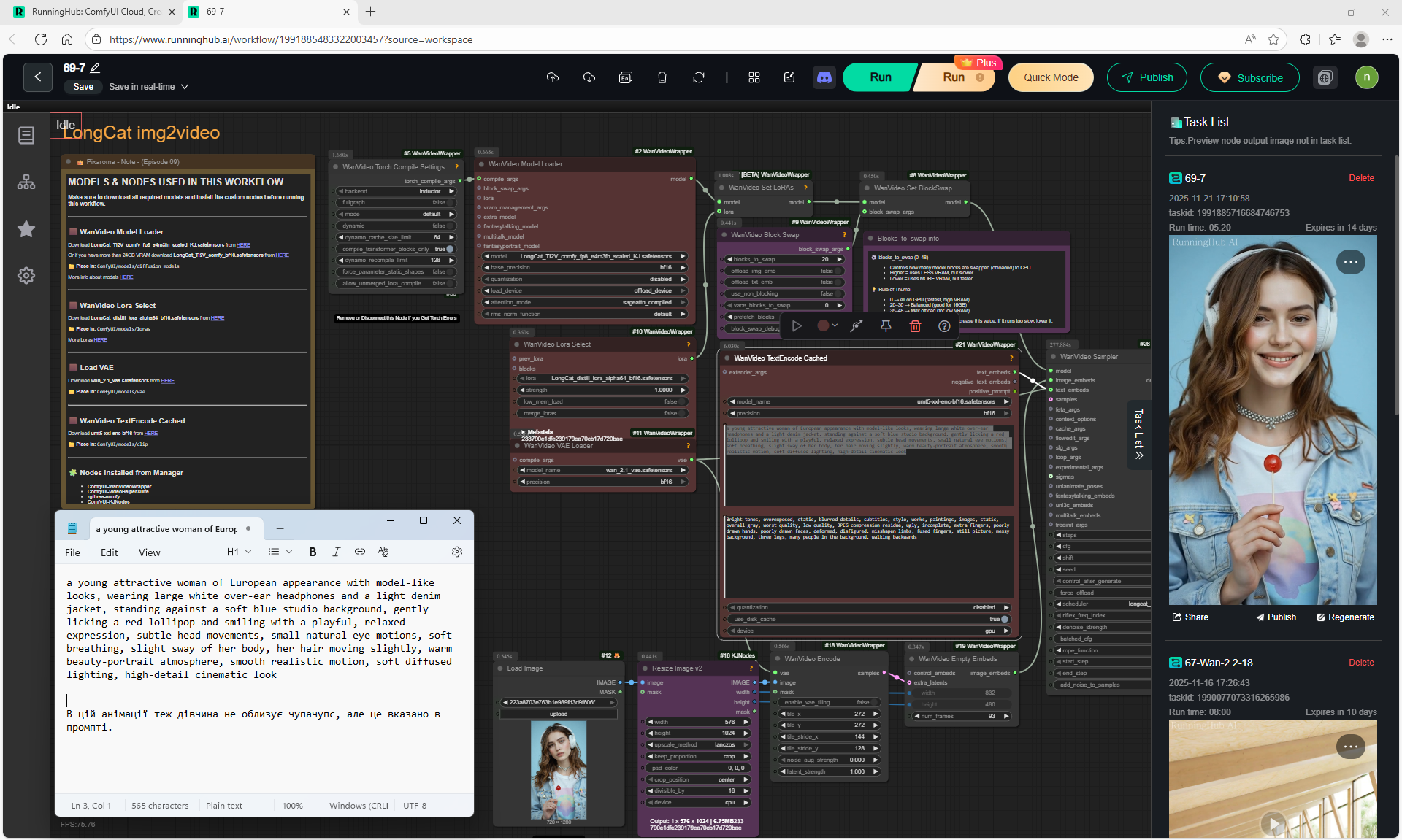
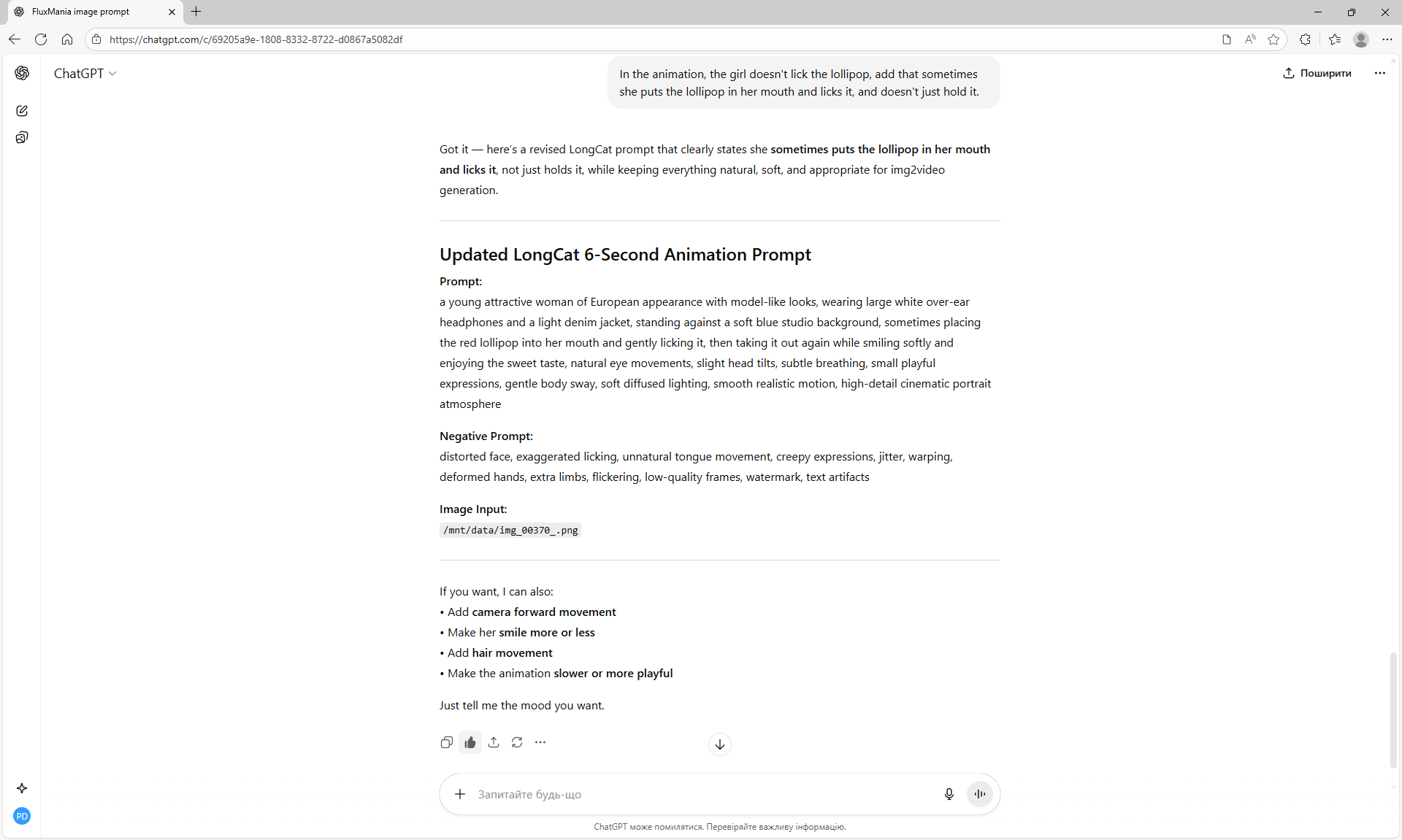
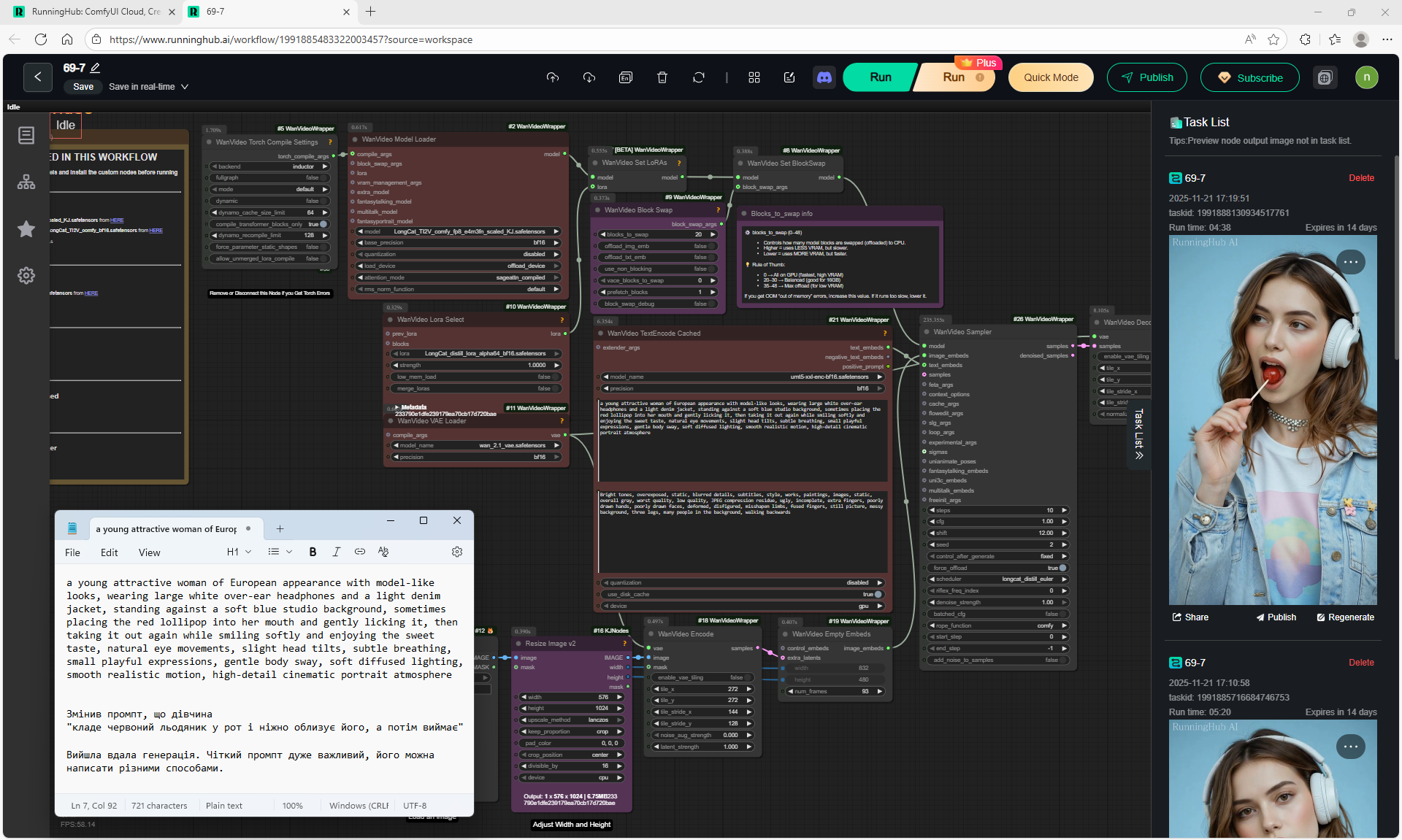
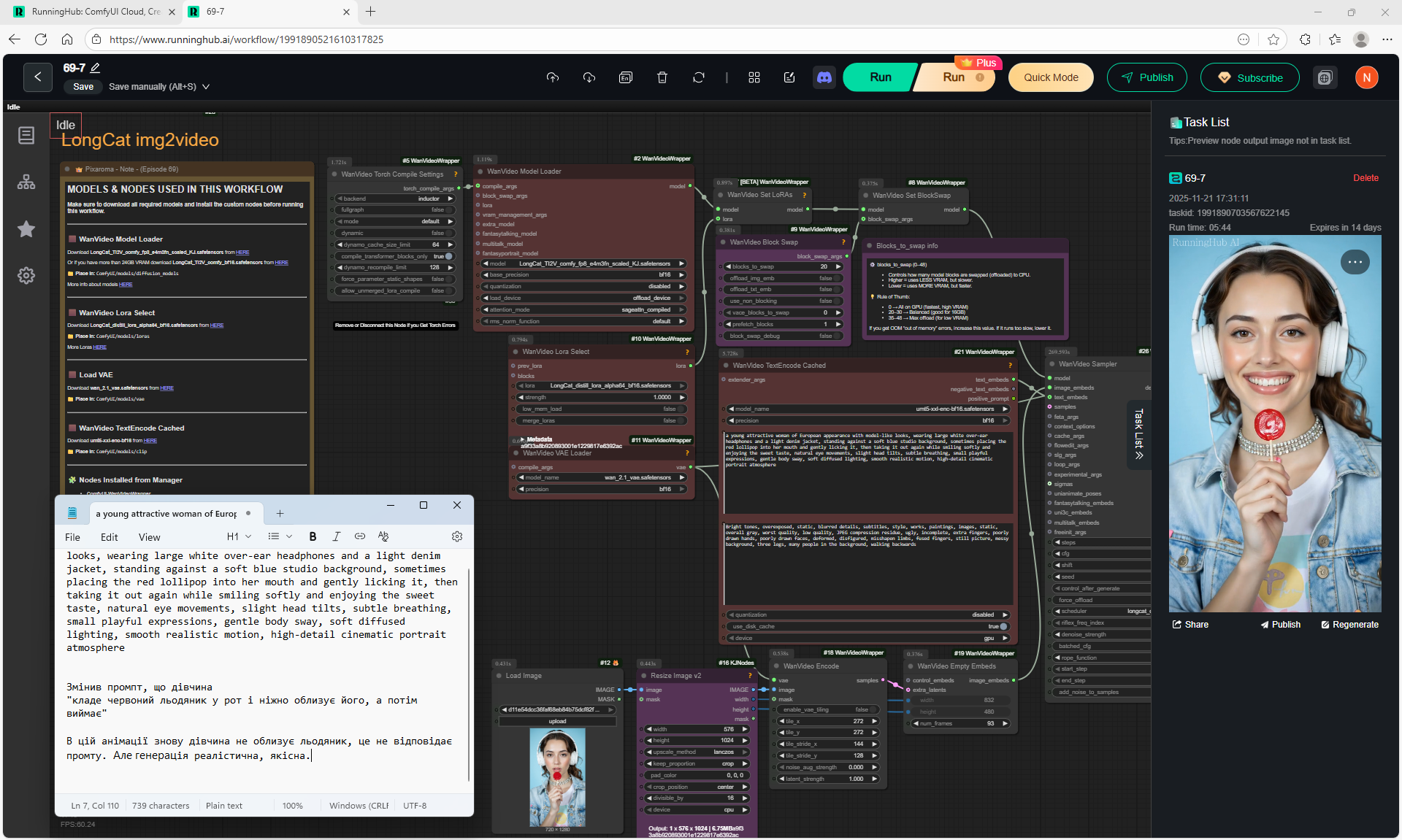
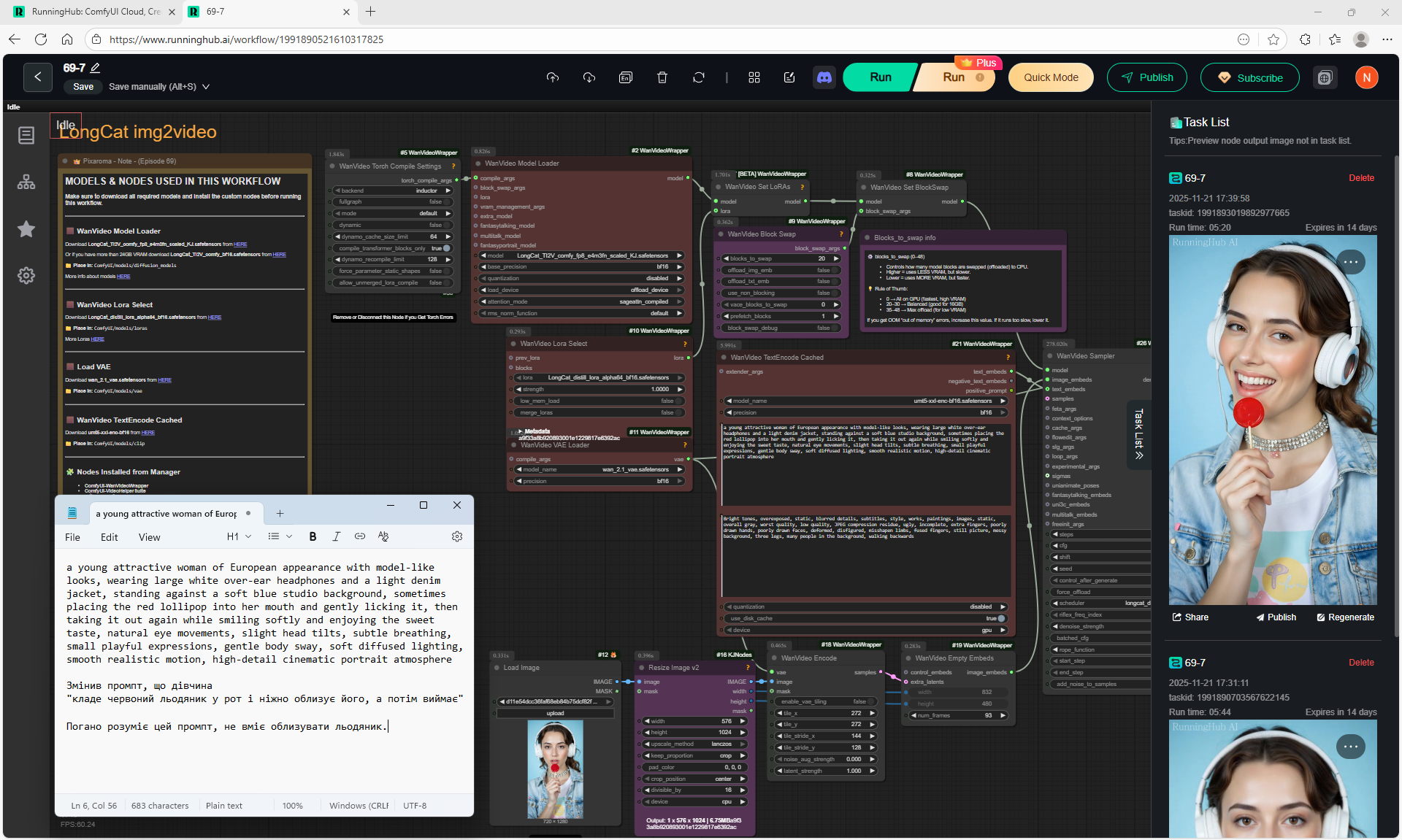
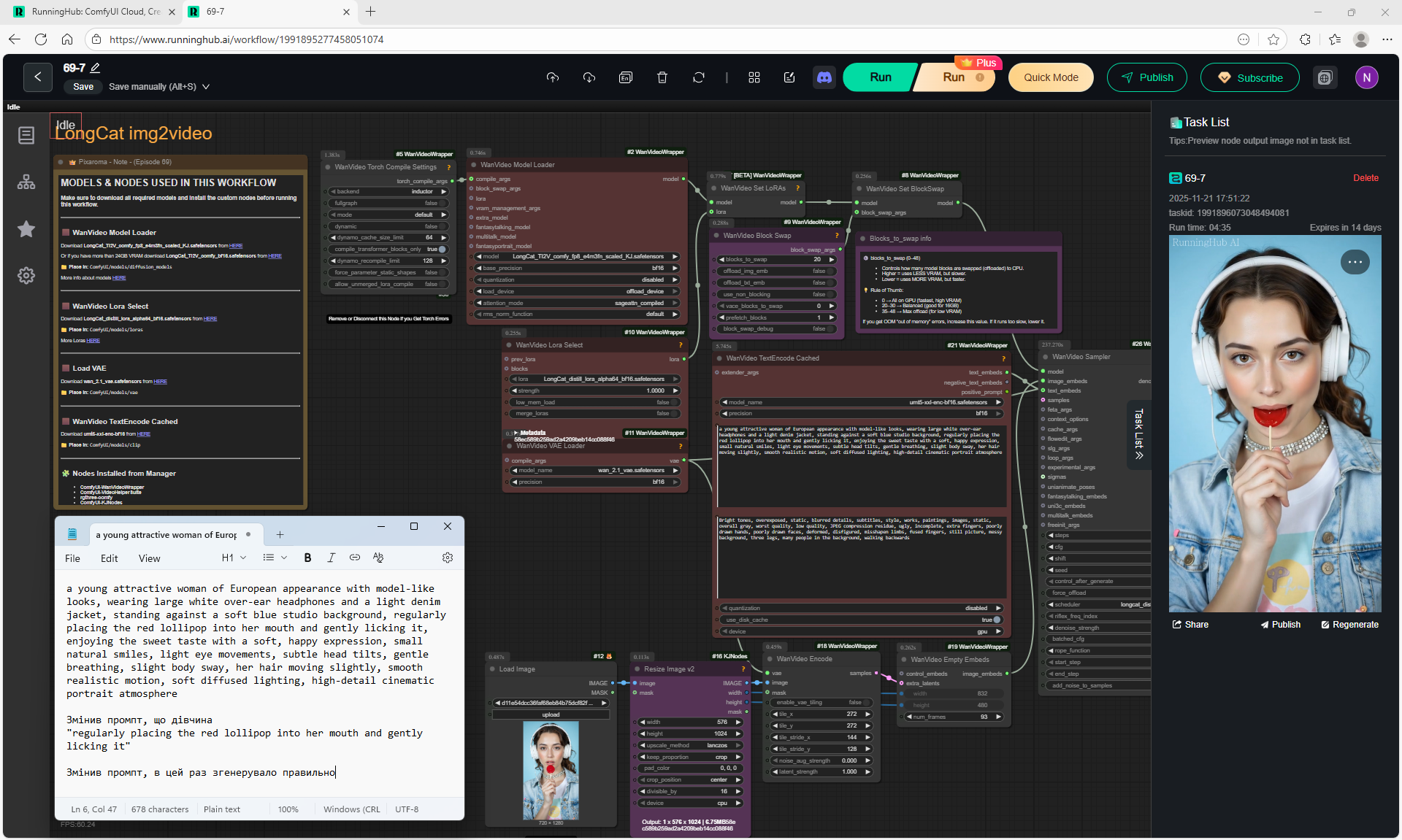
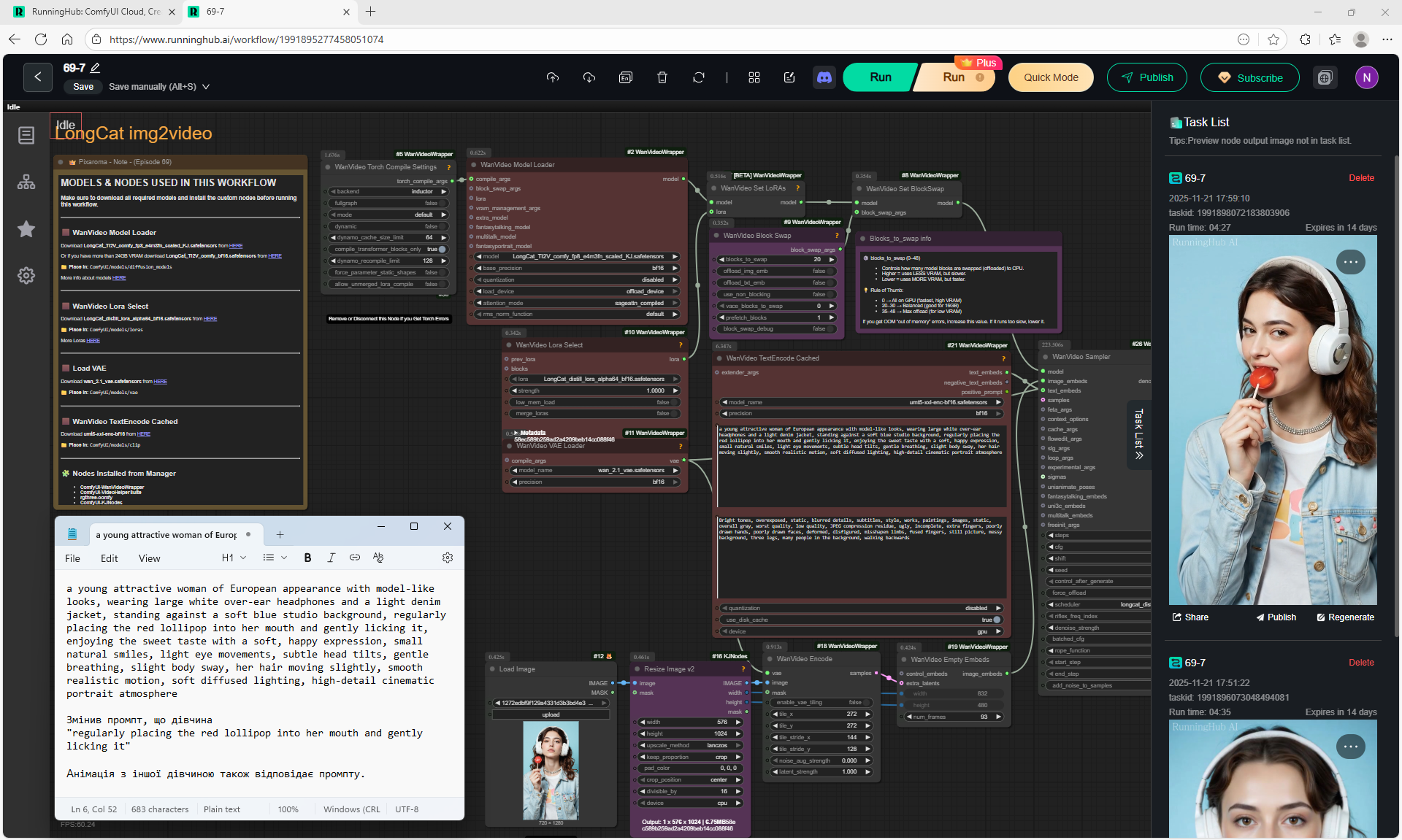
Animations with a girl sucking chupachups rarely turned out correctly. It is necessary to clarify prompt, that a girl puts a lollipop in her mouth, licks it. It was rarely generated correctly. Generated once clearly correct, but there was a glitch in the tongue movement. There were many animations where the girl doesn't lick the lollipop, but just moves her hand with it.




The animations of the mouse from the house and its movements on the LongCat model are correct. The first animation is without glitches.
There are some flaws: sometimes the door may not open correctly or disappear, the light may turn on but not be reflected in the windows, the door opening may wobble. You can specify the prompt in more detail to get better animation.















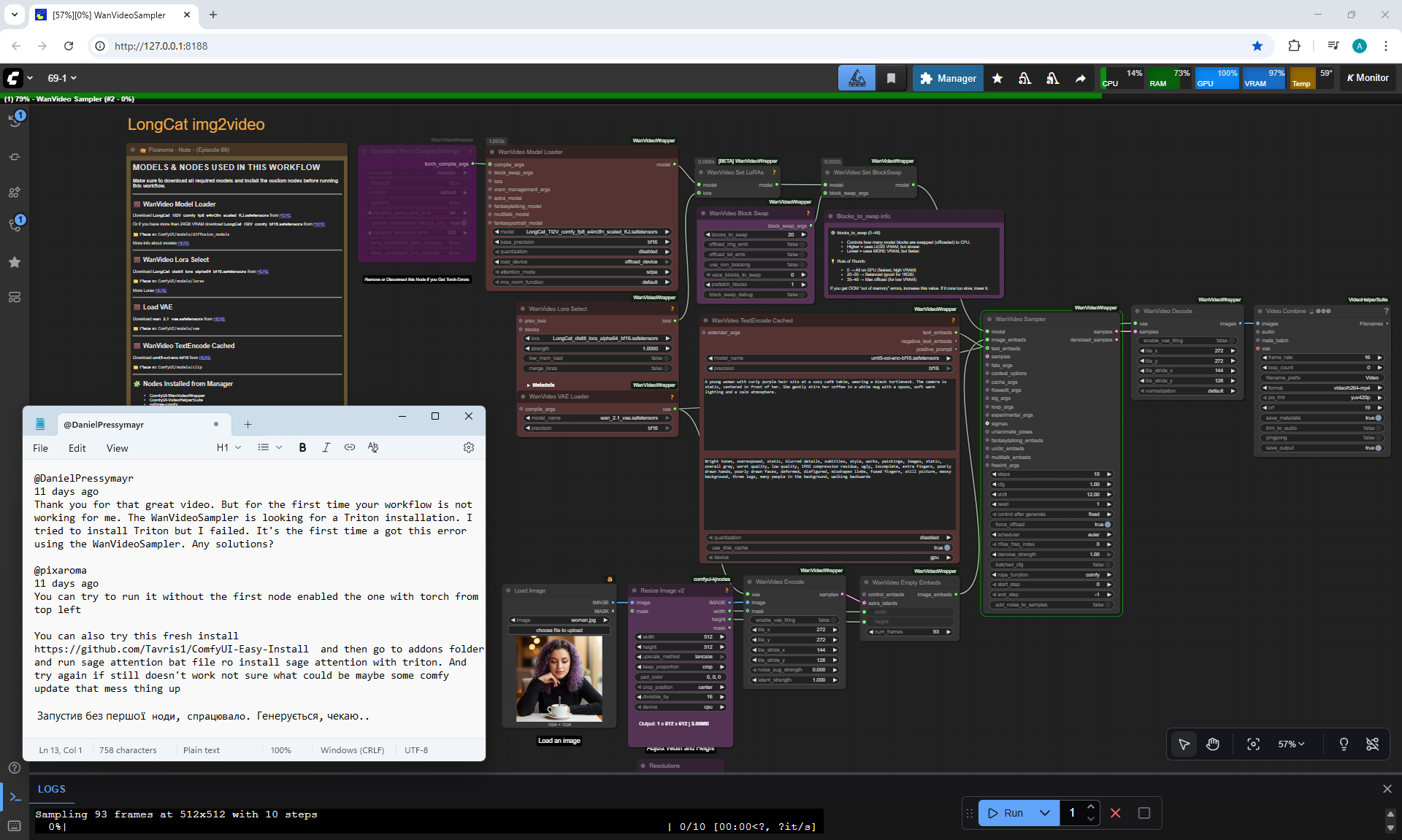
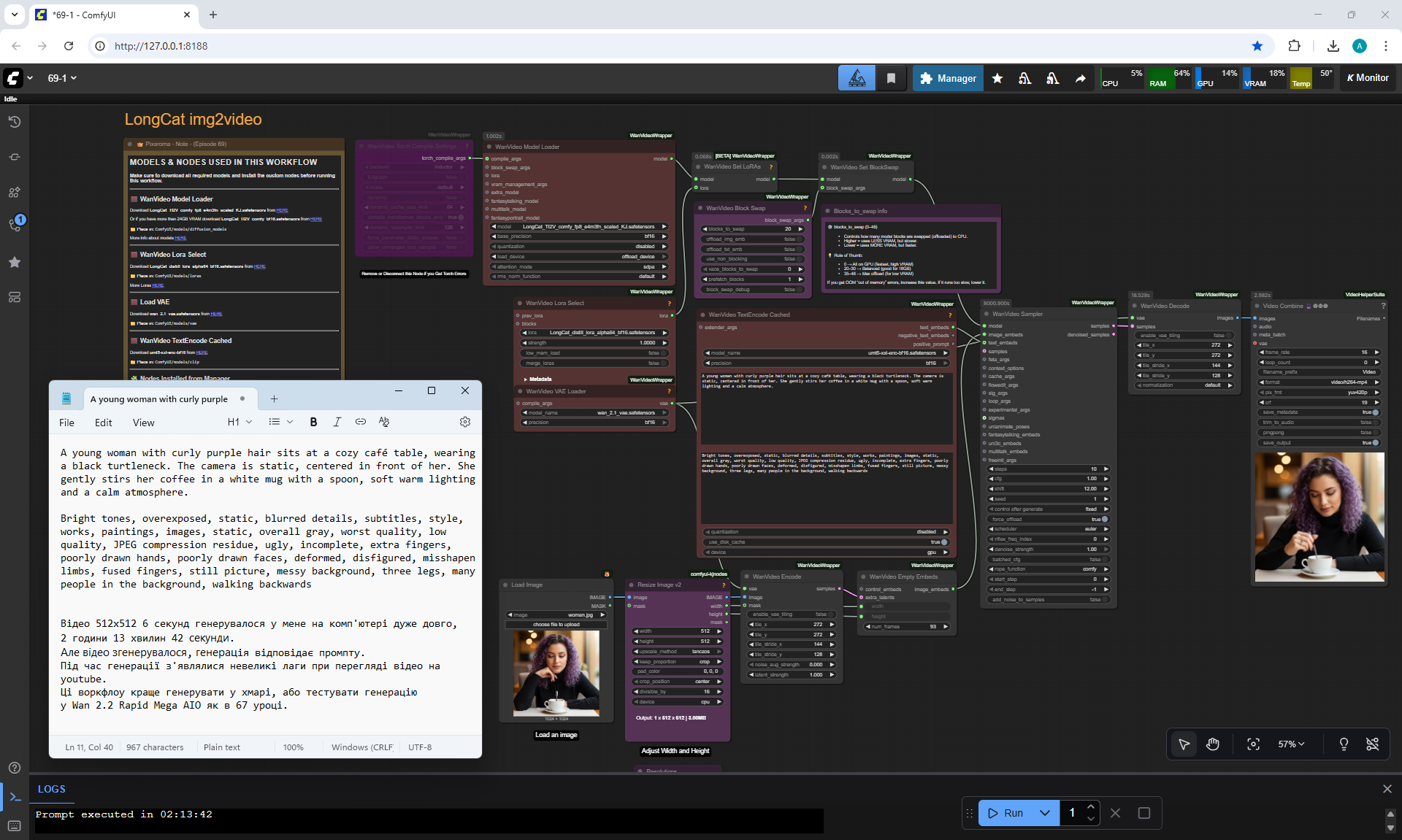
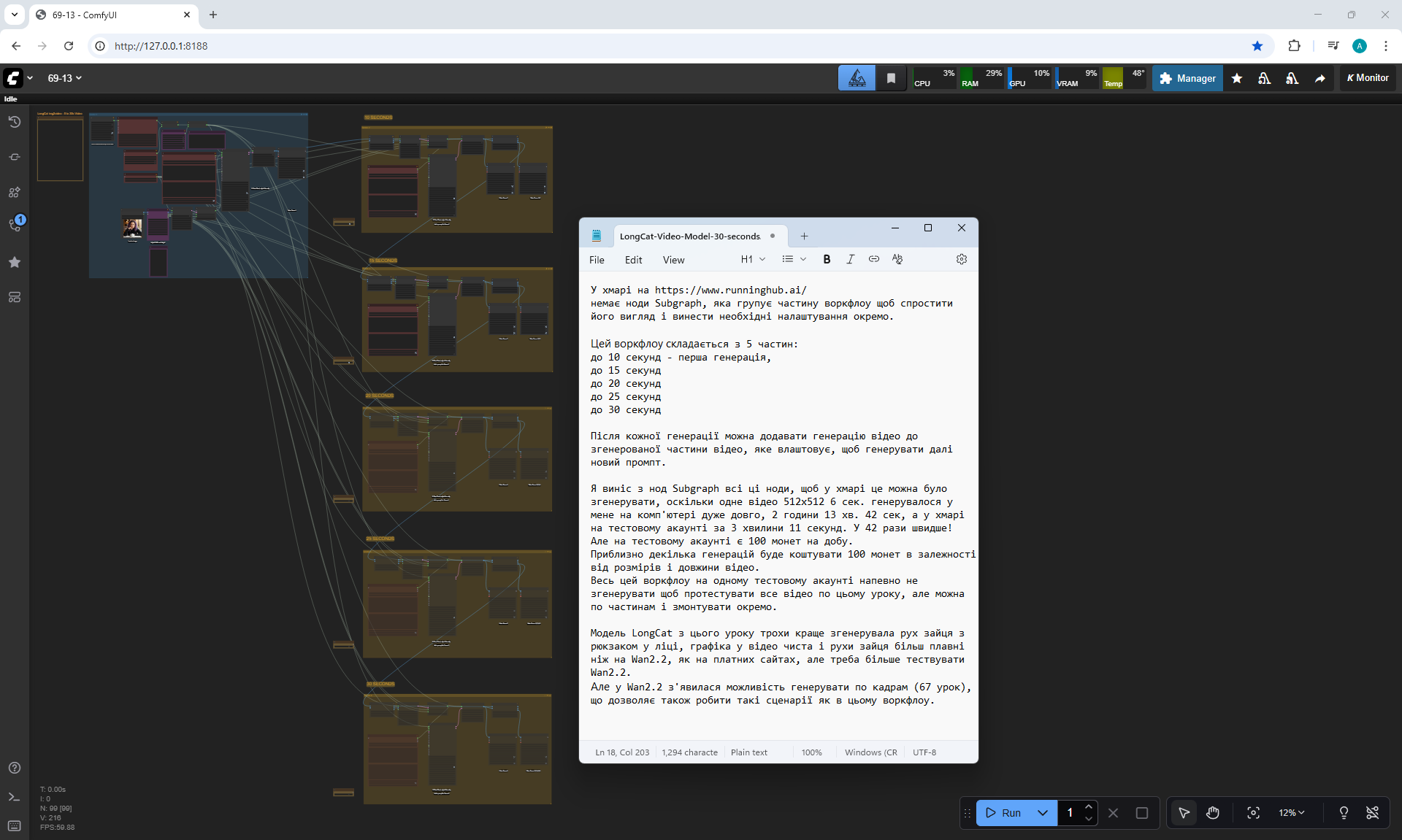
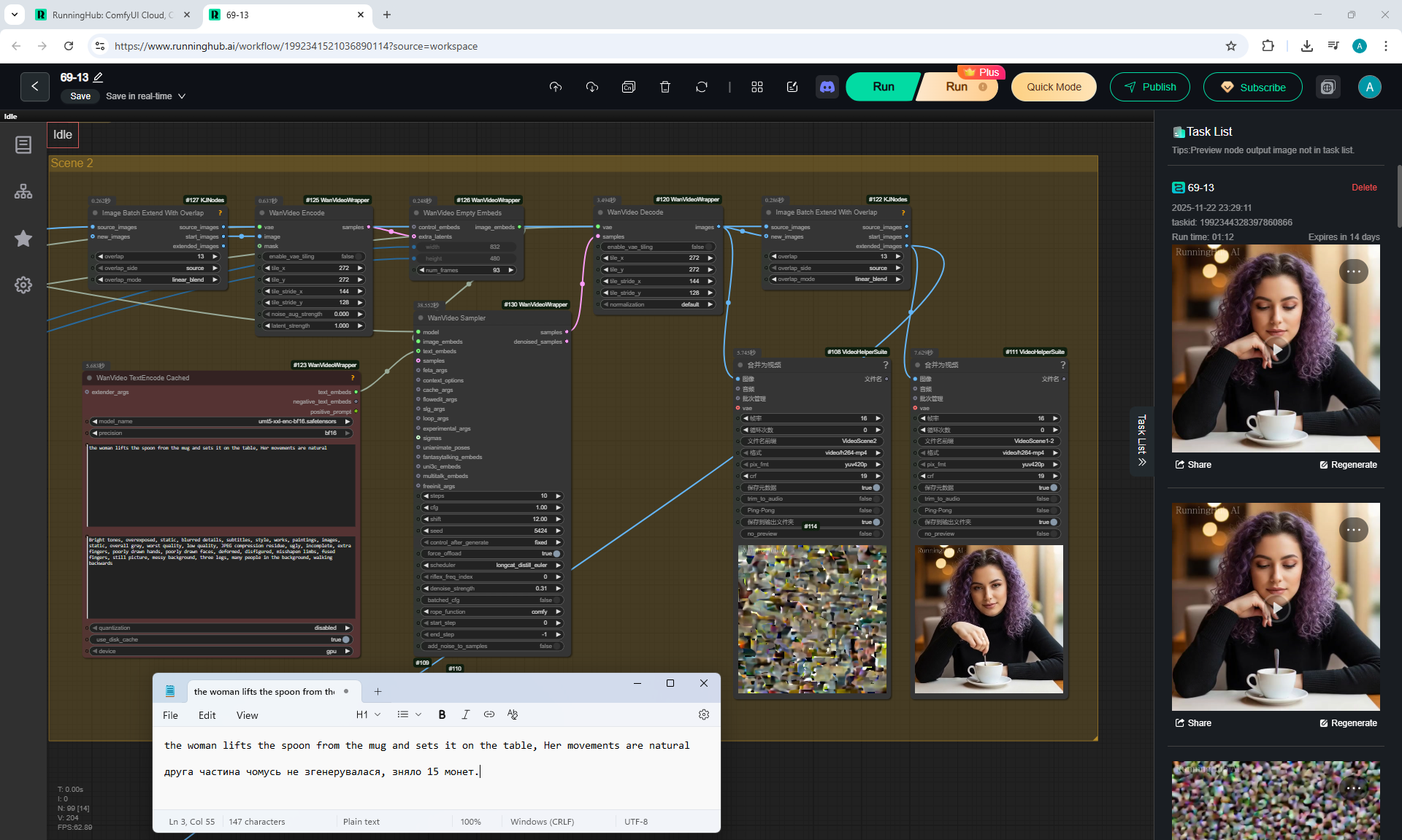
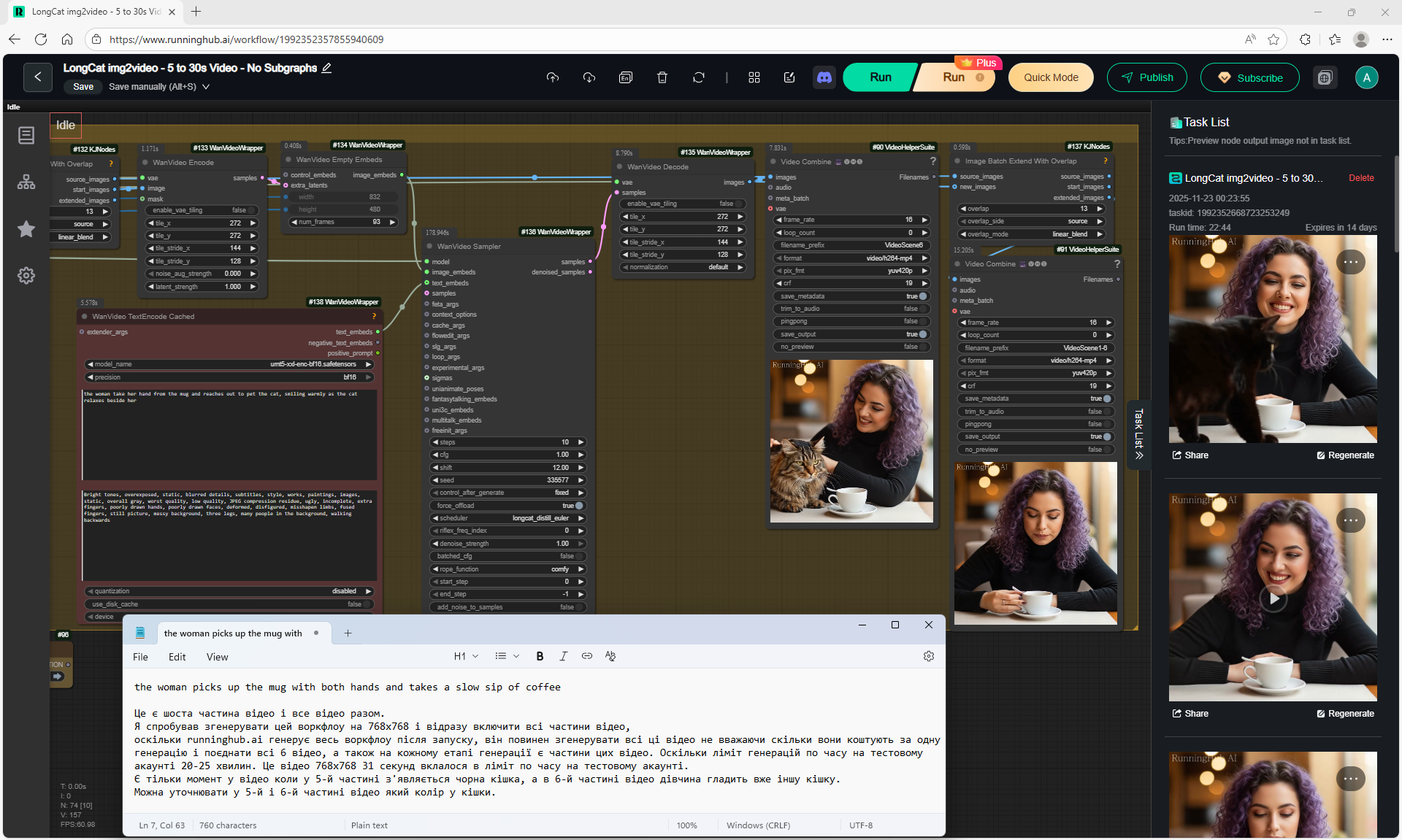
In total, there were 6 videos of 91 frames in the 768x768 video, resulting in 31 seconds.
Prompts for each part:
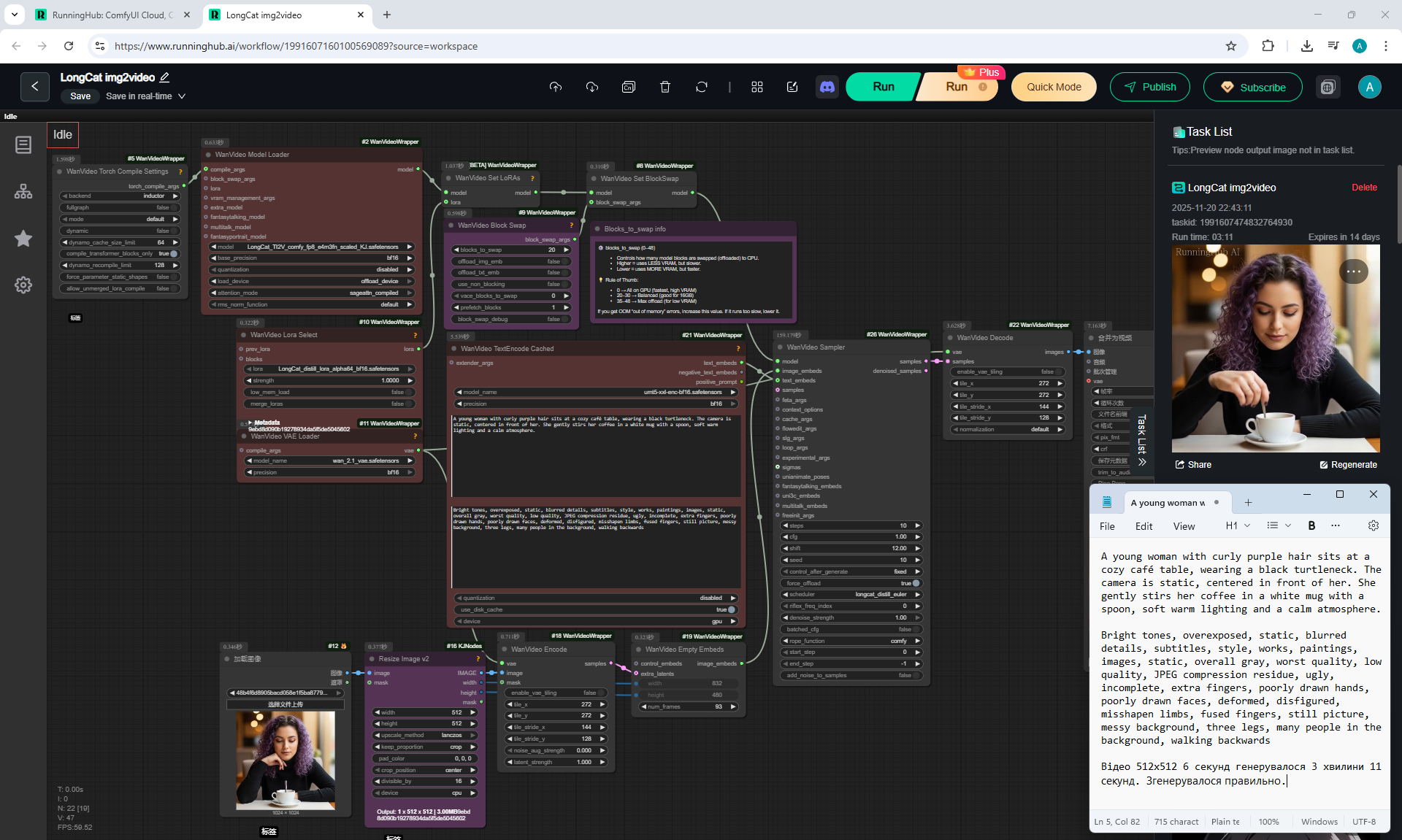
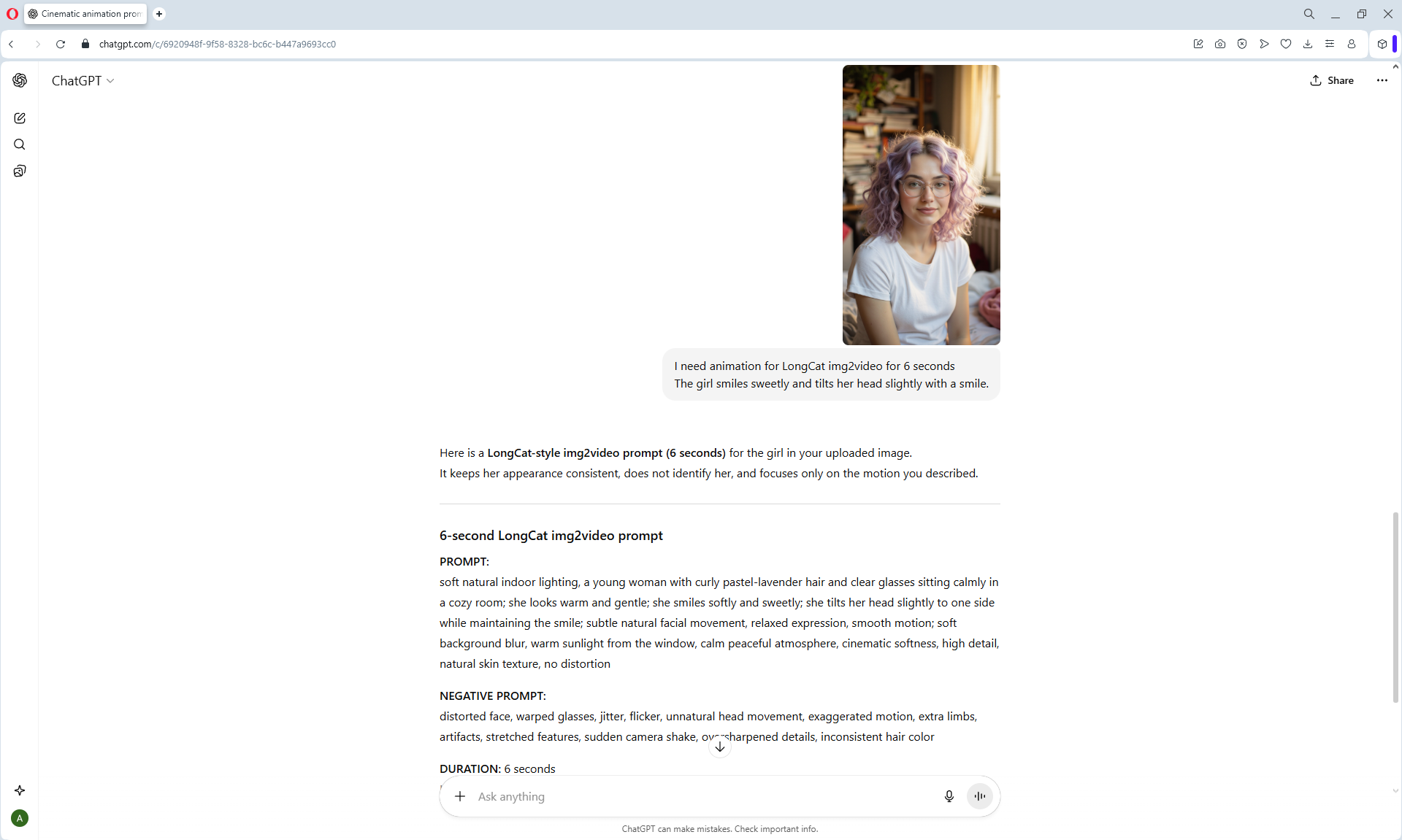
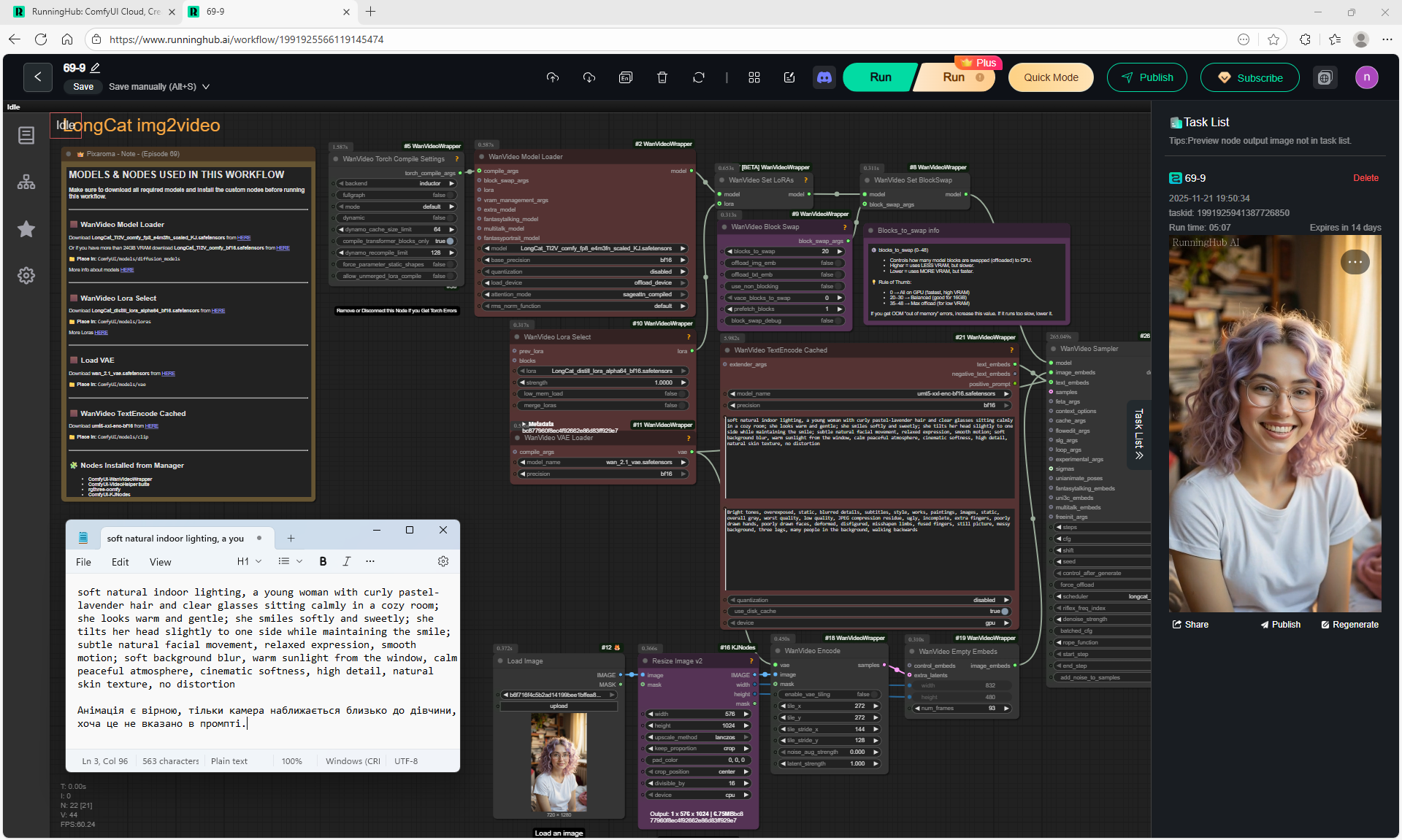
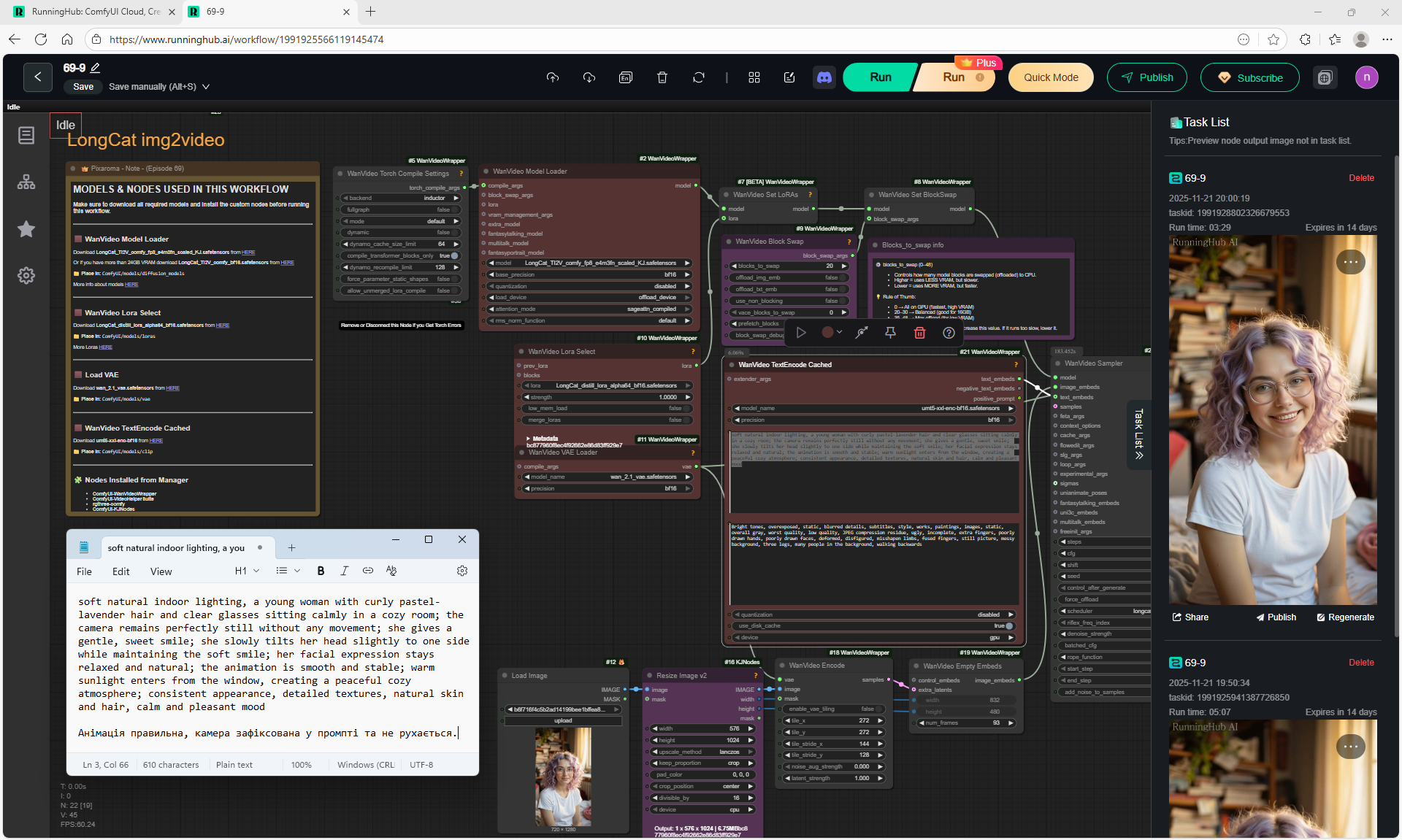
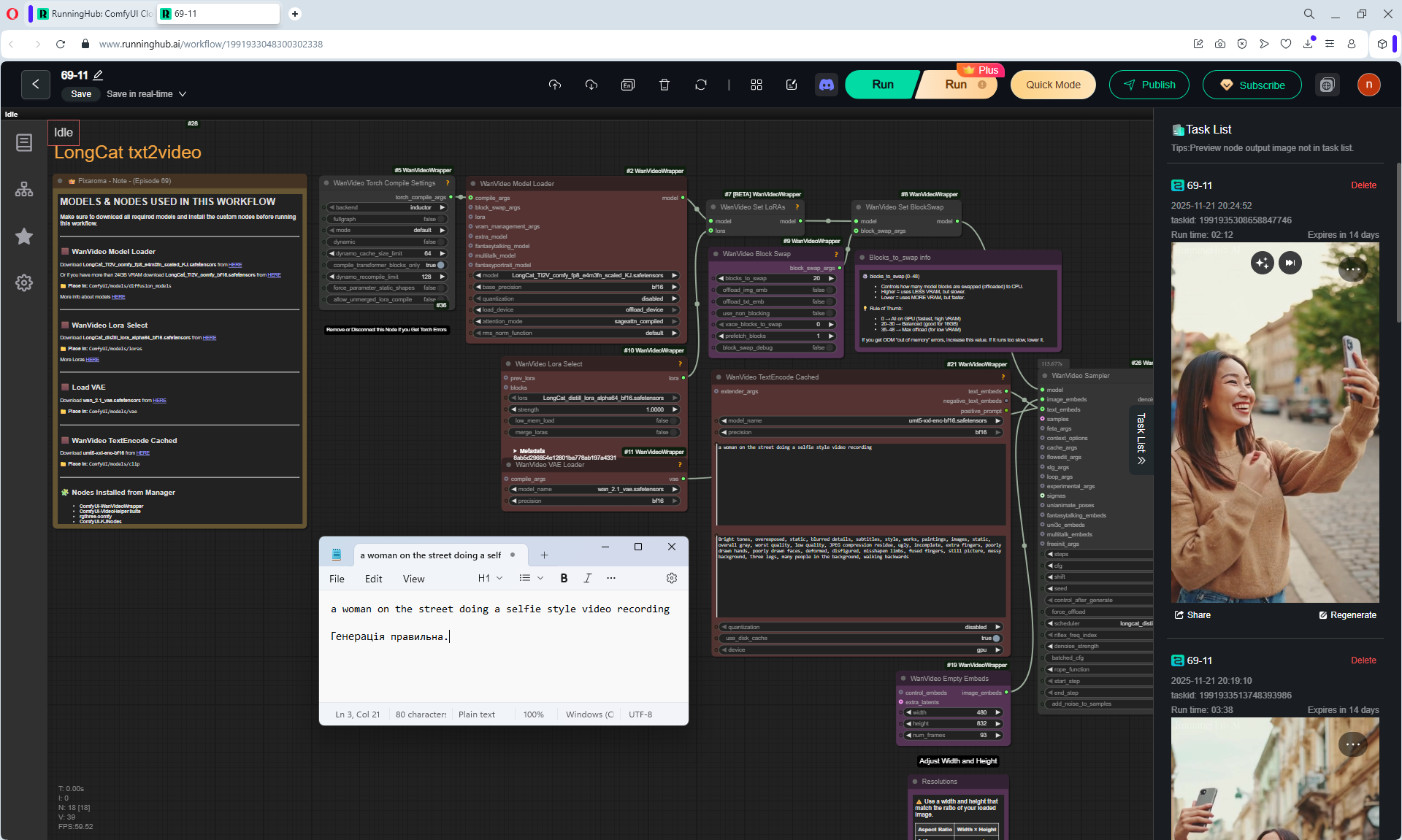
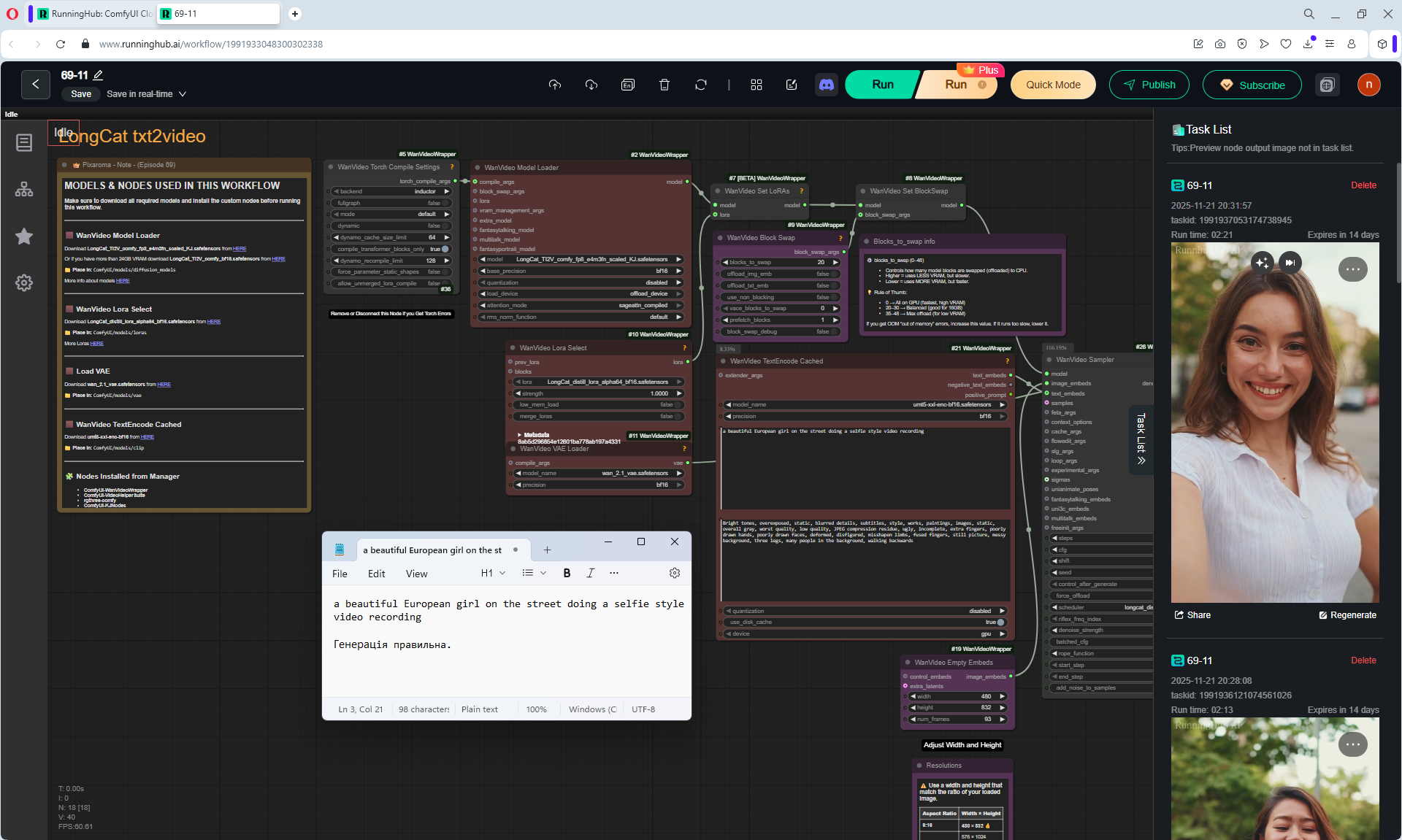
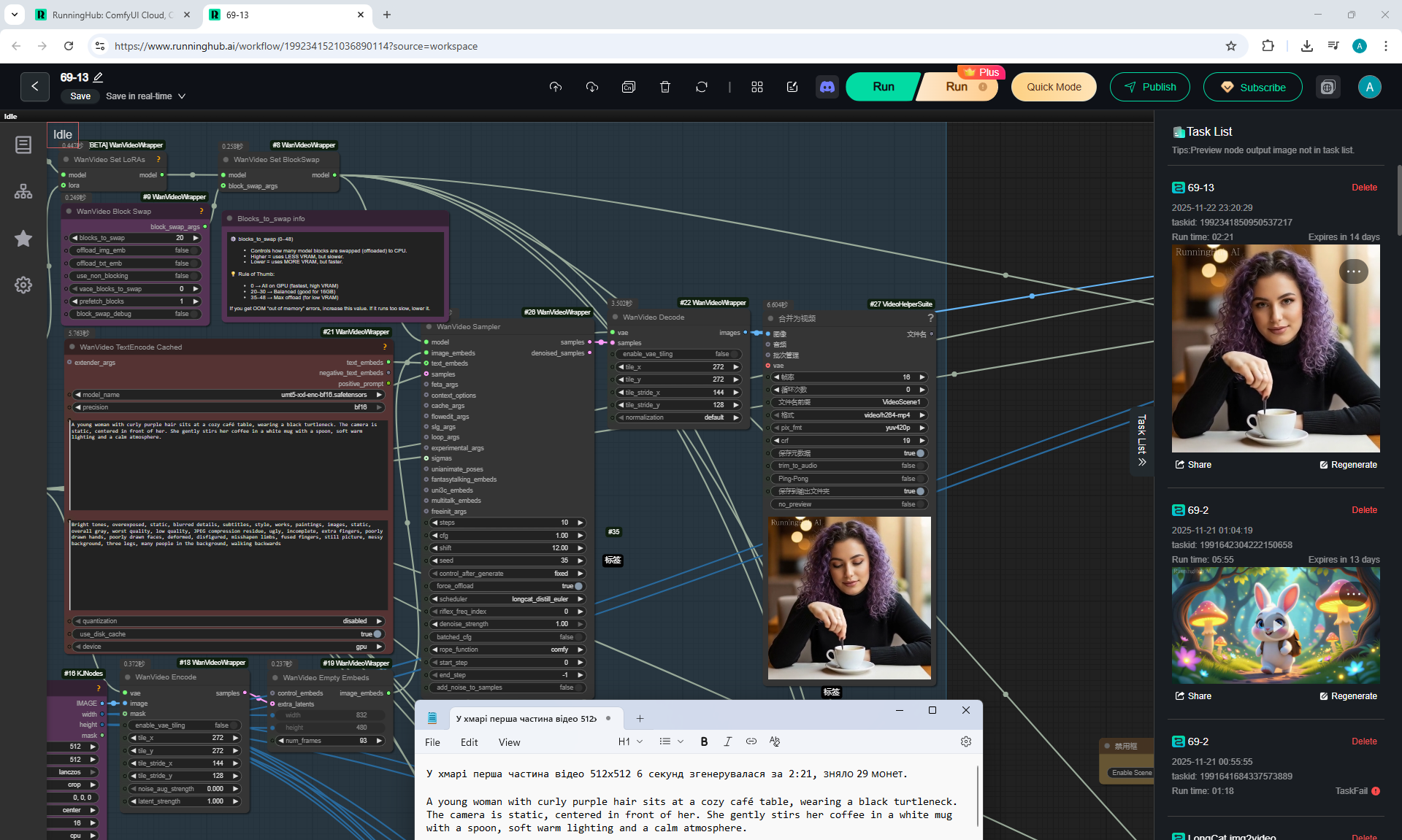
1. A young woman with curly purple hair sits at a cozy café table, wearing a black turtleneck. The camera is static, centered in front of her. She gently stirs her coffee in a white mug with a spoon, soft warm lighting and a calm atmosphere.
2. the woman lifts the spoon from the mug and sets it on the table, Her movements are natural
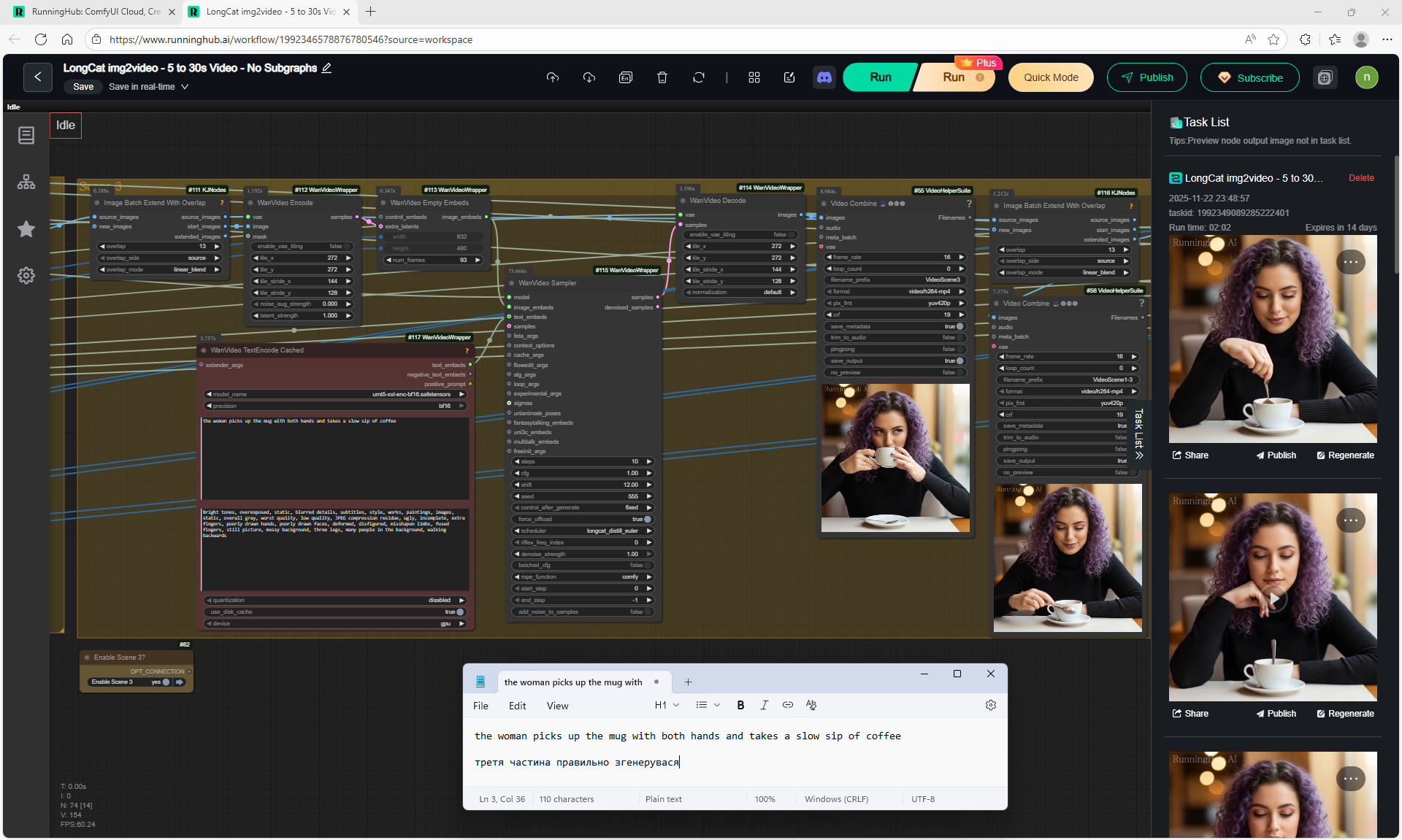
3. the woman picks up the mug with both hands and takes a slow sip of coffee
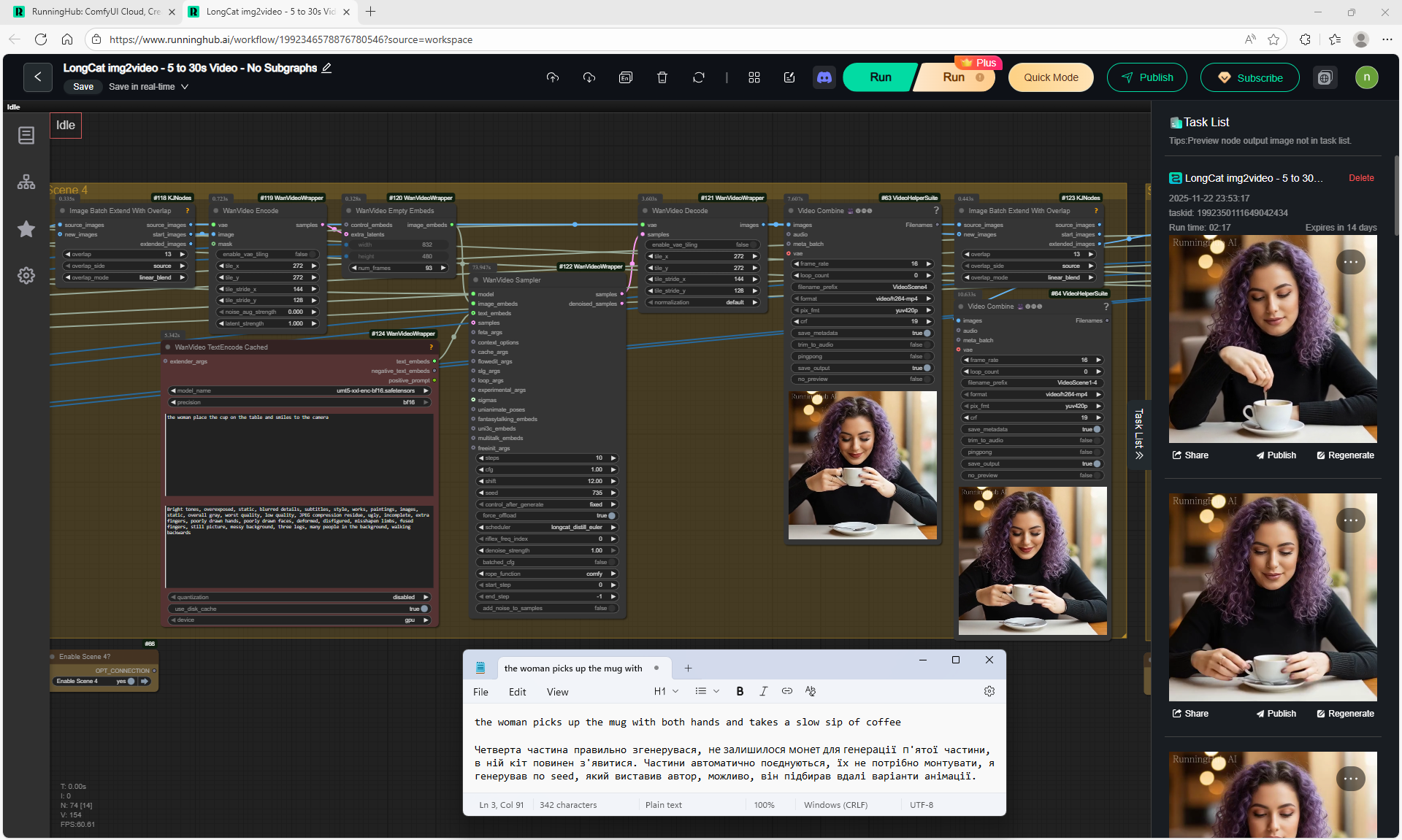
4. the woman place the cup on the table and smiles to the camera
5. a black cat walking into frame from the side, jumping onto the table next to the mug. The woman looks at the cat with surprise and a gentle smile.
6. the woman take her hand from the mug and reaches out to pet the cat, smiling warmly as the cat relaxes beside her
The recommended size is maximum 768x768.
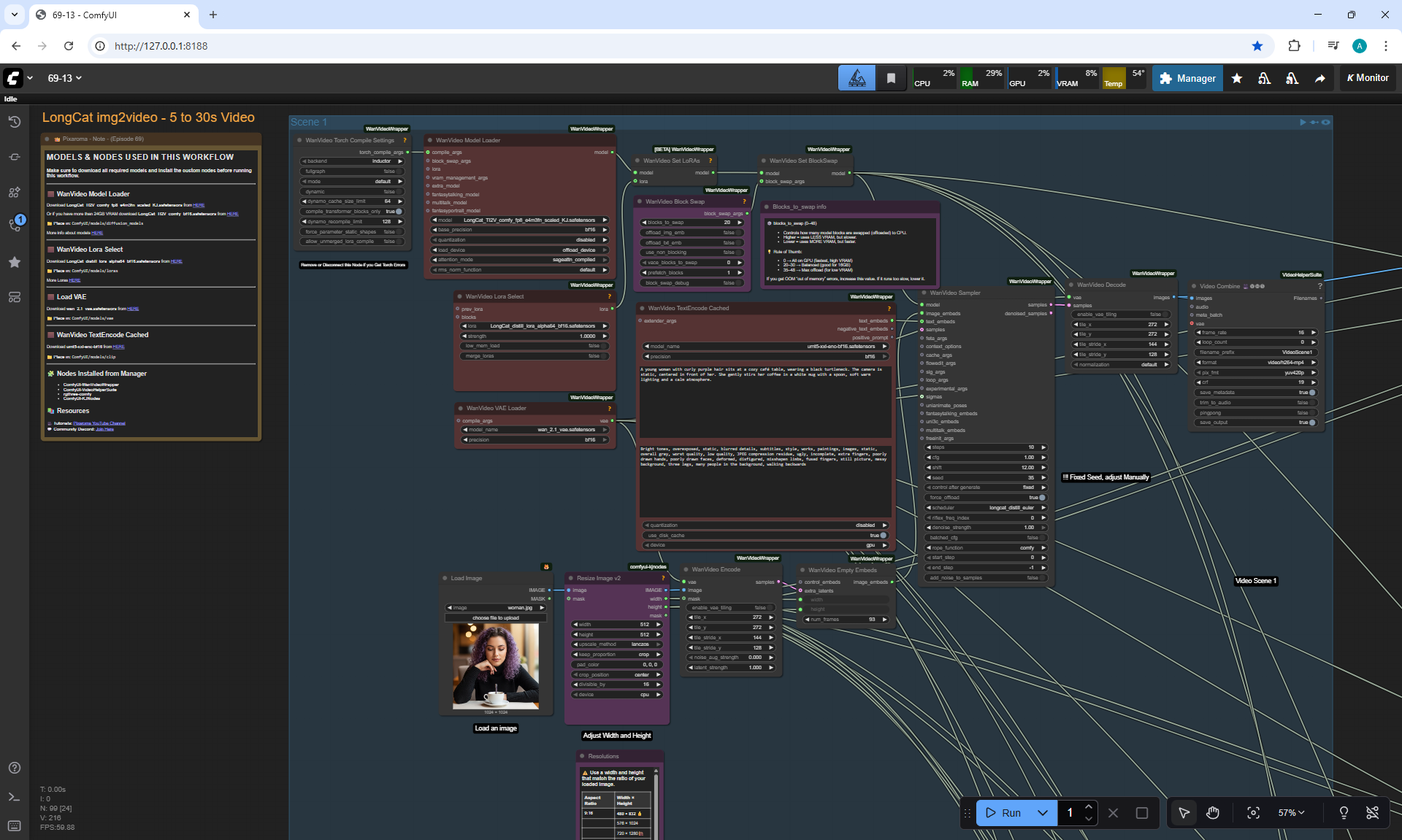
The LongCat model now has the ability to make
many prompts for the following parts of the video using one image.
This allows you not to edit them separately.
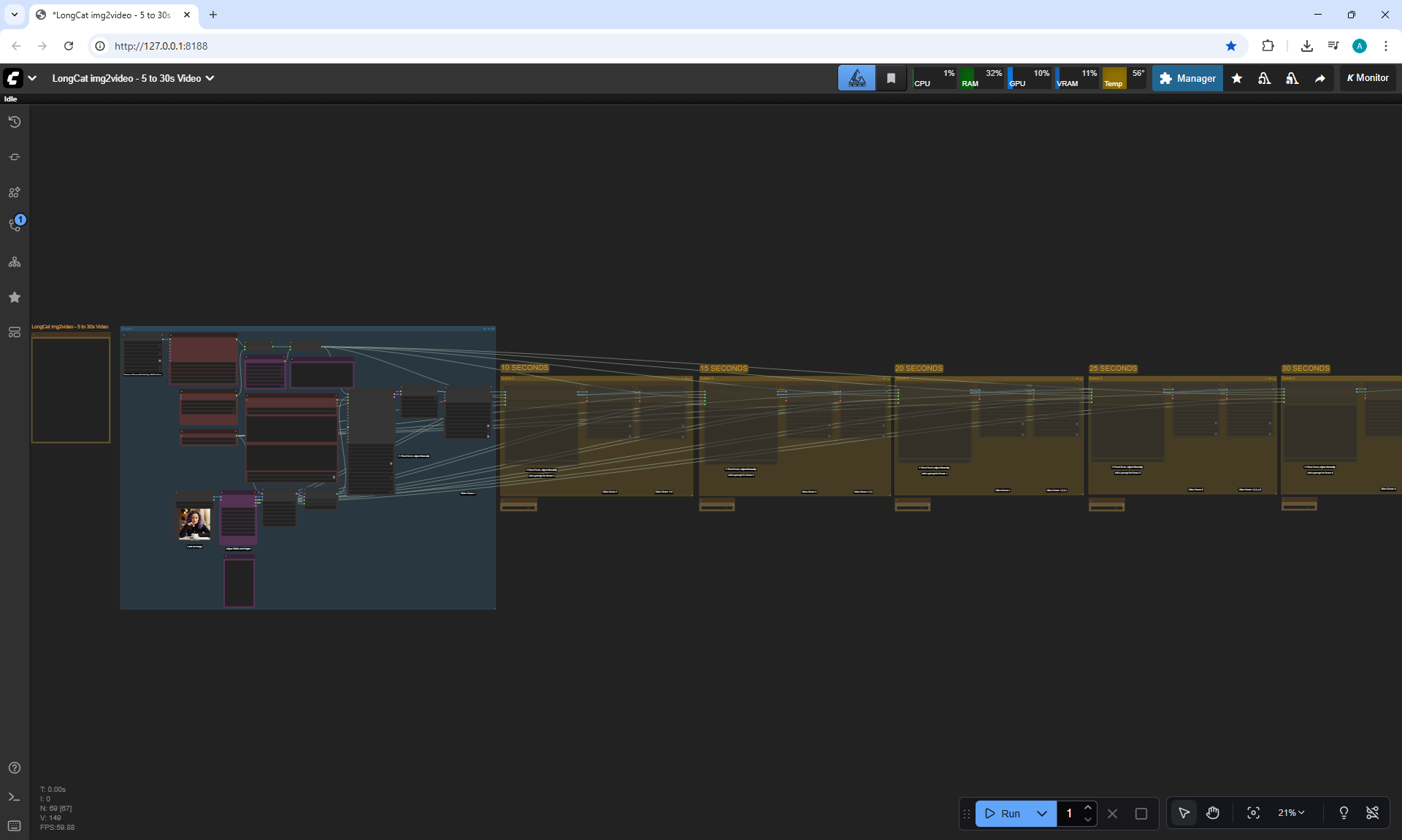
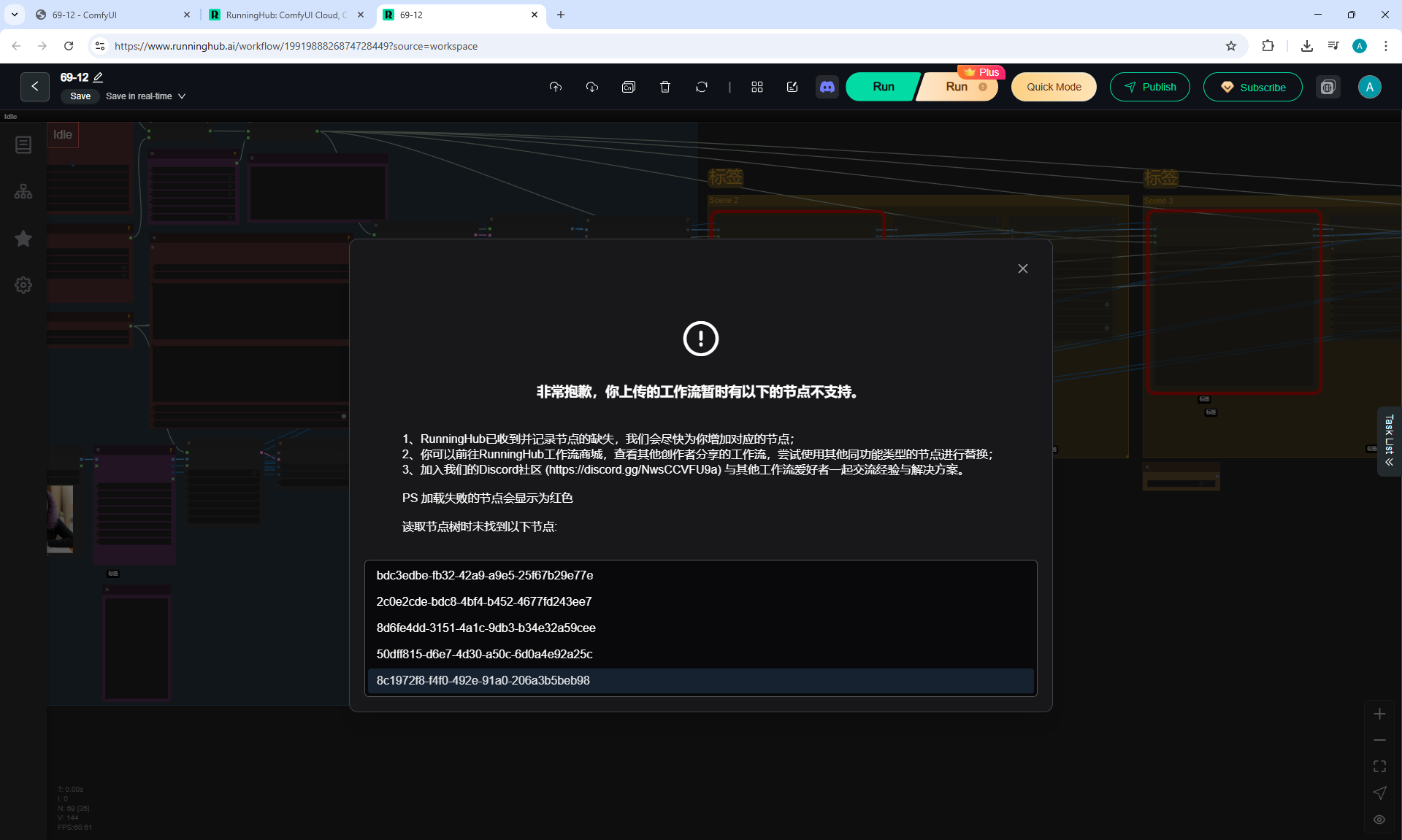
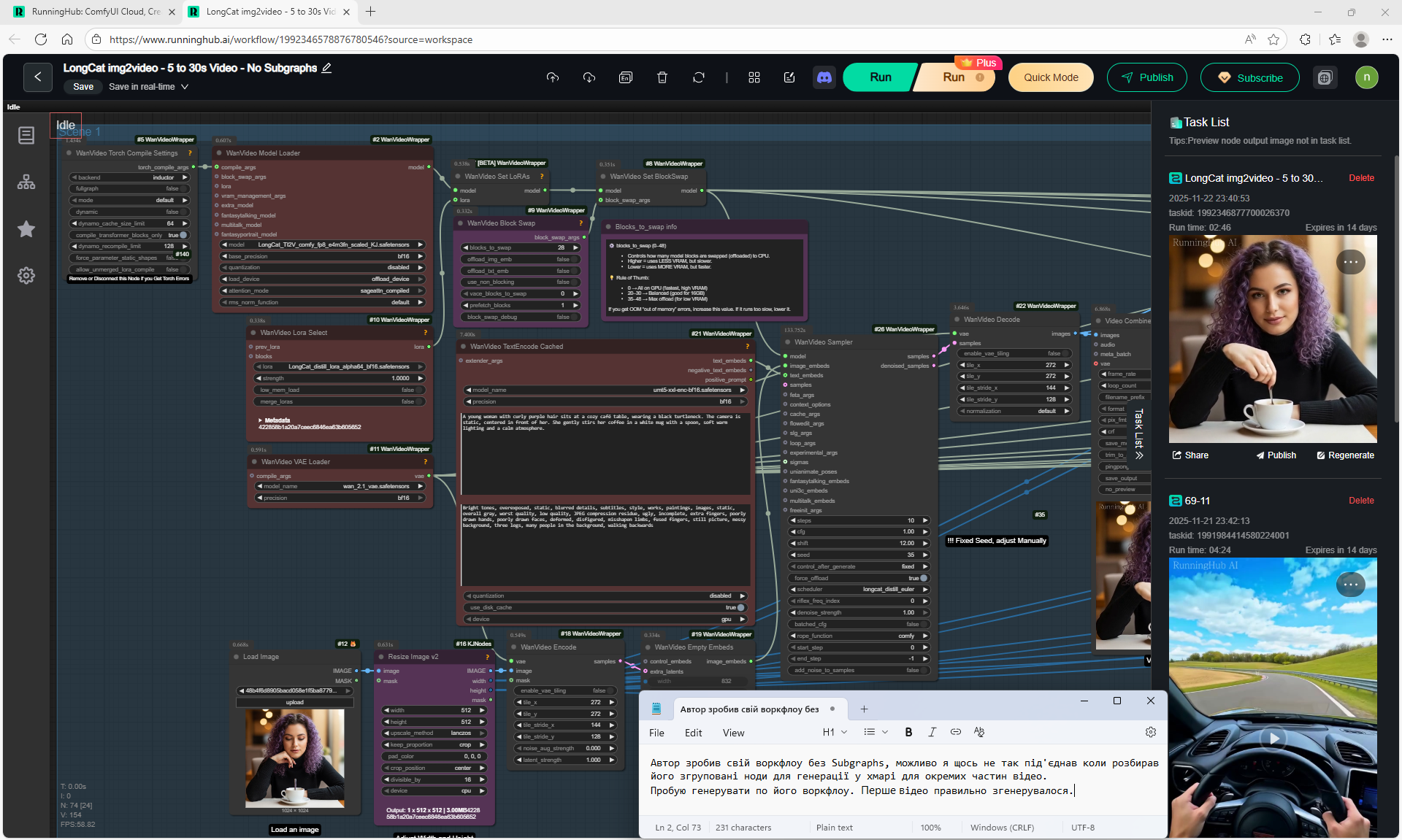
At each stage of video generation, you can test a separate part of the animation and move on to the next one if it suits you. Video generation requires a very powerful video card, you can generate it on the site runninghun.ai via the author's forkflow link
LongCat img2video - 5 to 30 sec.
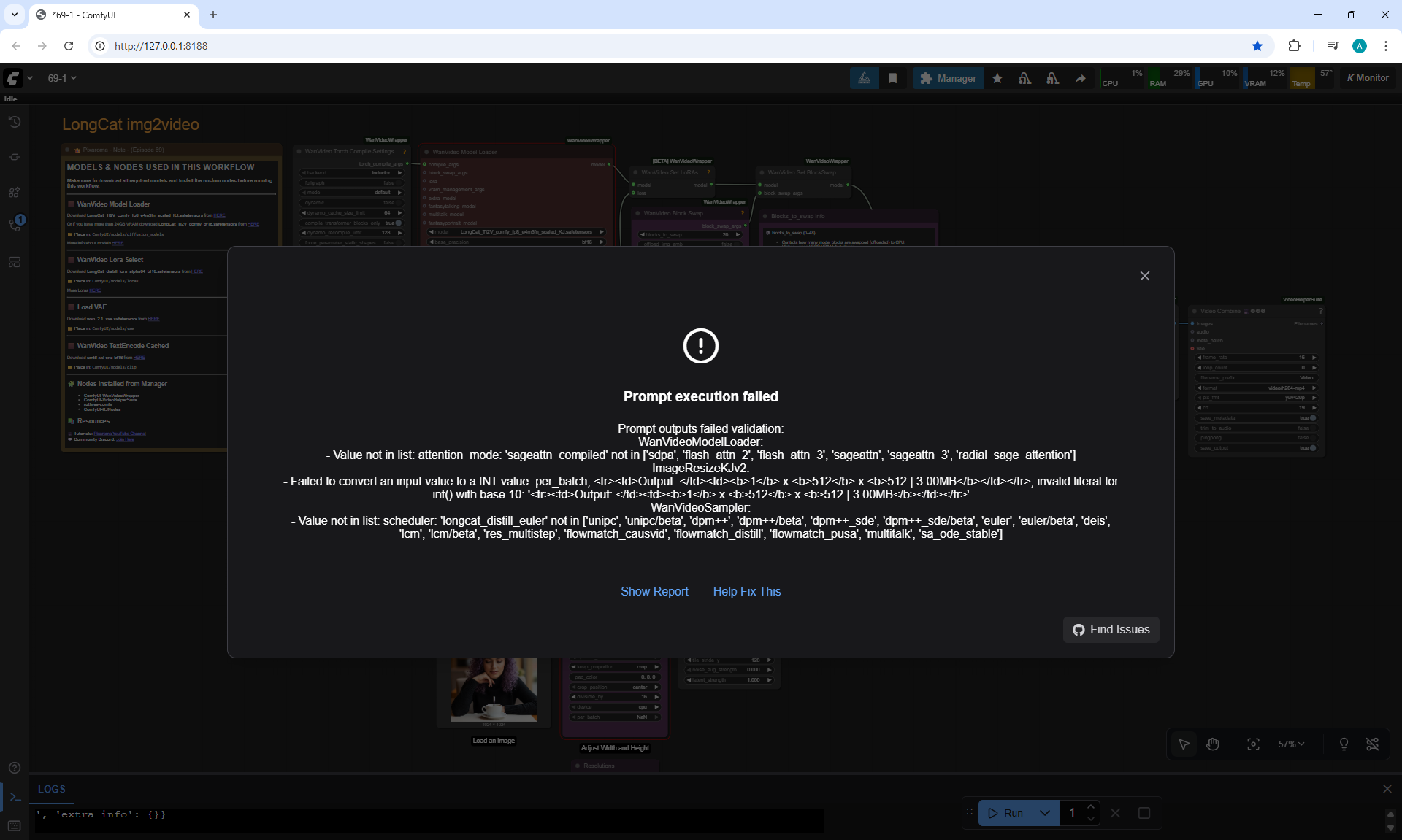
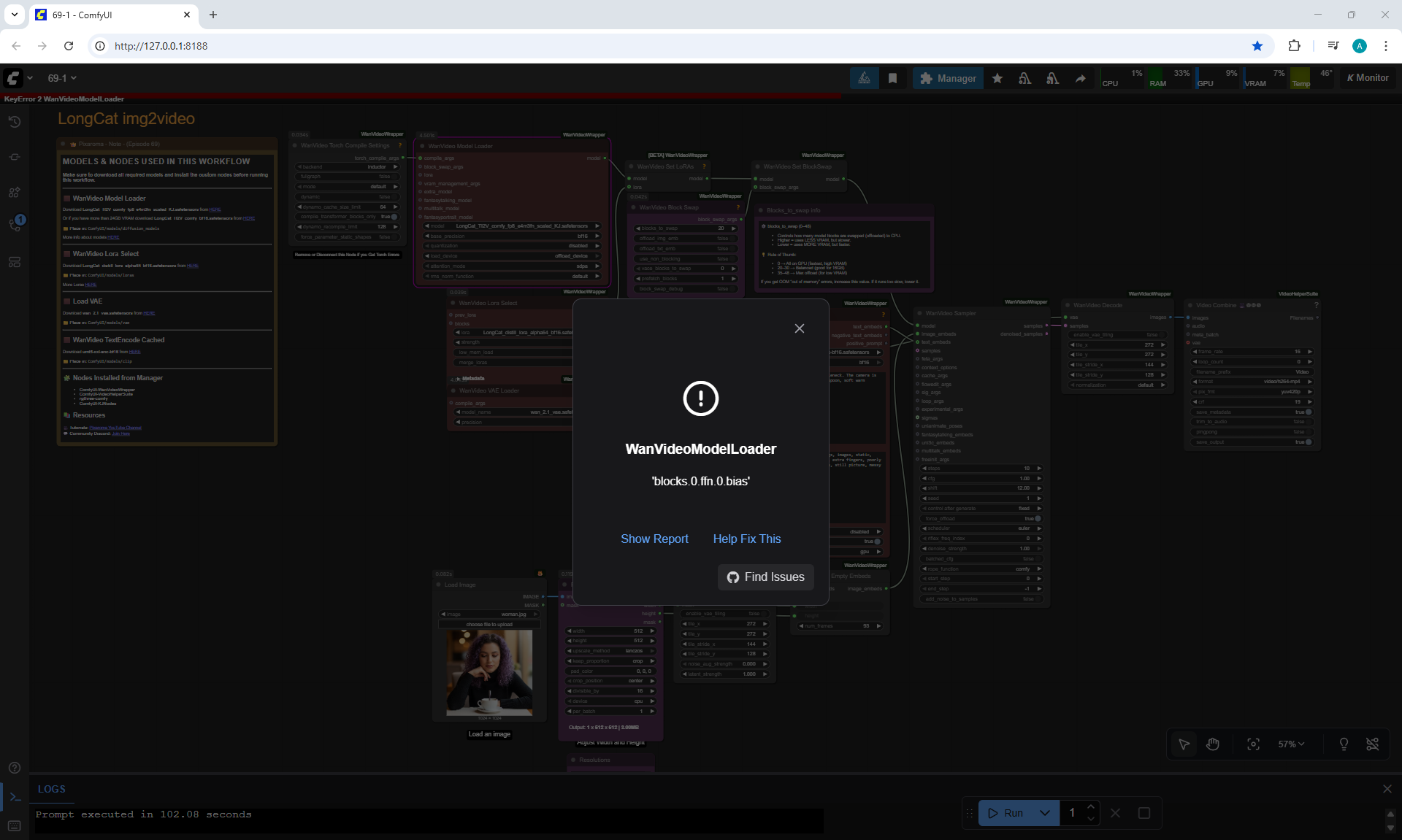
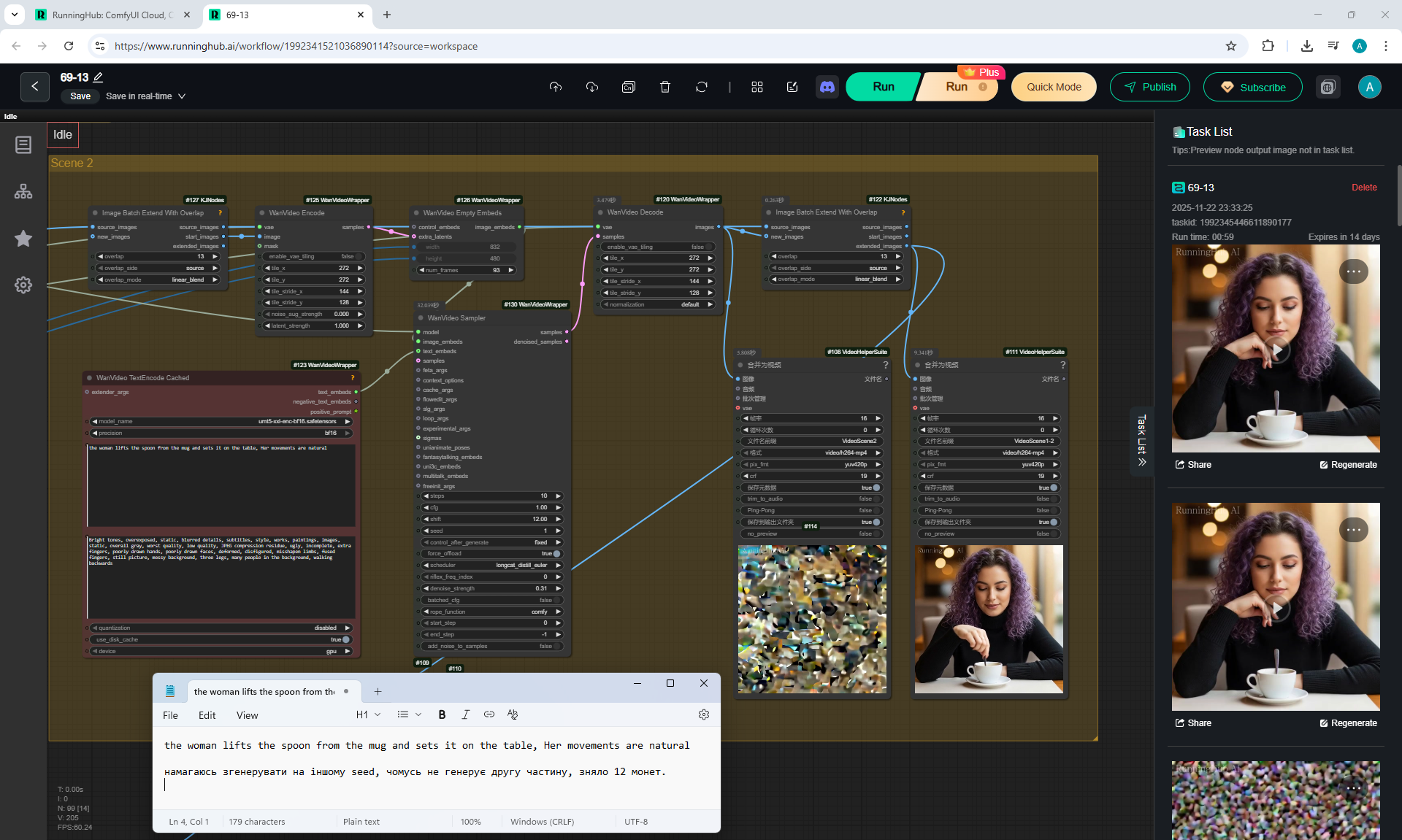
There are some minor glitches in the generation that are fixed by tweaking the prompt and generating other variants. For example, in one part of the animation a black cat appears, then another cat appears, without specifying that the cat is black.
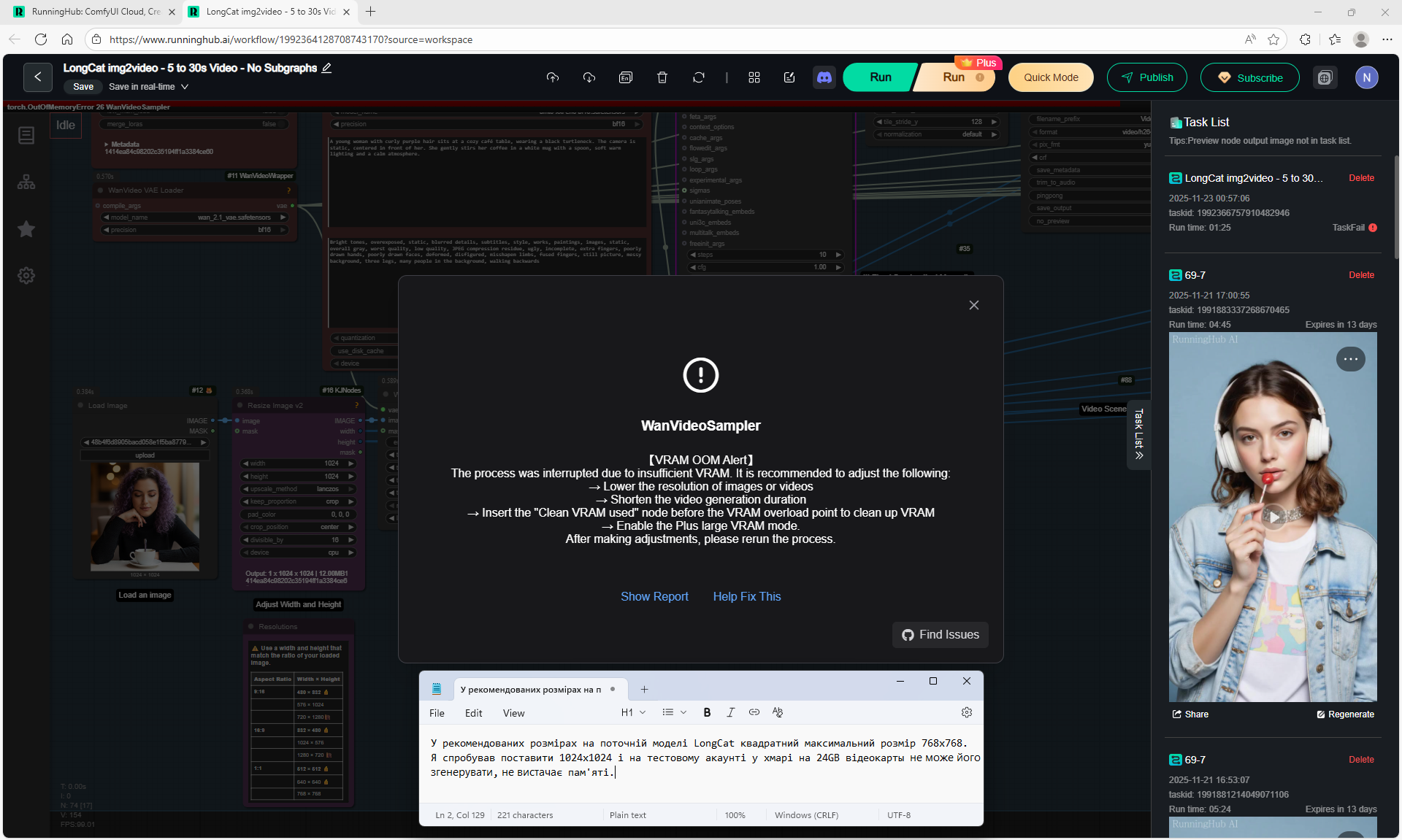
Maximum generation sizes: 720x1280, 1280x720, 768x768, no 1024x1024 size.
I tried to generate 1024x1024 on a test account, necessary to do this on a paid account, it might generate at 1024x1024, but I read that the maximum square size for LongCat in this version is 768x768.


Prompt for video:
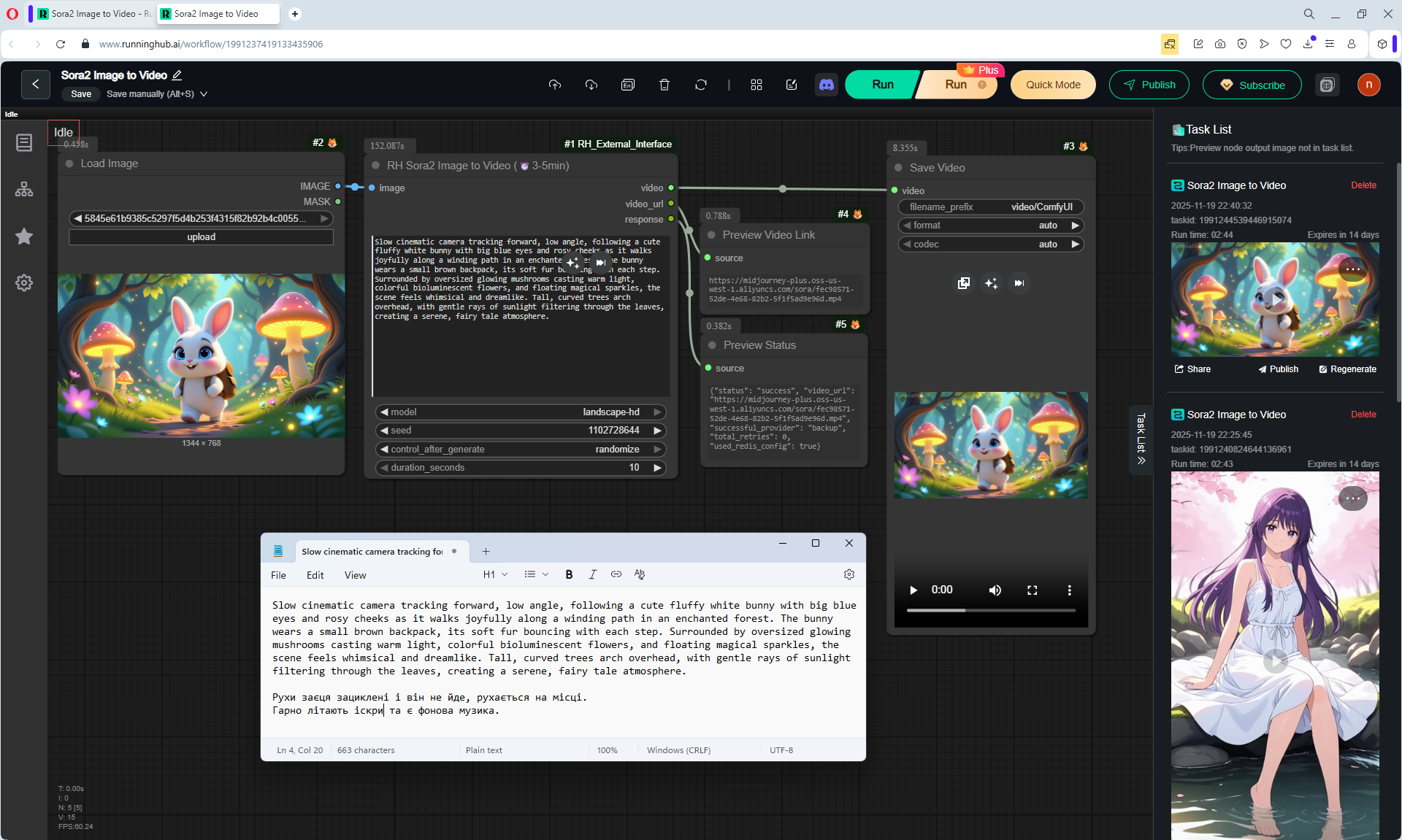
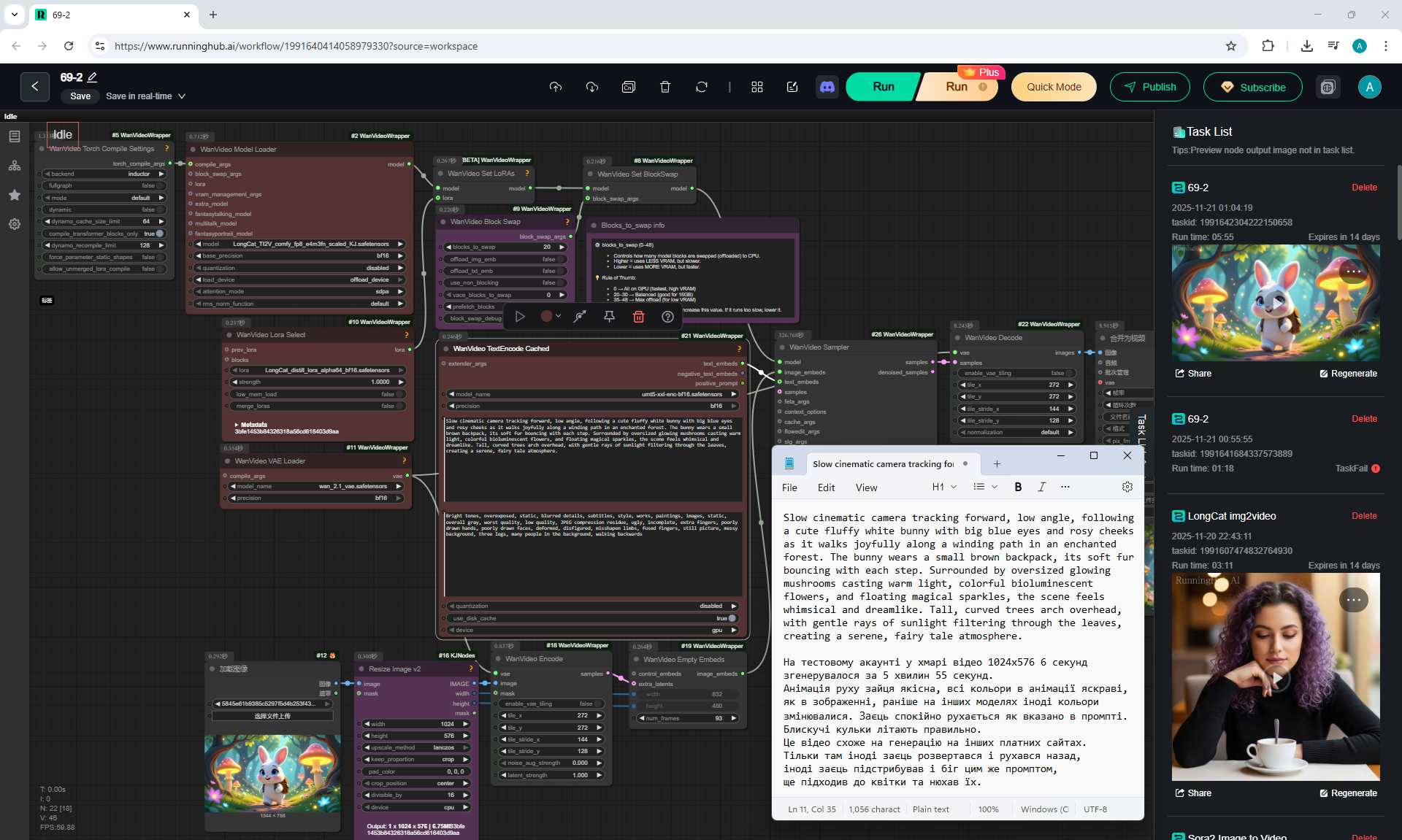
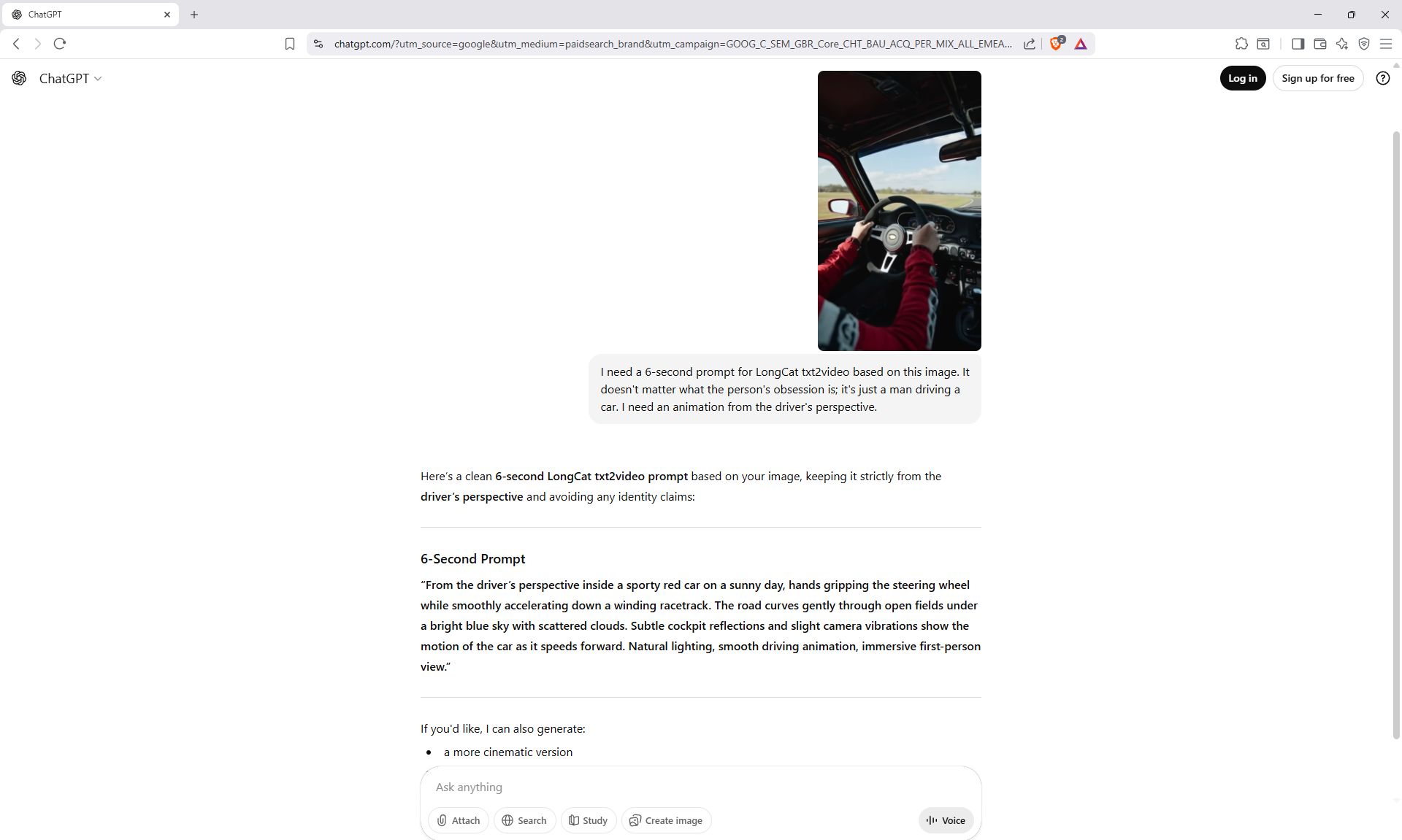
Slow cinematic camera tracking forward, low angle, following a cute fluffy white bunny with big blue eyes and rosy cheeks as it walks joyfully along a winding path in an enchanted forest. The bunny wears a small brown backpack, its soft fur bouncing with each step. Surrounded by oversized glowing mushrooms casting warm light, colorful bioluminescent flowers, and floating magical sparkles, the scene feels whimsical and dreamlike. Tall, curved trees arch overhead, with gentle rays of sunlight filtering through the leaves, creating a serene, fairy tale atmosphere.
