ComfyUI Tutorial Series 31-40
I learned ComfyUI from these tutorials ComfyUI Tutorial Series
Ep01 - Introduction and Installation
Ep02 - Nodes and Workflow Basics
Ep03 - TXT2IMG Basics
Ep04 - IMG2IMG and LoRA Basics
Ep05 - Stable Diffusion 3 Medium
Ep06 - Get 300 Free Art Styles
Ep07 - Working With Text - Art Styles Update
Ep08 - Flux 1: Schnell and Dev Installation Guide
Ep09 - How to Use SDXL ControlNet Union
Ep10 - Flux GGUF and Custom Nodes
Ep11 - LLM, Prompt Generation, img2txt, txt2txt Overview
Ep12 - How to Upscale Your AI Images
Ep13 - Exploring Ollama, LLaVA, Gemma Models
Ep14 - How to Use Flux ControlNet Union Pro
Ep15 - Styles Update, Prompts from File & Batch Images
Ep16 - How to Create Seamless Patterns & Tileable Textures
Ep17 - Flux LoRA Explained! Best Settings & New UI
Ep18 - Easy Photo to Cartoon Transformation!
Ep19 - SDXL & Flux Inpainting Tips with ComfyUI
Ep20 - Sketch to Image Workflow with SDXL or Flux!
Ep21 - How to Use OmniGen in ComfyUI
Ep22 - Remove Image Backgrounds with ComfyUI or Photoshop
Ep23 - How to Install & Use Flux Tools, Fill, Redux, Depth, Canny
Ep24 - Unlock Flux Redux & Inpainting with LoRA
Ep25 - LTX Video – Fast AI Video Generator Model
Ep26 - Live Portrait & Face Expressions
Ep27 - Photo to Watercolor, Oil & Digital Paintings – Workflow
Ep28 - Create Flux Consistent Characters + Train Loras Online
Ep29 - How to Replace Backgrounds with AI
Ep30 - Game Design with AI and Photoshop
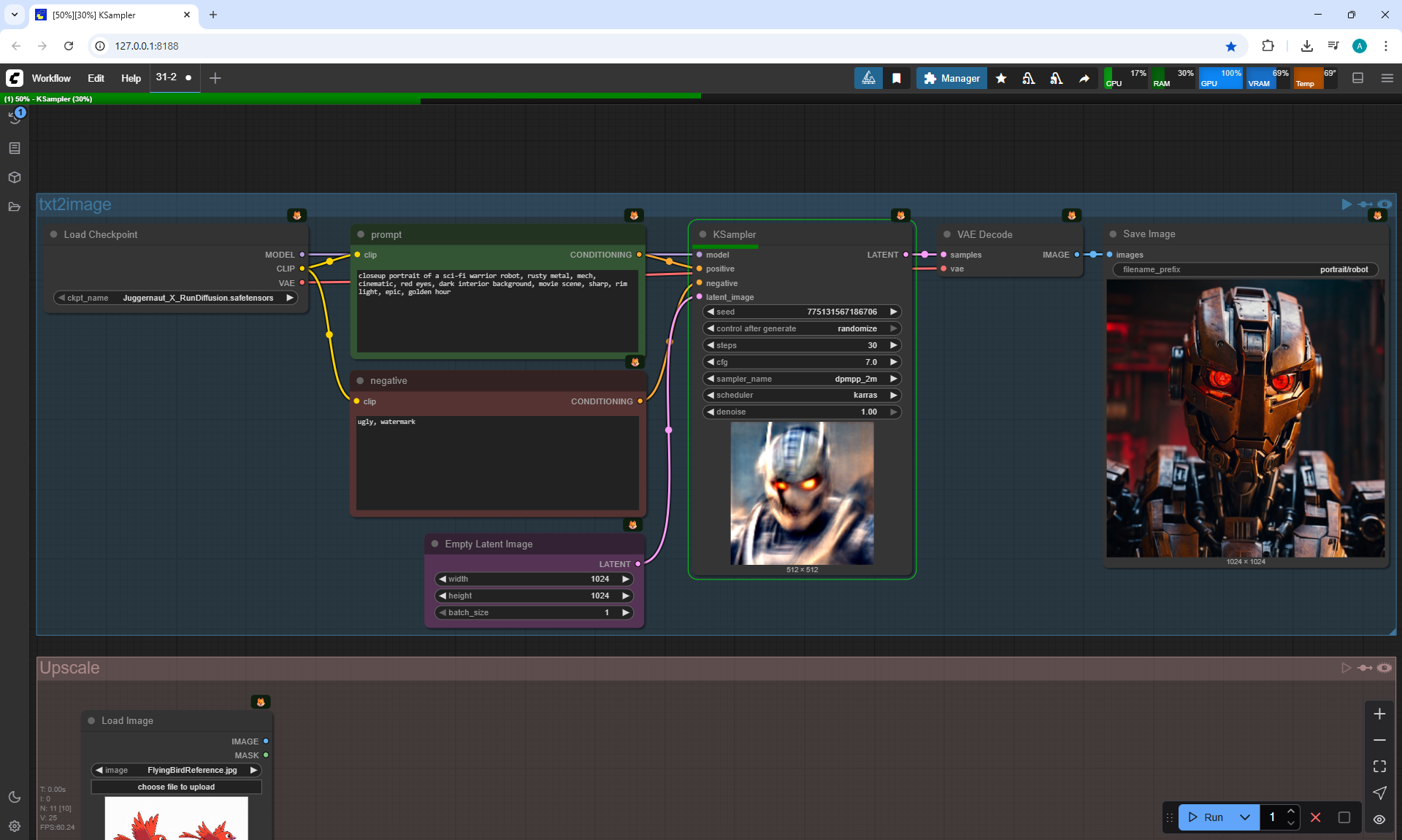
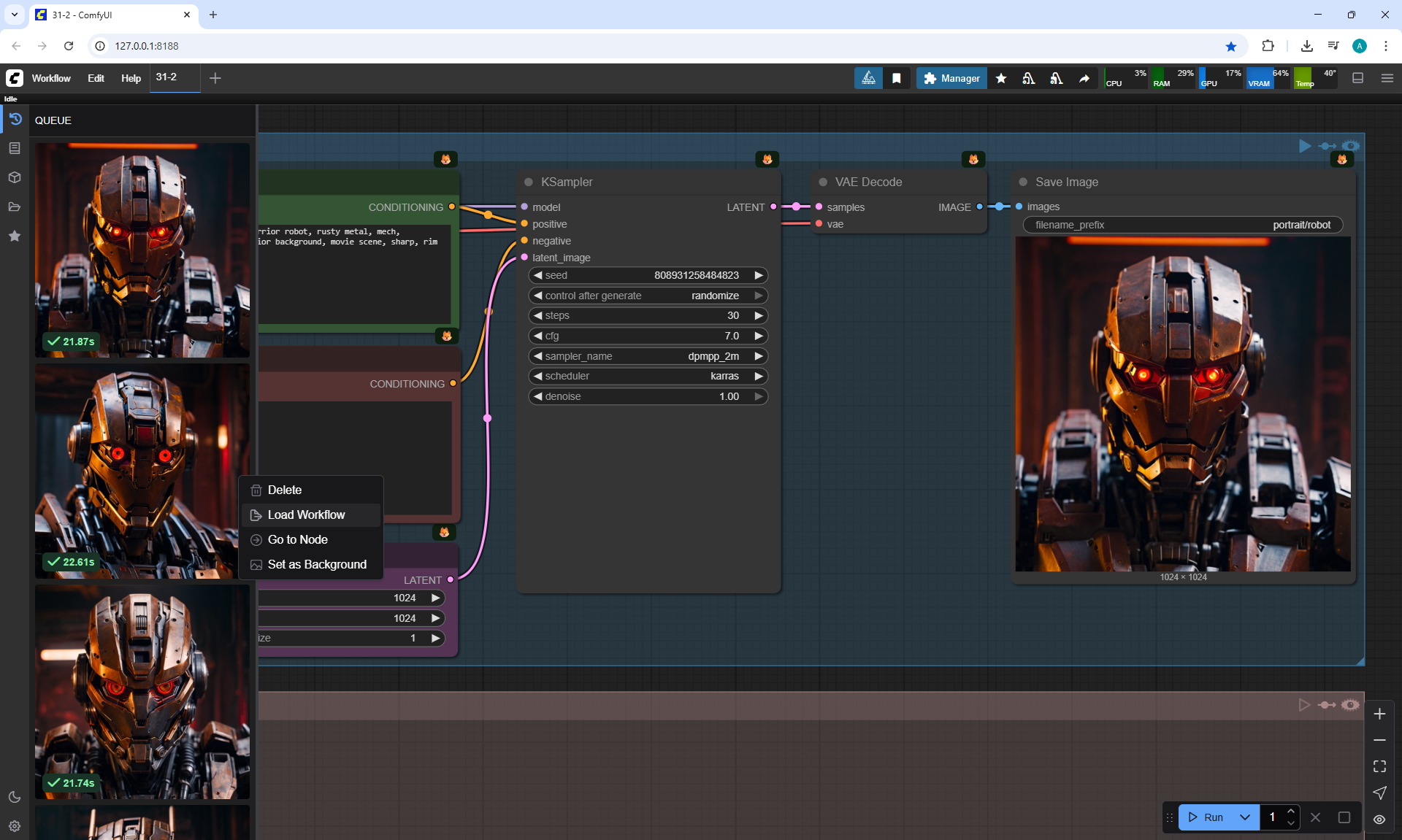
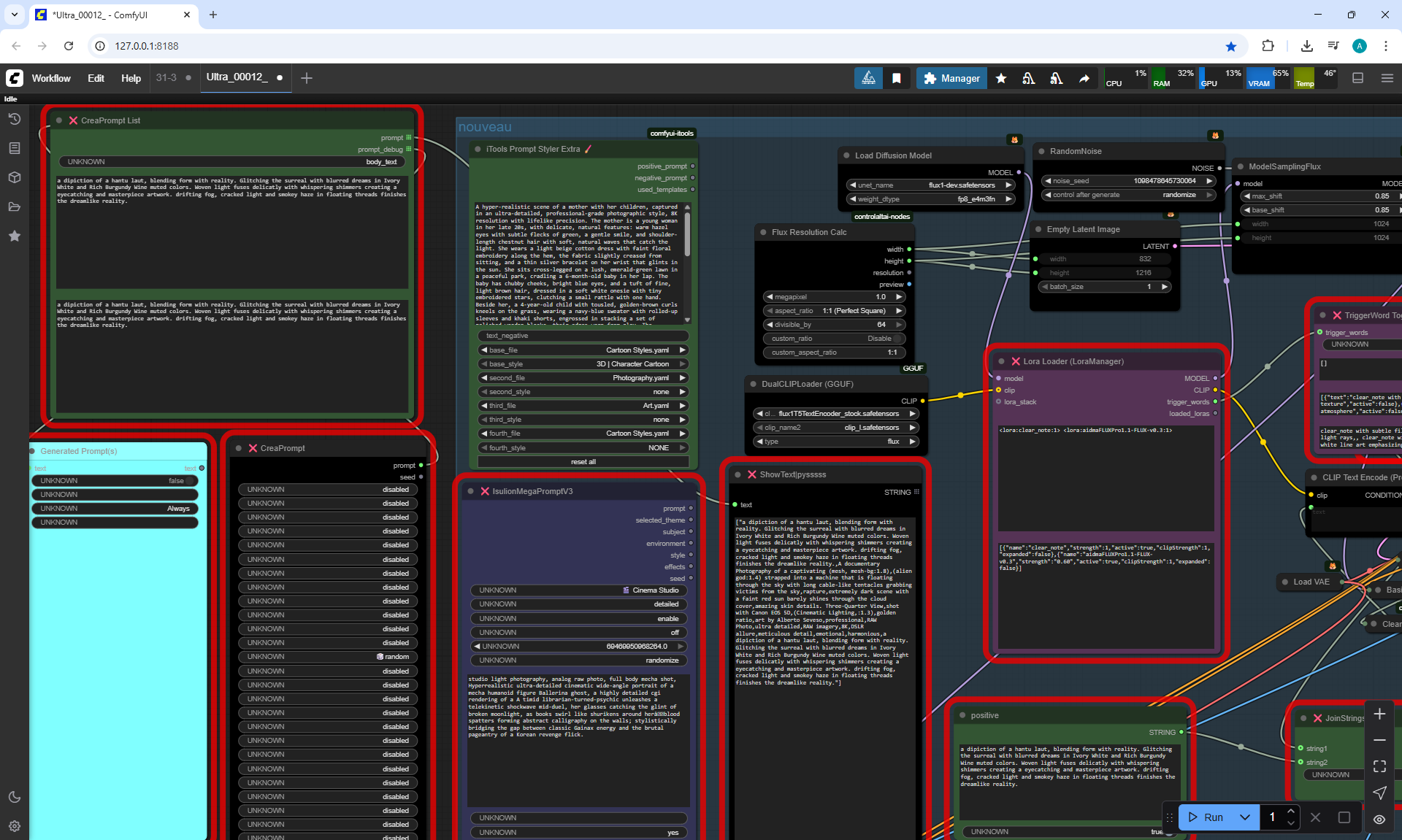
Ep31 - ComfyUI Tips & Tricks You Need to Know
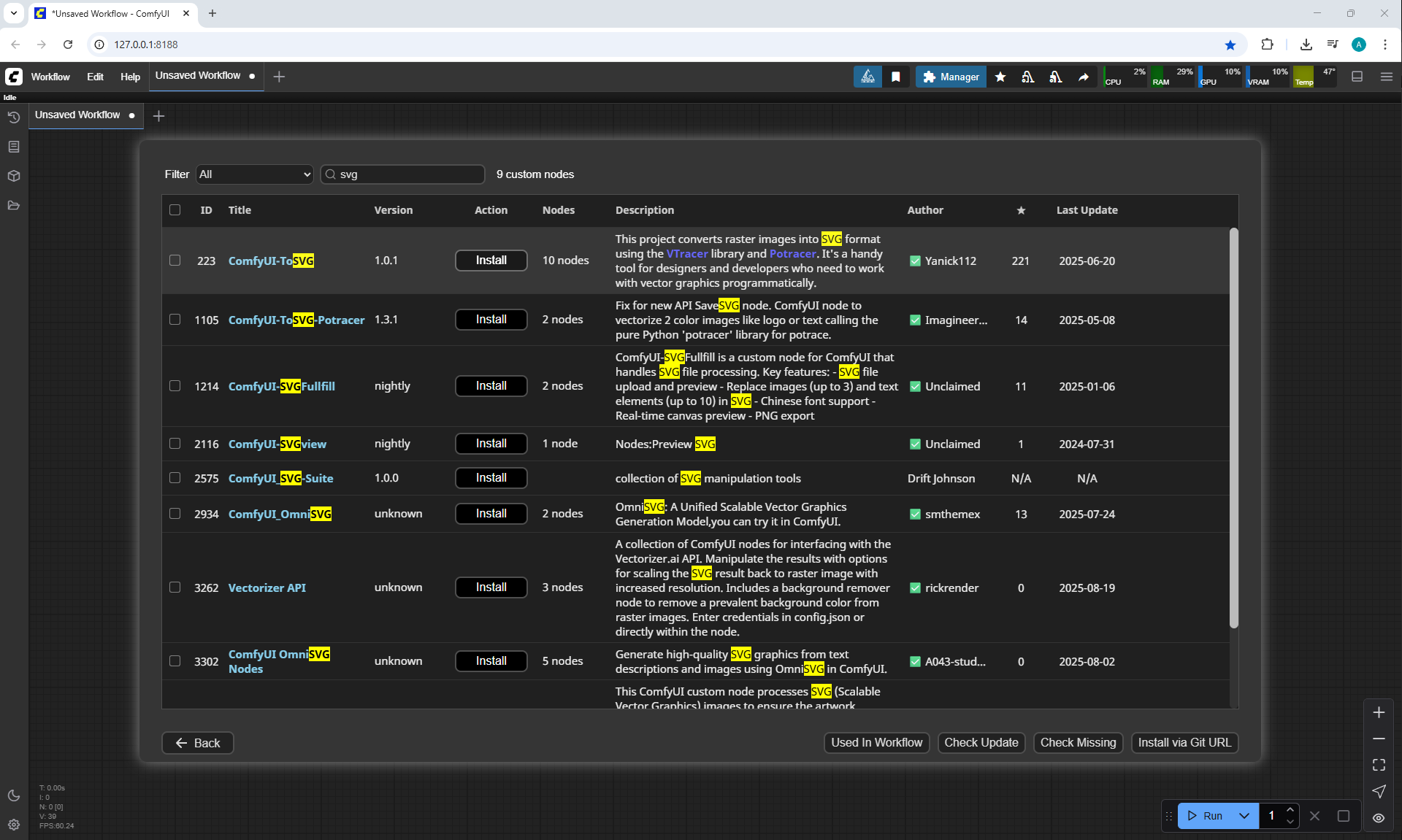
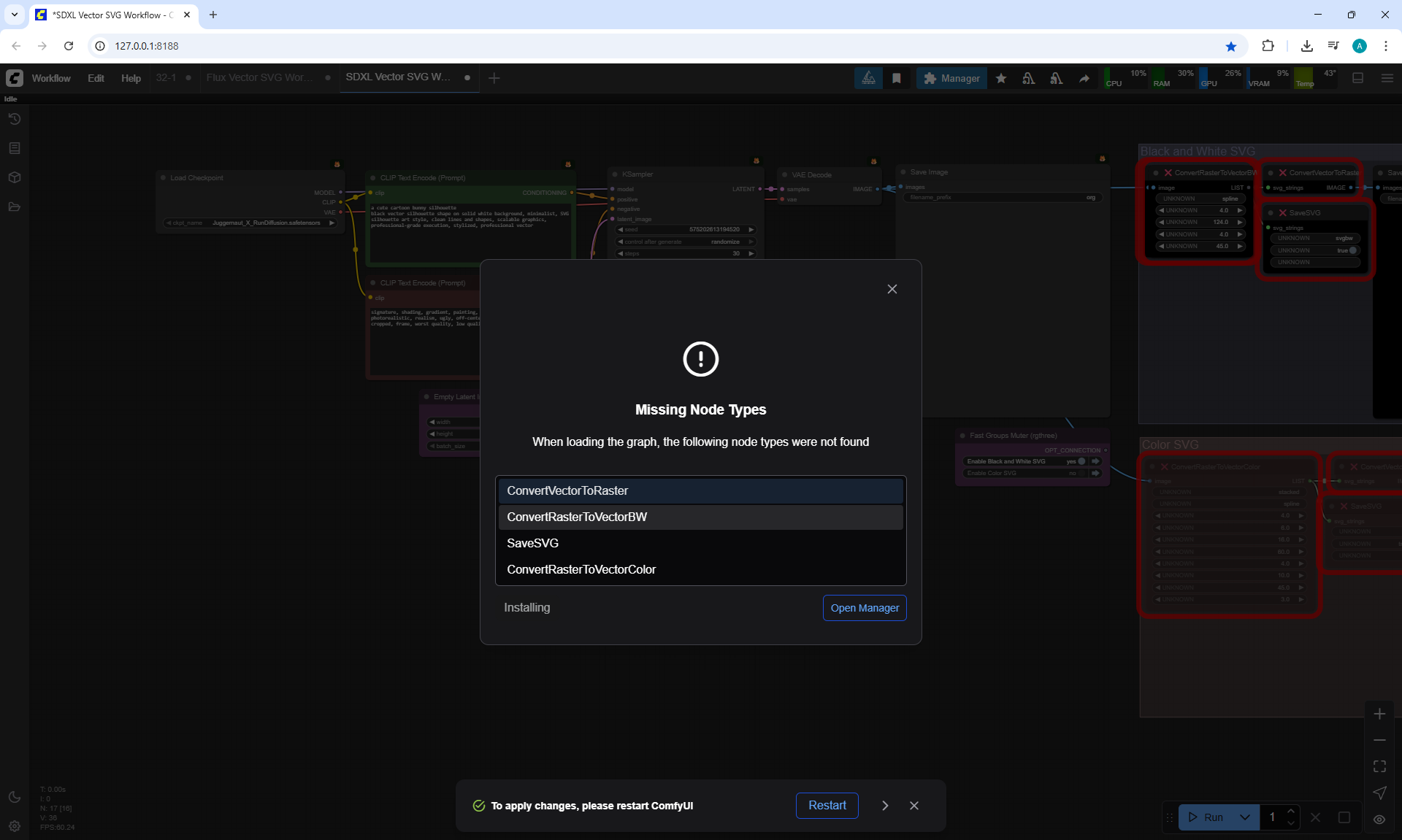
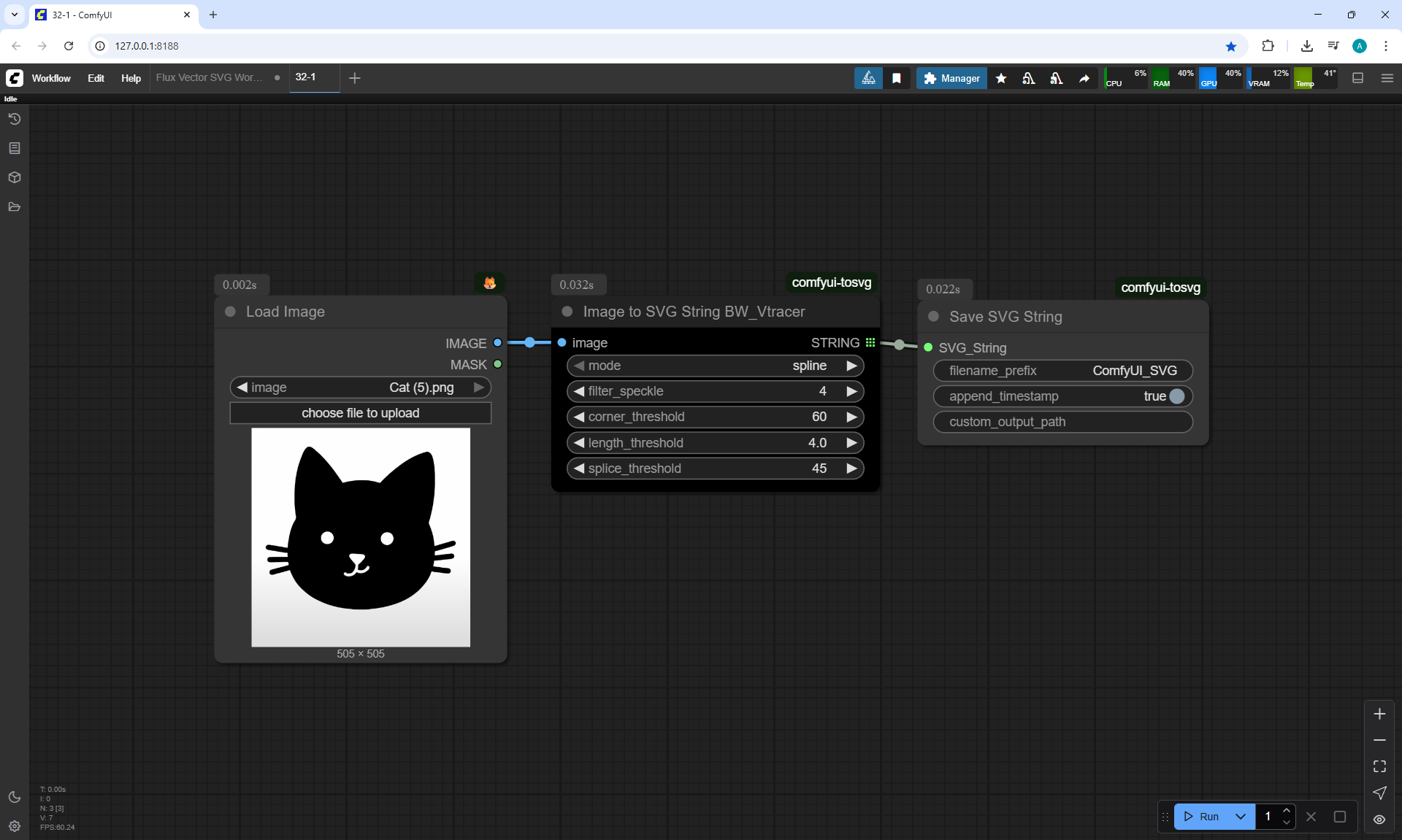
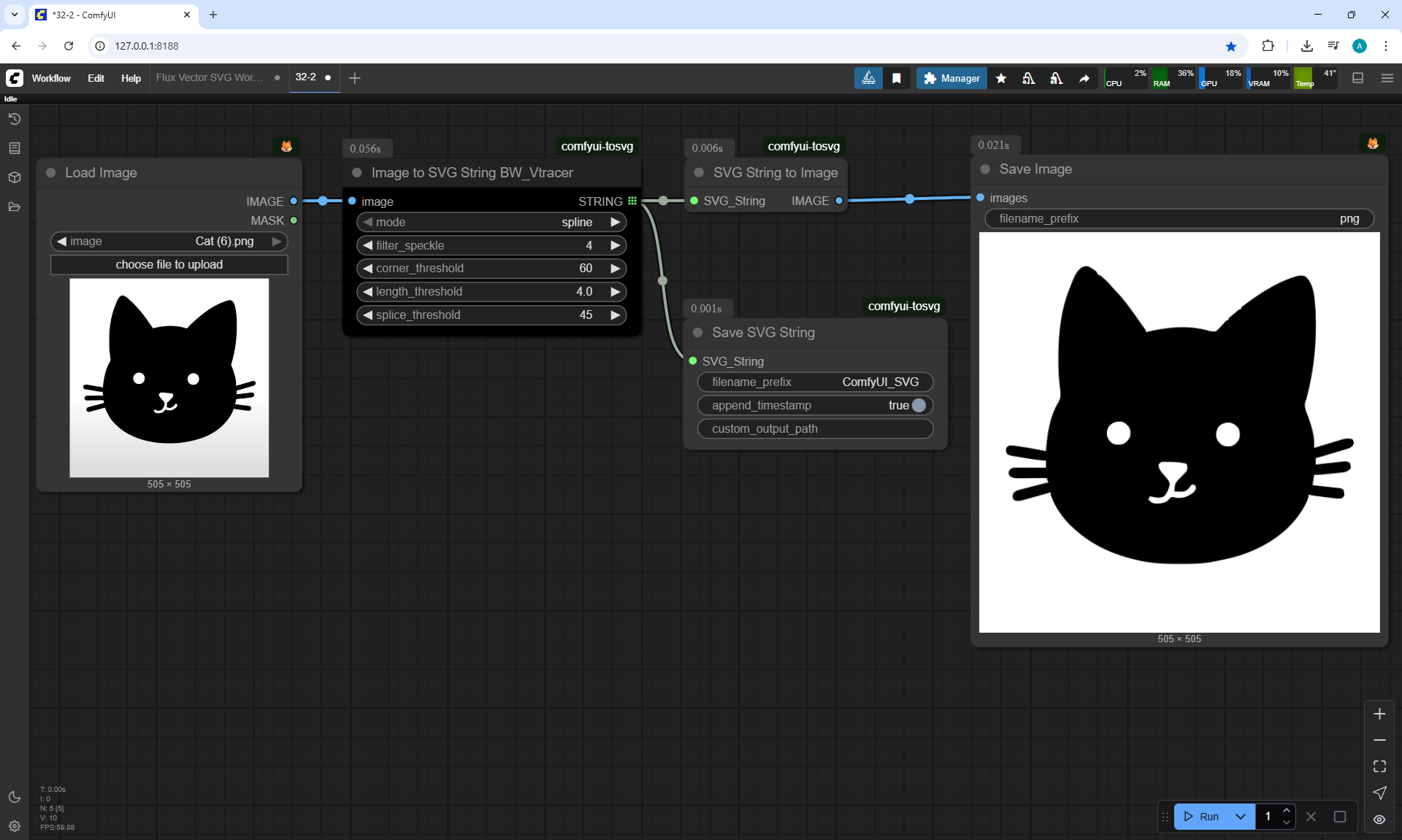
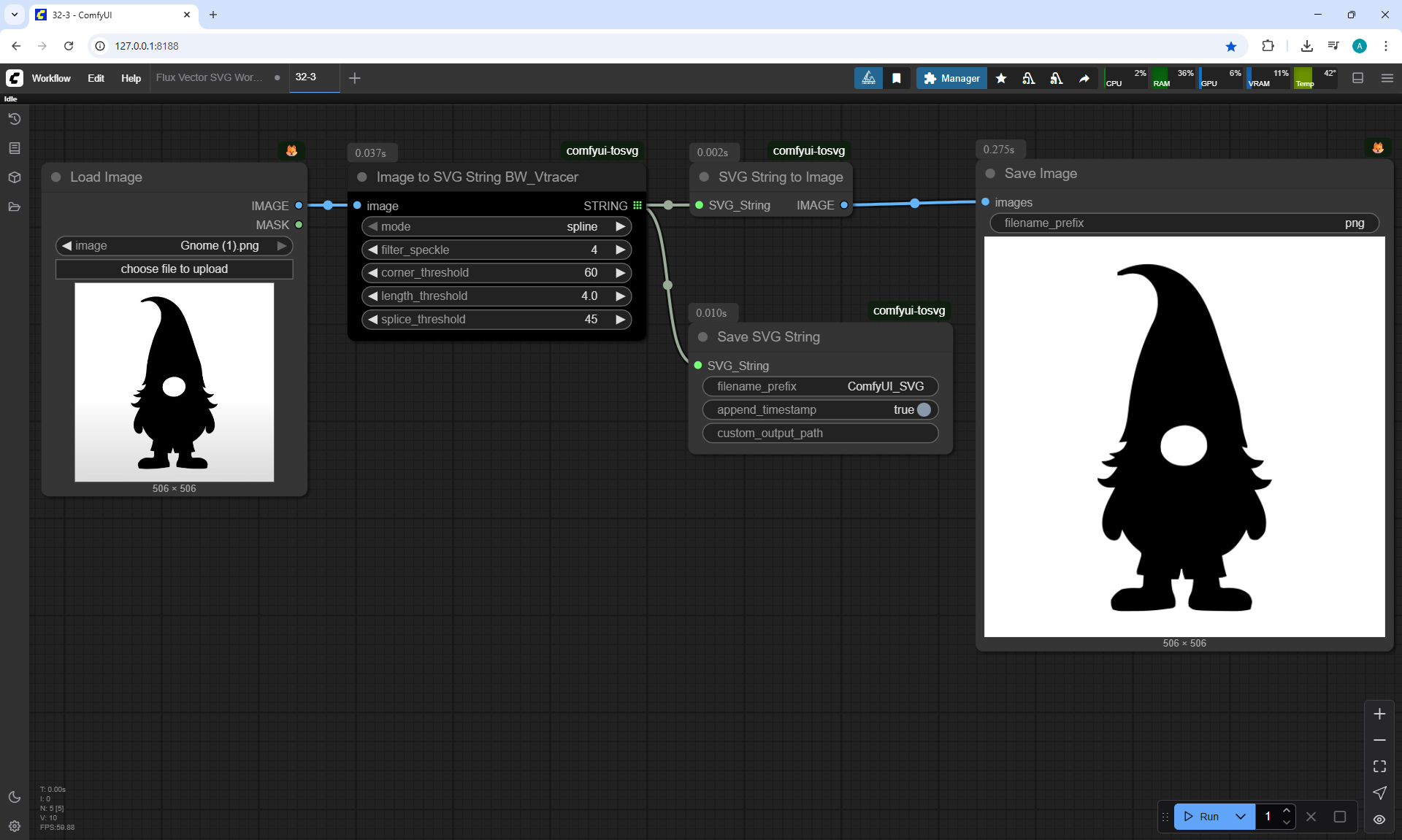
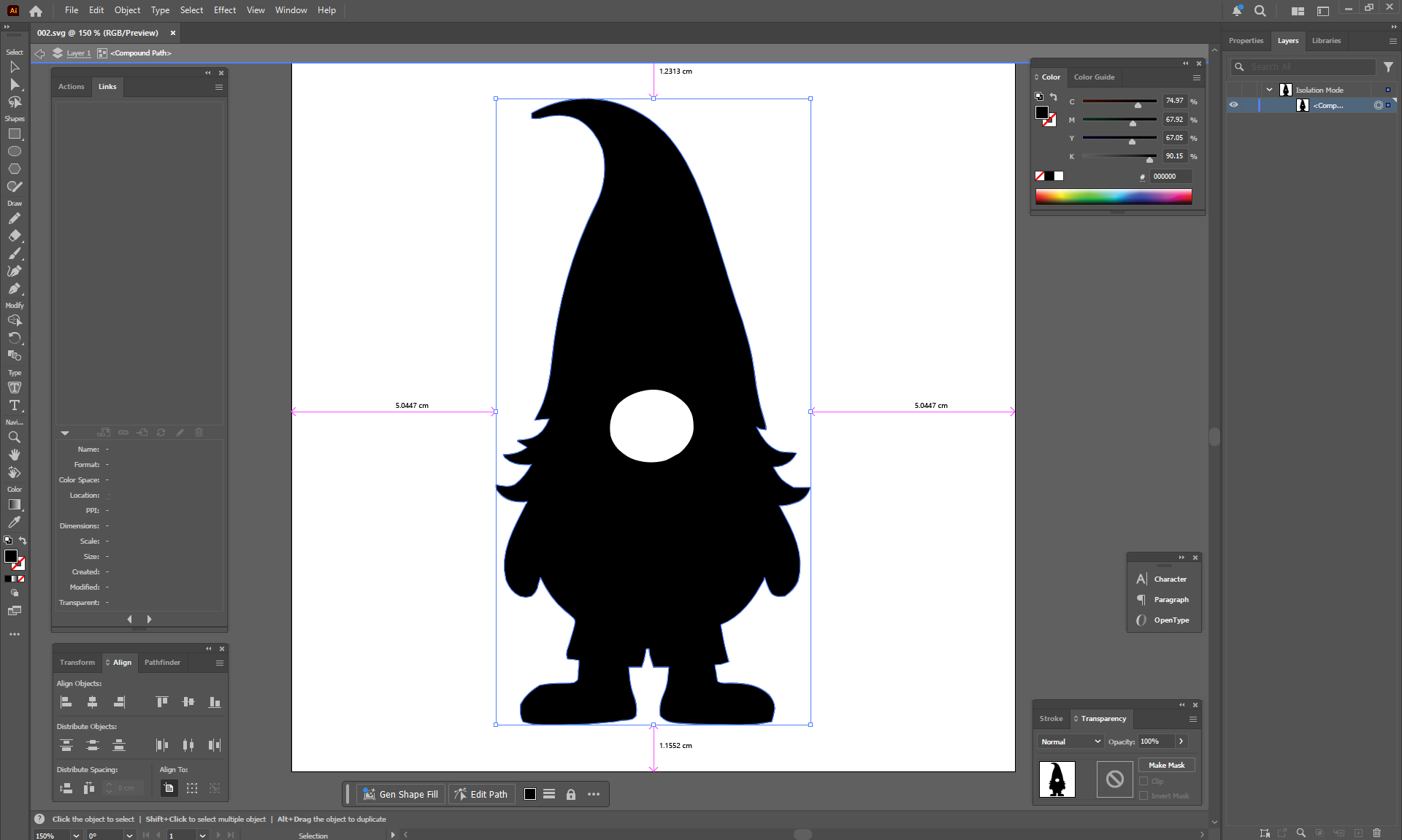
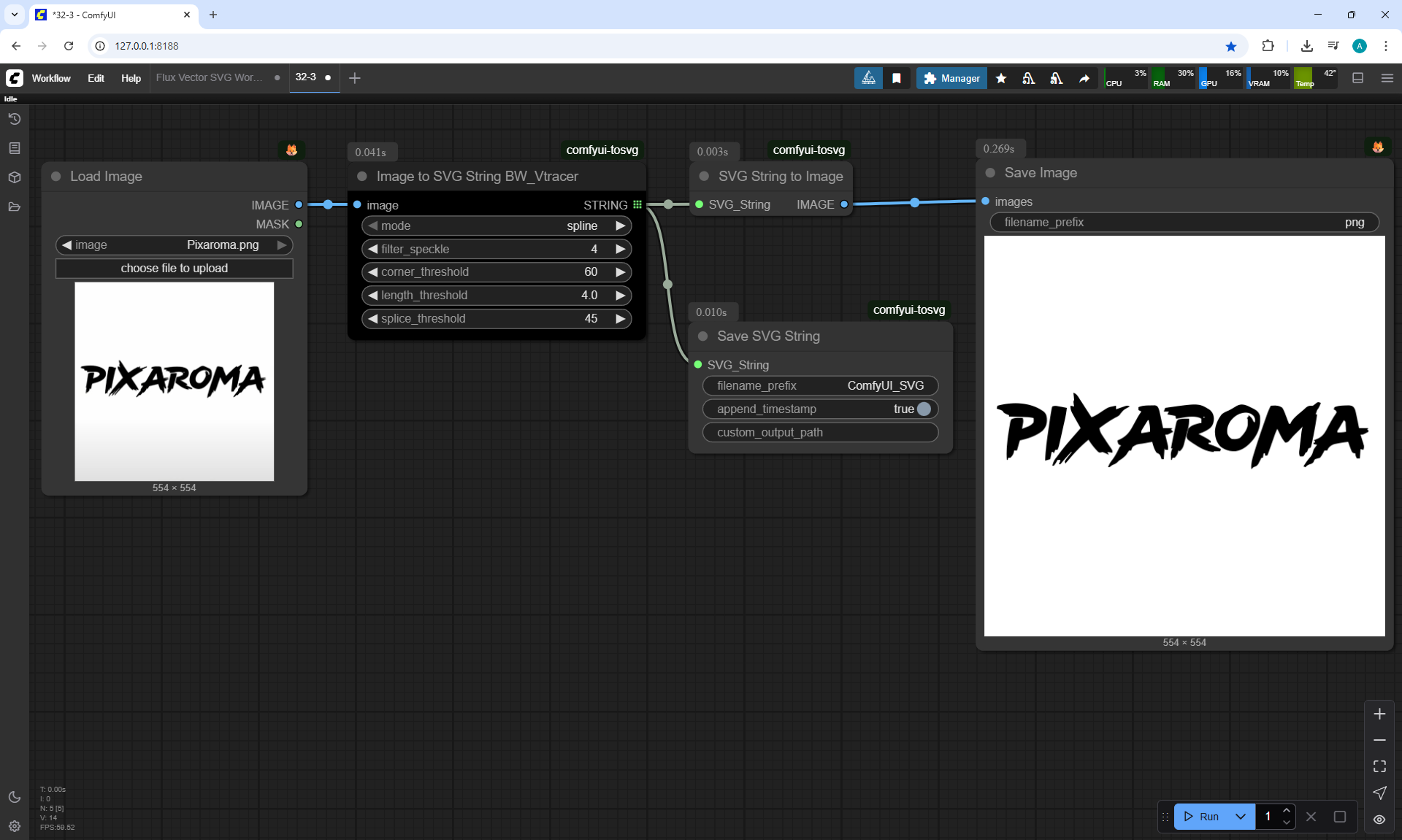
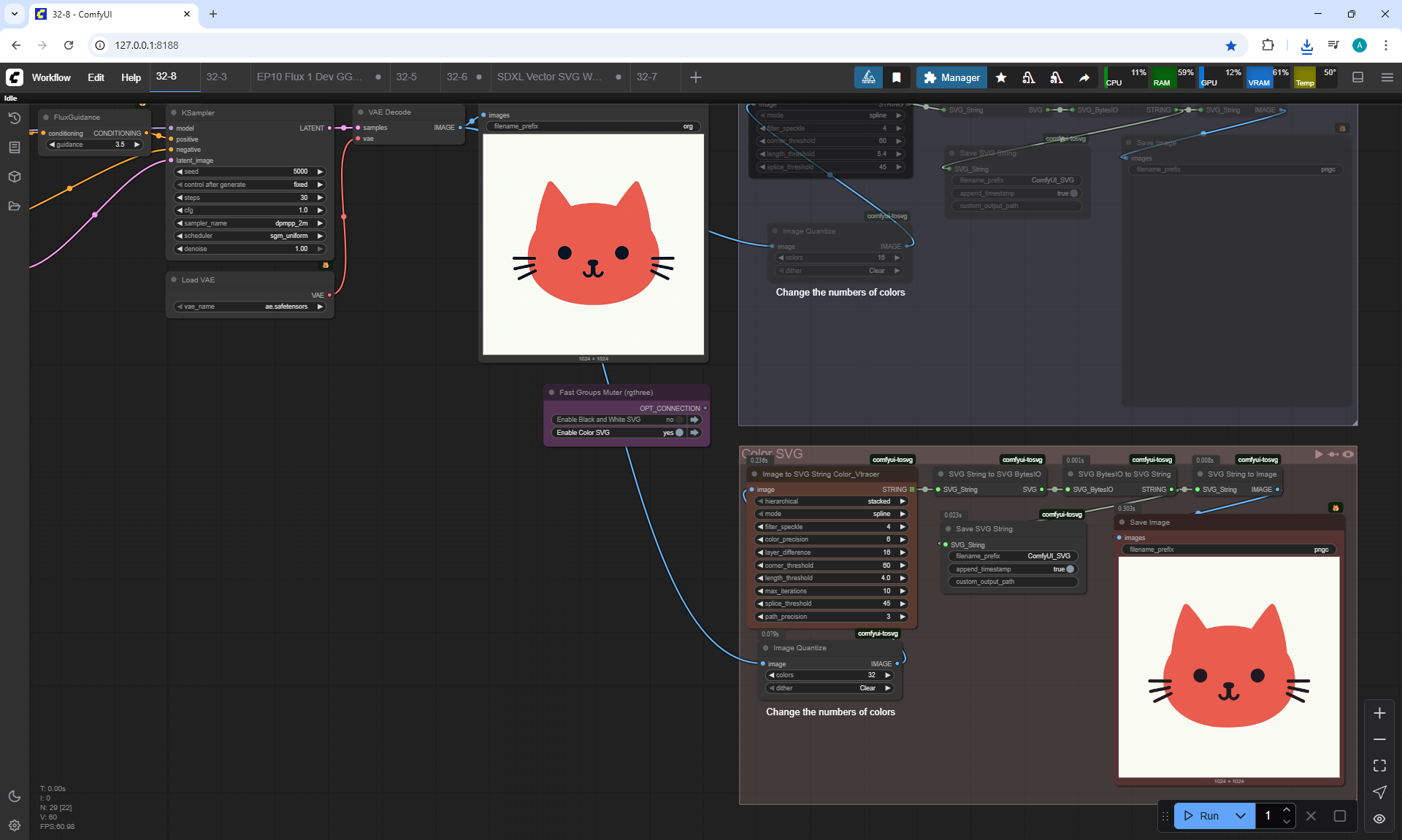
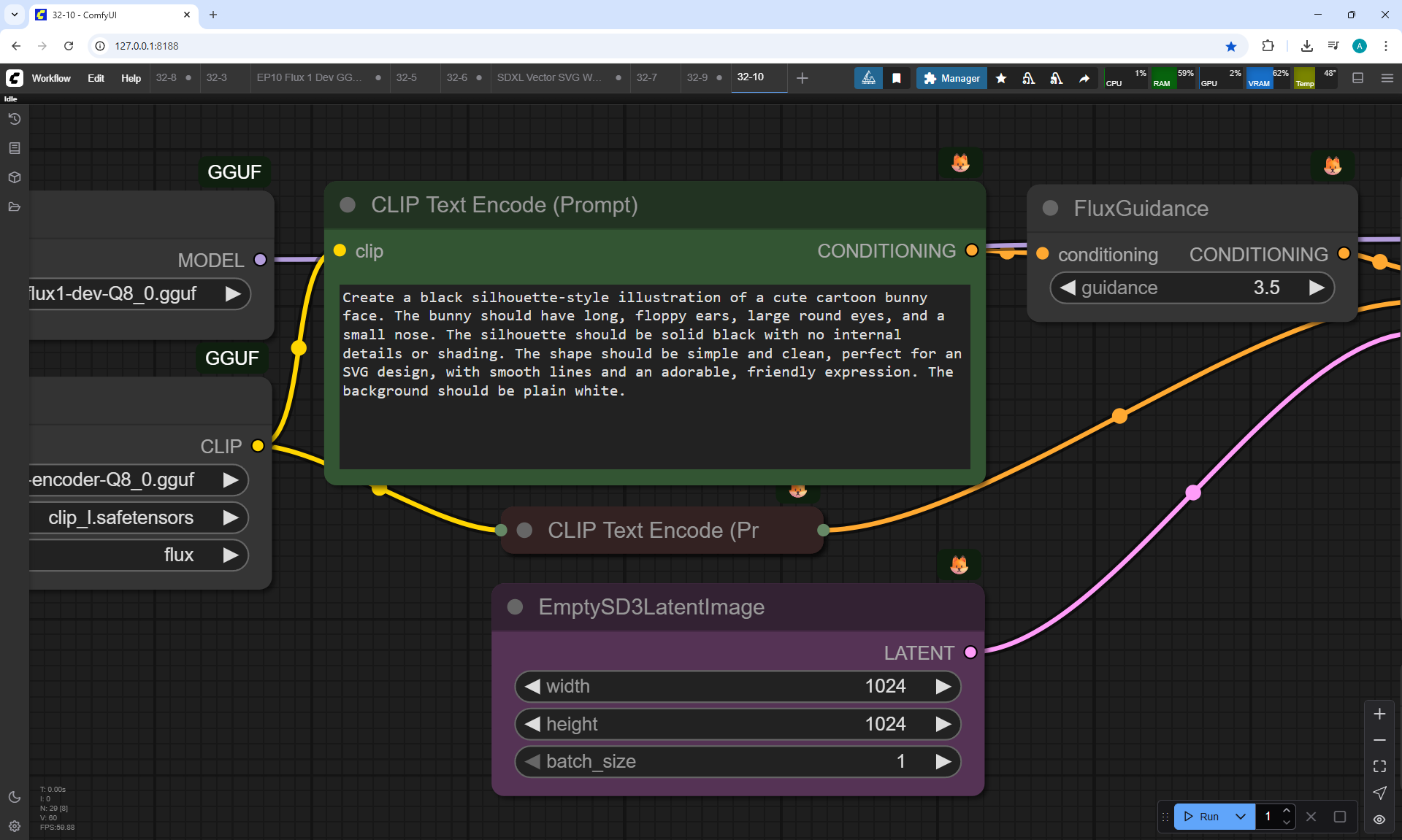
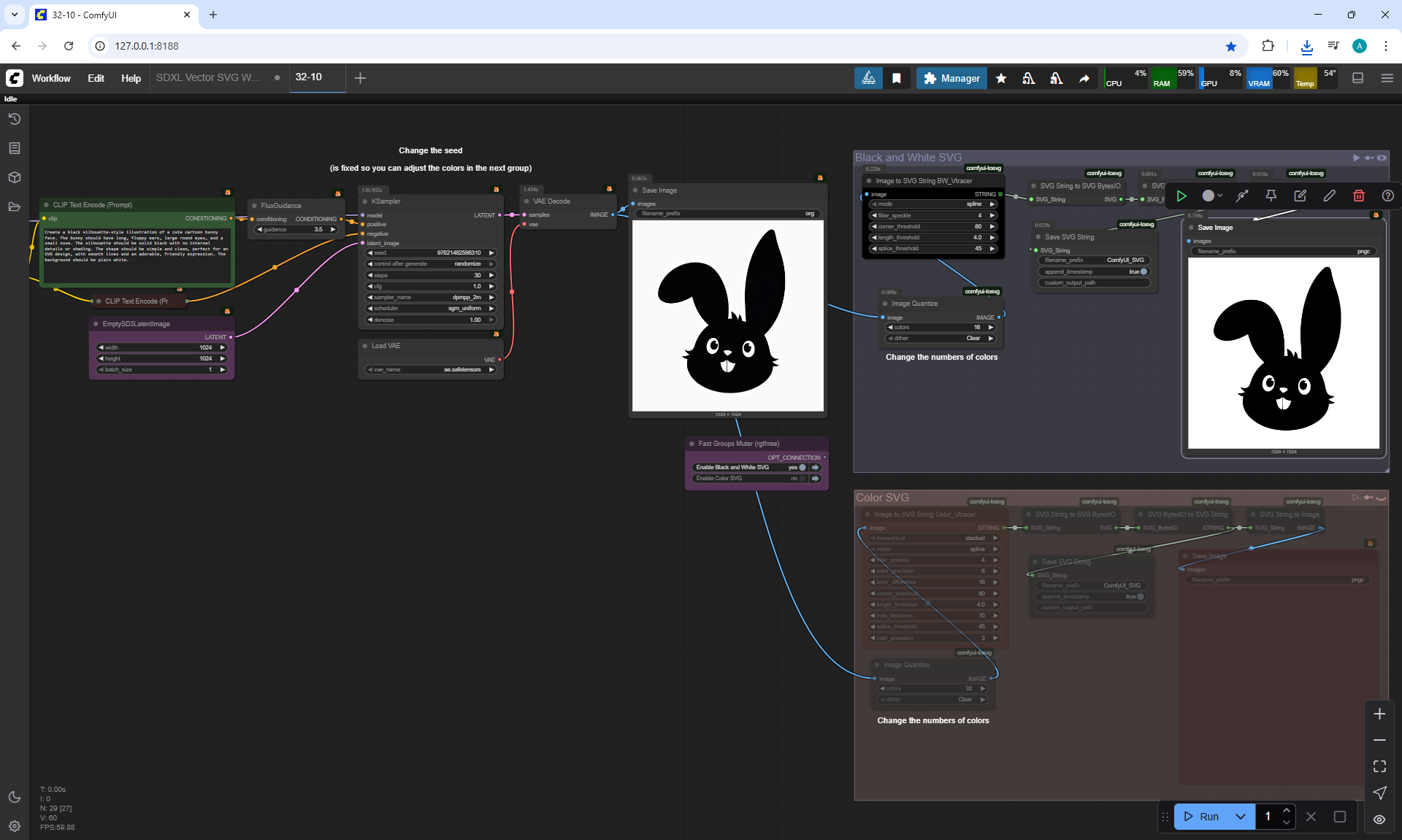
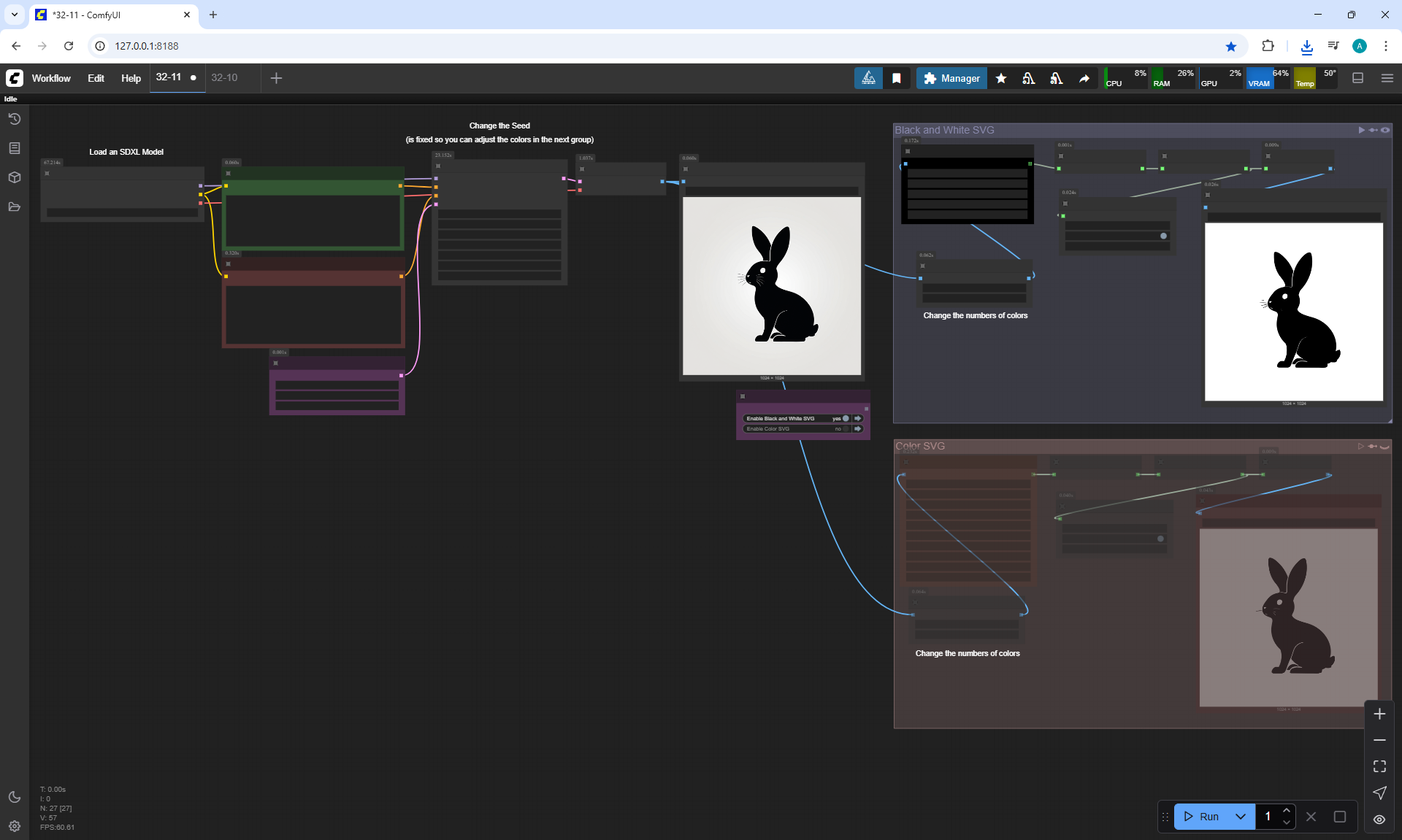
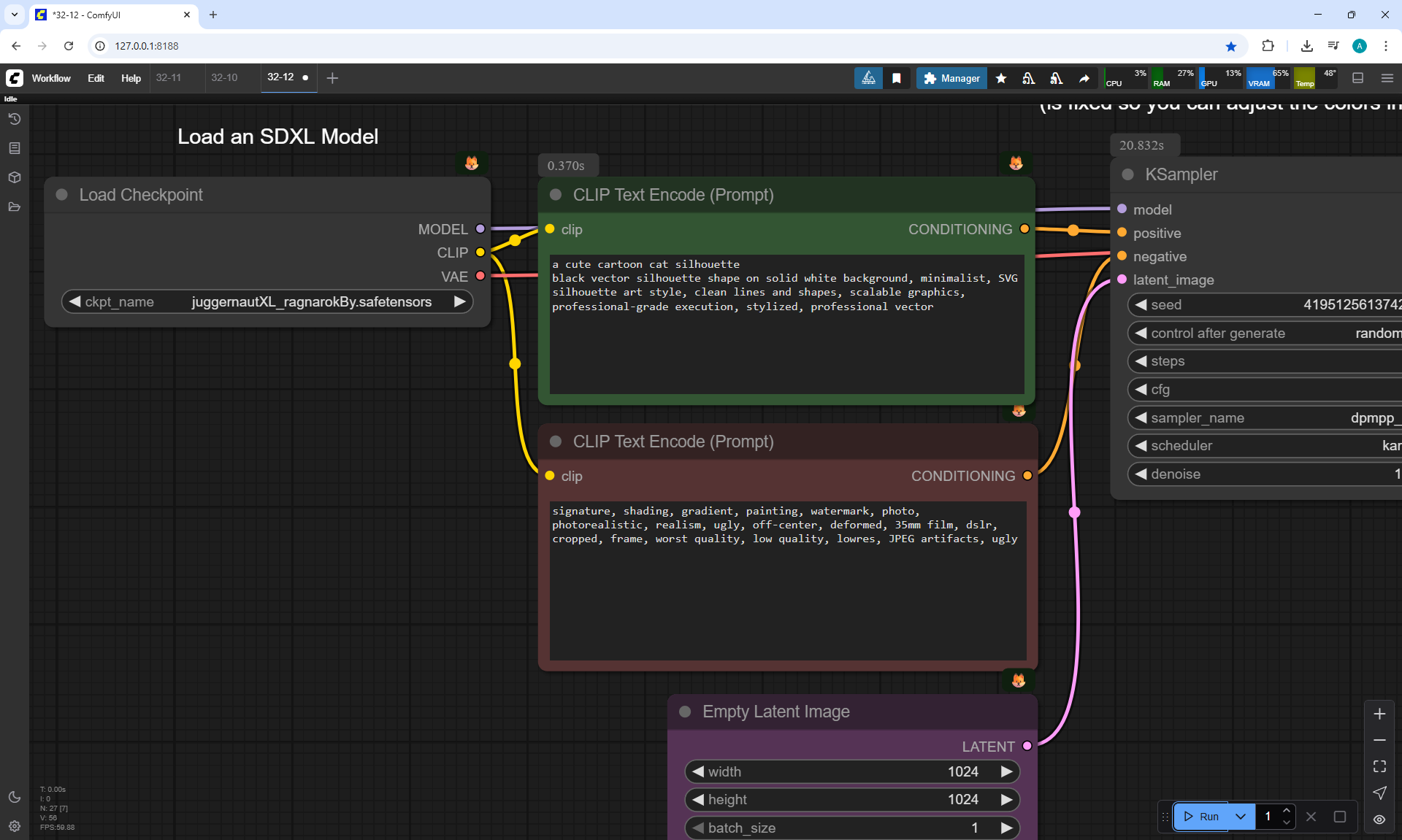
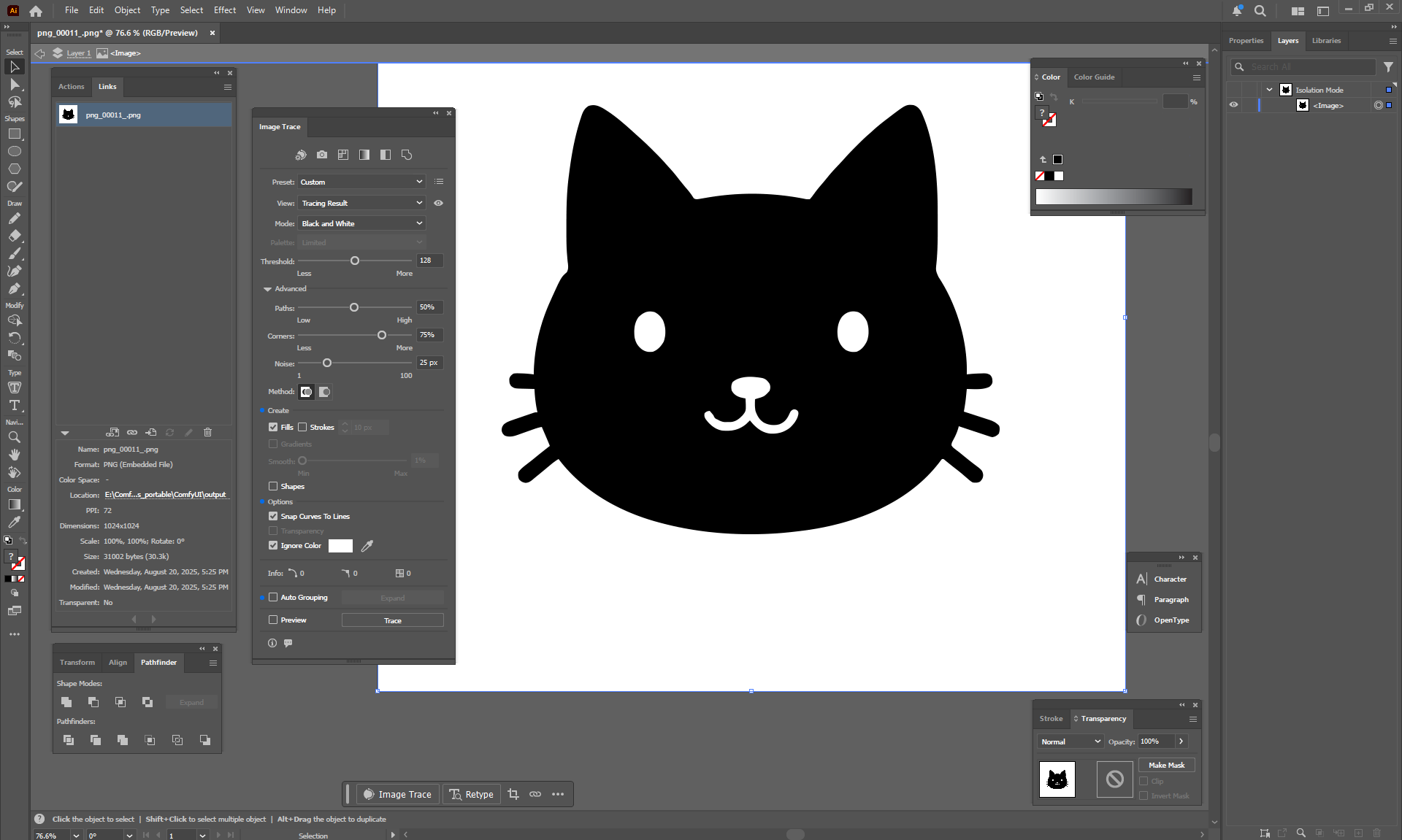
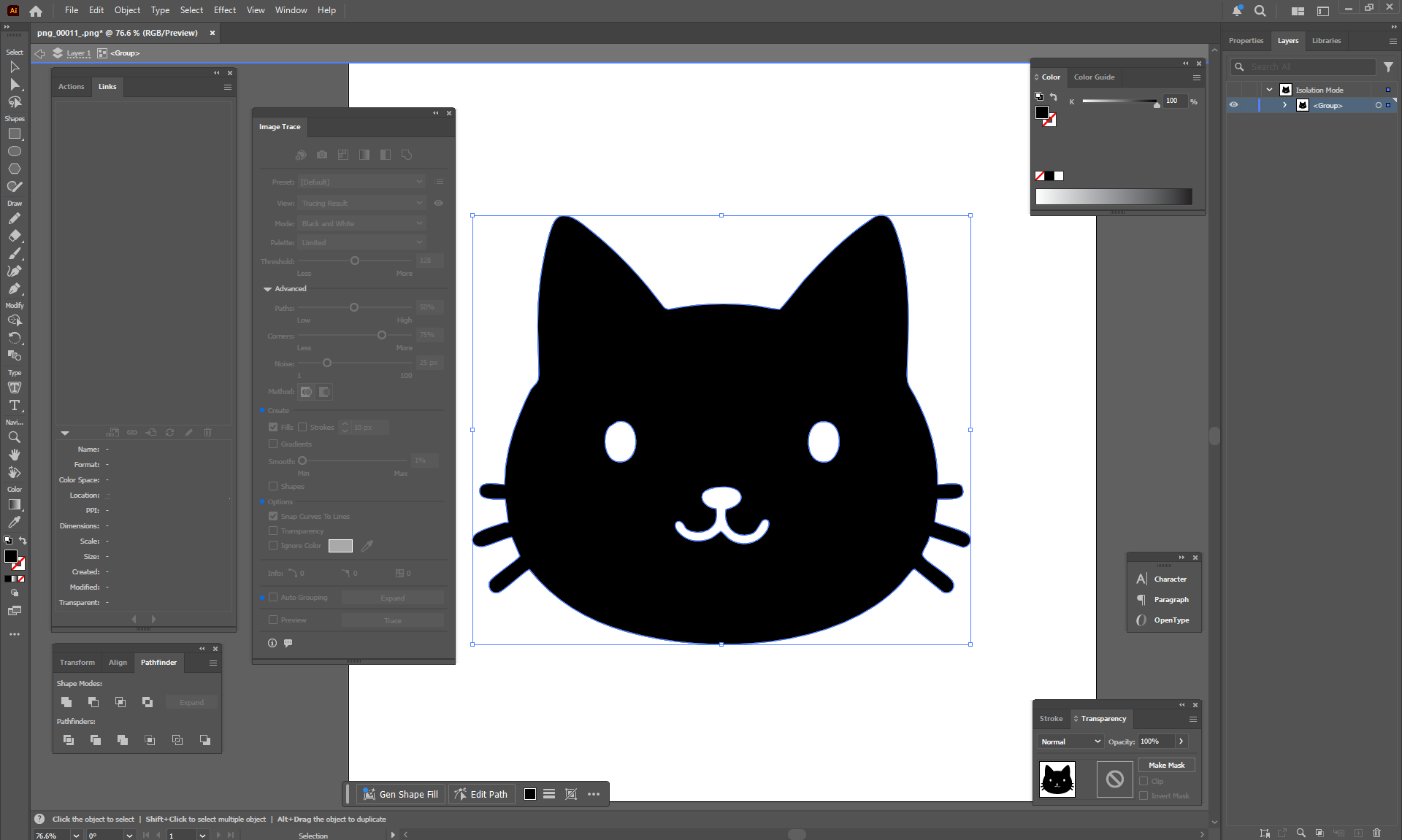
Ep32 - How to Create Vector SVG Files with AI
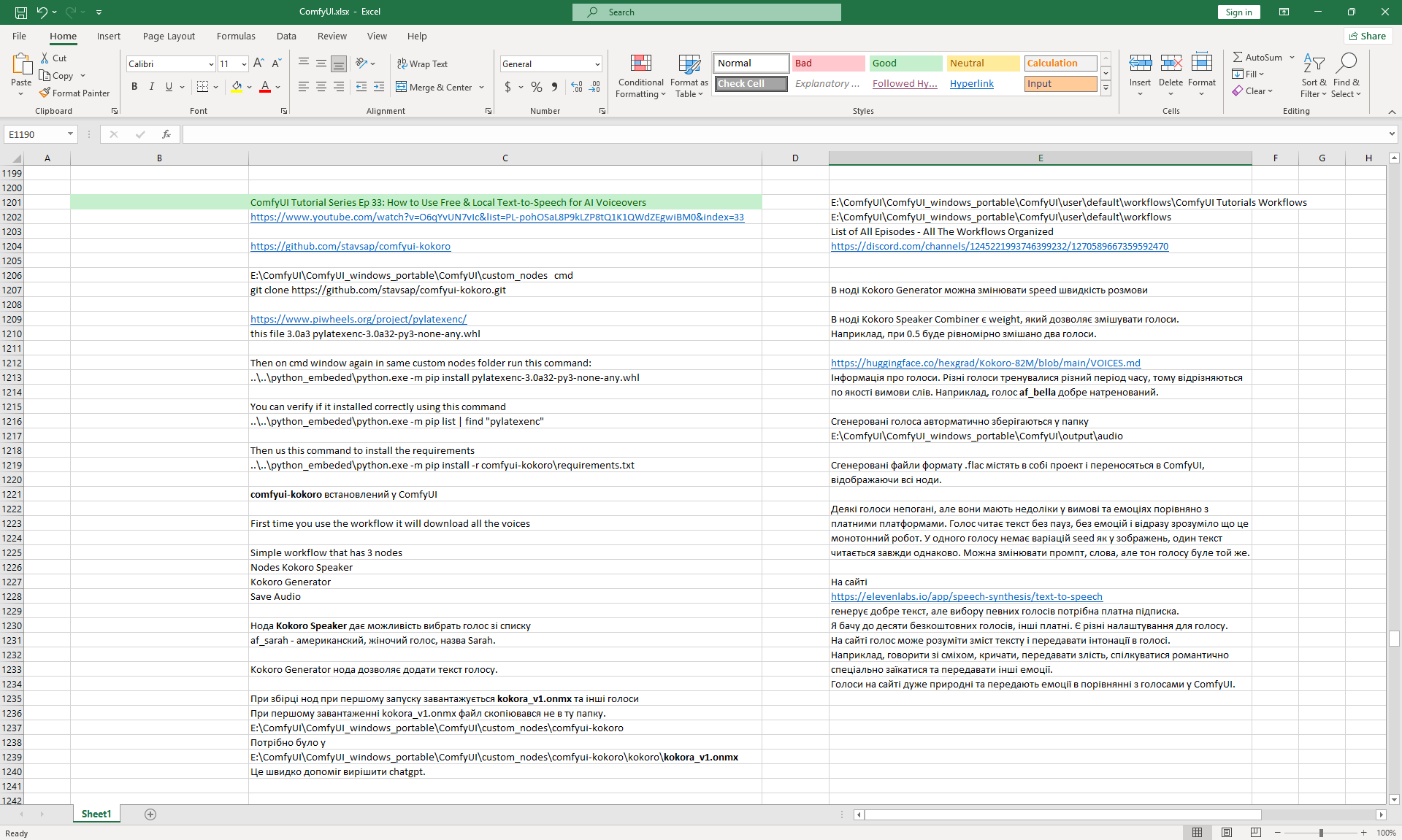
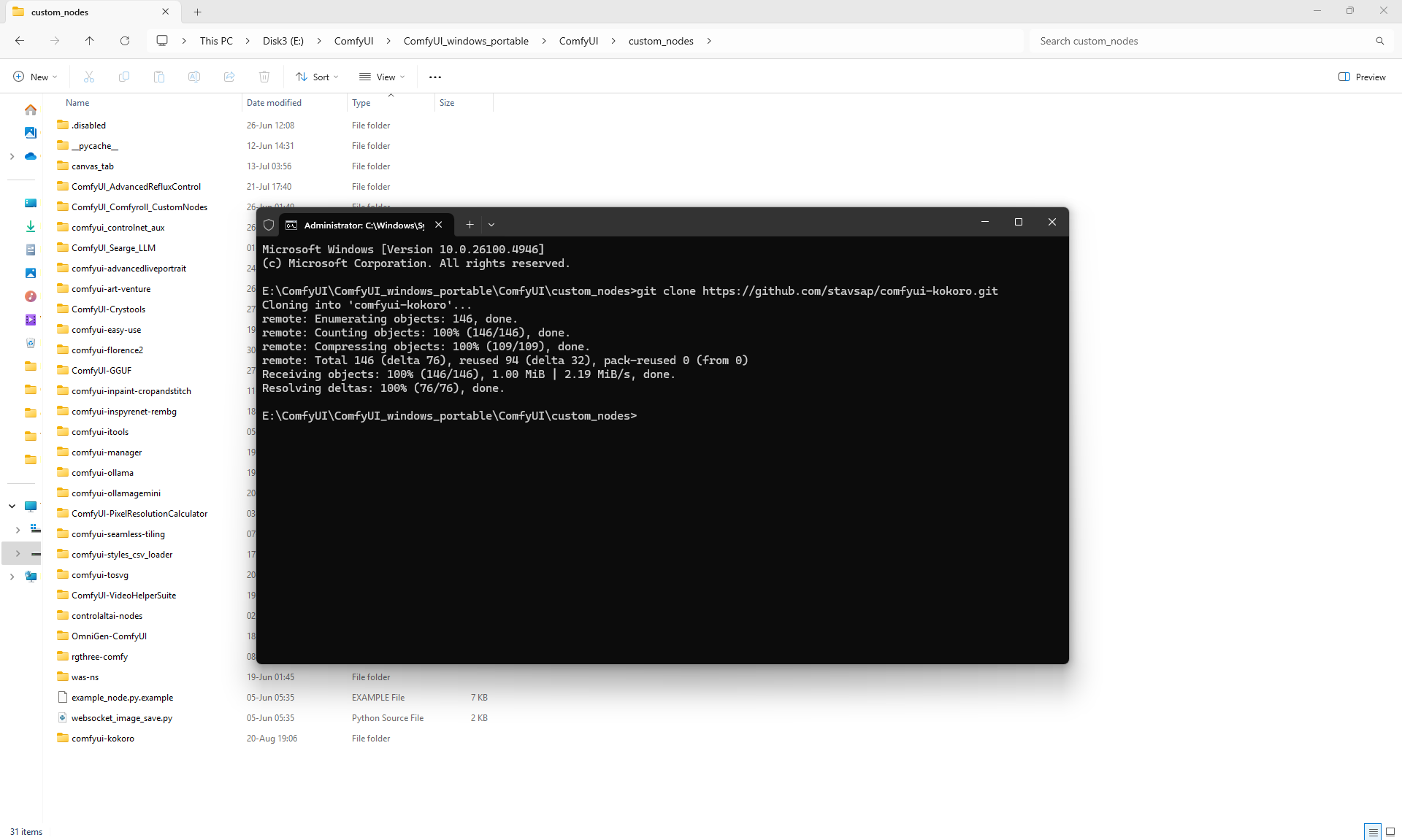
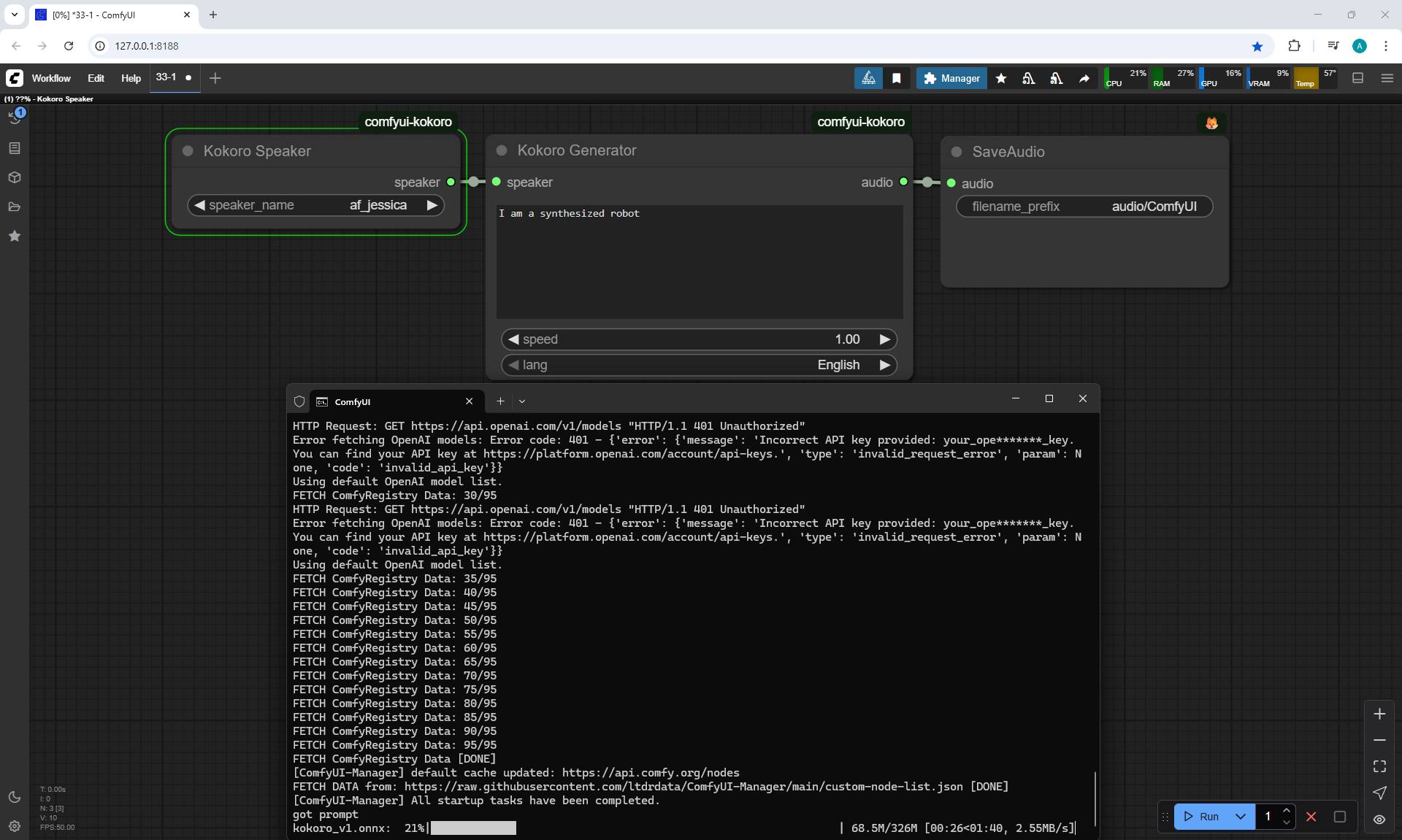
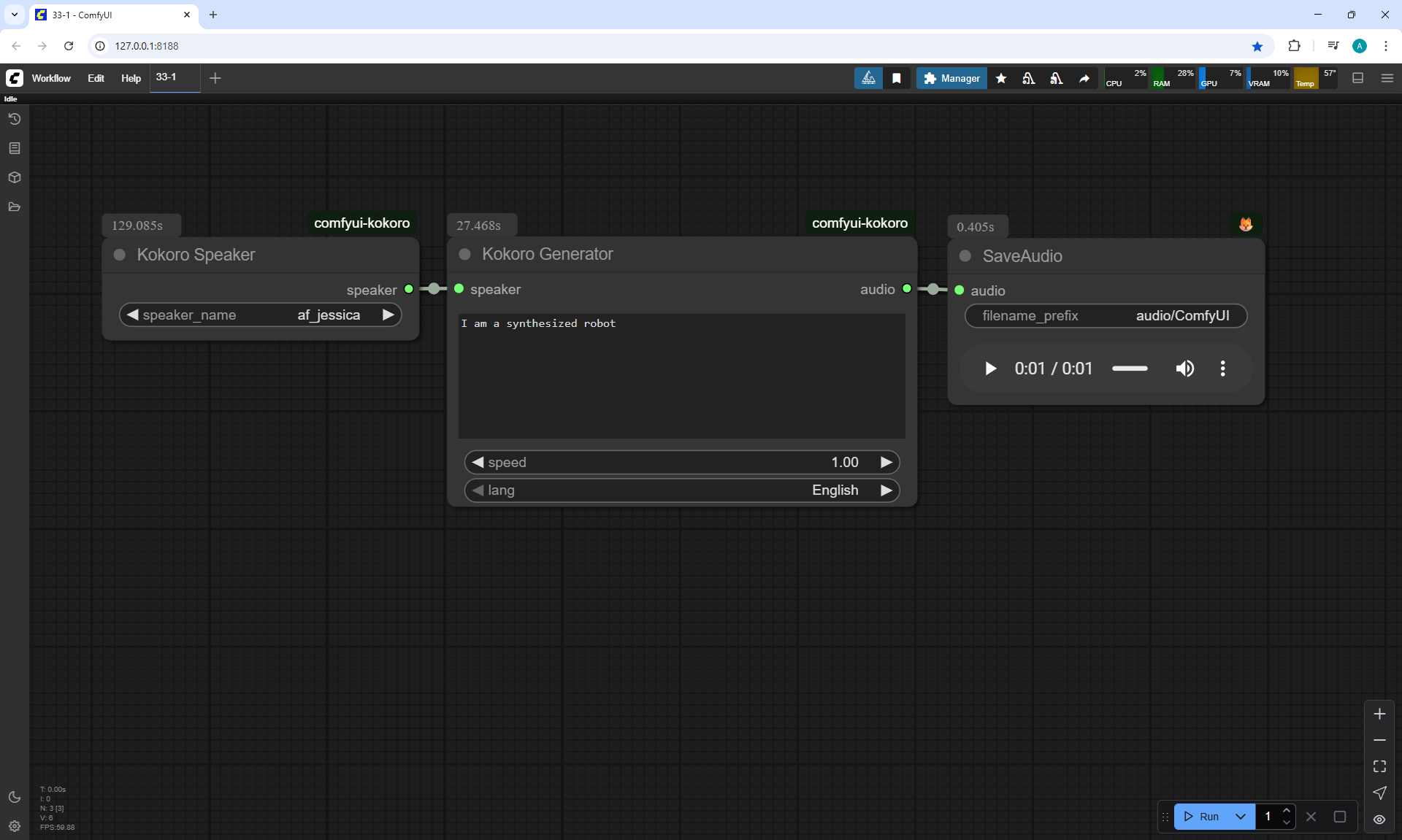
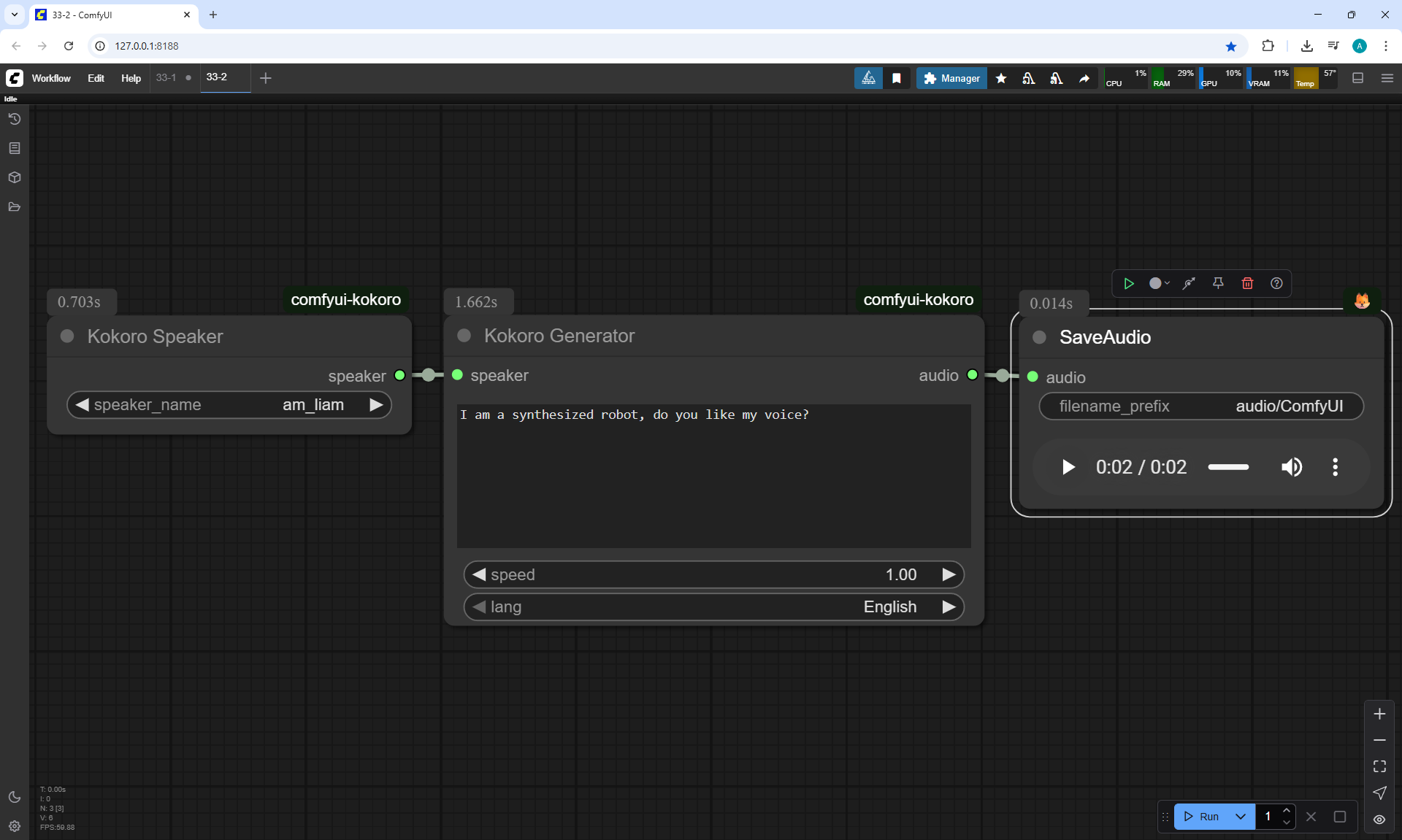
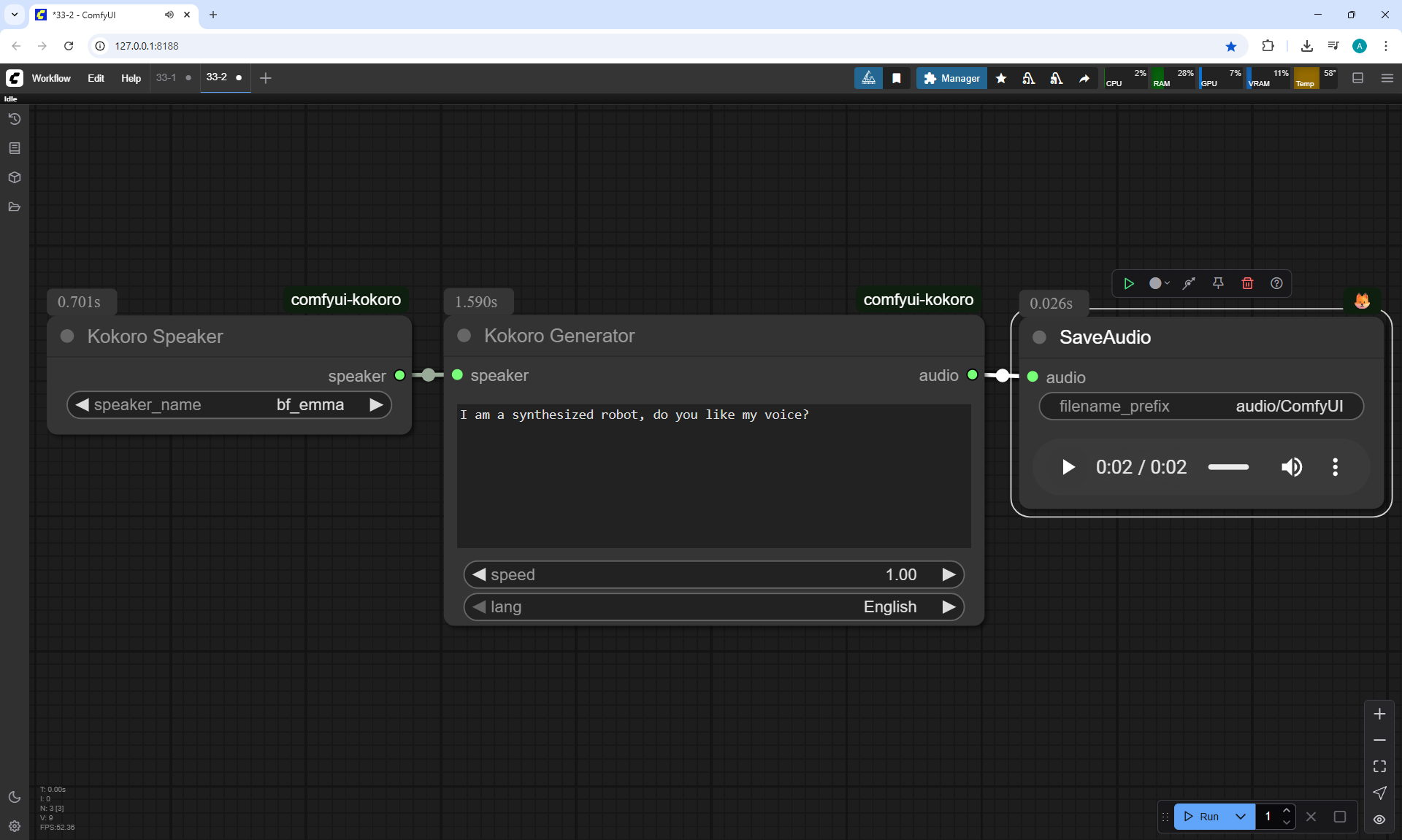
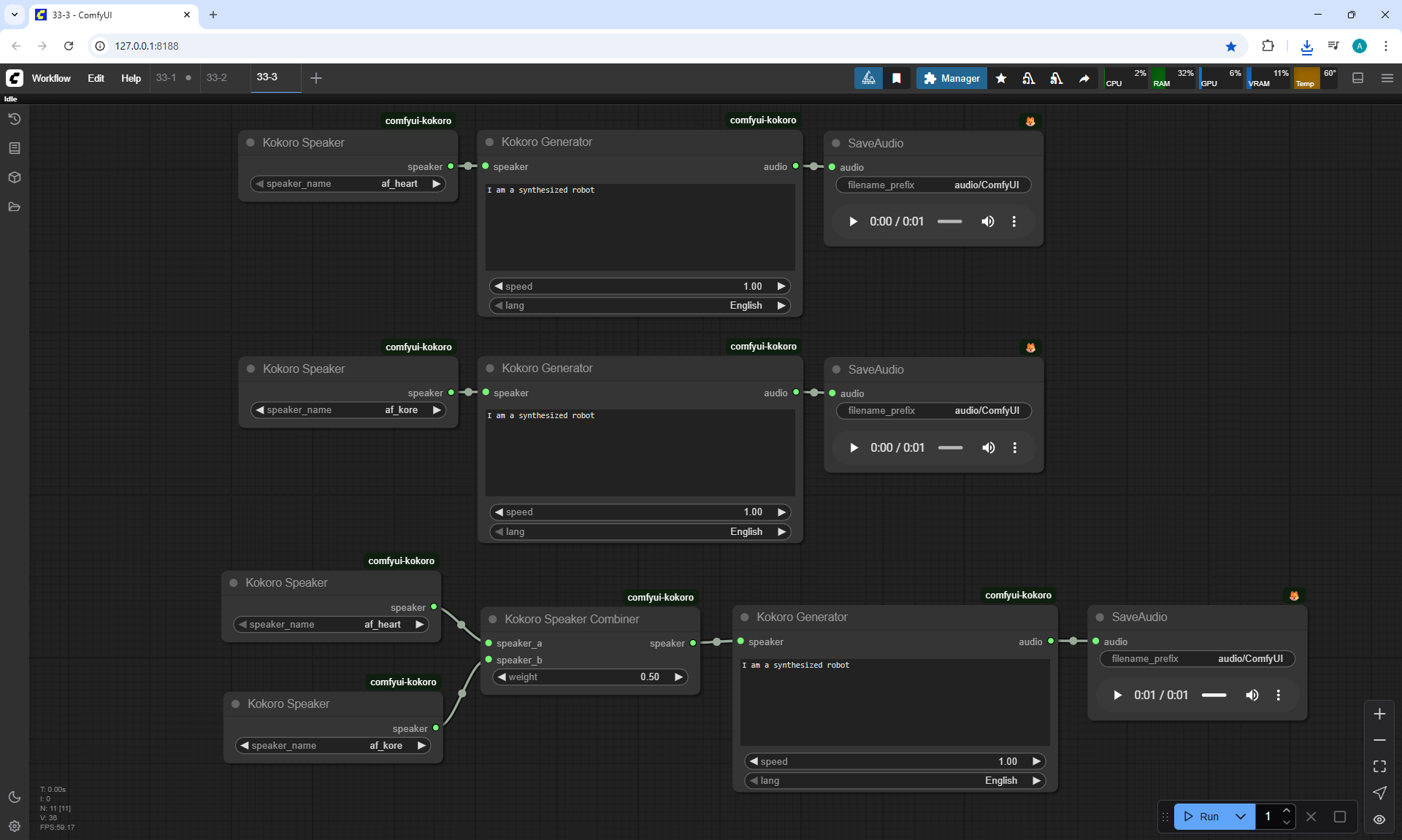
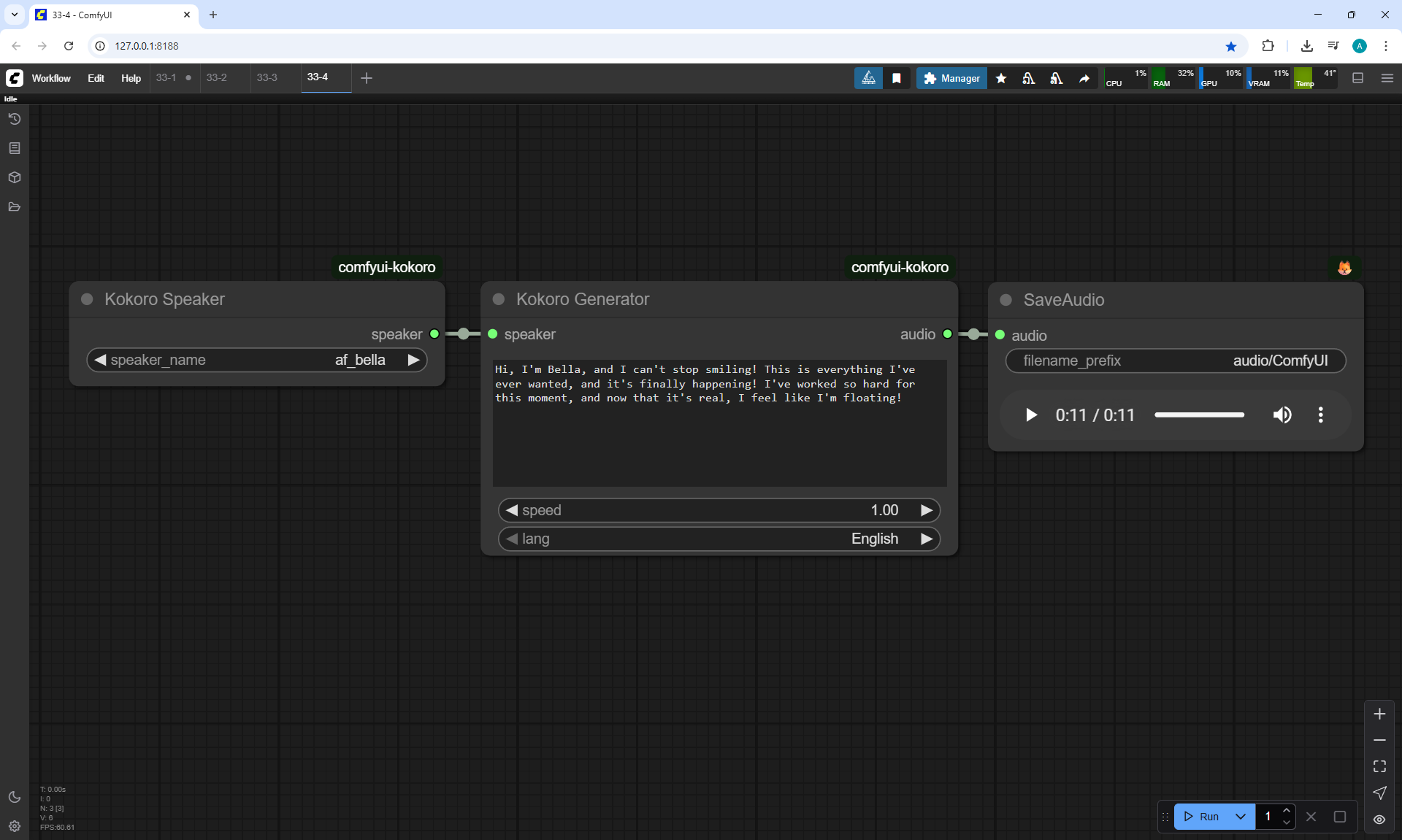
Ep33 - How to Use Free, Local Text-to-Speech for AI Voiceovers
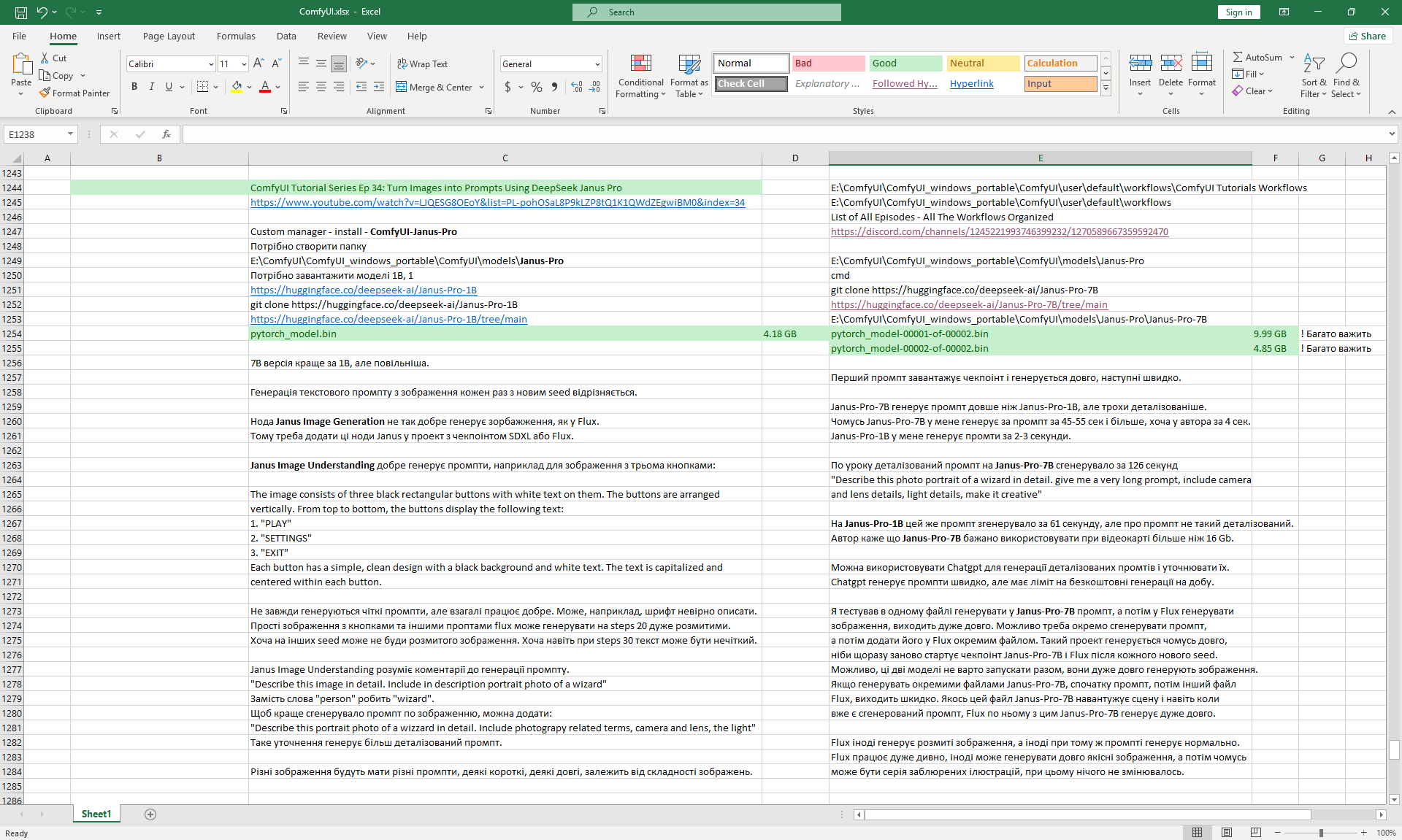
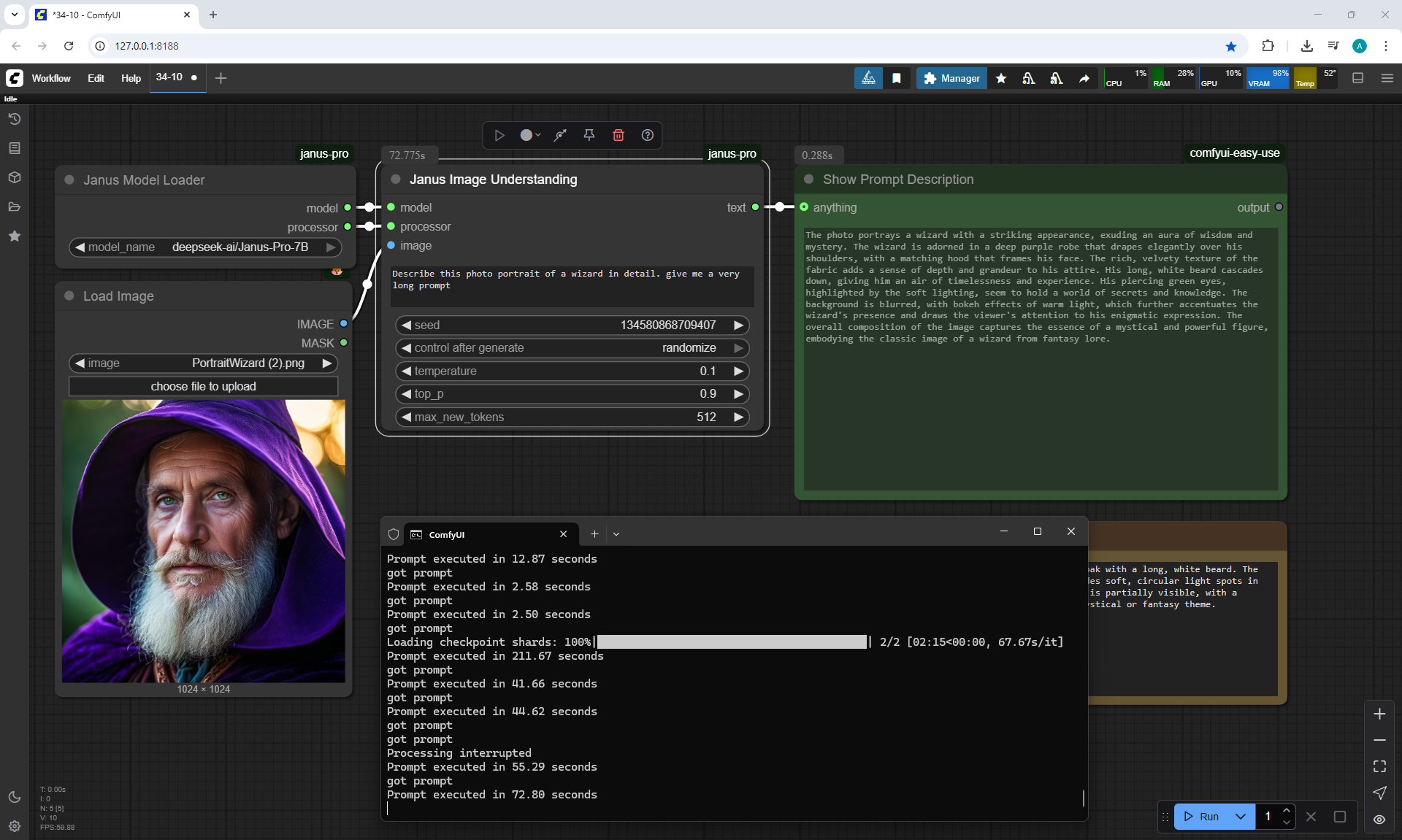
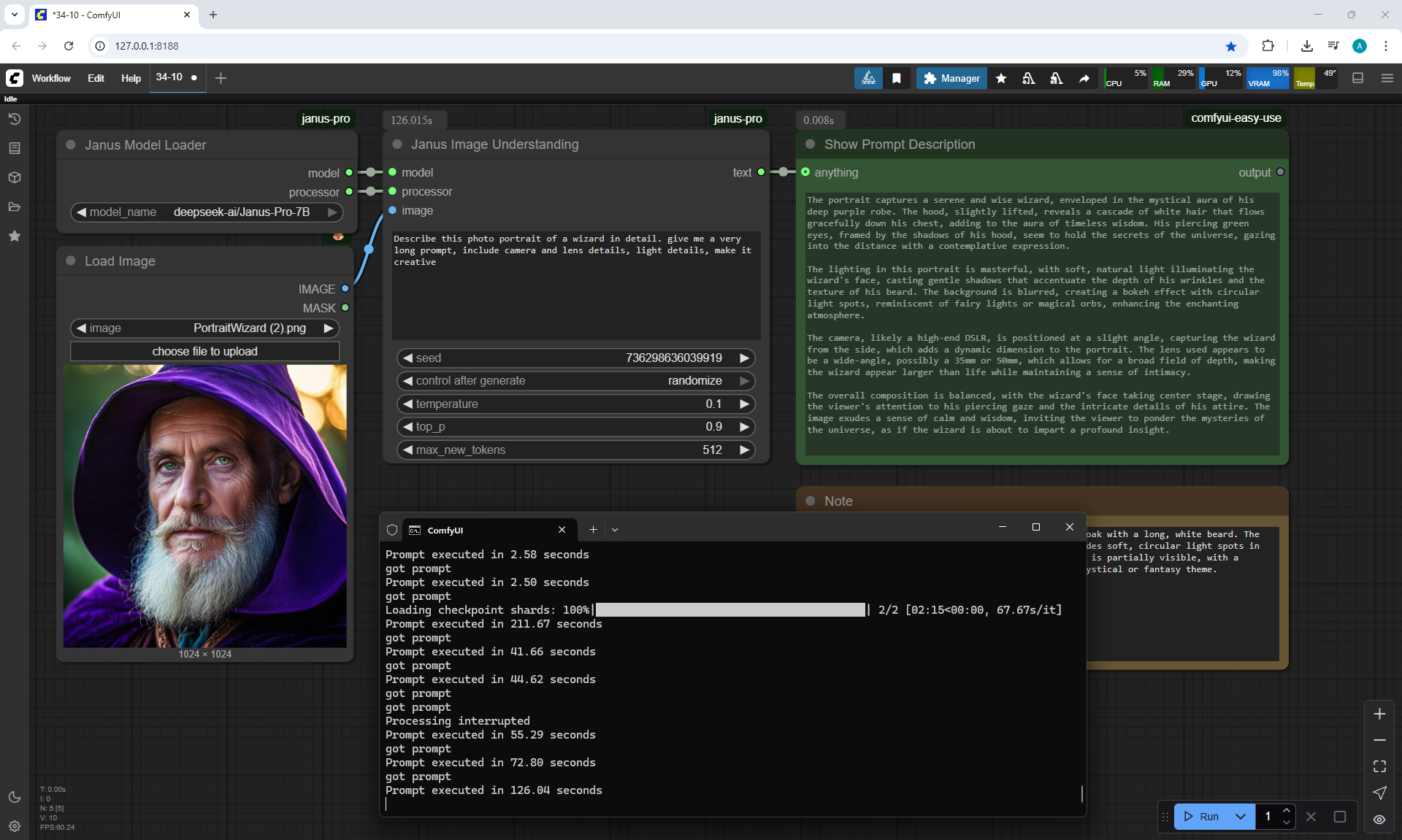
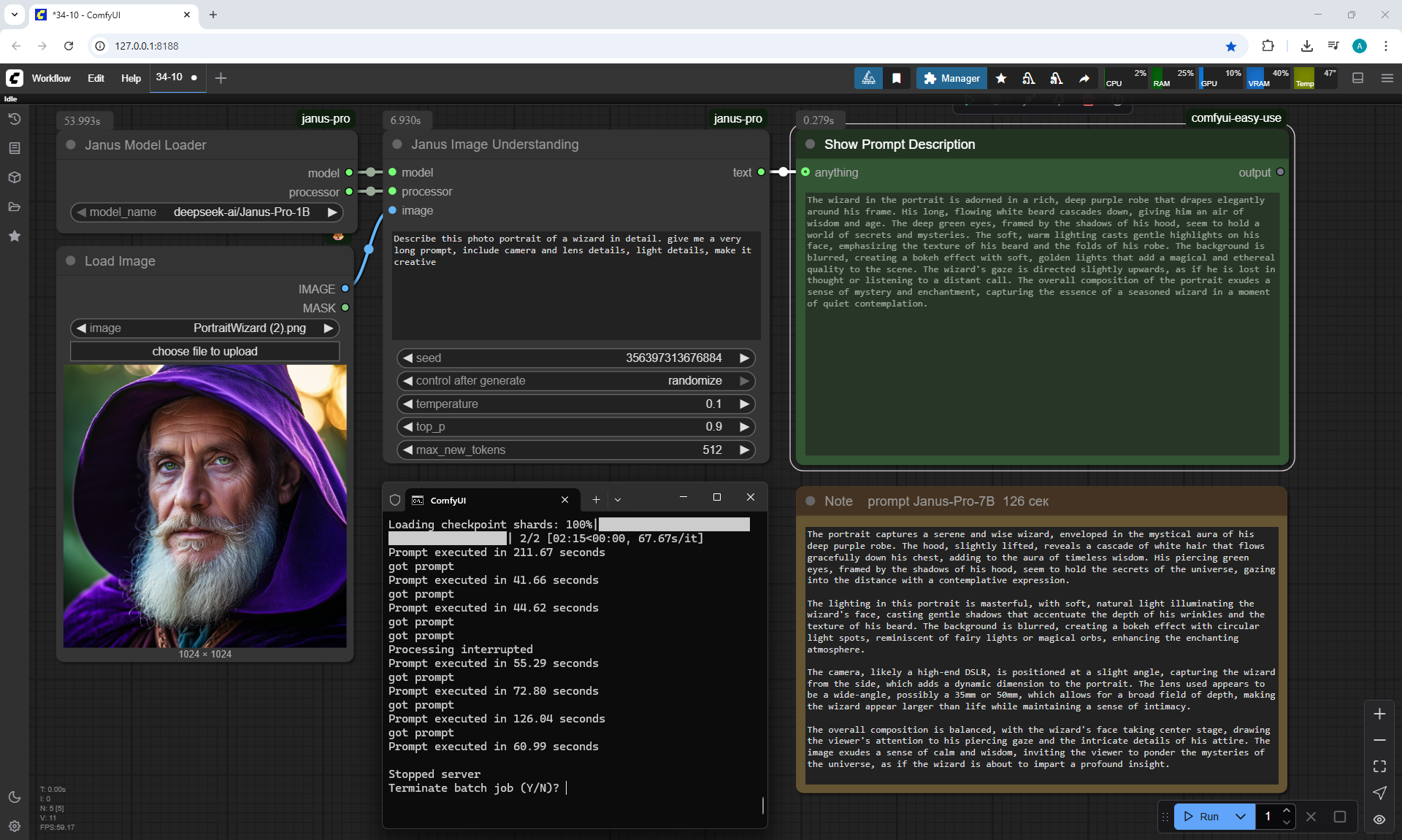
Ep34 - Turn Images into Prompts Using DeepSeek Janus Pro
Ep35 - How to Run ComfyUI in the Cloud
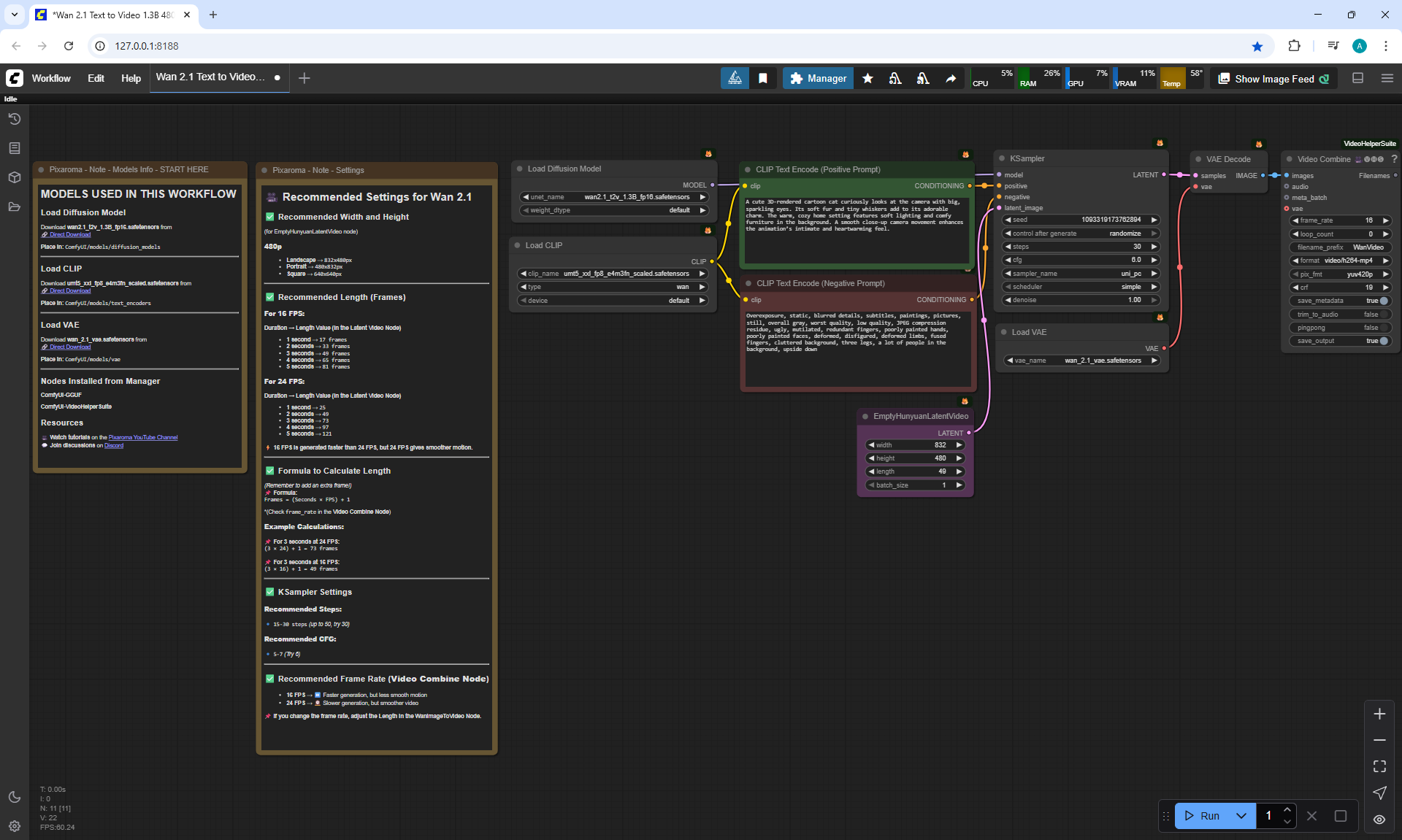
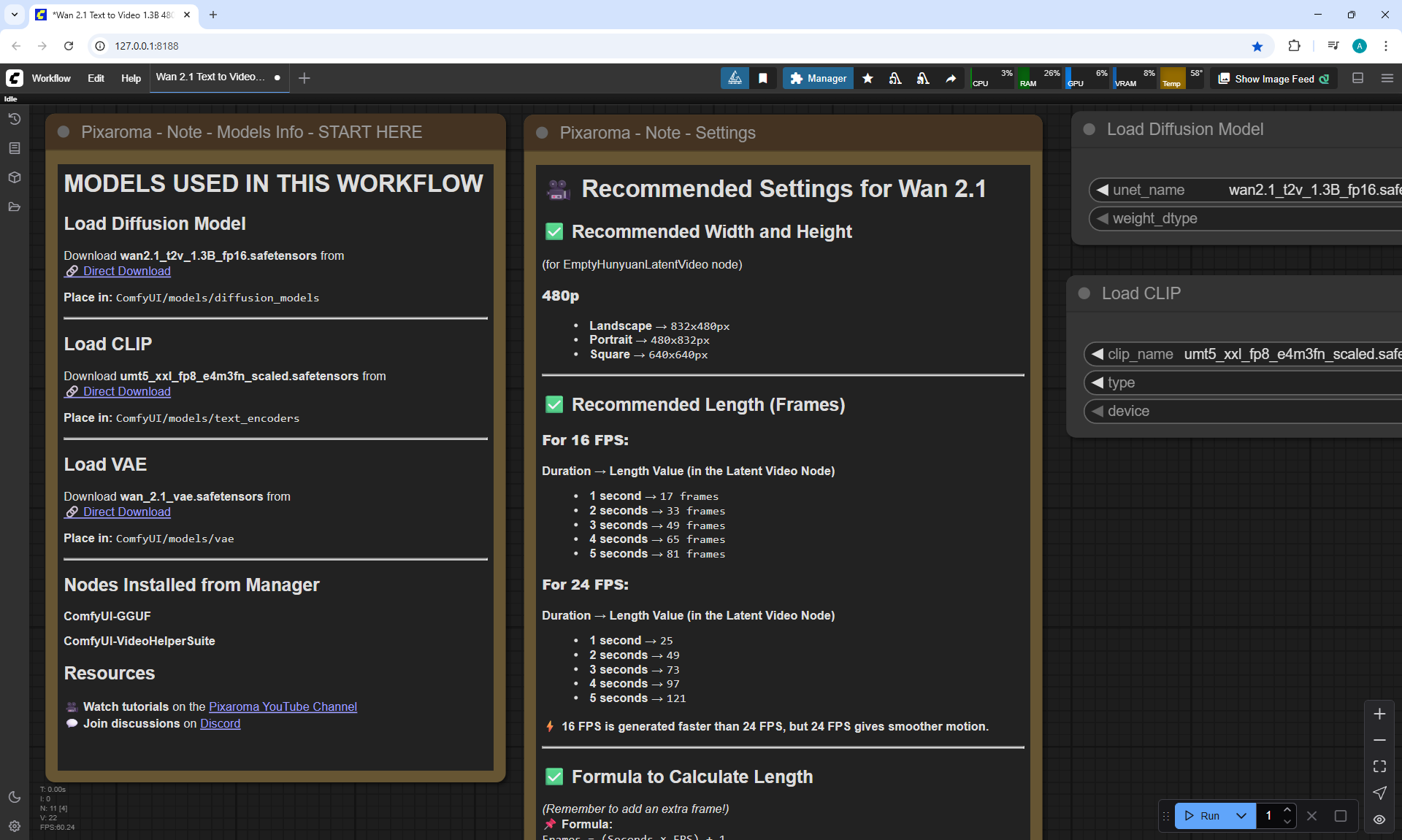
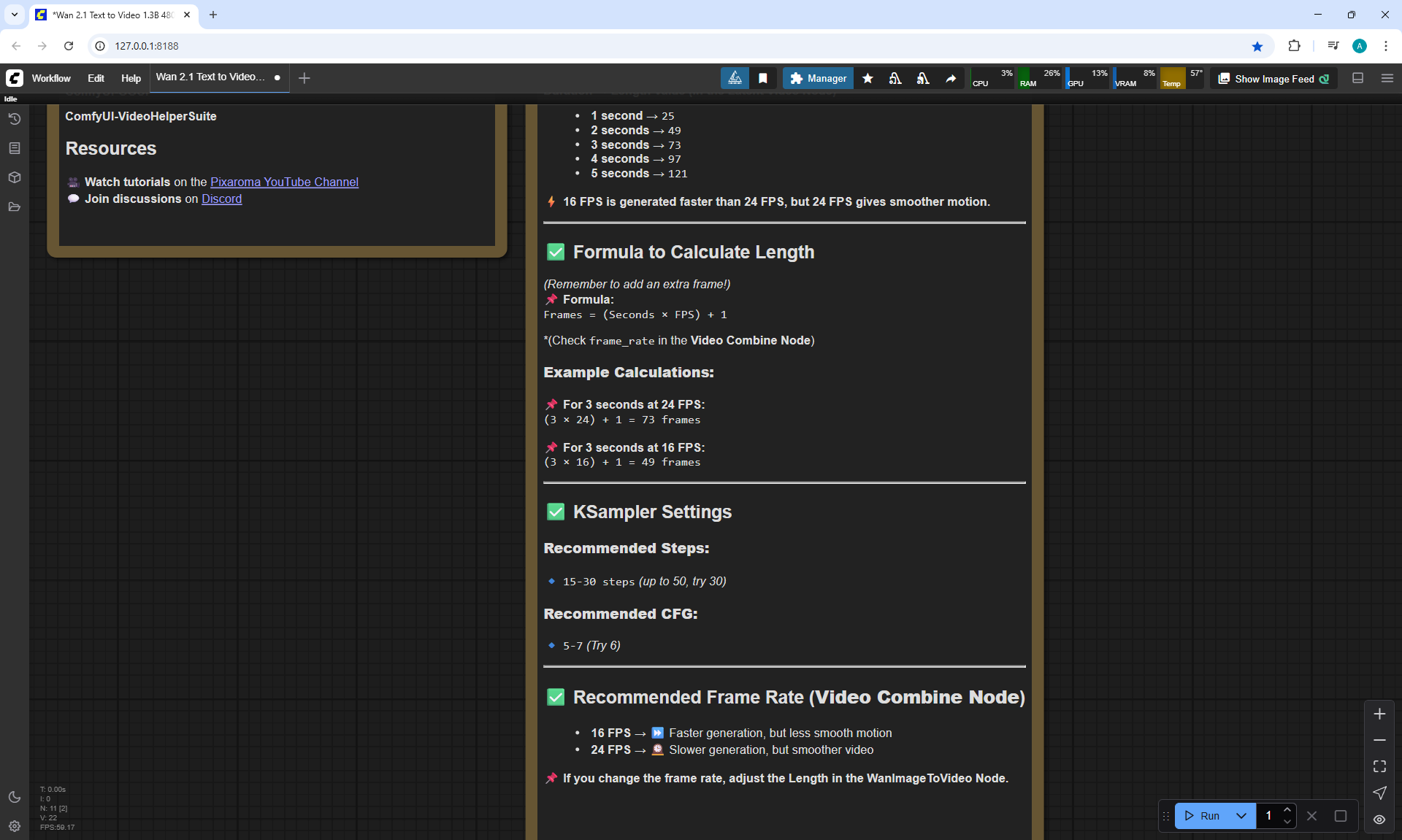
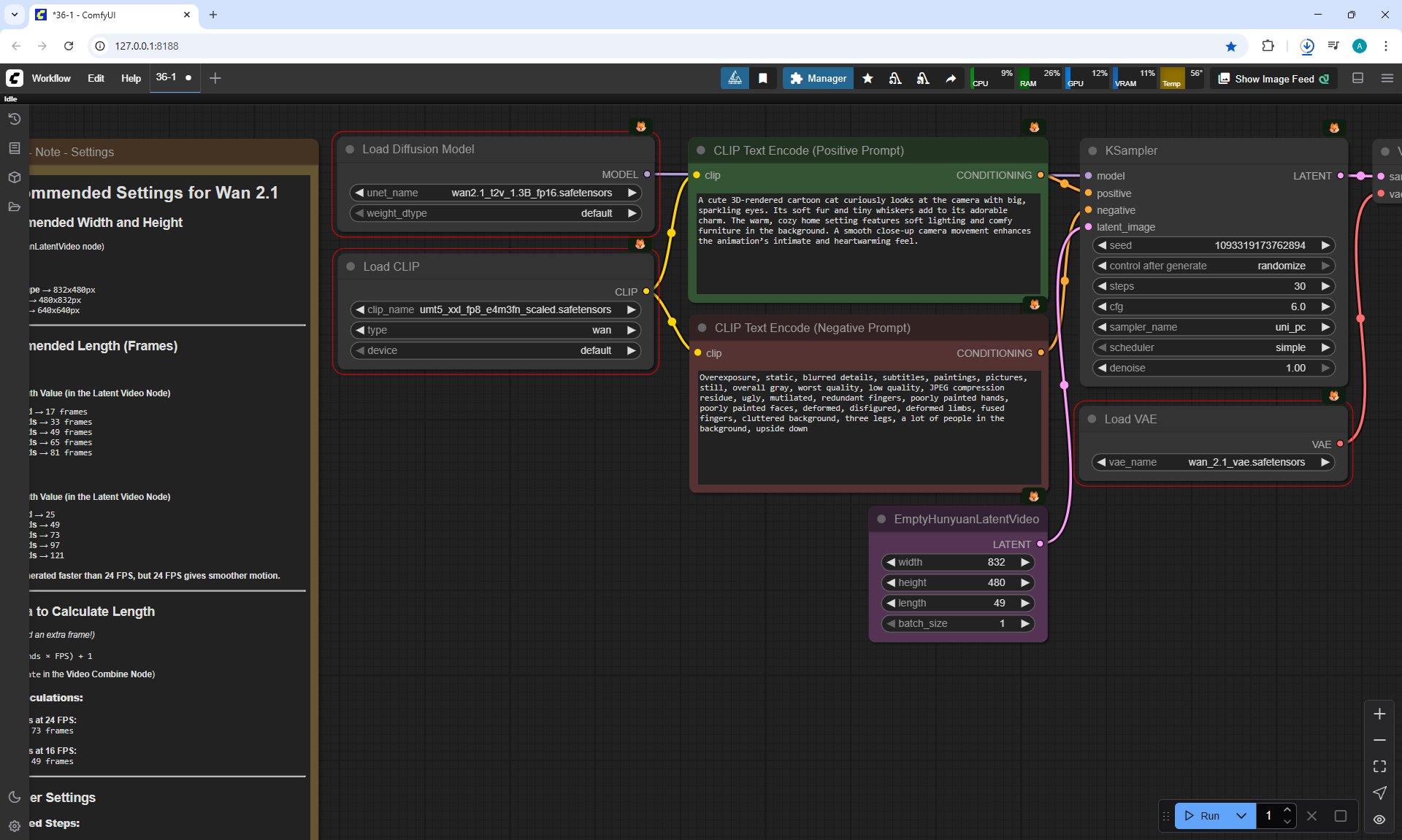
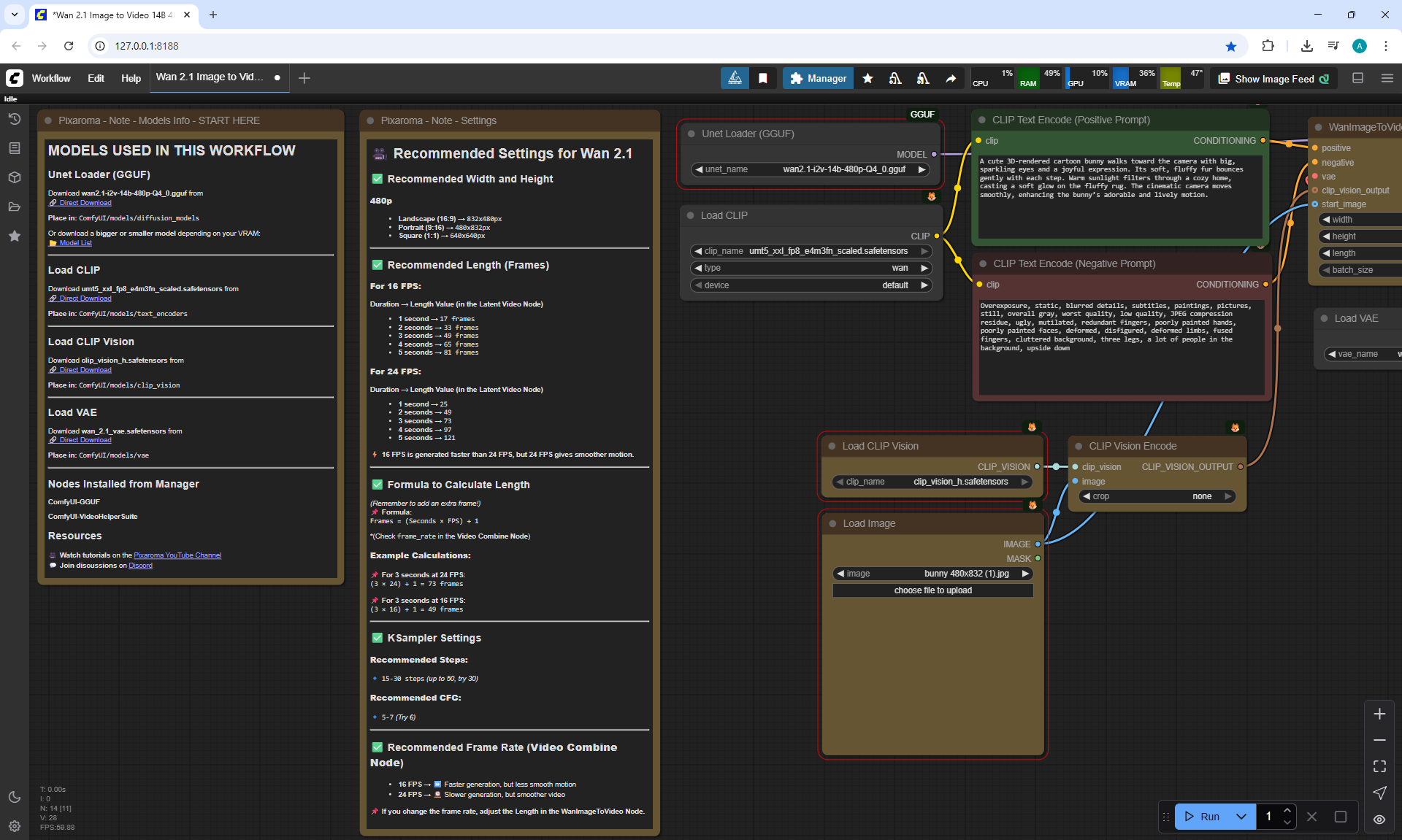
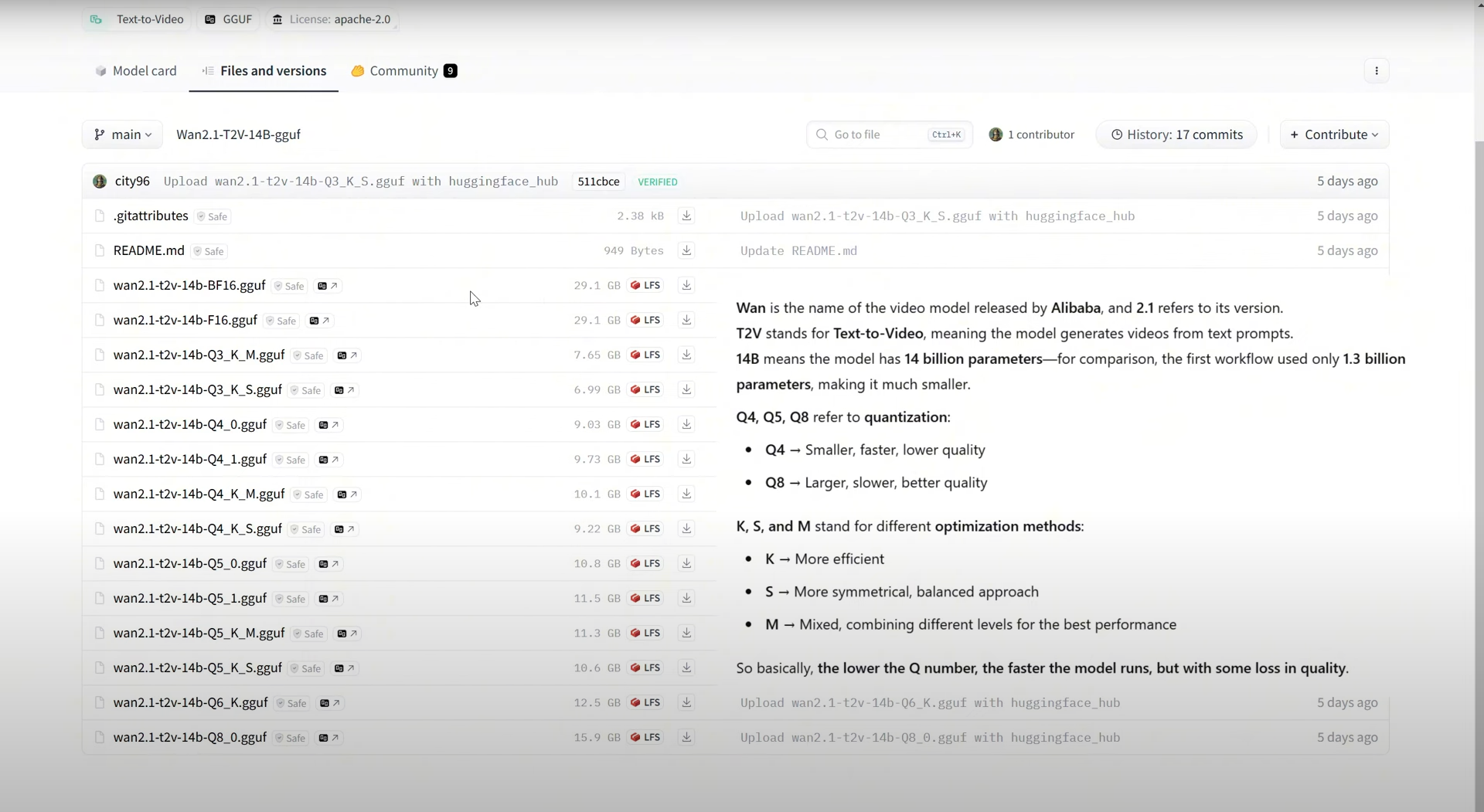
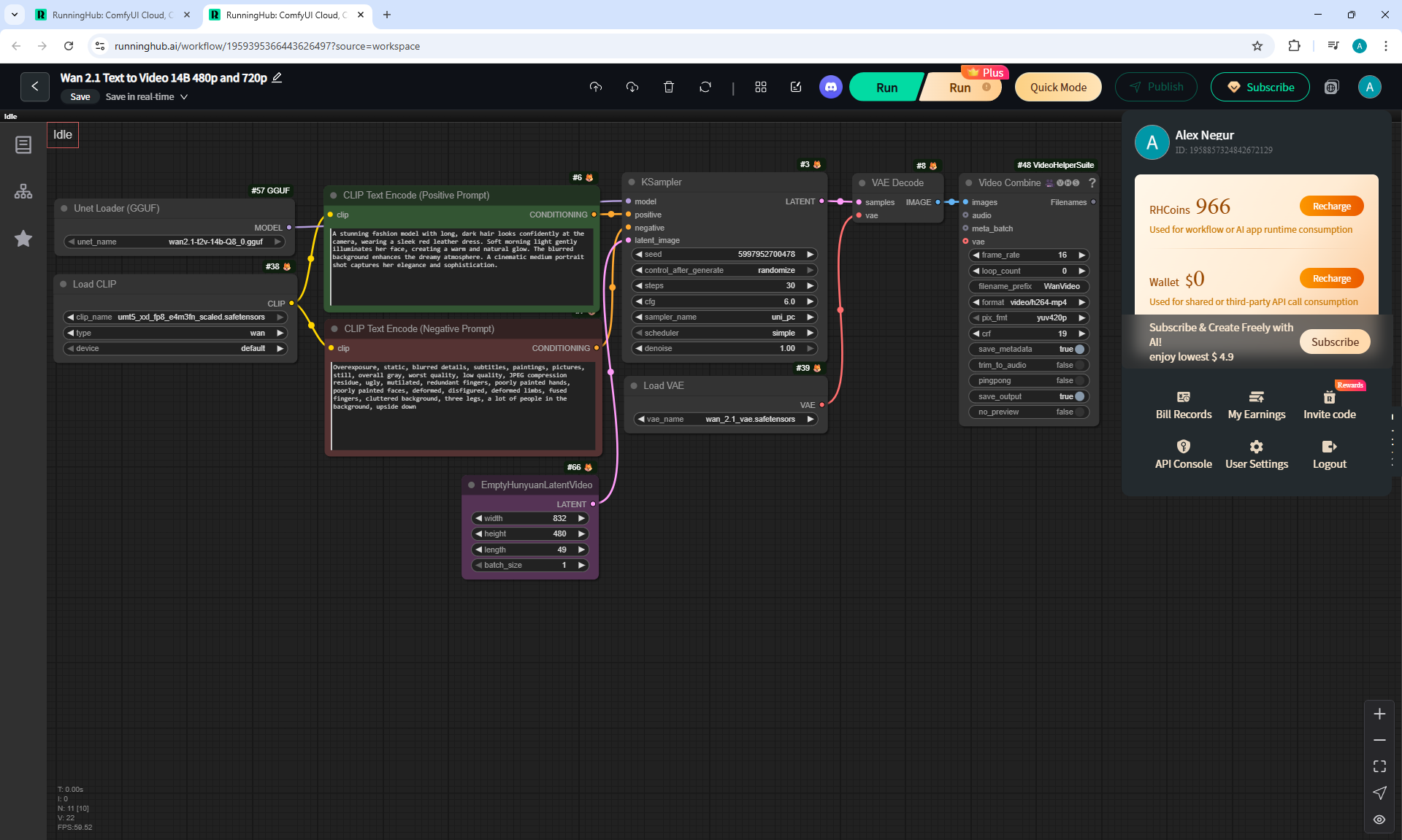
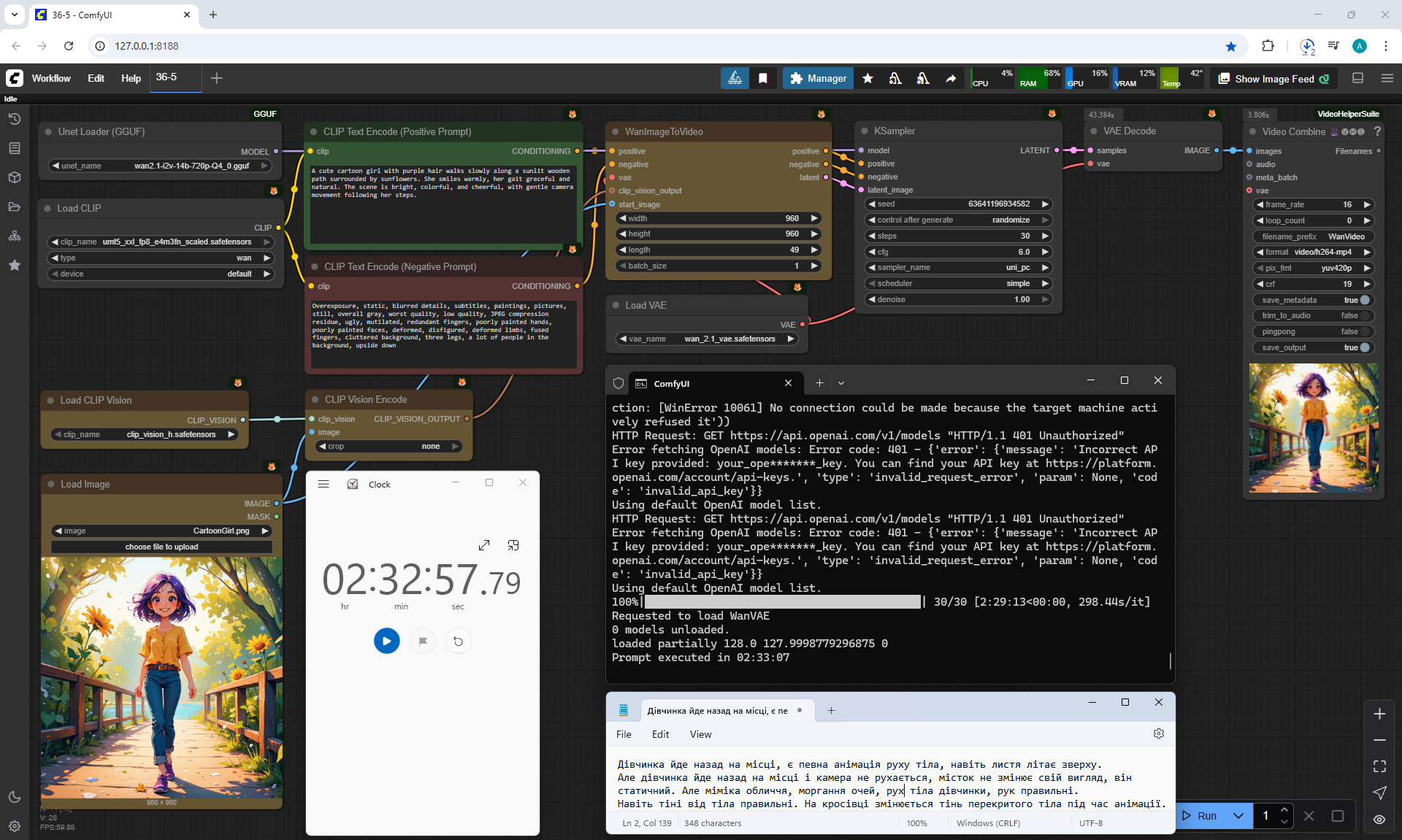
Ep36 - WAN 2.1 Installation – Turn Text & Images into Video!
Ep37 - LTX 0.9.5 Installation, Images to Video Faster Than Ever!
Ep38 - Bring Portraits to Life! Talking Avatar with Sonic
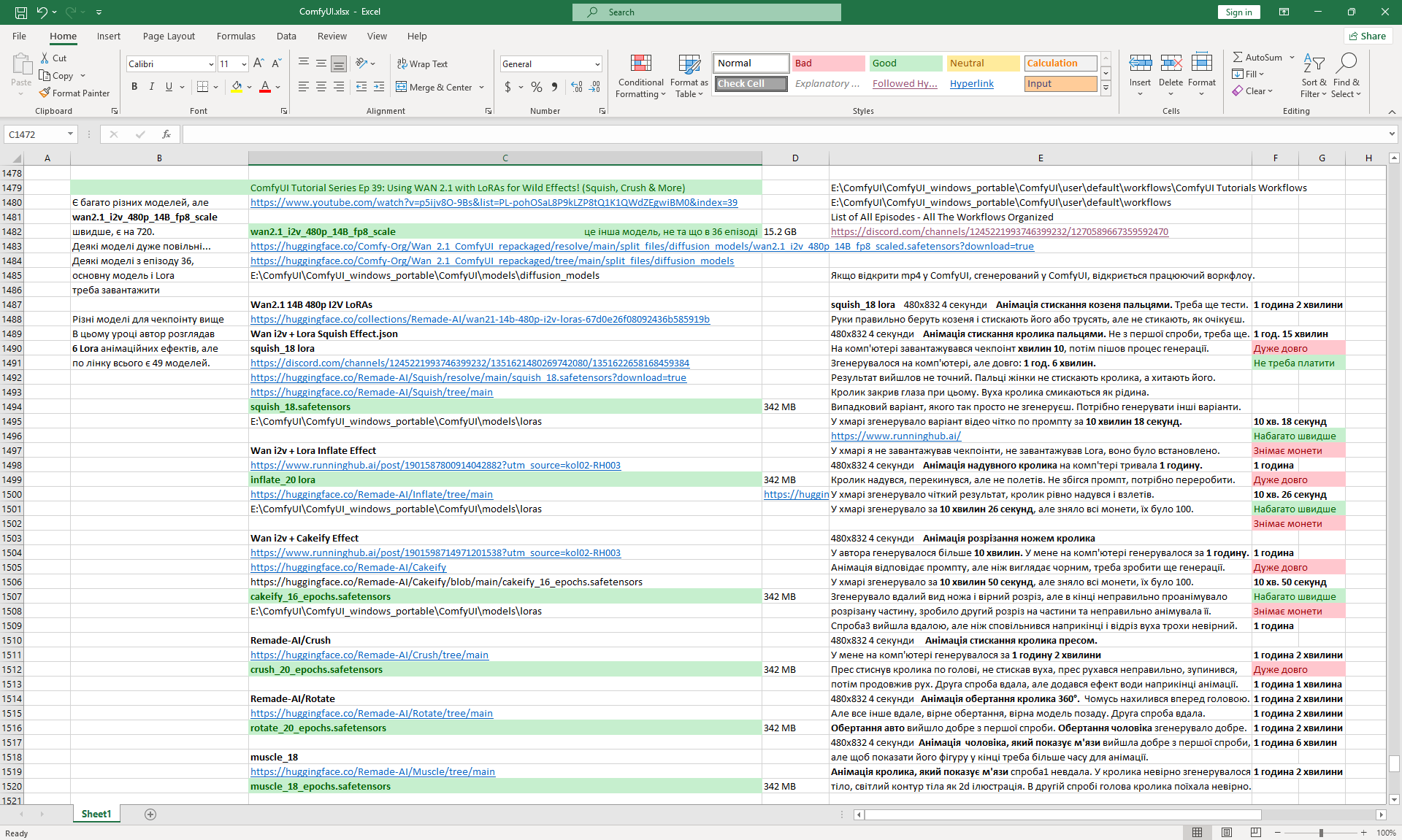
Ep39 - Using WAN 2.1 with LoRAs for Wild Effects: Squish, more
Ep40 - TeaCache: Speed Up Your Workflows with Smart Caching
Ep41 - How to Generate Photorealistic Images - Fluxmania
Ep42 - Inpaint & Outpaint Update + Tips for Better Results
Ep43 - KayTool – Align Nodes, Tweak Image Colors, Monitor
Ep44 - HiDream AI – How to Set Up & Choose the Best Model
Ep45 - Unlocking Flux Dev ControlNet Union Pro 2.0 Features
Ep46 - How to Upscale Your AI Images (Update)
Ep47 - Make Free AI Music with ACE-Step V1
Ep48 - LTX 0.9.7 – Turn Images into Video at Lightning Speed!
Ep49 - txt2video, img2video & video2video with Wan 2.1 VACE
Ep50 - Generate Stunning AI Images for Social Media, 50+ Free
Ep51 - Nvidia Cosmos Predict2 Image & Video
Ep52 - Master Flux Kontext – Inpainting, Editing & Character ..
Ep Nunchaku - Speed Up Flux Dev & Kontext with This Trick
Ep53 - Flux Kontext LoRA Training with Fal AI - Tips & Tricks
Ep54 - Create Vector SVG Designs with Flux Dev & Kontext
Ep55 - Sage Attention, Wan Fusion X, Wan 2.2 & Video Upscale ..
Ep56 - Flux Krea & Shuttle Jaguar Workflows
Ep57 - Qwen Image Generation Workflow for Stunning Results
Ep58 - Wan 2.2 Image Generation Workflows
Ep59 - Qwen Edit Workflows for Smarter Image Edits
Ep60 - Infinite Talk (Audio-Driven Talking AI Characters)
Ep61 - USO - Unified Style and Subject-Driven Generation
Ep62 - Nunchaku Update | Qwen Control Net, Qwen Edit & Inpa..
Ep63 - API Nodes - Run Nano Banana, GPT-5 & Seedream 4
Ep64 - Nunchaku Qwen Image Edit 2509
Ep65 - VibeVoice Free Text to Speech Workflow
Ep66 - Qwen Outpainting Workflow + Subgraph Tips
Ep67 - Fluxmania Nunchaku + Wan2.2 and Rapid AIO Workflows
Ep68 - How to Create Anime Illustrations - NetaYume v3.5
Ep69 - Create Long Videos with LongCat Video Model
Ep70 - Nunchaku Qwen Loras - Relight, Camera Angle & Scene..
Ep71 - QwenVL 3 - Get Prompts From Images & Video
Ep72 - Z-Image Turbo Workflows, ControlNet Esse.. & LoRA Trai..
Ep73 - Final Episode & Z-Image ControlNet 2.0
ComfyUI Tutorial Series Ep 31: ComfyUI Tips & Tricks You Need to Know