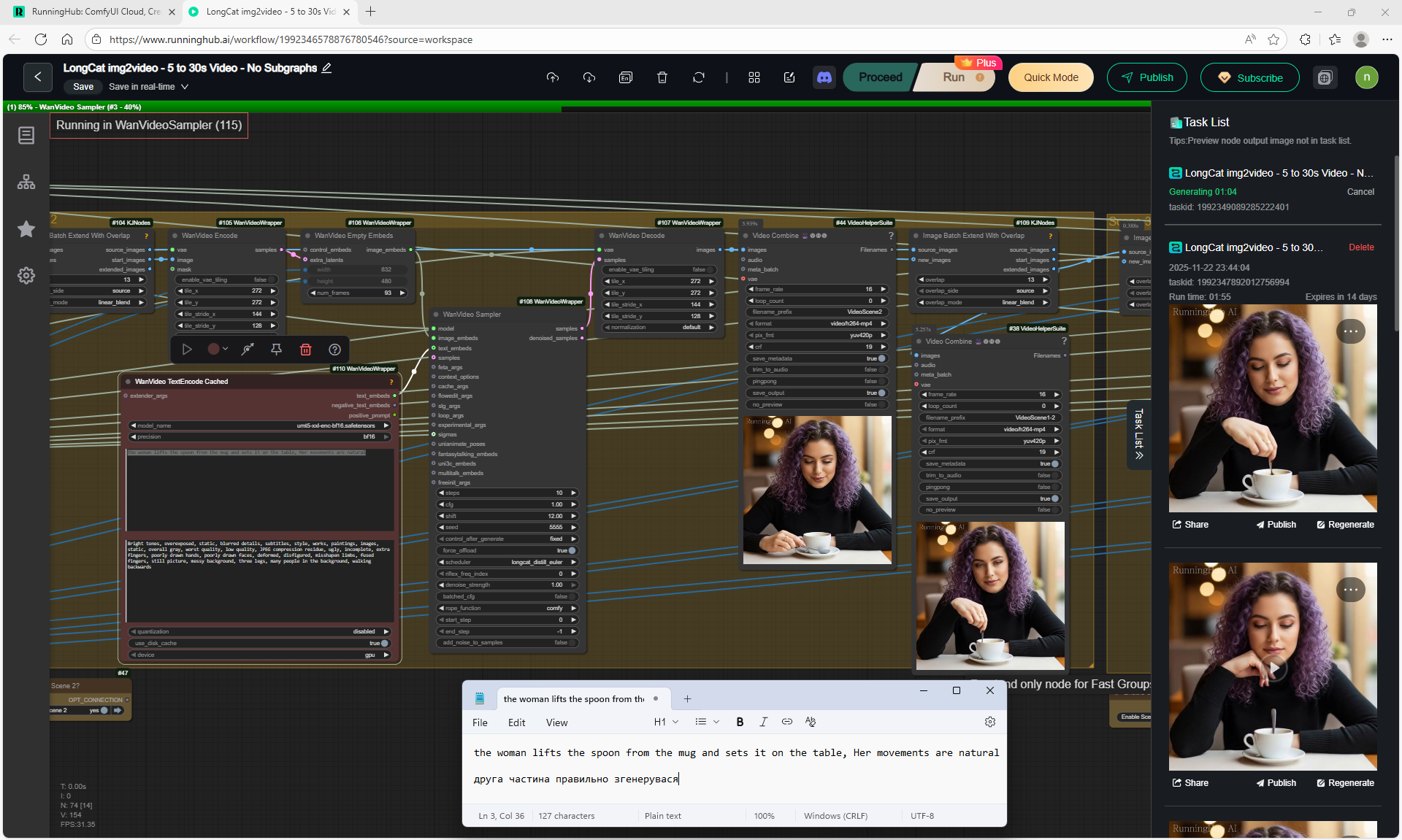
The animation on LongCat is high-quality, the movement of the hare is correct, light. Sparks are animated correctly. The hare did not lose detail during the animation, for example, on wool, the camera has depth of field, there is focus on the hare and detailed grass is visible, and in the near background the grass is blurred. Good lighting with the sun's rays, as in the picture.
Does not add sounds as it did model Image2Video Sora2 in the previous lesson 68.
The only thing is, at the end, the camera can be moved a little so that it doesn't cut off the hare, you can test other options.
Overall, the animation is good, already approaching the quality of paid models.
In the latest lessons I have extensively tested animation generation on various models with this hare.
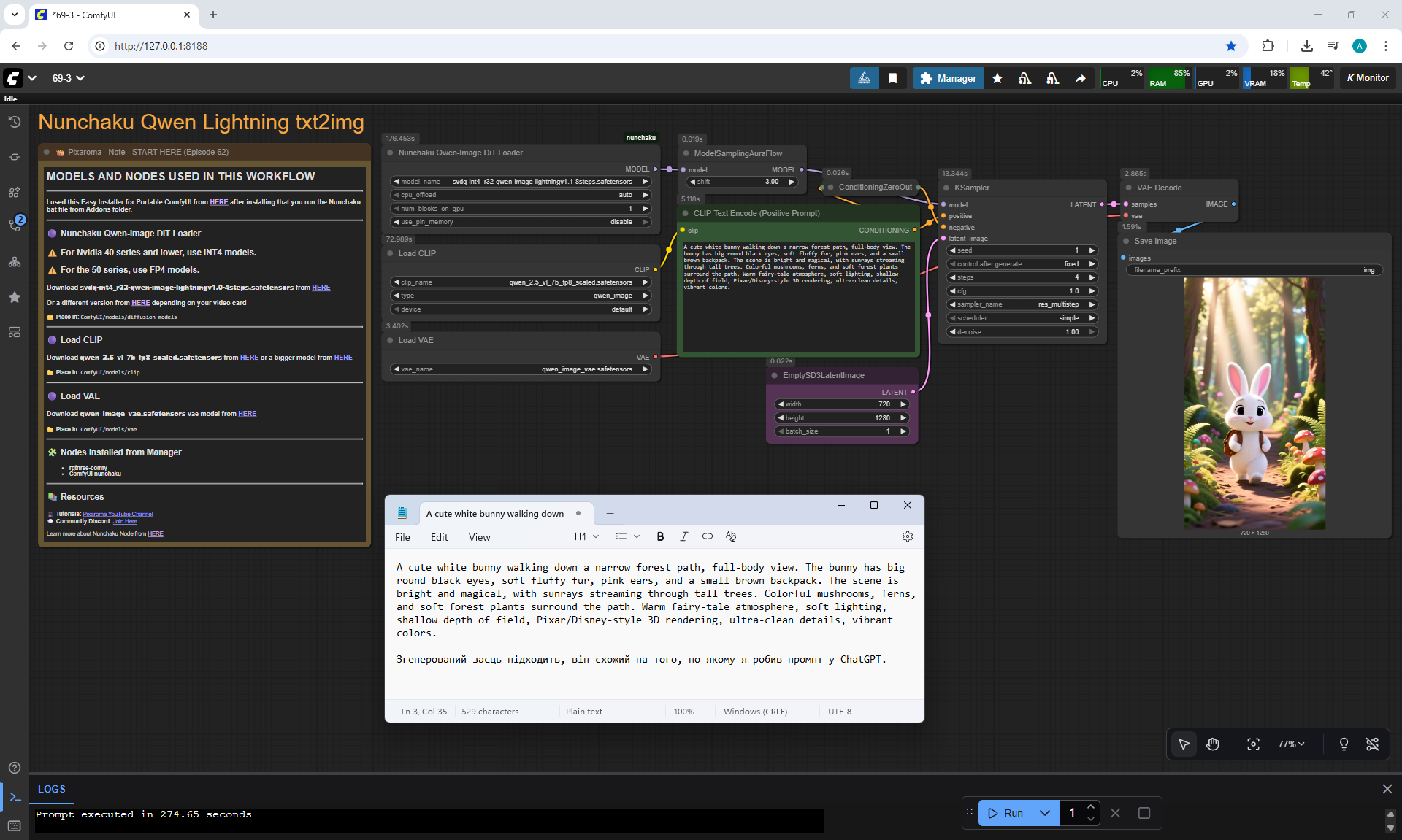
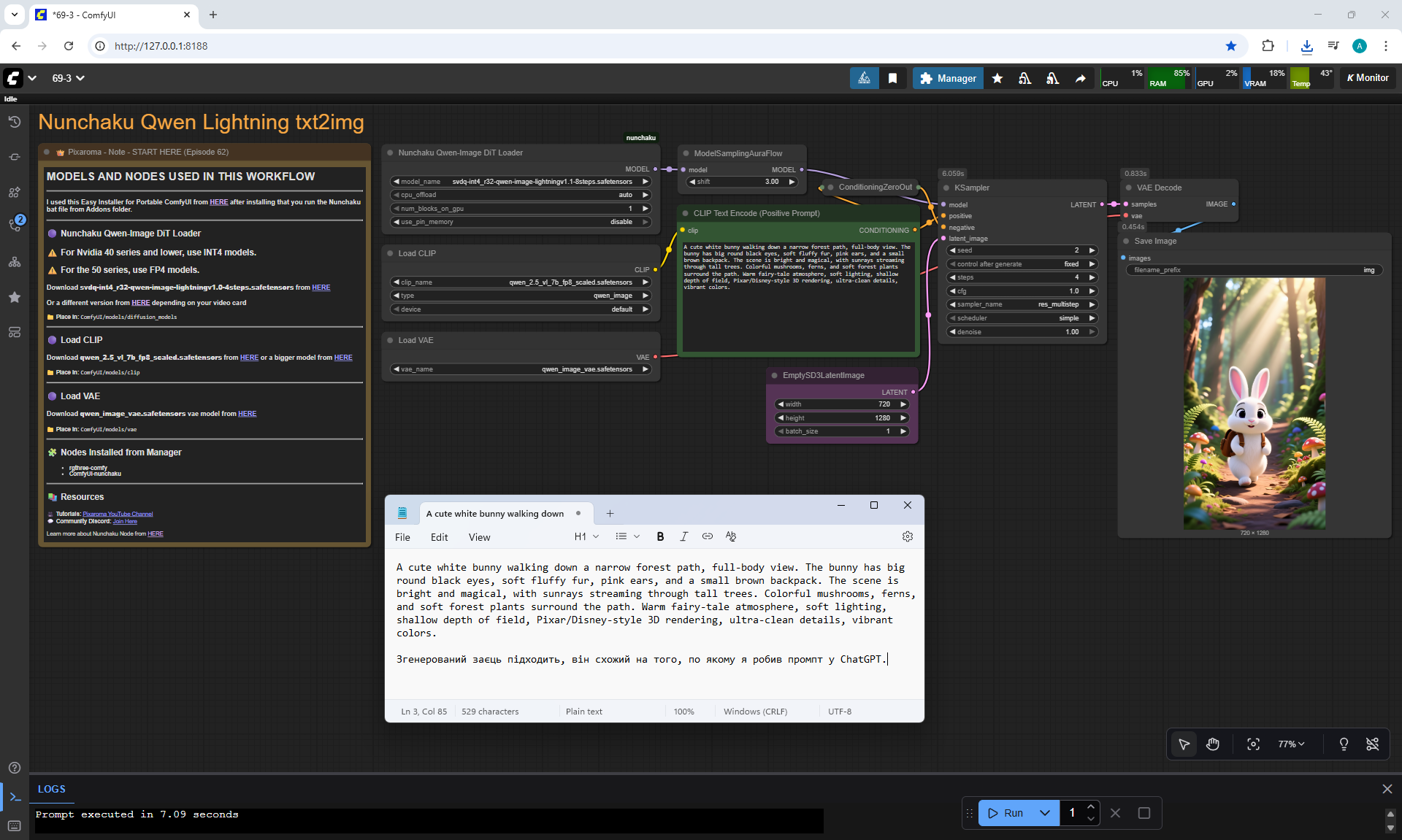
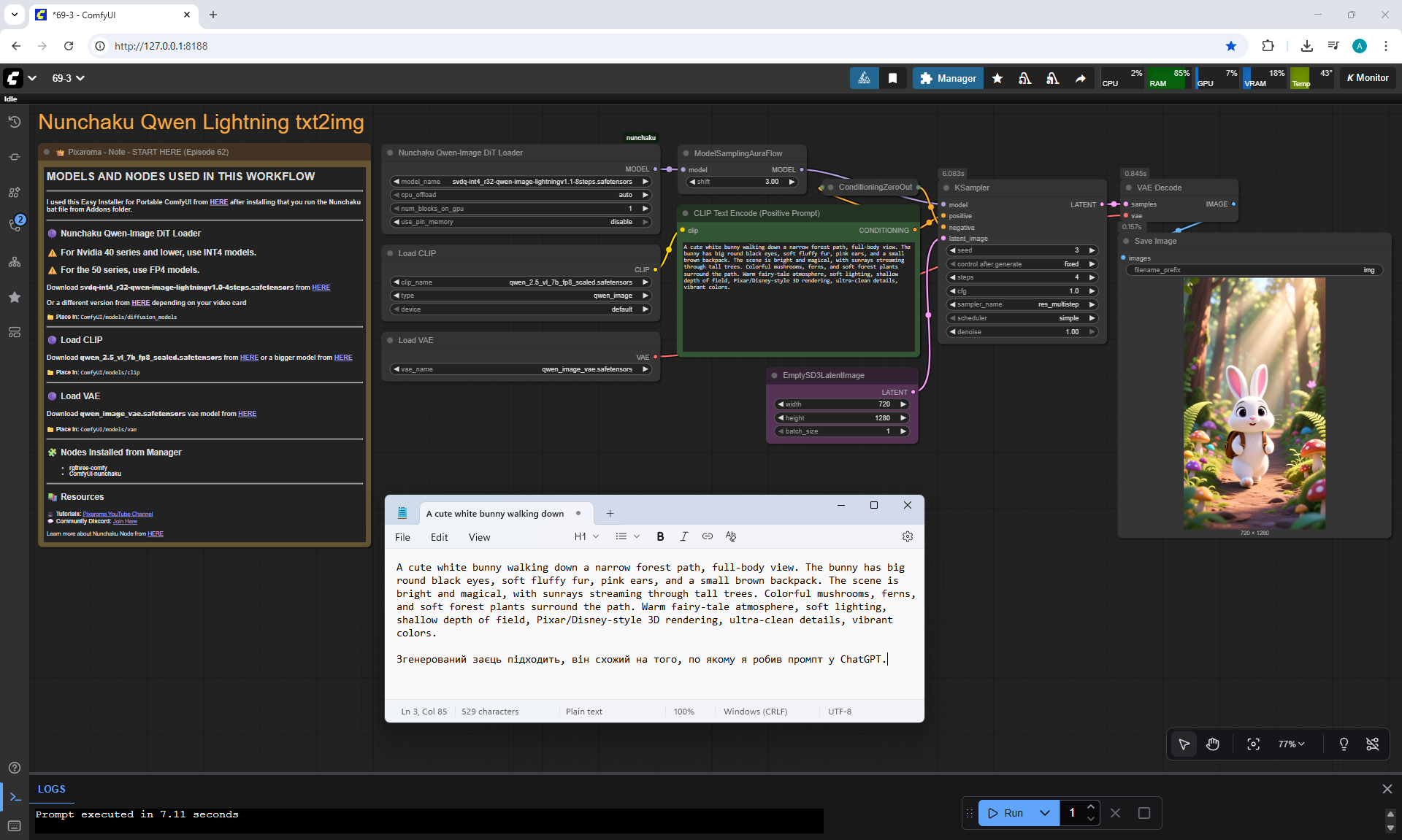
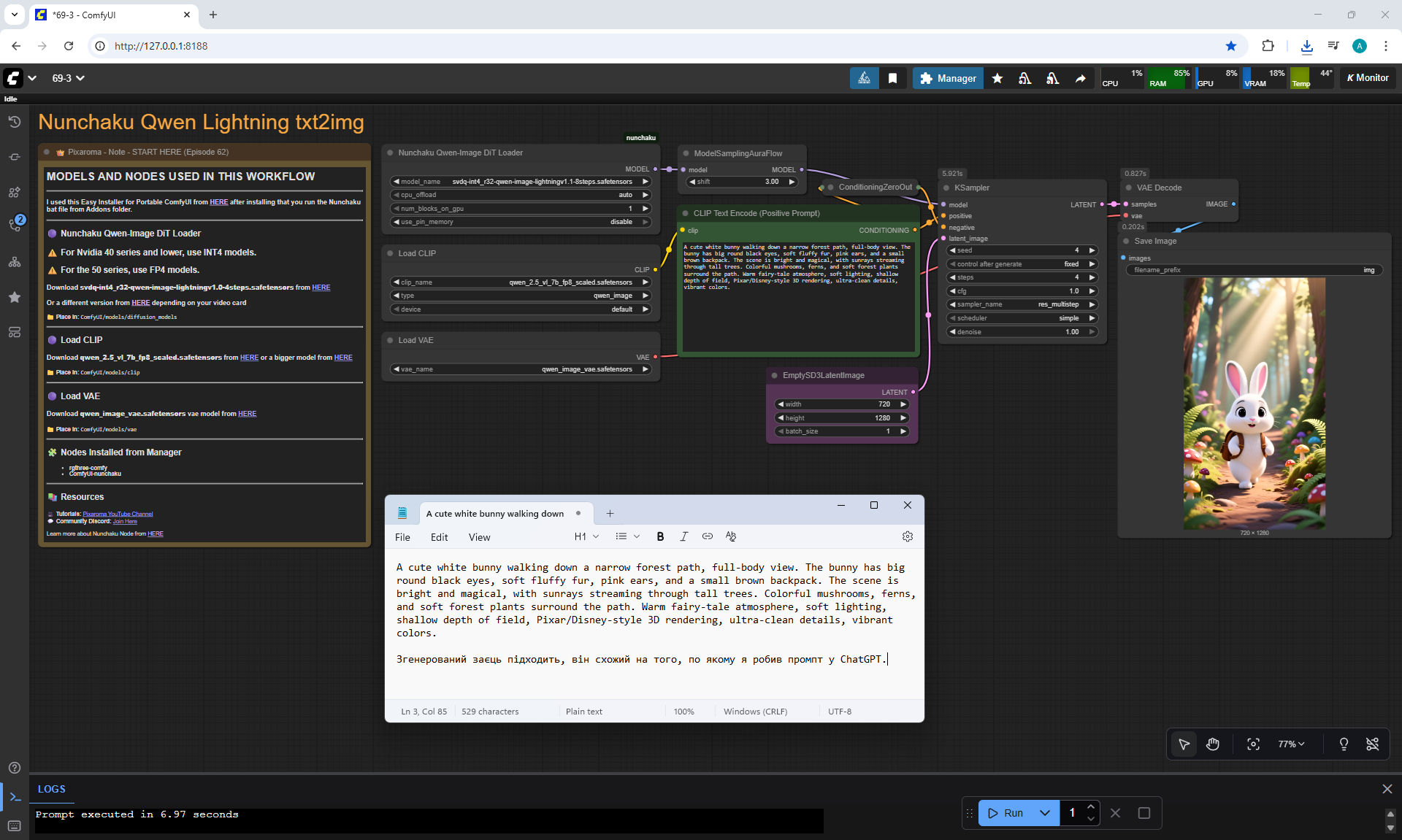
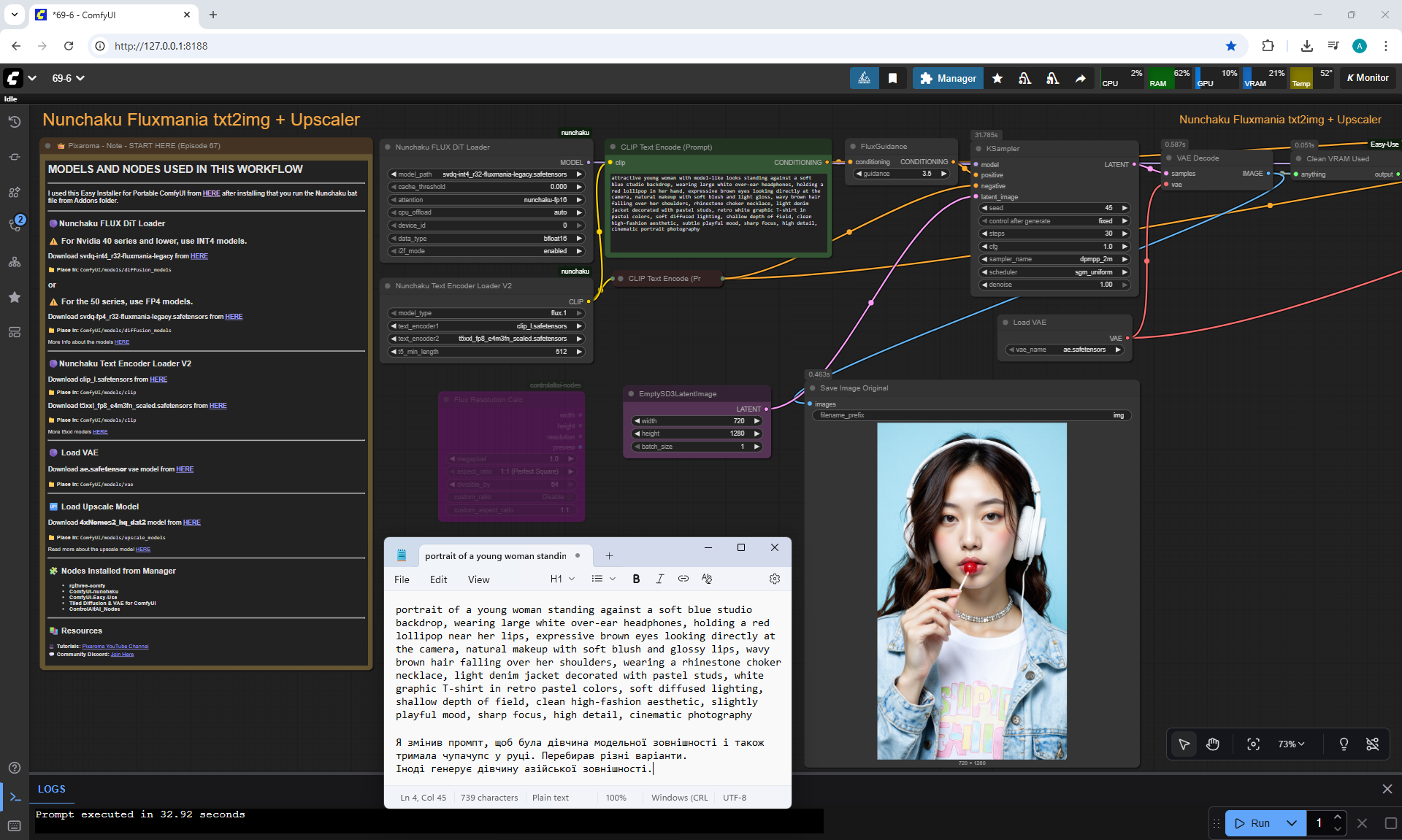
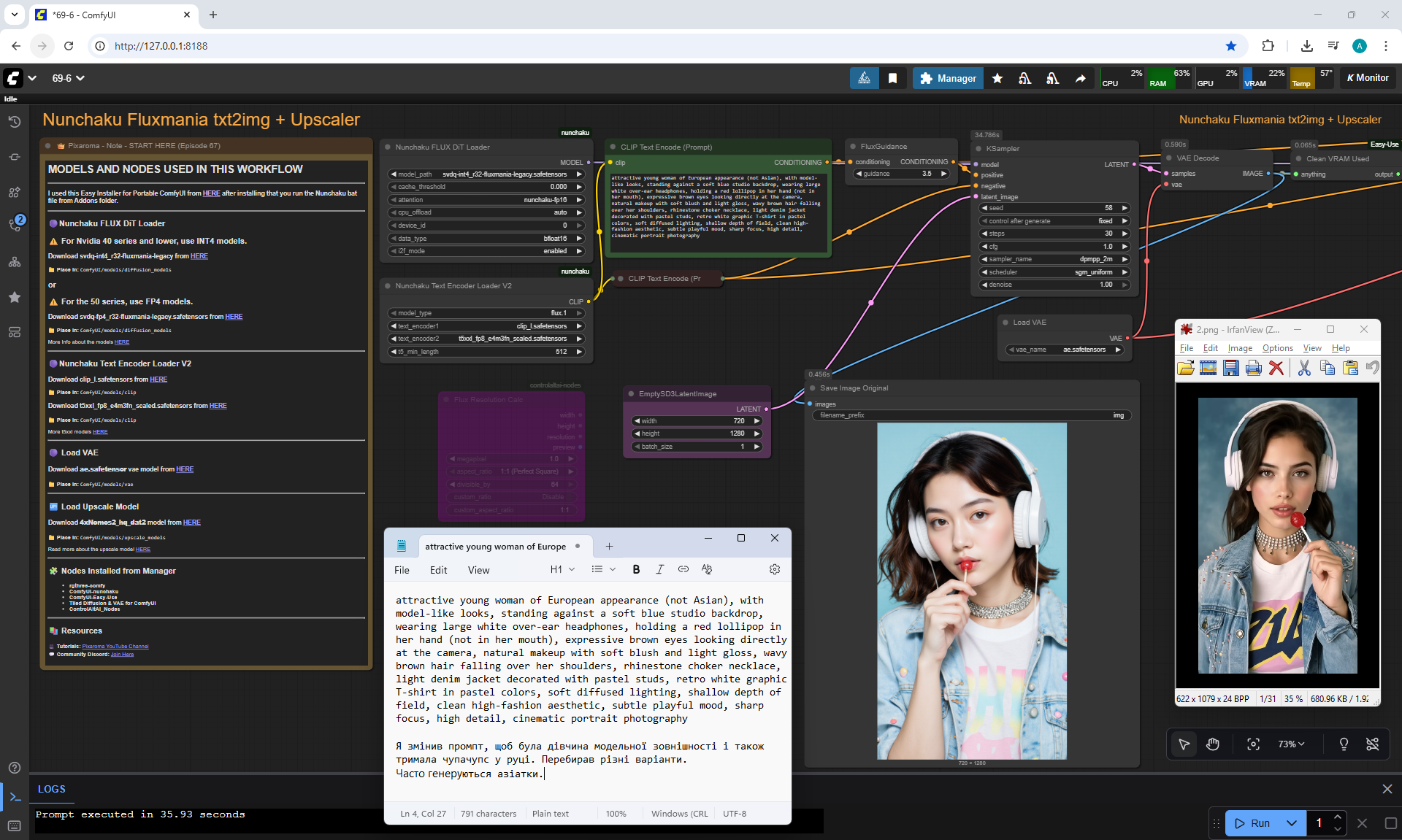
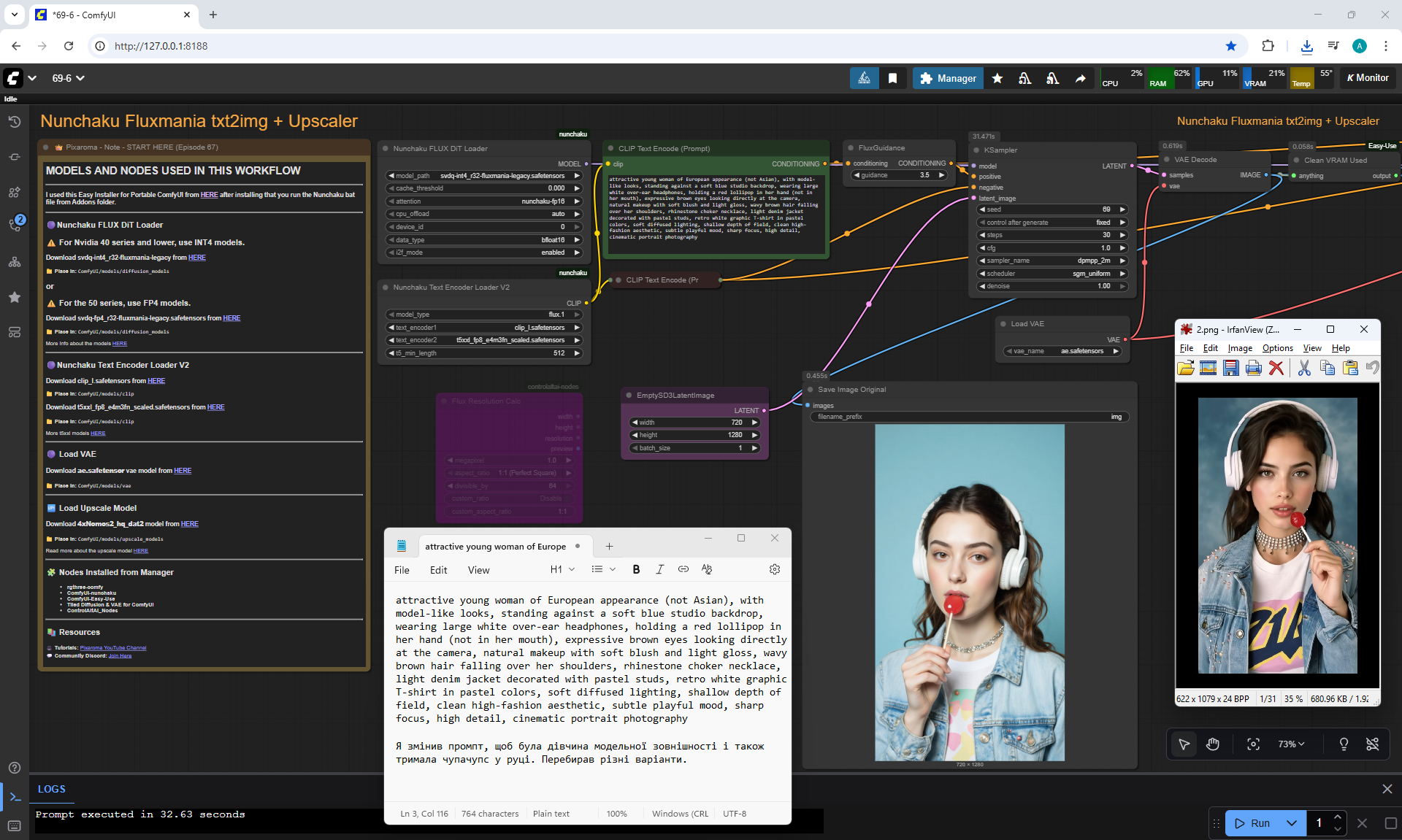
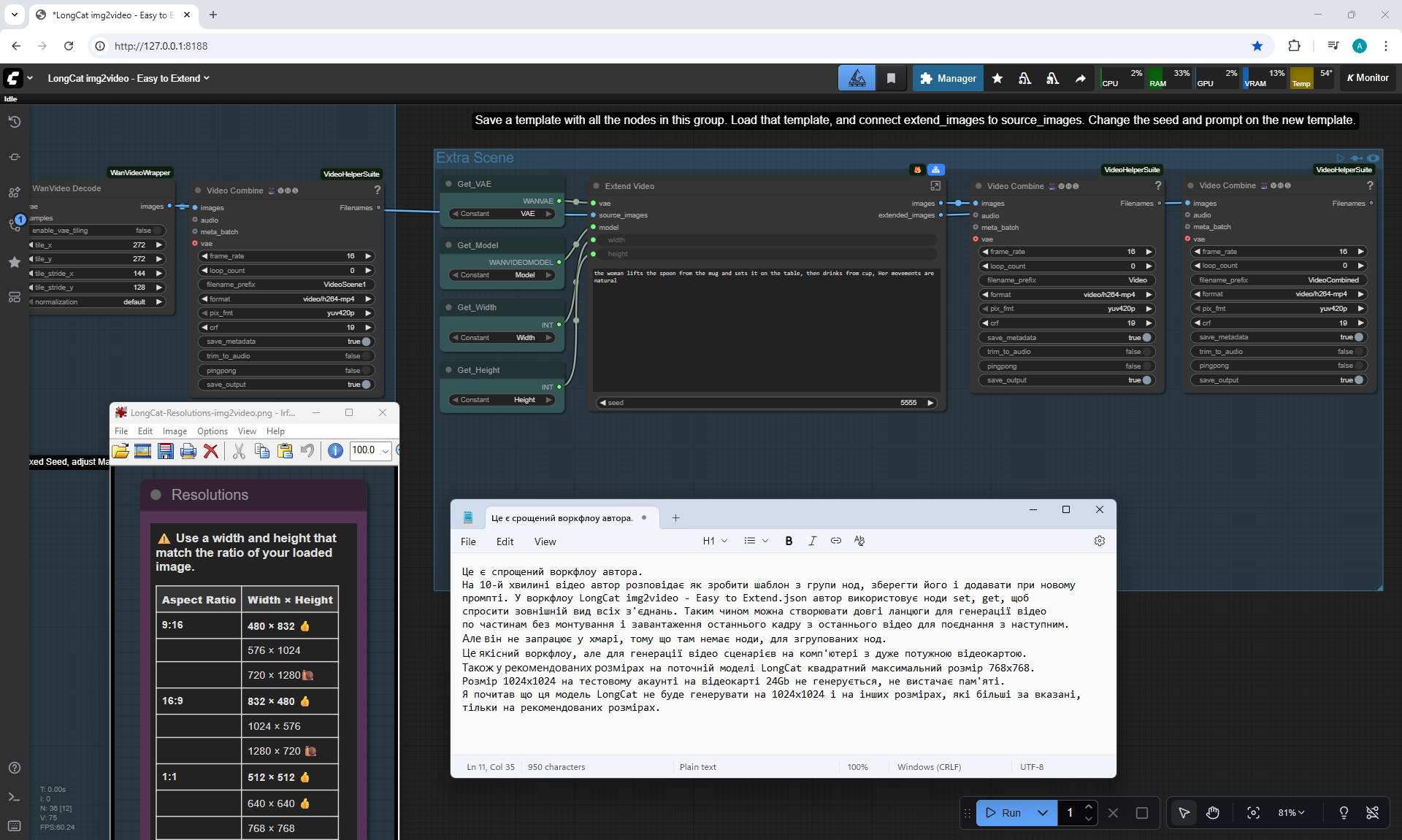
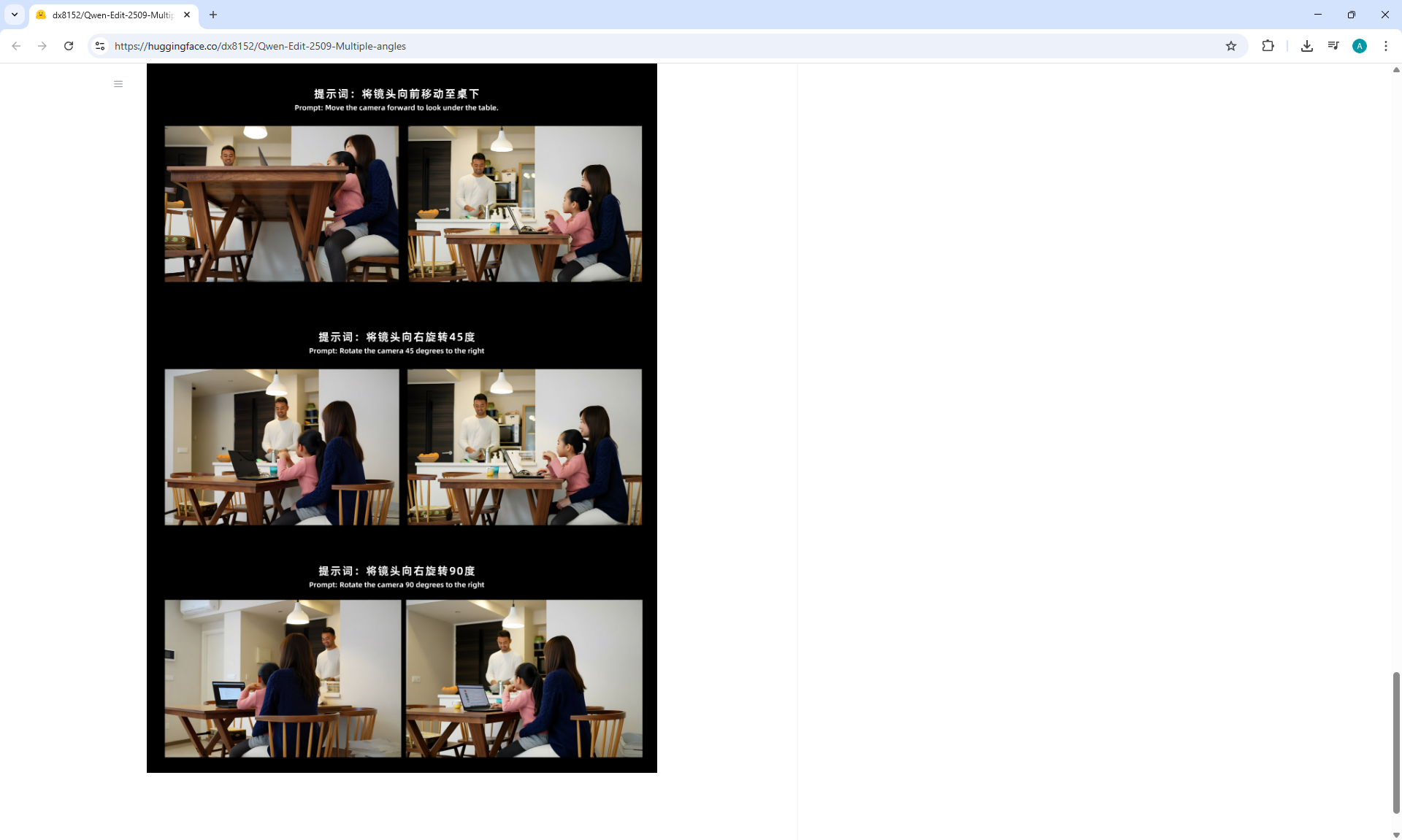
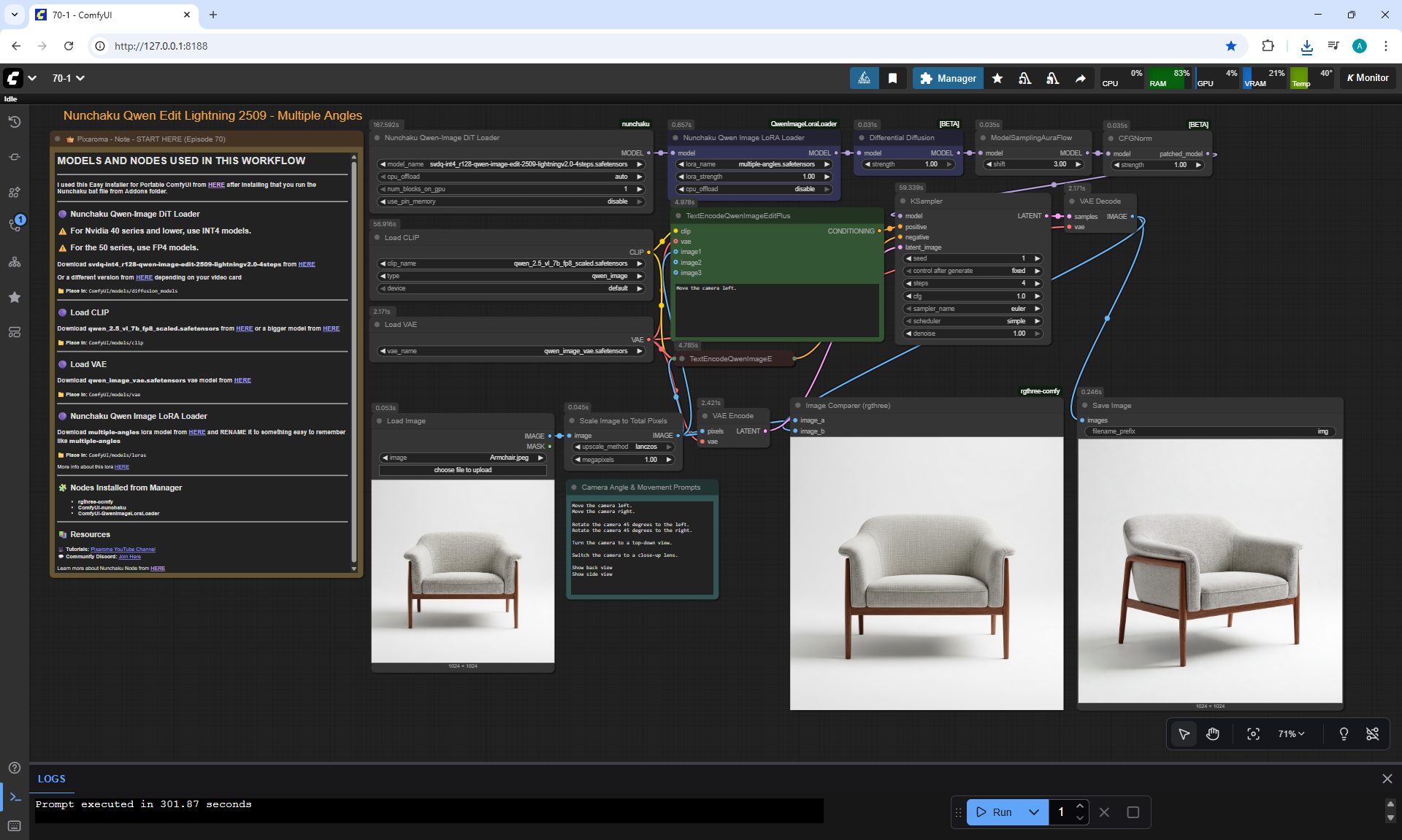
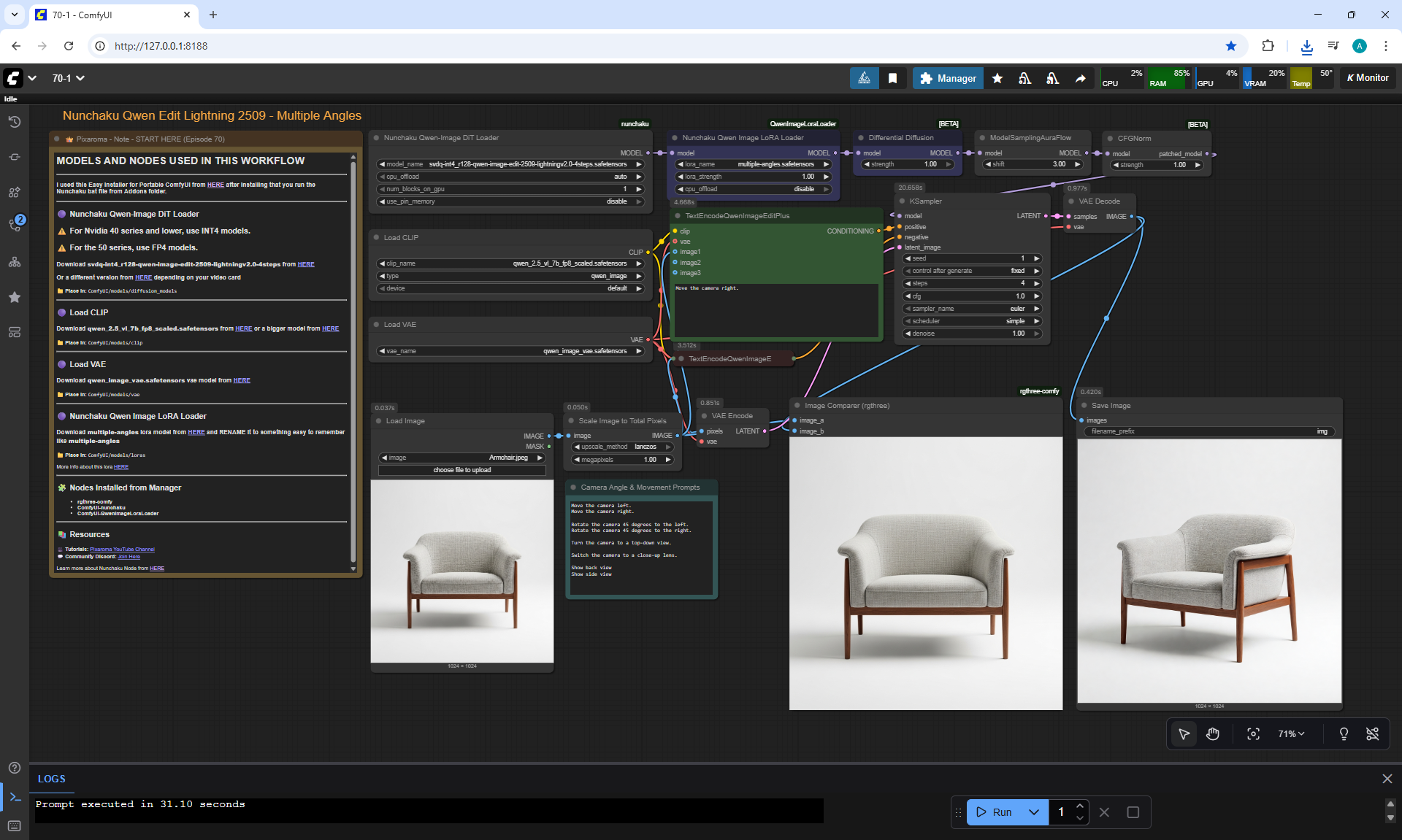
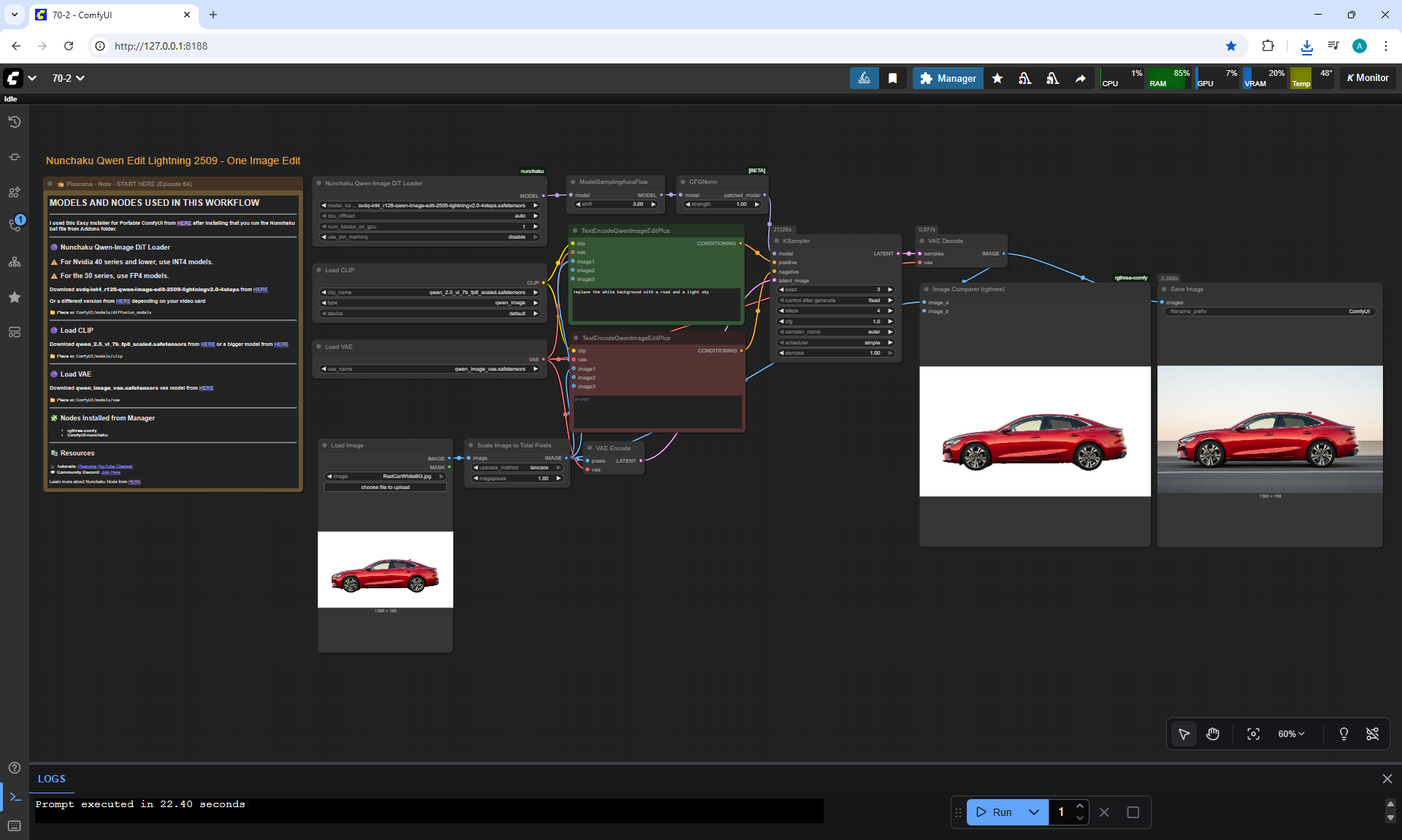
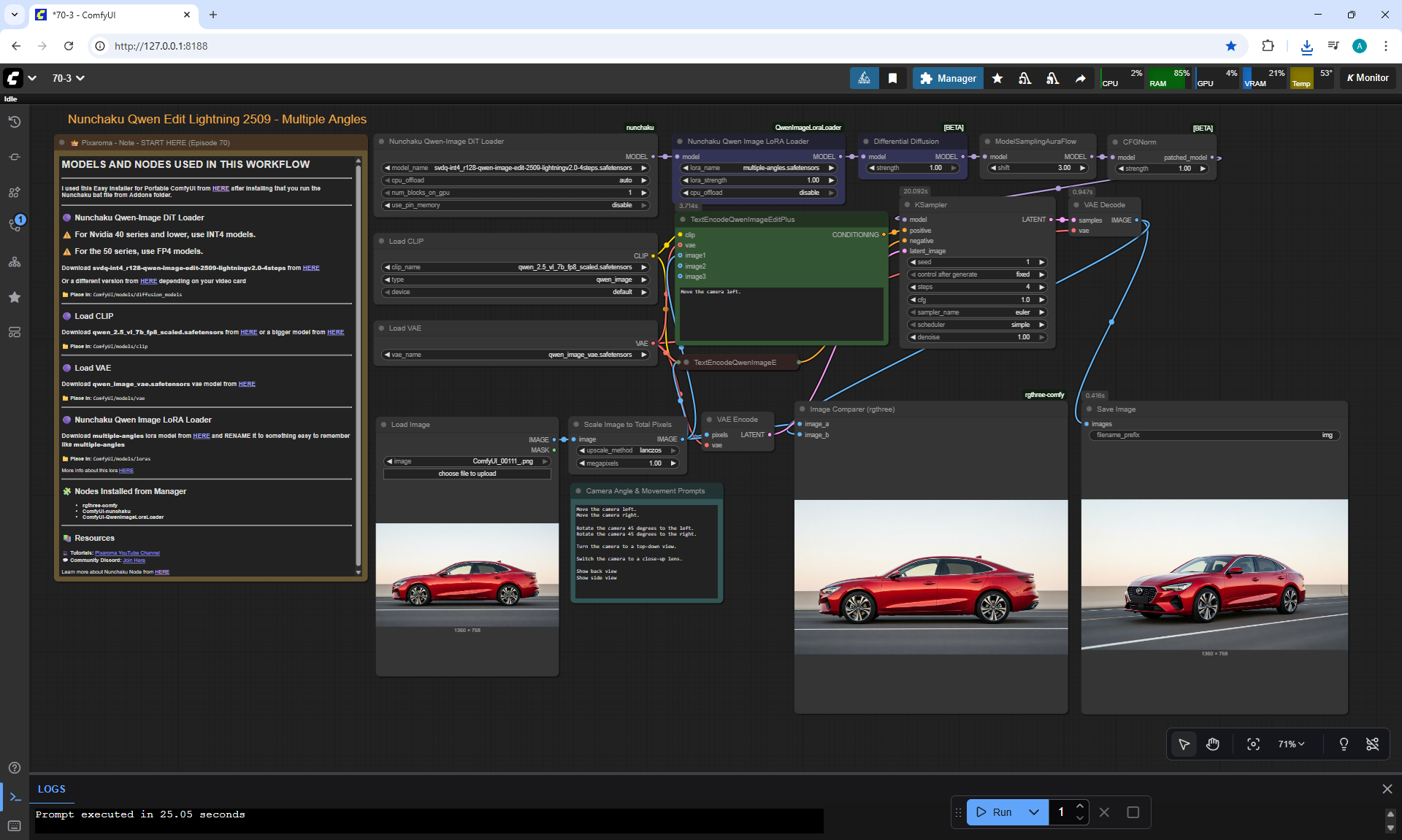
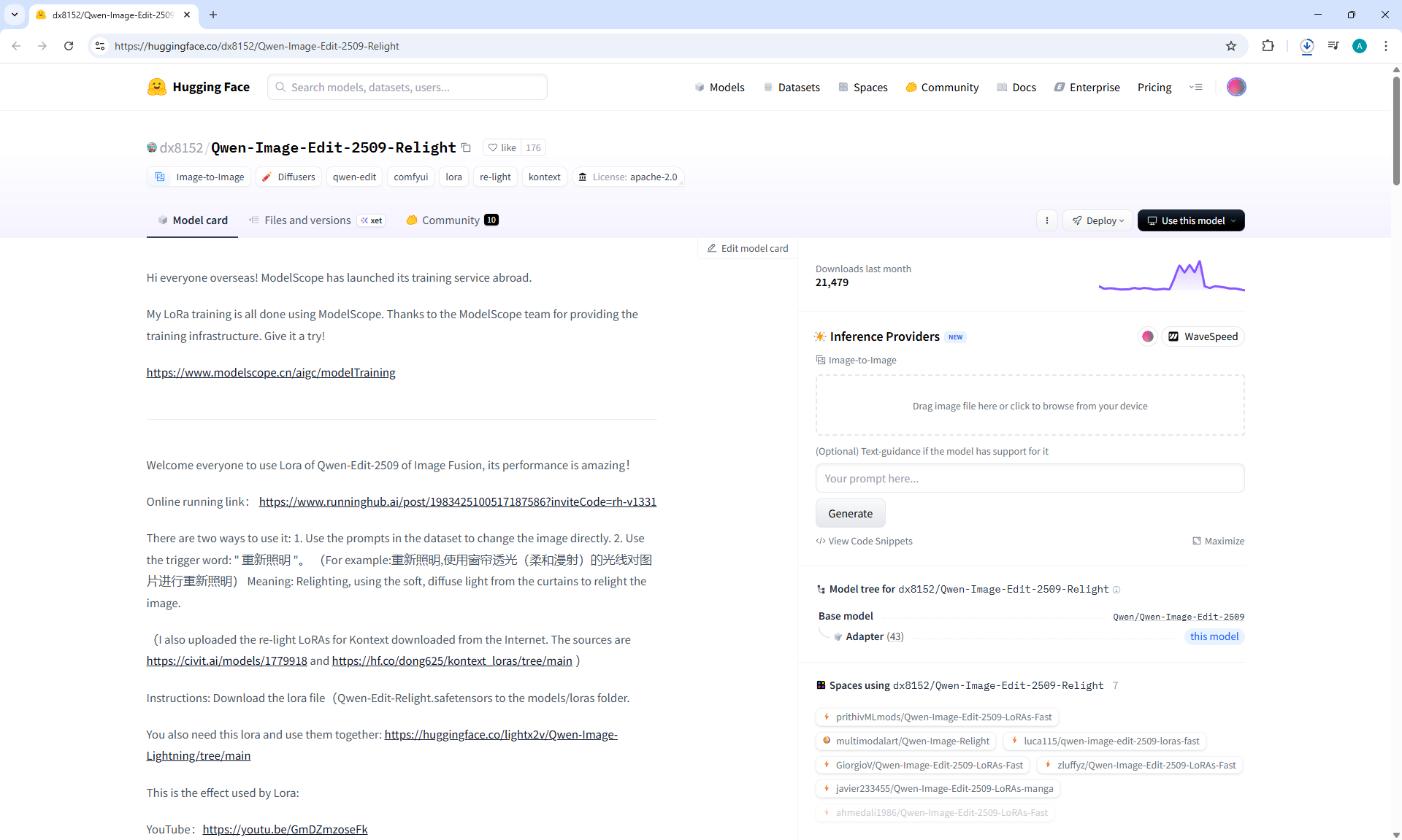
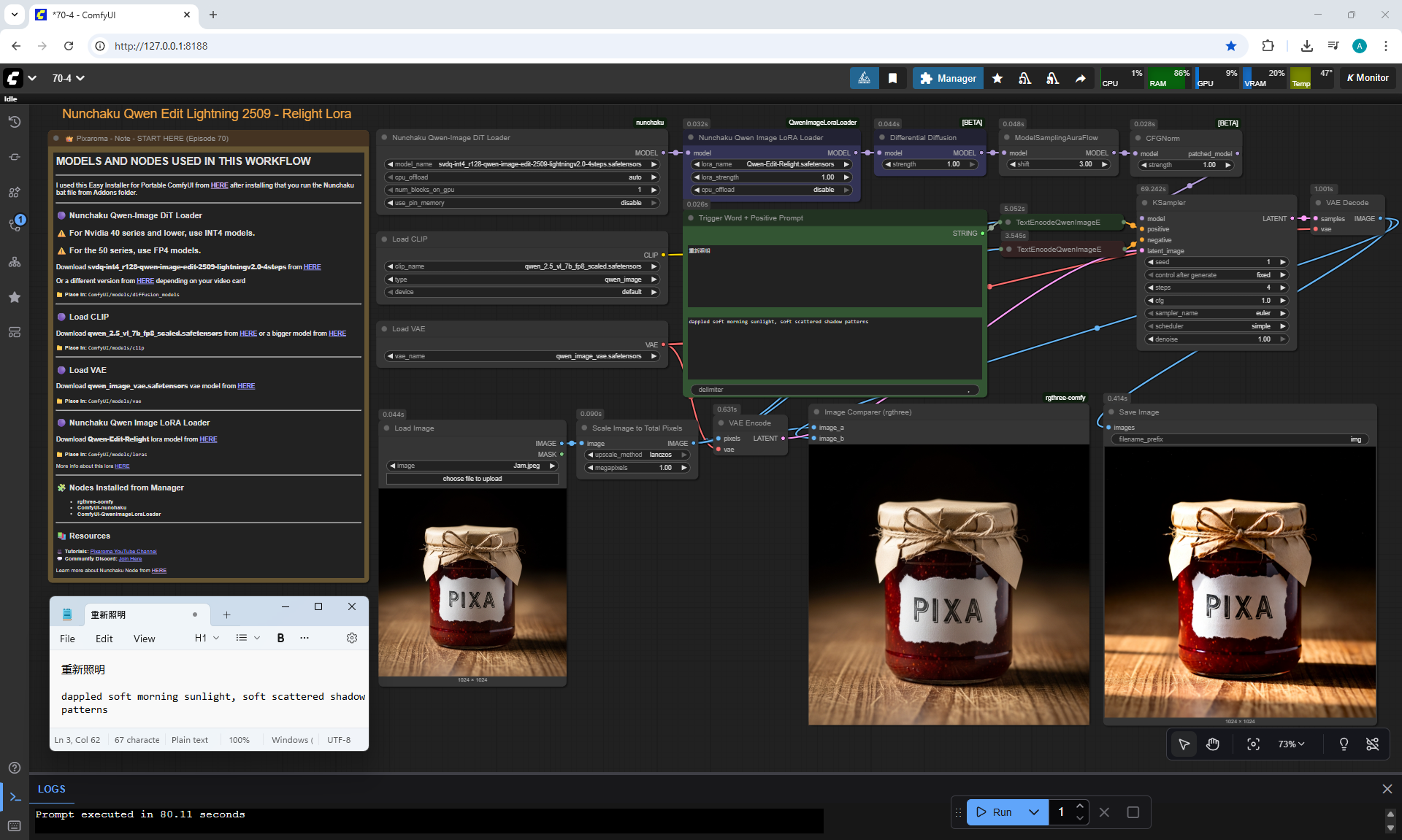
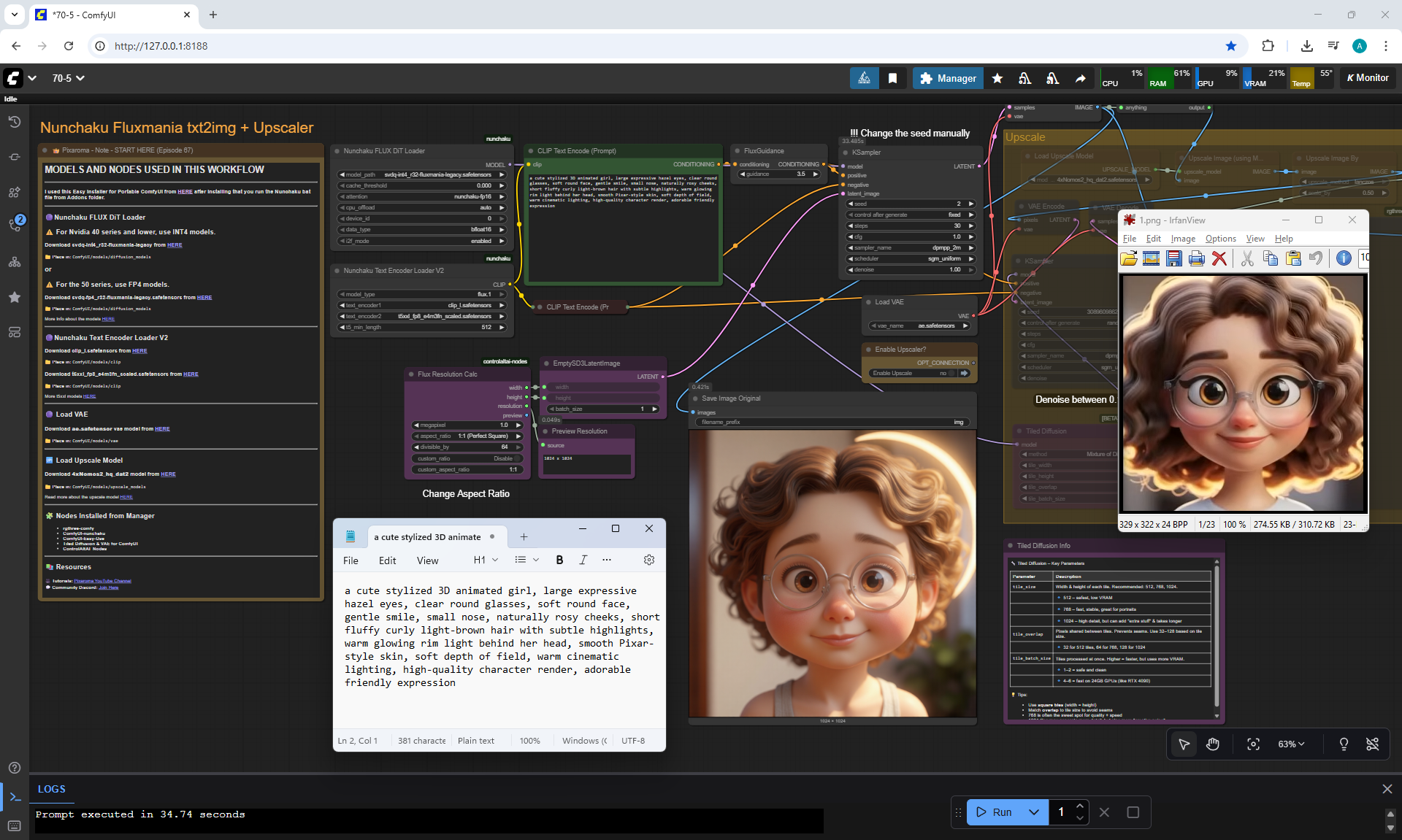
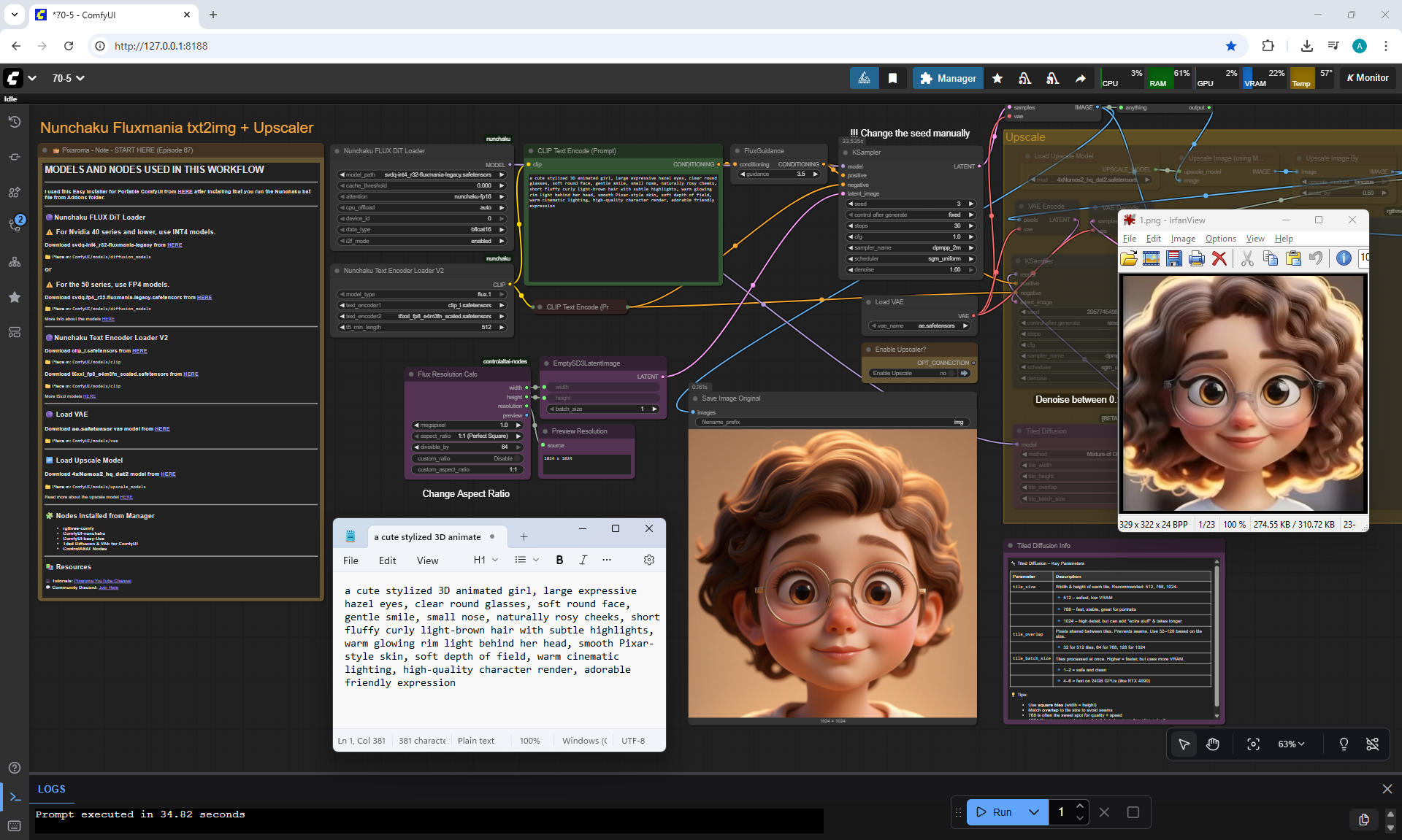
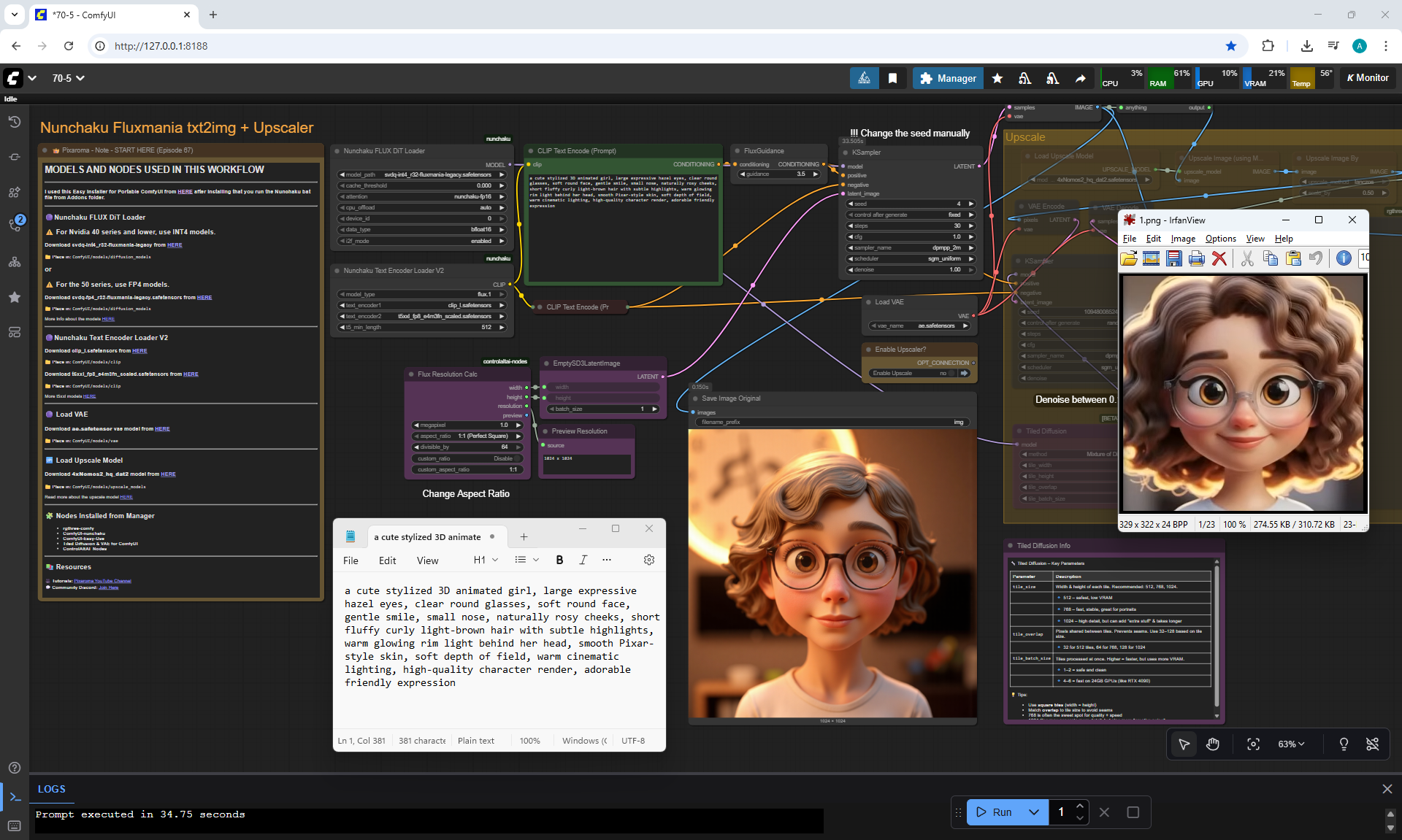
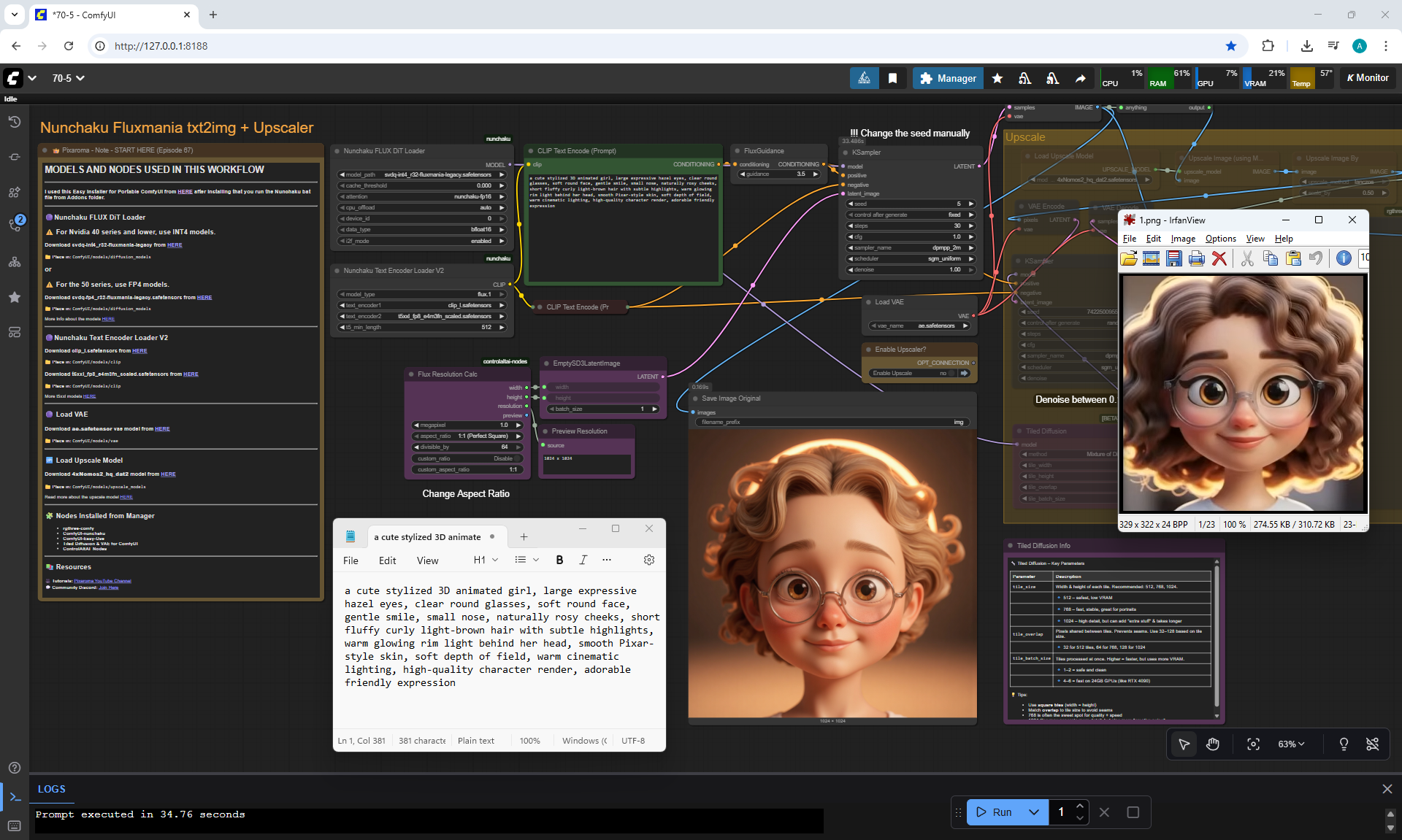
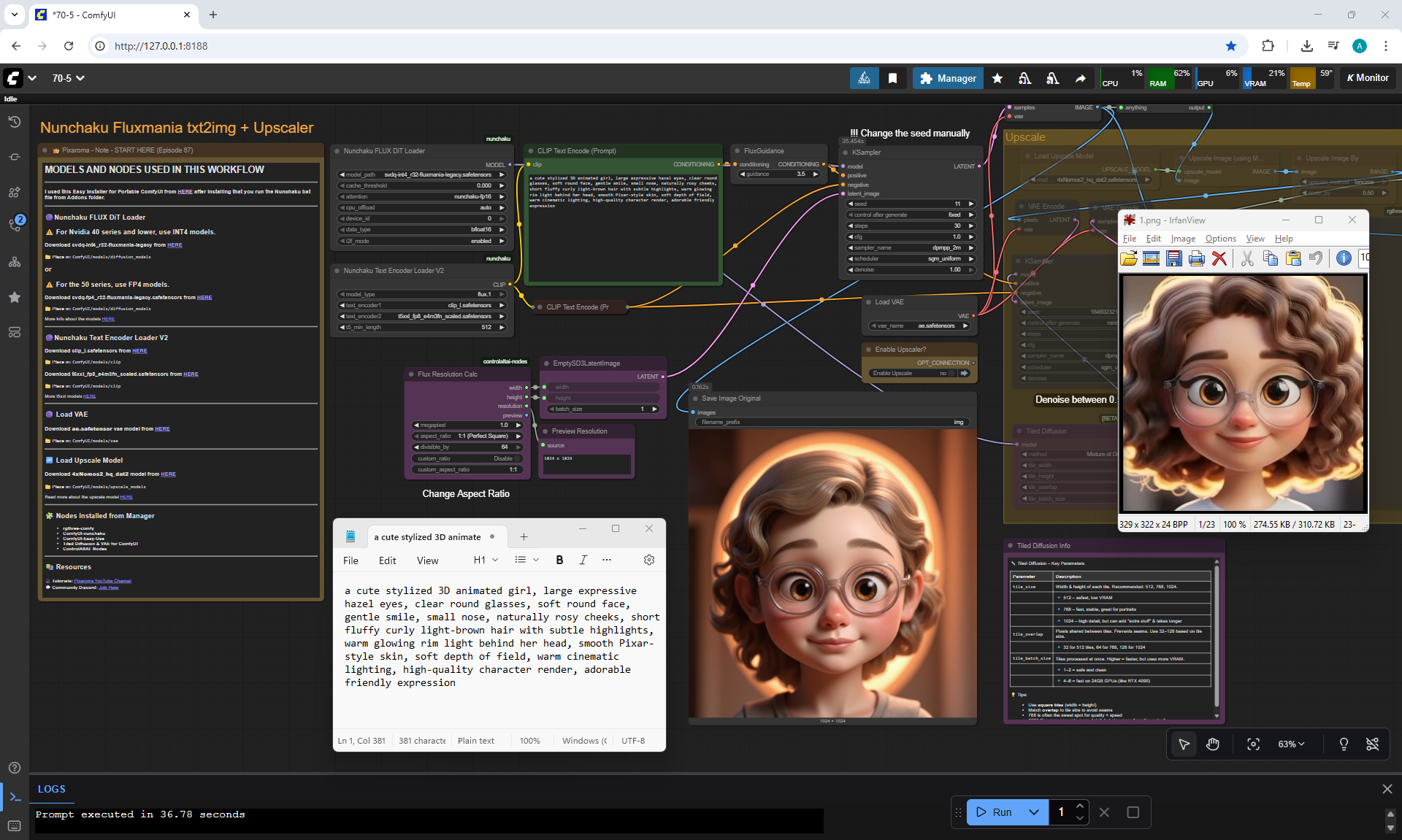
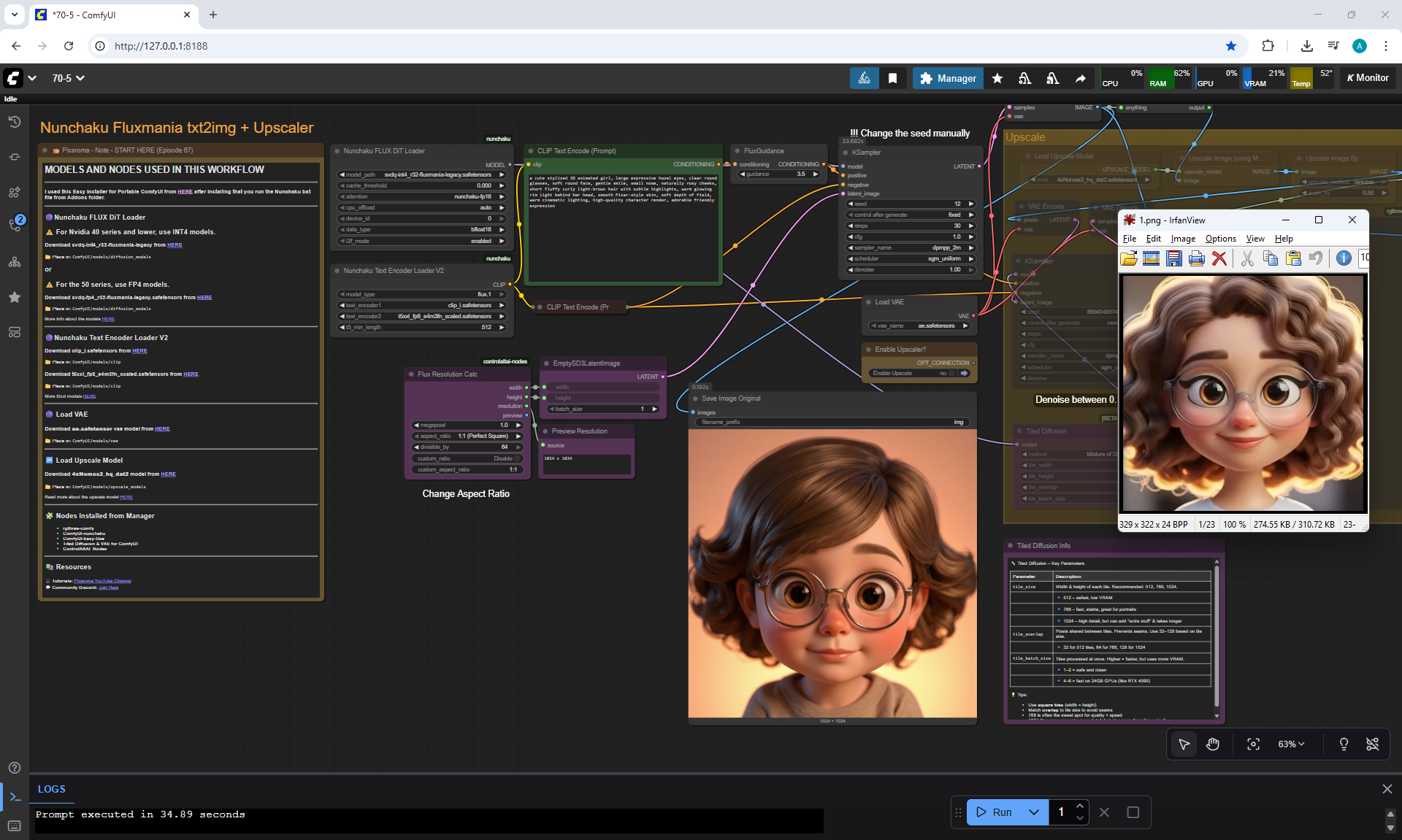
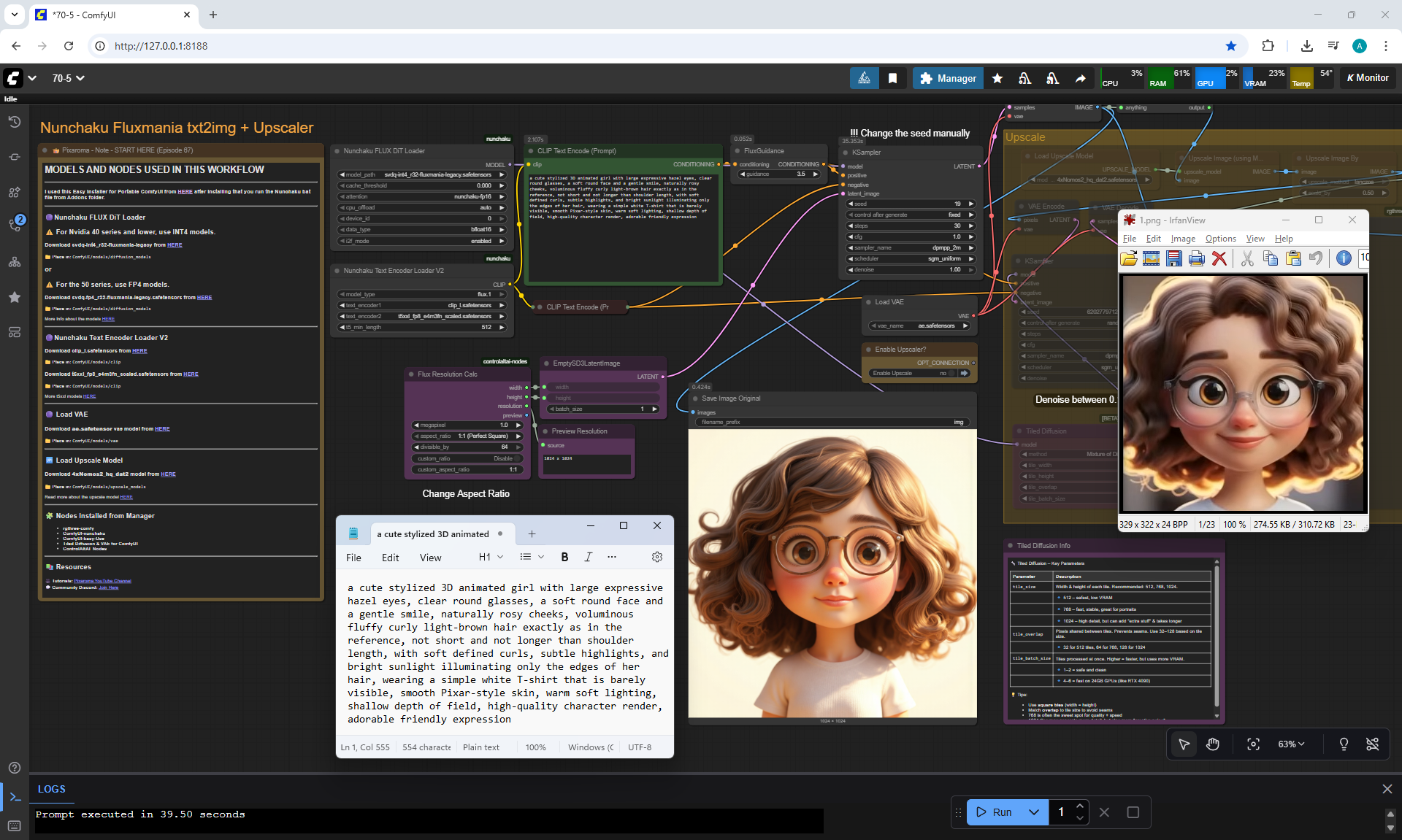
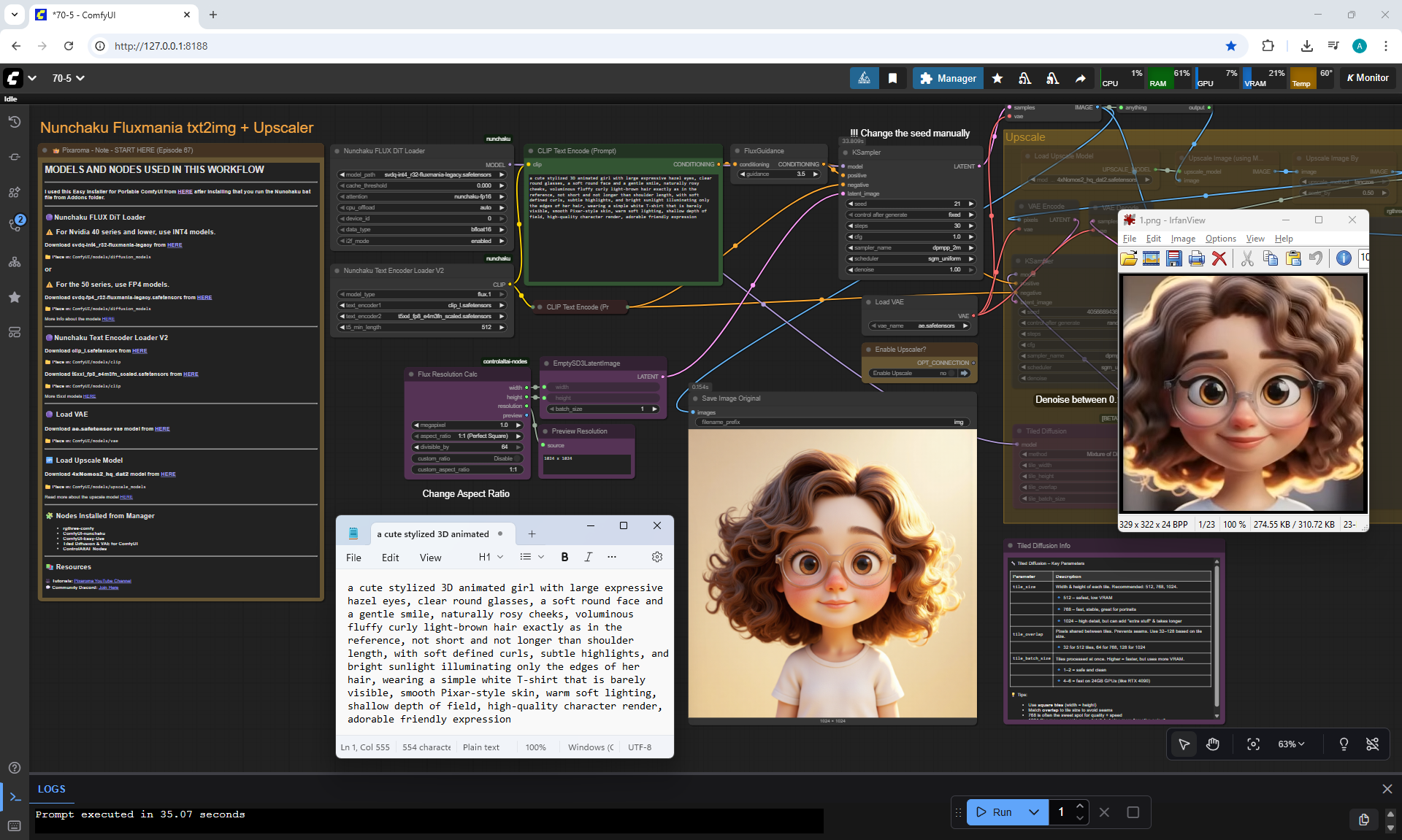
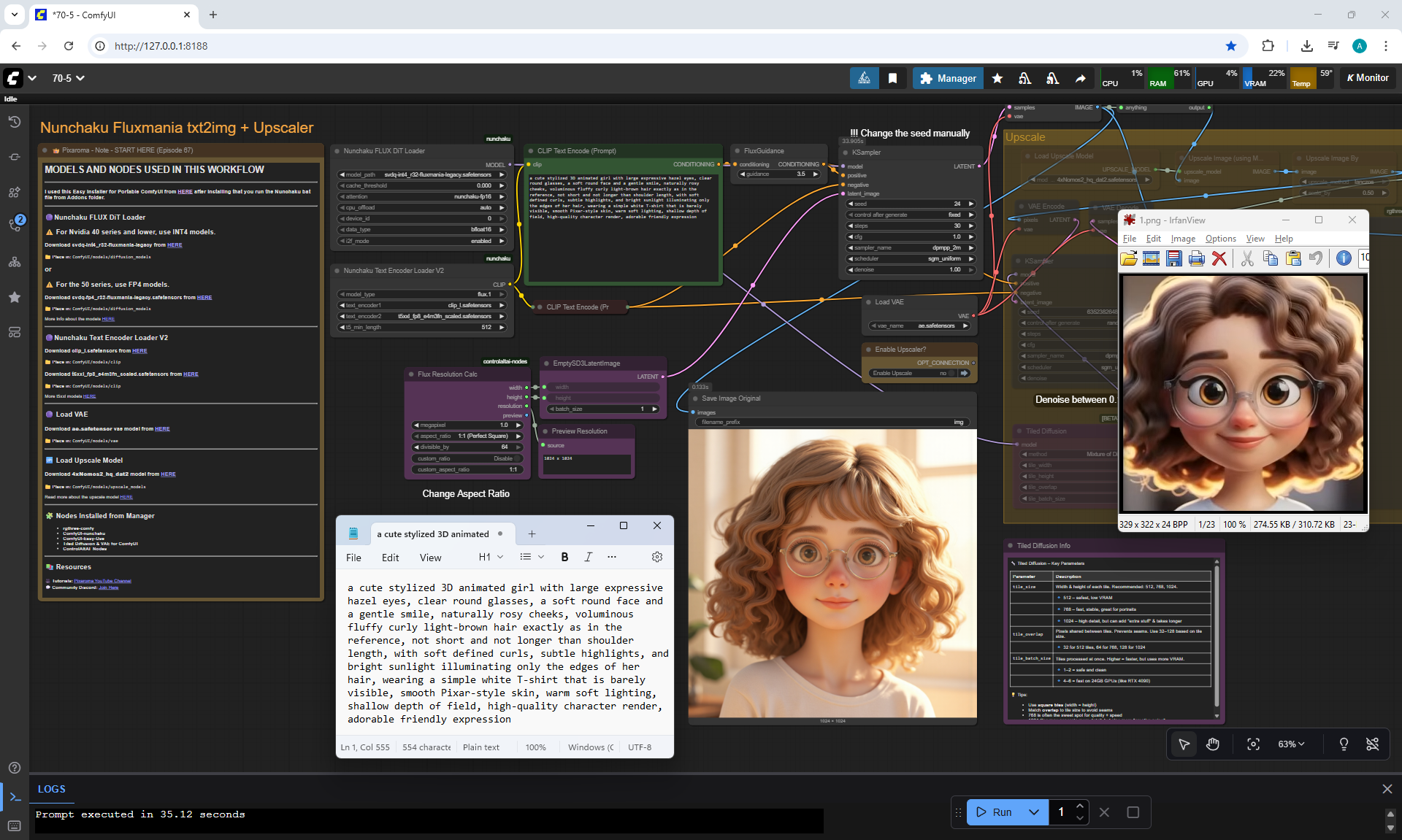
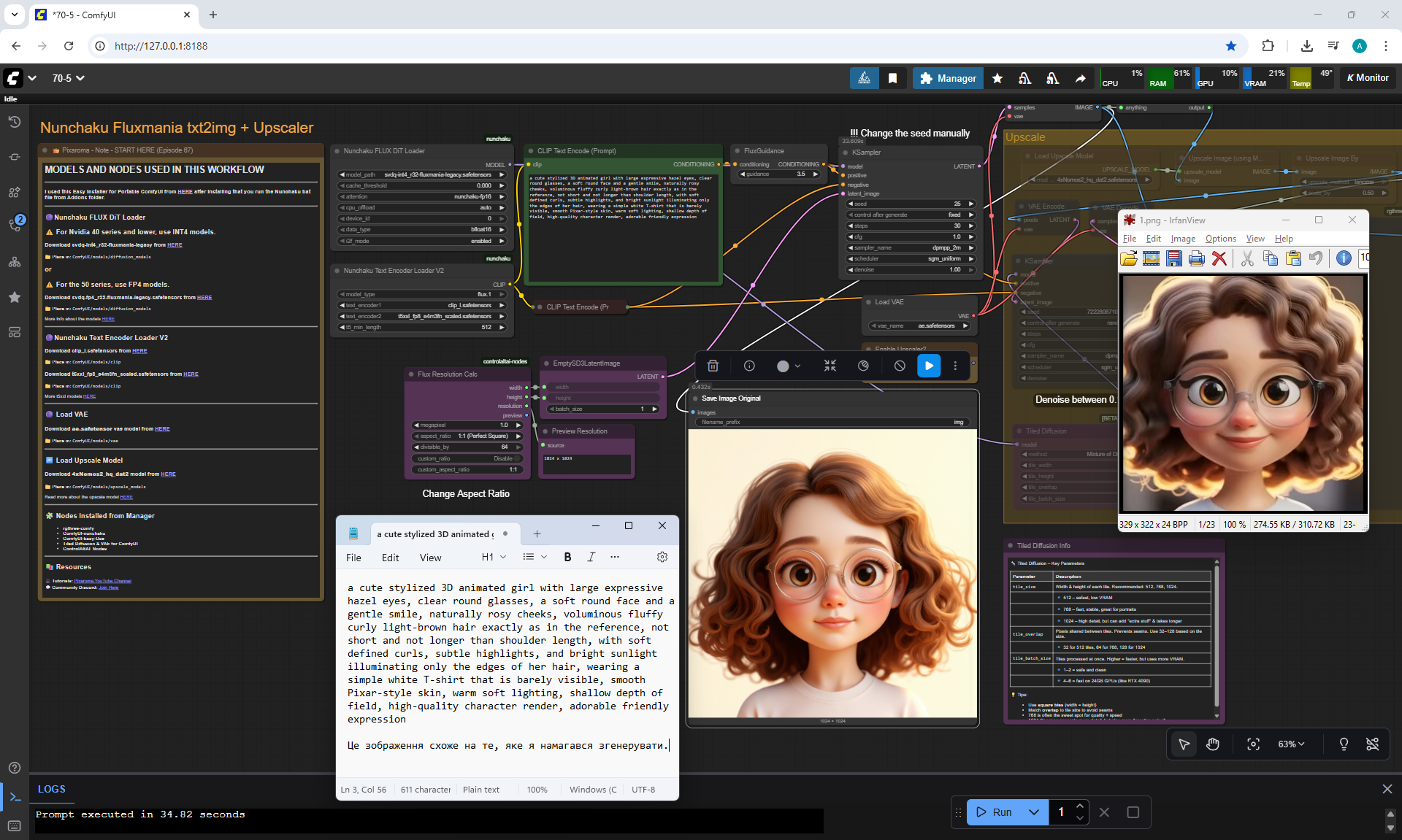
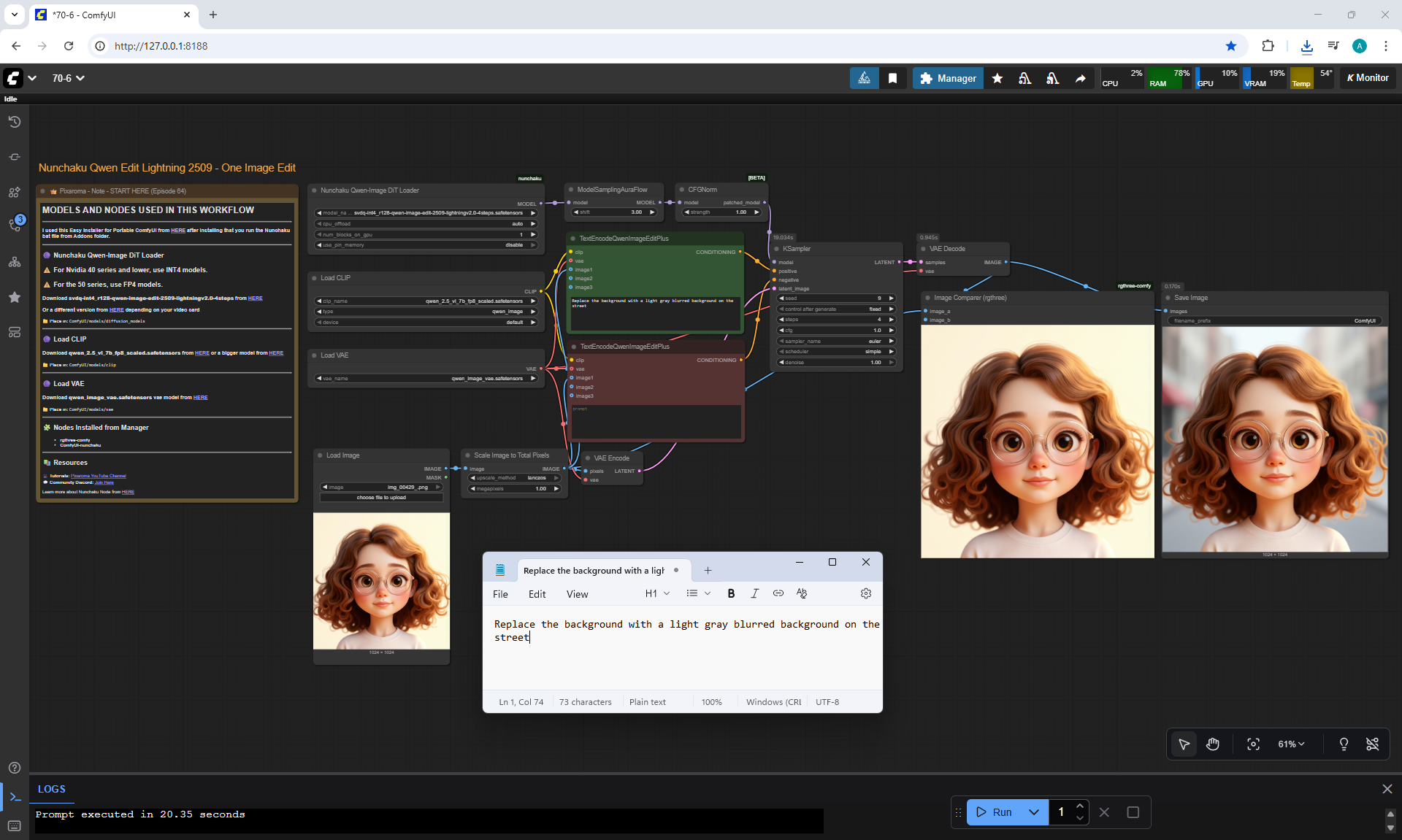
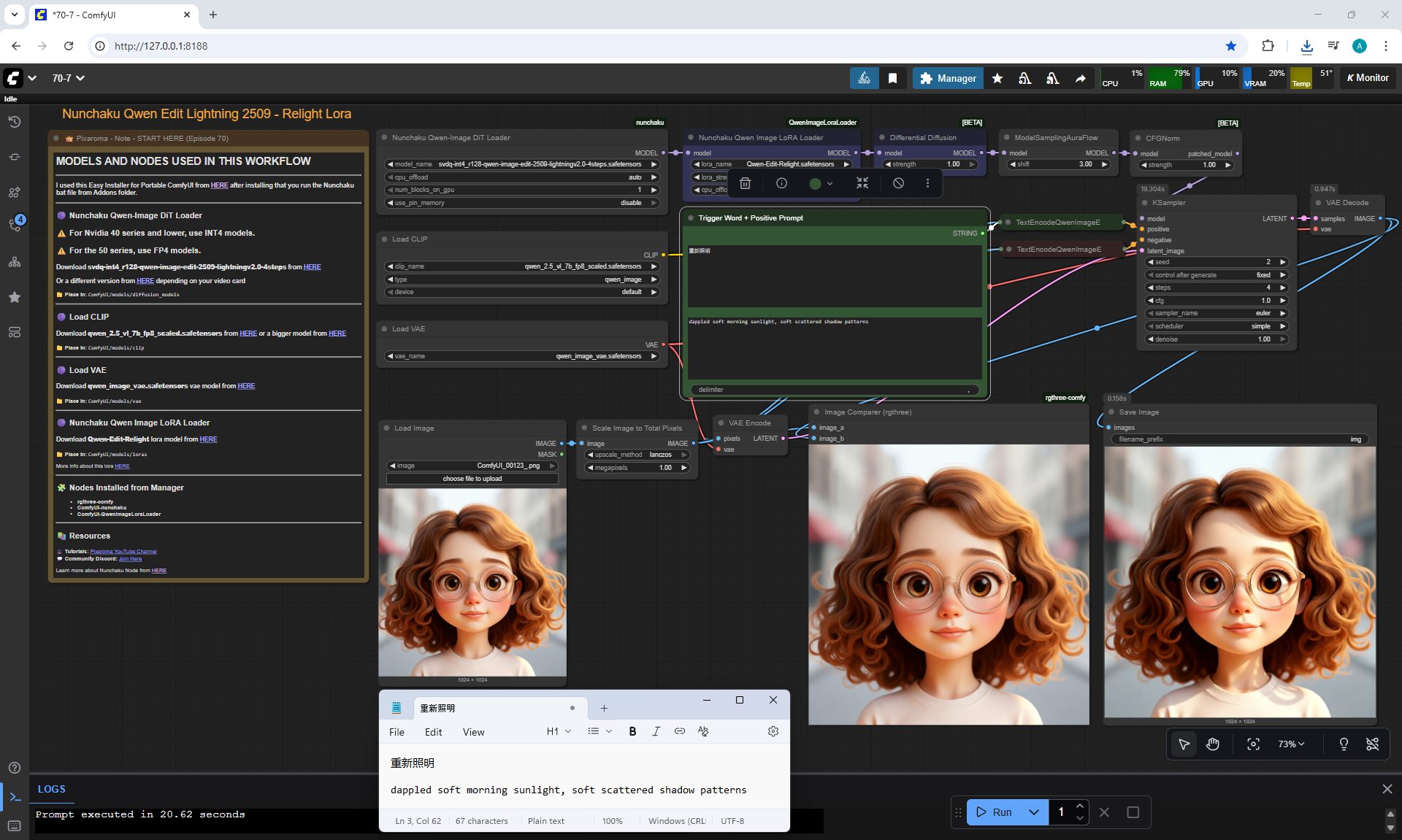
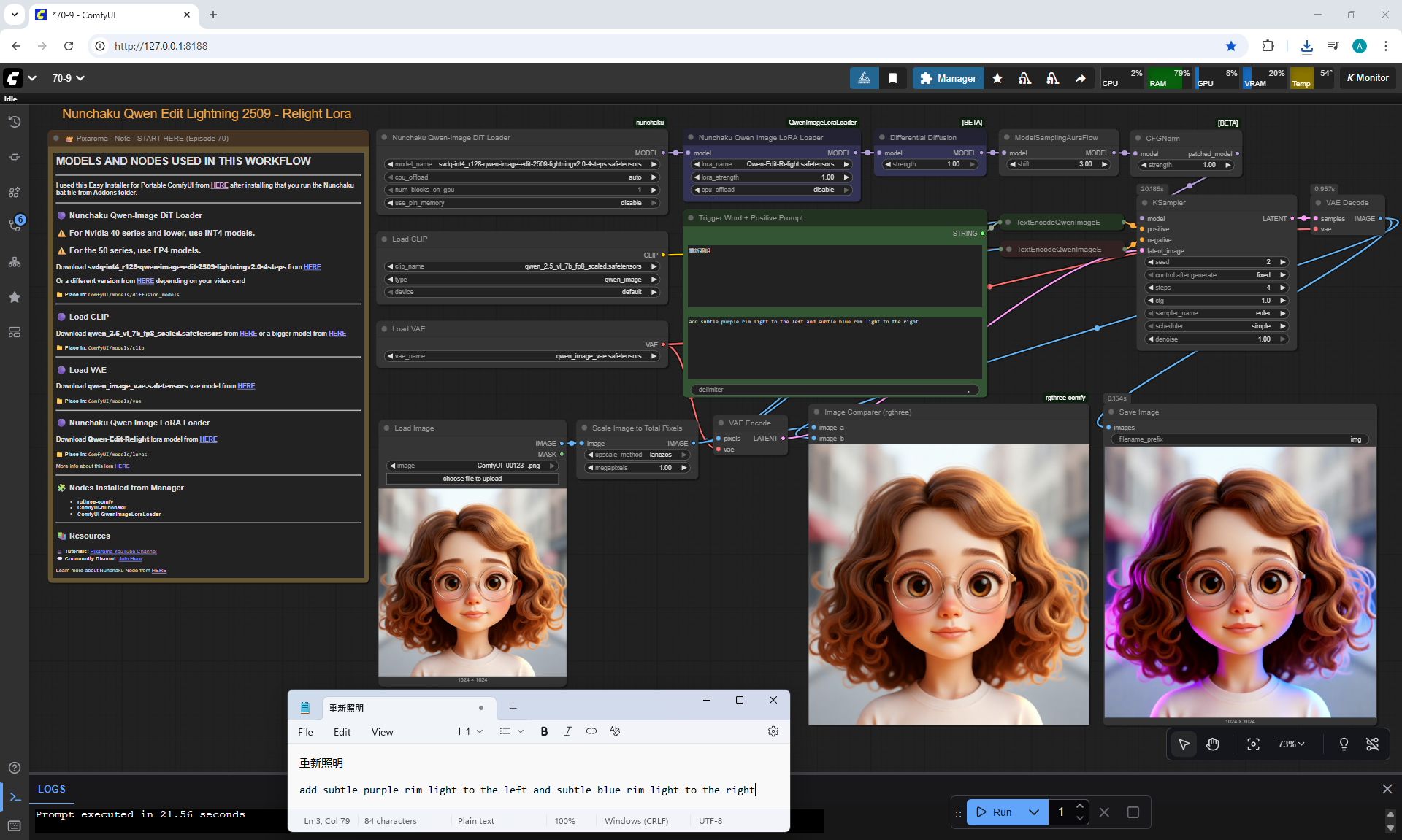
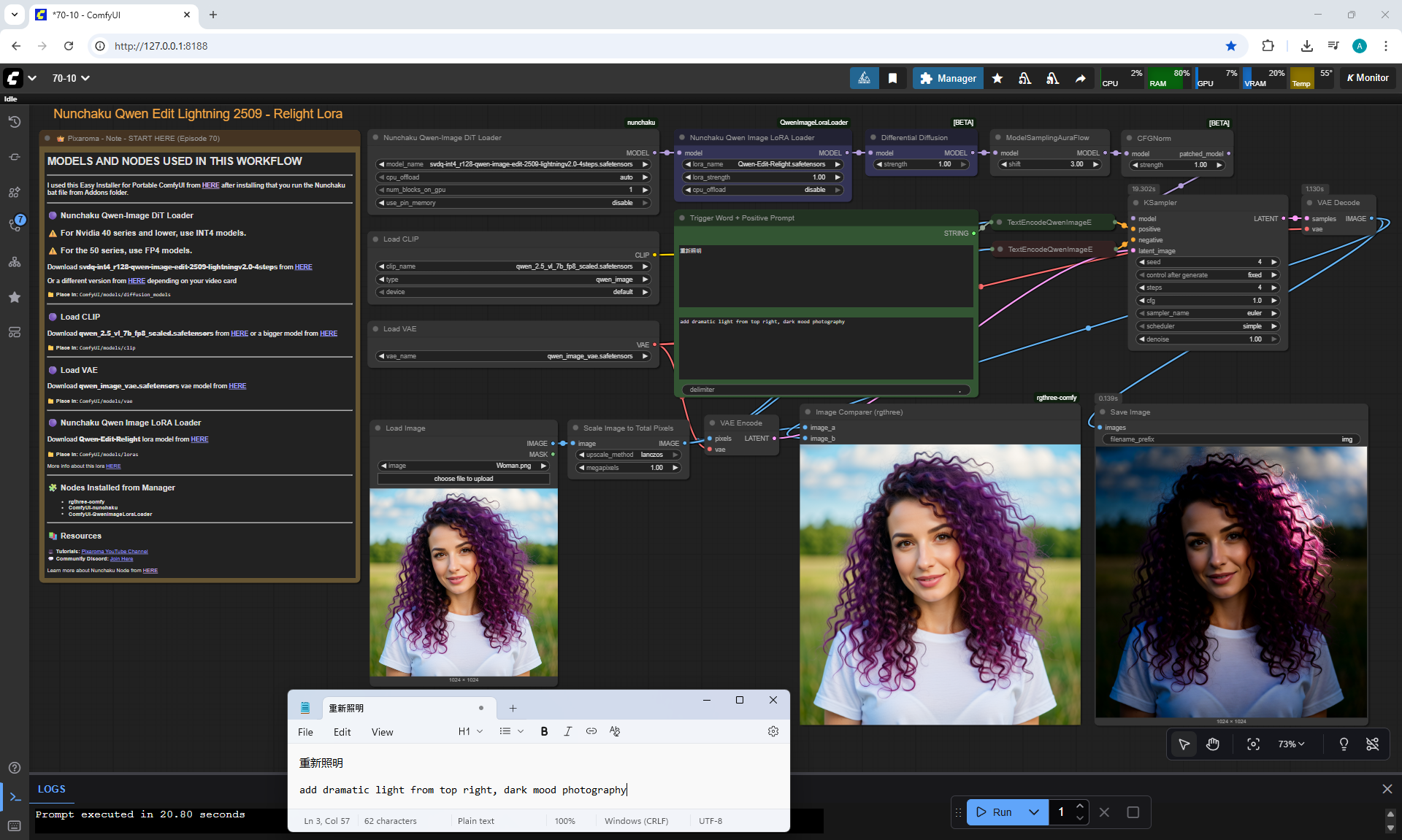
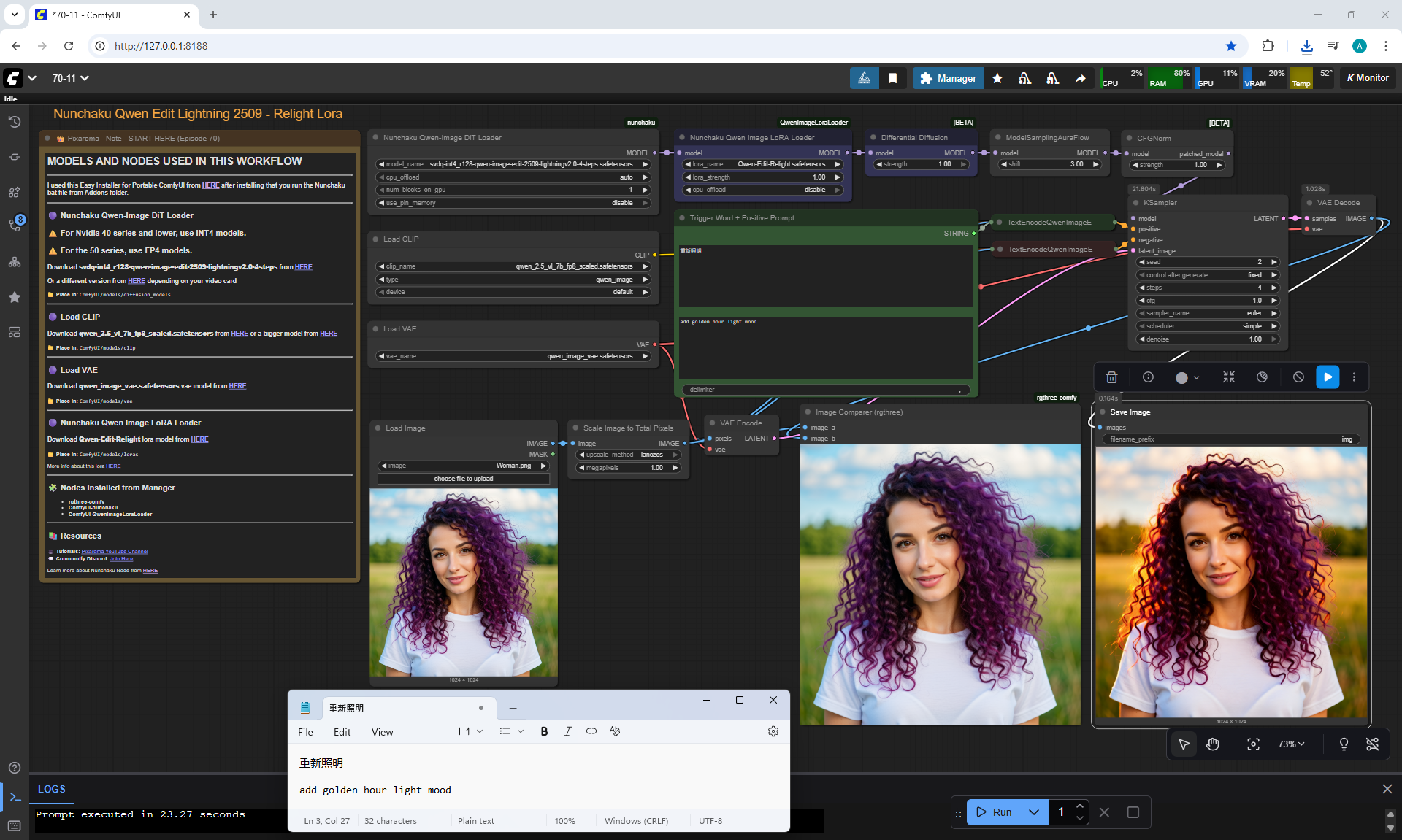
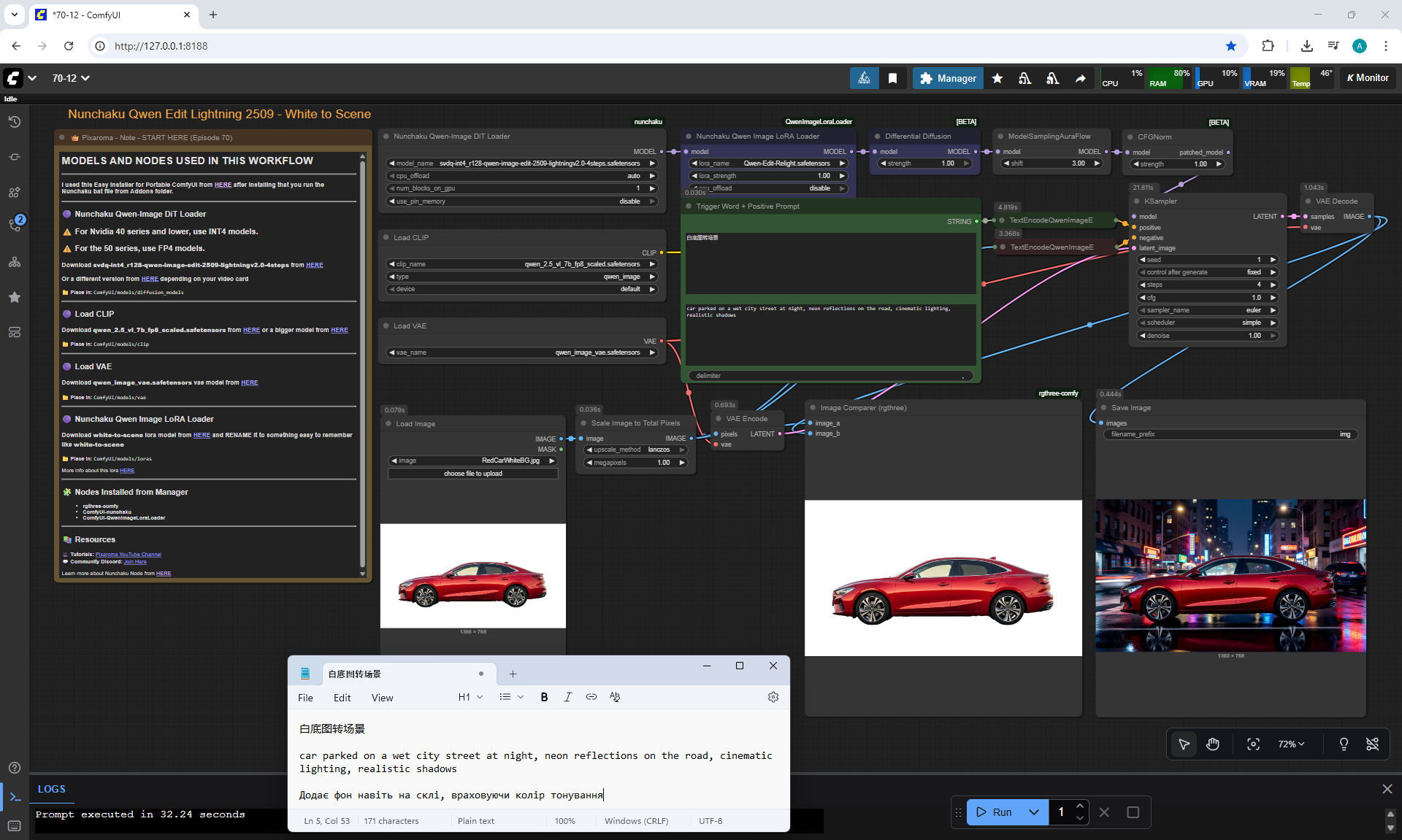
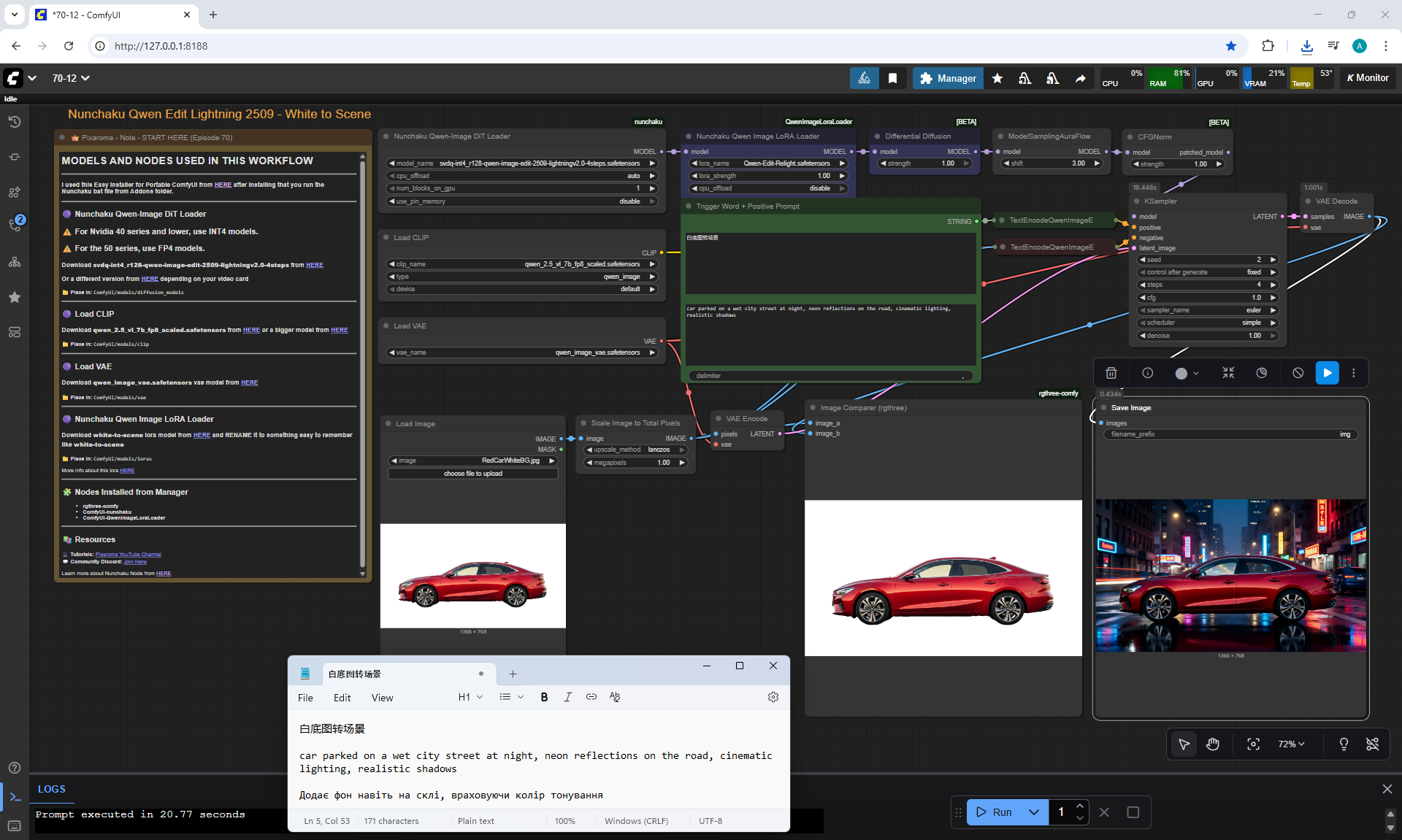
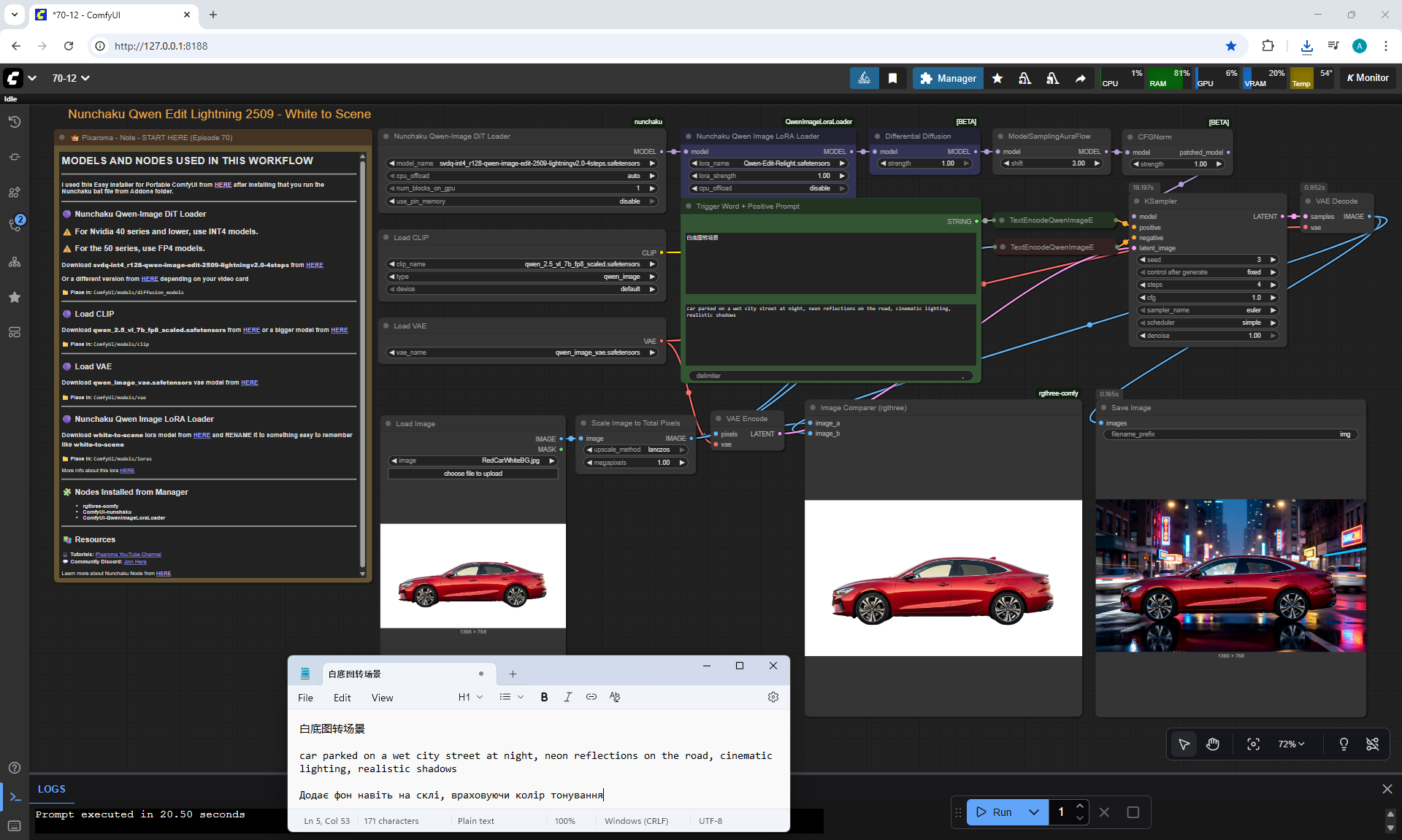
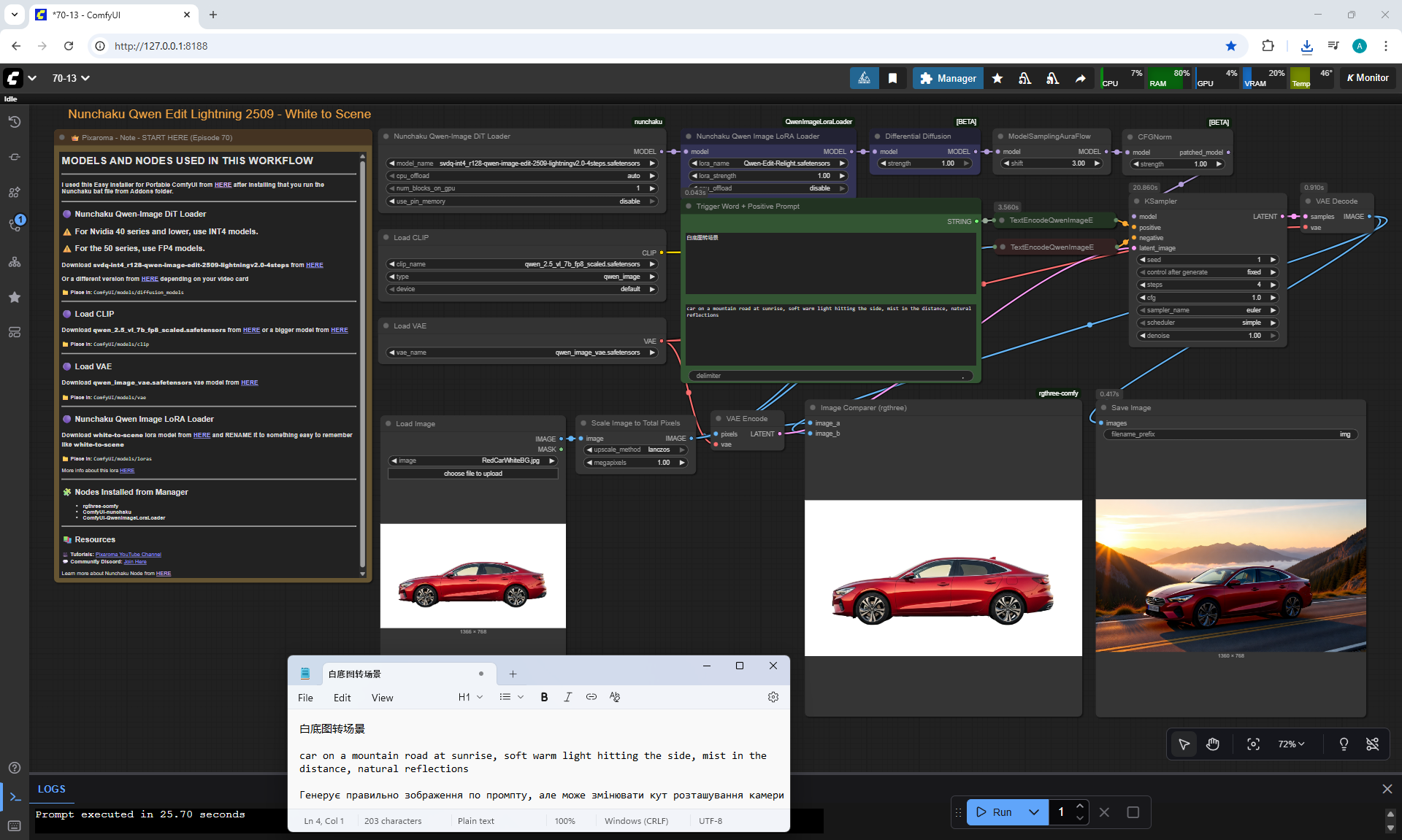
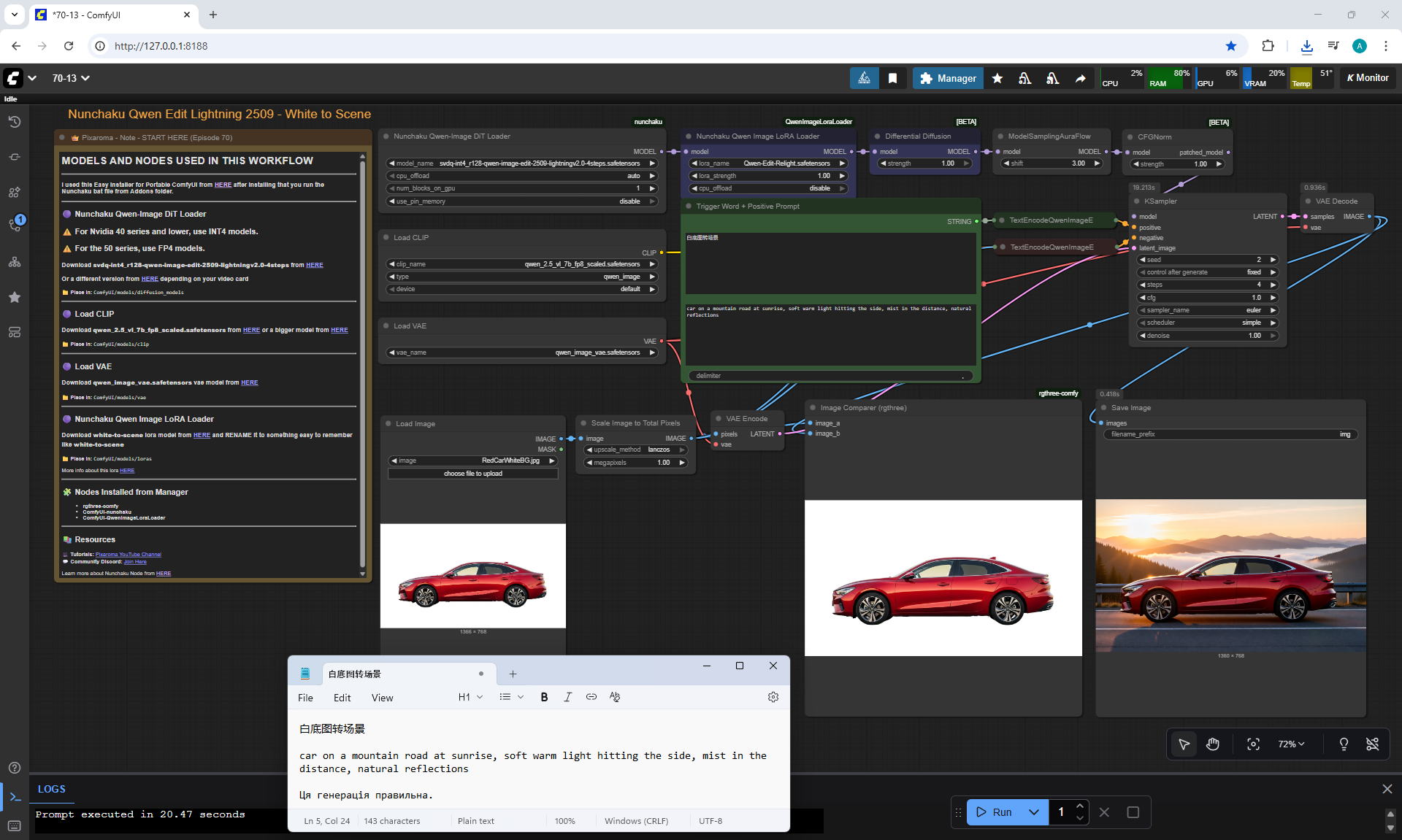
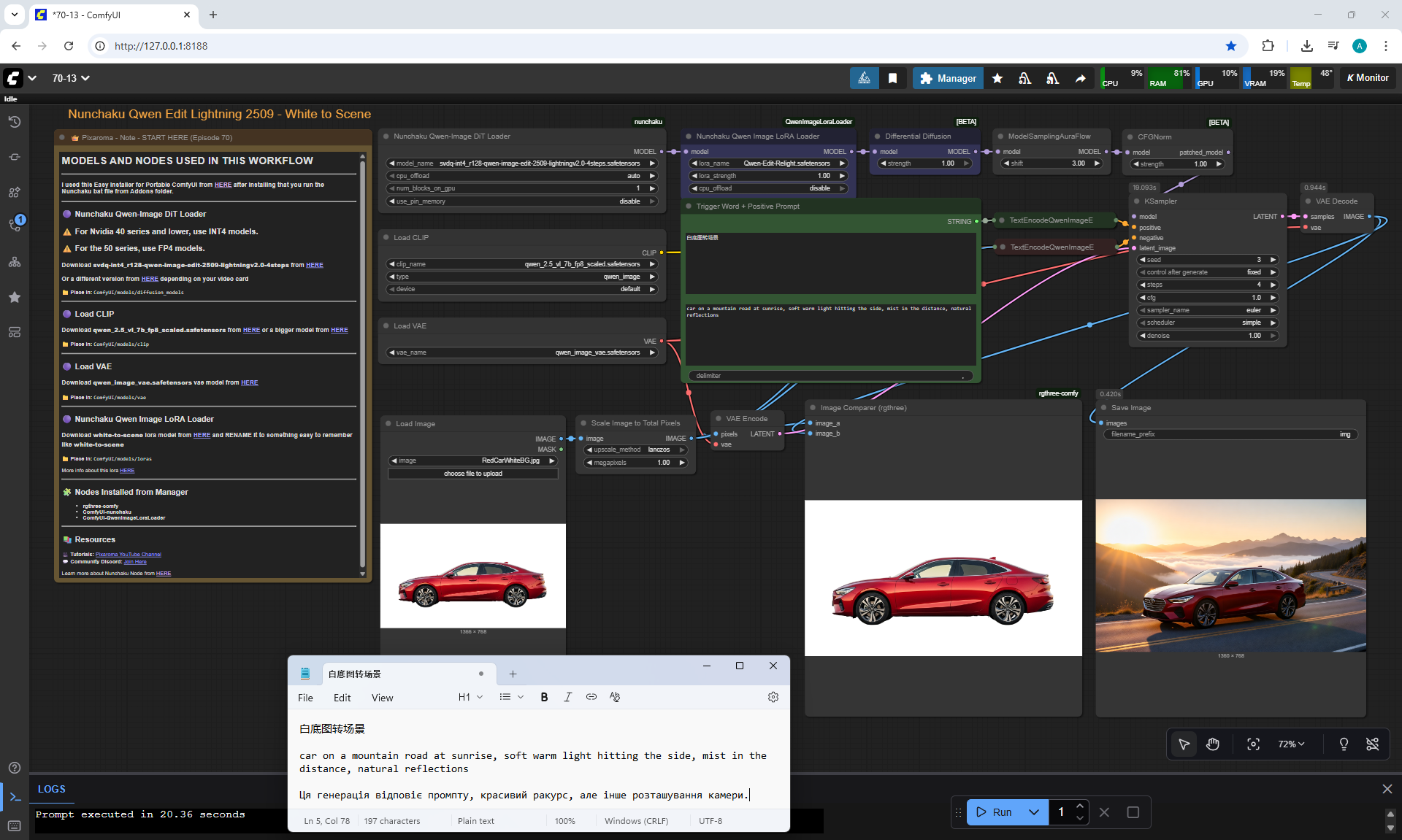
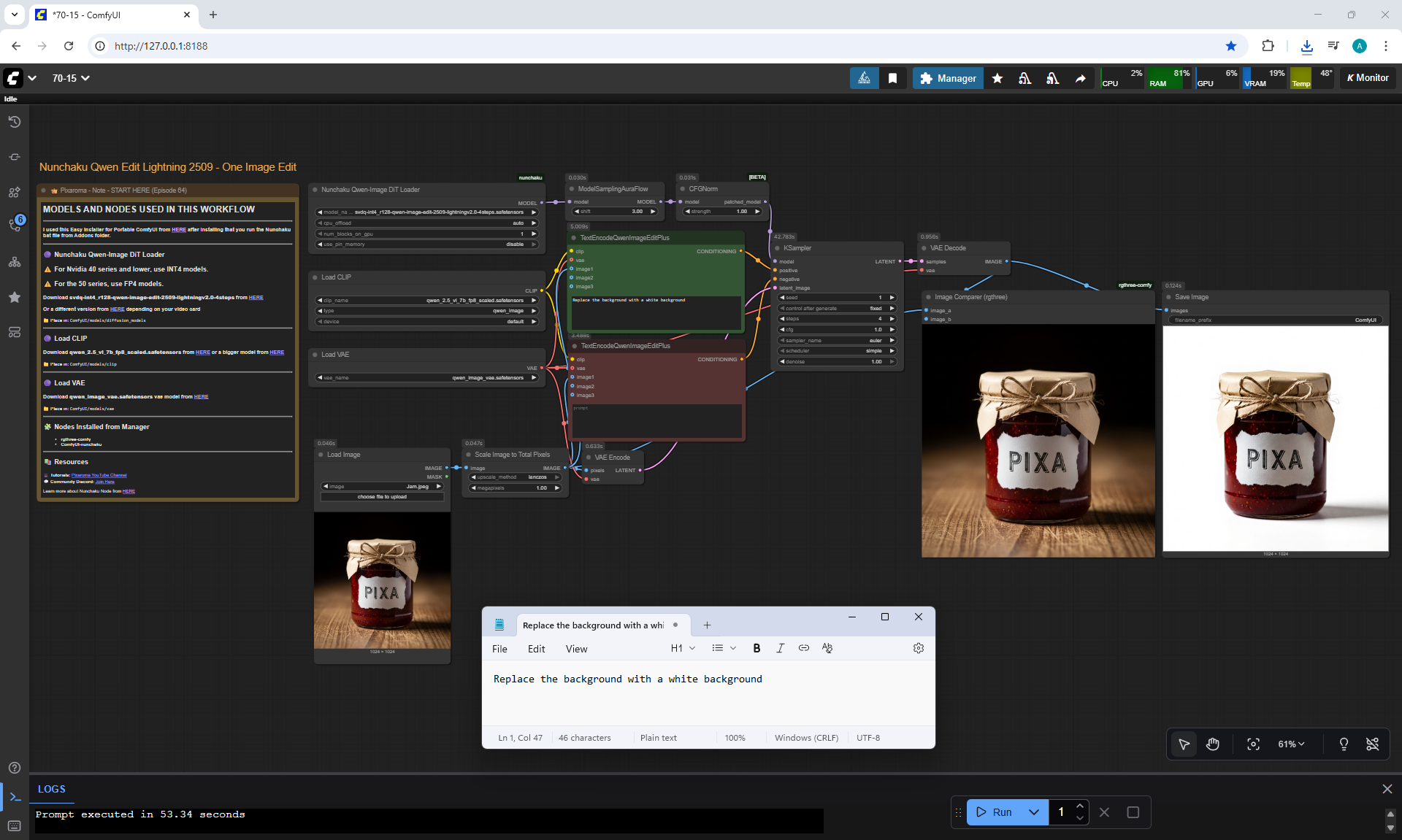
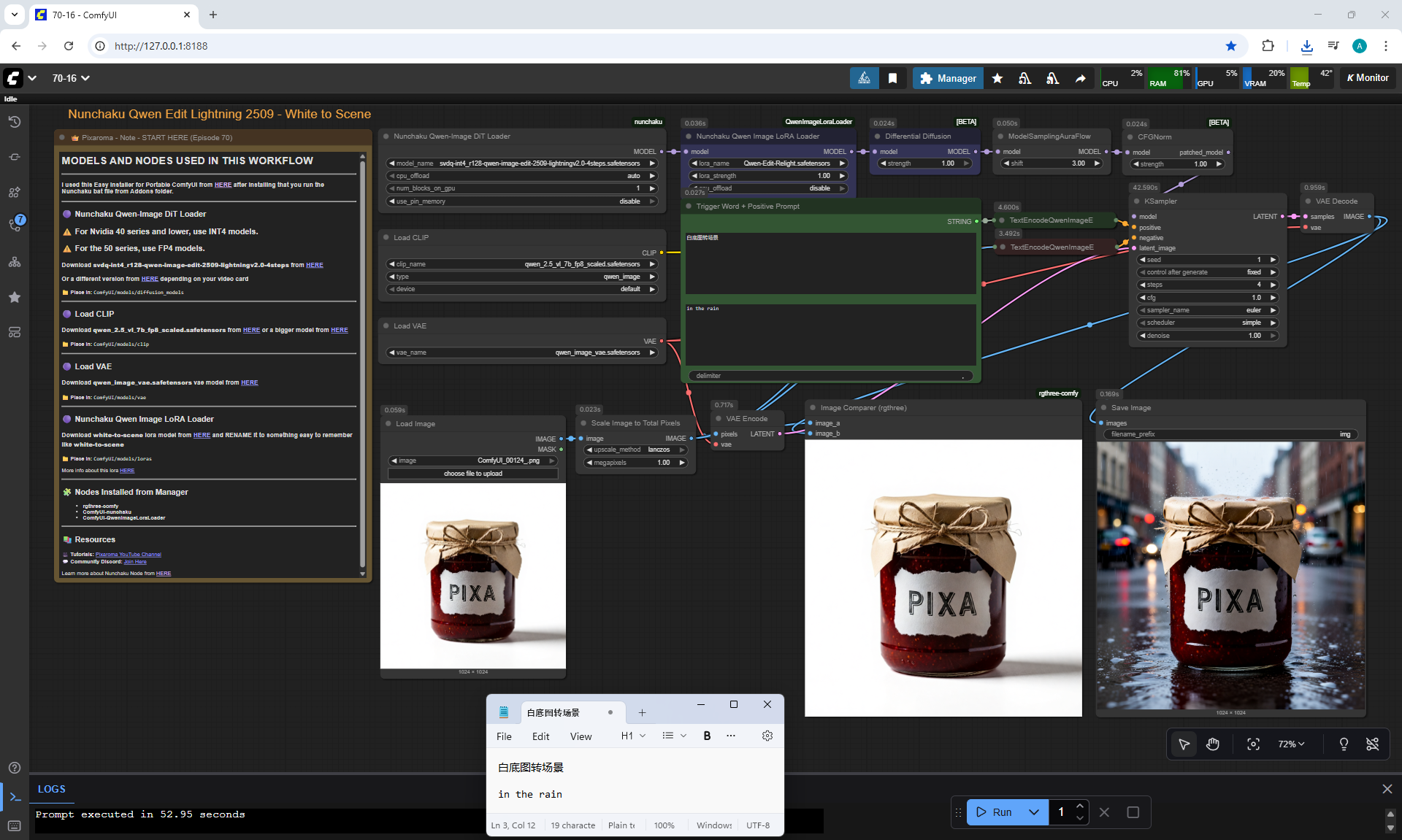
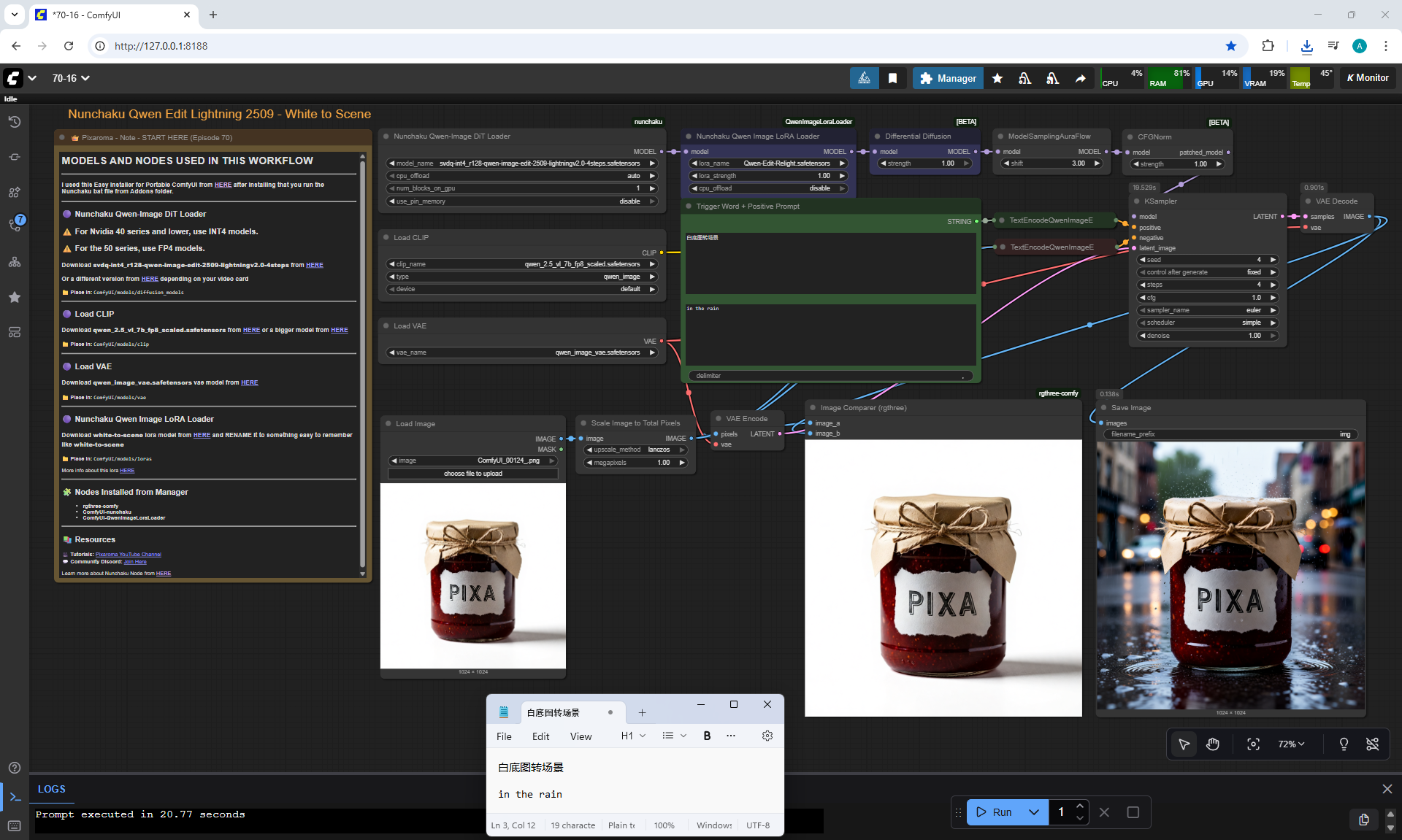
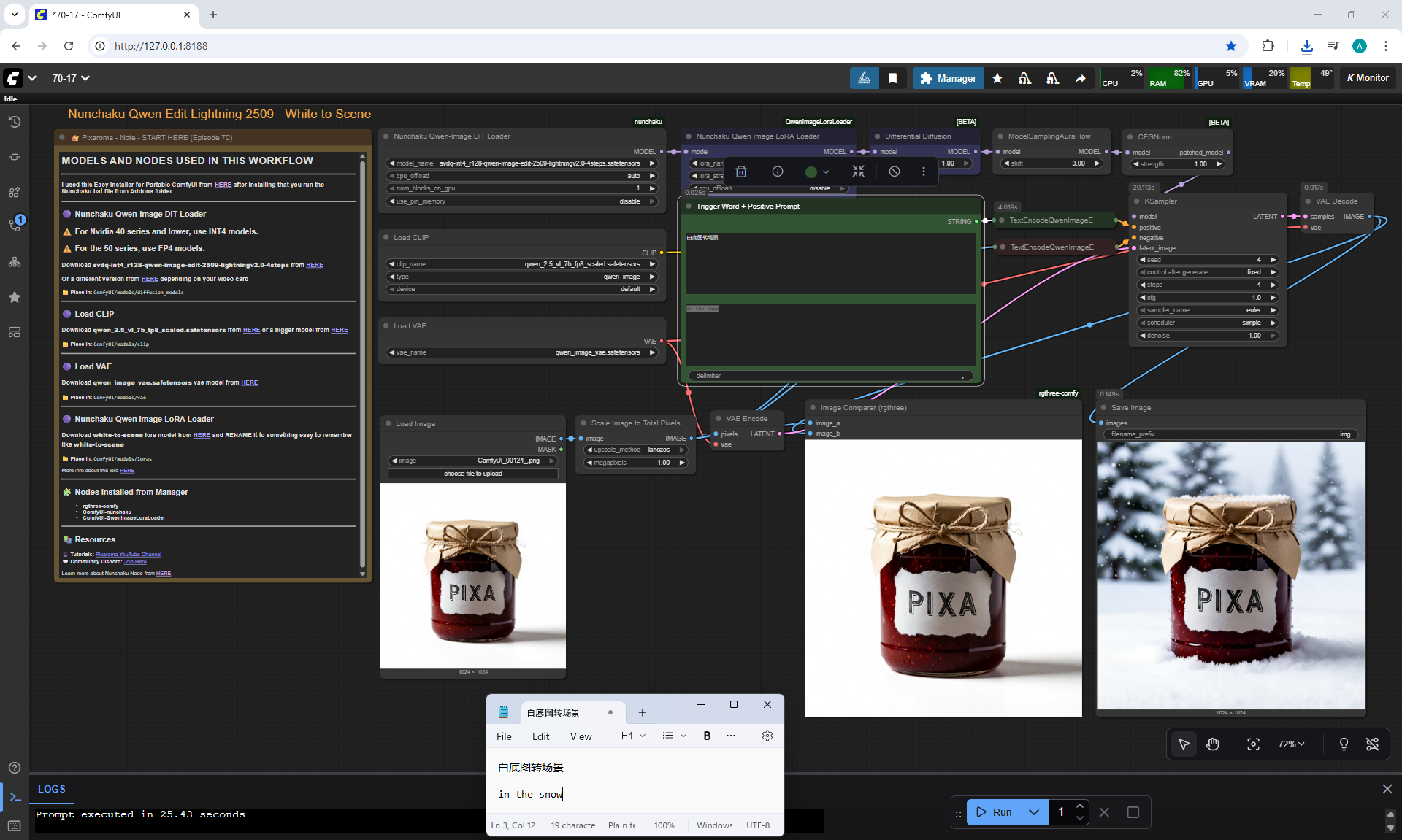
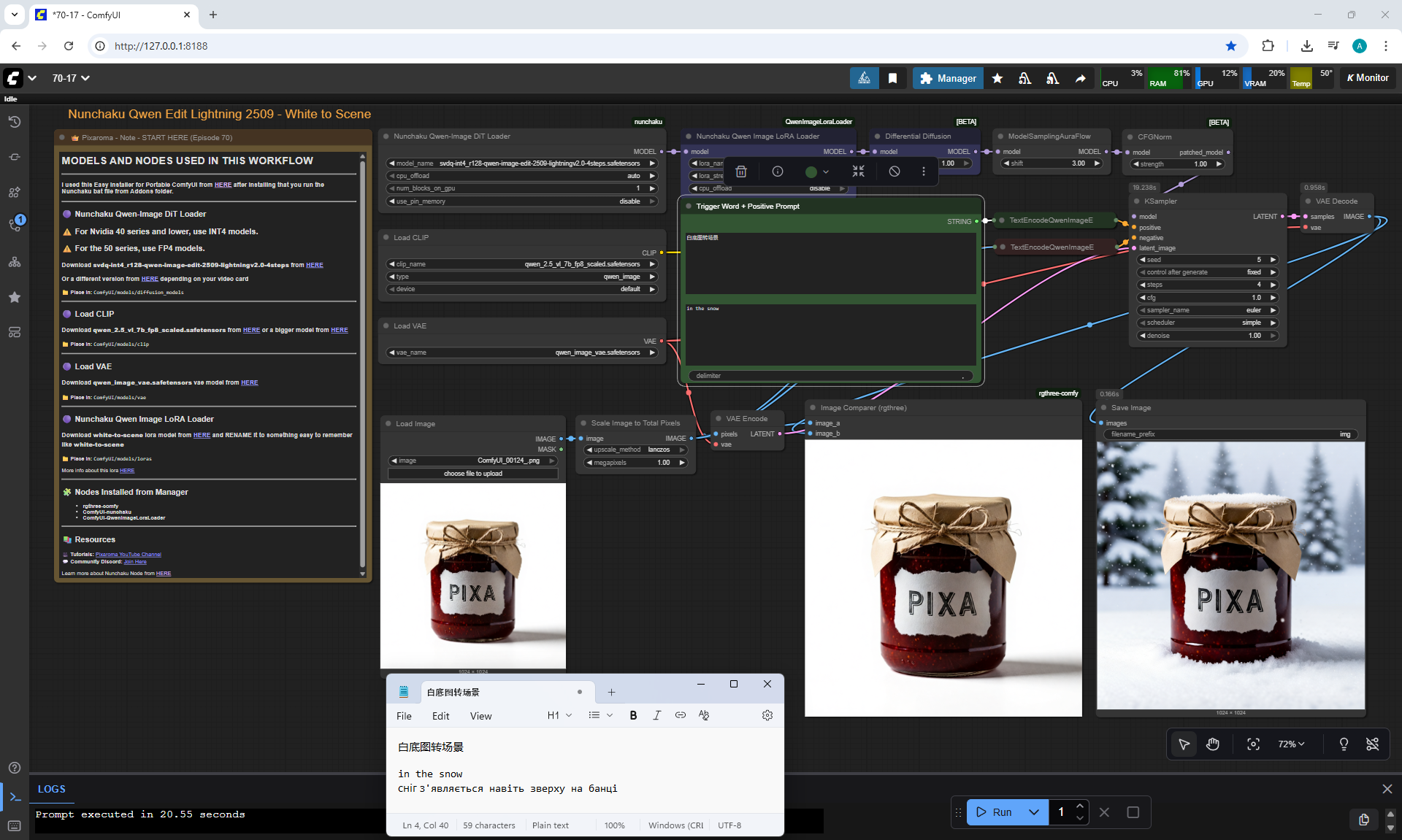
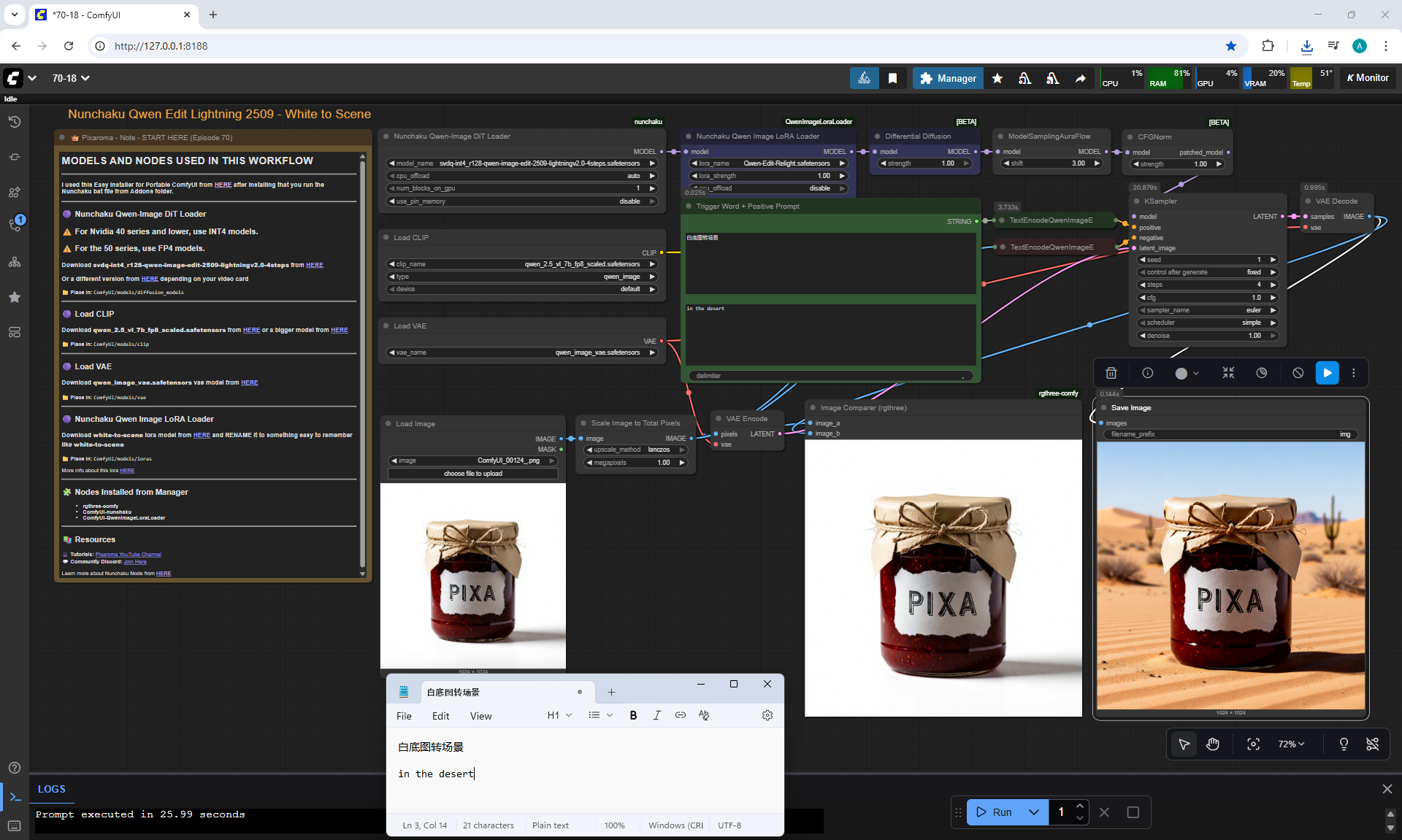
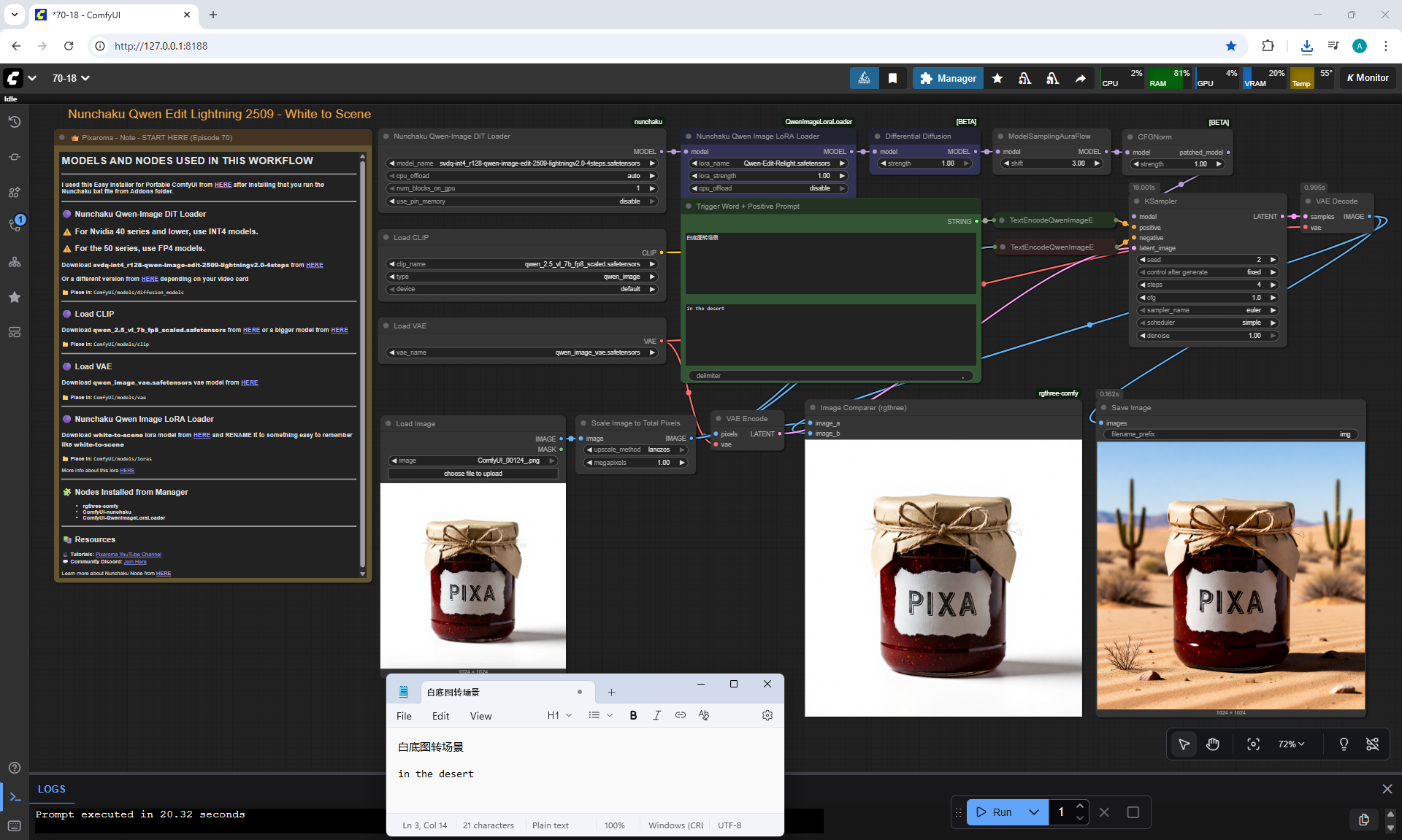
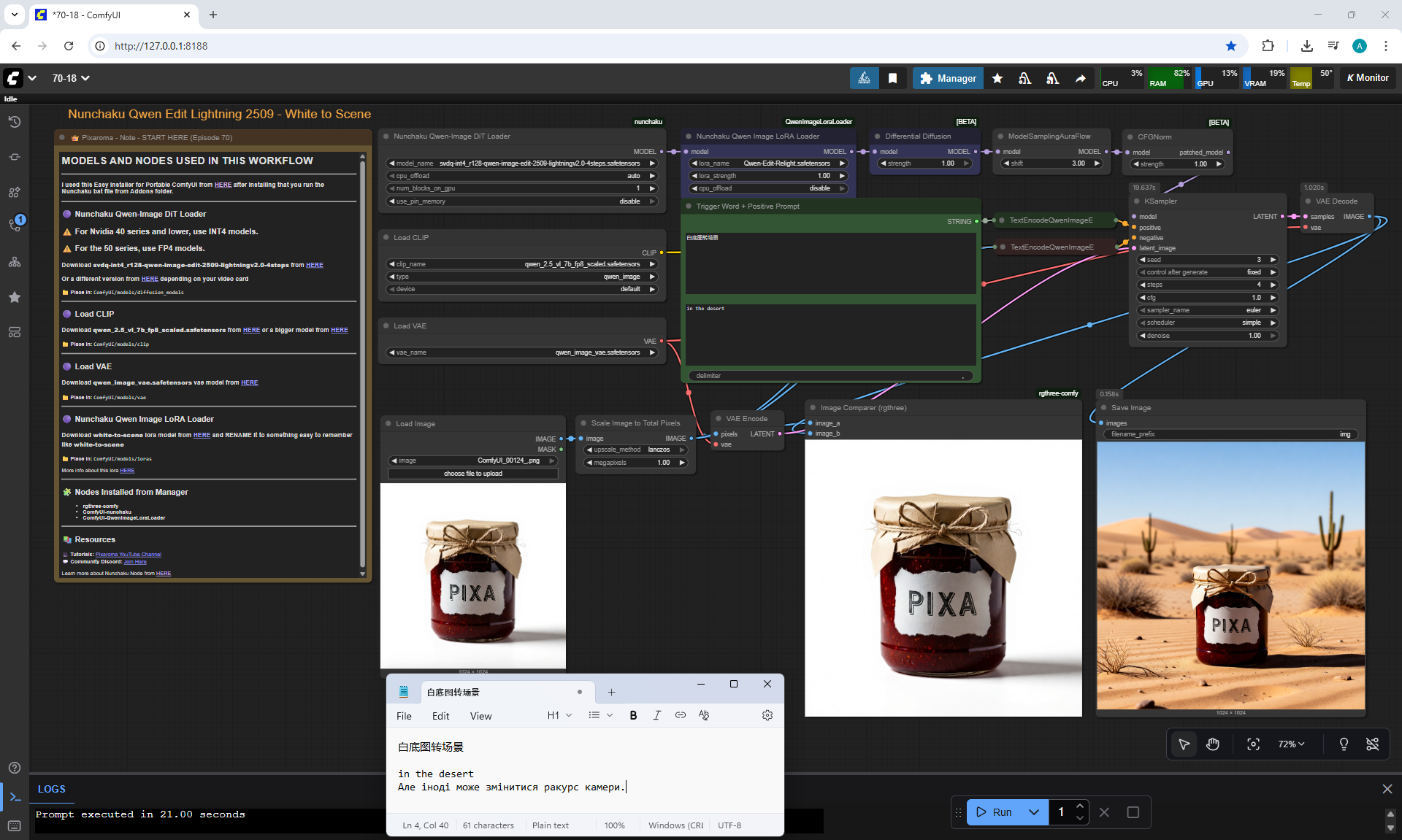
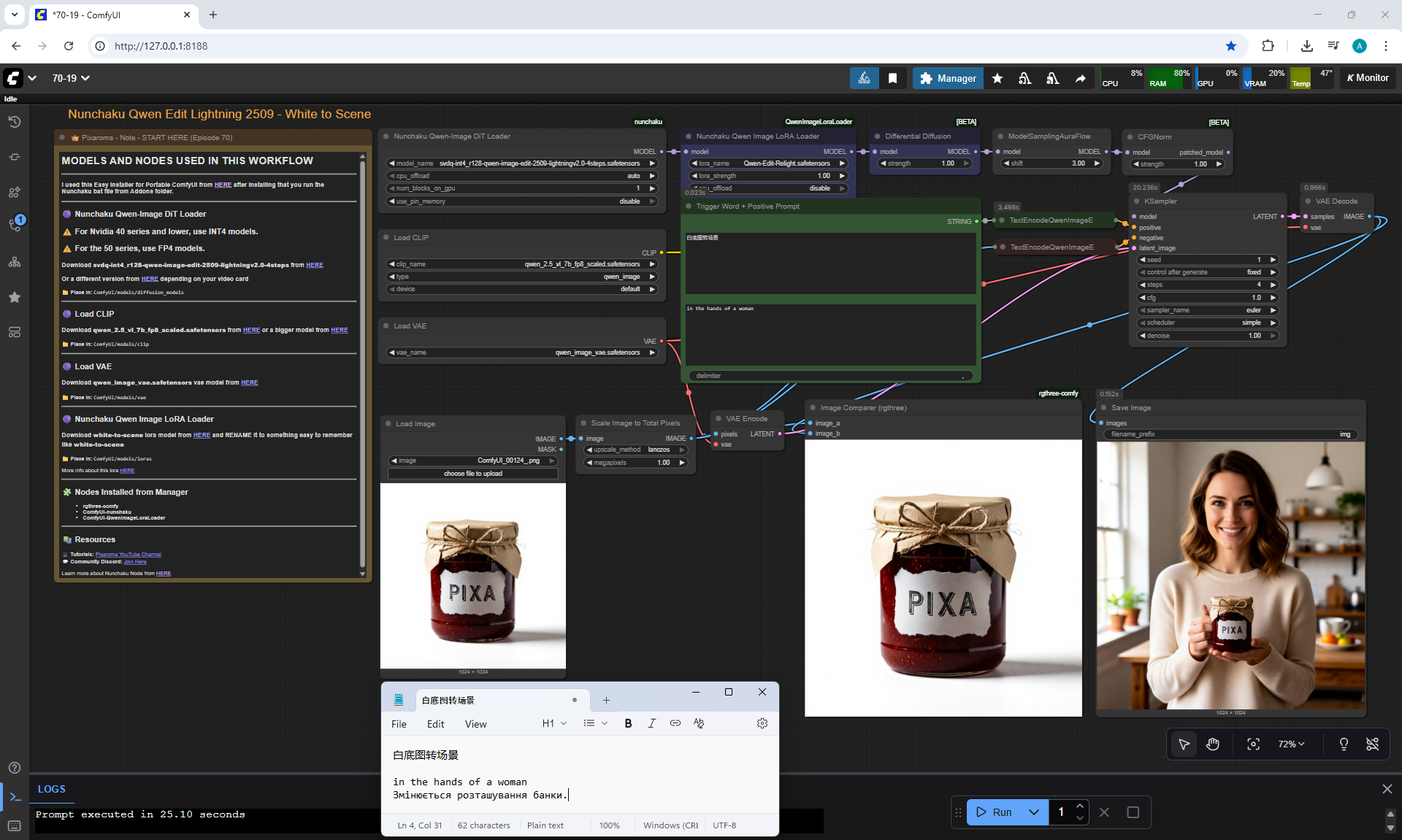
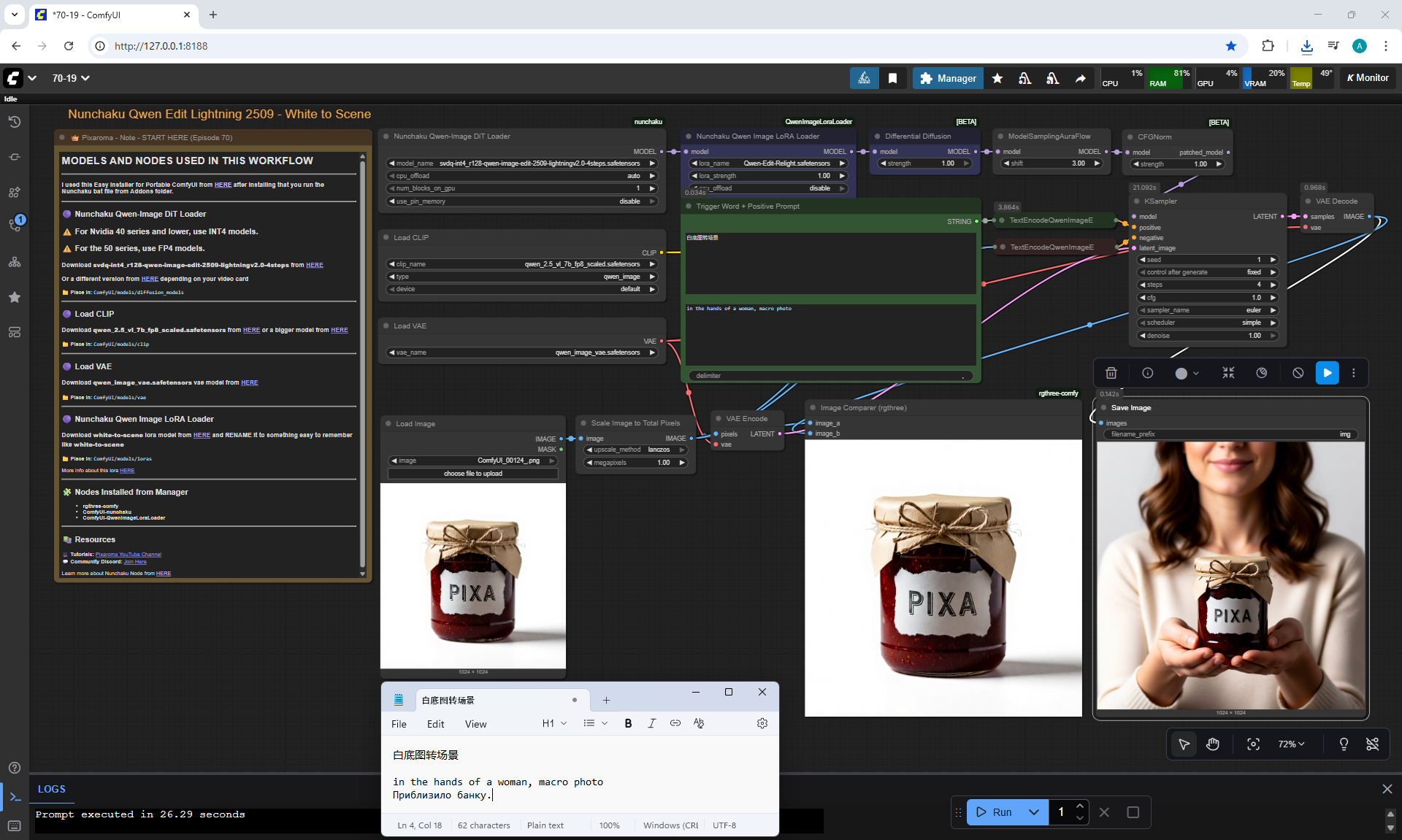
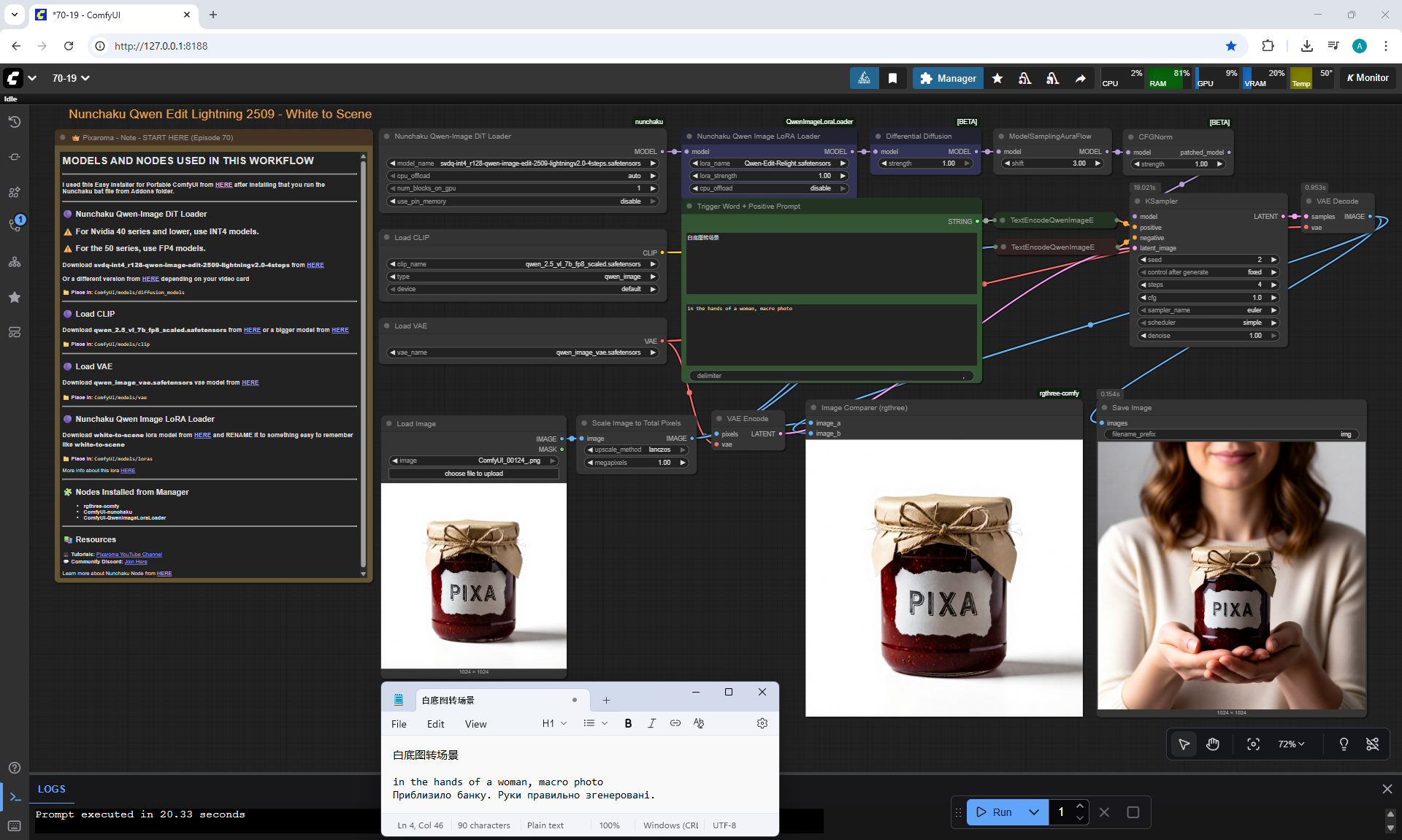
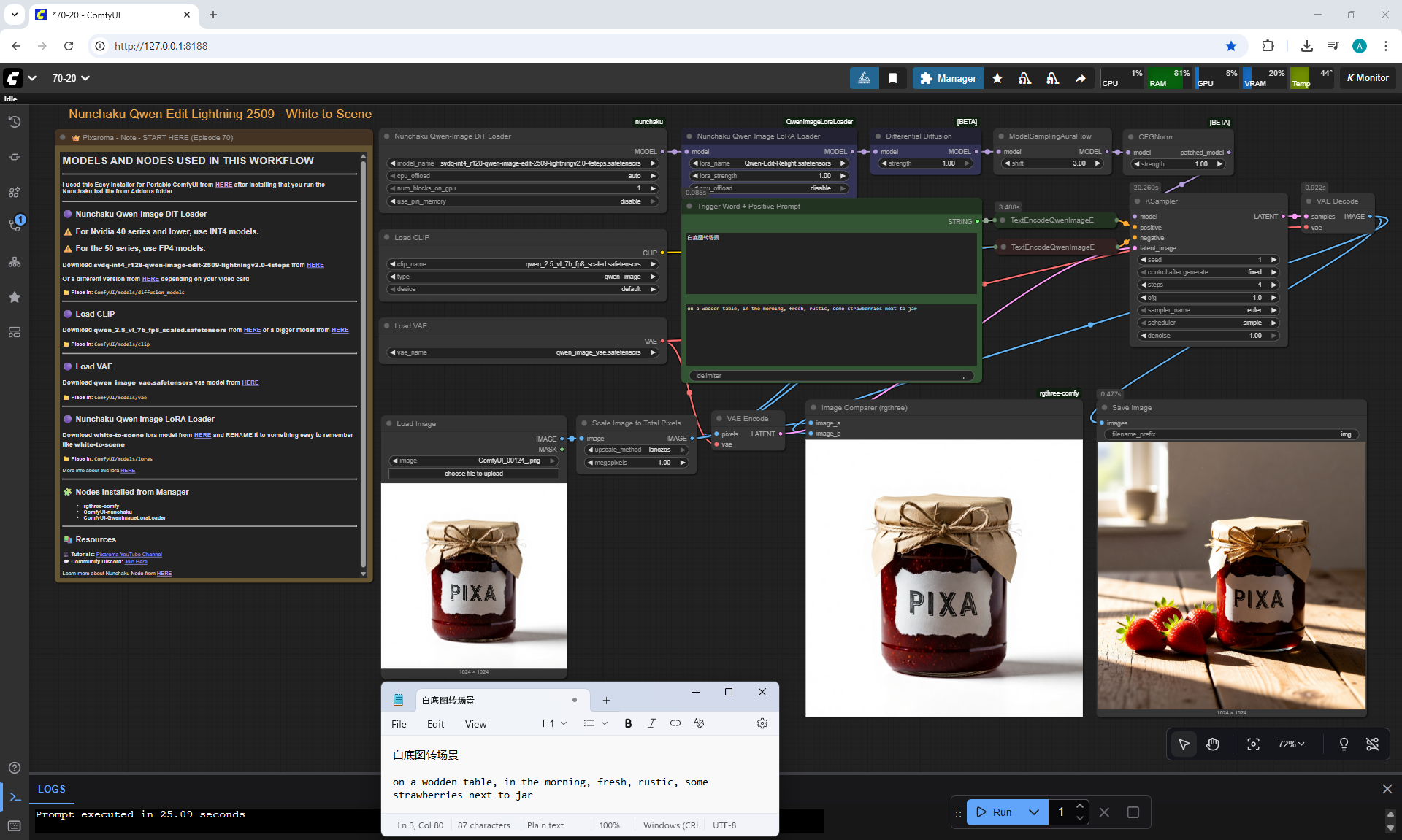
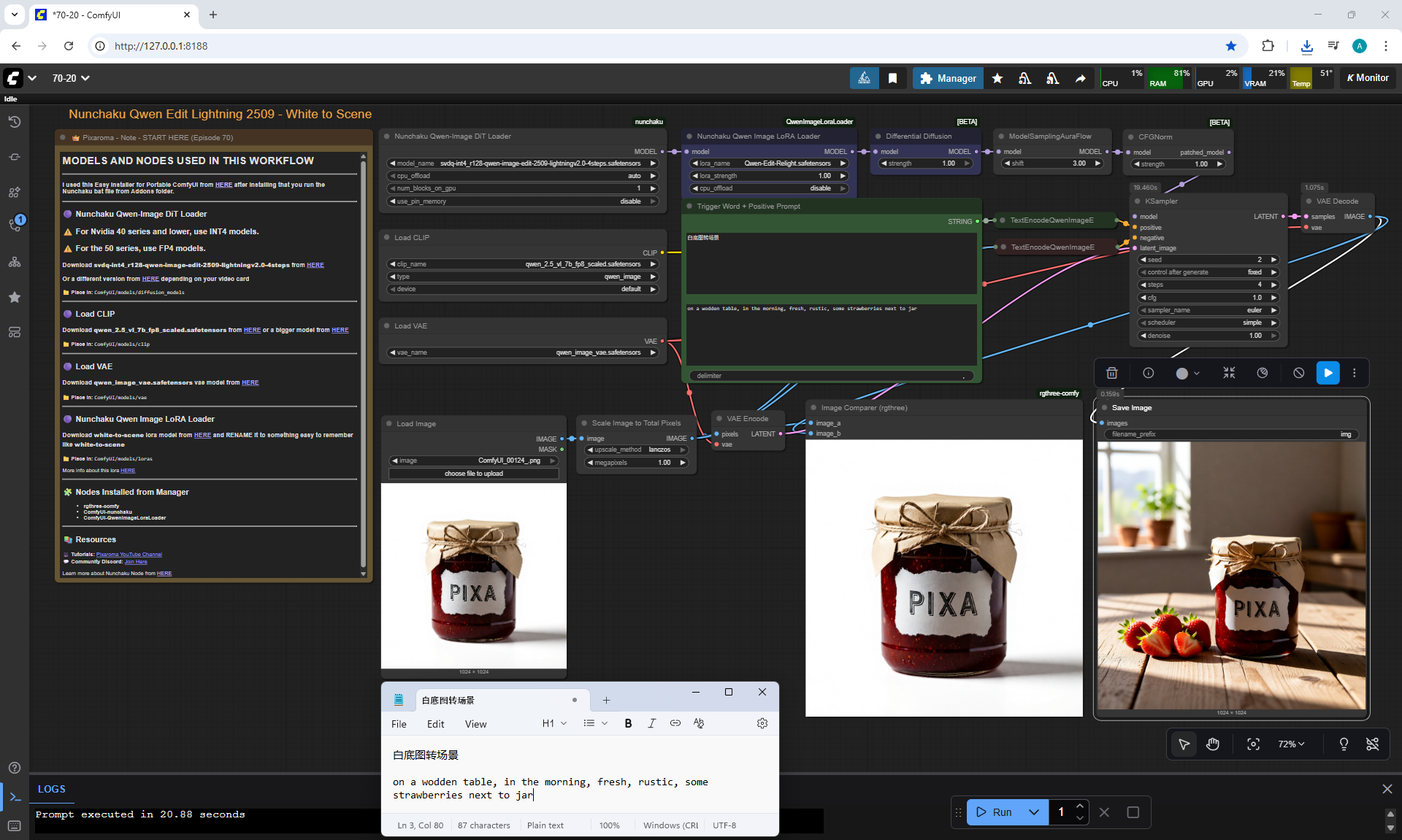
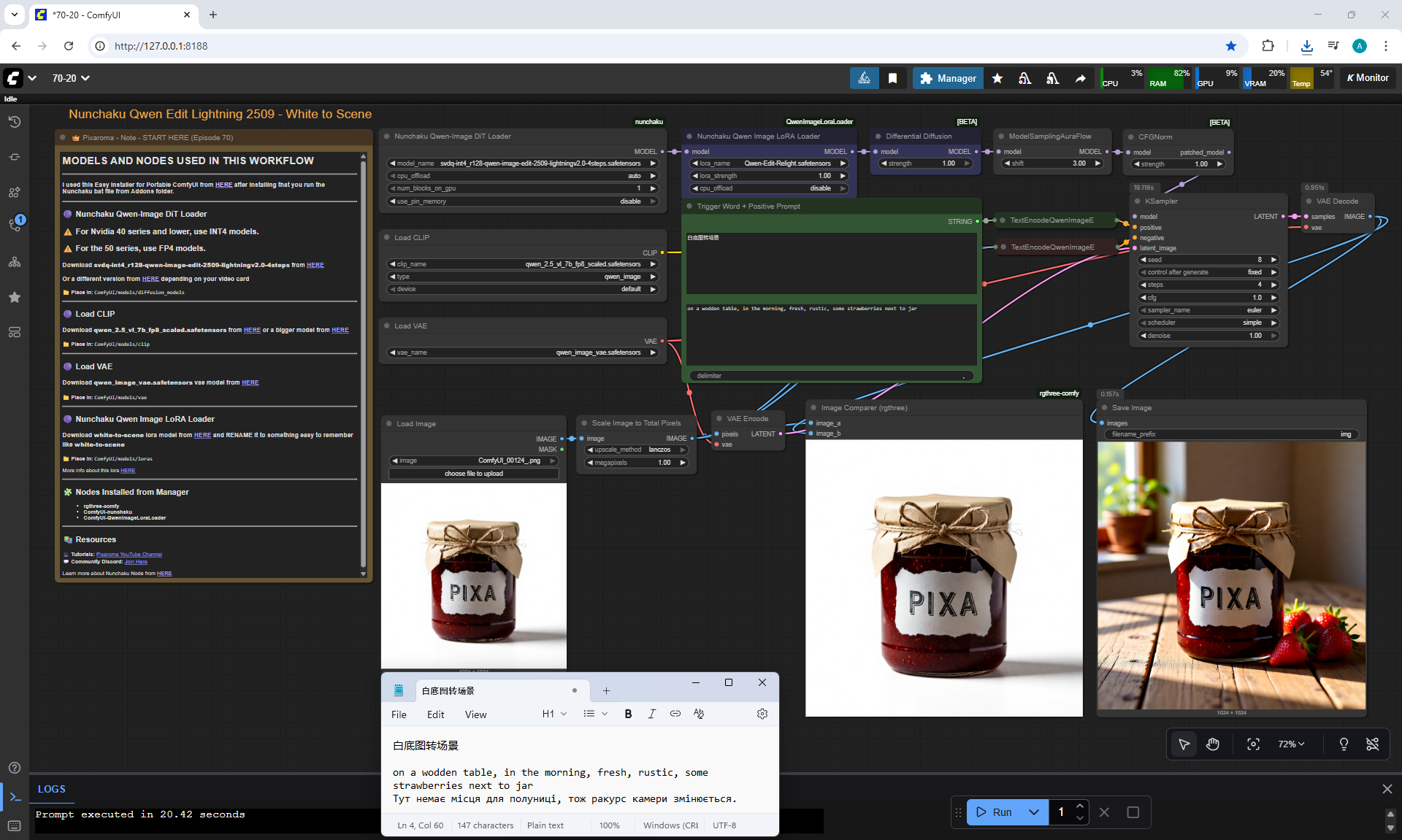
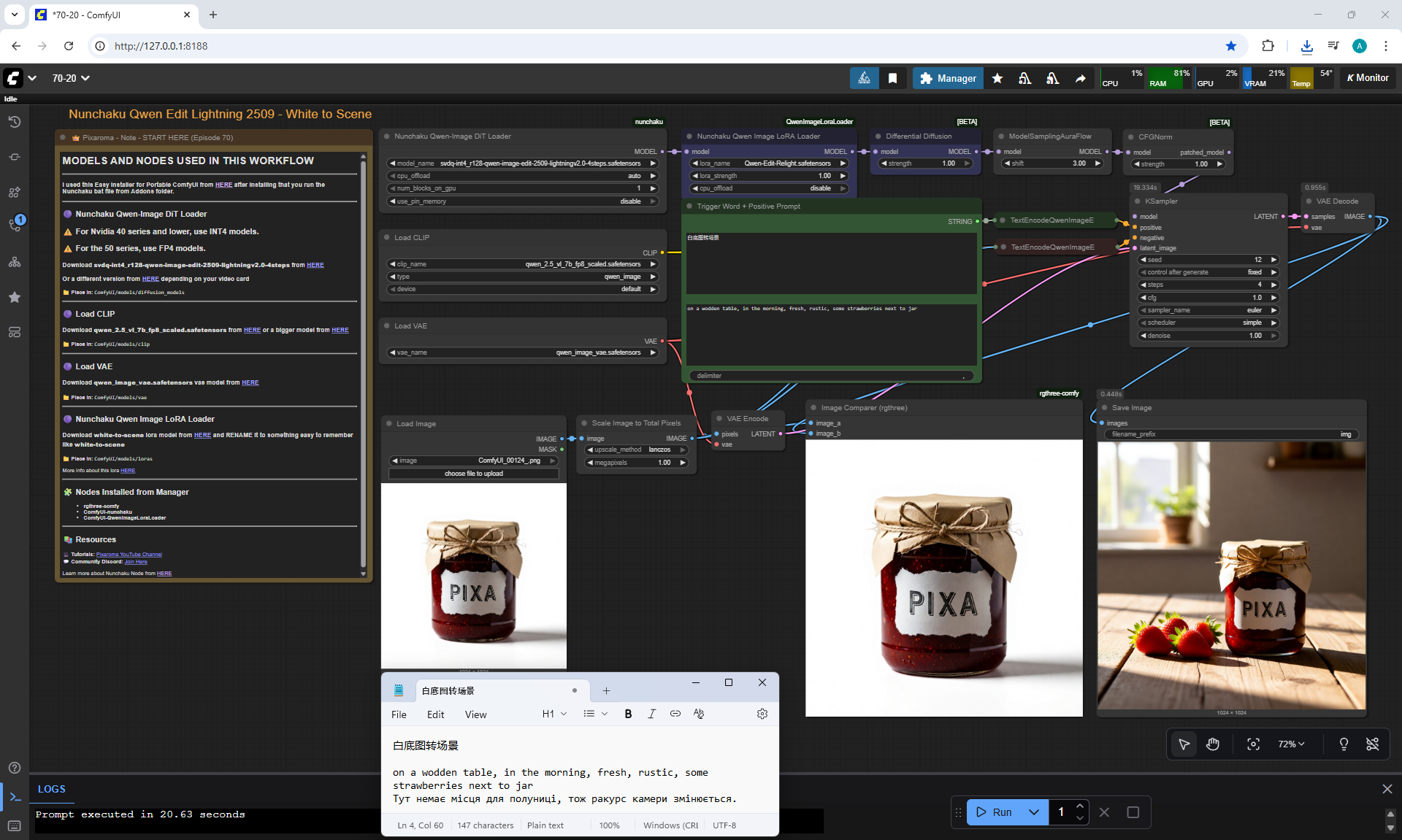
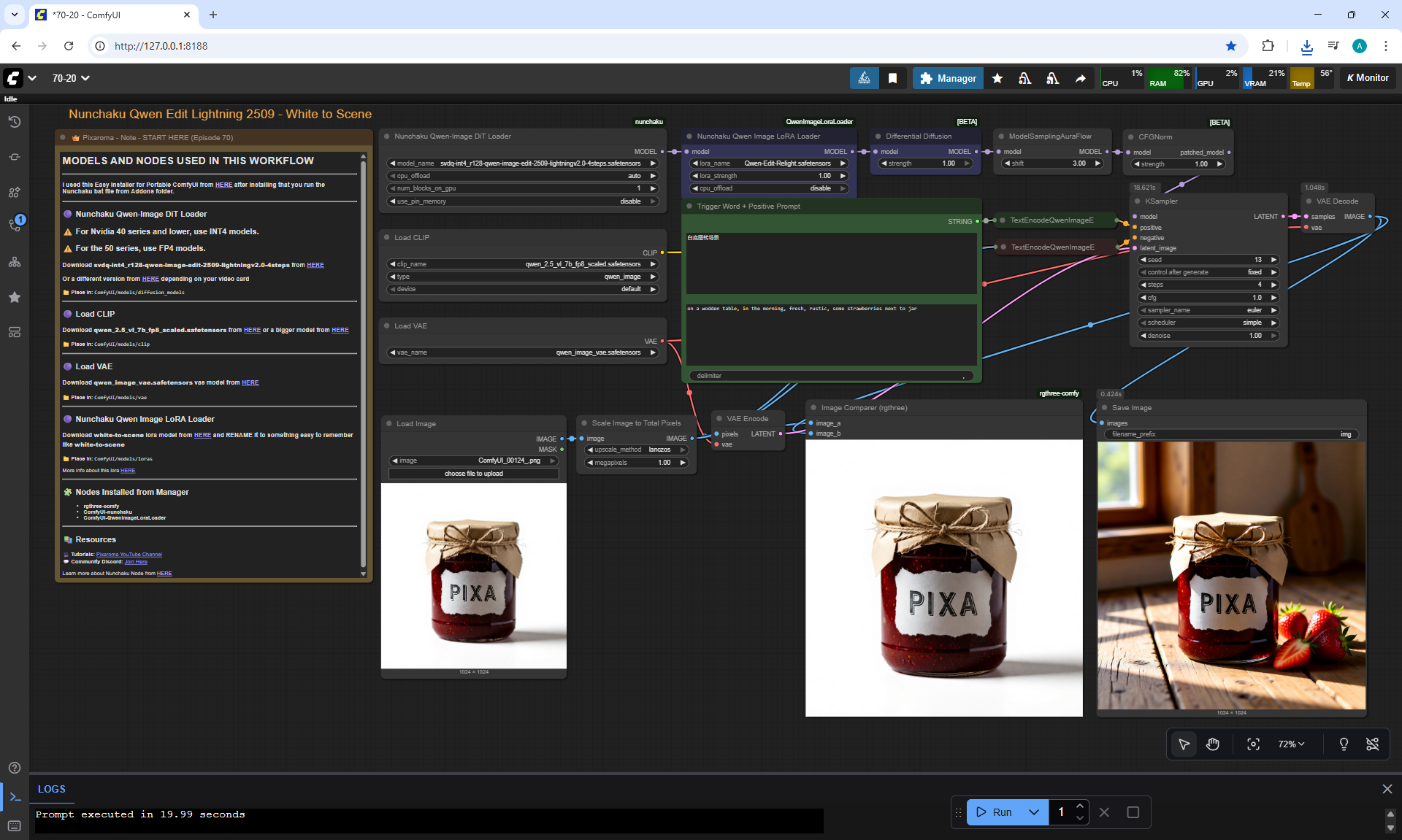
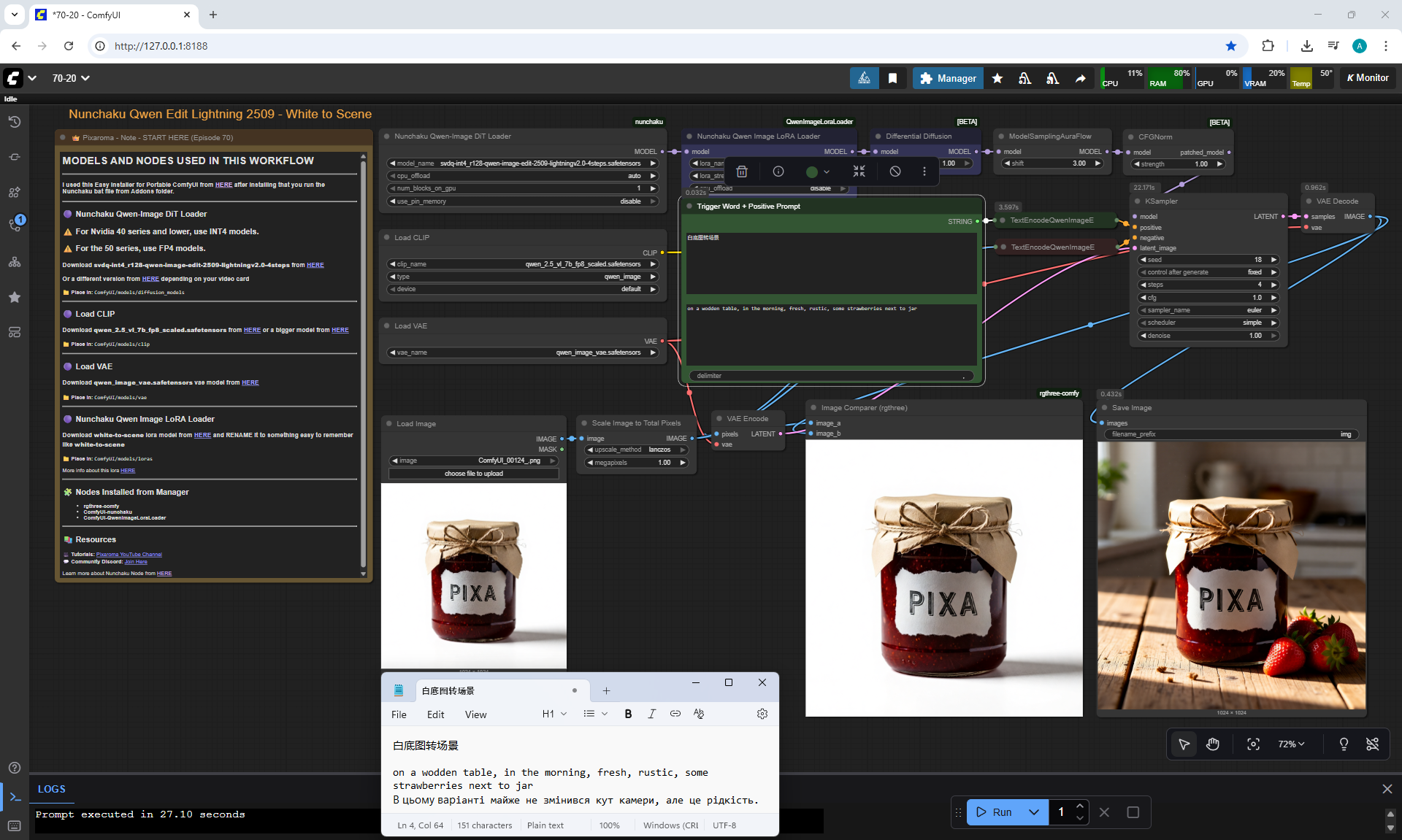
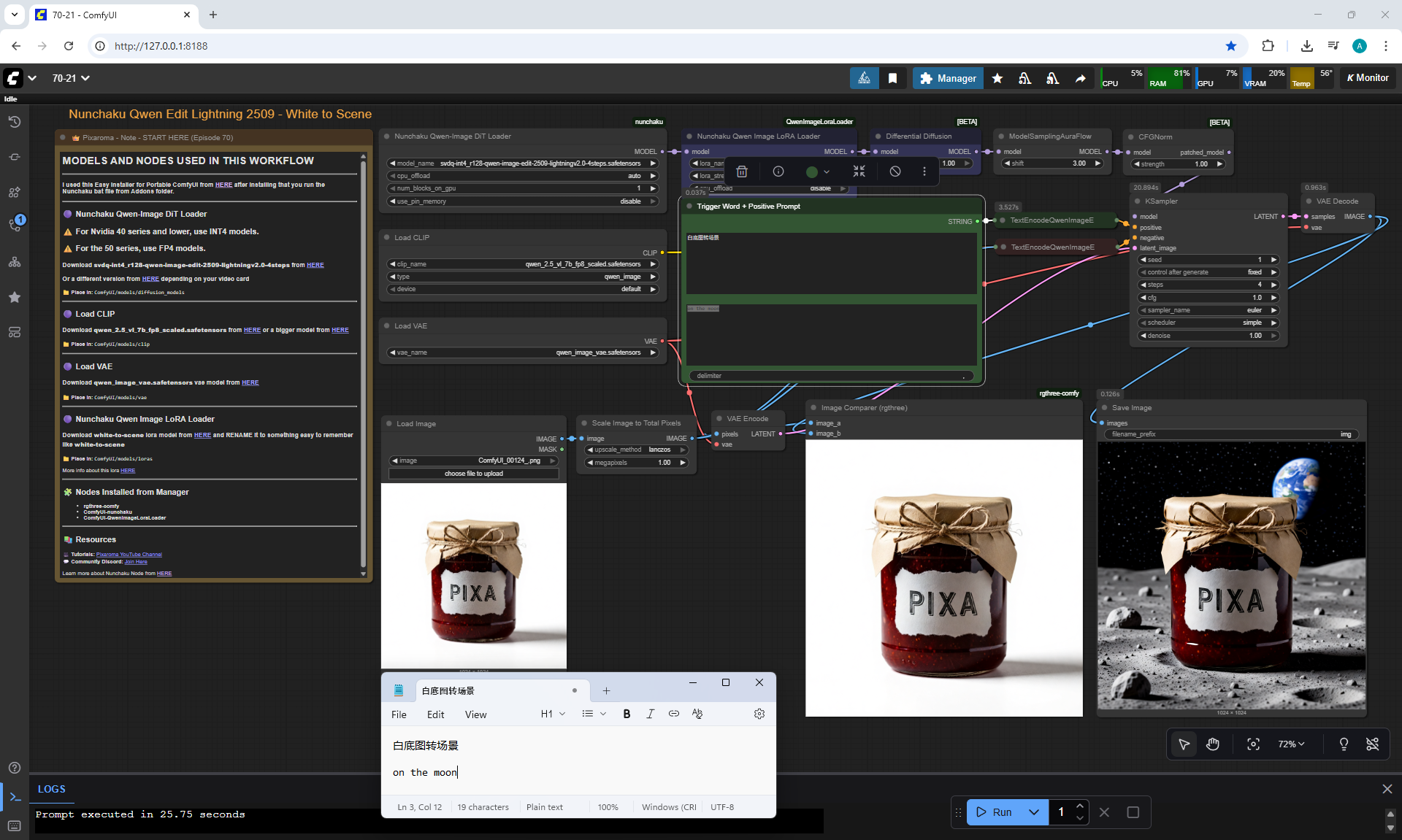