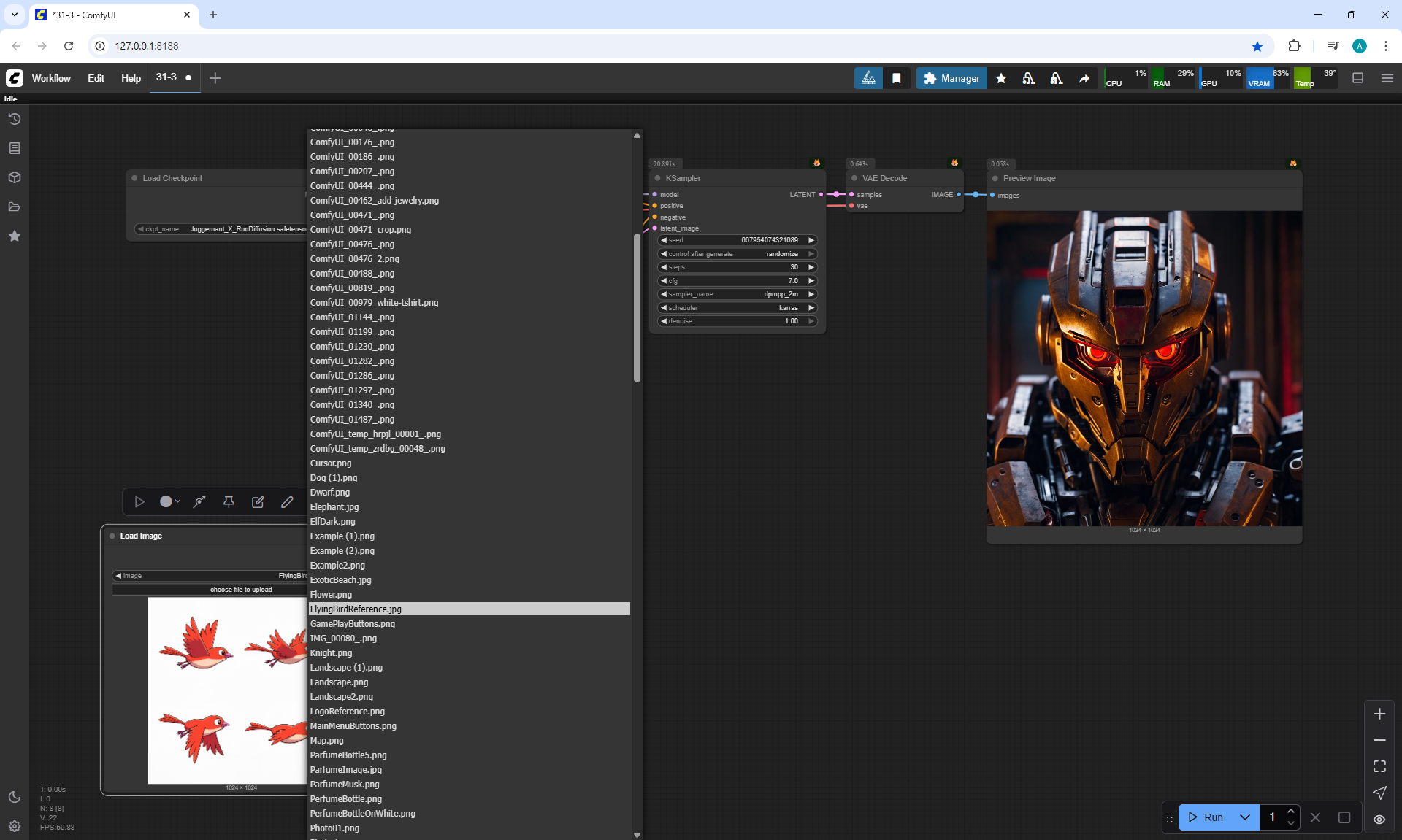
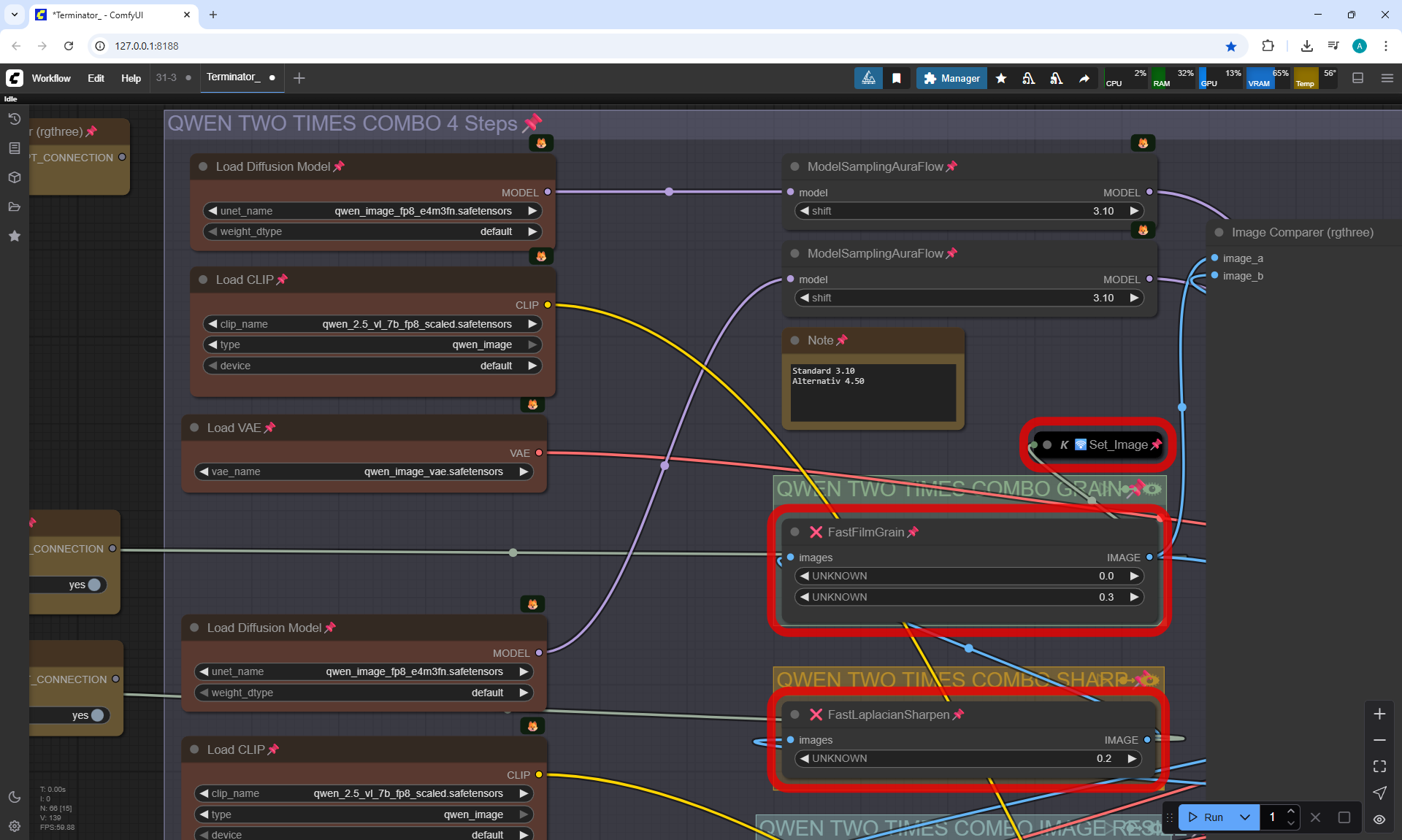
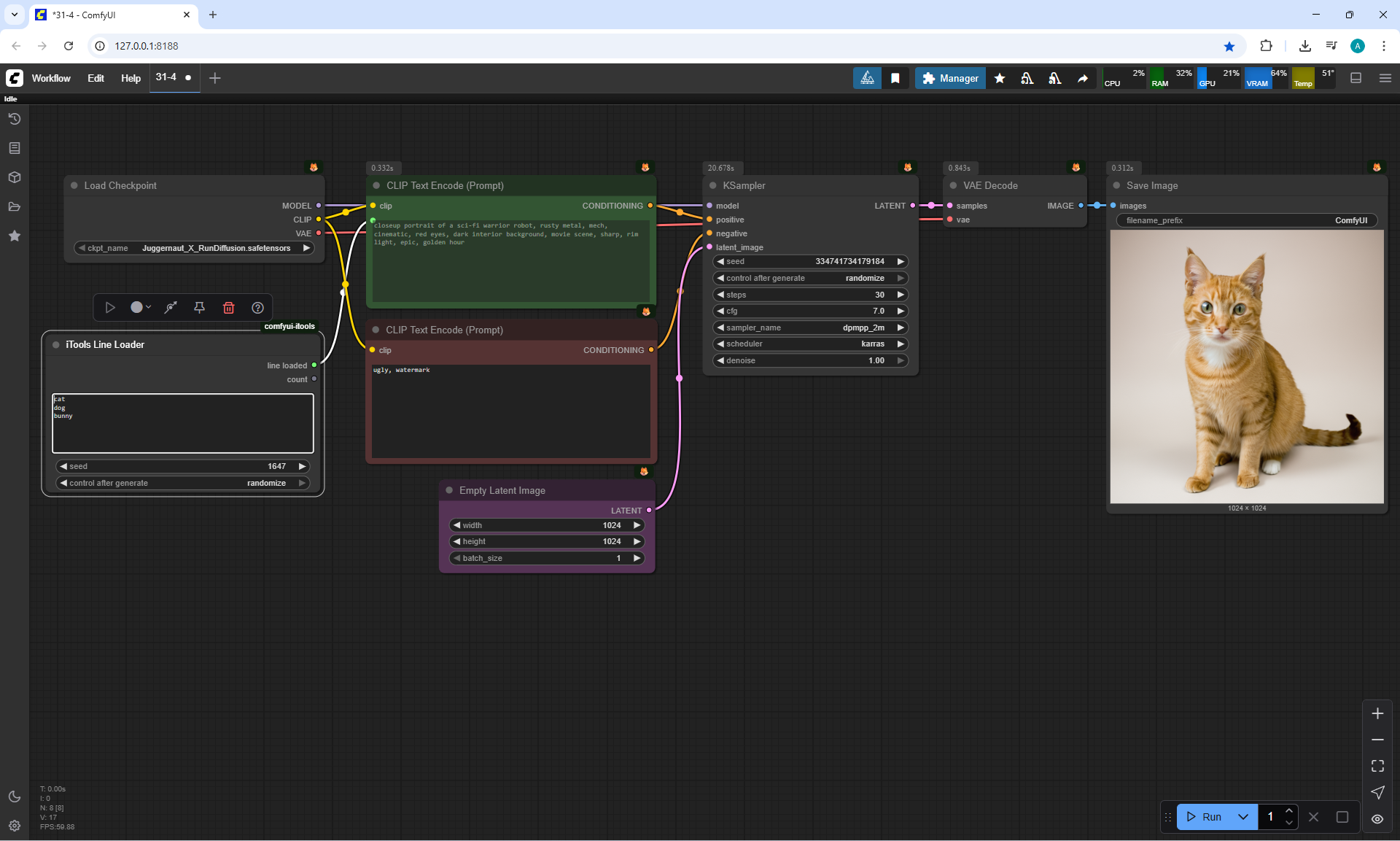
ComfyUI Tutorial Series Ep 32: How to Create Vector SVG Files with AI





















ComfyUI Tutorial Series Ep 33: How to Use Free & Local Text-to-Speech for AI Voiceovers
001.flac
002.flac
003.flac
004.flac
005.flac
006.flac
007.flac
008.flac
009.flac
010.flac
011.flac
012.flac
I created these sounds in ComfyUI, using ComfyUI Kokoro. There are no emotions in these sounds yet.
ElevenLabs: British Radio Host Storyteller: David.mp3
ElevenLabs: British Radio Host Storyteller: Alice.mp3
ElevenLabs: British Radio Host Storyteller: Grandpa.mp3
ElevenLabs: British Radio Host Storyteller: Callum.mp3
I created these sounds on the website https://elevenlabs.io
They have human emotions in their voices.
The site generates text well, but you need a paid subscription to choose certain voices.
I see up to ten free voices, others are paid. There are different settings for the voice.
On the site, the voice can understand the content of the text and convey intonations in the voice.
For example, speak with laughter, shout, convey anger, communicate romantically,
specifically stutter and convey other emotions.
The voices on the site are very natural and convey emotions compared to the voices in ComfyUI.
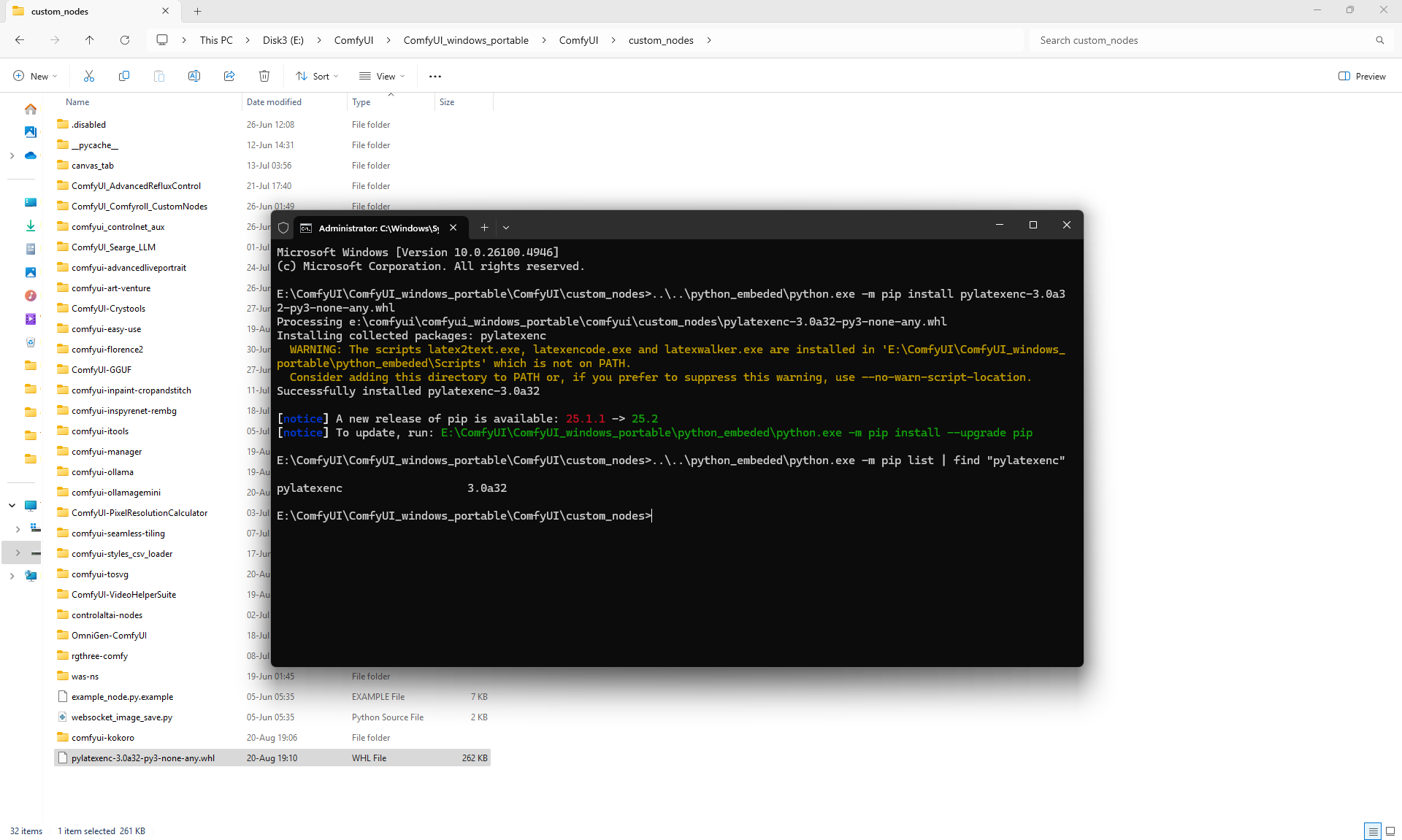
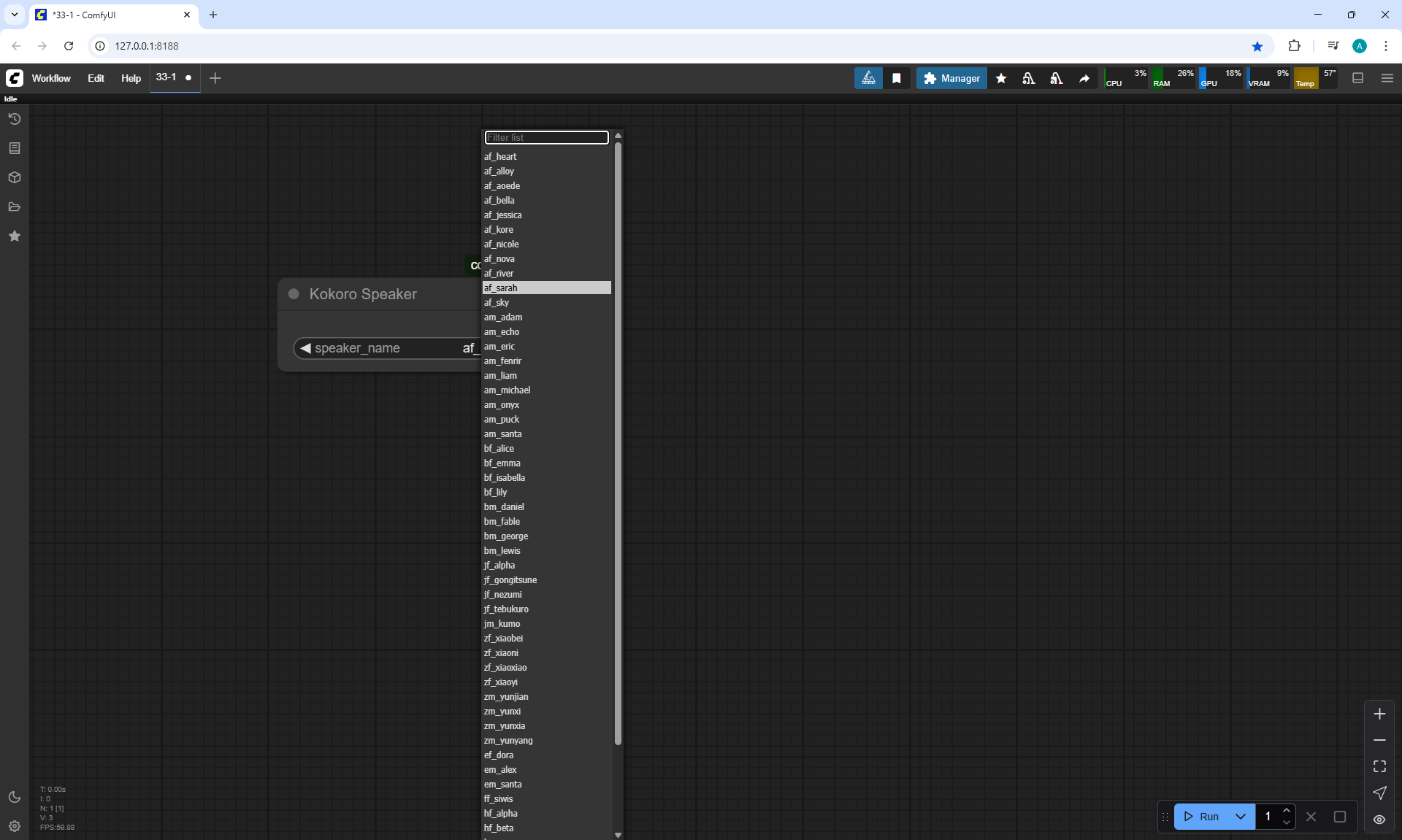
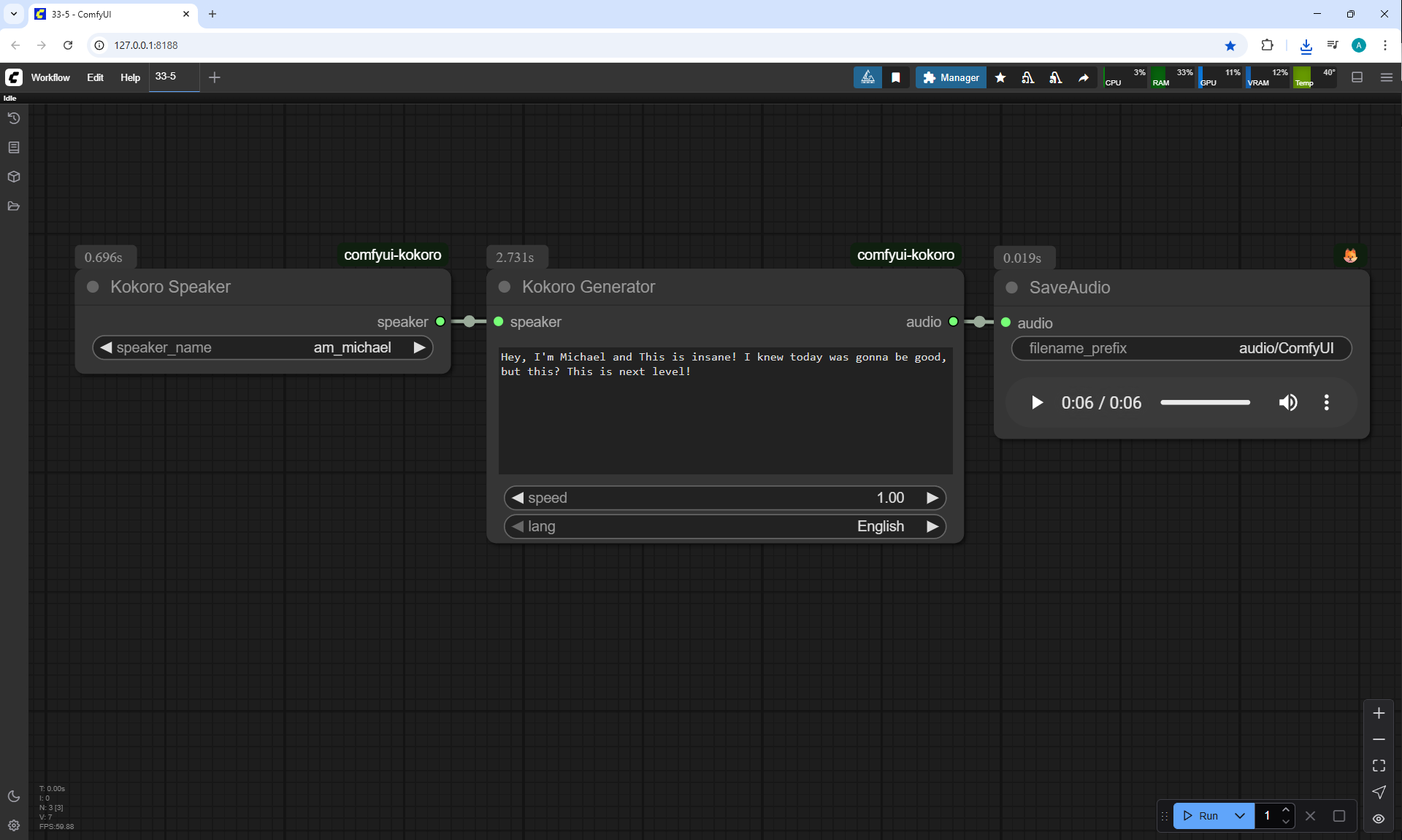
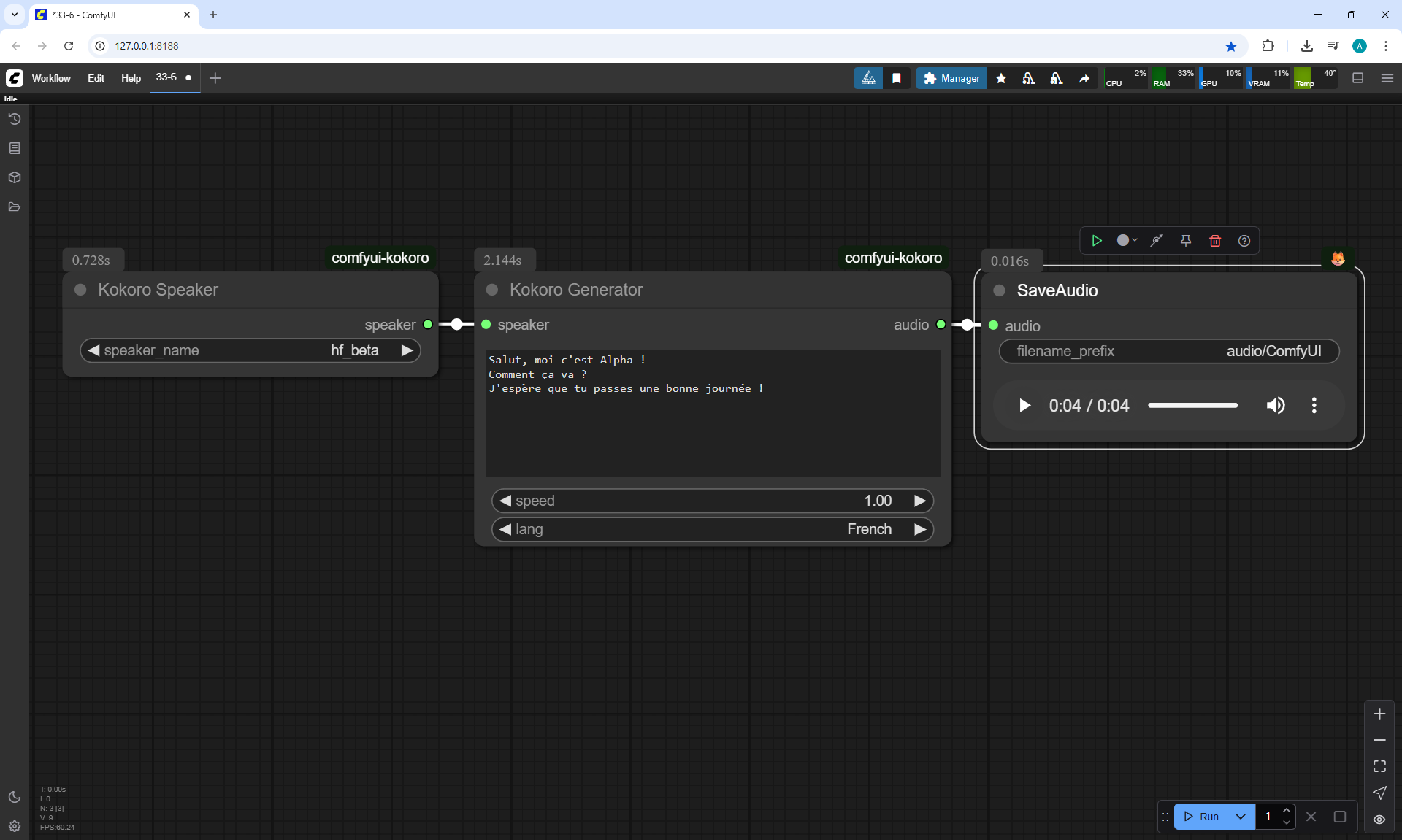
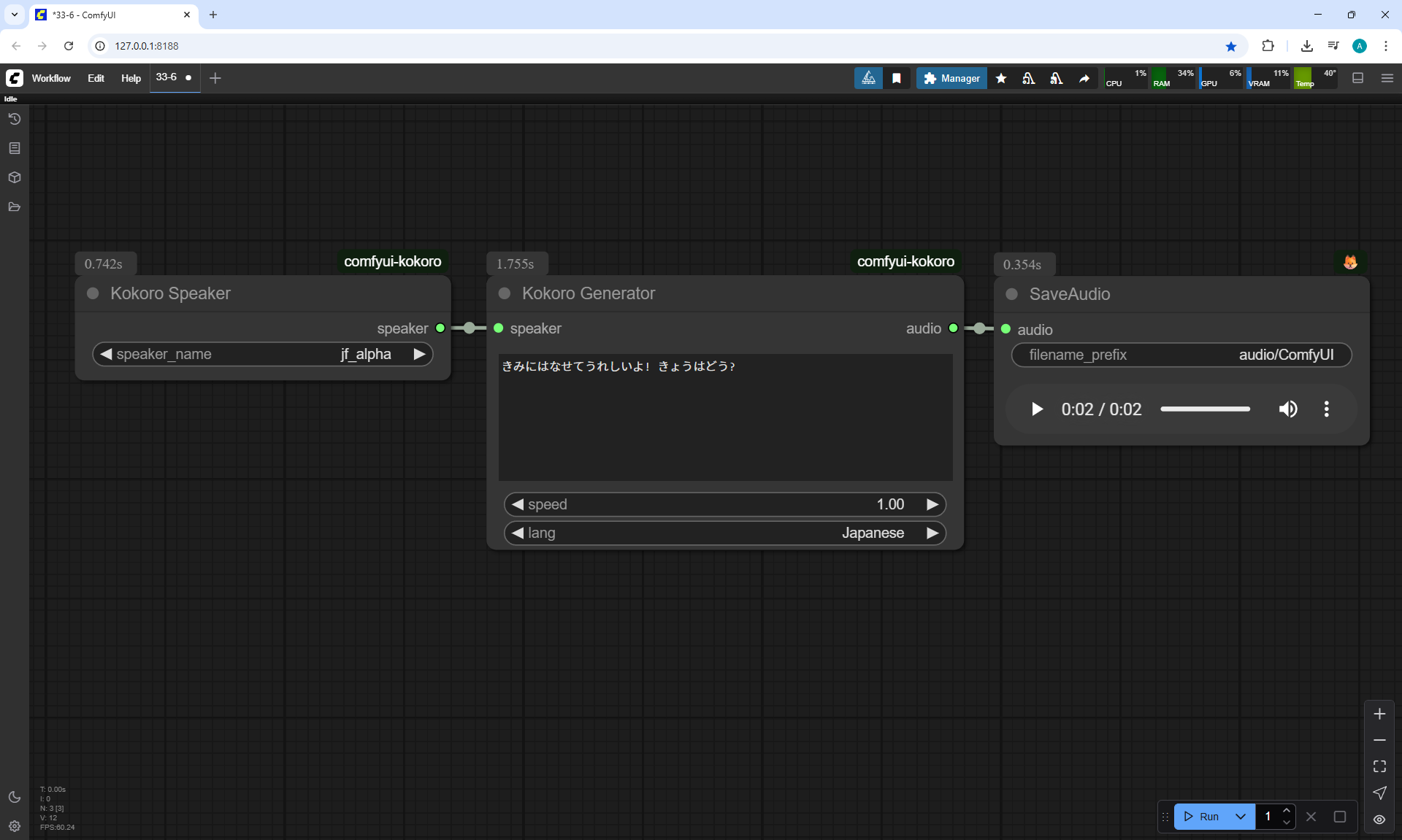
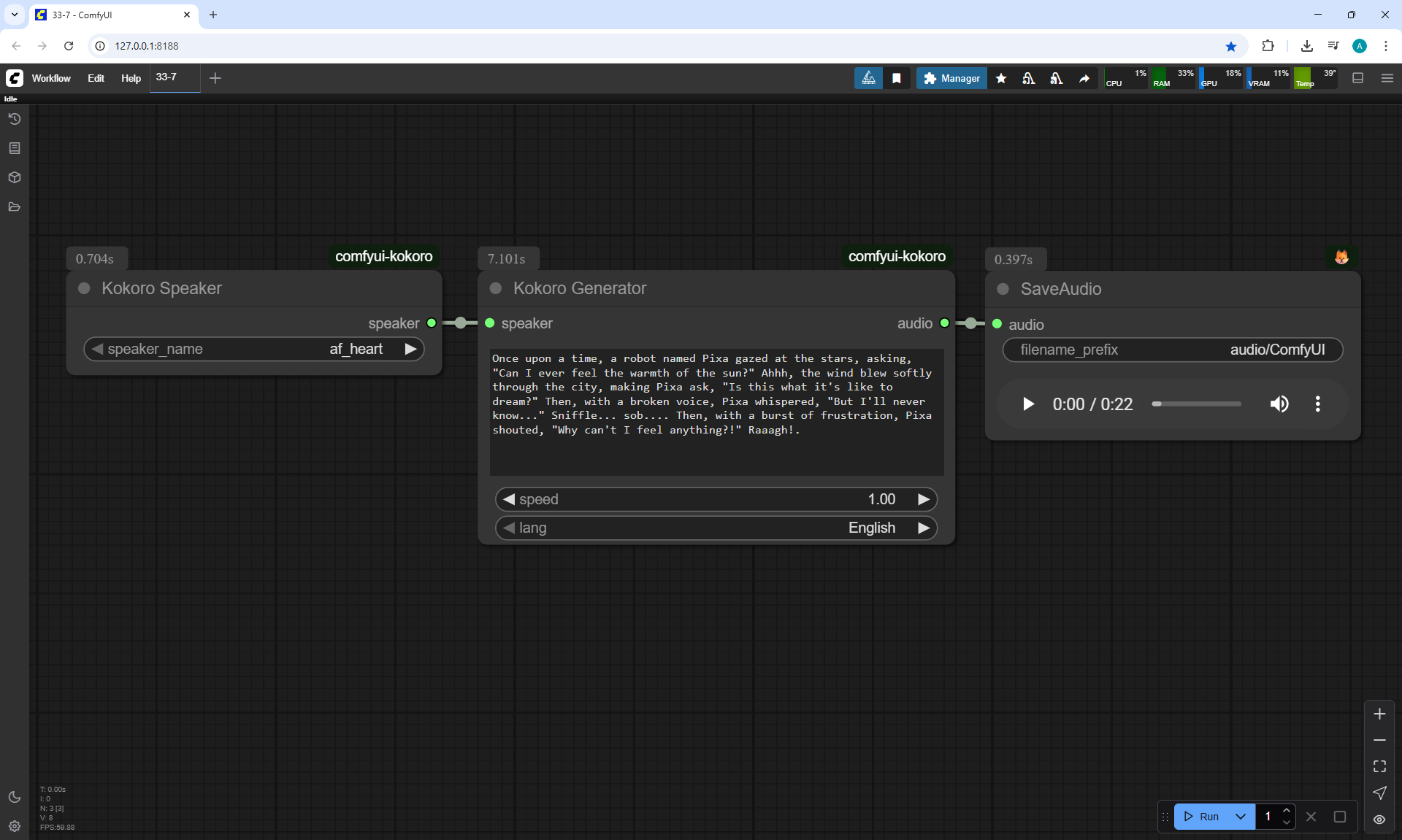
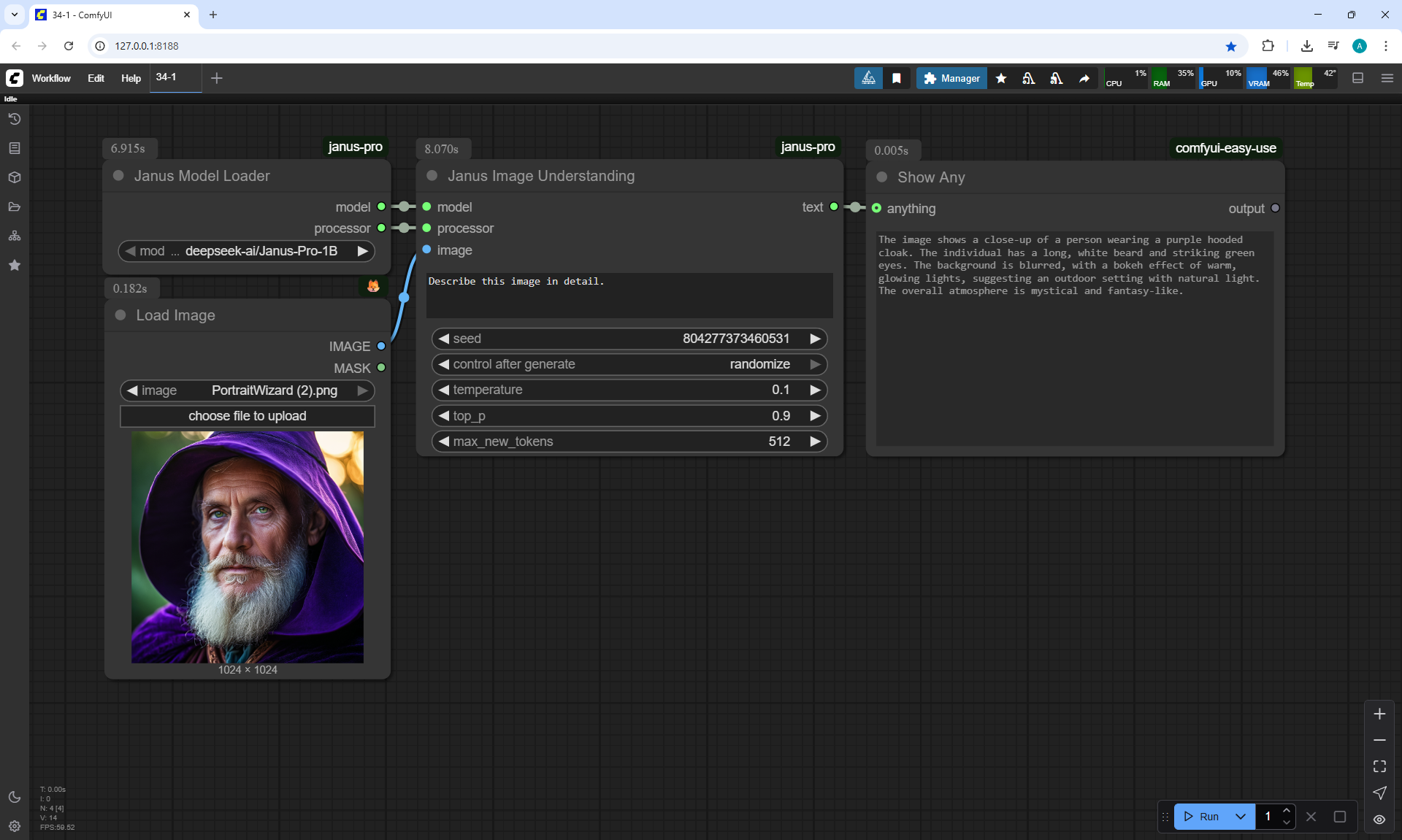
ComfyUI Tutorial Series Ep 34: Turn Images into Prompts Using DeepSeek Janus Pro



