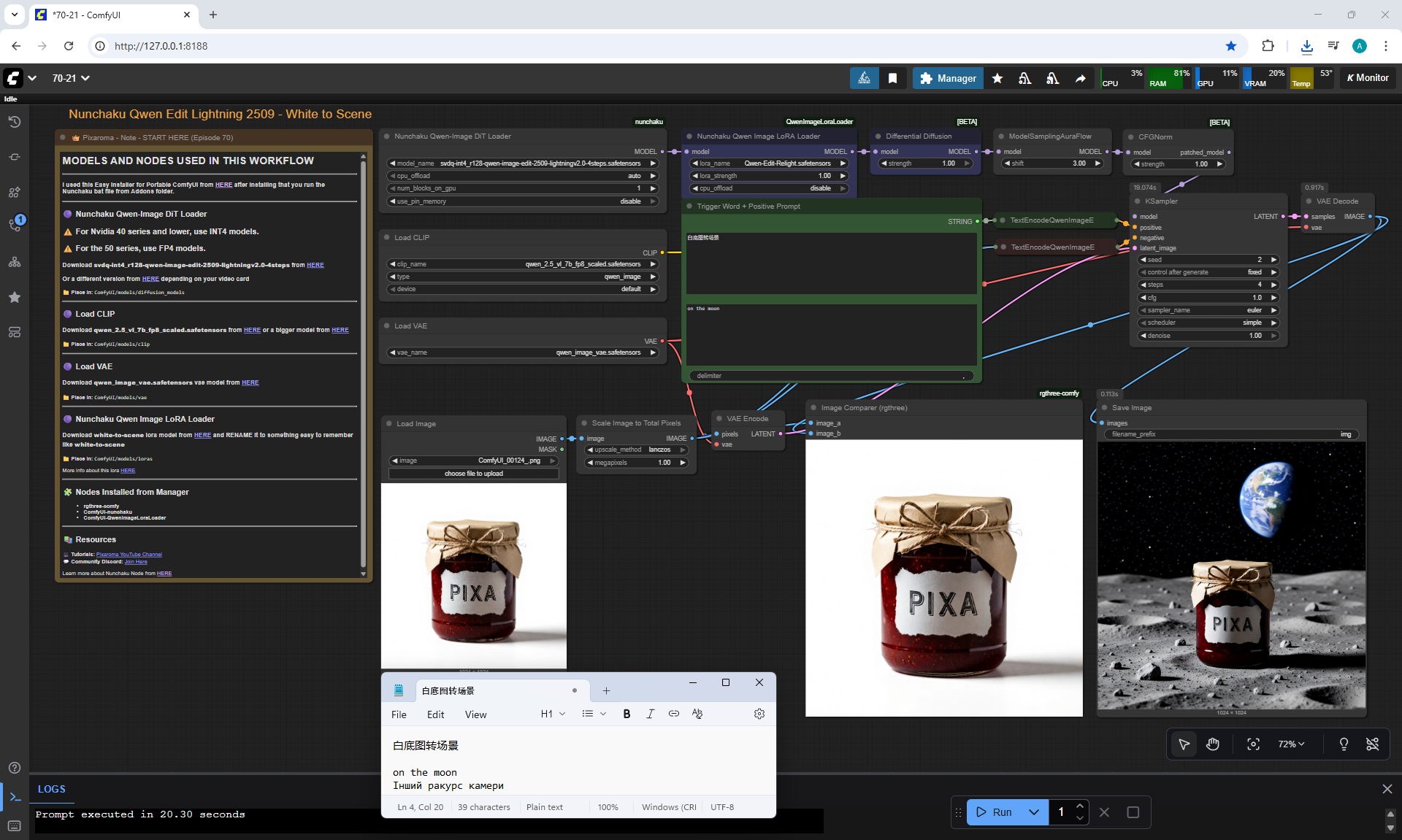
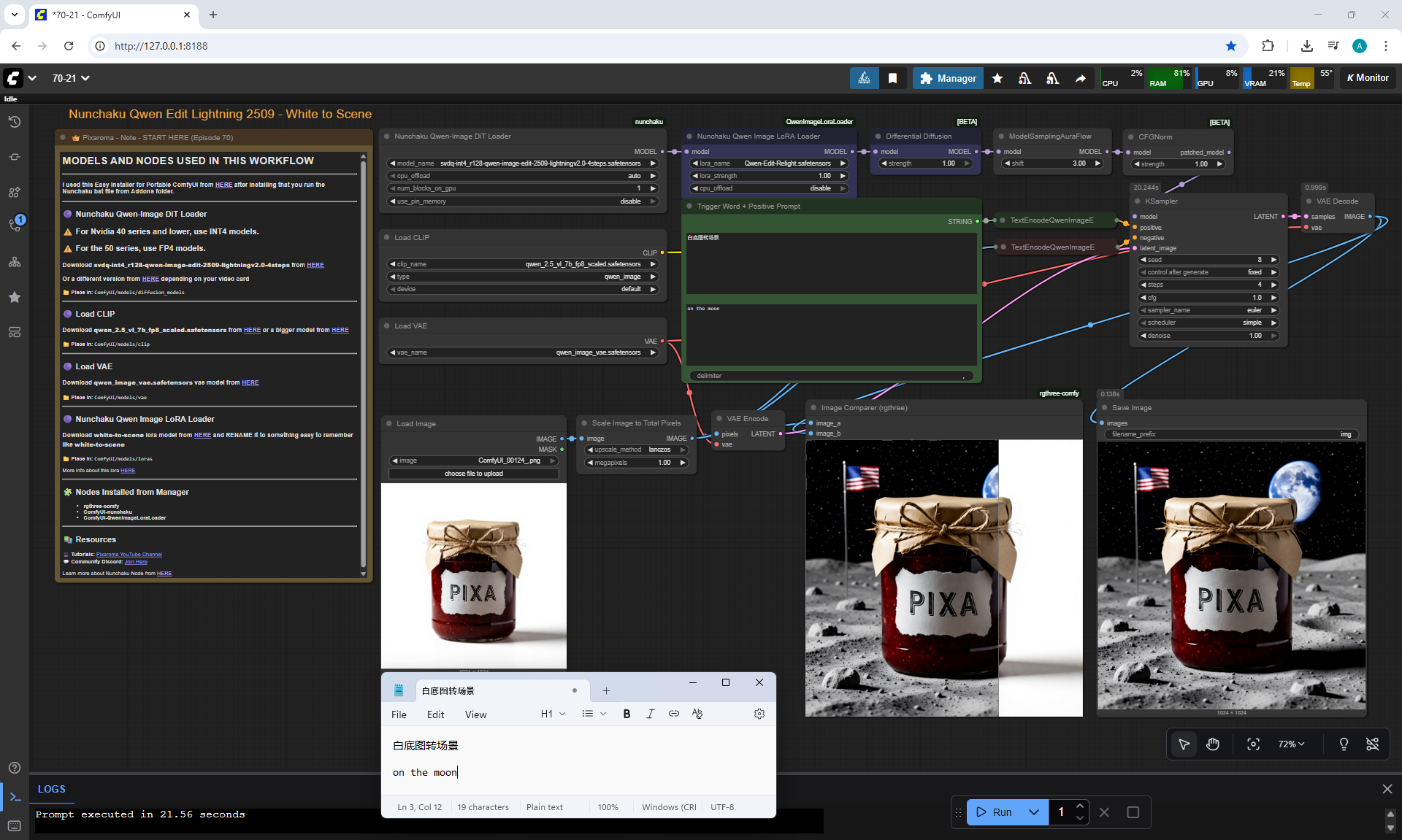
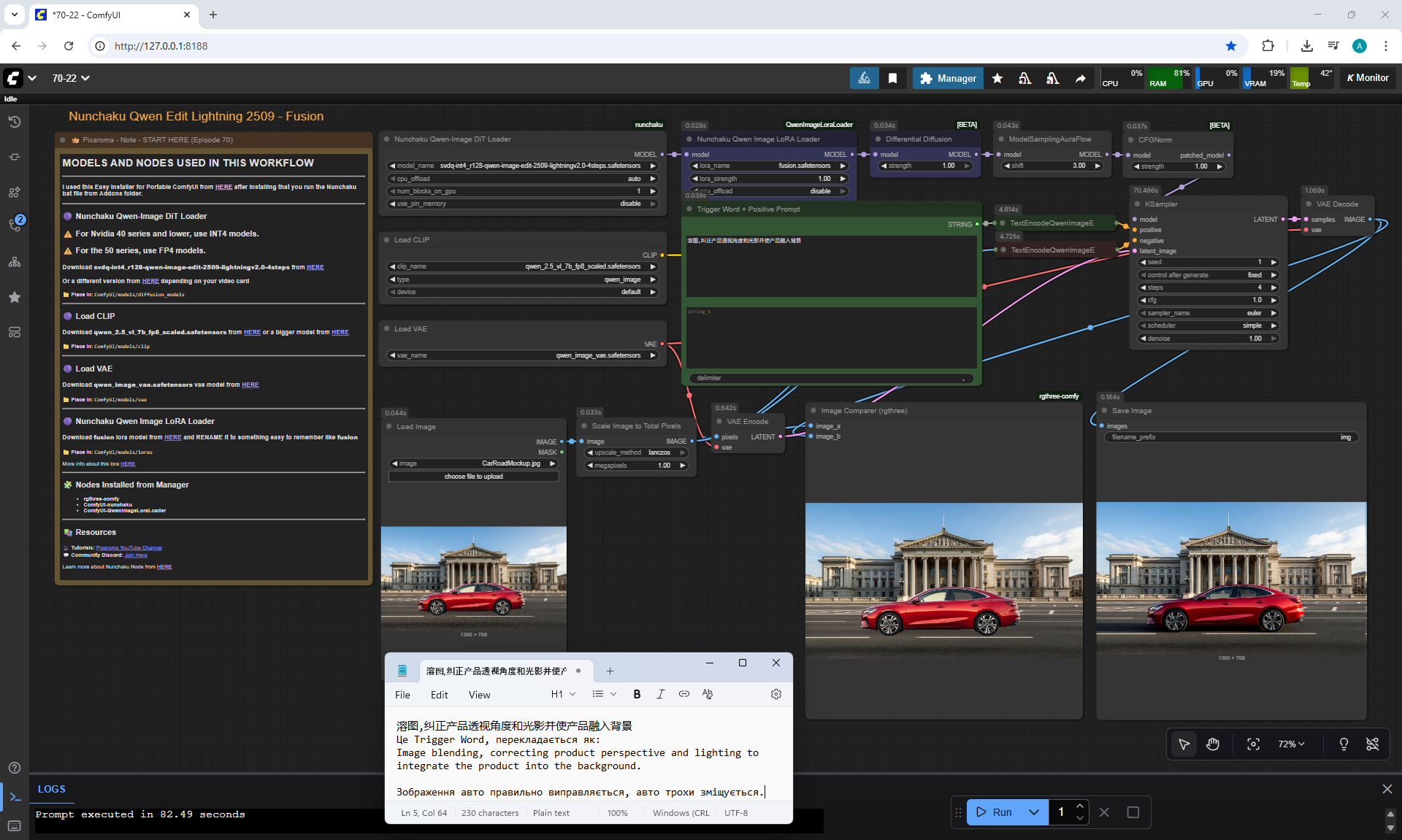
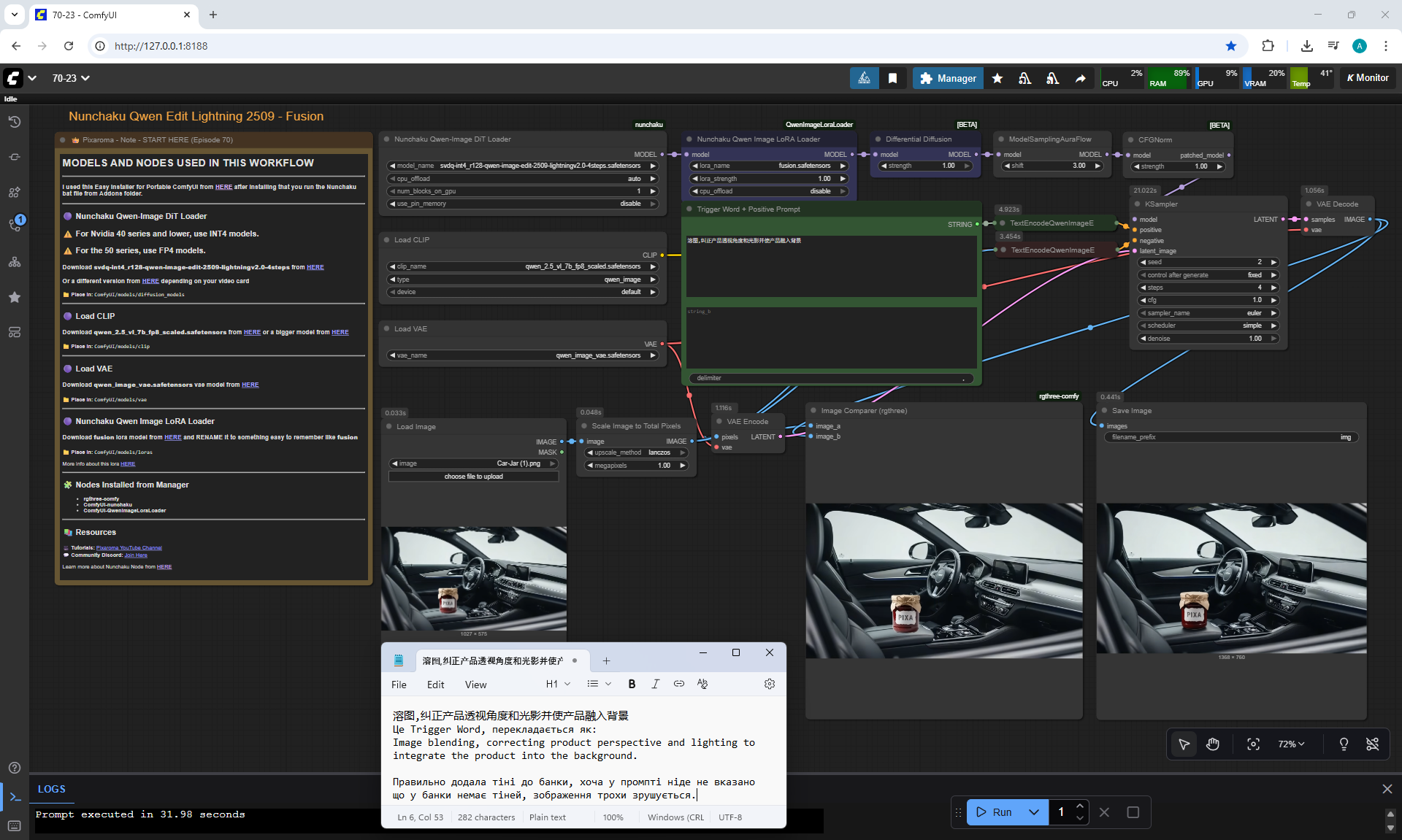
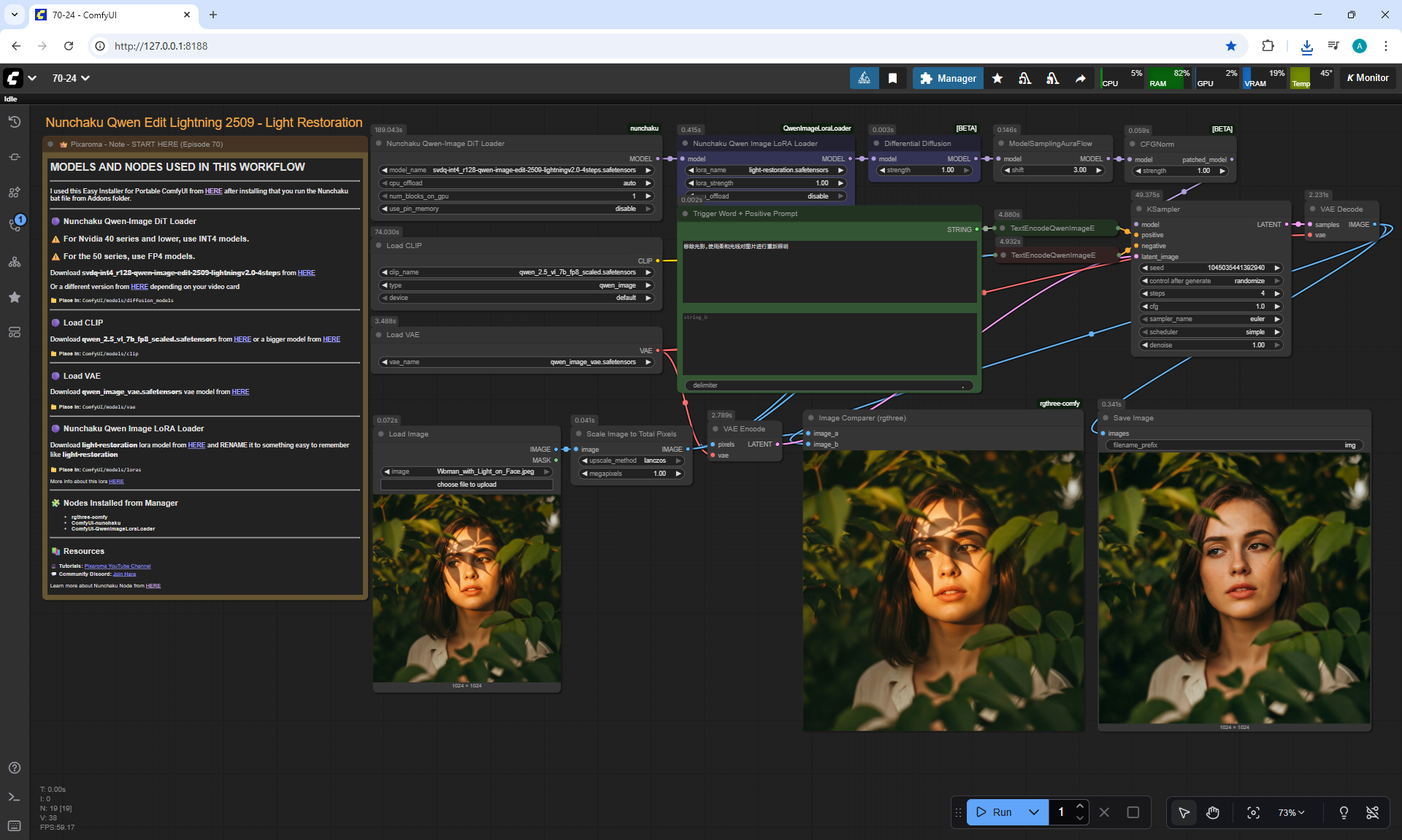
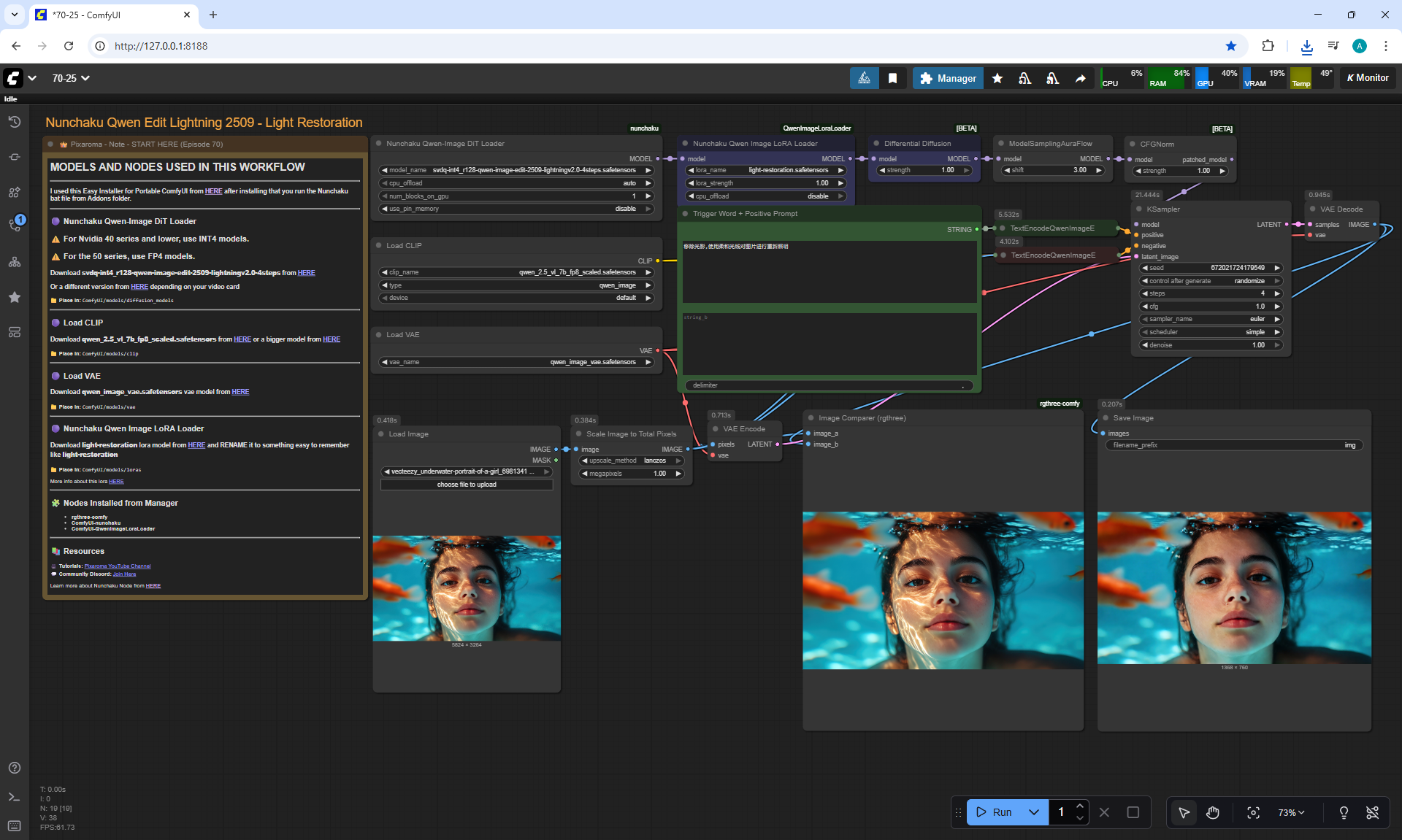
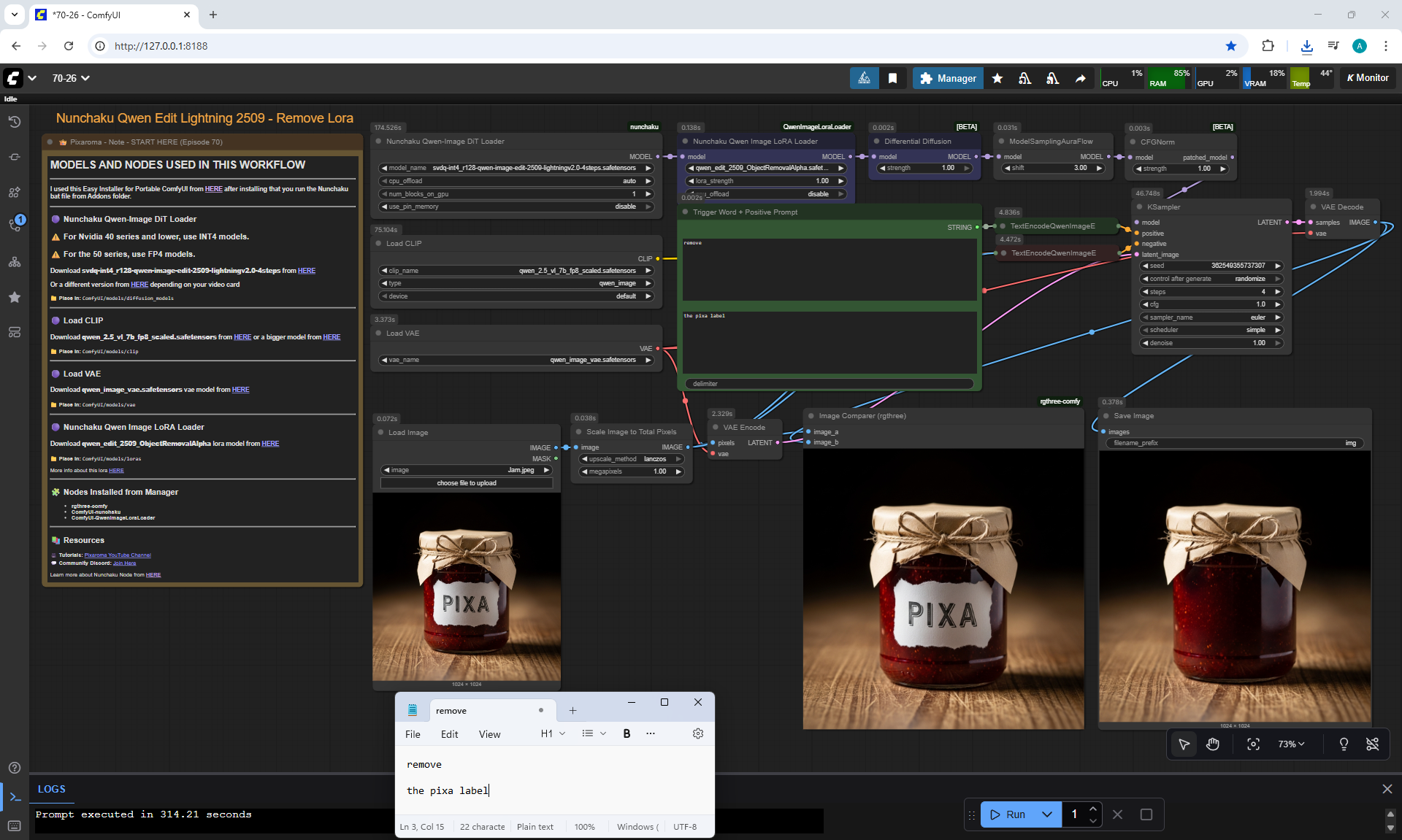
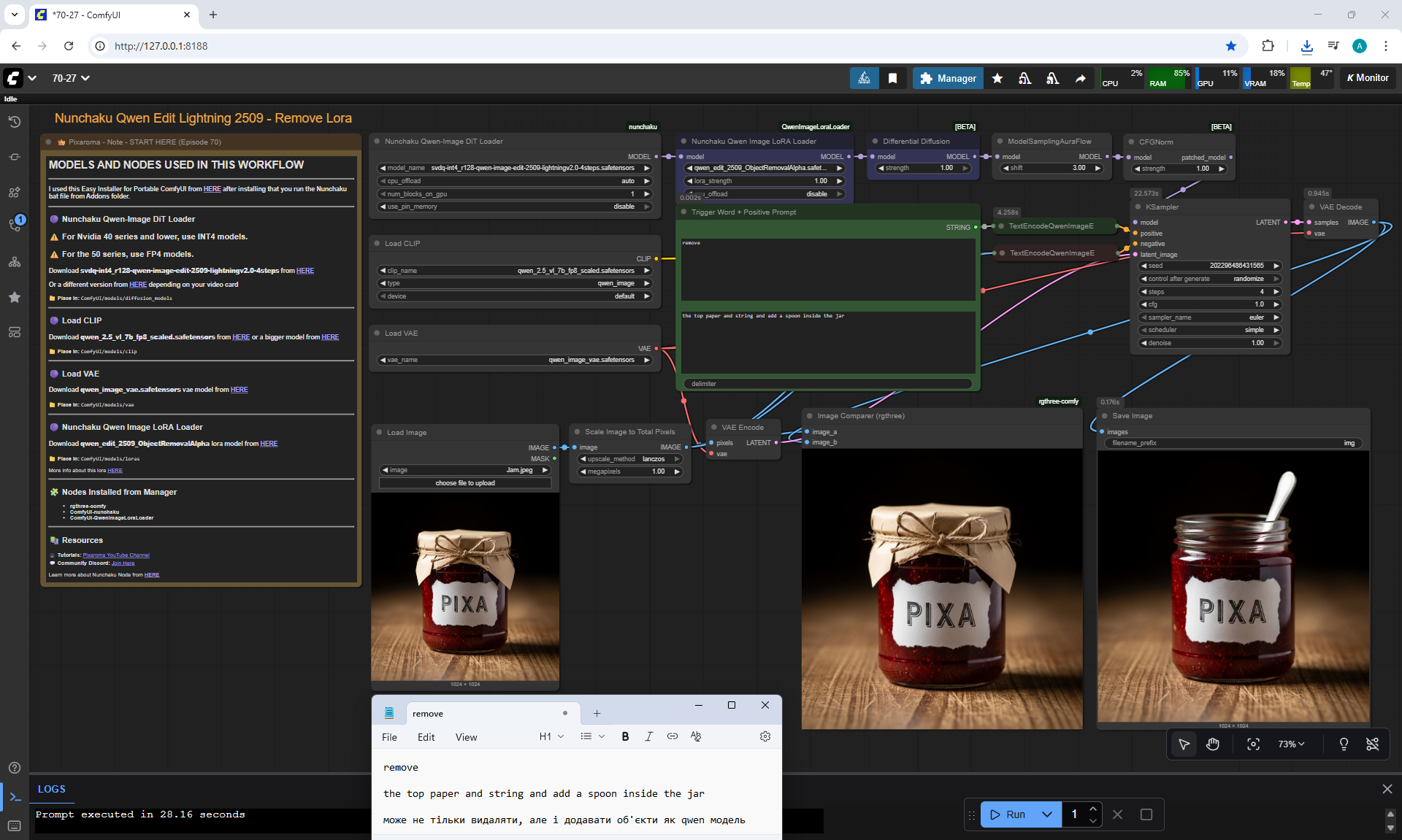
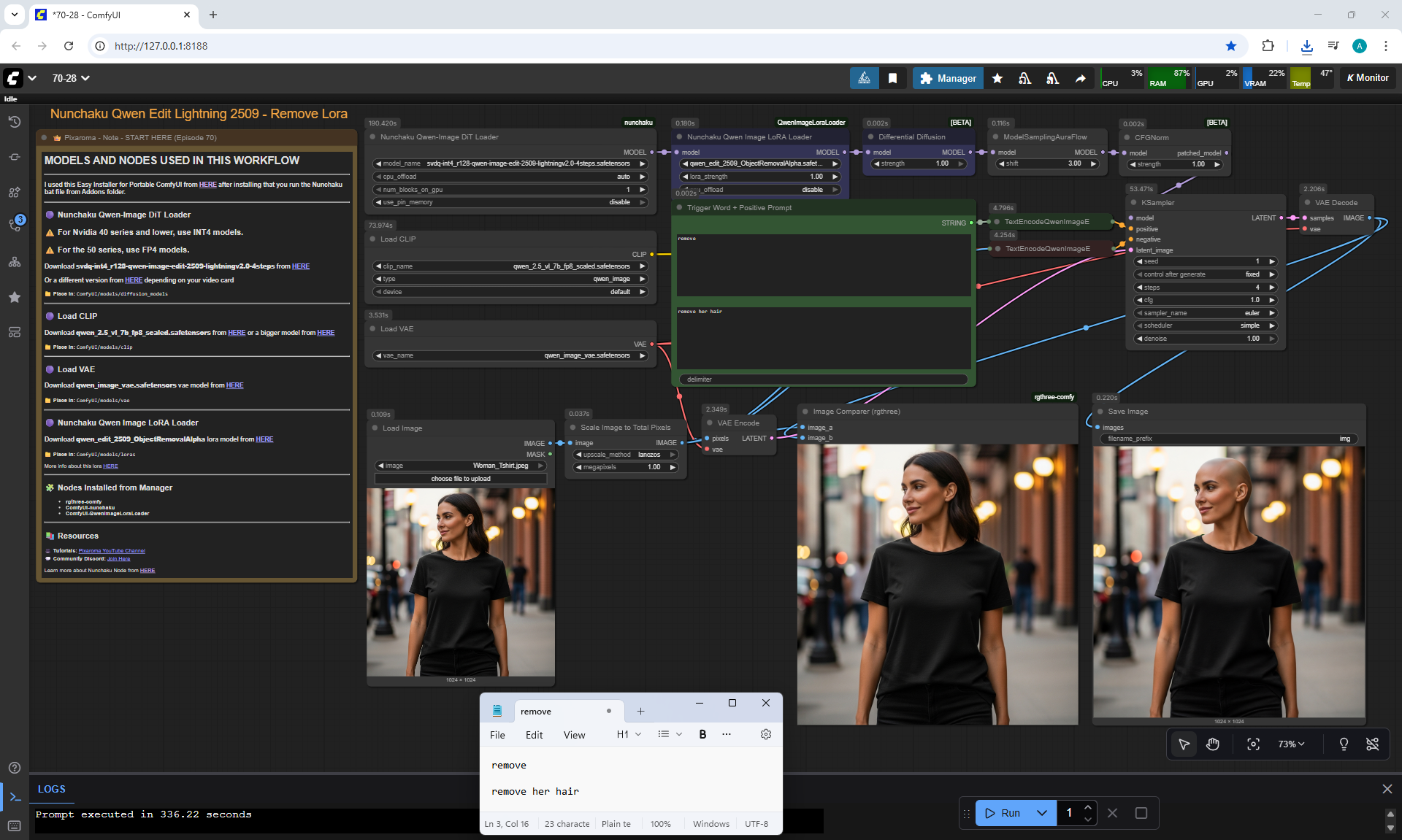
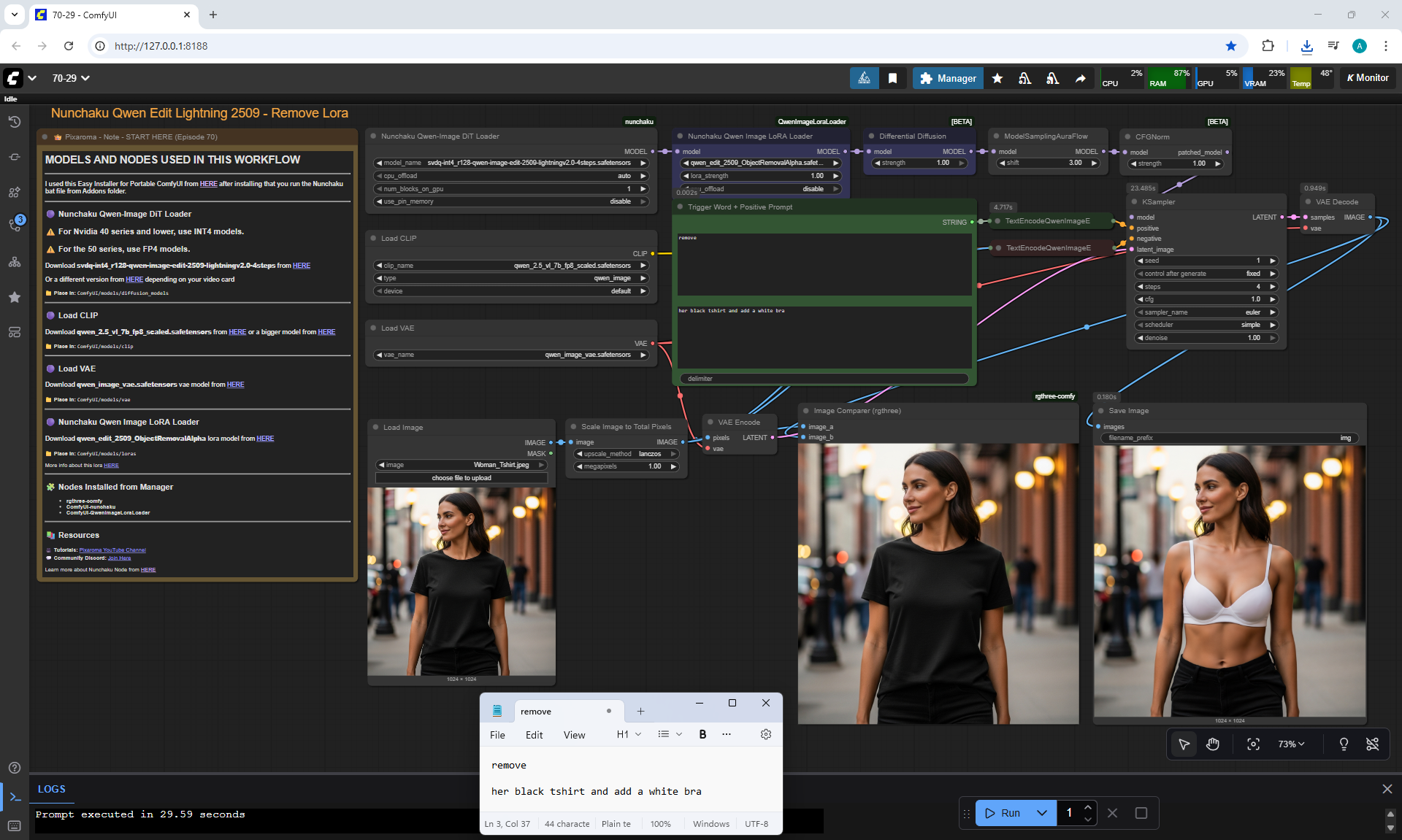
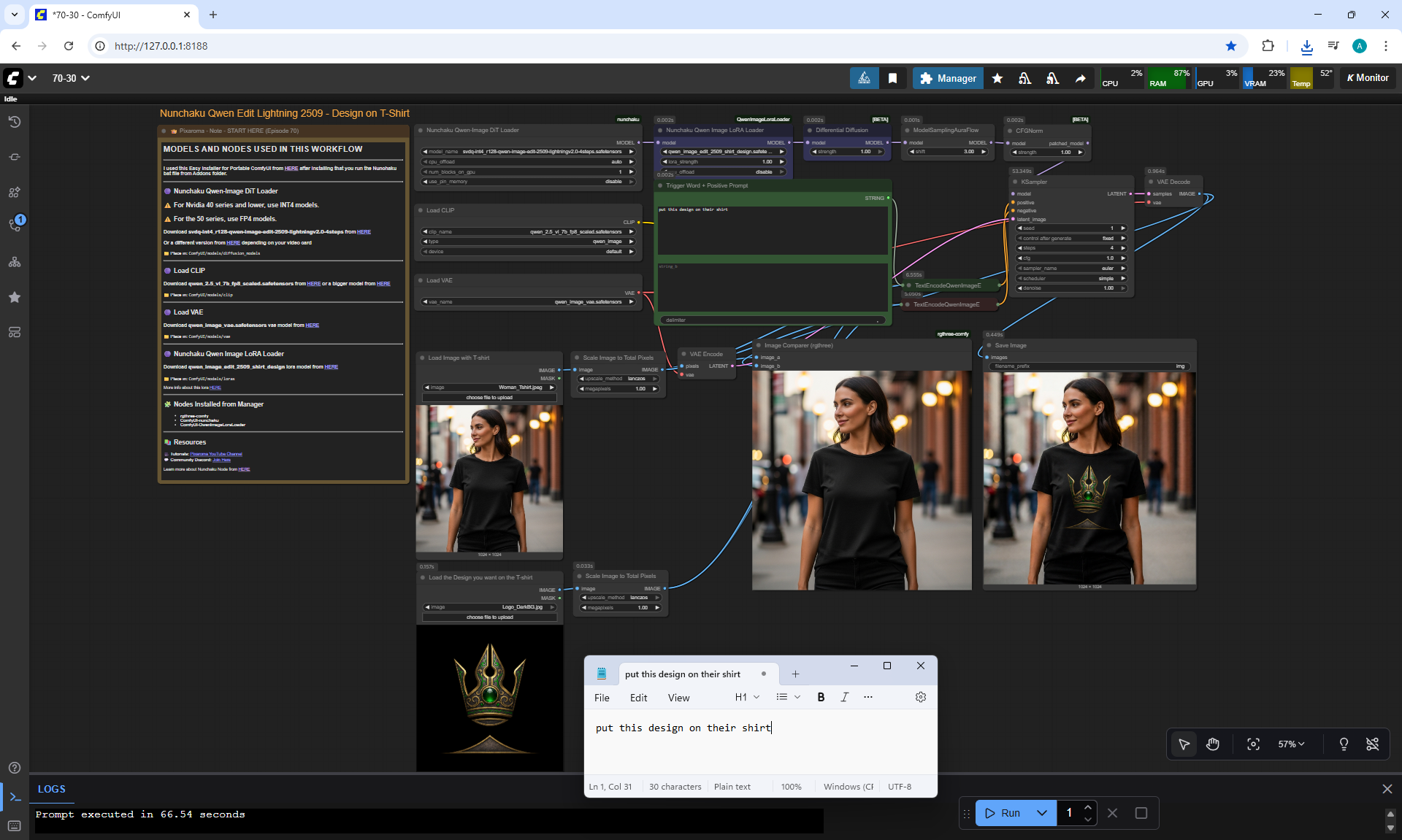
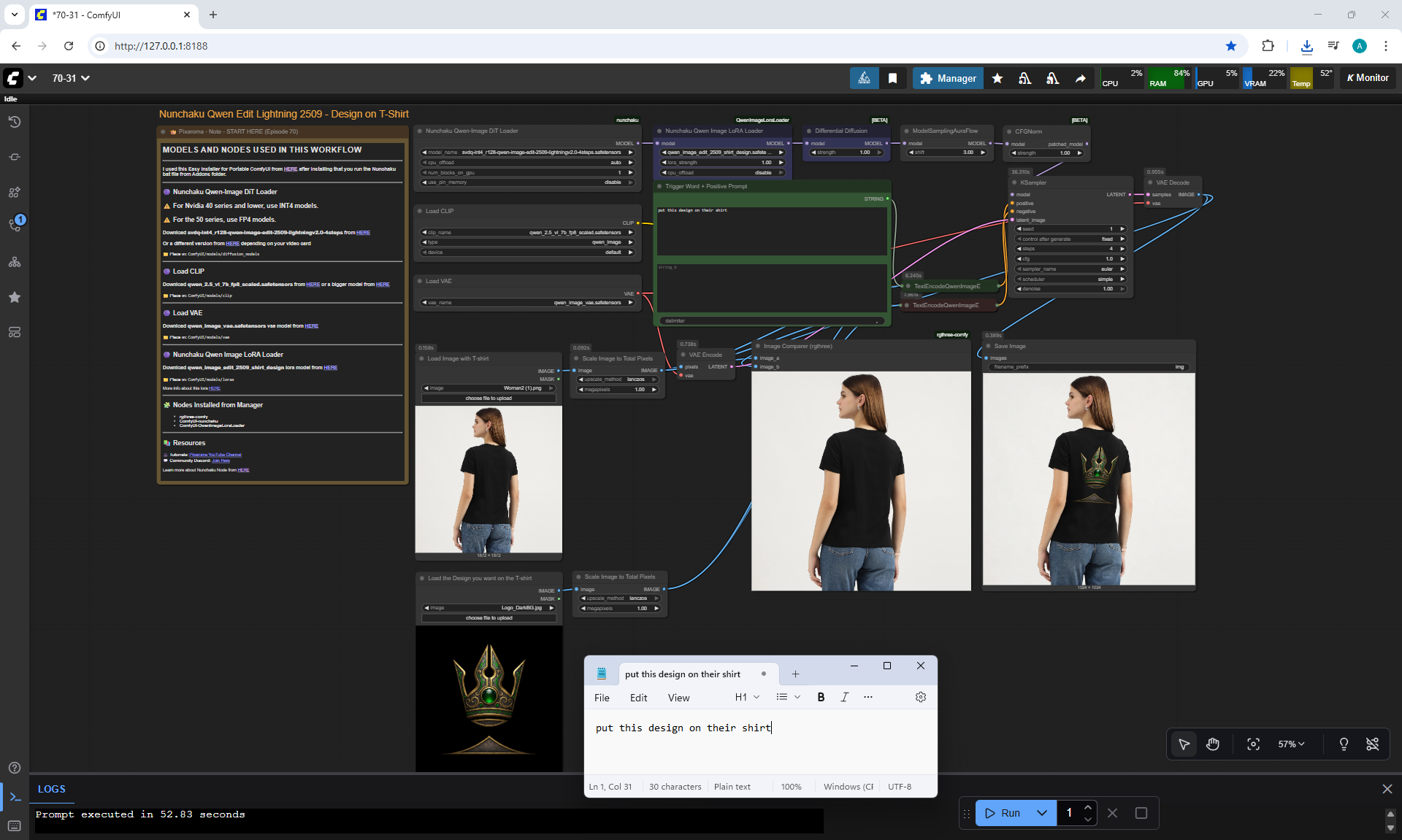
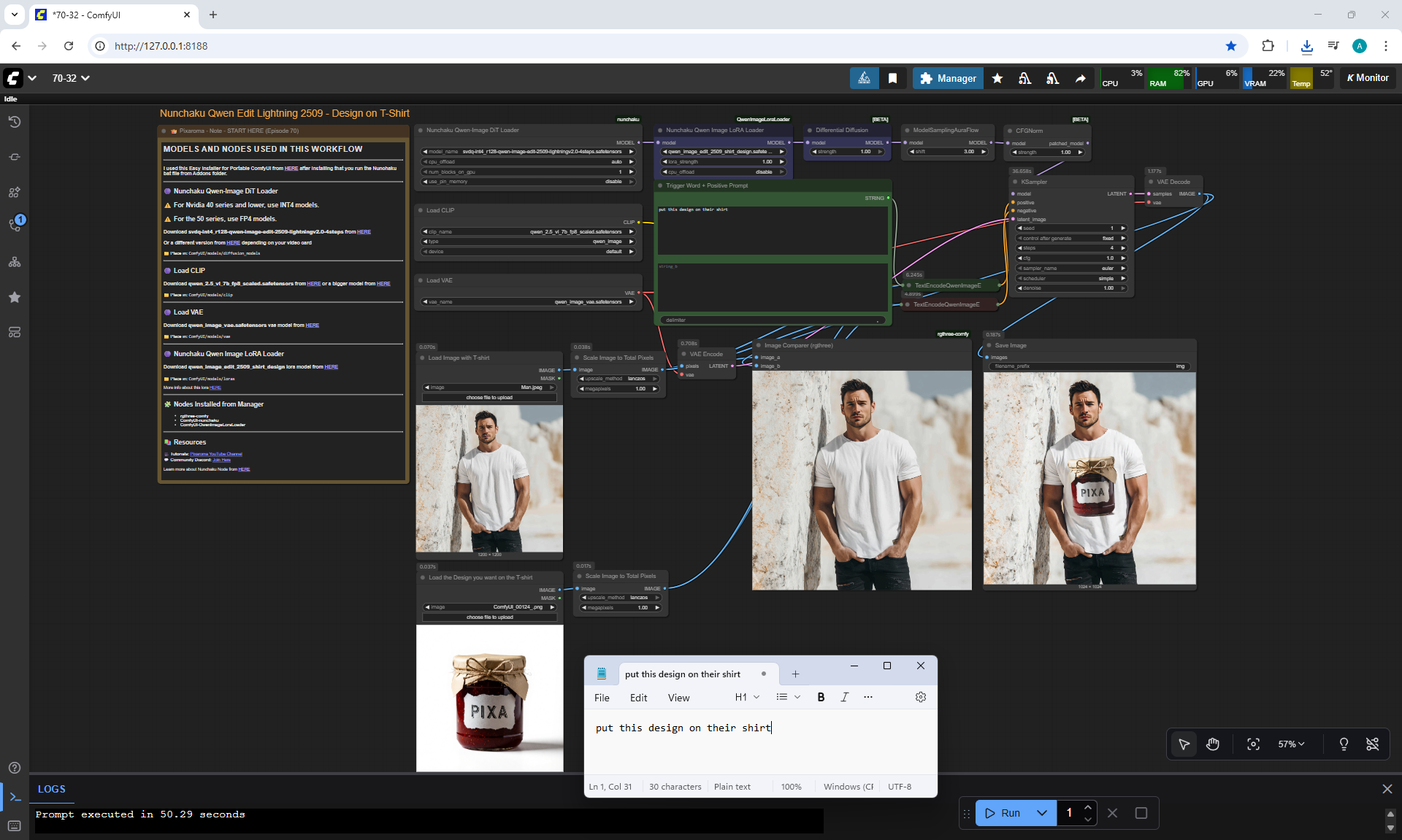
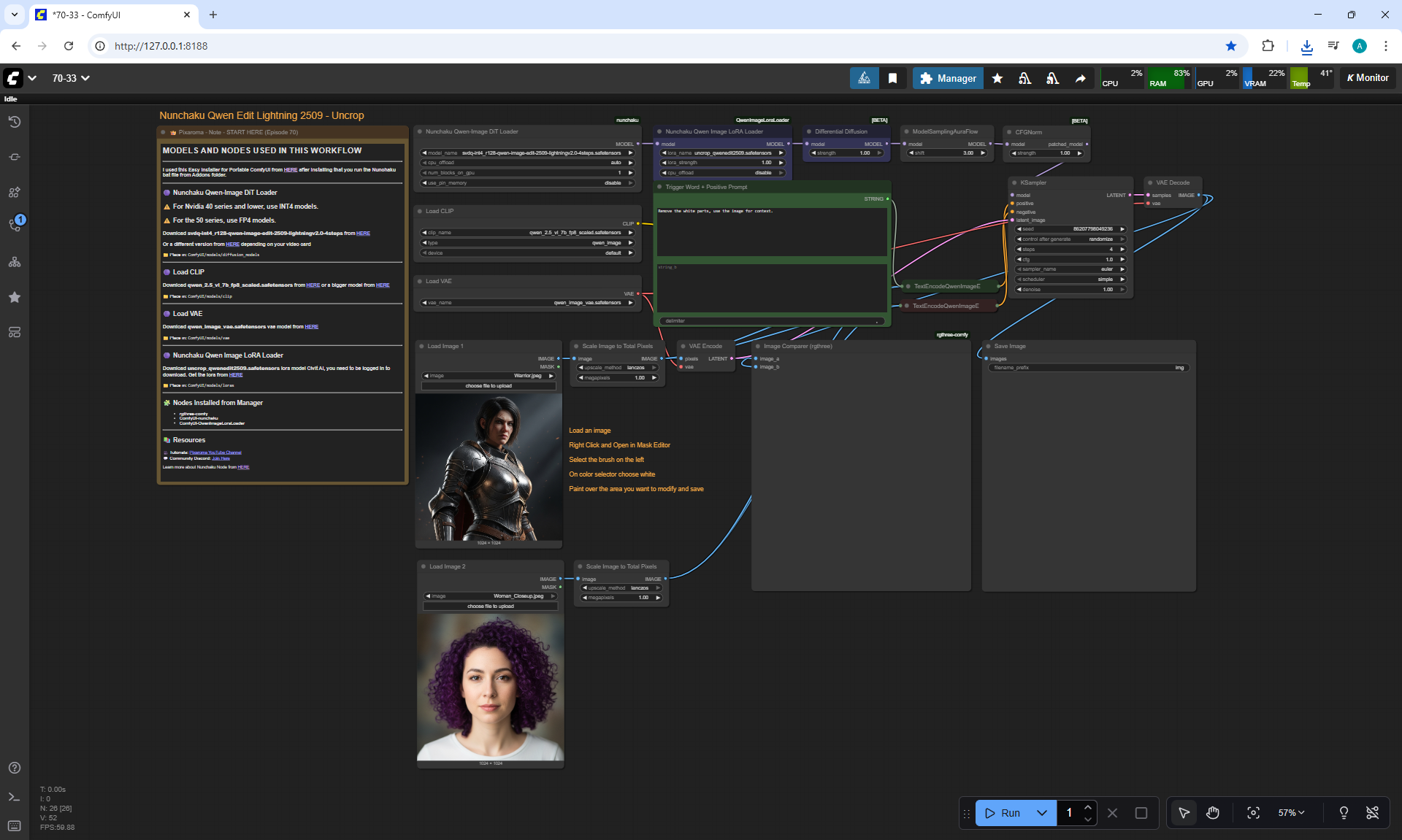
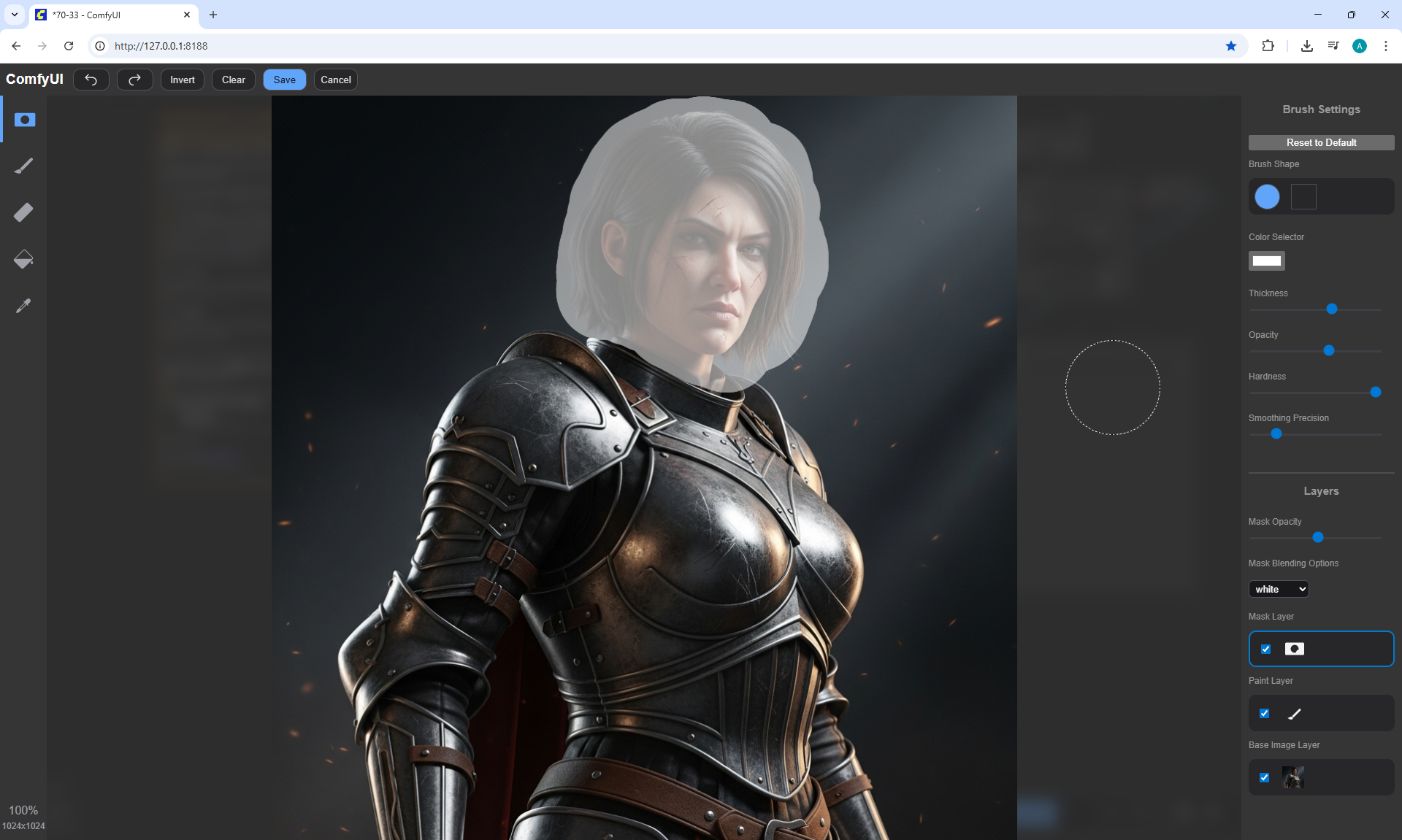
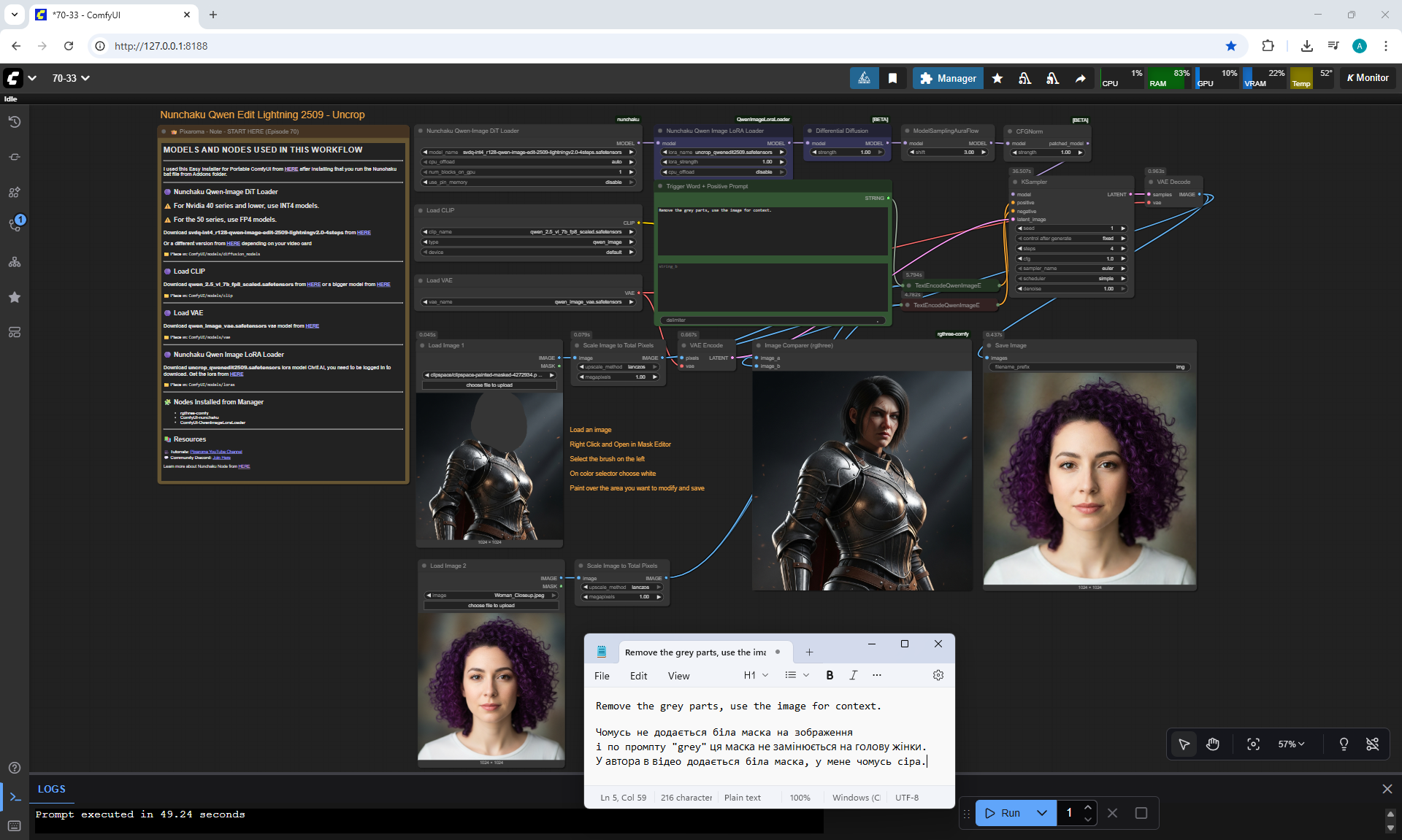
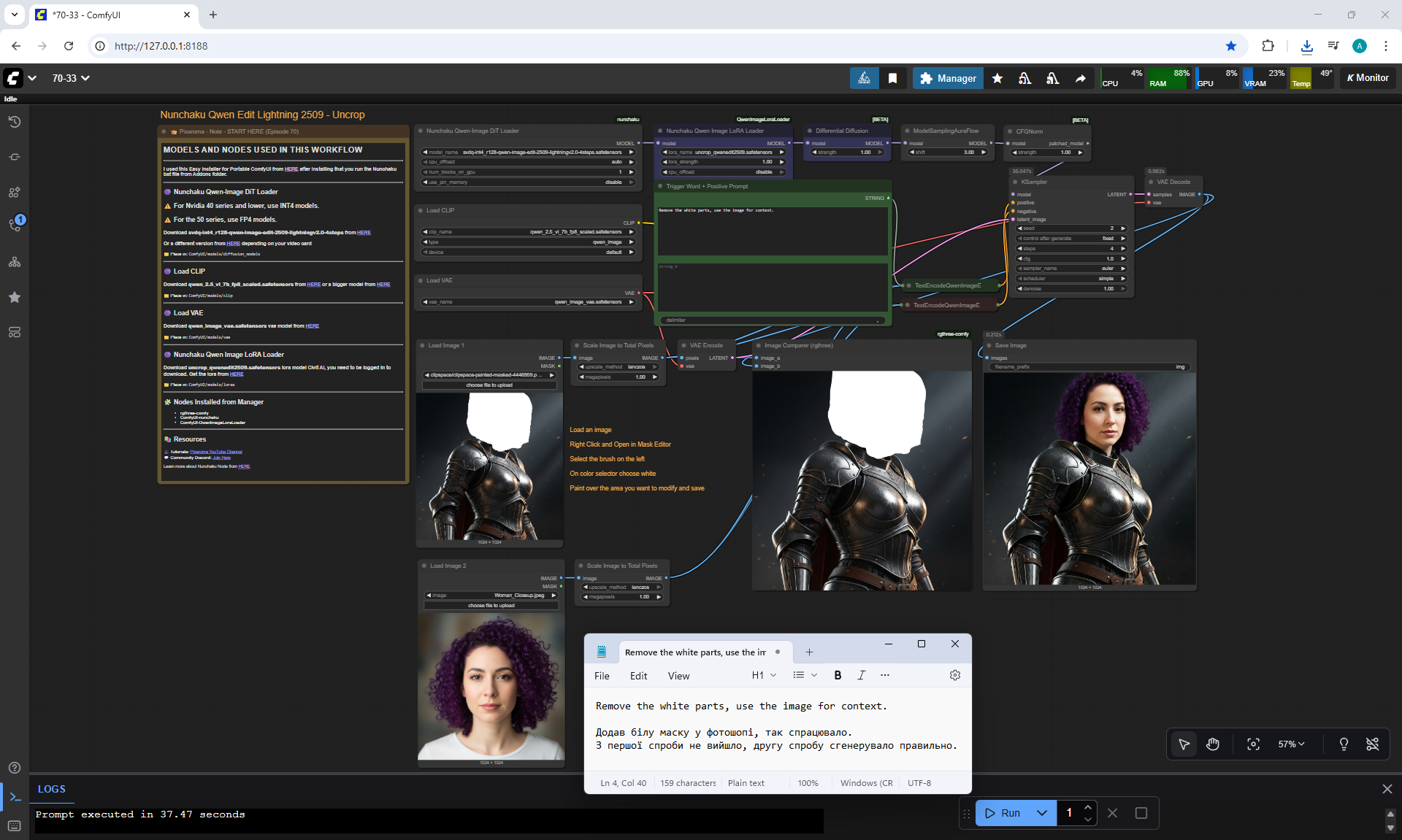
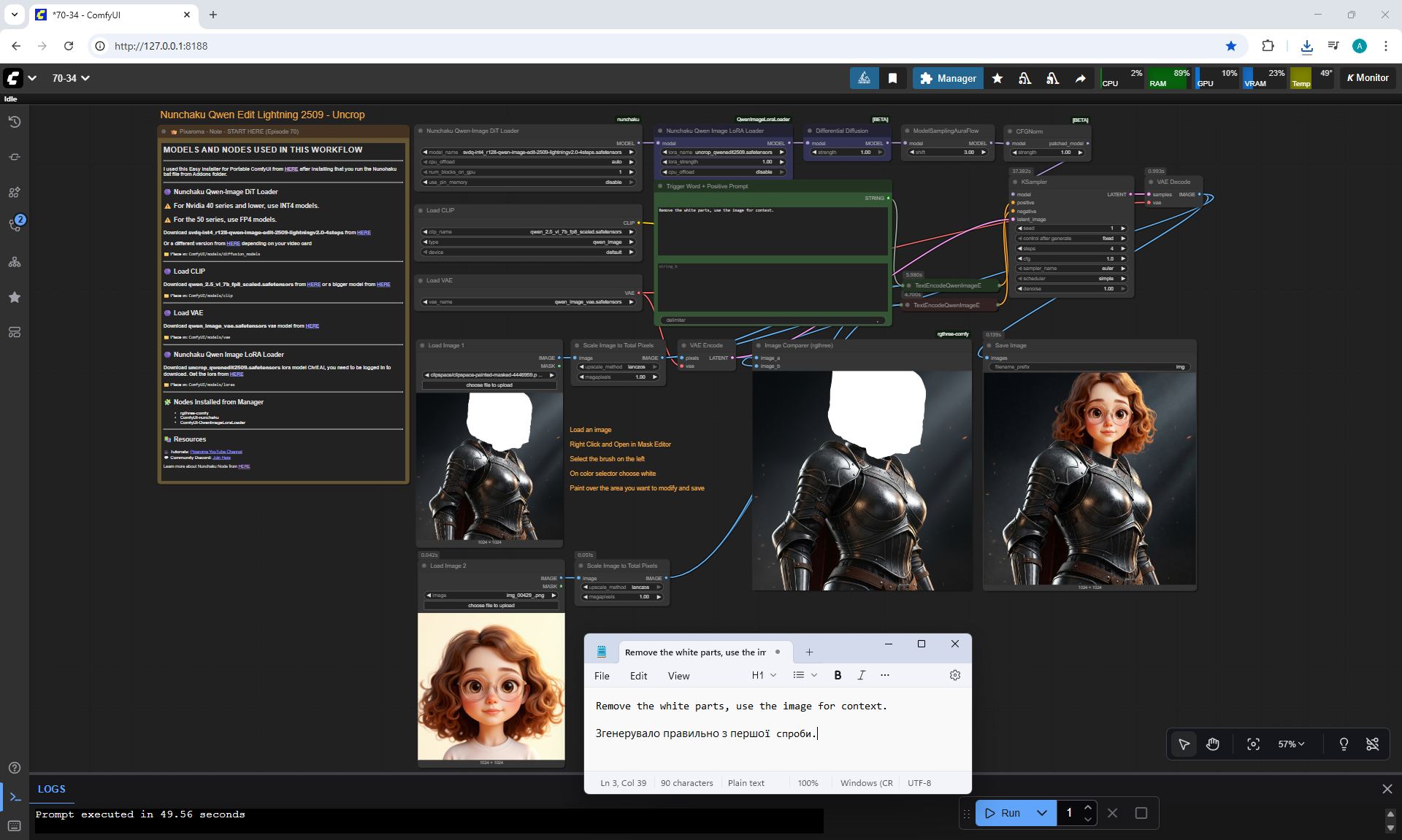
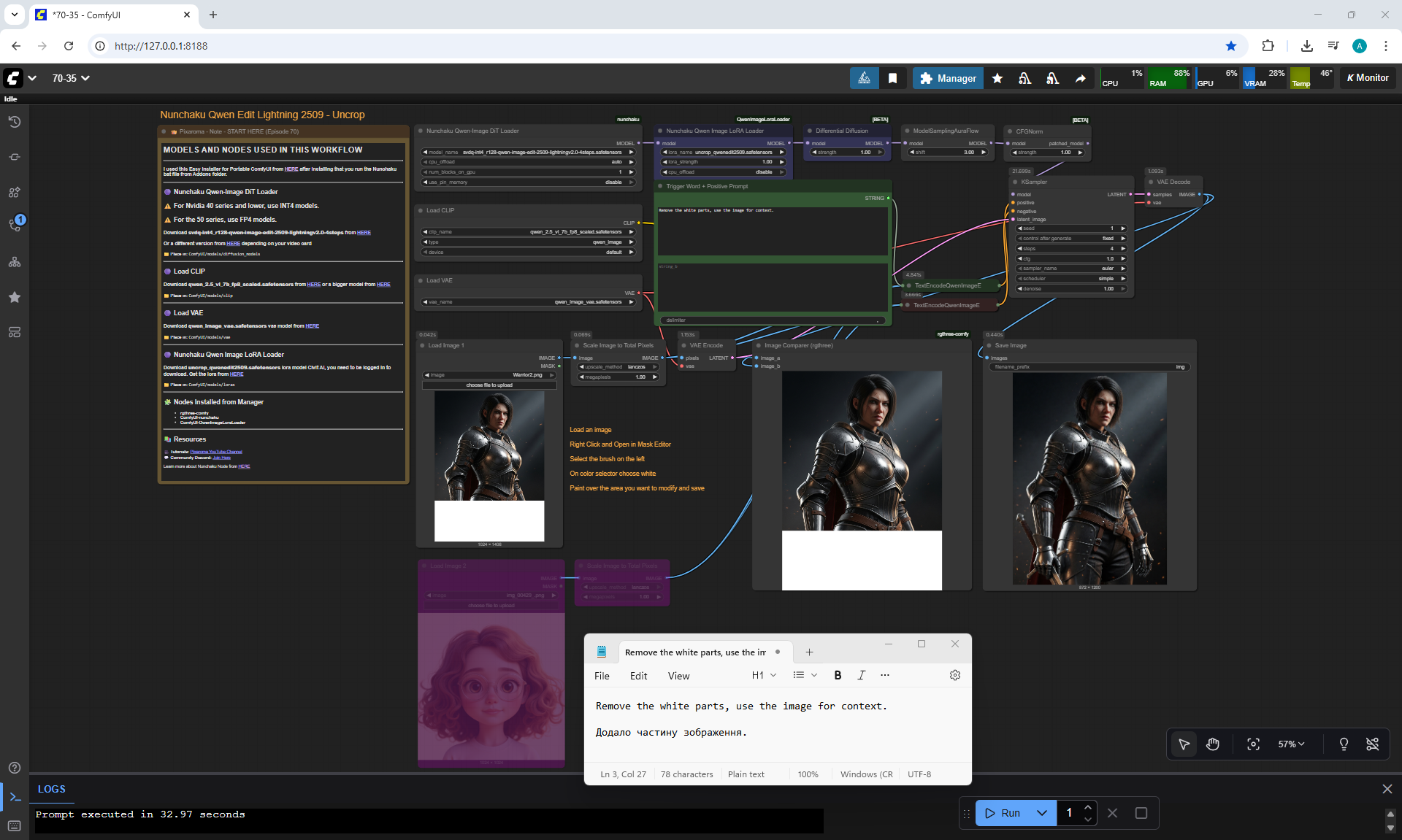
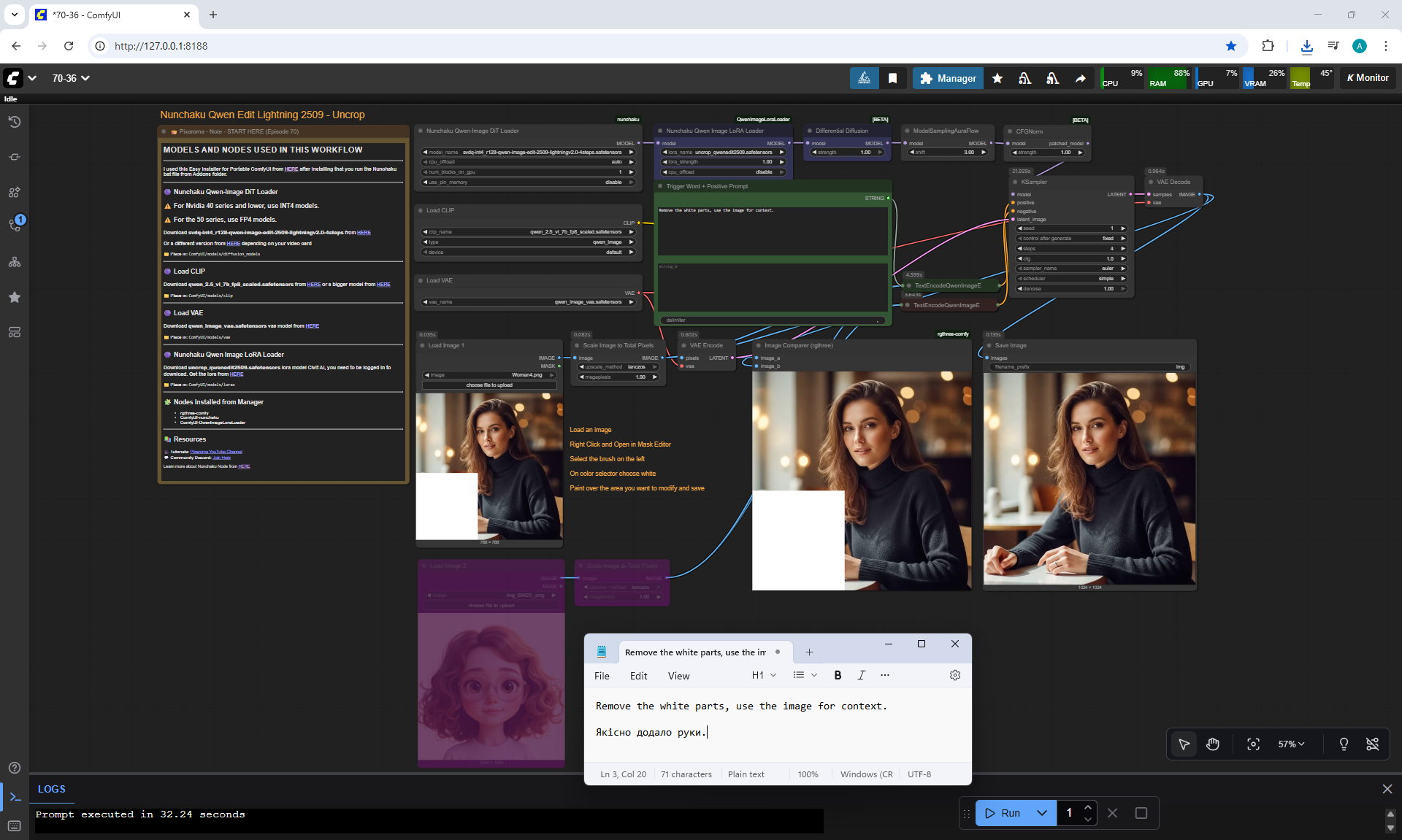
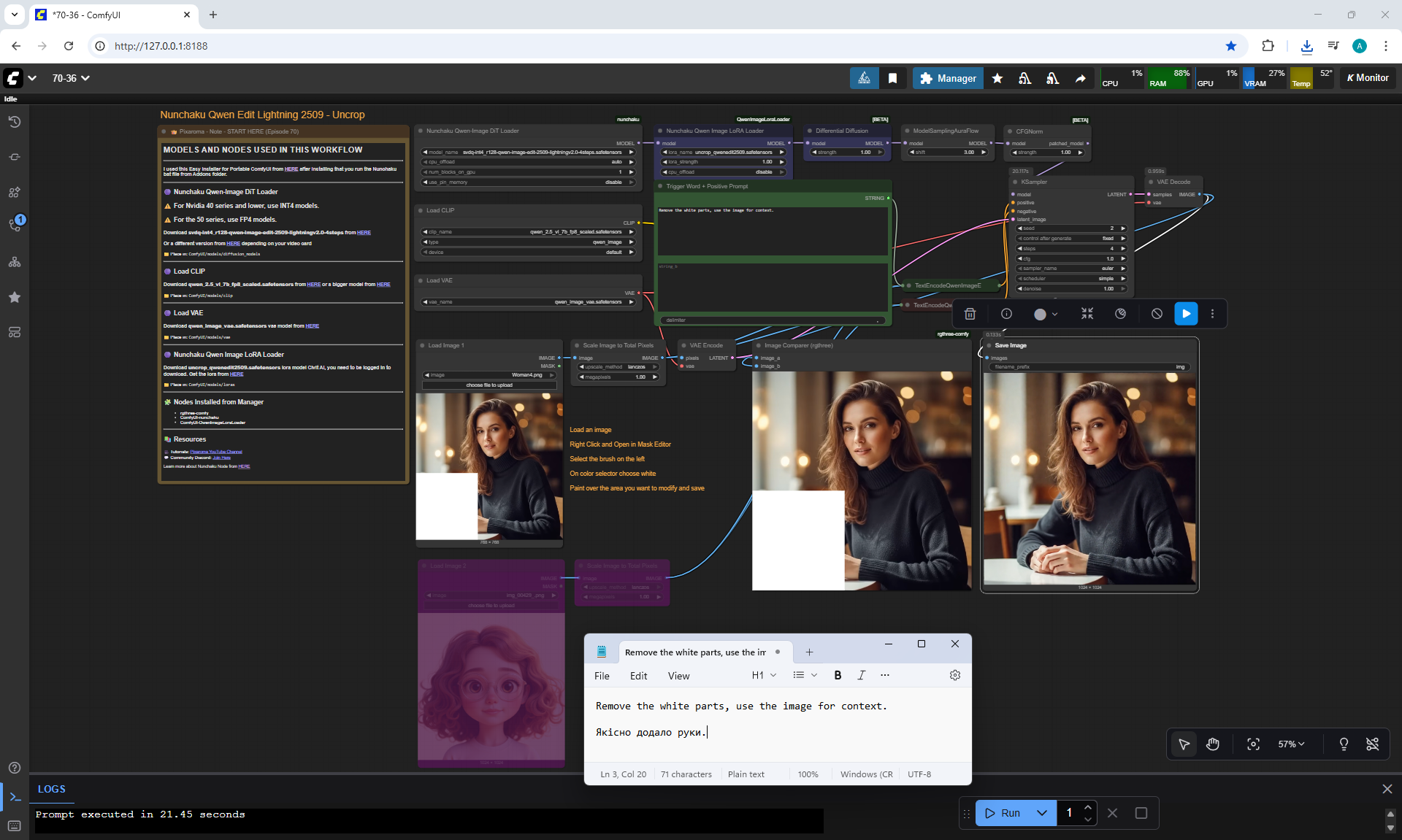
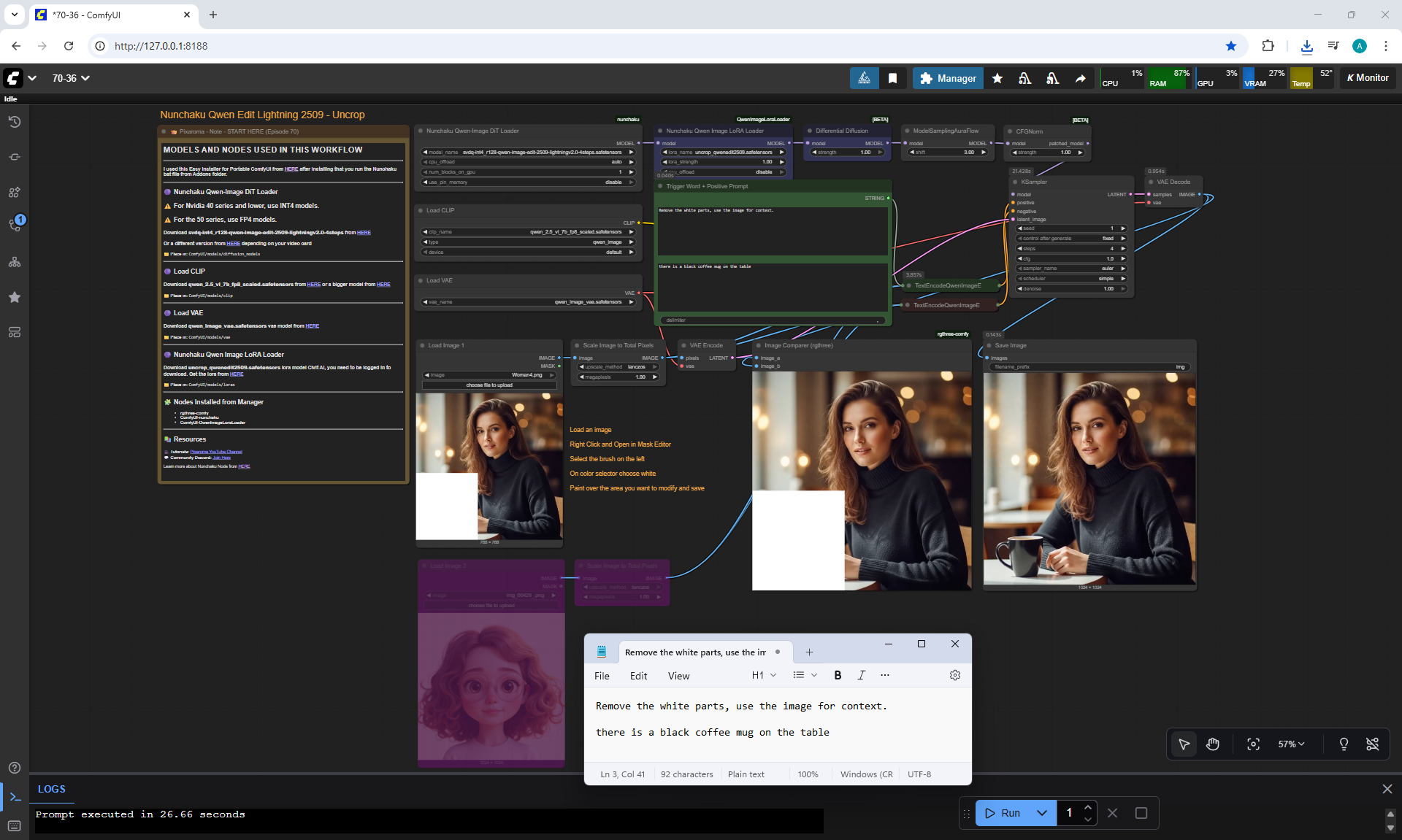
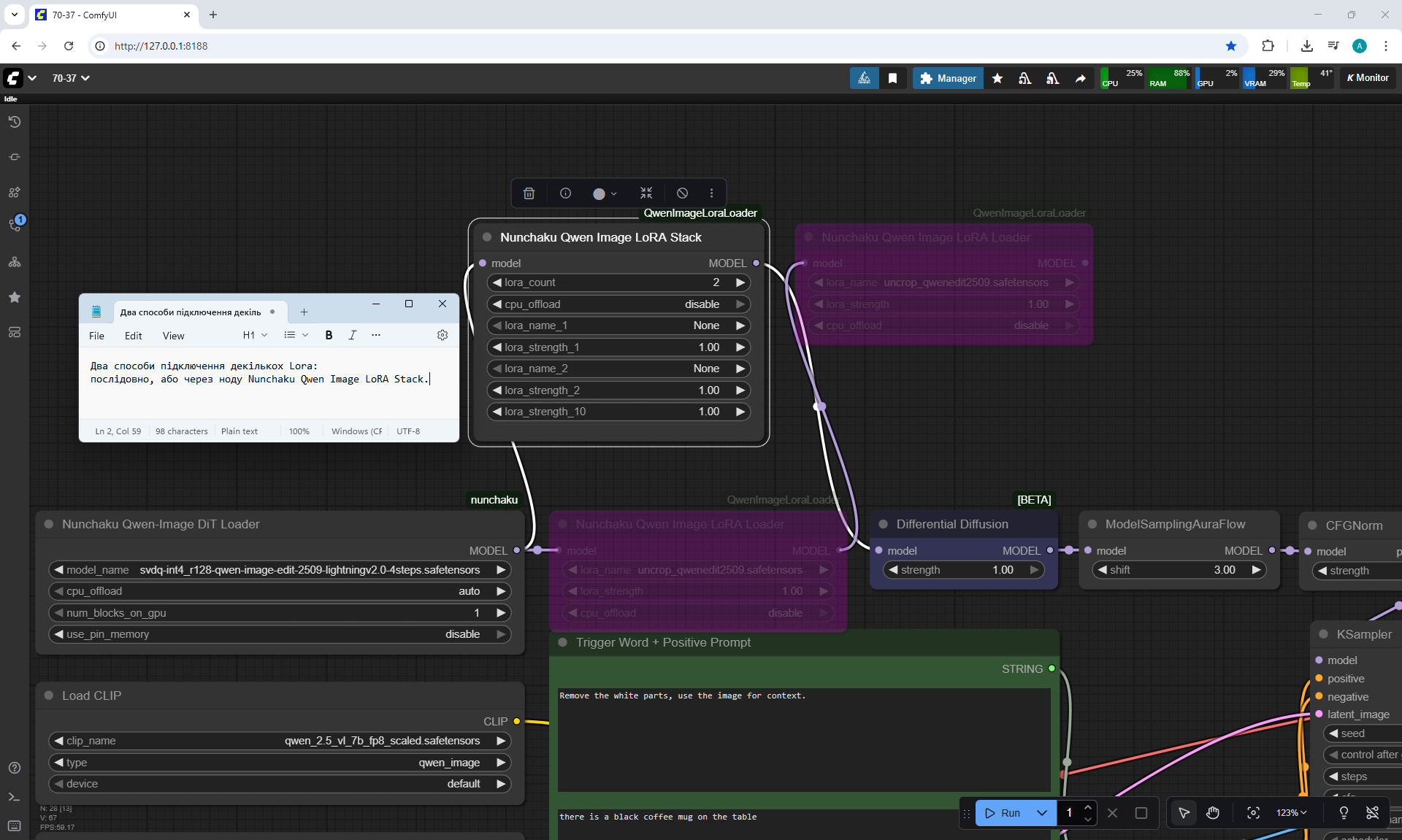
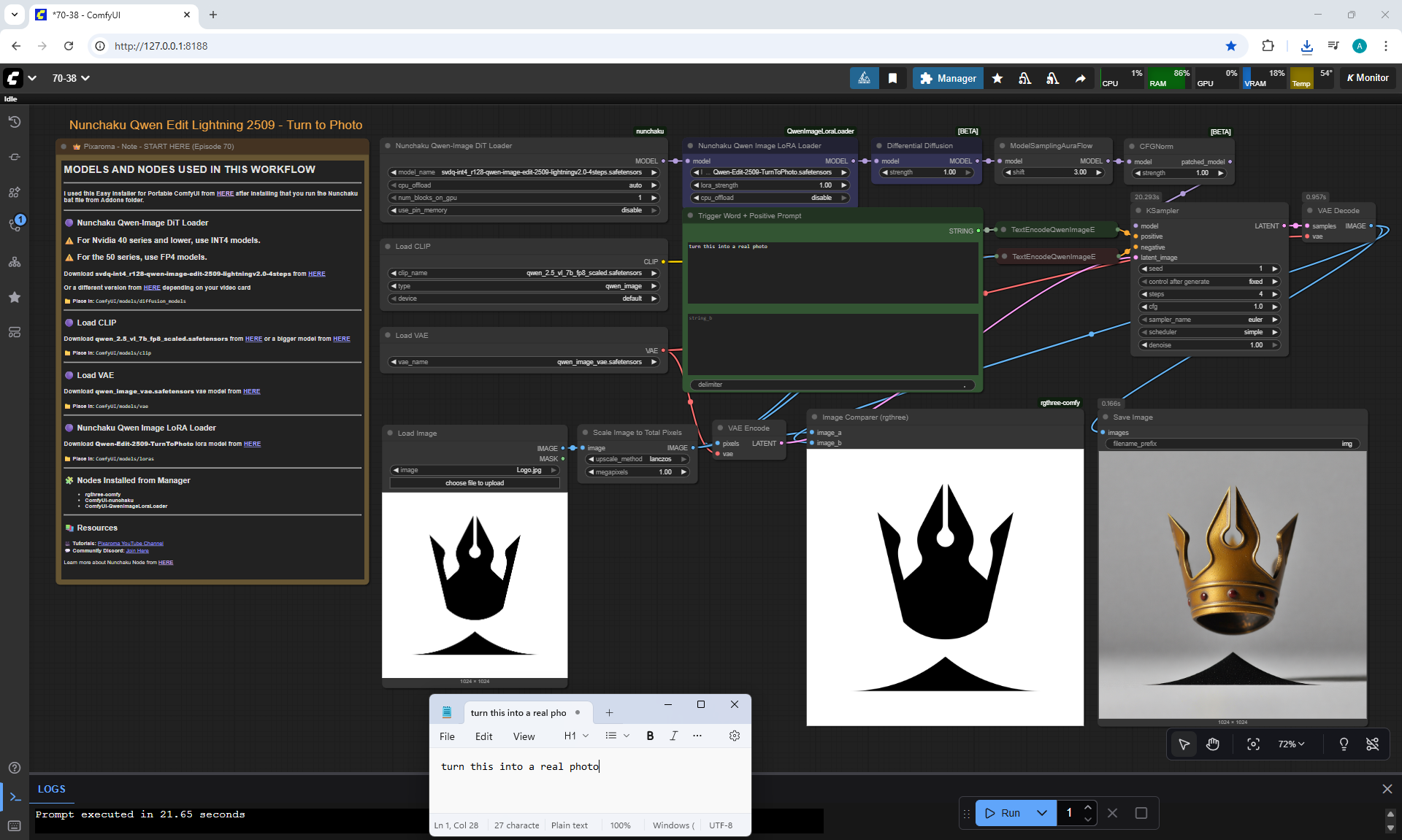
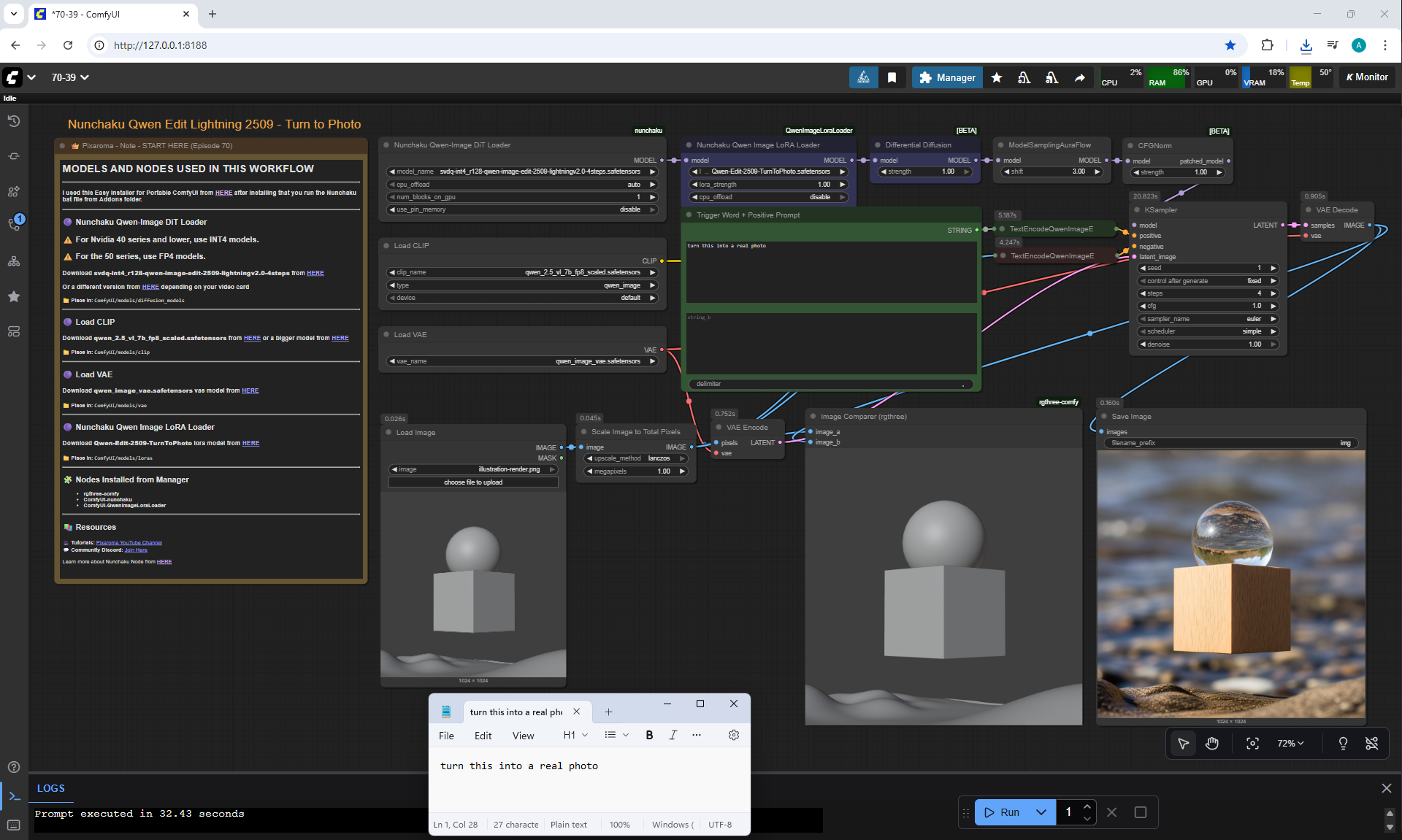
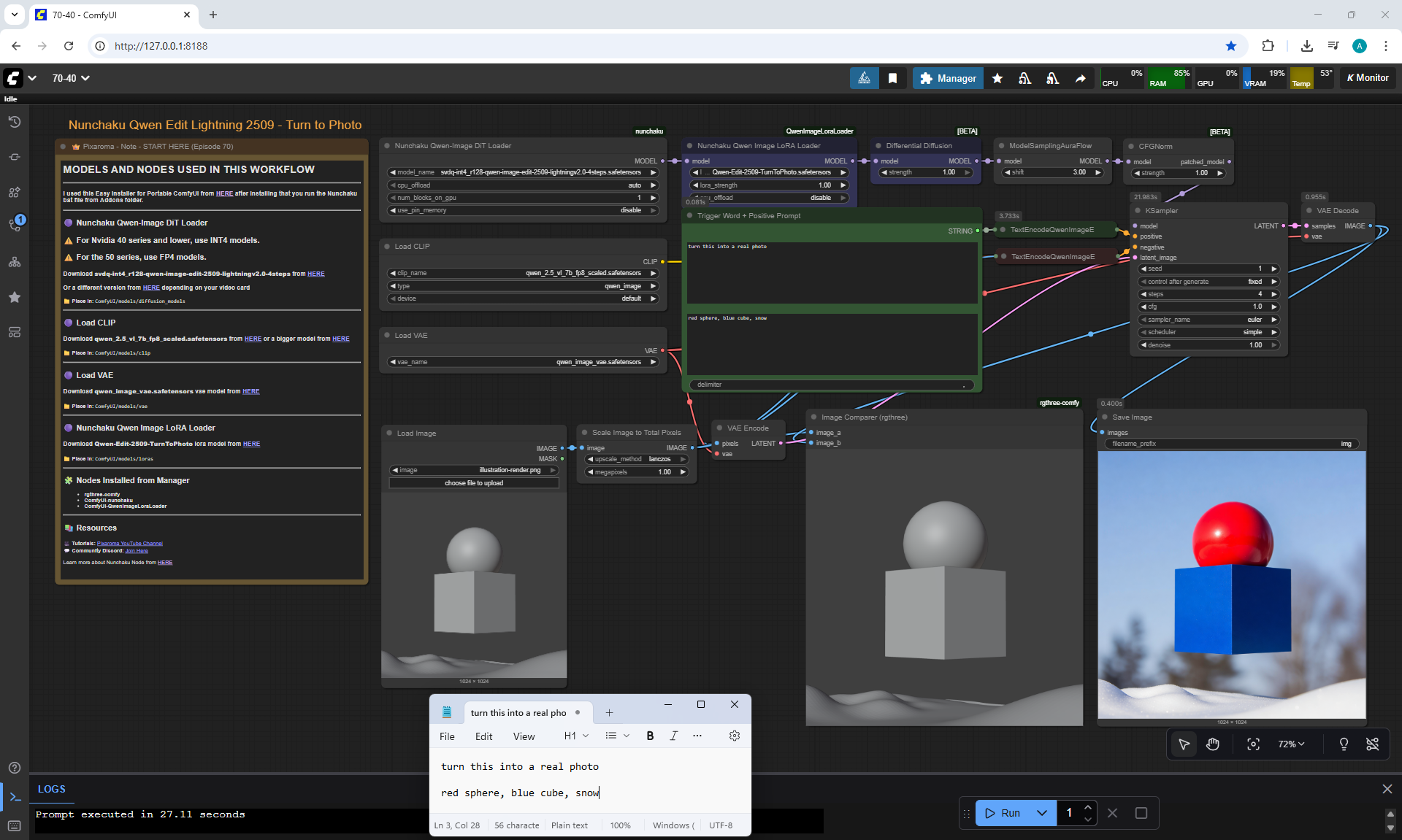
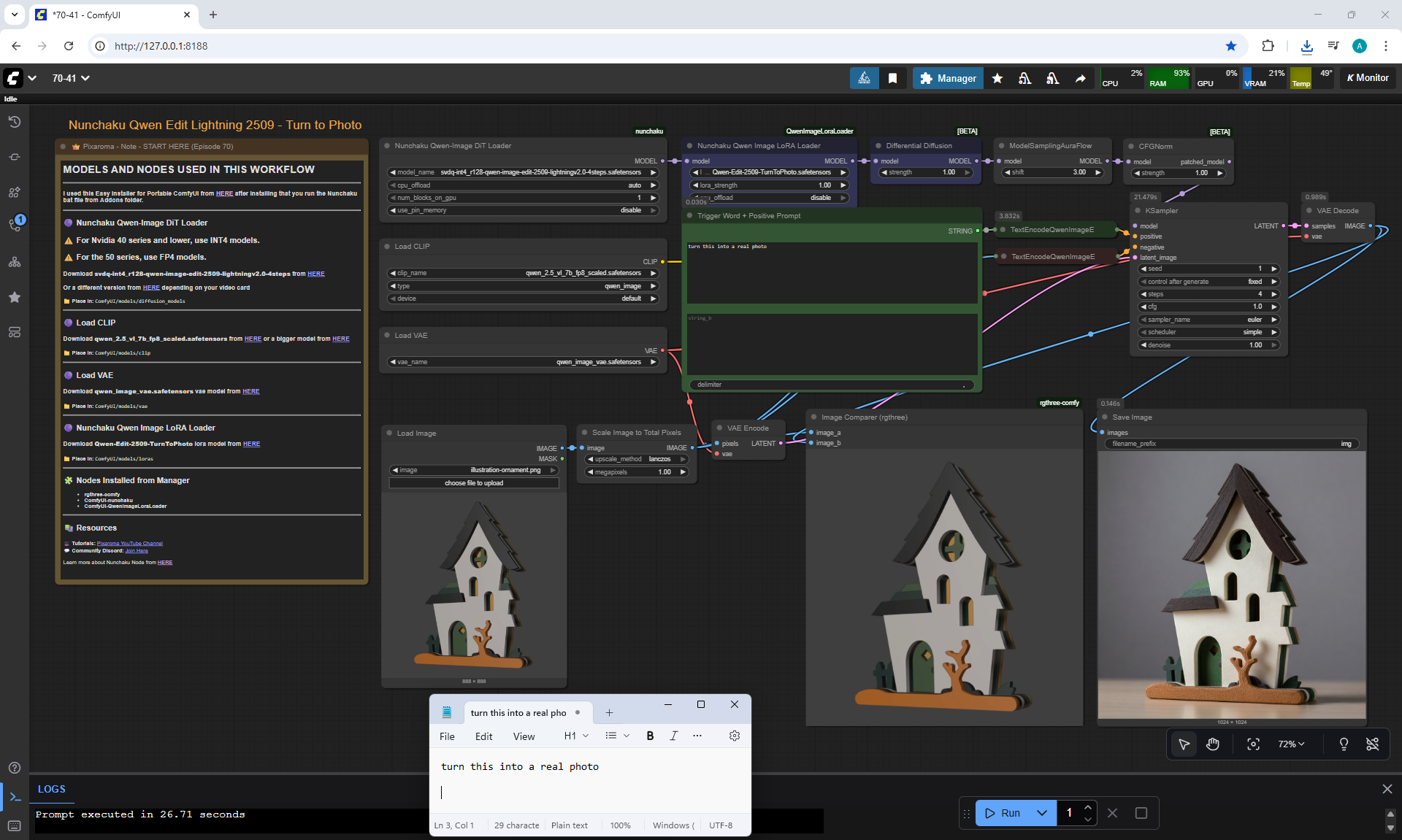
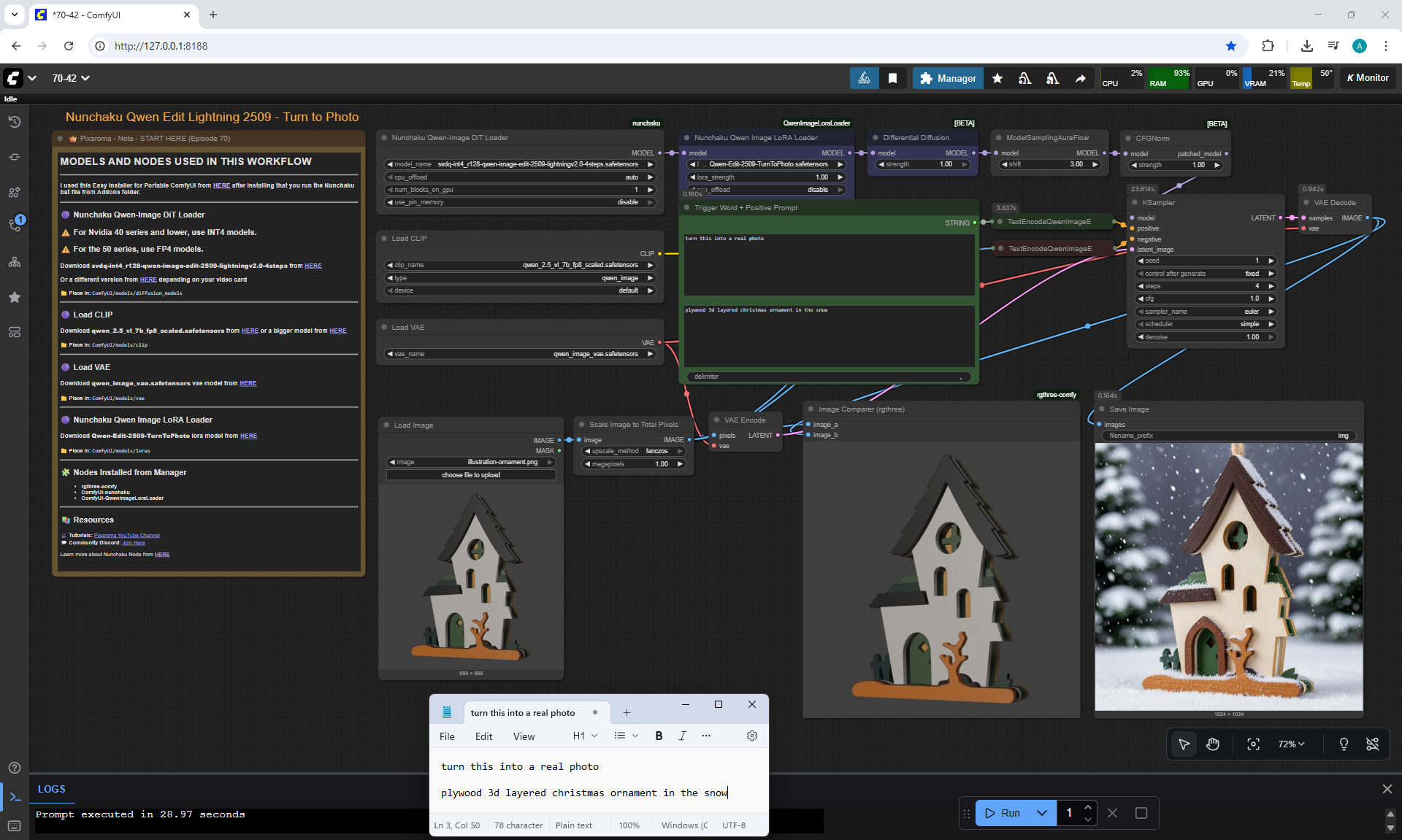
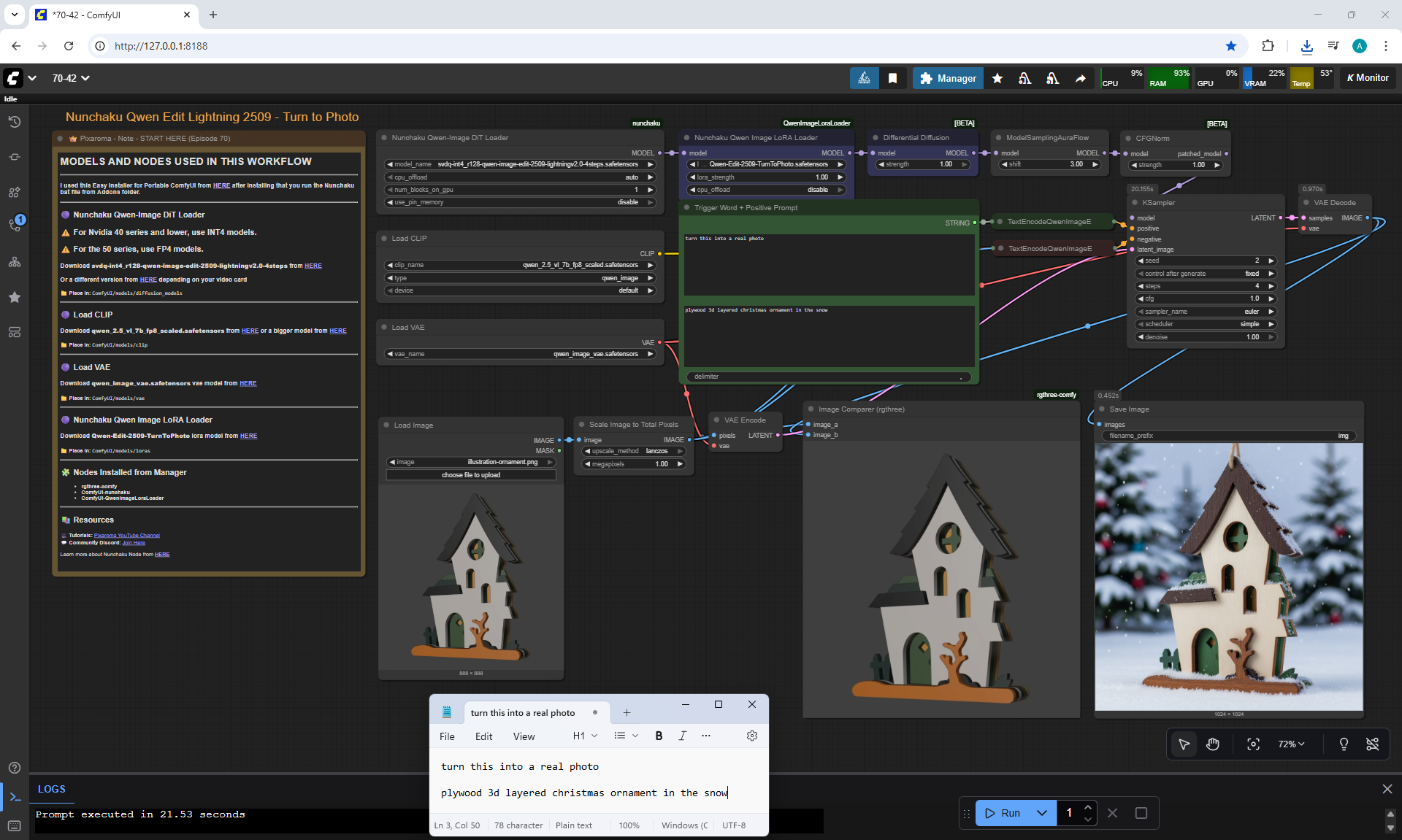
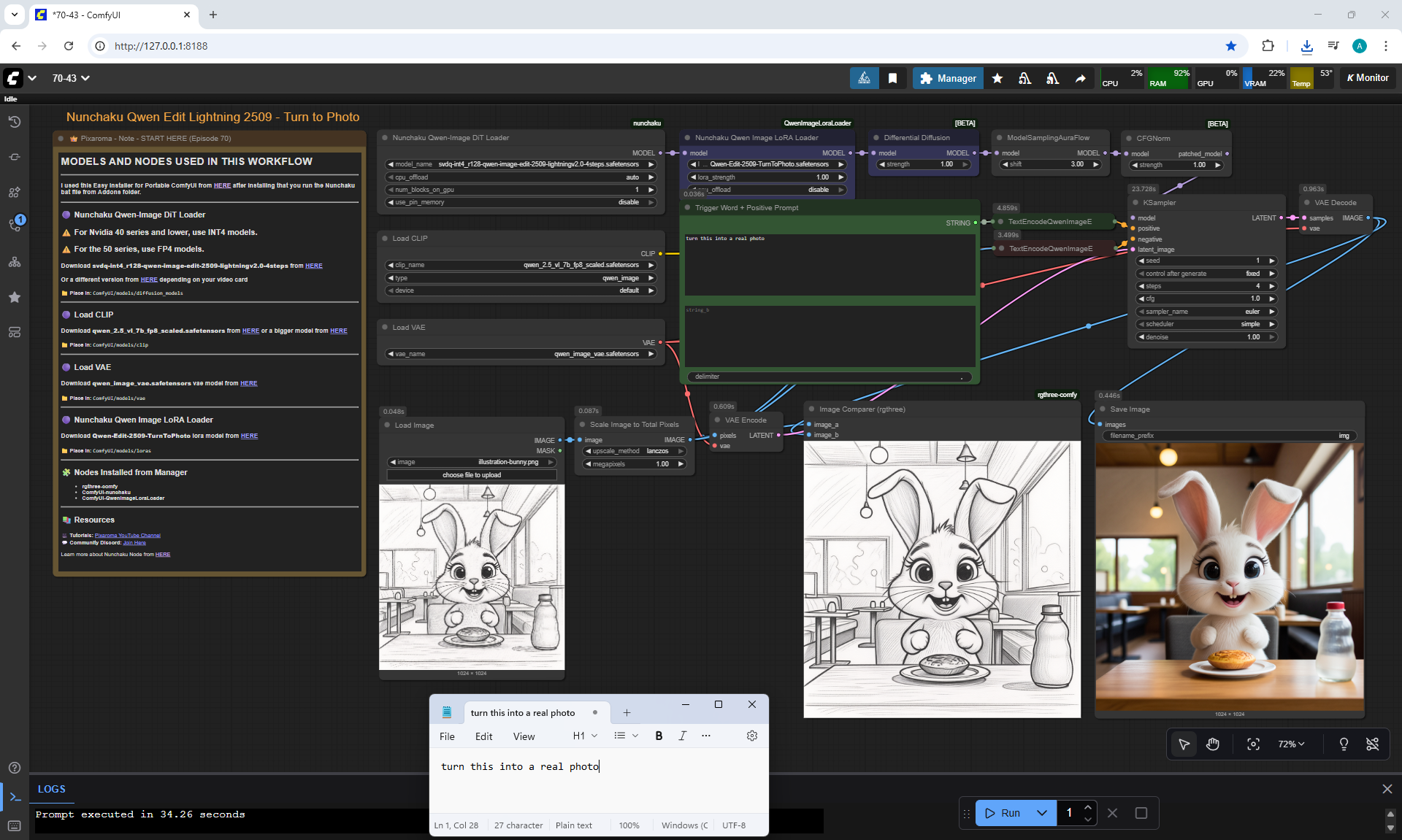
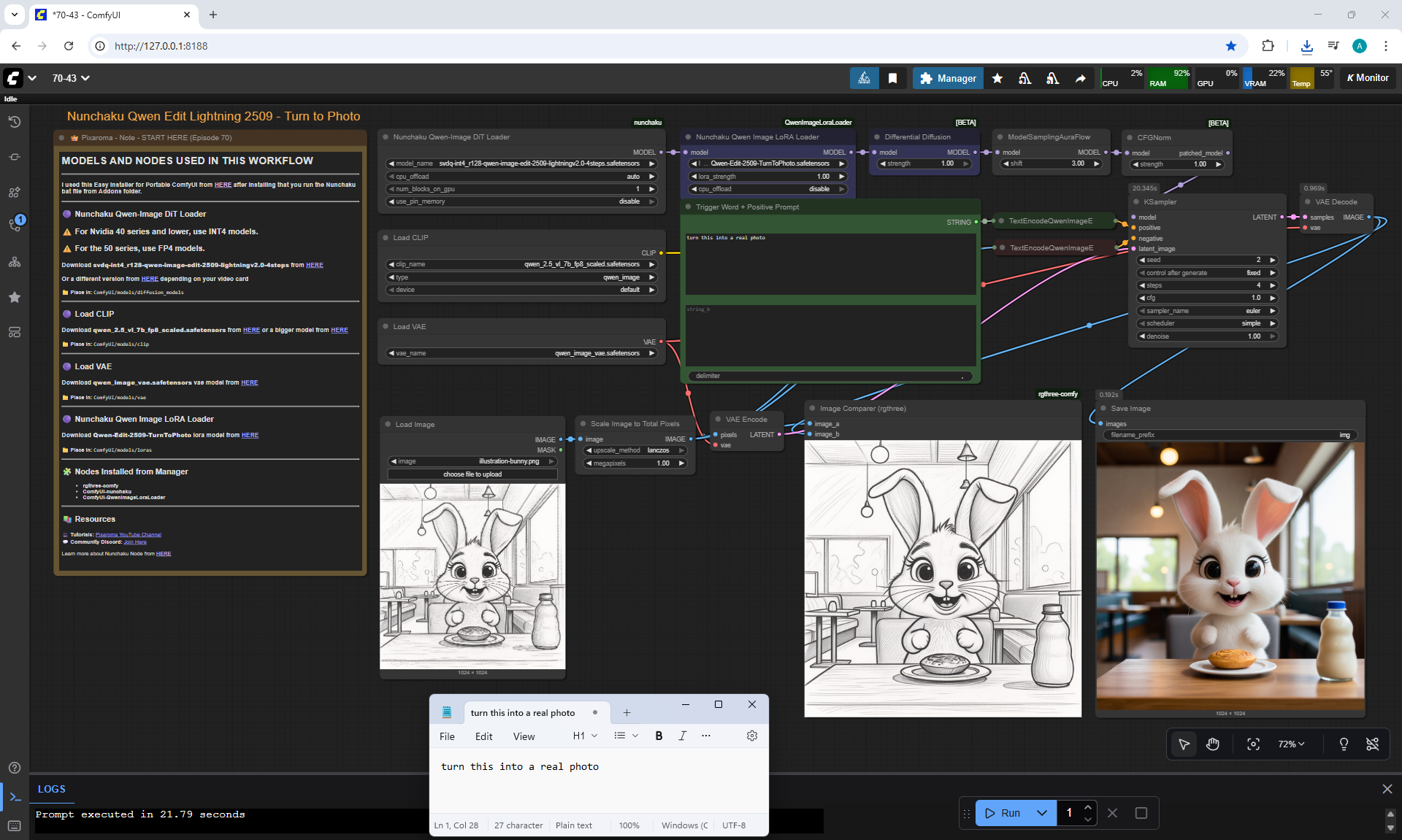
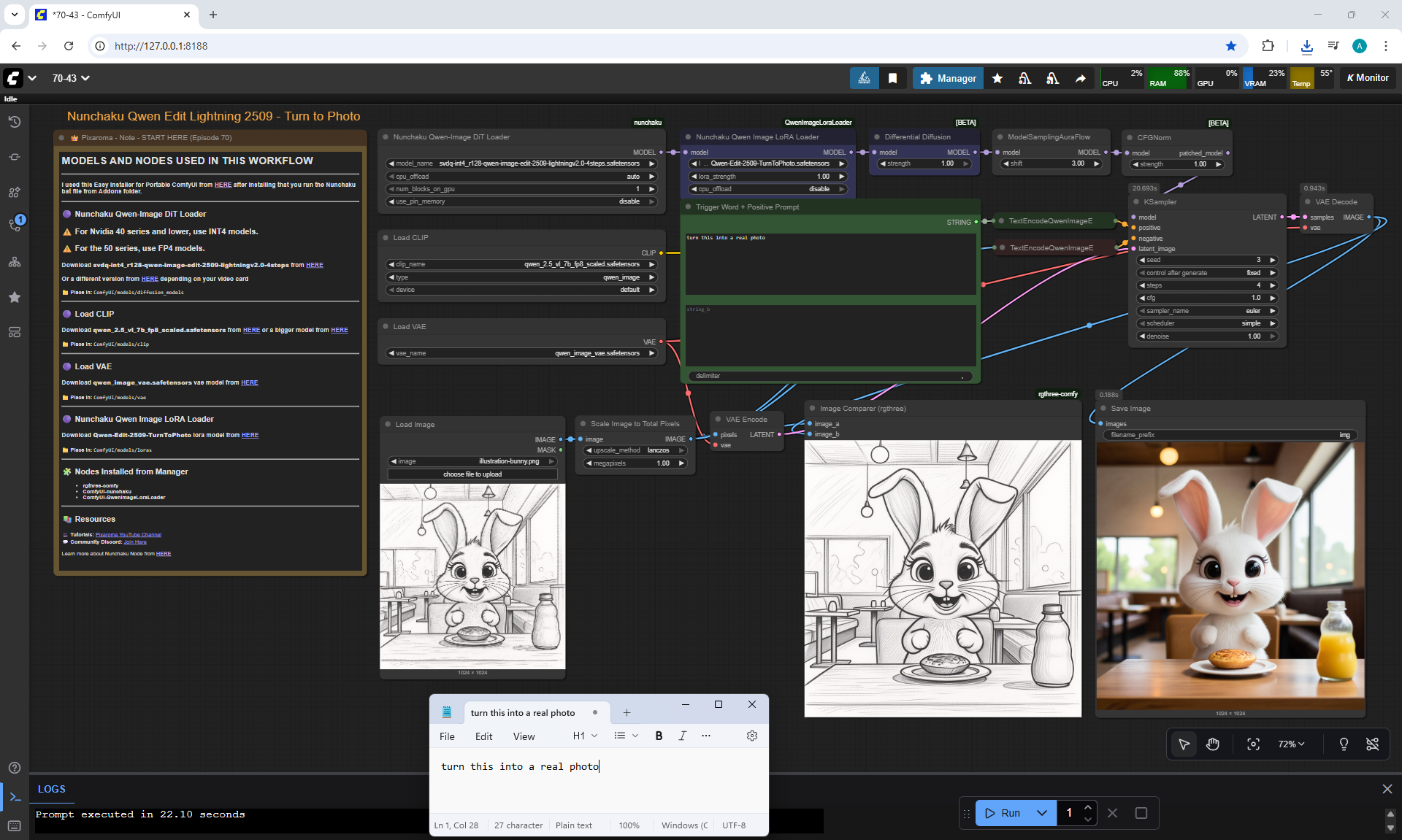
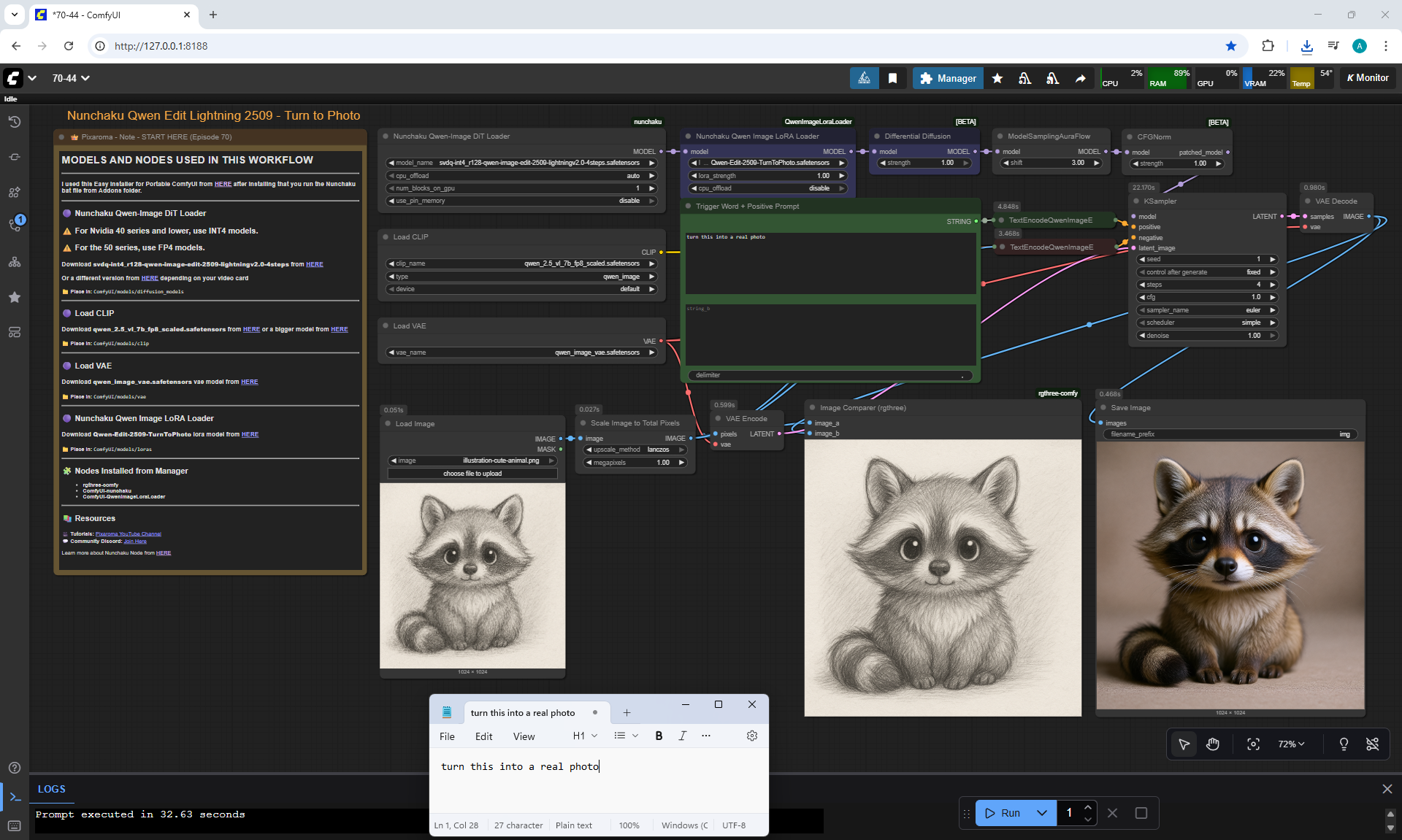
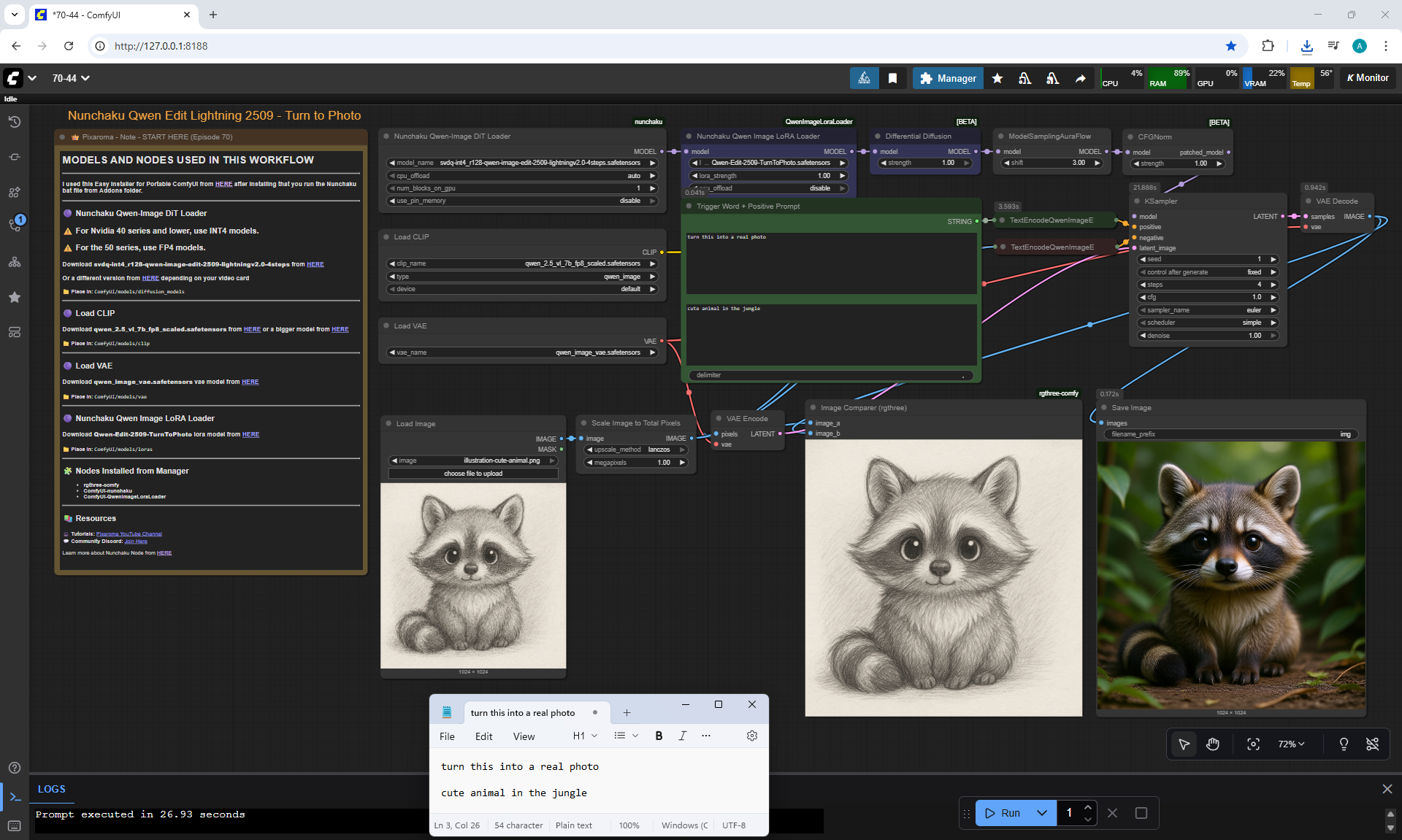
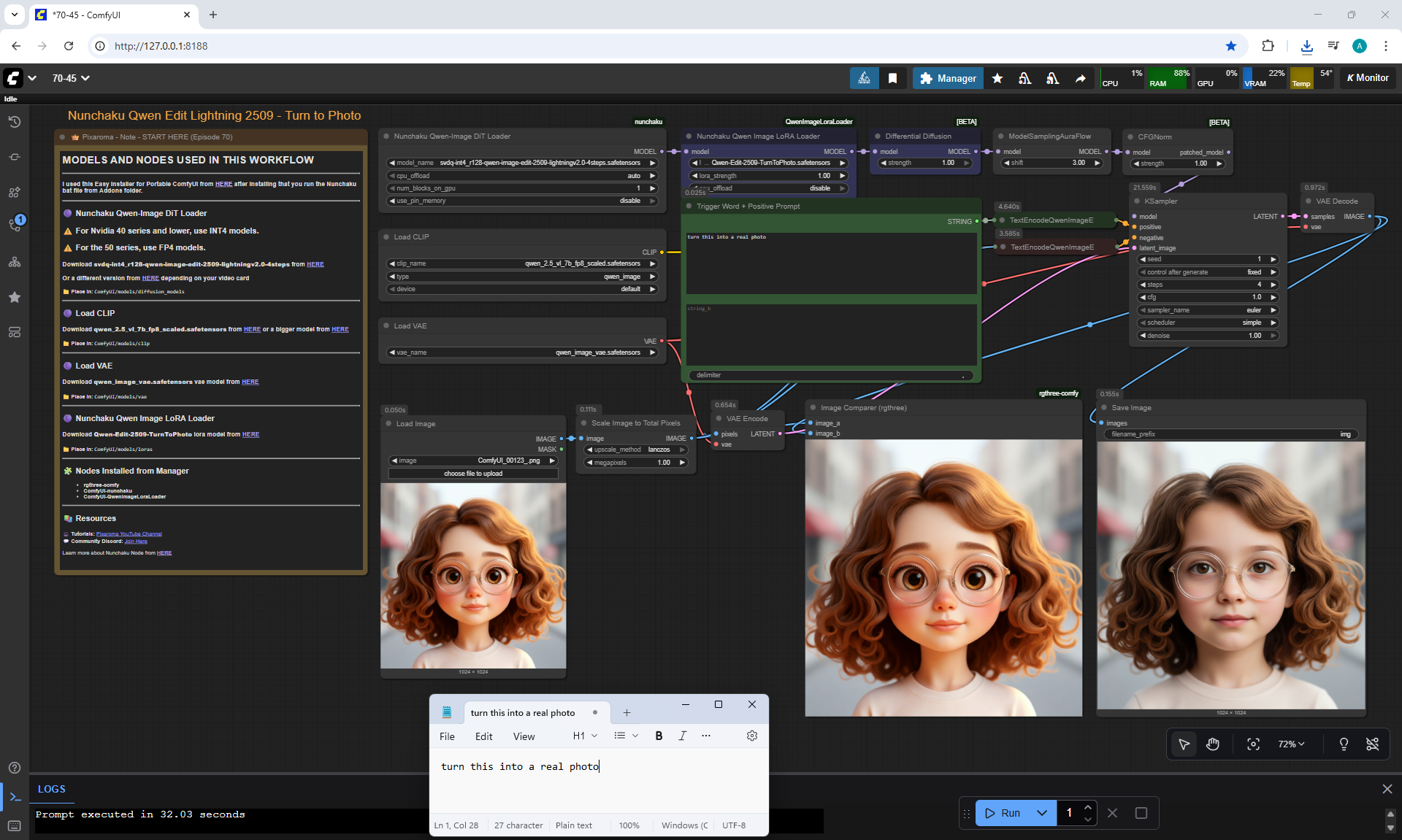
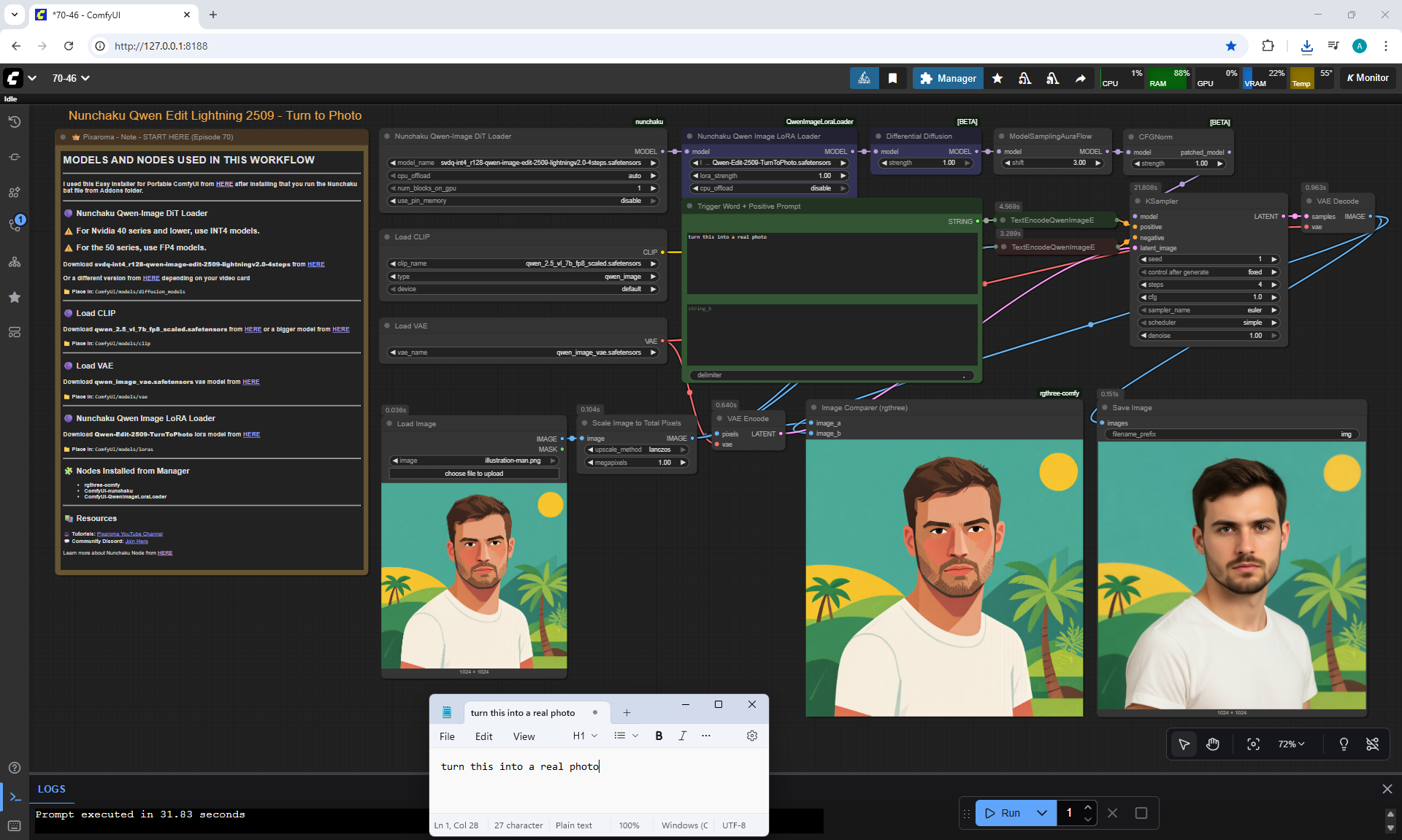
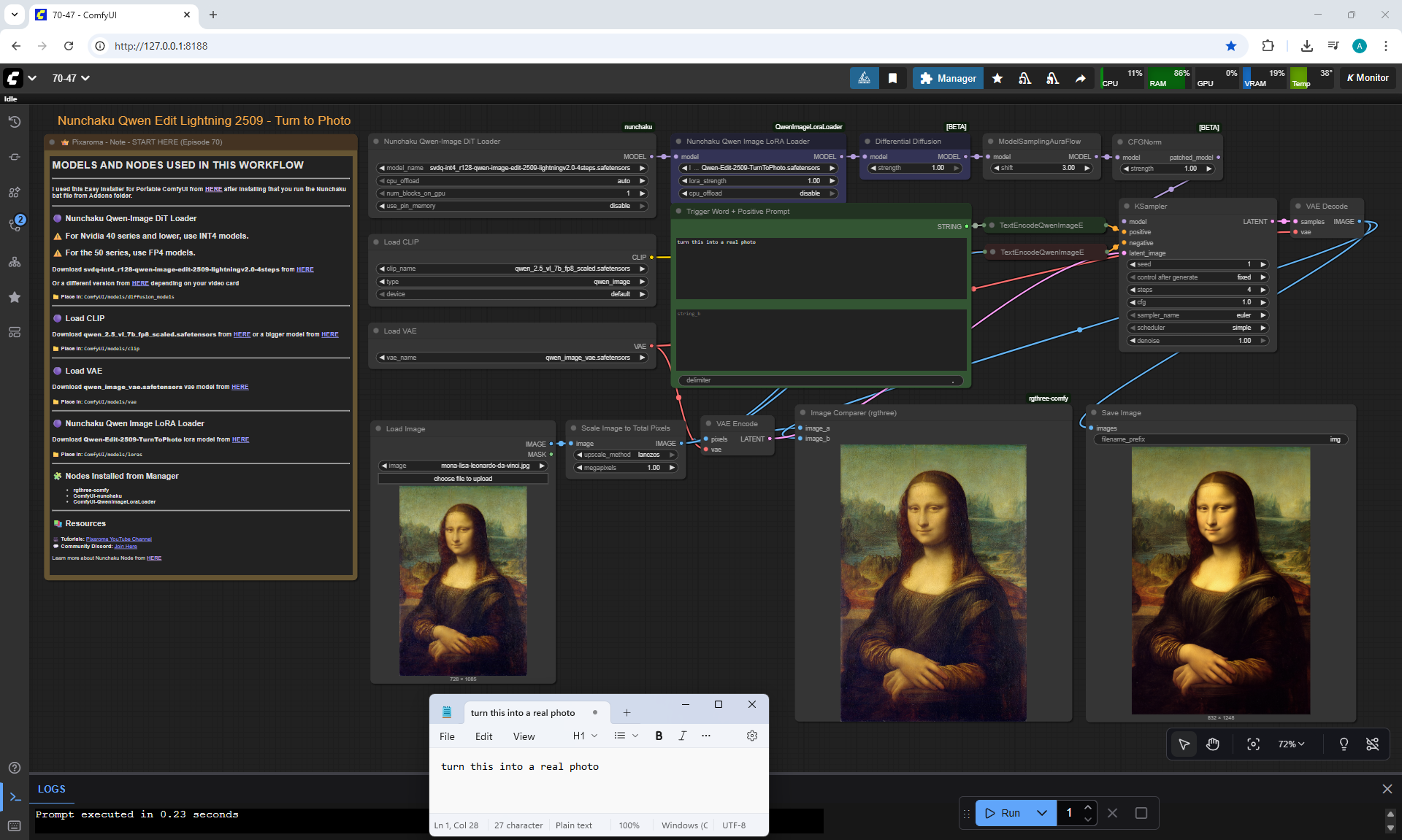
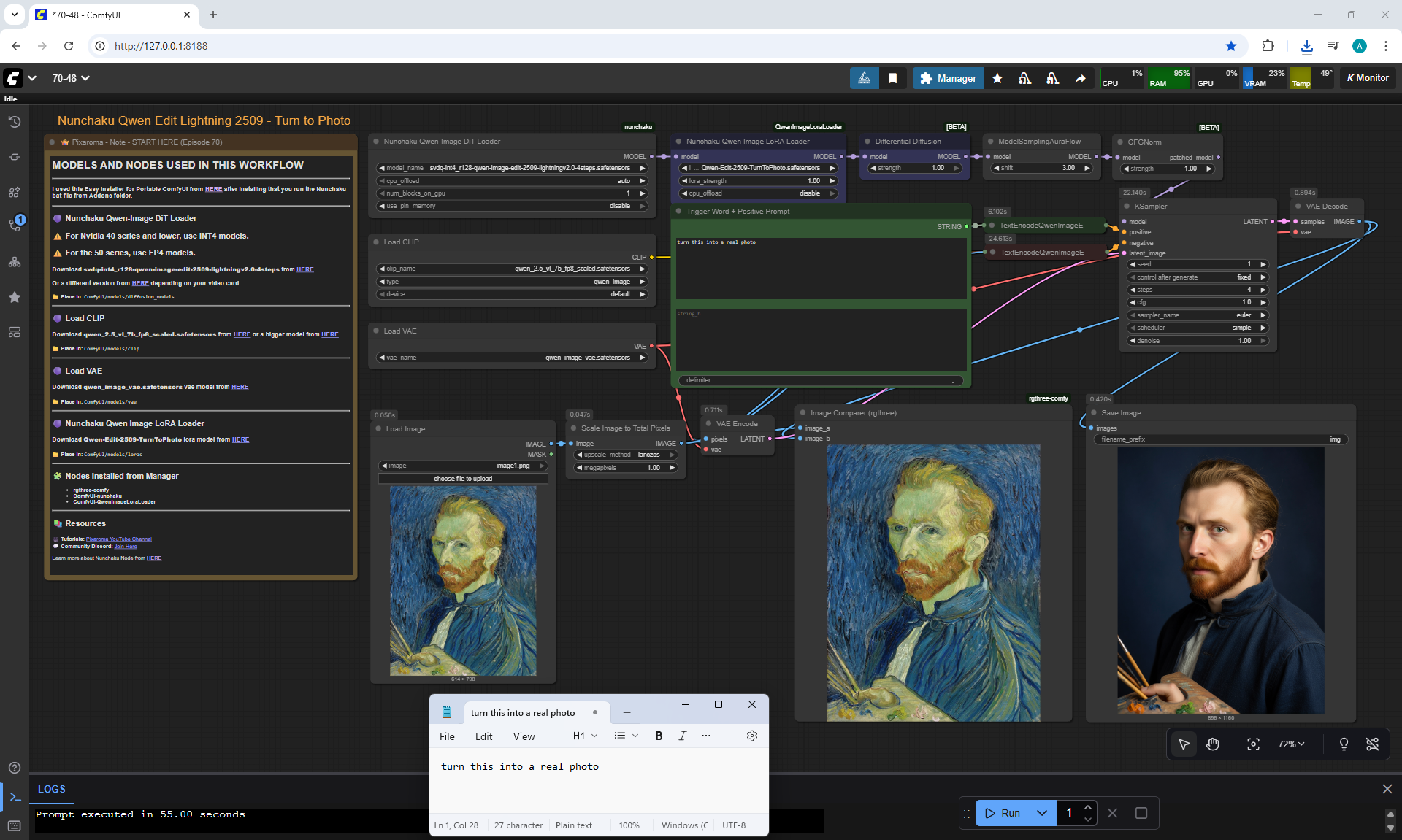
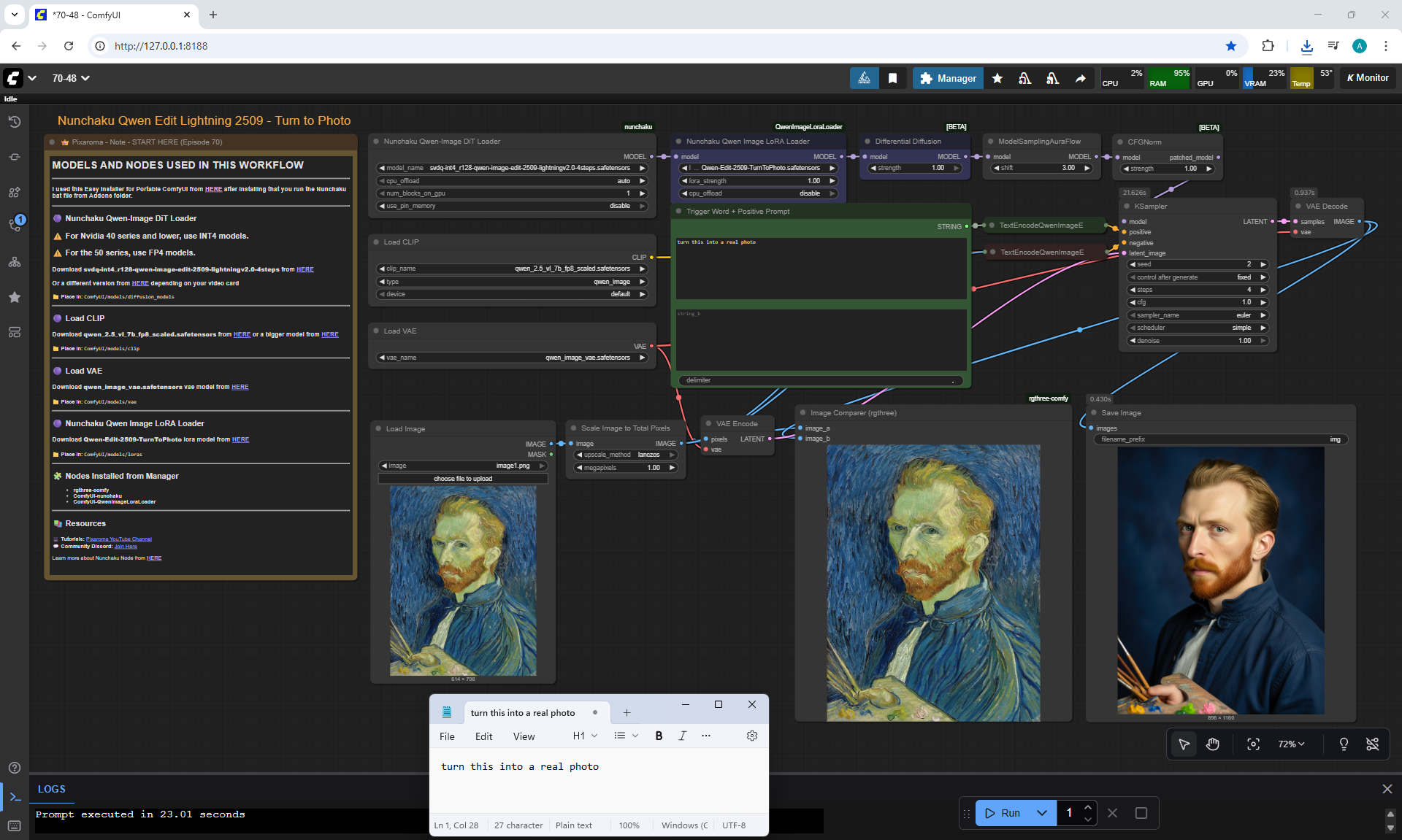
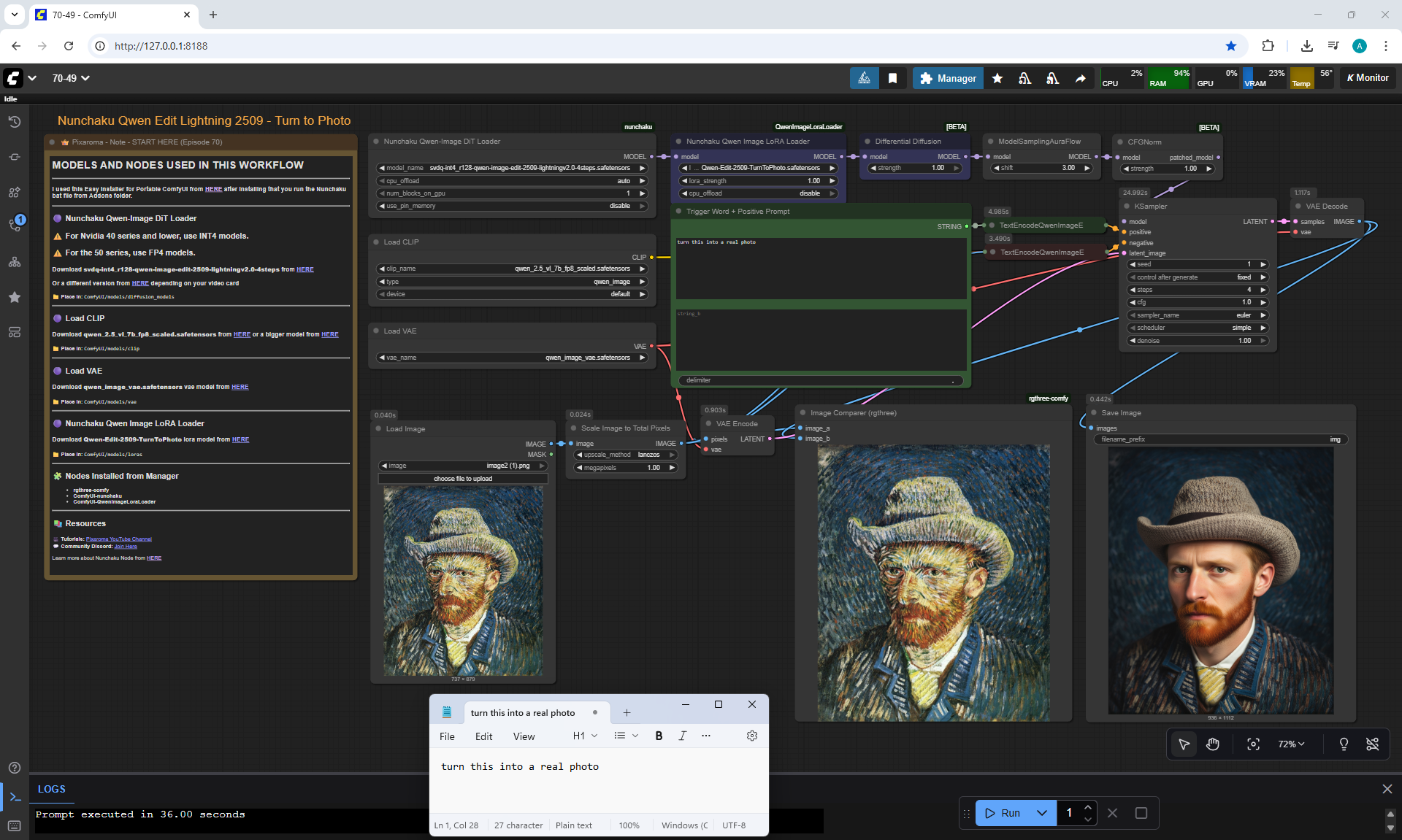
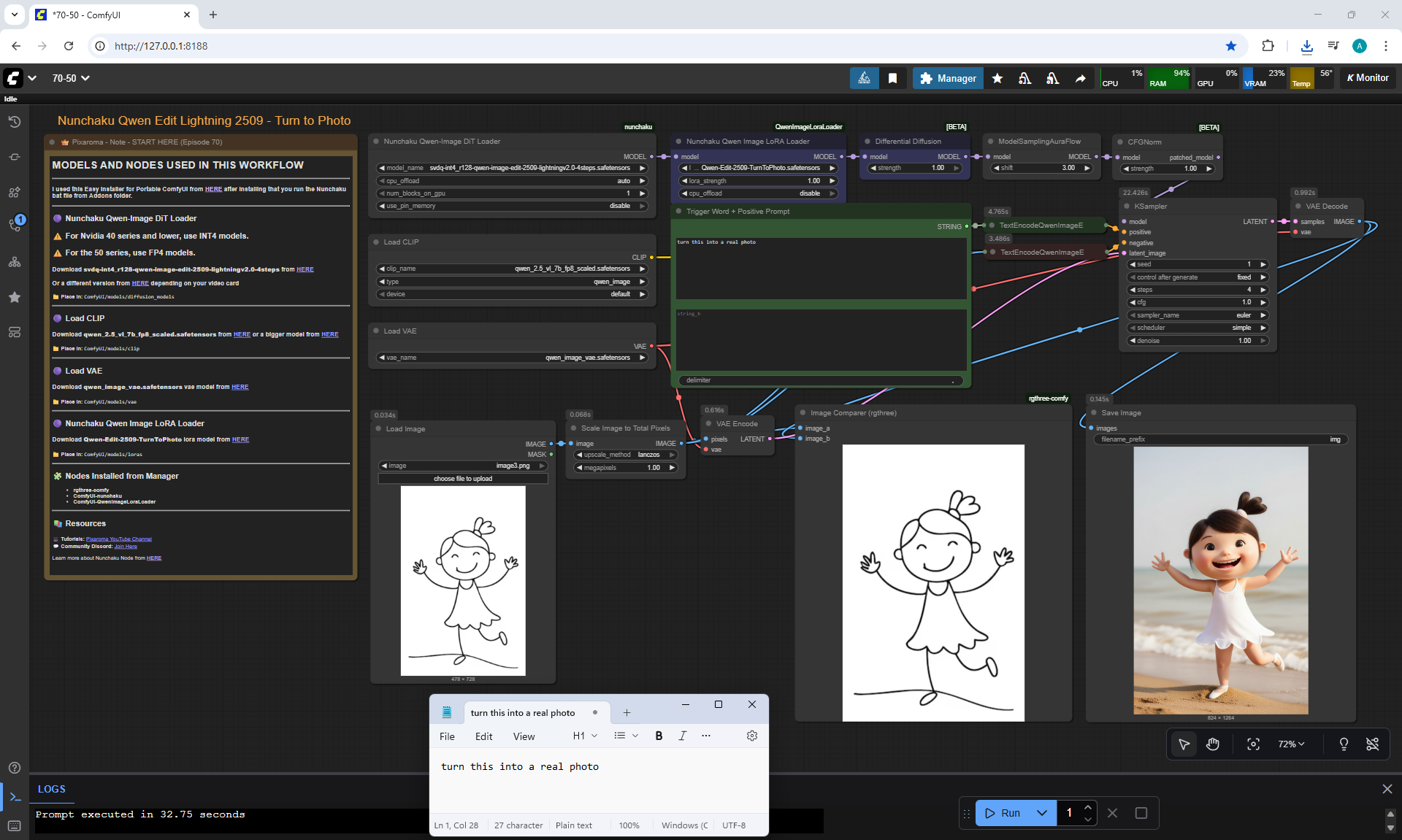
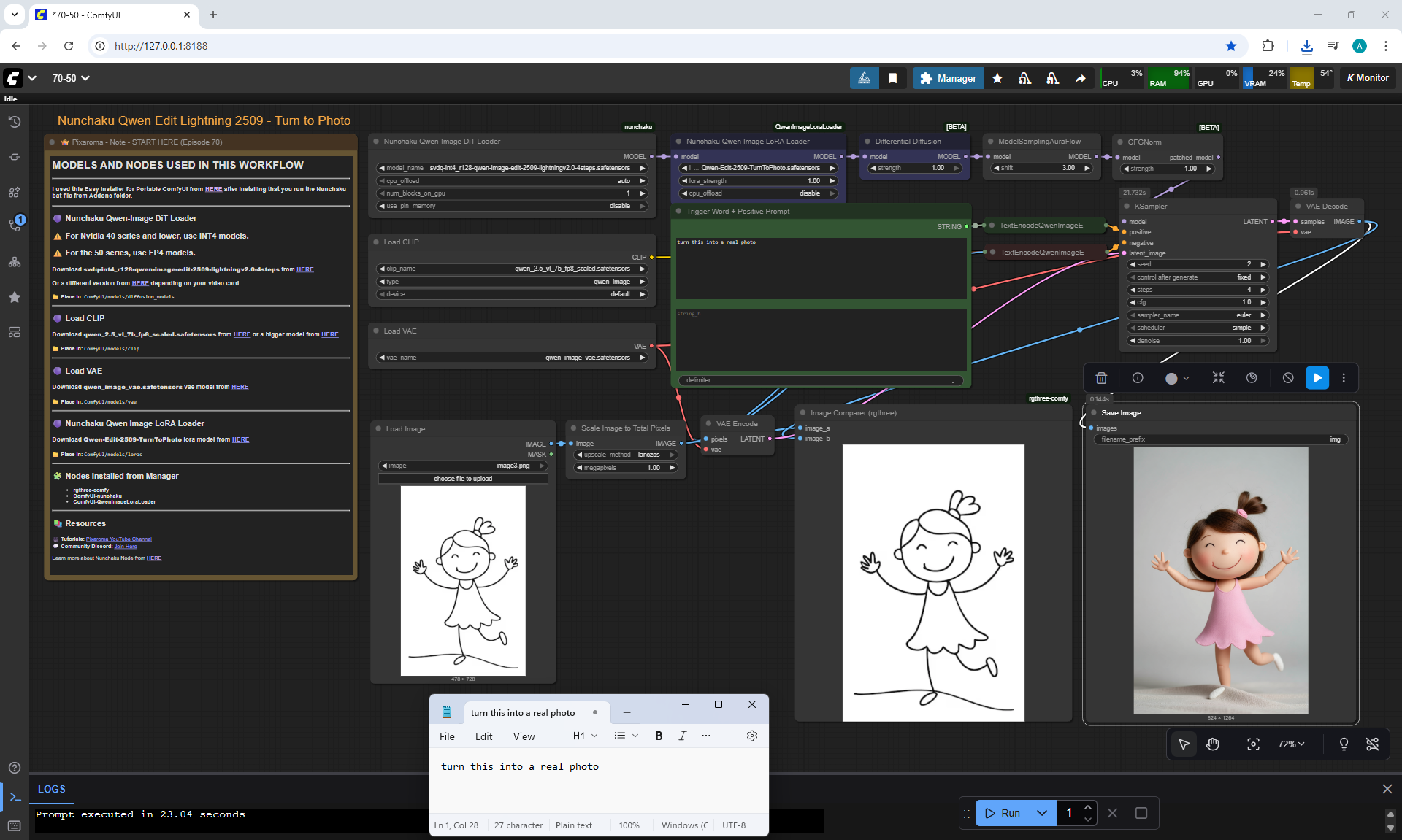
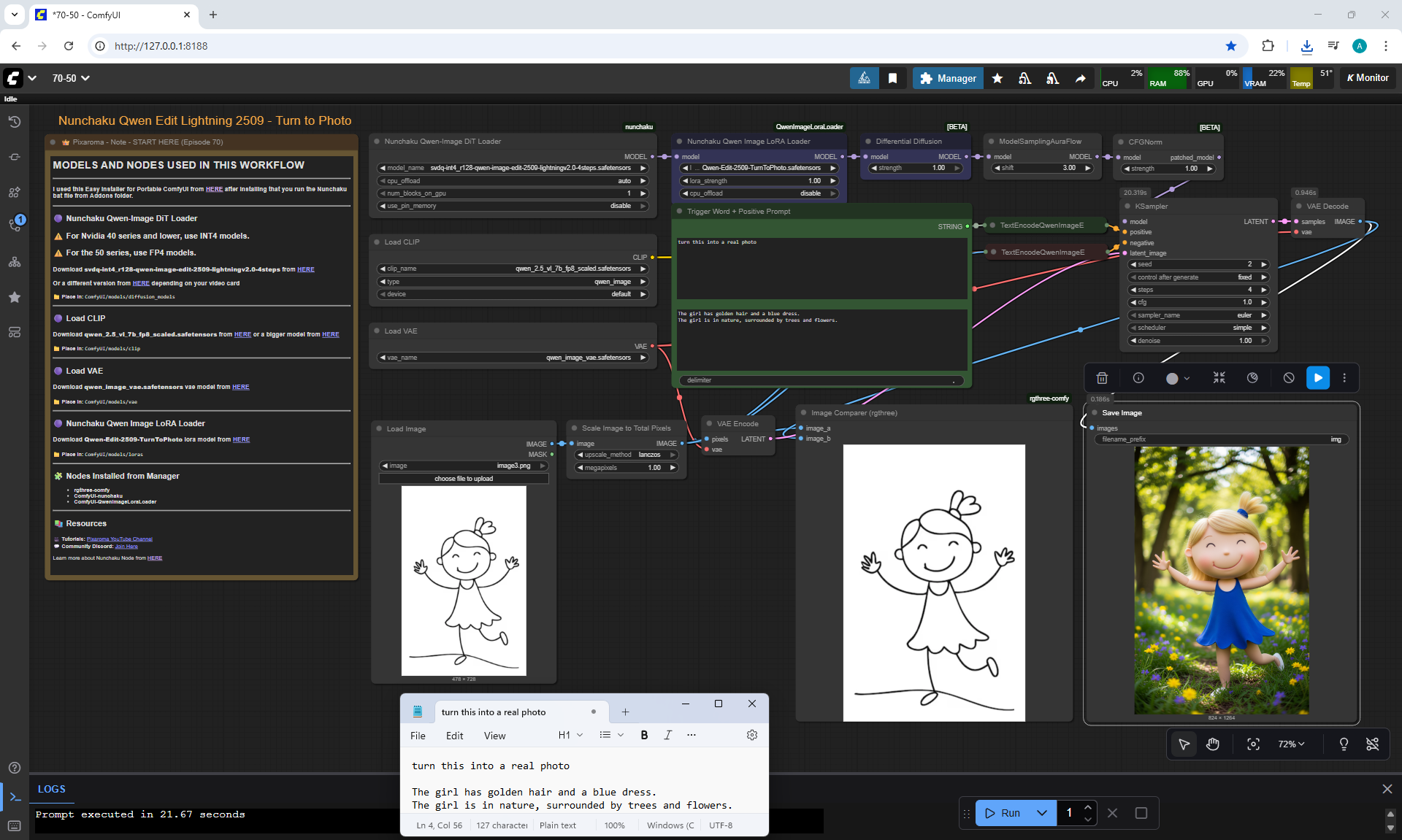
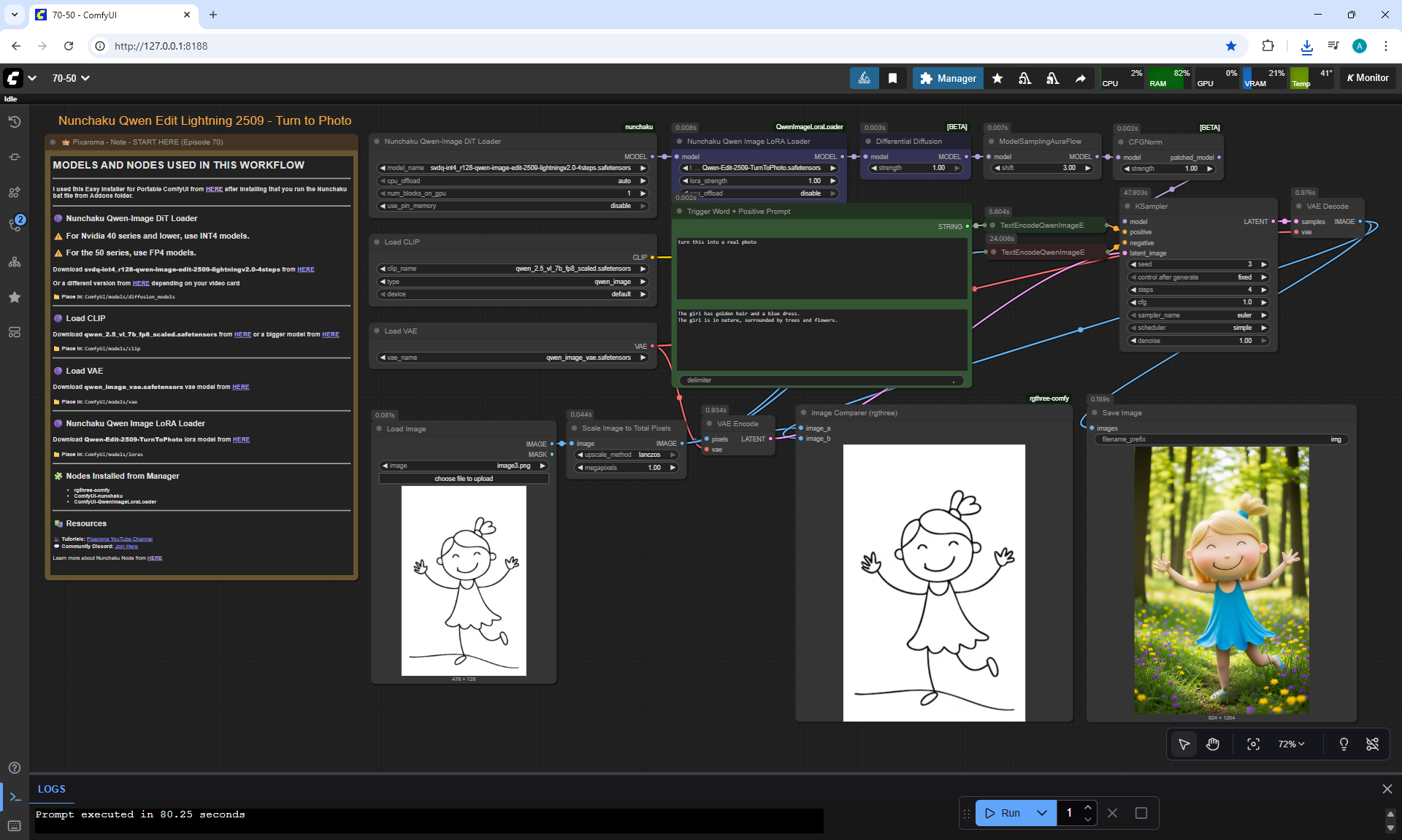
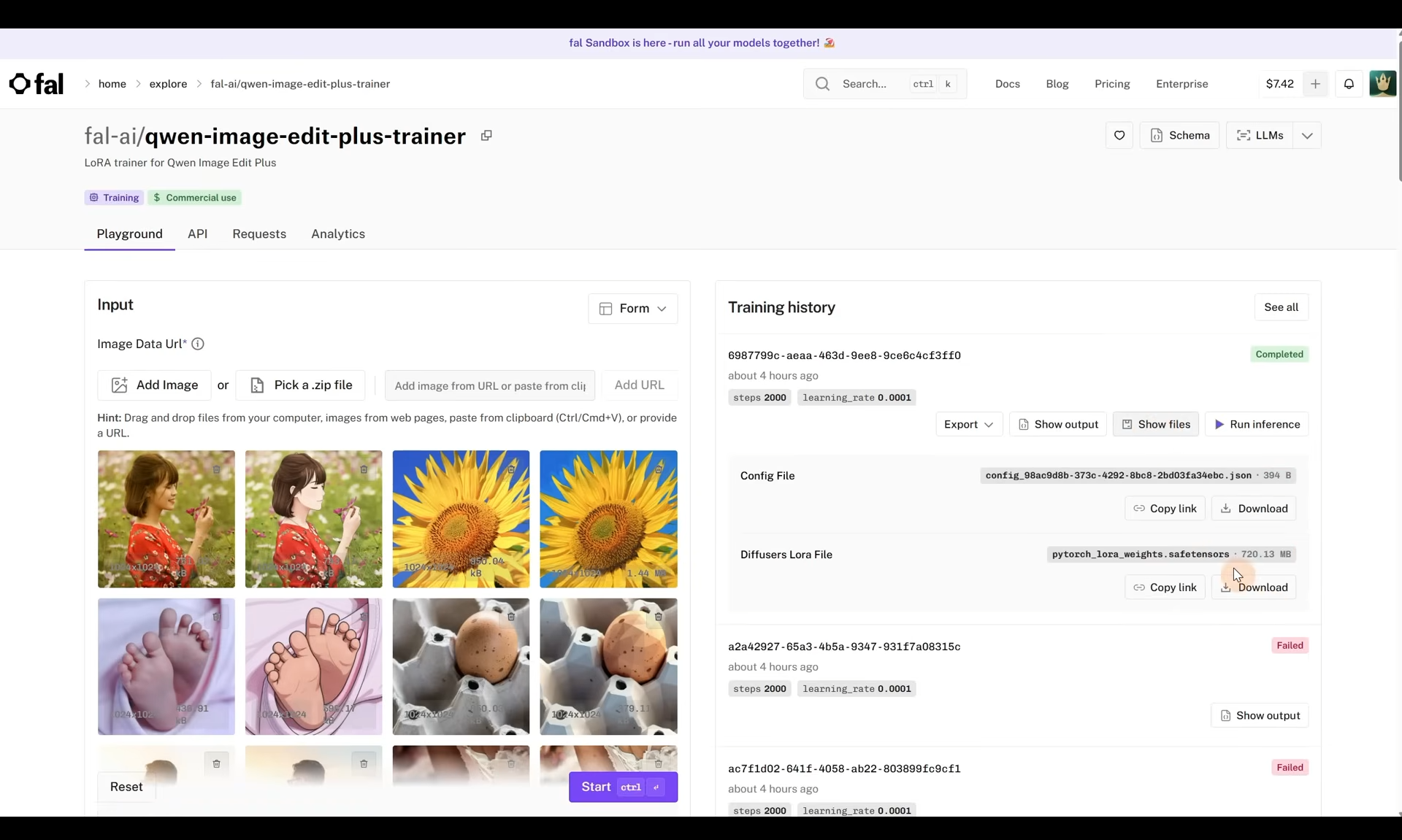
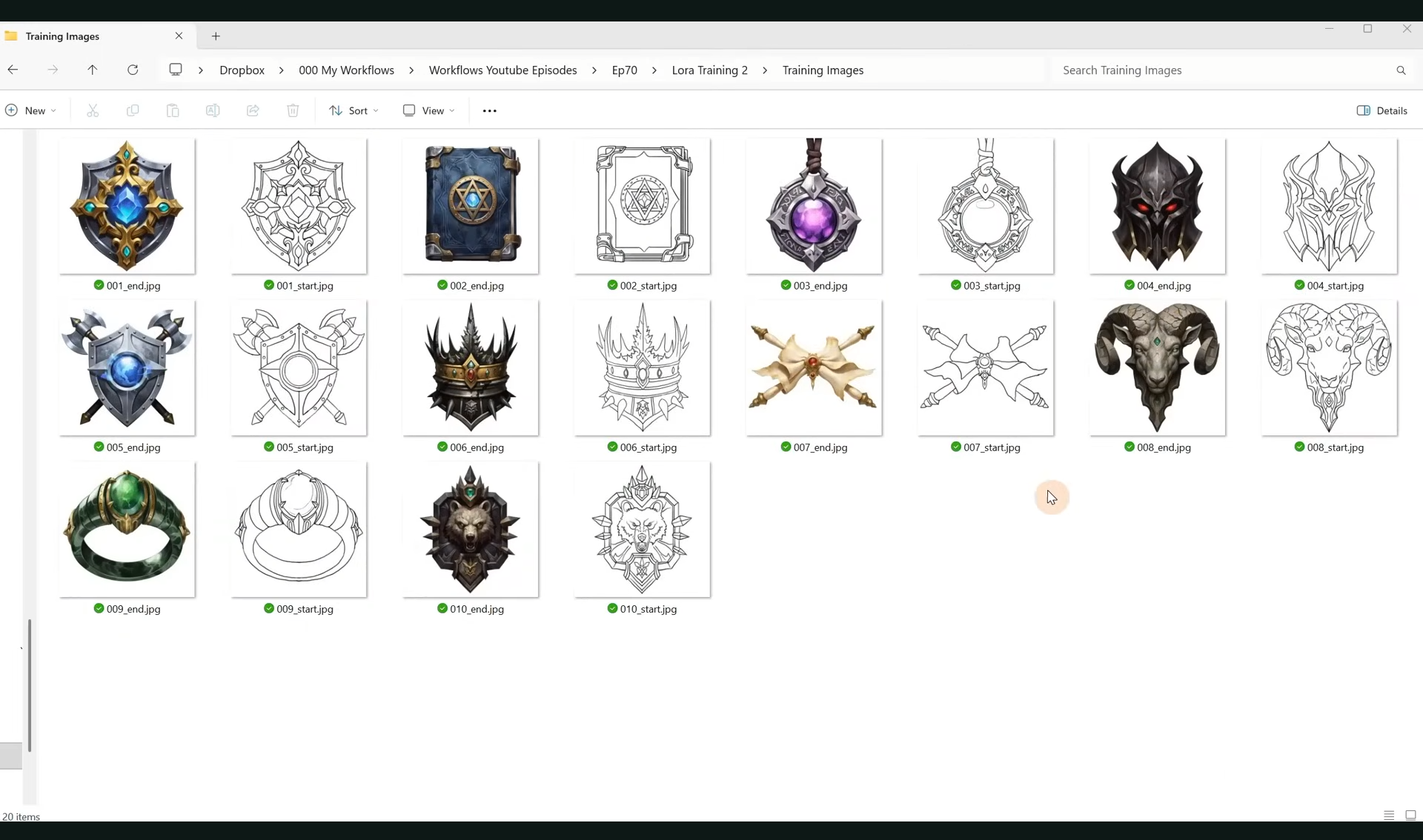
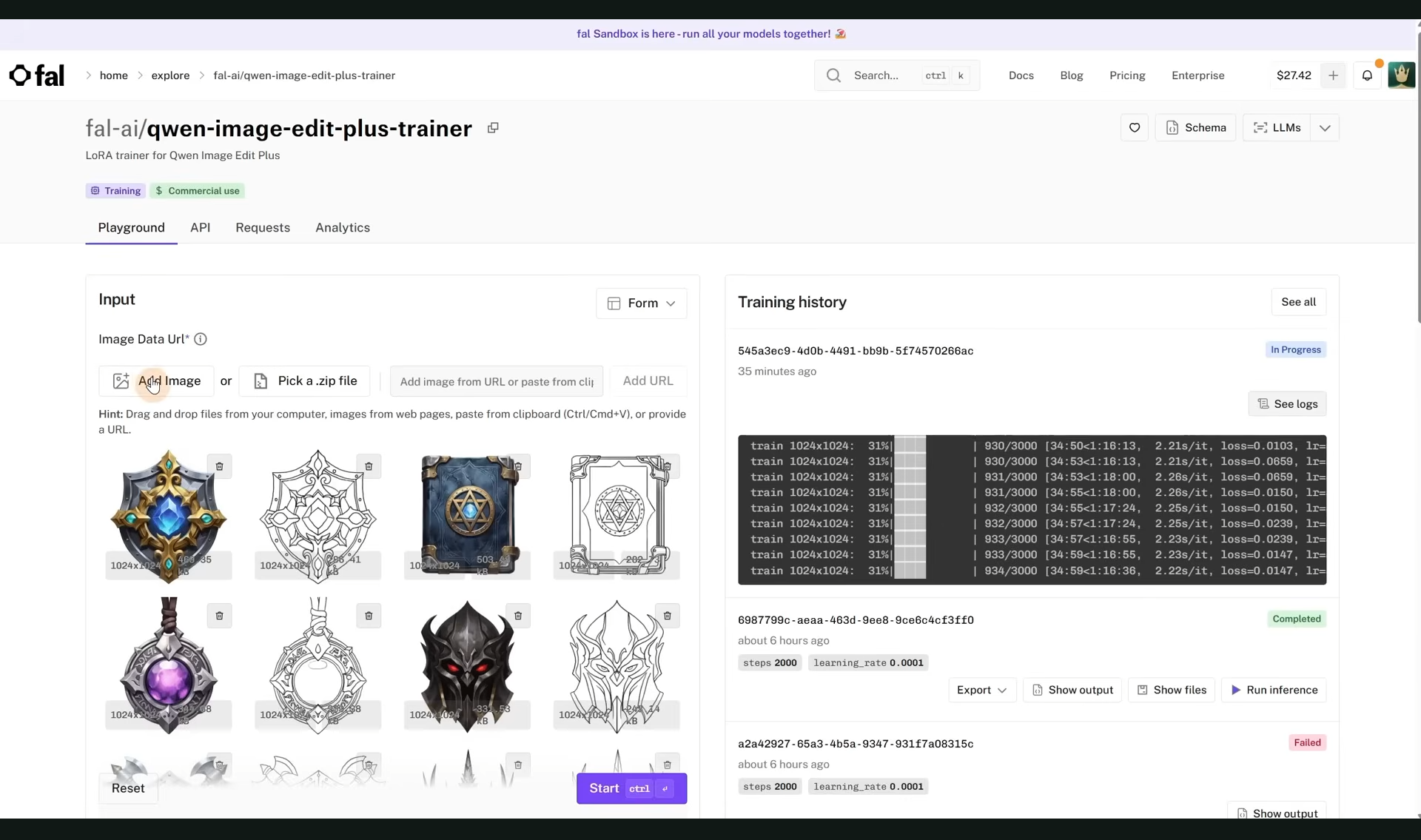
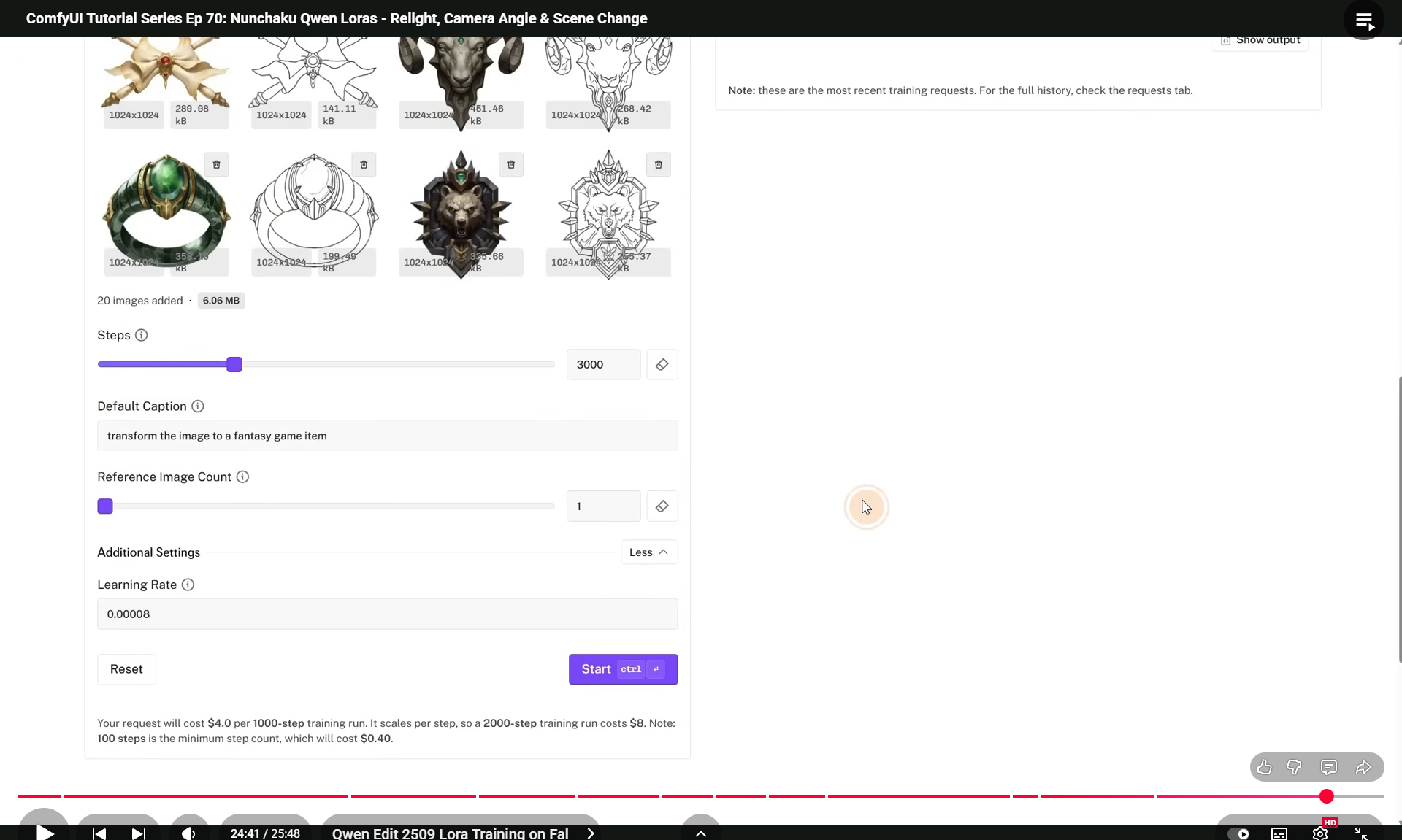
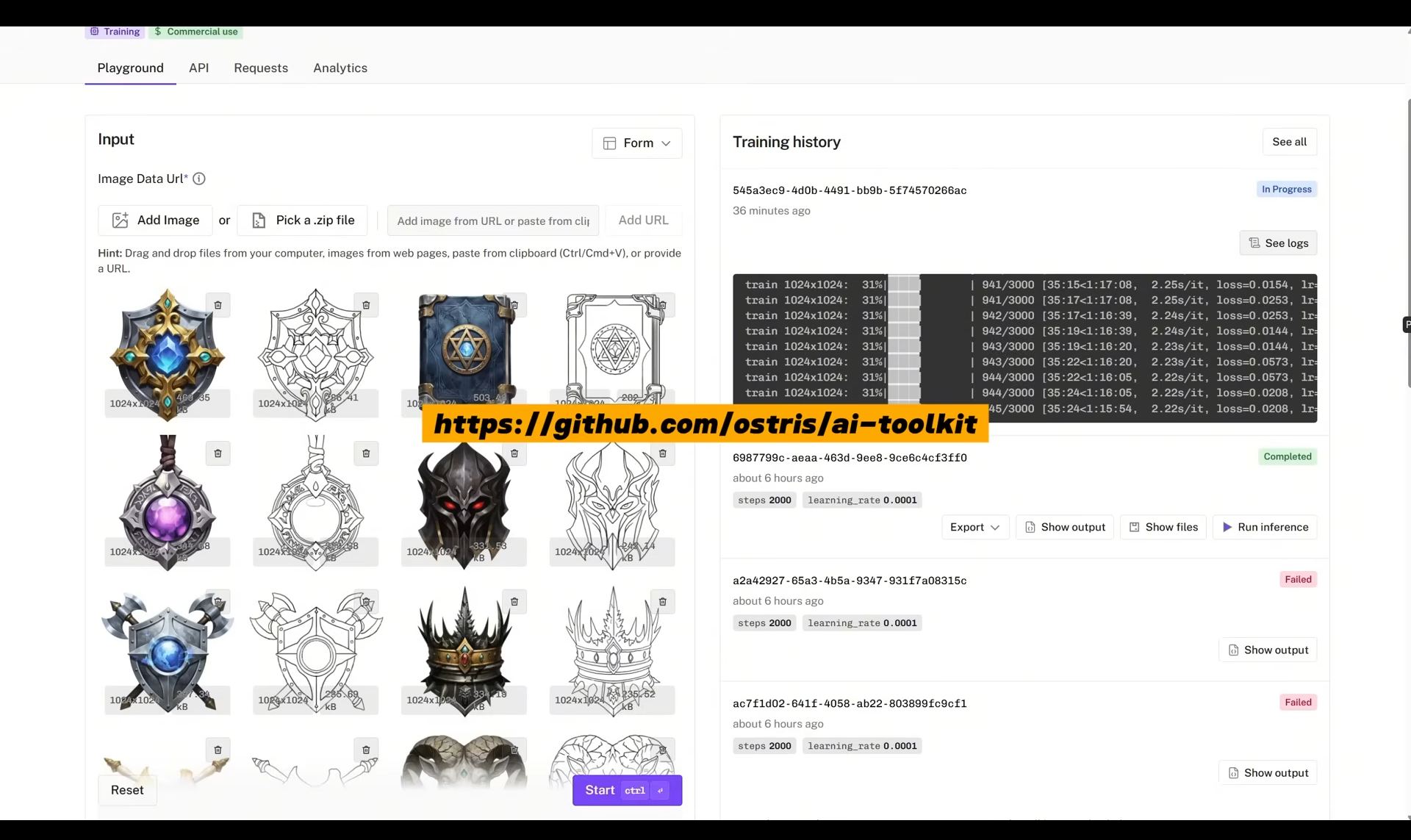
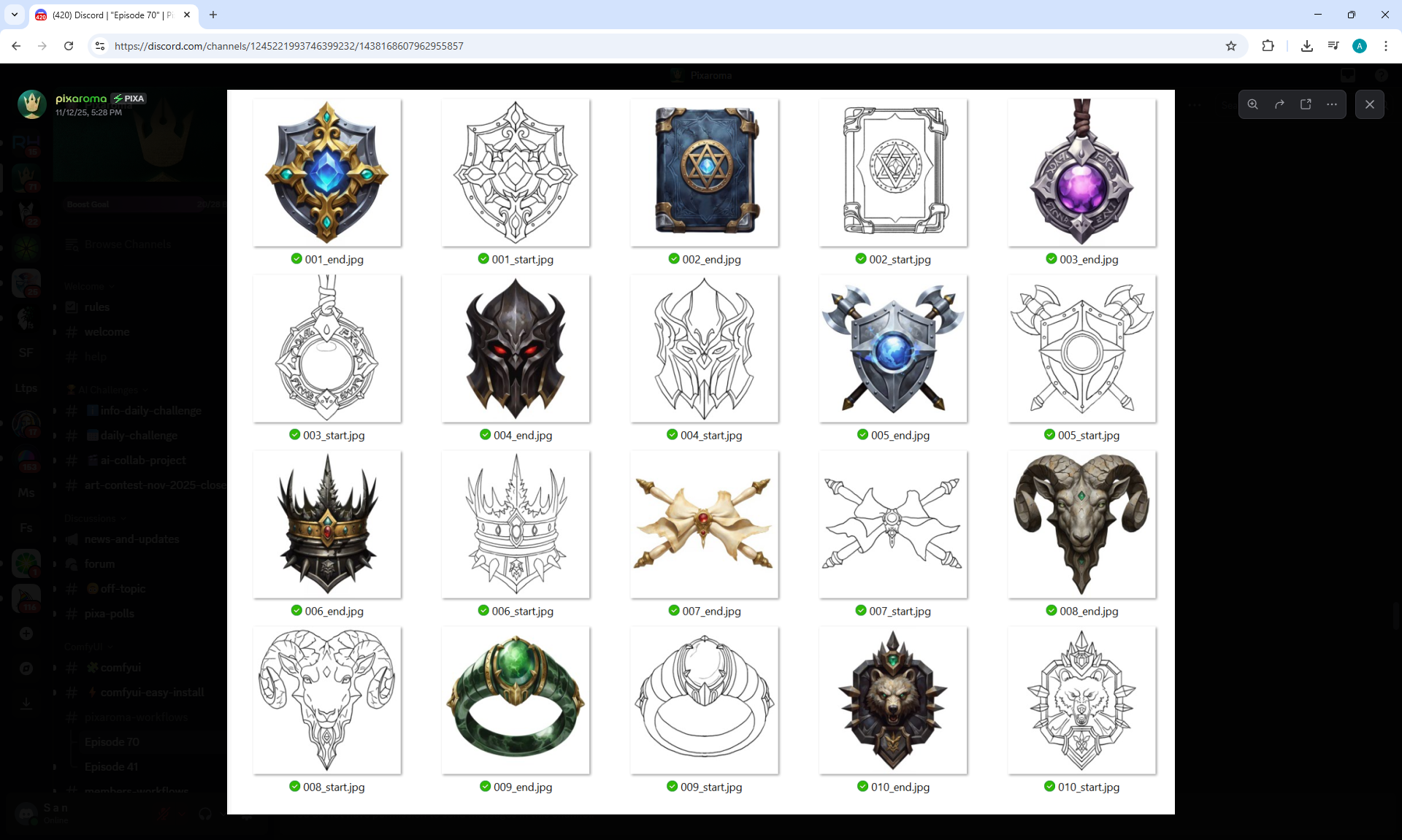
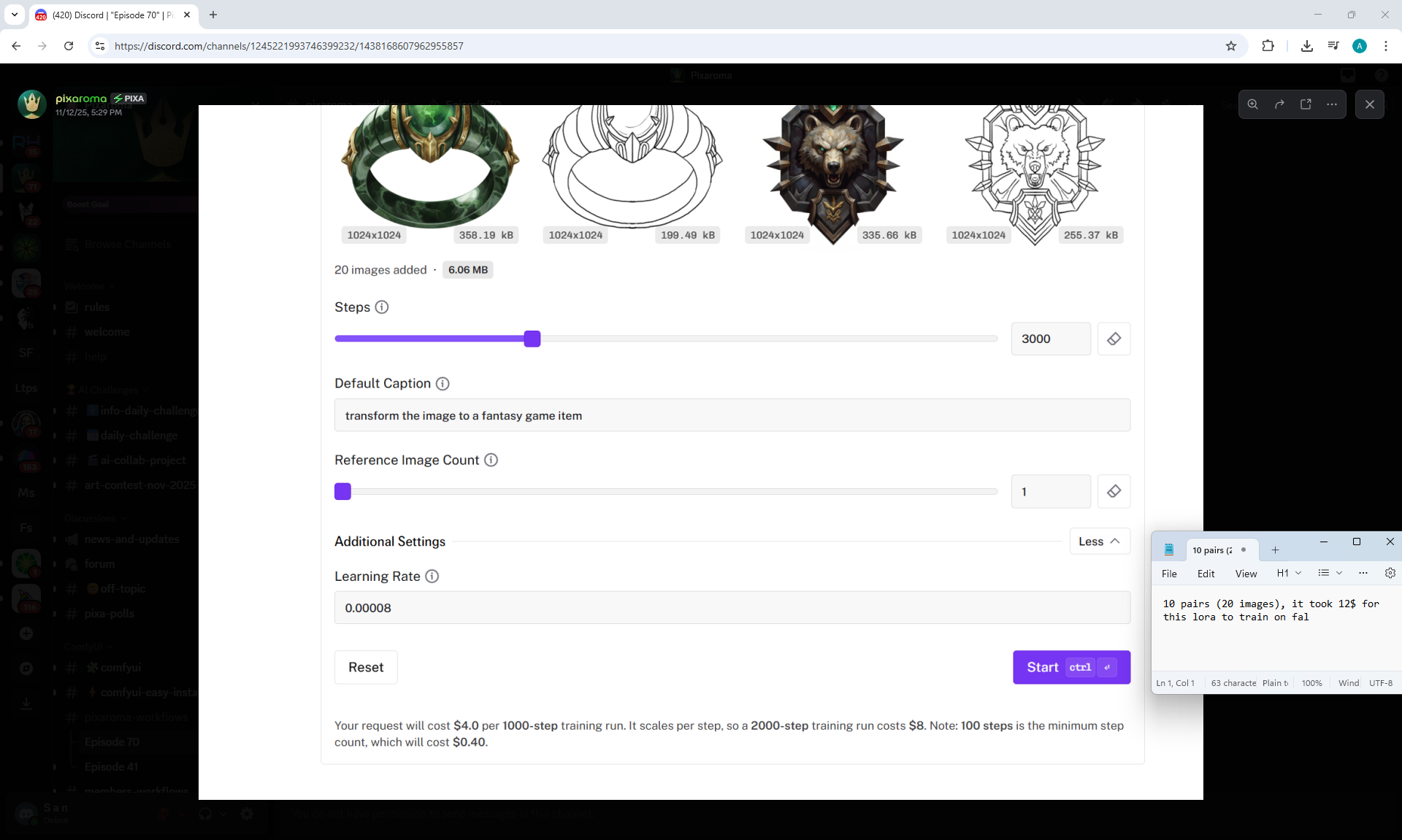
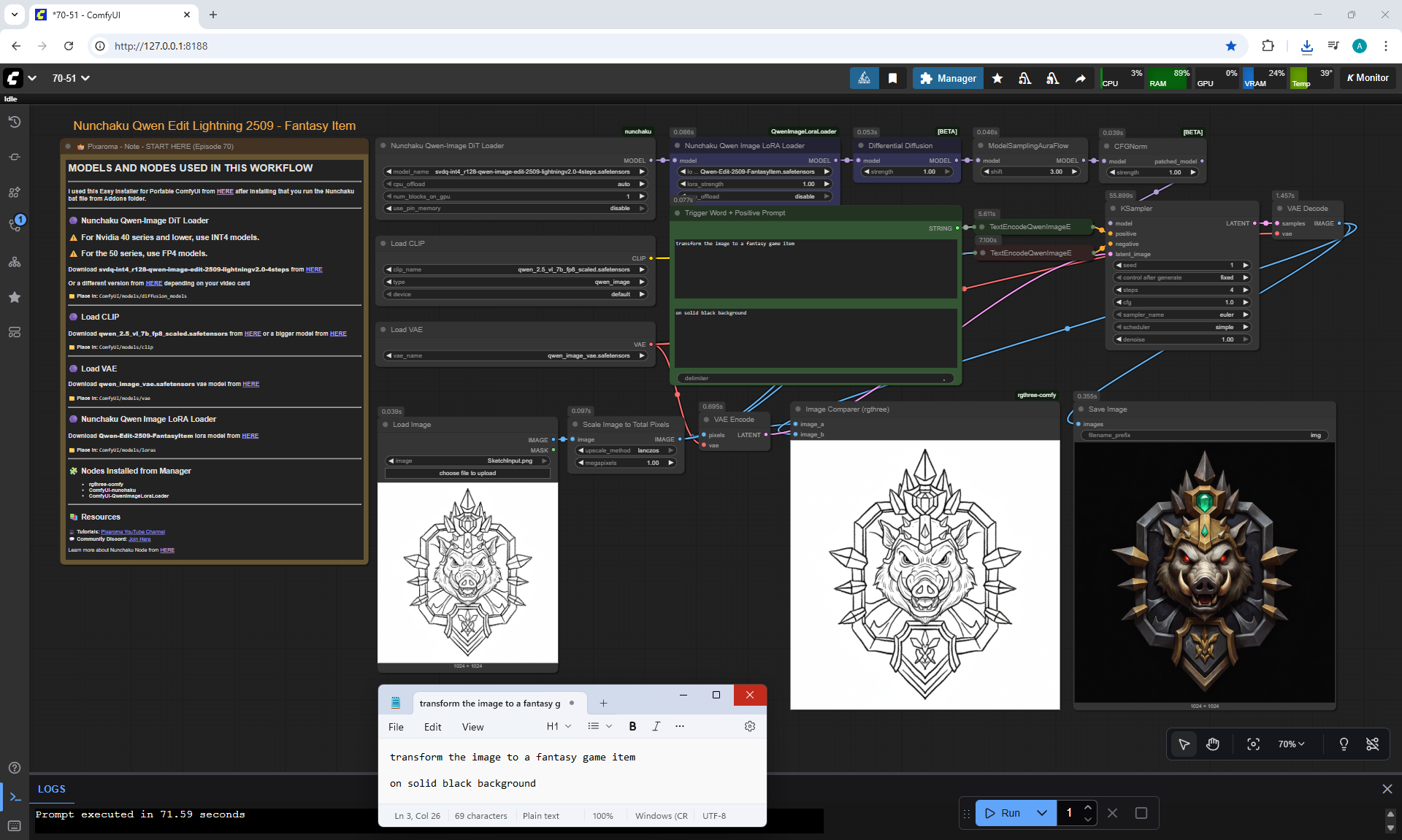
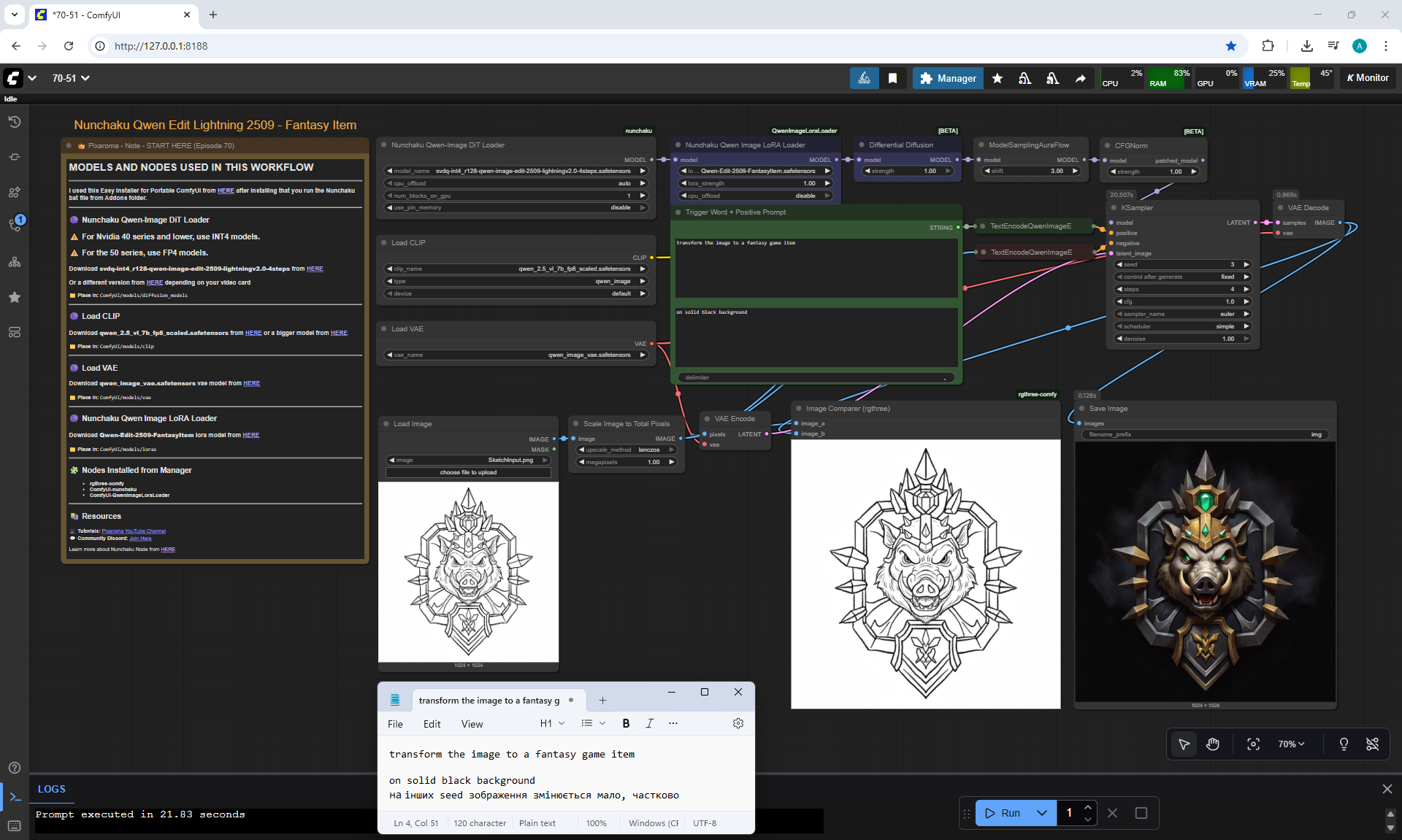
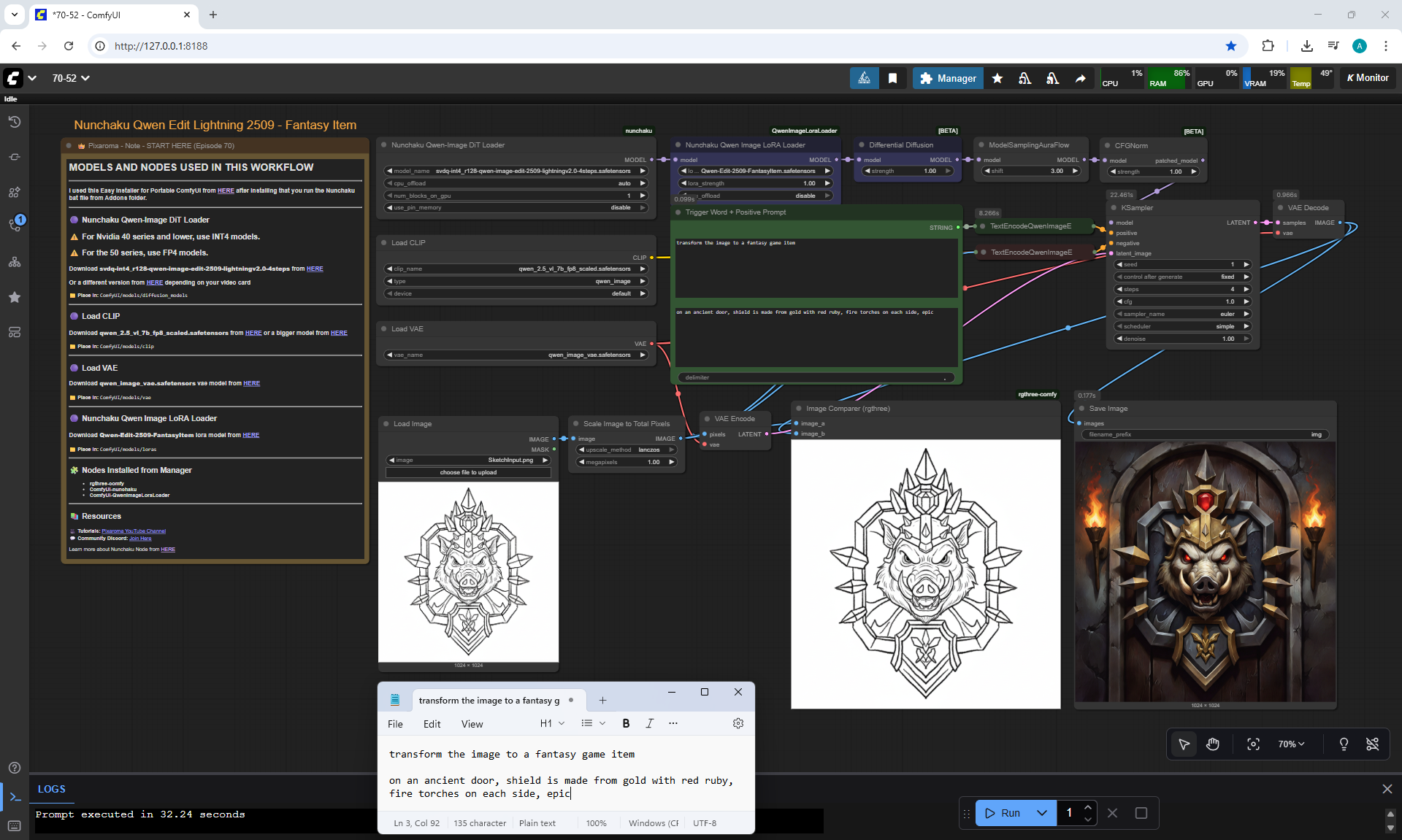
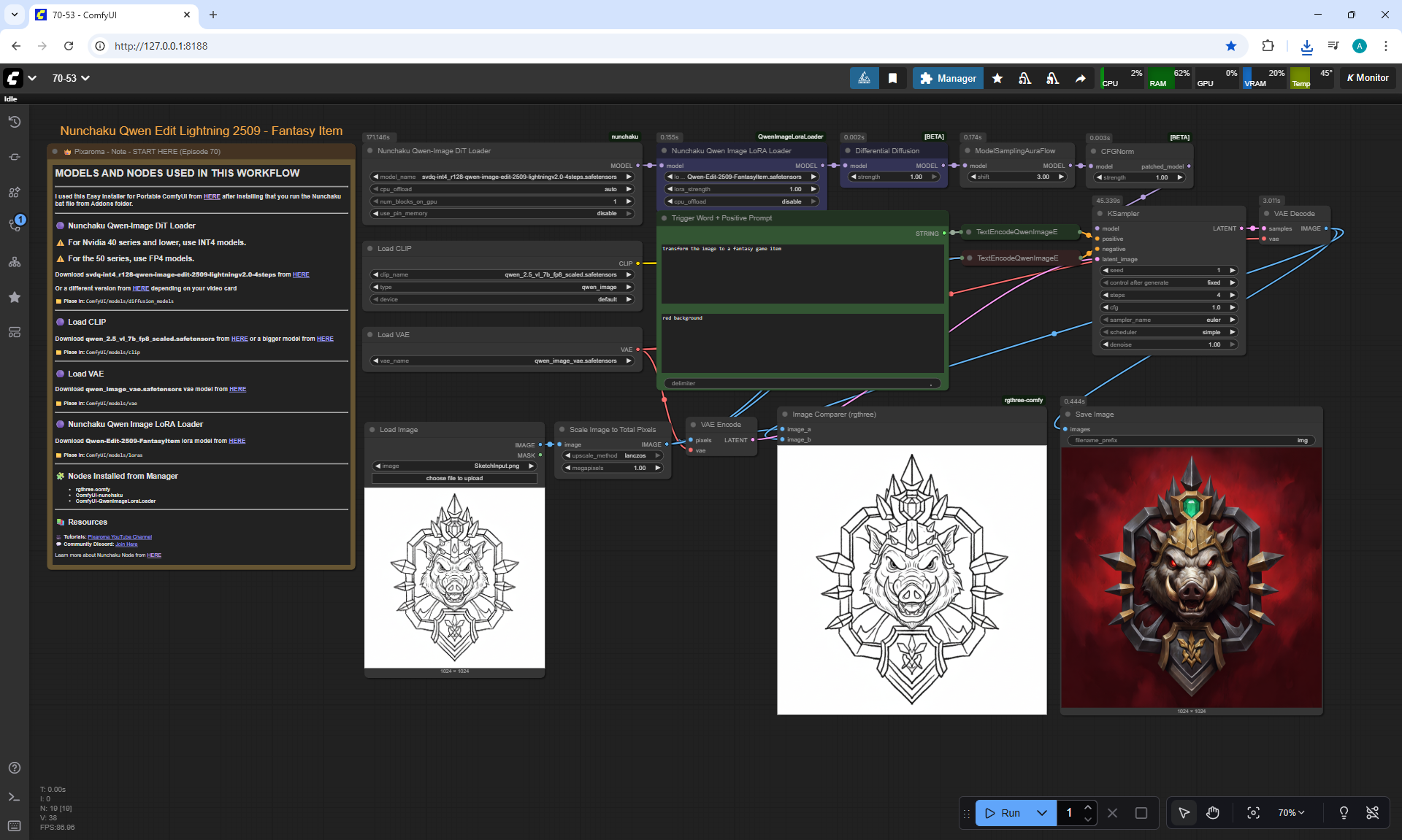
ComfyUI Tutorial Series Ep 70: Nunchaku Qwen Loras - Relight, Camera Angle & Scene Change














































































































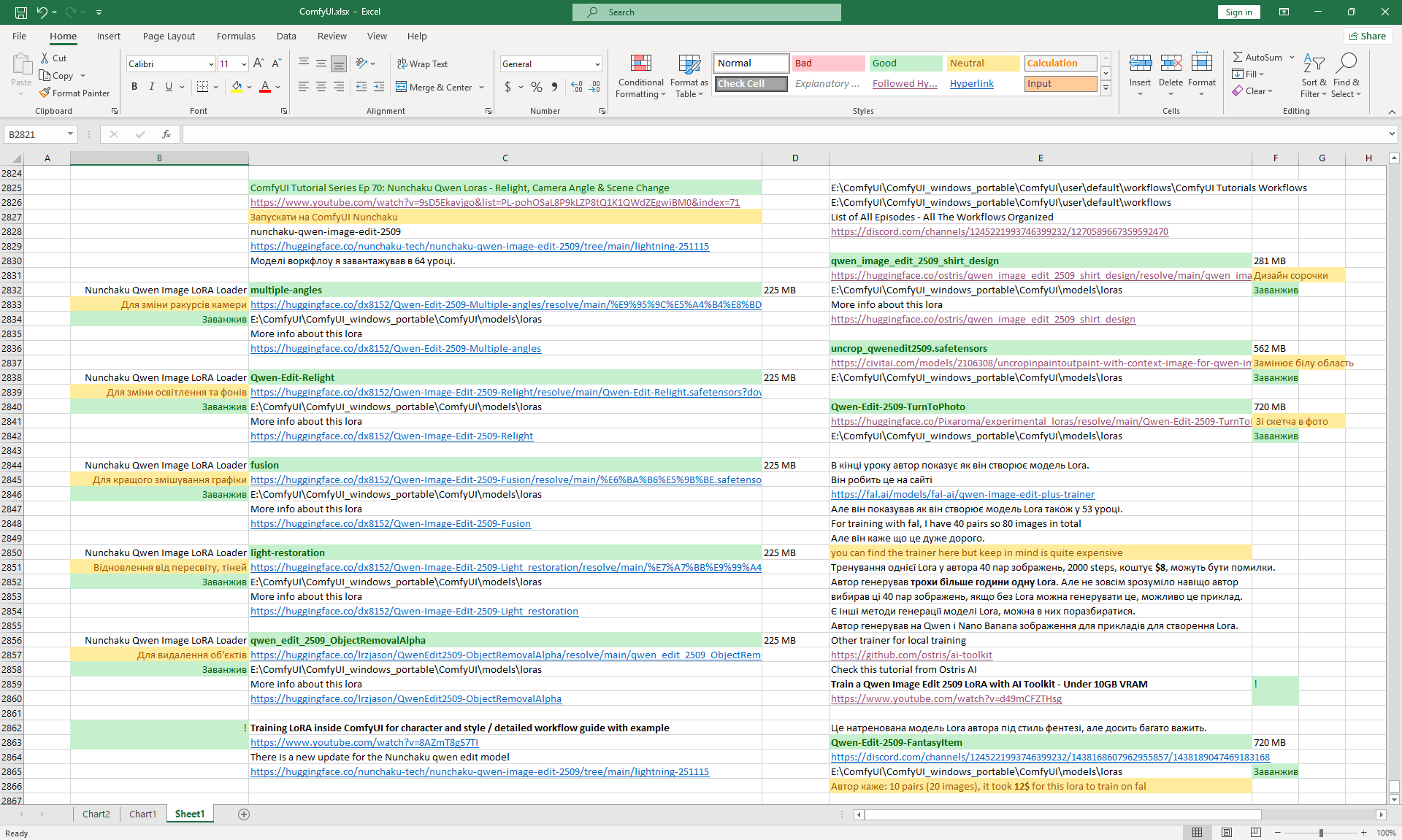
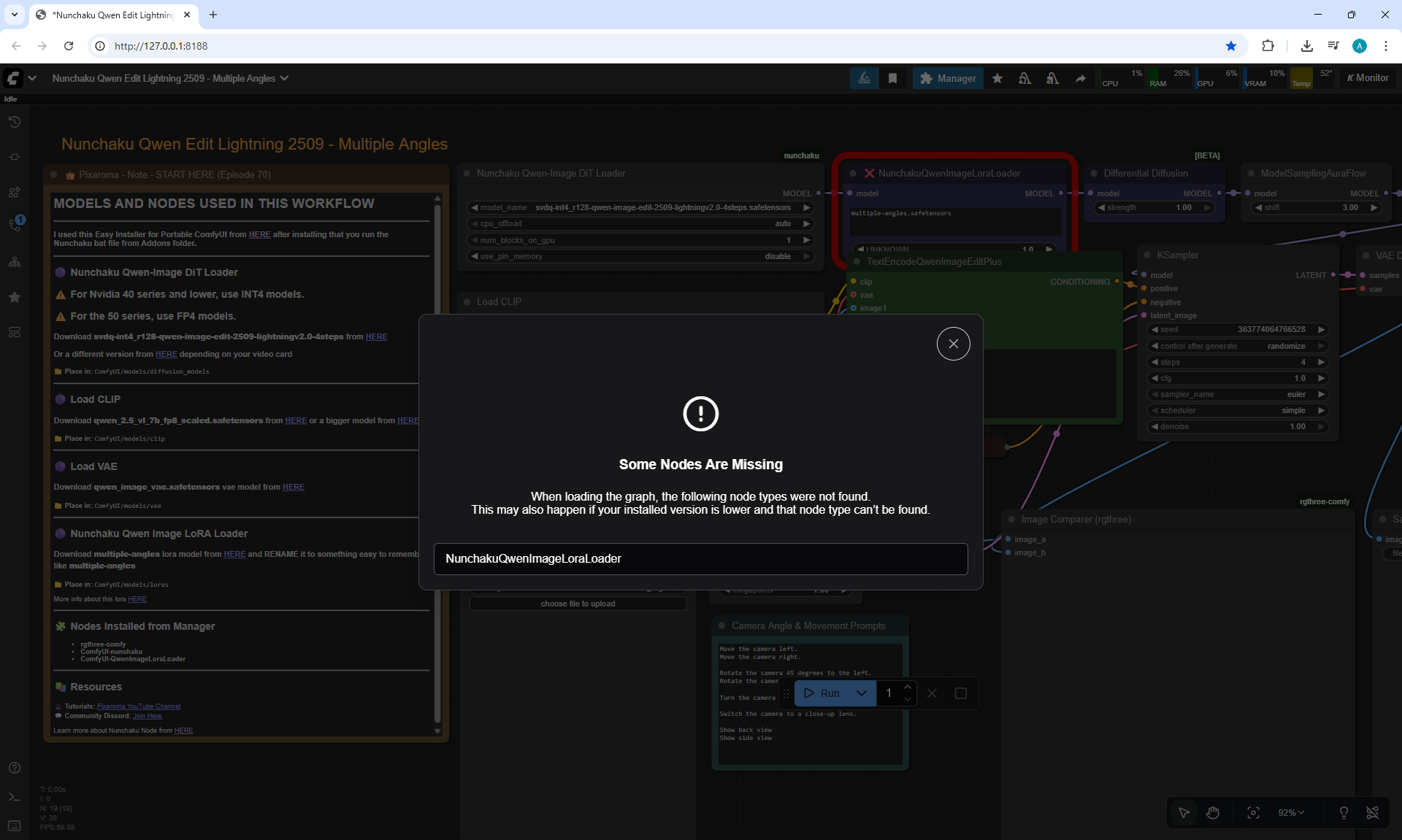
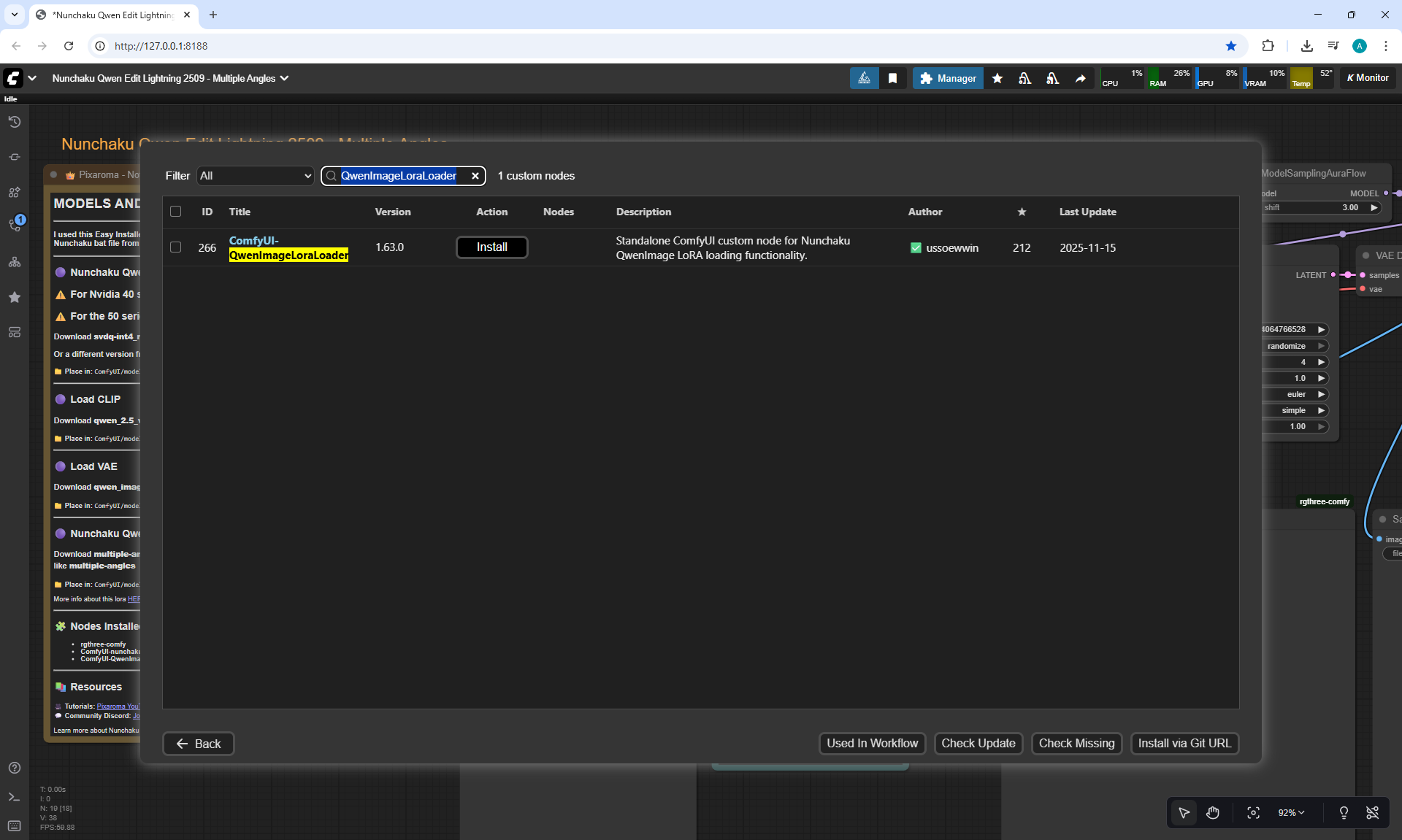

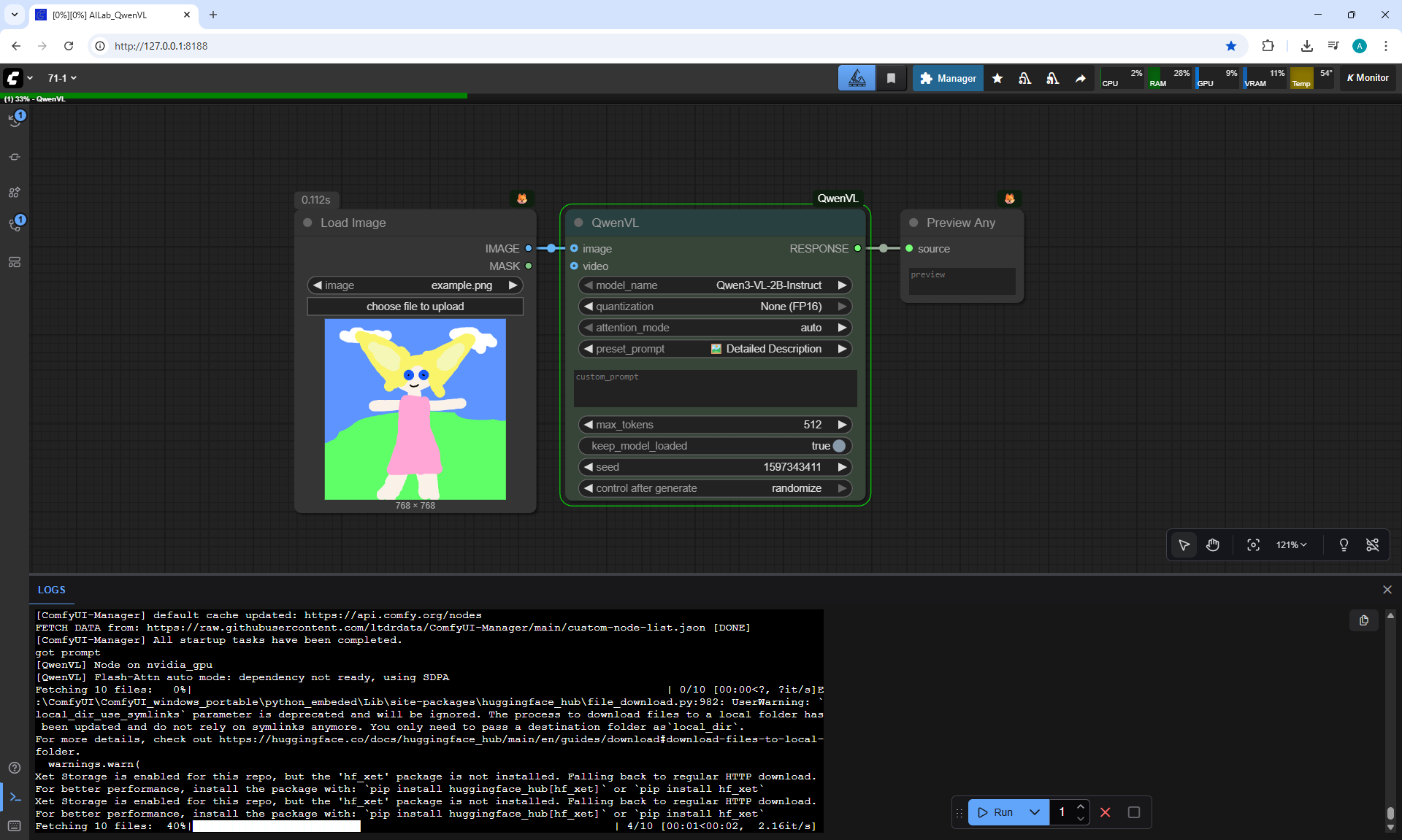
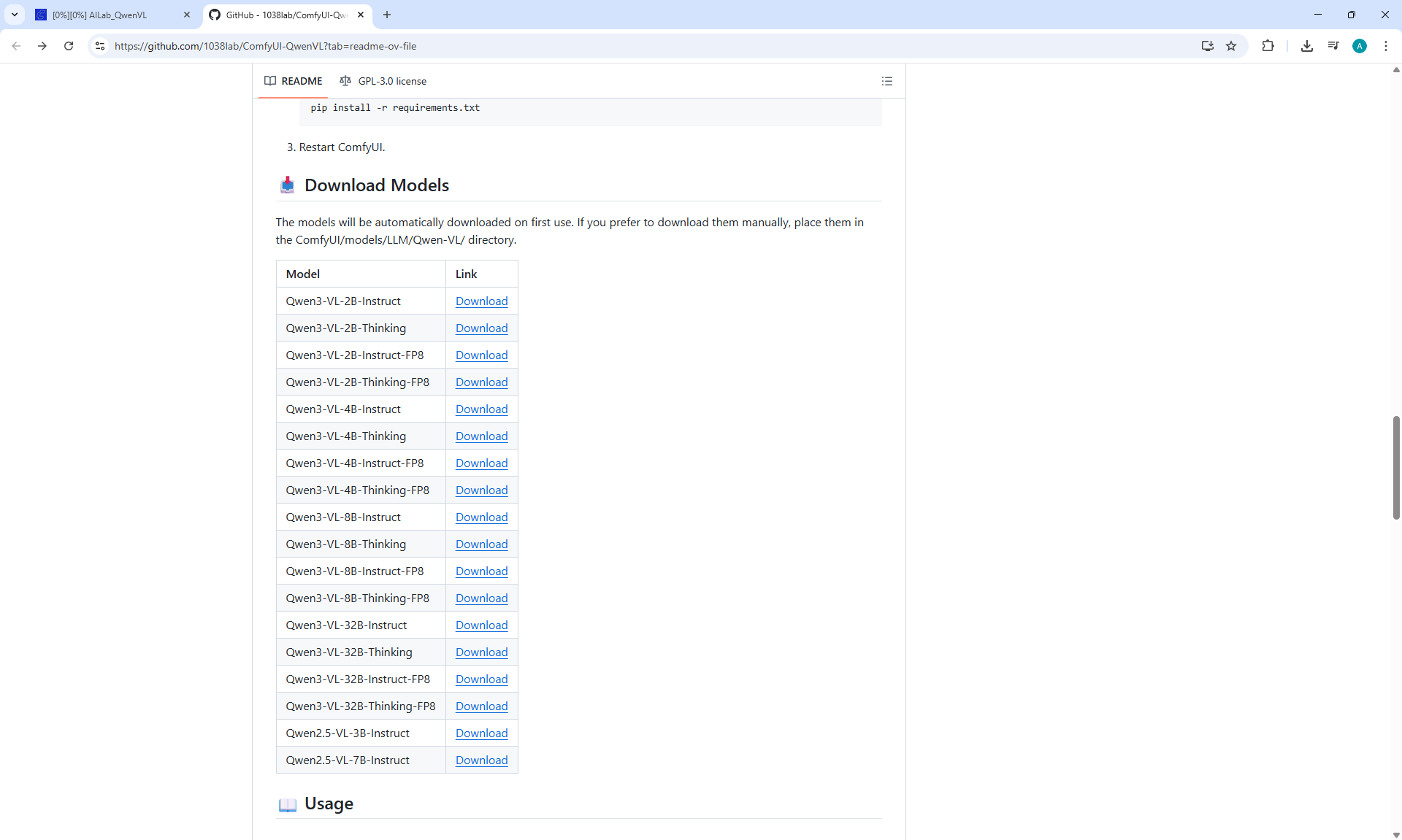
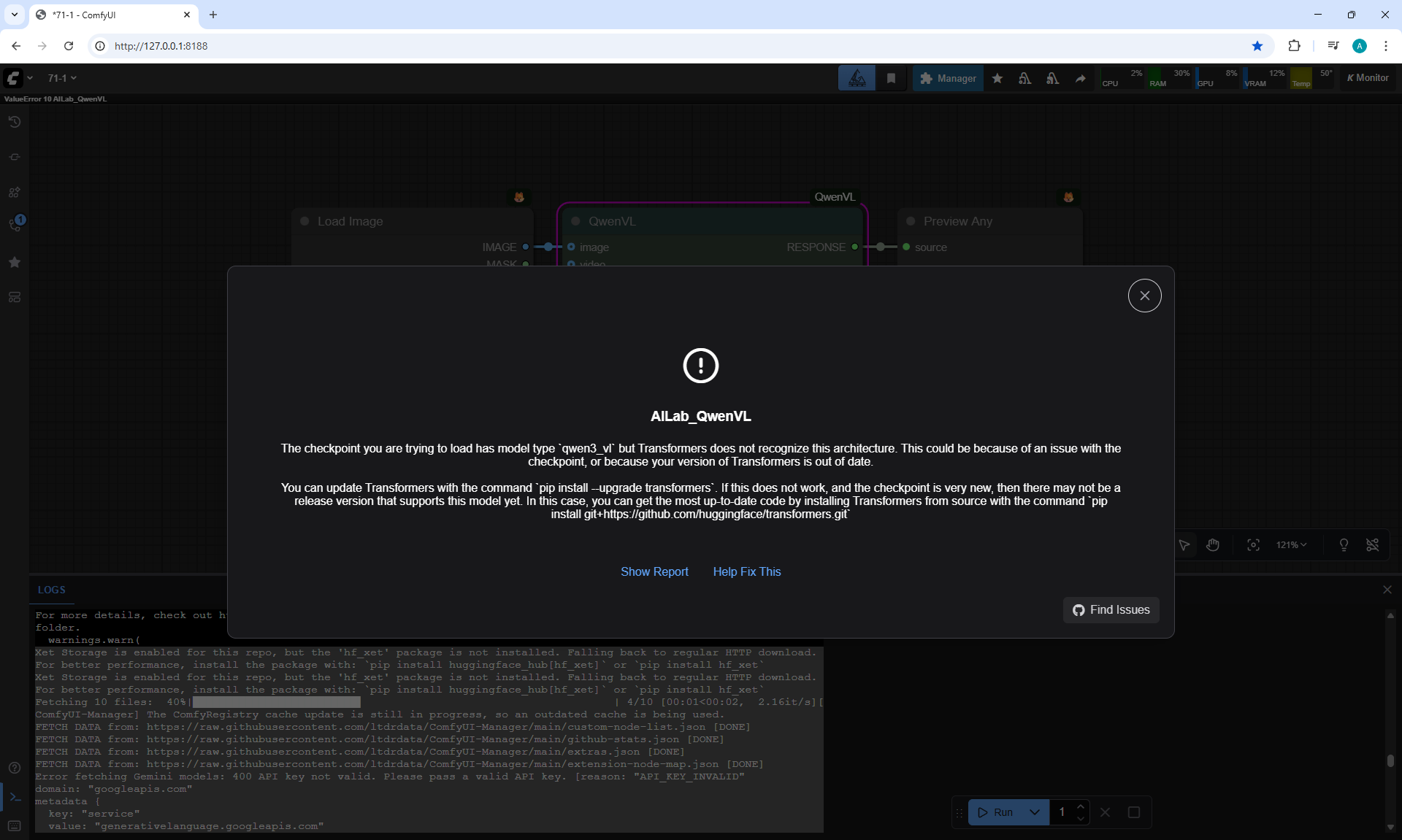
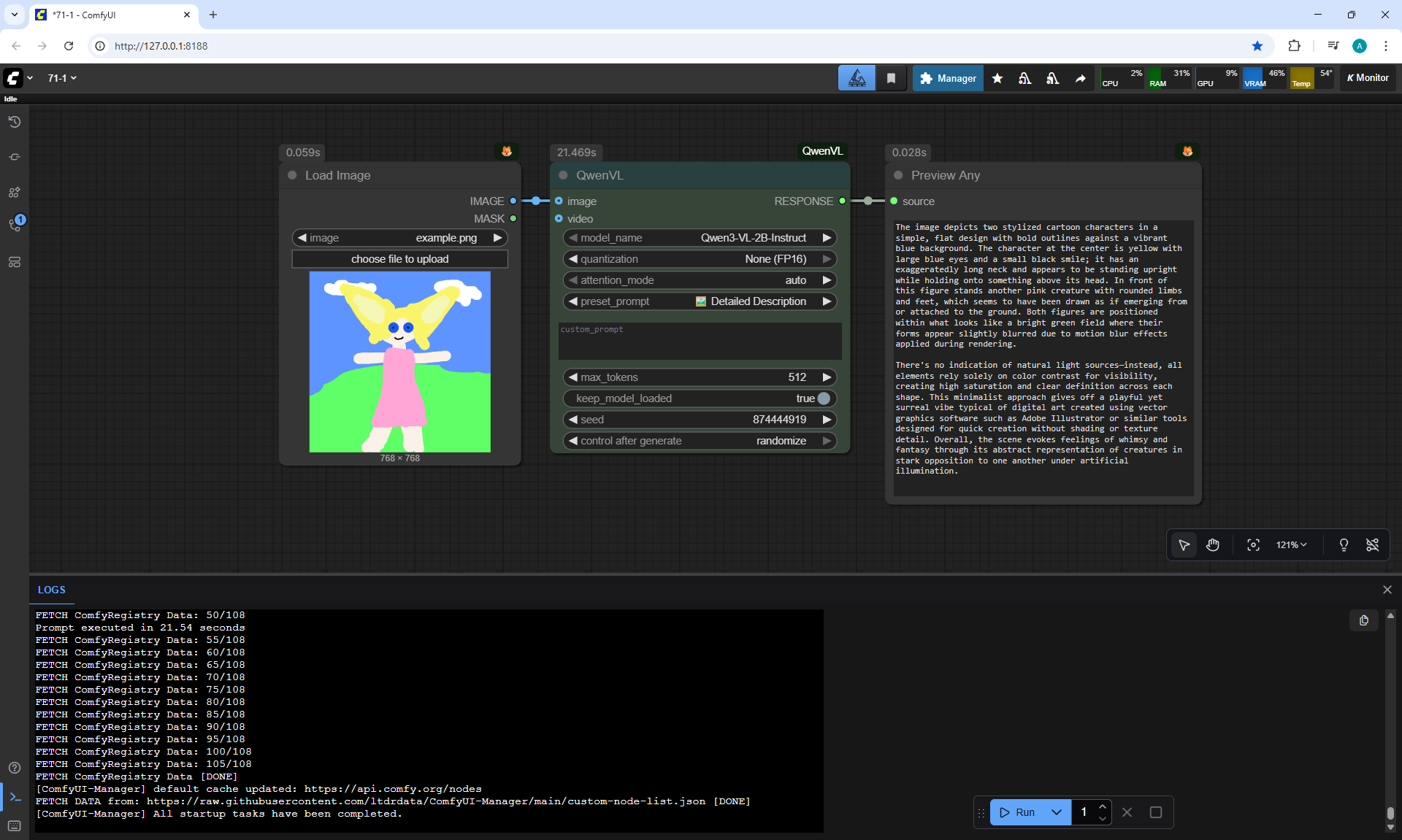
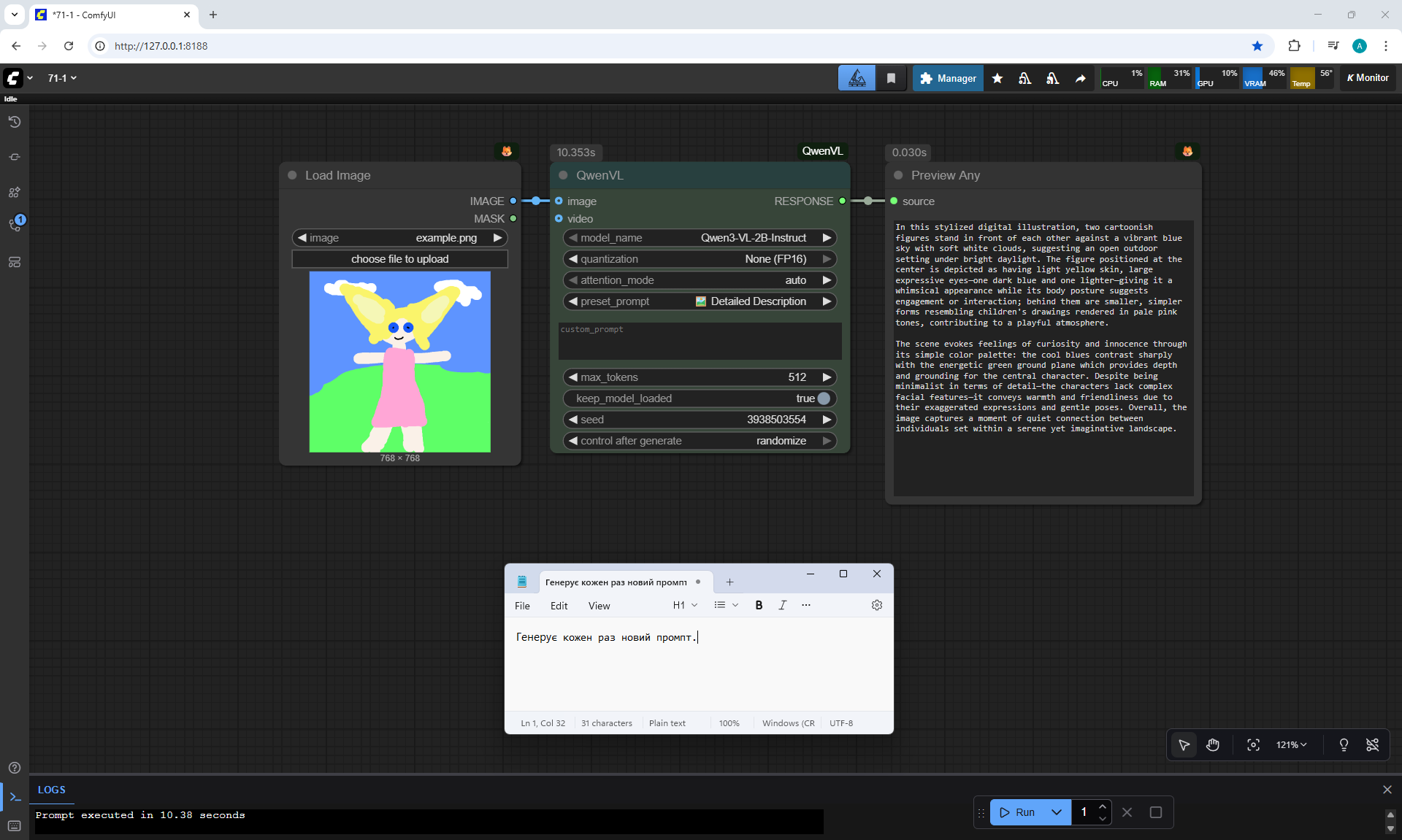
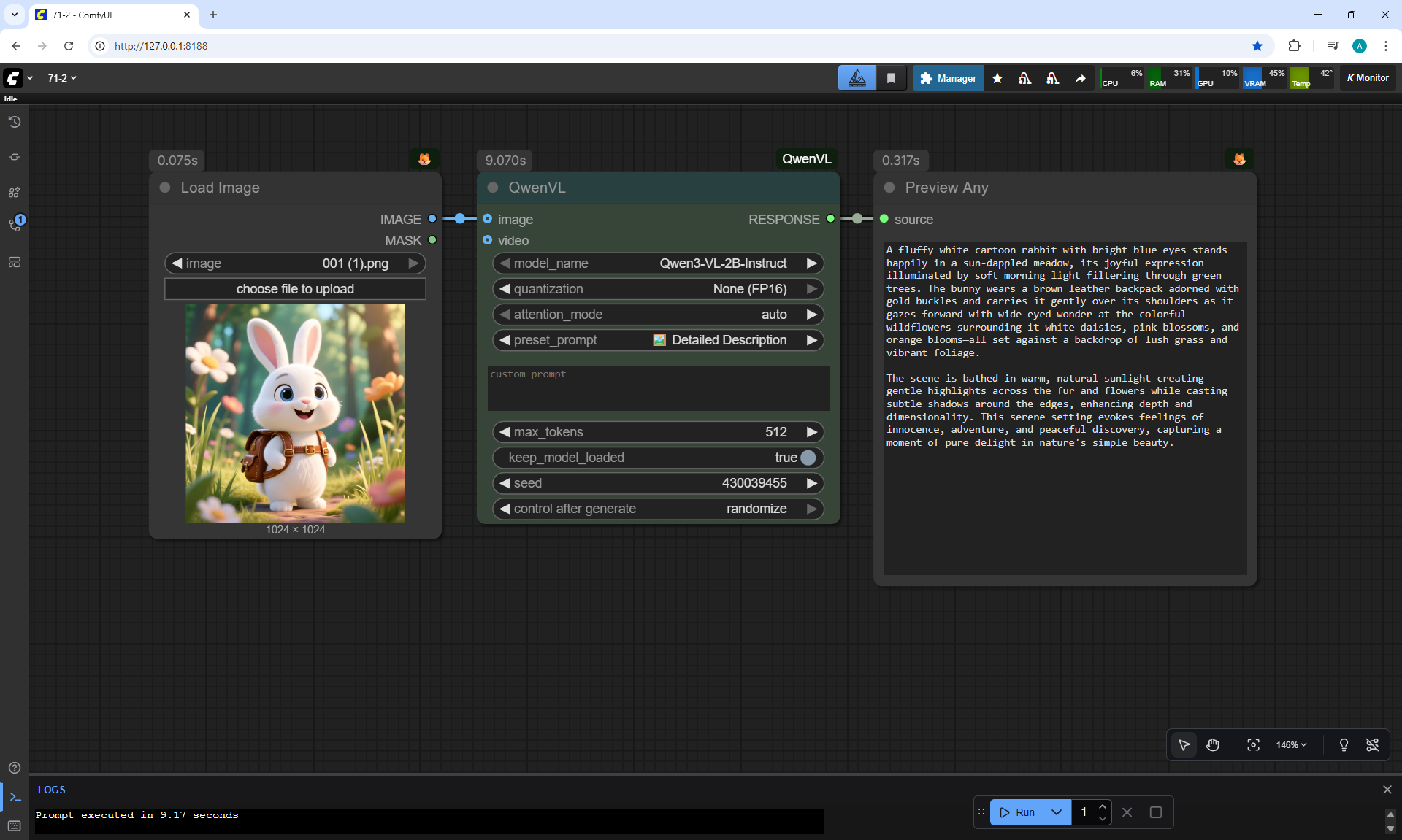
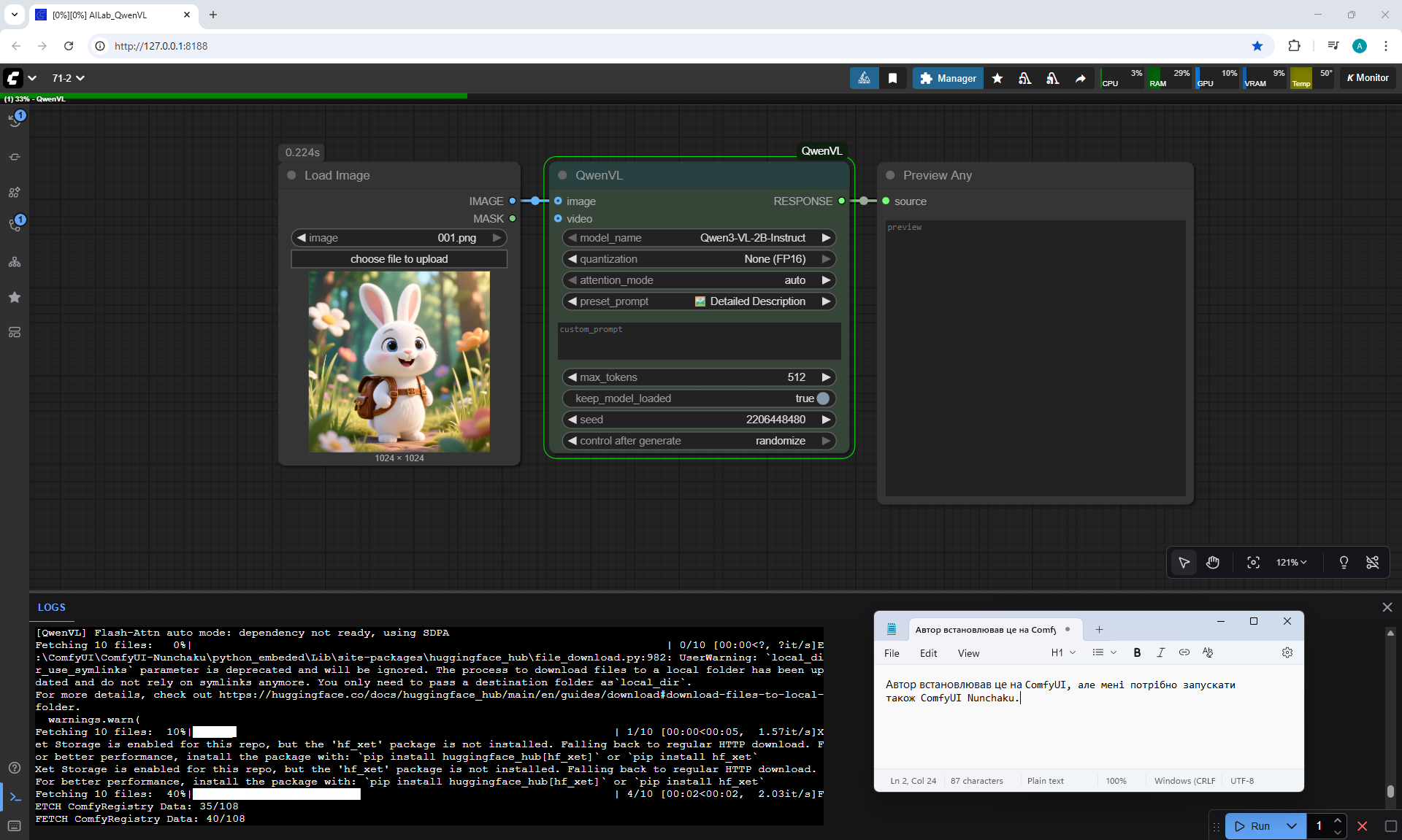
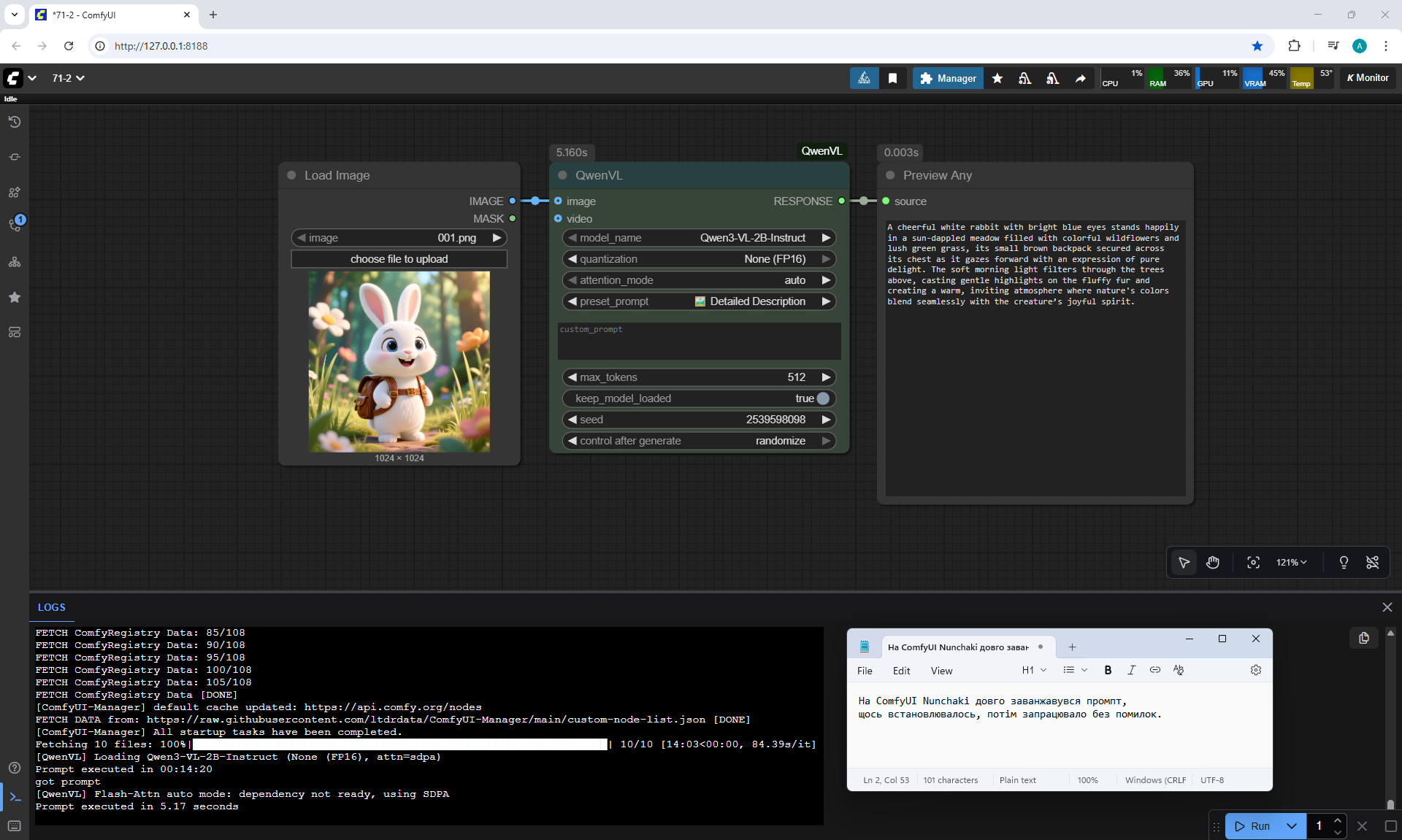
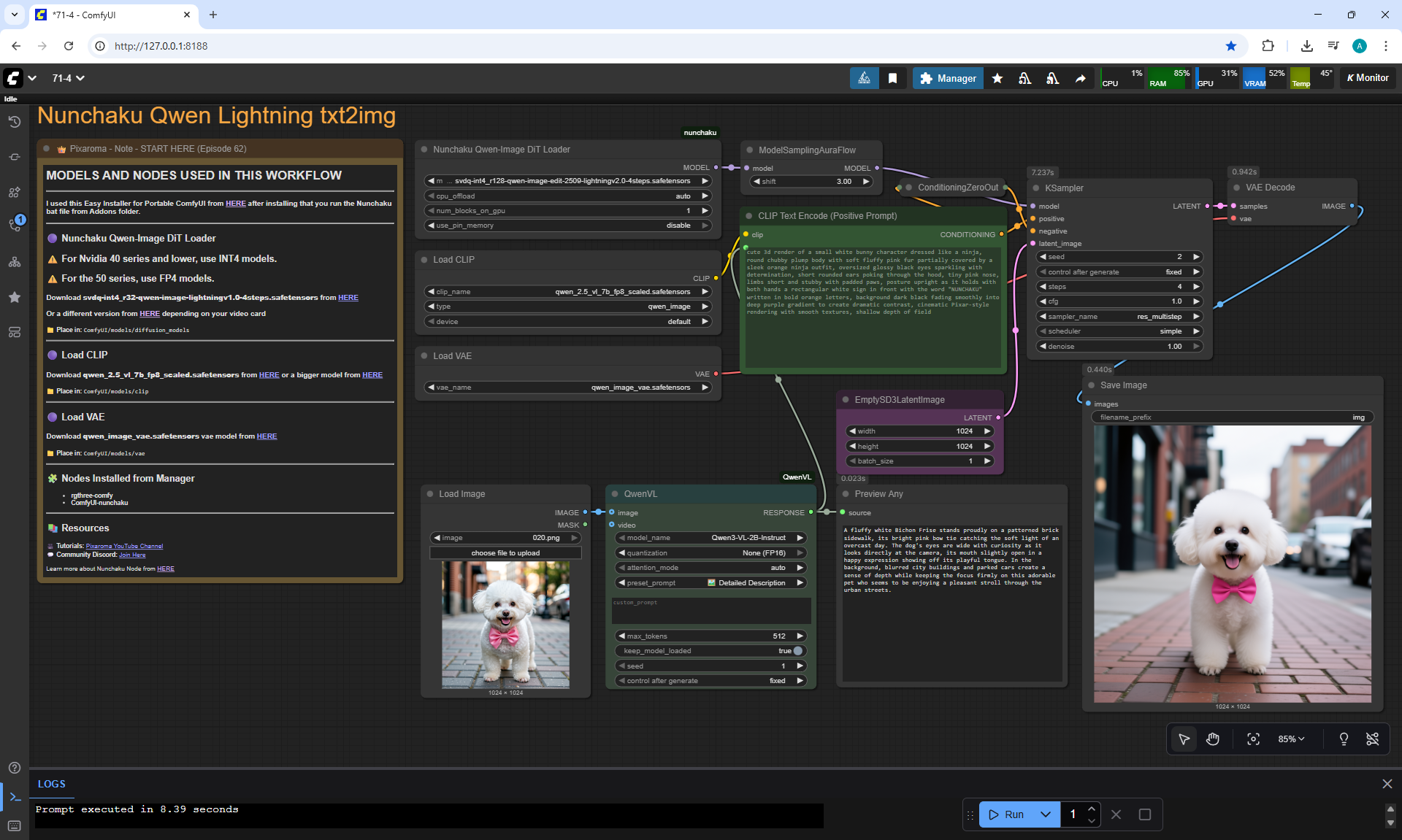
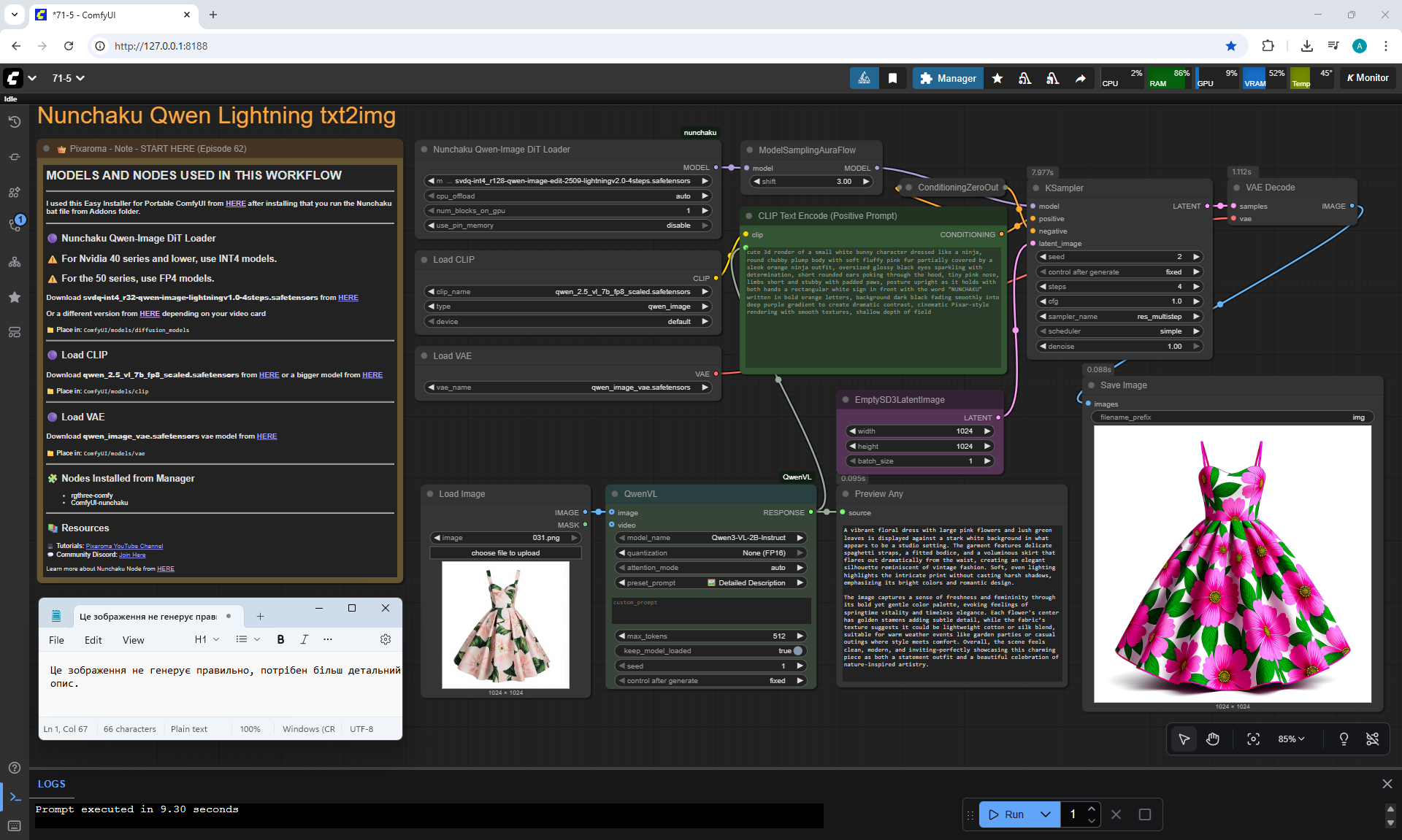
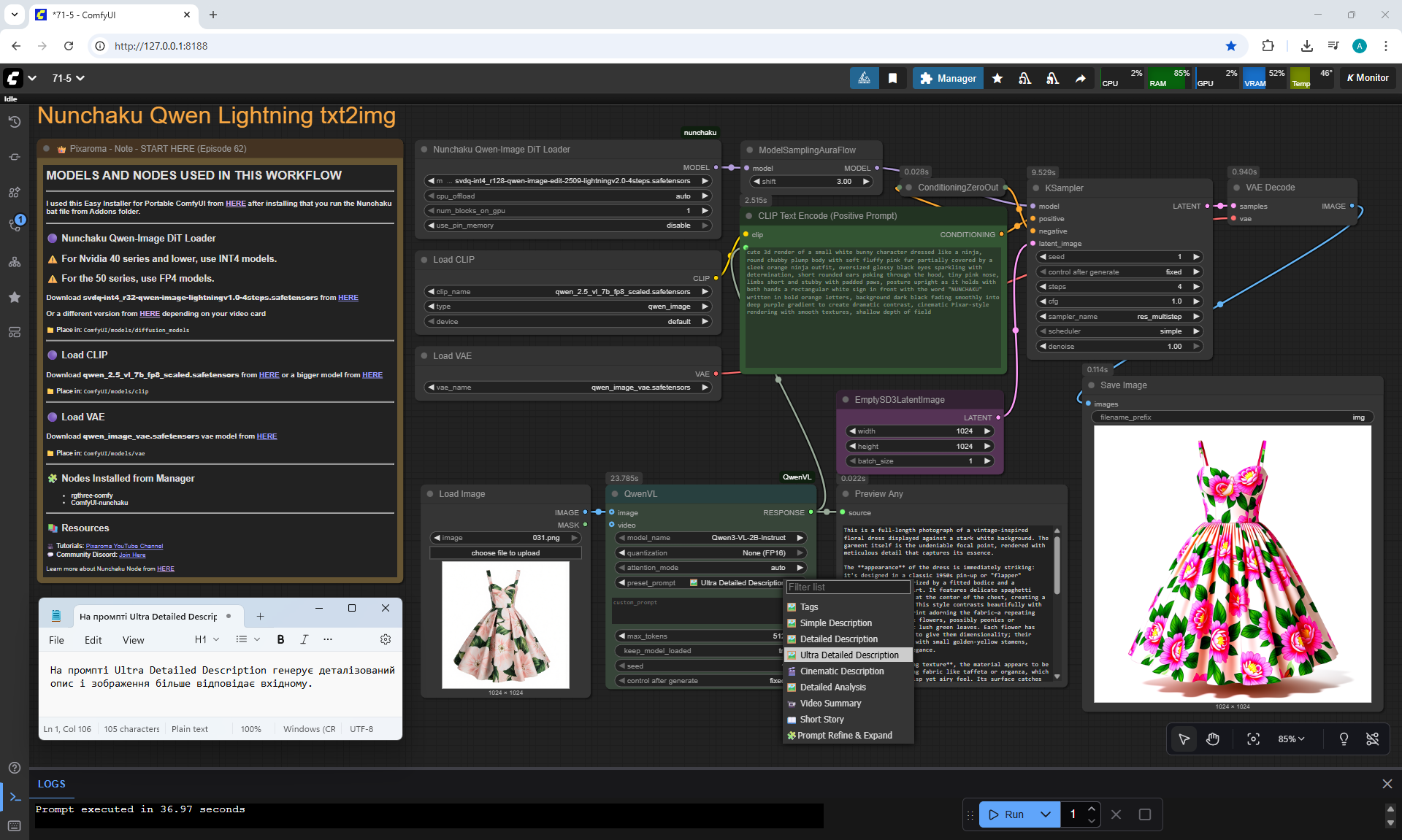