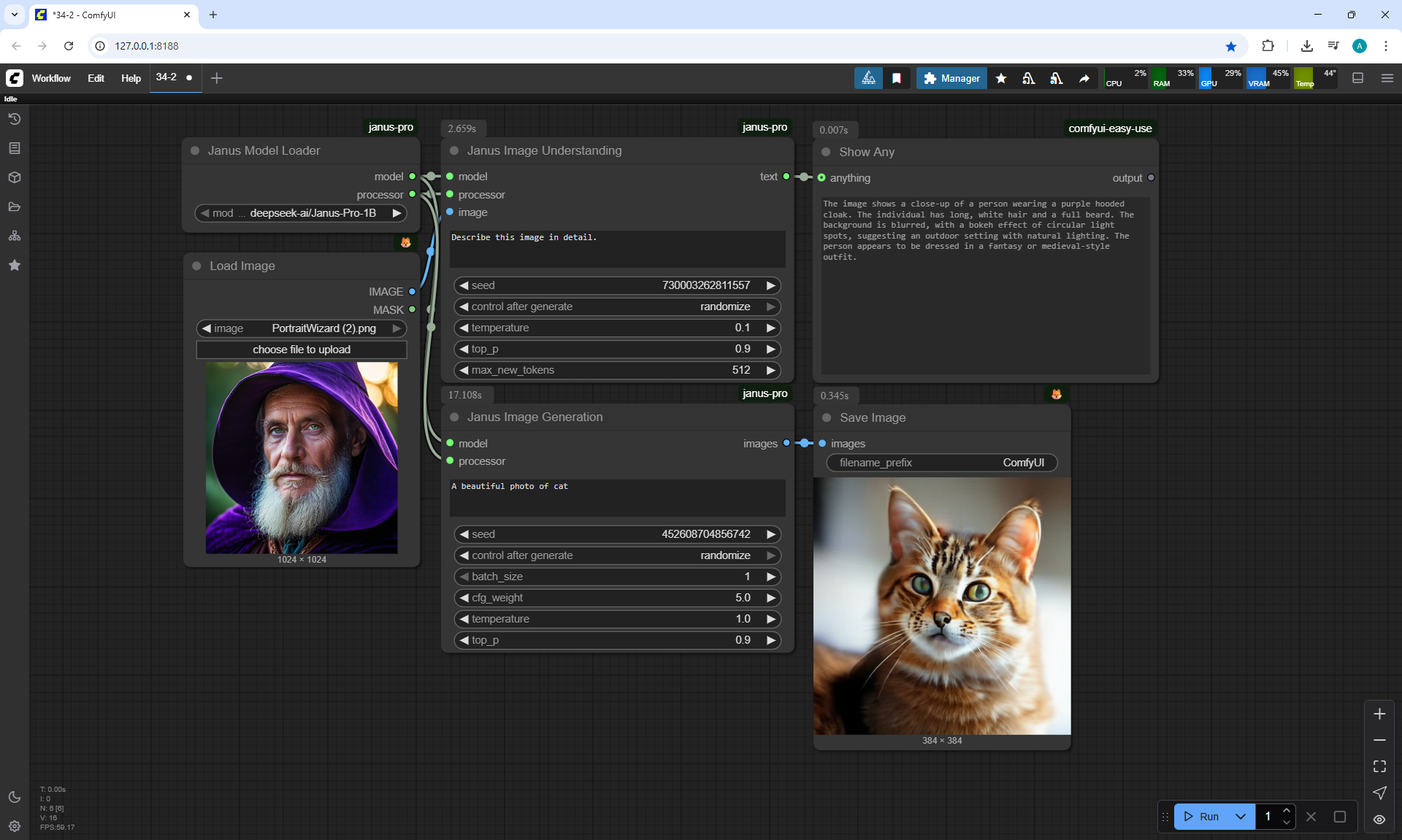
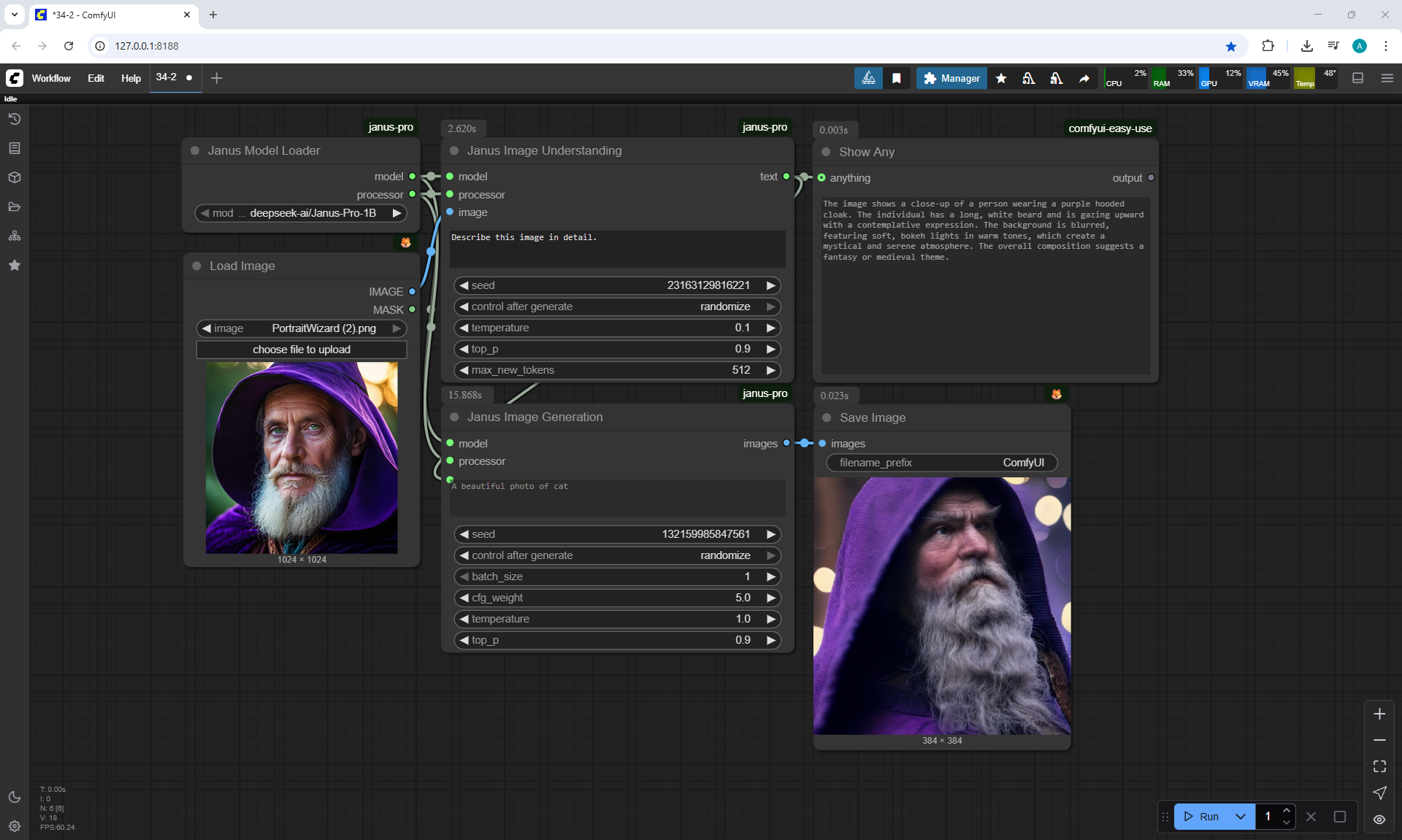
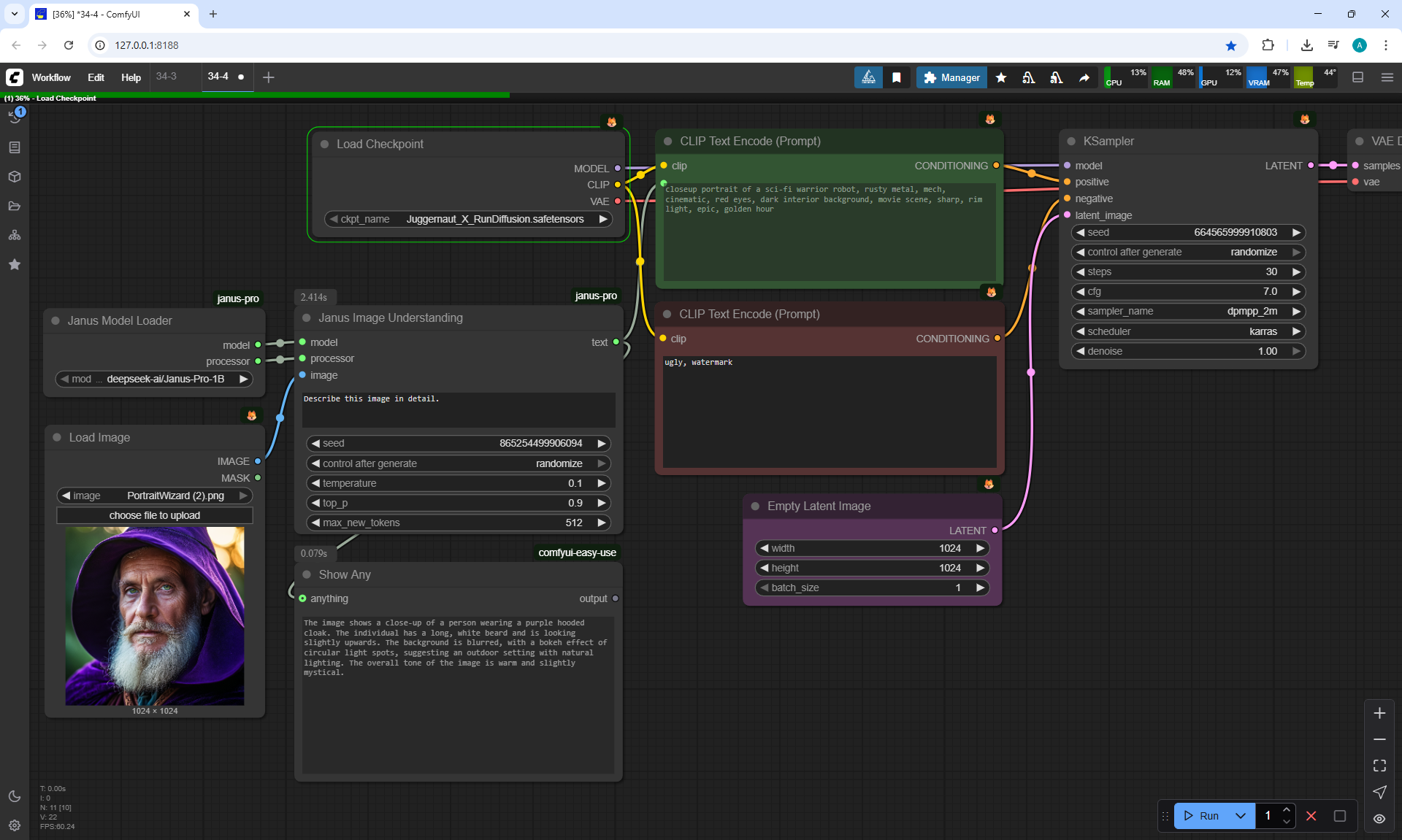
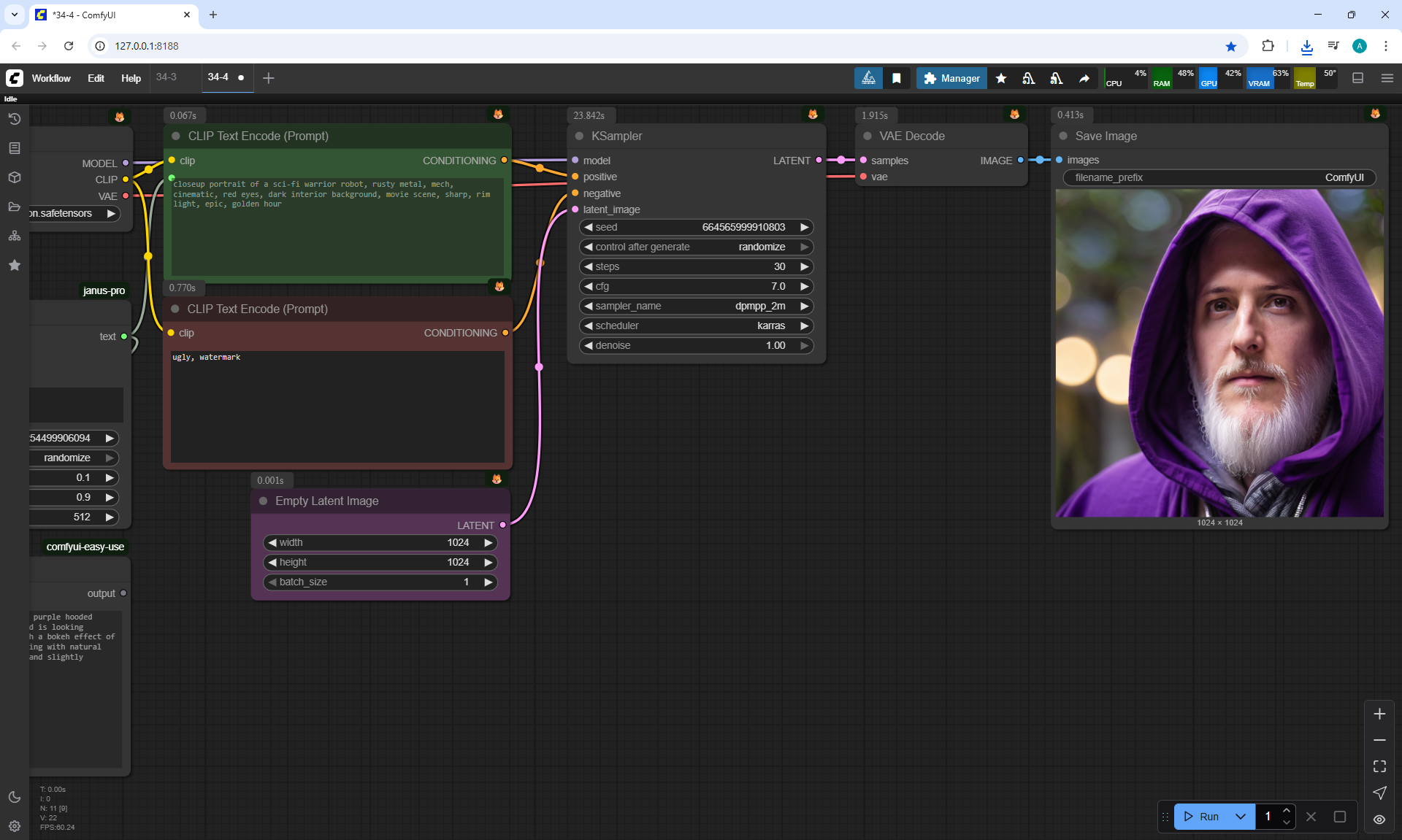
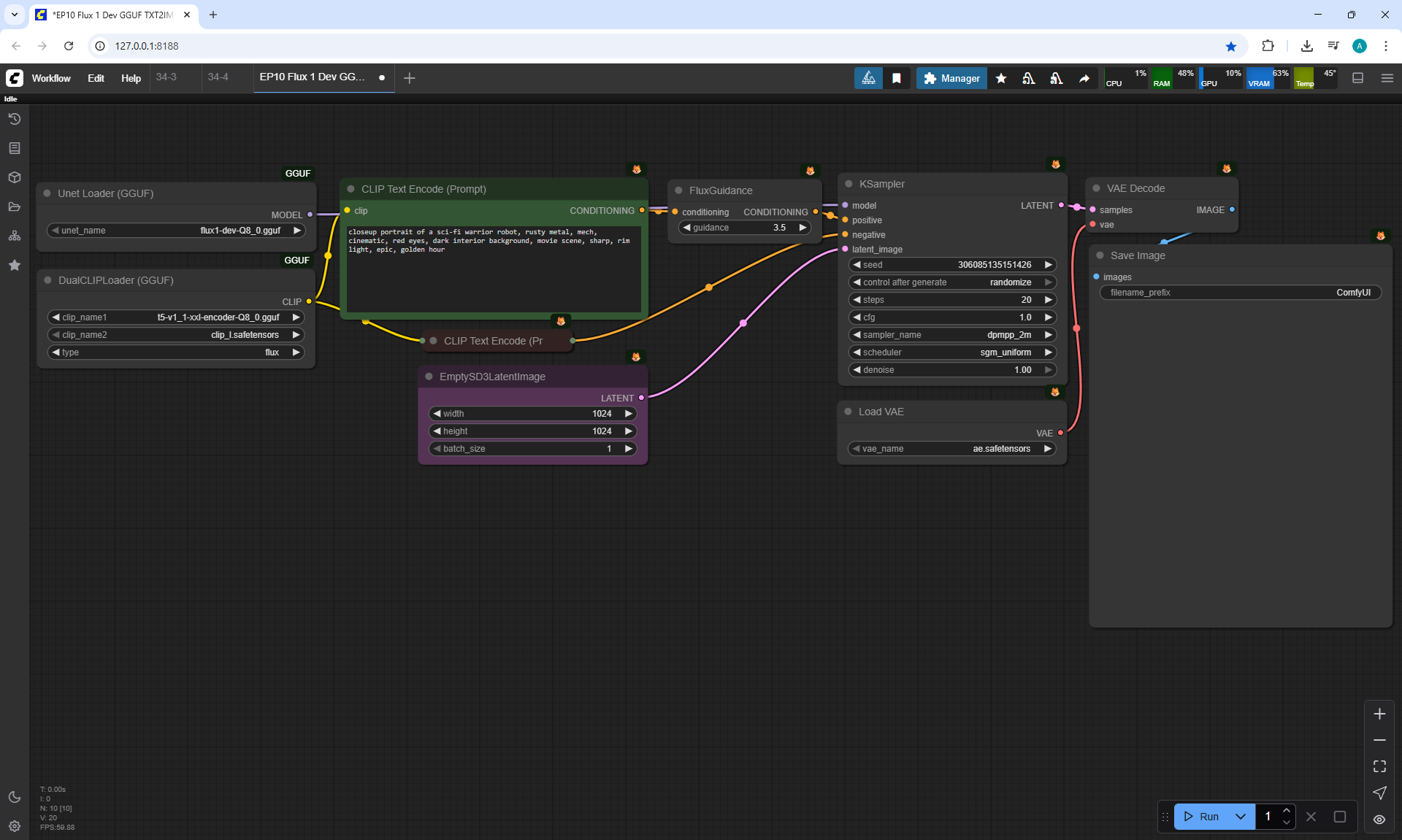
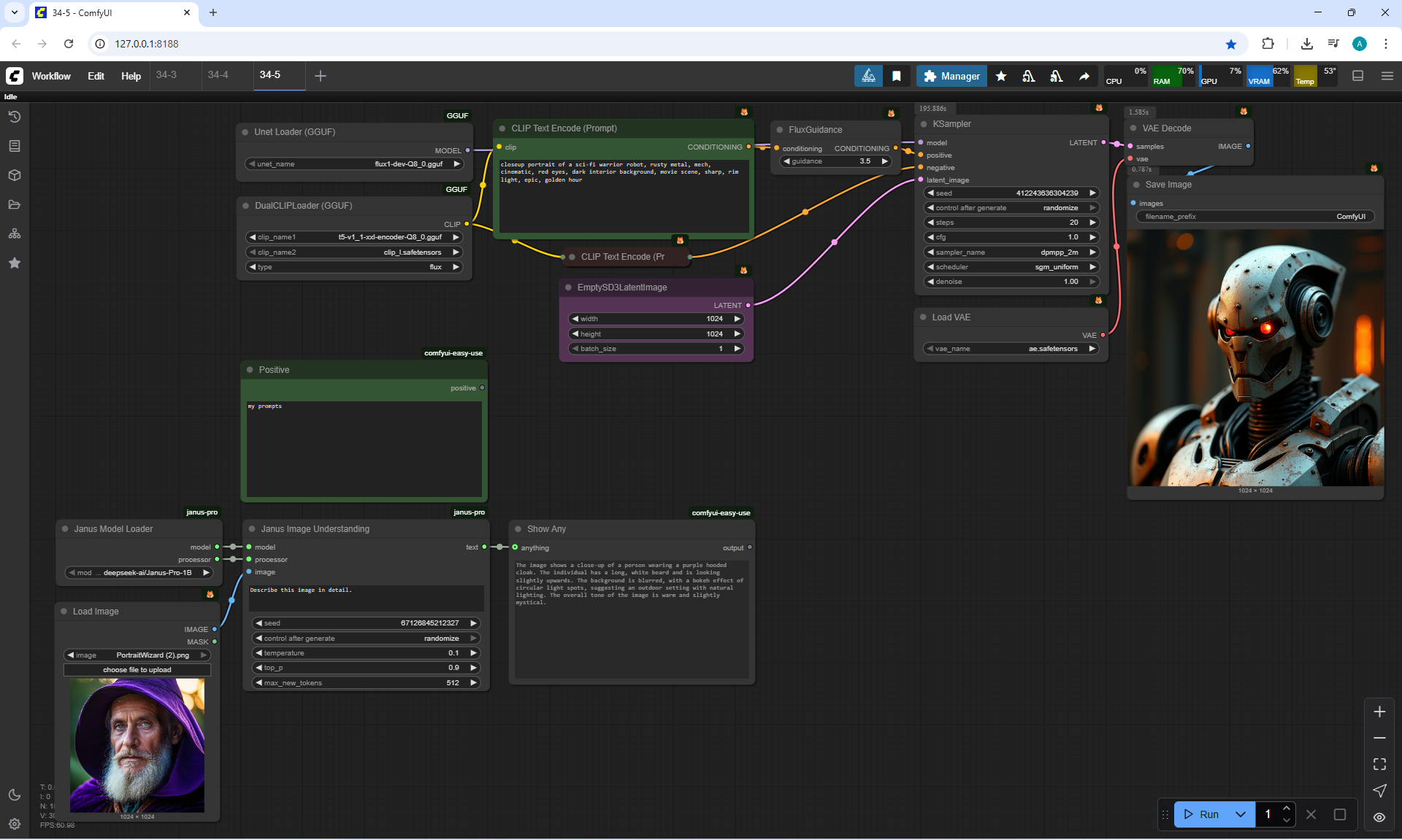
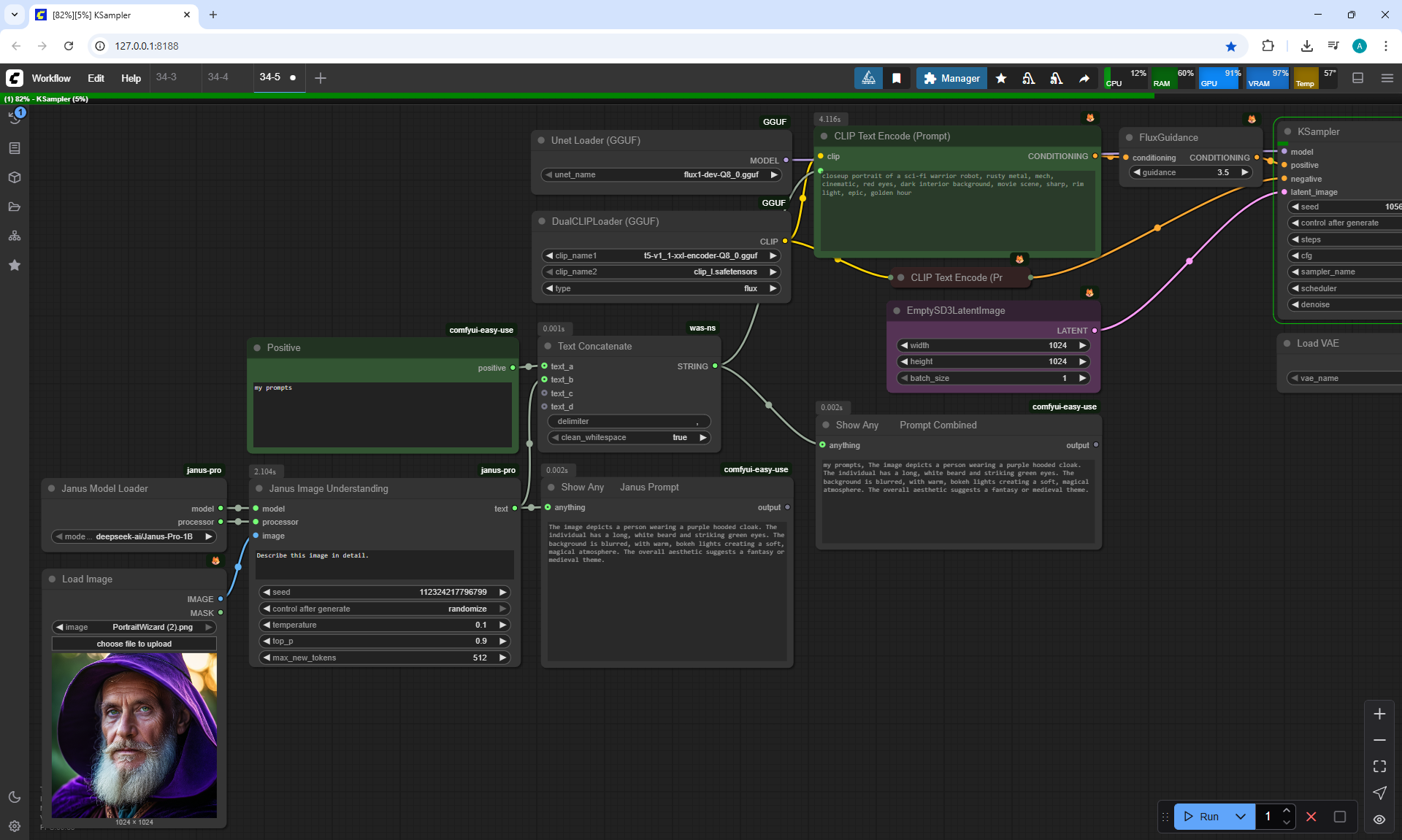
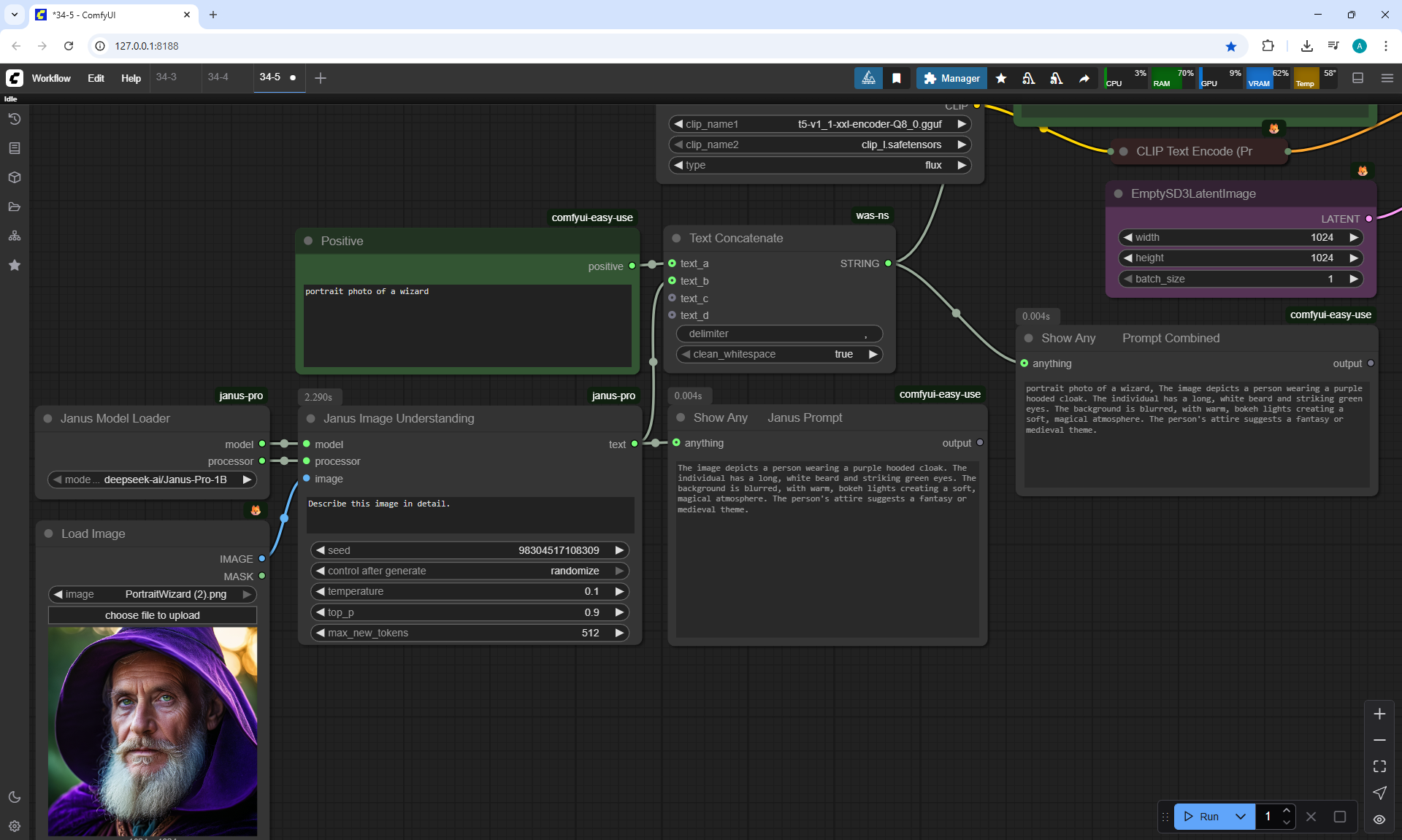
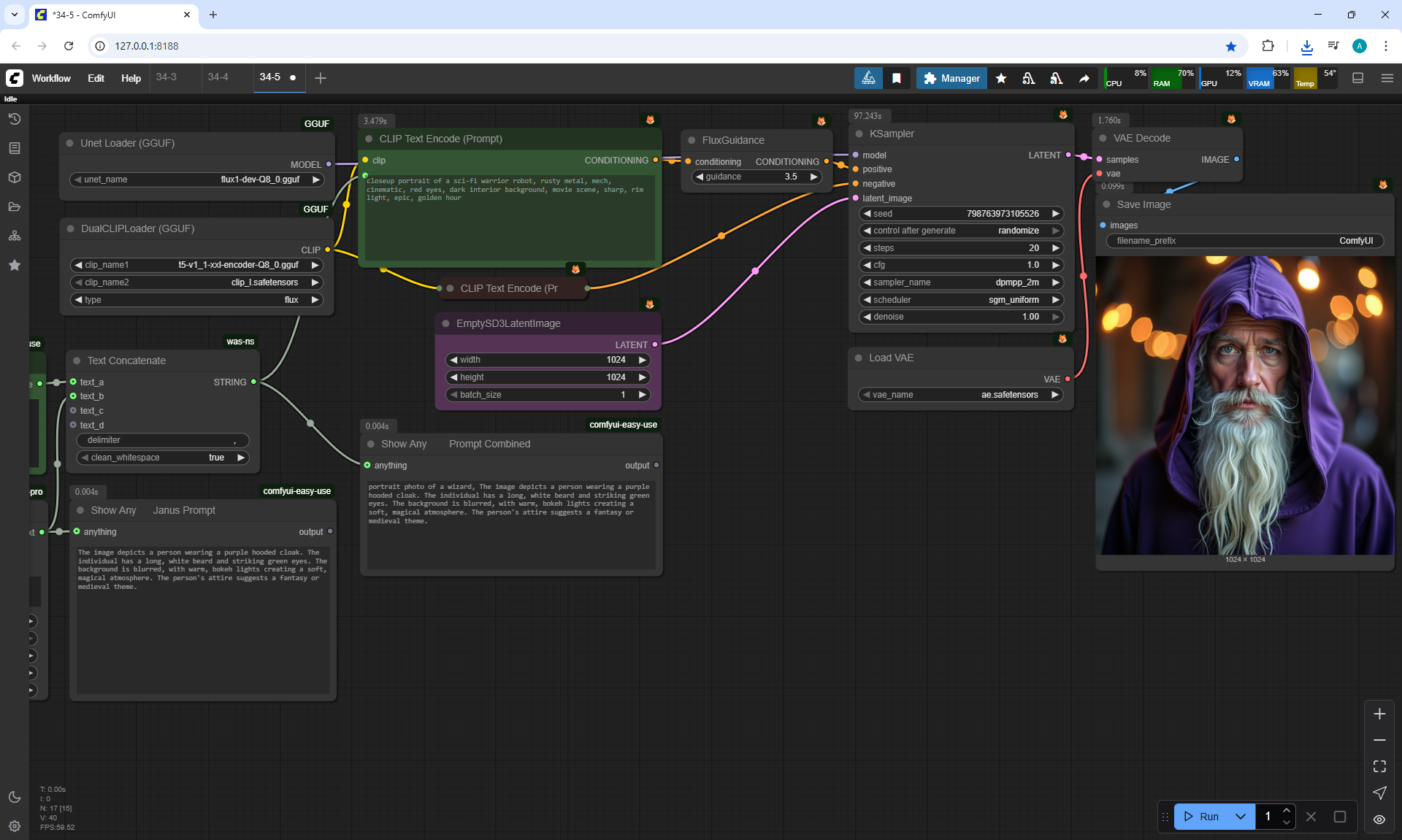
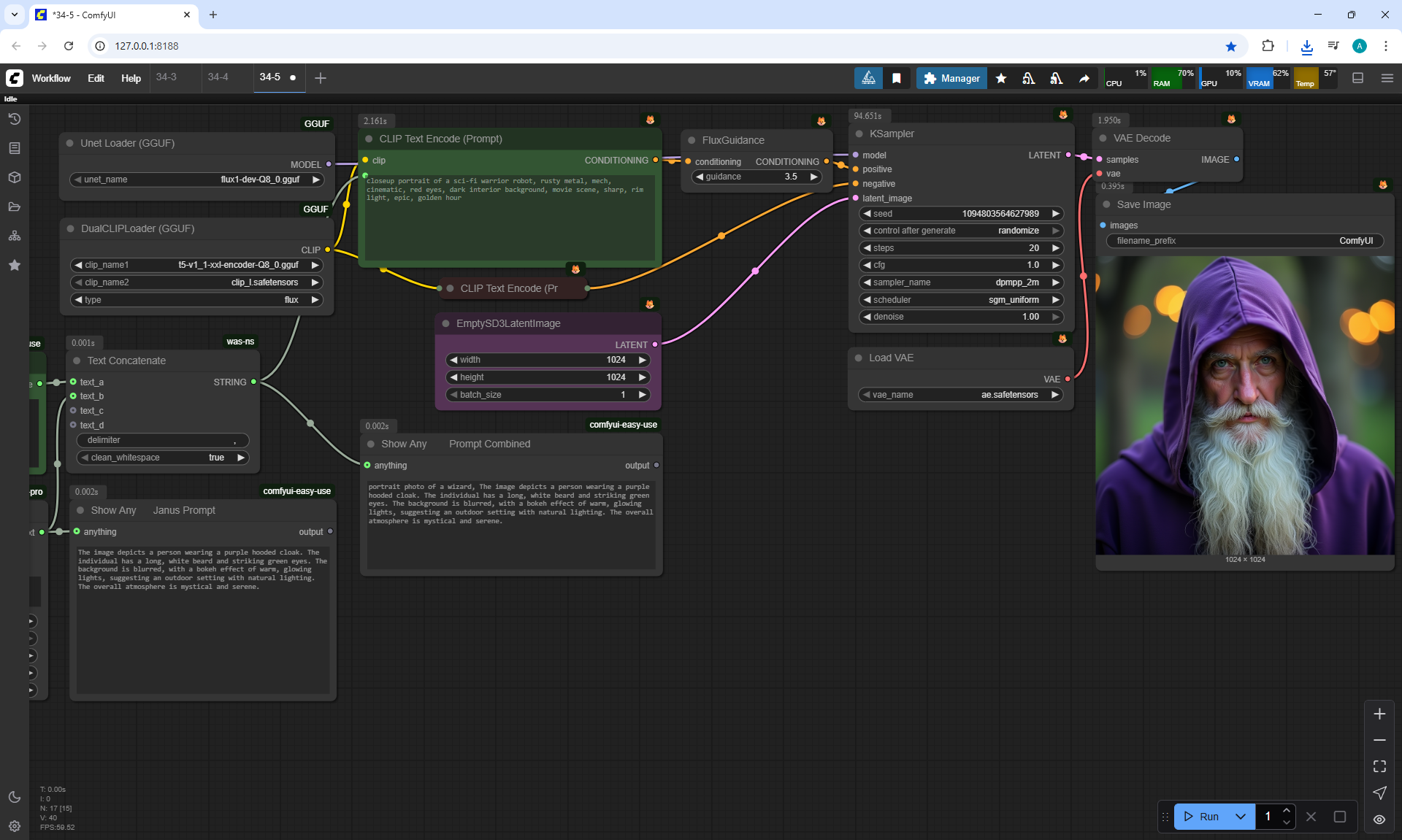
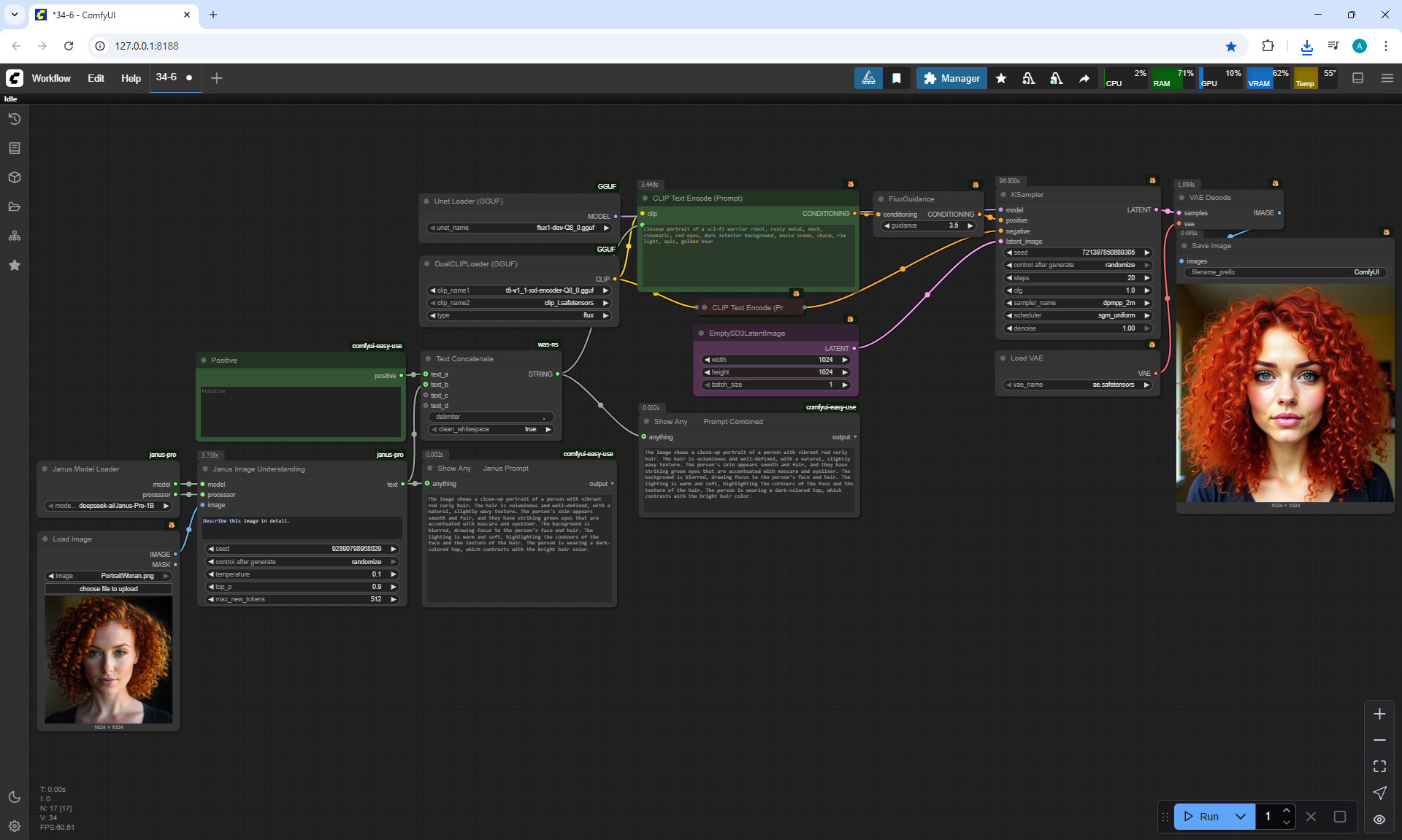
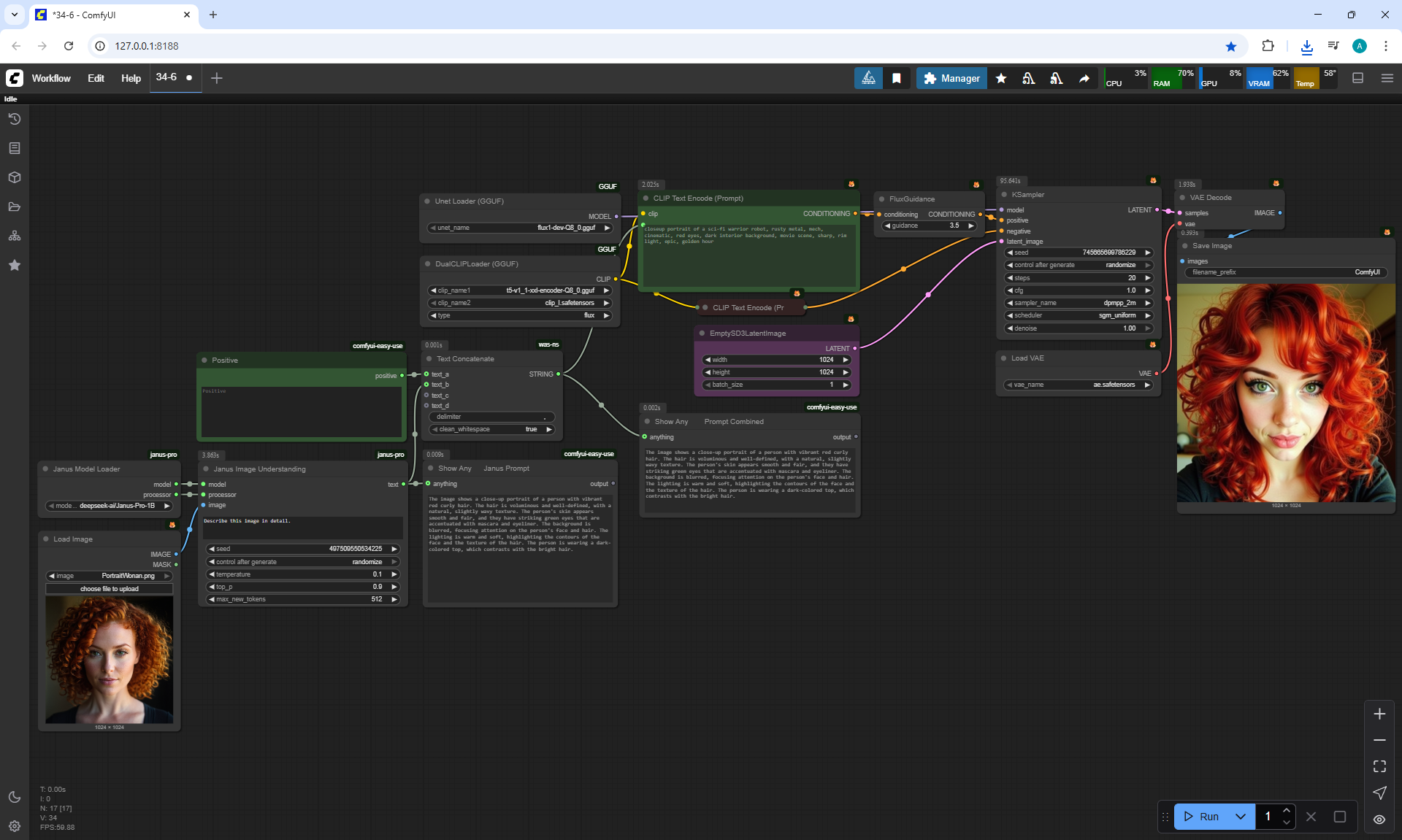
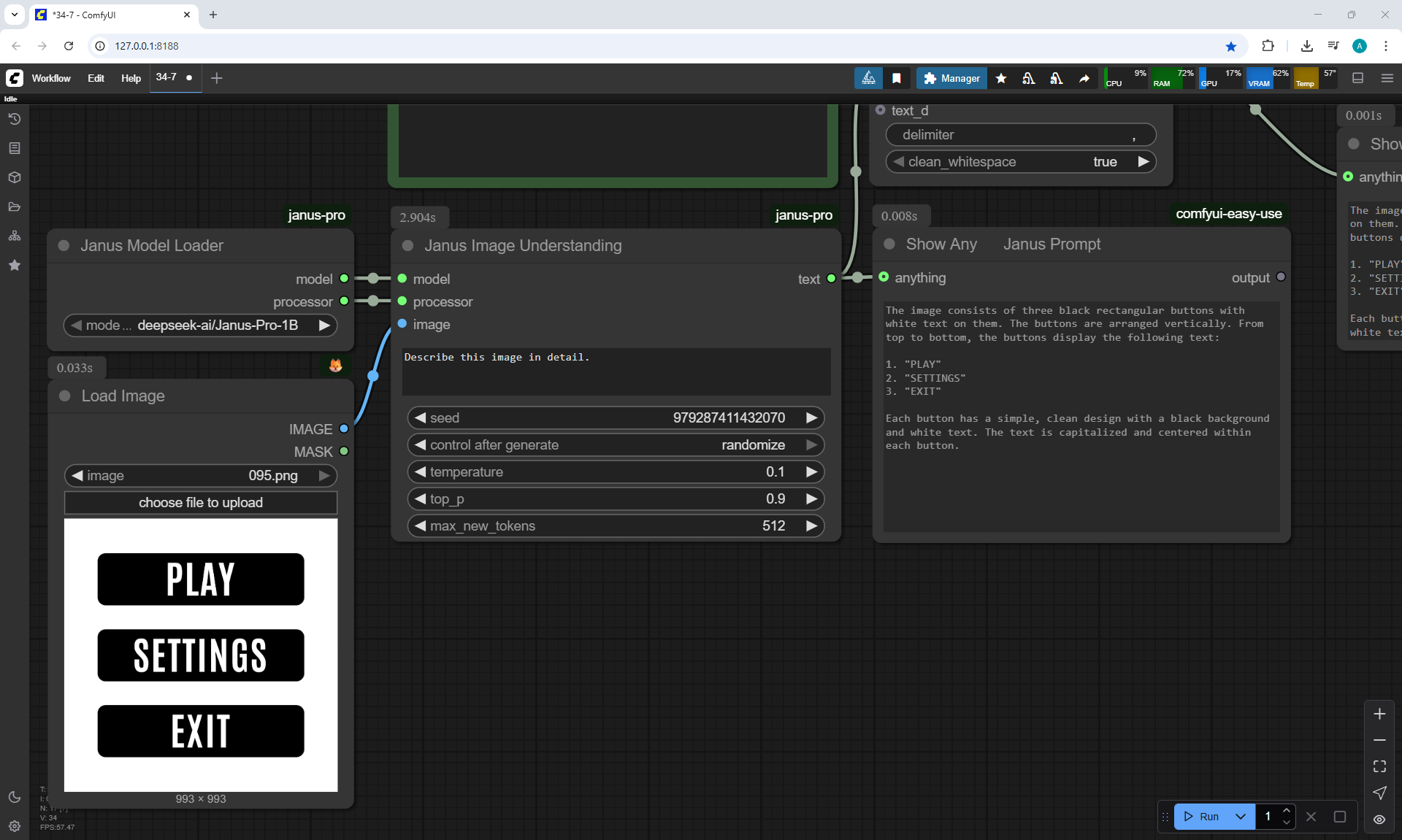
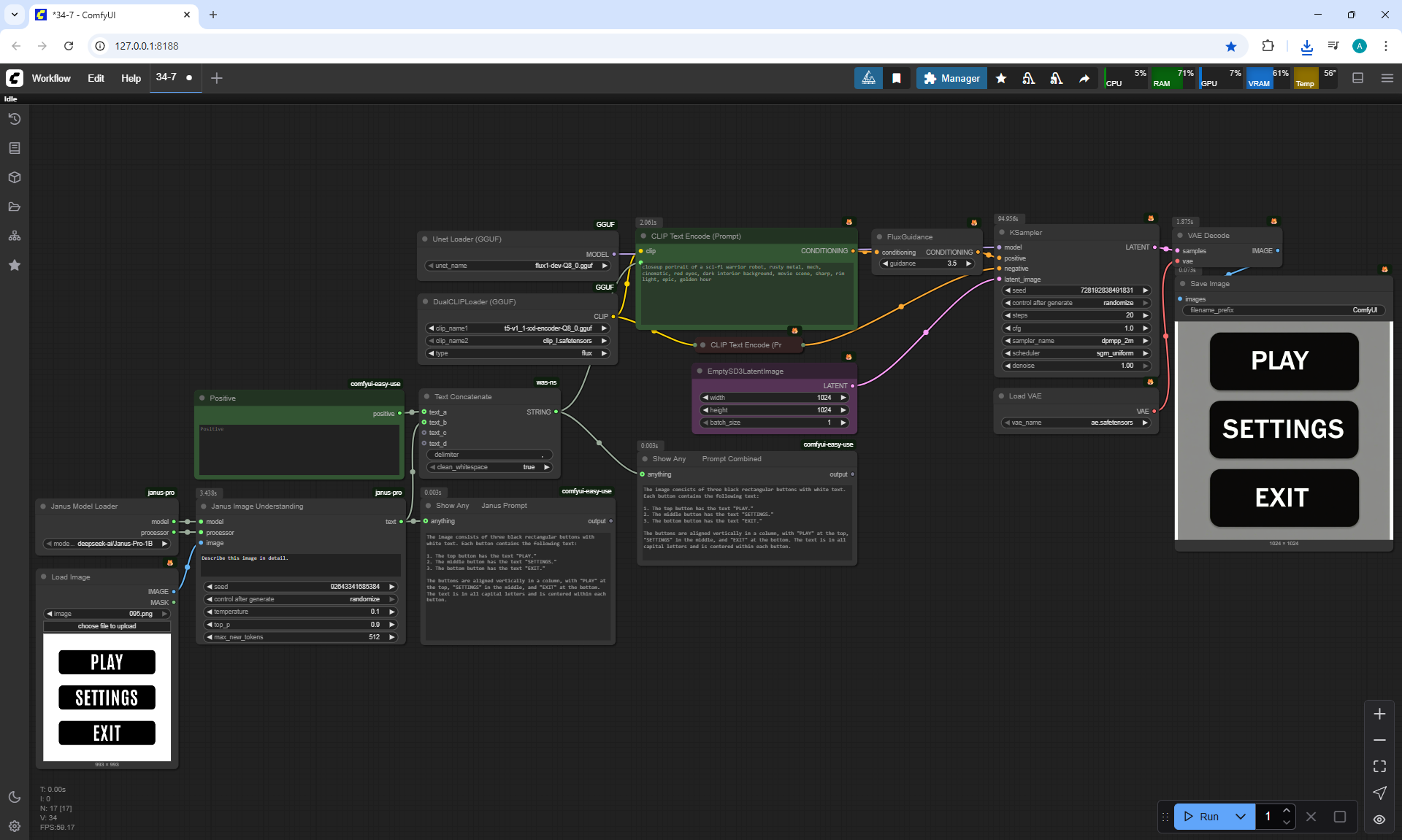
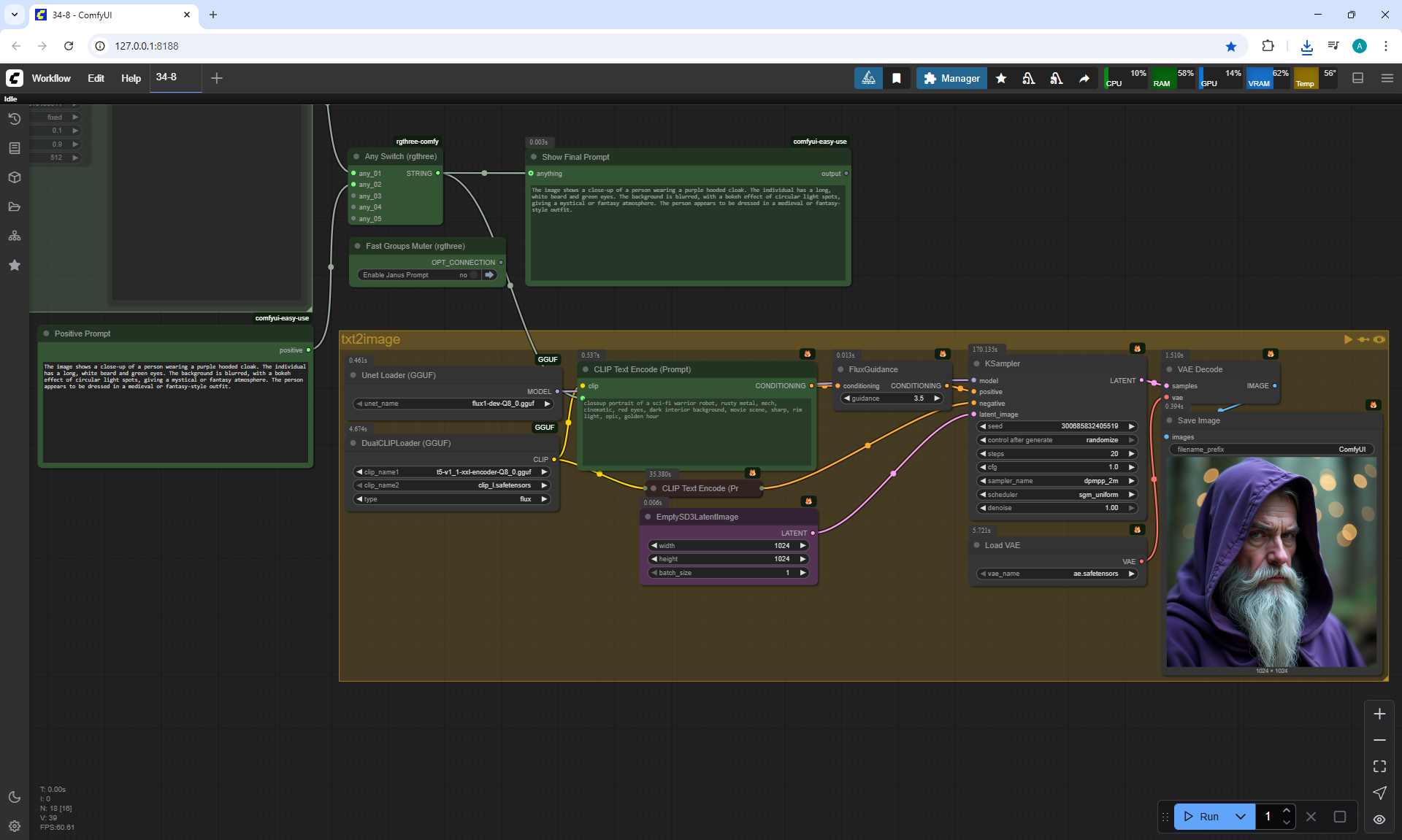
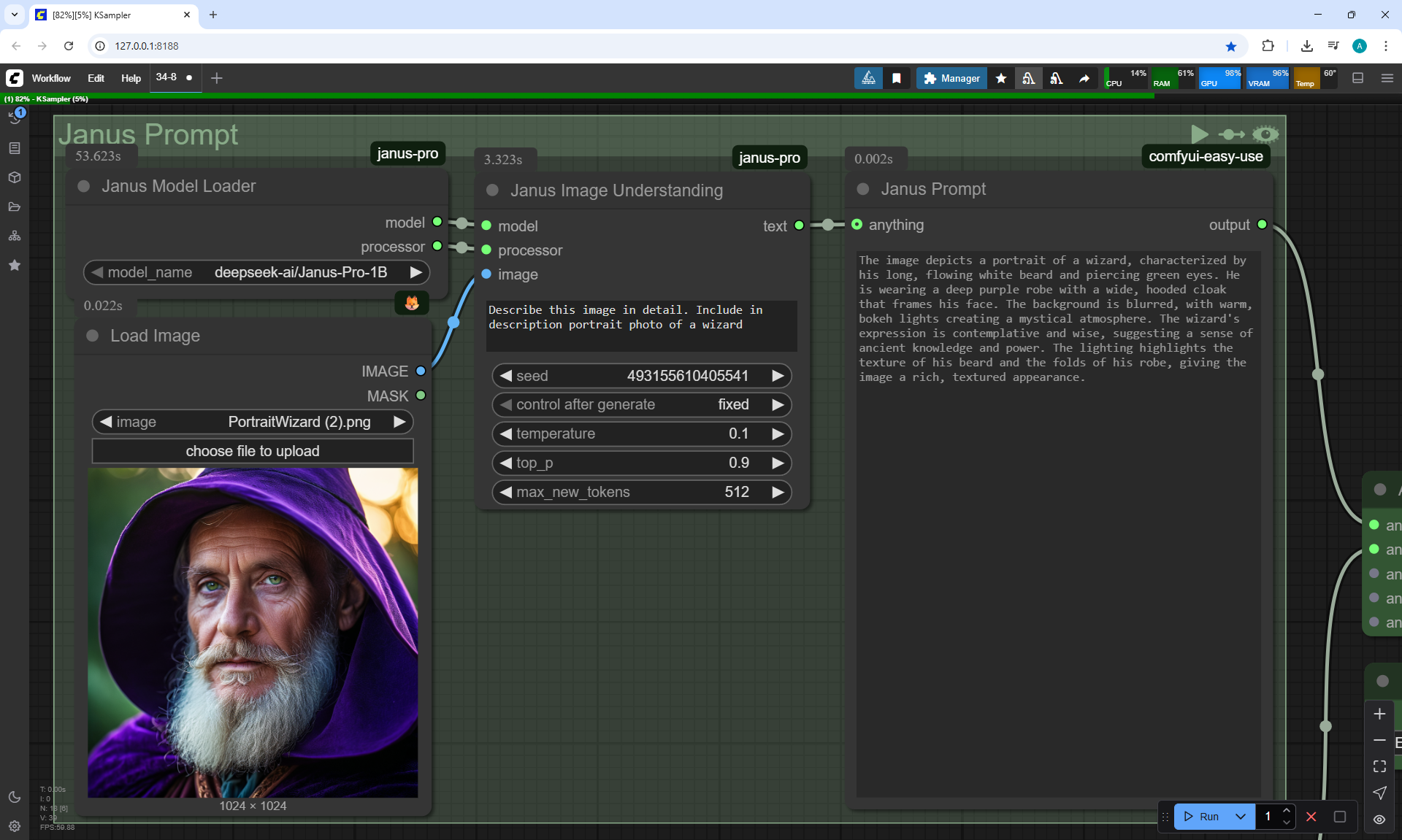
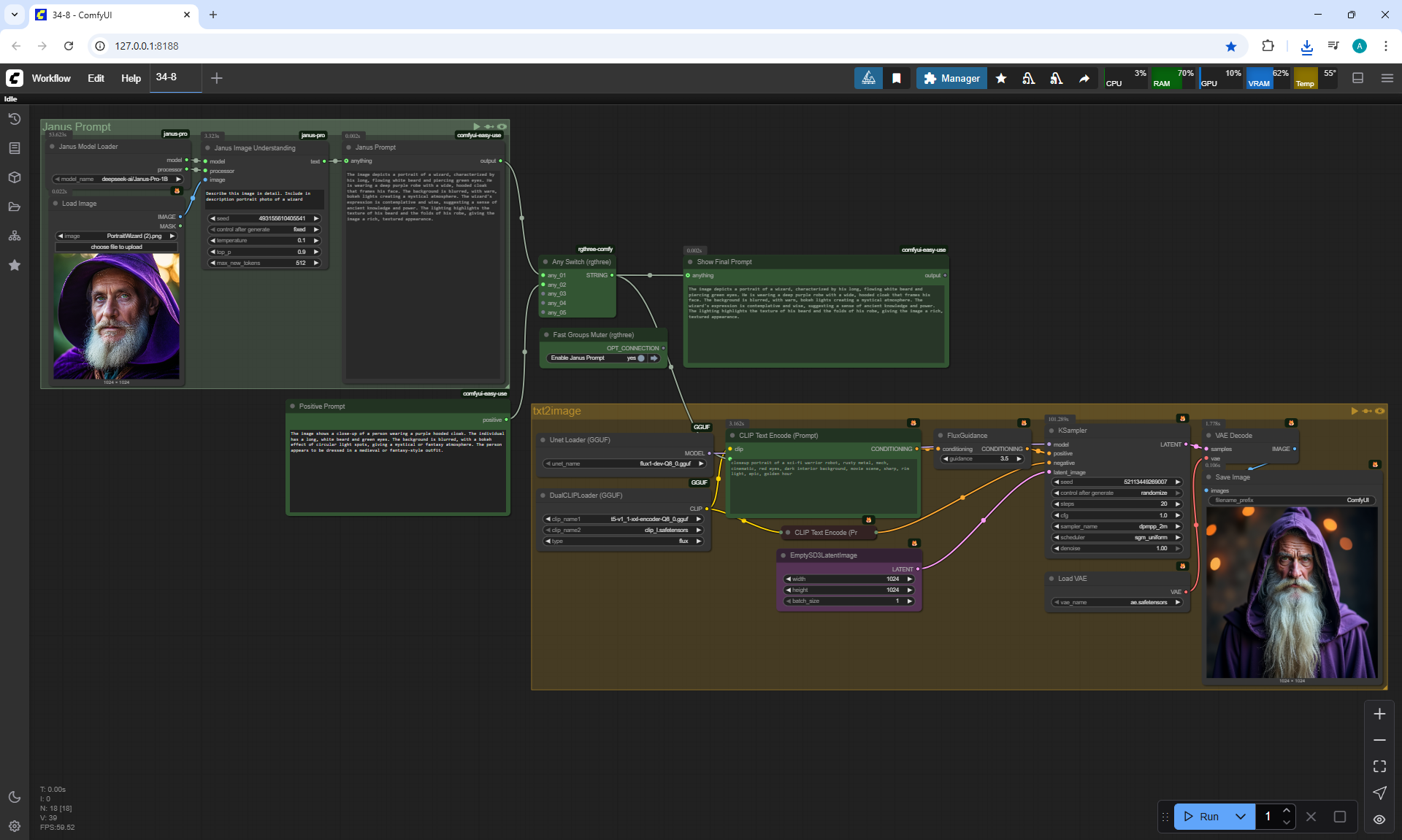
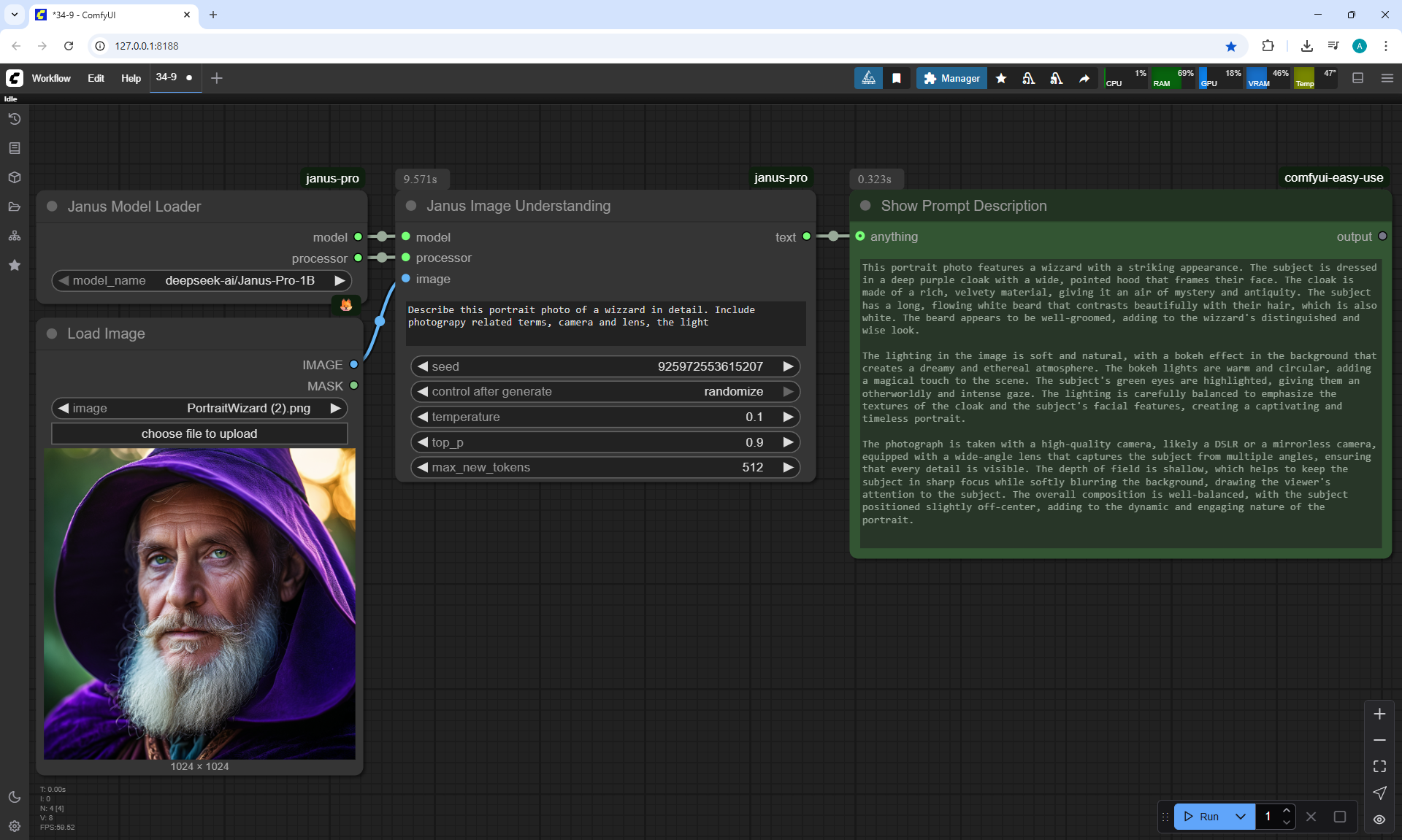
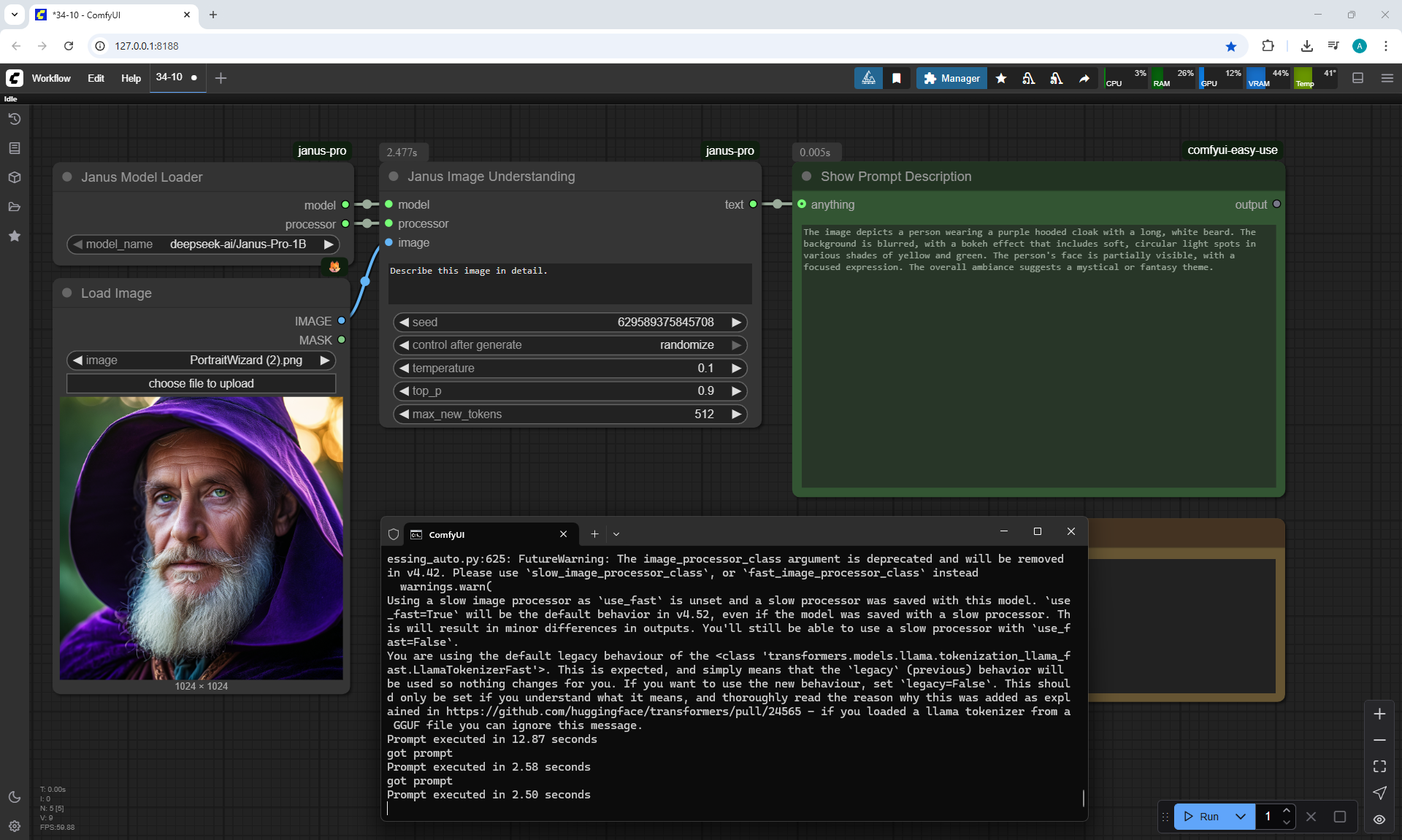
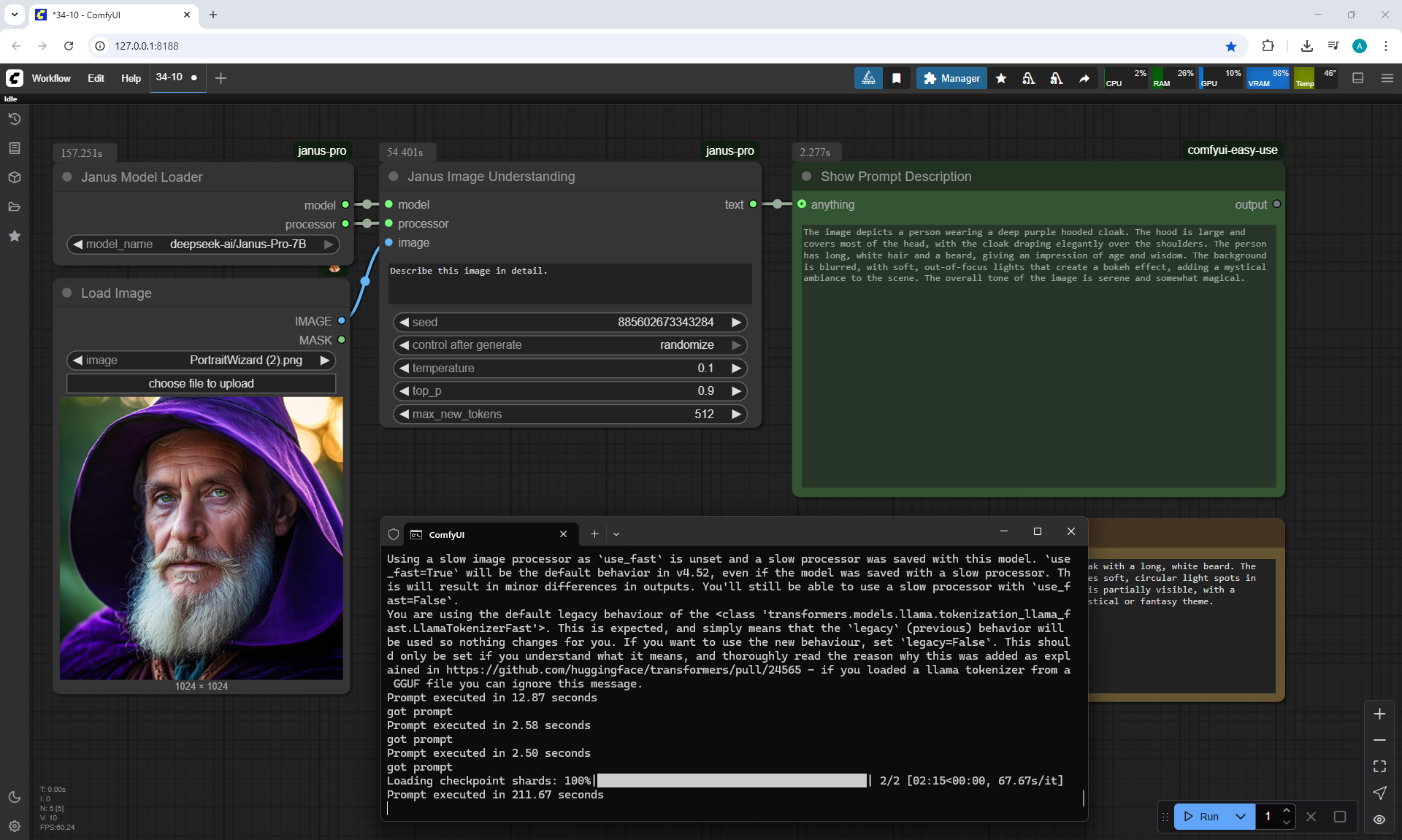
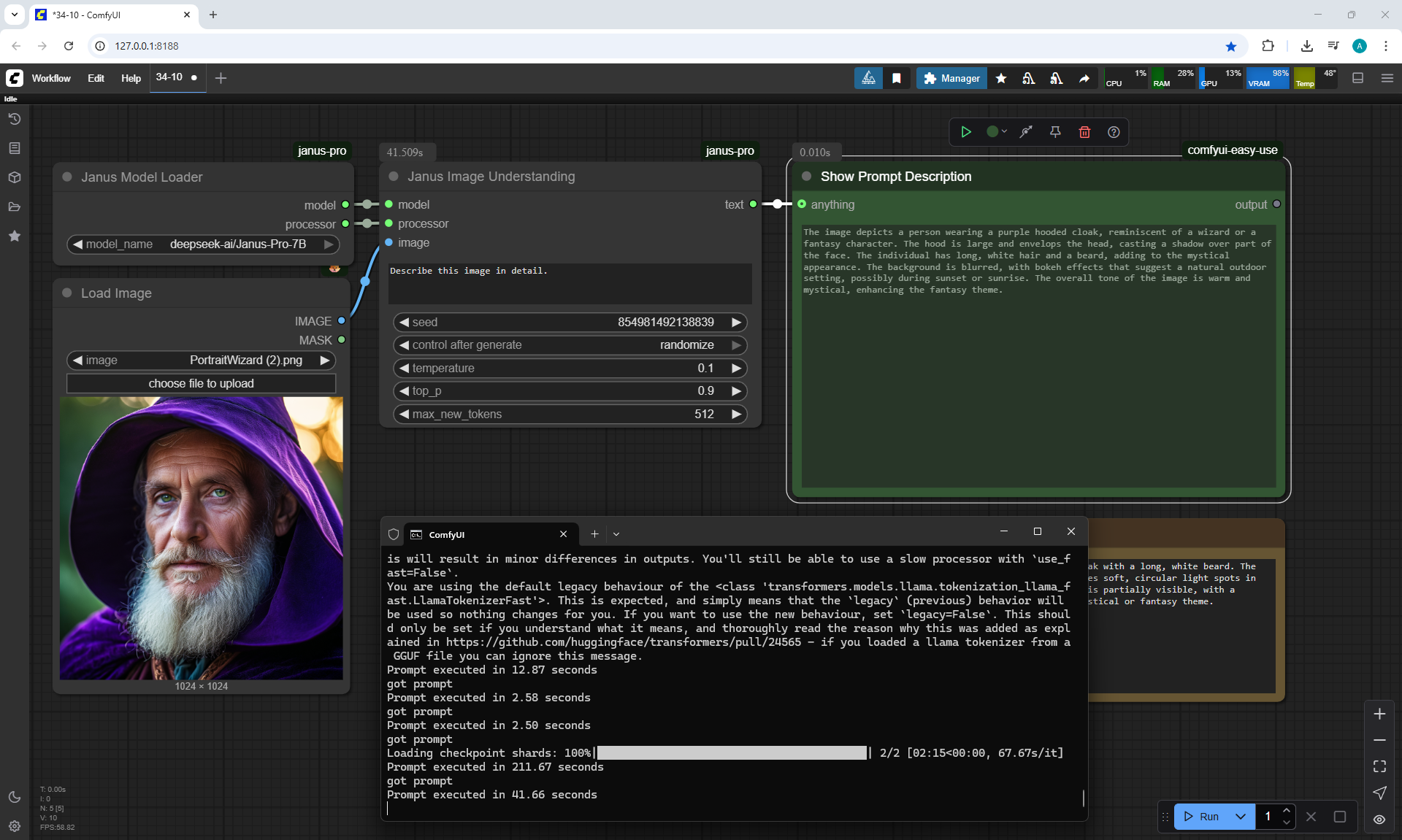
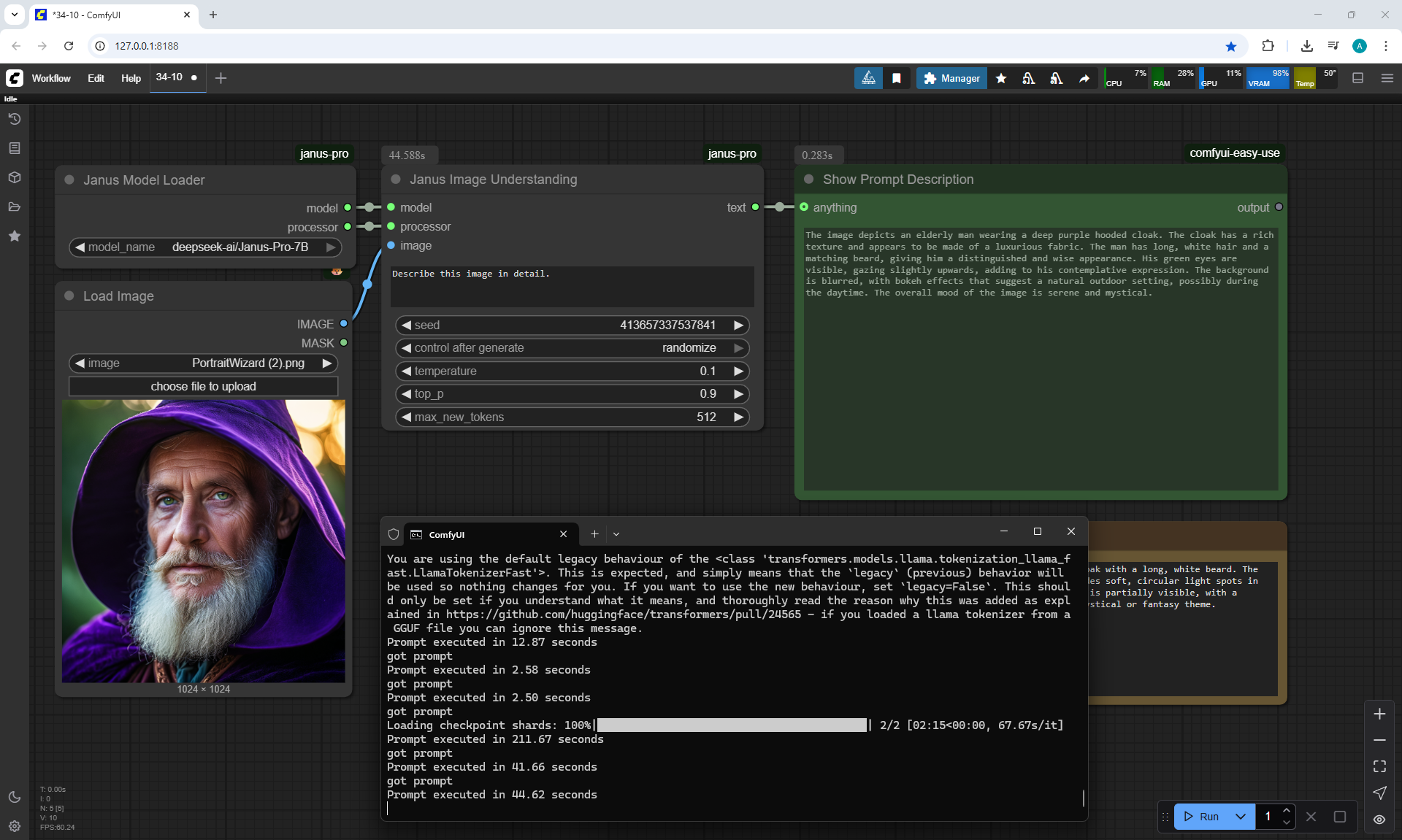
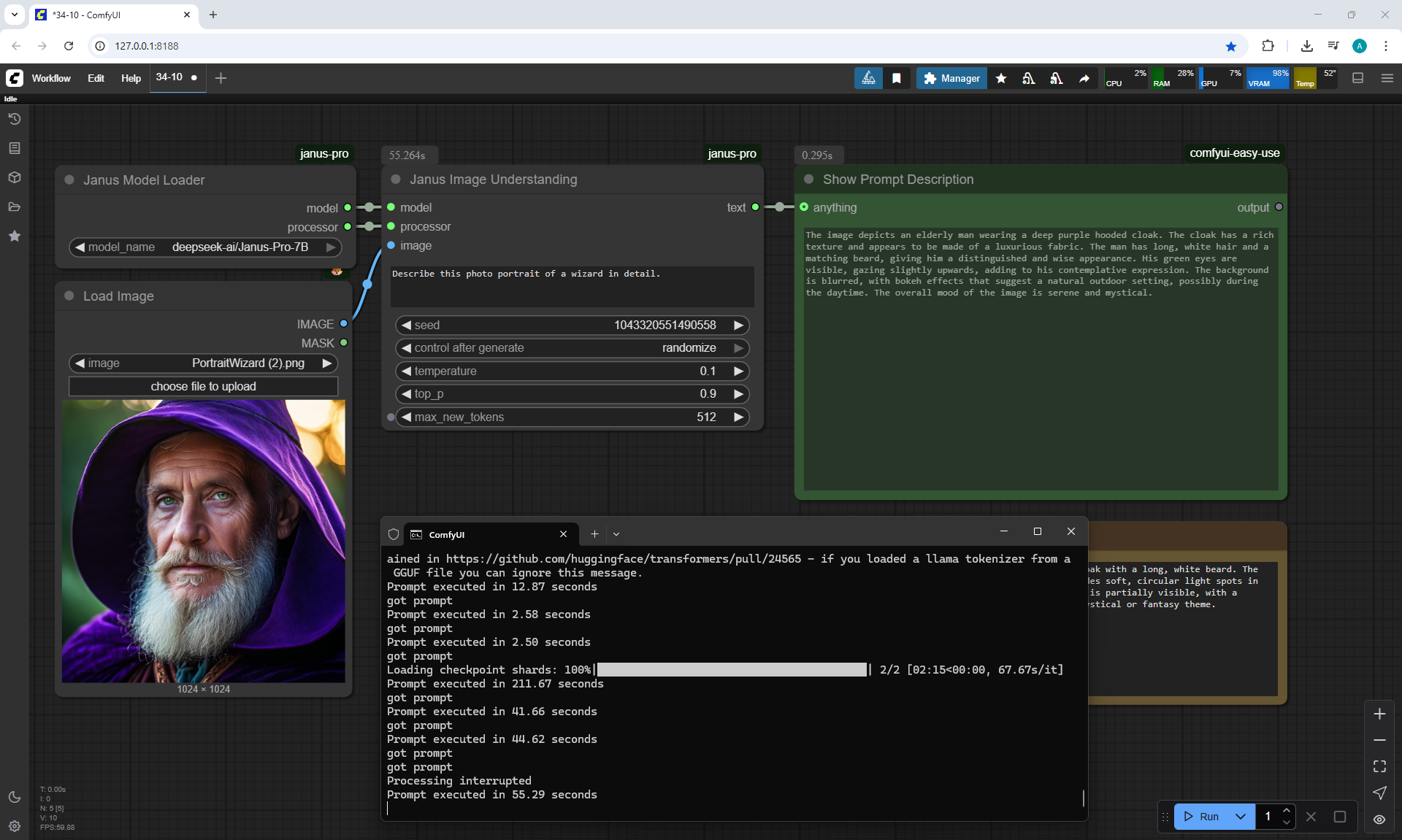
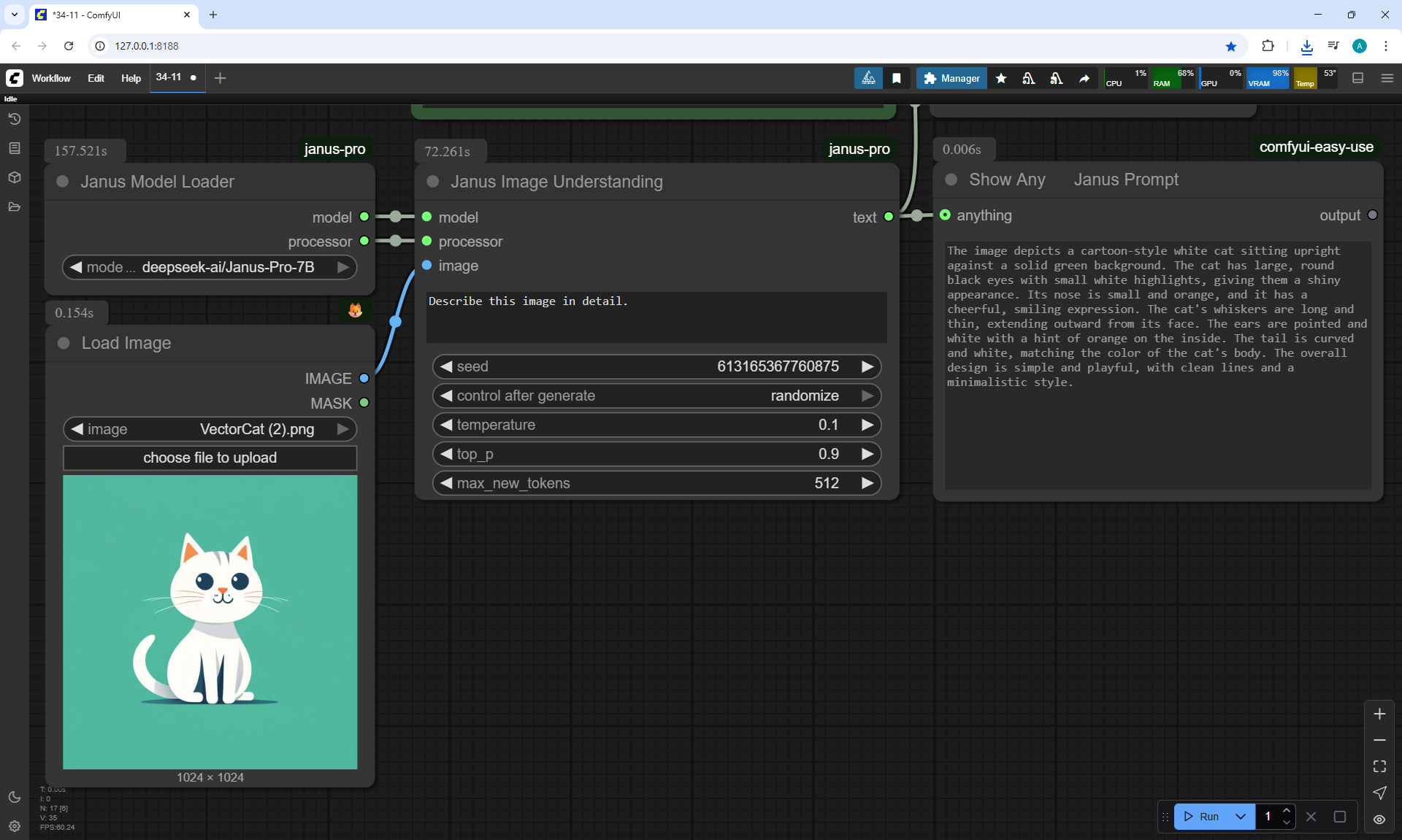
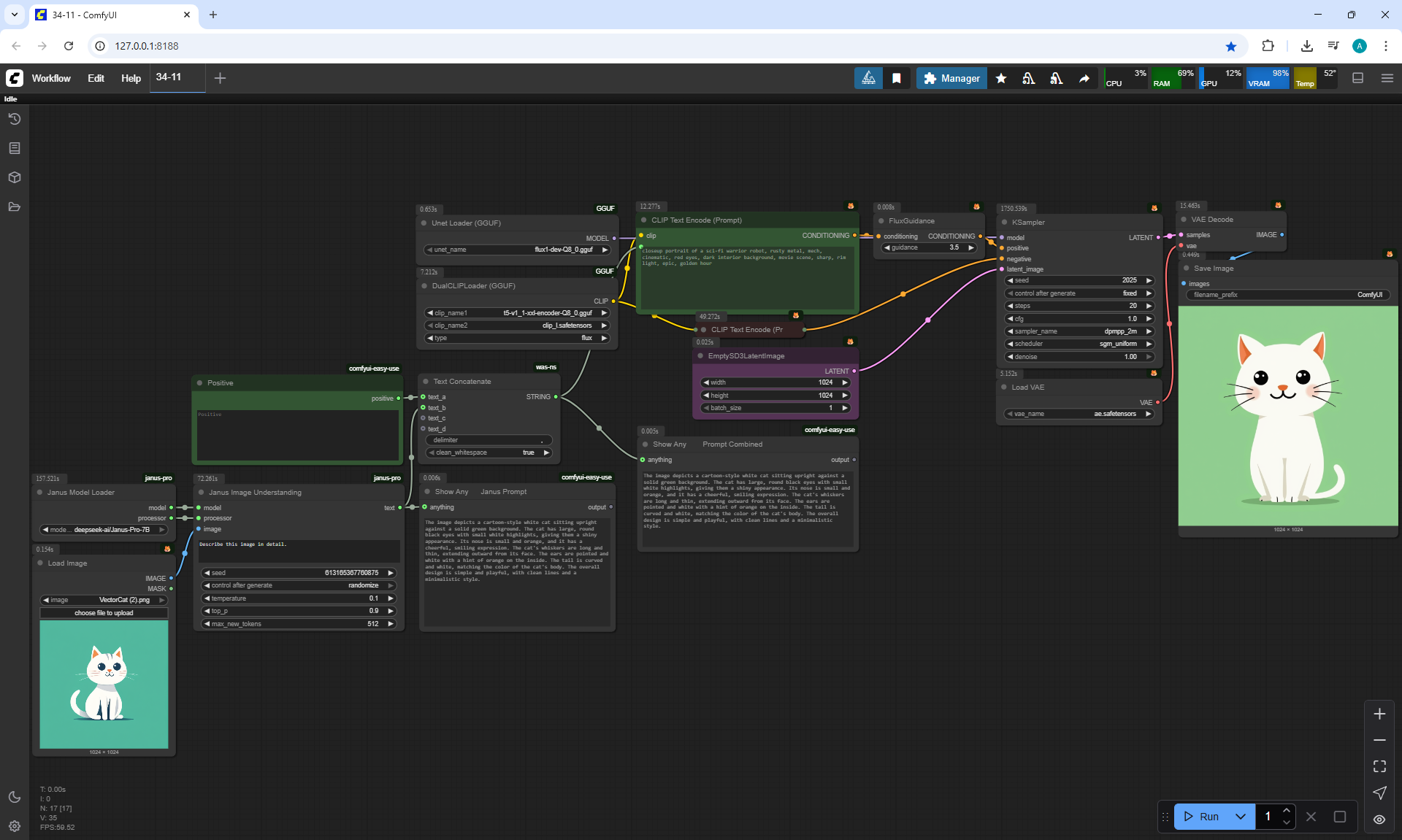
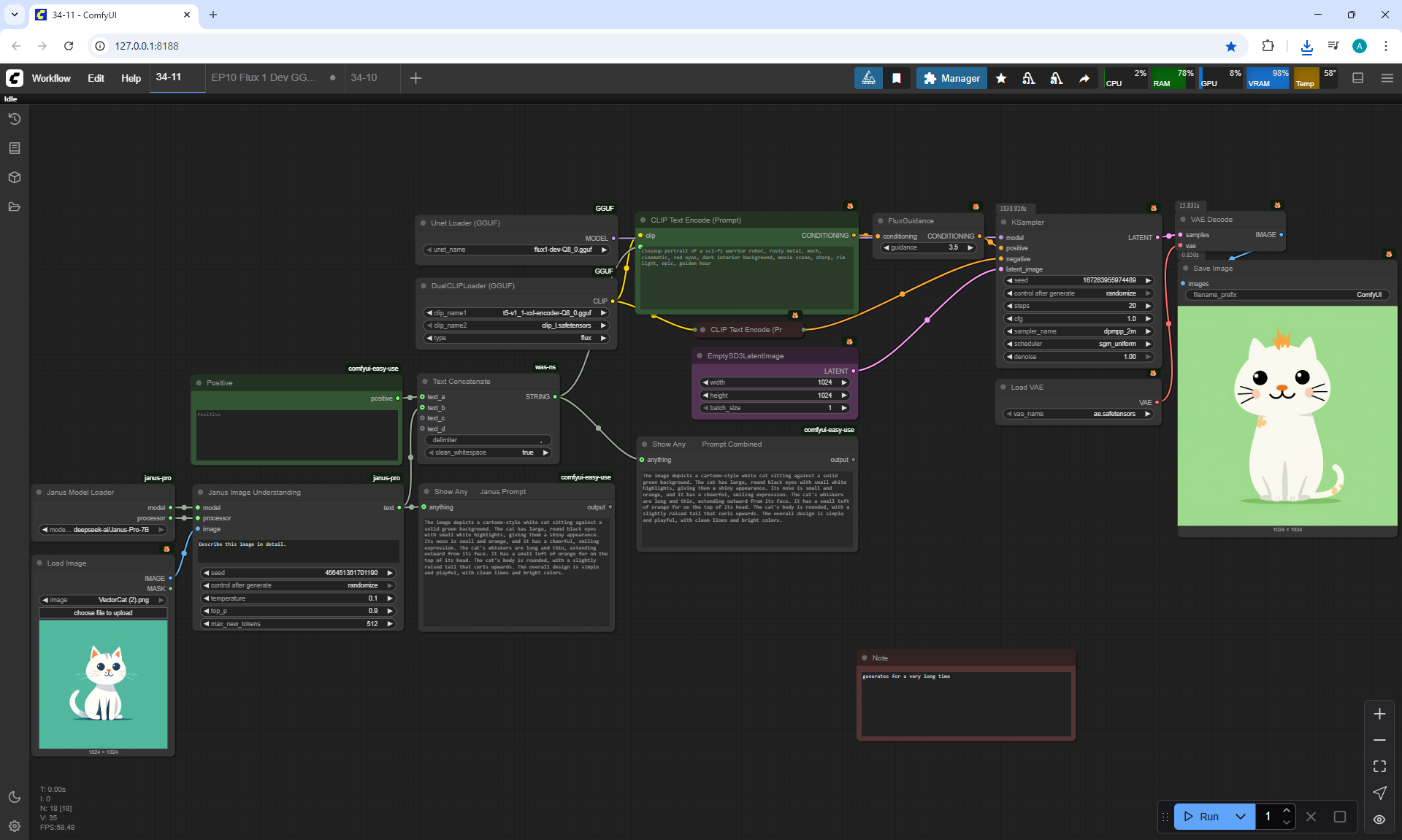
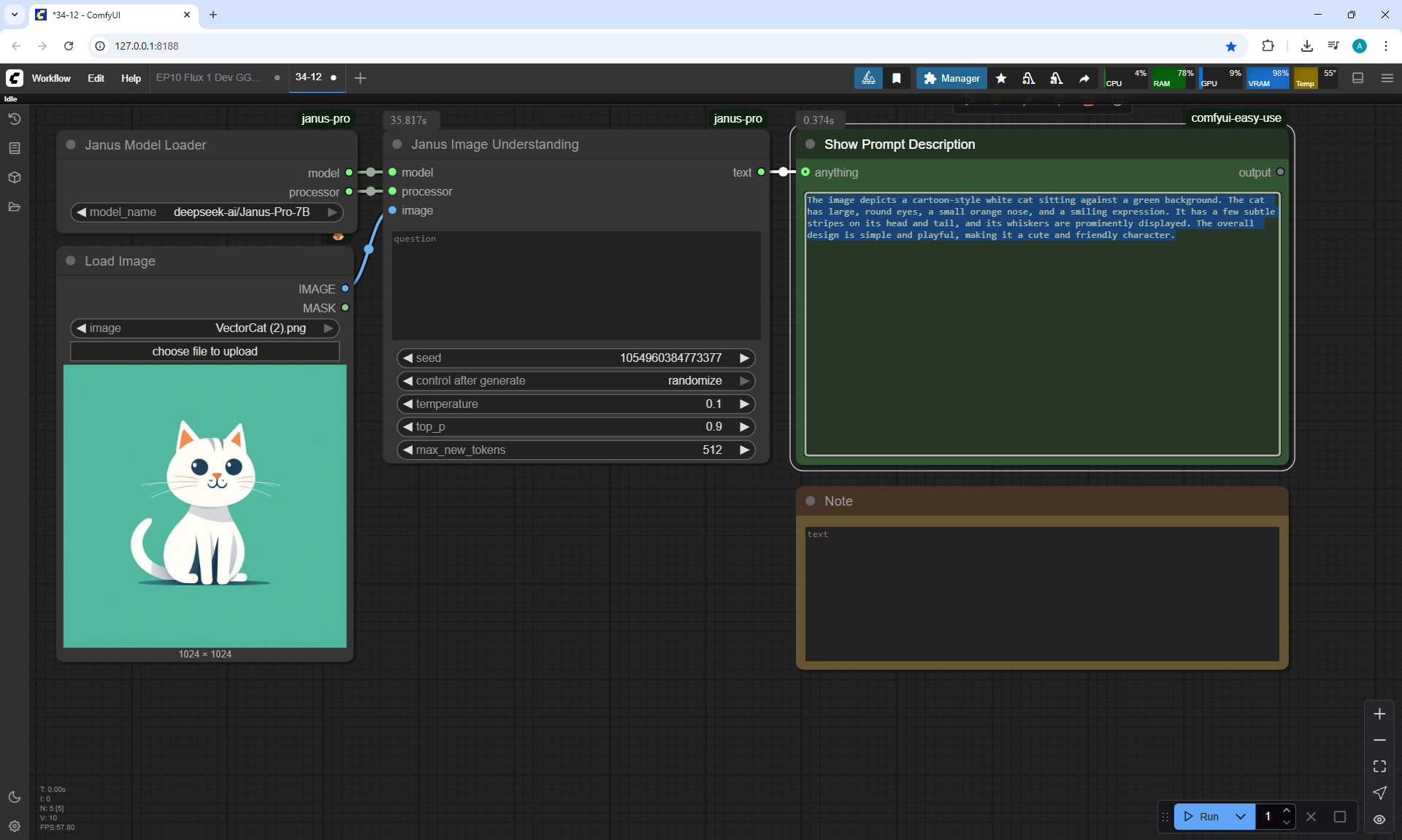
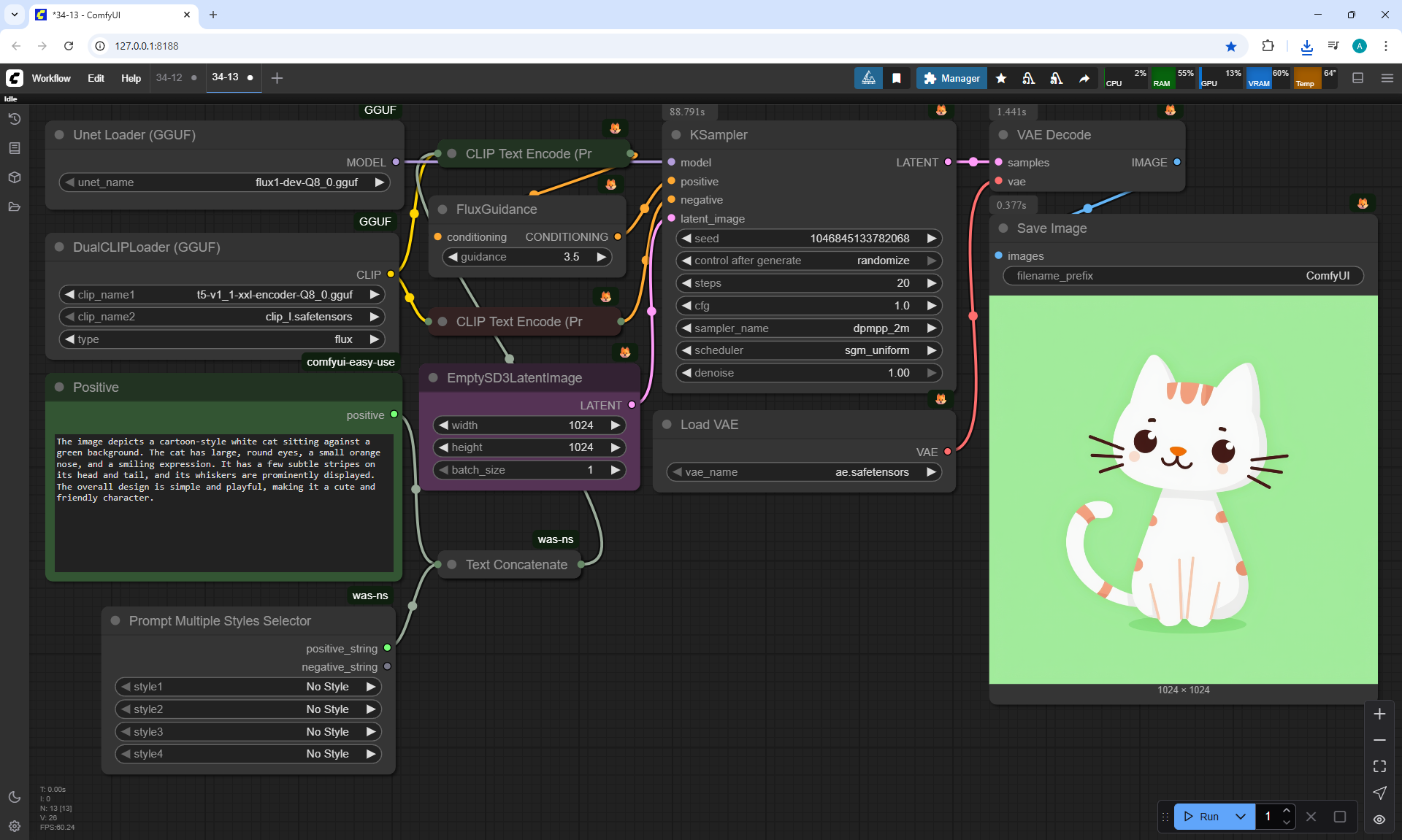
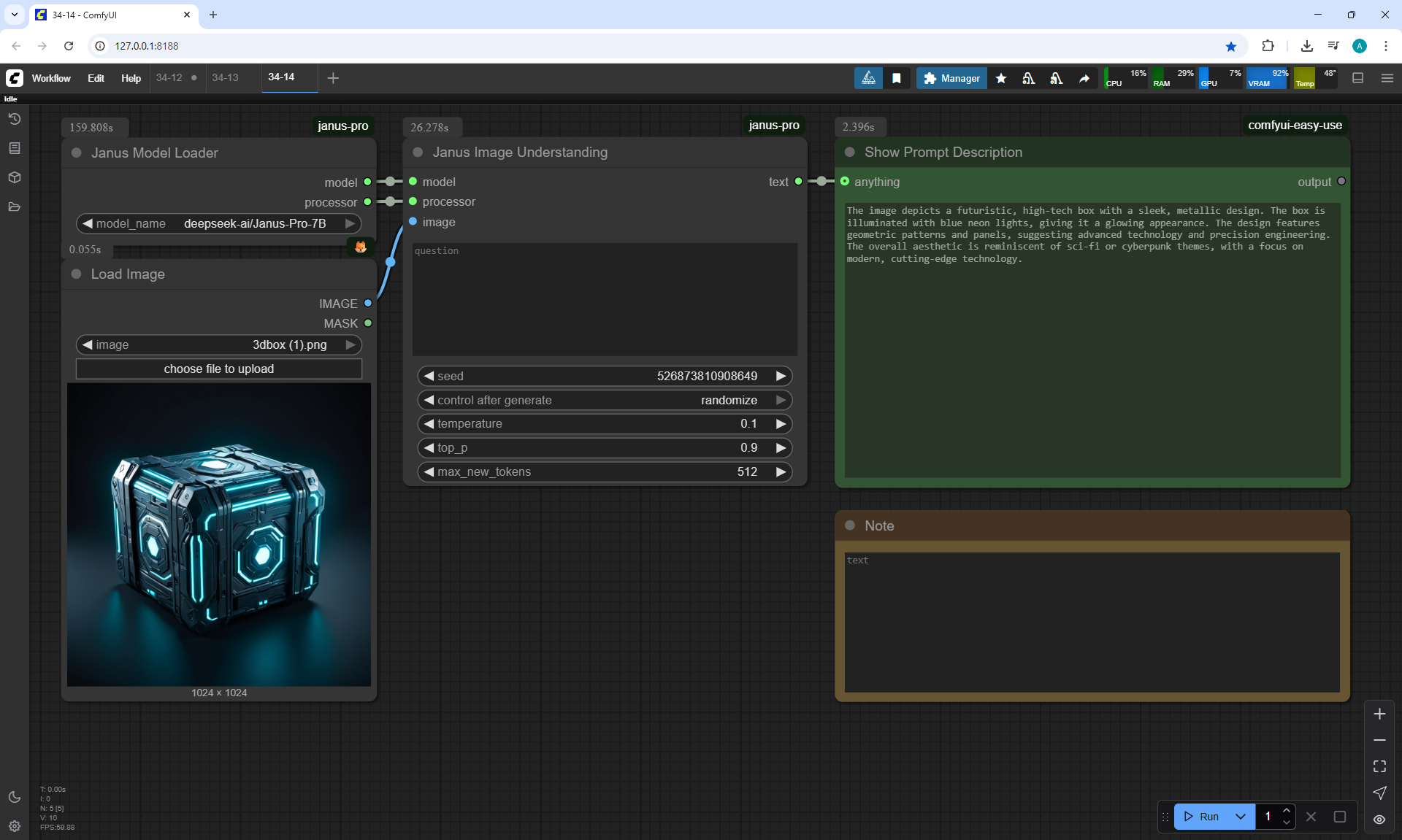
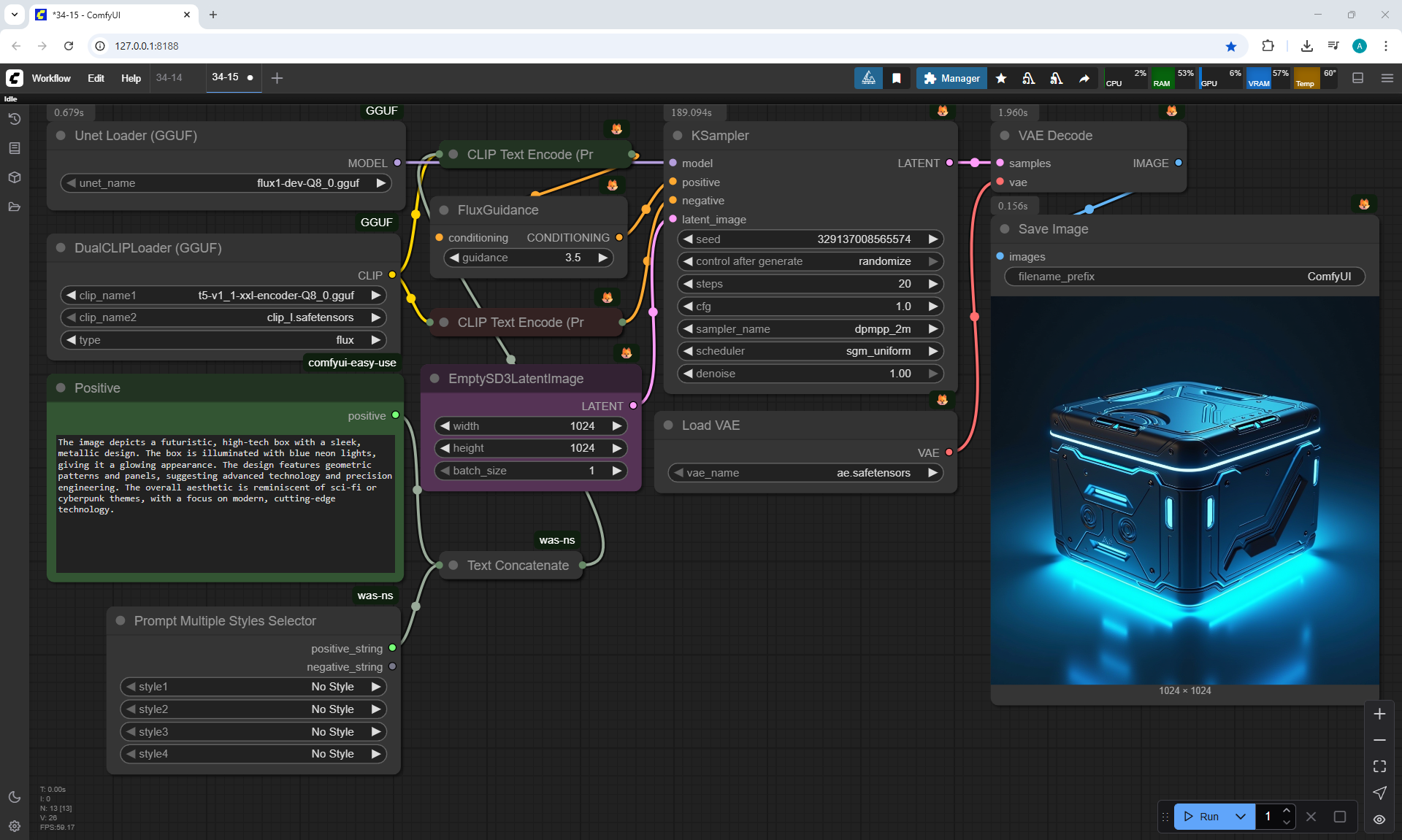
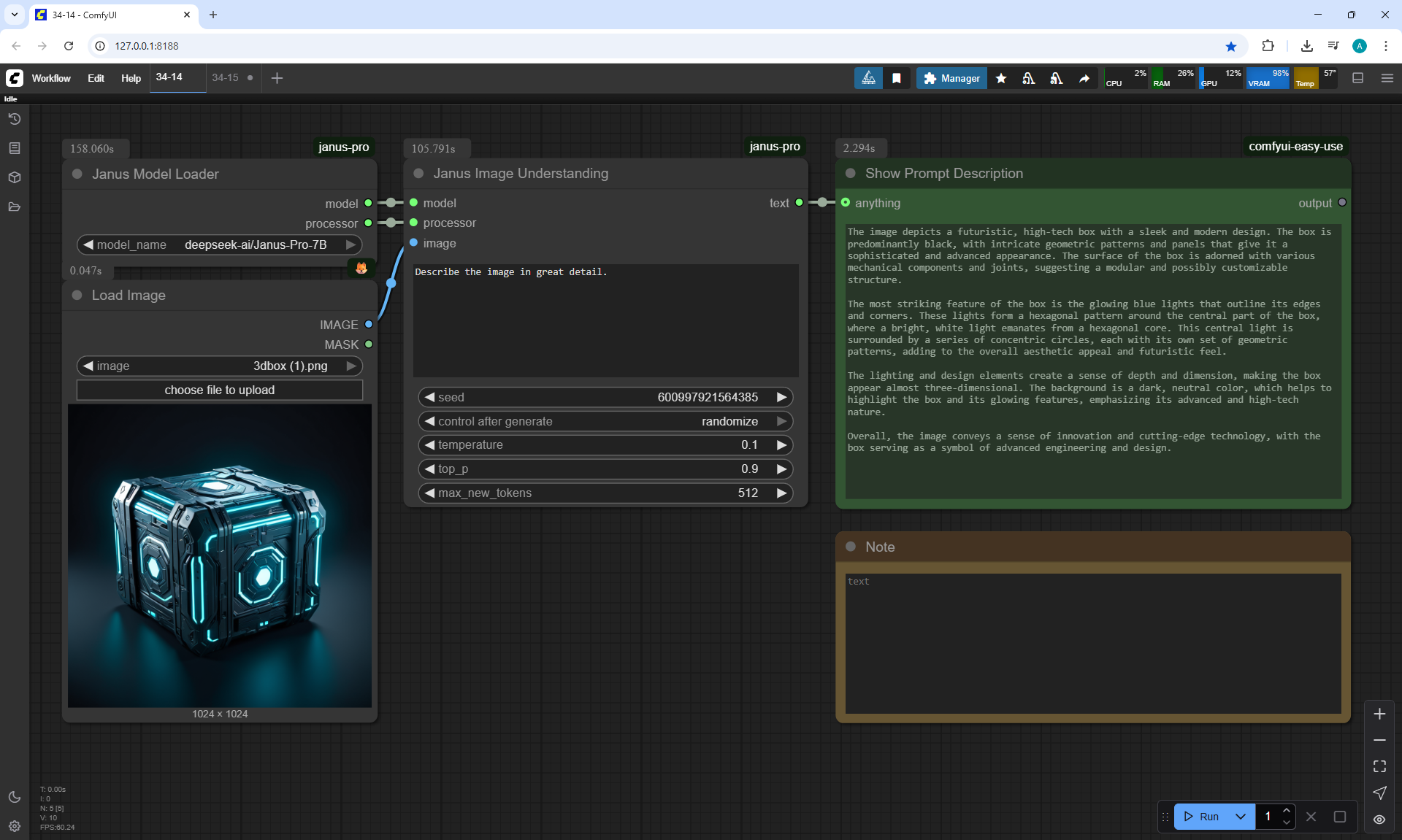
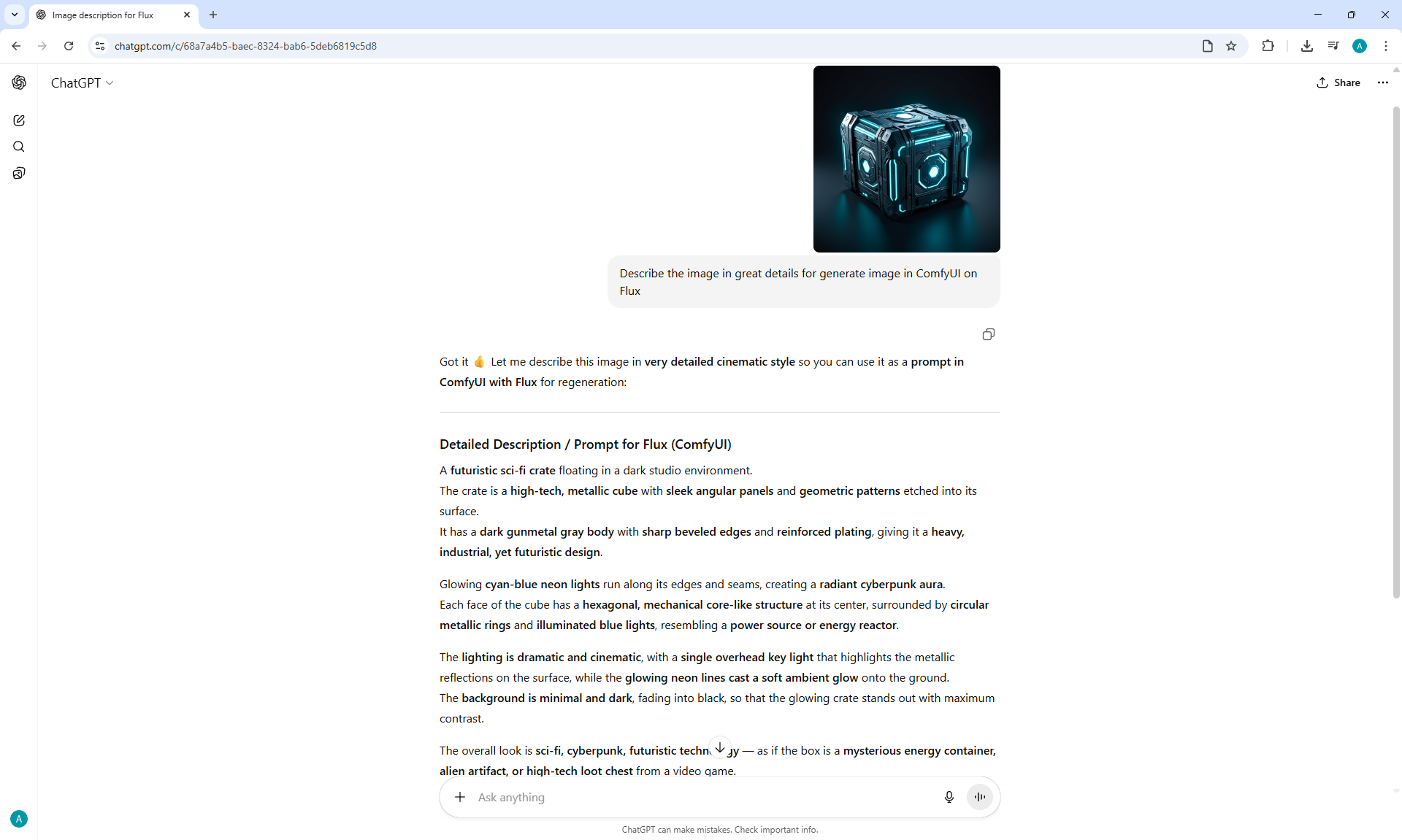
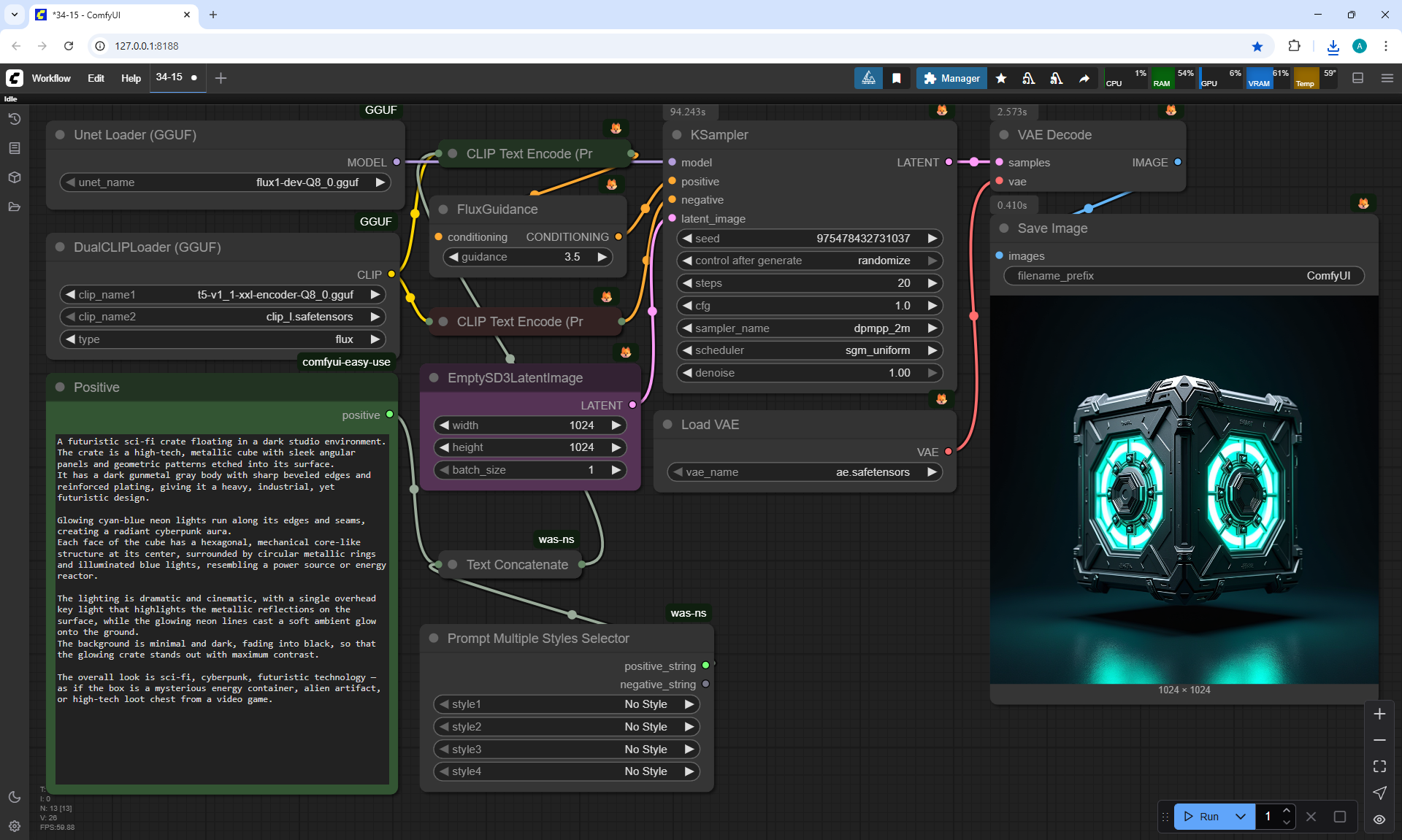
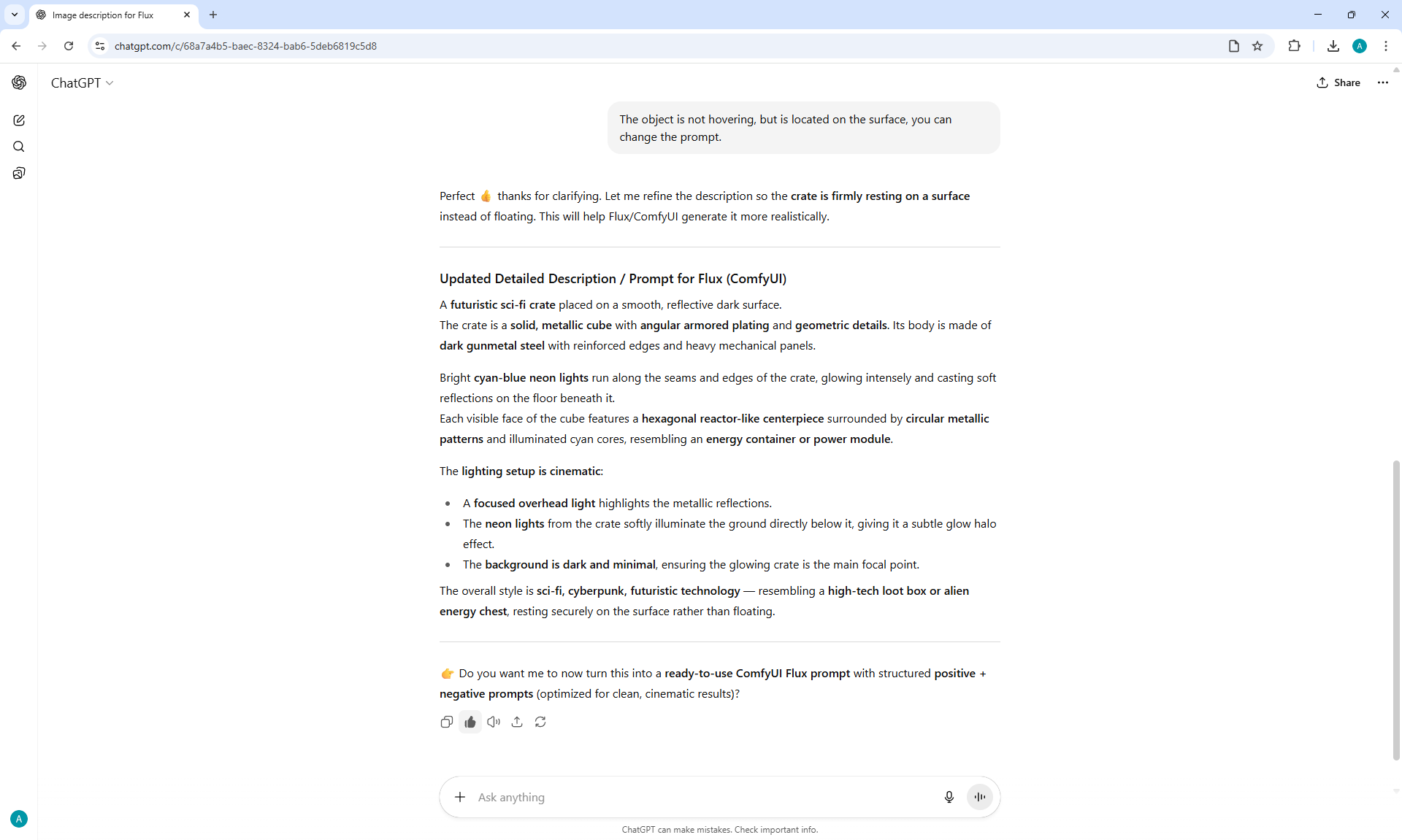
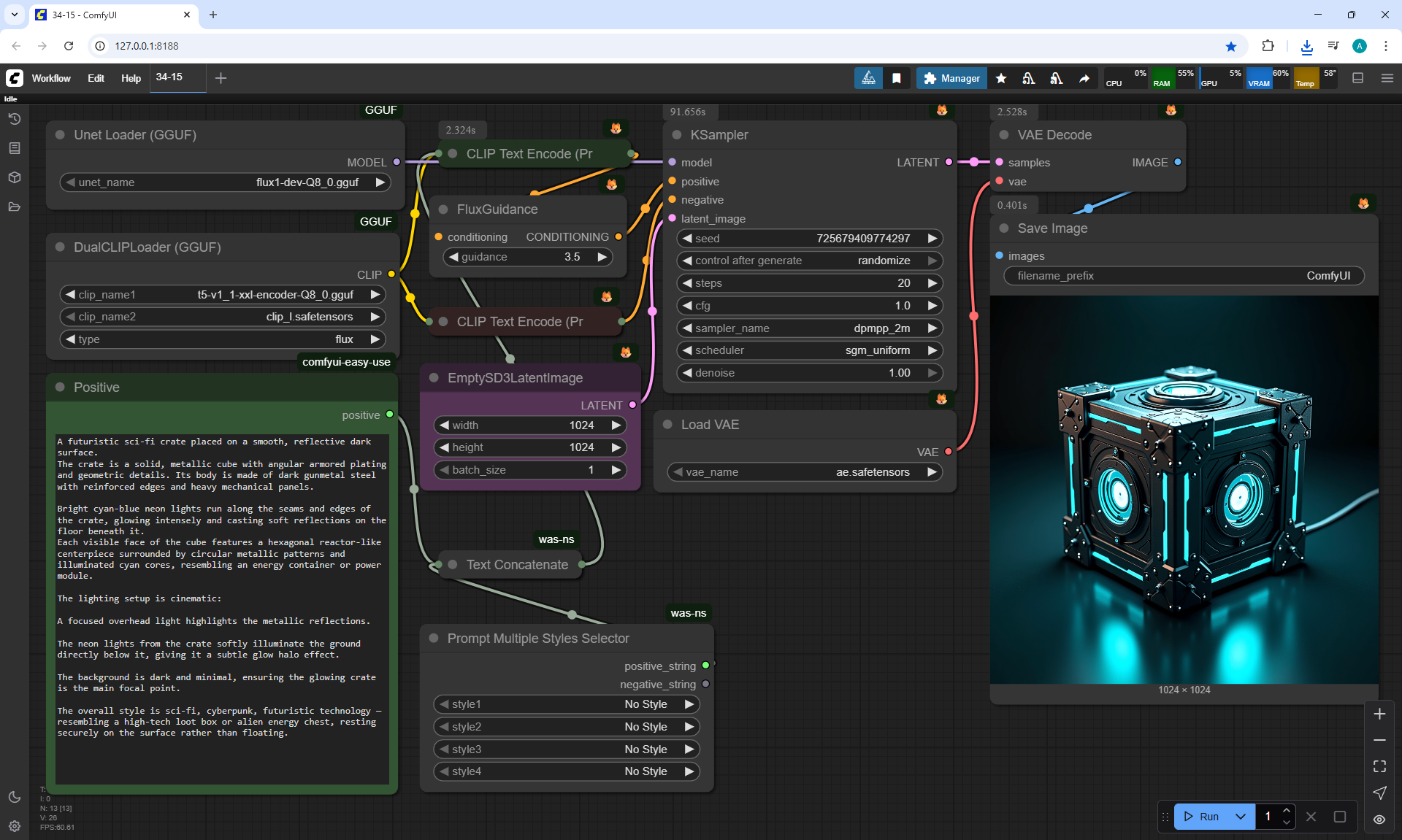
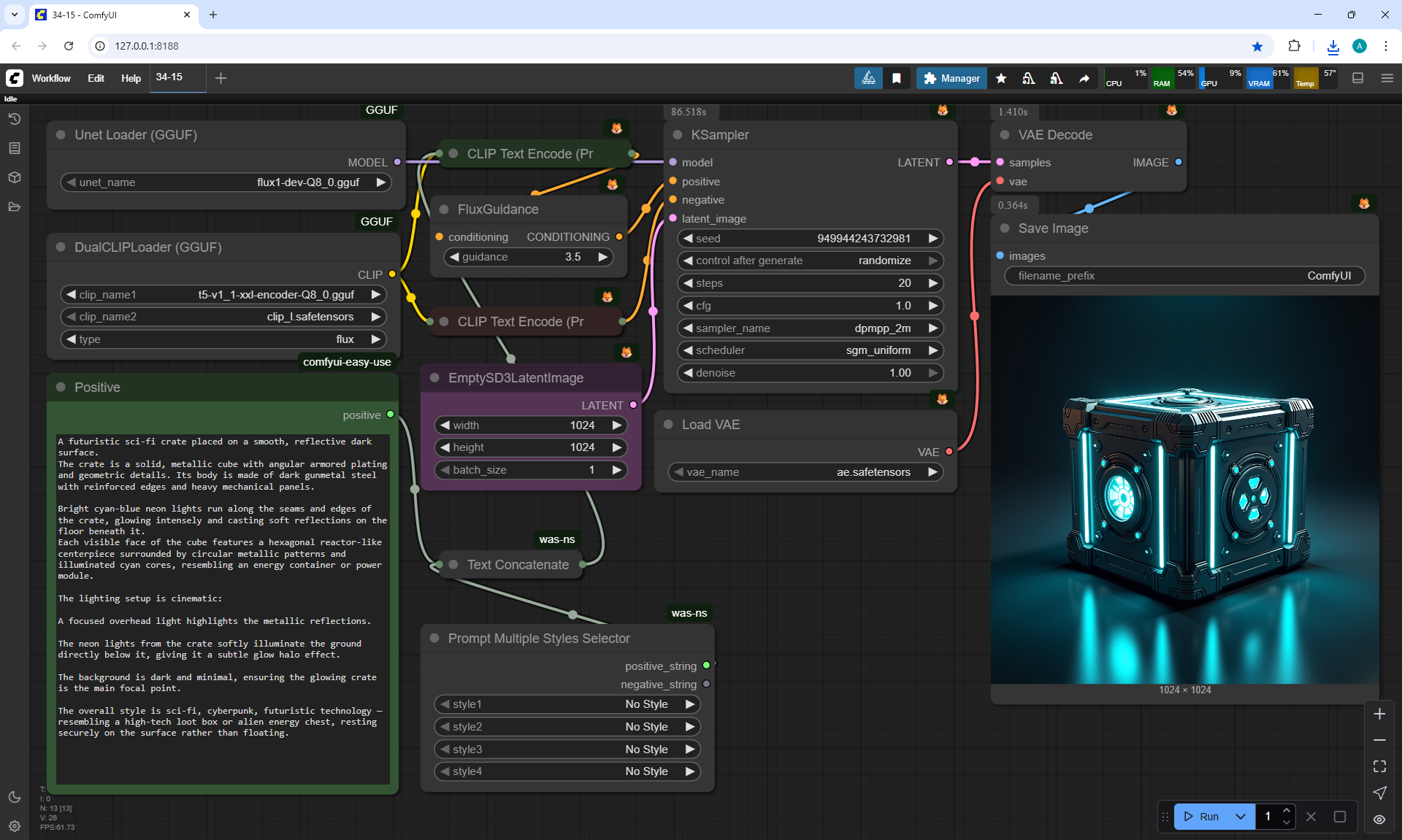
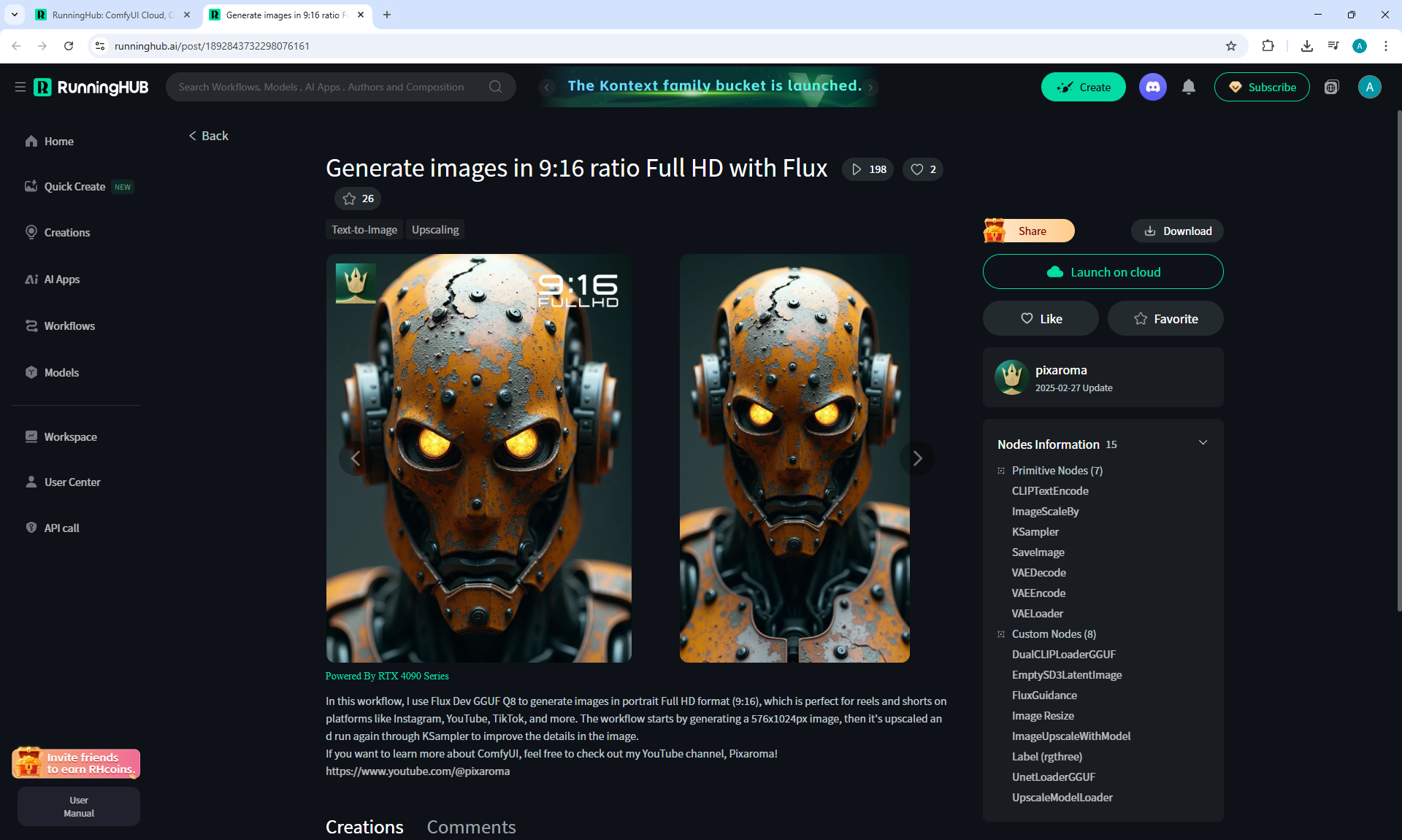
ComfyUI Tutorial Series Ep 35: How to Run ComfyUI in the Cloud





