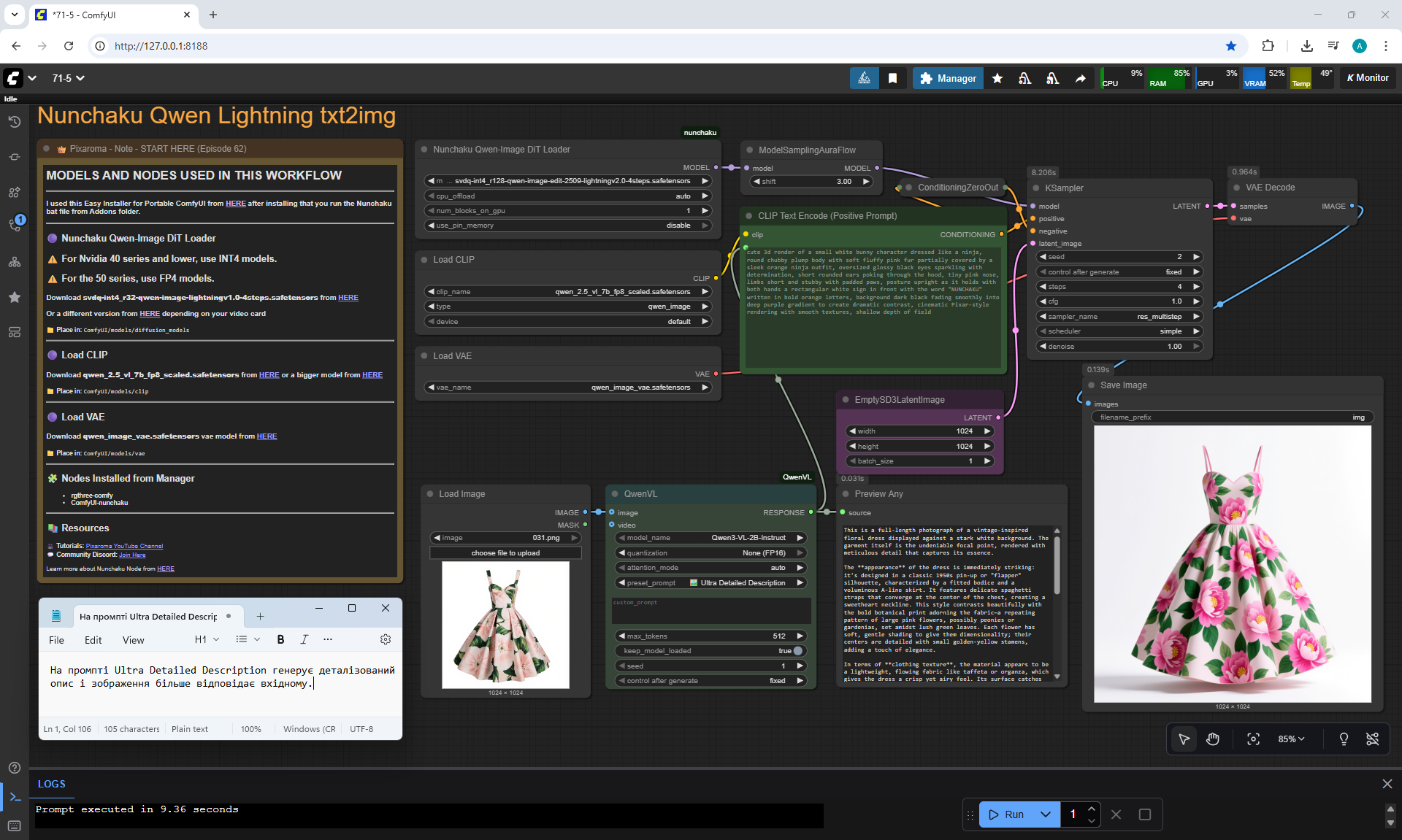
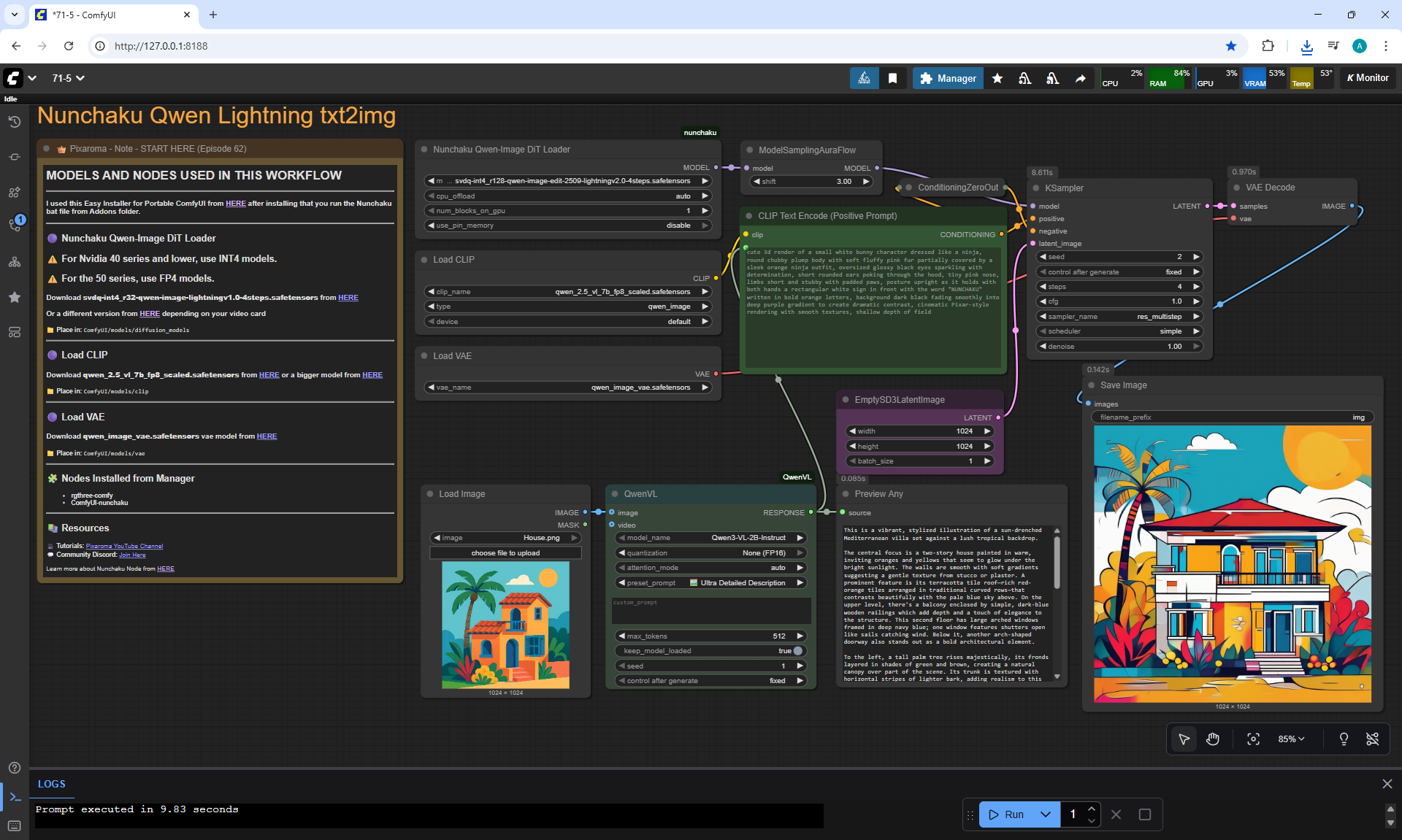
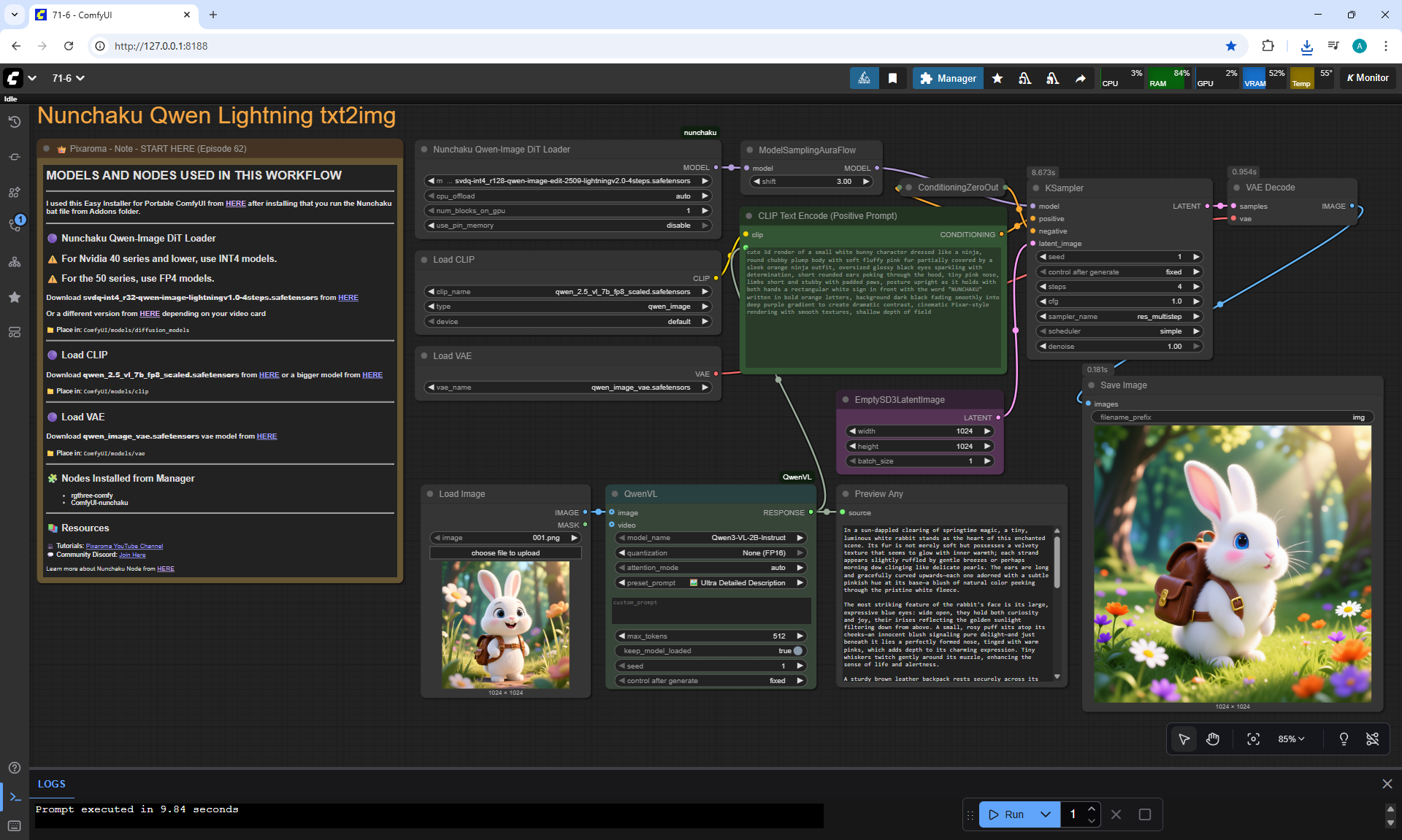
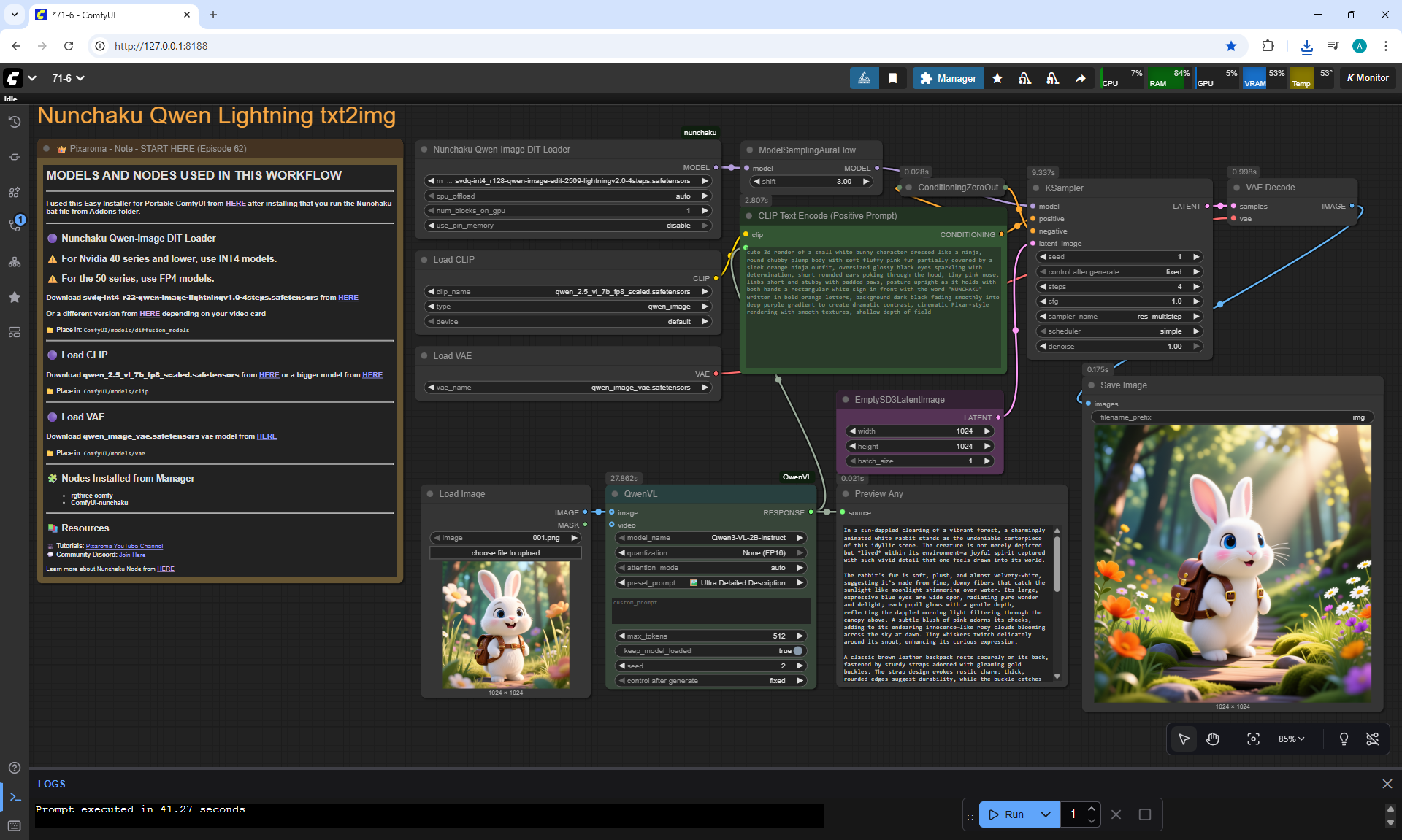
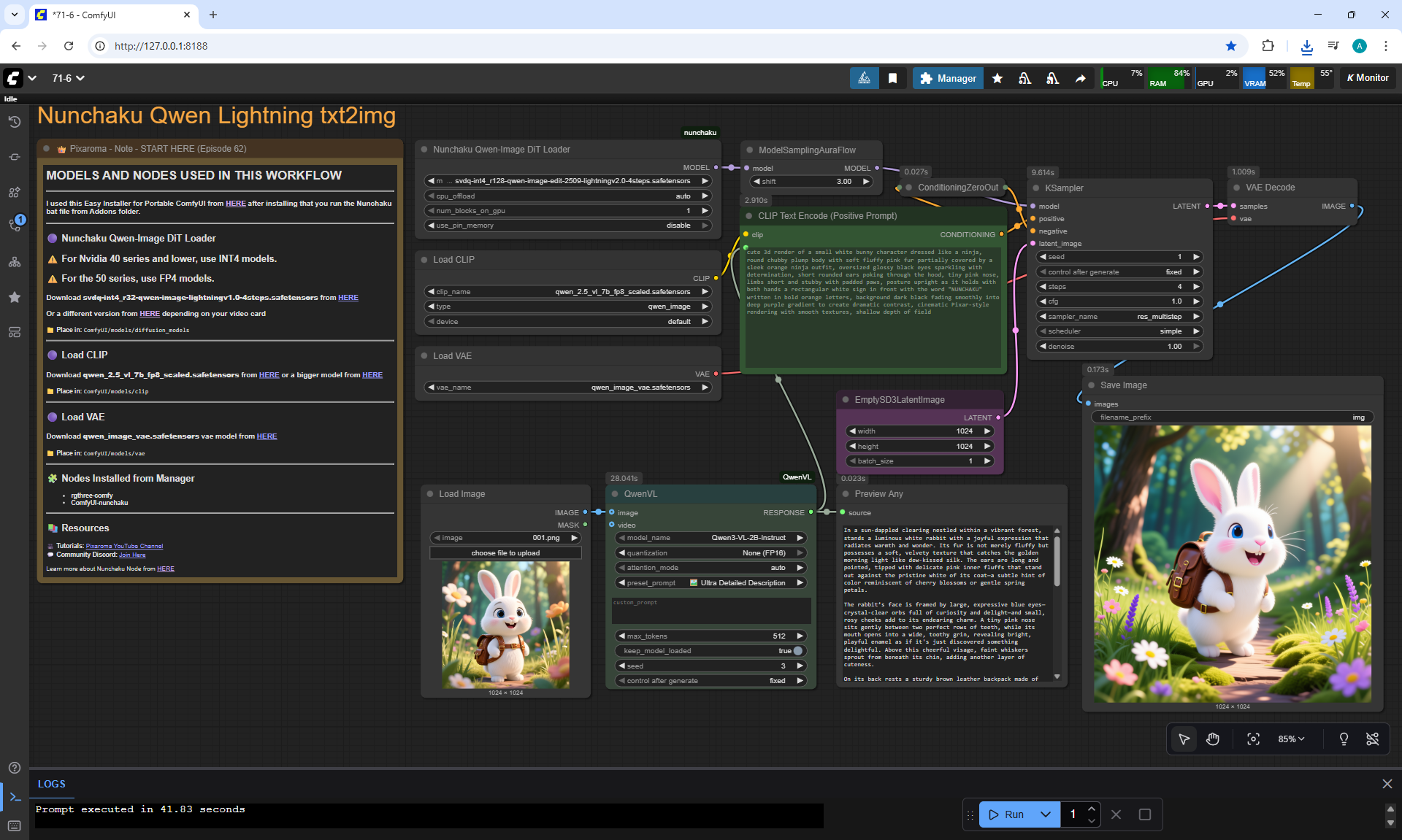
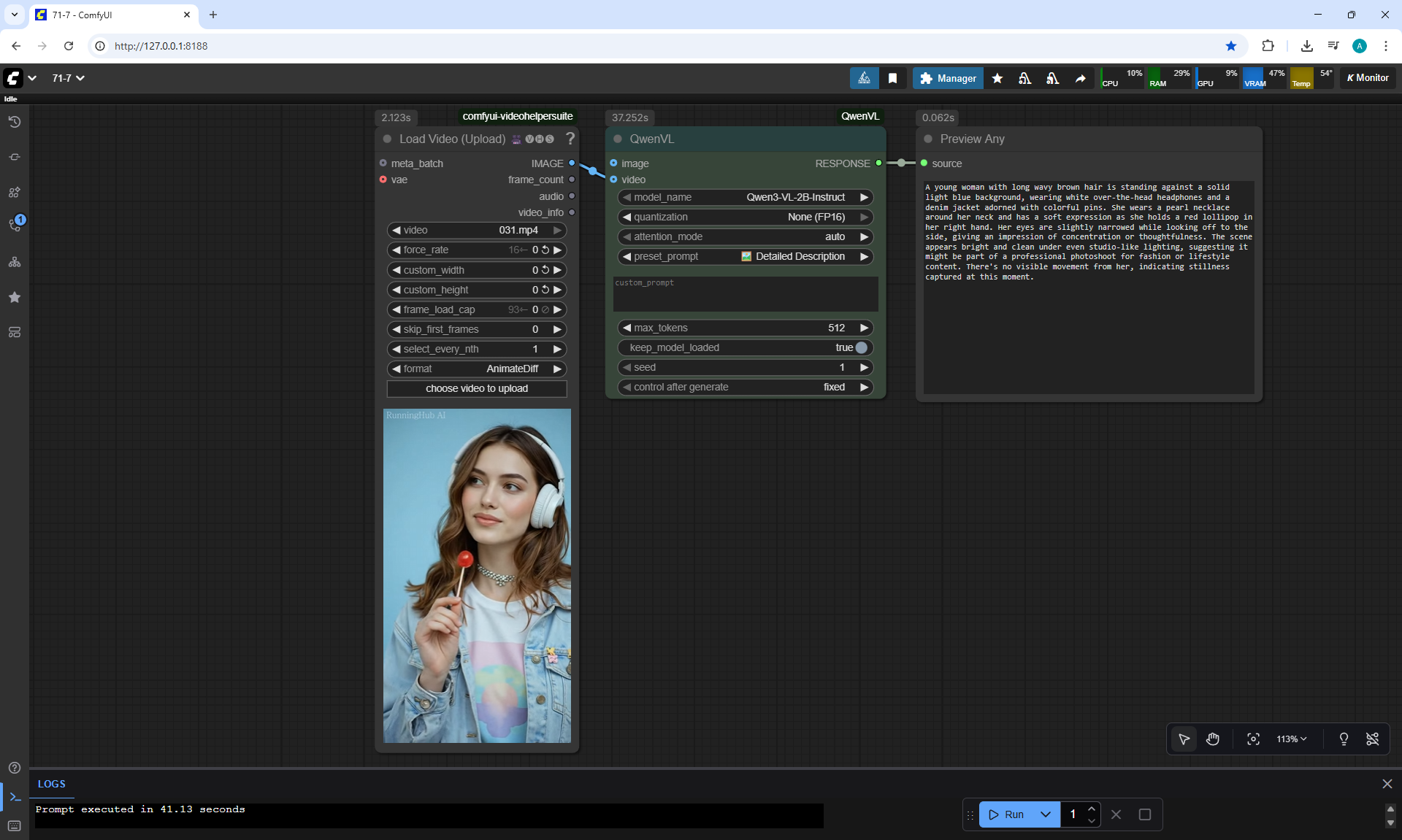
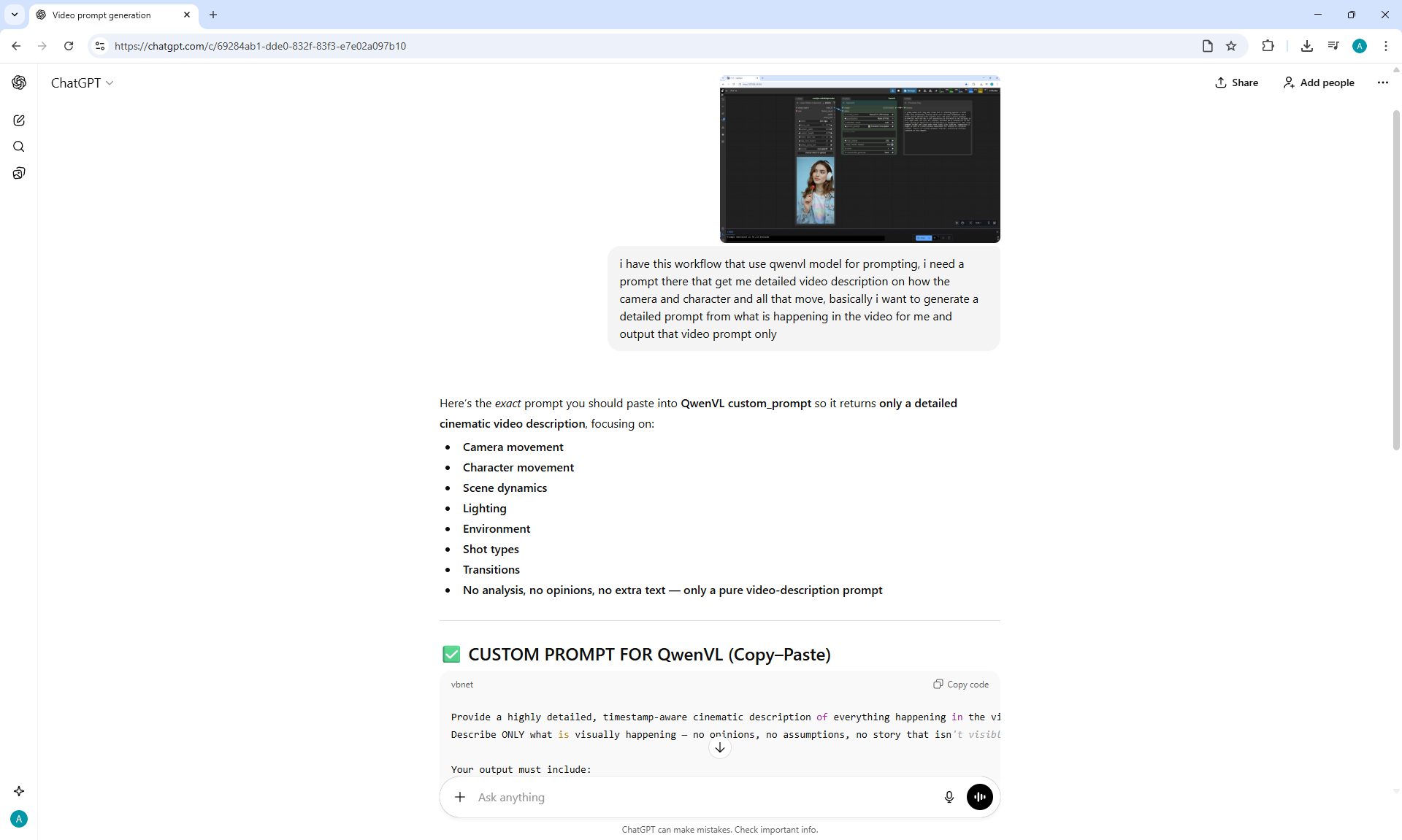
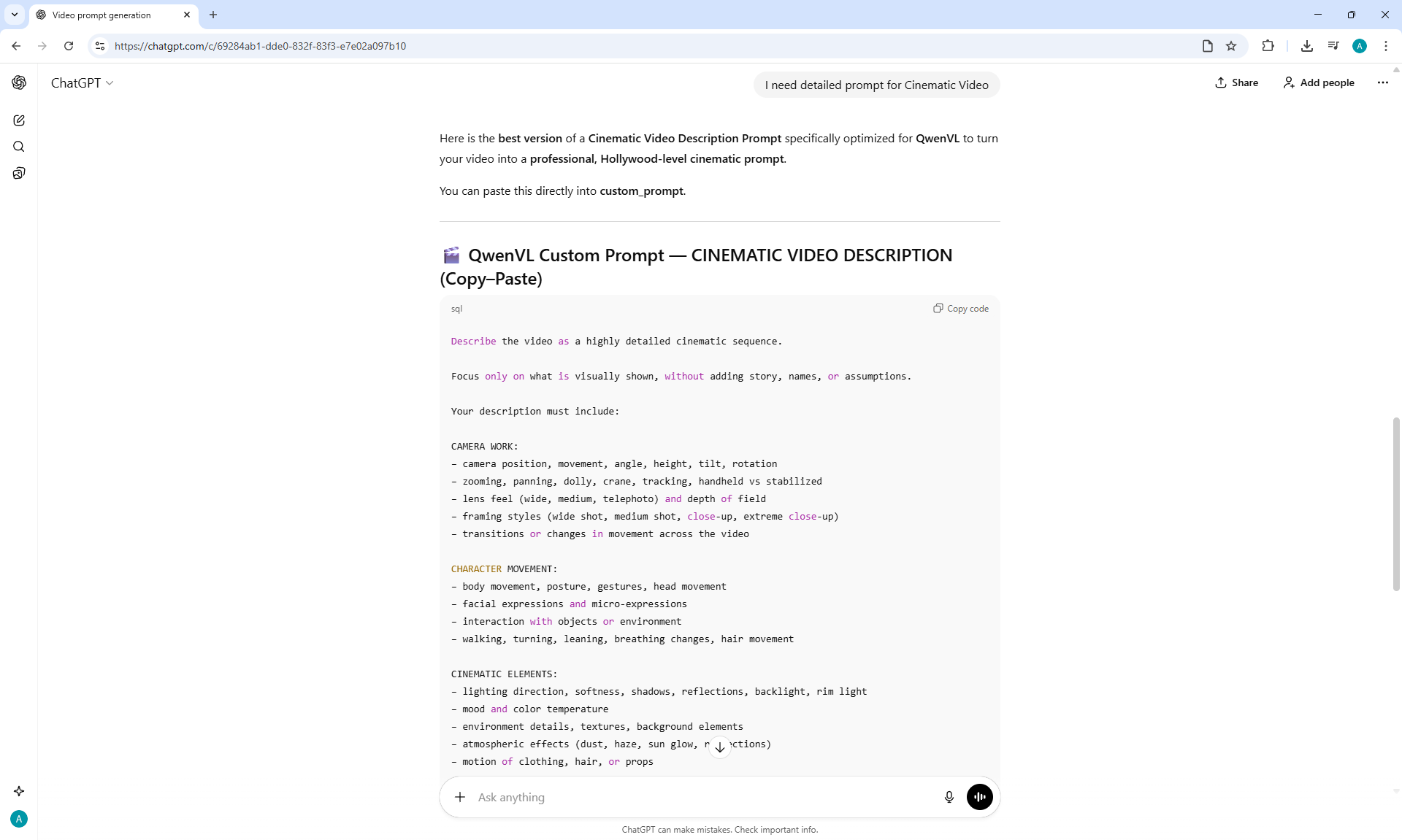
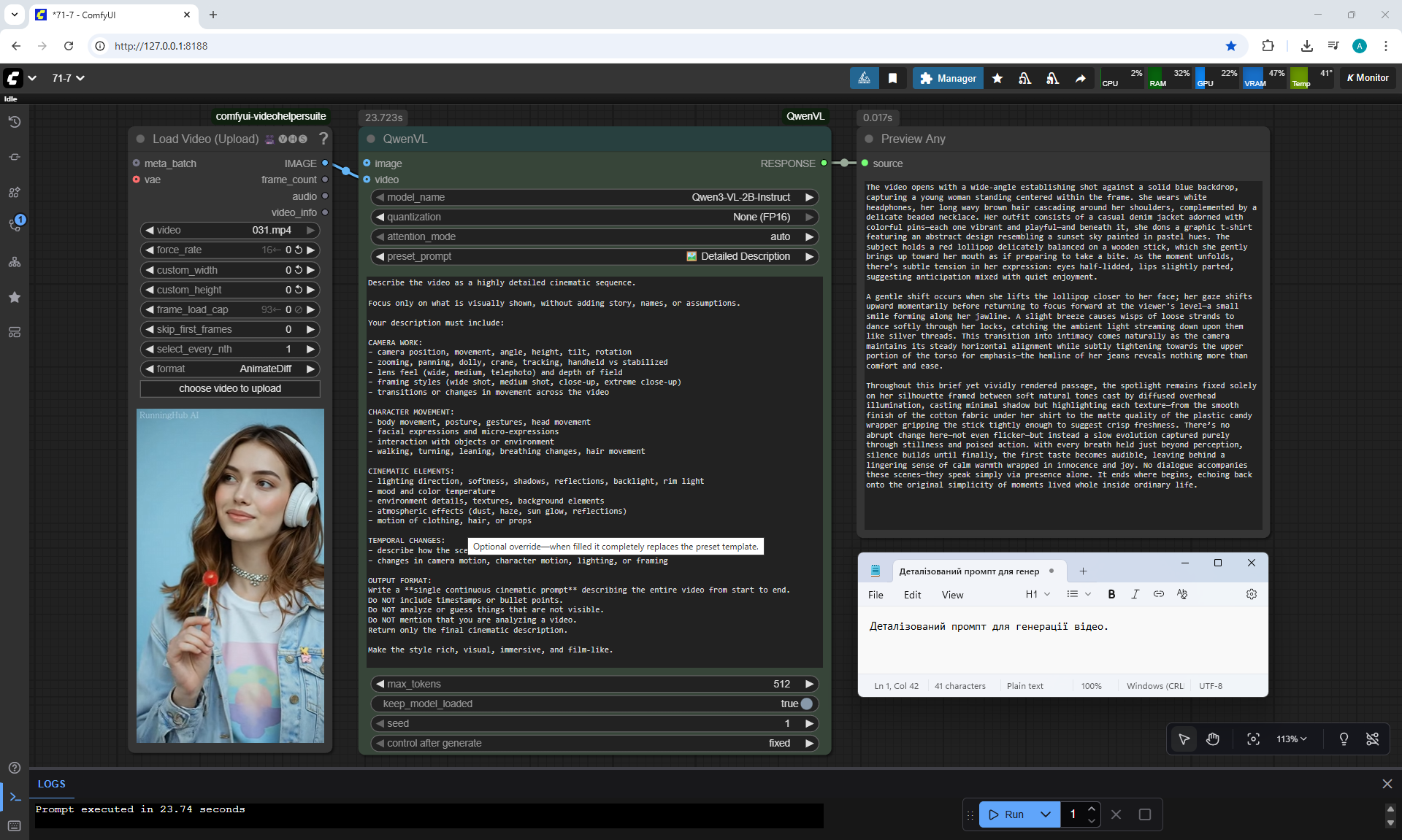
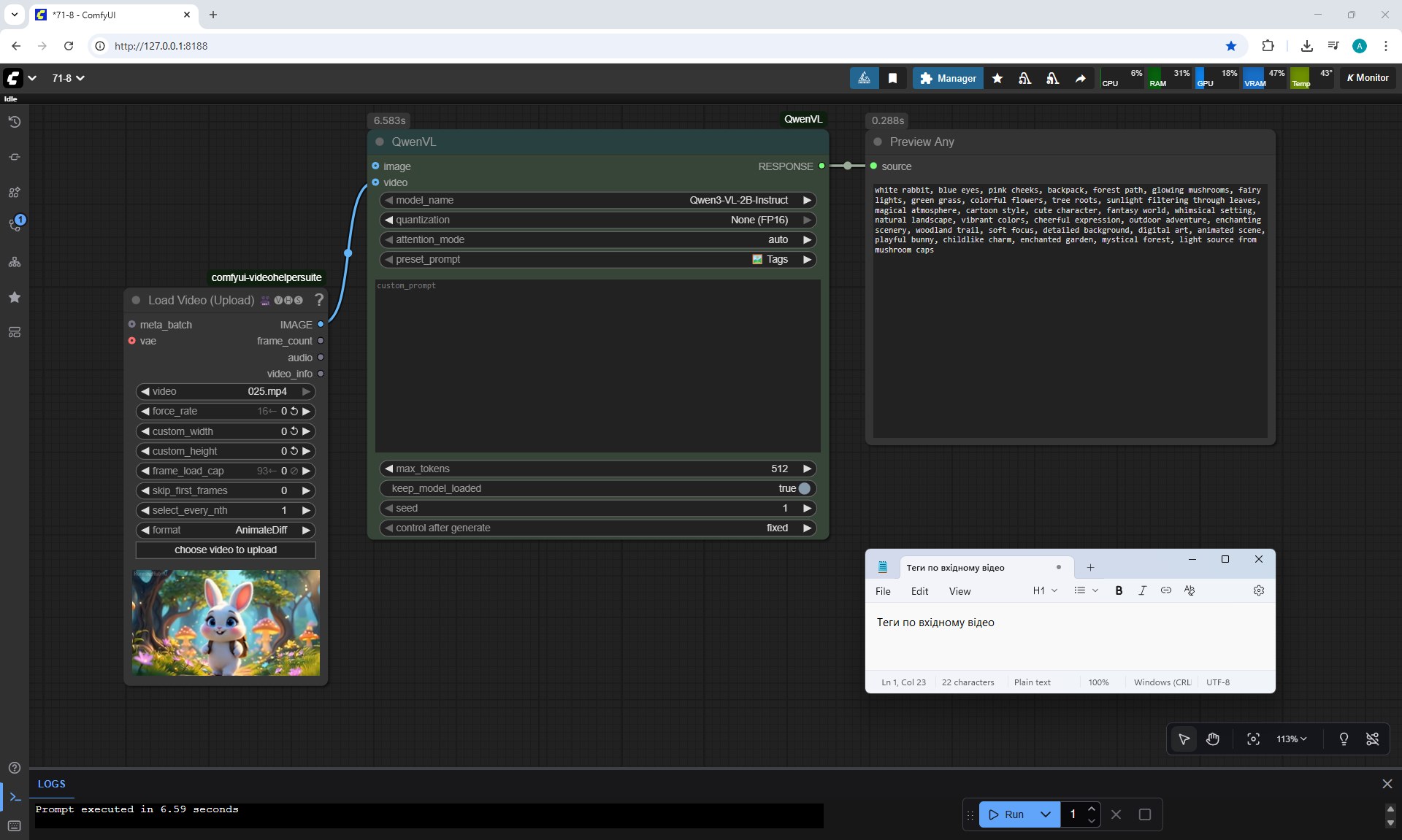
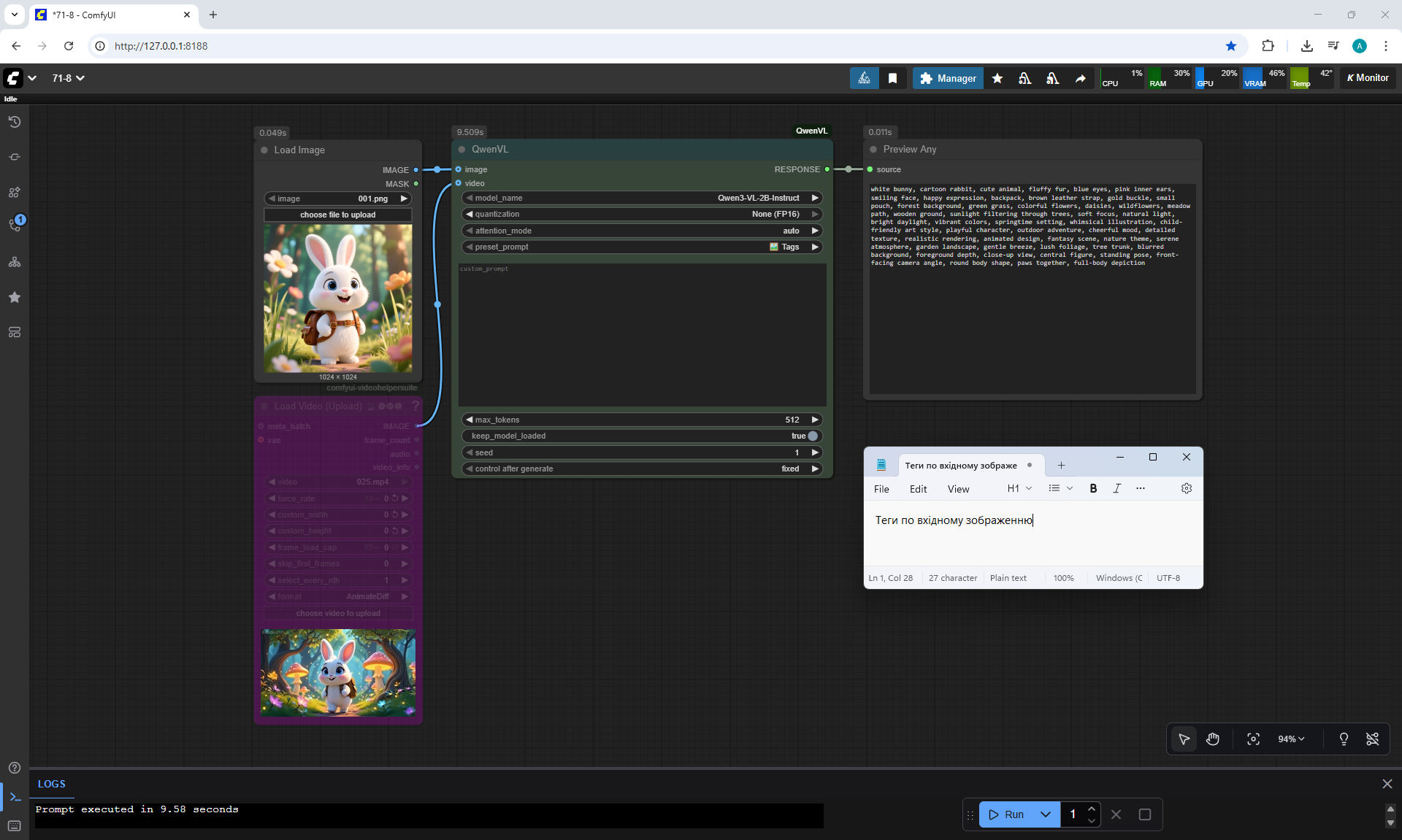
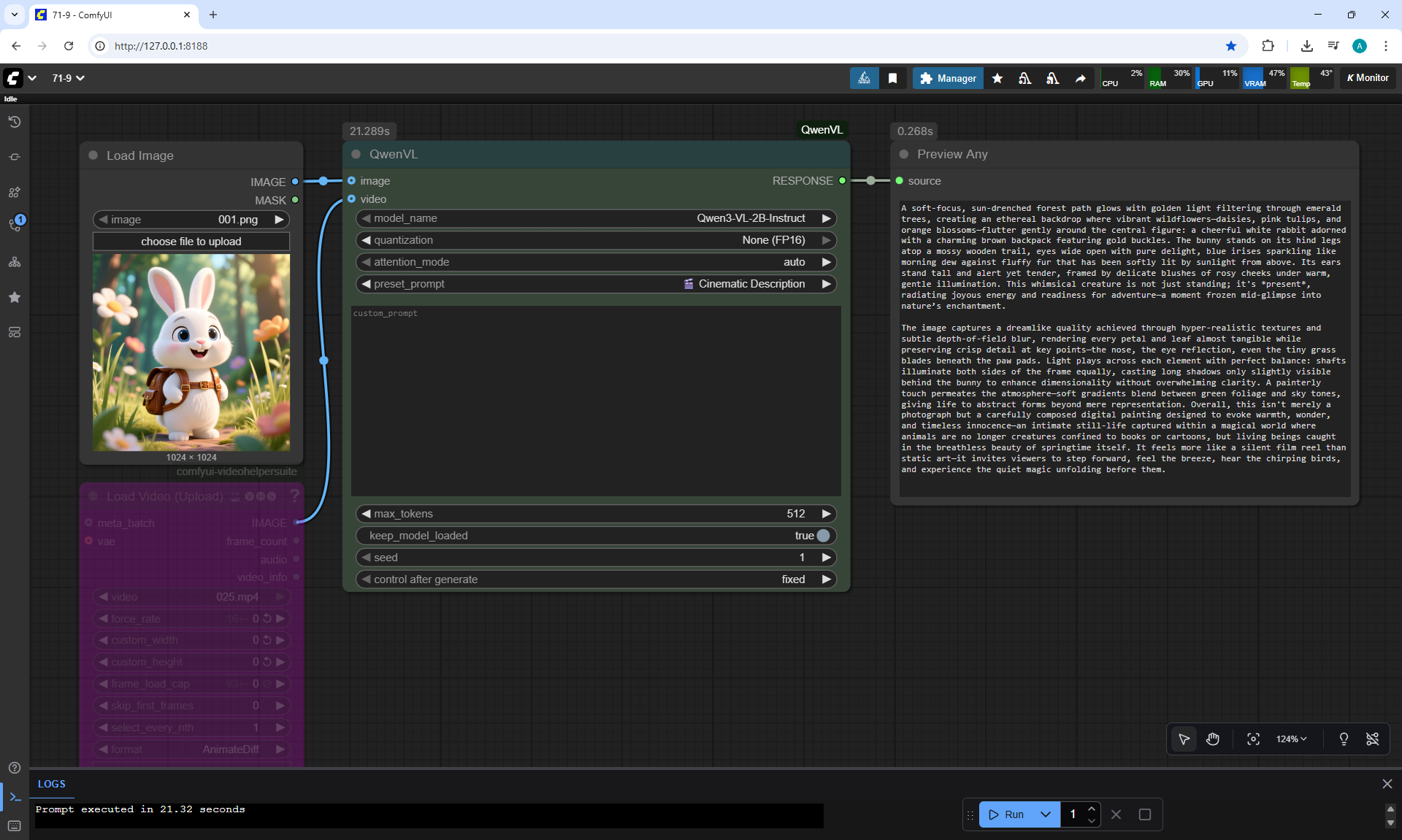
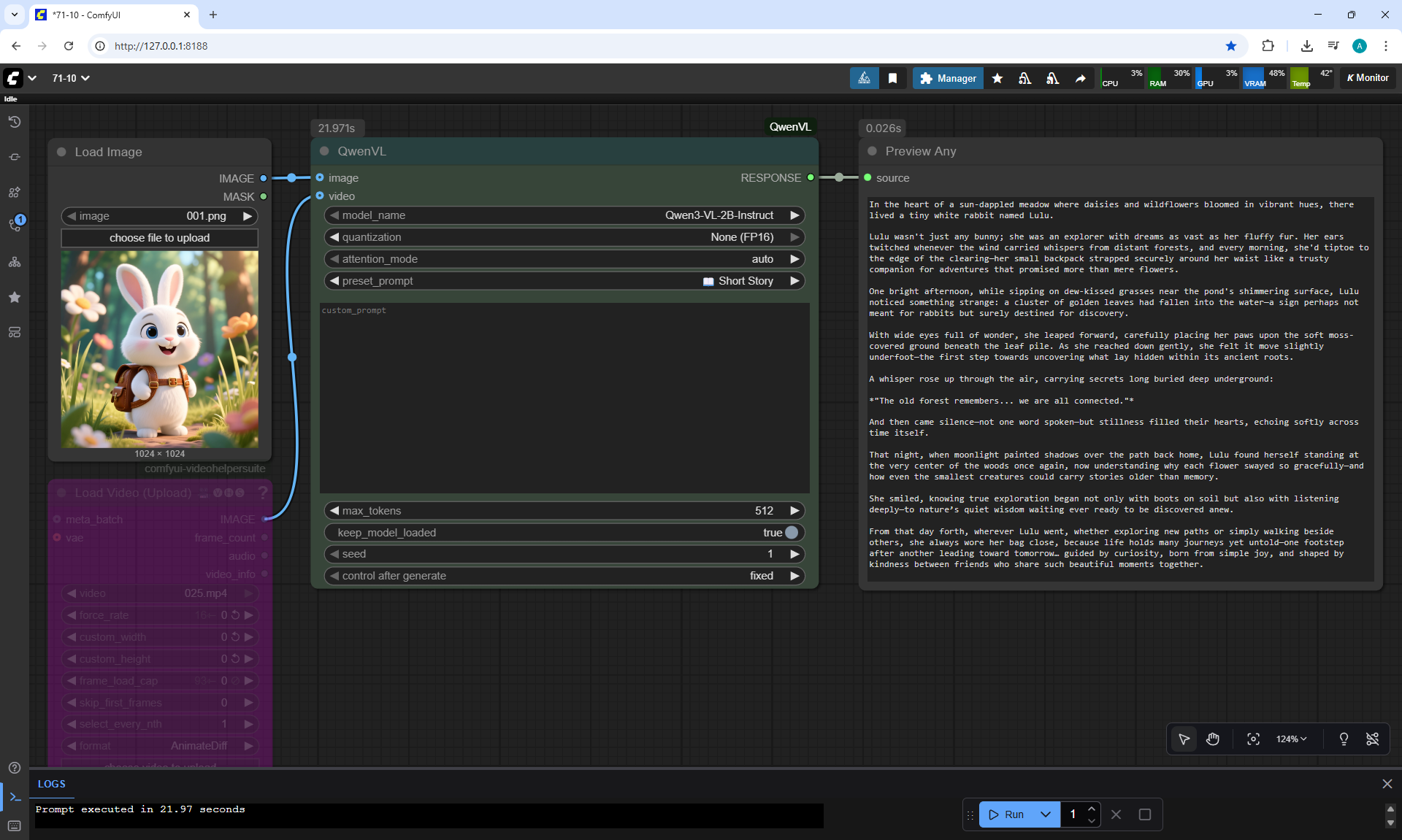
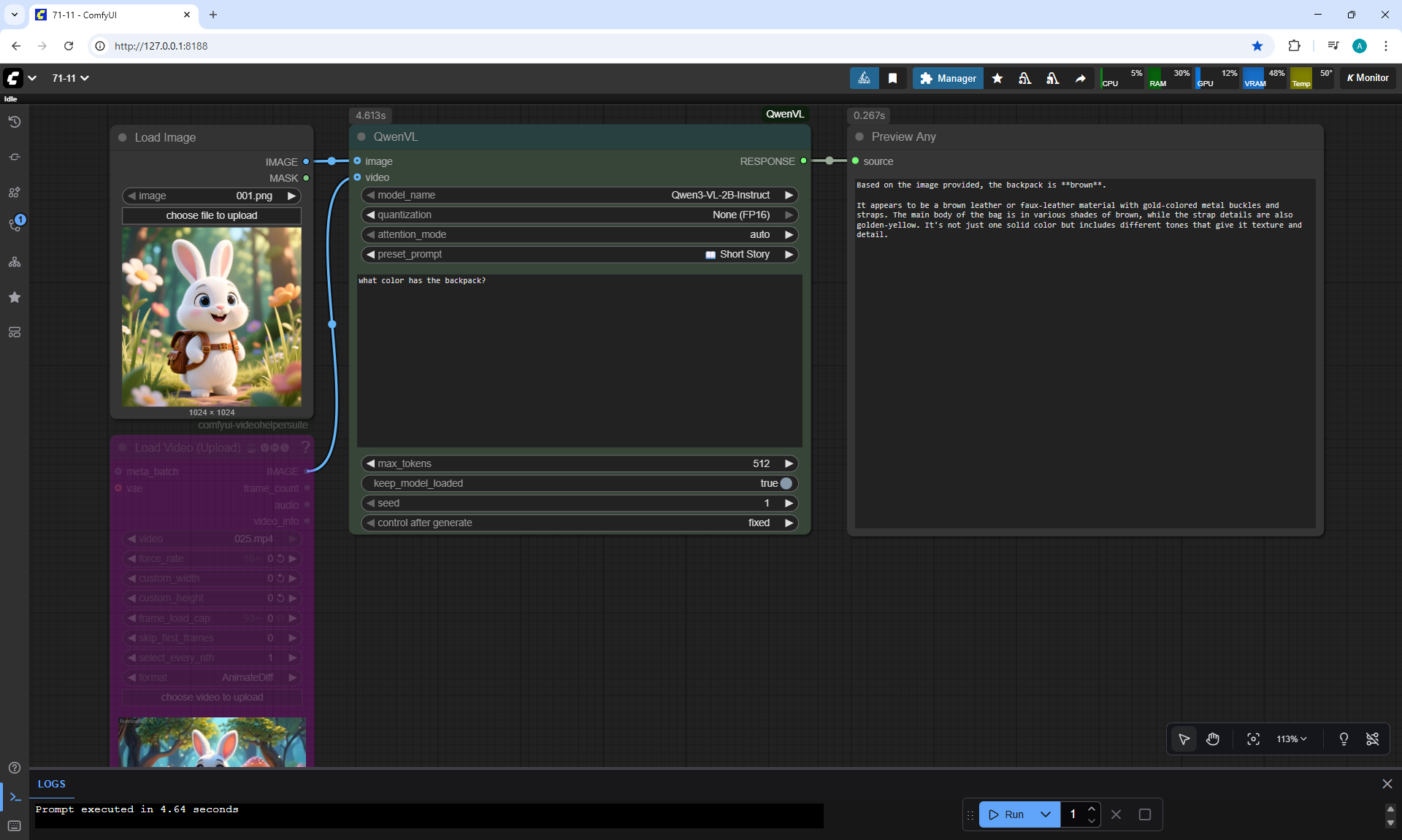
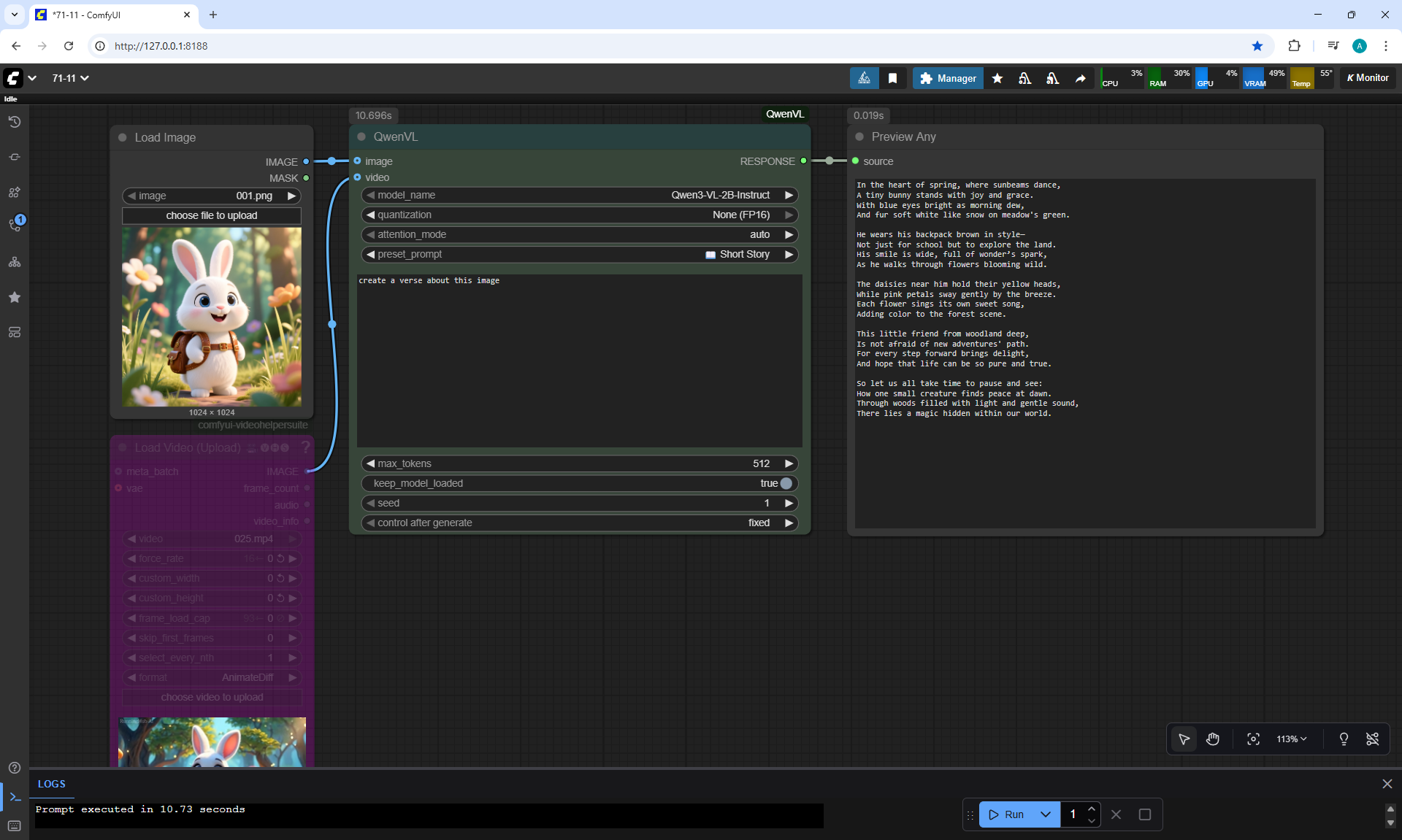
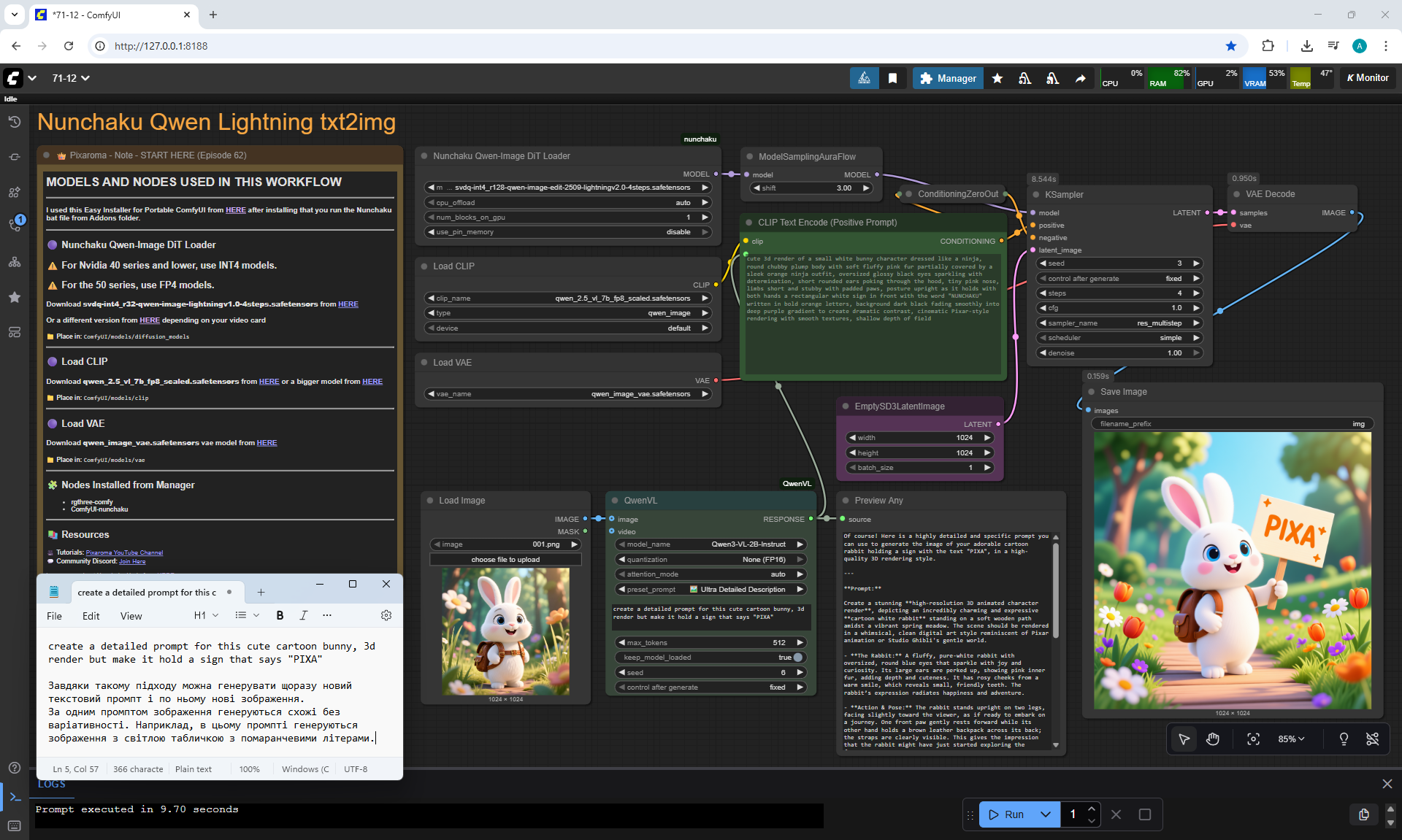
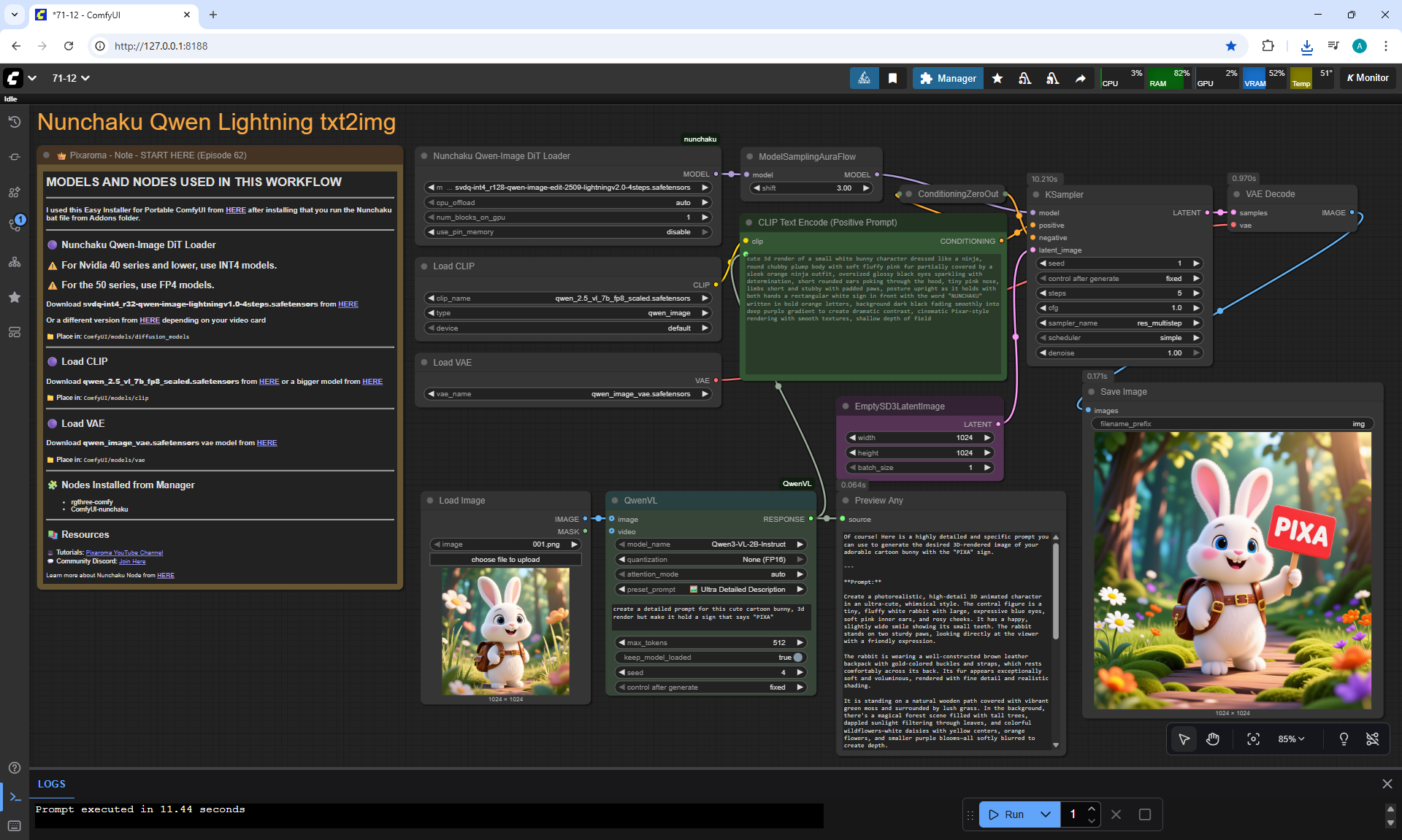
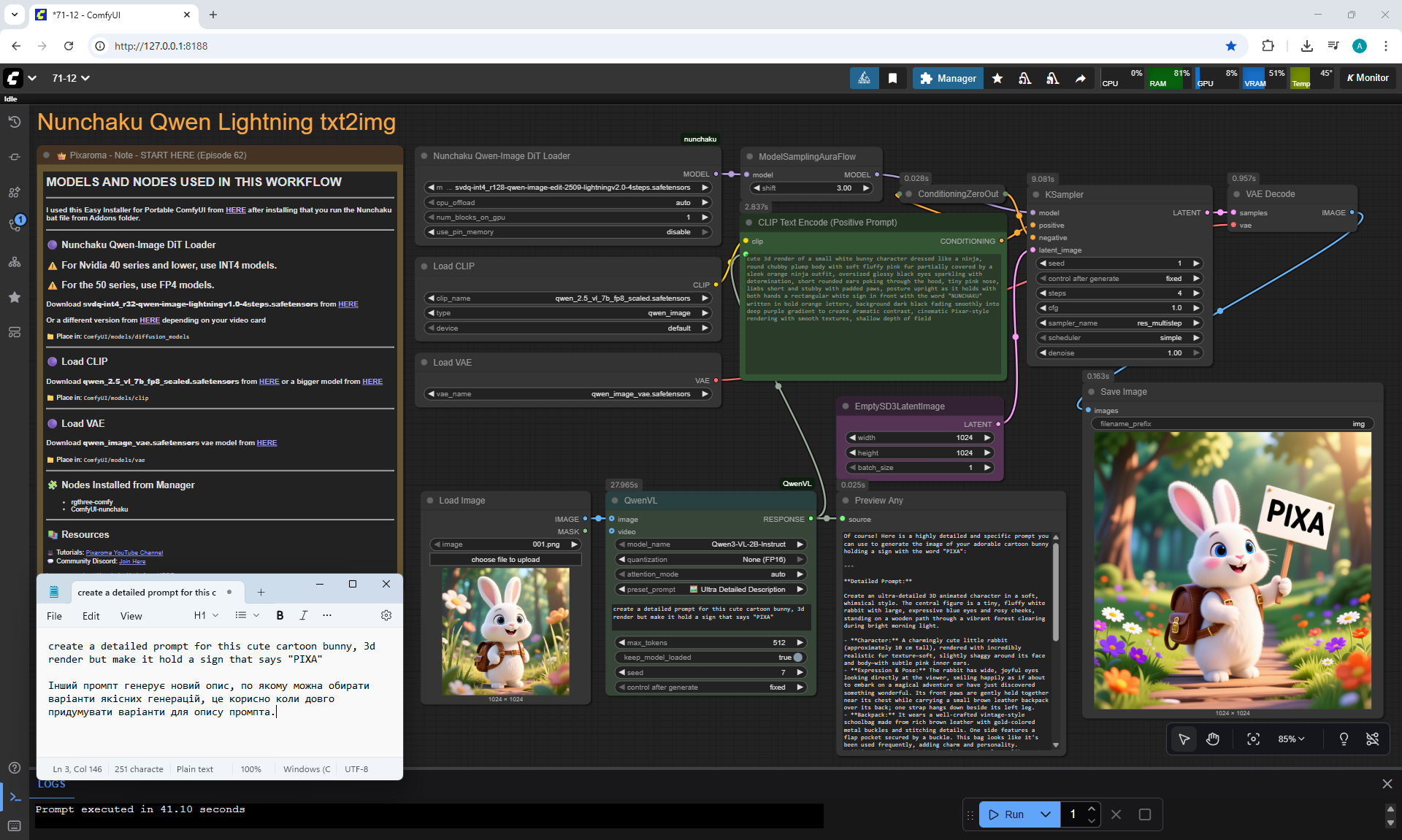
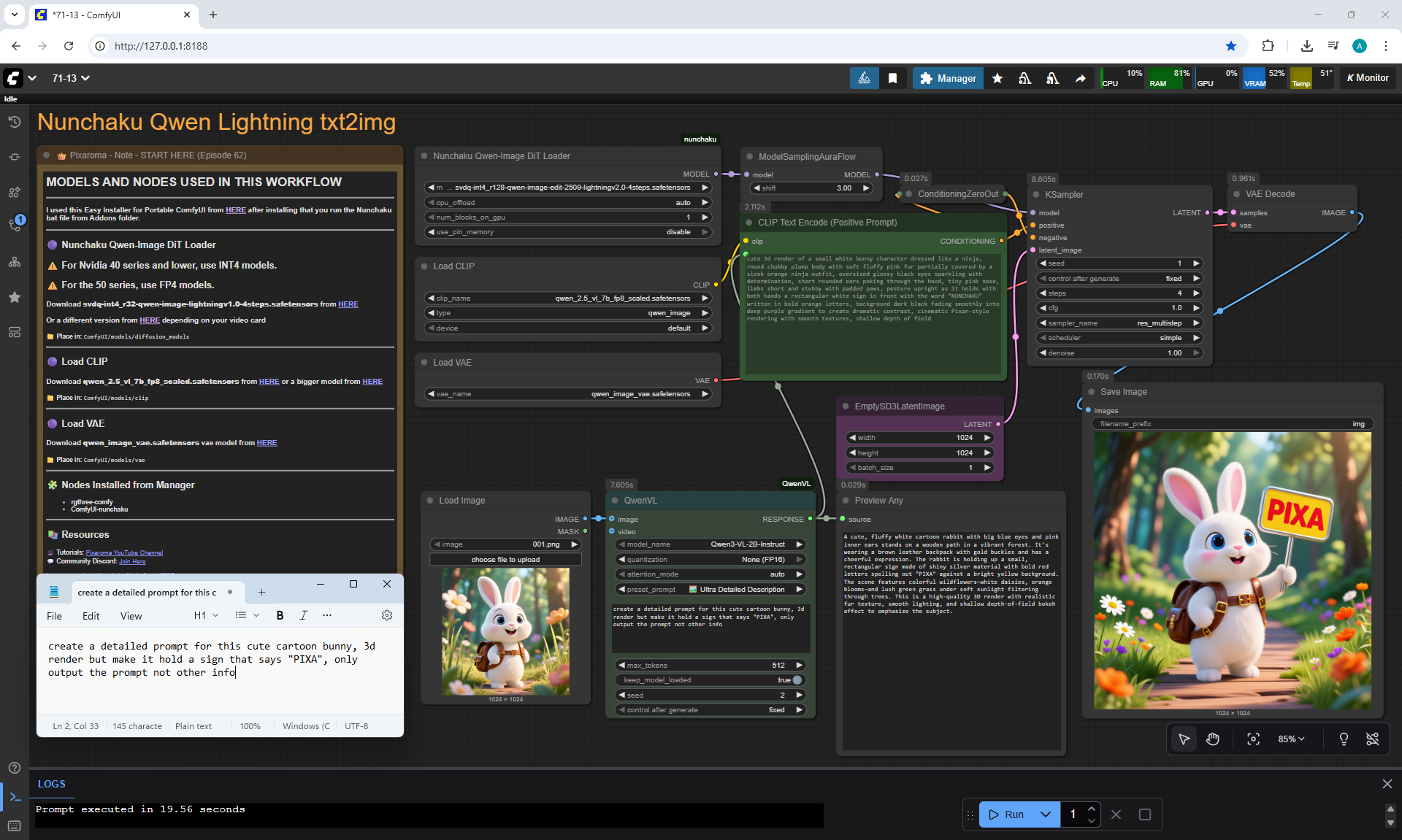
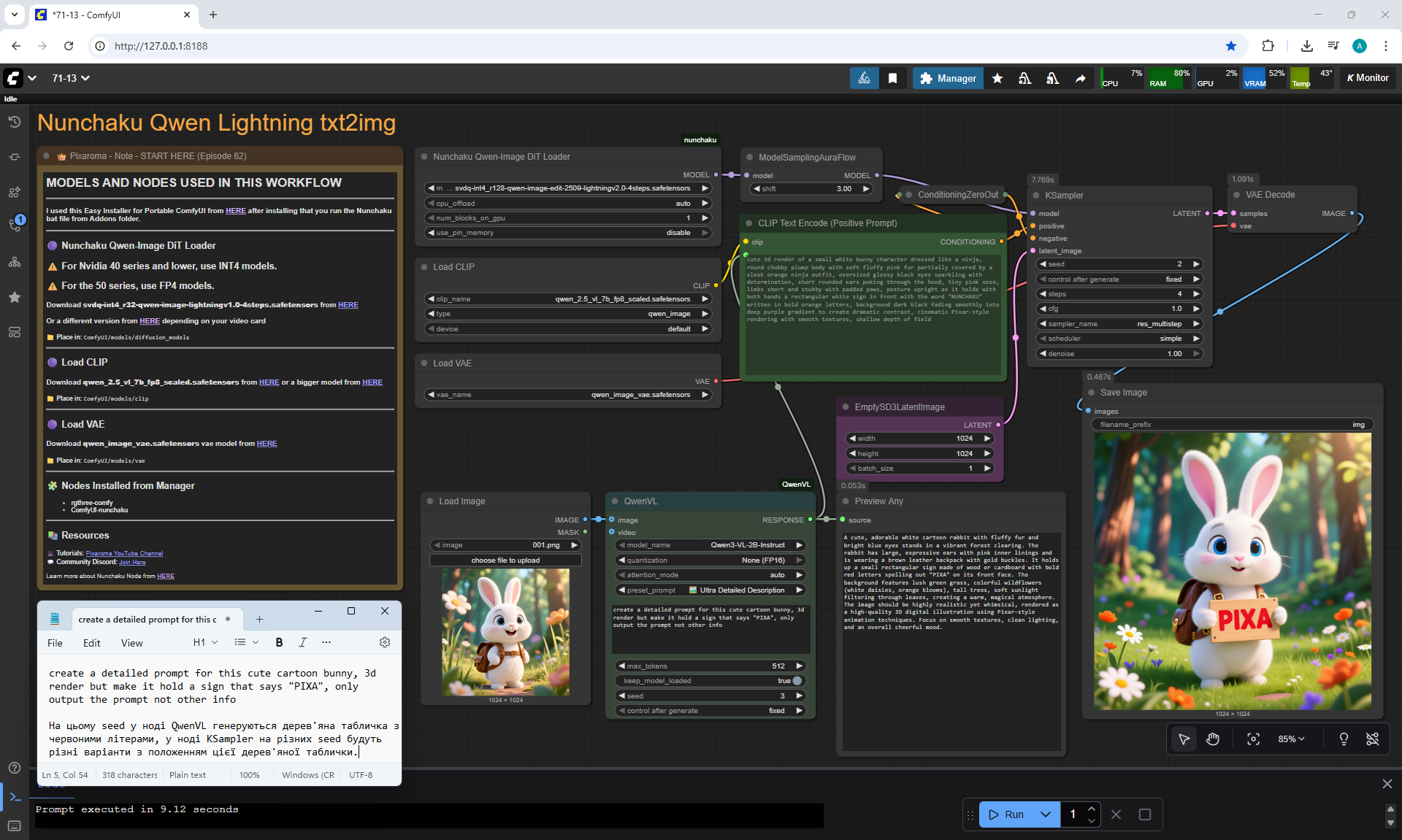
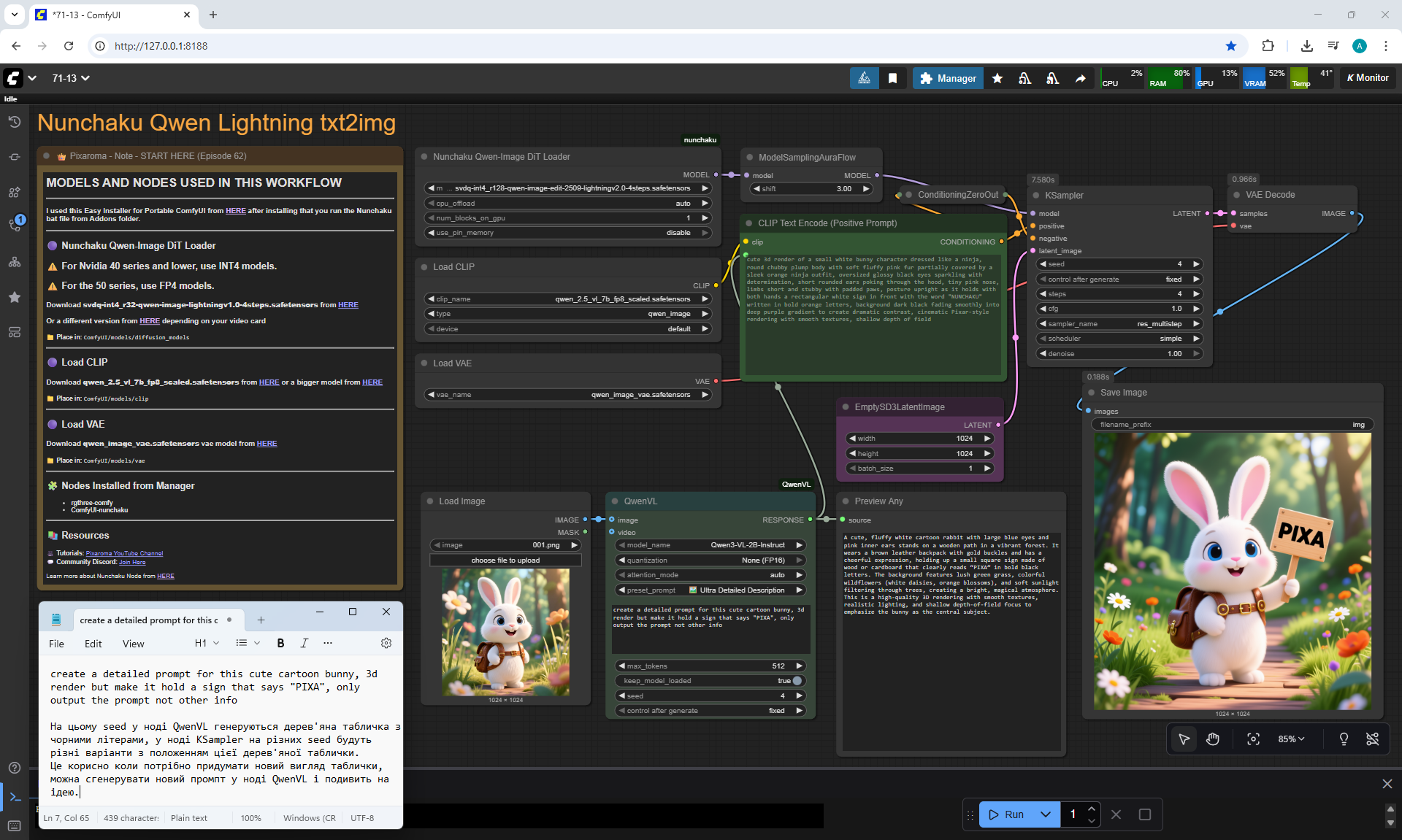
ComfyUI Tutorial Series Ep 71: QwenVL 3 - Get Prompts From Images & Video

















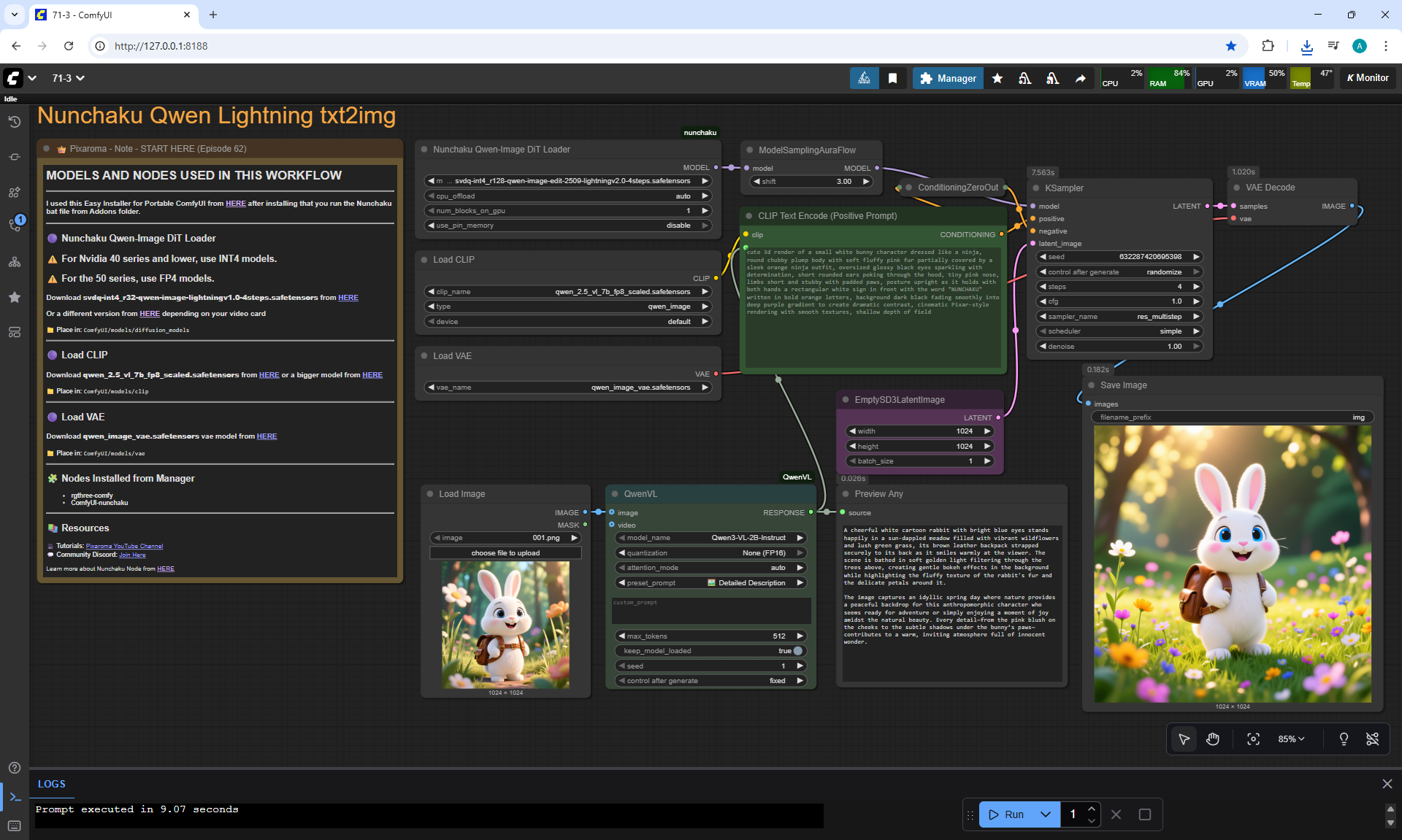
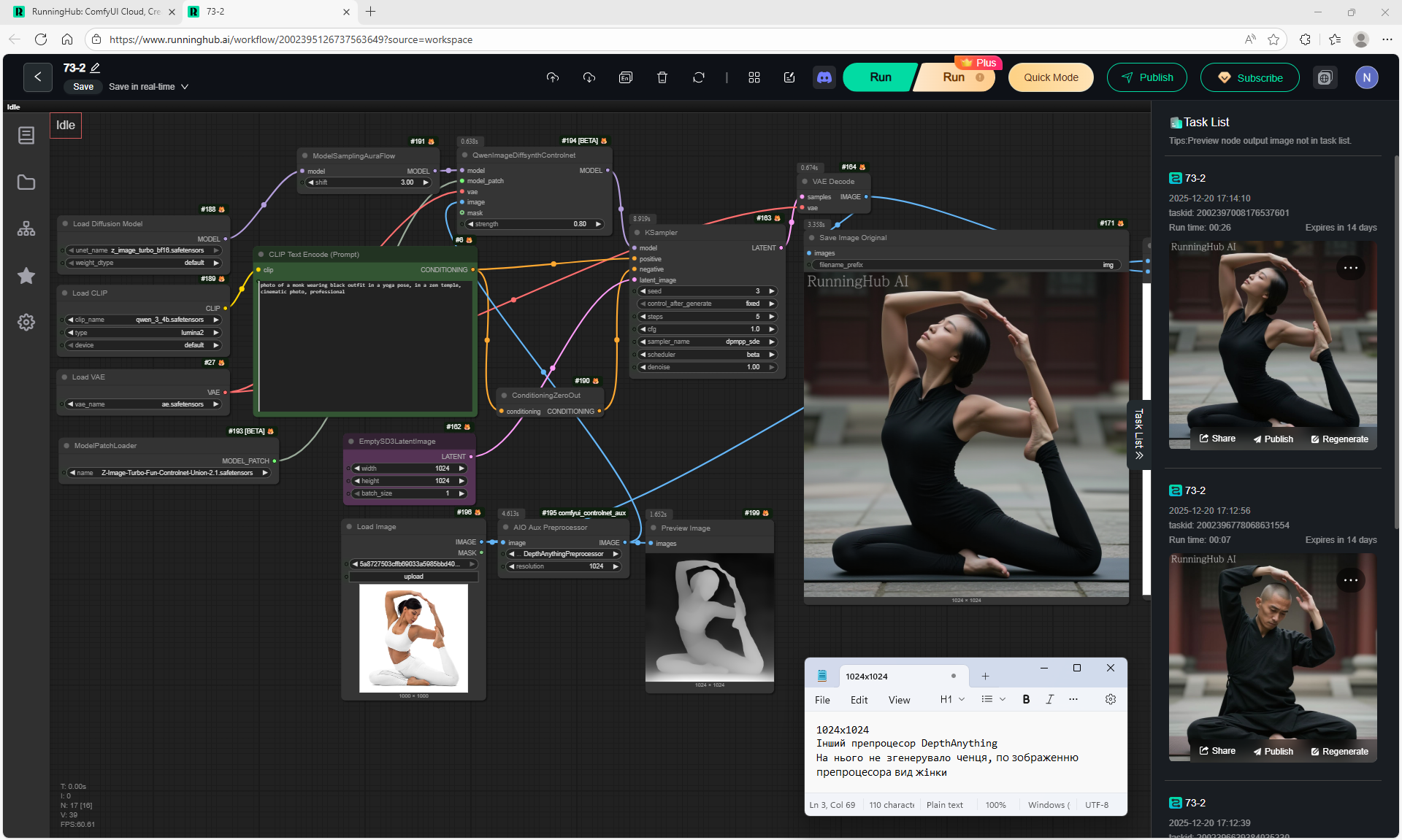
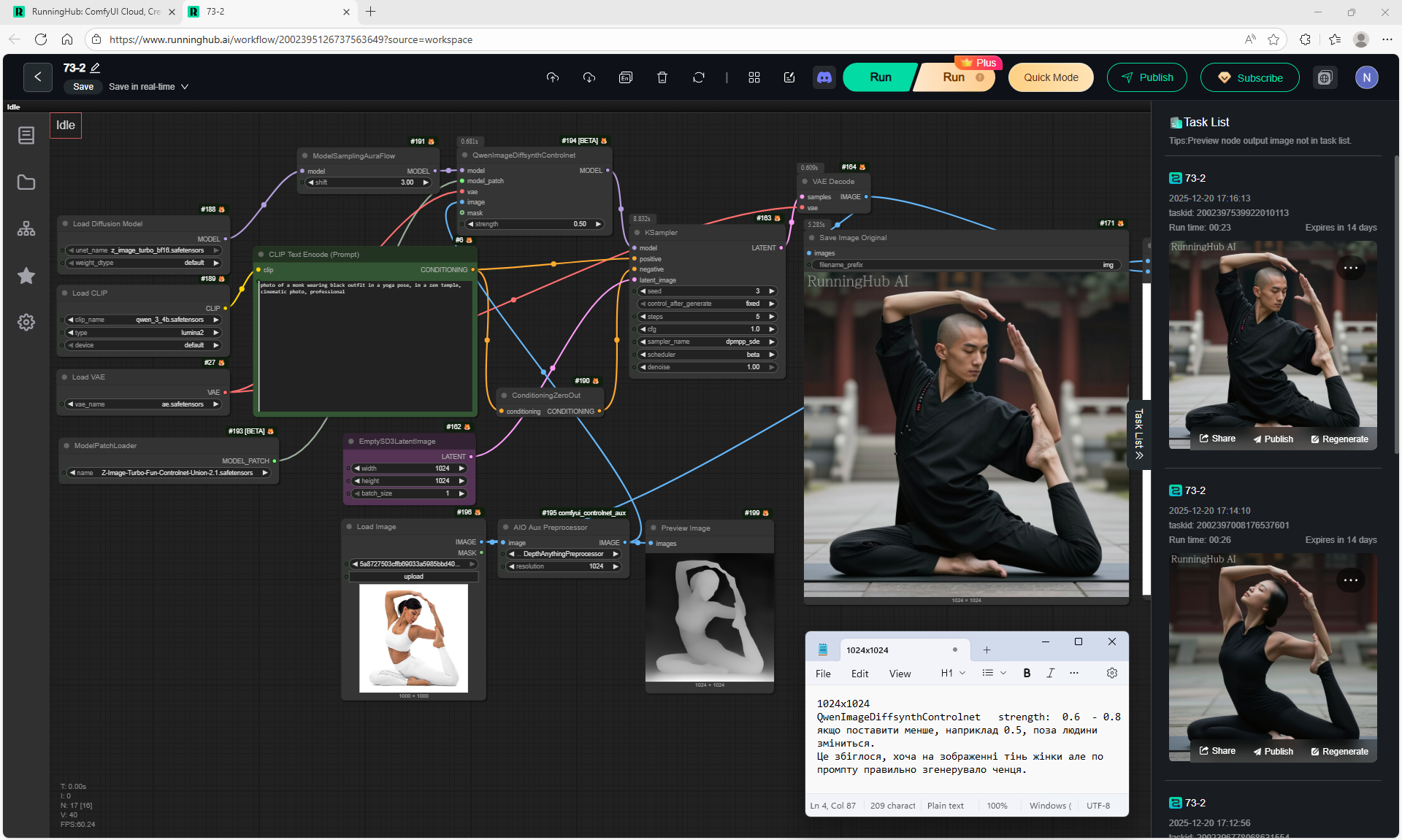
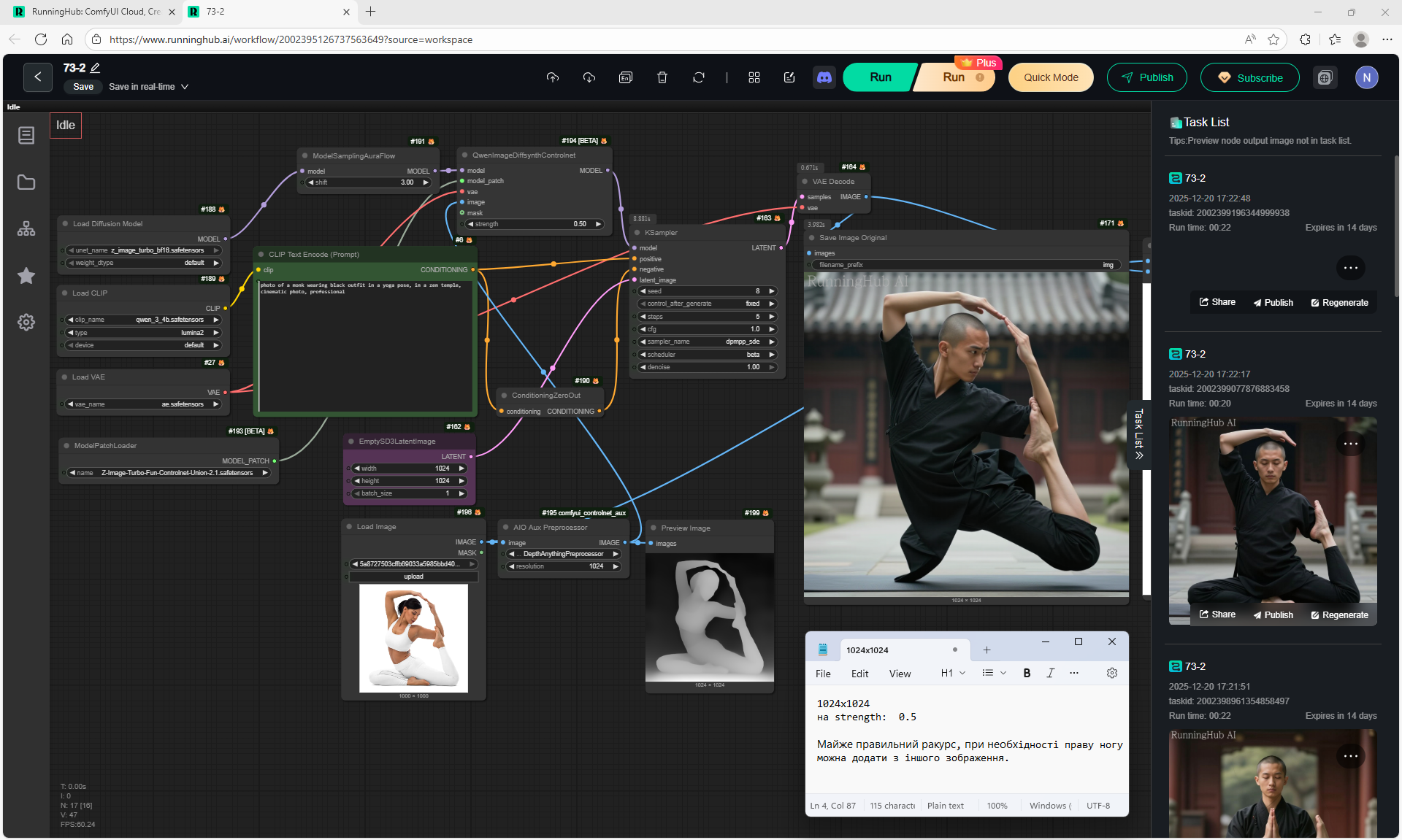
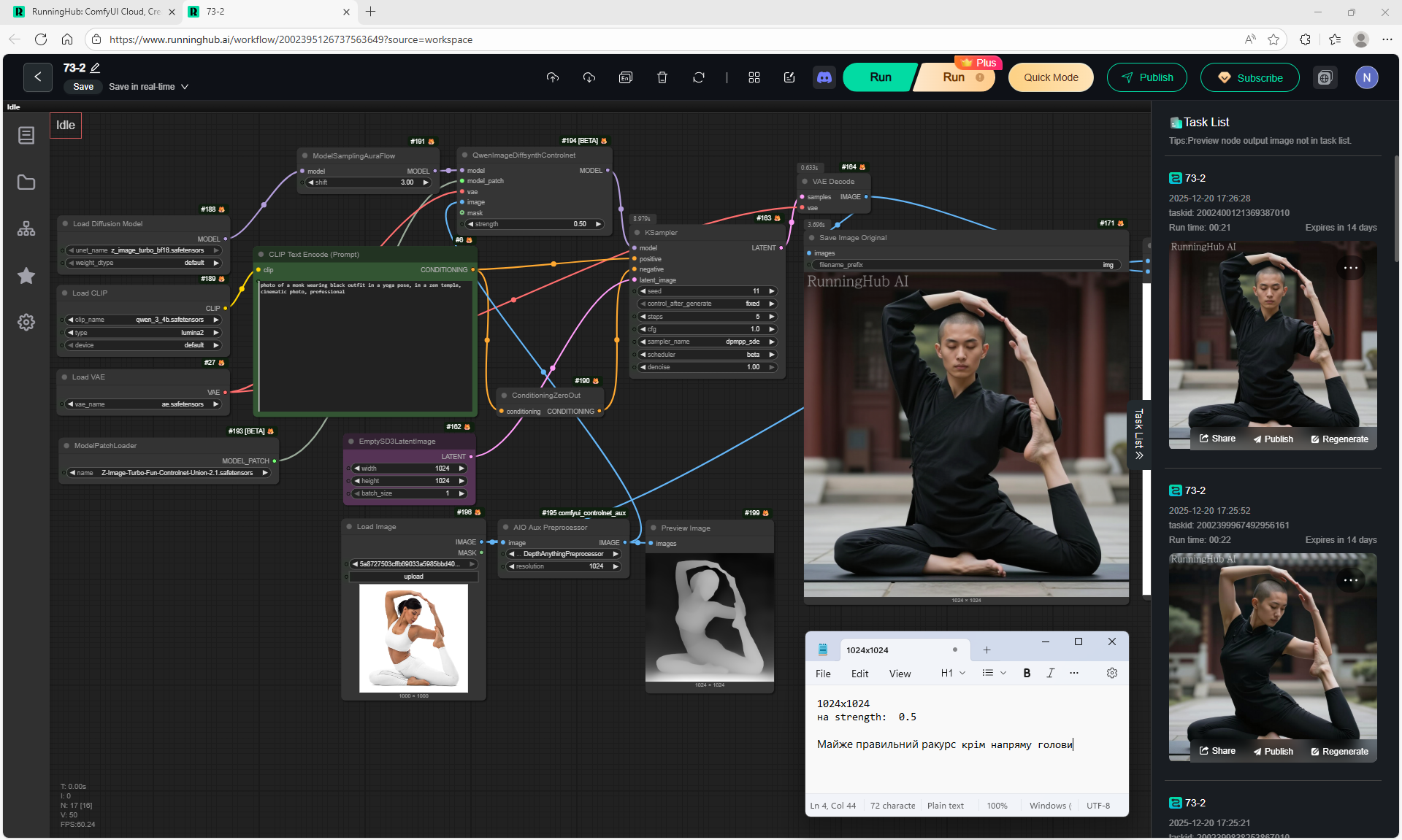
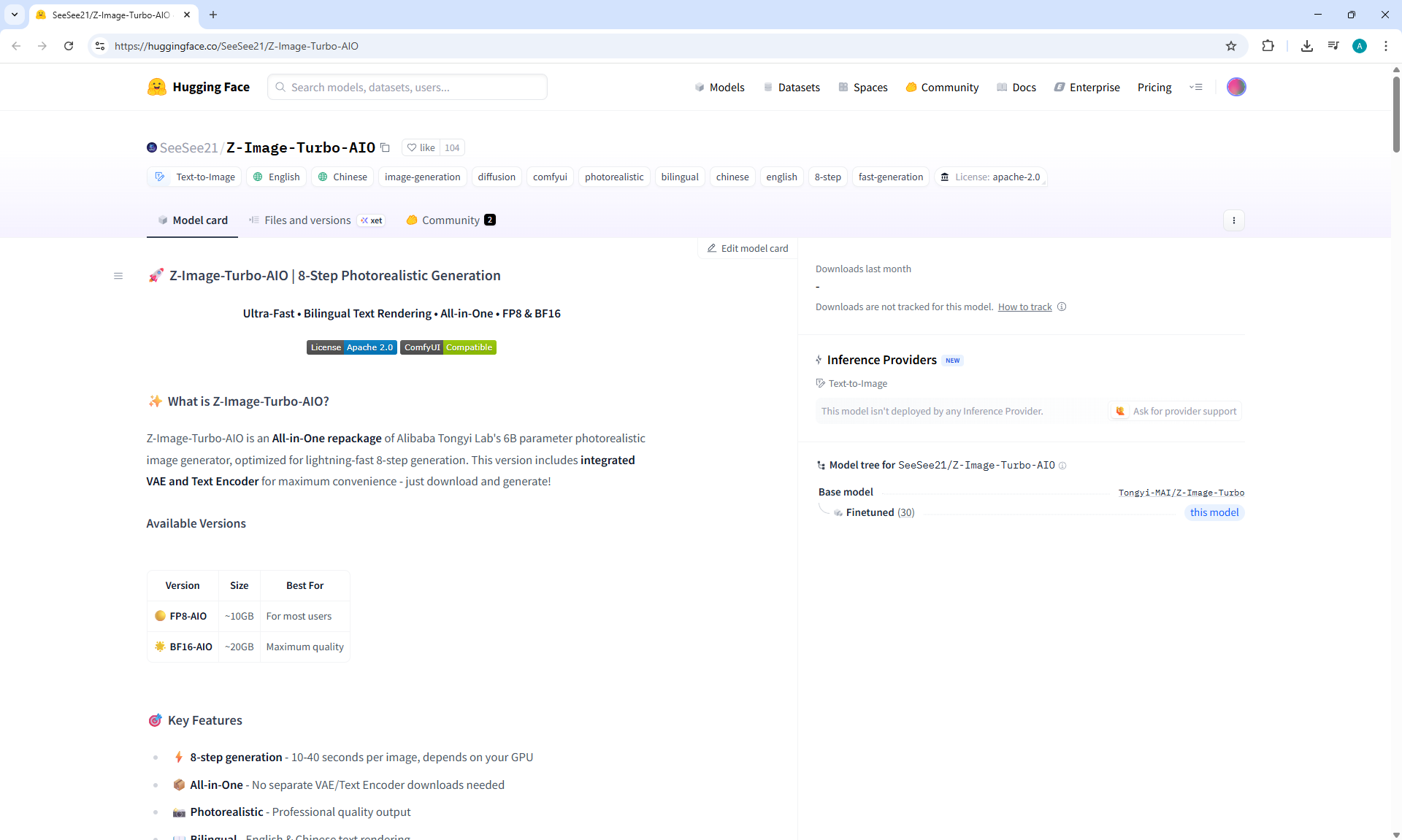
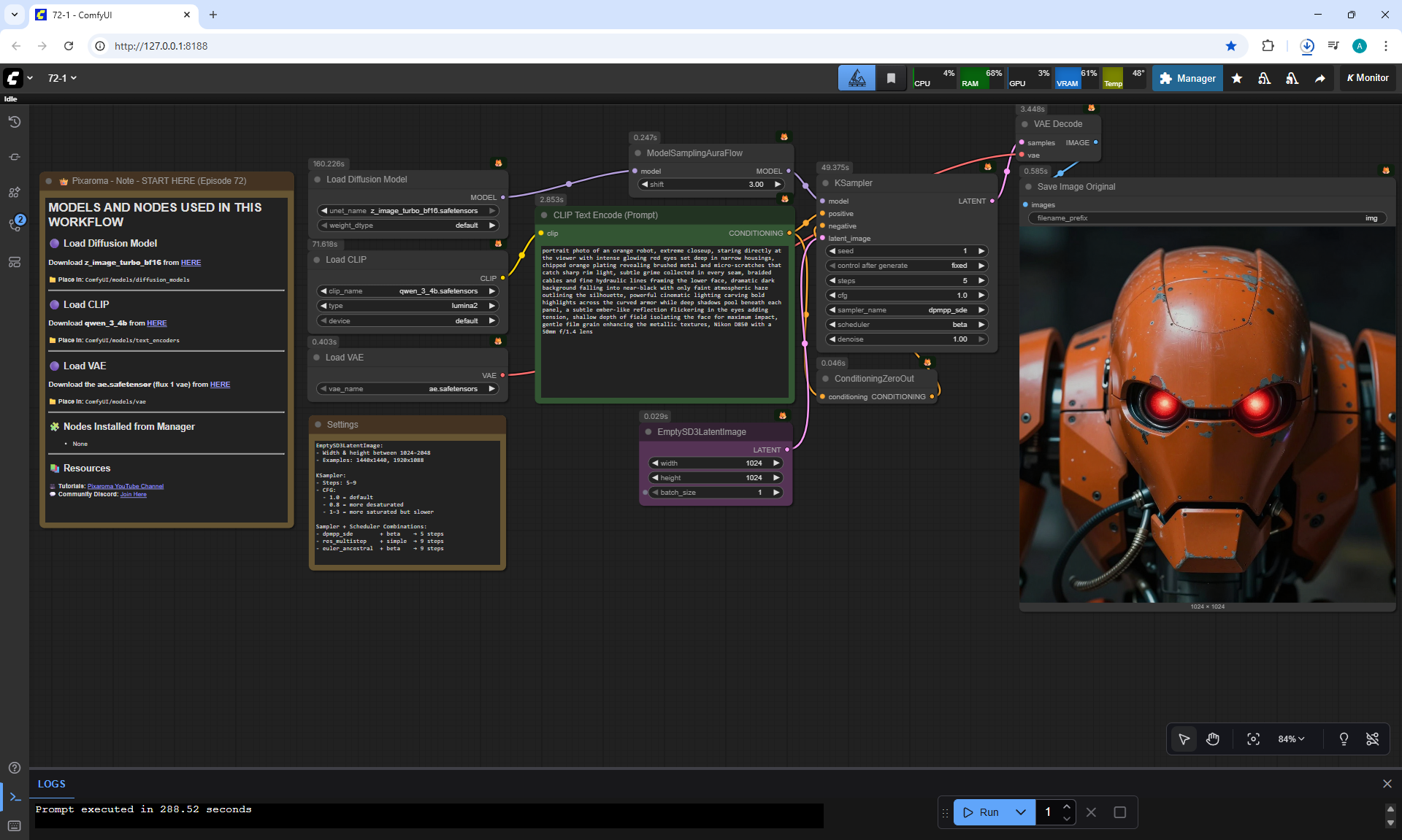
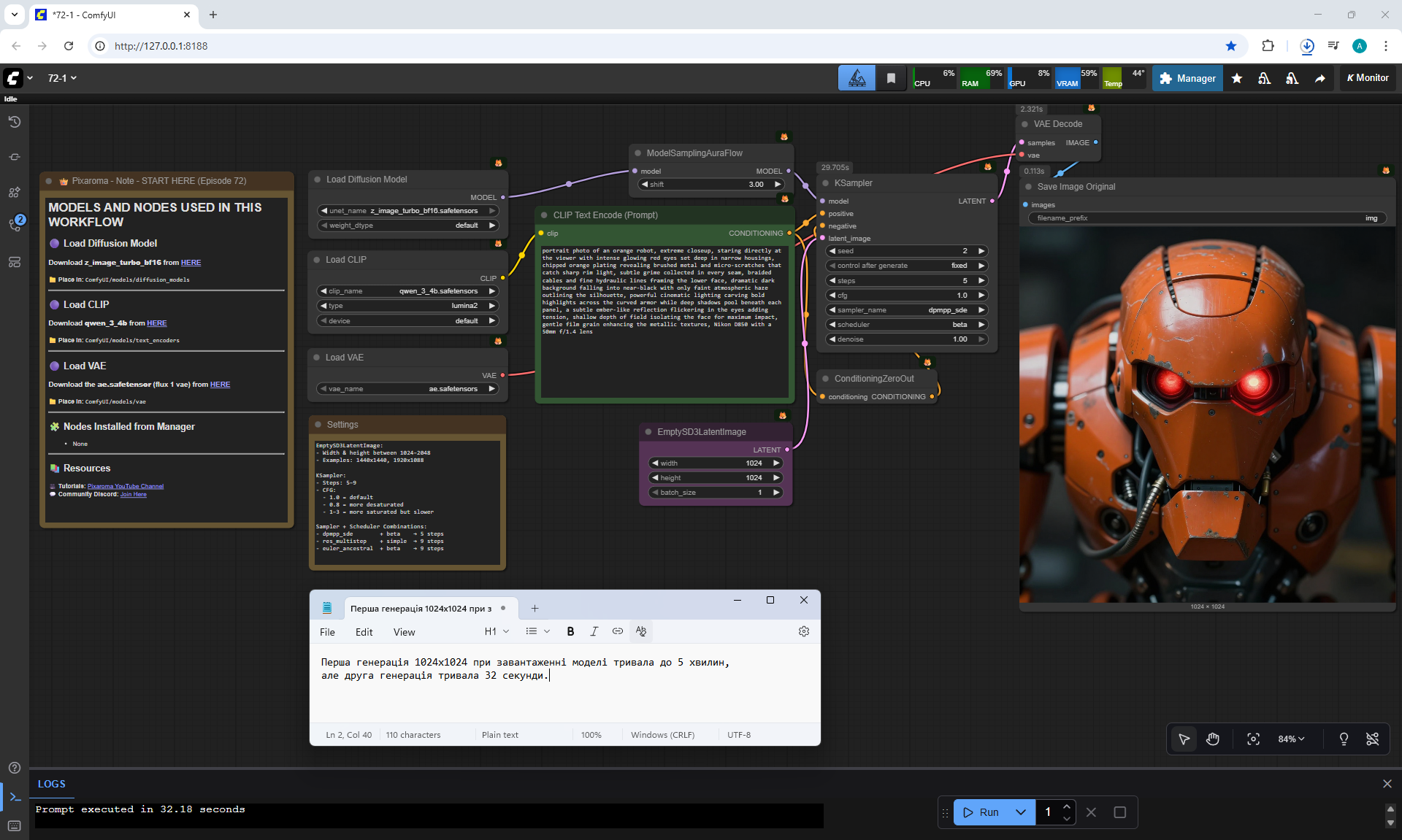
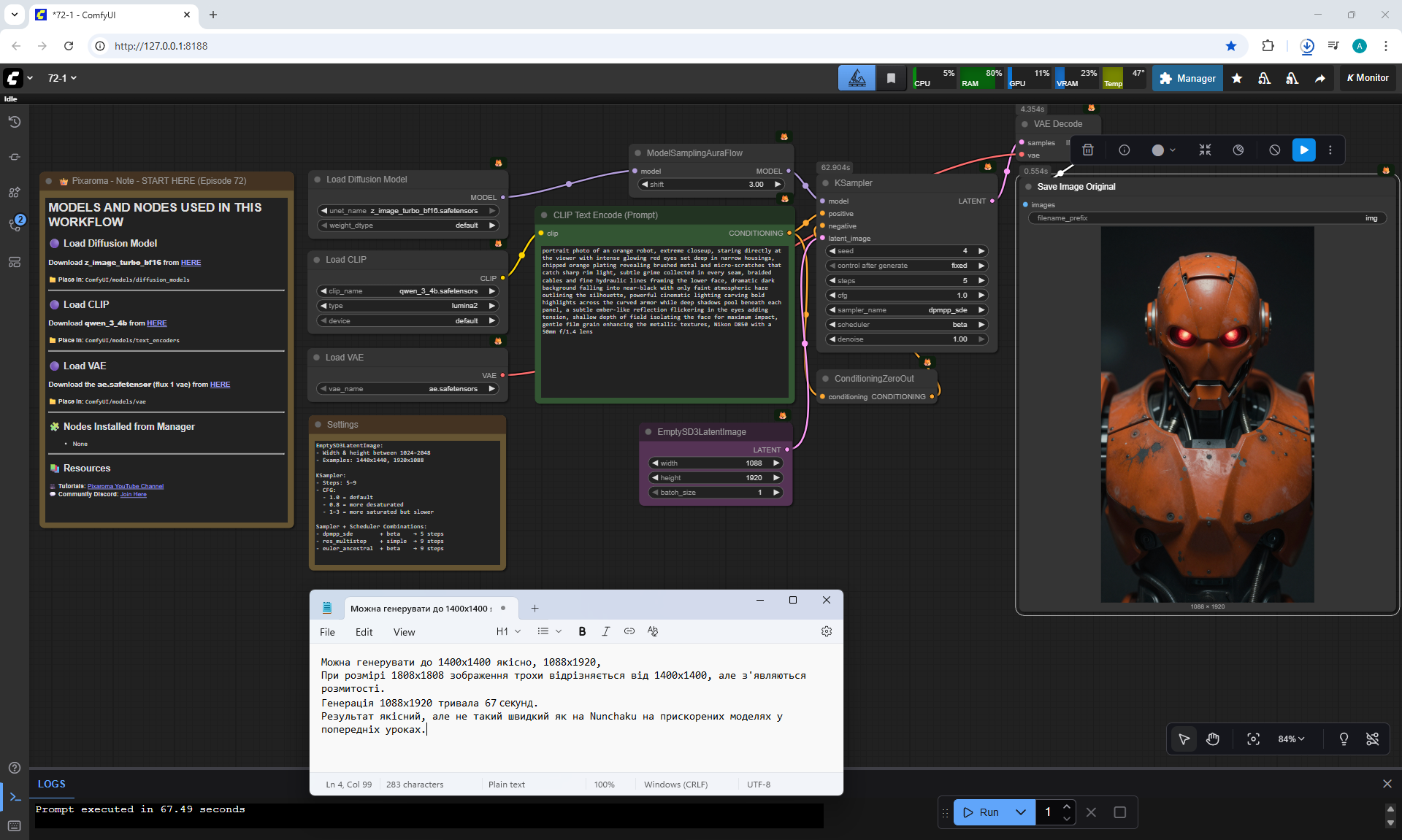
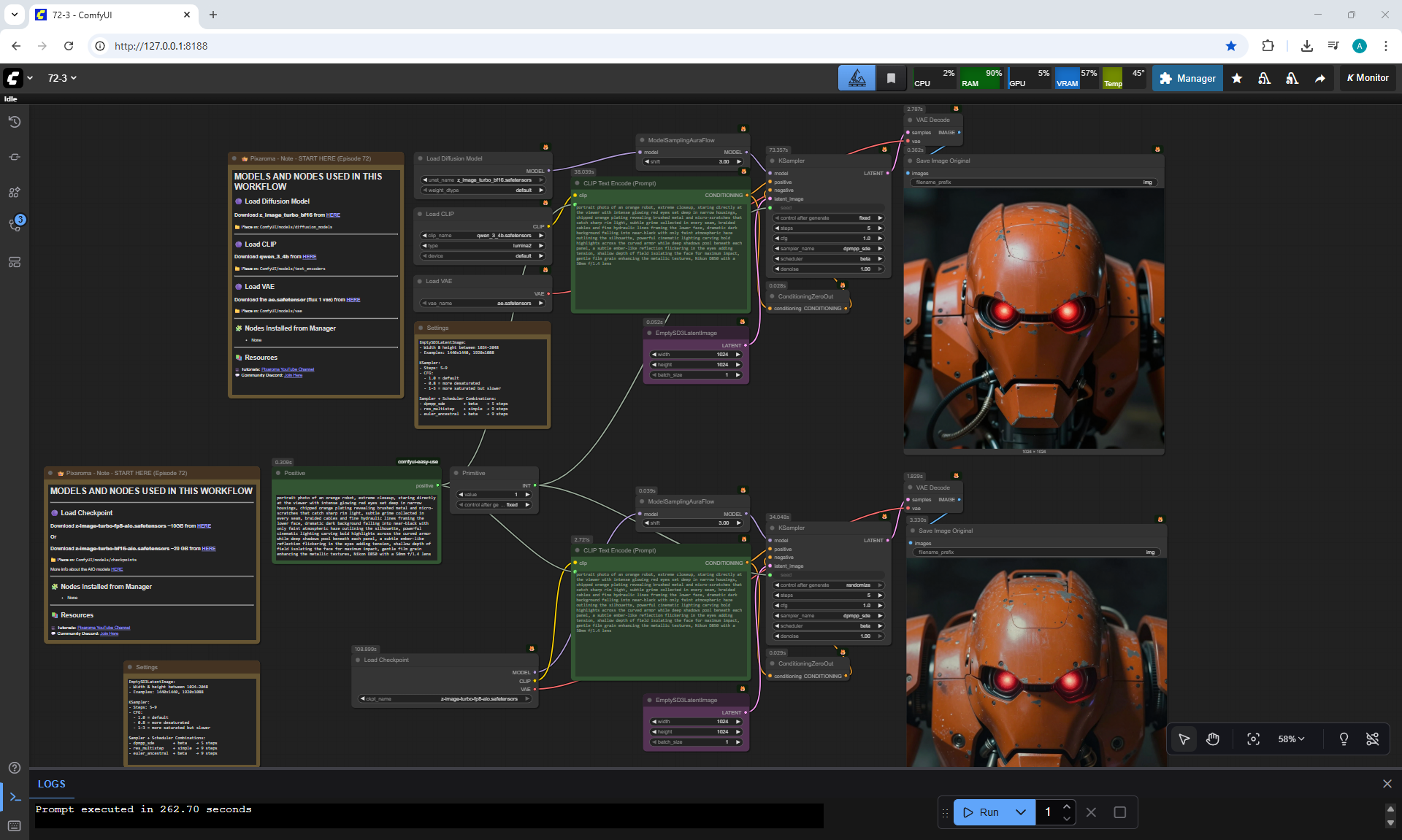
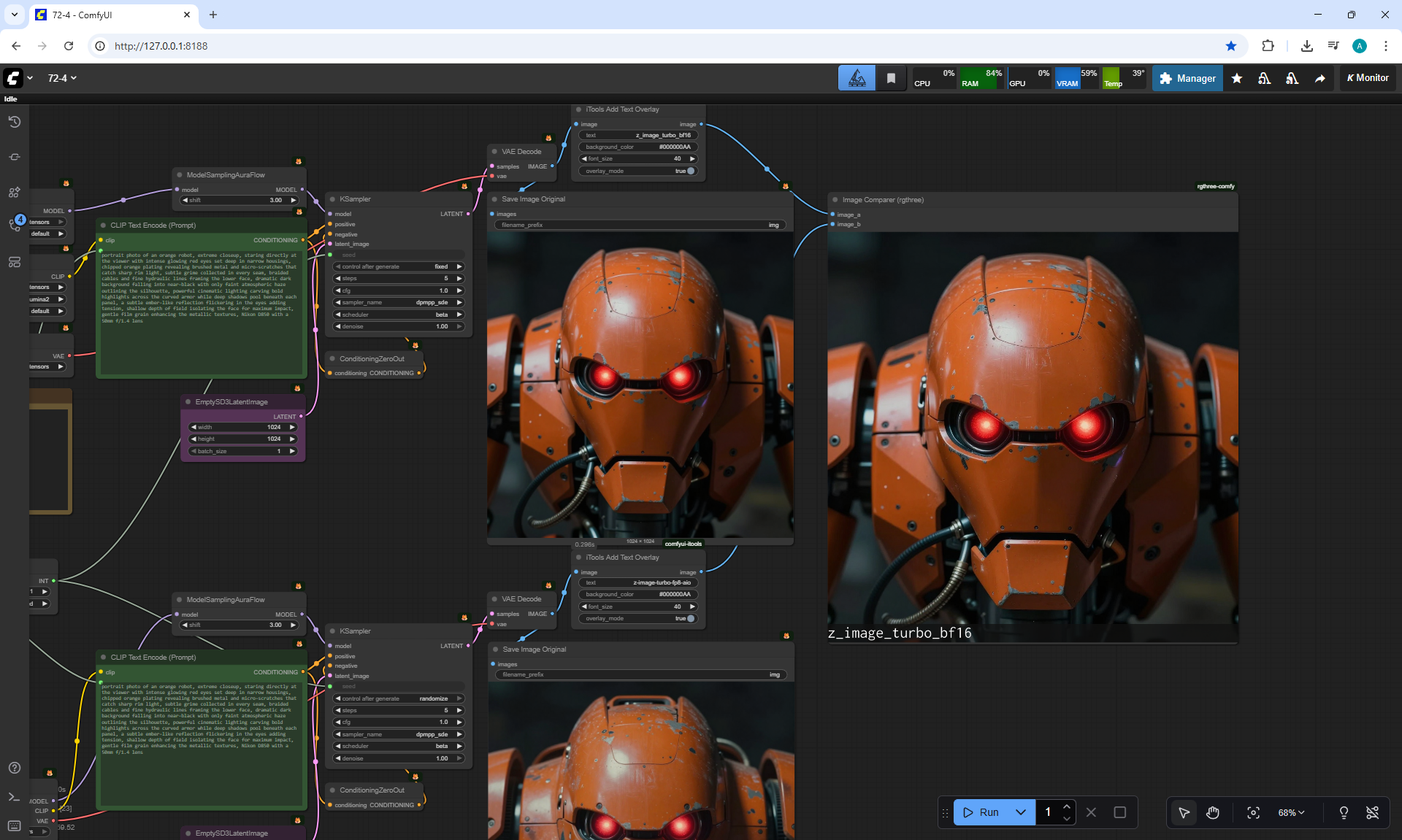
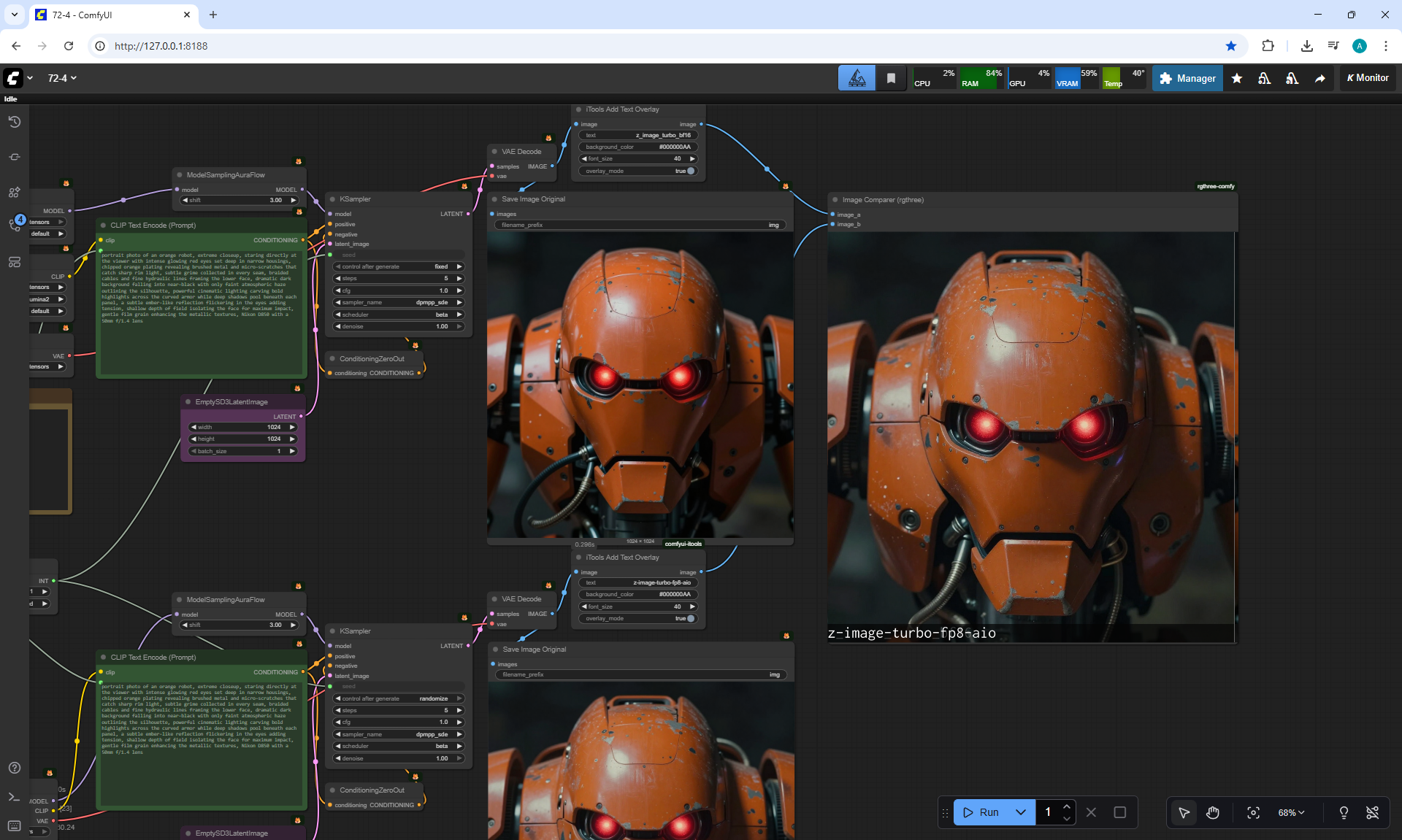
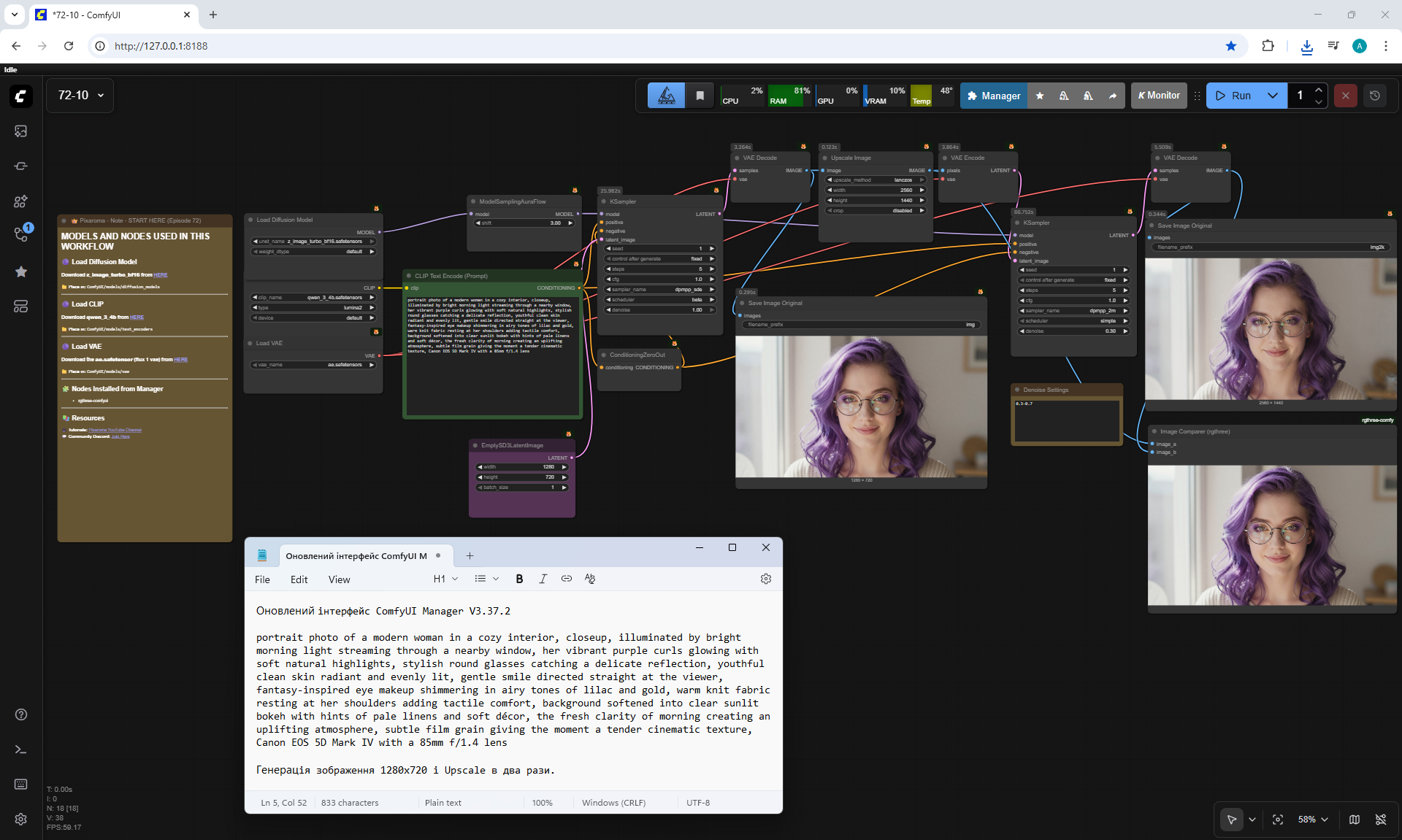
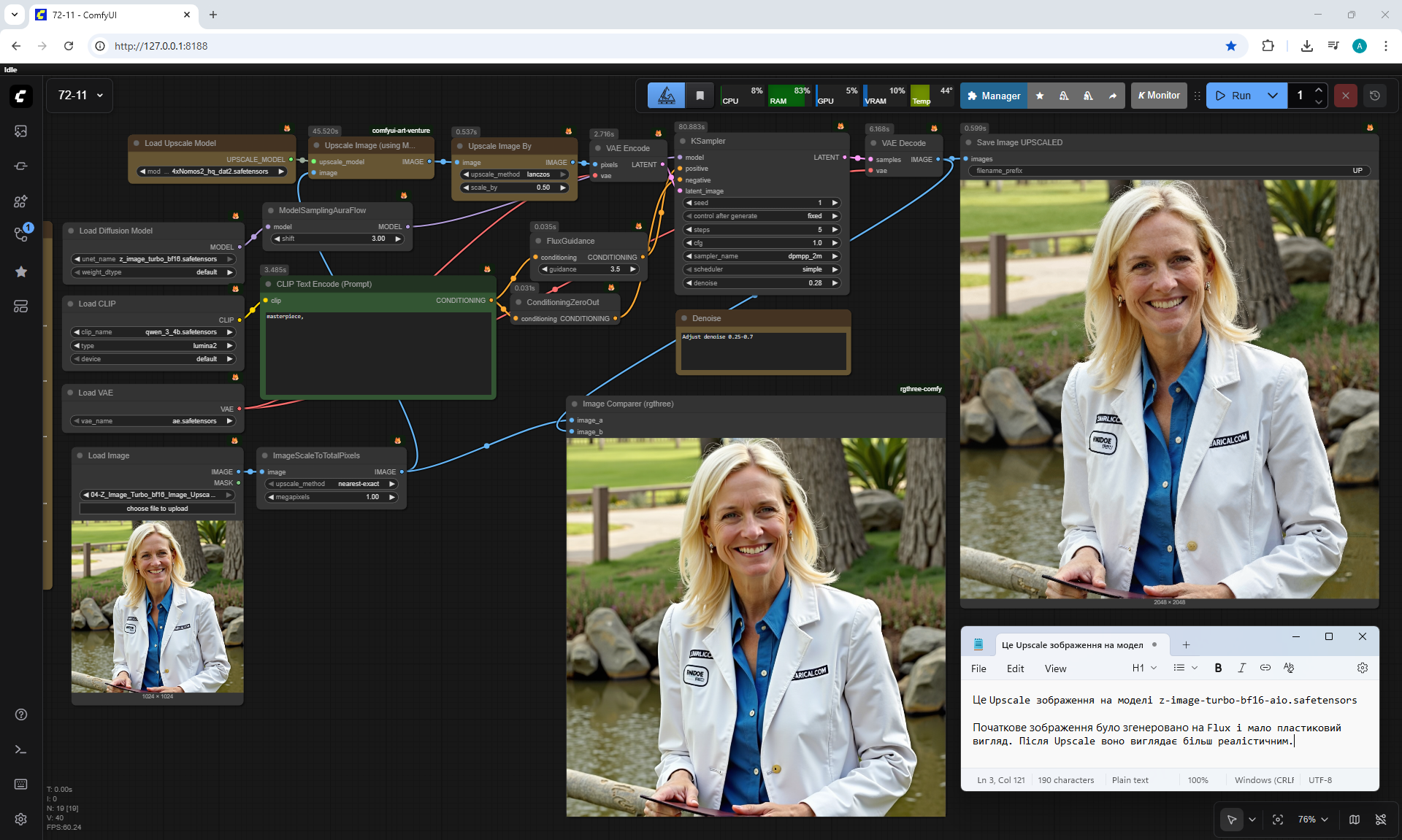