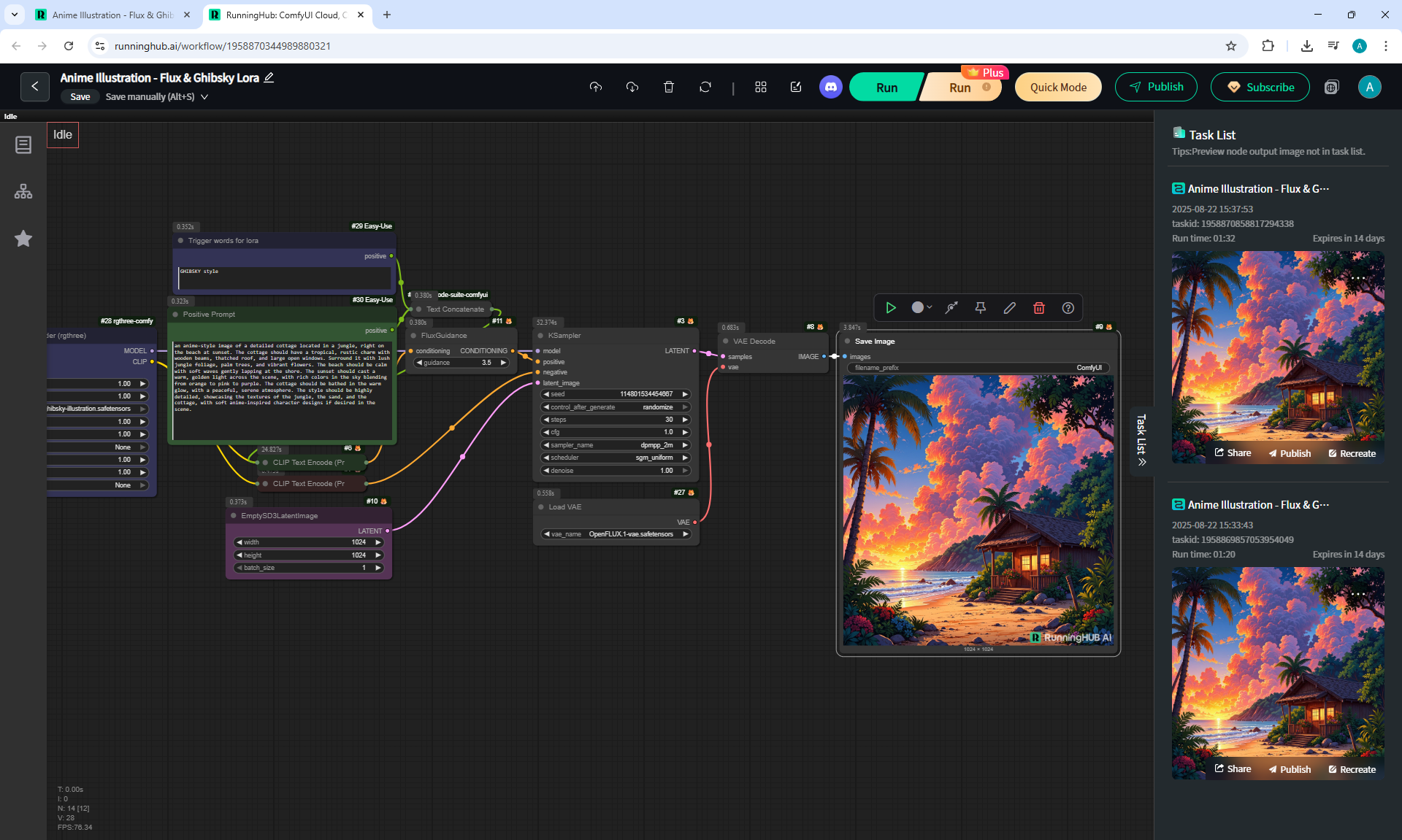
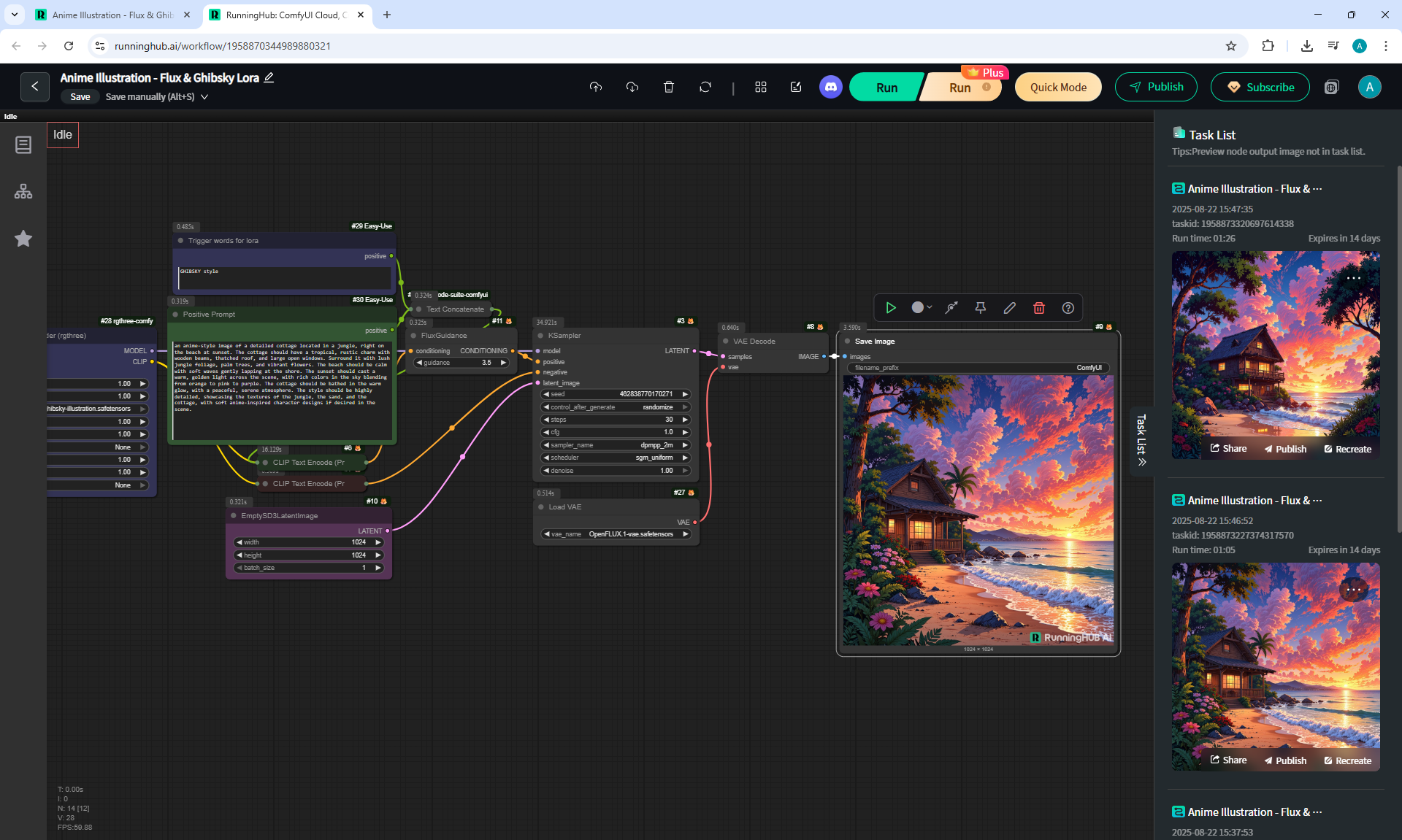
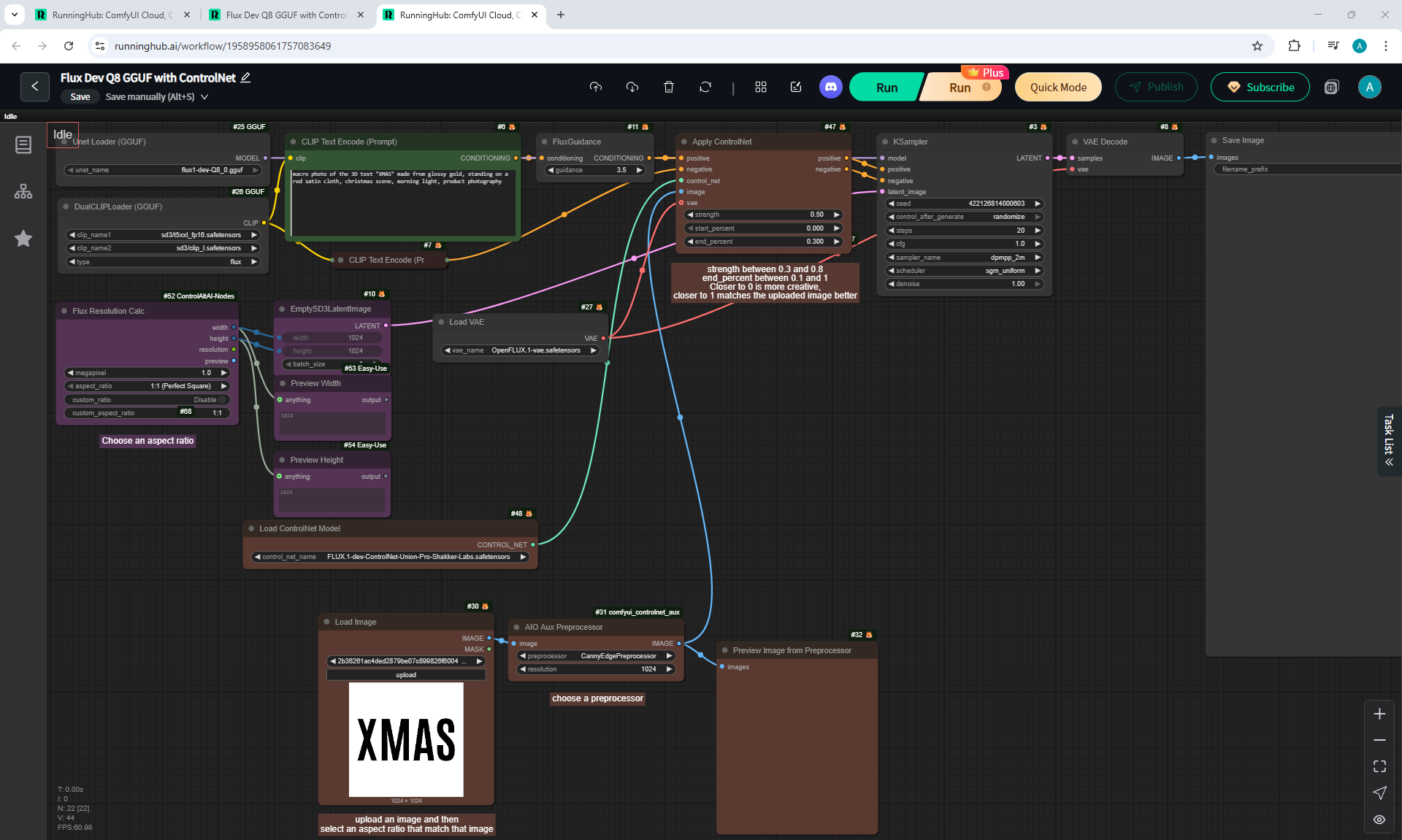
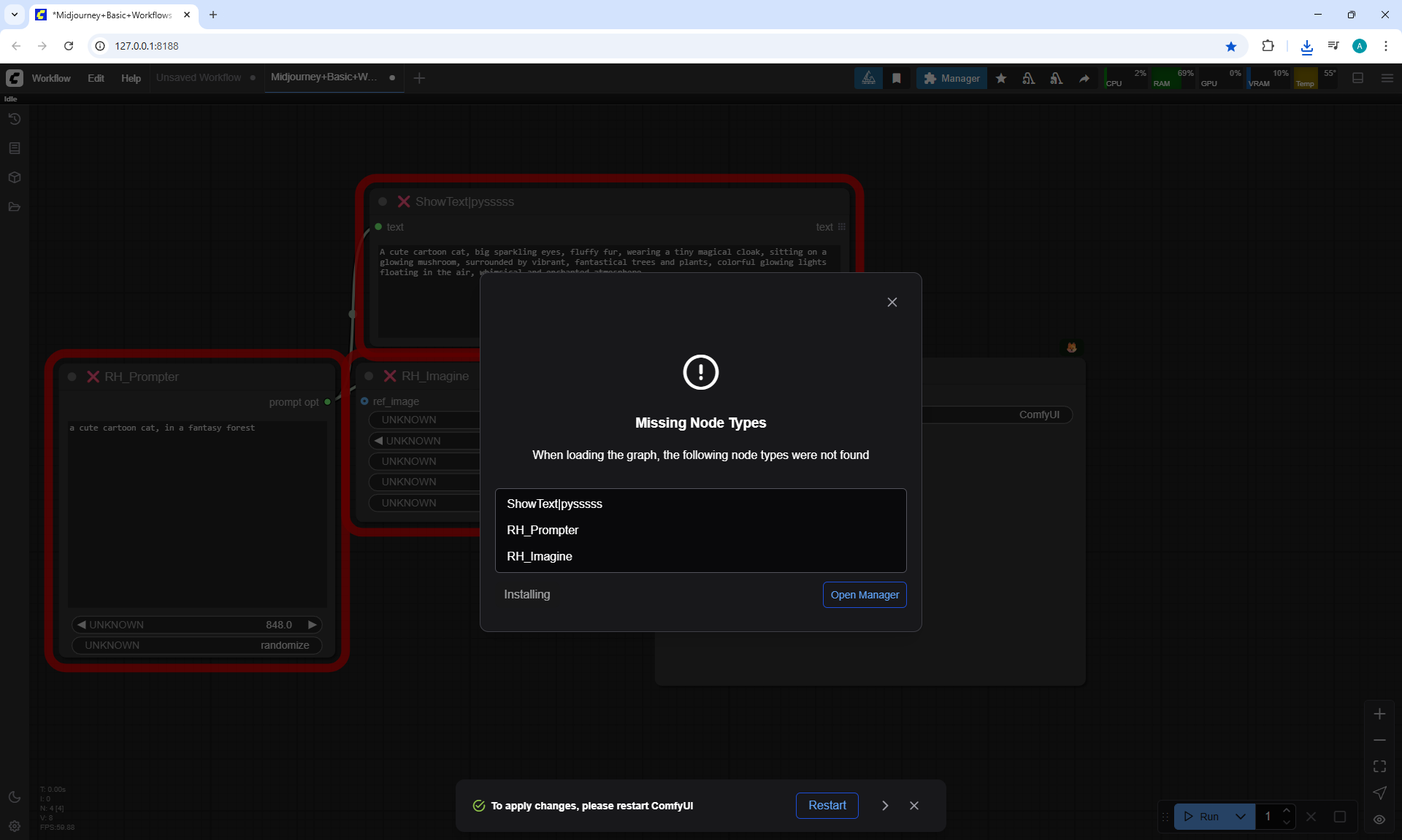
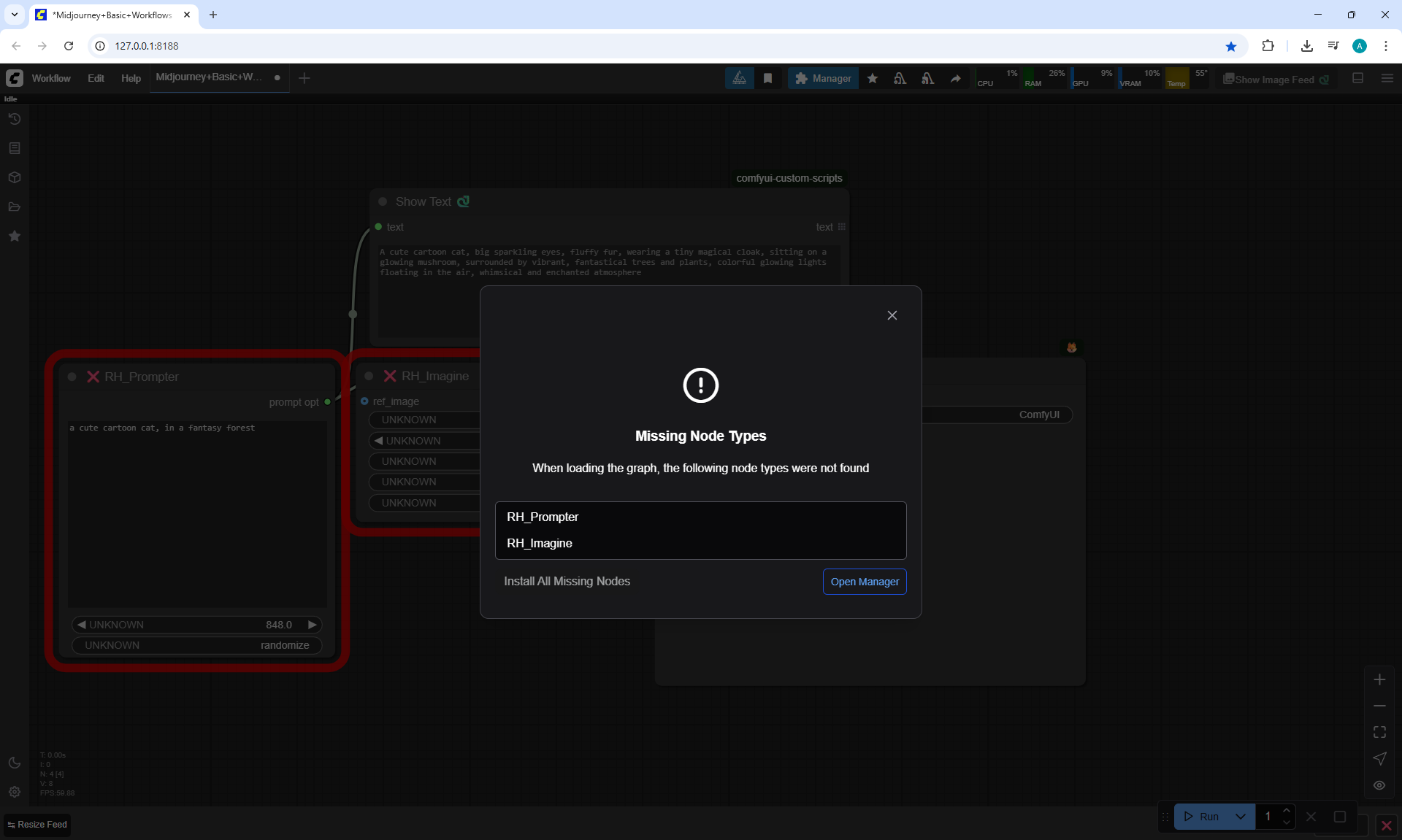
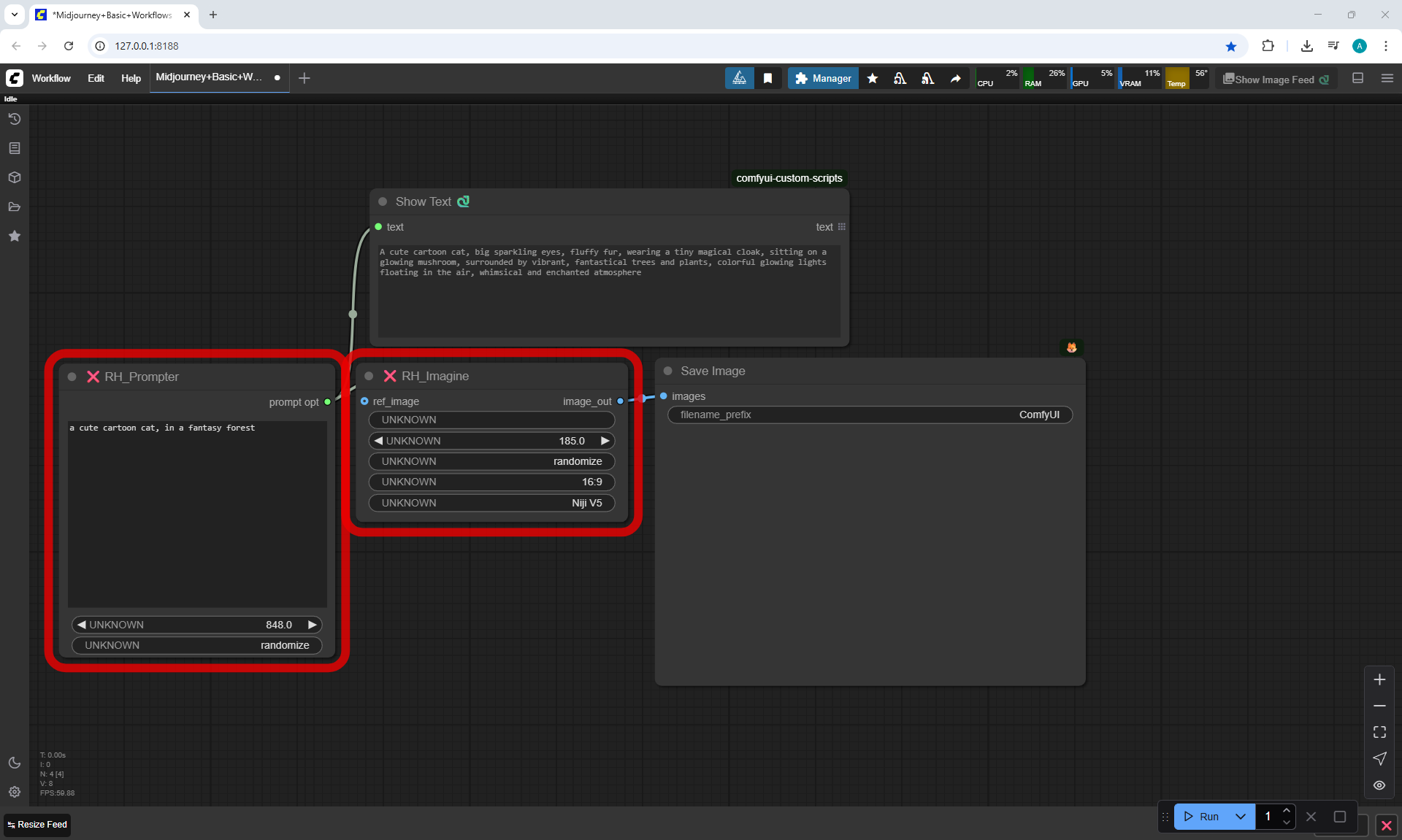
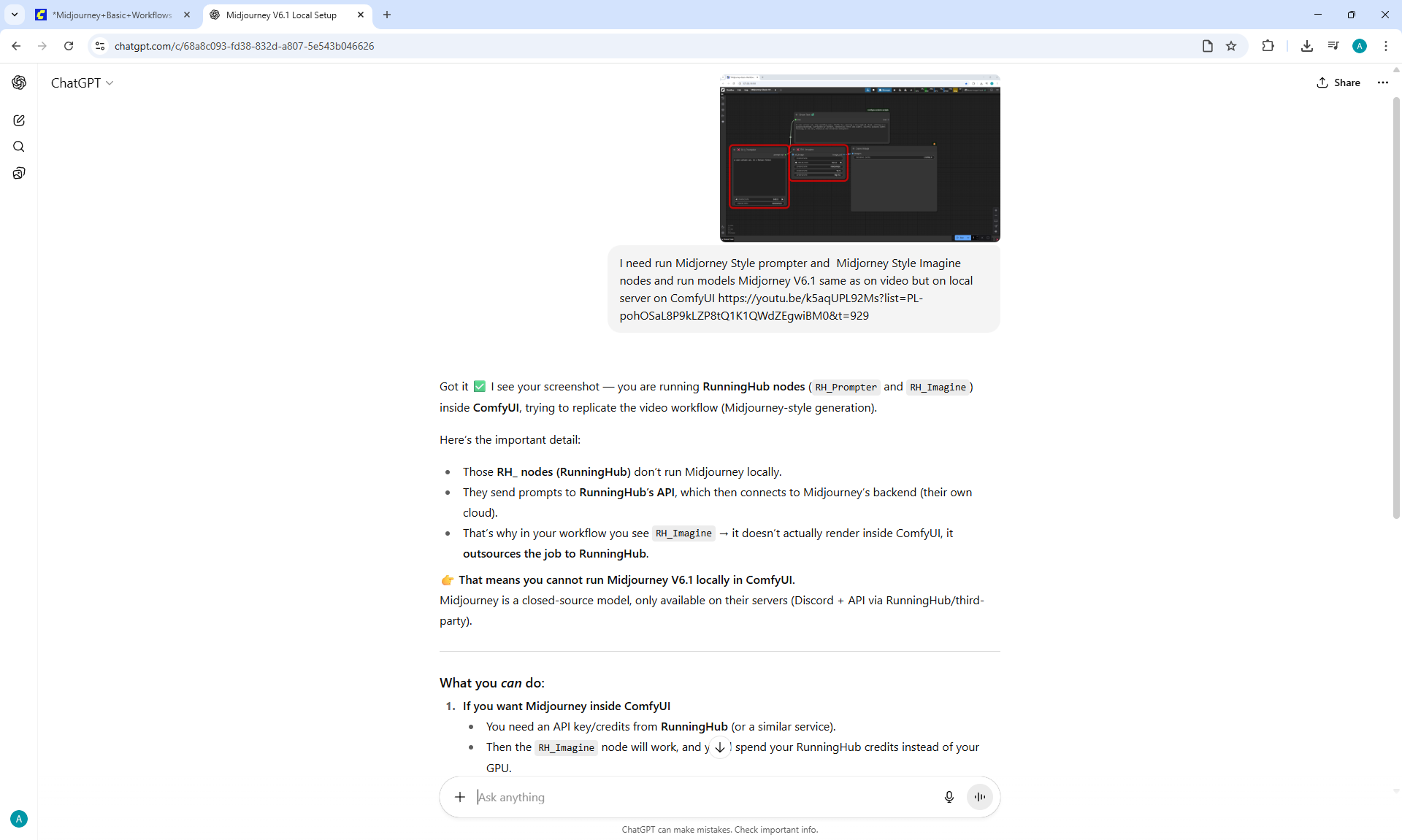
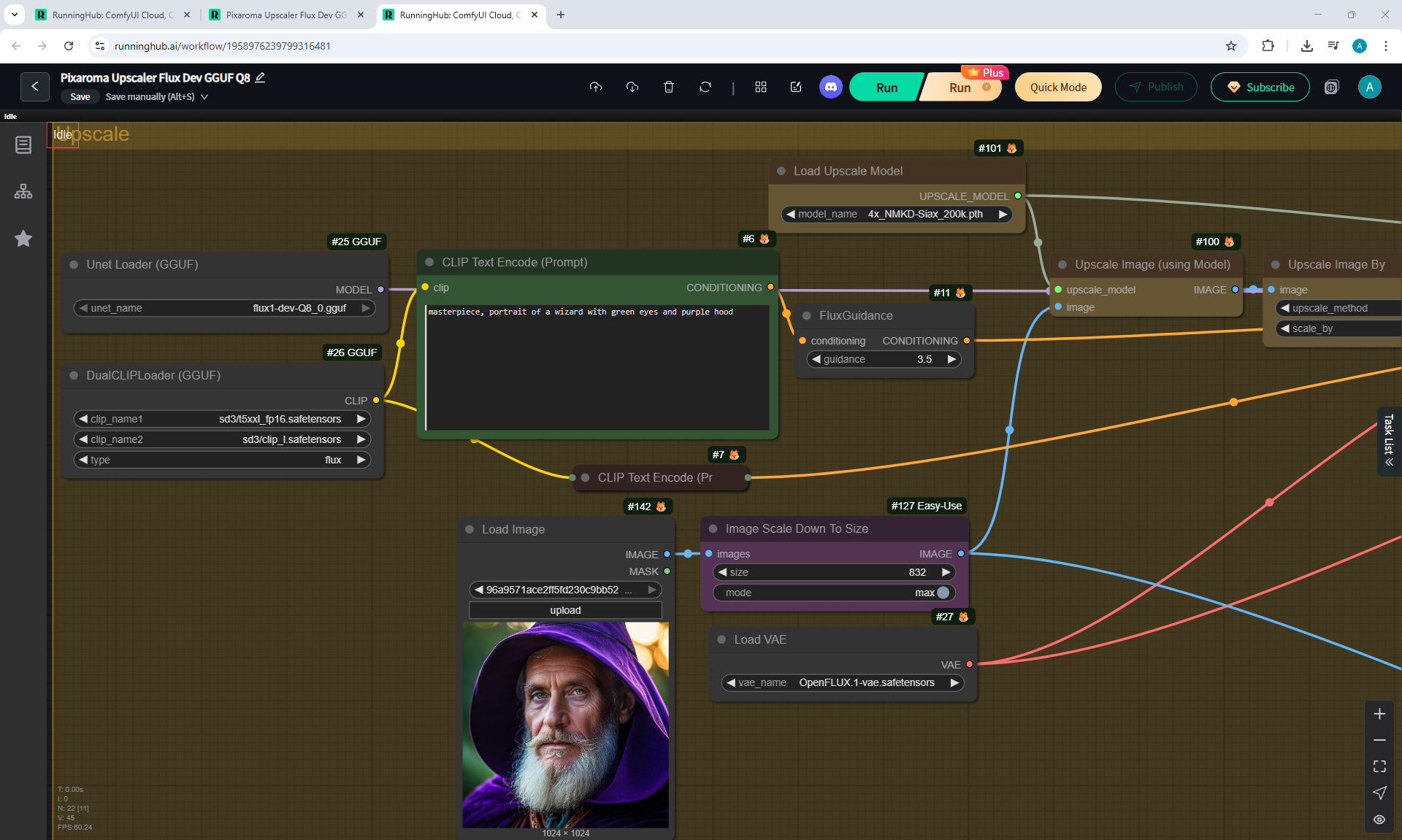
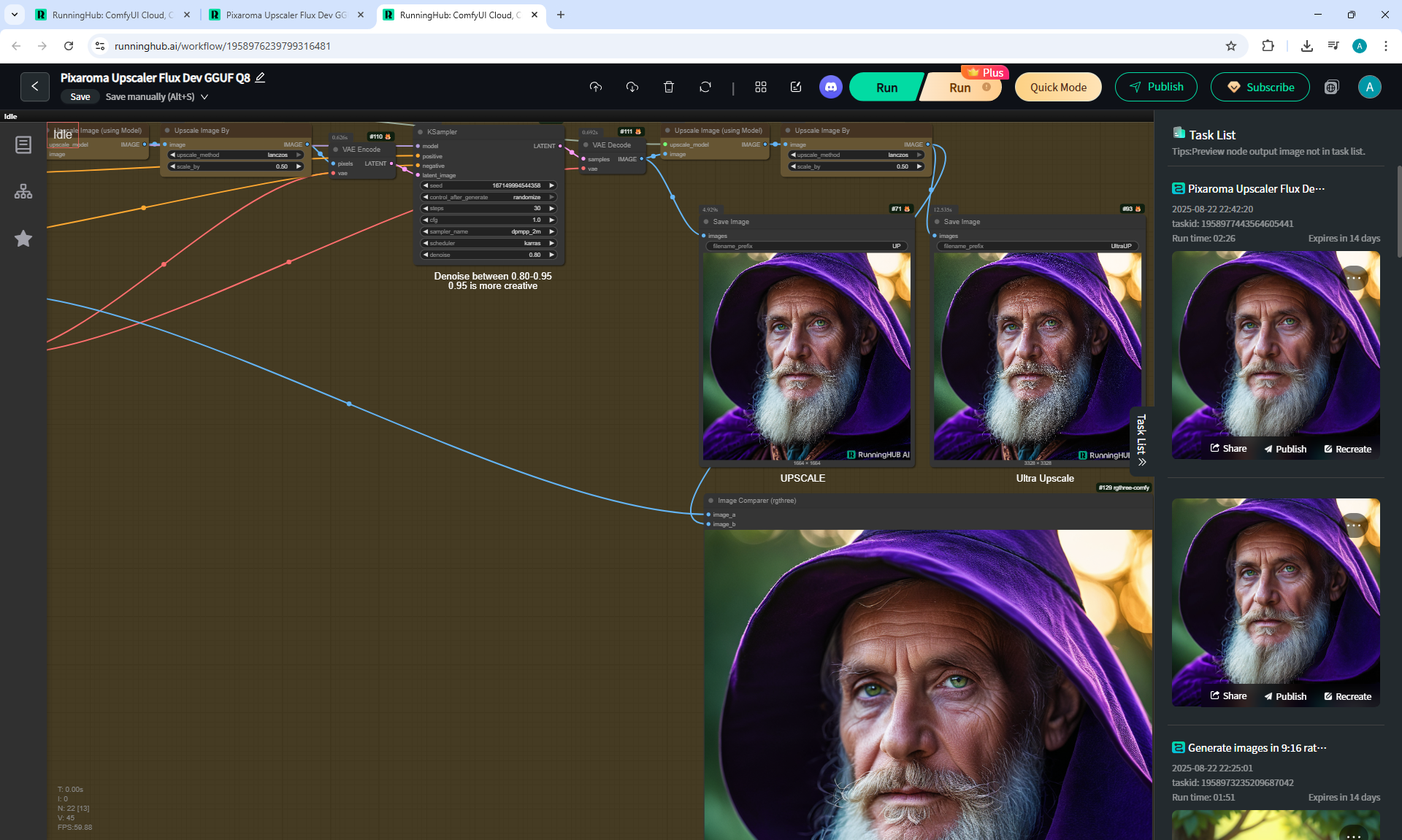
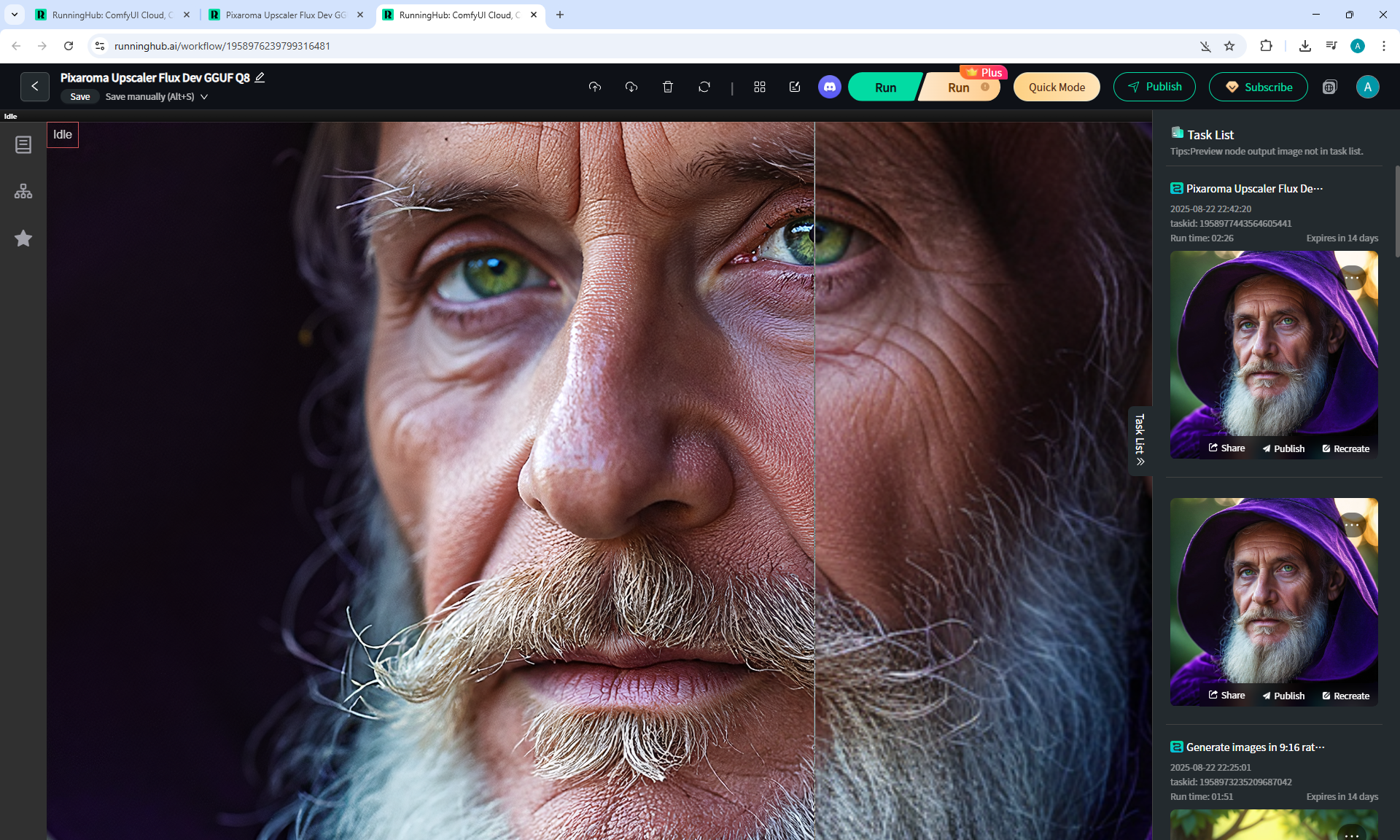
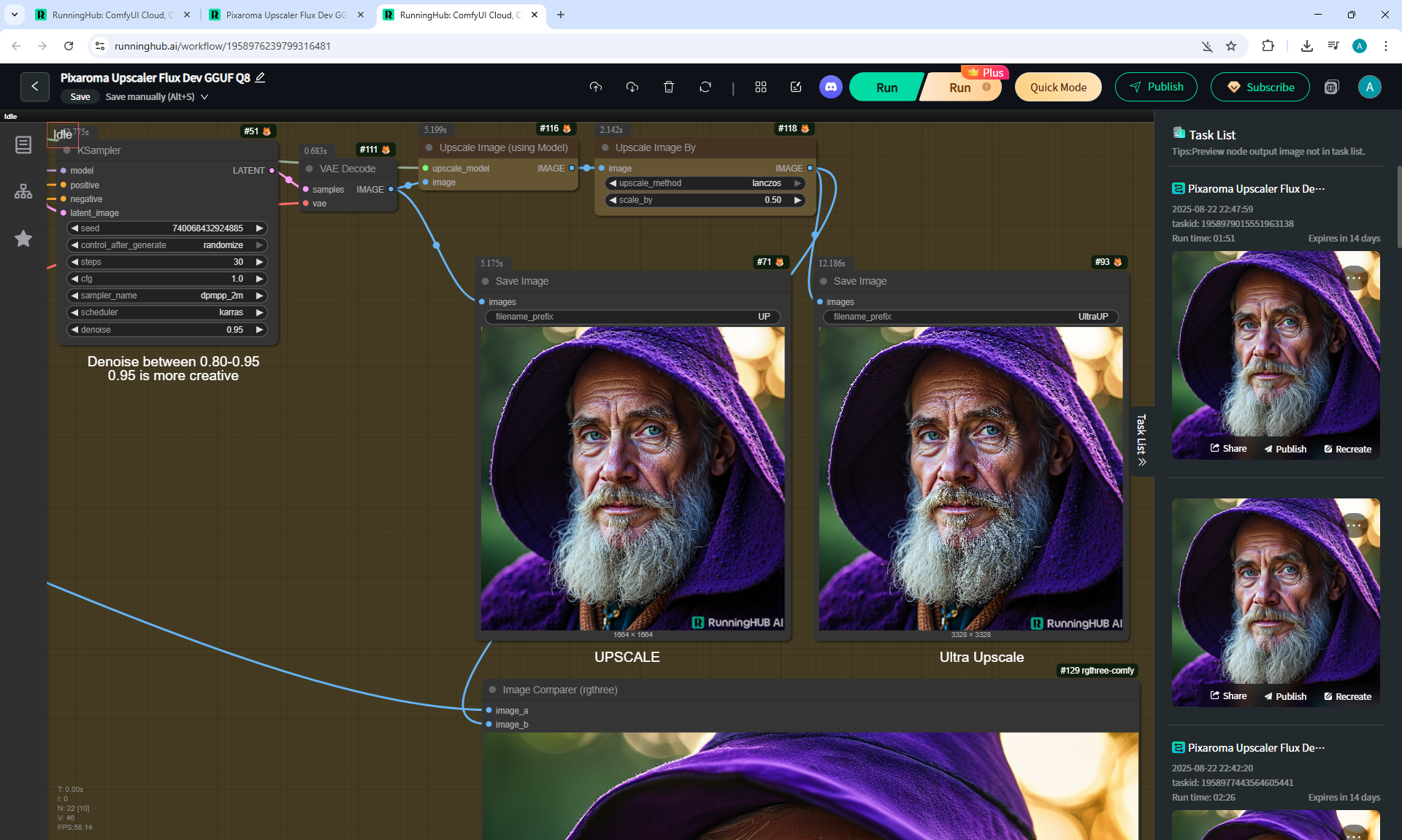
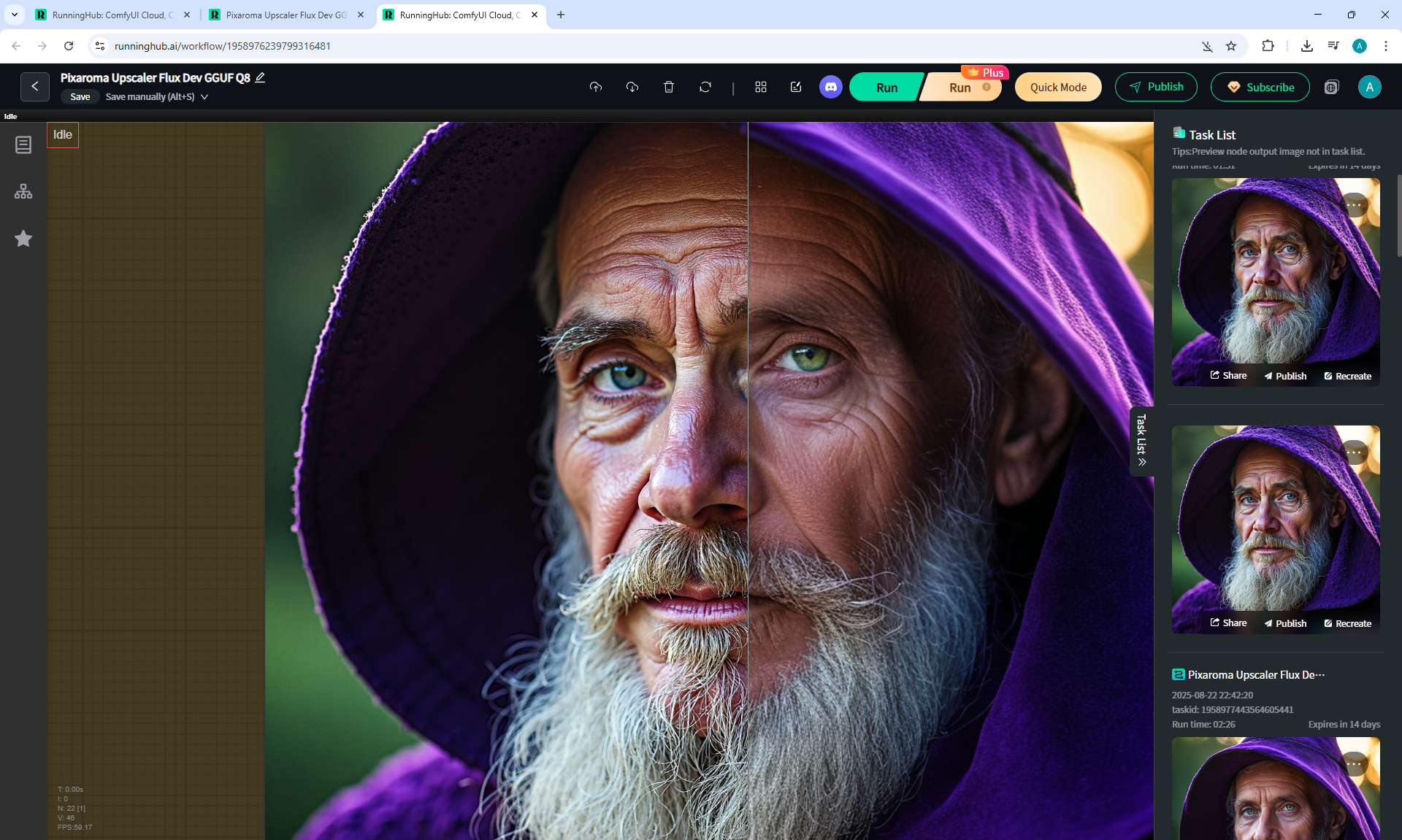
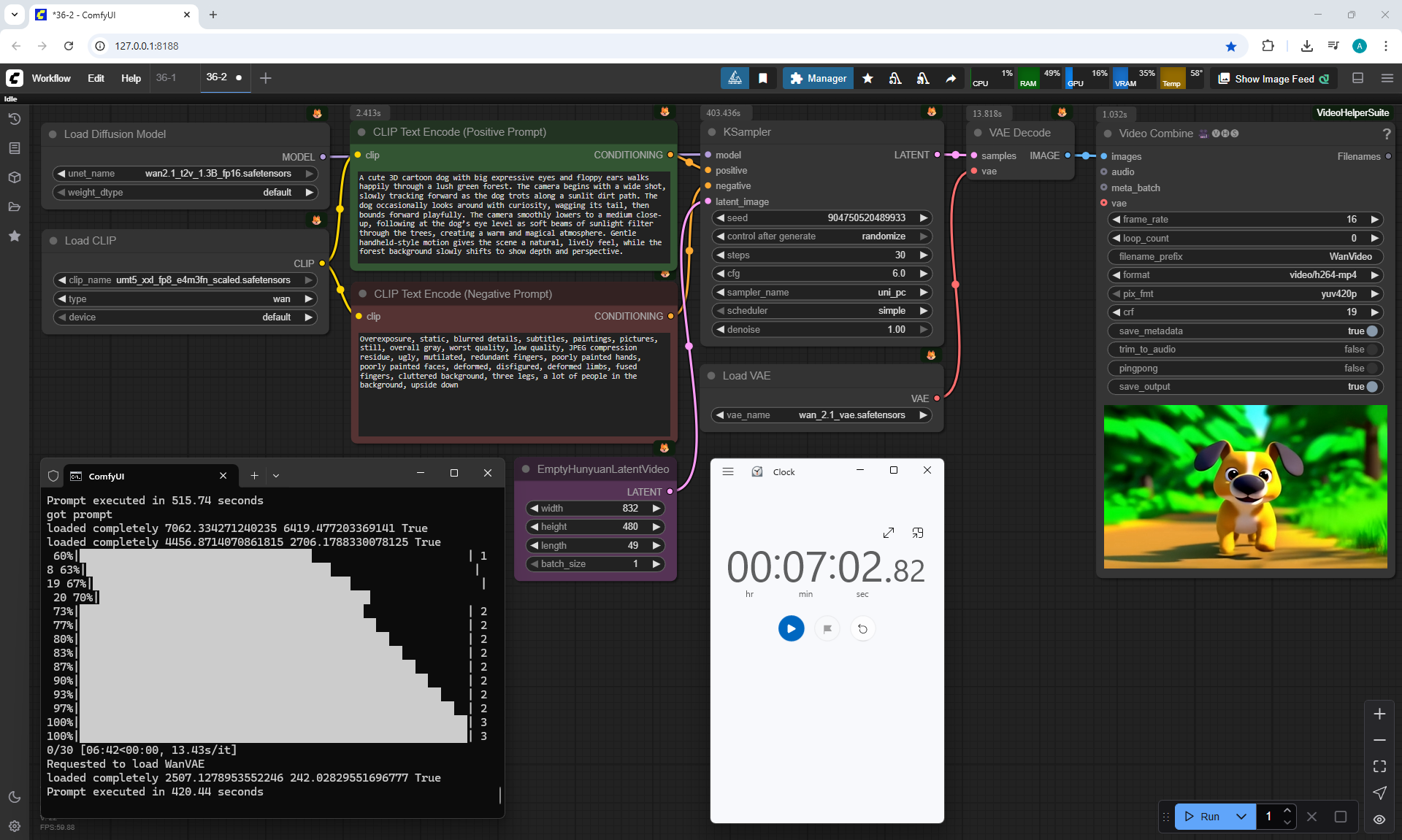
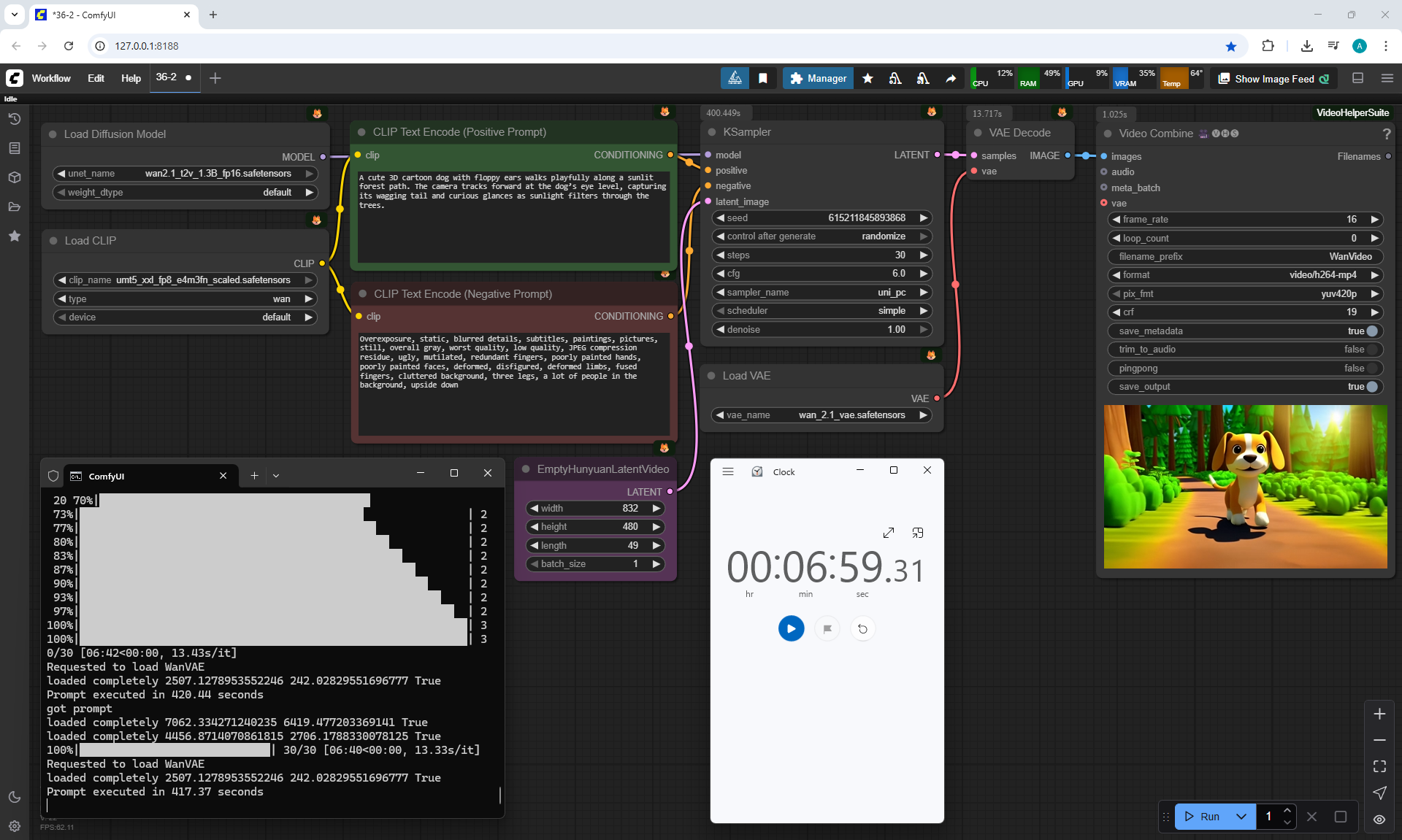
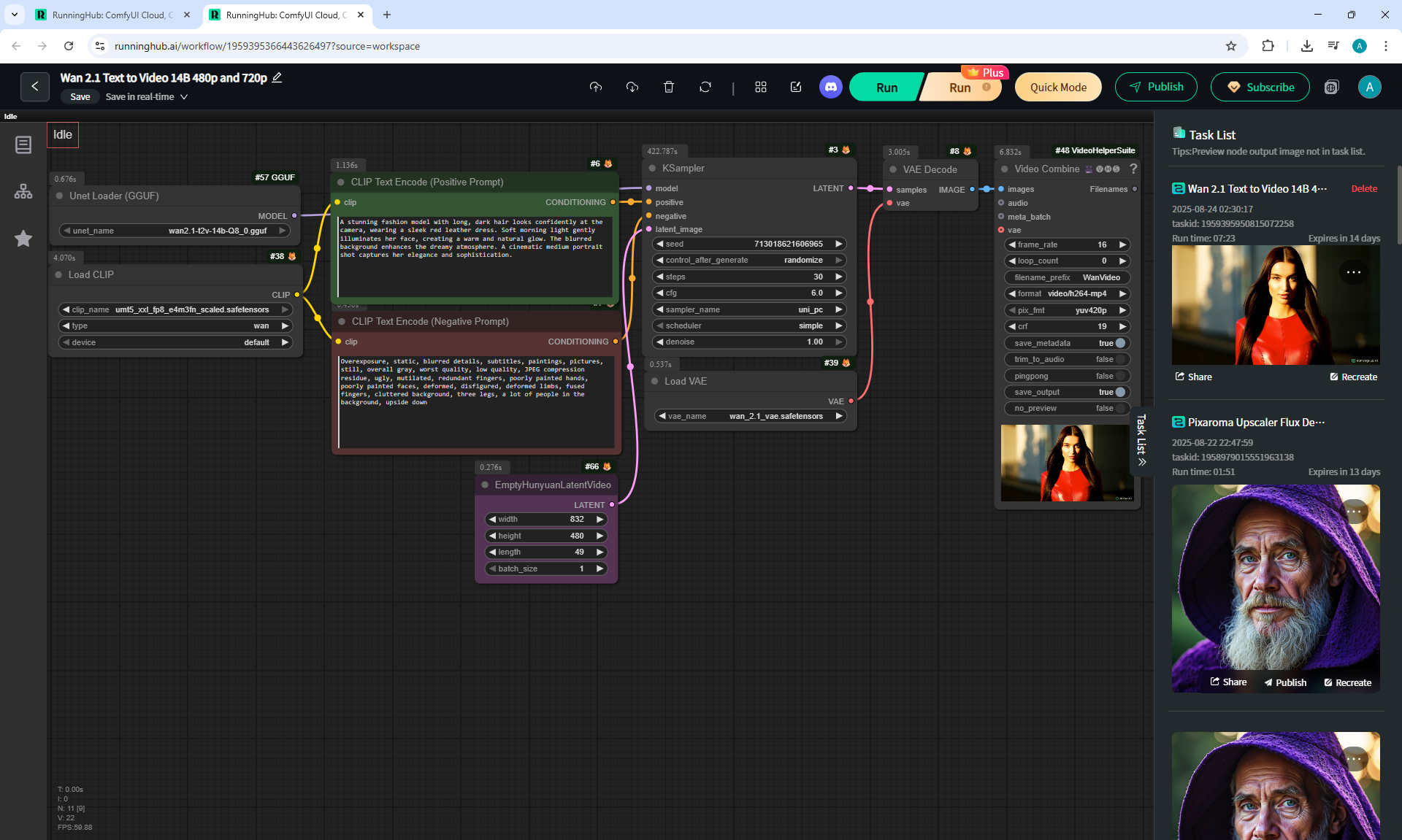
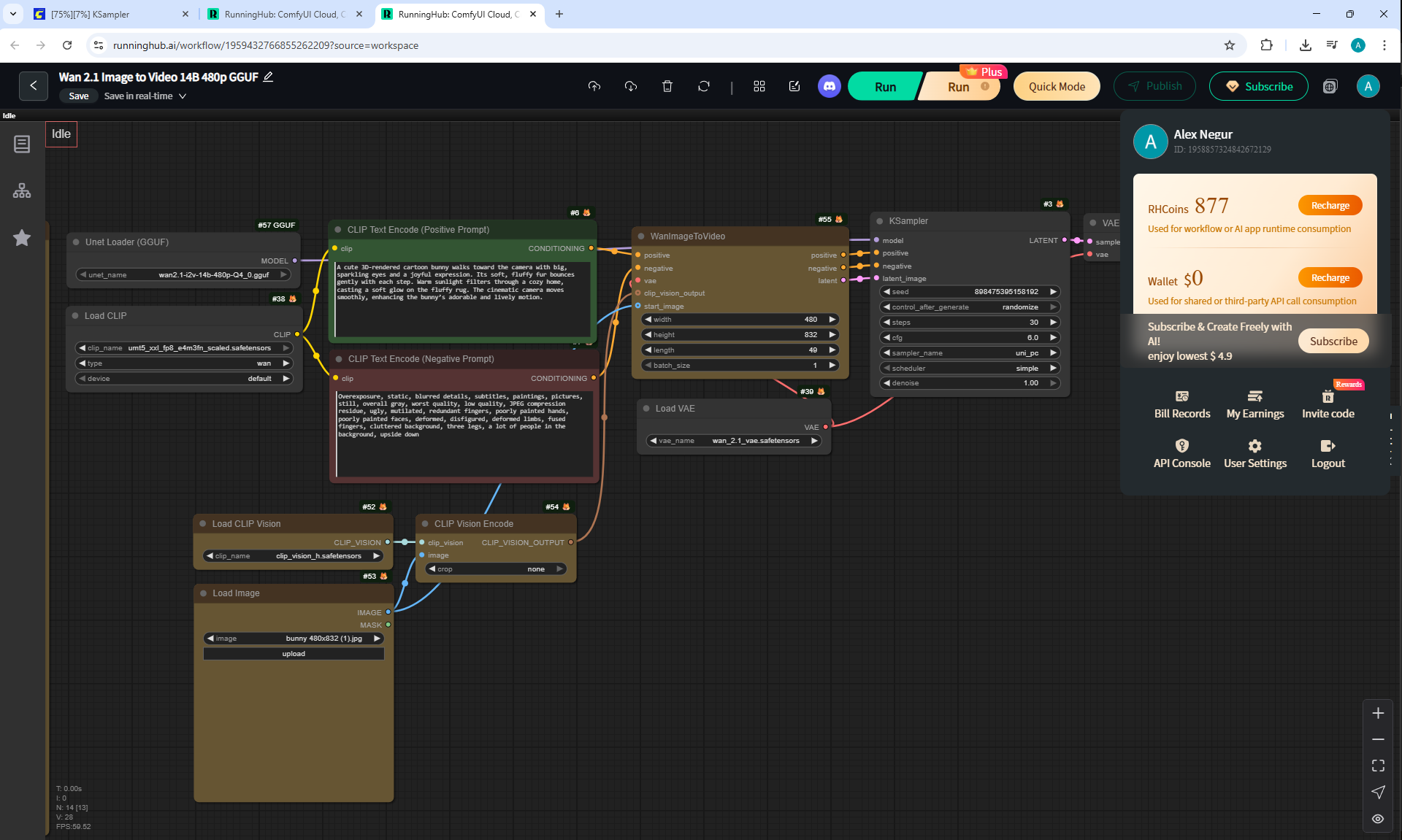
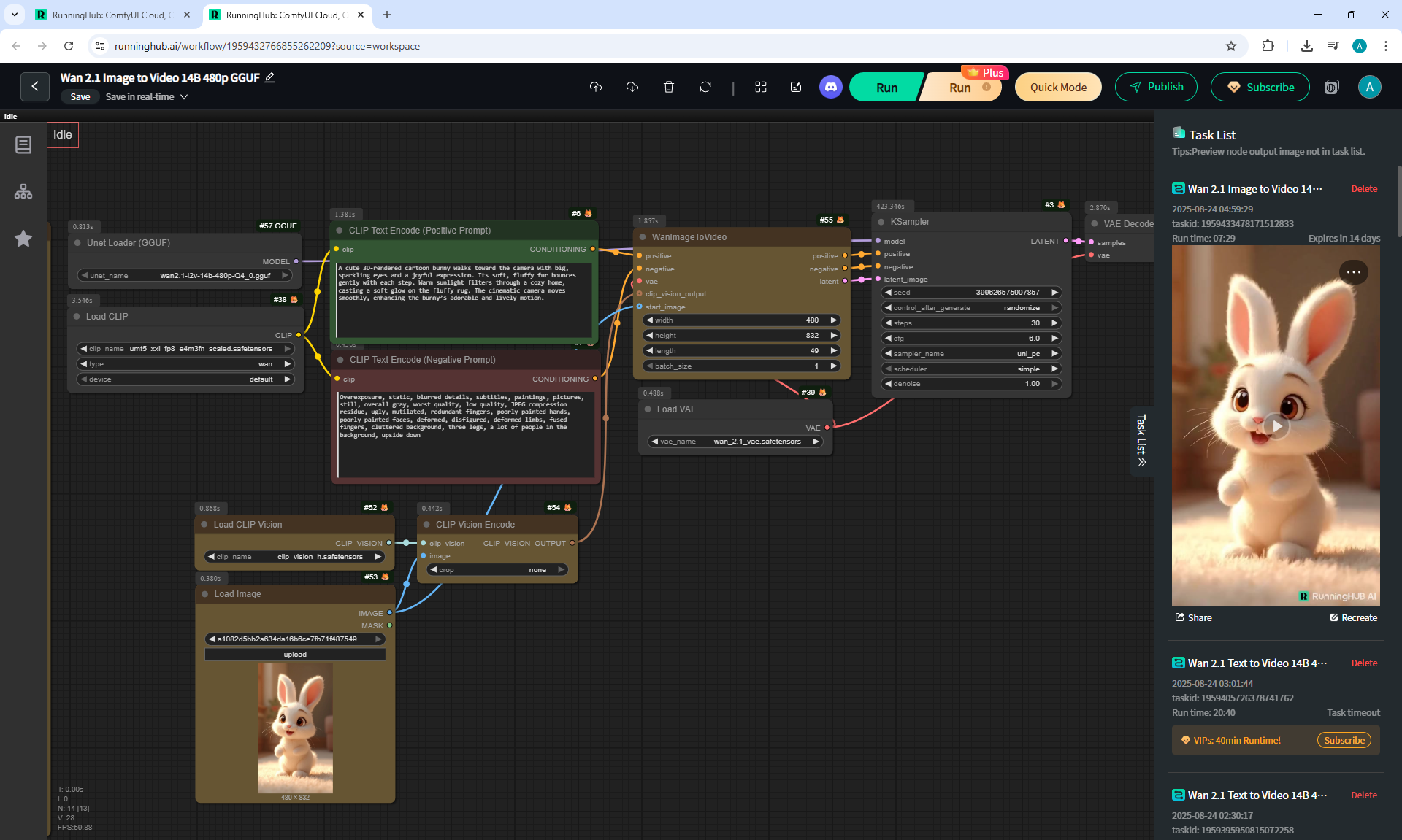
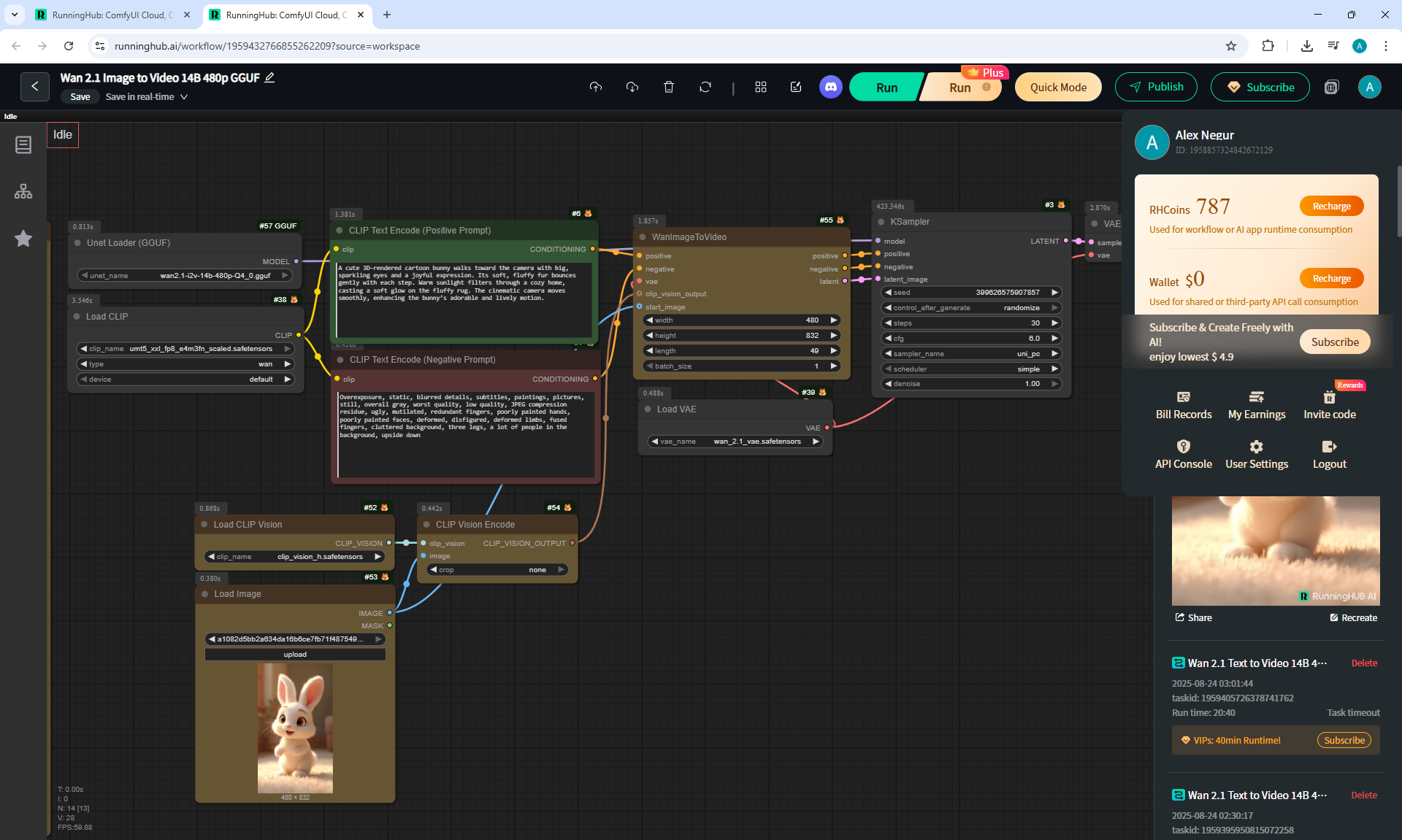
ComfyUI Tutorial Series Ep 36: WAN 2.1 Installation – Turn Text & Images into Video!

















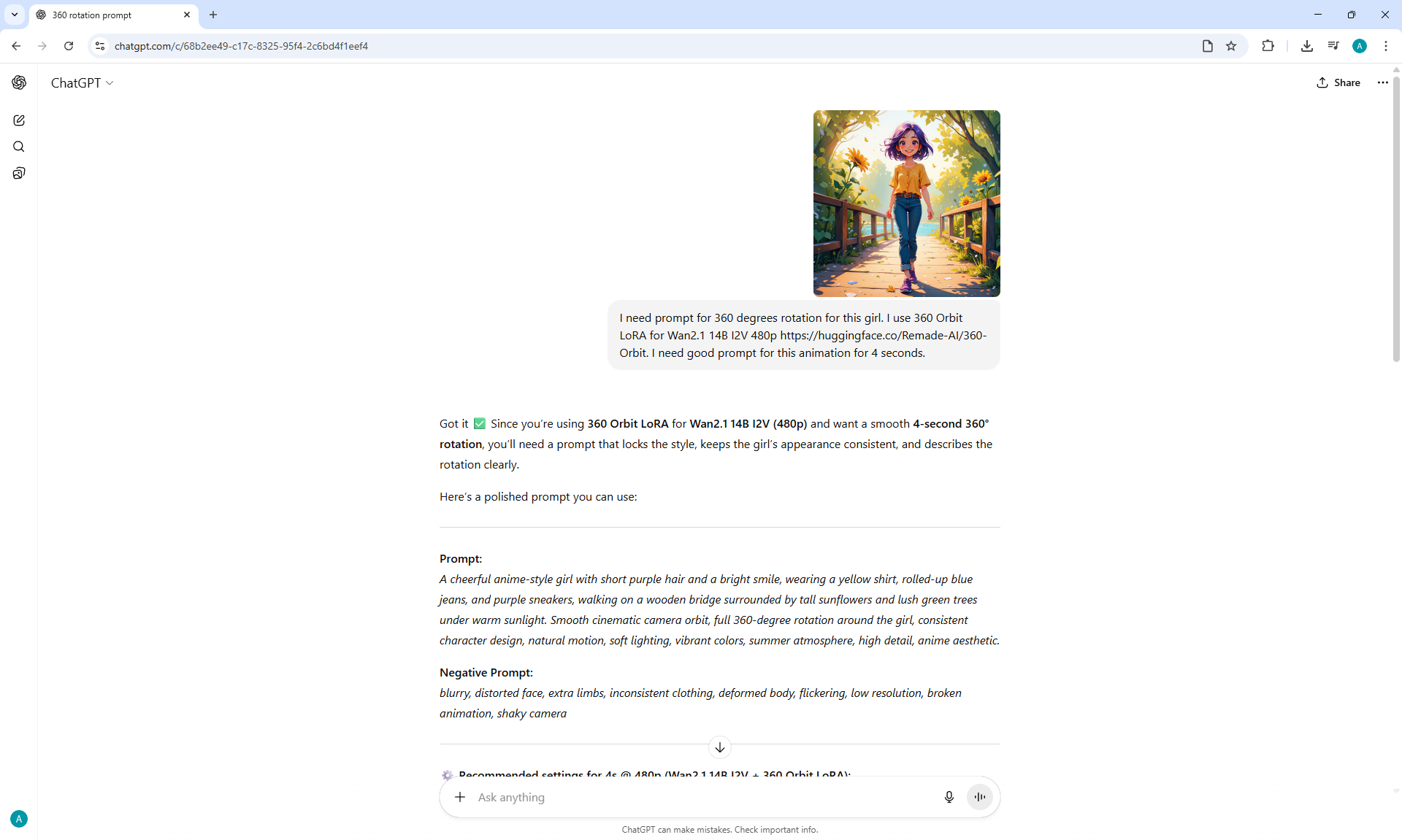
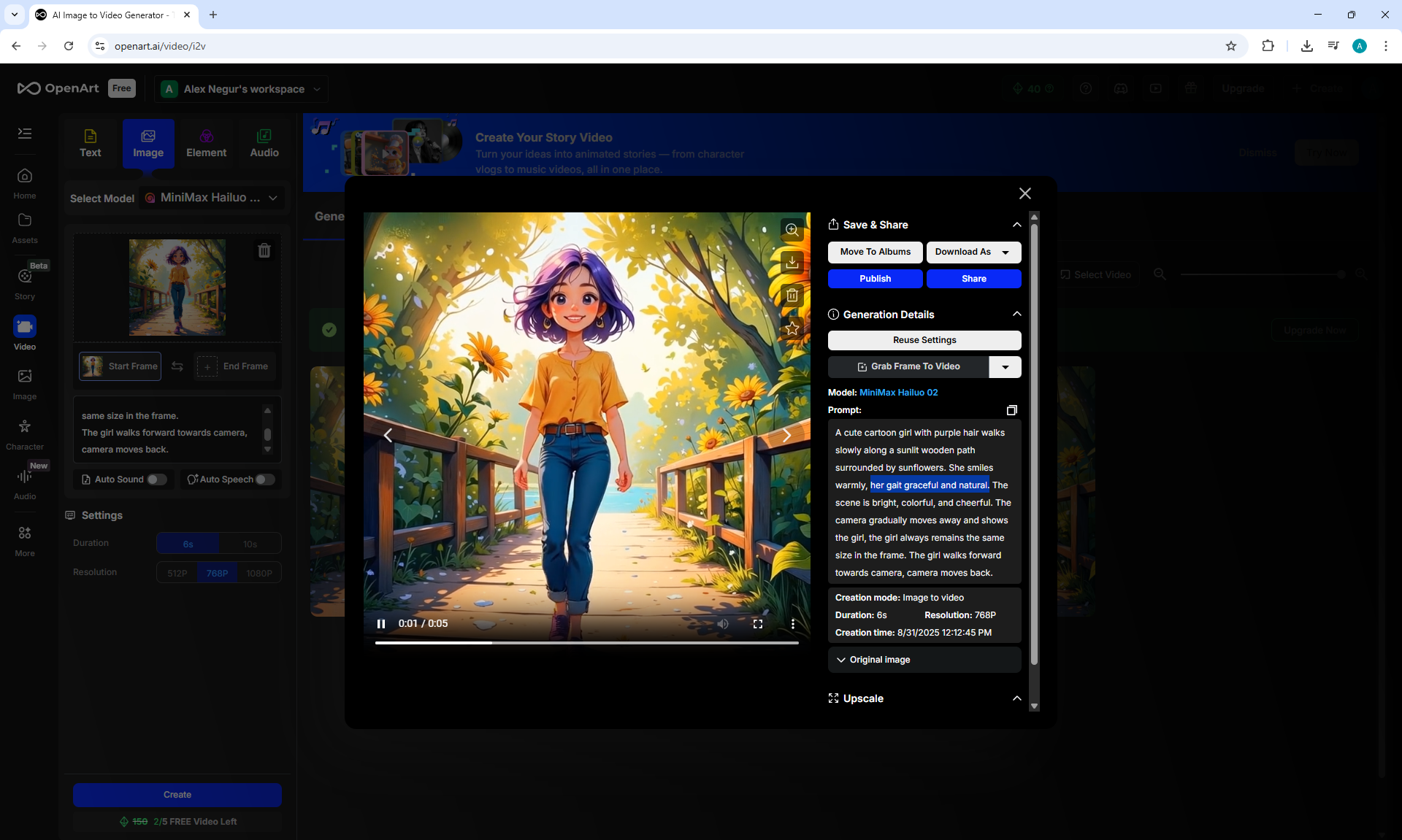
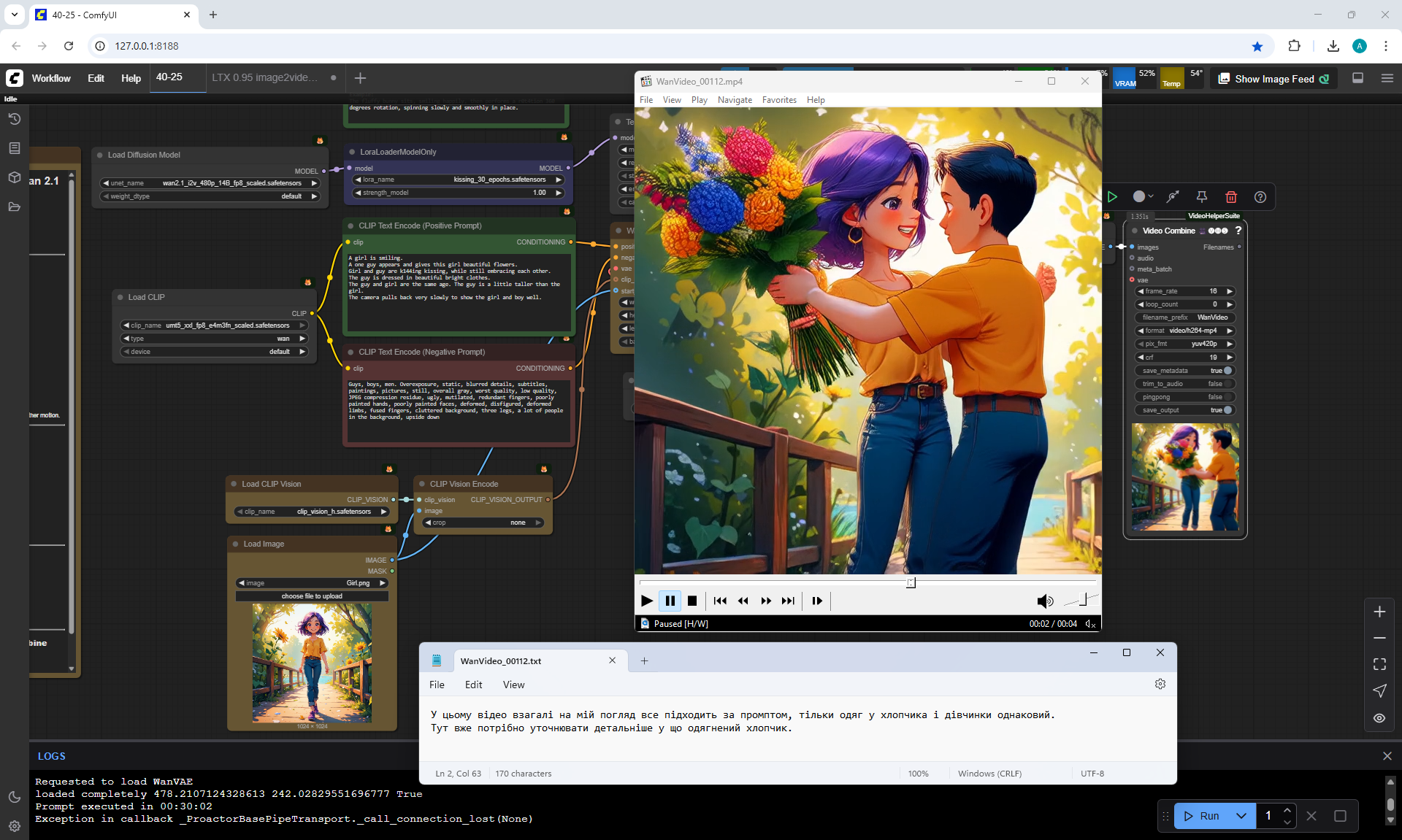
I generated this girlin episode 28.