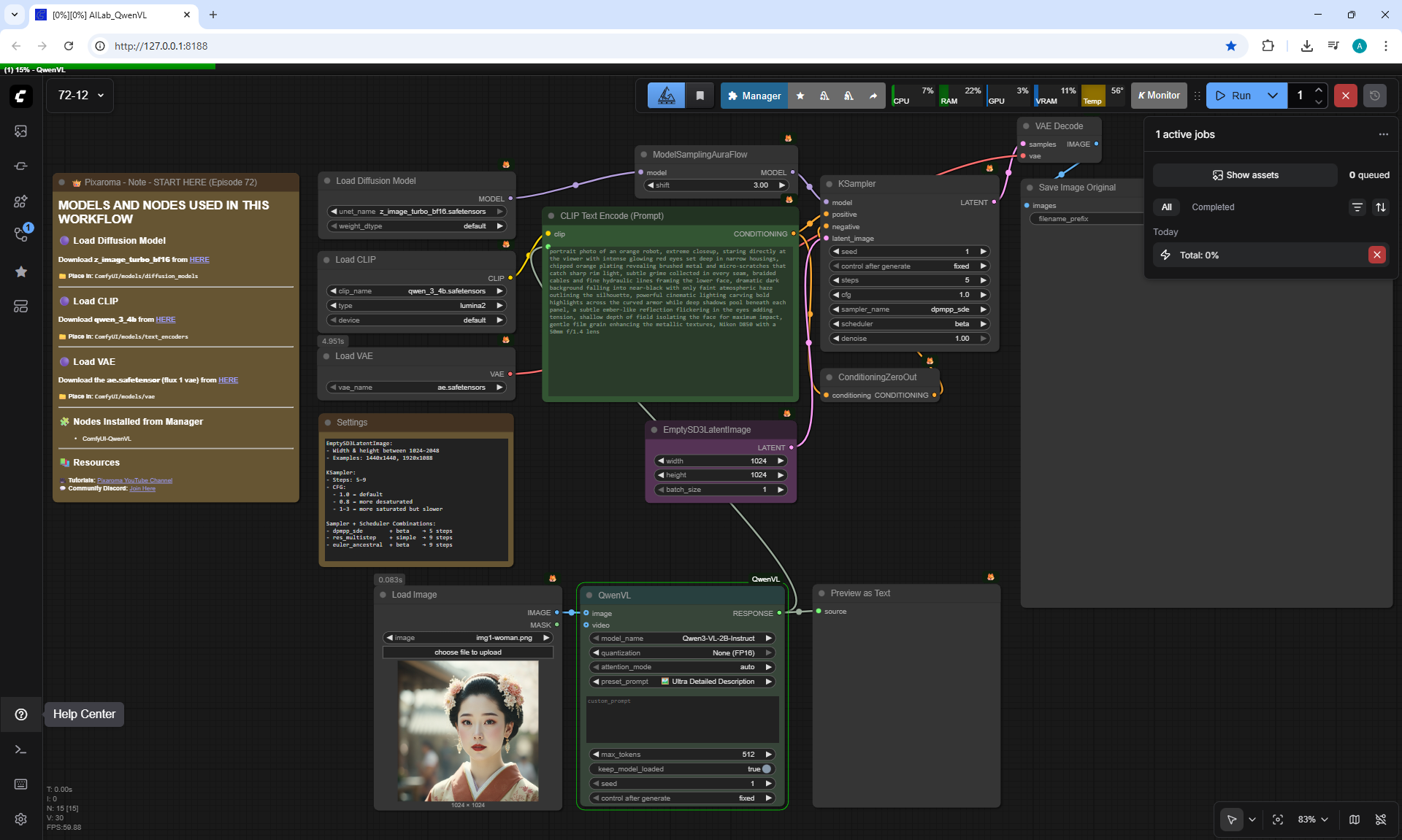
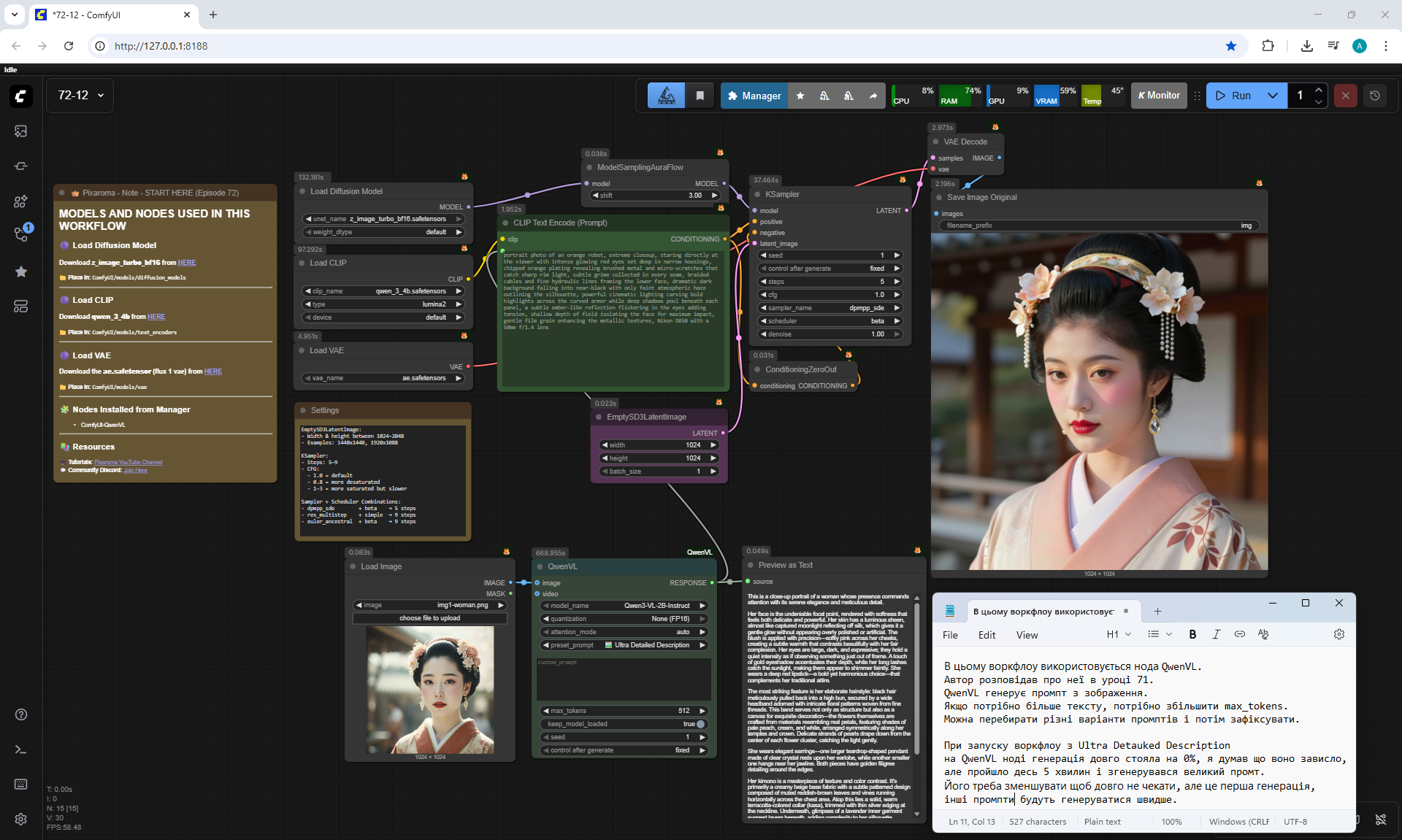
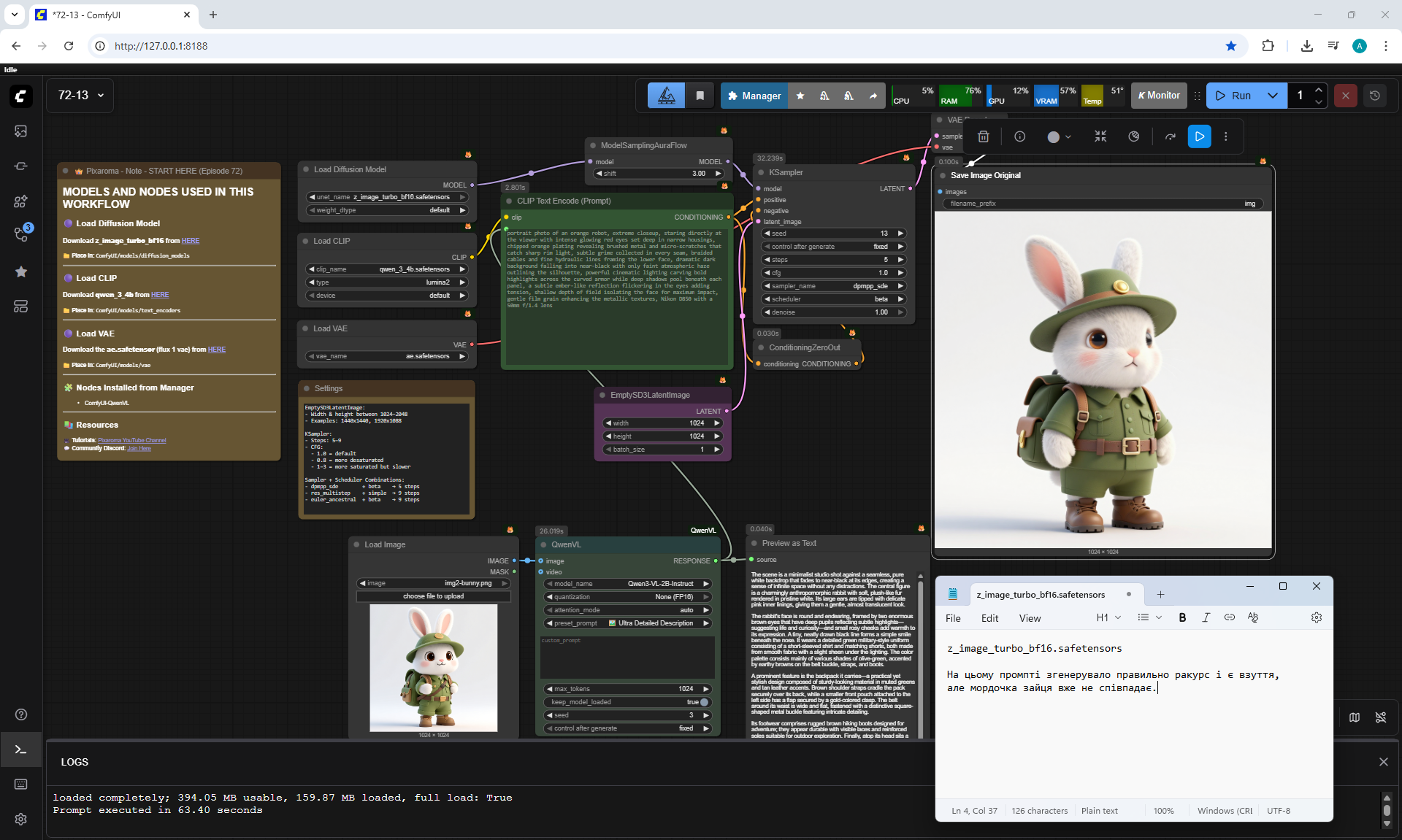
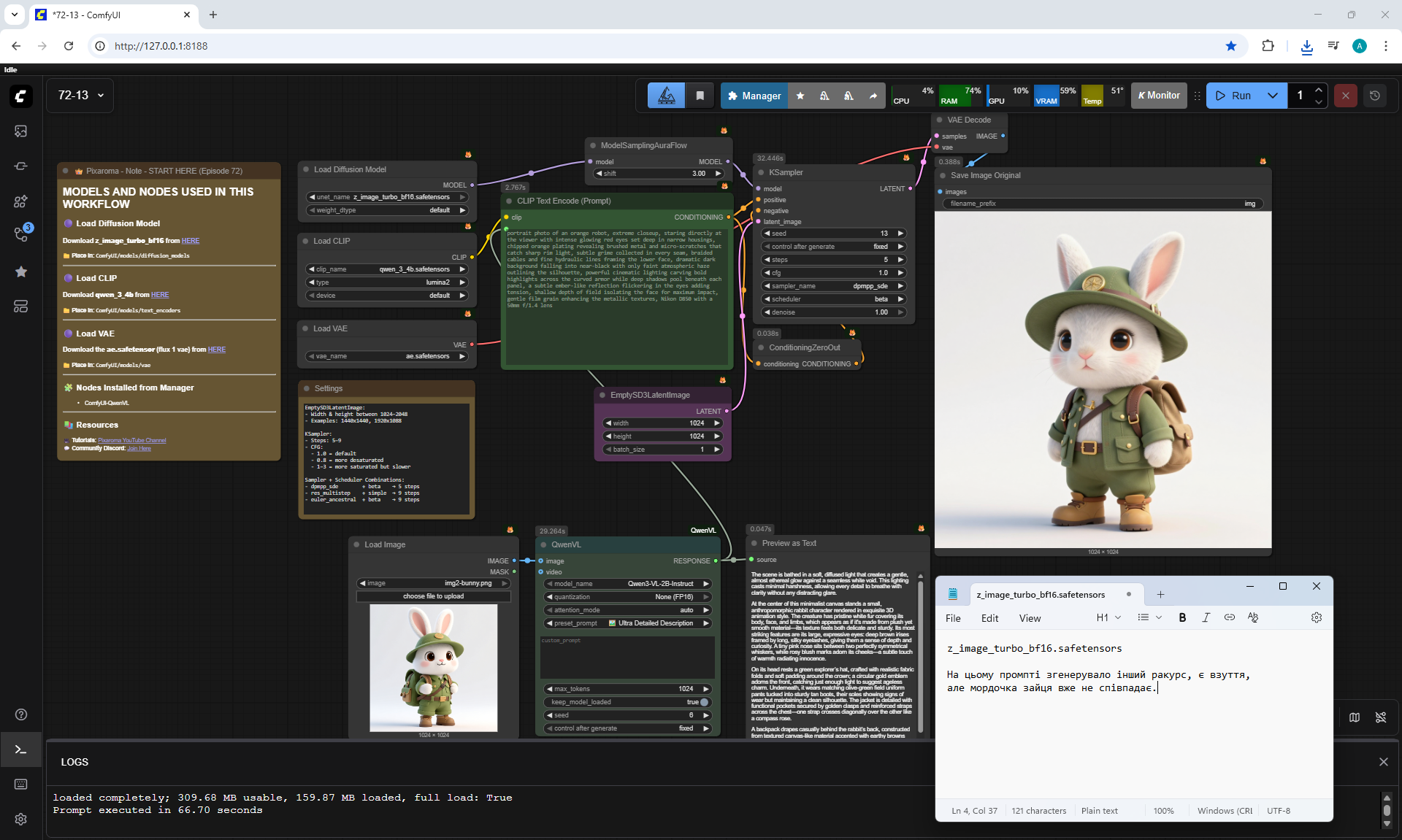
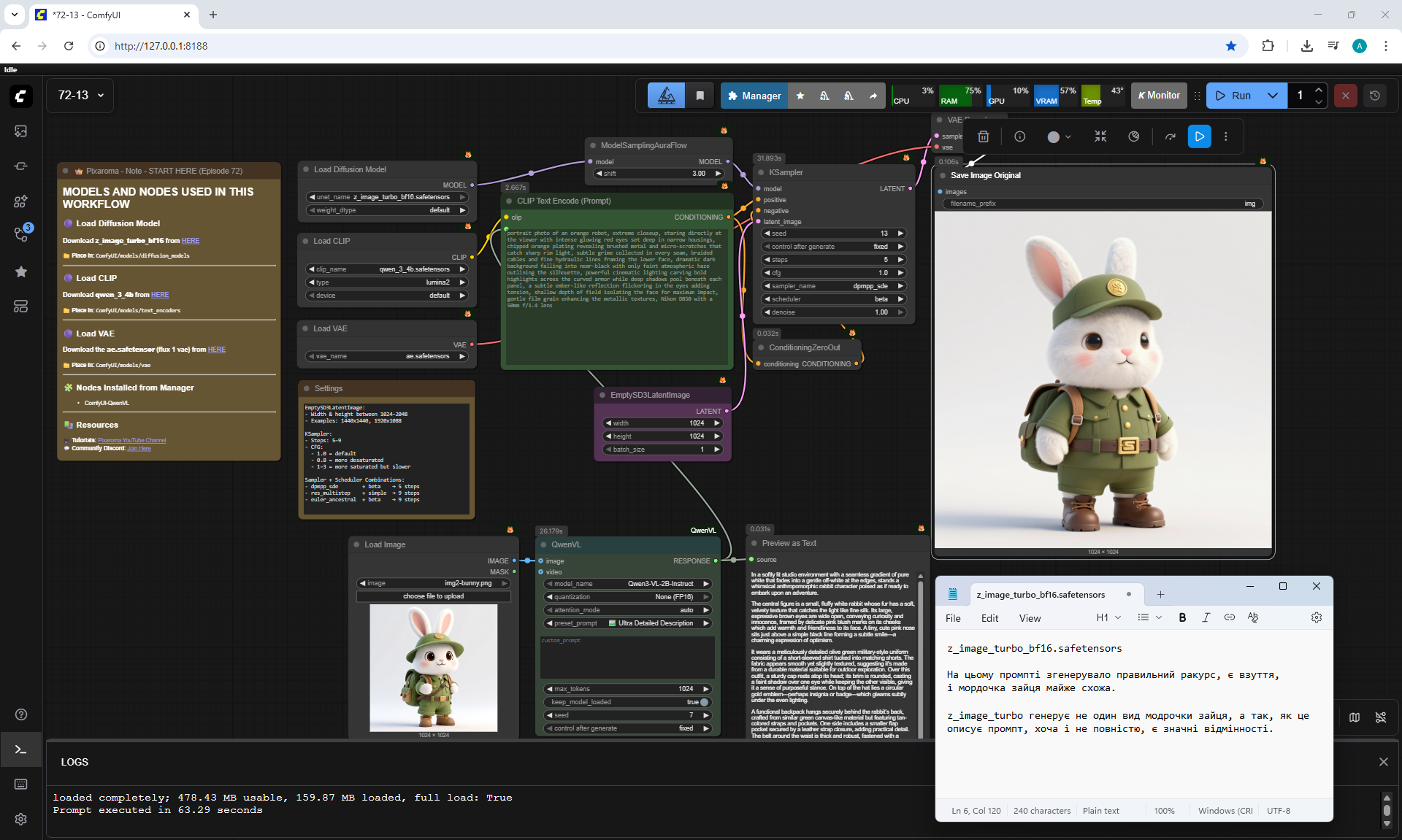
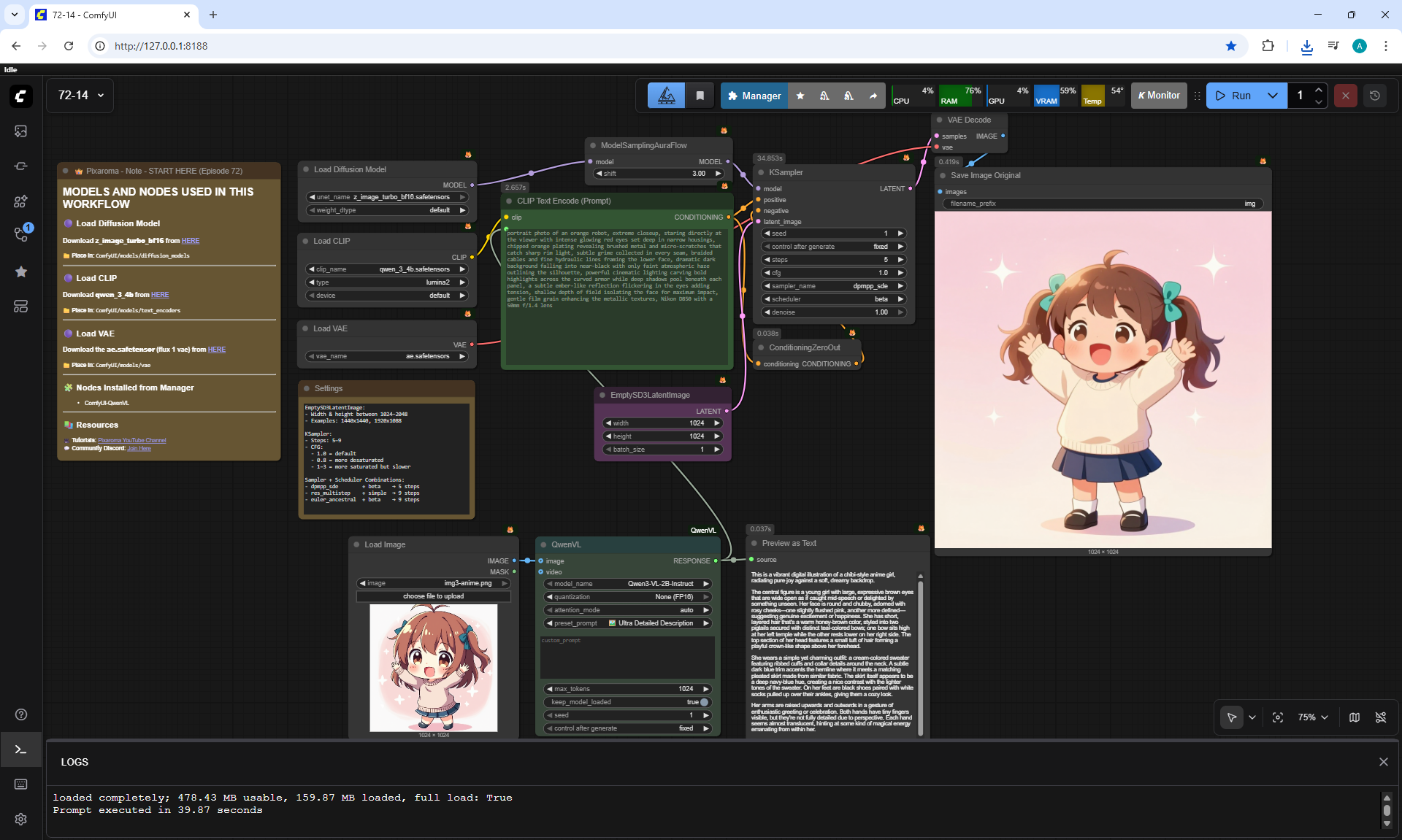
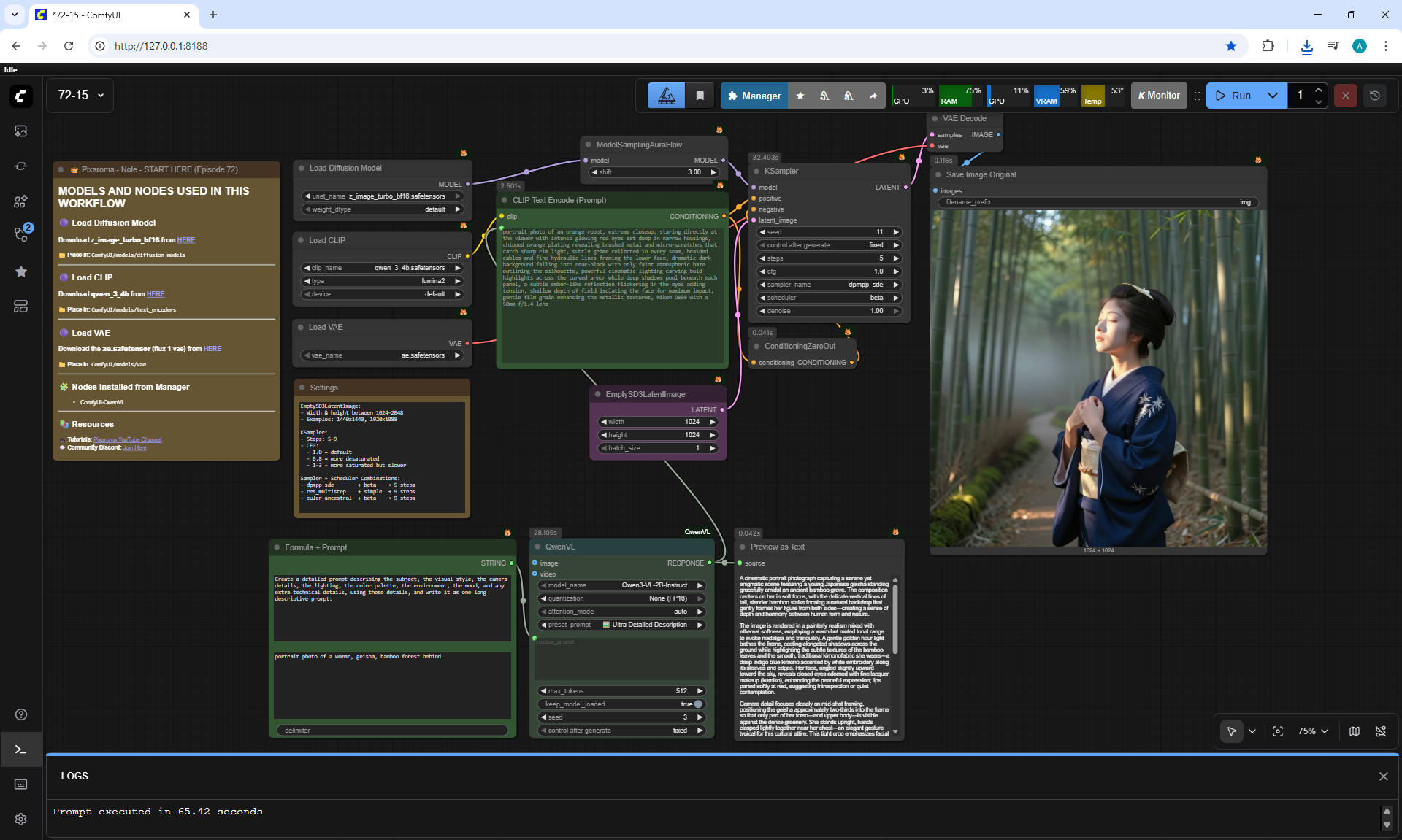
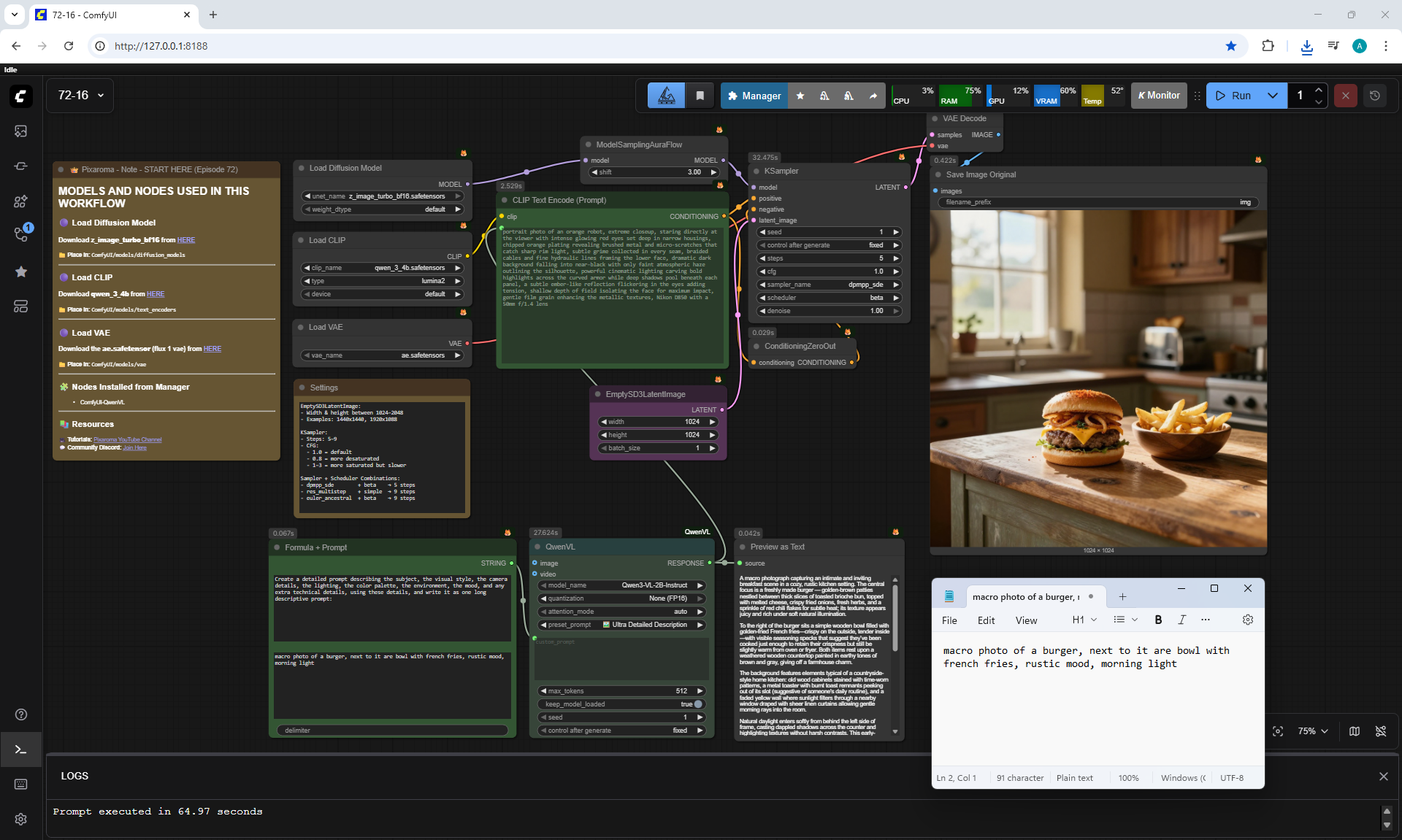
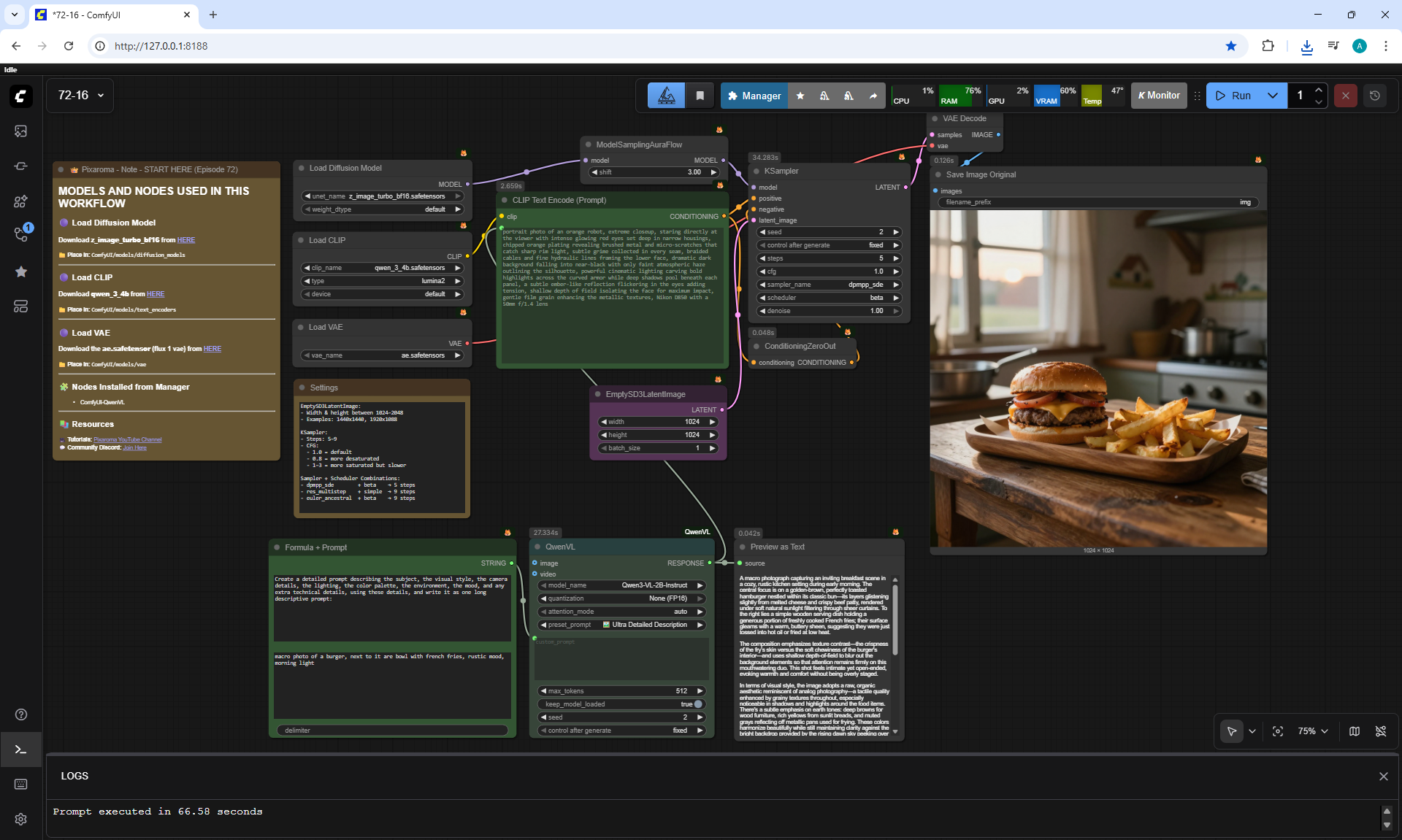
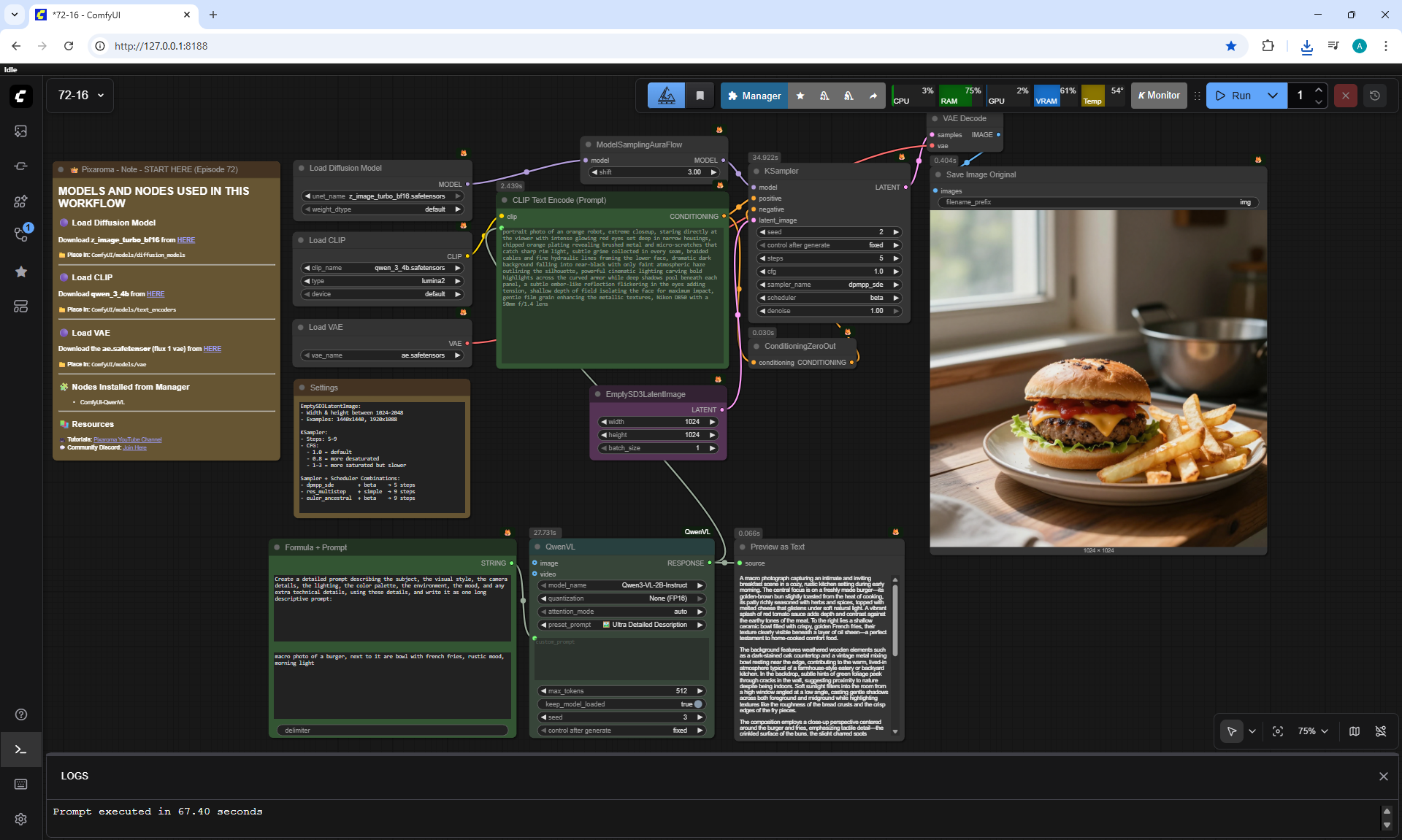
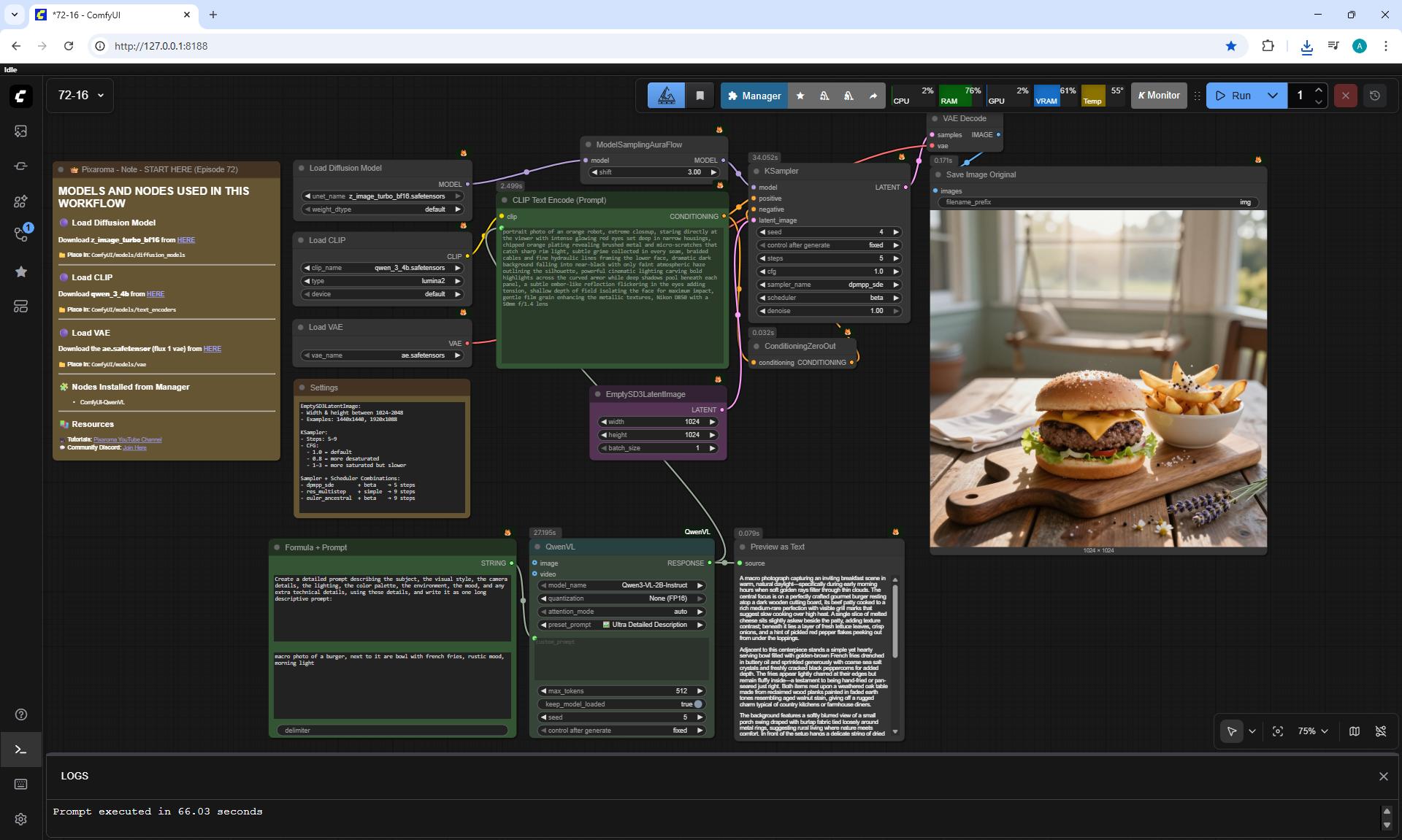
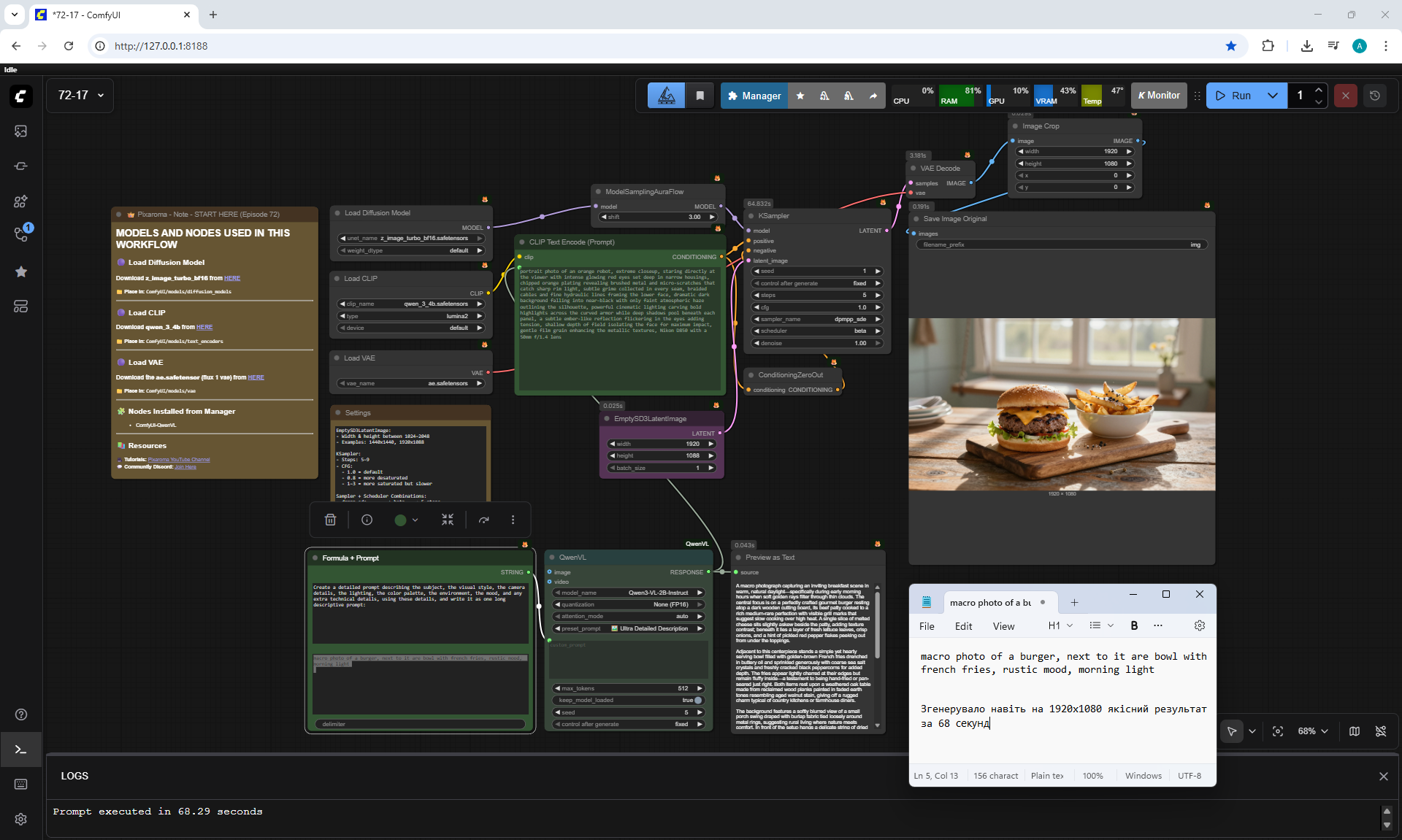
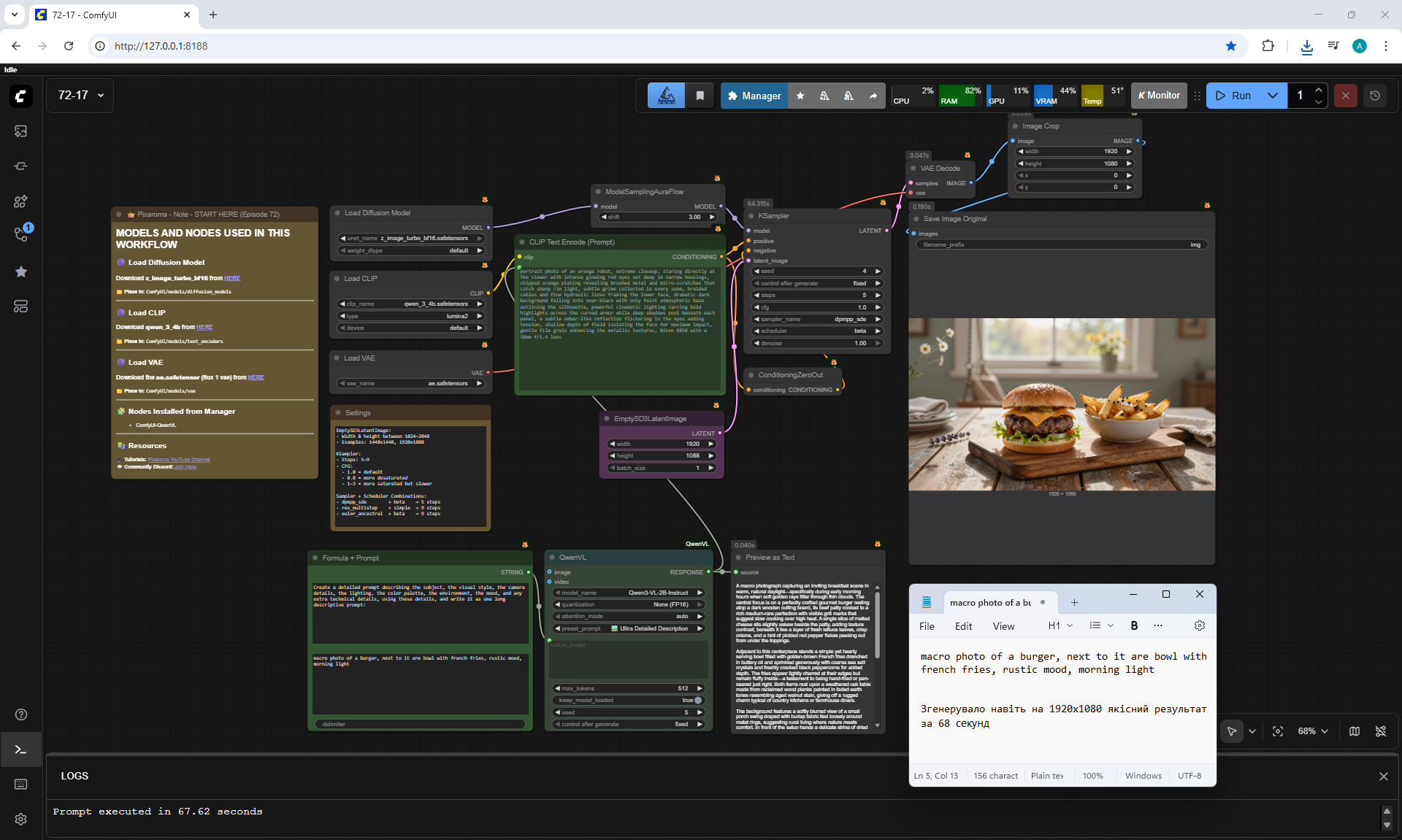
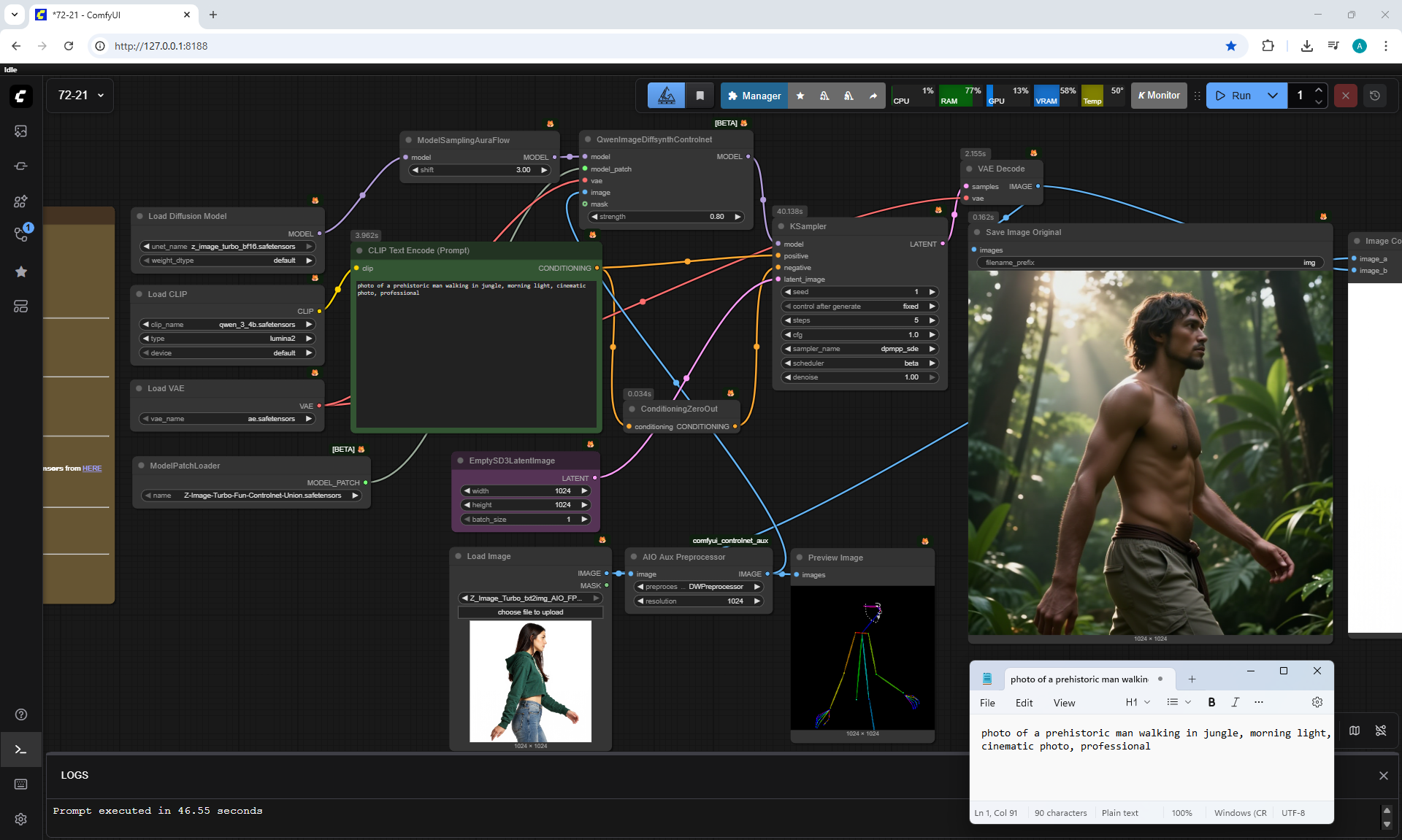
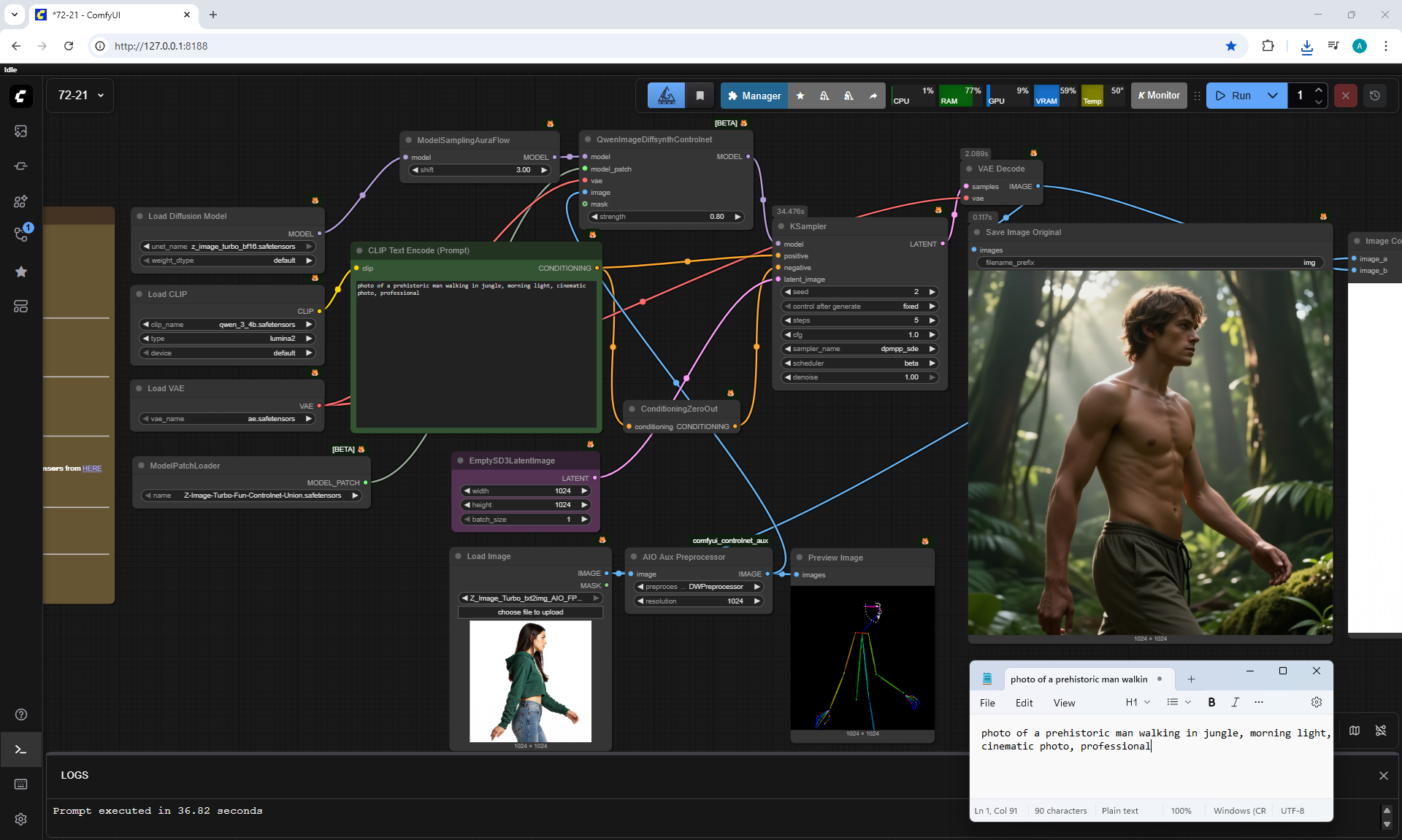
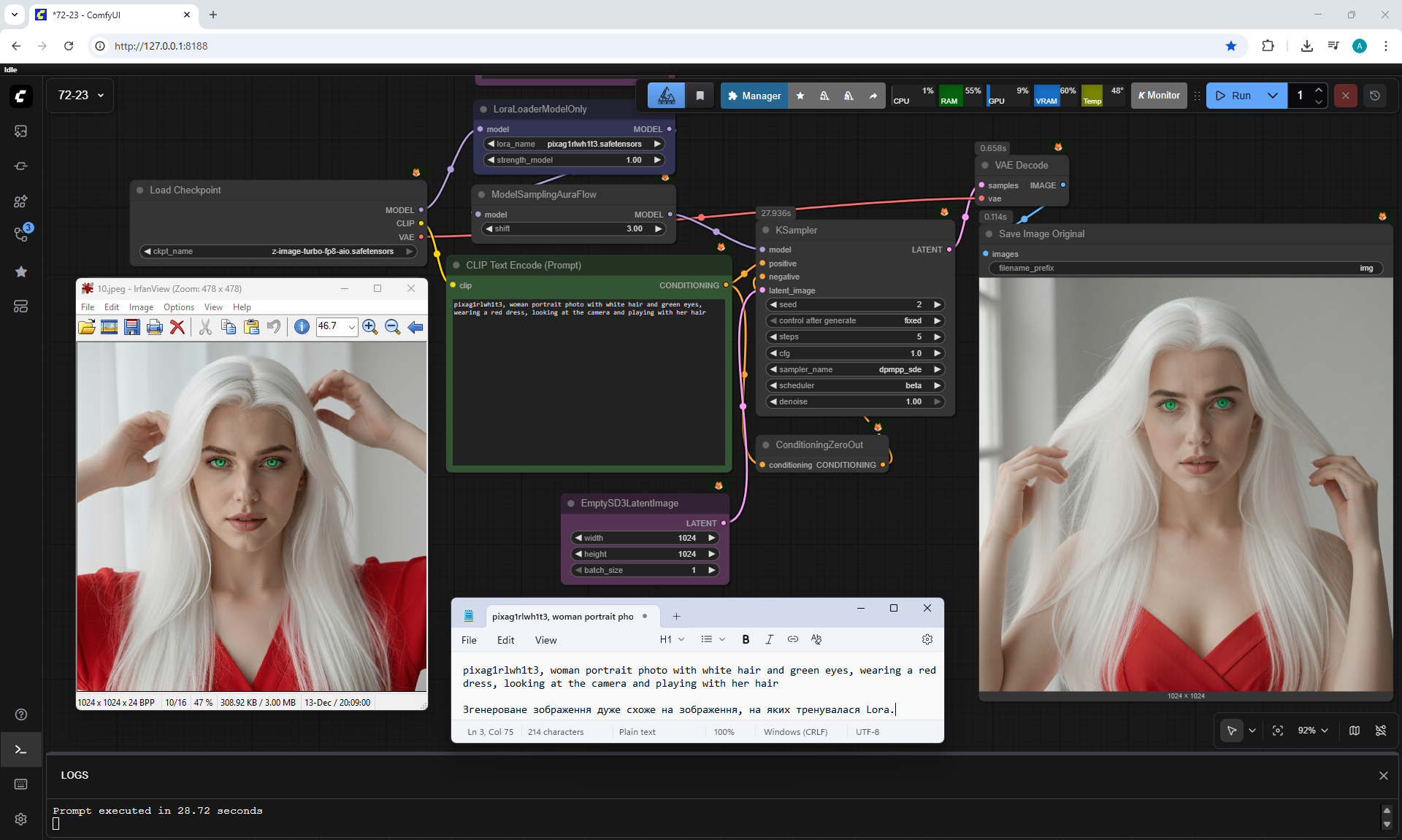
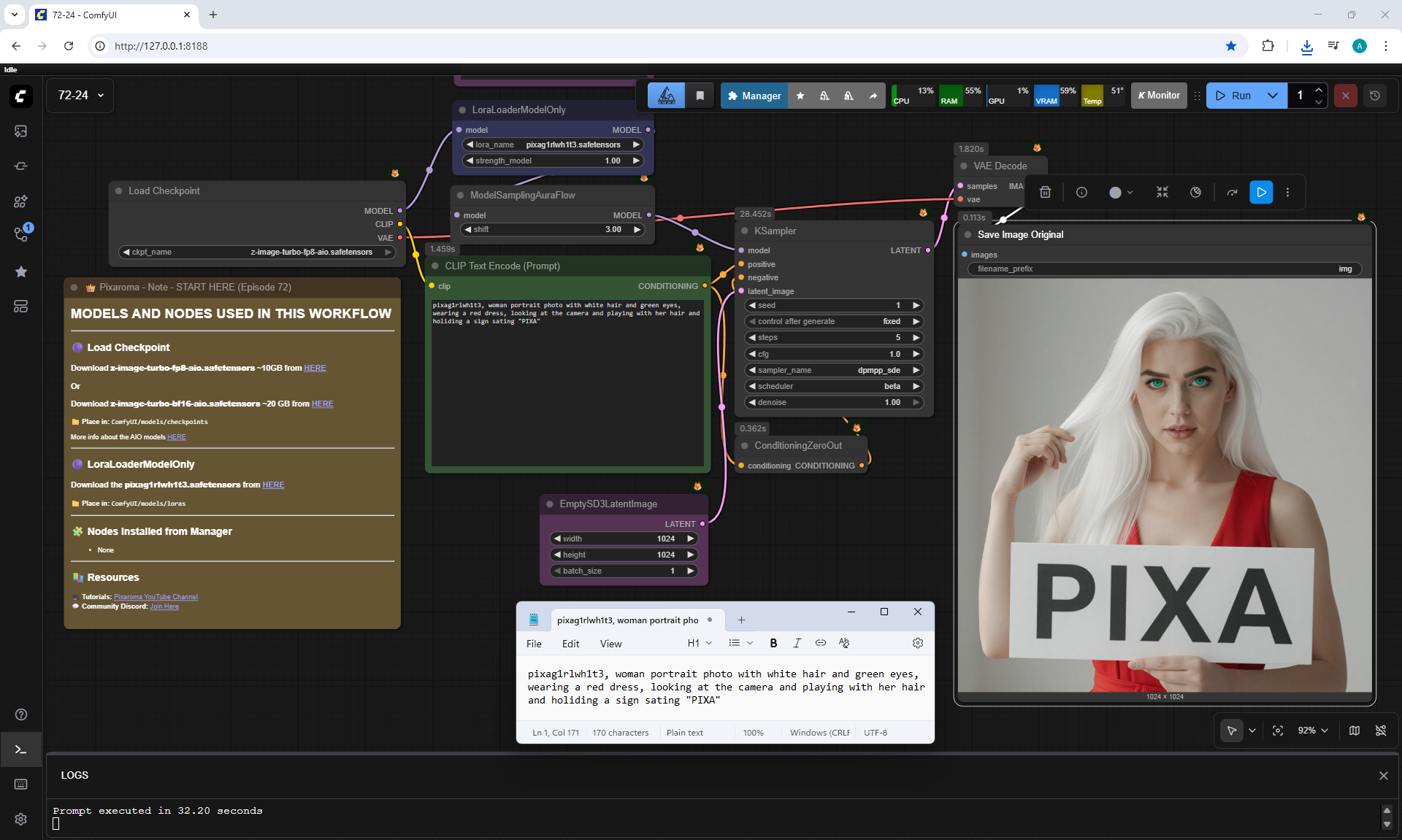
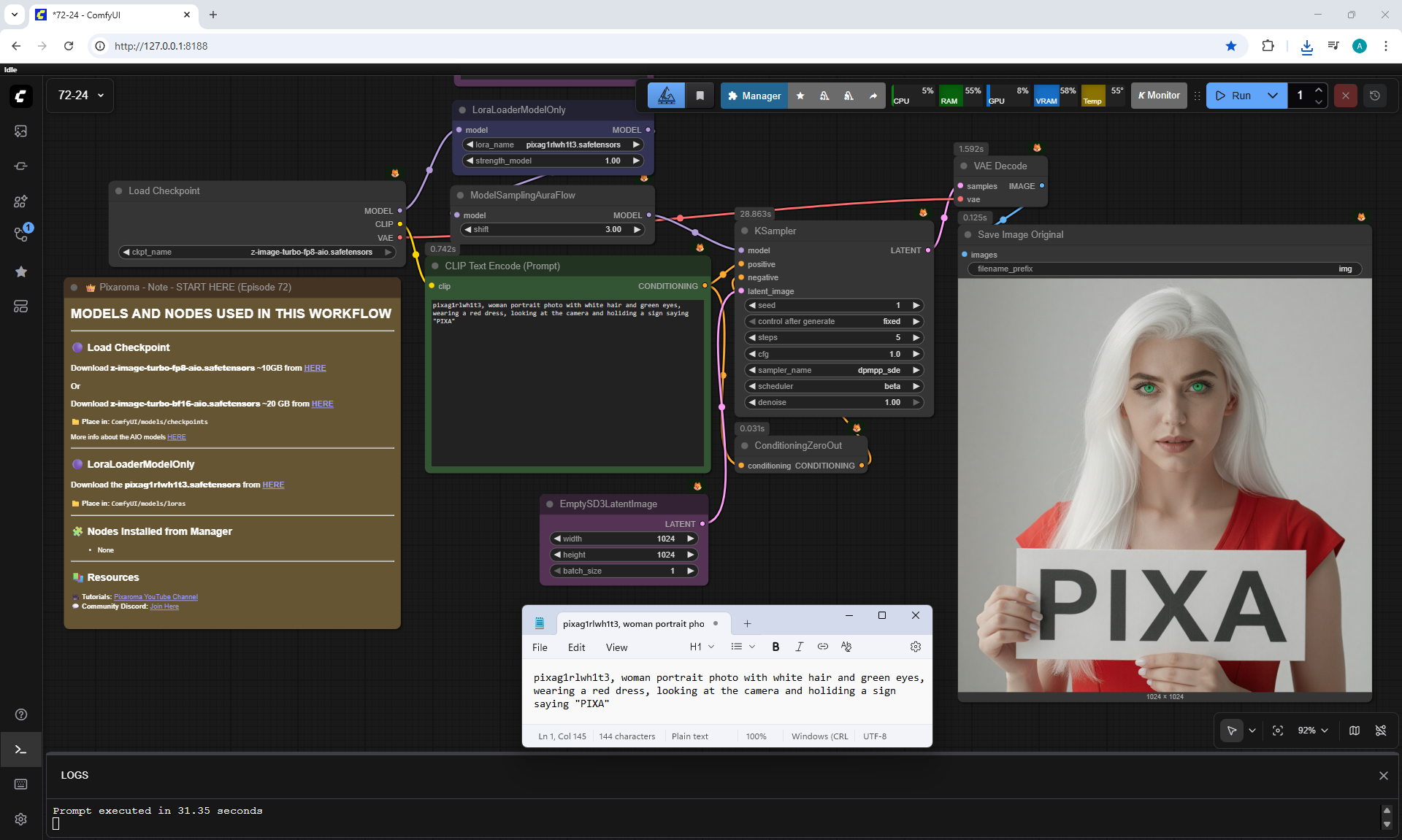
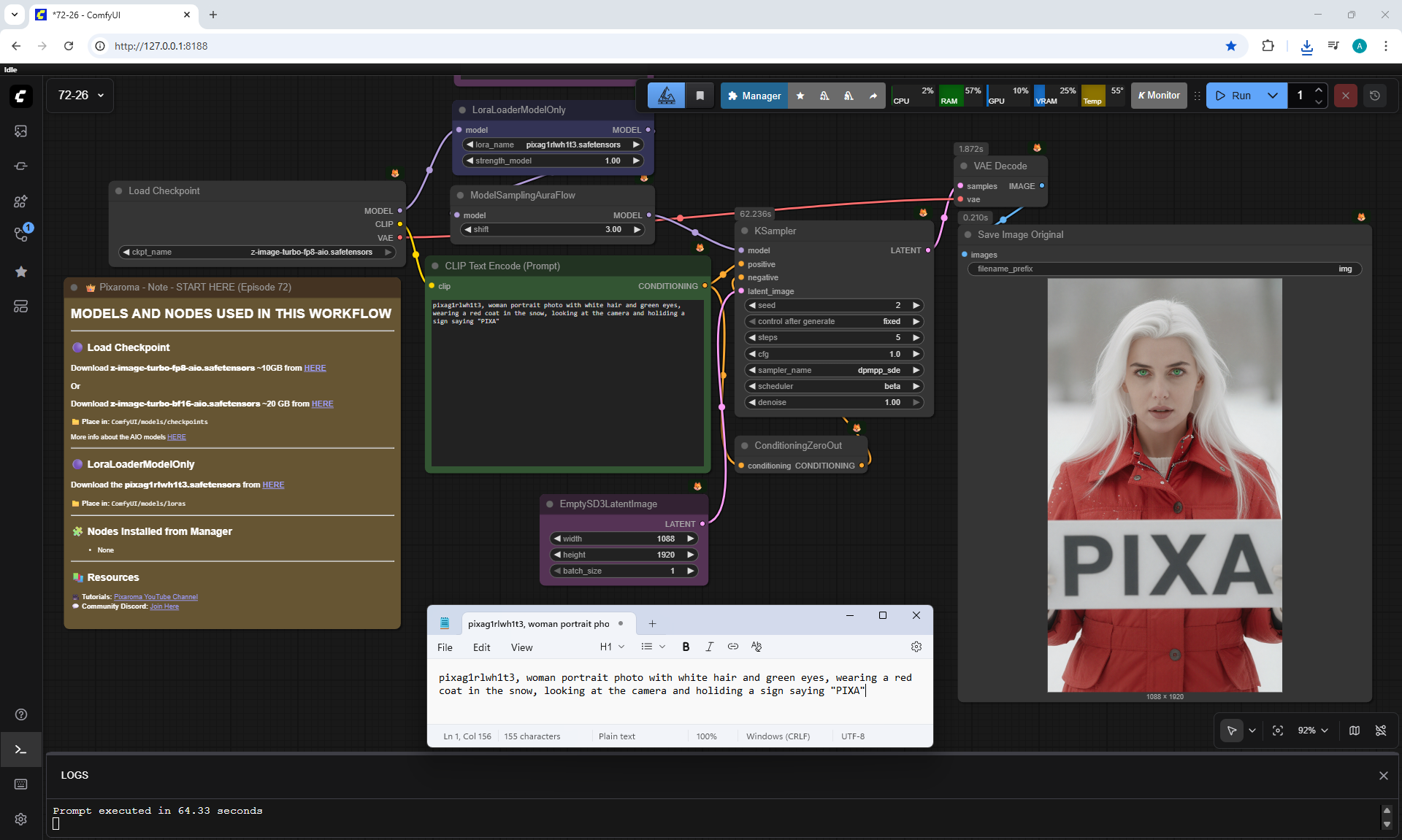
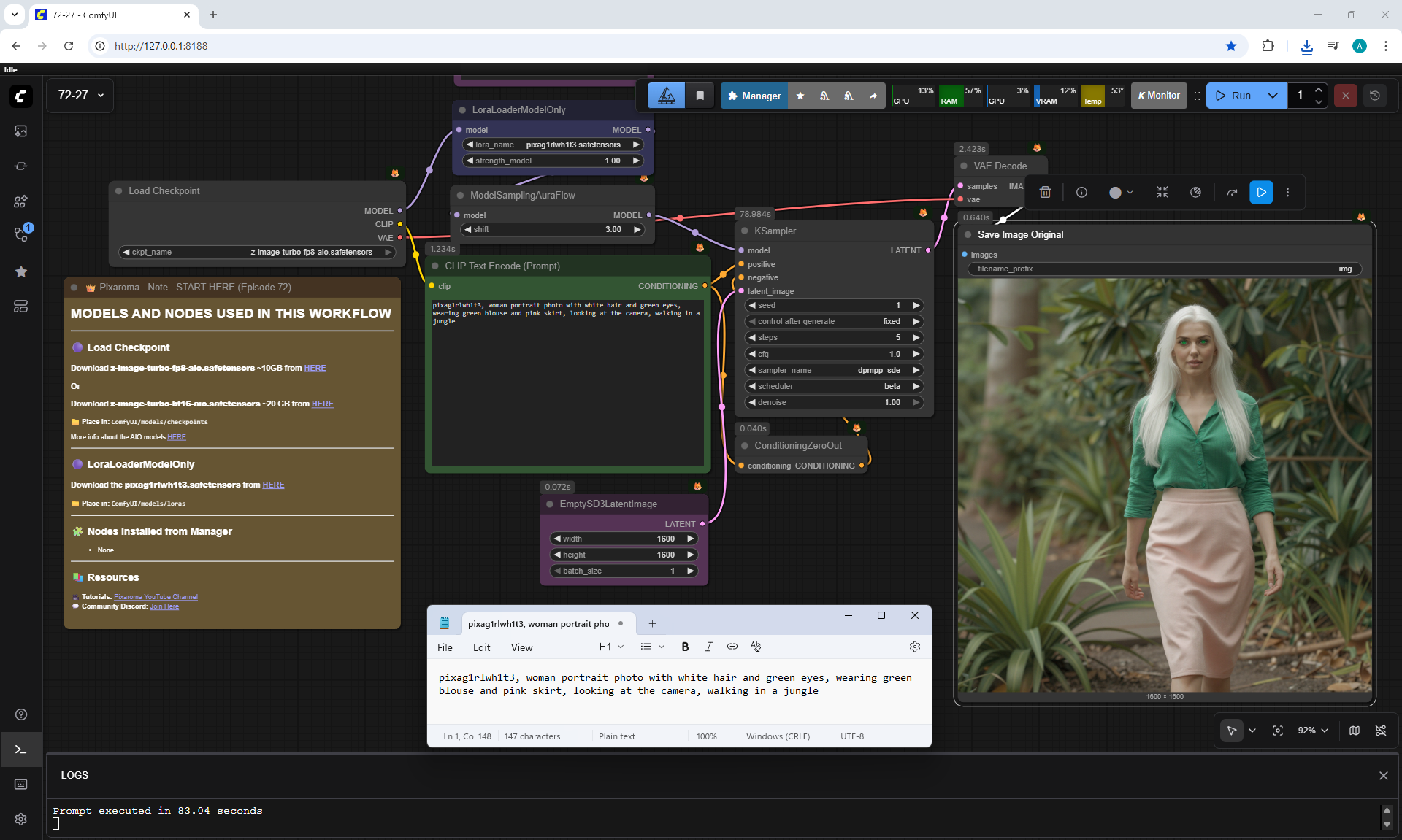
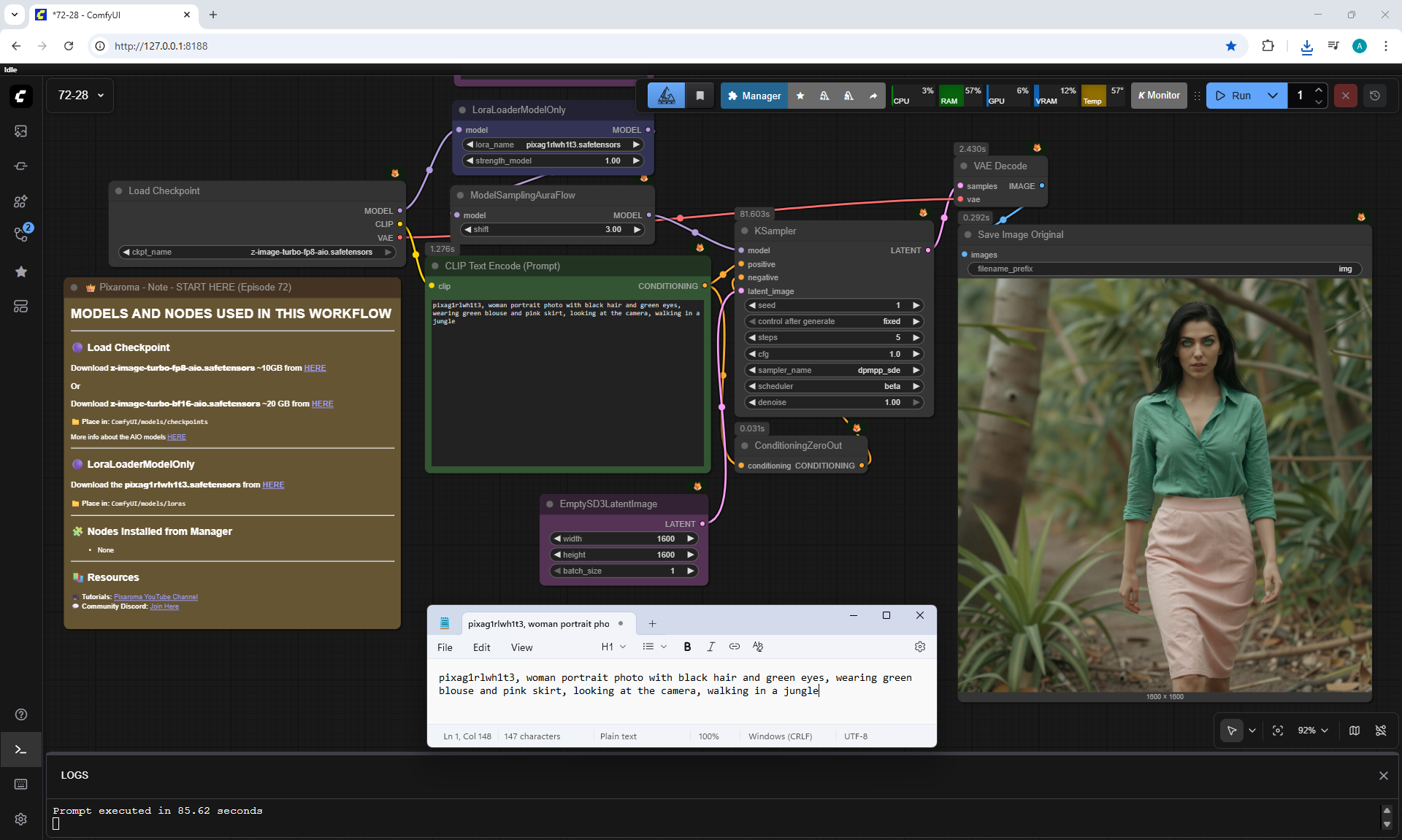
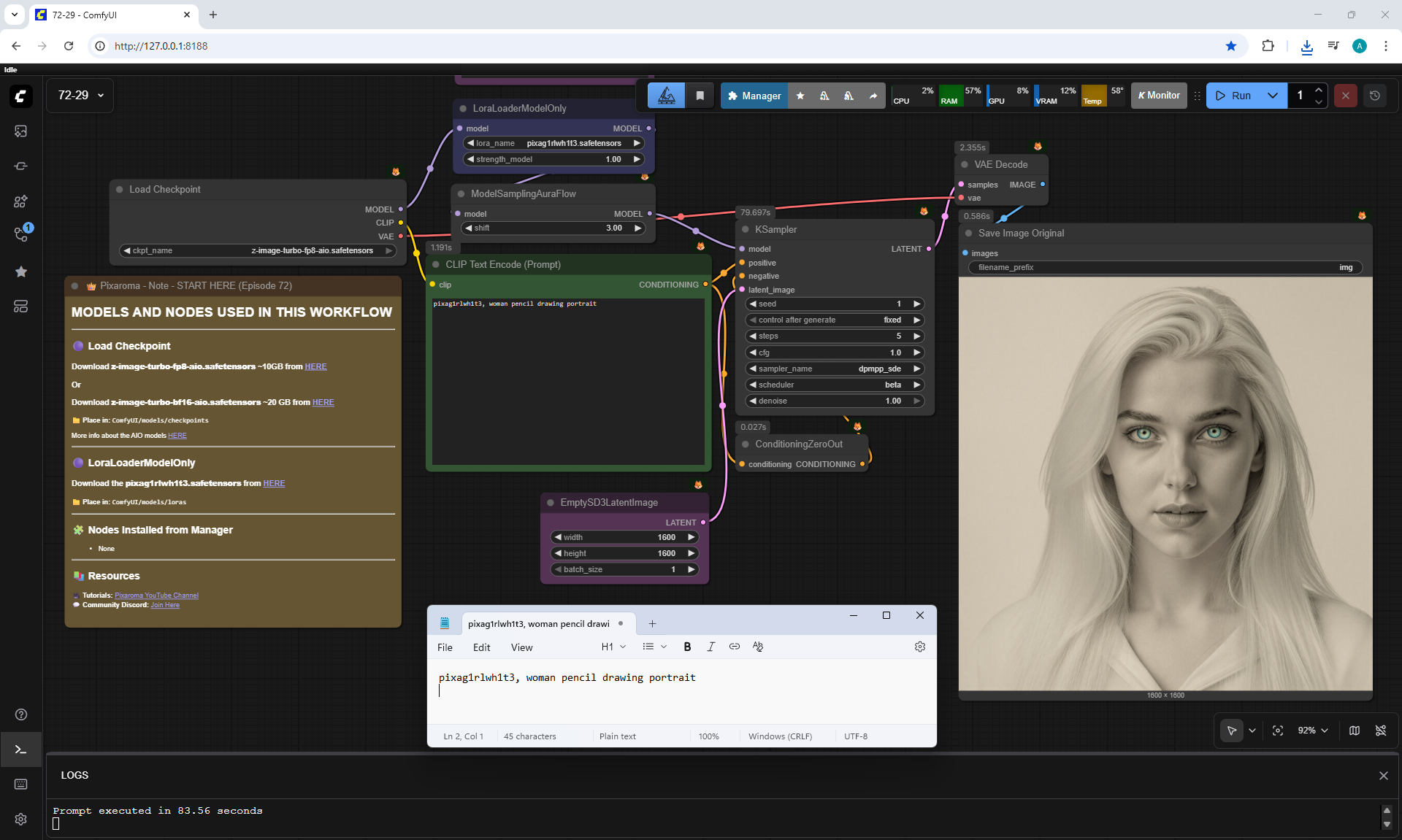
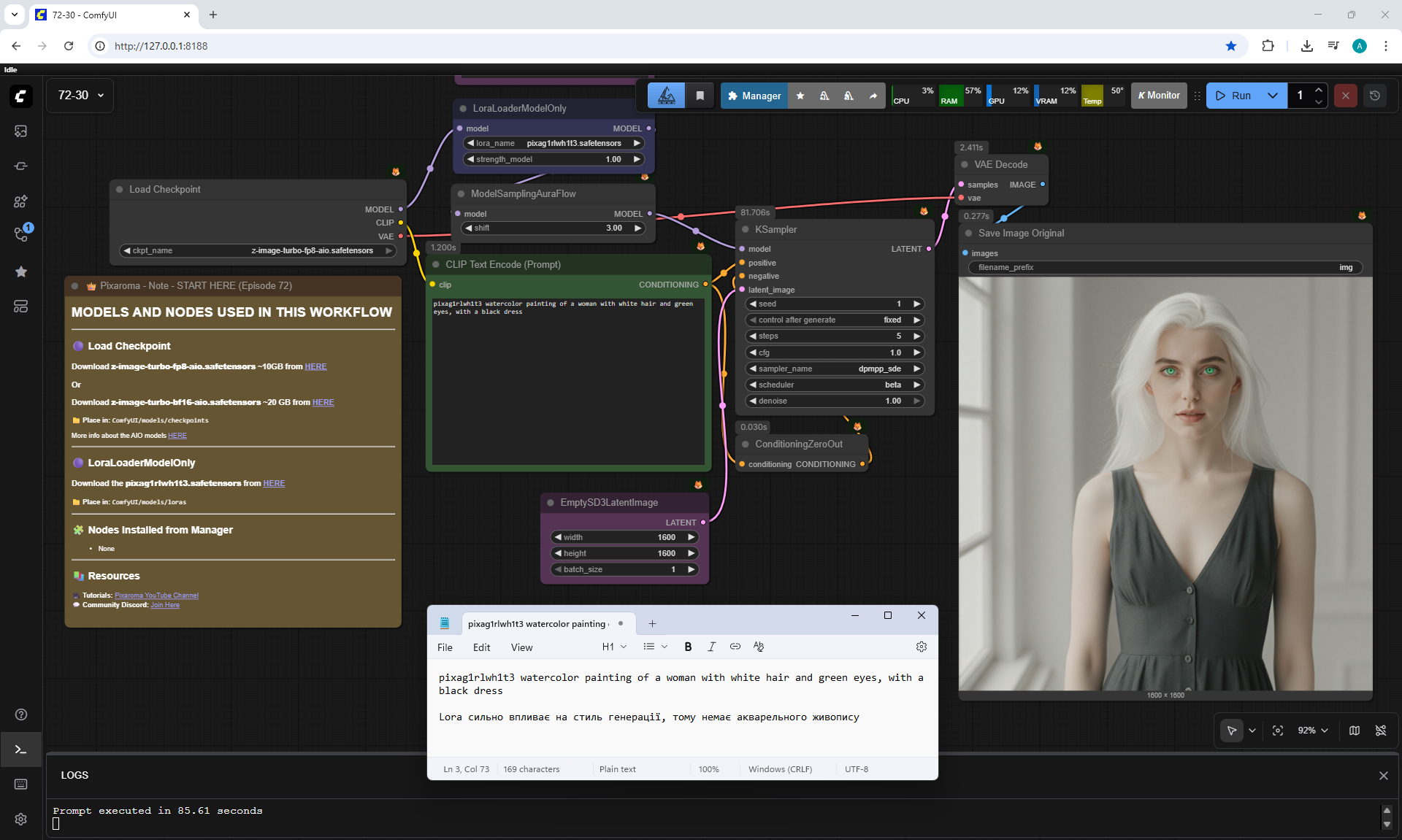
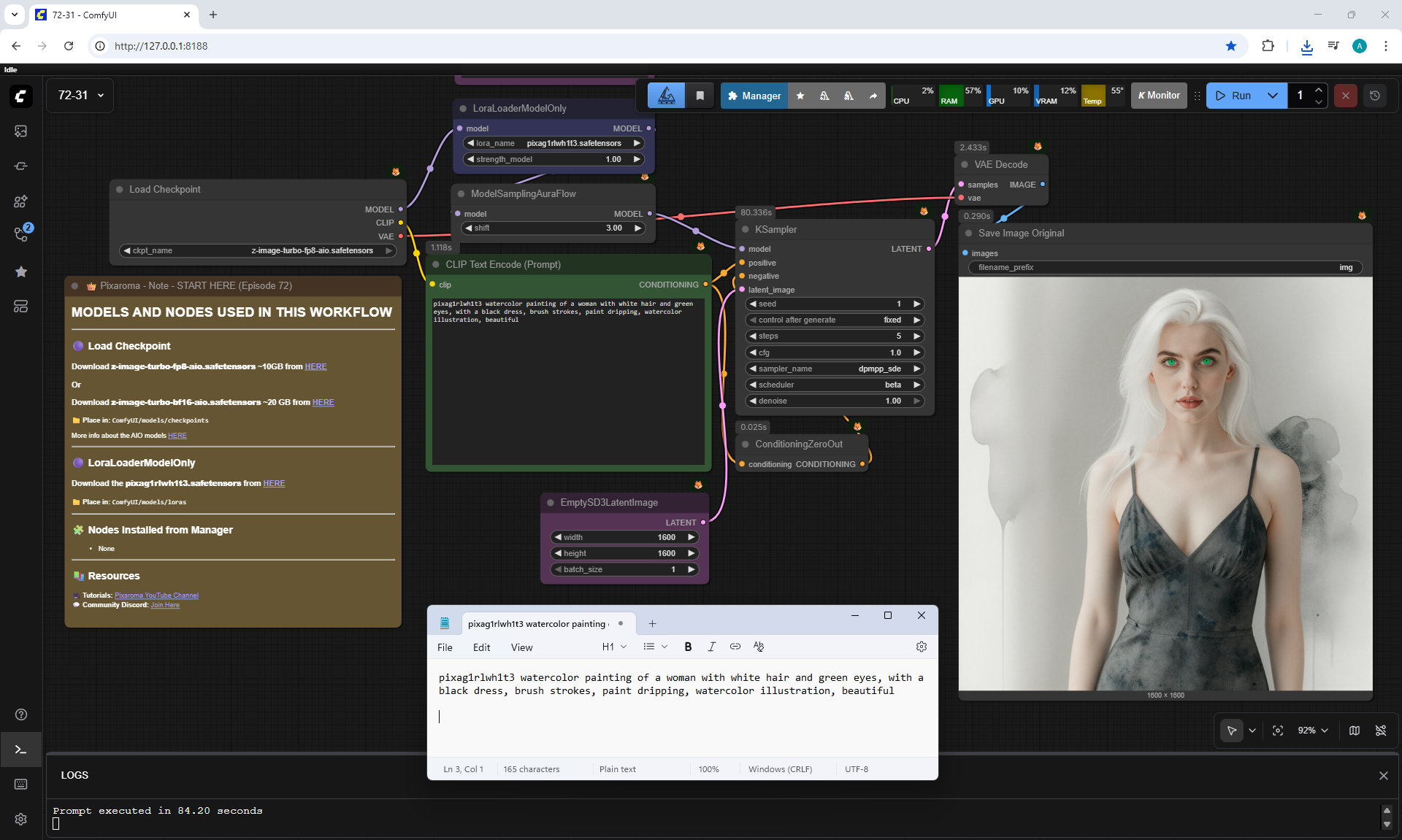
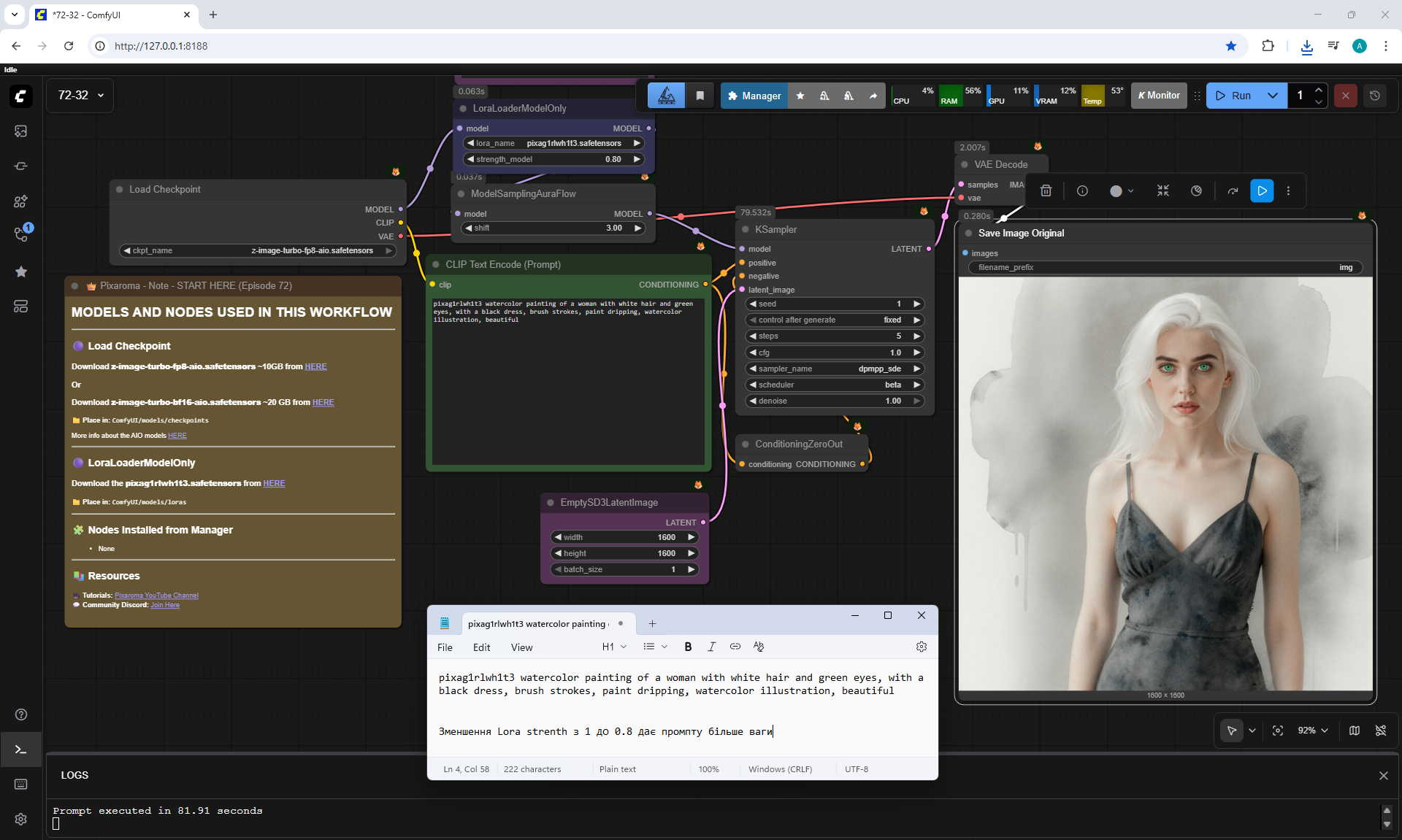
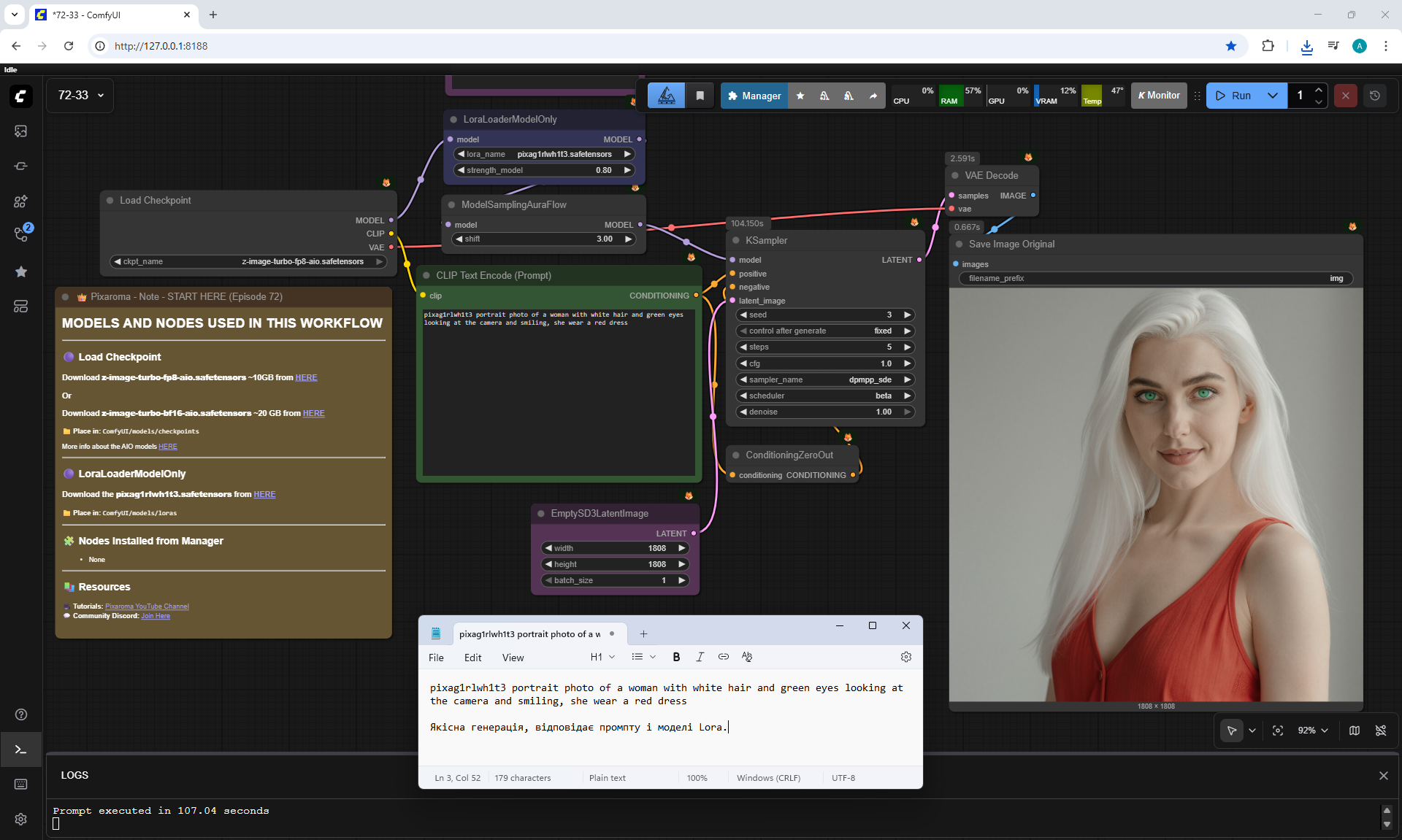
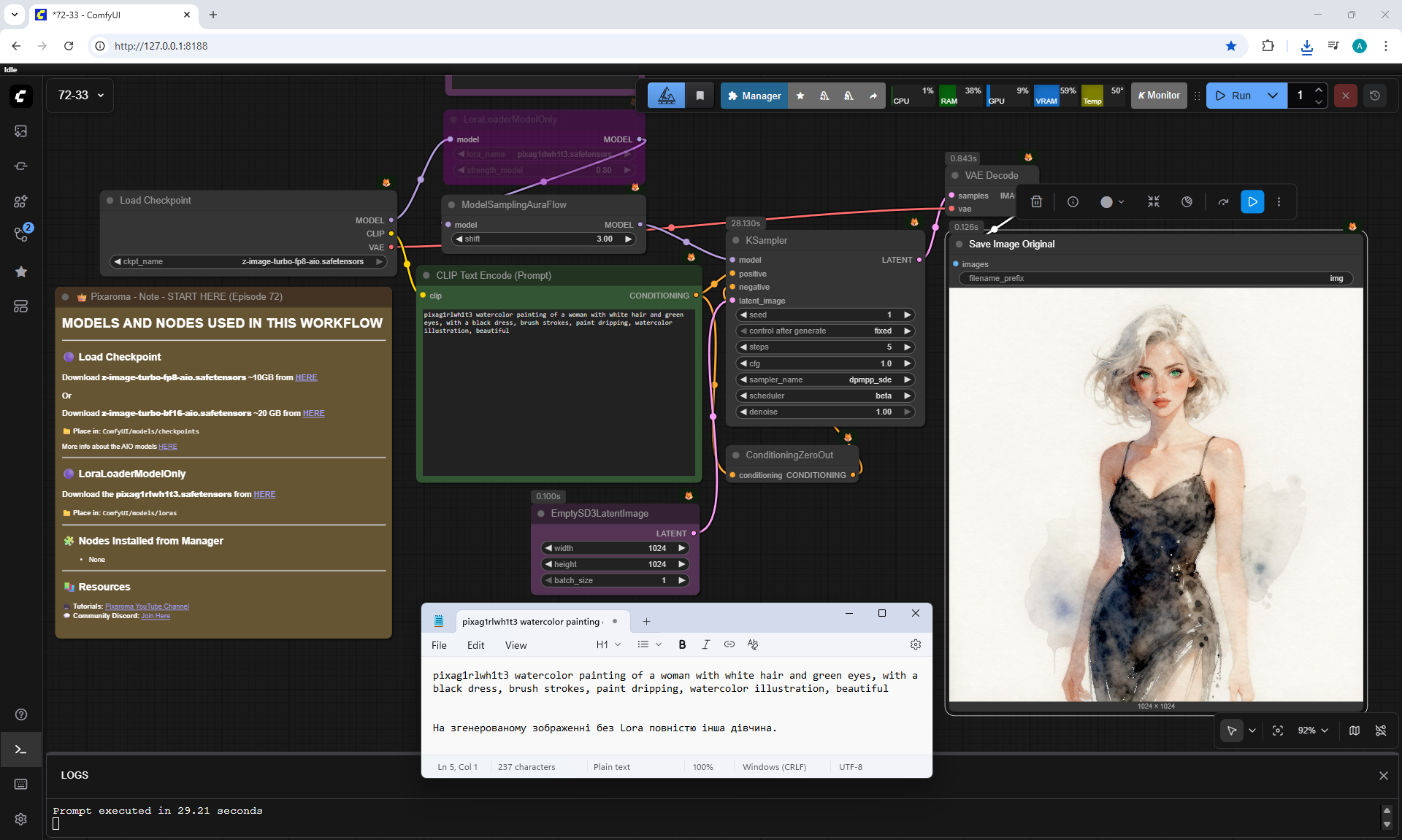
ComfyUI Tutorial Series Ep 72: Z-Image Turbo Workflows, ControlNet Essentials & LoRA Training











































































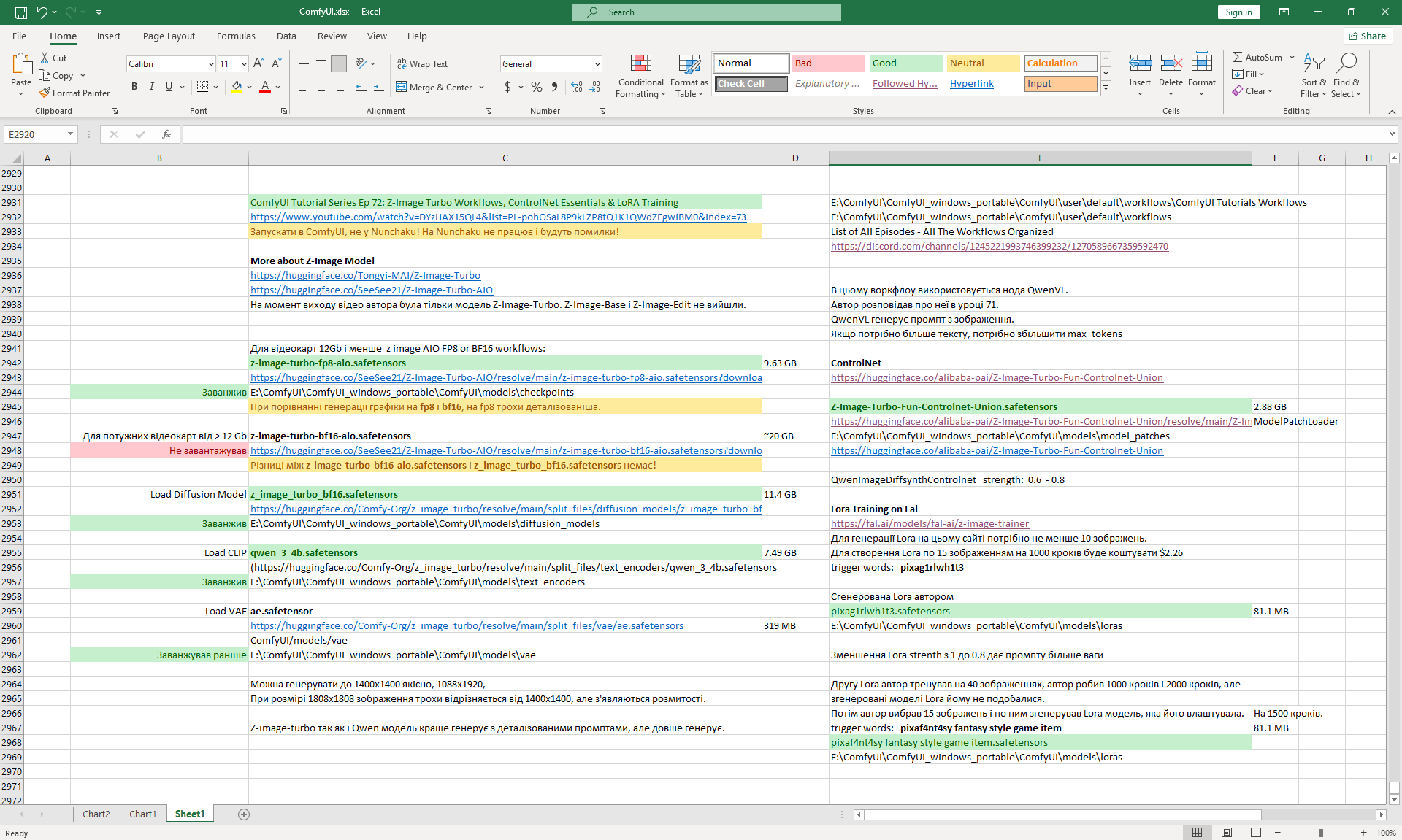
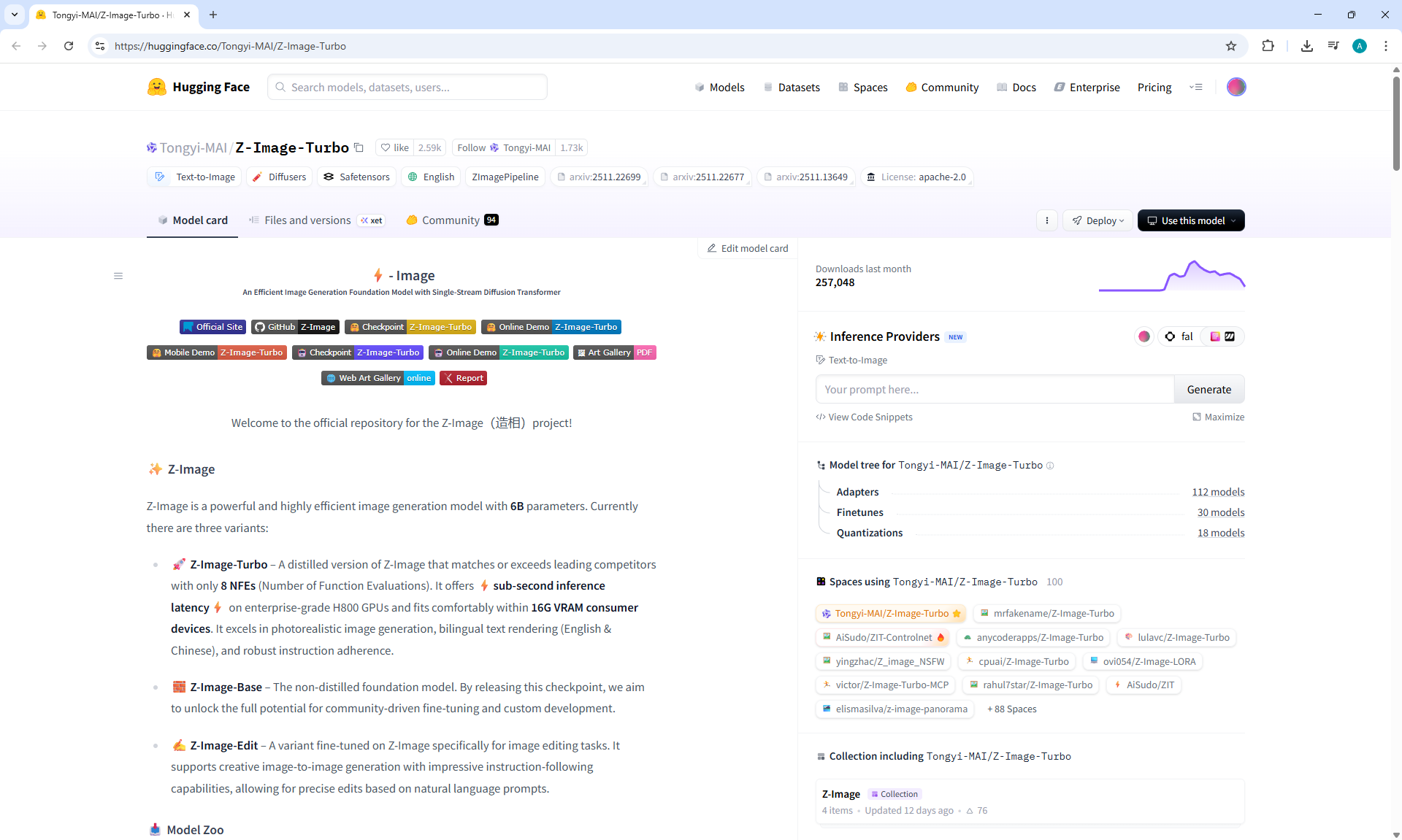
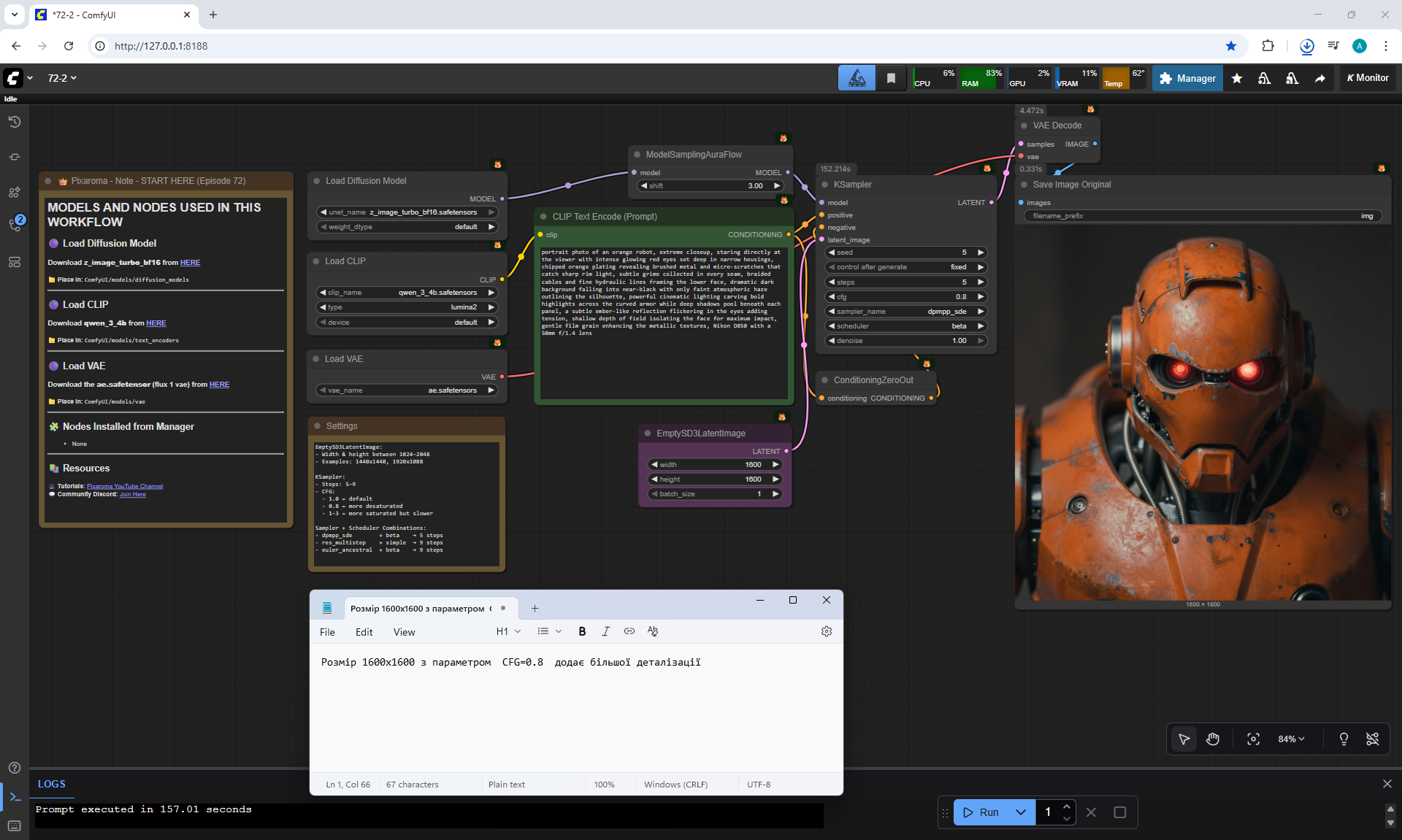
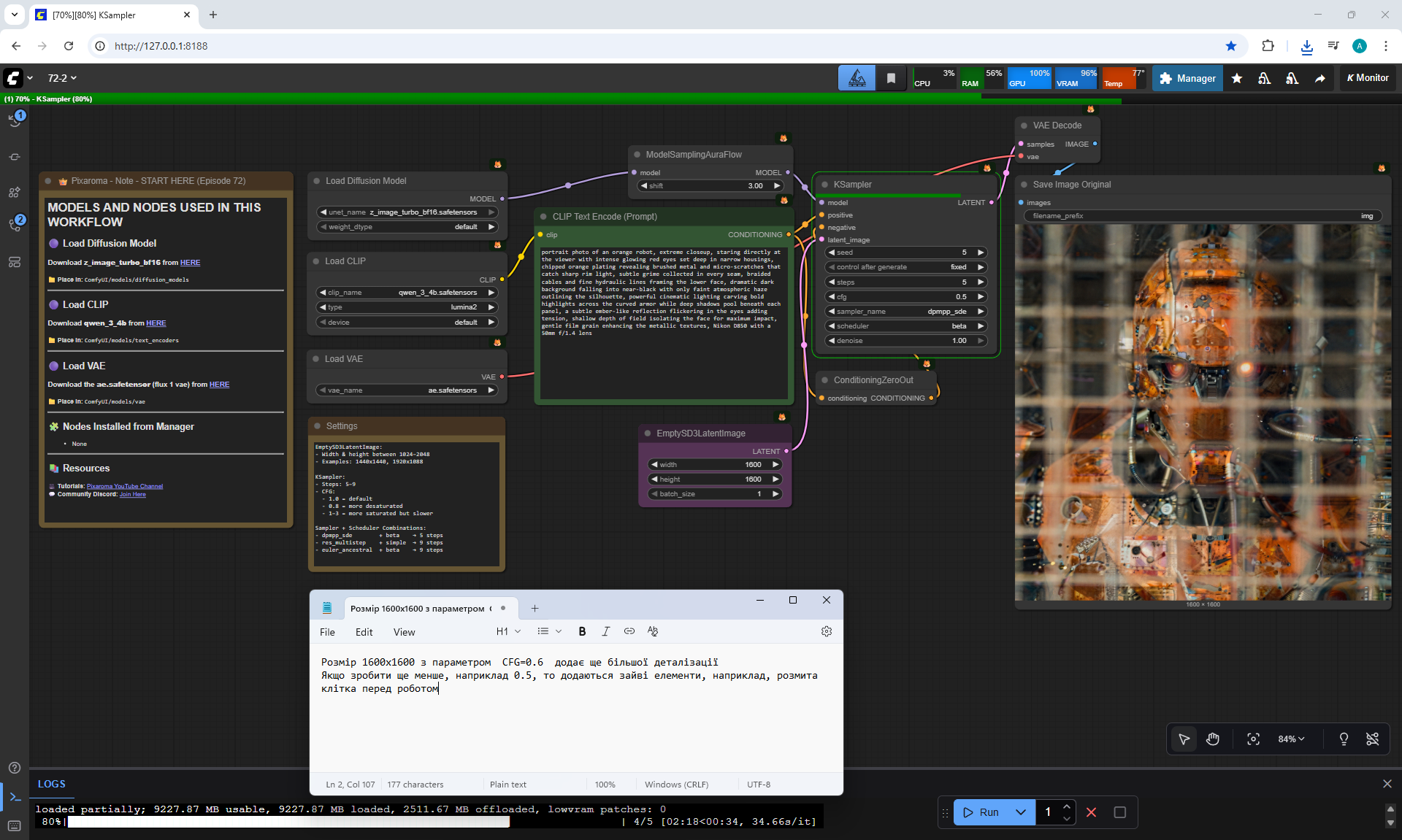
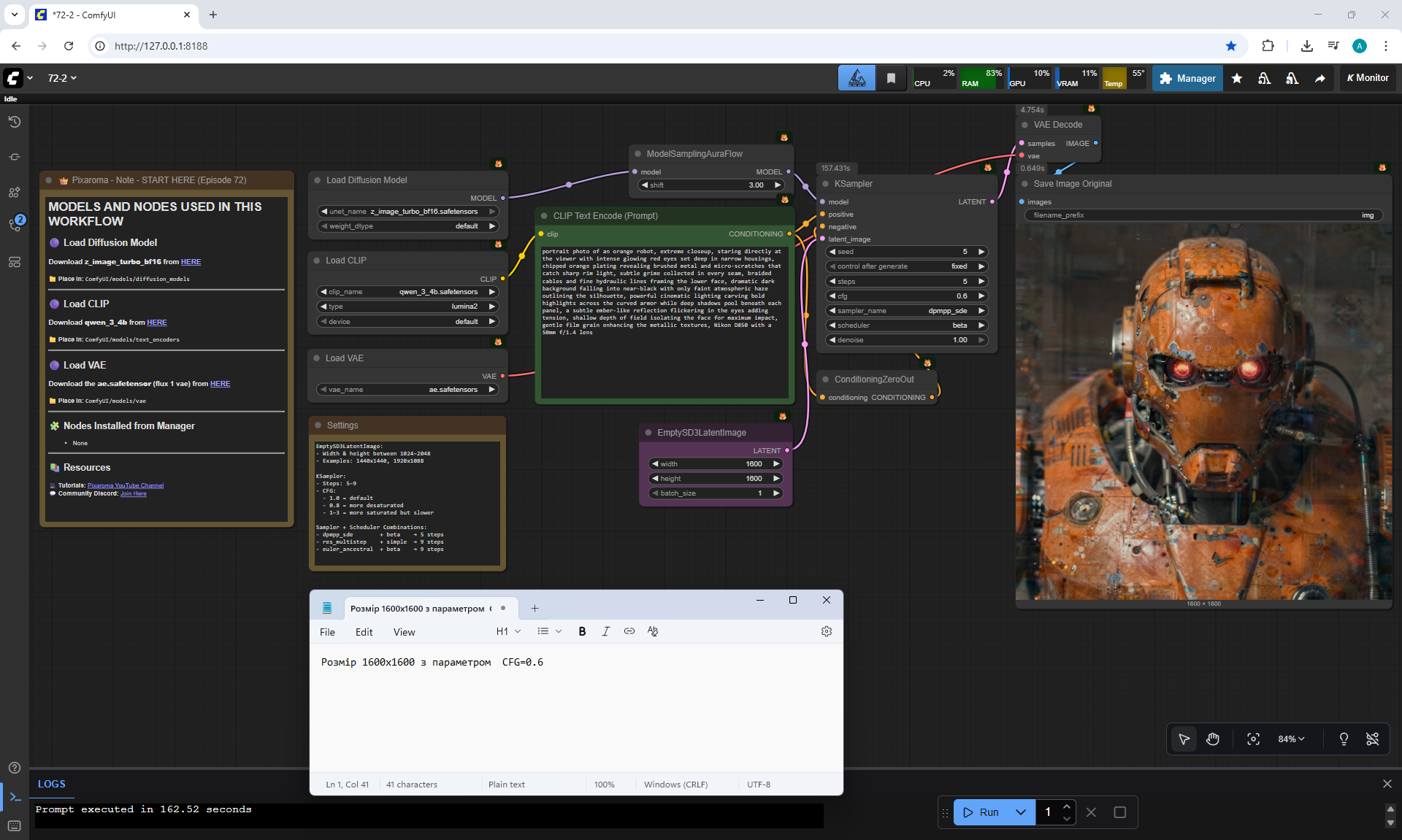
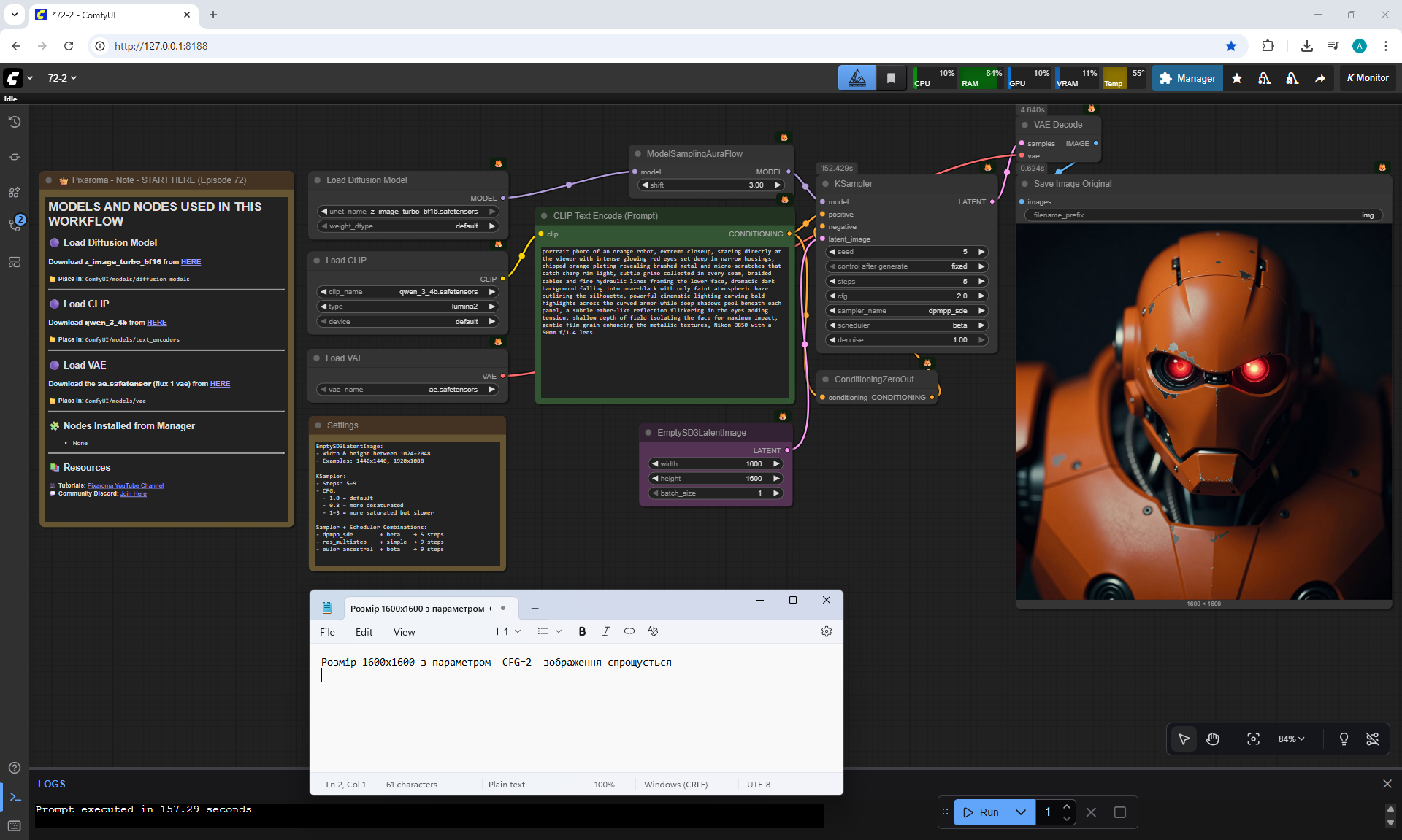