I generated a video with this girl based on the prompt:
A cute cartoon girl with purple hair walks slowly along a sunlit wooden path surrounded by sunflowers. She smiles warmly, her gait graceful and natural. The scene is bright, colorful, and cheerful, with gentle camera movement following her steps.
The girl instead of moving forward moves backward, tries to do a moon walk. You can do an inversion of the animation.
But the movement of the figure, facial expressions are well animated, there are volumetric movements of the hands, head and other parts of the body. There are also shadows on the girl and from her, there is a small animation of leaves. The animation comes out lively, natural.
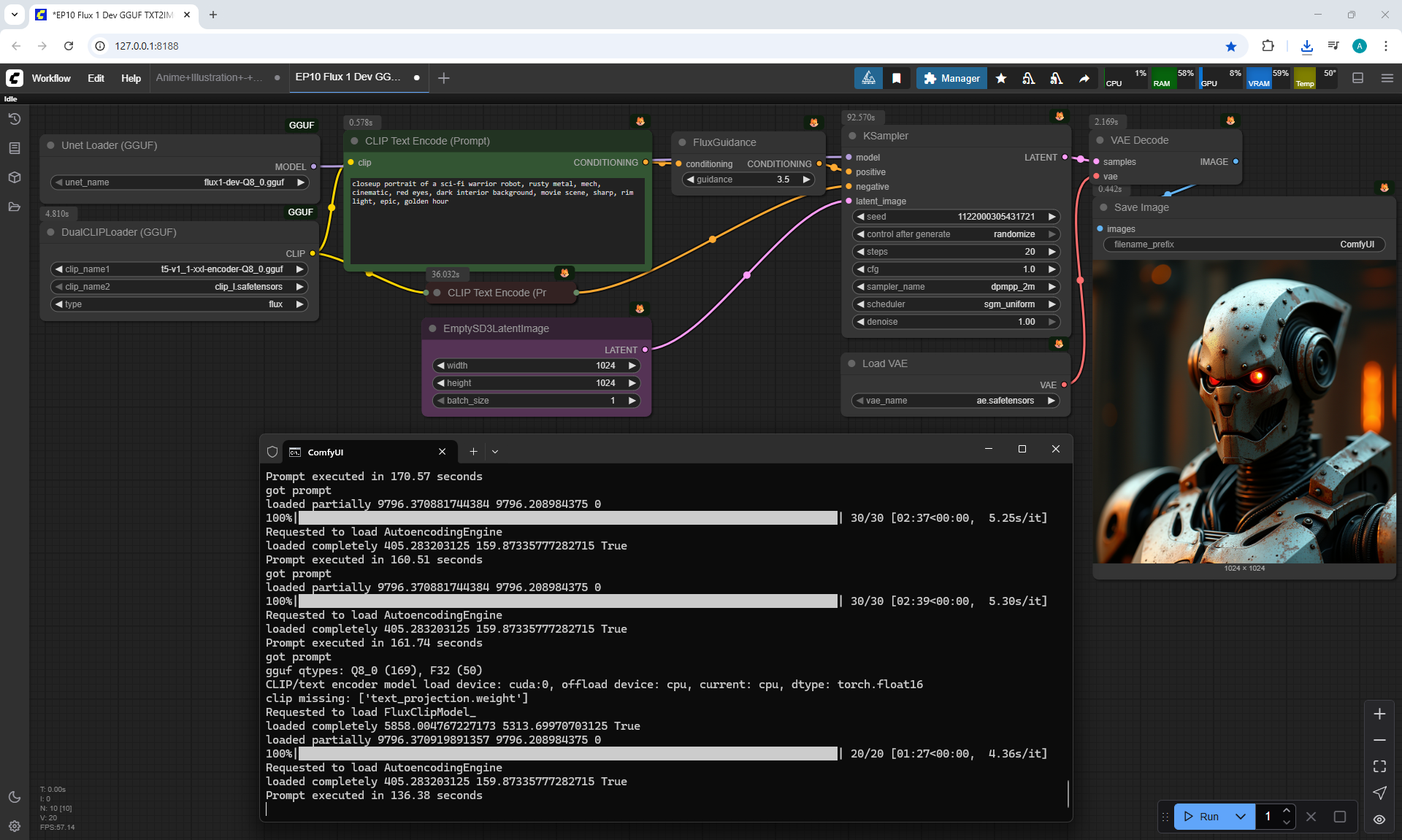
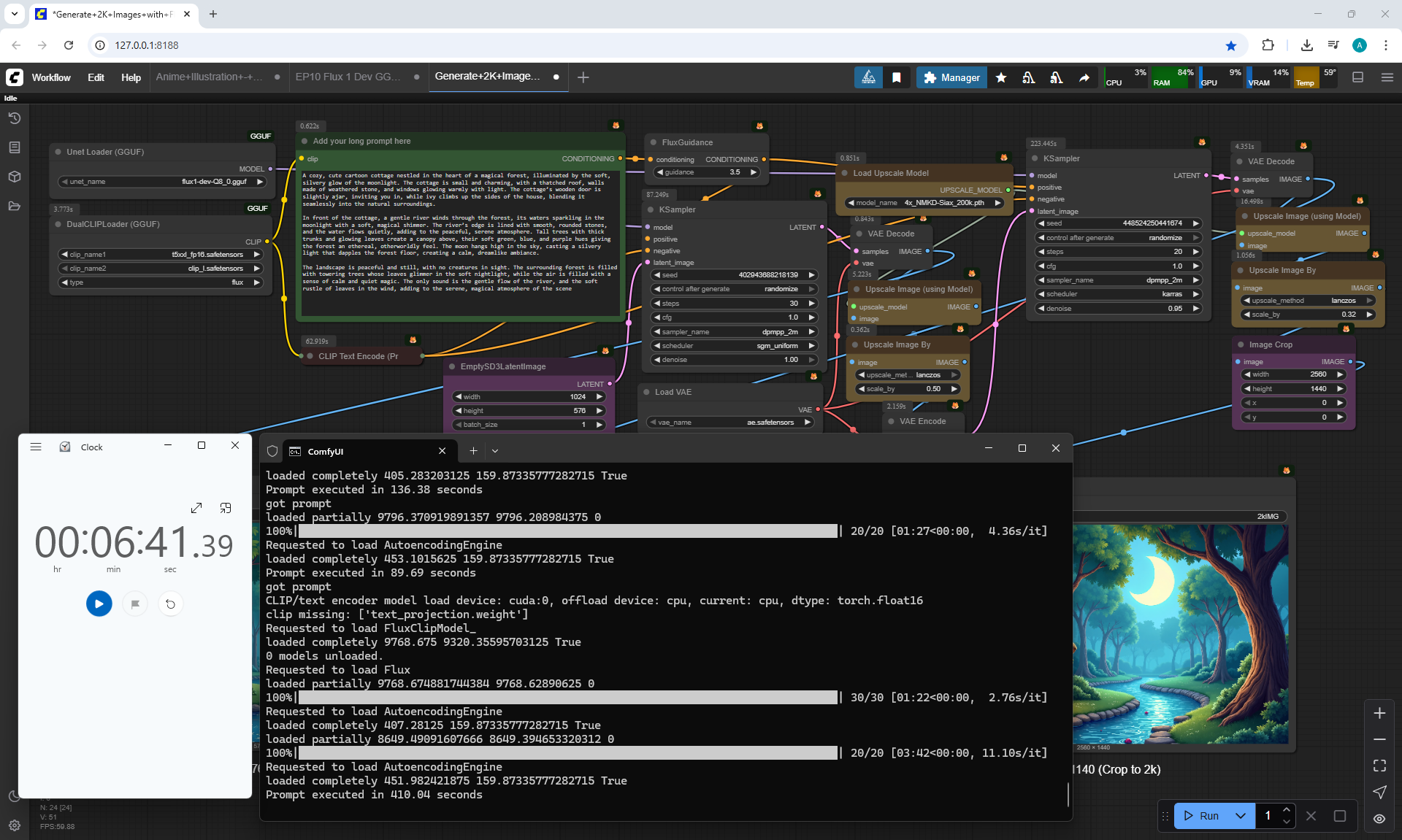
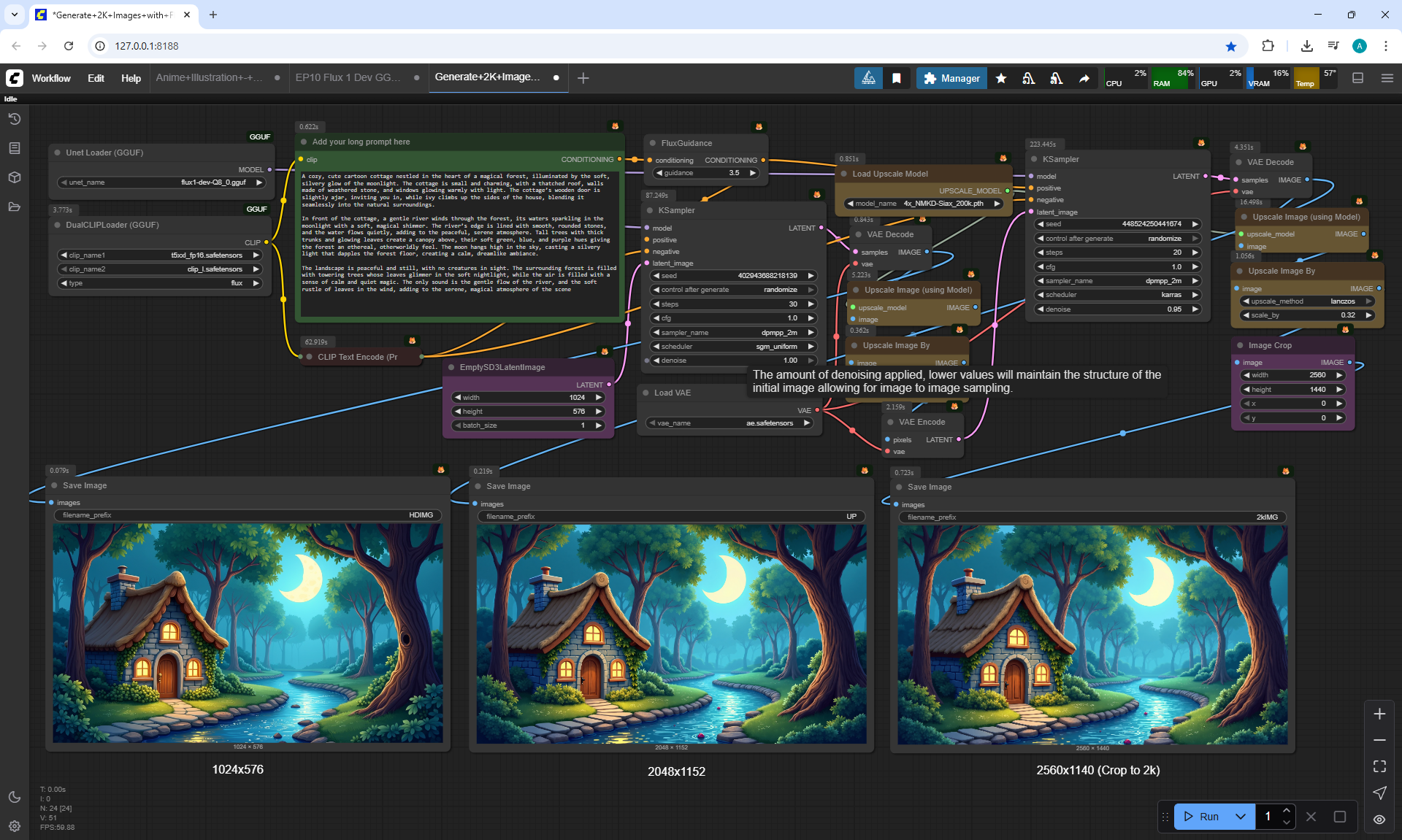
I generated this video 960x960 16fps 3 seconds on wan2.1-i2v-14b-720p-Q4_0.gguf, on the local ComfyUI server.
The generation lasted 2 hours 33 minutes. Very long.
I know that you can generate in the cloud, it will be much faster, I tested how it generates on my computer in ComfyUI.
You can use other paid sites for generating graphics, it will be generated quickly.
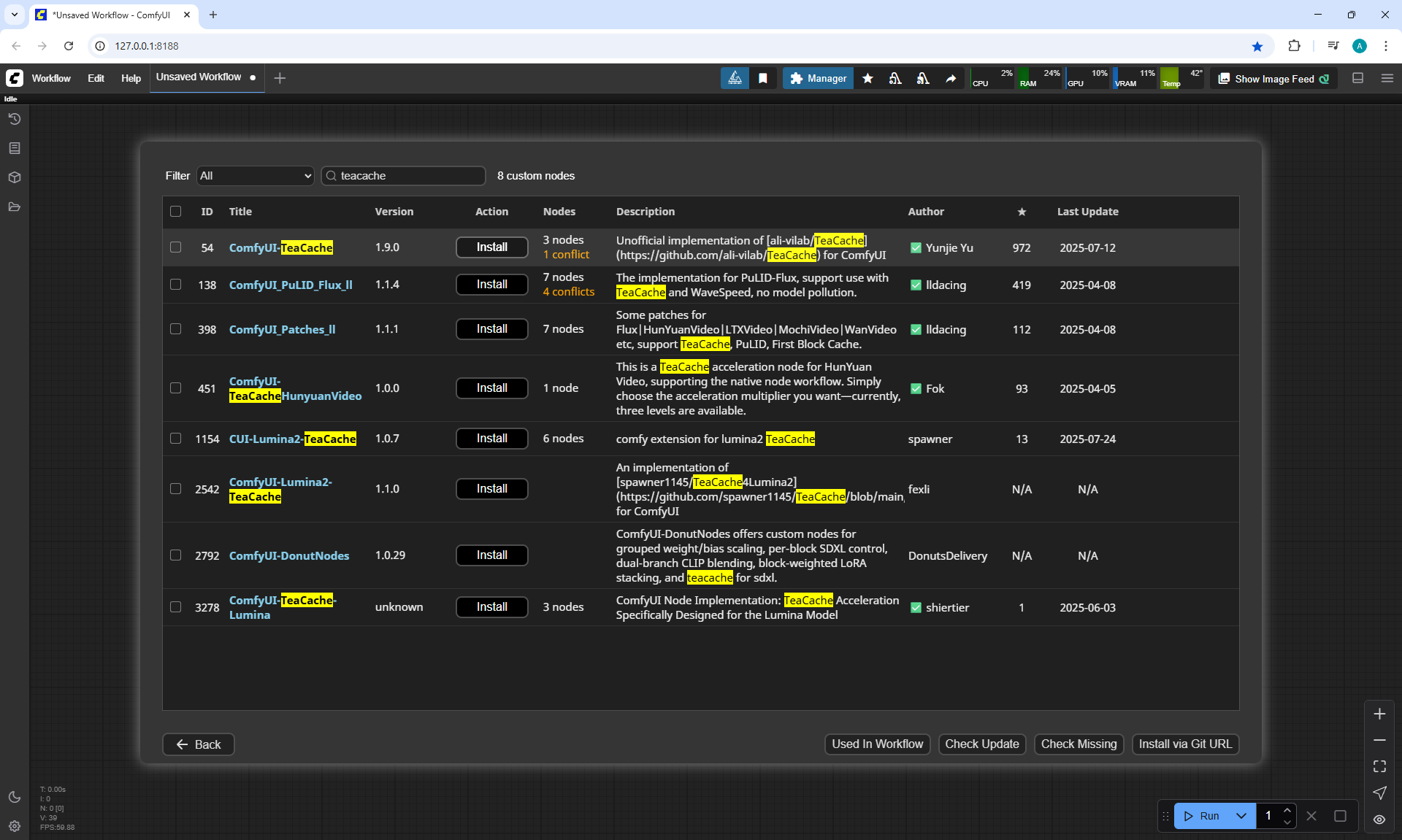
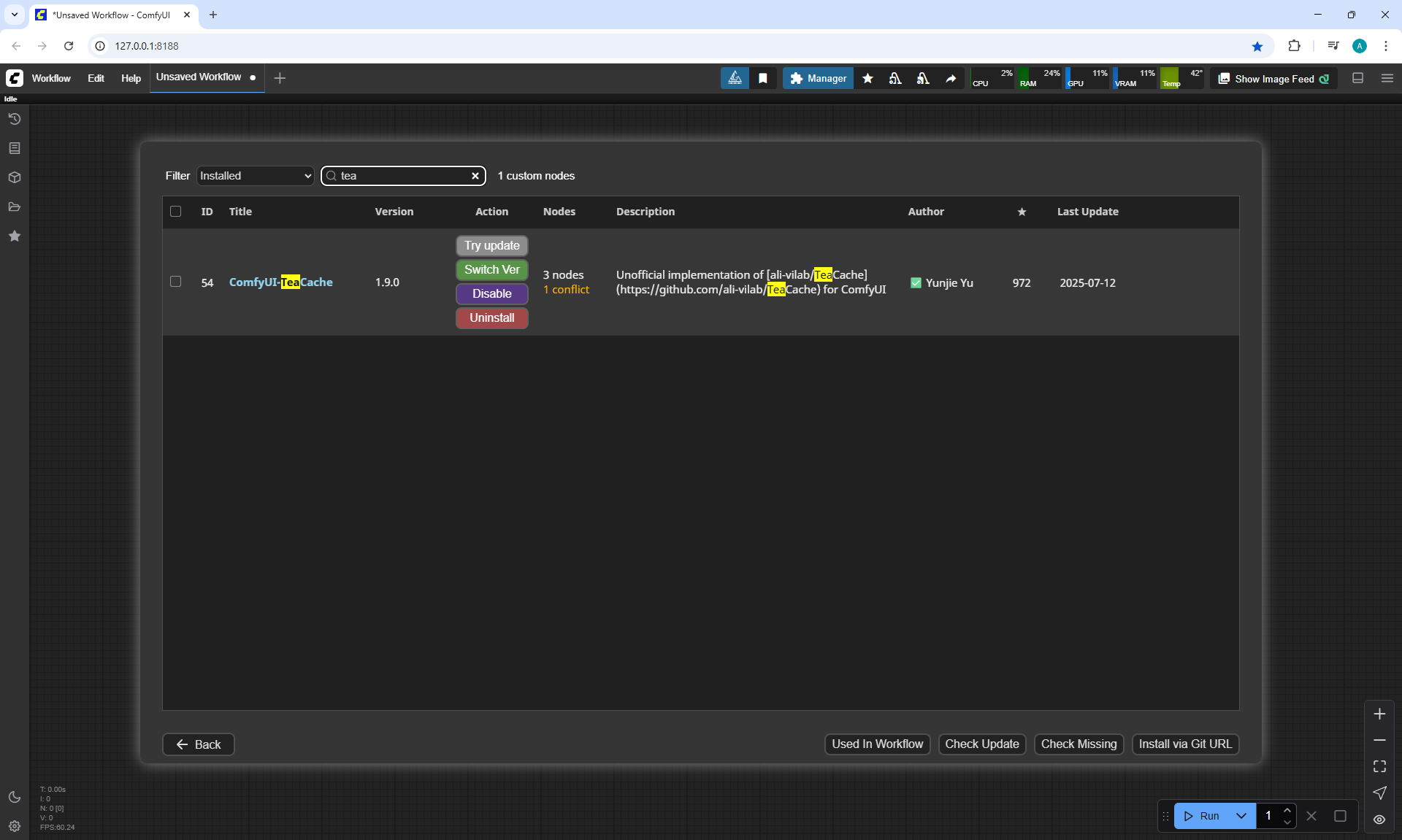
When I was doing this lesson, there were other checkpoints wan2.1, wan2.2 appeared, and I also did not reach the TeaCache node, which greatly speeds up generation in ComfyUI, the author will talk about this in the next episodes.
In this animation, the scene does not move during the girl's movement, the girl's step slides in place. The camera does not follow the girl.
In lesson 40, I generated different videos with this girl and another woman and took this into account in the prompt.
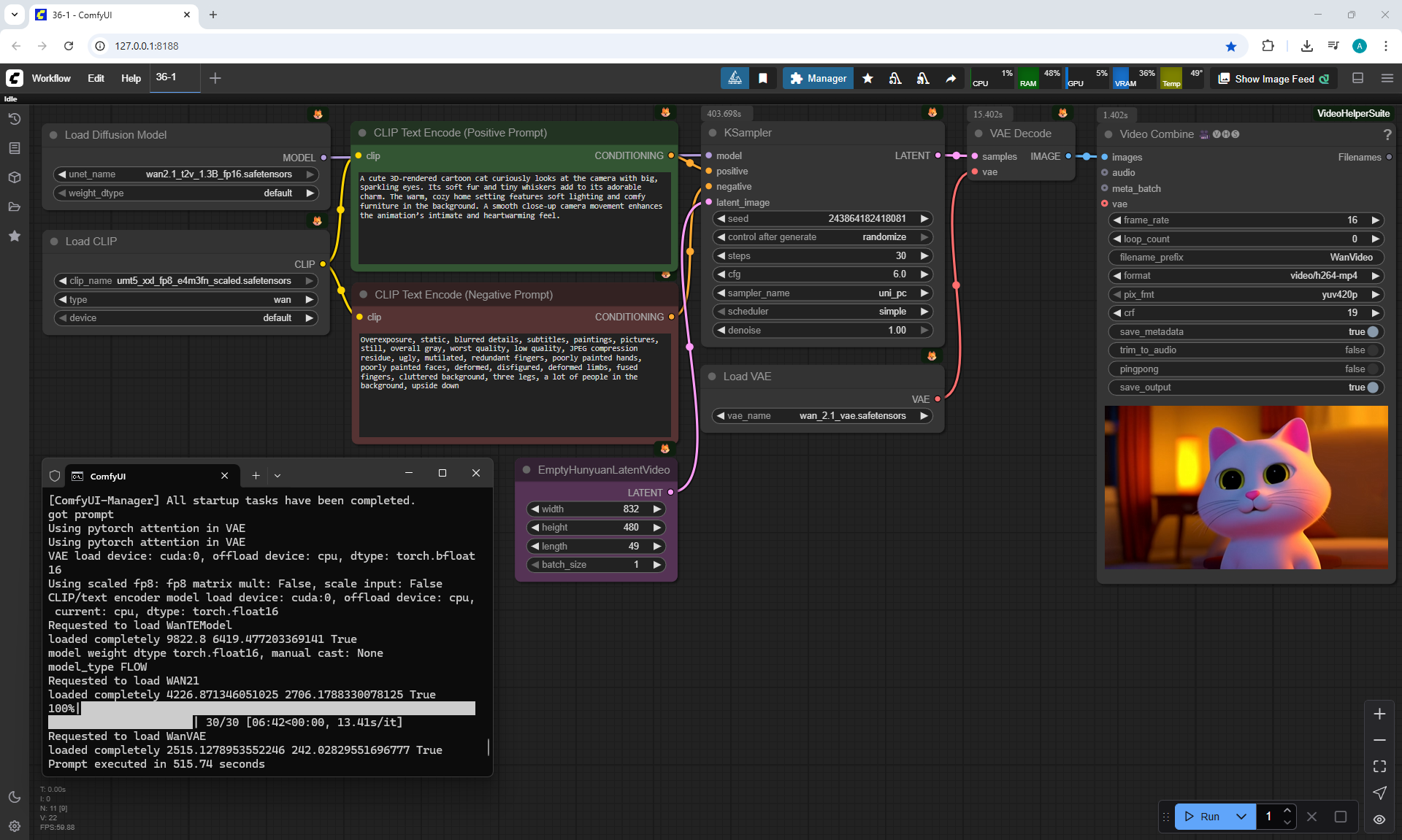
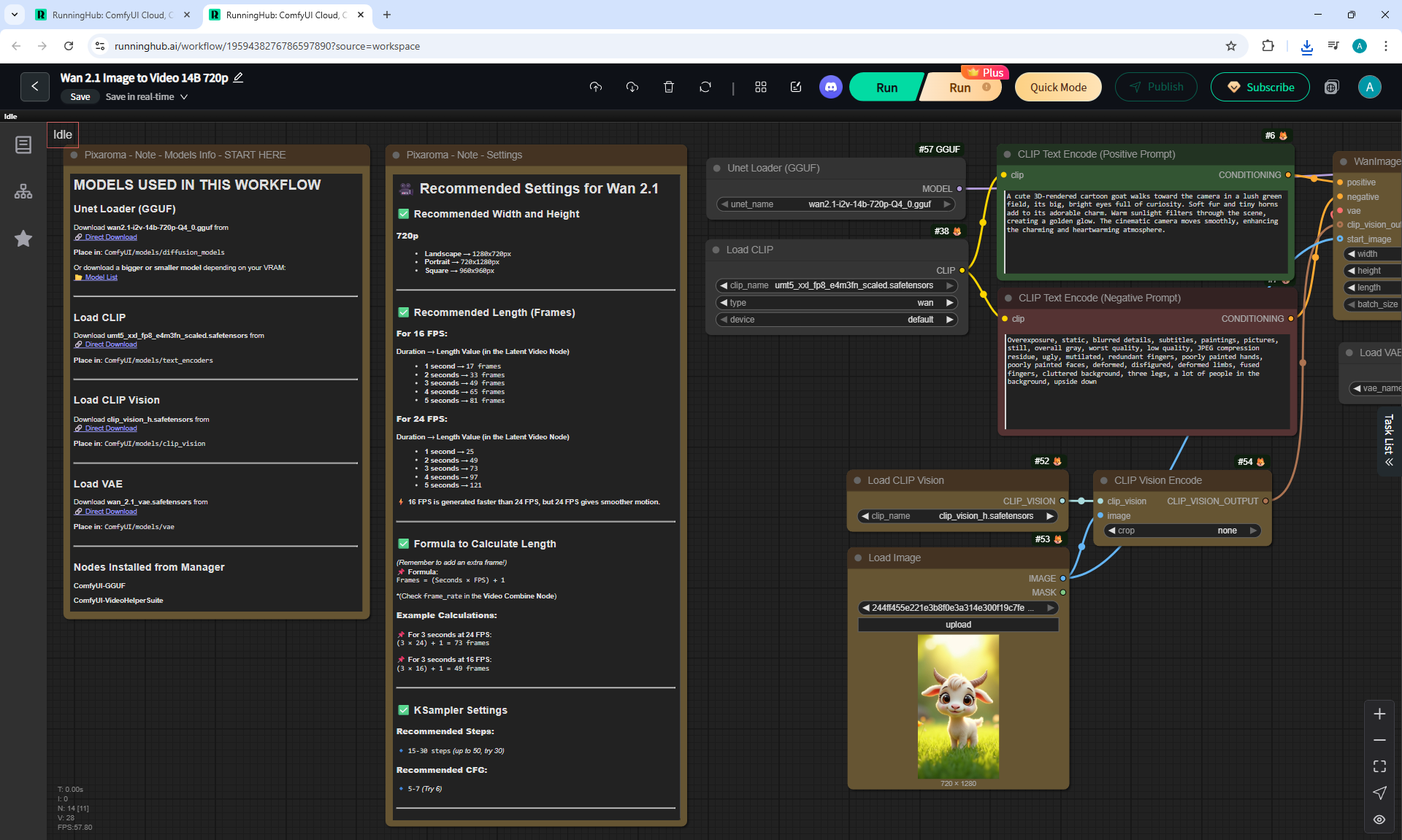
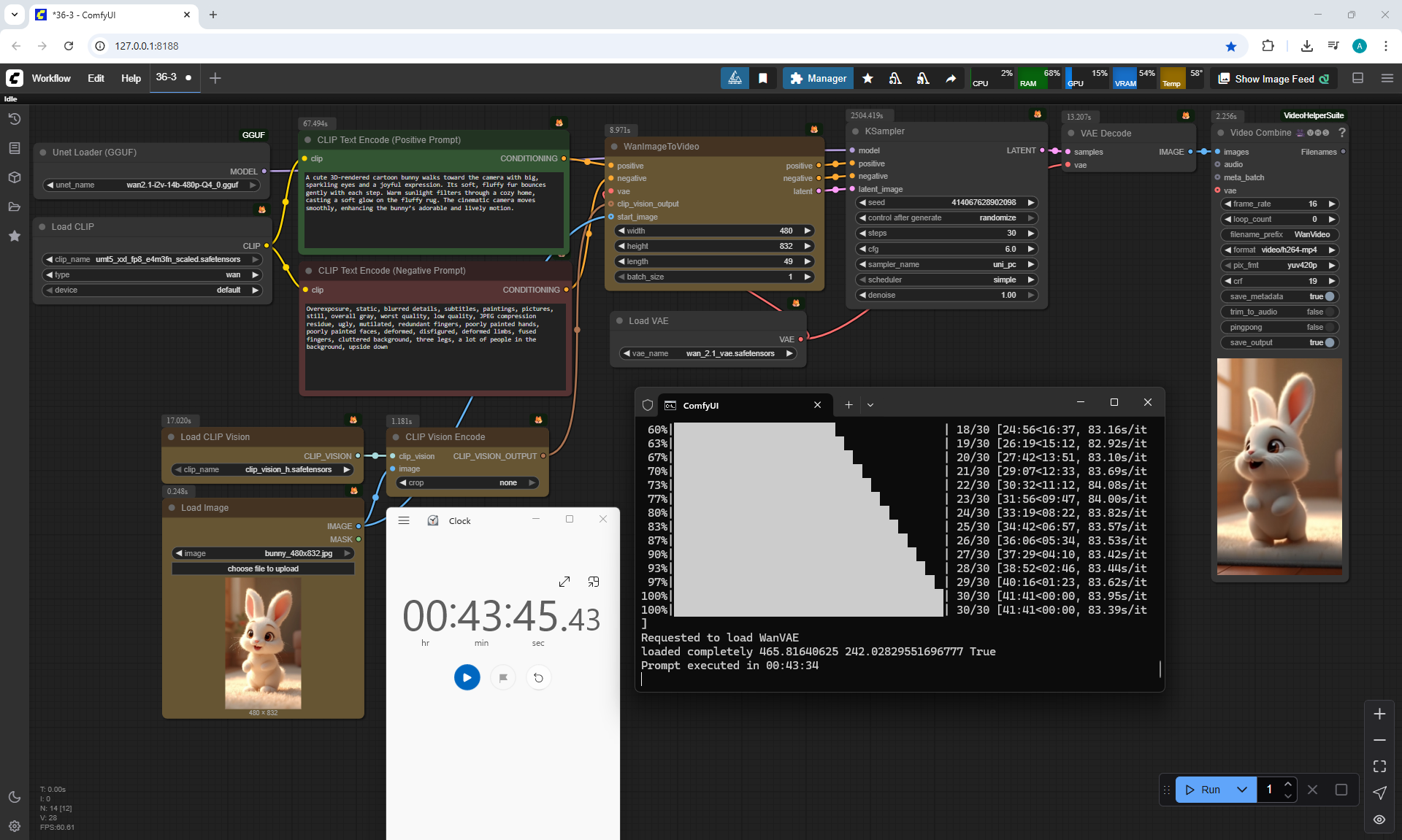
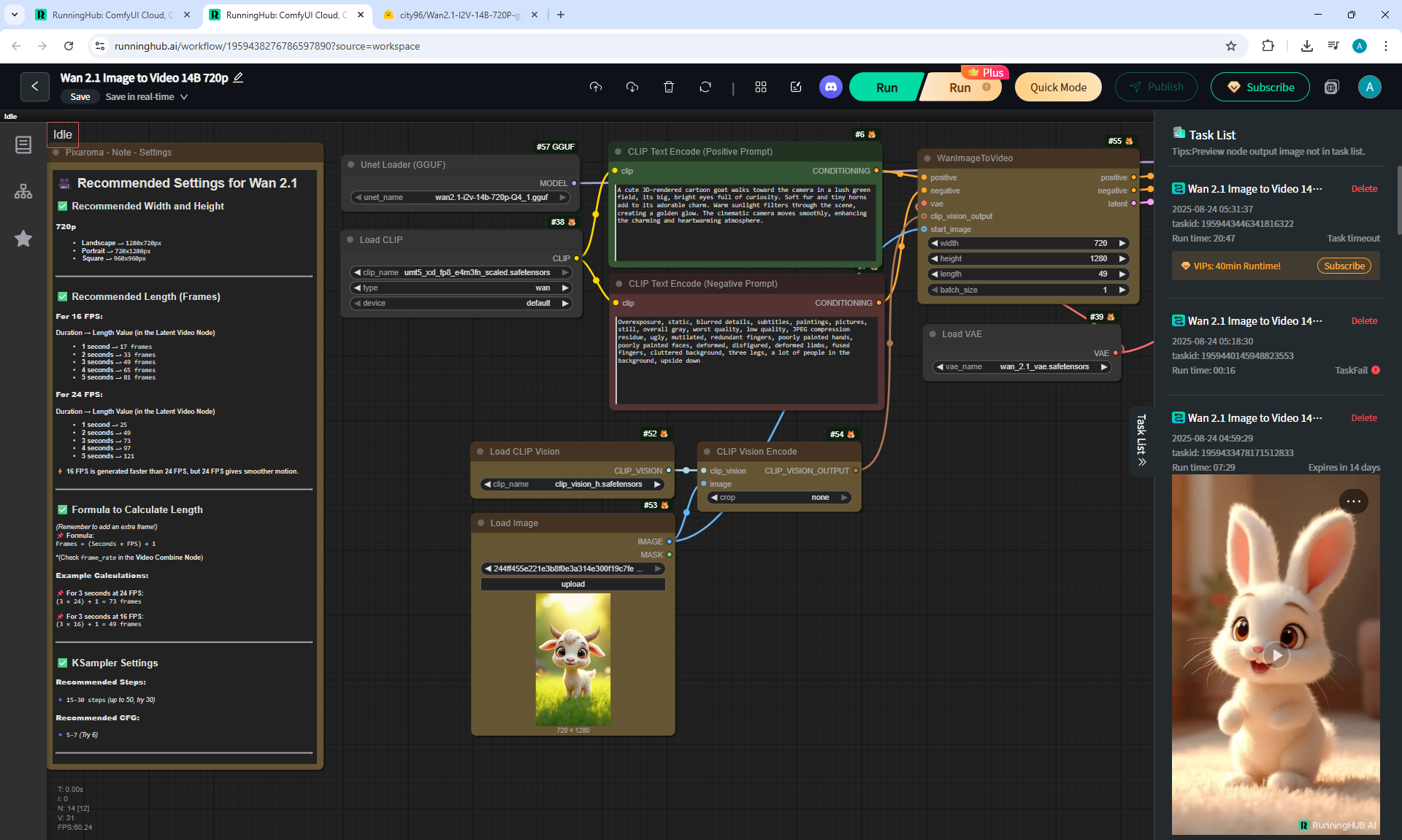
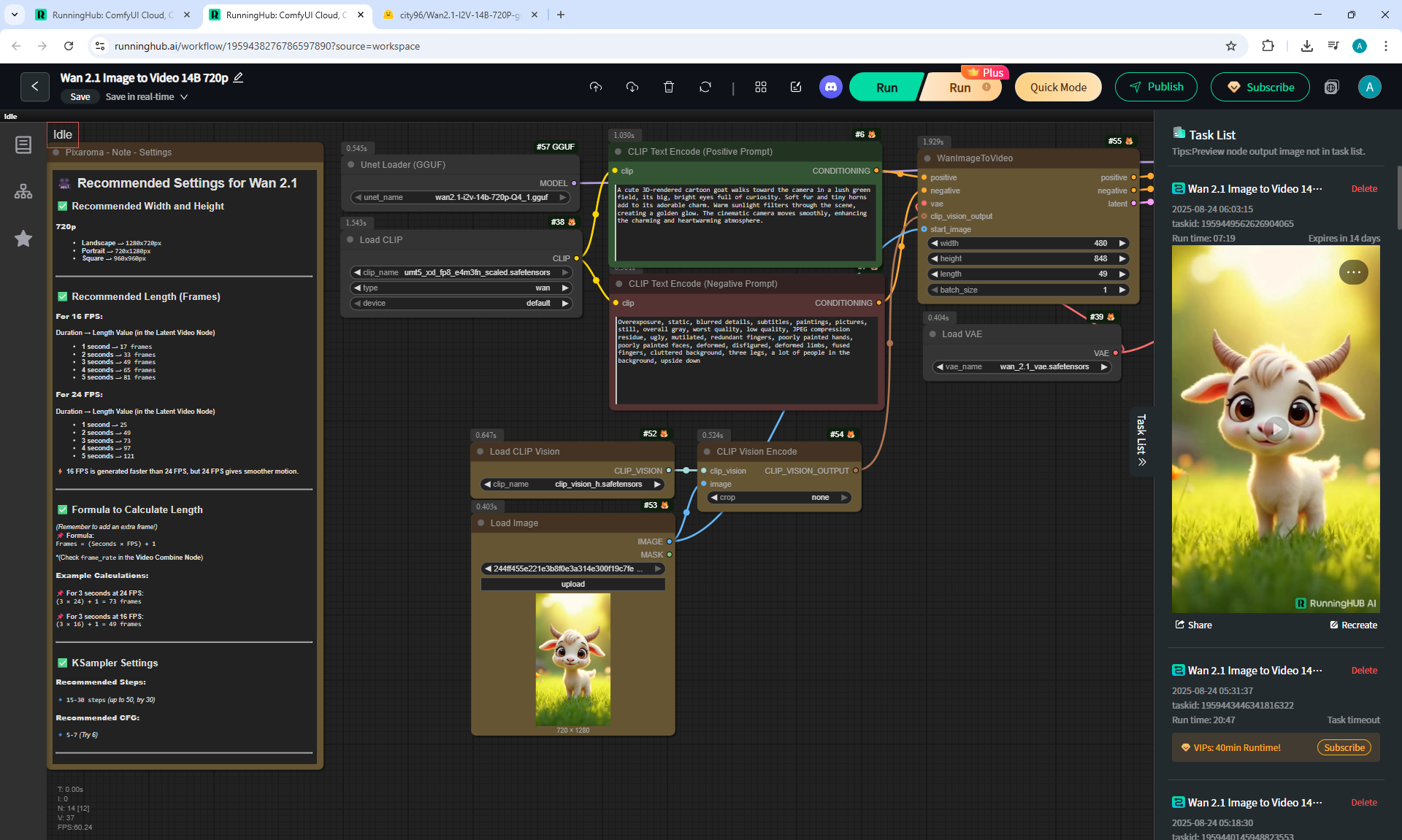
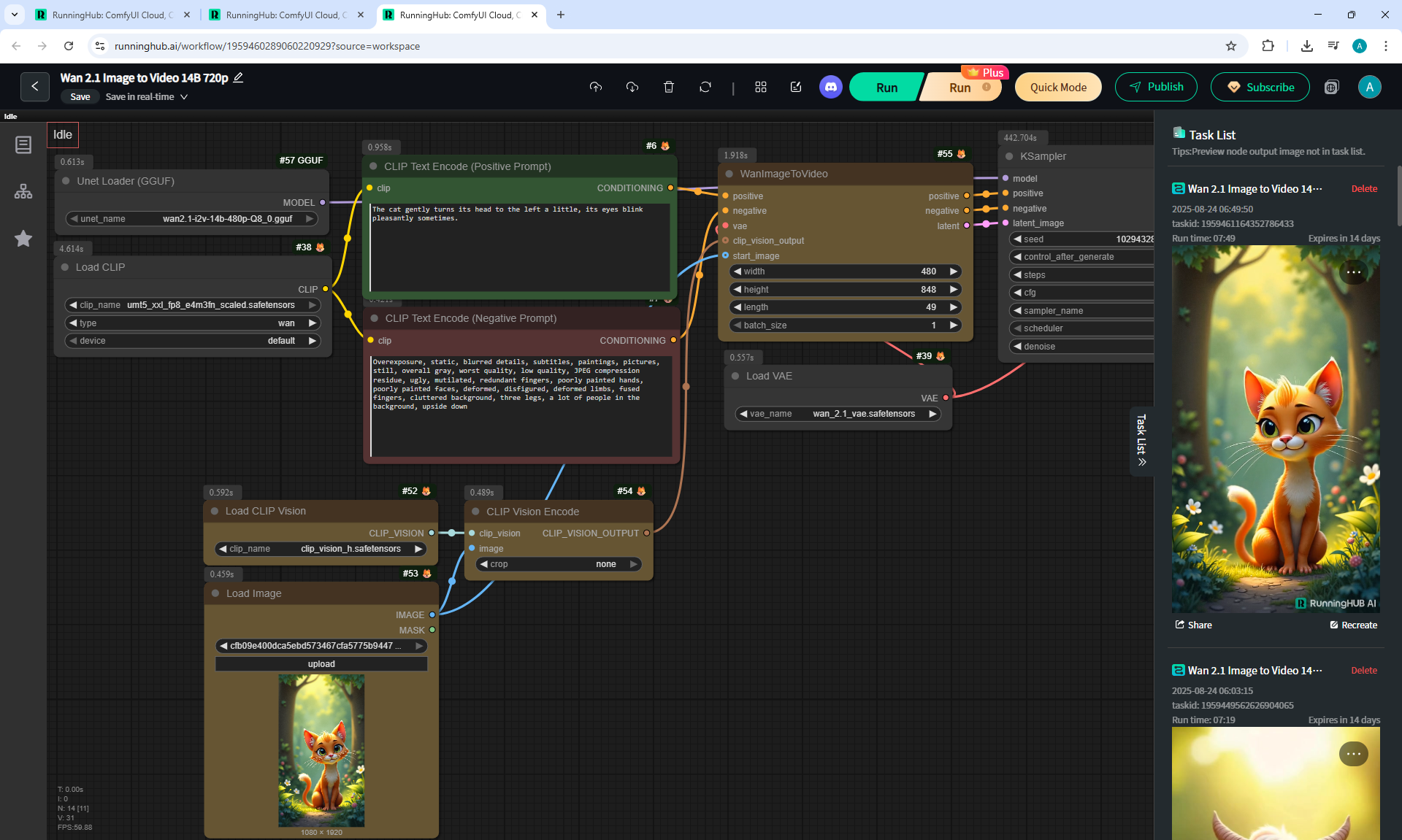
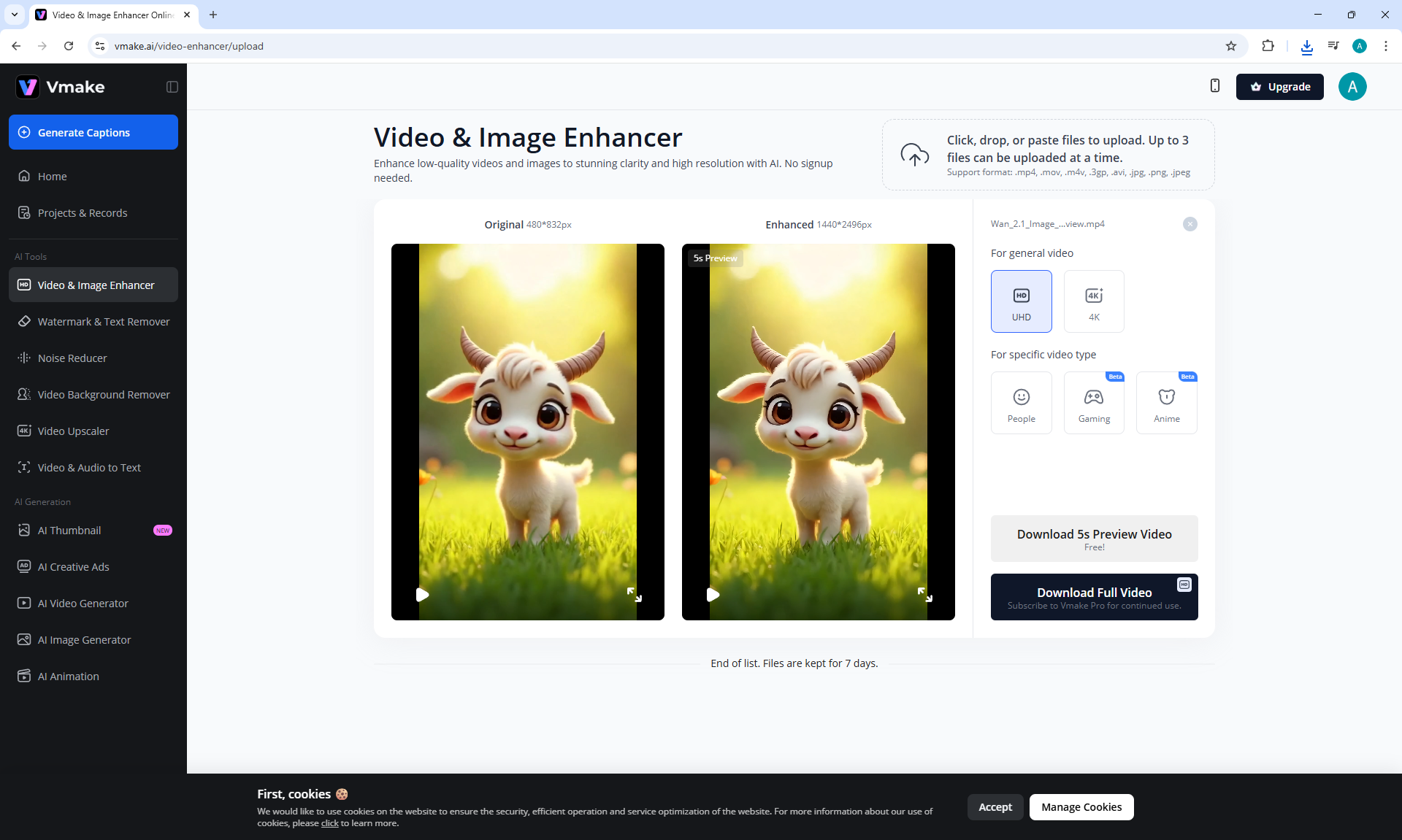
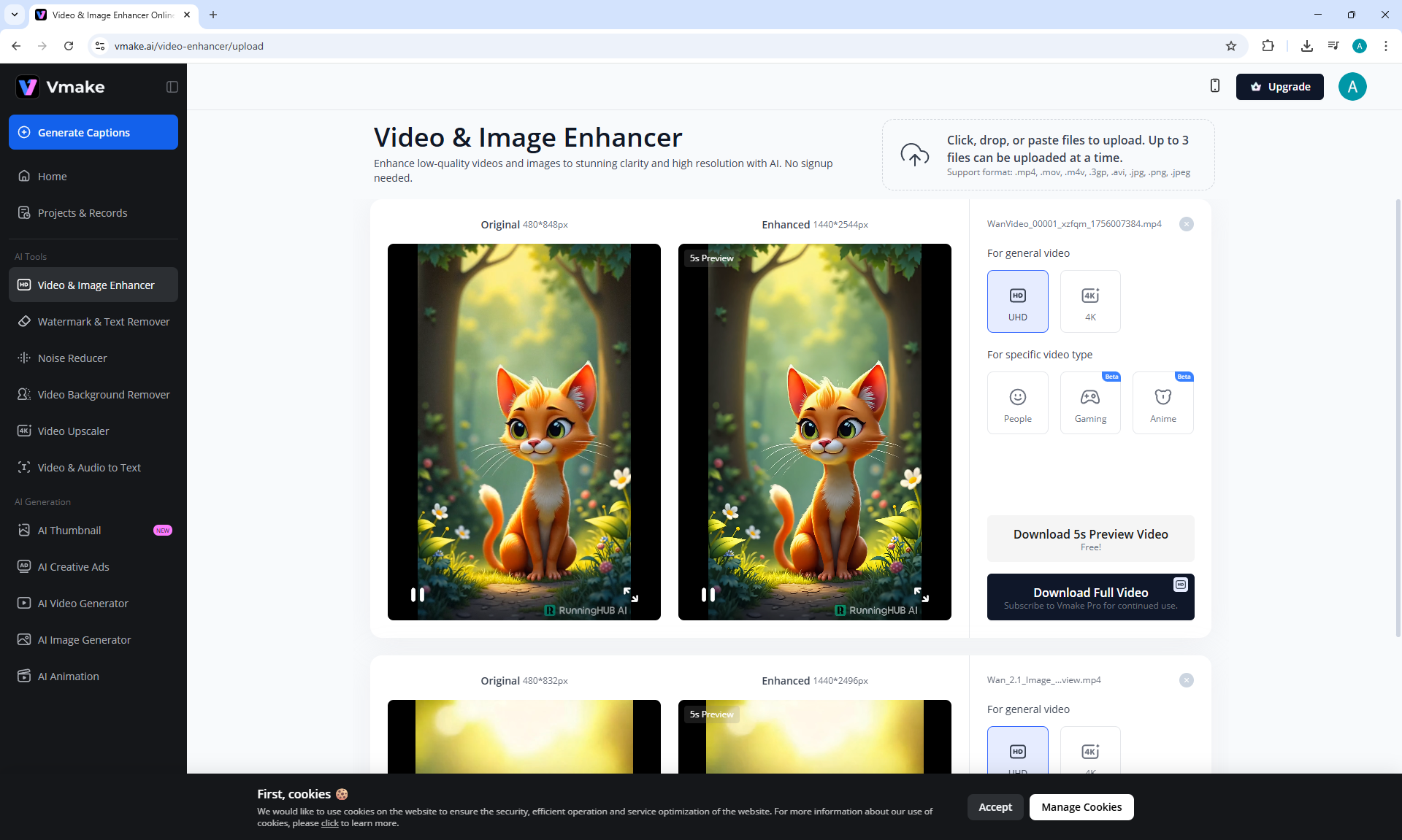
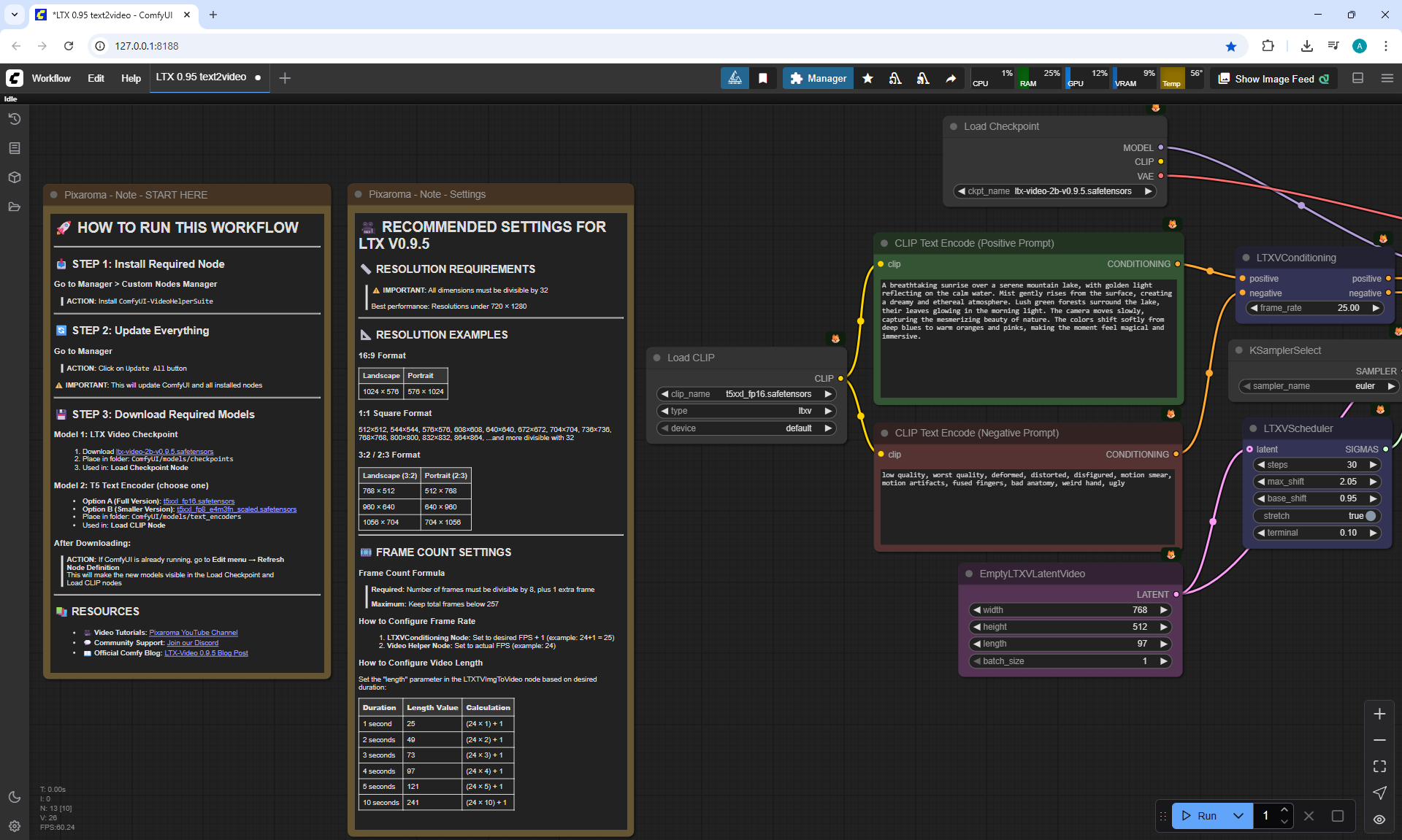
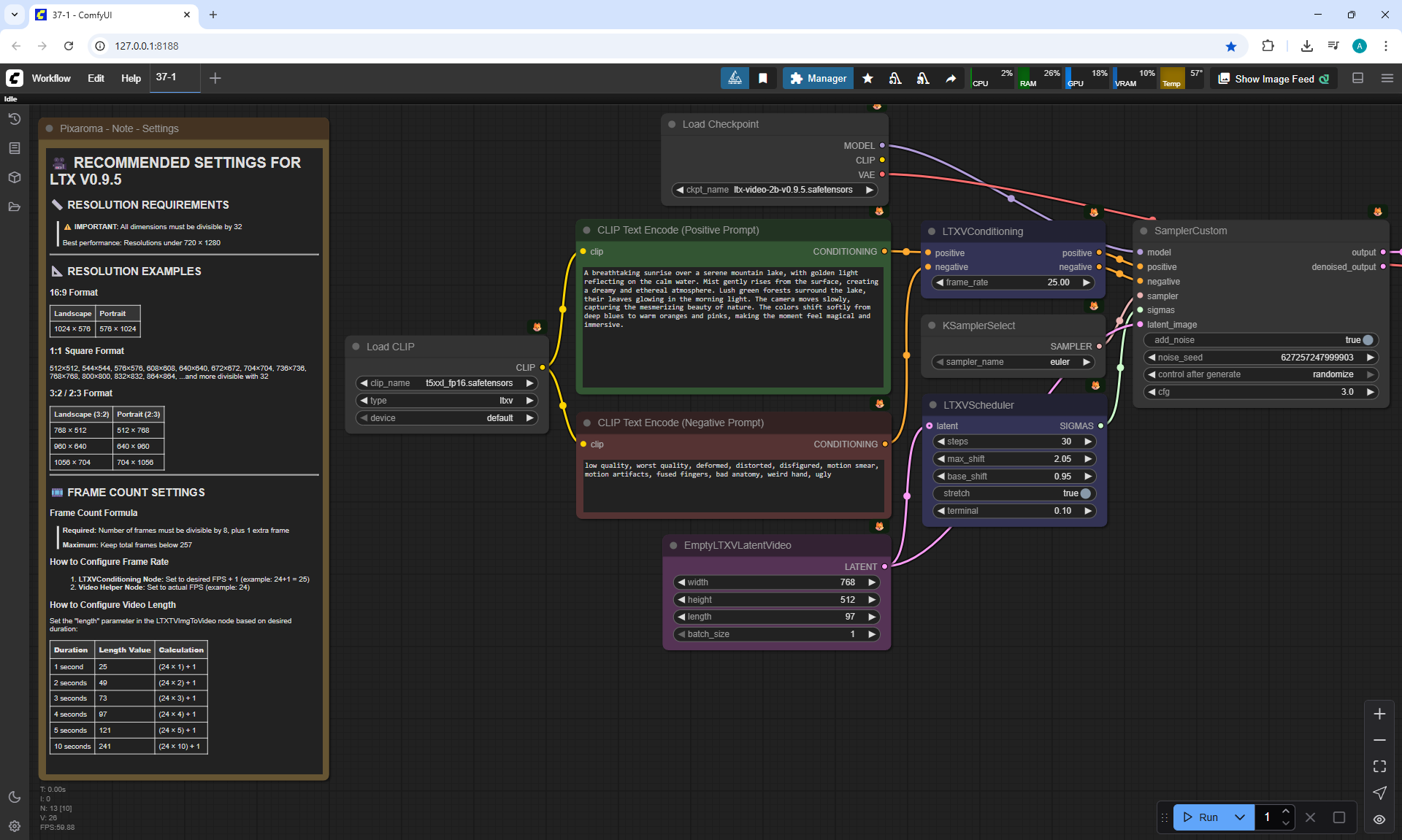
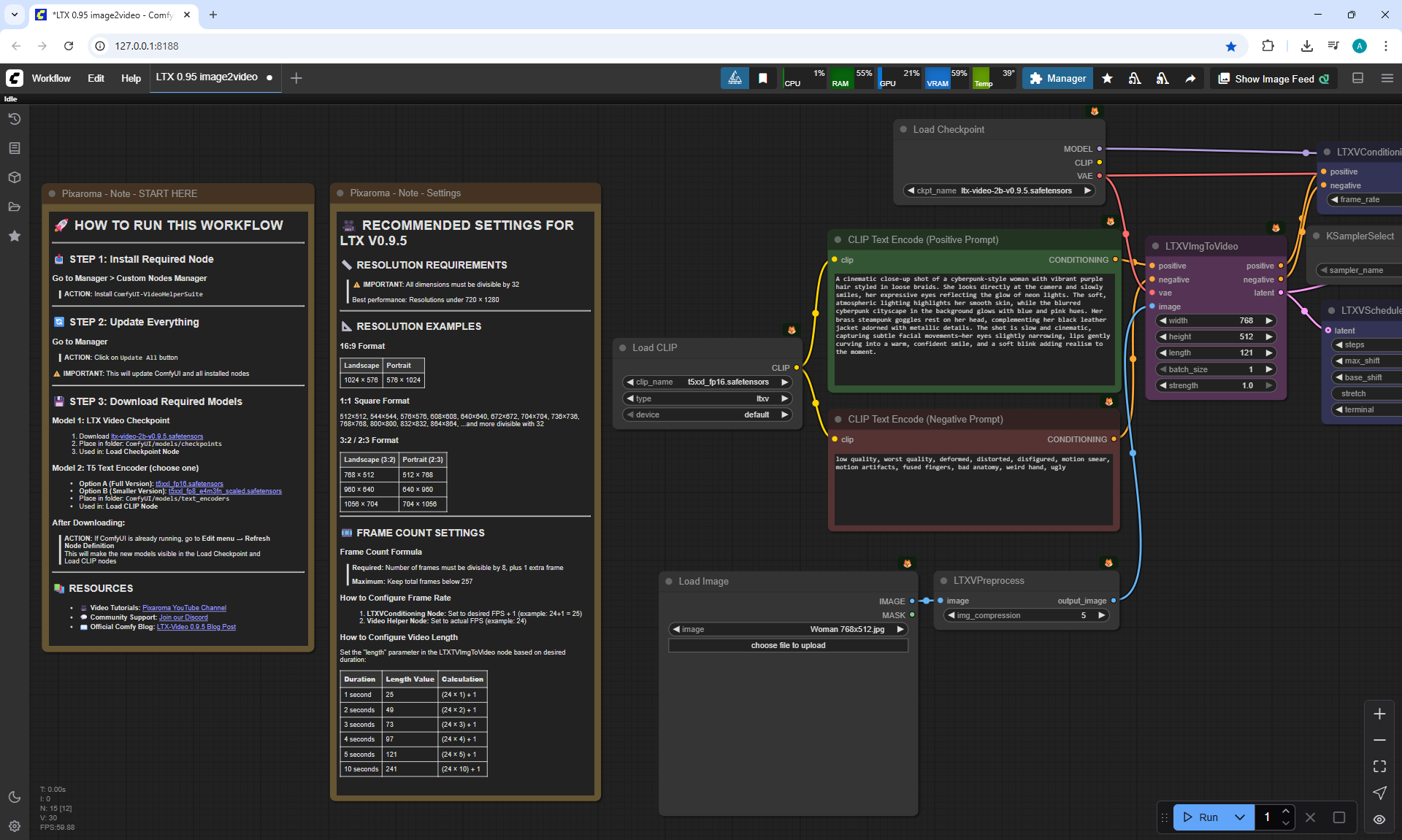
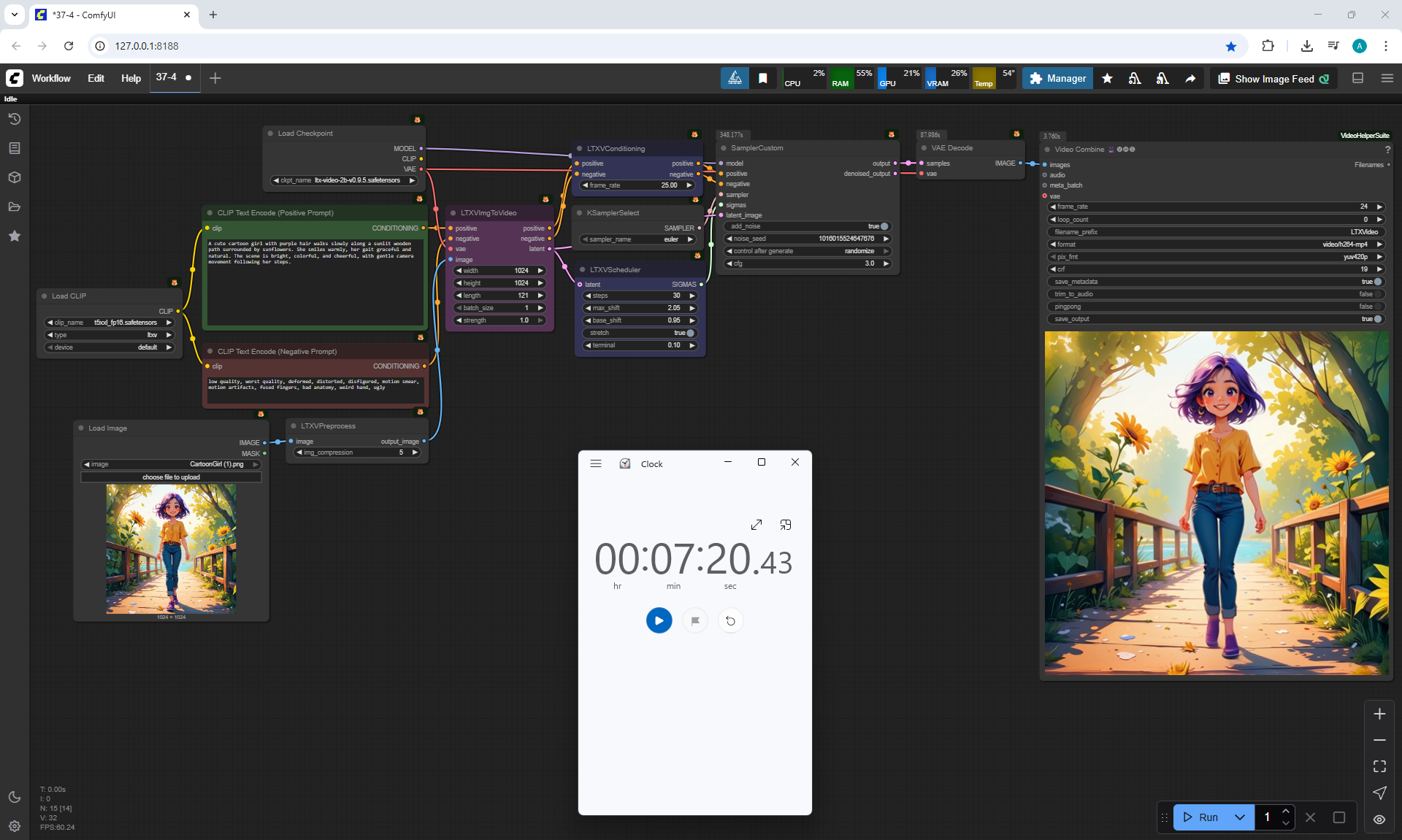
ComfyUI Tutorial Series Ep 37: LTX 0.9.5 Installation – Images to Video Faster Than Ever!






LTX V0.9.5 videos can be created when there is no complex animation, when the animation is of average quality in the mechanics of movements.
Such animation is generated much faster than Wan, but the animation quality is worse.
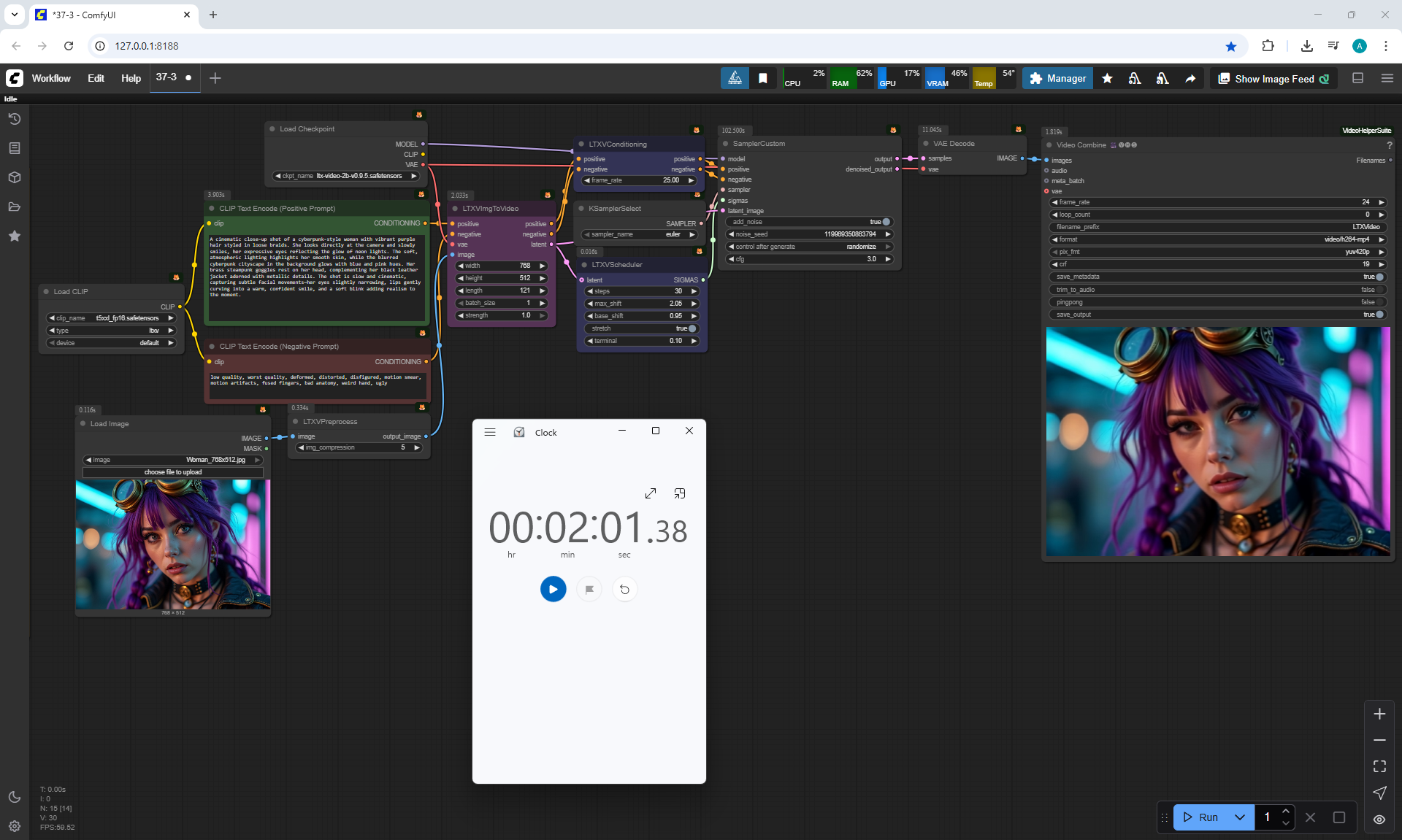
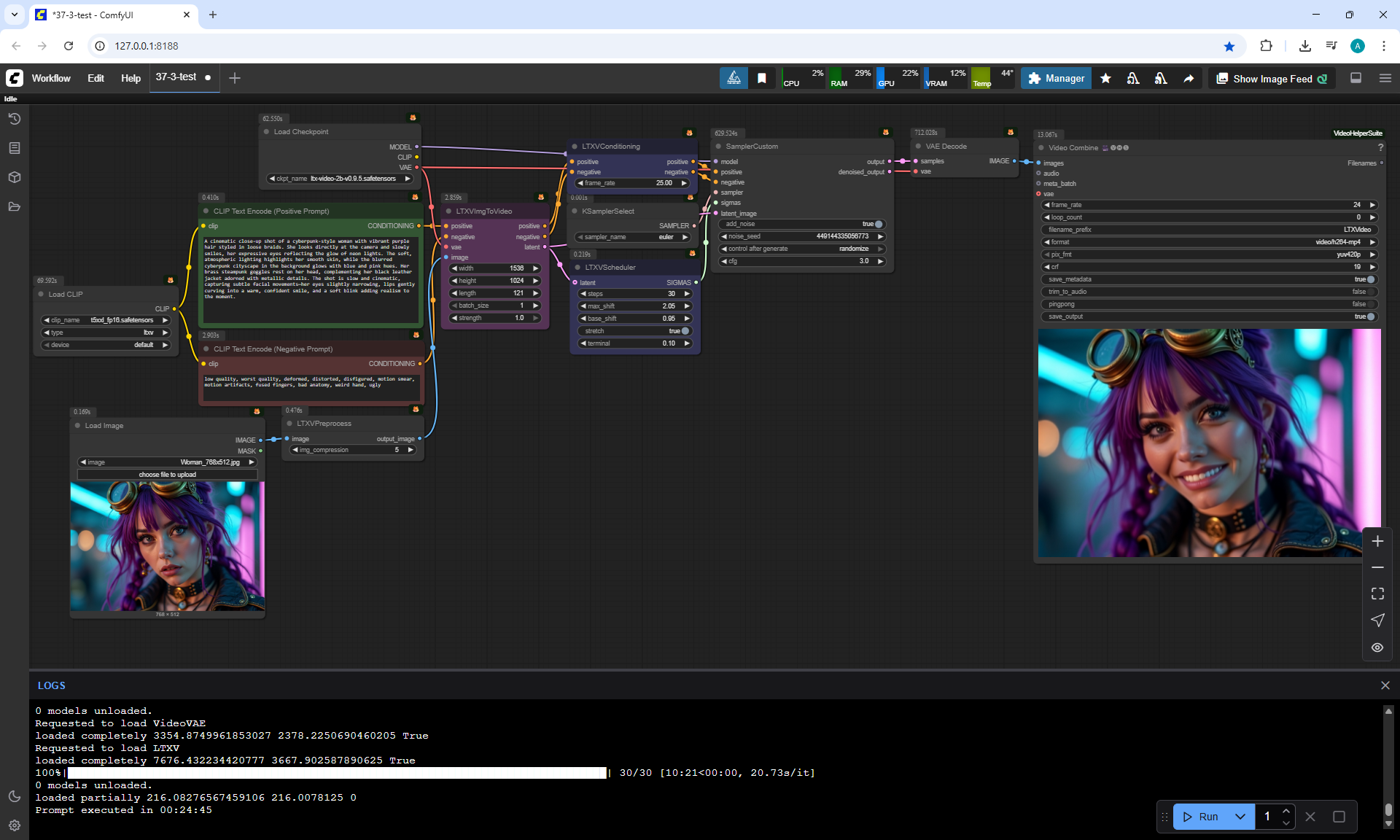
These LTX V0.9.5 videos 768x512 4 seconds were generated in 3 minutes 33 seconds on my computer in ComfyUI.
It will be faster in the cloud, the author talks about this in episode 35.
These videos are generated by a text prompt without images.





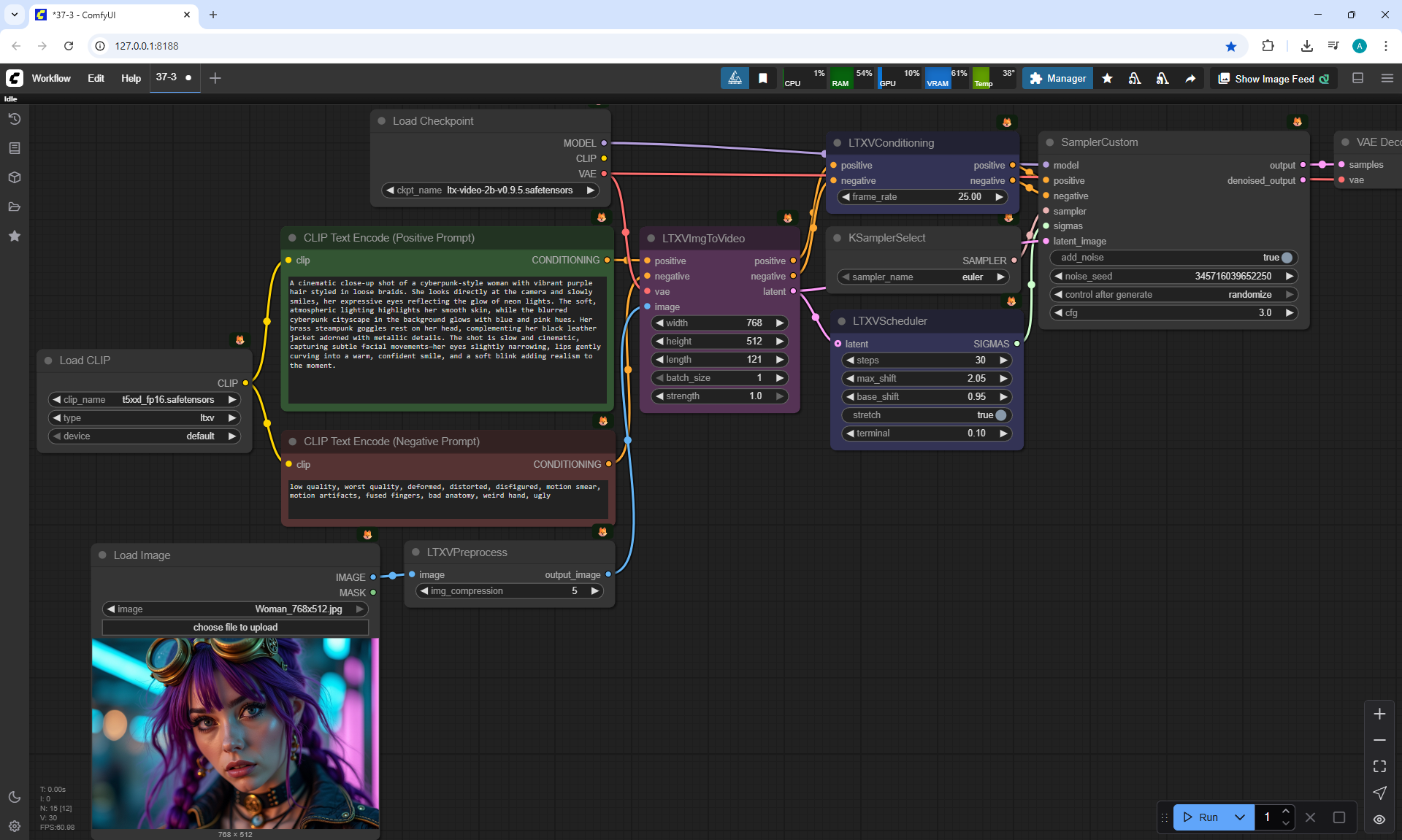
Here we use an input image of a girl and a text description for the animation:
"A cinematic close-up shot of a cyberpunk-style woman with vibrant purple hair styled in loose braids. She looks directly at the camera and slowly smiles, her expressive eyes reflecting the glow of neon lights. The soft, atmospheric lighting highlights her smooth skin, while the blurred cyberpunk cityscape in the background glows with blue and pink hues. Her brass steampunk goggles rest on her head, complementing her black leather jacket adorned with metallic details. The shot is slow and cinematic, capturing subtle facial movements—her eyes slightly narrowing, lips gently curving into a warm, confident smile, and a soft blink adding realism to the moment."
In LTX V0.9.5 video at 768×512 size there are defects, for example, poorly drawn eyes, eyelashes, teeth.
There are given video dimensions, which can be used in generation. There are square, 16:9, 3:2, 2:3. It is better not to use more than 720x1280=921600. That is, the maximum recommended value is 960x960 for square videos. Videos with other aspect ratios may have glitches.
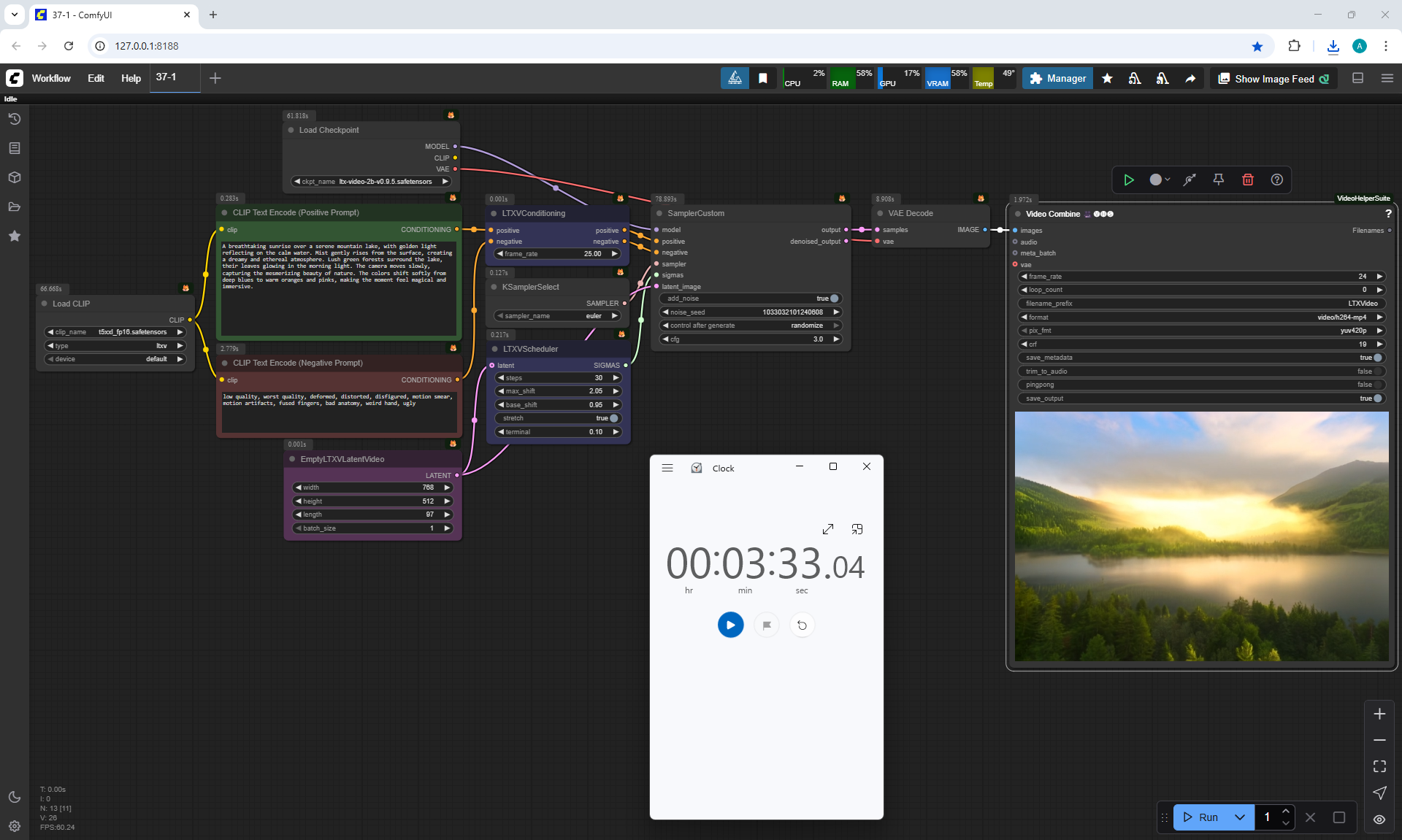
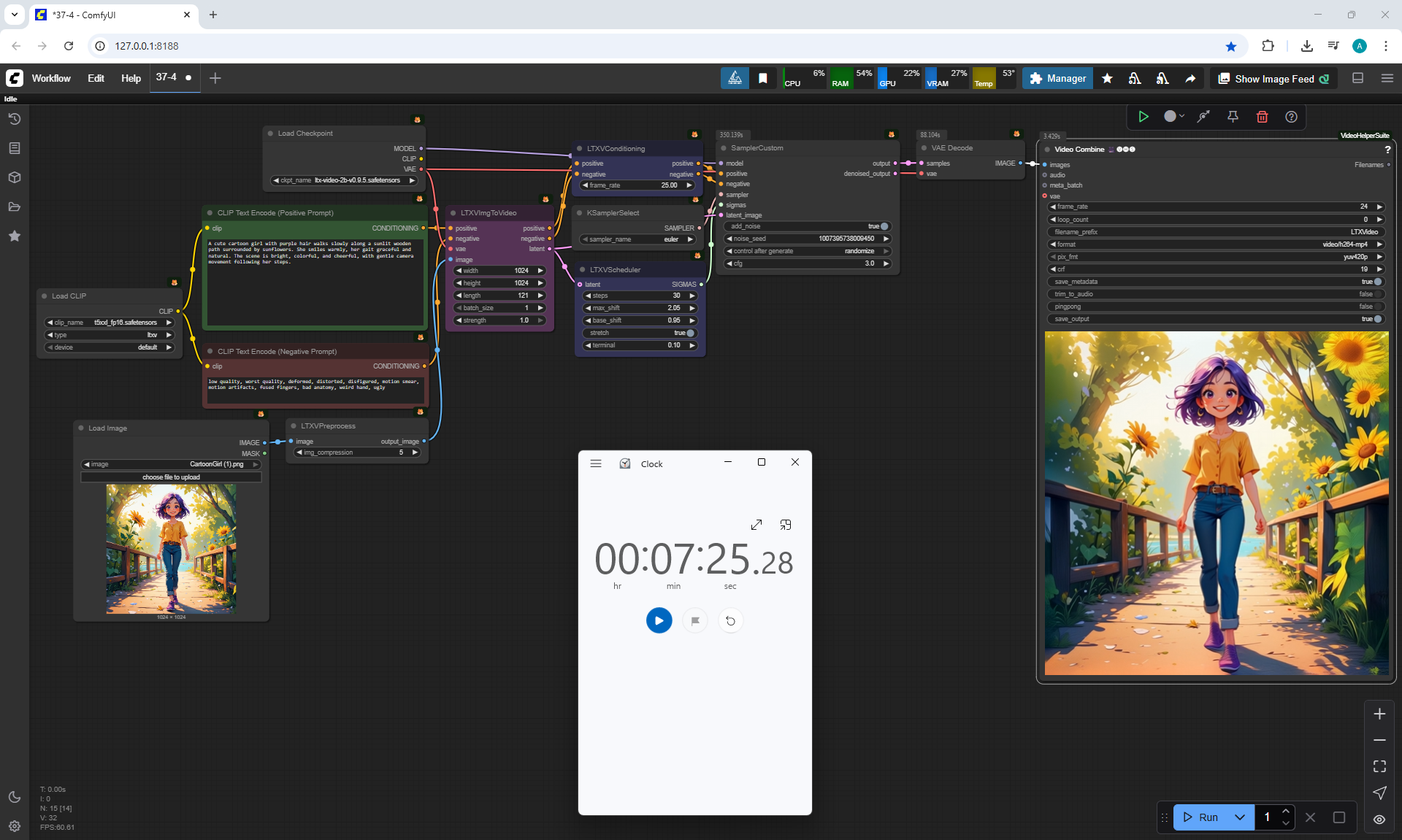
A video with this animation of a girl turning her head with a size of 768×512 for 5 seconds was generated in about 2 minutes.
Although the recommendation does not specify large sizes, I decided to test and double the size.

I generated 1536×1024 5 seconds in 24 minutes 25 seconds on a computer.
The video turned out to be successful without failures: the eyes, eyelashes, teeth are clearly drawn, there are no such defects as there were on 768×512. Such a video can be resized by half to 768×512 and there will be no defects.
But the hair is not detailed, the video looks a little blurry.
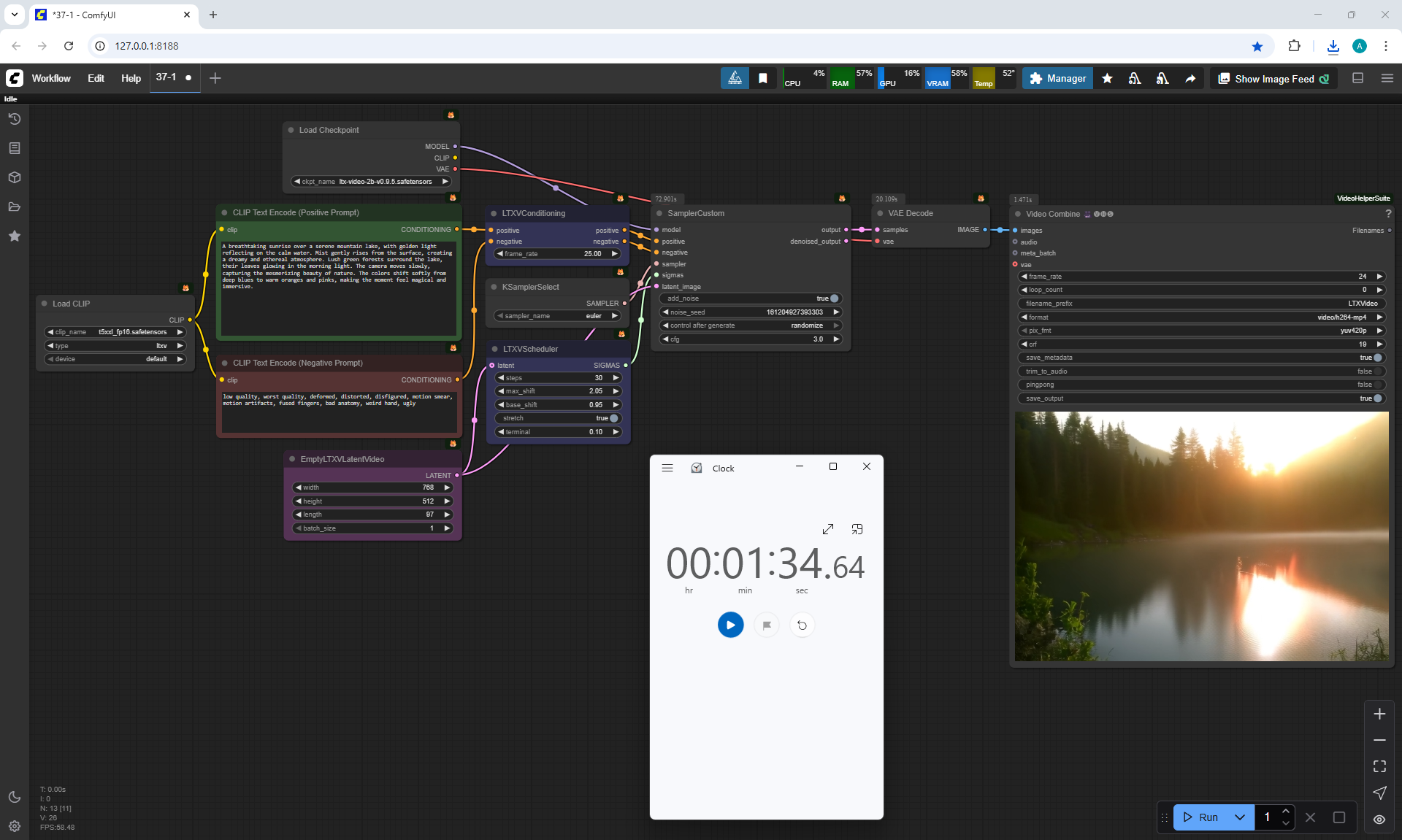
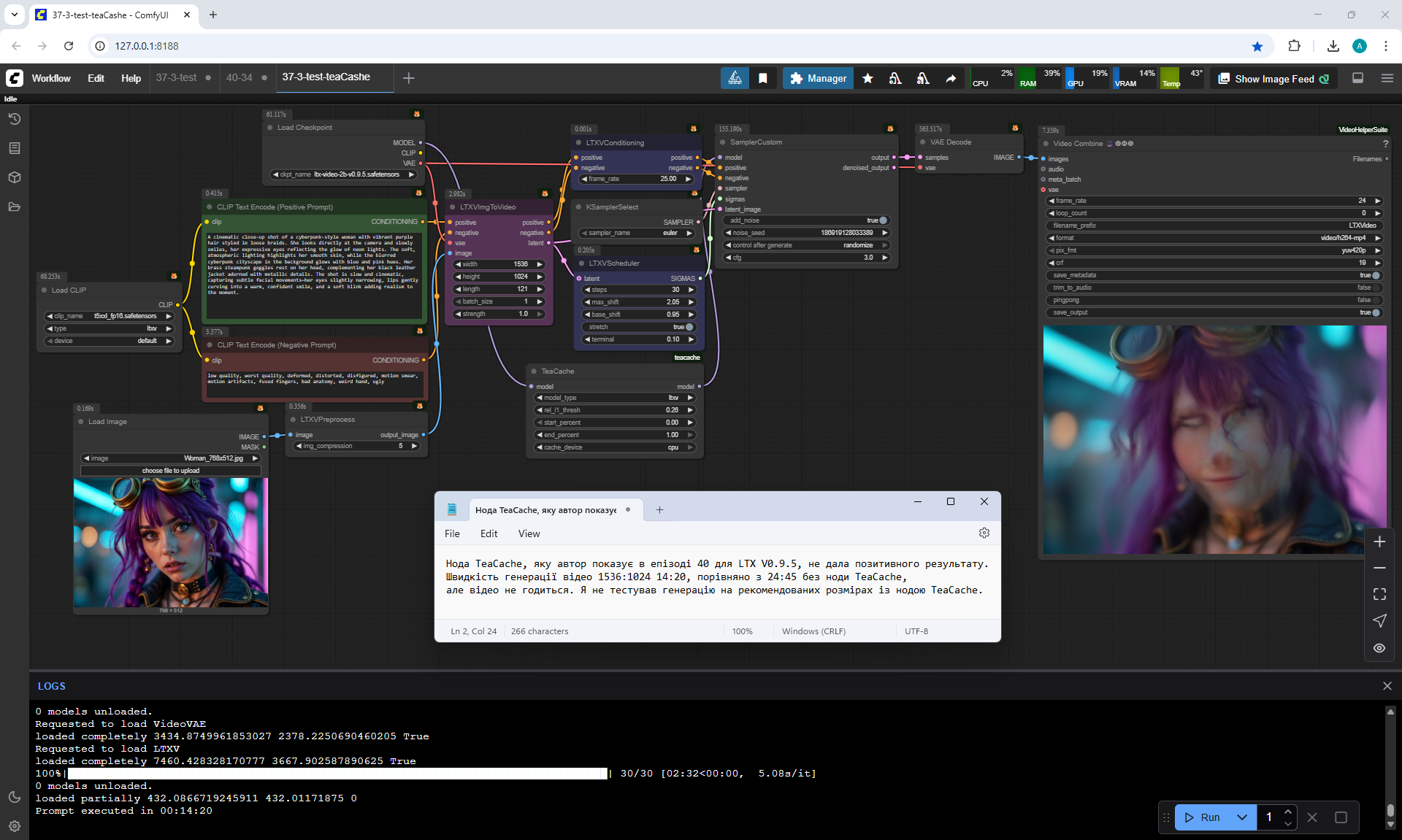
At the time of this episode, I did not know about TeaCashe, the author talks about it in episode 40.
Already after episode 40, when I added this material to the site, I tested LTX V0.9.5 at sizes larger than recommended, generated at 1536×1024 and also generated with the TeaCashe node.
The TeaCache node that the author shows in episode 40 for LTX V0.9.5 did not give a positive result, the video has defects, blurred effects. The video generation speed is 1536:1024 14:20, compared to 24:45 without the TeaCache node, but the video is not suitable.




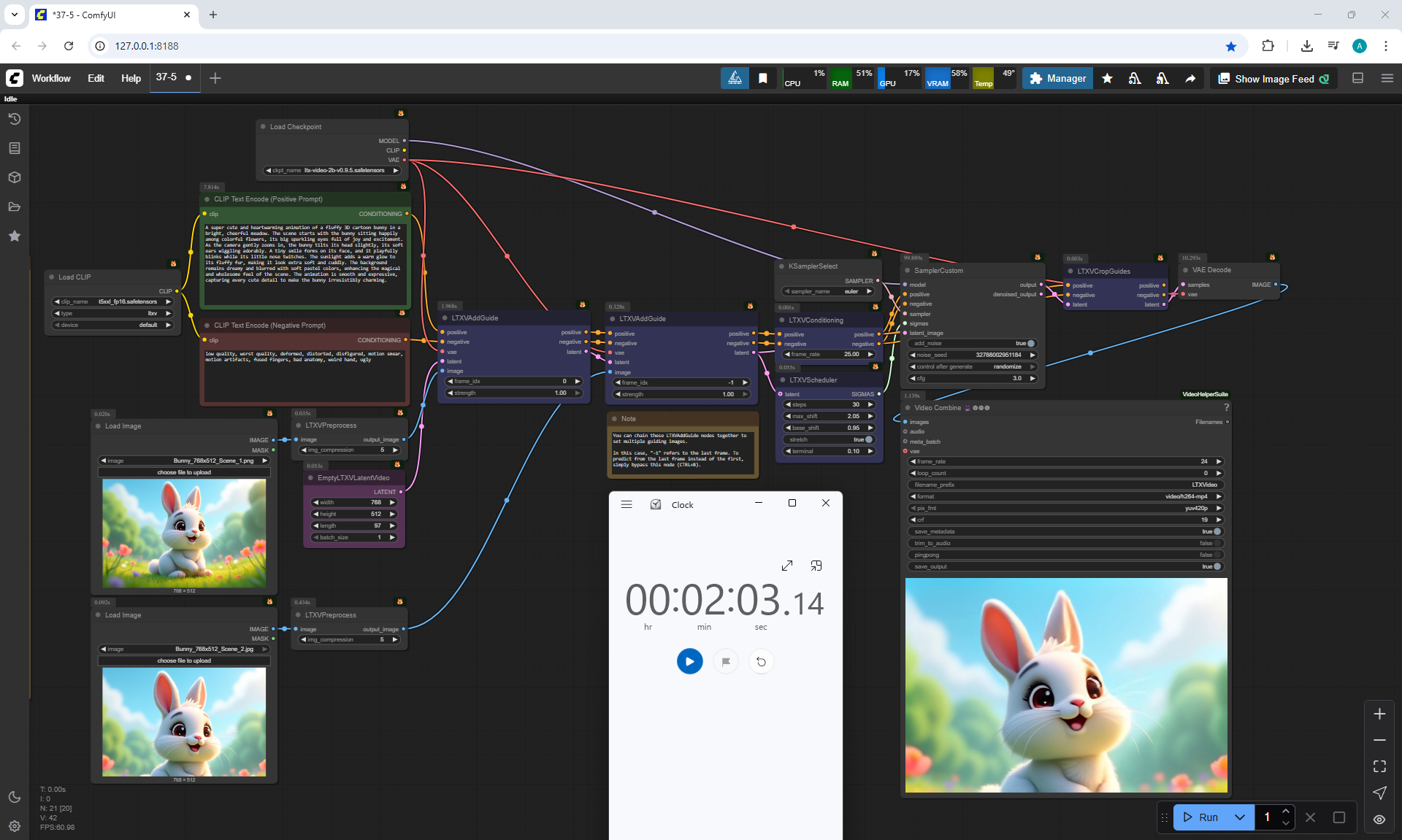
I generated this girl in episode 28.
I tested on LTX V0.9.5 how the animation of this girl's gait will look.
The animation is not of high quality, there are glitches, the girl moves, but her legs barely move, there is no dynamics in the body, the arms move a little, but the body itself does not animate. At the same time, the camera moves with the girl, the bridge and the new environment are drawn correctly.
The speed of video generation on LTX V0.9.5 is much higher than on Wan, 1024x1024 5 seconds turned out in 7 minutes, 20 seconds.




In LTX V0.9.5 it is possible to set the start and end frames. You can make many frames, making complex scenarios.







In LTX, you can set the animation sequence by frames, so all the animation will be generated based on these frames and descriptions. The idea is good, but in the example of a rabbit coming out of a mushroom house, you can see that the door opens with defects and the rabbit is also drawn blurry.








The example of a stone falling into a car also shows defects when the stone lies on the car for a long time, then smoke comes out, and then the car is pushed through. Perhaps the author set the time incorrectly or it was necessary to take shots with smoke when the stone had already fallen into the car, since the moment of the stone pushing into the car is very short, compared to the appearance of smoke.



This 1056x704 5 second video on LTX 0.9.5 was generated in 10 minutes 22 seconds for me.
Relatively good animation, blinking eyes, other animations, correct rotation of the robot's head in space.
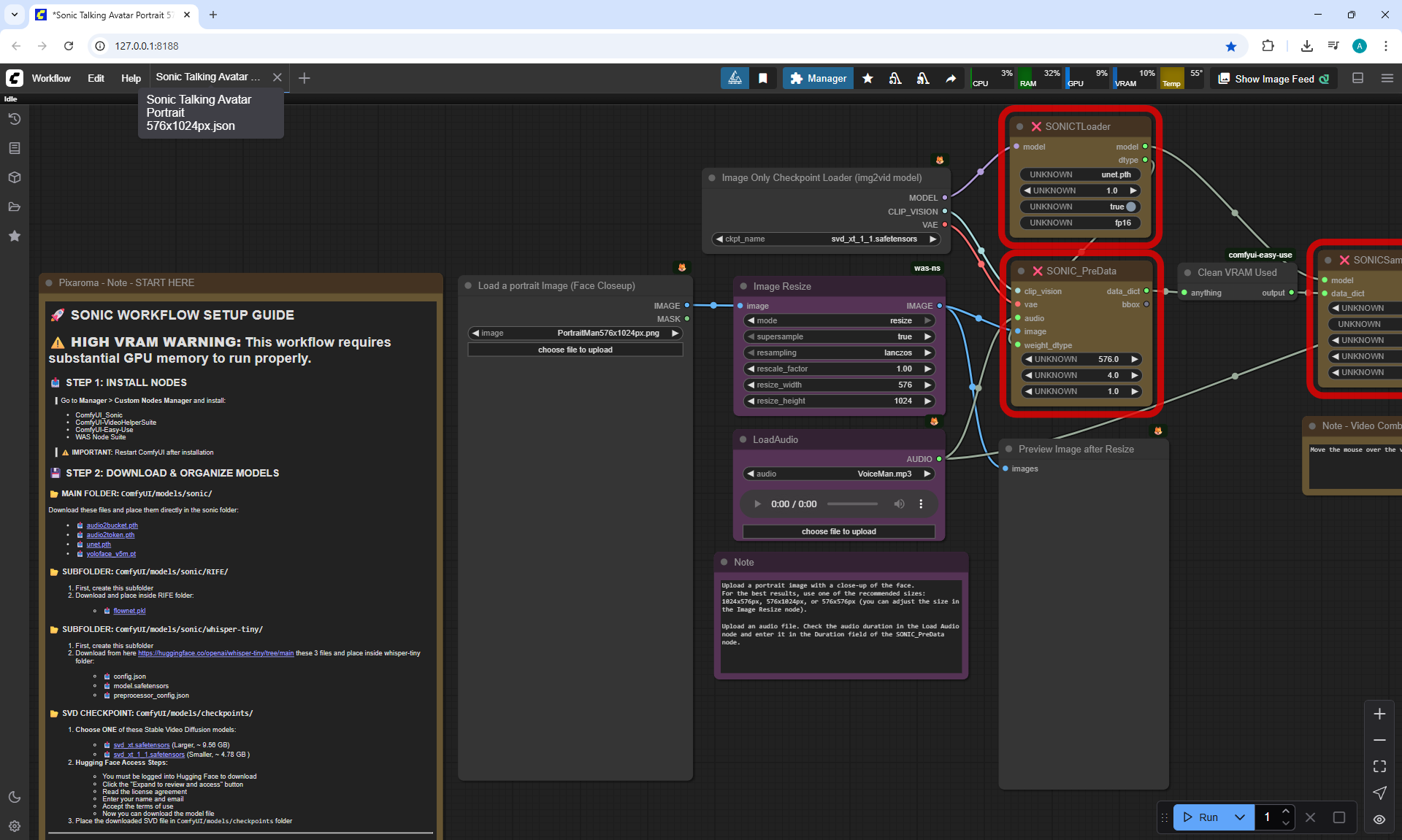
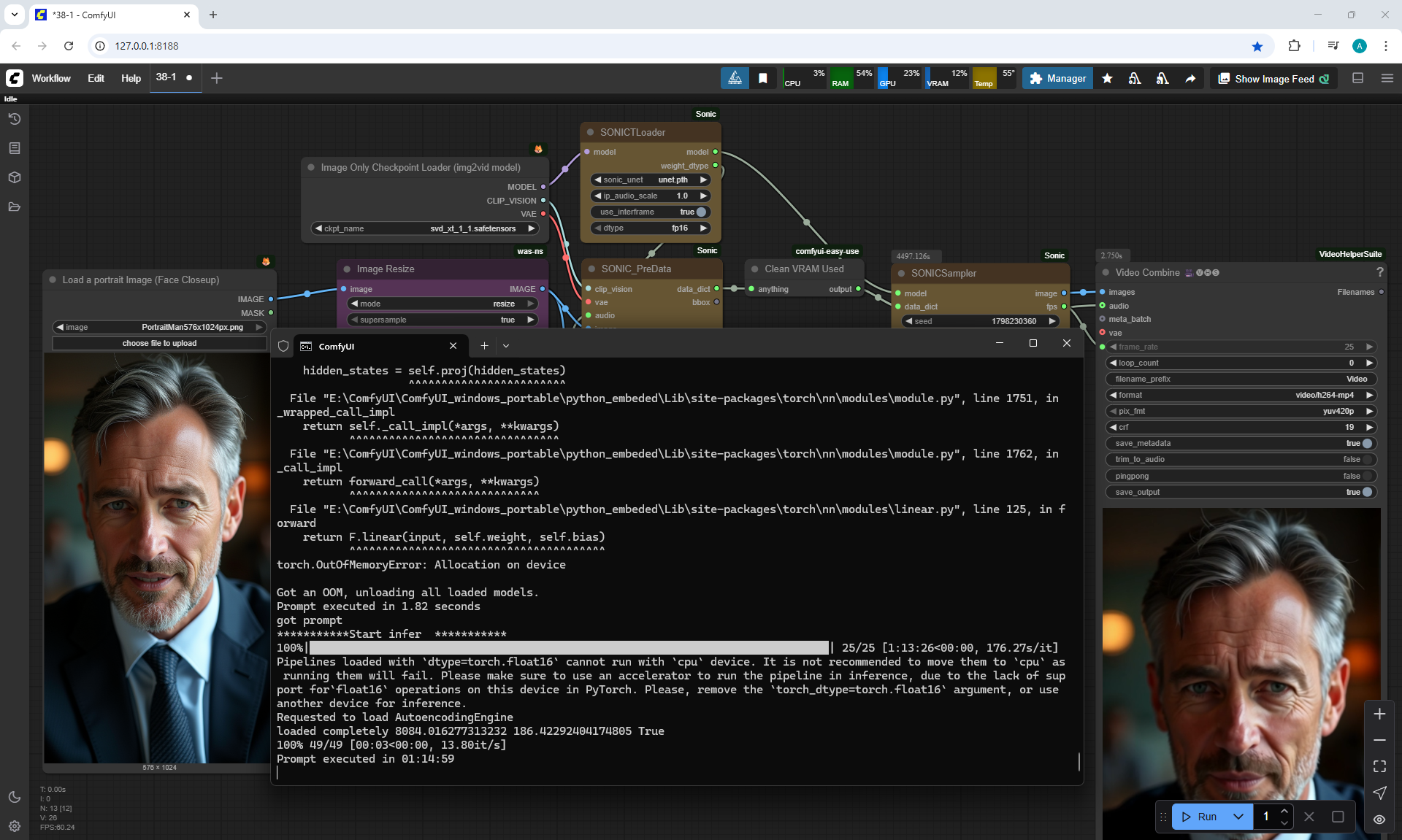
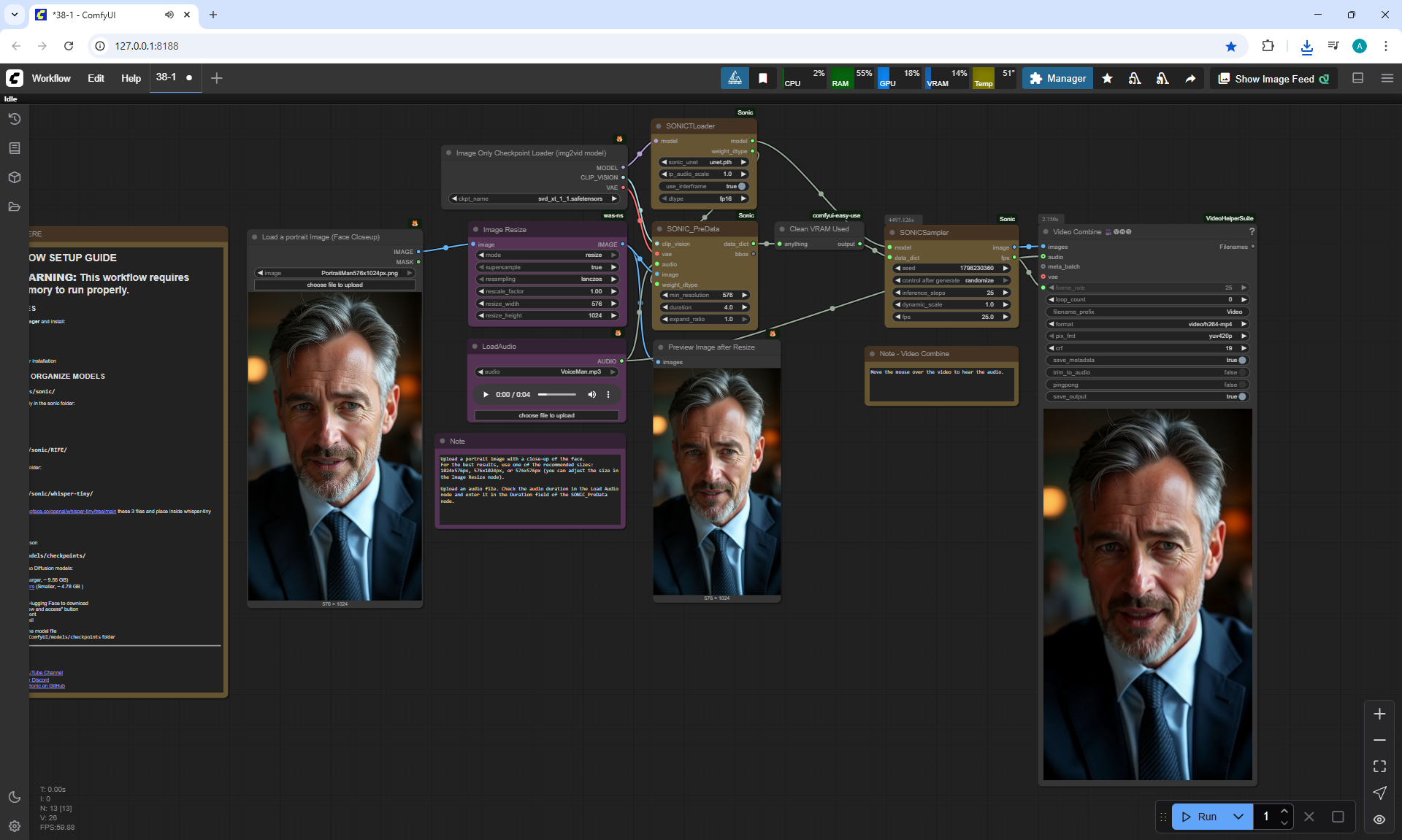
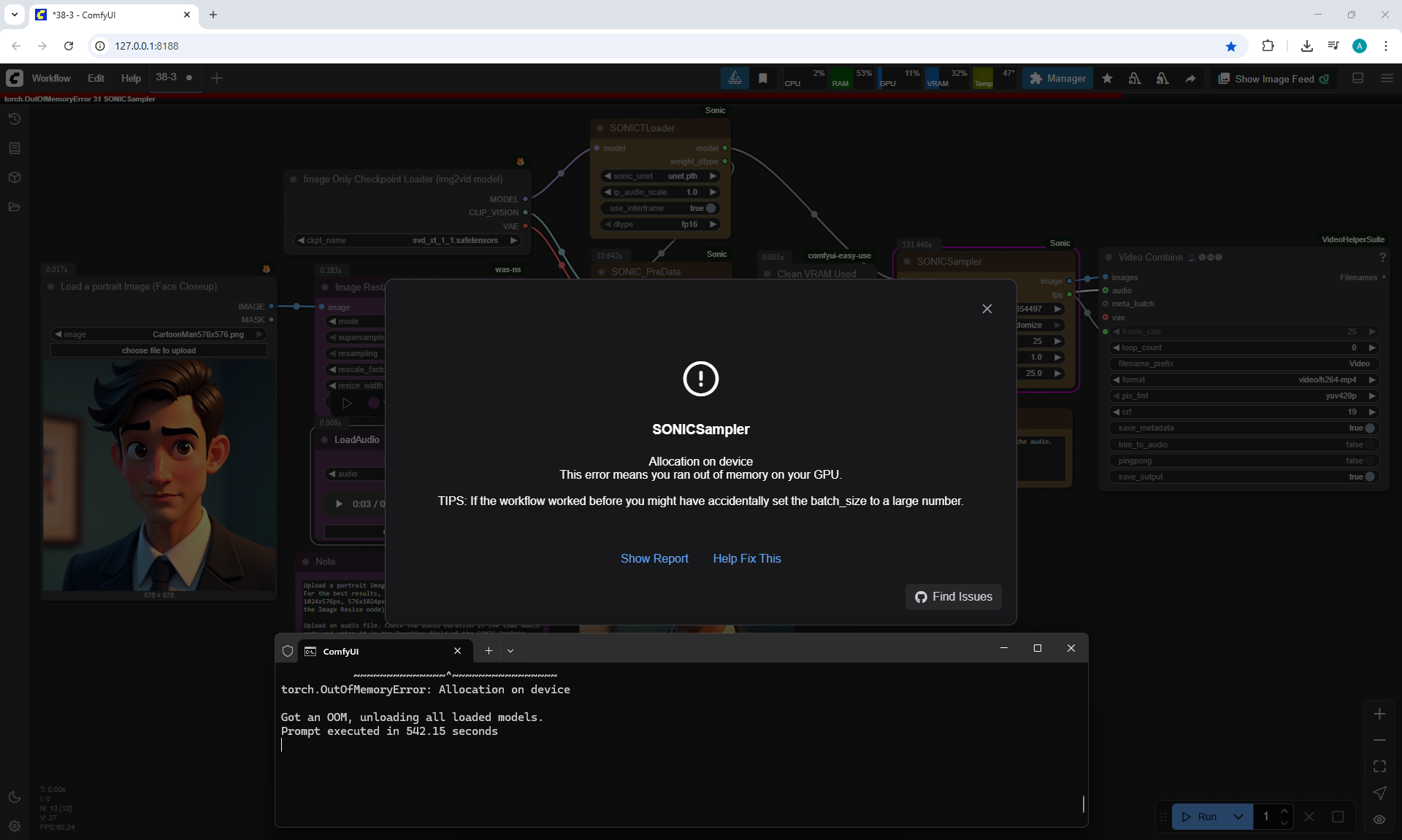
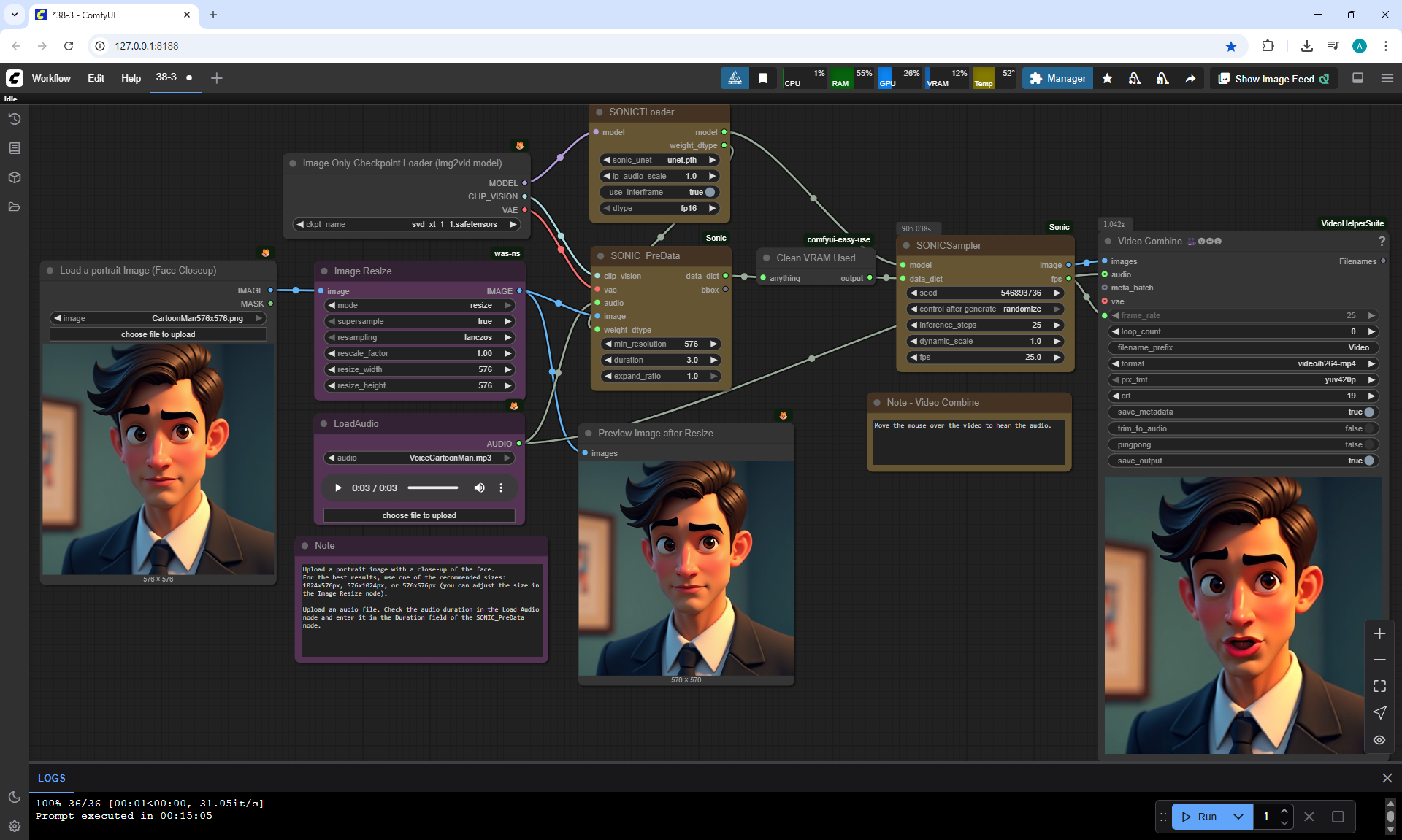
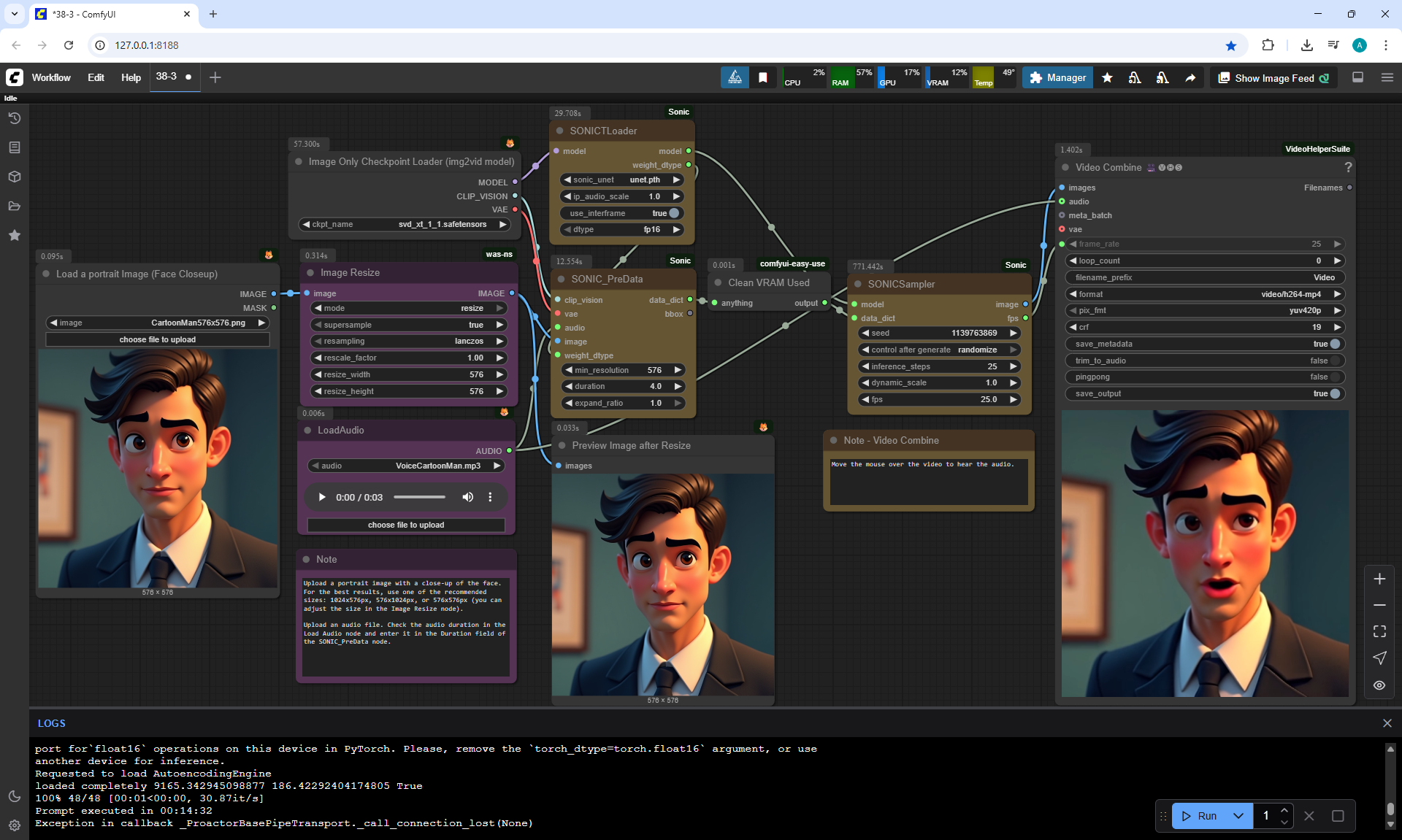
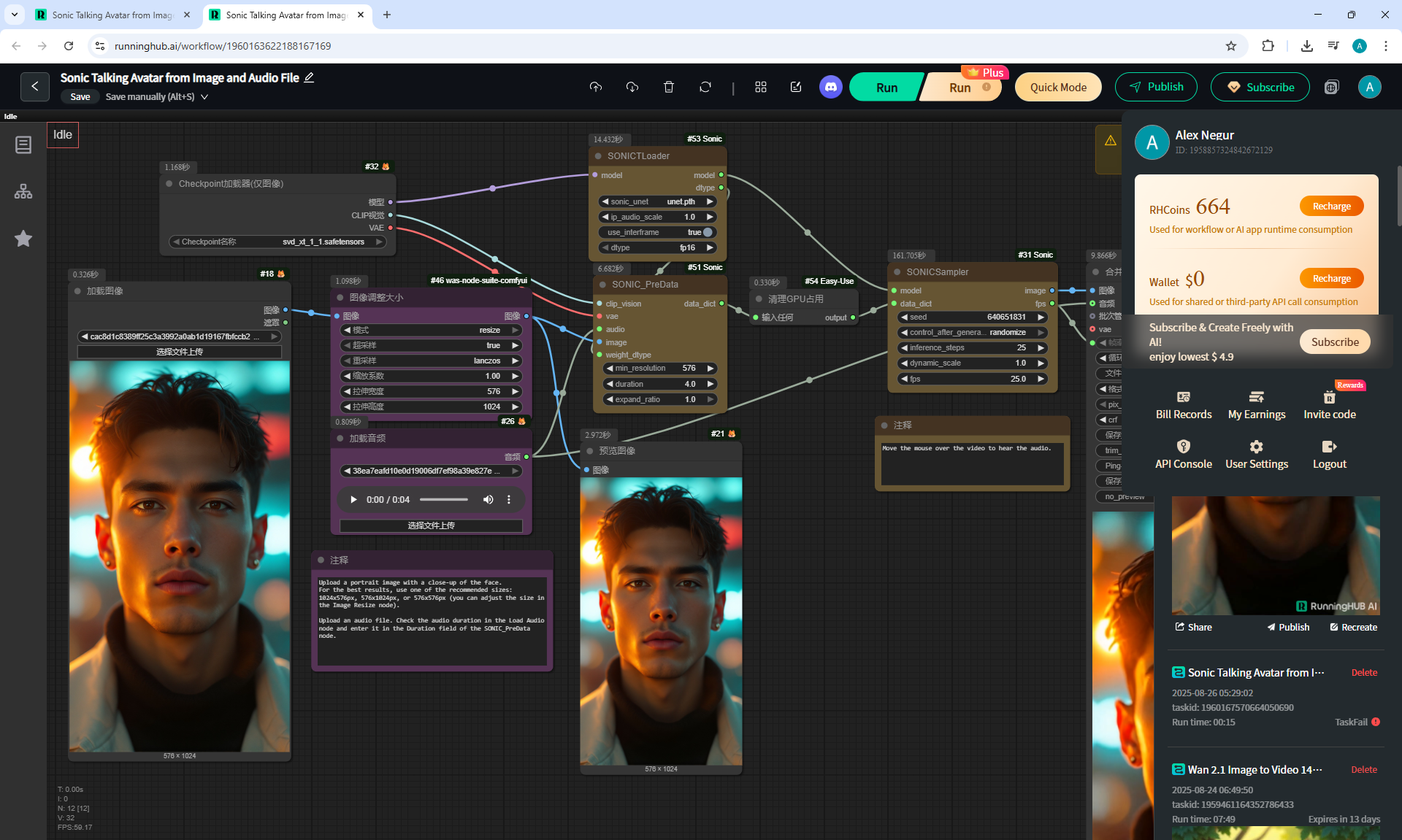
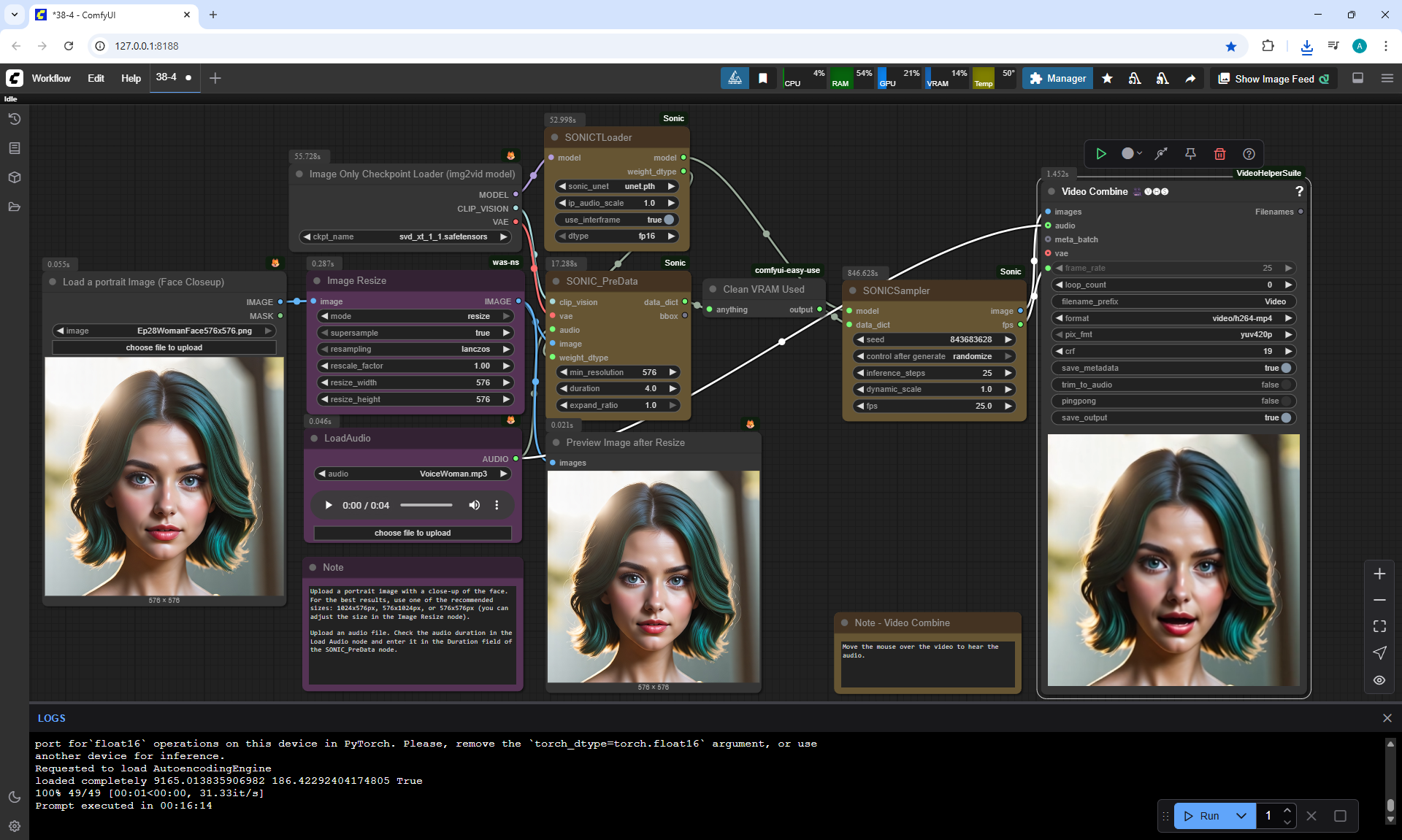
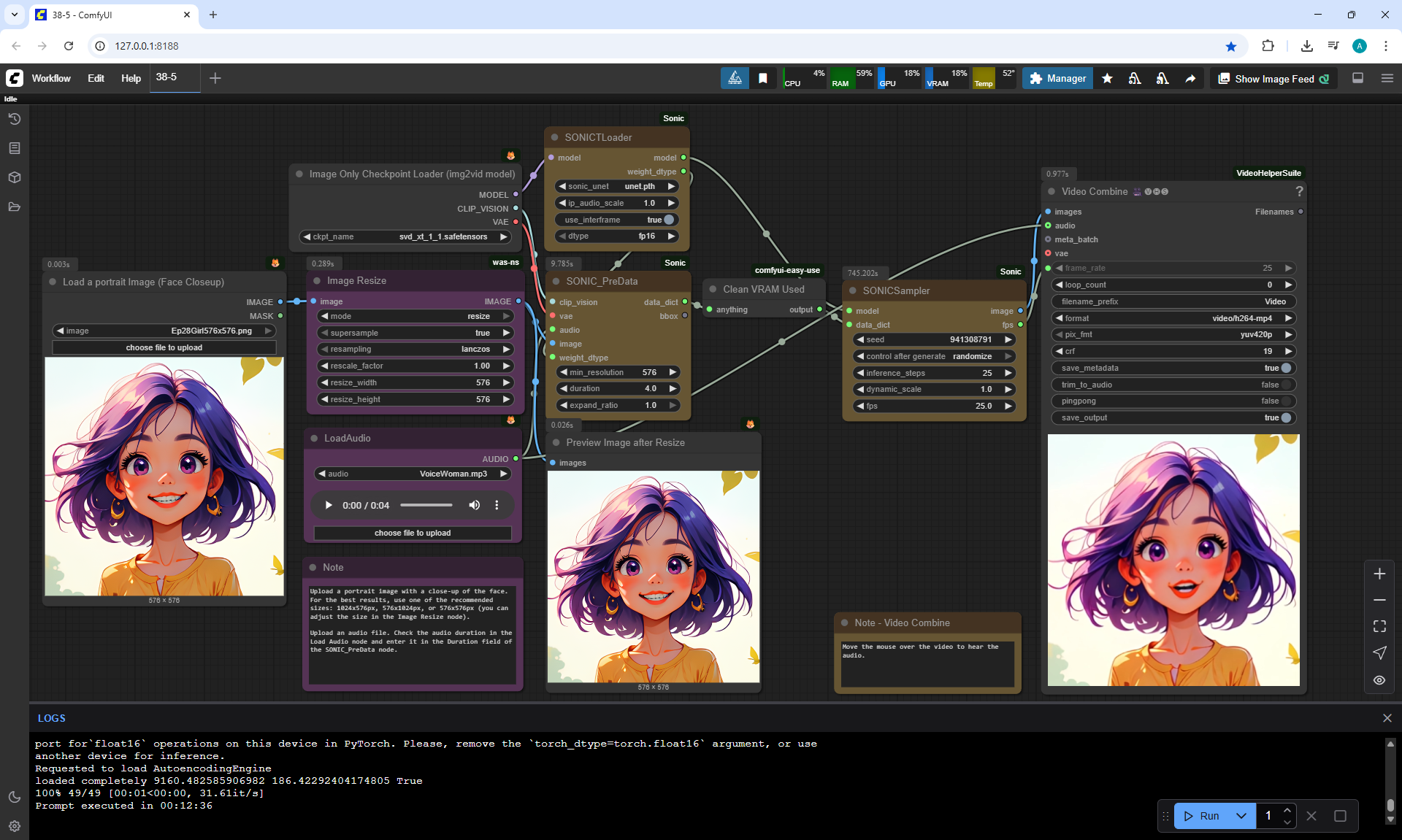
ComfyUI Tutorial Series Ep 38: Bring Portraits to Life! Talking Avatar with Sonic


VoiceMan.mp3






VoiceWoman.mp3




VoiceCartoonMan.mp3
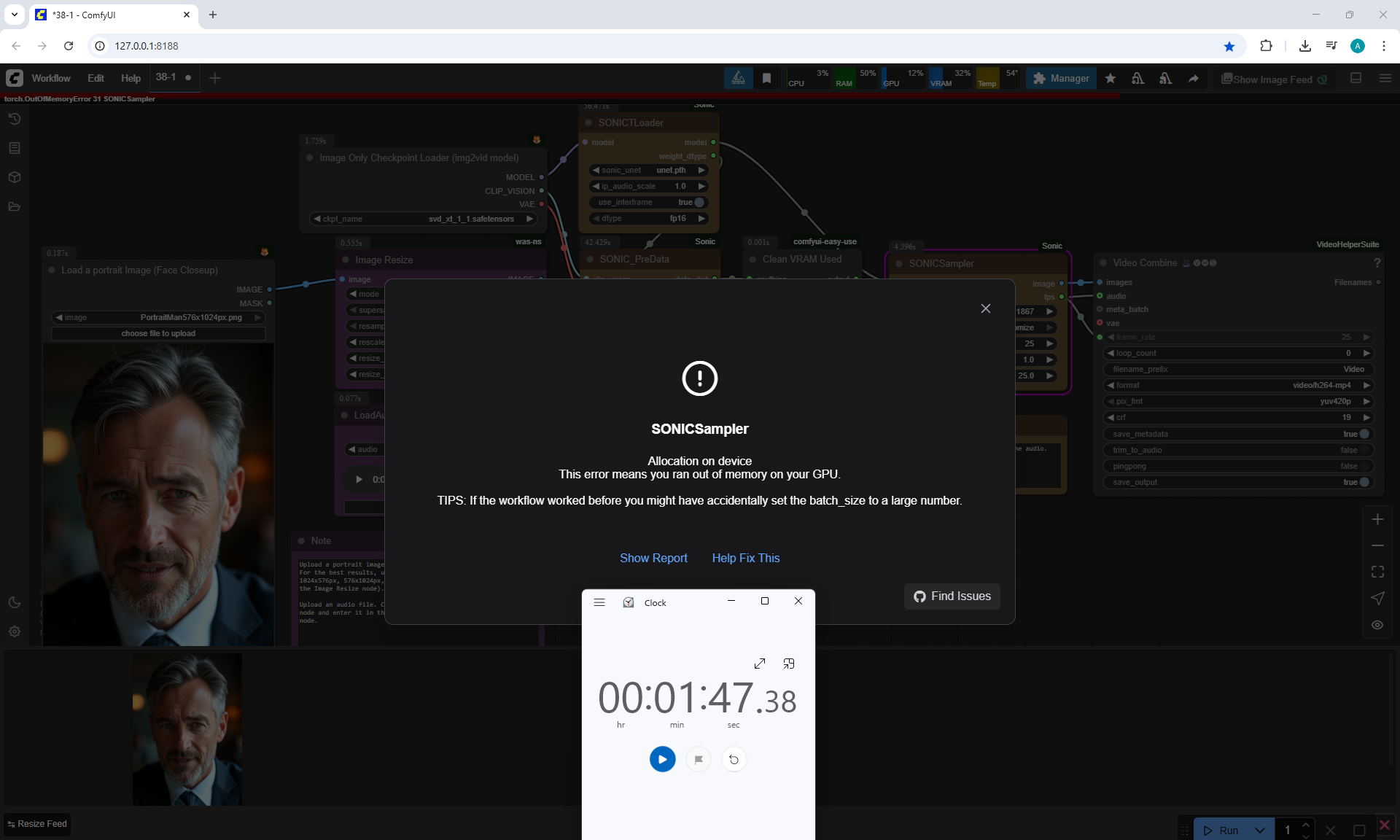
To generate such videos with lip sync in ComfyUI, you need a video card of at least 20 Gb.
I tested generating a 576x1024 video for 5 seconds on my 12 Gb video card,
I managed to generate it in 1 hour and 15 minutes.
I tested photos of people, took 30-40 seconds of a song in a different language, generated the video in the cloud.
You can lip sync in different languages, generated a video for one image and the person sang correctly.
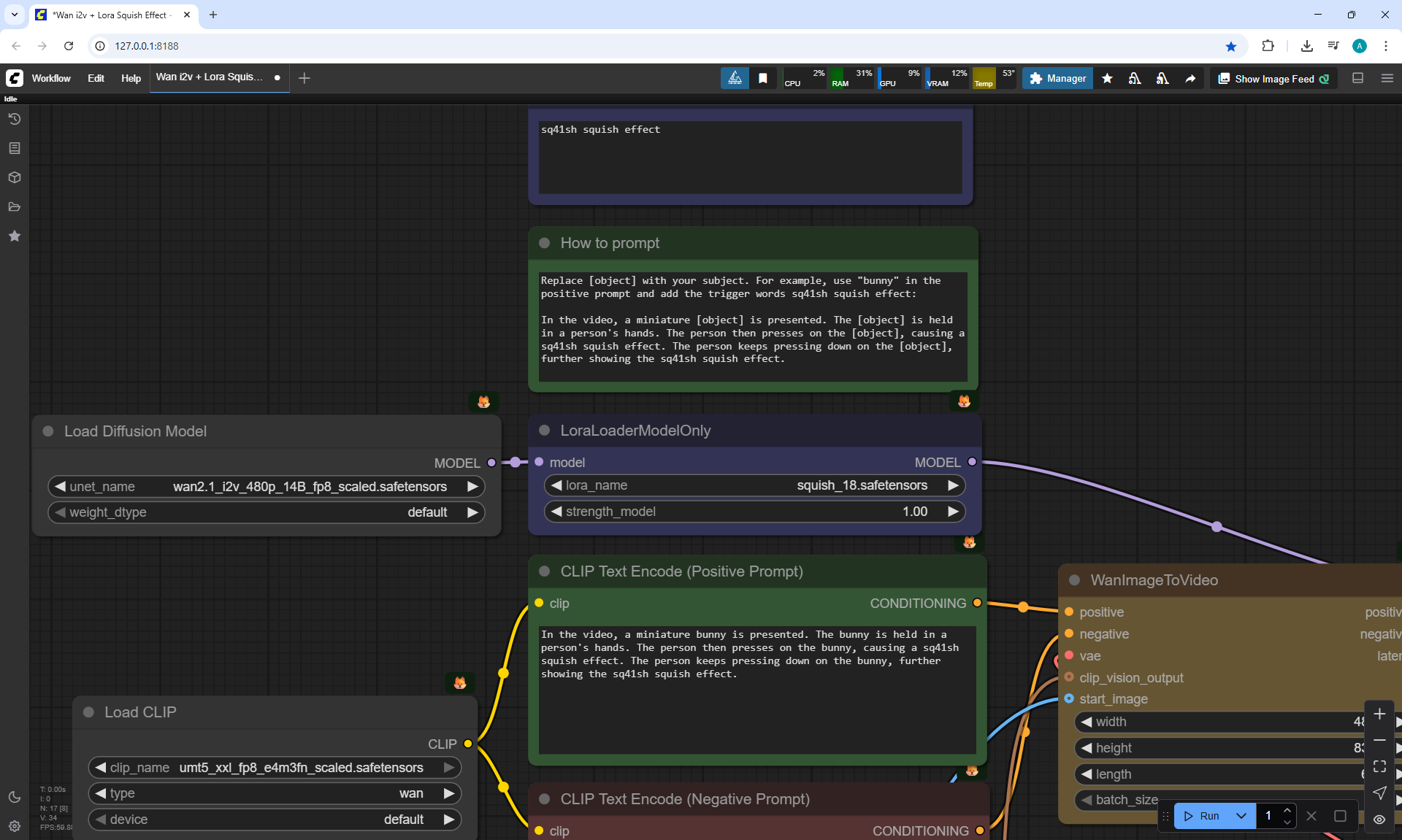
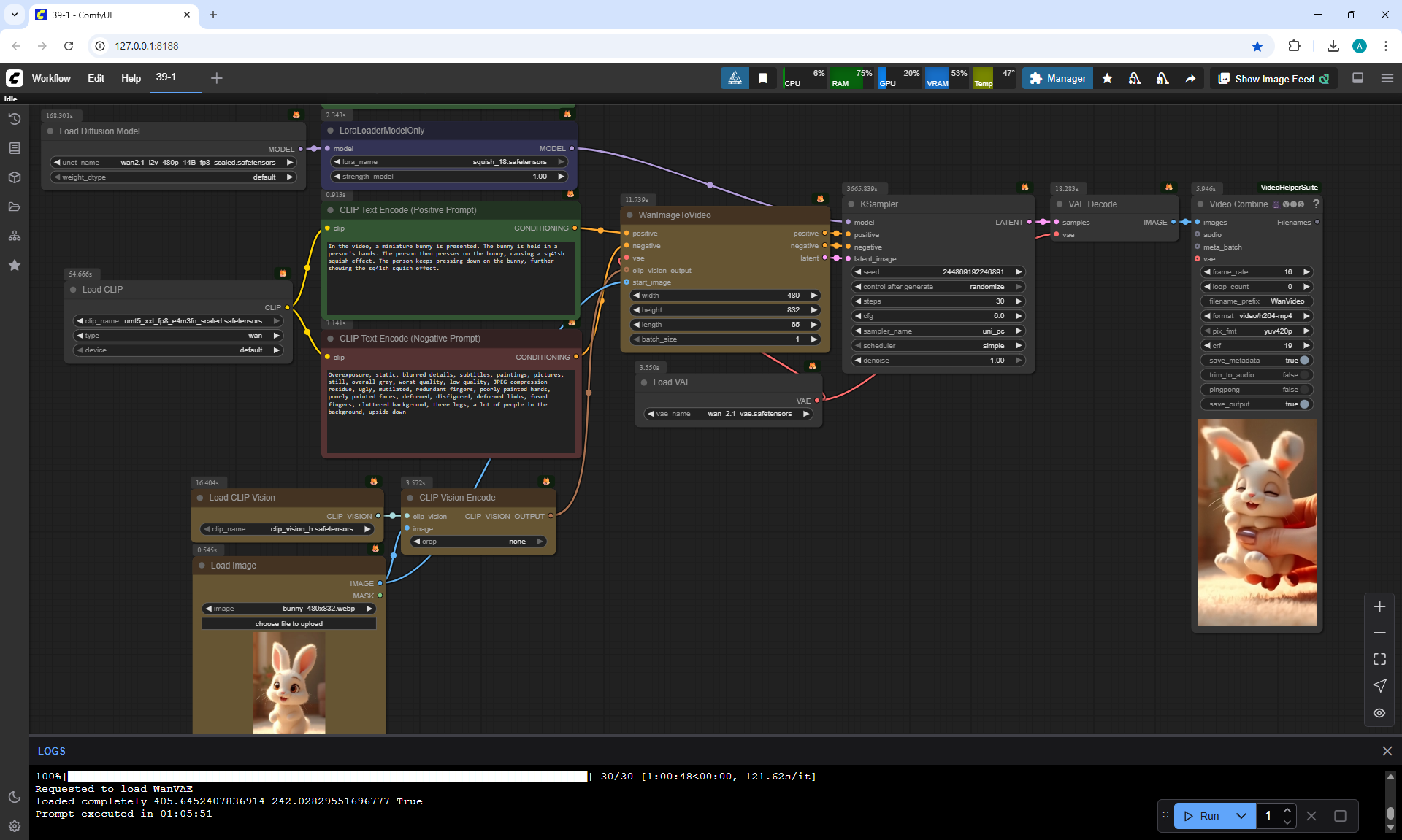
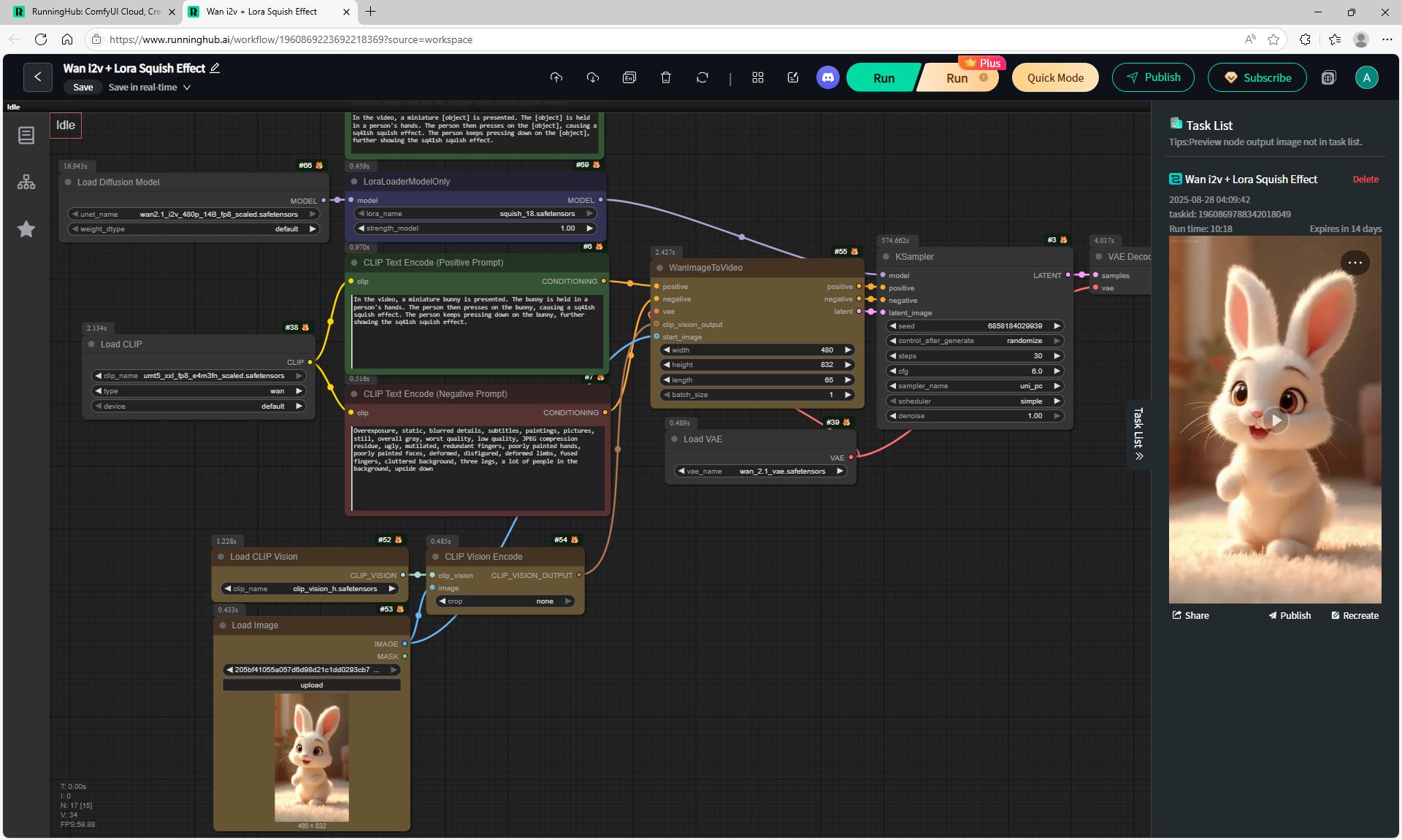
ComfyUI Tutorial Series Ep 39: Using WAN 2.1 with LoRAs for Wild Effects! (Squish & More)





In this tutorial, I used additional LoRa on Wan2.1 14B 480p I2V to generate videos with effects: squeezing with fingers, inflating, cutting a cake with a knife, rotating, squeezing with a press, showing muscles.
Wan2.1 14B 480p I2V LoRAs
But not all videos were generated correctly on the first or even many attempts.
For example, carefully squeezing a bunny with your fingers to make a lump, which is twisted and squeezed several times, successful generation was achieved on the second attempt.
When inflating the bunny, it did not fly up on the first attempt, it tilted and fell, the second attempt was successful.








When cutting with a knife, there were unsuccessful attempts, the wrong parts of the cake appeared, which were cut, also the knife was very black, the knife could cut along one contour, and then when the knife moved, the cut changed differently.
When squeezing with a press, it could not hit the object clearly and squeeze it crookedly.
There was an effect of water after squeezing, which I did not plan to see.





When rotating around its axis, objects successfully rotated,
the person and the car rotated correctly the first time, the hare leaned forward once, on the second attempt the hare rotated correctly, it did not fall.
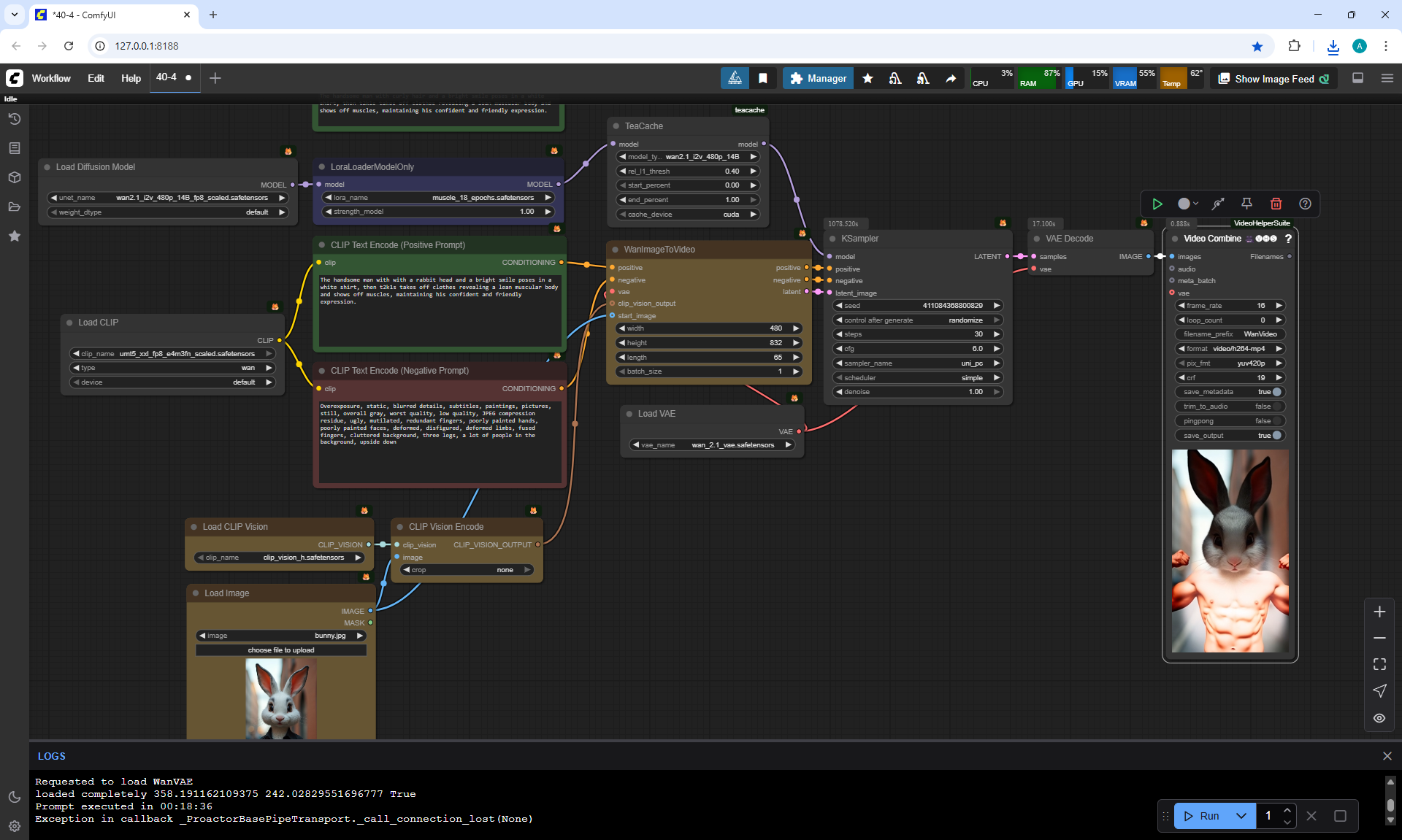
The video where the person shows his muscles was successfully generated, each time different ideas.




When I made a video of squeezing with fingers for a goat, the hands constantly perform unexpected actions: shaking the rabbit, the goat, holding it wrong, squeezing it badly, twisting it differently, squeezing with two hands, pulling the head with the fingers. The results of squeezing are very different from expectations.