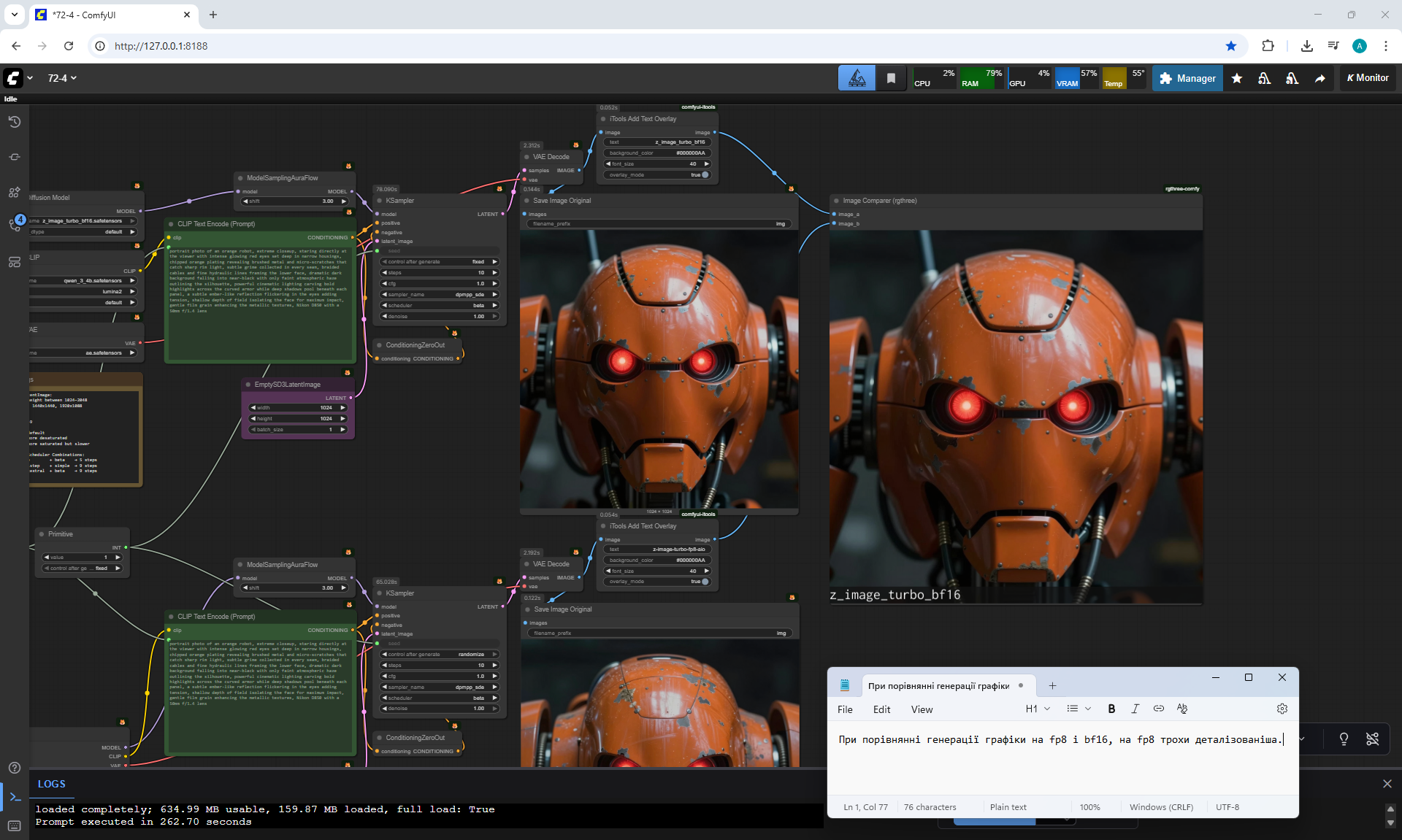
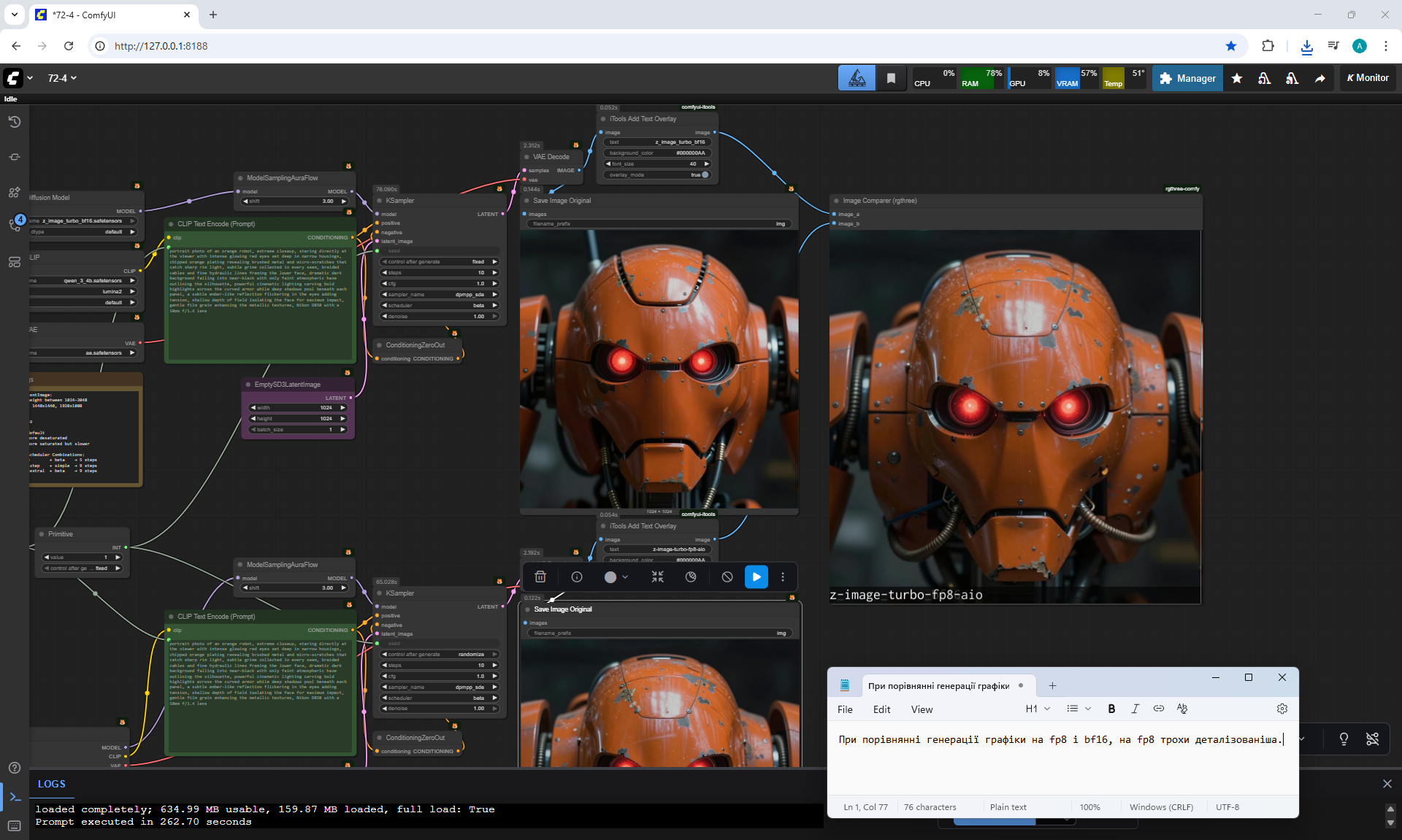
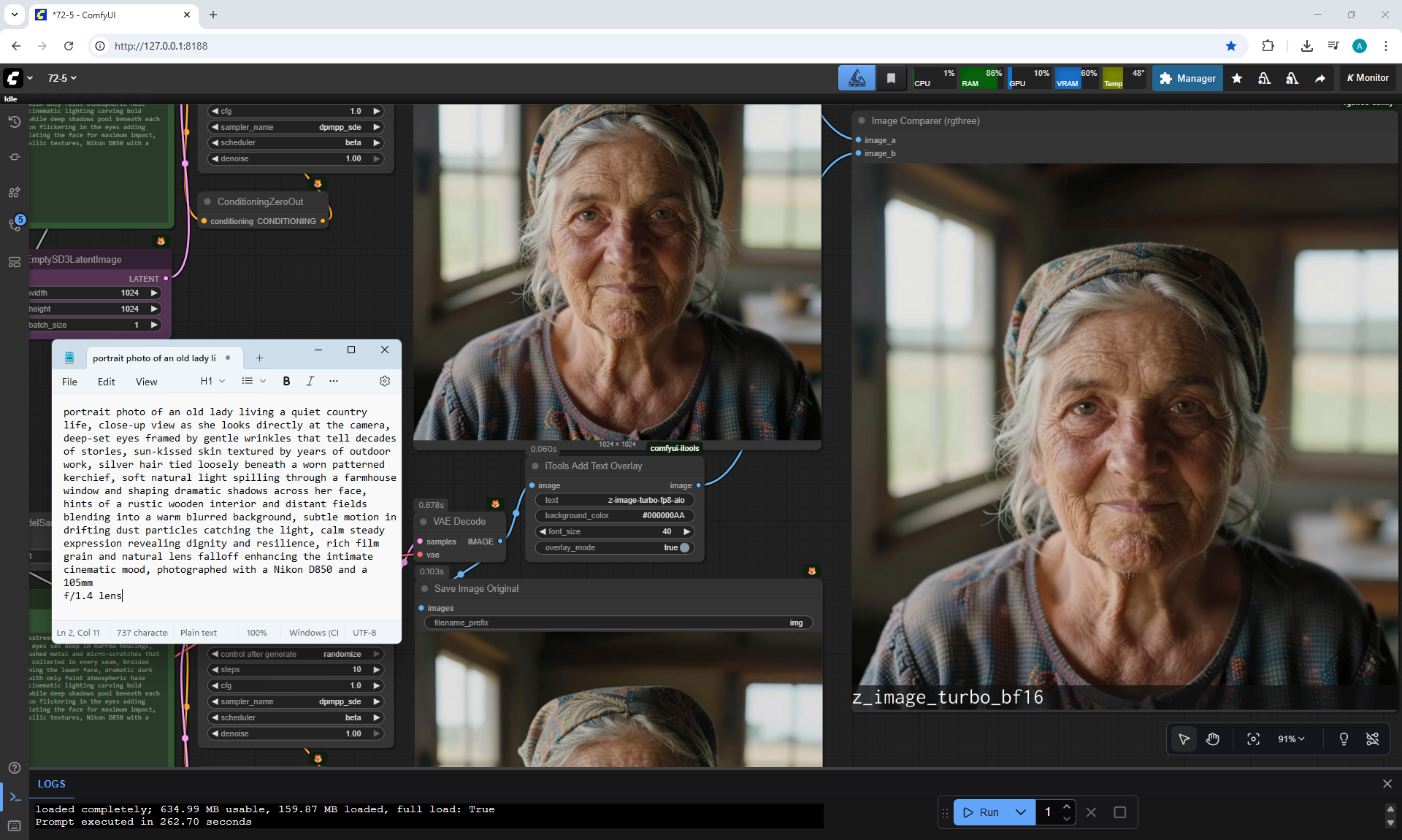
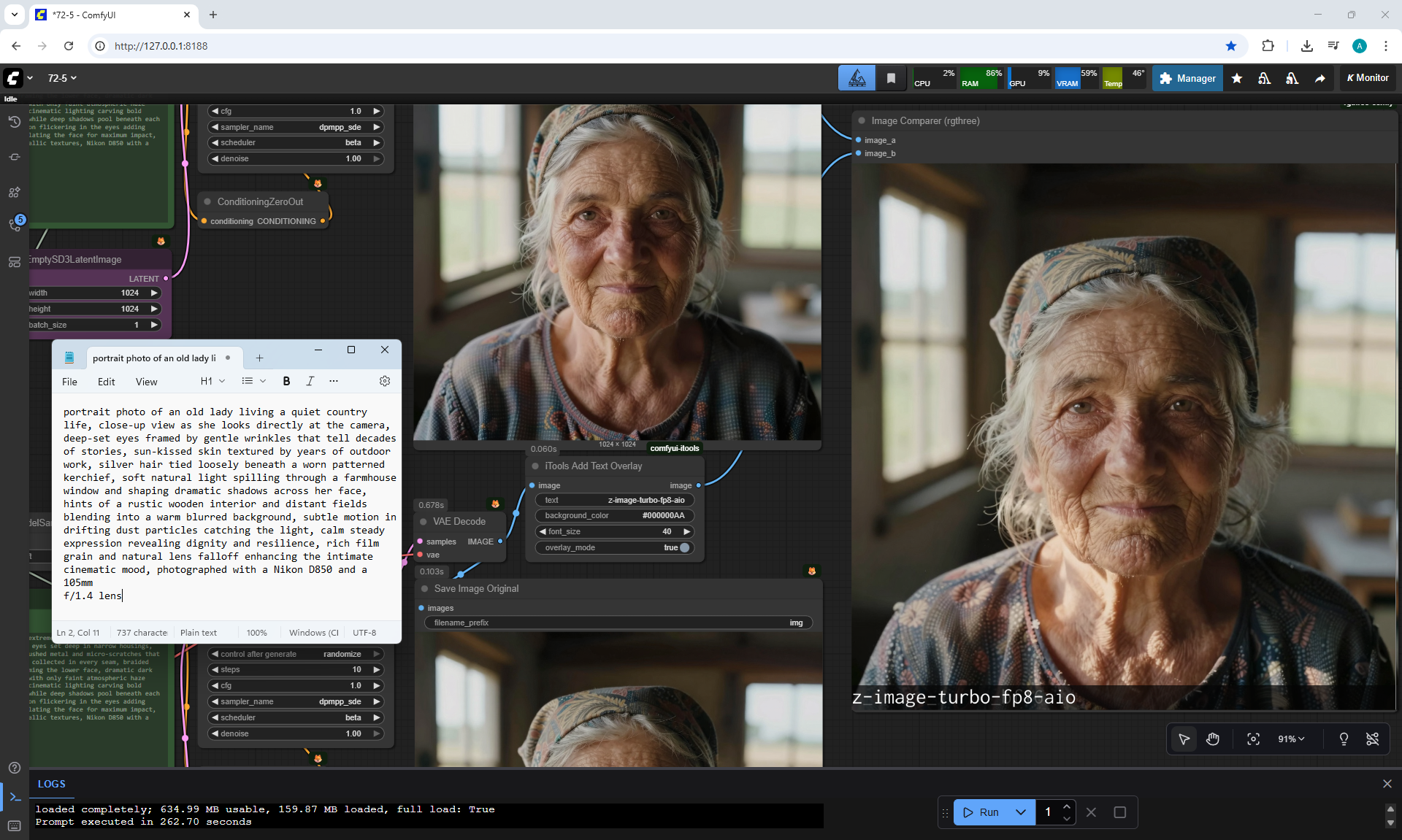
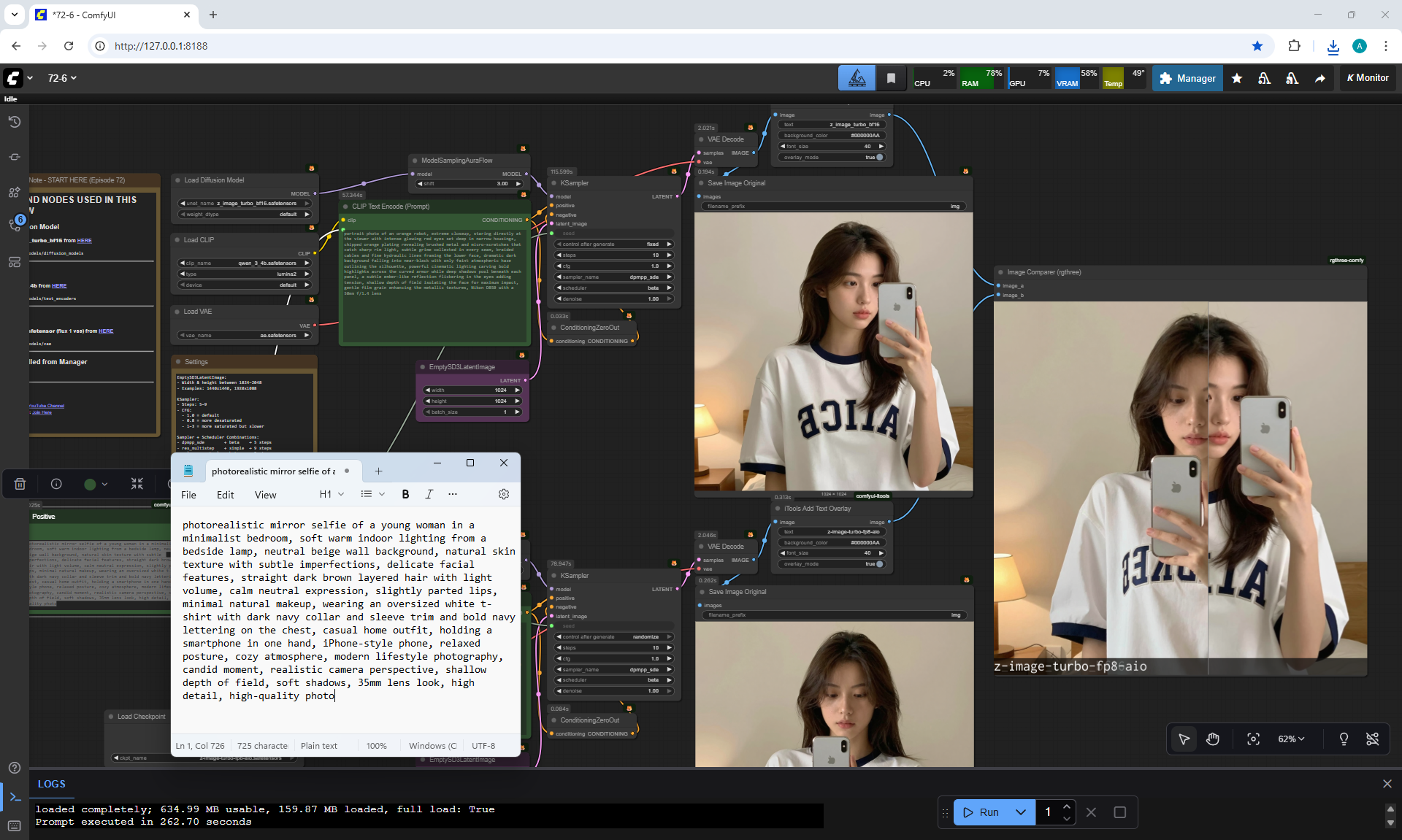
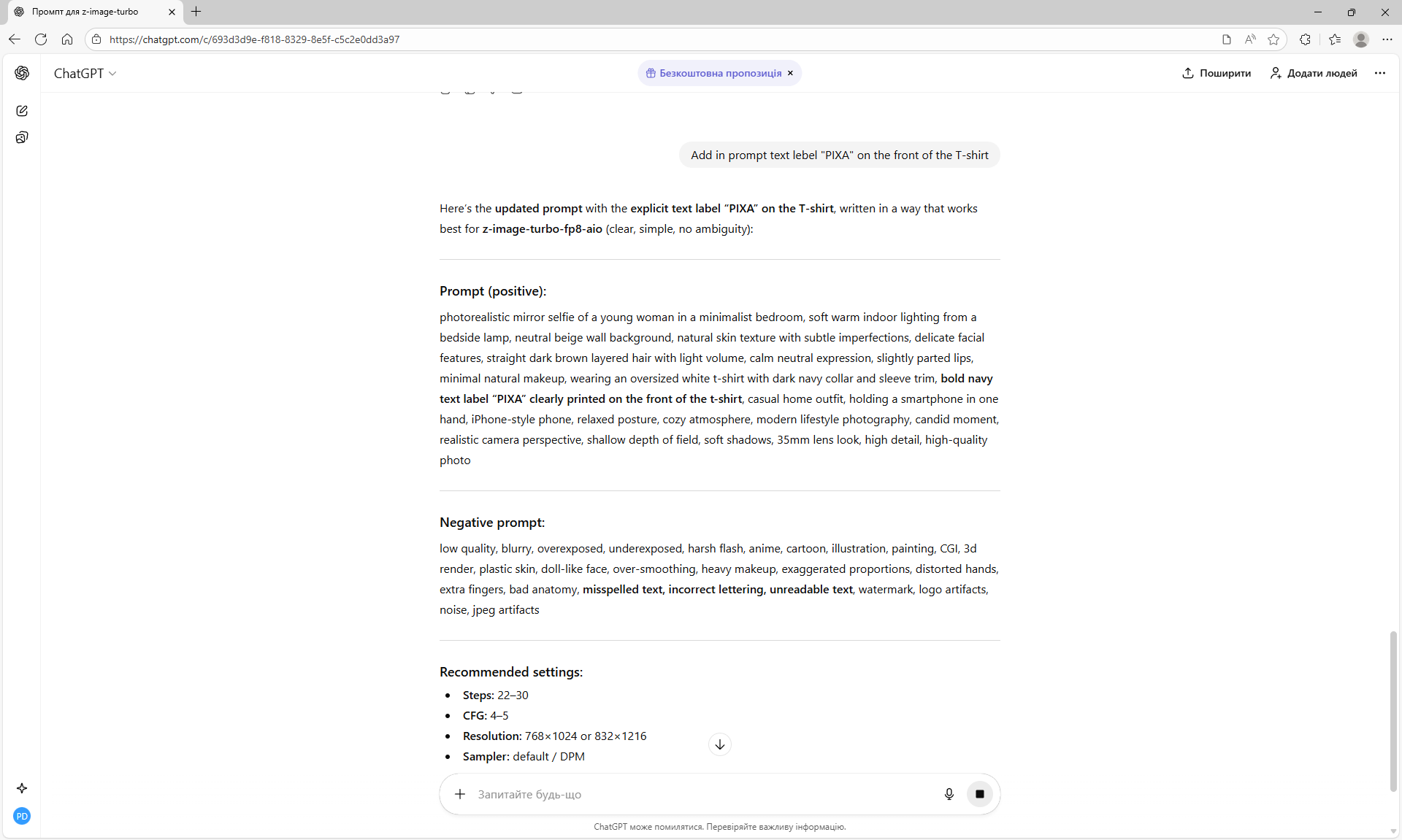
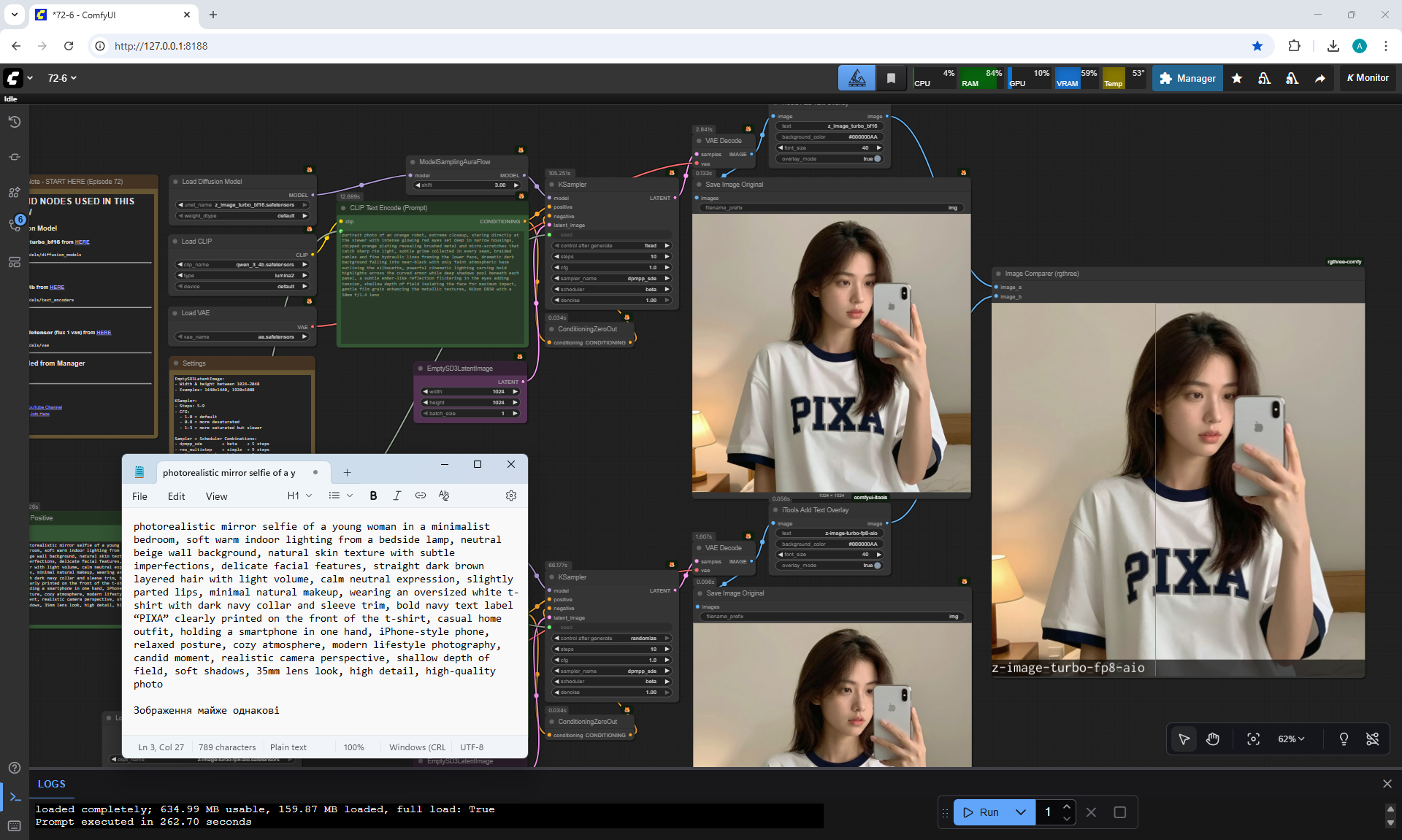
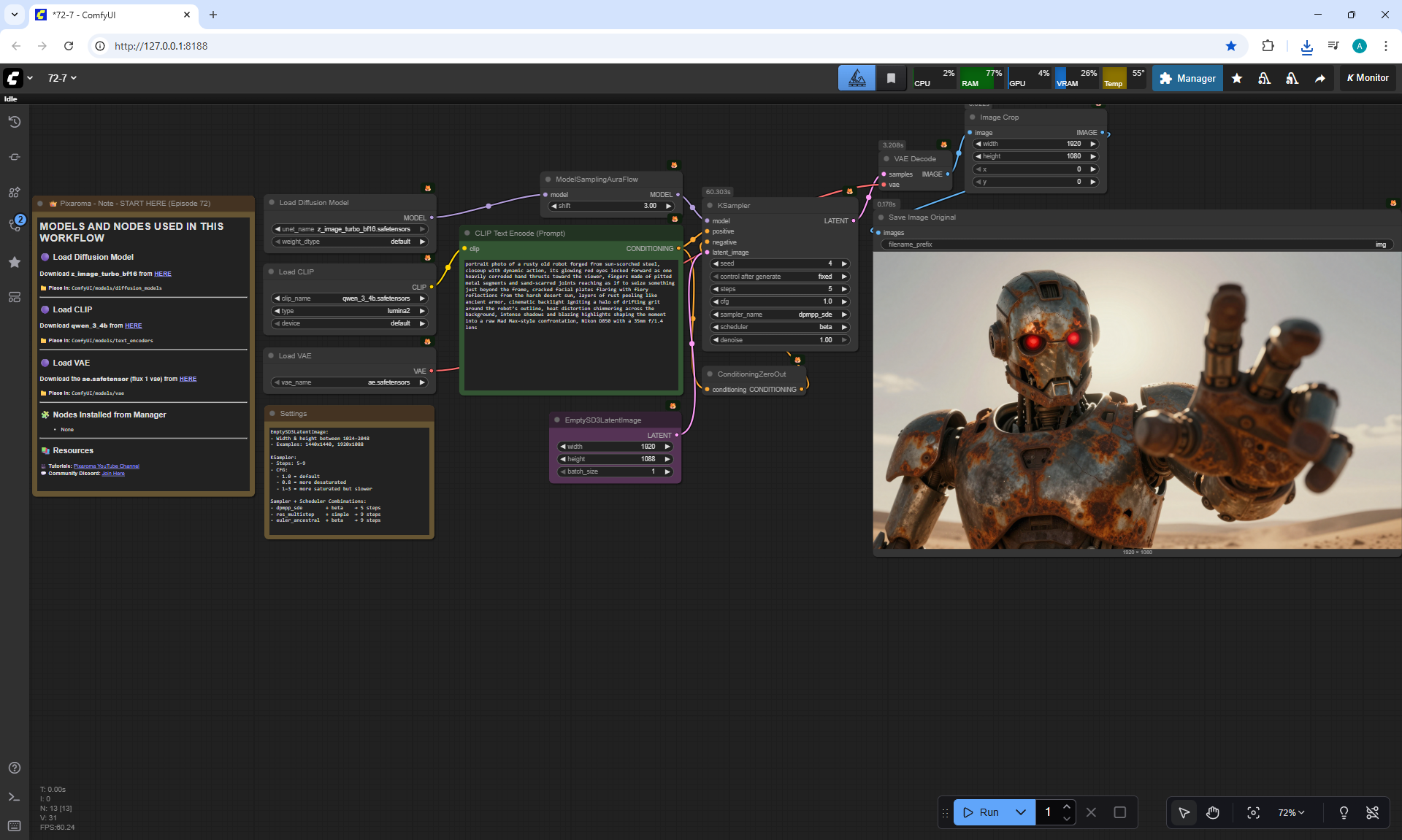
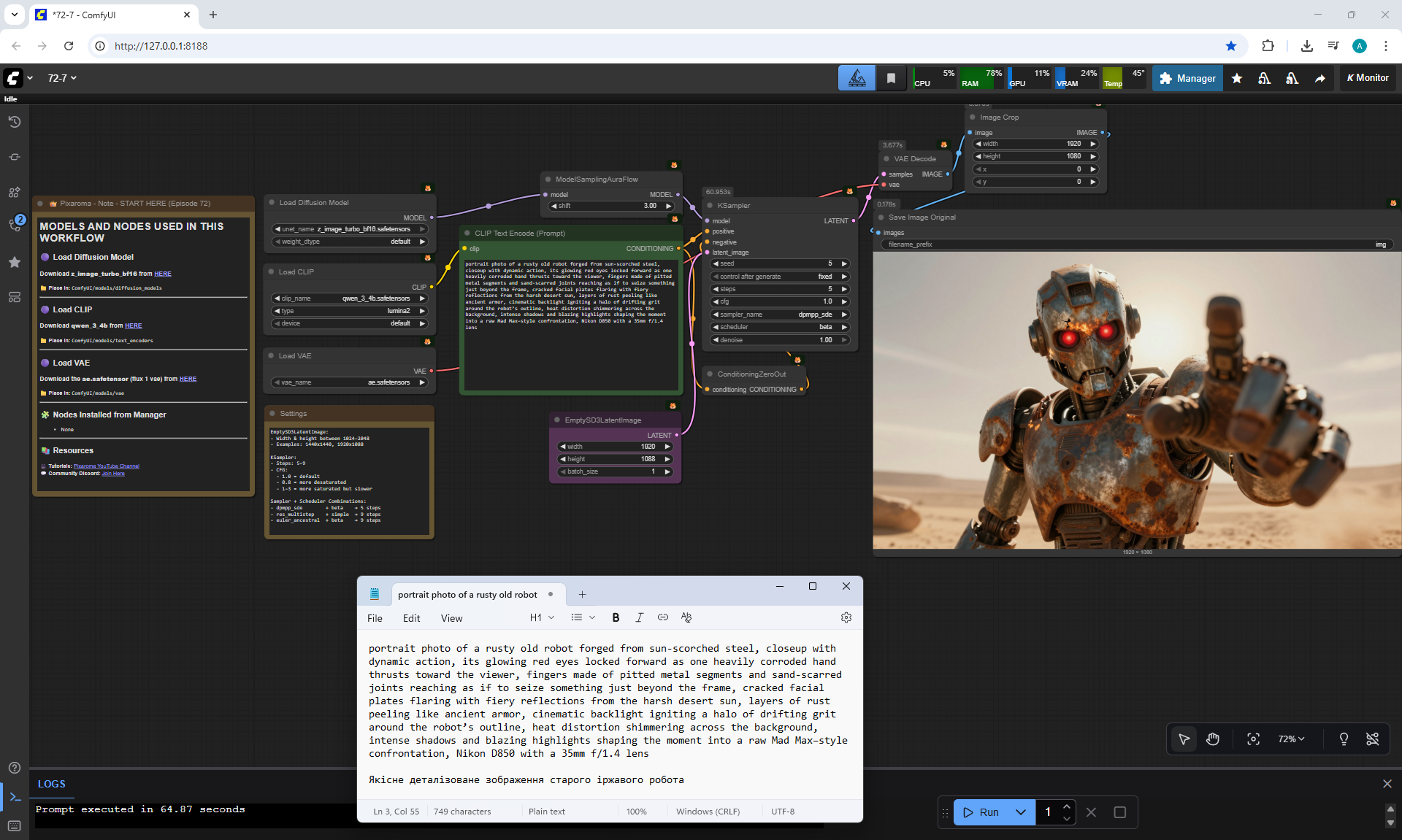
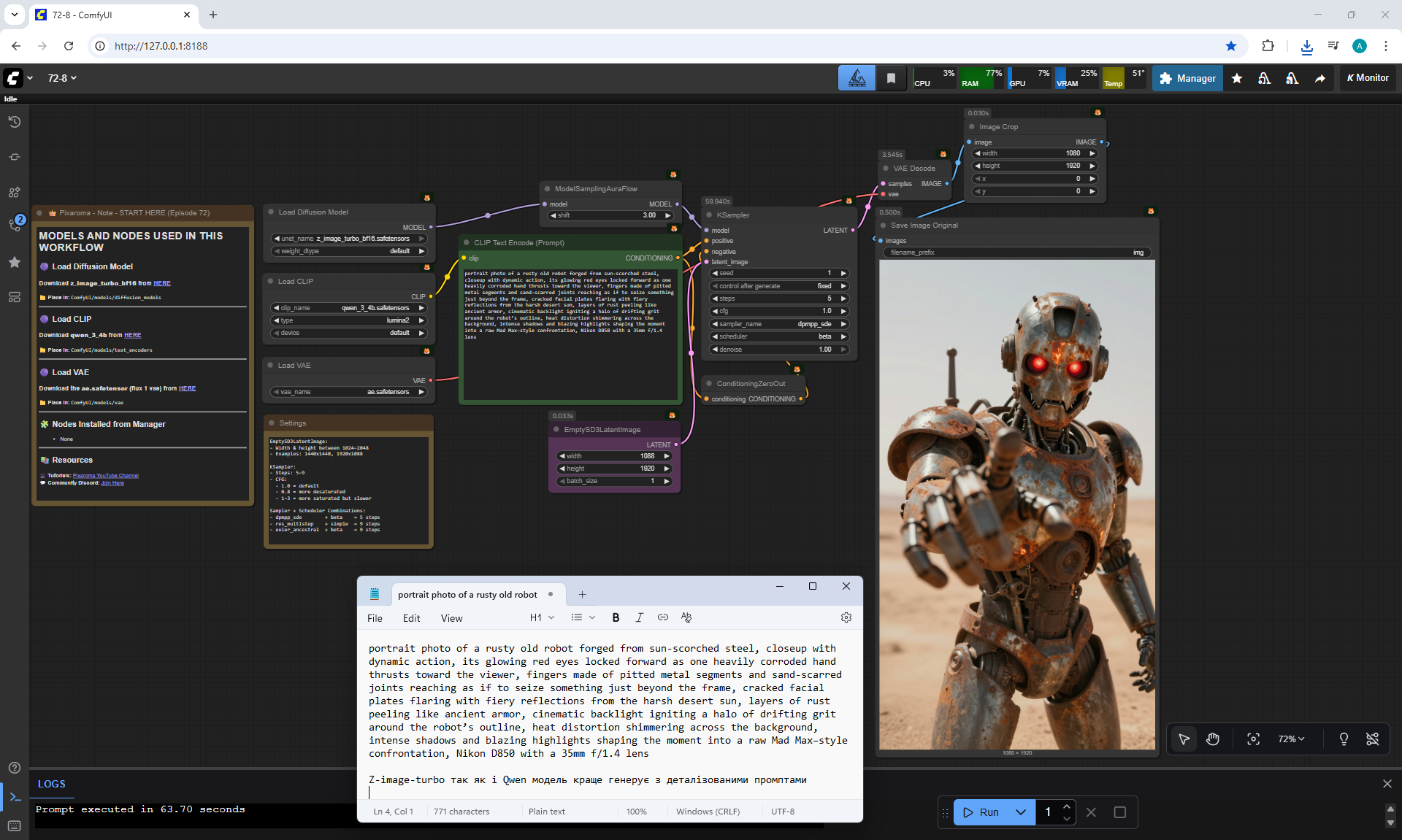
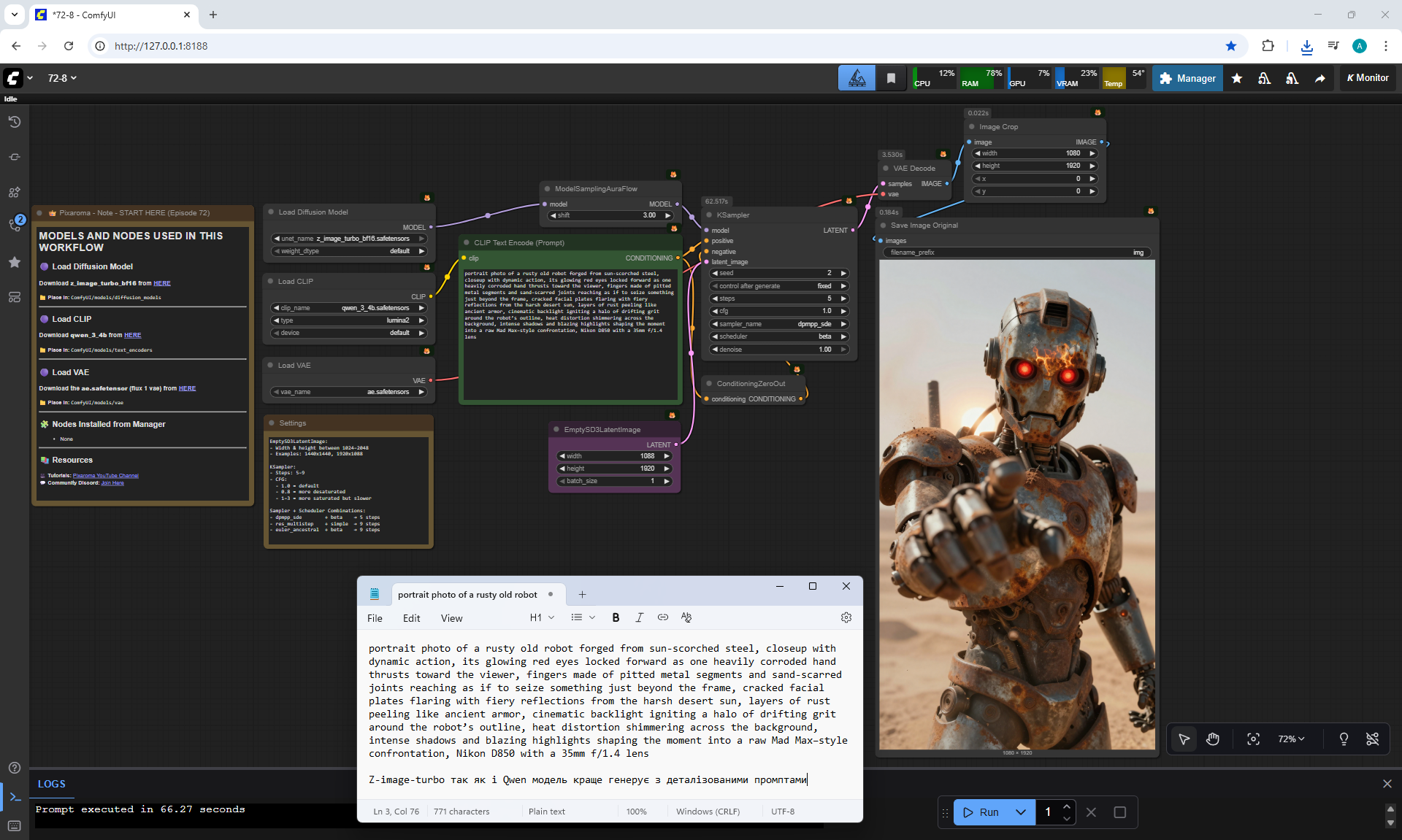
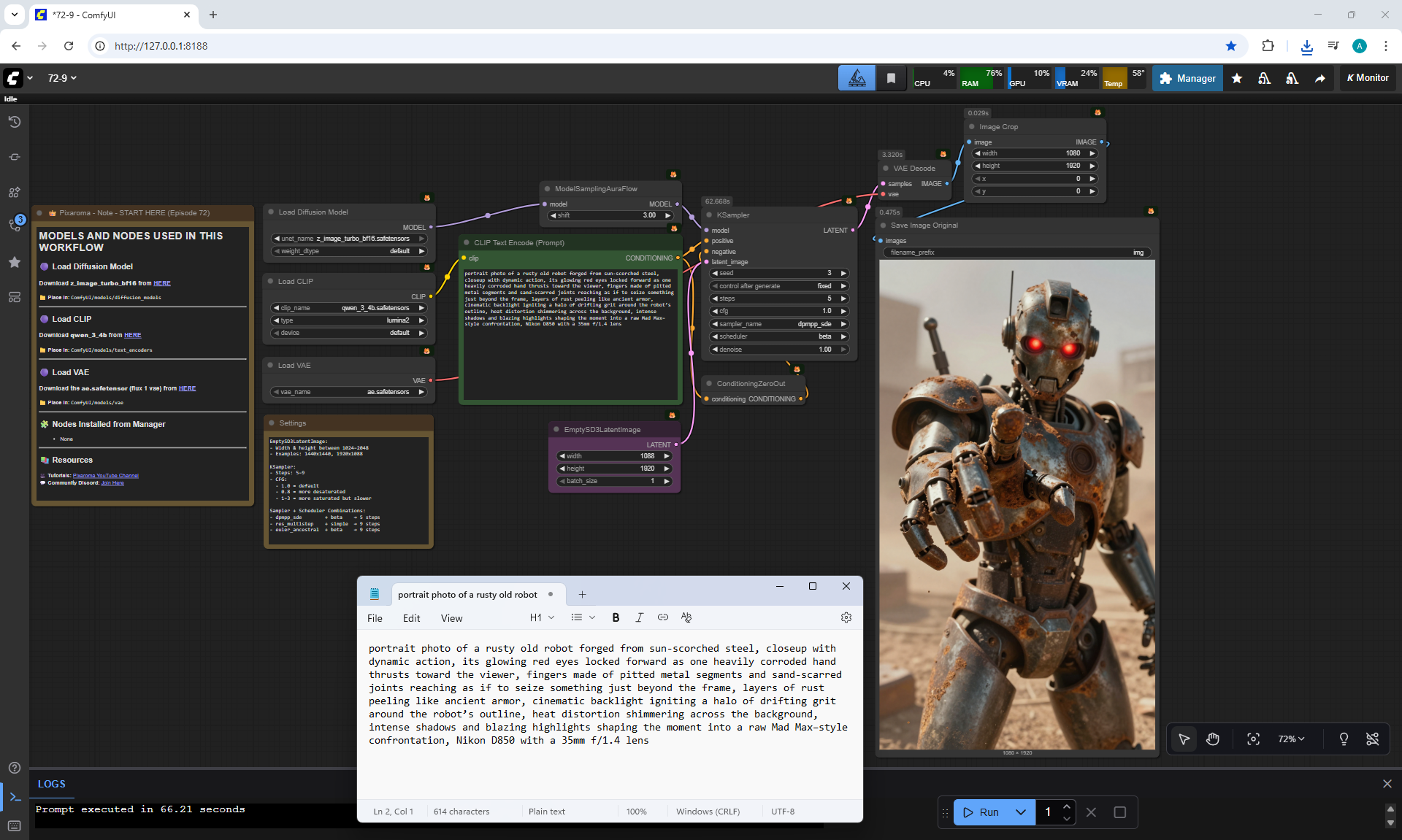
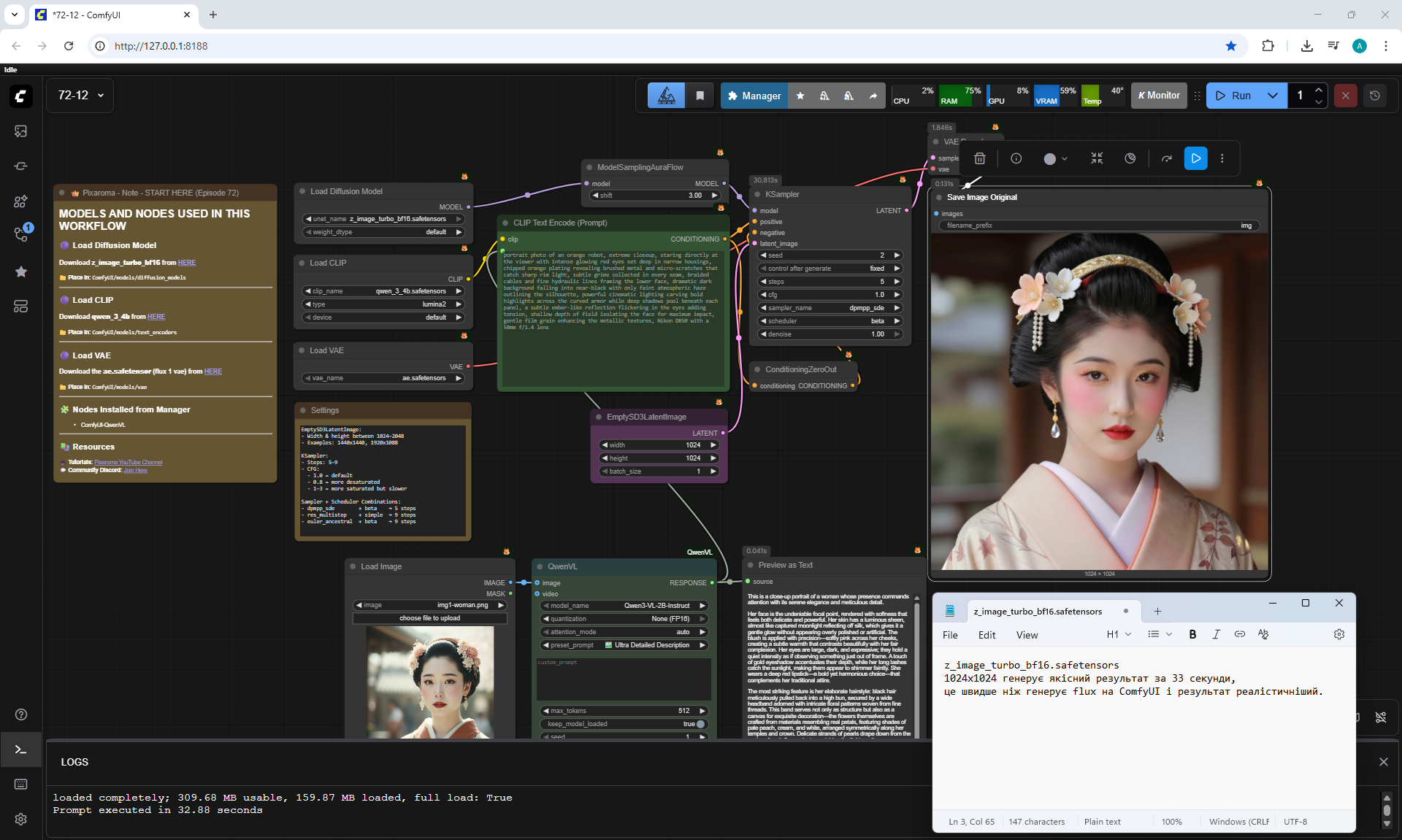
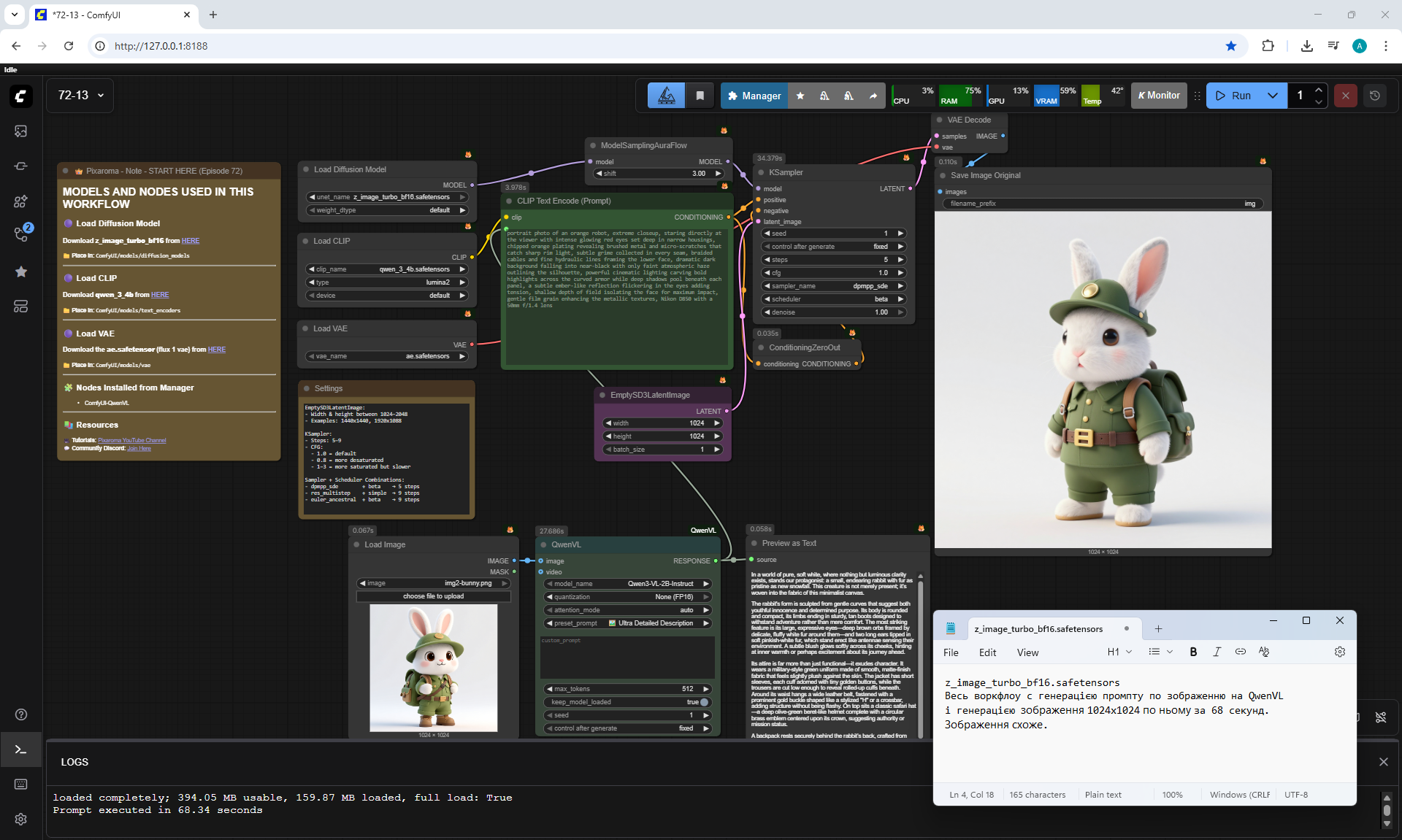
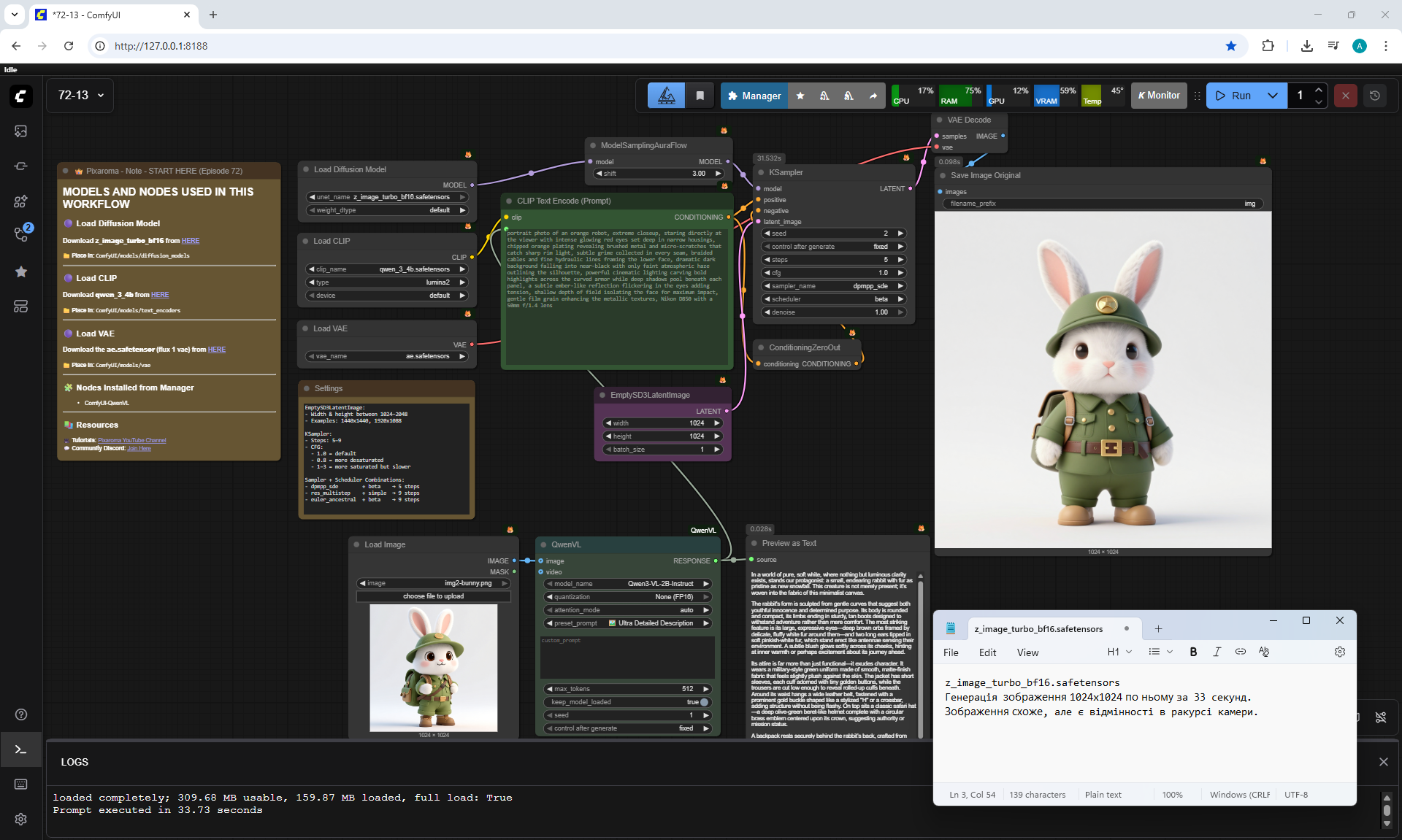
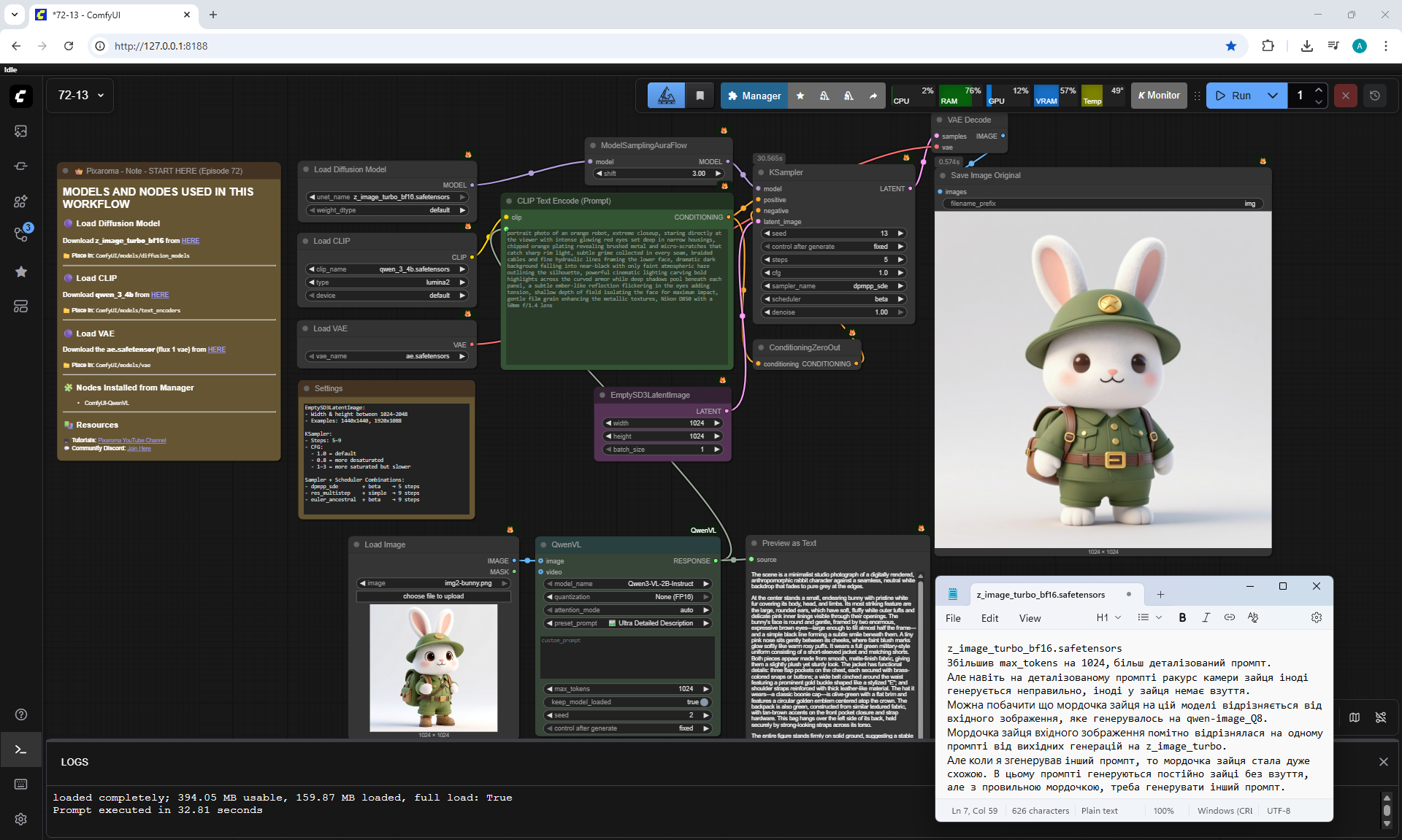
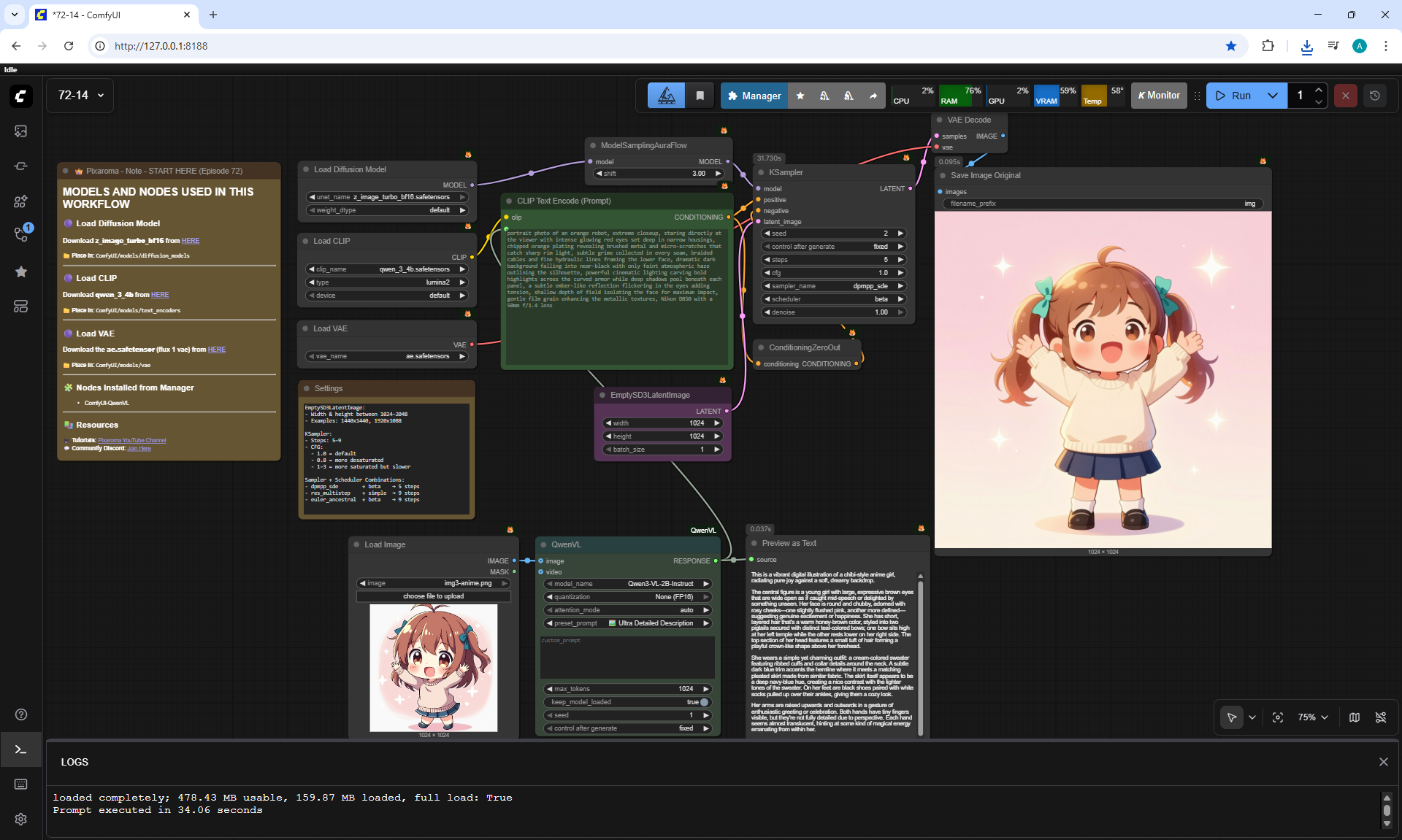

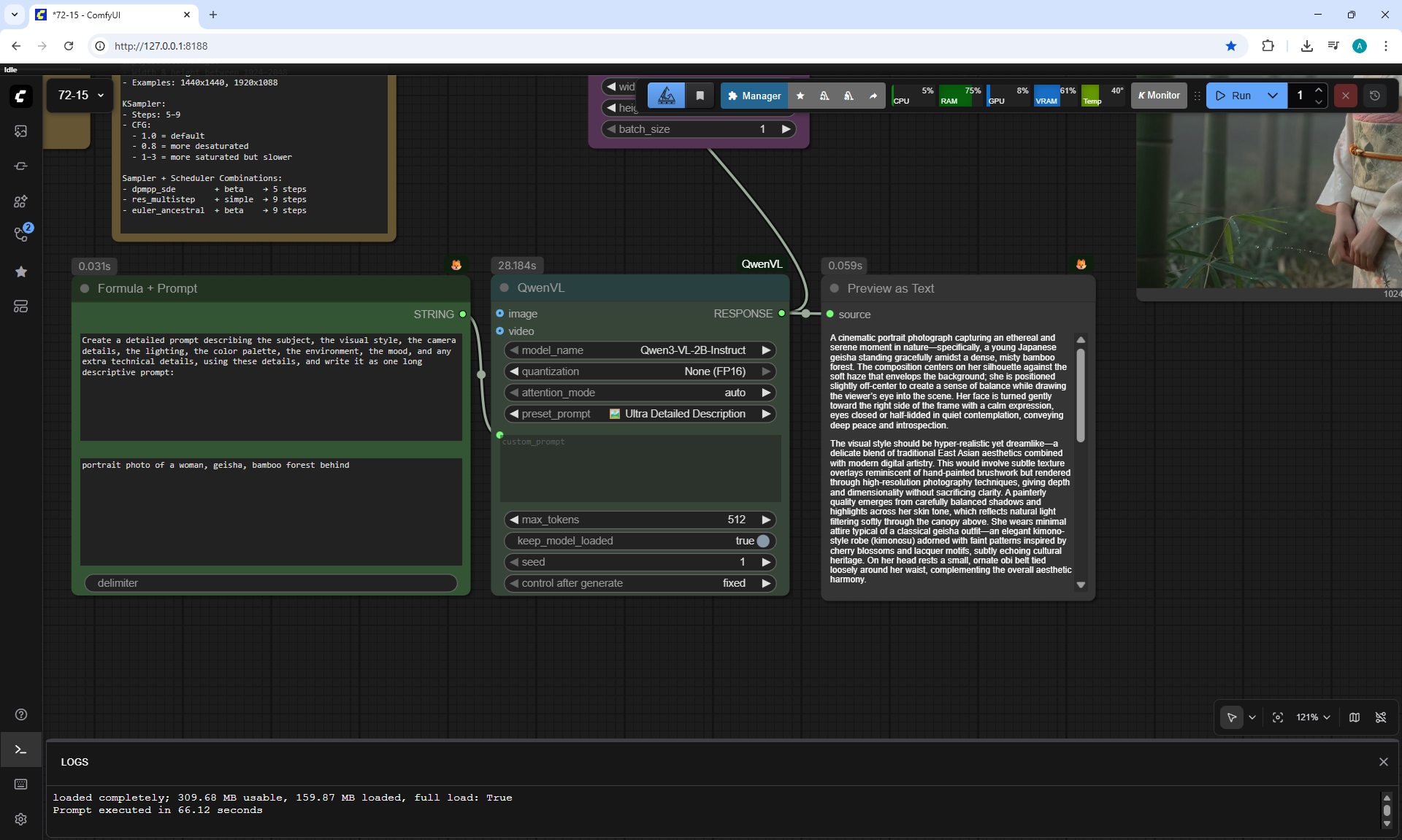
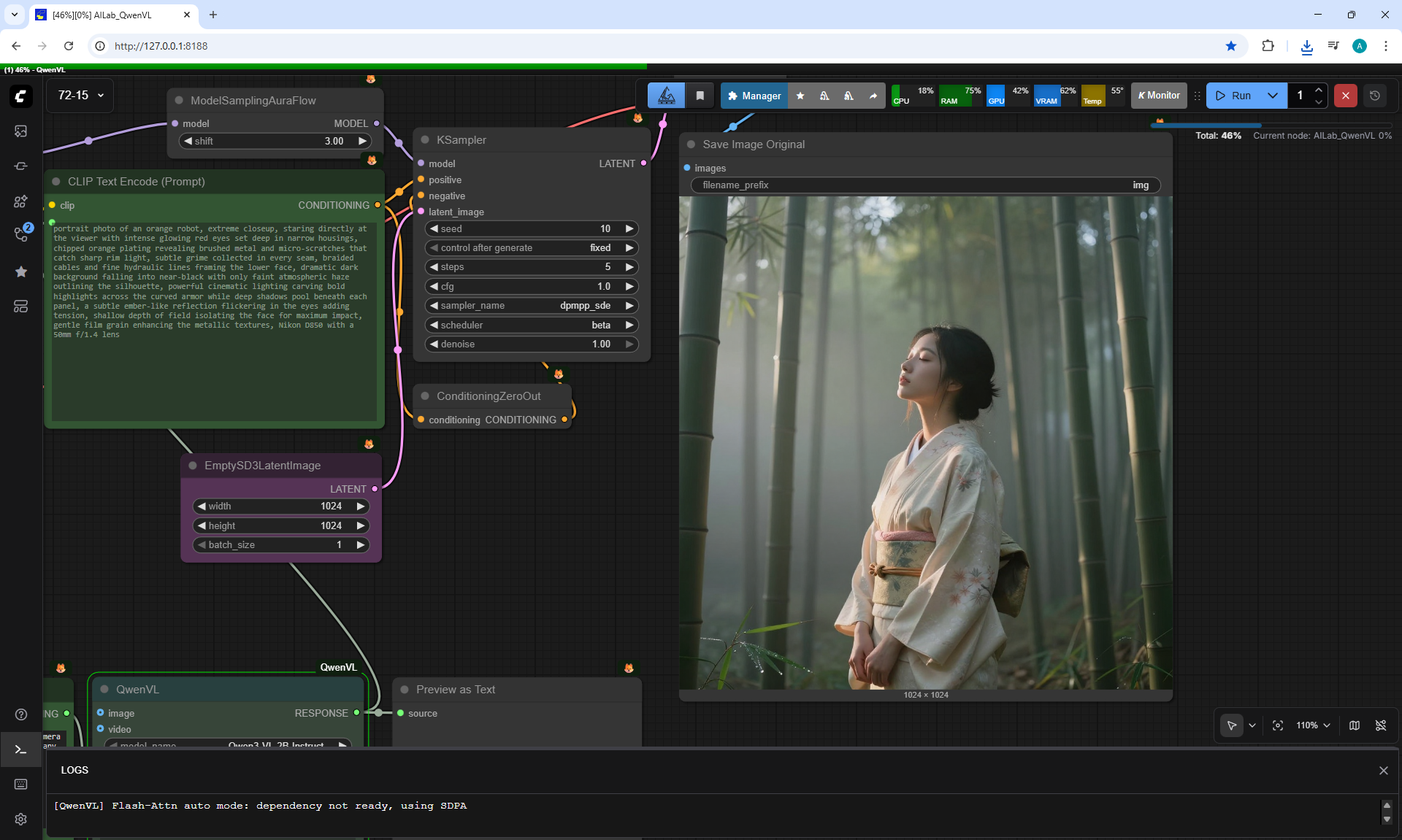
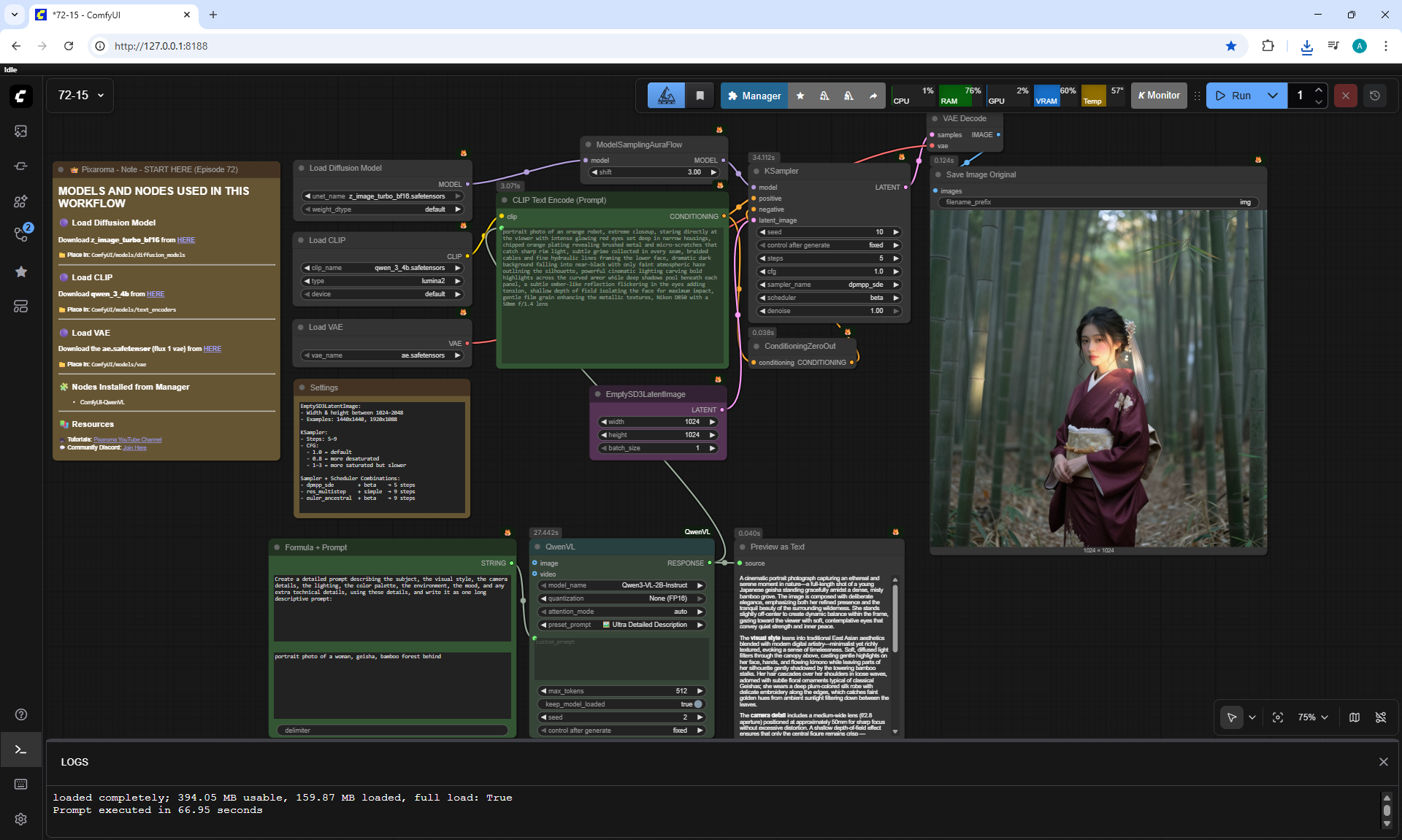
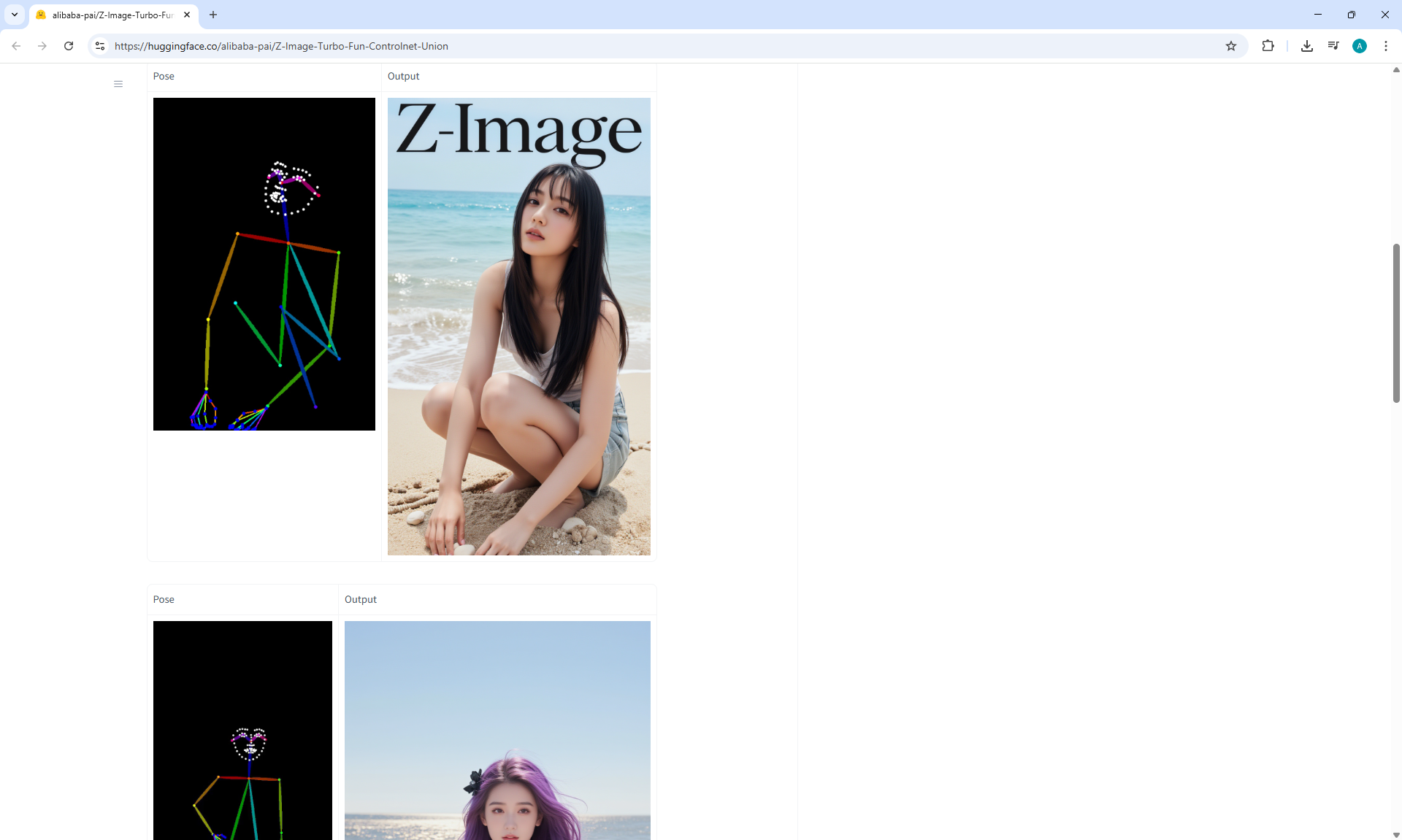
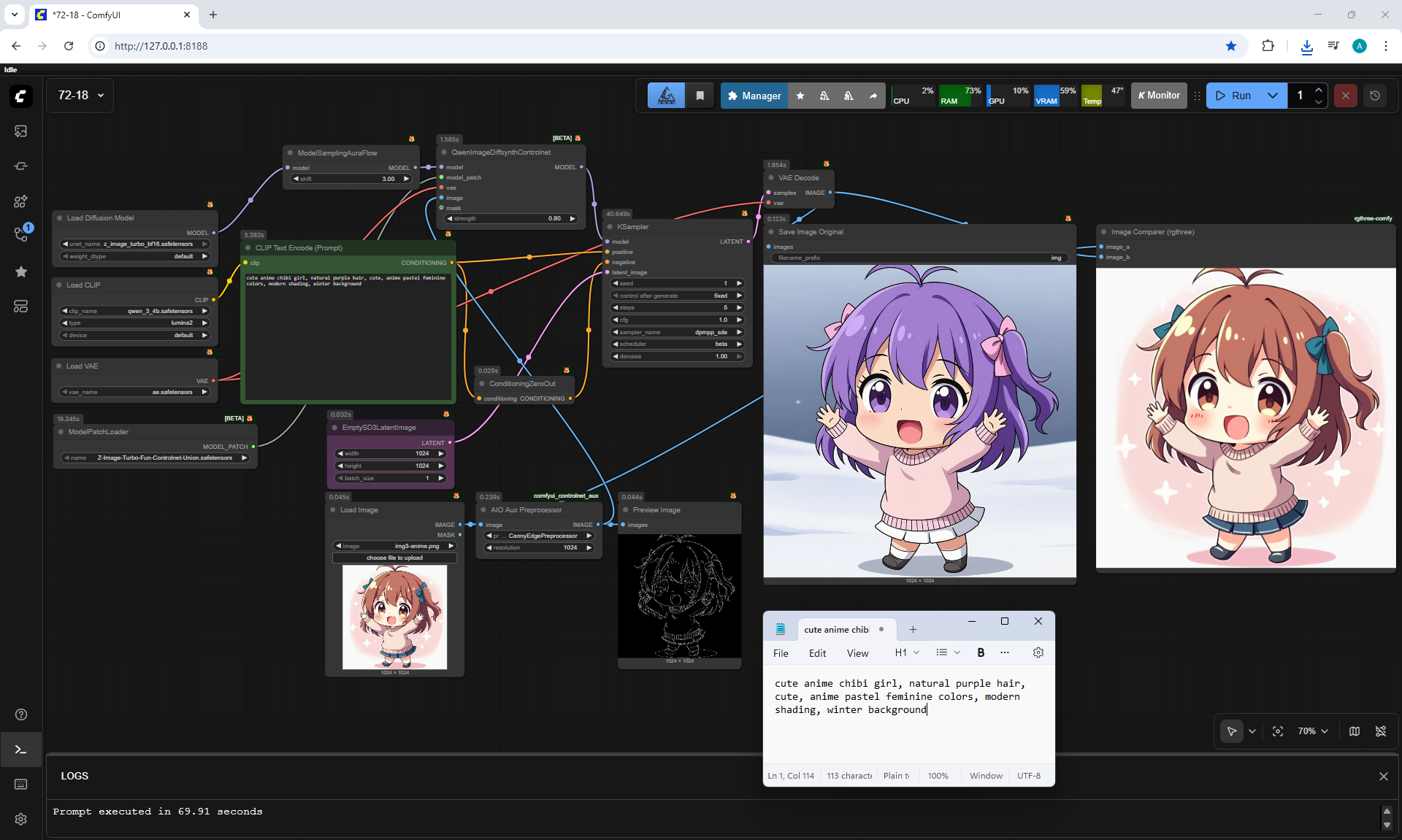
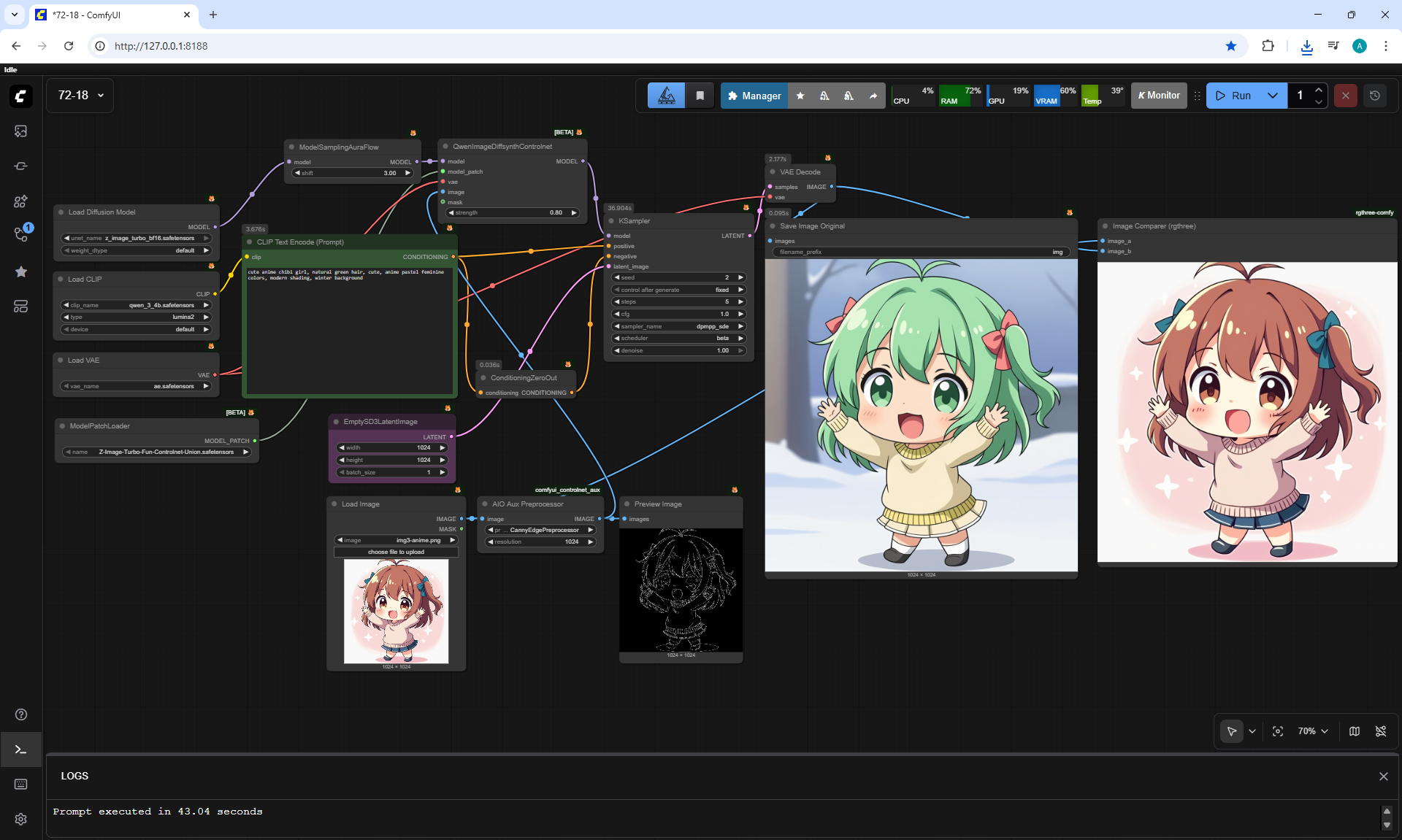
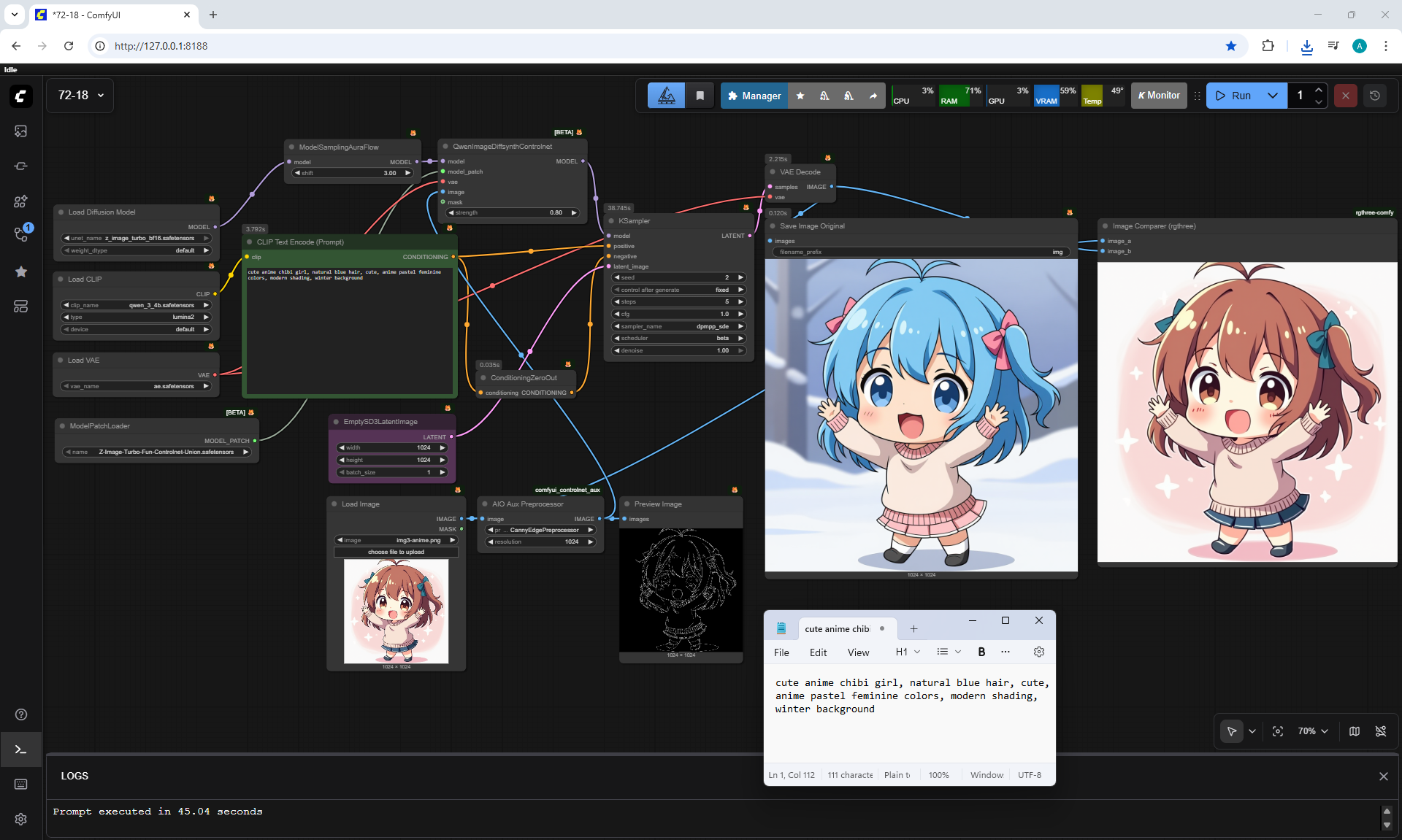
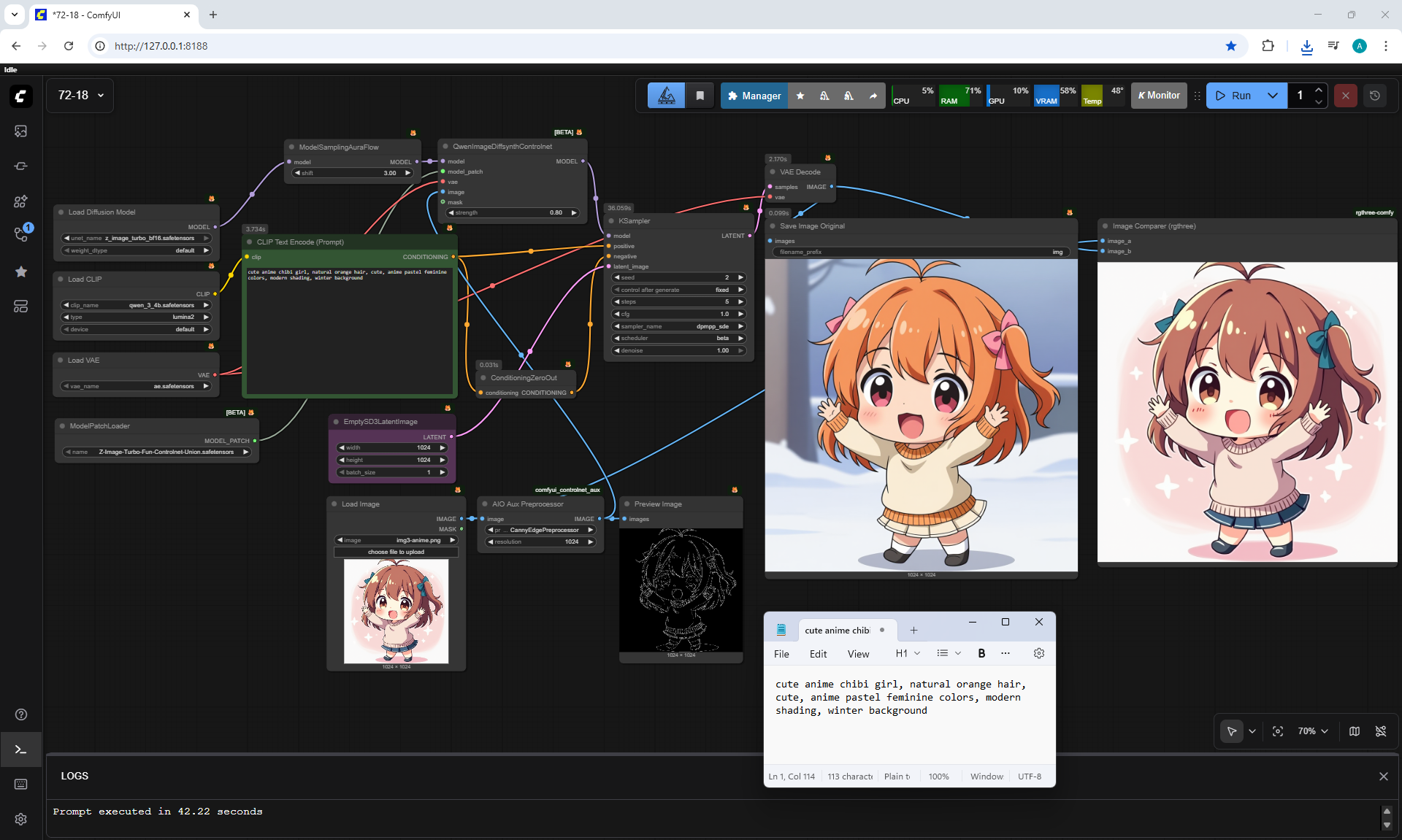
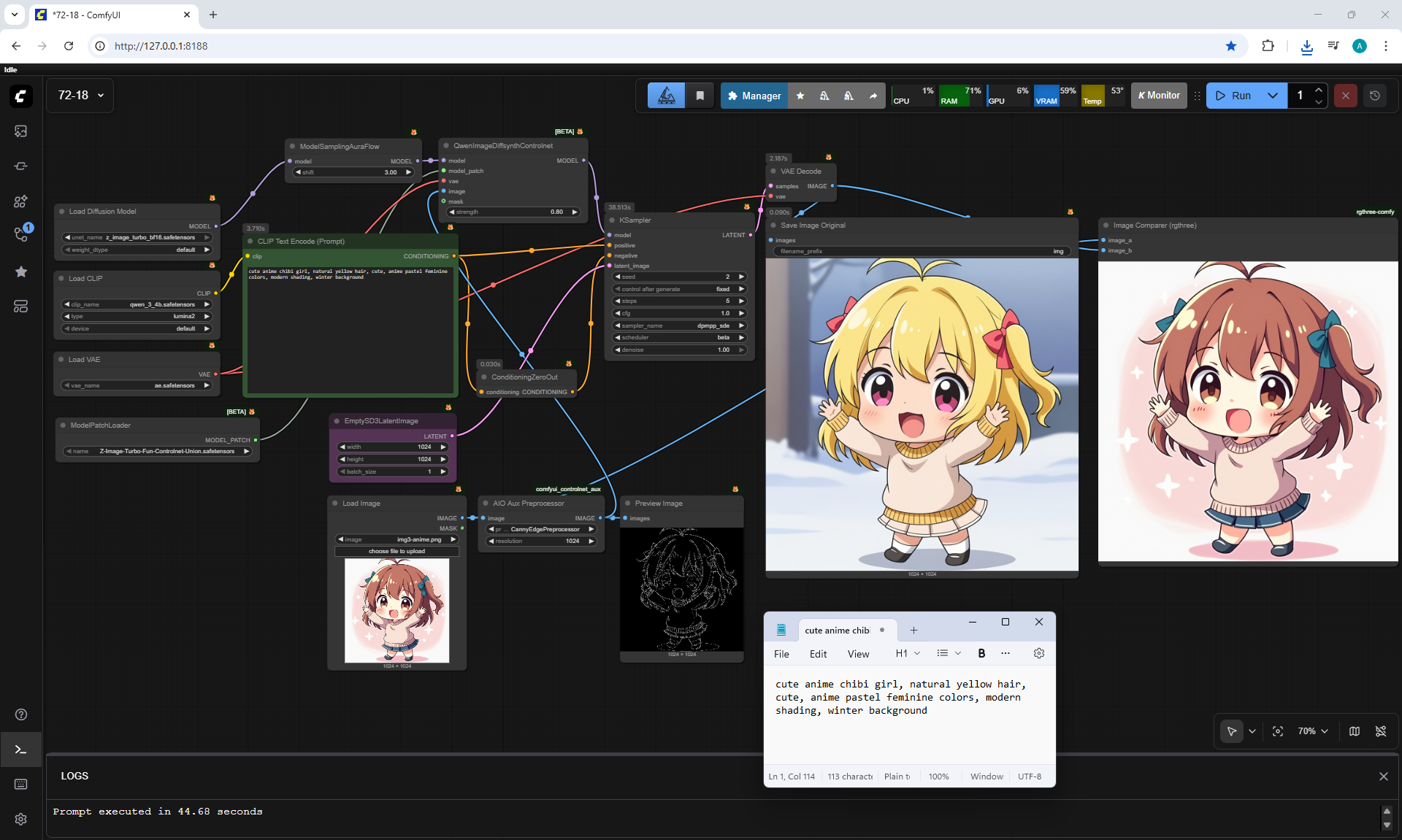
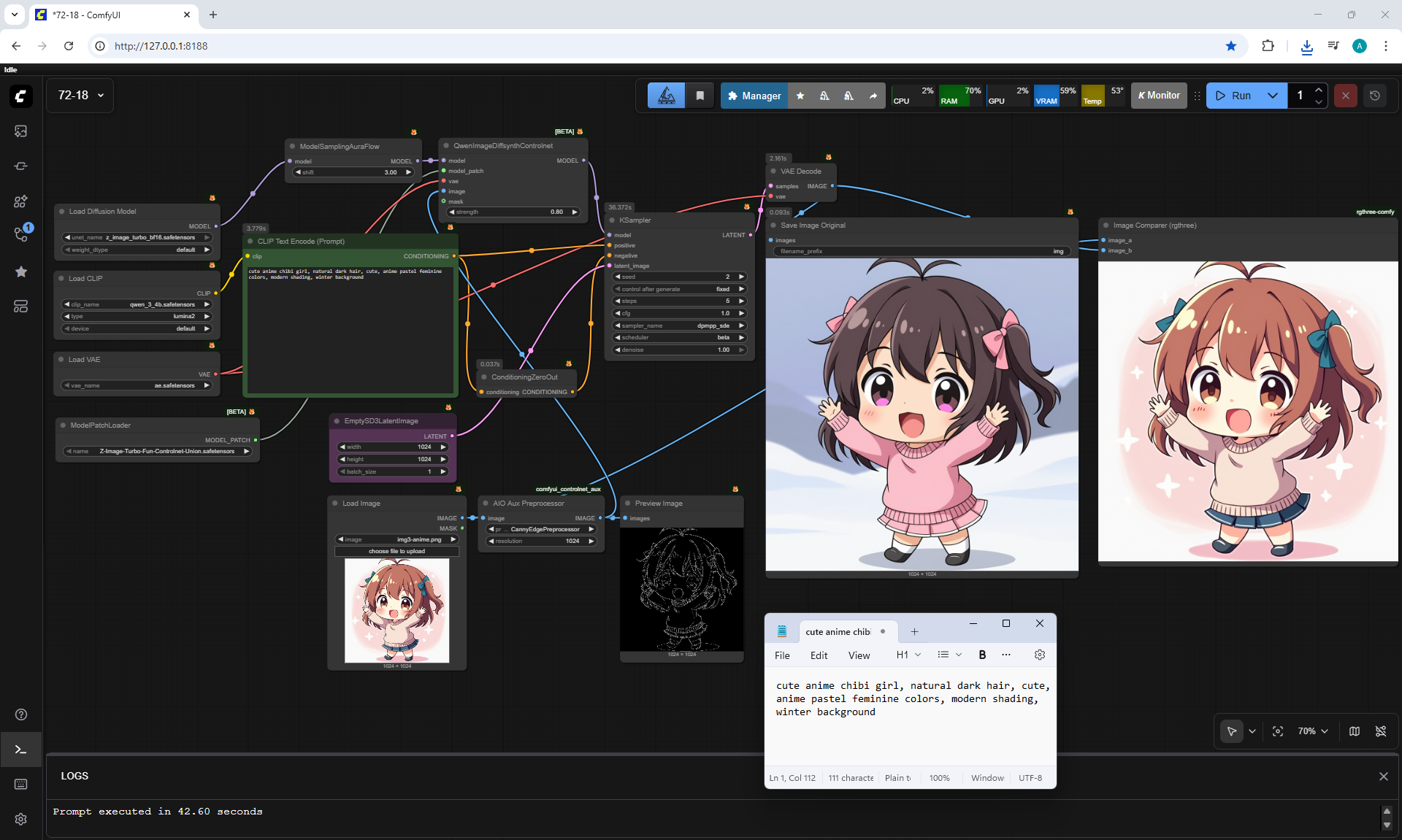
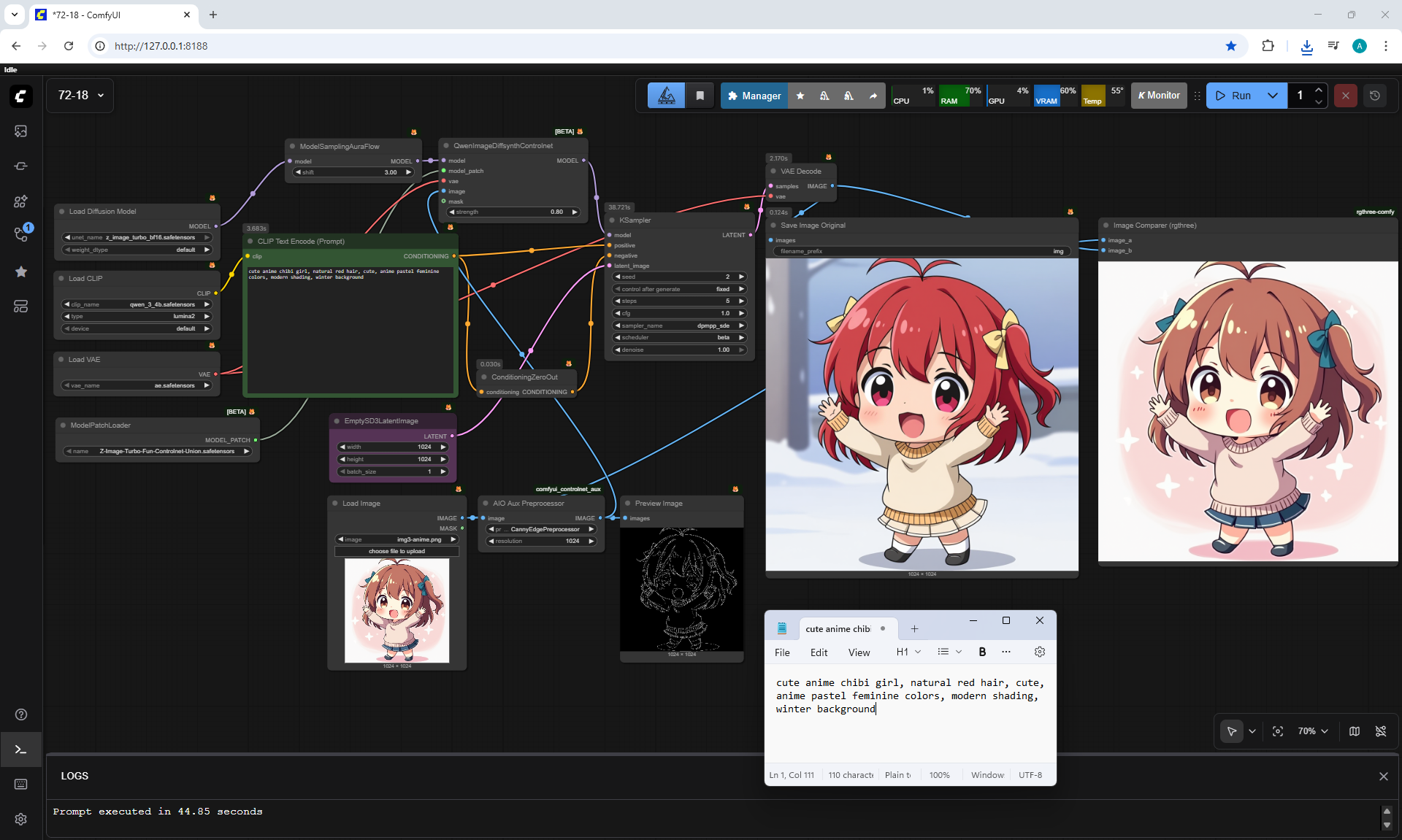
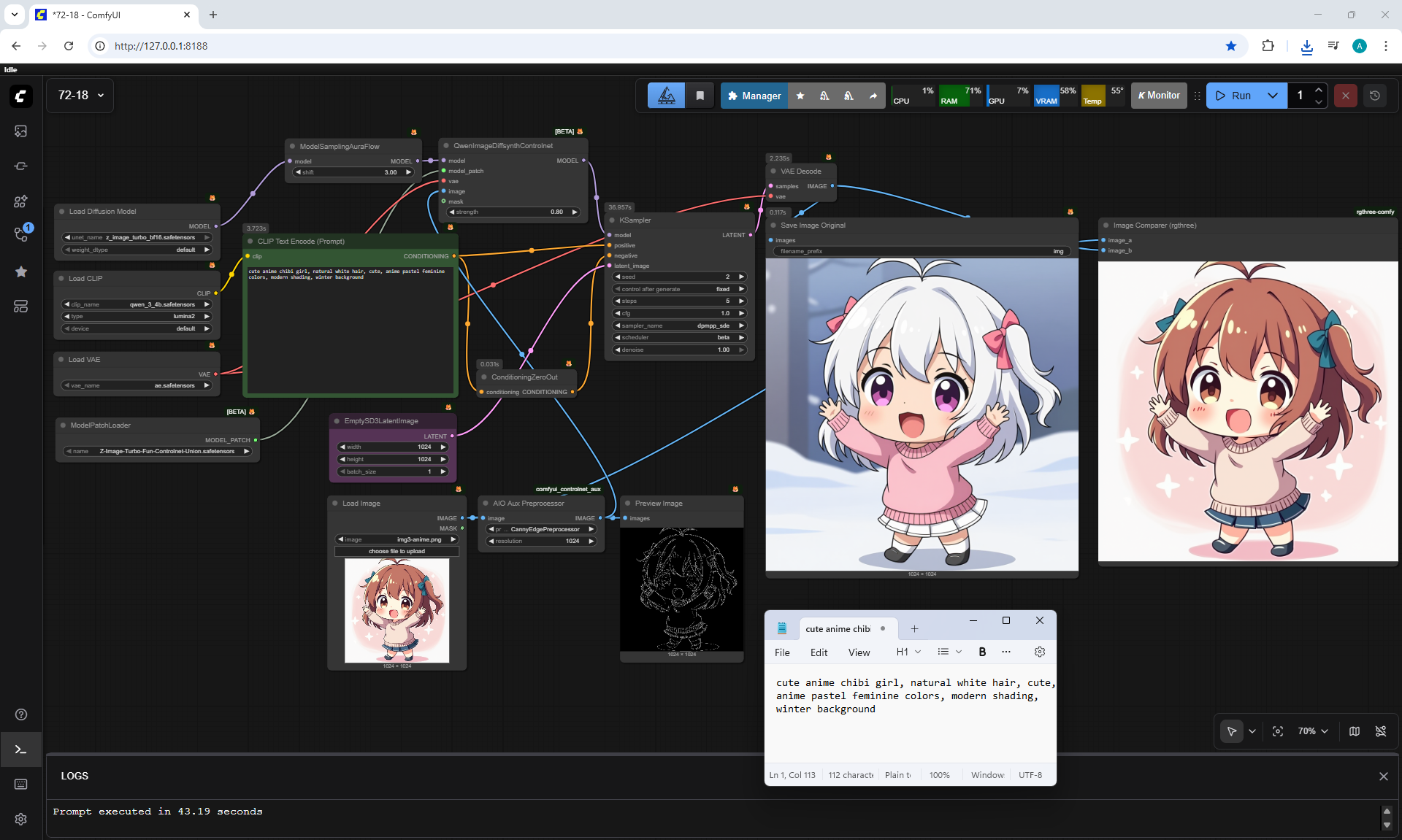
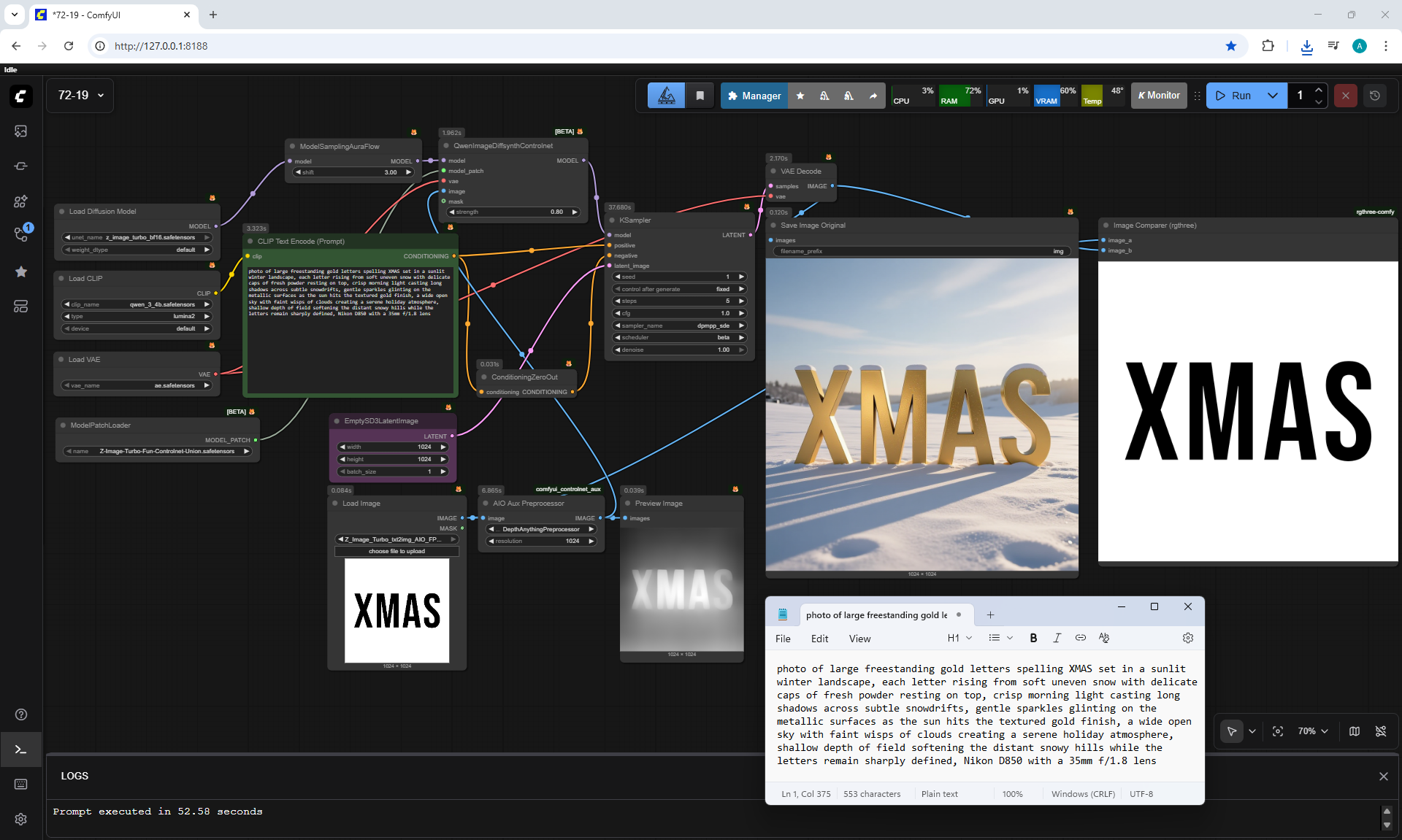
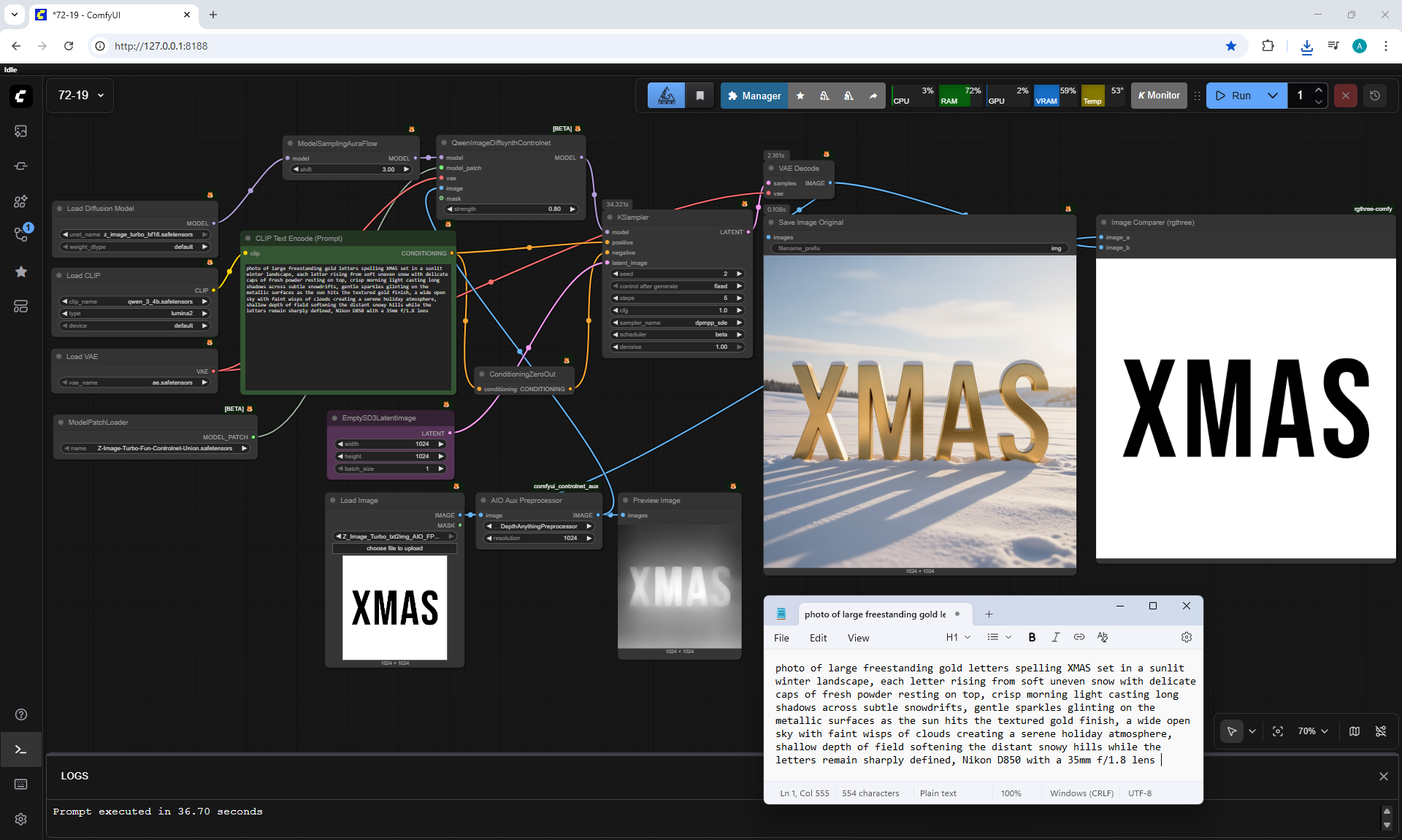
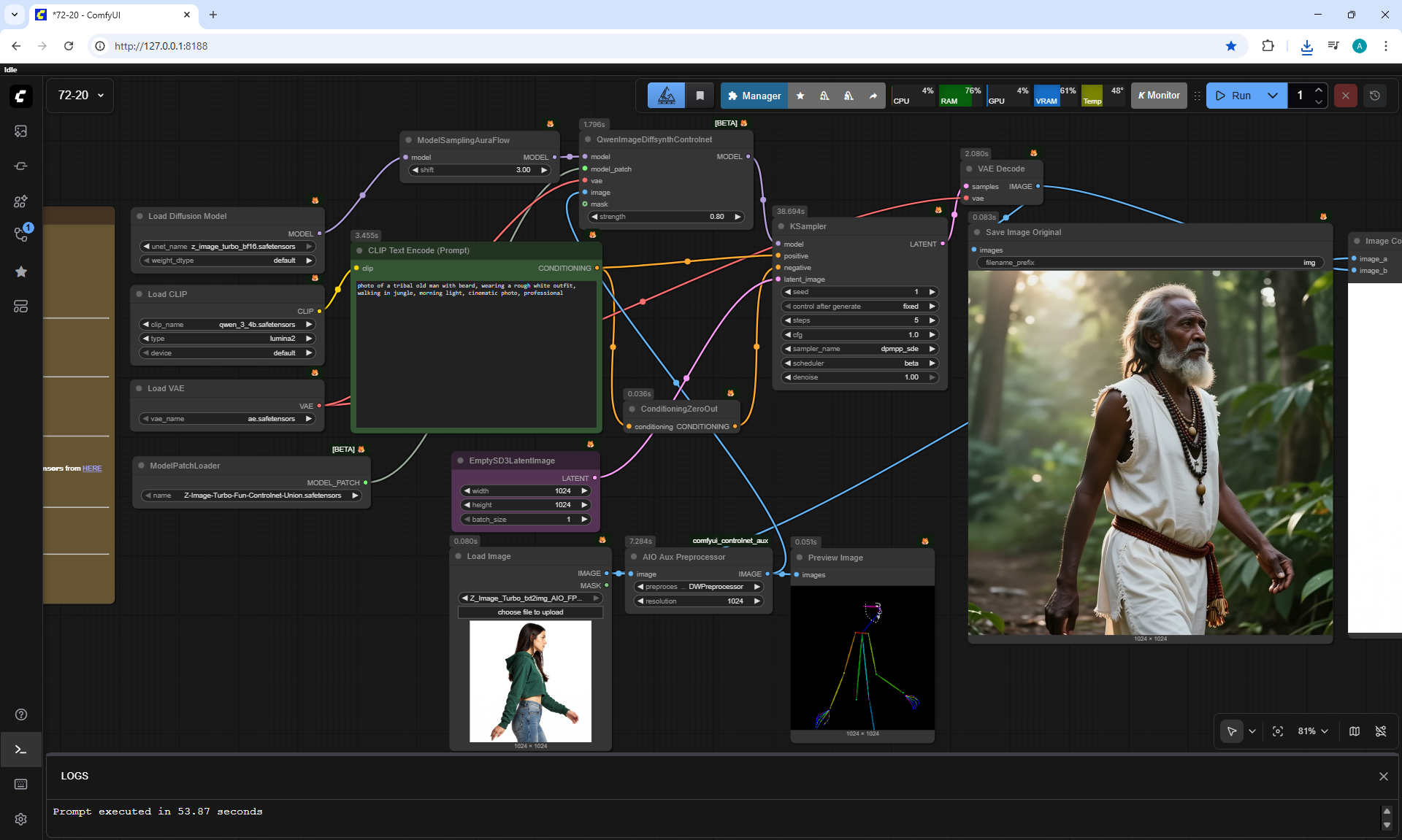
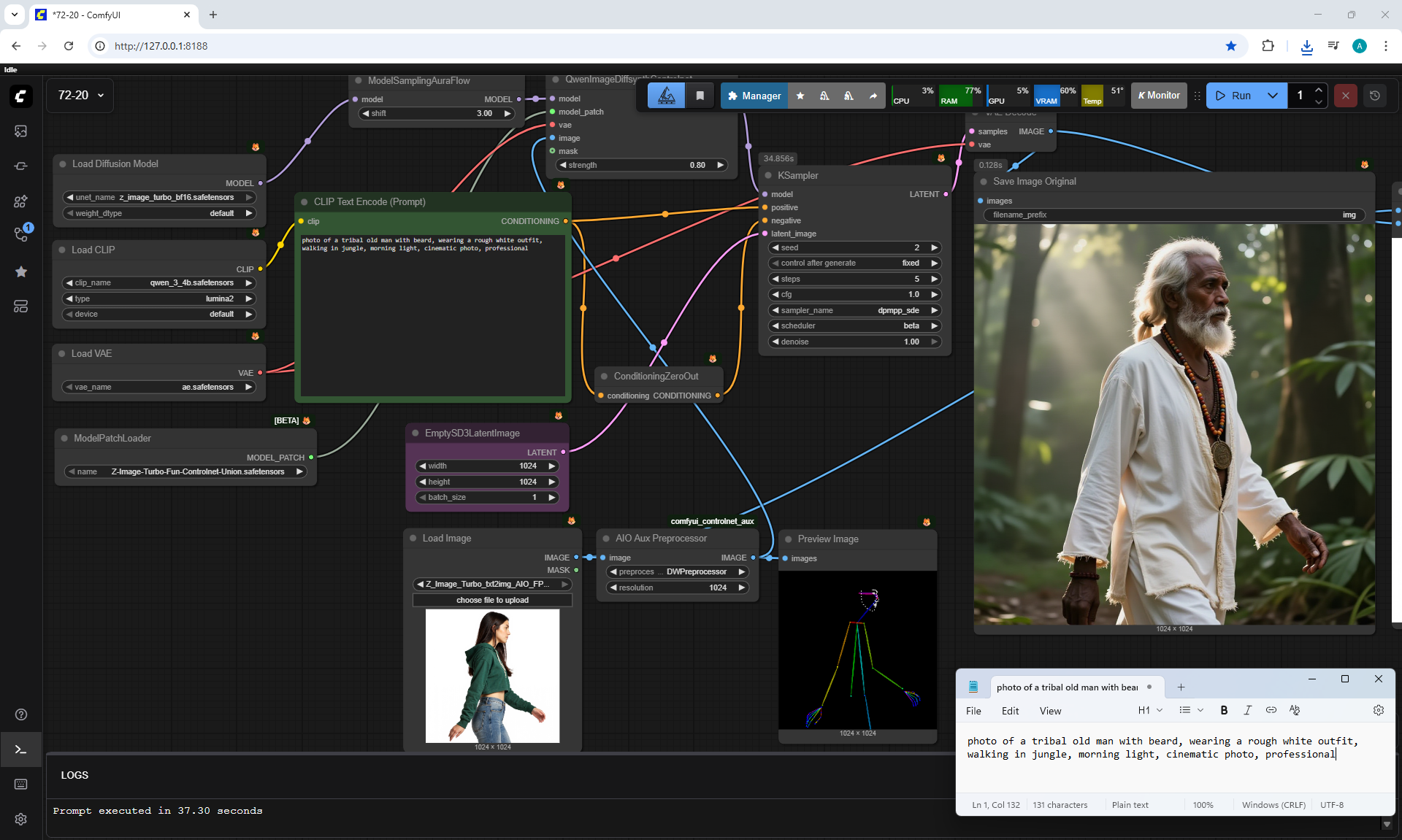
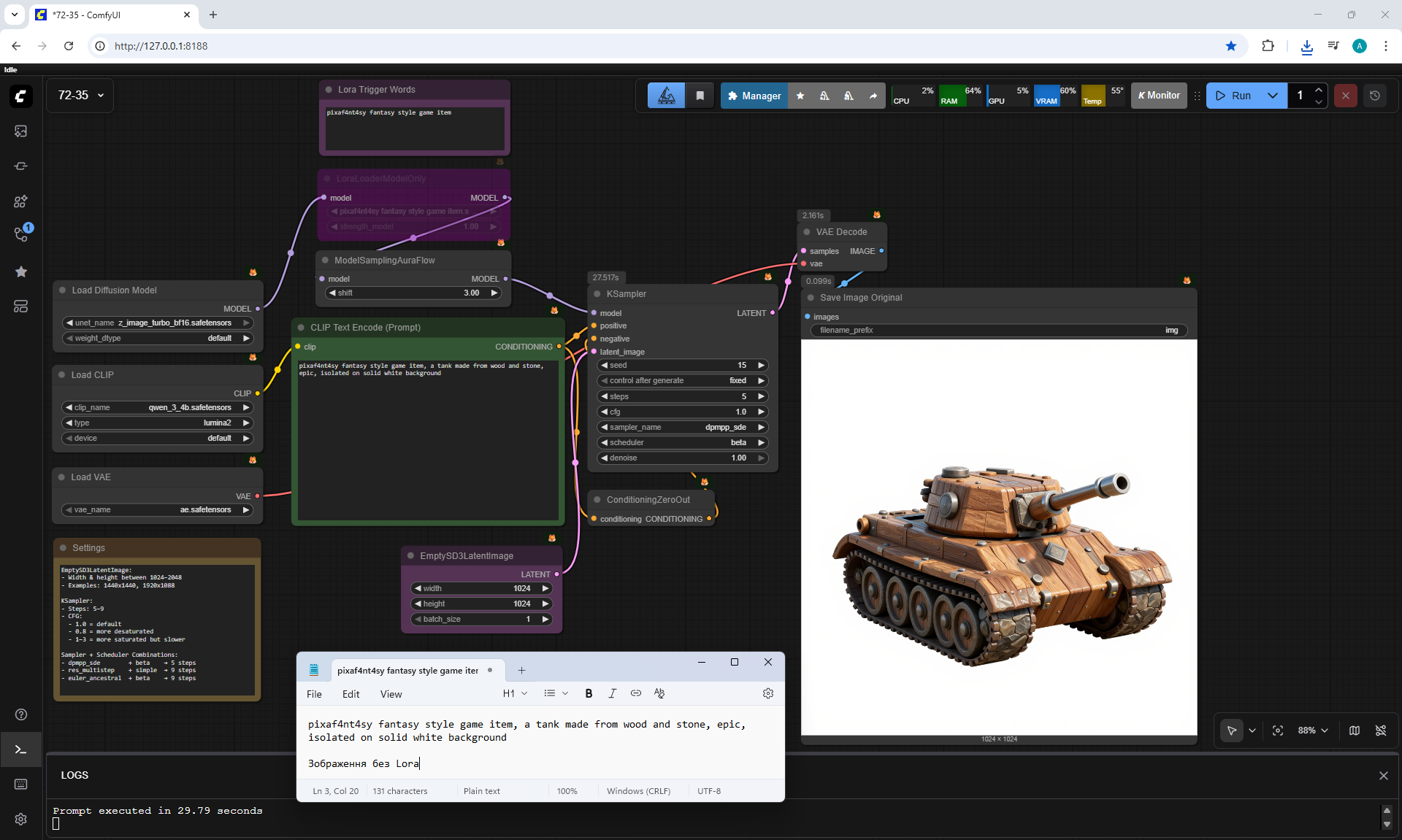
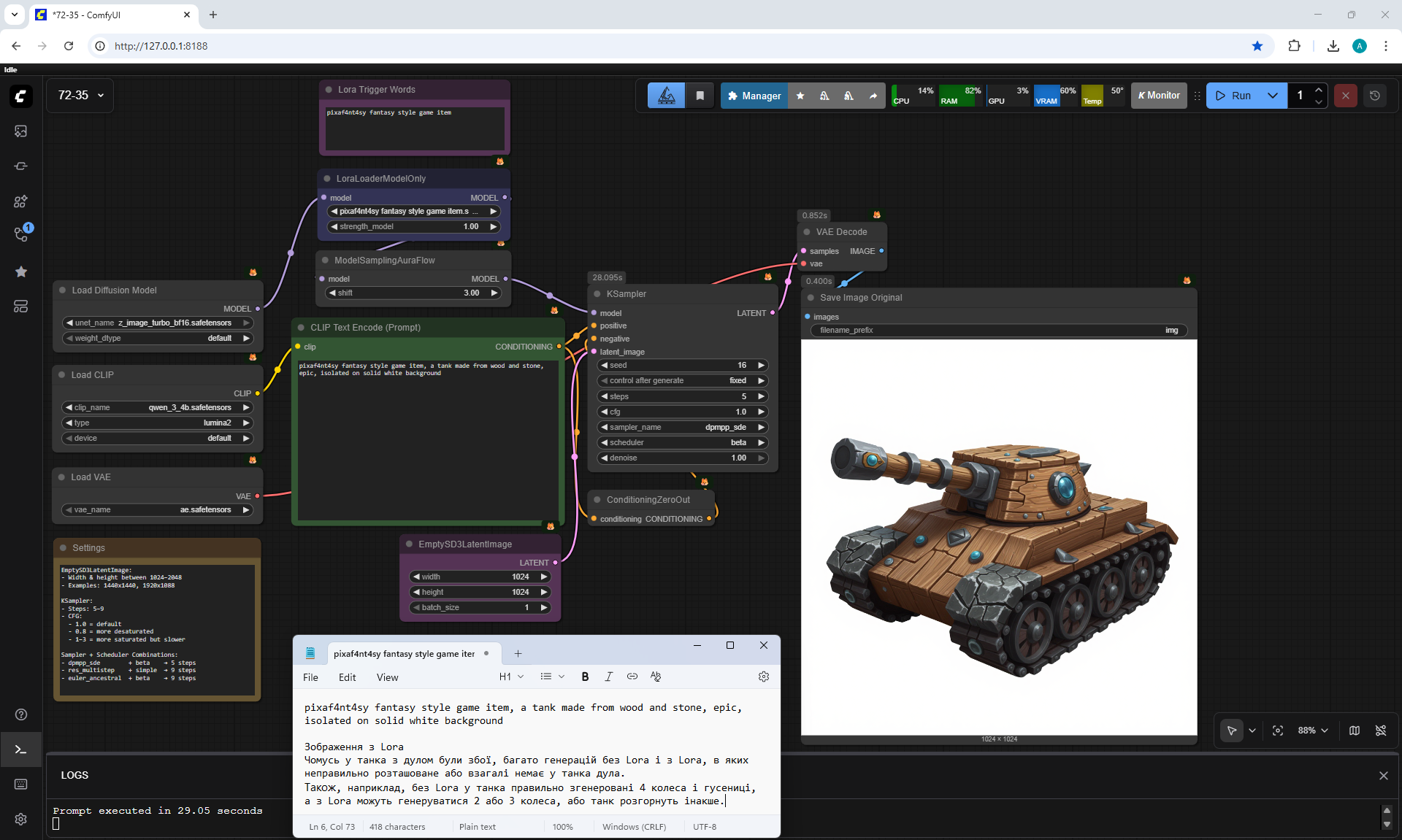
ComfyUI Tutorial Series Ep 73: Final Episode & Z-Image ControlNet 2.0