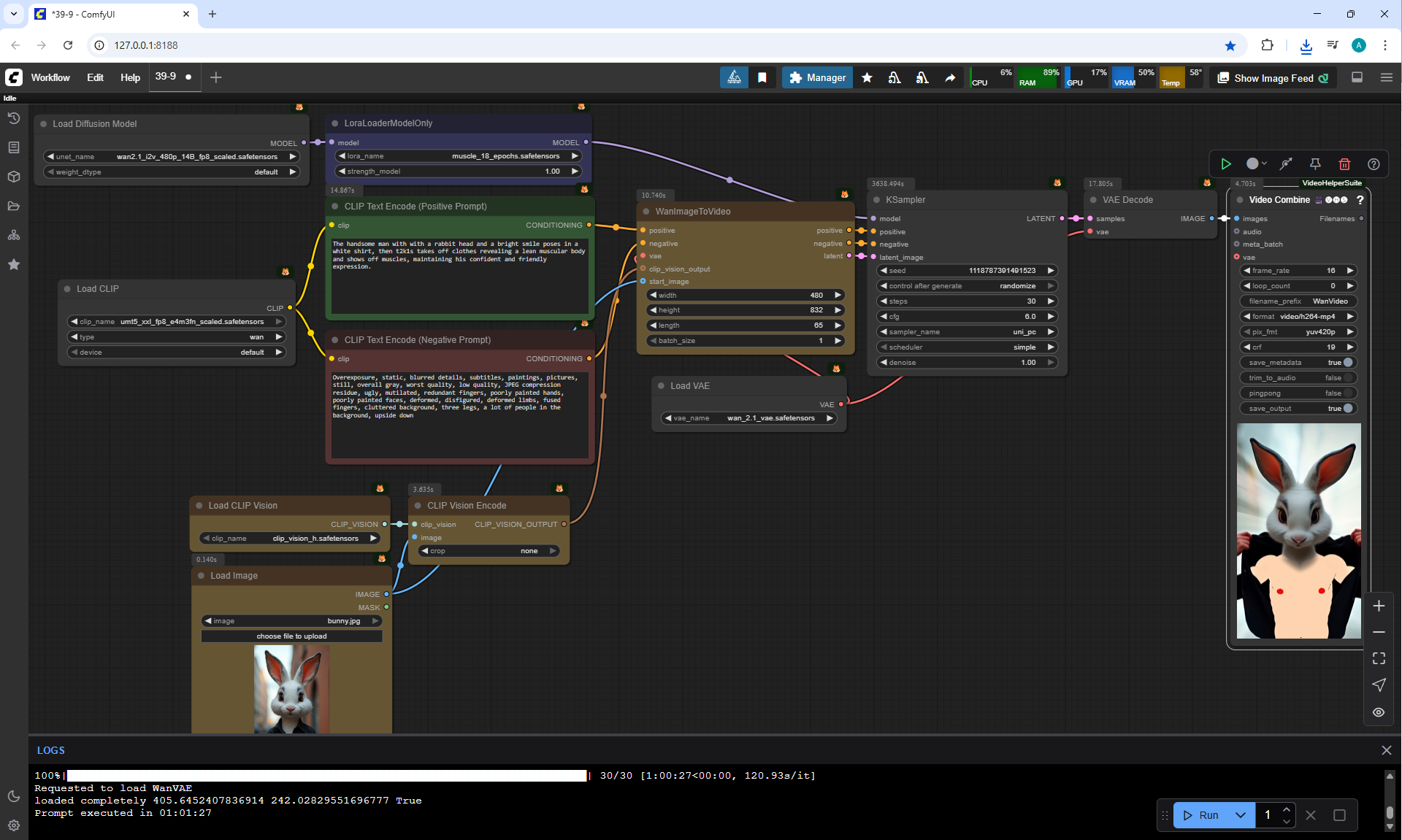
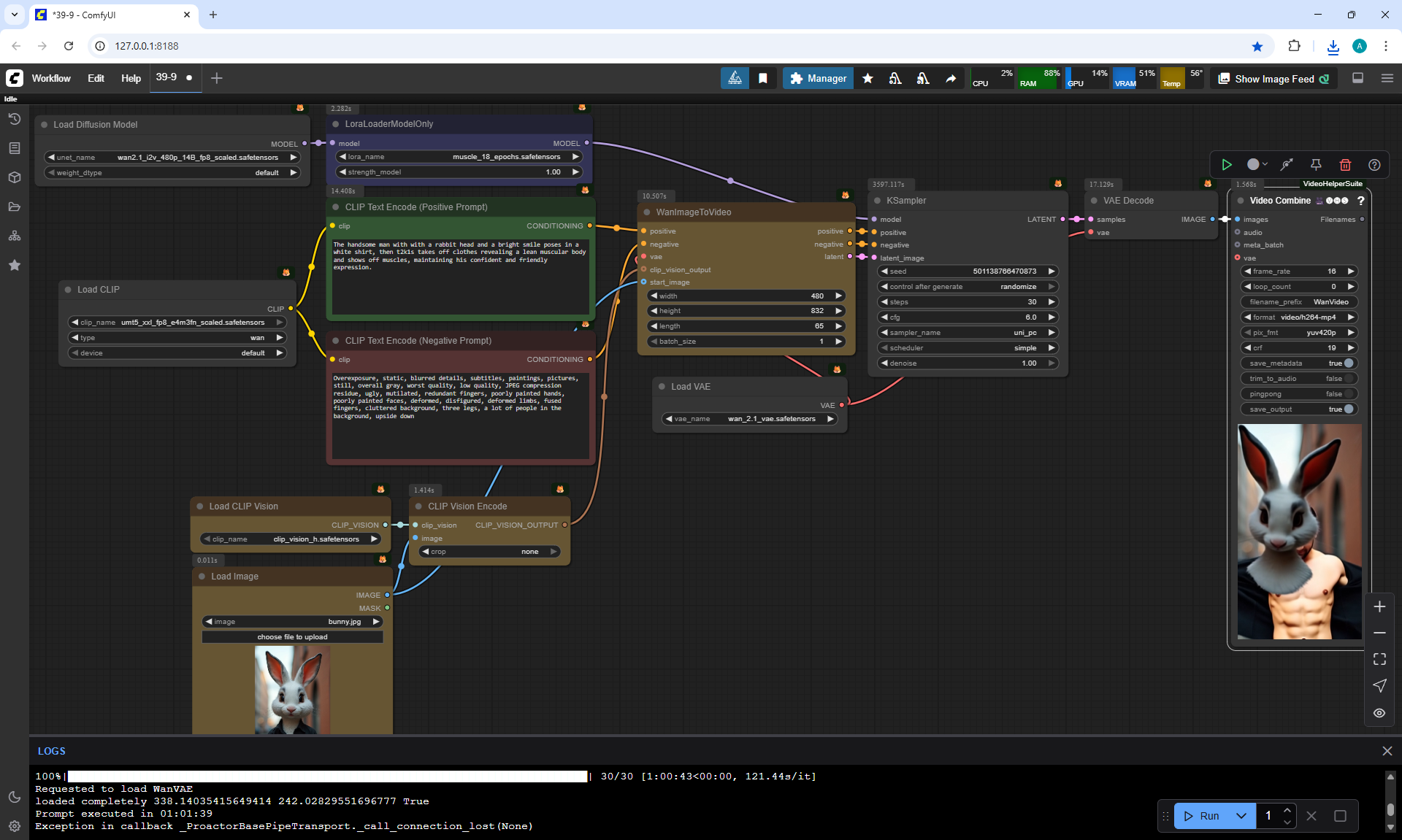
I tried to generate a display of the rabbit's muscles, as the author did. But every time there were failures. Either the muscles were drawn very simply, as in the style of 2D graphics, or the head flew off.
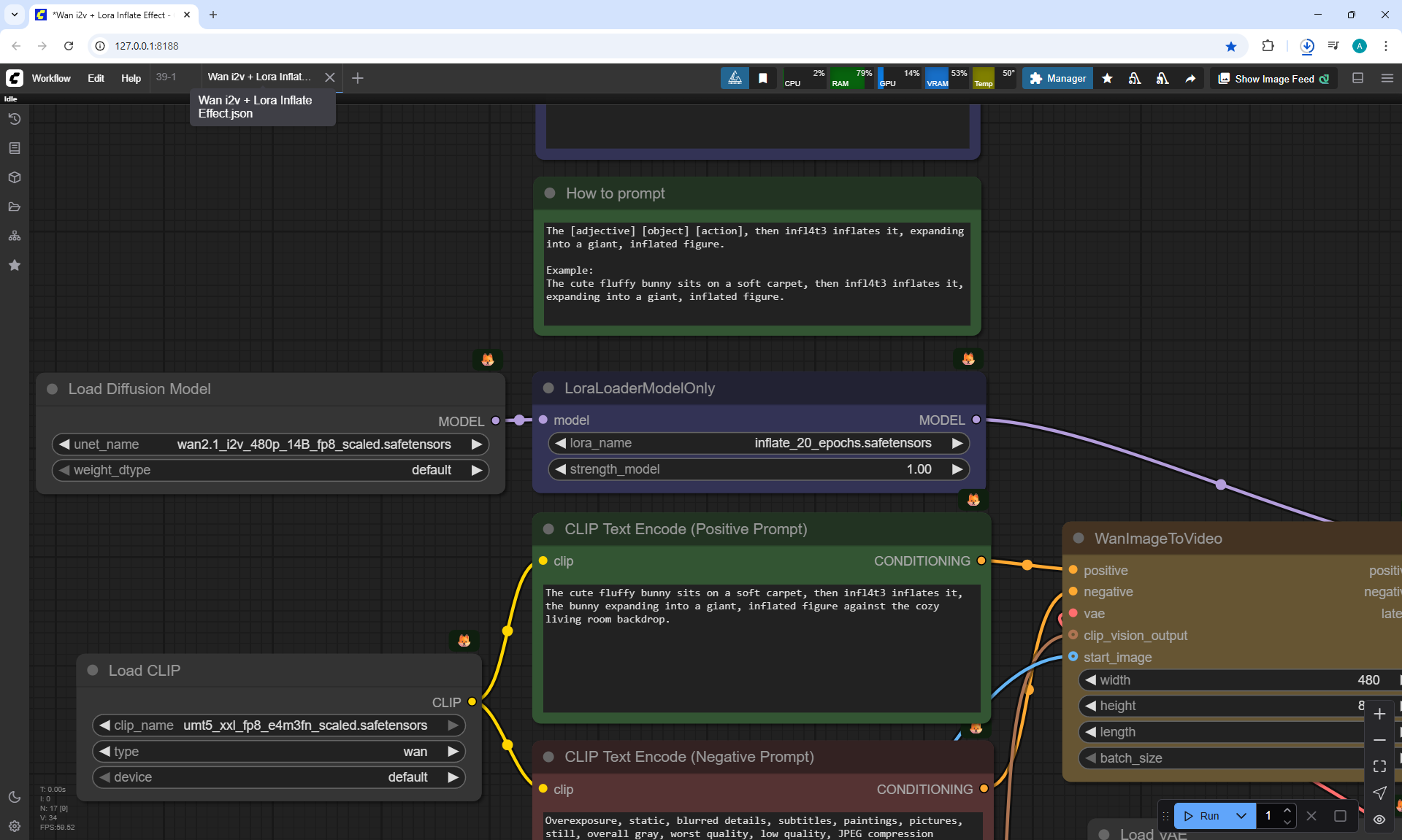
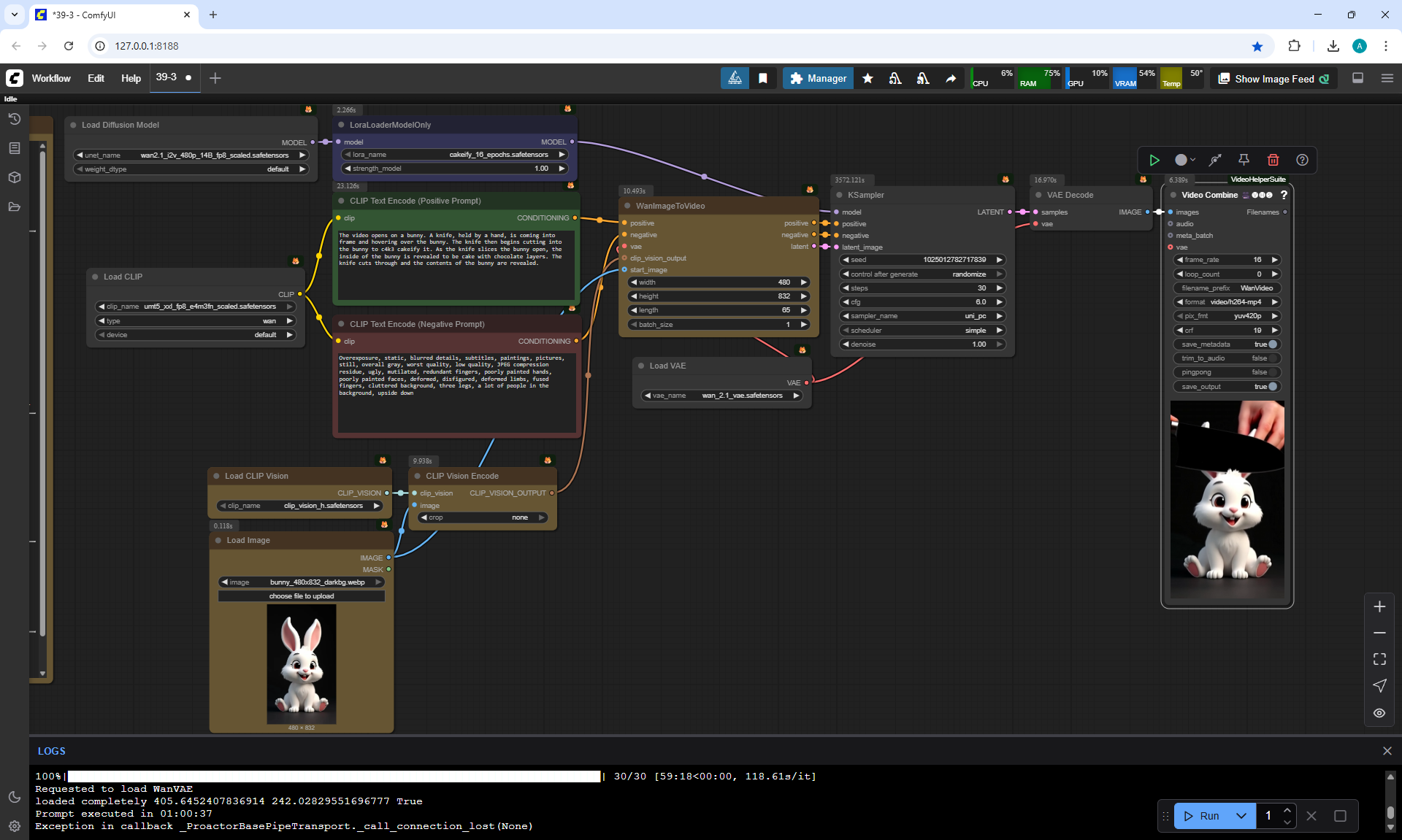
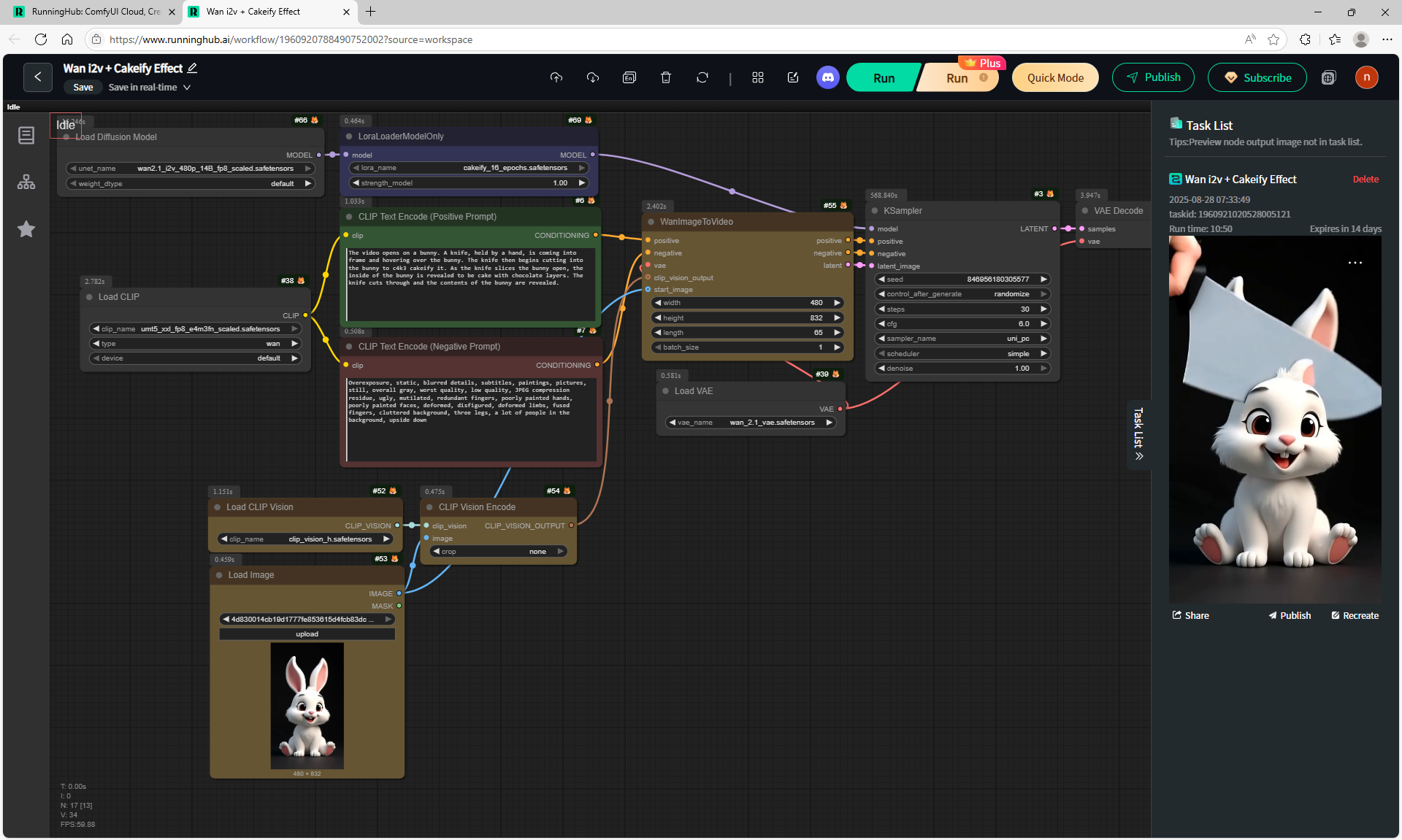
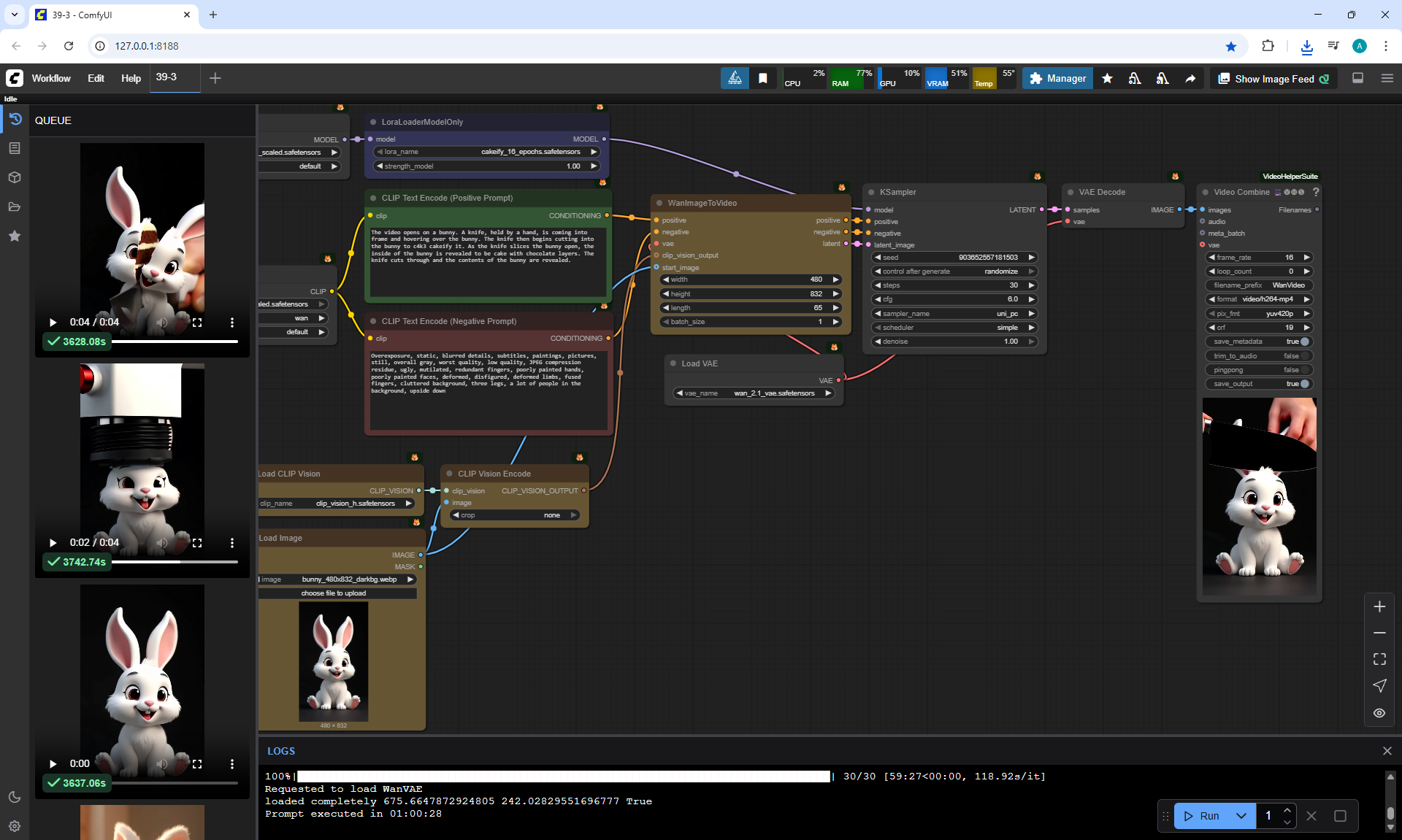
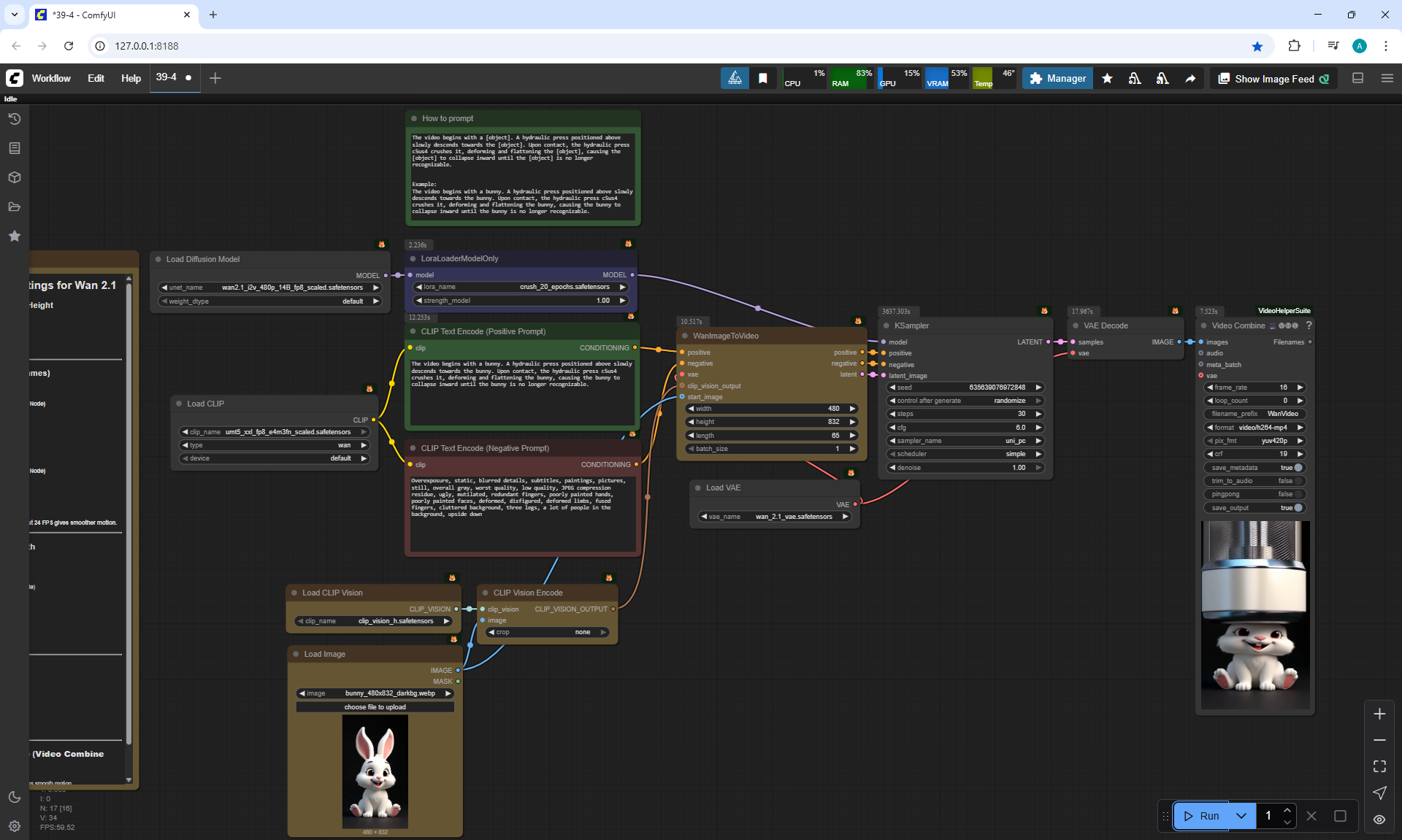
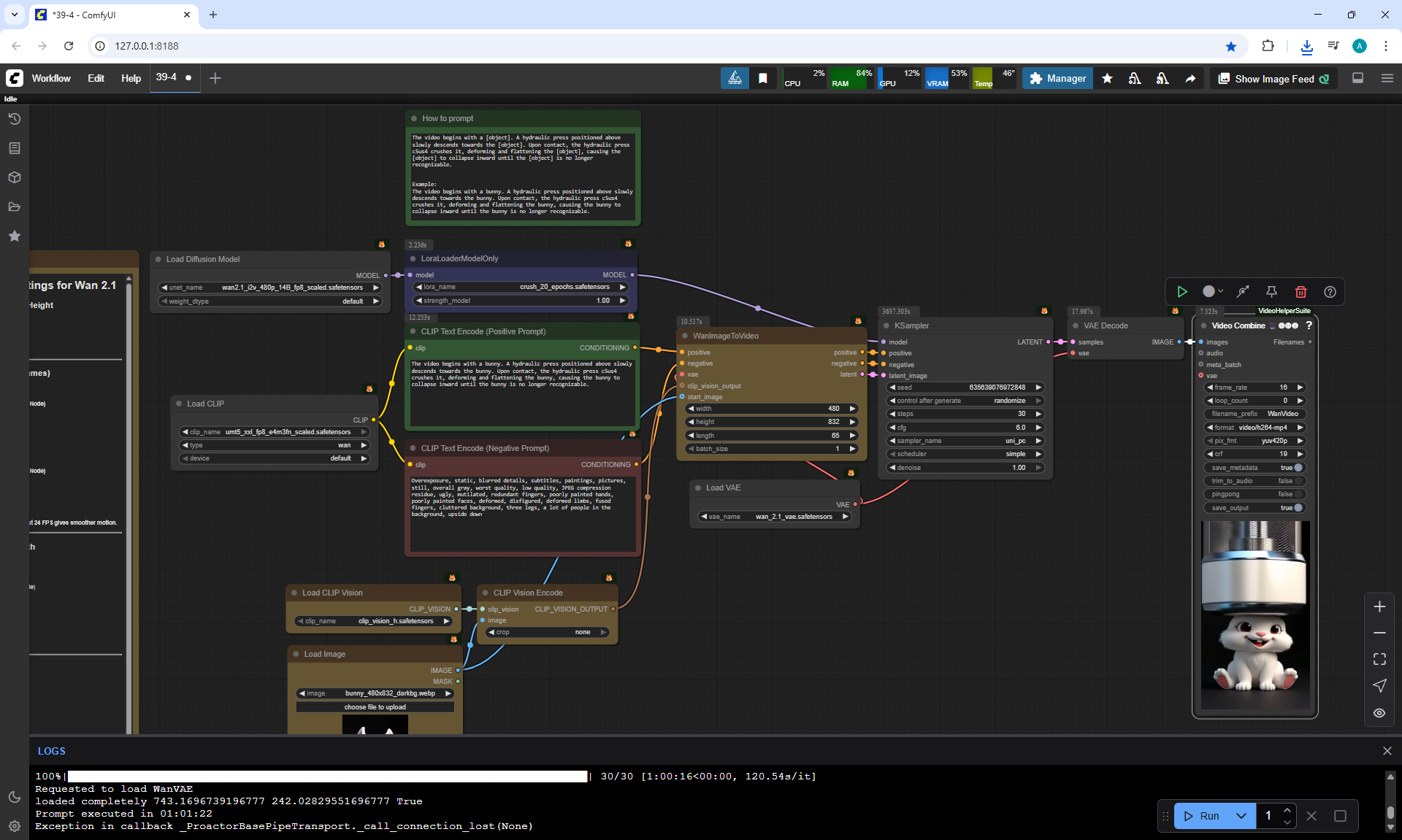
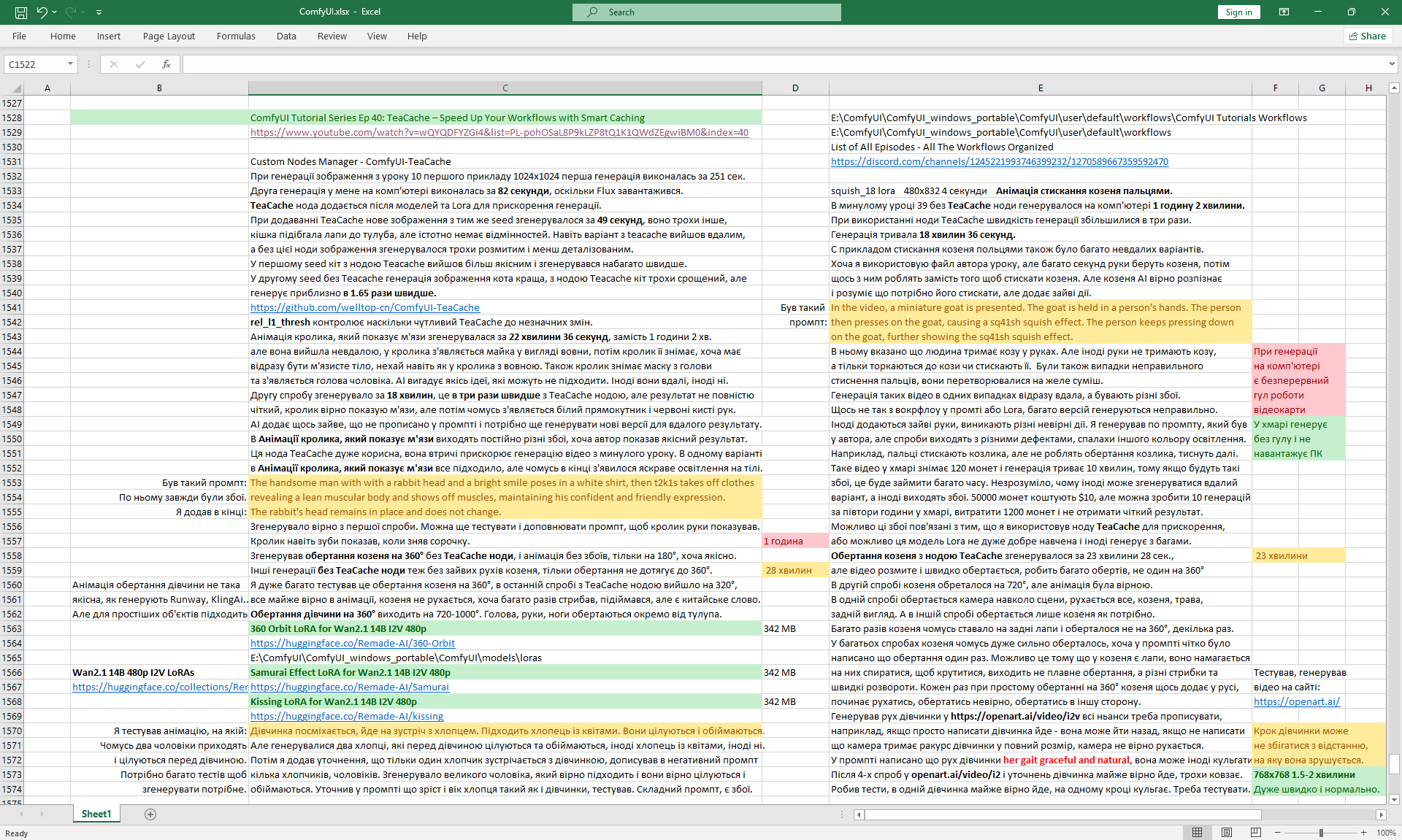
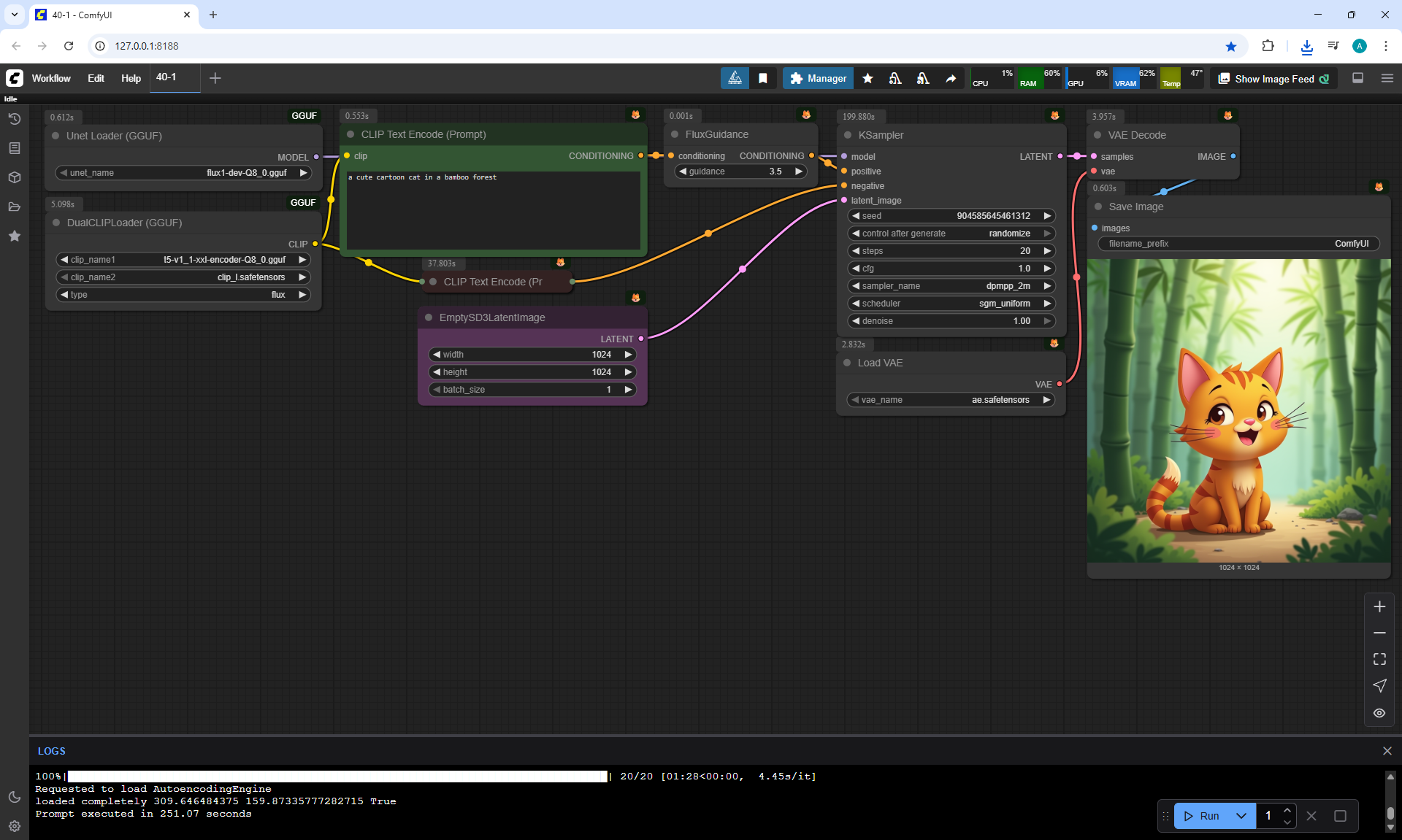
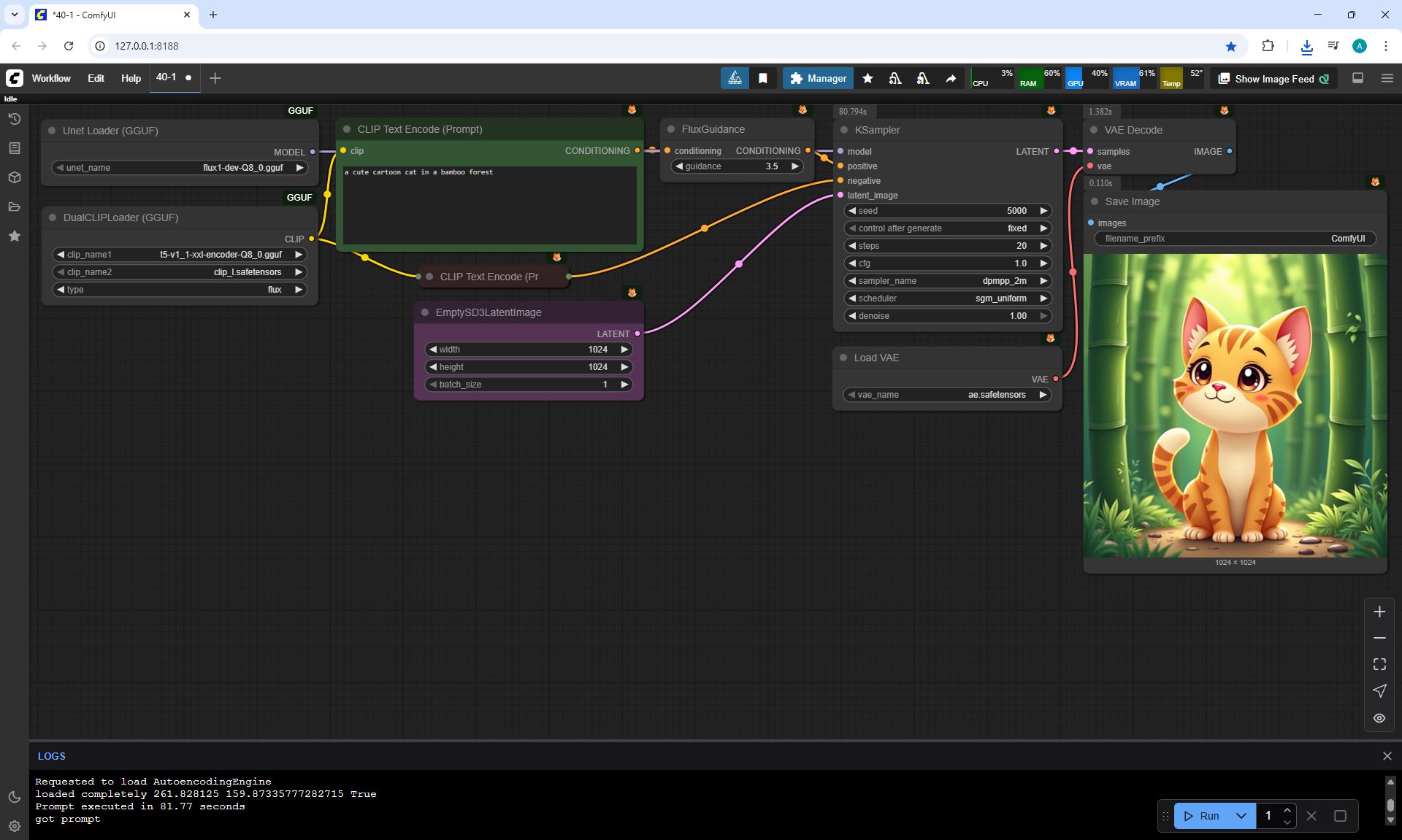
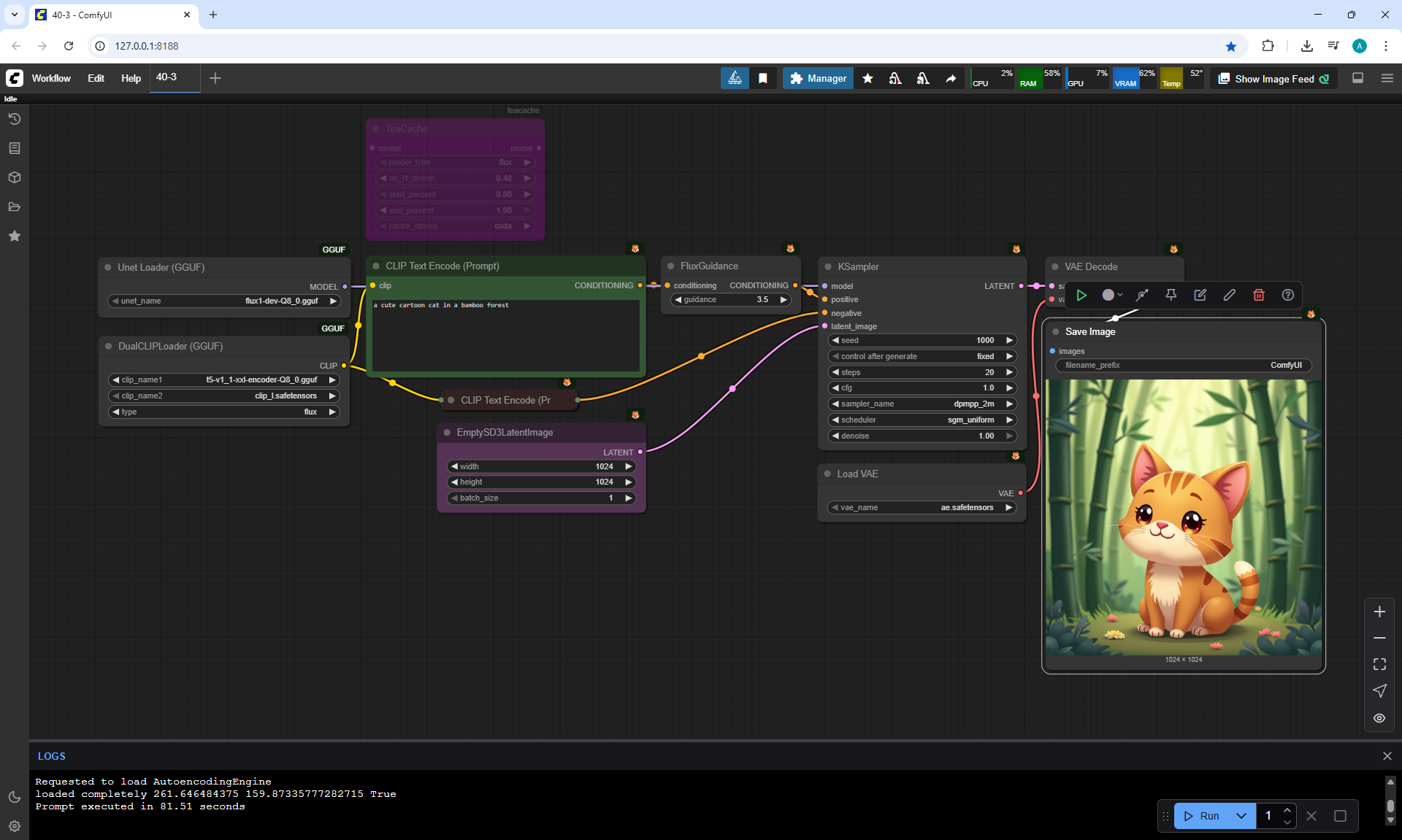
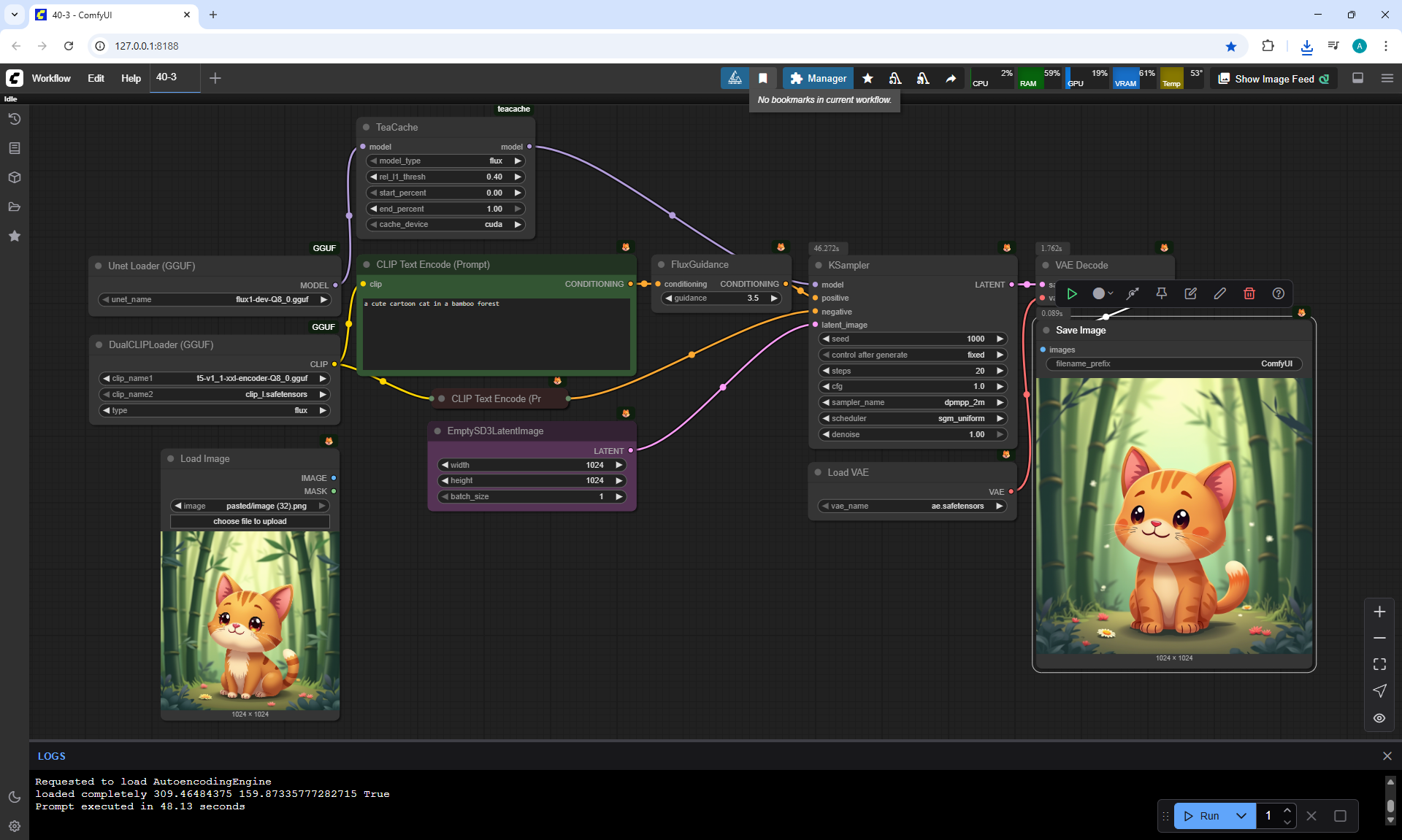
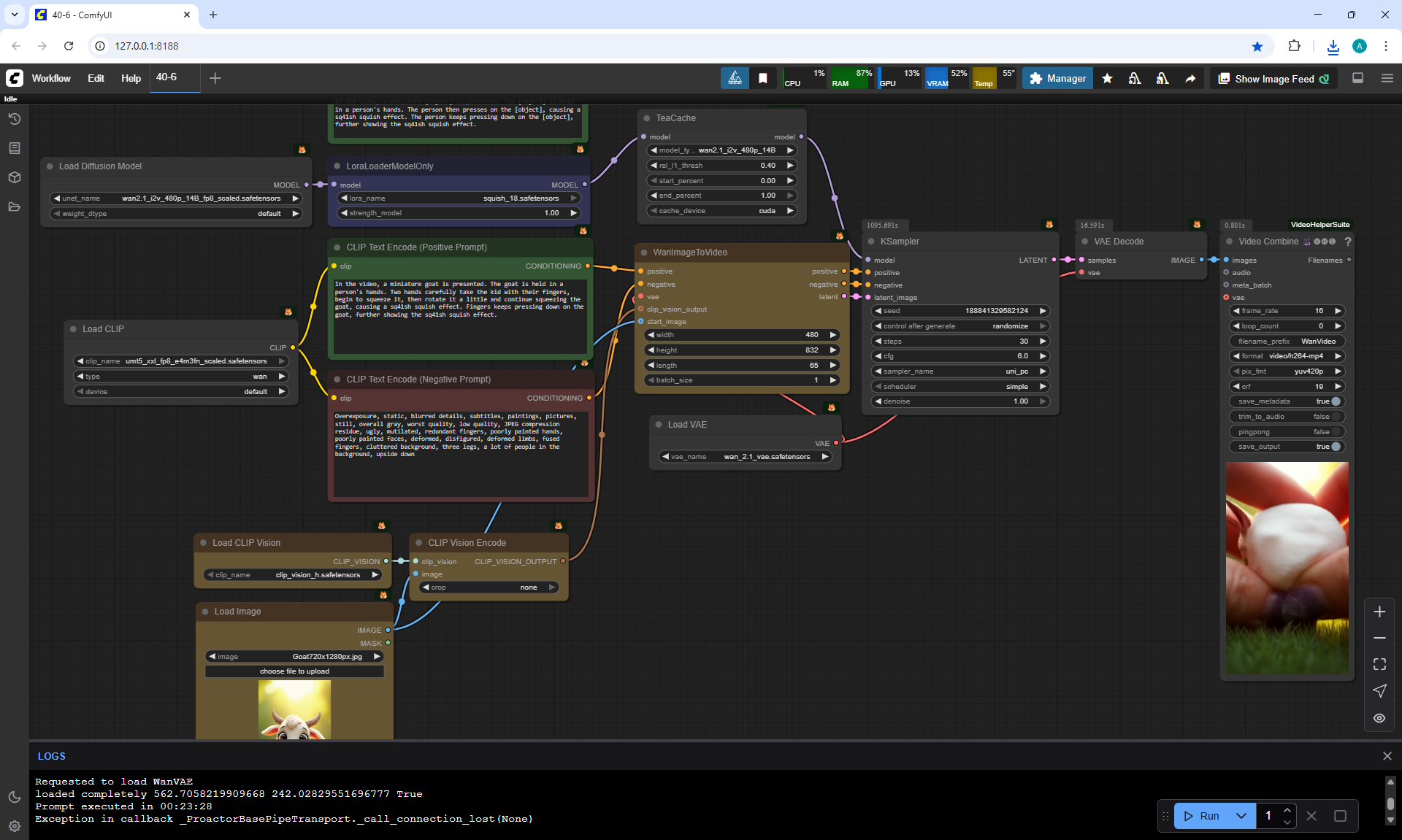
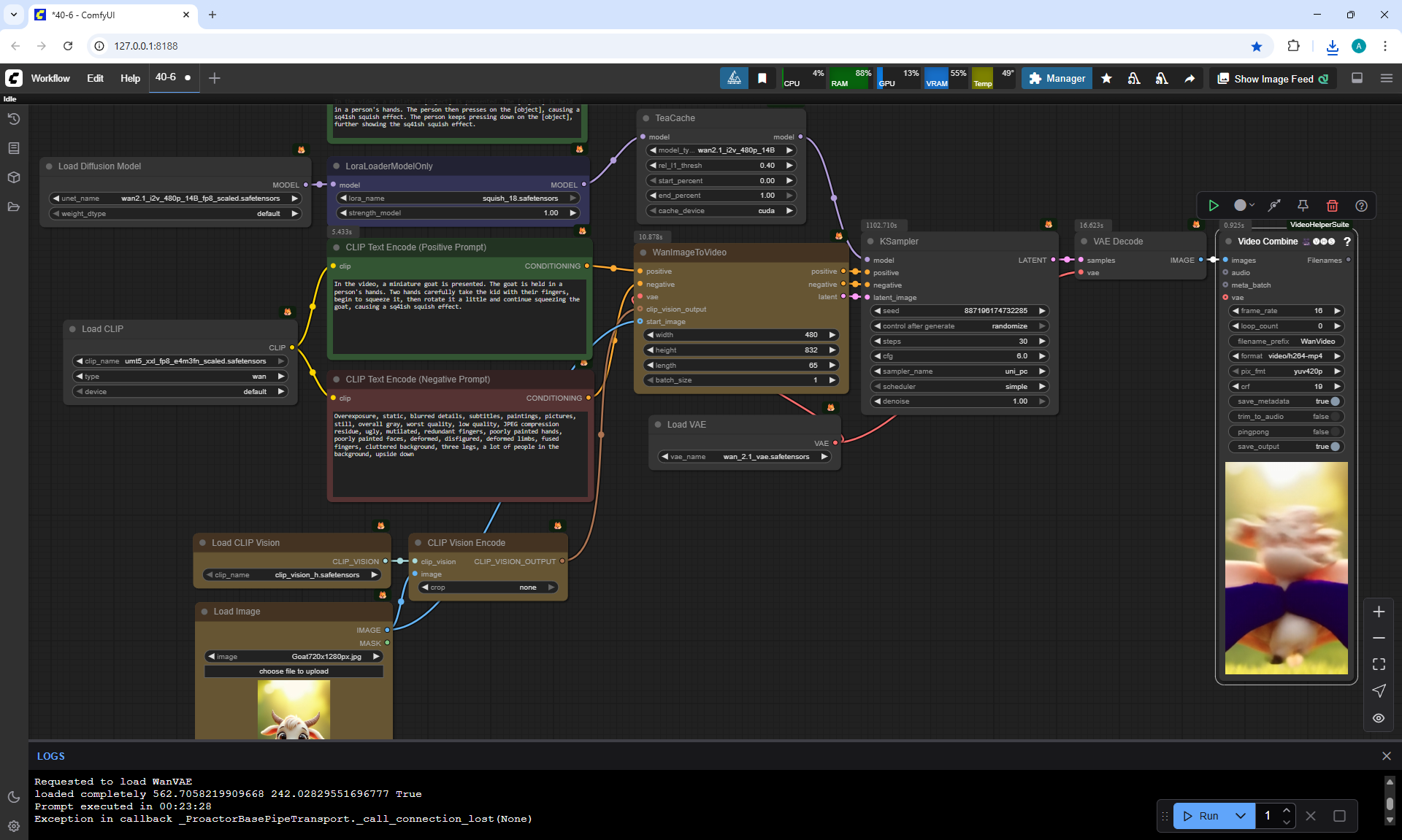
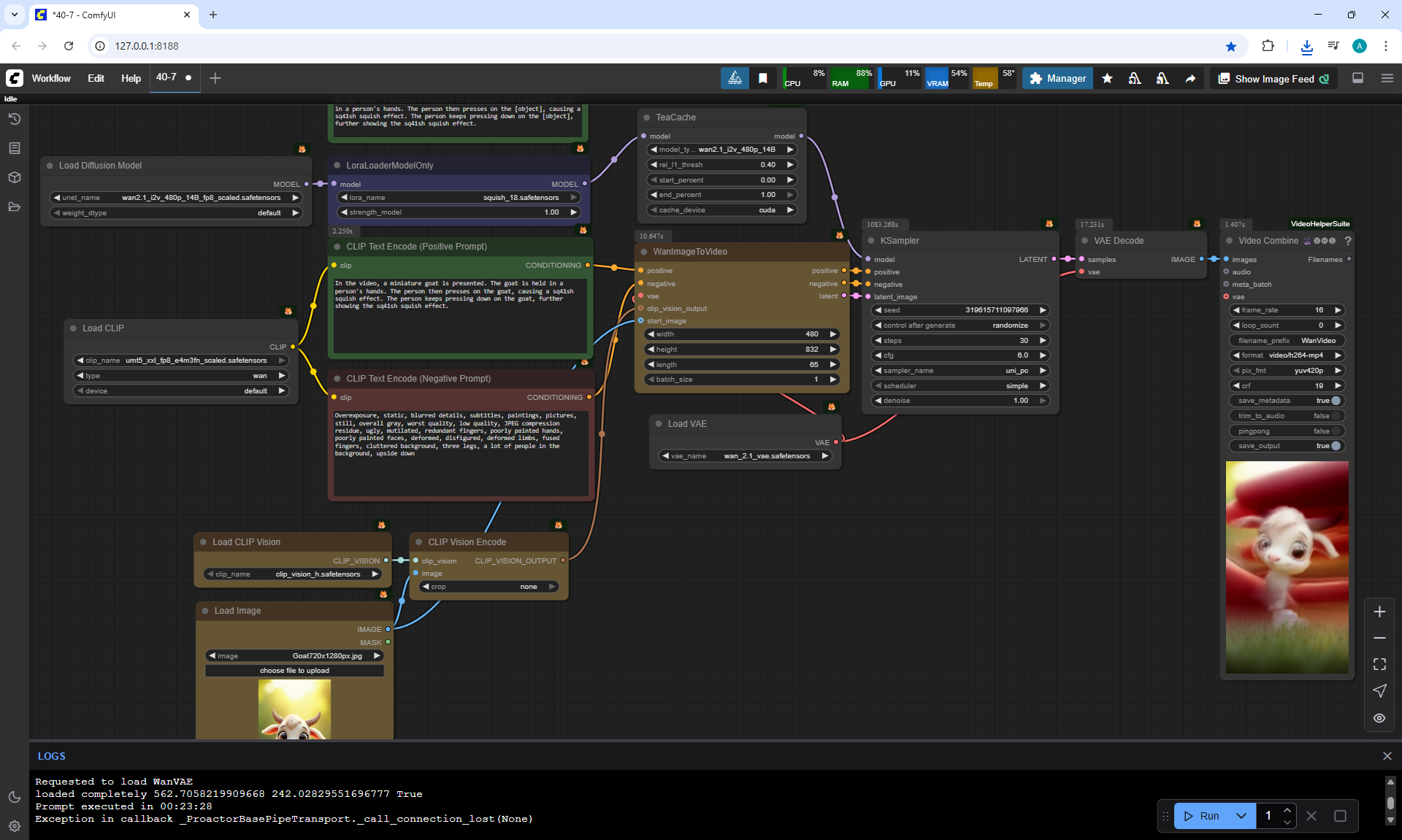
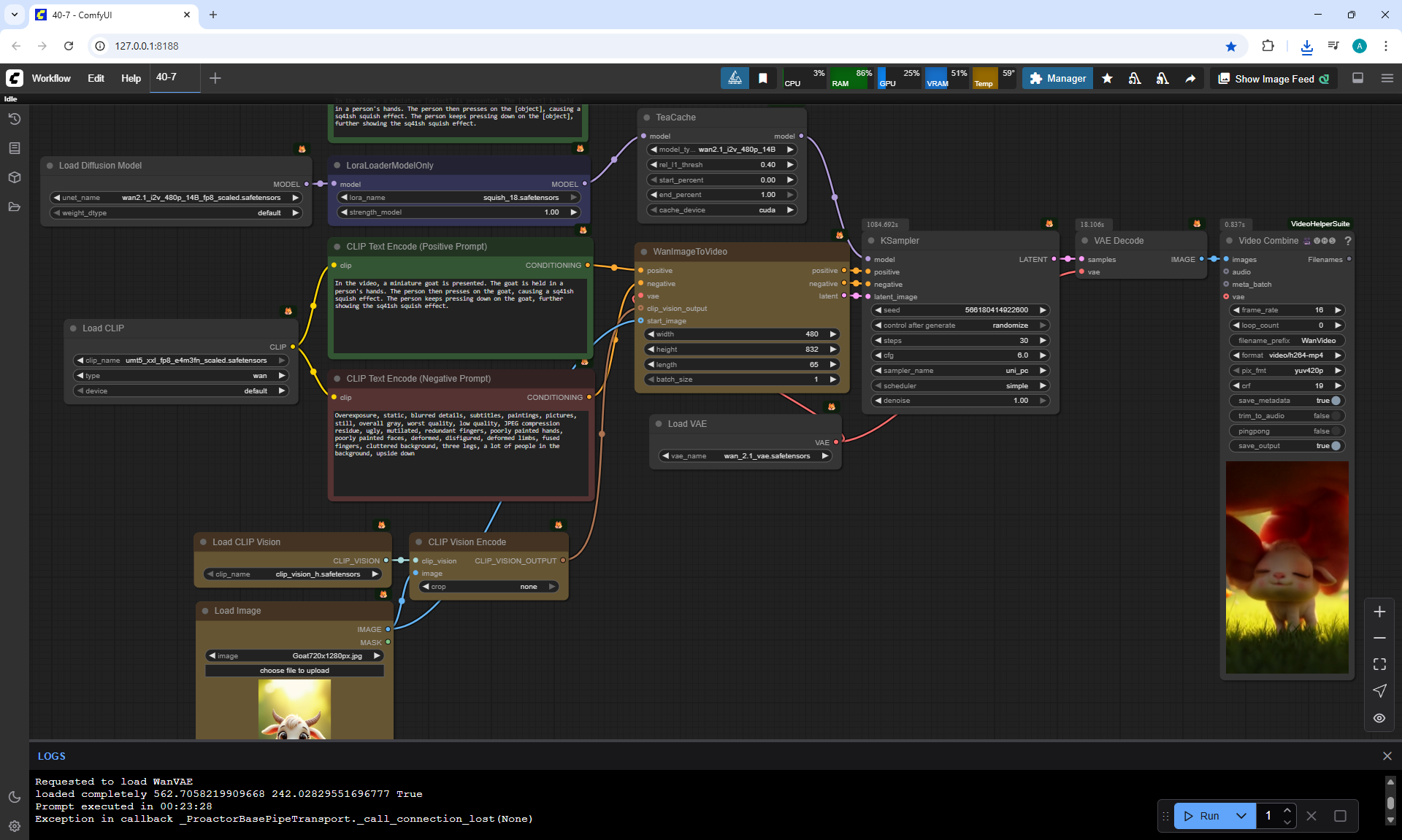
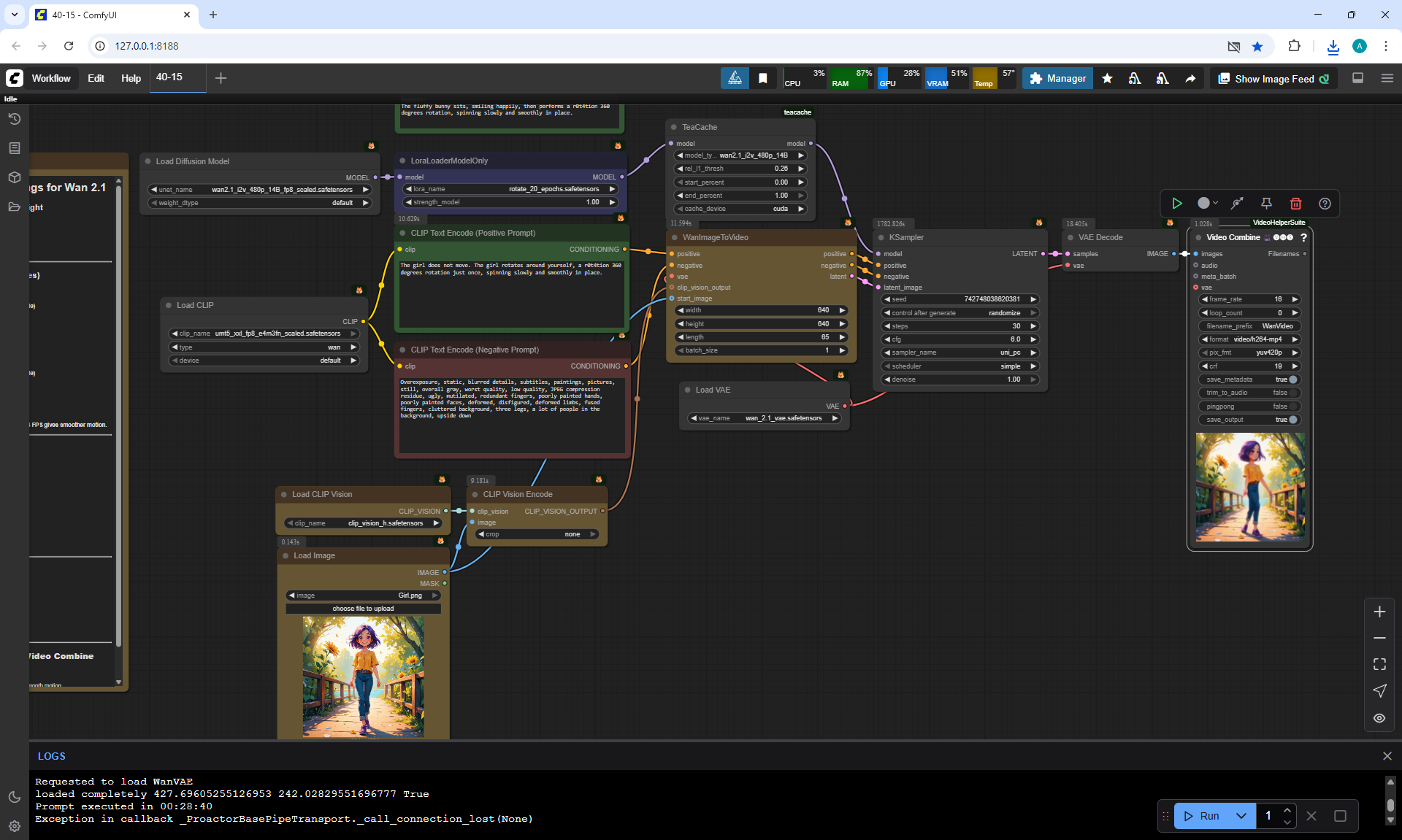
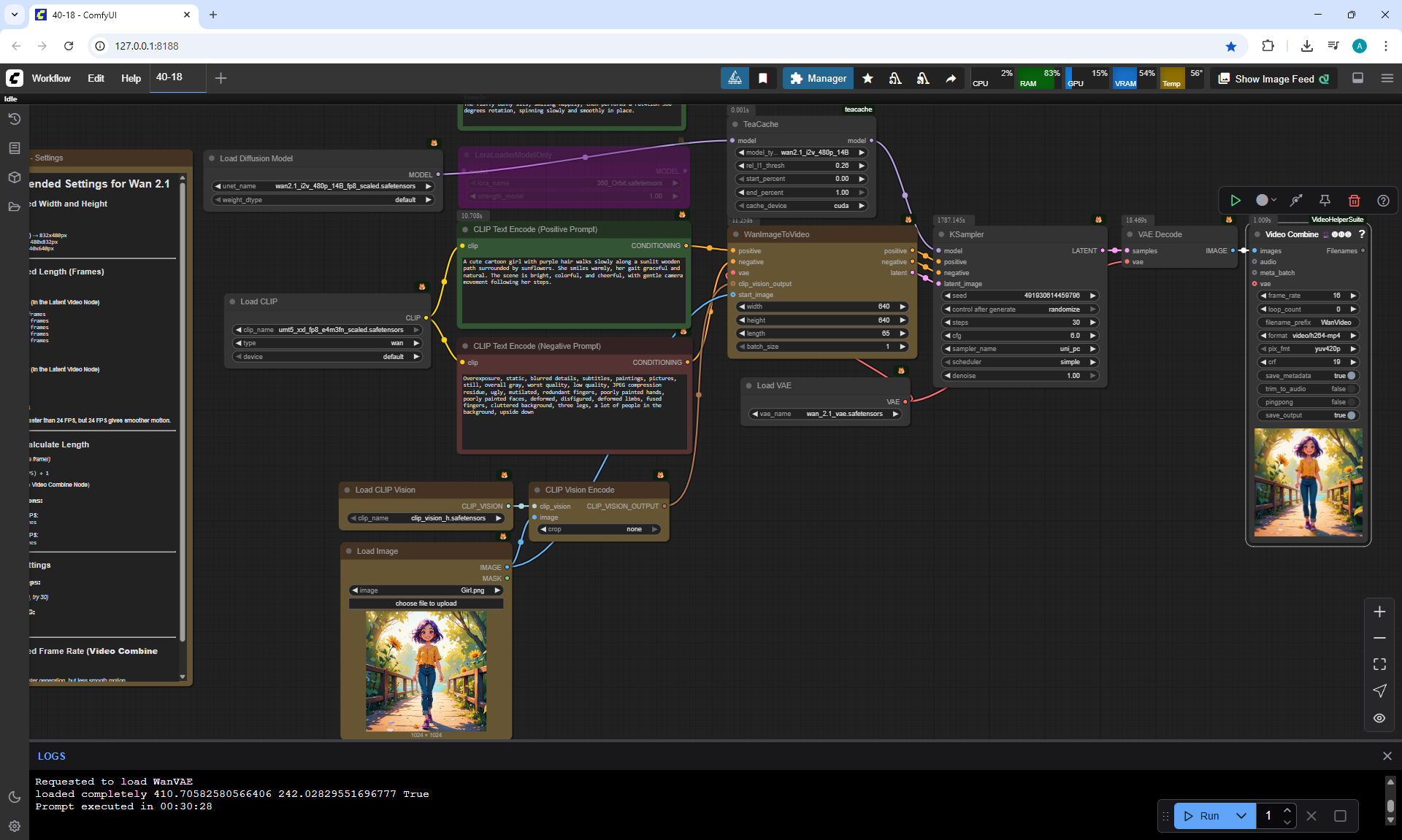
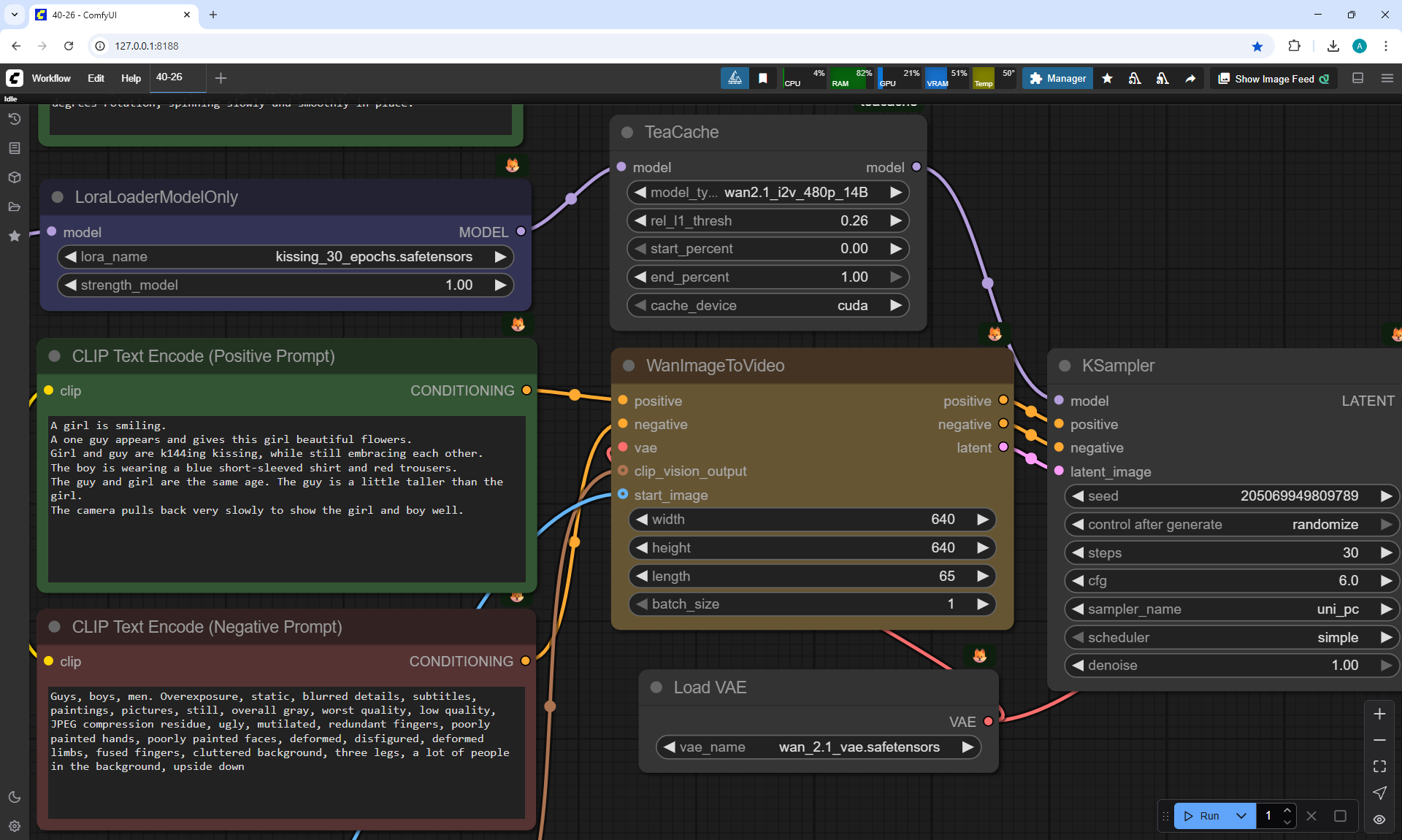
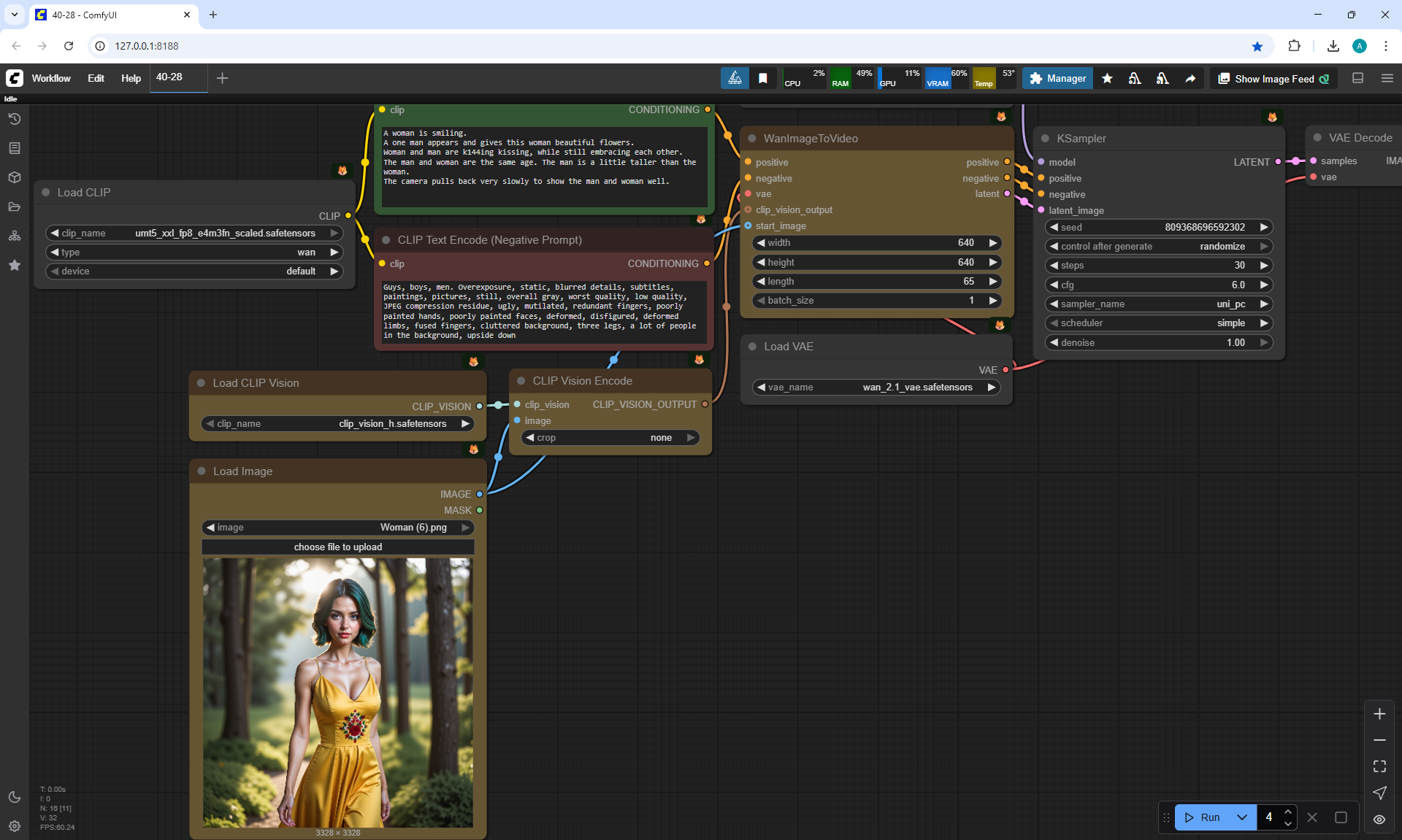
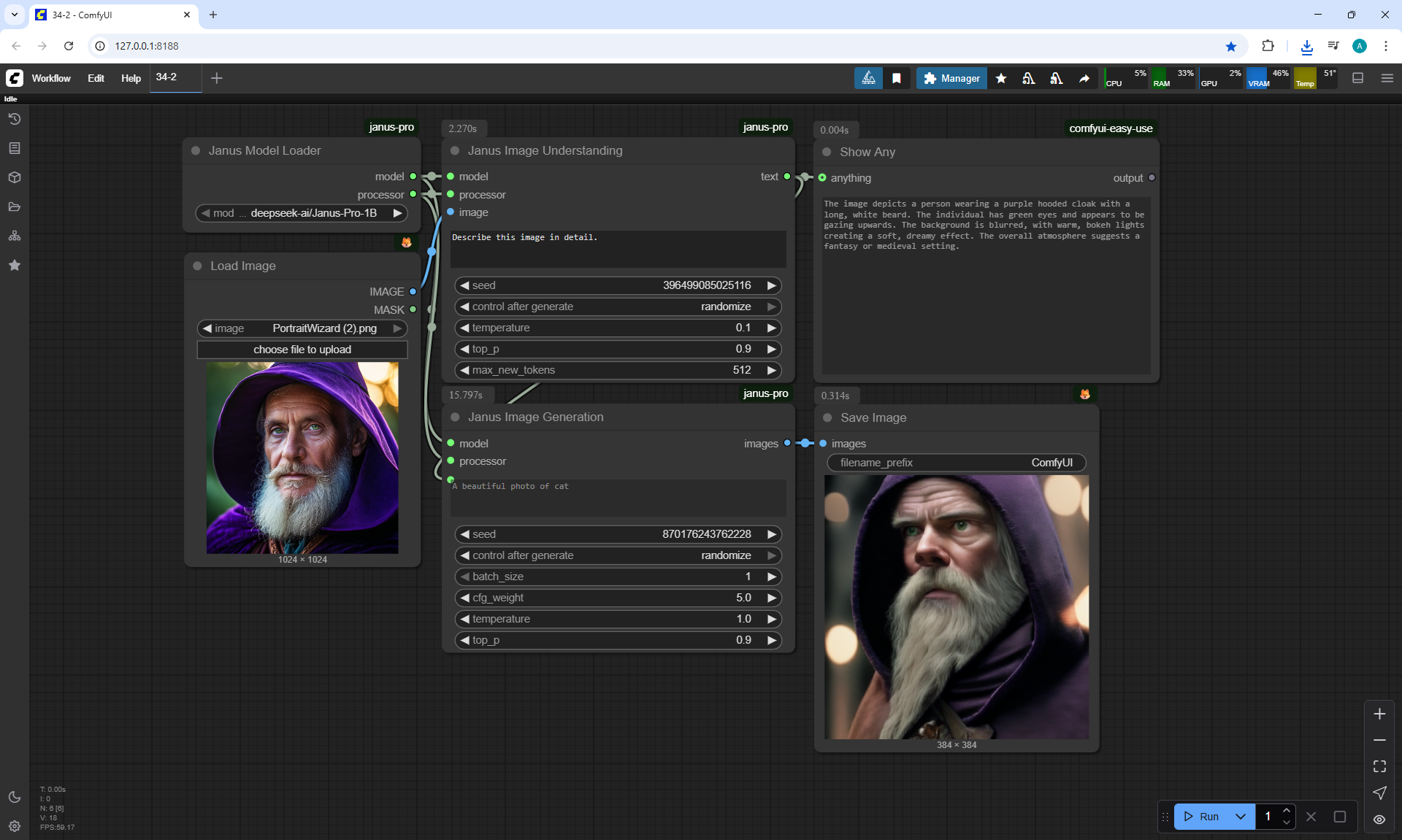
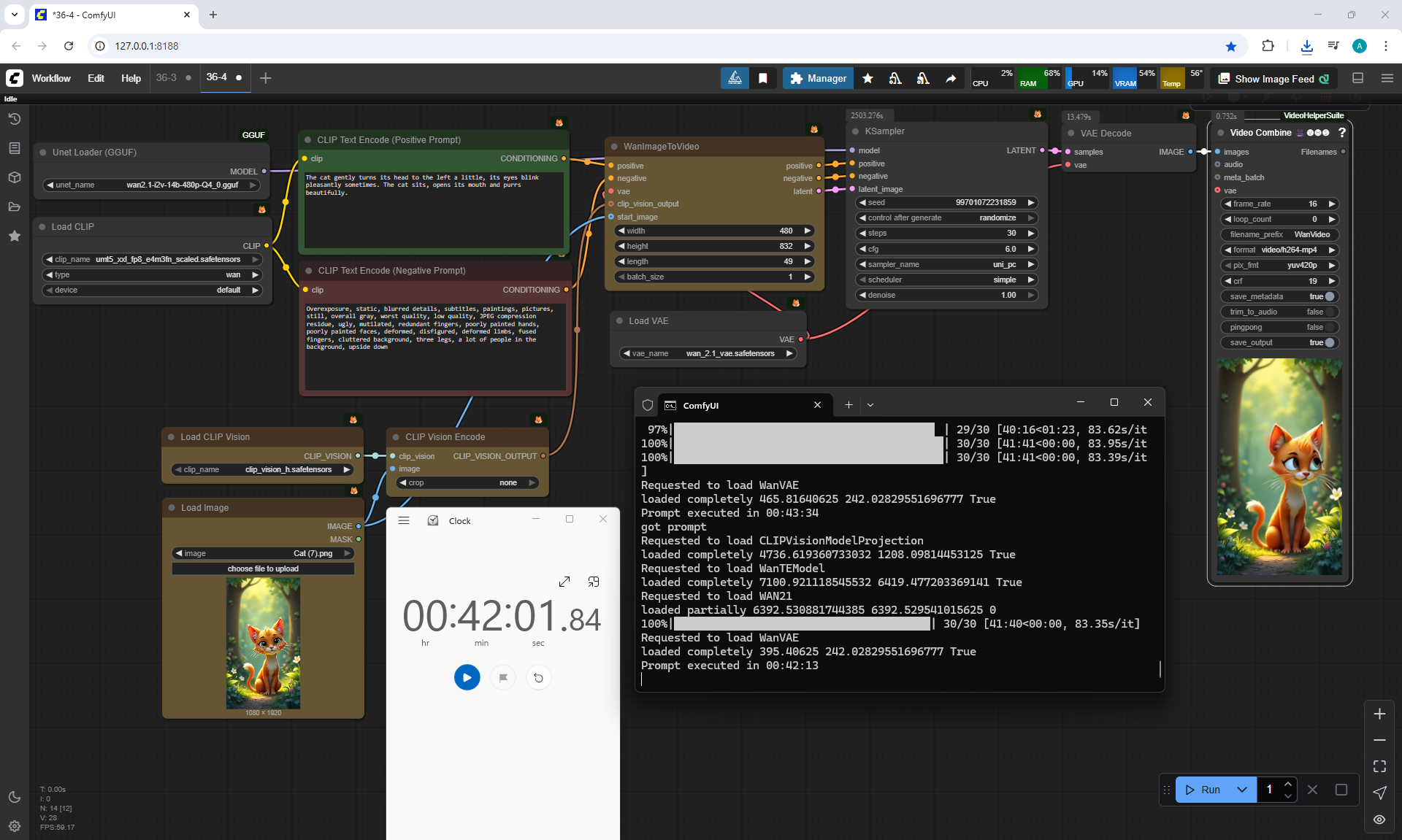
ComfyUI Tutorial Series Ep 40: TeaCache – Speed Up Your Workflows with Smart Caching
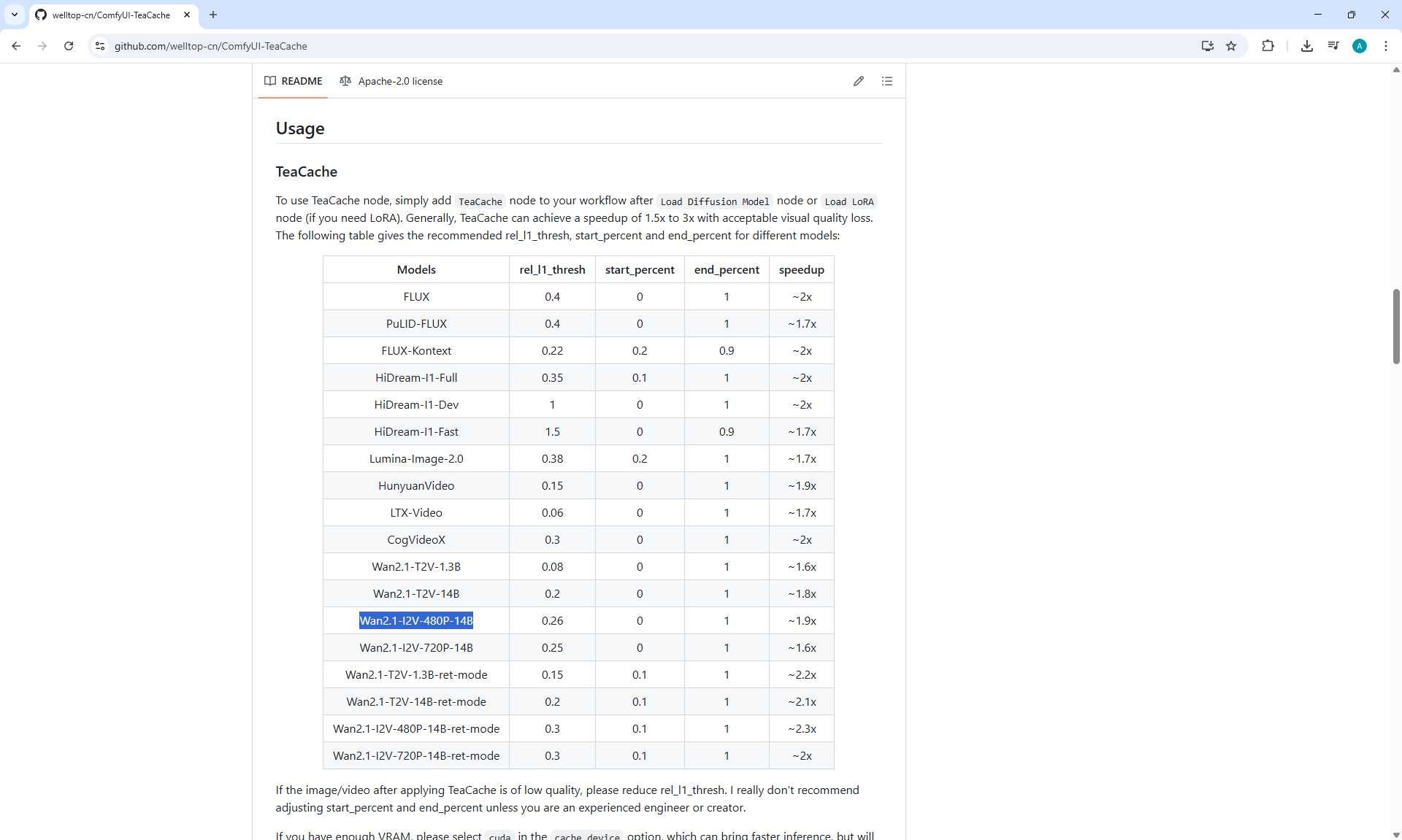
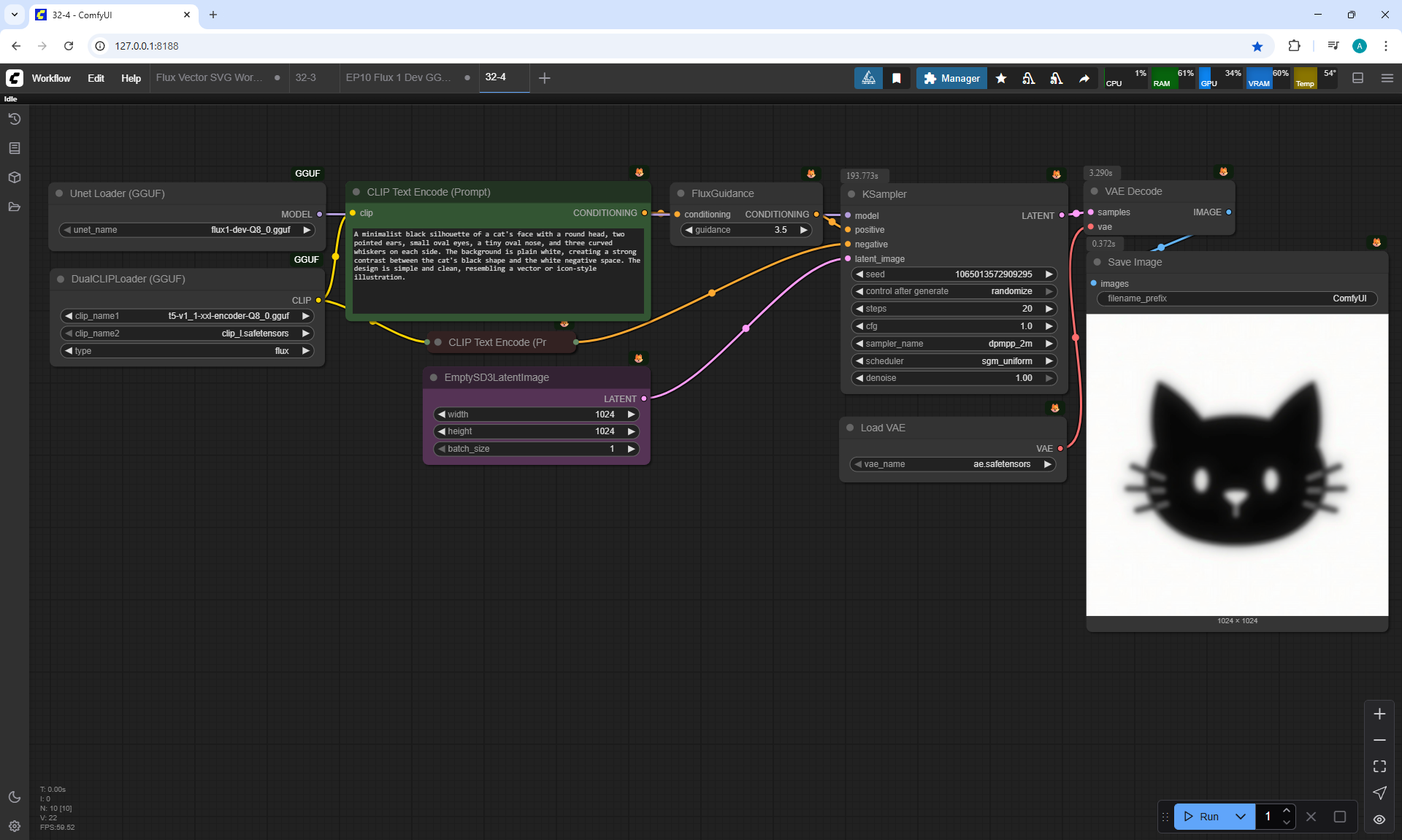
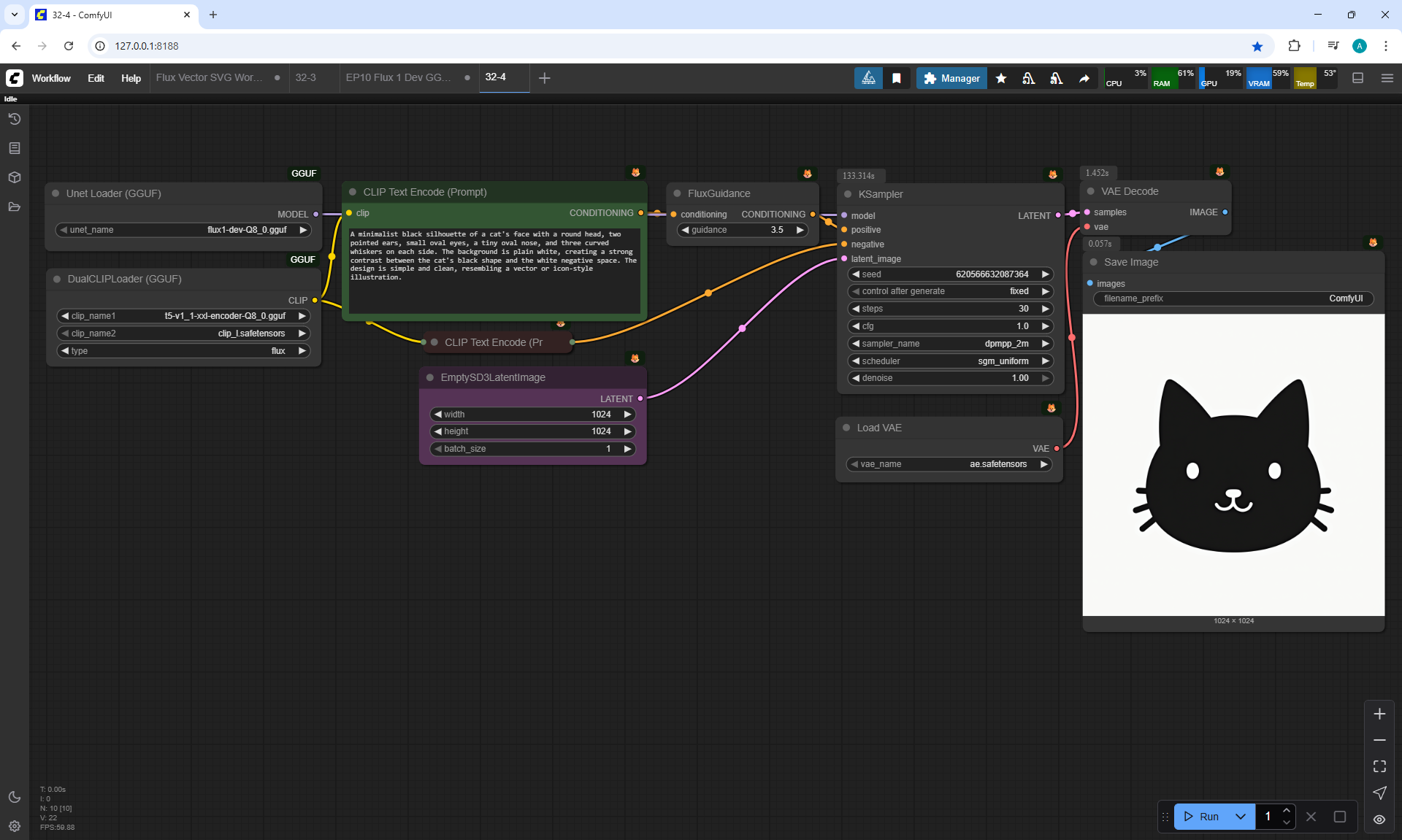
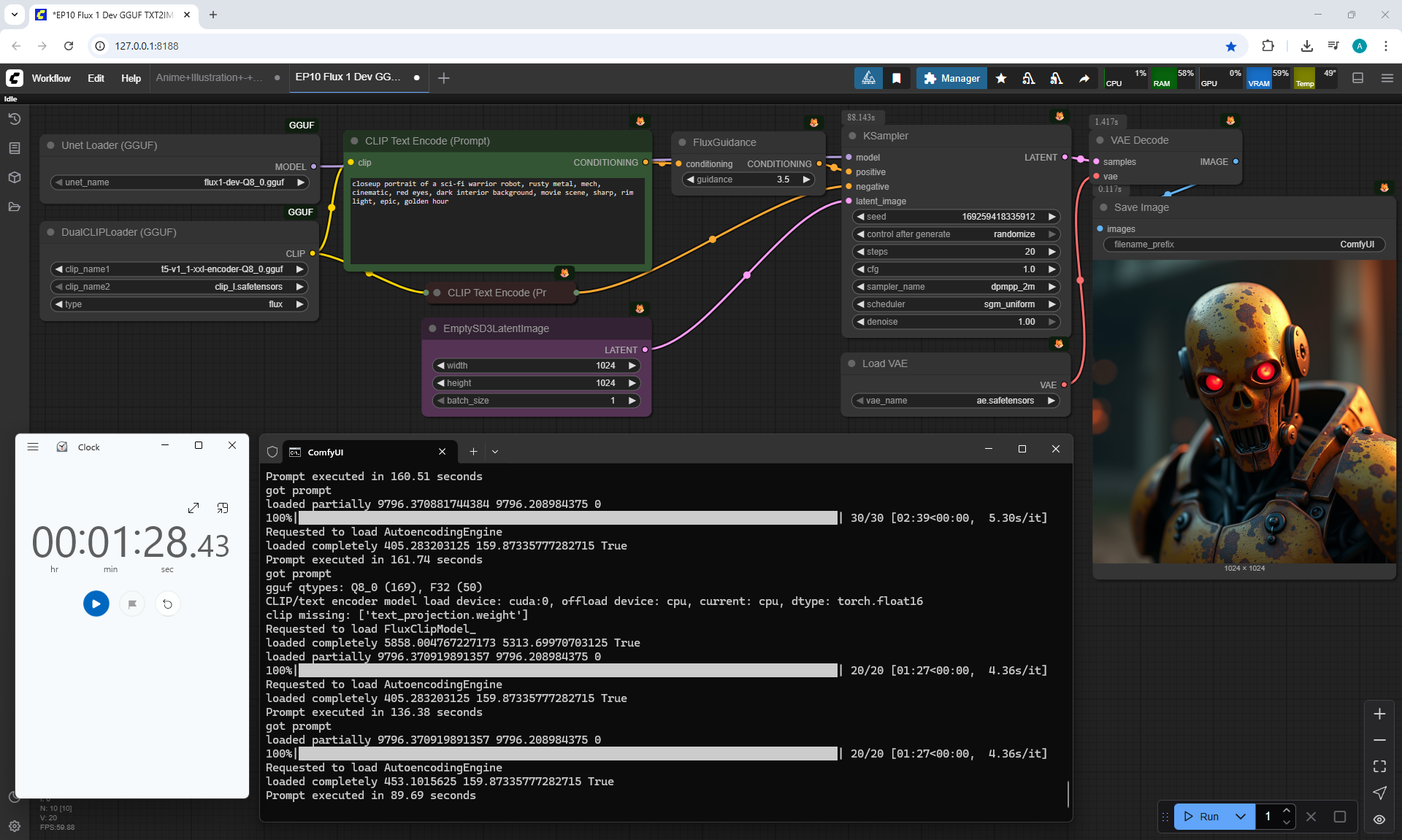
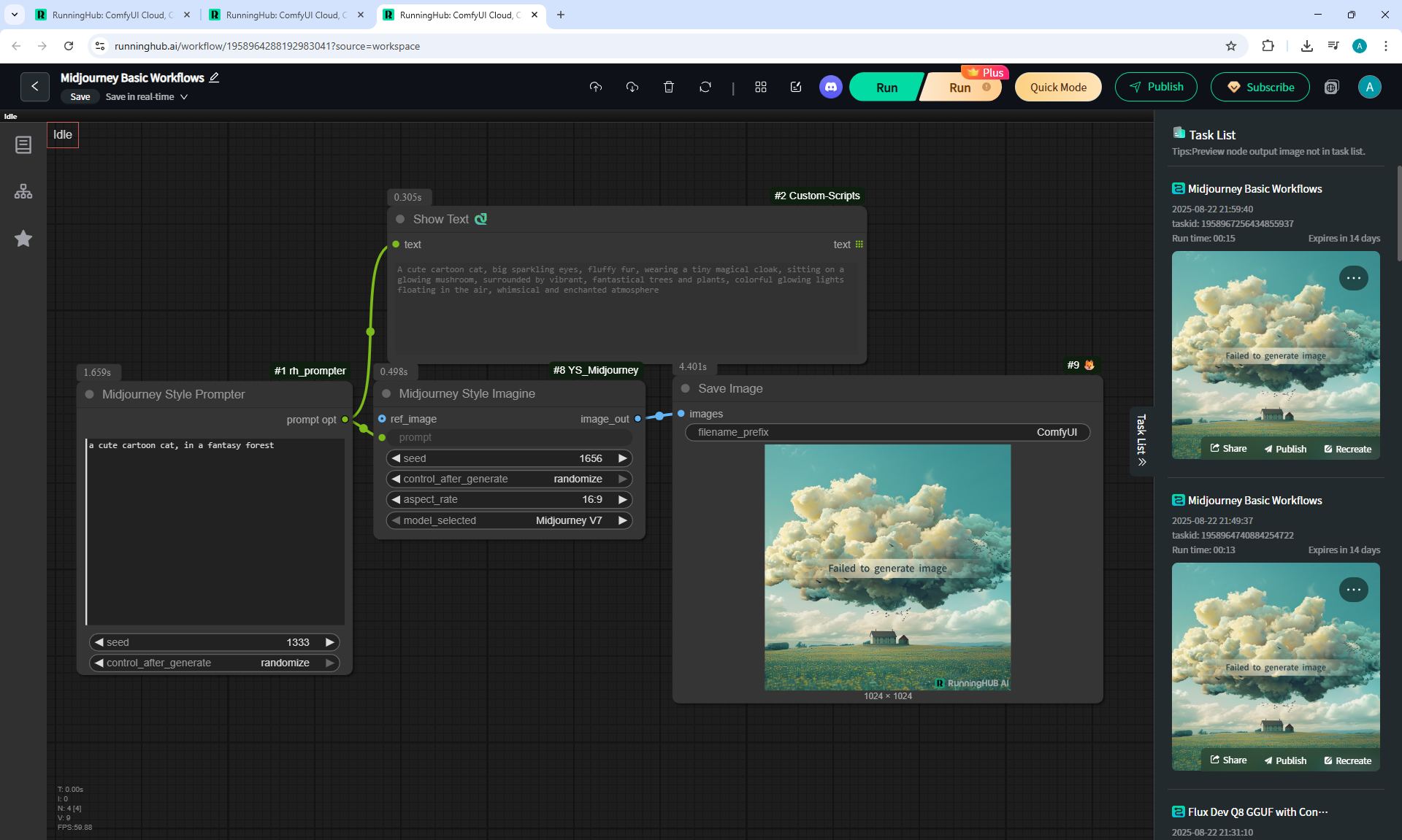
In this lesson, the author talked about the TeaCache node, which allows you to significantly accelerate video generation on Wan2.1. This node can also be used to generate graphics. The results differ slightly with the same seed, but the generation speed is higher.




In these images with a cat, there are options with two identical seeds without the TeaCashe node and with it.
The generation speed without the TeaCashe node 1024x1024 for me is 82 seconds with the TeaCashe node in 48 seconds.
The differences in the image are insignificant. This is generation on a computer, in the cloud it will be faster and also with the TeaCashe node faster.
In the last episode, the author considered 6 LoRa animation effects, but by link Wan2.1 14B 480p I2V LoRAs there are 49 models.
In this tutorial I did a lot of testing with video generation on Wan2.1 14B 480p I2V with this TeaCache node and with other LoRa.
I decided to test how else LoRa works with the kiss and samurai effect.









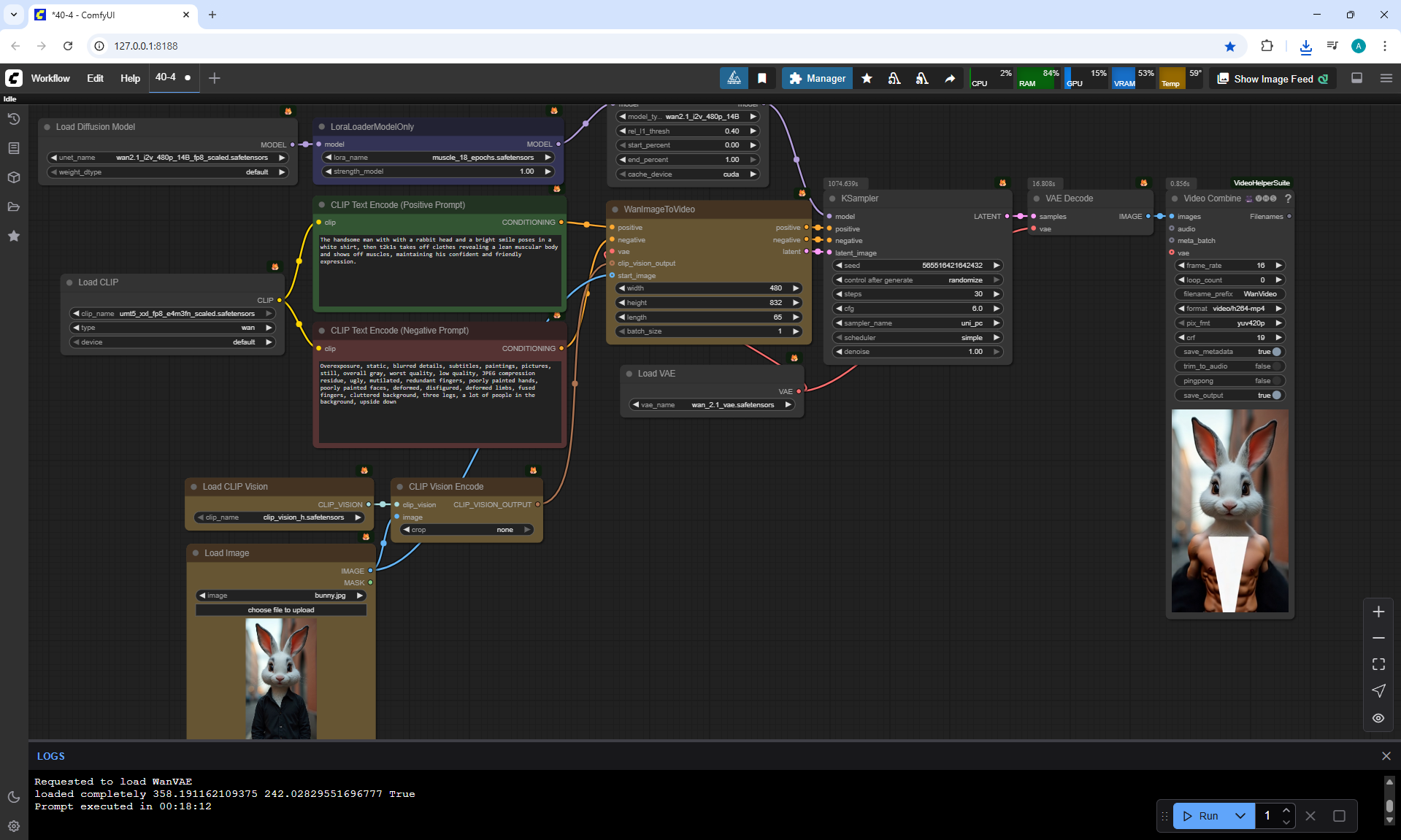
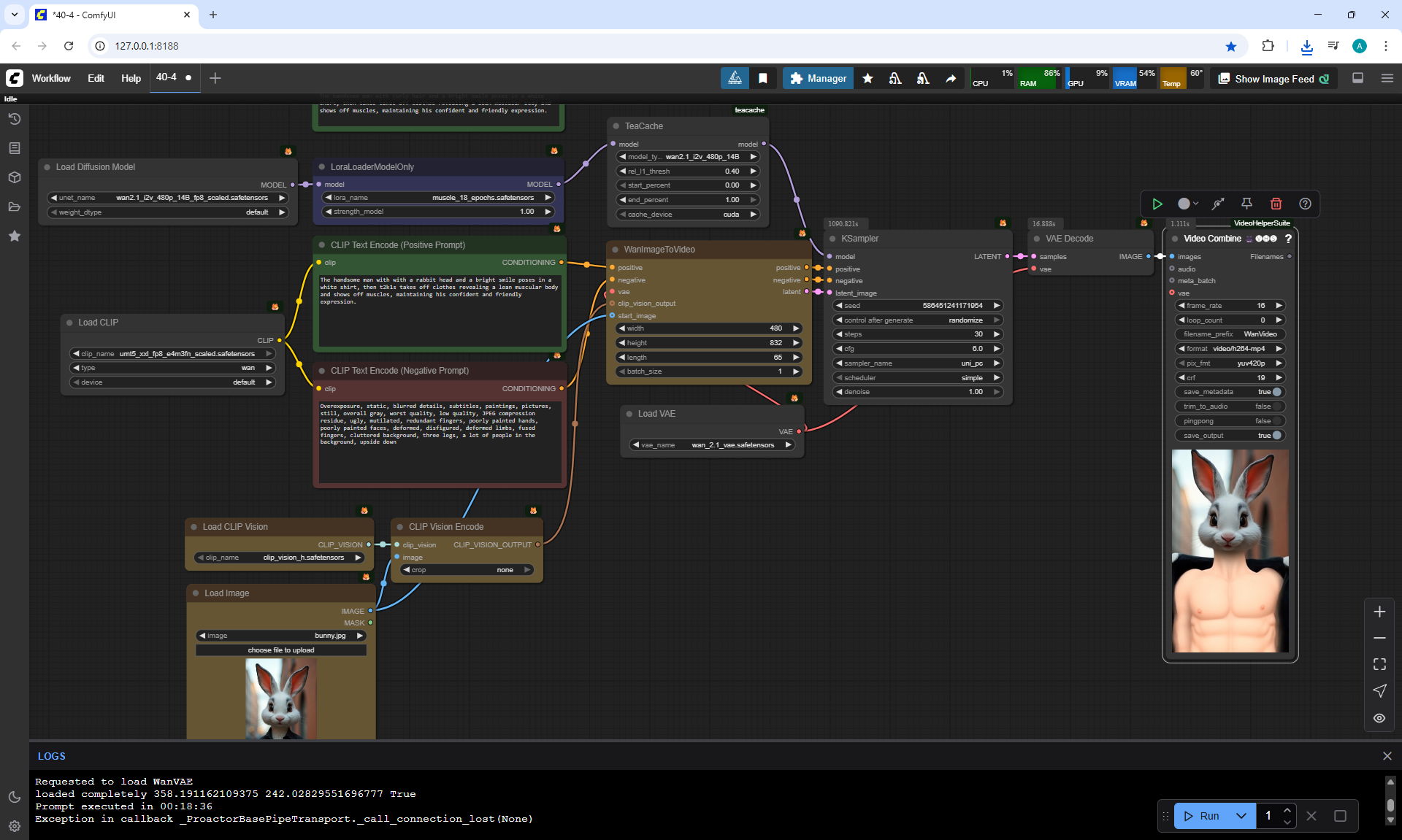
To correctly generate the rabbit's muscle display, as the author did, I made many attempts. Often the rabbit's head was changed to a human head, the rabbit's fur on its belly was removed like a T-shirt. For a long time it did not work out that the head remained from the rabbit and a beautiful muscular body appeared, although this was prescribed in the prompt. The last option is successful.














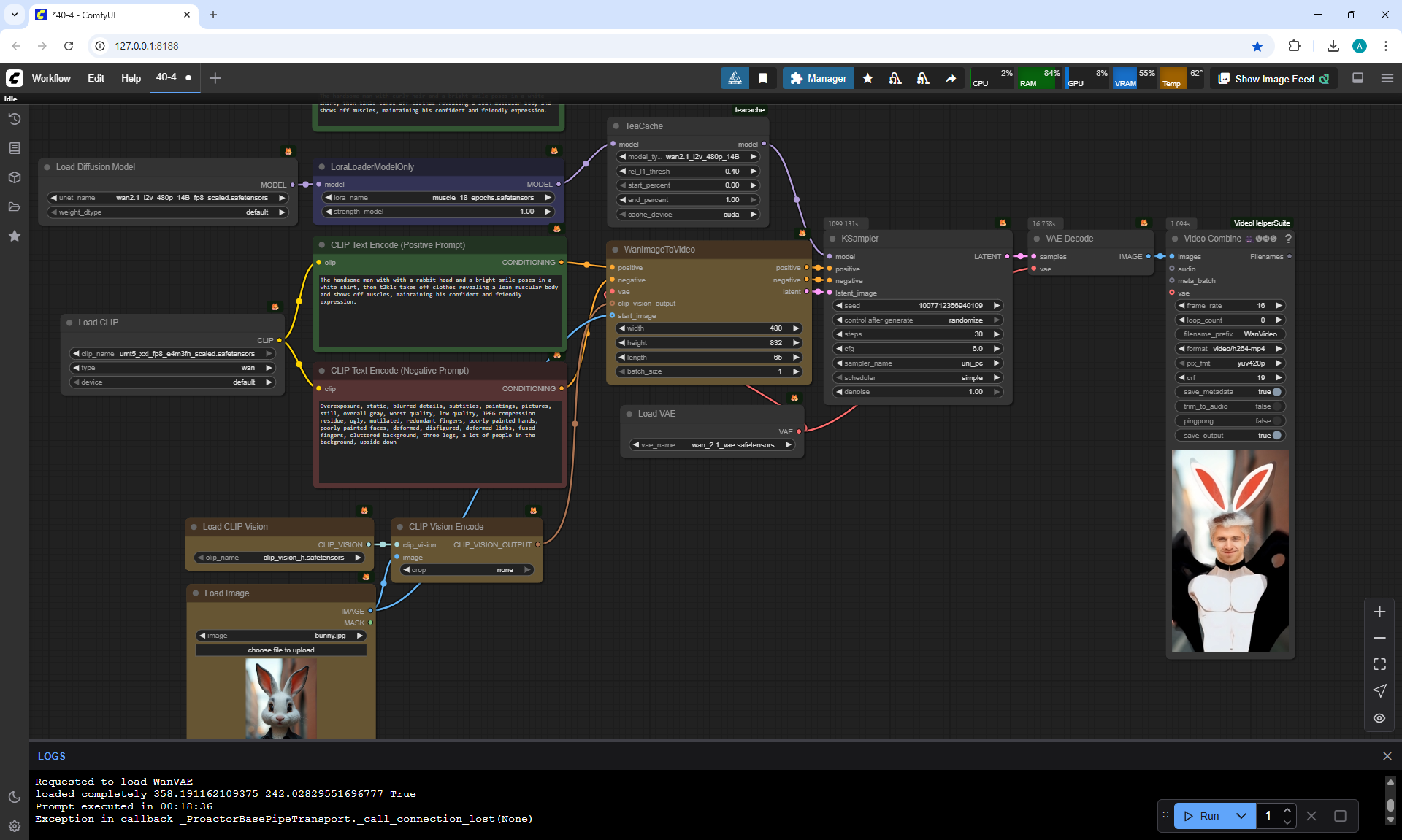
I tried to generate a video of the goat being twisted and squeezed with fingers, but there were many unsuccessful attempts. Extra fingers appeared, the goat was dangling, blurred, there were various inappropriate defects. For the bunny in the last lesson, a successful option turned out, for the goat it did not work.















The goat's 360° rotation was generated with glitches.
The prompt stated that there was only one turn throughout the entire animation.
But the rotation was 180°, so 2-3 times instead of one.
There were situations when the camera started to go up and shoot the rabbit from a different angle, although the camera should not move in the prompt.
There were options when, instead of the goat's rotation, the camera rotated around it many times.
There were options when the goat started to spin on its own, rose on its hind legs, there were cases when the goat had additional blurred body parts during the rotation, more legs, then disappeared.
There were cases when the goat rotates in one direction correctly, and then suddenly the reverse rotation begins and various glitches occur. It happens that the animation is almost successful and some small glitch or the animation is blurry.
You generate a new version, and there the goat starts jumping a lot, the camera spins, something uncontrollable happens.
The last options turned out to be successful. With the same prompt, you can get one successful option or many unsuccessful ones.
Perhaps it depends on the image.
















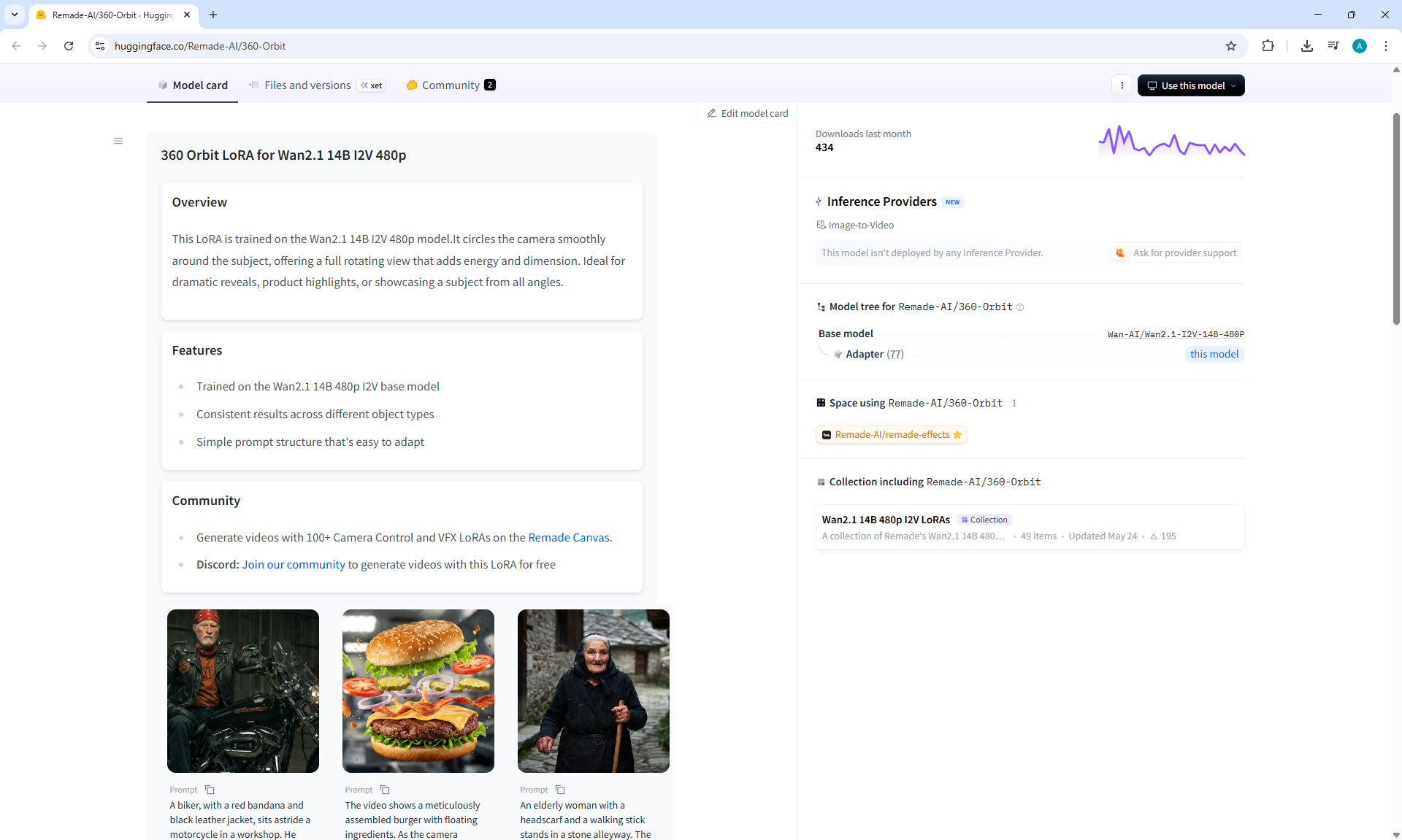
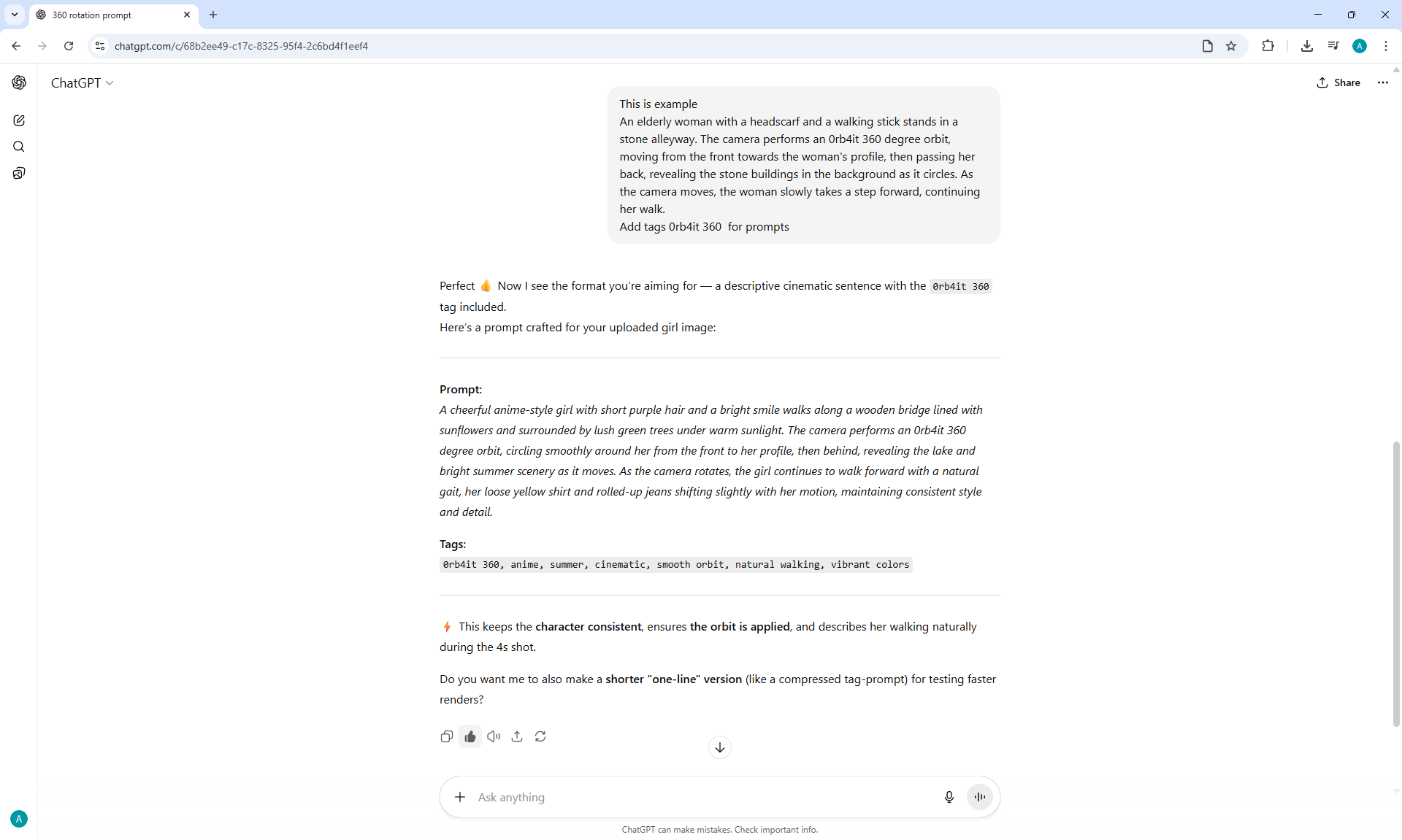
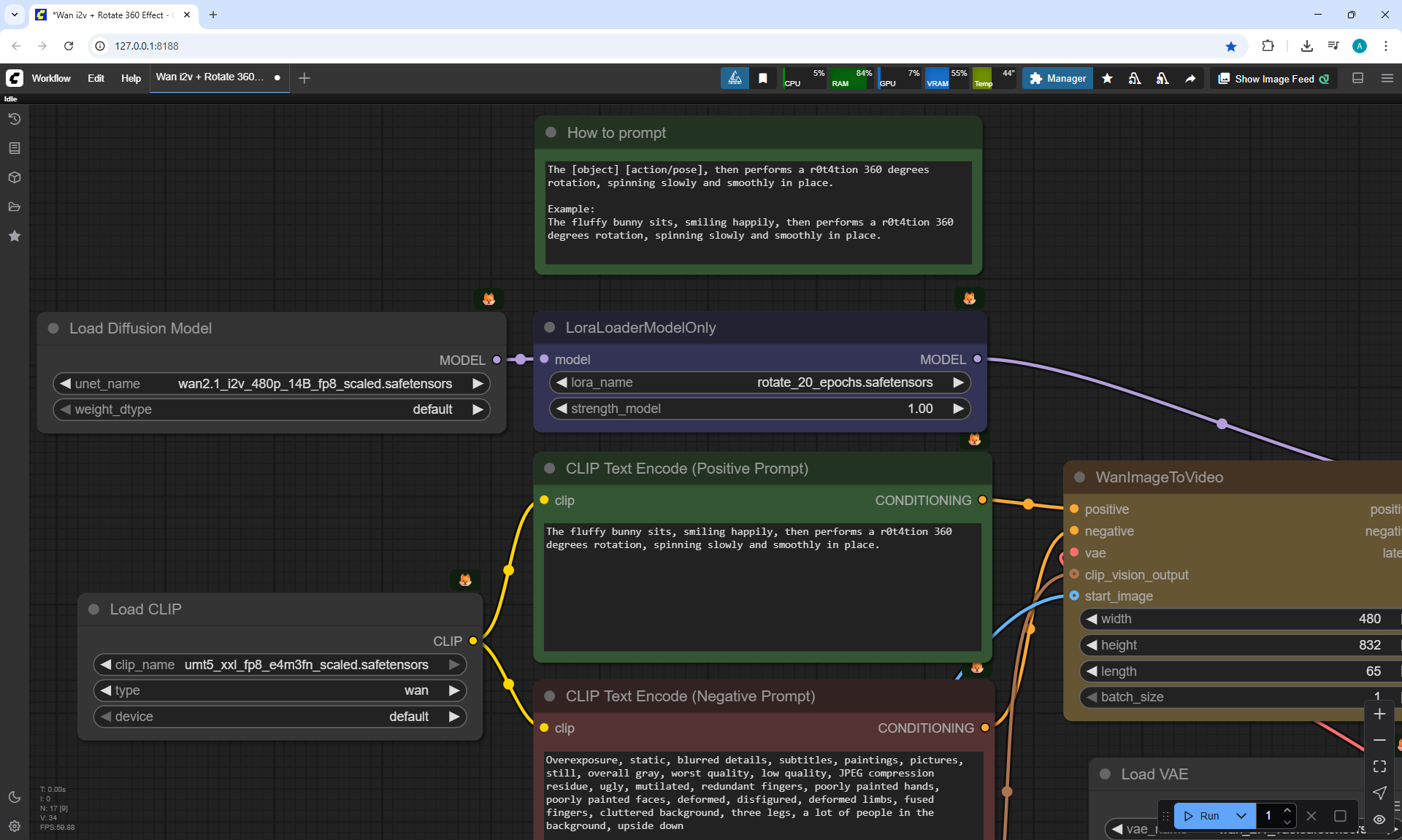
I generated a 360° rotation of the girl using Lora from the list:
Wan2.1 14B 480p I2V LoRAs
360 Degree Rotation Effect LoRA for Wan2.1 14B I2V 480p and
360 Orbit LoRA for Wan2.1 14B I2V 480p, tested both.
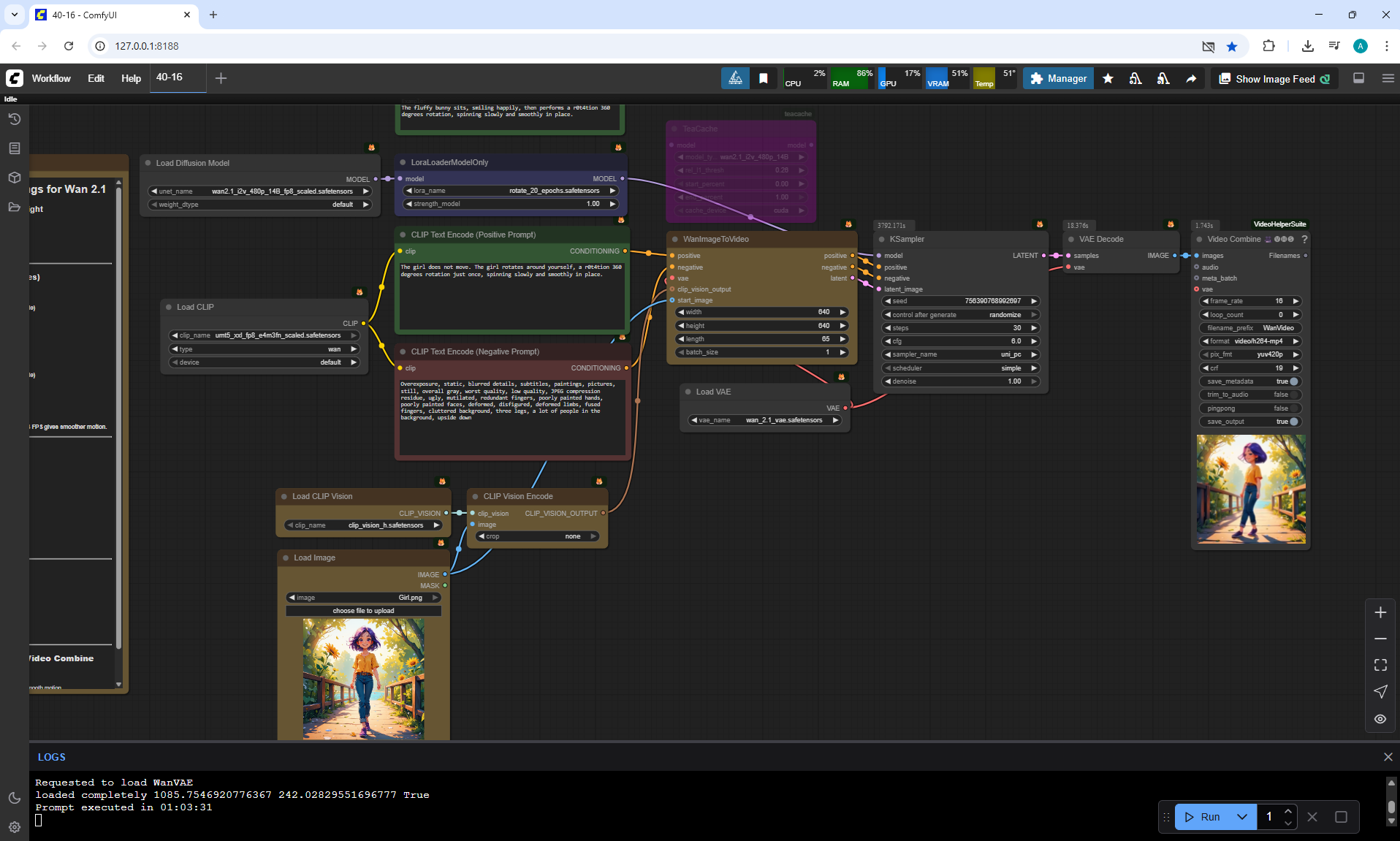
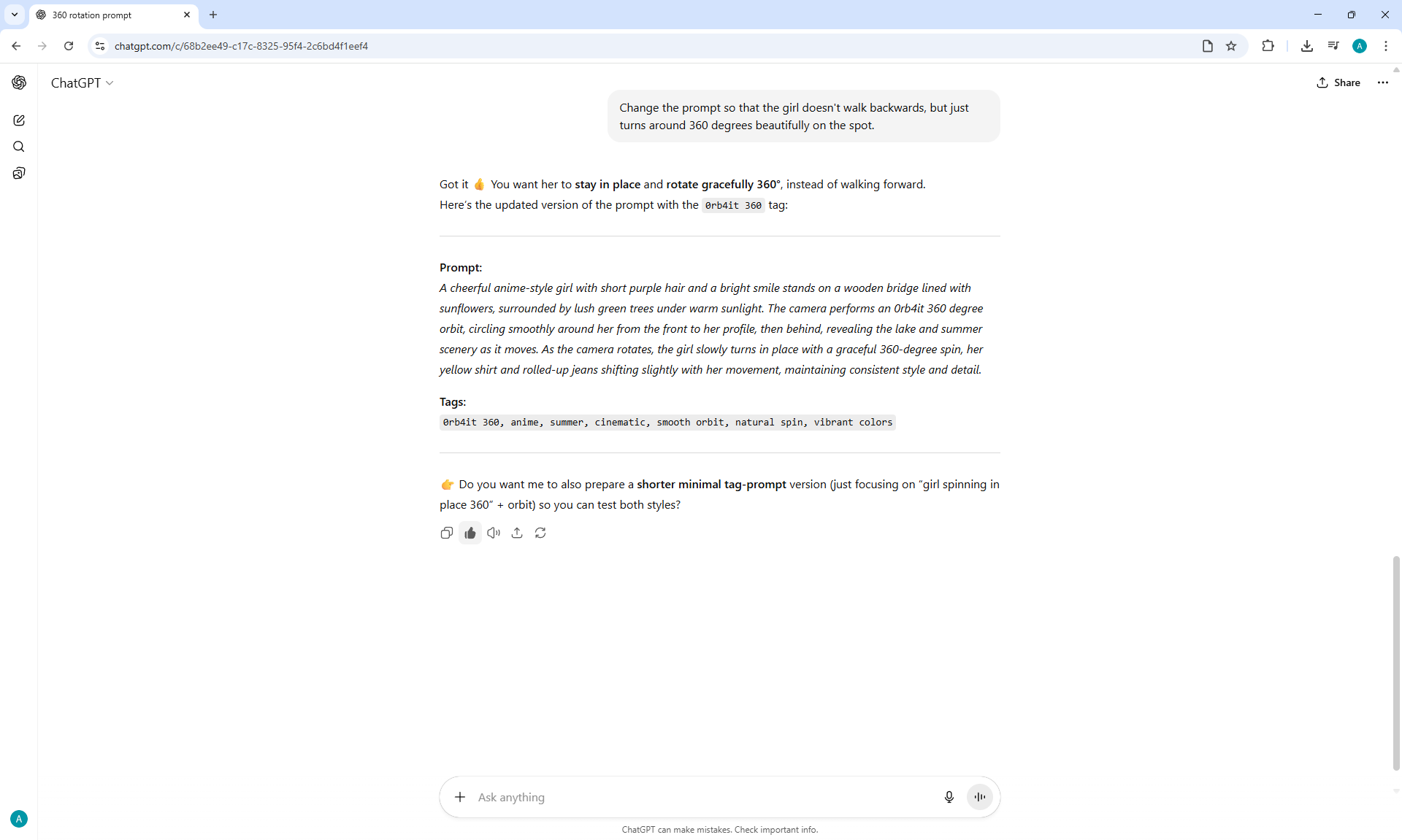
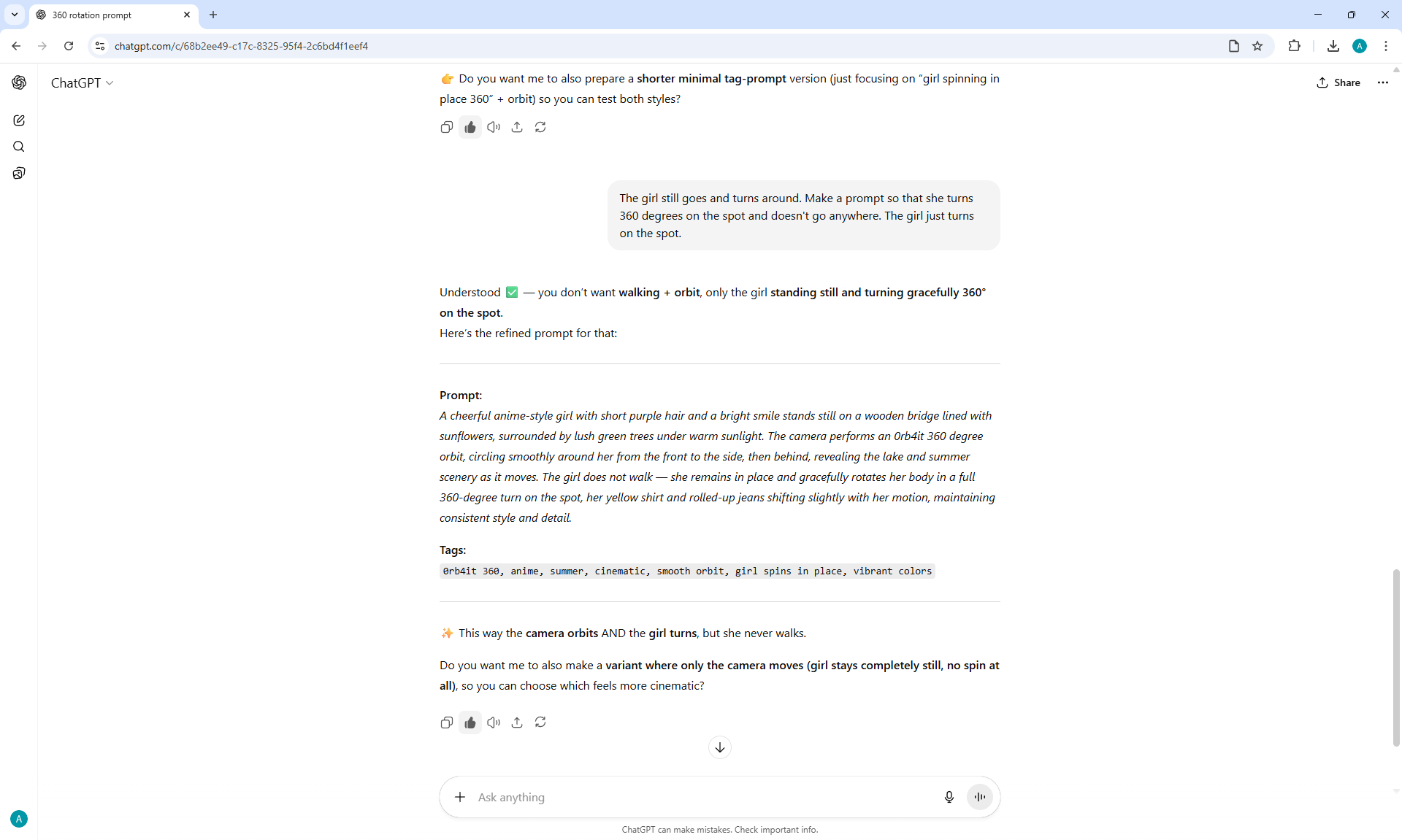
It is not clear why, but instead of the girl turning 360° on the node 360 Orbit LoRA for Wan2.1 14B I2V 480p at the prompt:
"A cheerful anime-style girl with short purple hair and a bright smile stands still on a wooden bridge lined with sunflowers, surrounded by lush green trees under warm sunlight. The camera performs an 0rb4it 360 degree orbit, circling smoothly around her from the front to the side, then behind, revealing the lake and summer scenery as it moves. The girl does not walk — she remains in place and gracefully rotates her body in a full 360-degree turn on the spot, her yellow shirt and rolled-up jeans shifting slightly with her motion, maintaining consistent style and detail."
ComfyUI constantly generates a dance or some kind of action. It's beautiful and dance is suitable for this girl, but there was no dance in the prompt, all the animations are not just rotations, but many animations, then the girl waves her arms and spins, then runs somewhere, then makes 3-5 rotations instead of one, then starts to lean and fall.
A good option
girl's rotation,
but the girl turns many times not just in place, but makes many movements.
It can be seen that during her rotation she is still moving towards the camera and the camera moves away, focusing on her in the frame.
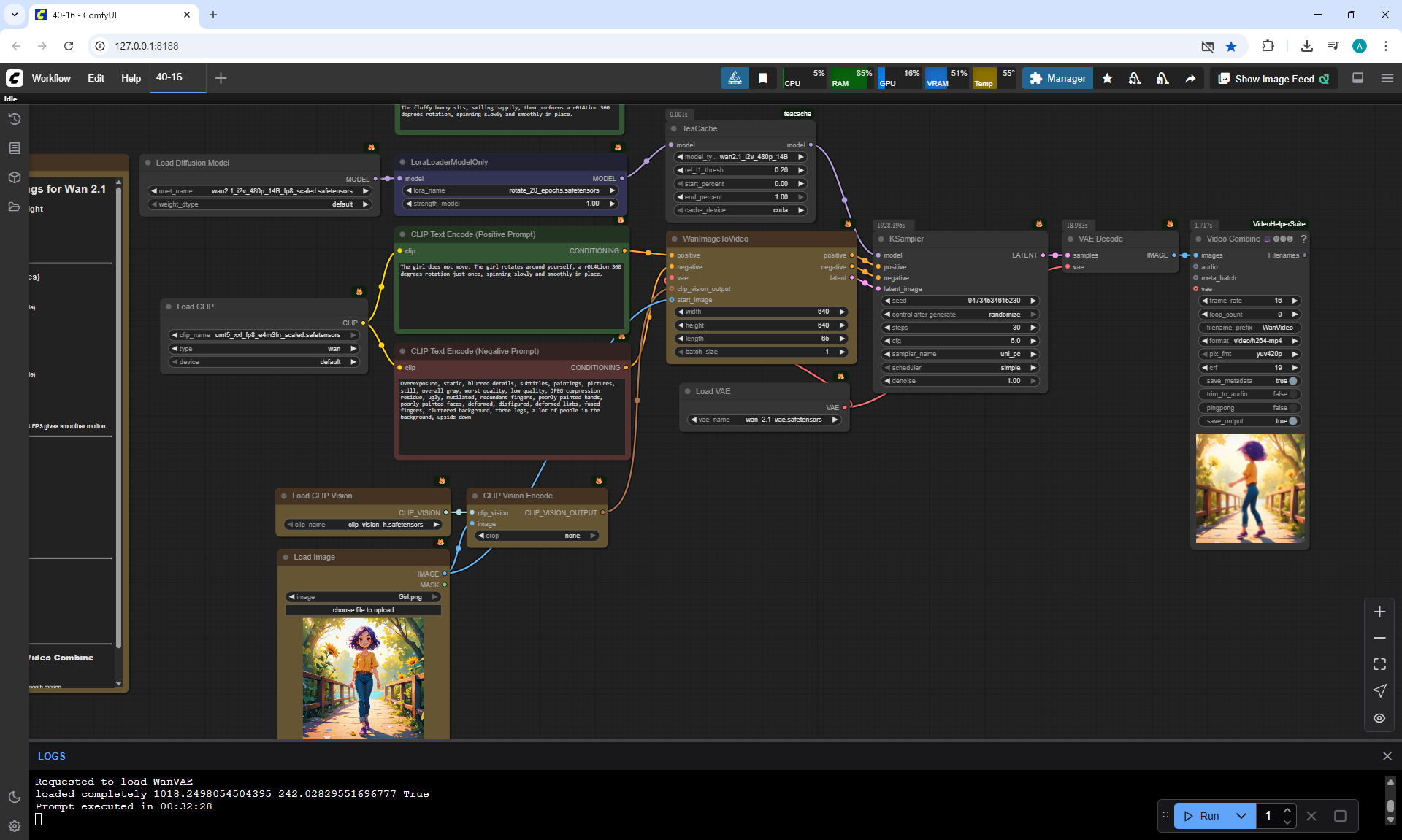
Another option
girl's rotation, like on a spinning disk, but the girl makes two rotations.
Unsuccessful variants of the girl's movement were generated. The girl can run arbitrarily, make smooth movements similar to sliding, but does not want to follow the prompt.





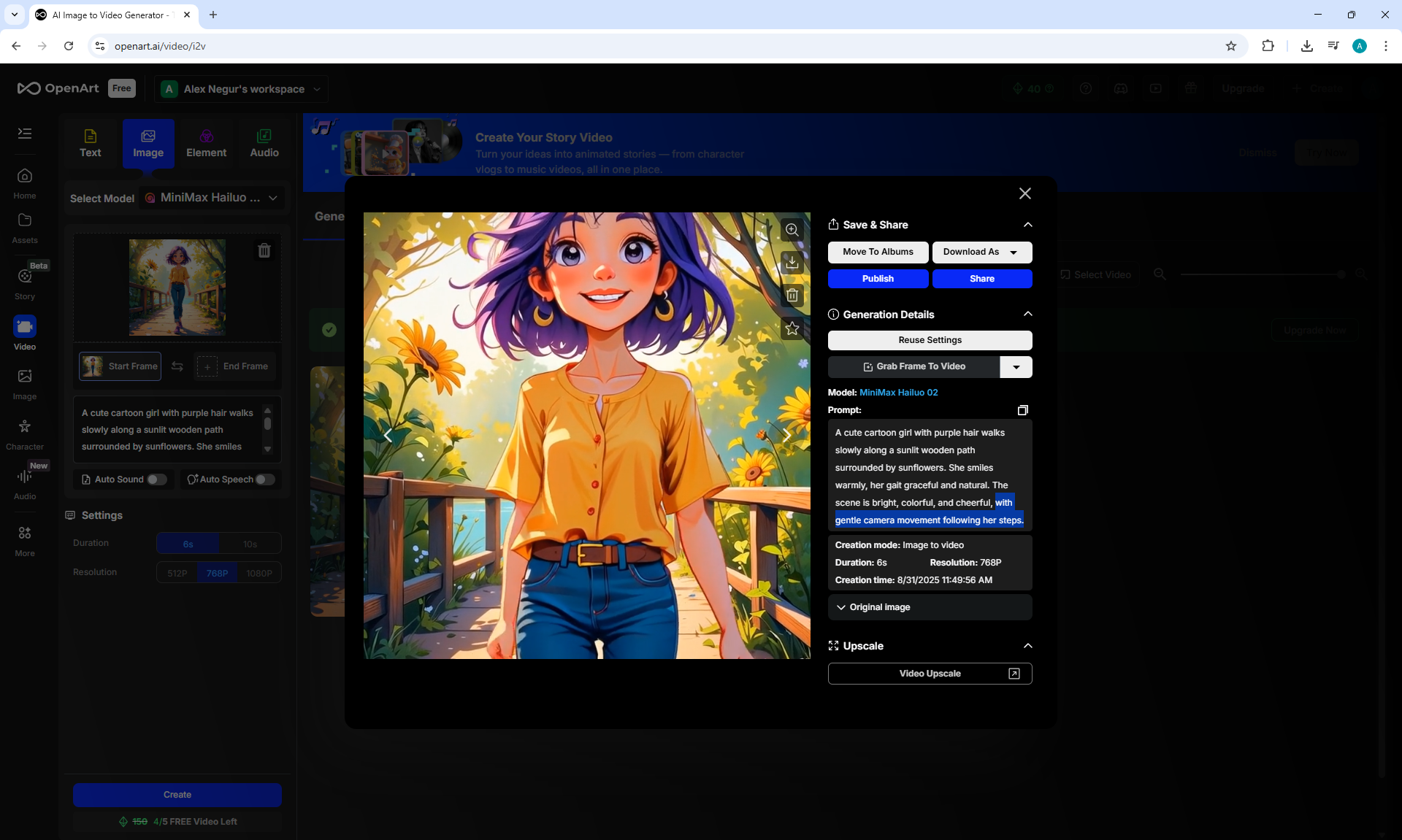
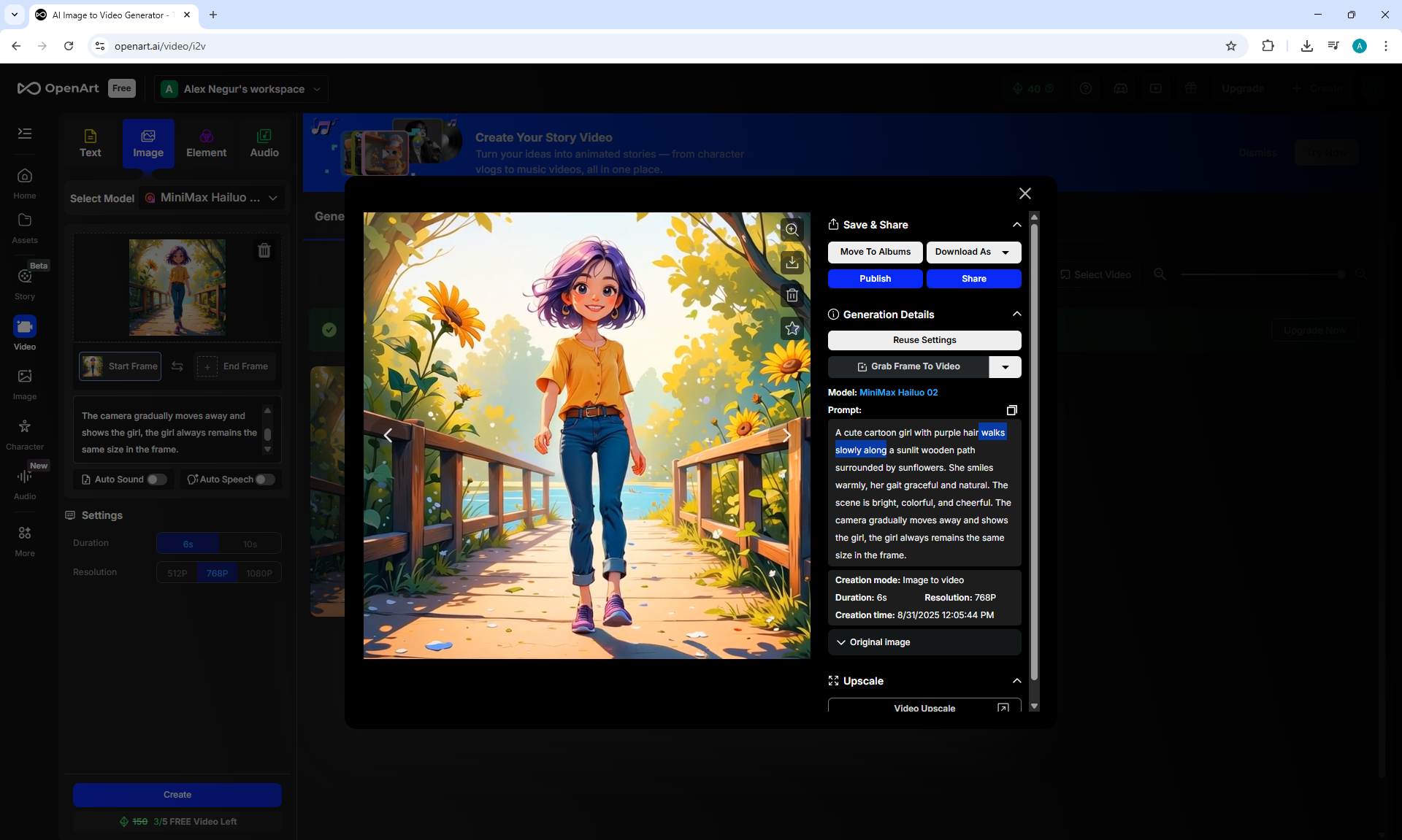
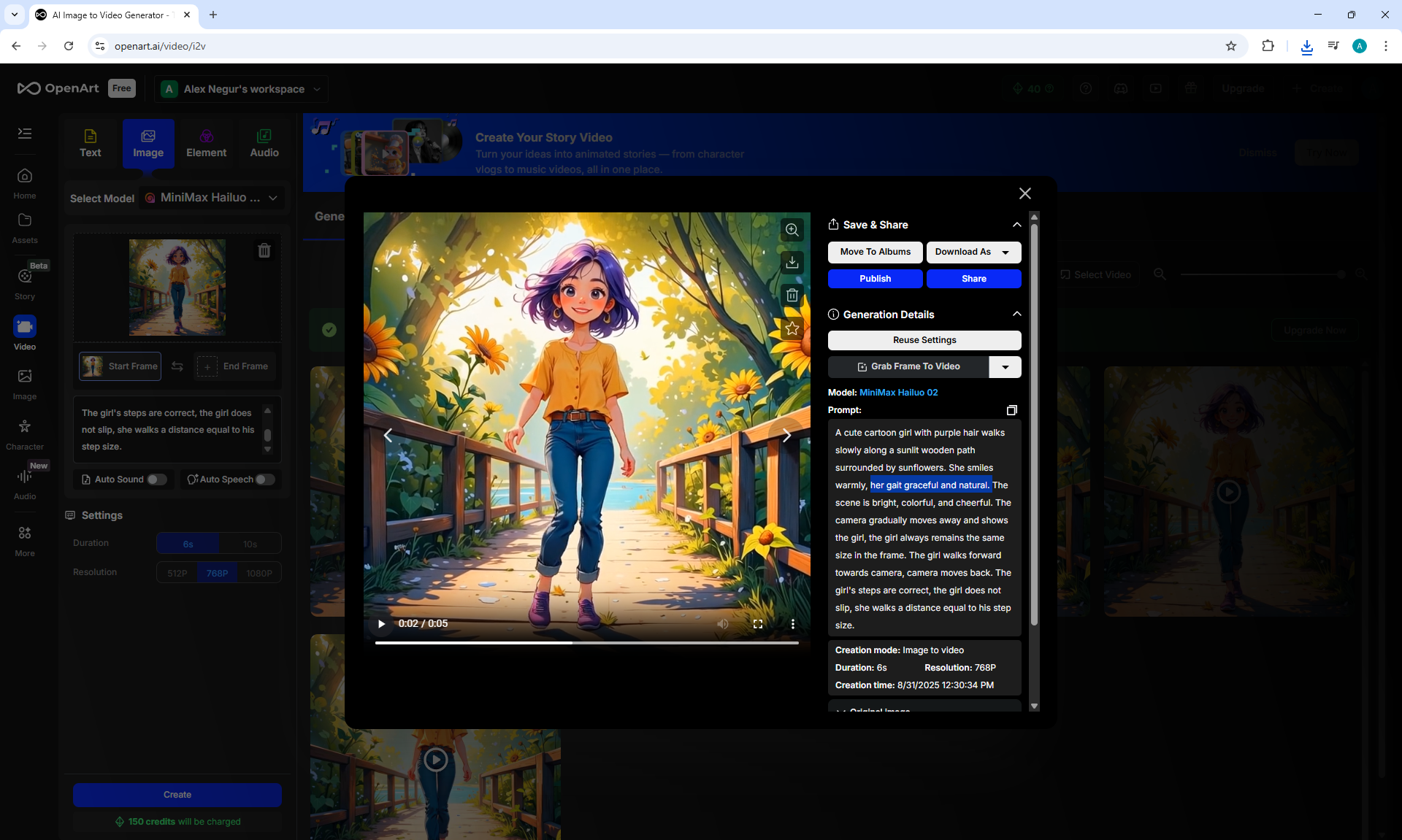
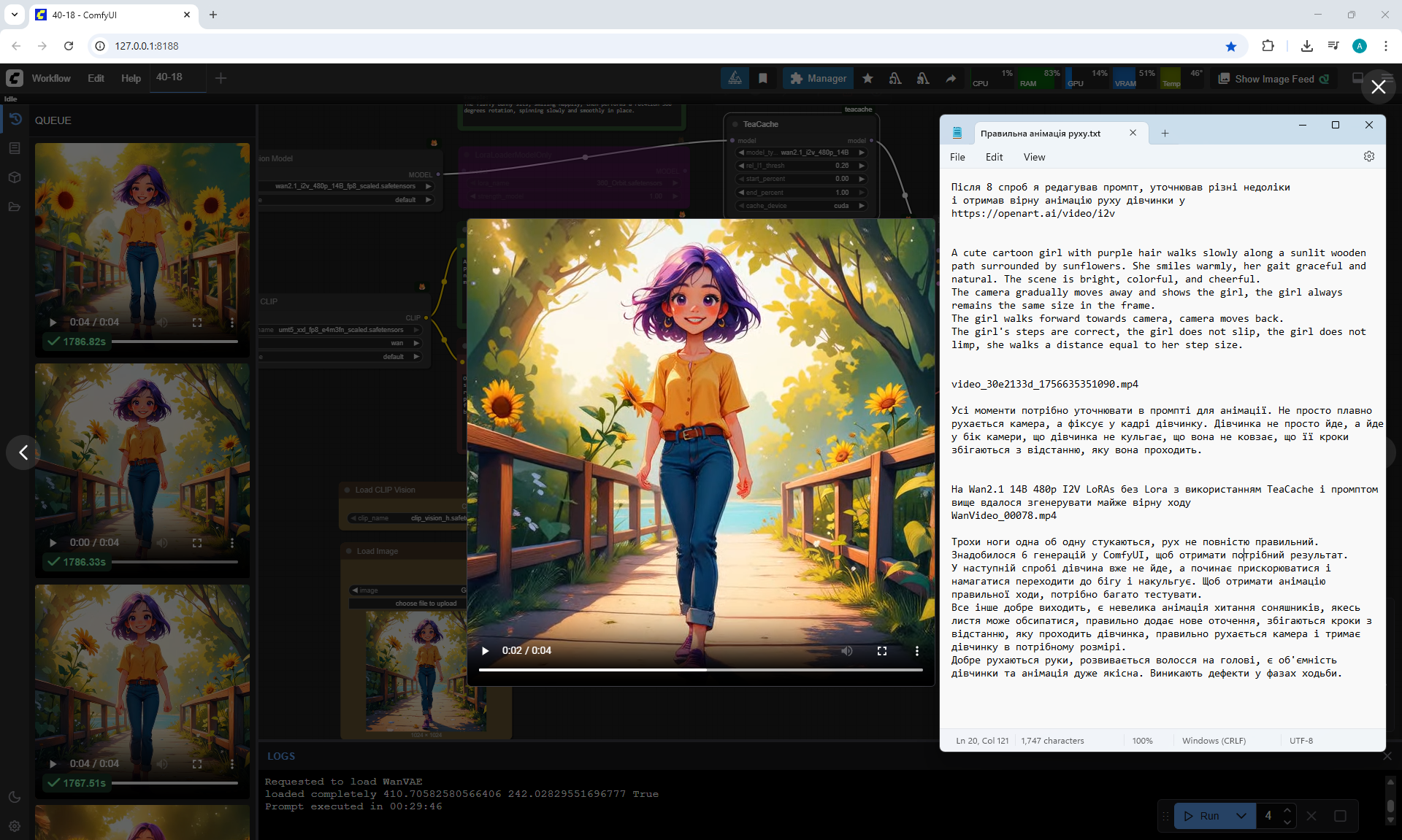
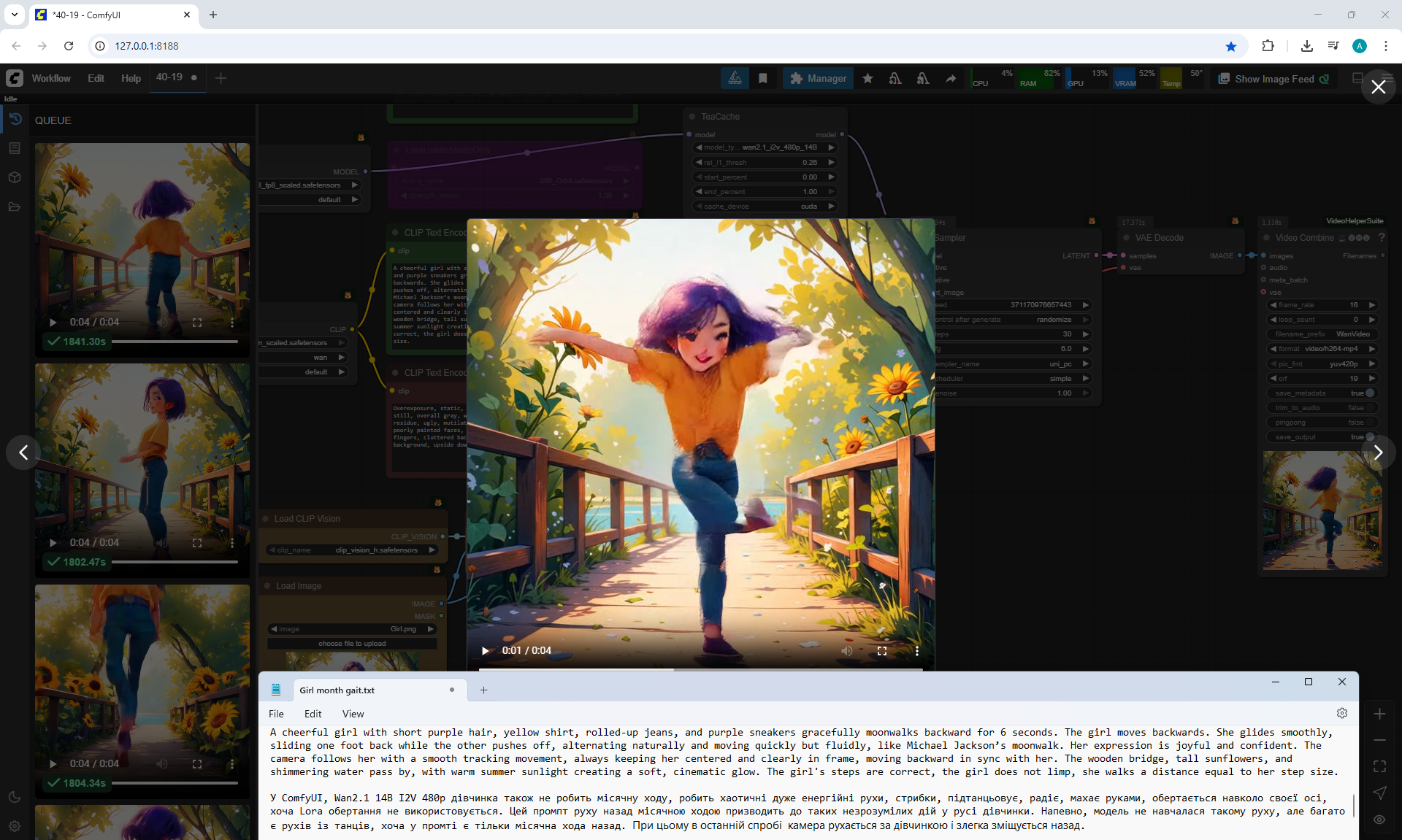
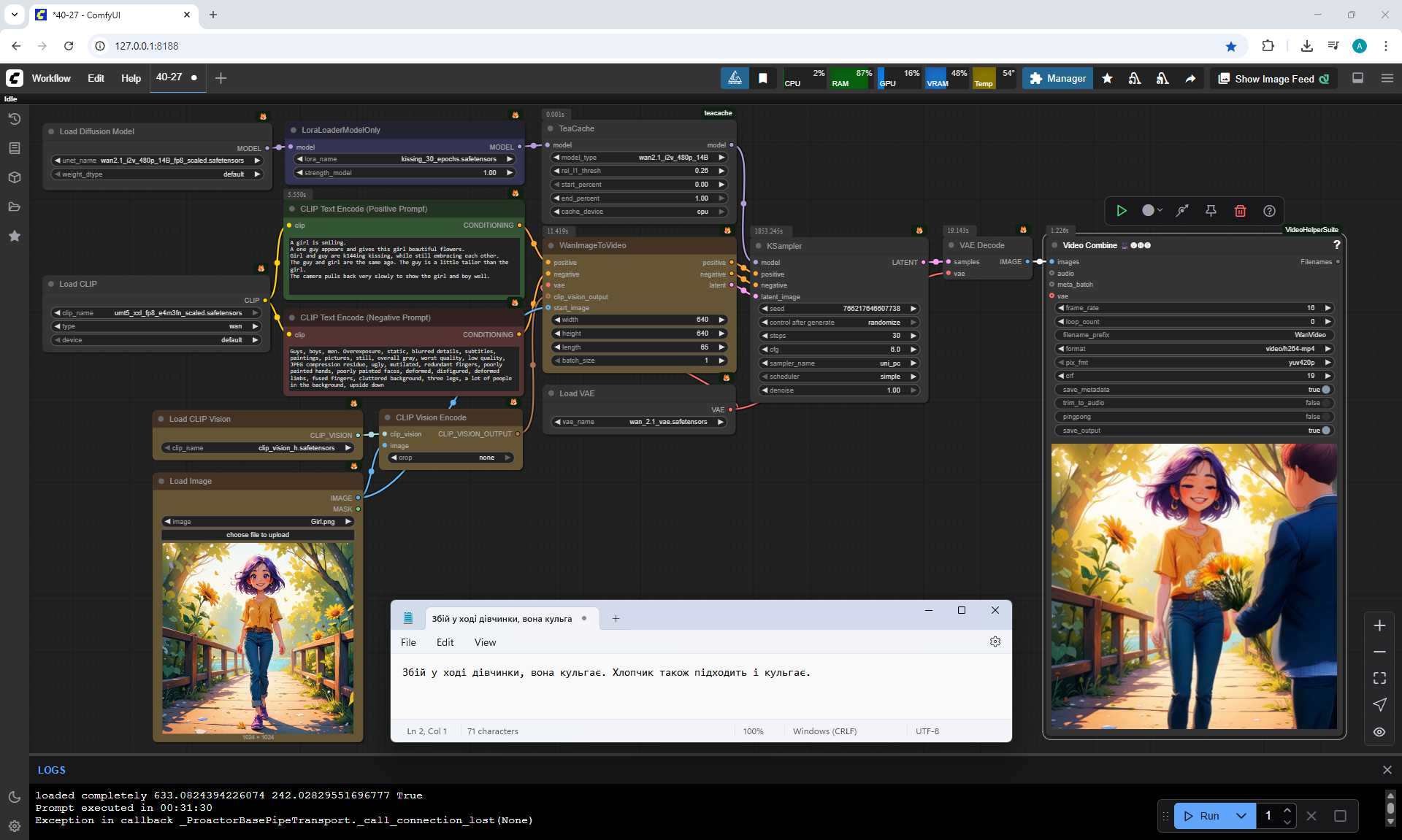
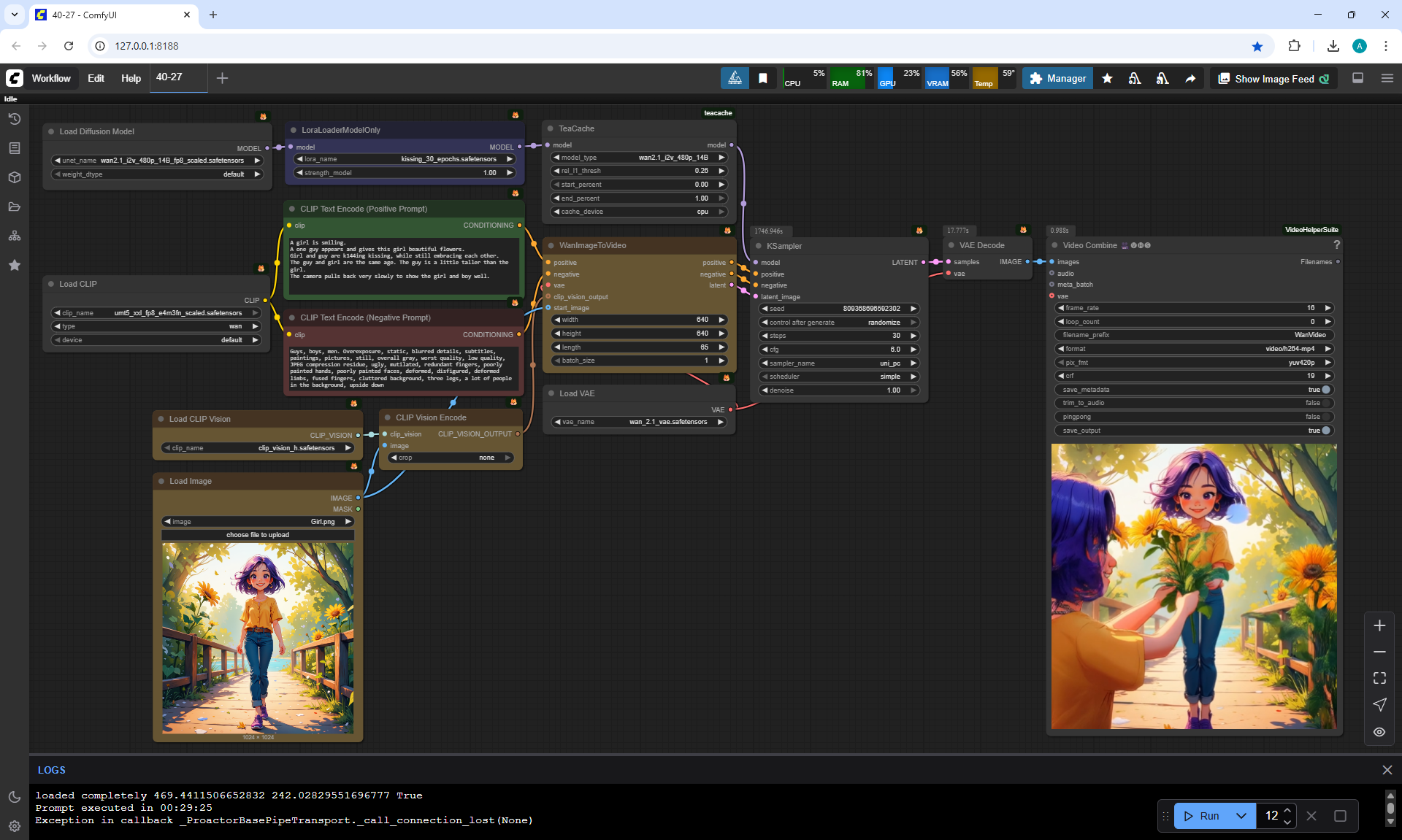
I generated the girl's walk, there were many unsuccessful attempts, edited the prompt, and clarified various shortcomings:
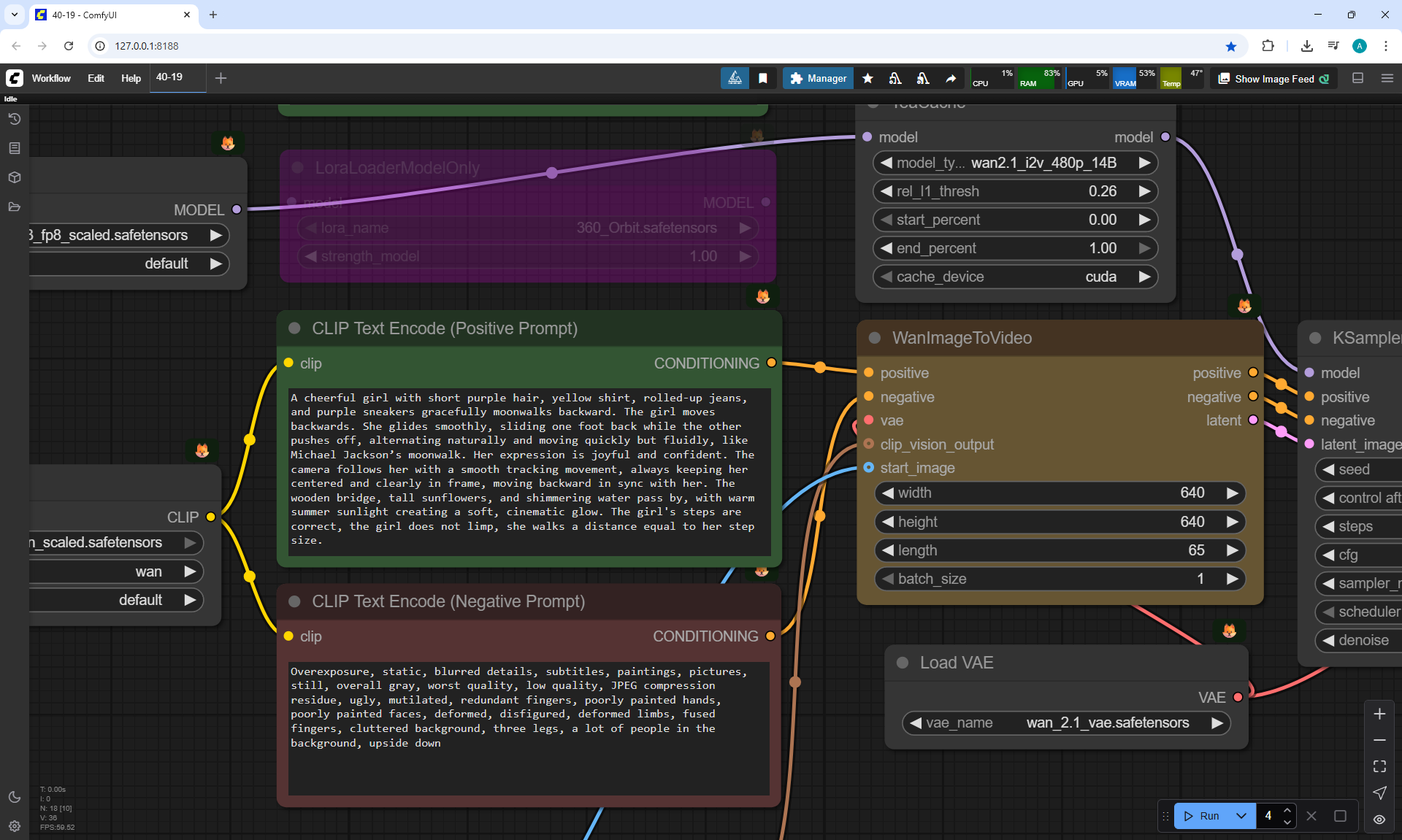
"A cute cartoon girl with purple hair walks slowly along a sunlit wooden path surrounded by sunflowers. She smiles warmly, her gait graceful and natural. The scene is bright, colorful, and cheerful.
The camera gradually moves away and shows the girl, the girl always remains the same size in the frame.
The girl walks forward towards camera, camera moves back.
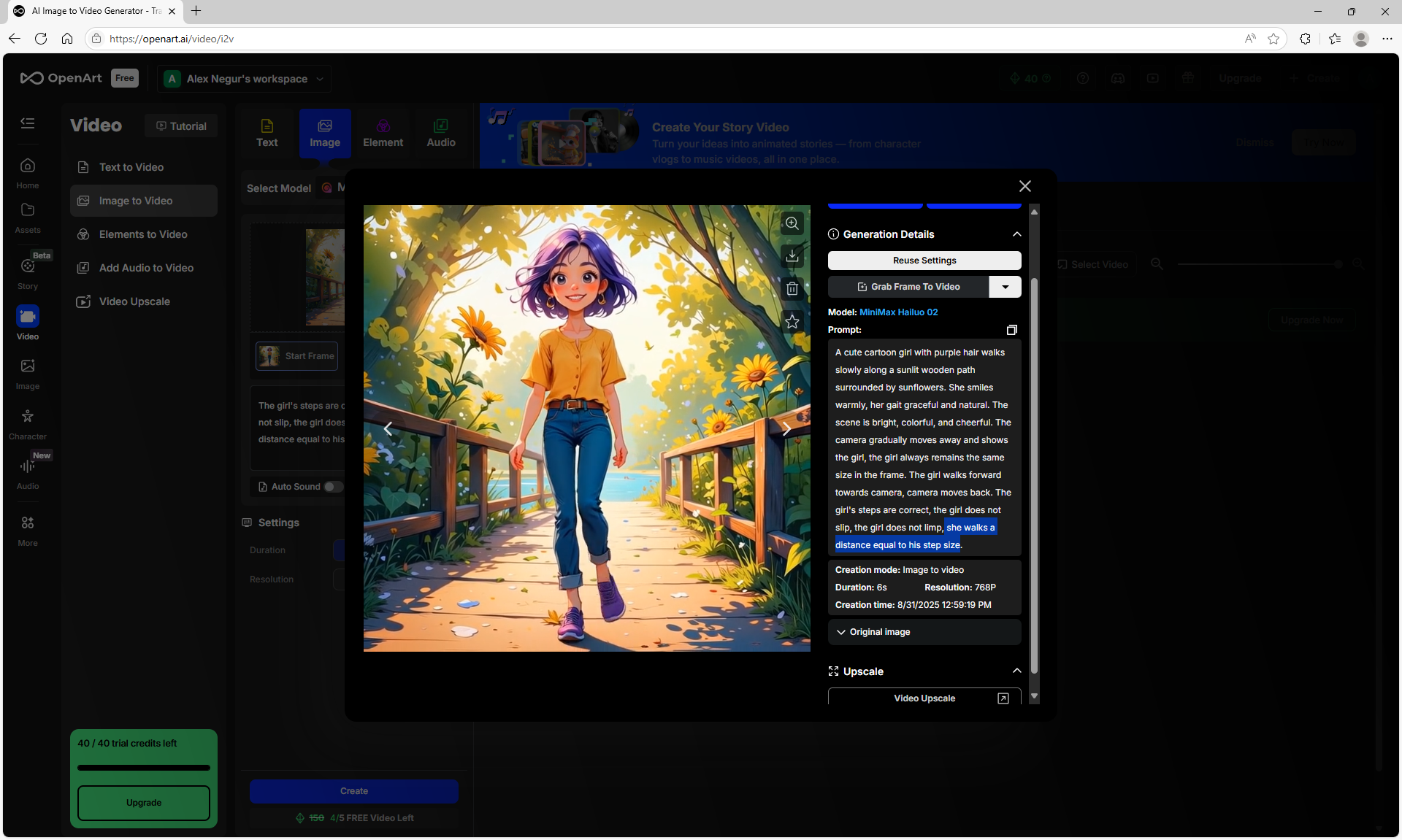
The girl's steps are correct, the girl does not slip, the girl does not limp, she walks a distance equal to her step size."
On Wan2.1 14B 480p I2V LoRAs without Lora using TeaCache and the prompt above managed to generate almost
accurate animation of the girl's movement.
But in the girl's movement, modesty in steps is noticeable, she walks almost without lifting her legs, the gait is not realistic, it looks like mechanical robot movements, people do not walk like that.
The legs knock against each other a little, the movement is not completely correct. It took 6 generations in ComfyUI to get the desired result.
In the next attempt, the girl no longer walks, but starts to accelerate and tries to switch to running and limps. To get the animation of the correct gait, you need to test a lot.
Everything else works well, there is an animation of swaying sunflowers, some leaves can fall, new surroundings are correctly added, the steps match the distance the girl covers, the camera moves correctly and keeps the girl at the right size.
The hands move well, the hair on her head develops, the girl has volume and the animation is very high quality. There are defects in the walking phases.









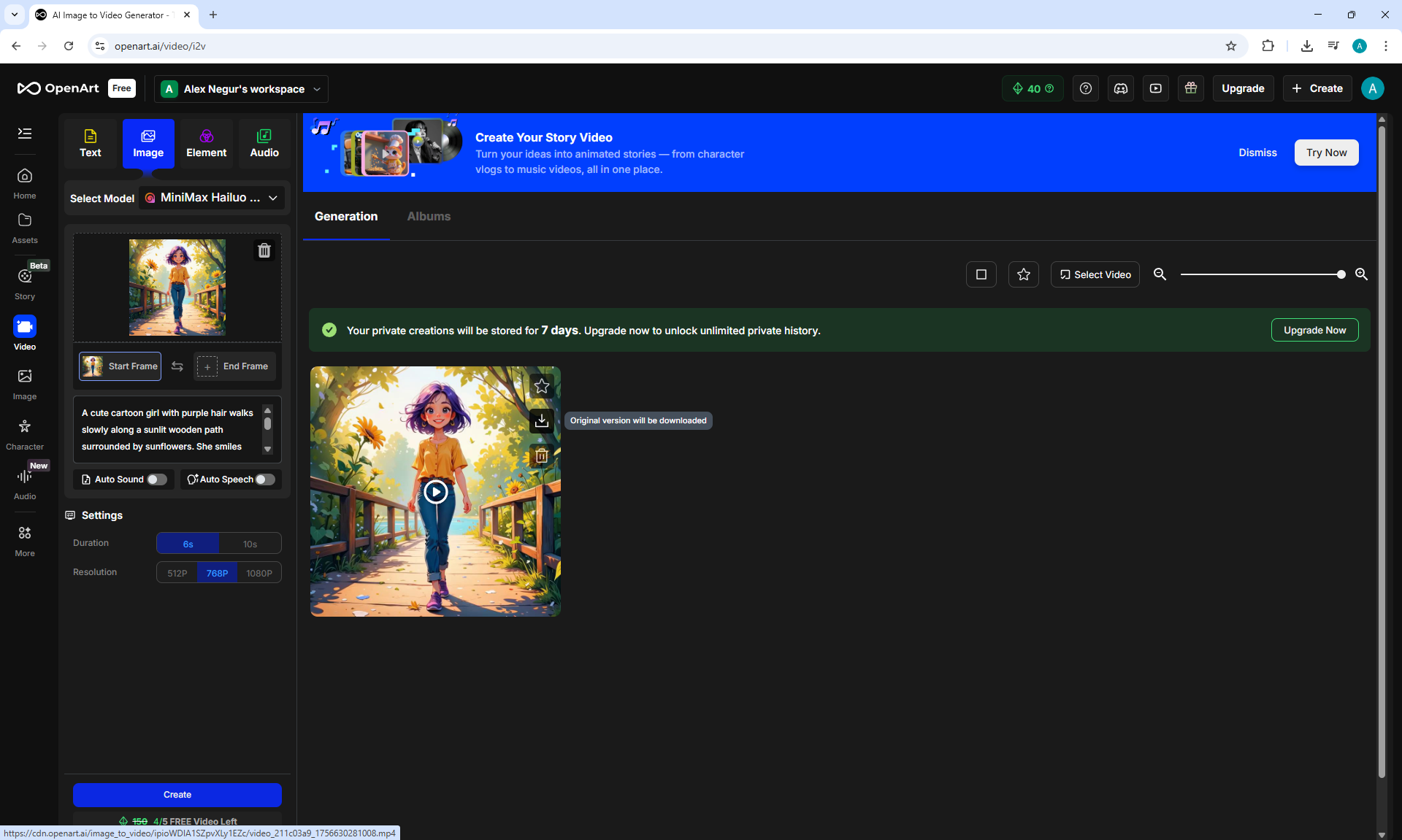
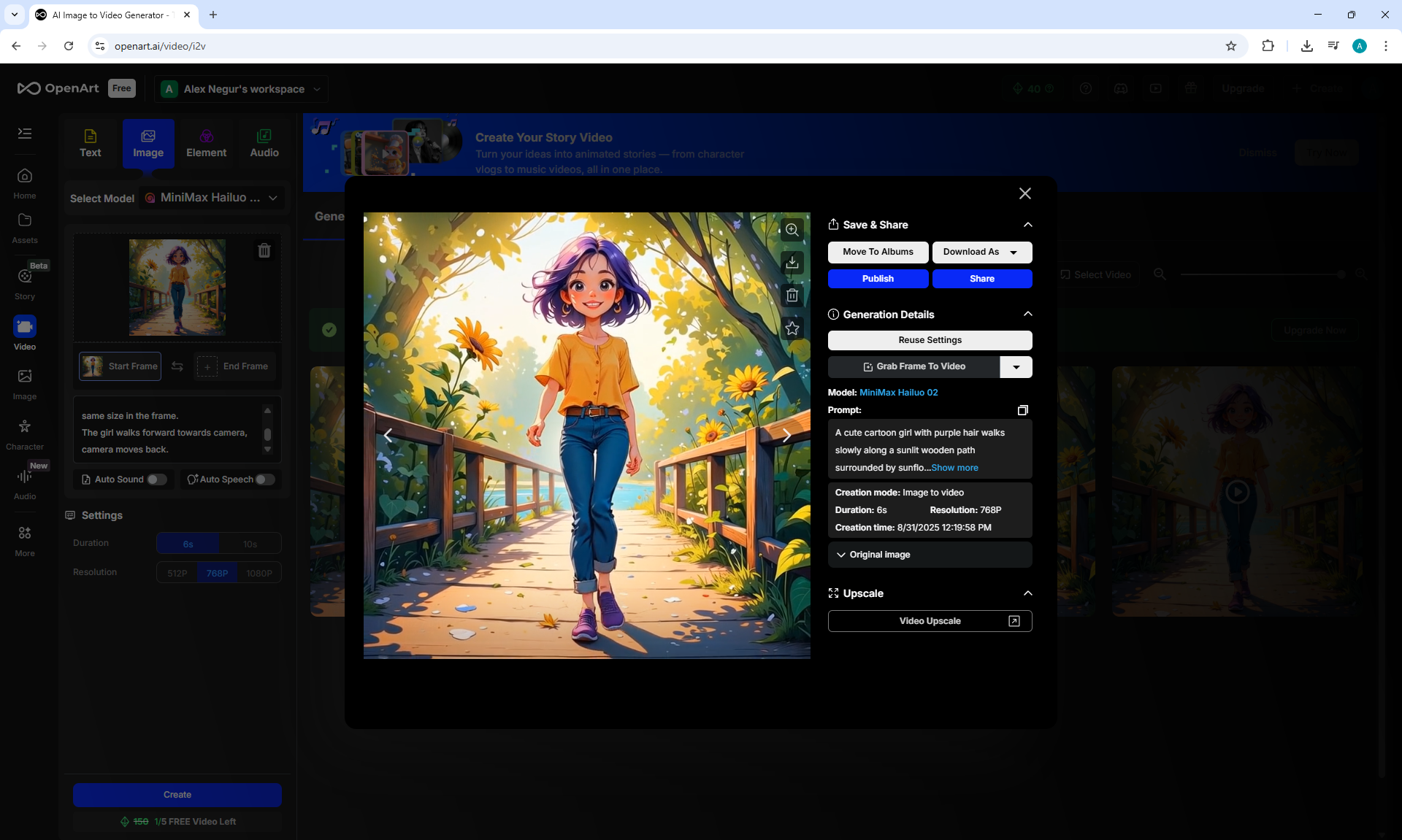
I generated this girl in episode 28.
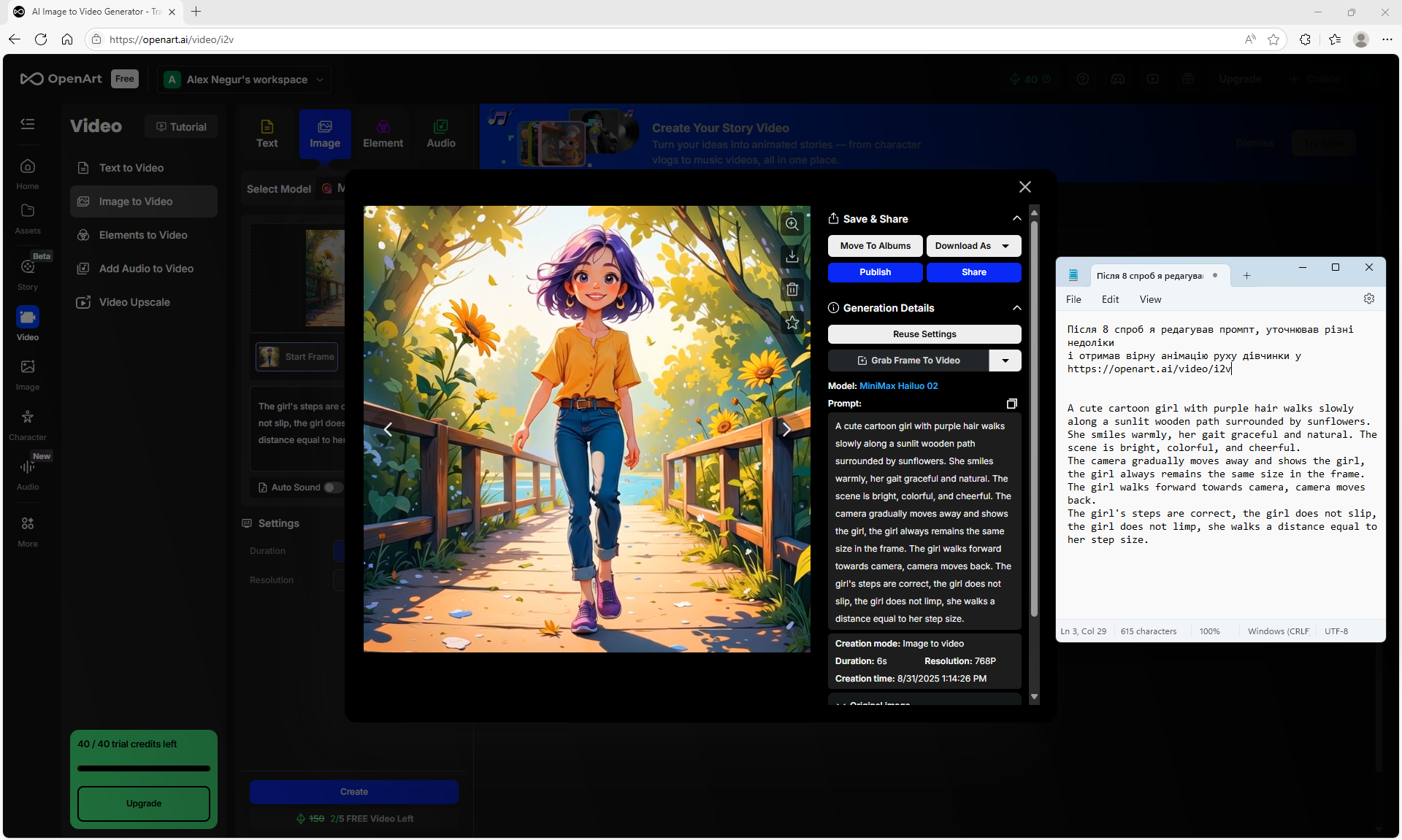
I tested how the site is generated. https://openart.ai/video/i2v such animation on the prompt. Above are examples. The animation of the movement is clearer than on Wan2.1 on ComfyUI. There are no movement defects, duplicated, distorted, blurred body parts.
After many attempts, I edited the prompt (above), clarified the shortcomings, and got accurate animation of the girl's movement.
All the points need to be specified in the prompt for the animation. The camera doesn't just move smoothly, but captures the girl in the frame. The girl doesn't just walk, but walks towards the camera, that the girl doesn't limp, that she doesn't slip, that her steps match the distance she covers.
After a successful generation of the prompt, subsequent generations may be unsuccessful.
For example, in the results there are examples where the girl moves her legs to the sides, bends her knees high.
The girl can start to do foot feints, to put them to the sides. The gait has its own style each time. For example, this gait with simple foot drop, this
walk with like a model, this a gait in which the girl spreads her arms slightly, but she slides in place.
It is unclear why the girl suddenly has such
strange walking with shifting feet at the end of the step, although the girl is moving correctly and the camera movement is correct.

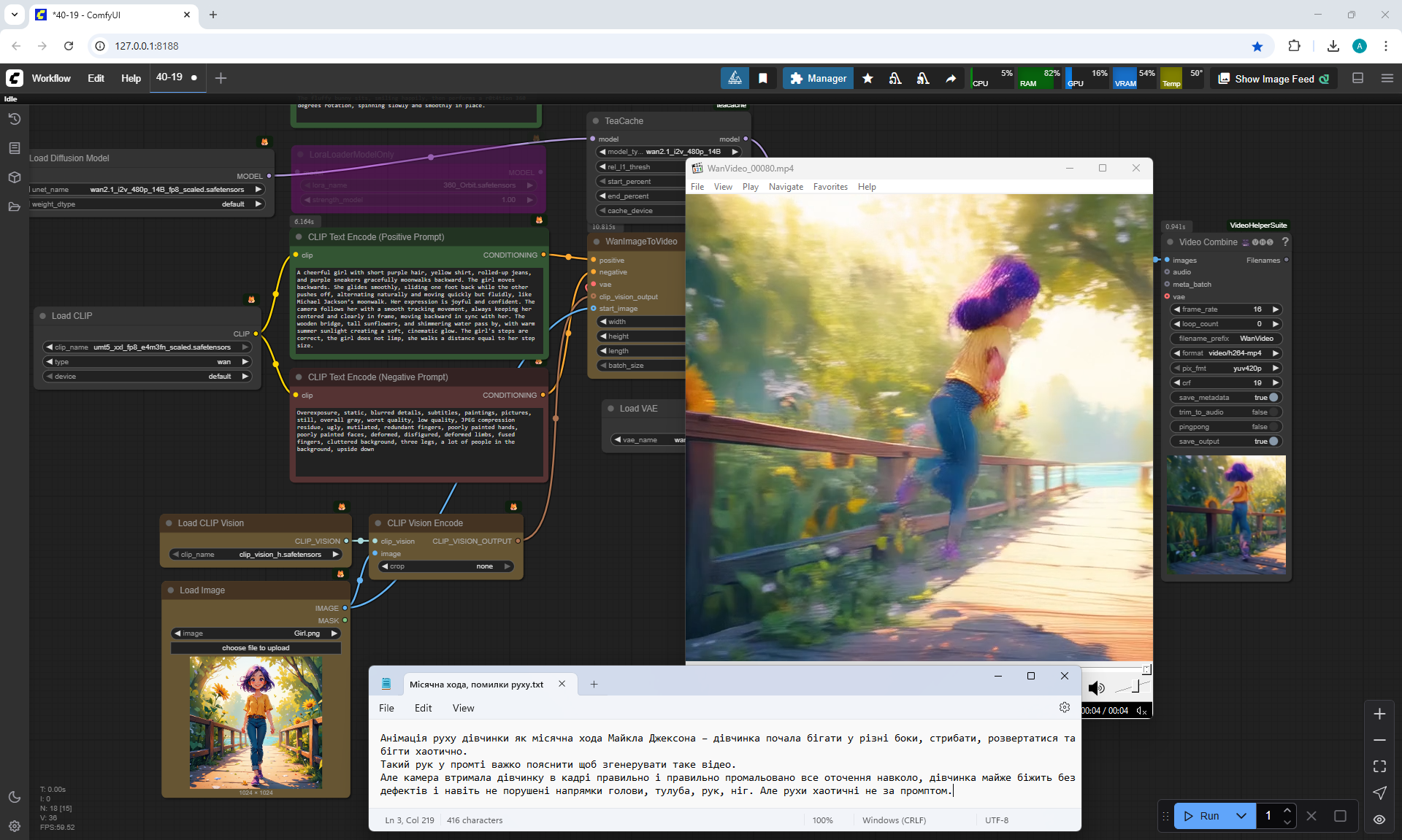
In this version, the girl's movement is somehow backwards. Maybe this is due to incorrect camera movement. The AI didn't understand where the girl should be moving. But the movement animation itself is successful. I decided to test how the girl's moonwalk is generated.



I tested the prompt for the moonwalk:
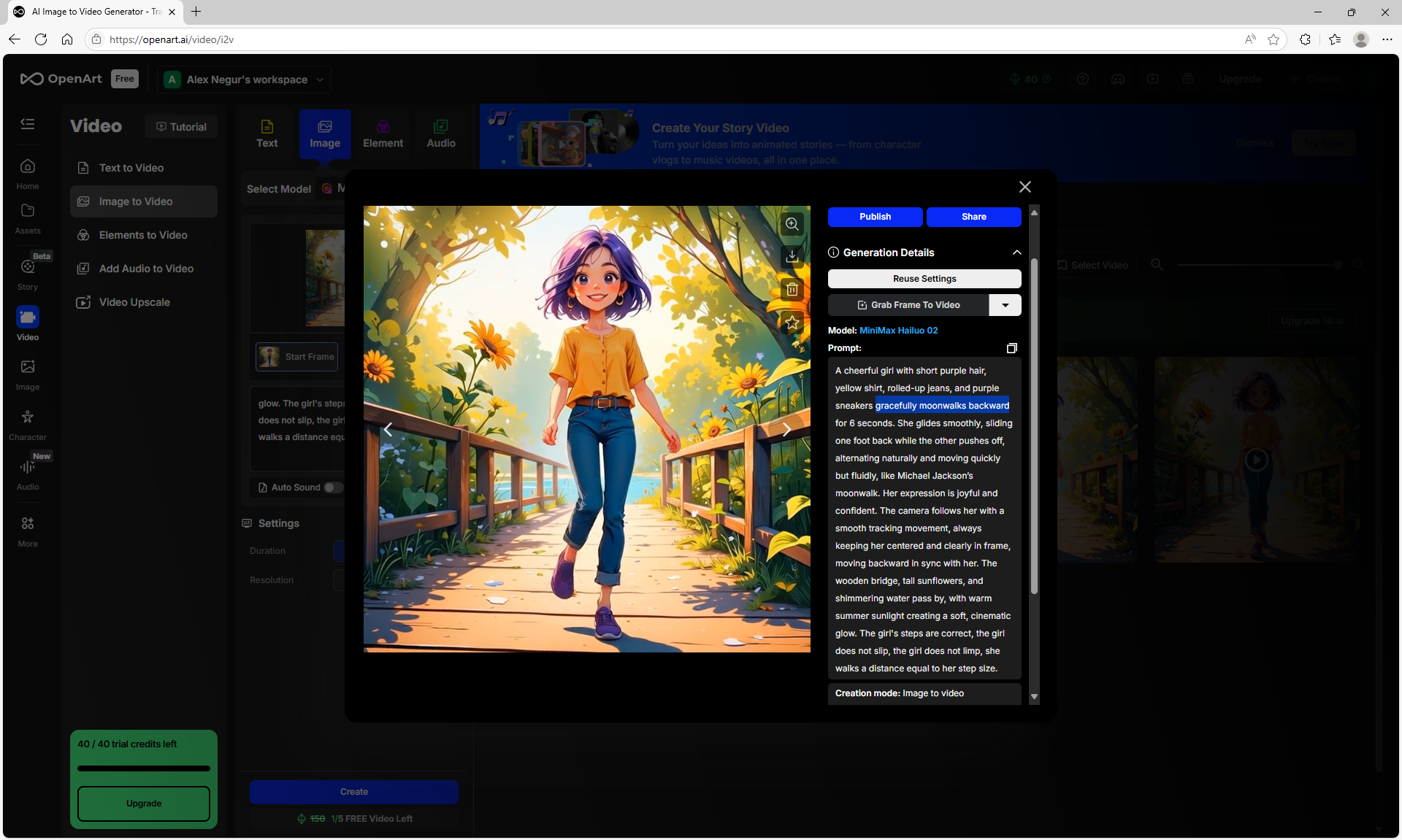
"A cheerful girl with short purple hair, yellow shirt, rolled-up jeans, and purple sneakers gracefully moonwalks backward for 6 seconds. The girl moves backwards. She glides smoothly, sliding one foot back while the other pushes off, alternating naturally and moving quickly but fluidly, like Michael Jackson’s moonwalk. Her expression is joyful and confident. The camera follows her with a smooth tracking movement, always keeping her centered and clearly in frame, moving backward in sync with her. The wooden bridge, tall sunflowers, and shimmering water pass by, with warm summer sunlight creating a soft, cinematic glow. The girl's steps are correct, the girl does not limp, she walks a distance equal to her step size."
I tested on the websitehttps://openart.ai/video/i2v.
The first generation does it wrong, the girl walks forward towards the camera, although it is written to walk backwards.
Before that, when there was just an animation of the gait, there were cases when the girl walked forward, on the contrary, here the prompt states that the girl walks backwards. The movement is not similar to the moonwalk, the legs move to the side. Perhaps the model has not learned the moonwalk.
More attempts - the girl does not walk backwards with a moonwalk, but dances, walks forward and does various dance tricks with her legs in different directions.


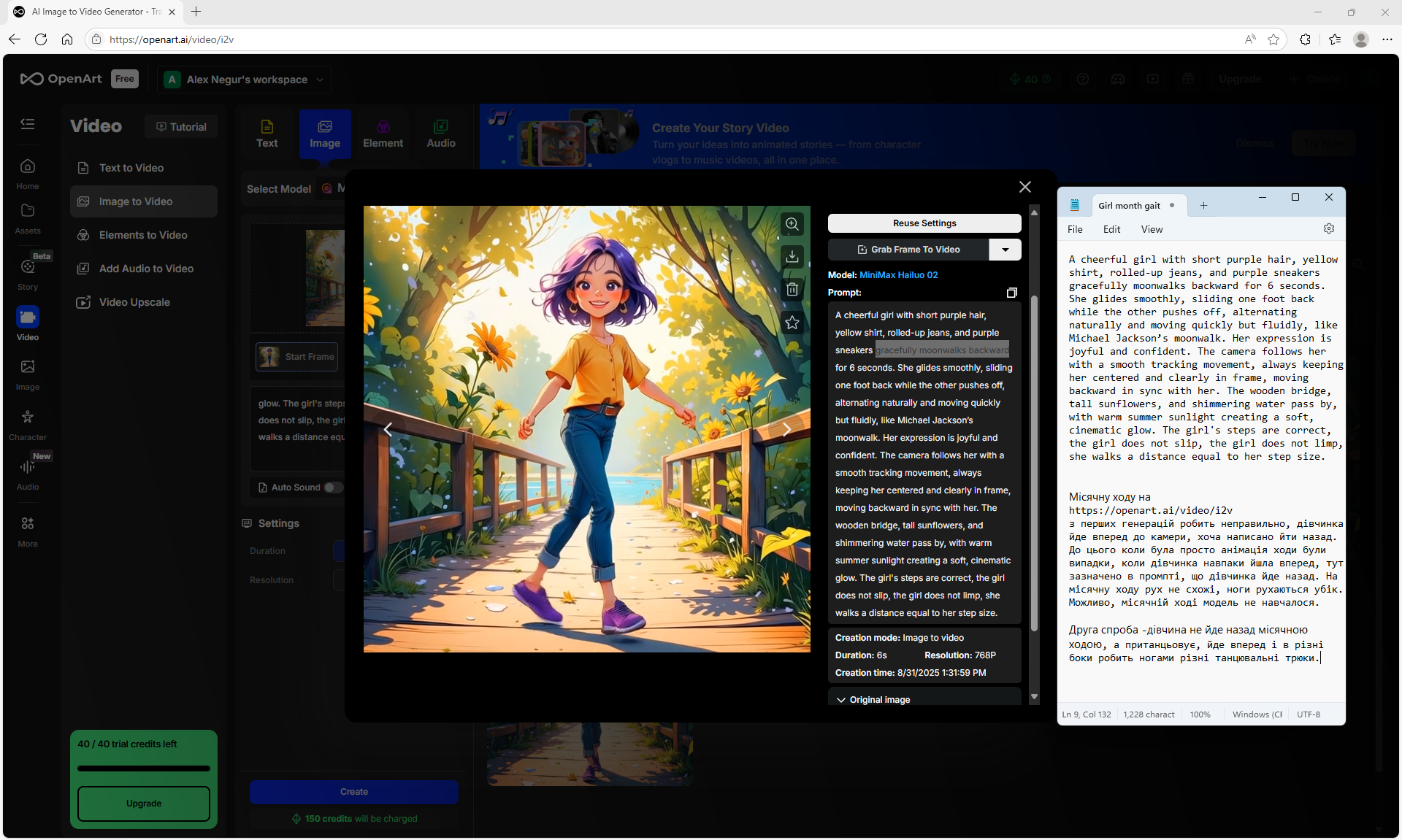
I tested another prompt for the moonwalk:
A cheerful girl with short purple hair, yellow shirt, rolled-up jeans, and purple sneakers gracefully moonwalks backward for 6 seconds. The girl moves backwards. She glides smoothly, sliding one foot back while the other pushes off, alternating naturally and moving quickly but fluidly, like Michael Jackson’s moonwalk. Her expression is joyful and confident. The camera follows her with a smooth tracking movement, always keeping her centered and clearly in frame, moving backward in sync with her. The wooden bridge, tall sunflowers, and shimmering water pass by, with warm summer sunlight creating a soft, cinematic glow. The girl's steps are correct, the girl does not limp, she walks a distance equal to her step size.
In ComfyUI on Wan2.1 14B I2V 480p the girl also does not do a moonwalk, she makes chaotic very energetic movements, jumps, dances, rejoices, waves her arms, rotates around her axis, although Lora rotation is not used. This prompt of moving backwards by a moonwalk leads to such incomprehensible actions in the girl's movement. Probably, the model did not learn such a movement, but there are many movements from dances, although in the prompt there is only a moonwalk backwards.
Animation of the girl's movement as Michael Jackson's moonwalk – the girl started running in different directions., jumping, turning around and run chaotically, jumping and dancing, waving your arms and spinning quickly, jumping like a kangaroo.










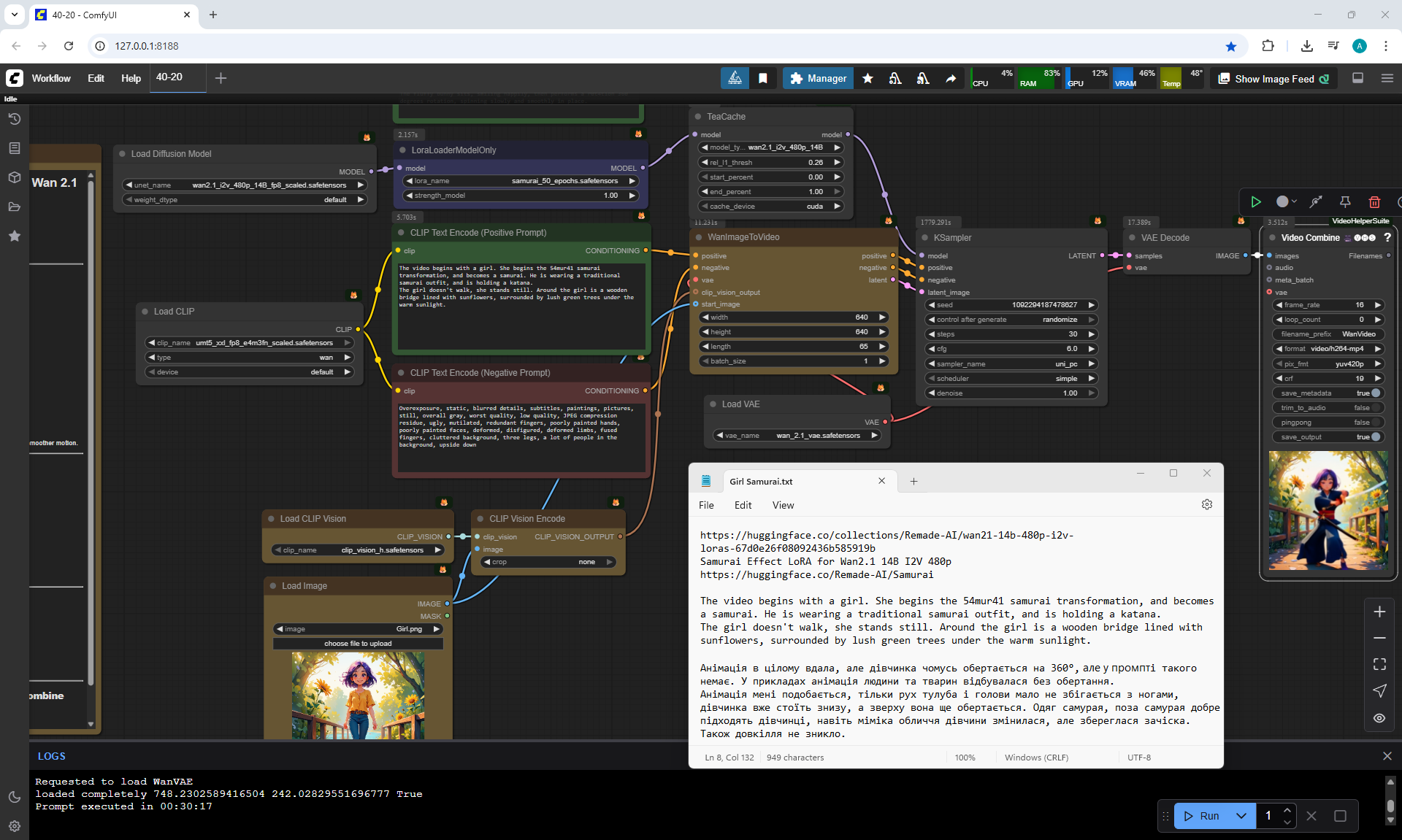
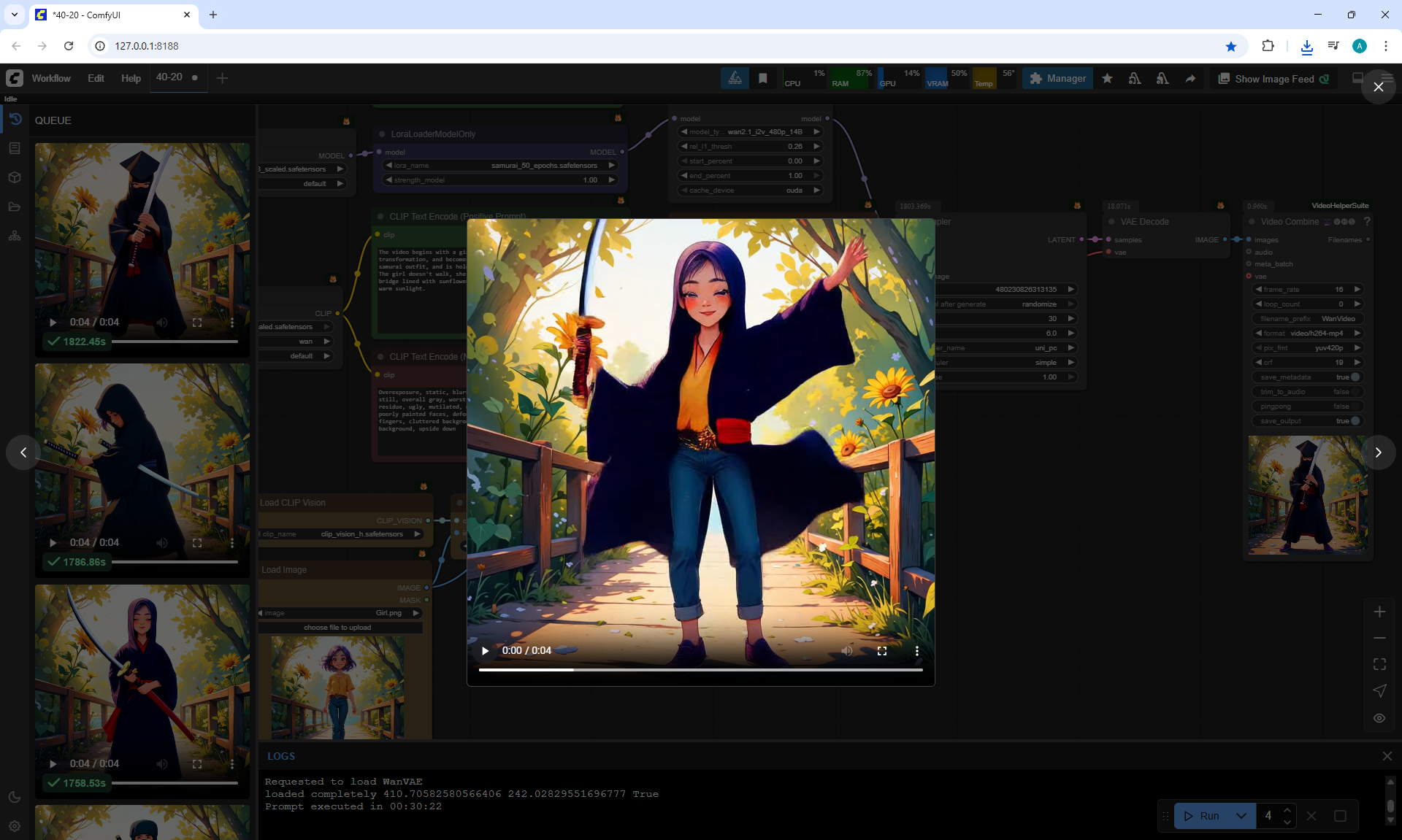
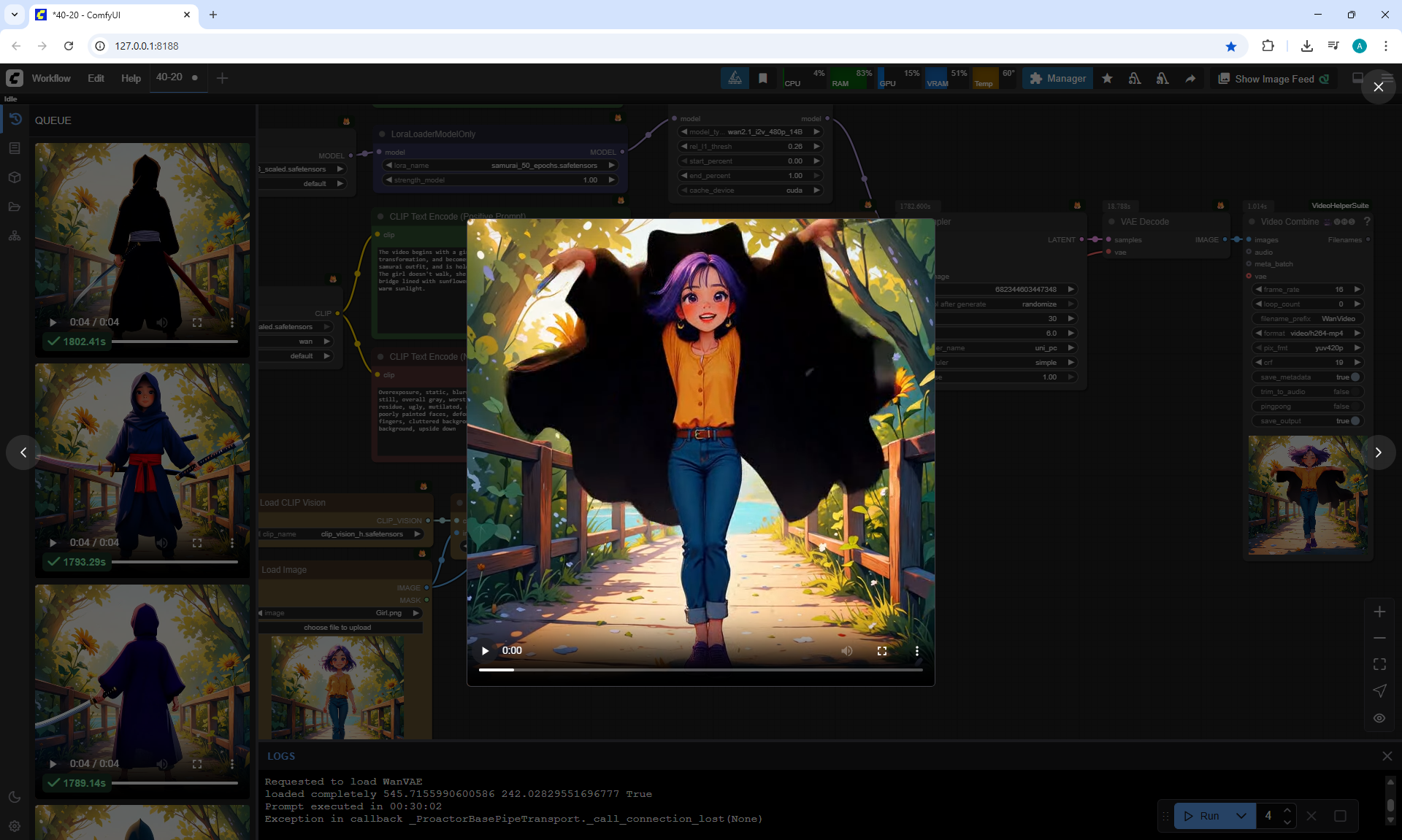
I tested LoRa animation effects with a samurai onWan2.1 14B 480p I2V LoRAs
Samurai Effect LoRA for Wan2.1 14B I2V 480p
Prompt:
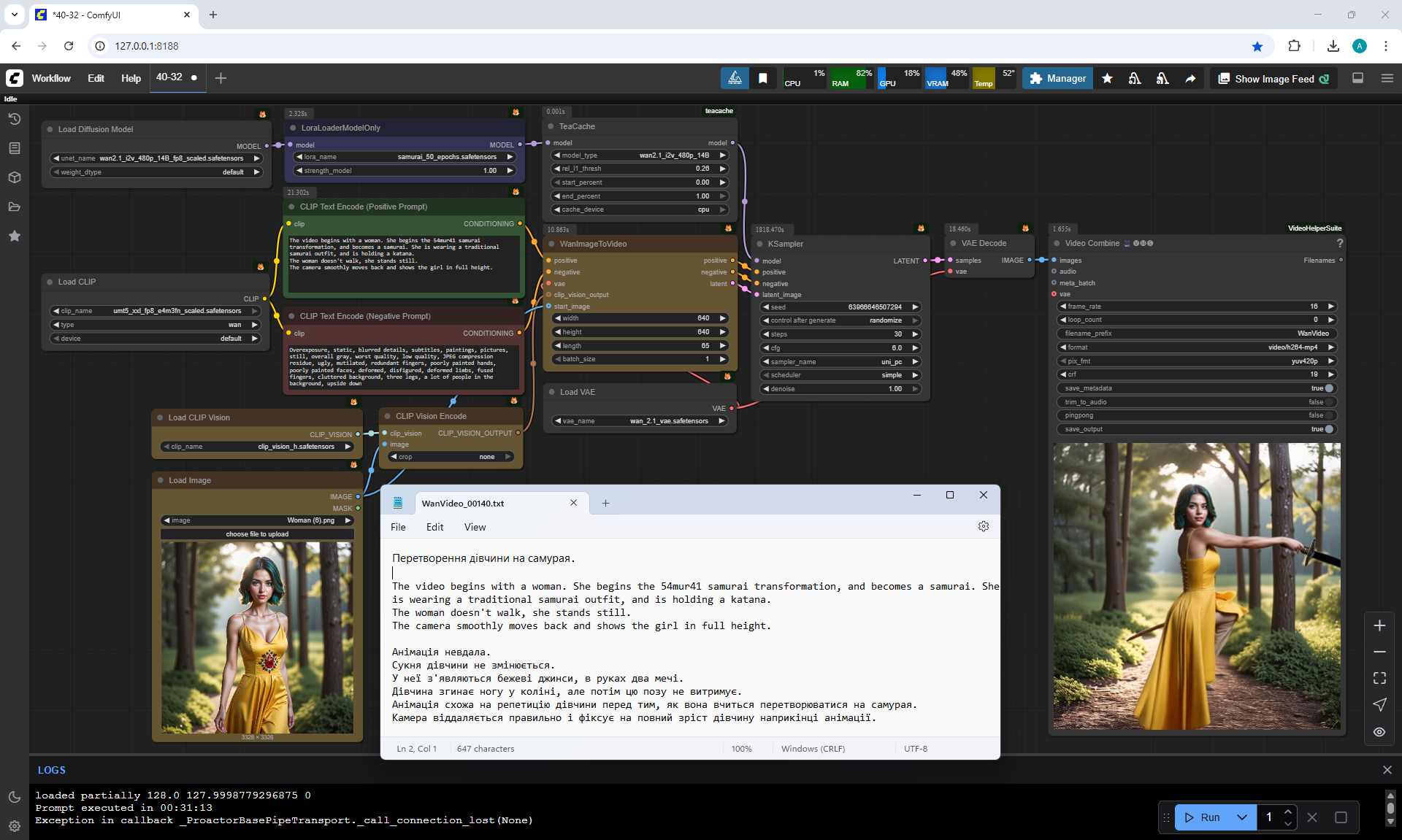
The video begins with a girl. She begins the 54mur41 samurai transformation, and becomes a samurai. He is wearing a traditional samurai outfit, and is holding a katana.
The girl doesn't walk, she stands still. Around the girl is a wooden bridge lined with sunflowers, surrounded by lush green trees under the warm sunlight.






I like the animations, but the movement of the torso and head sometimes almost coincides with the legs, the girl is already standing from below, and from above she is still turning.
In the first video The girl's legs don't turn., but the girl rotates 360°.
The samurai clothes, the samurai pose fit the girl well, even the girl's facial expressions have changed. Also the environment has not disappeared.
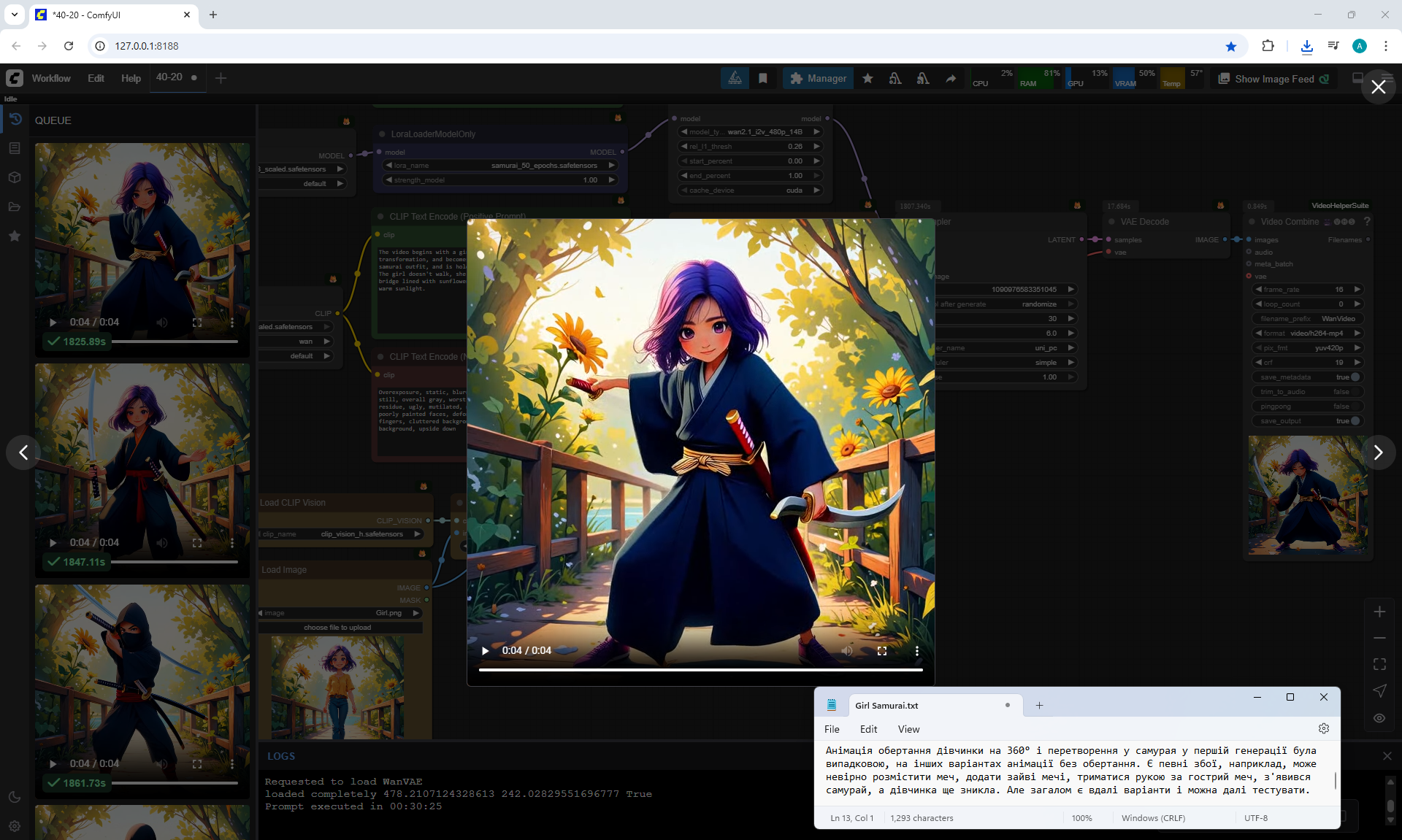
In this video at the end incorrect animation of the girl turning 180°, the legs do not move, and the girl turned back.
There are certain glitches, for example, you can incorrectly place the sword, add extra swords, hold on to a sharp sword with your hand, a samurai appeared, and the girl has not yet disappeared.
But in general, there are good options and you can continue to test.




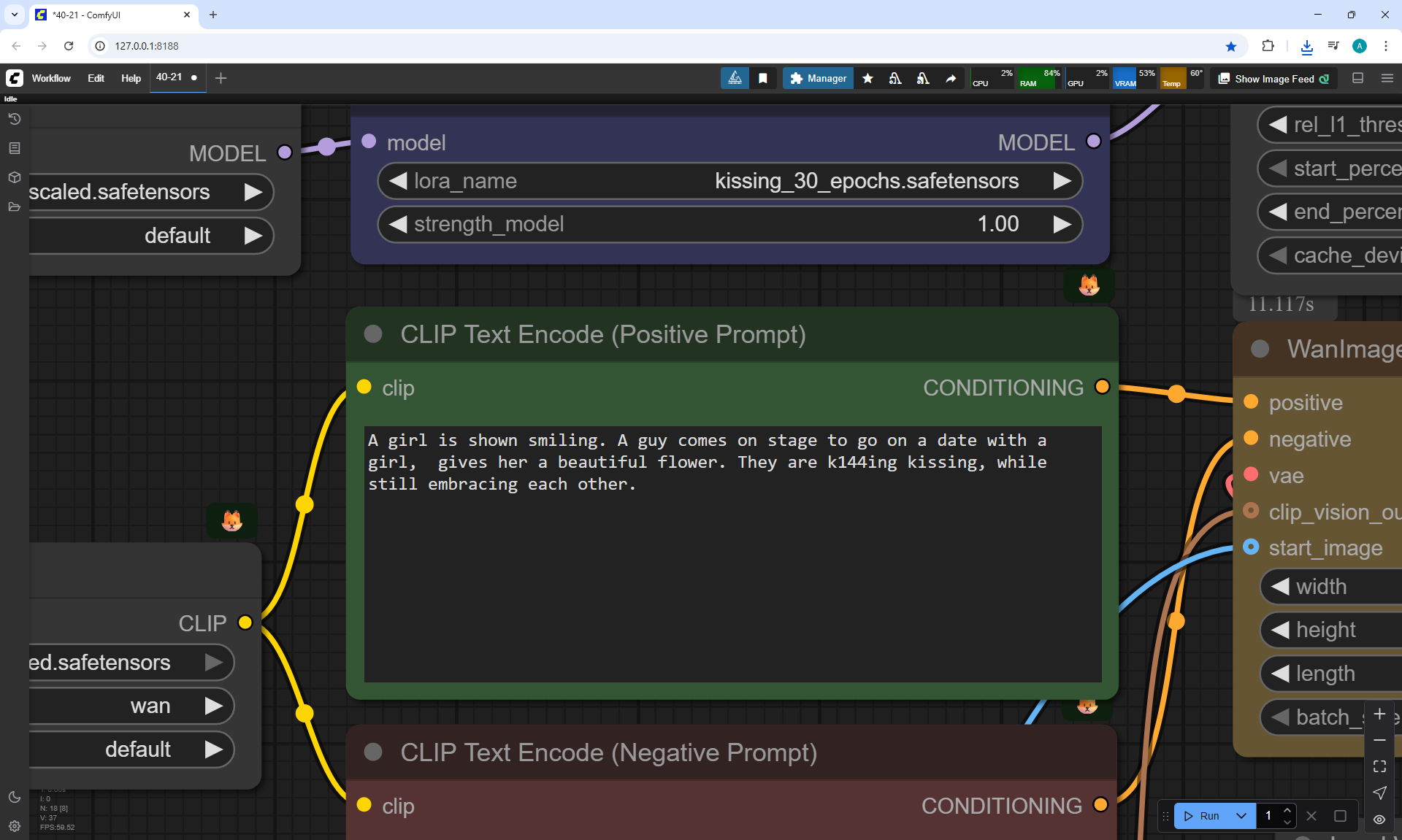
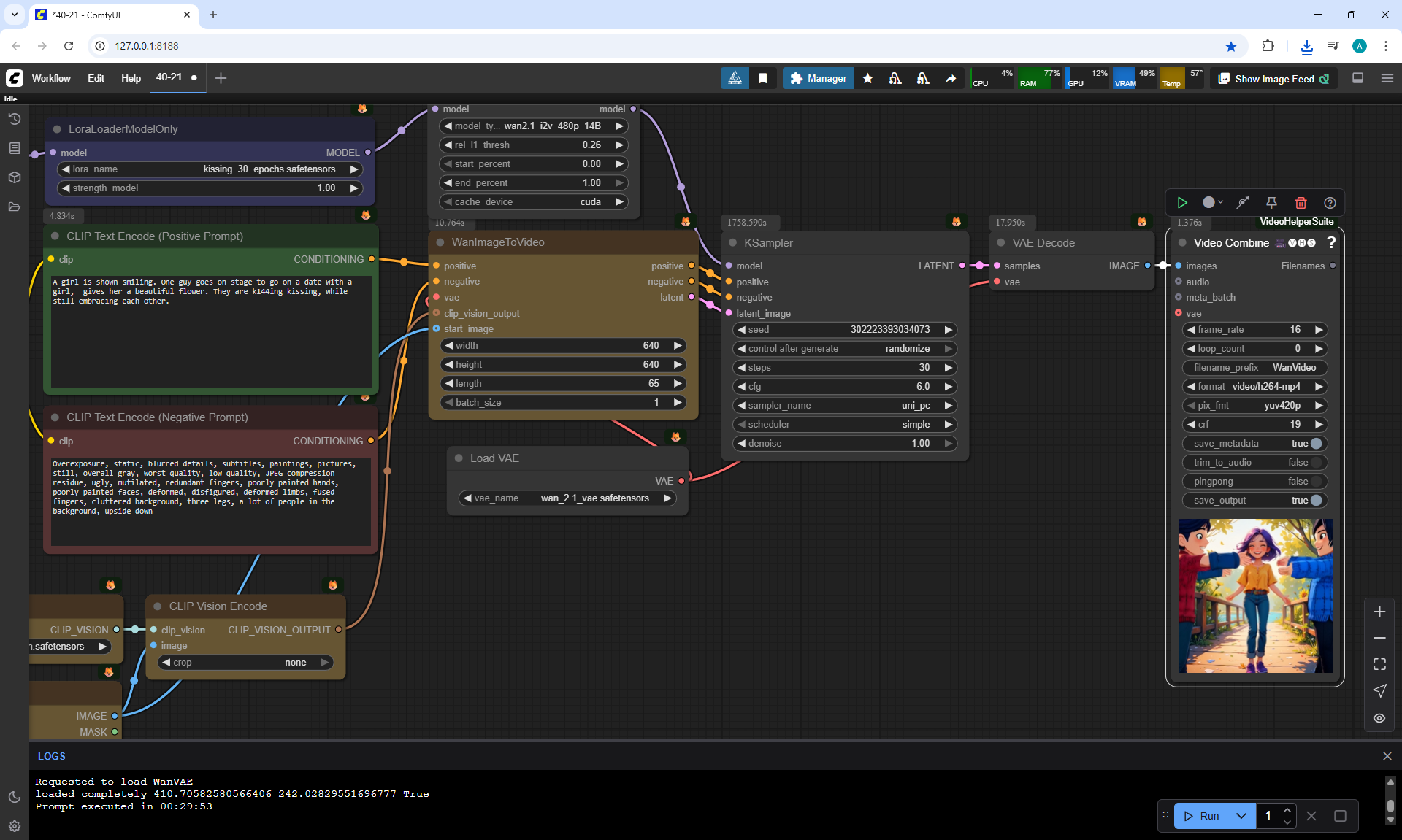
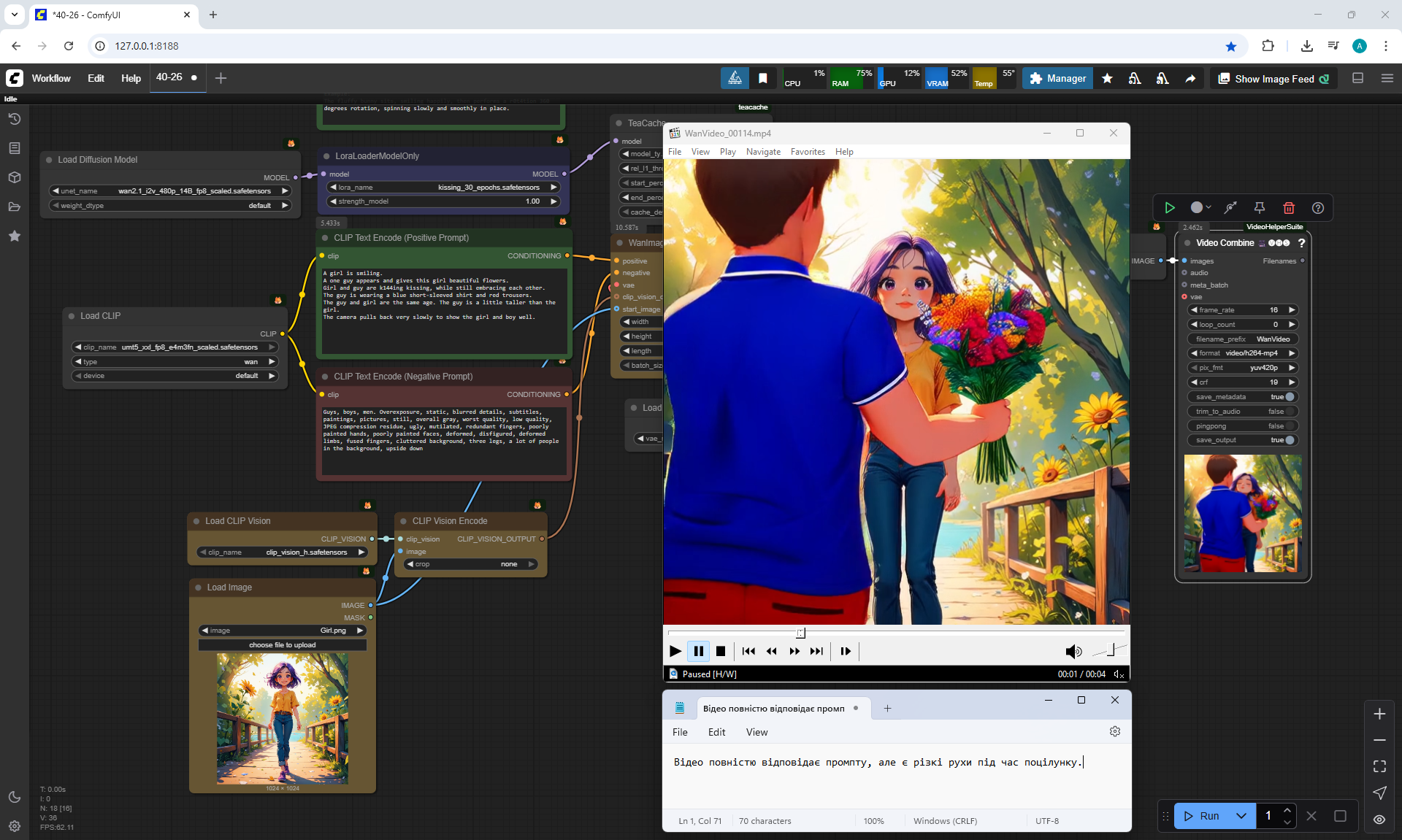
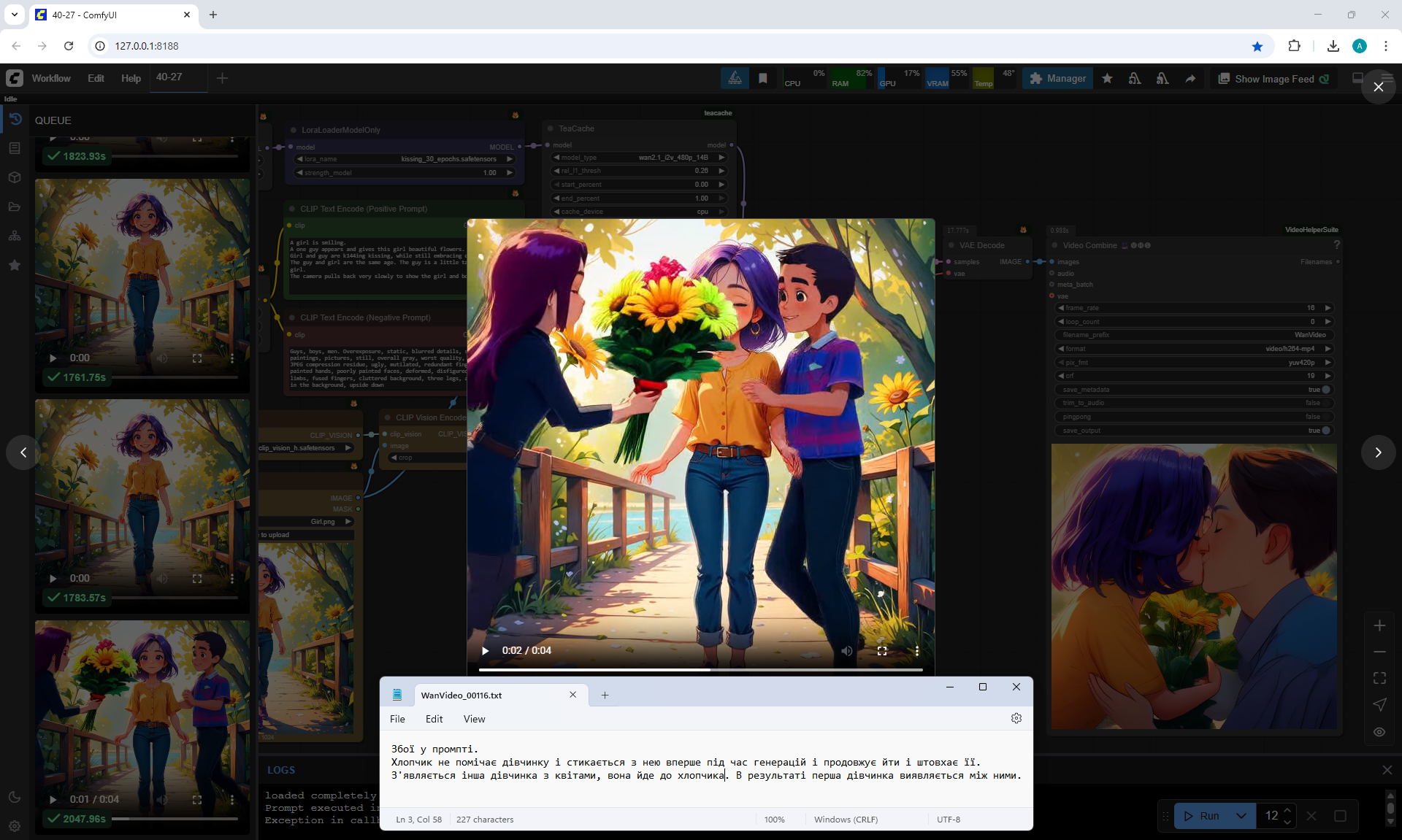
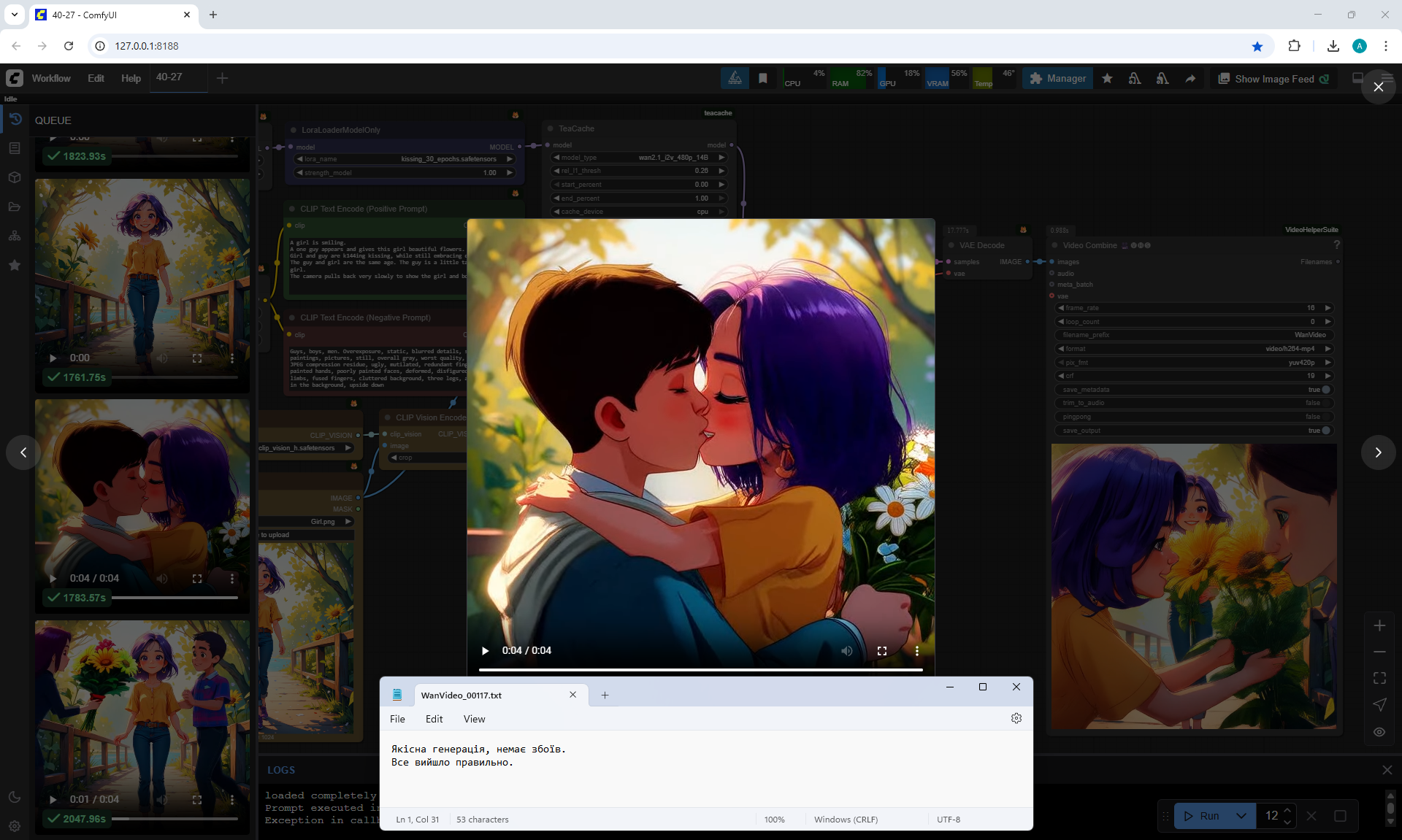
I tested LoRa animation effects with a kiss on Wan2.1 14B 480p I2V LoRAs
Kissing LoRA for Wan2.1 14B I2V 480p
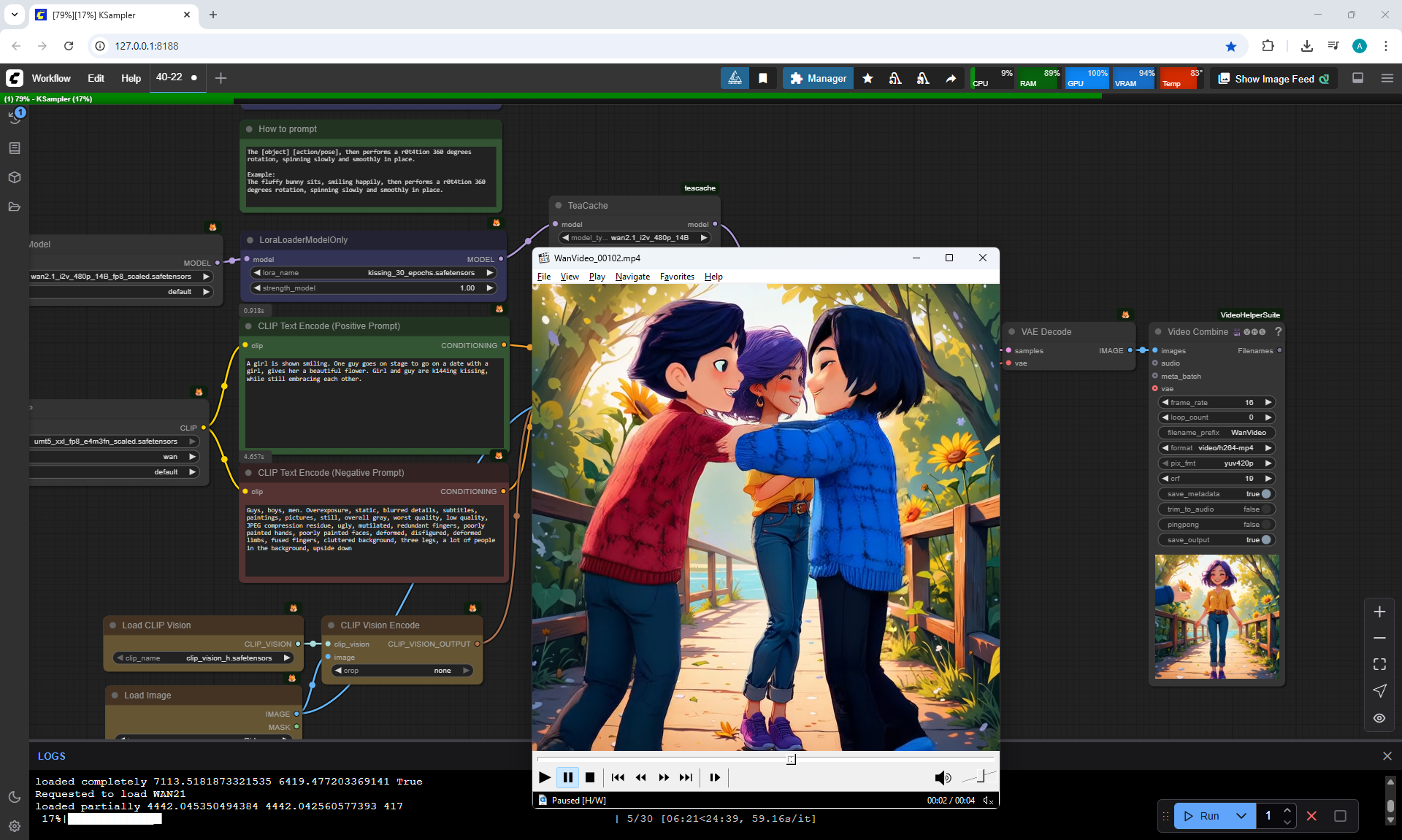
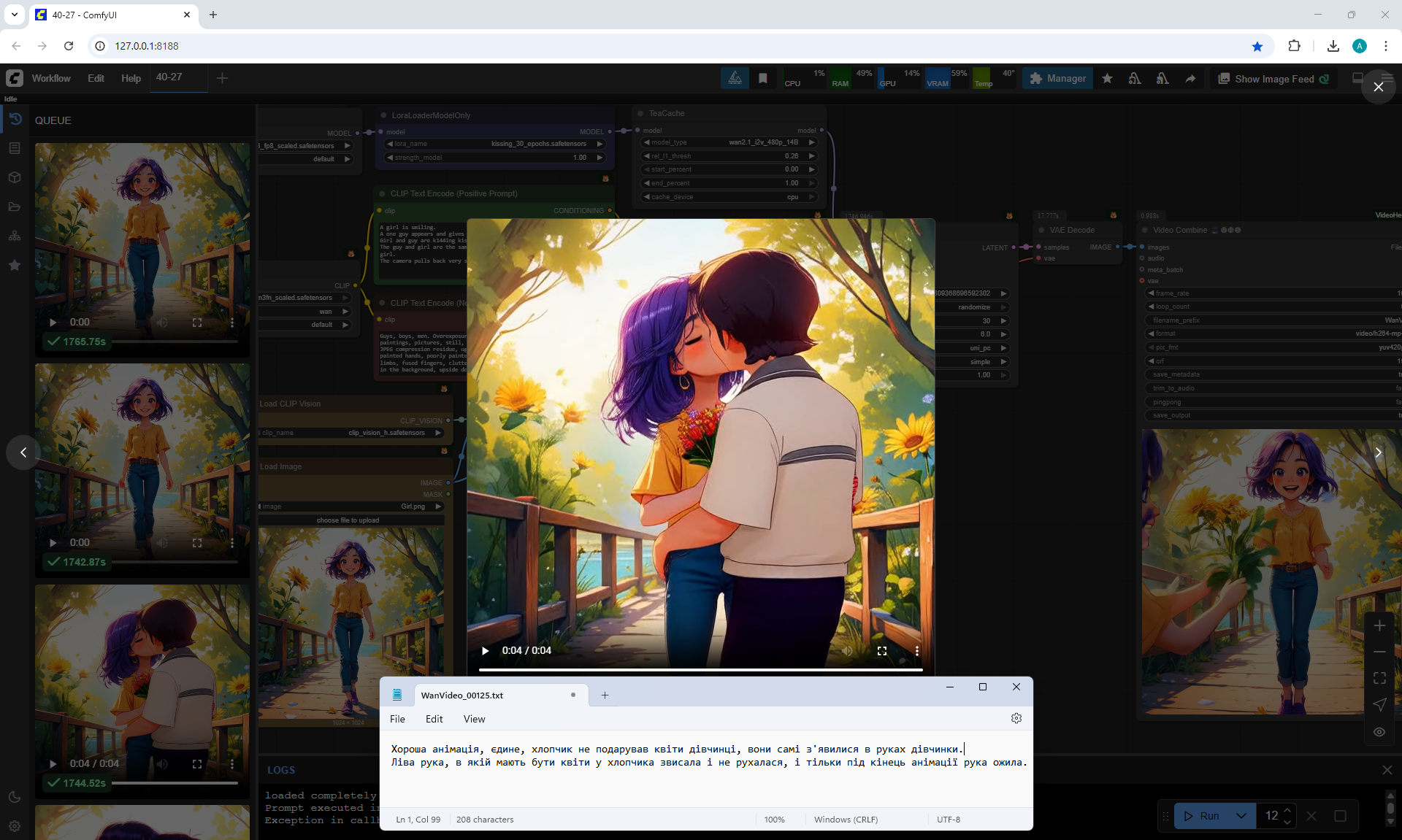
This girl I generated in lesson 28.
Prompt:
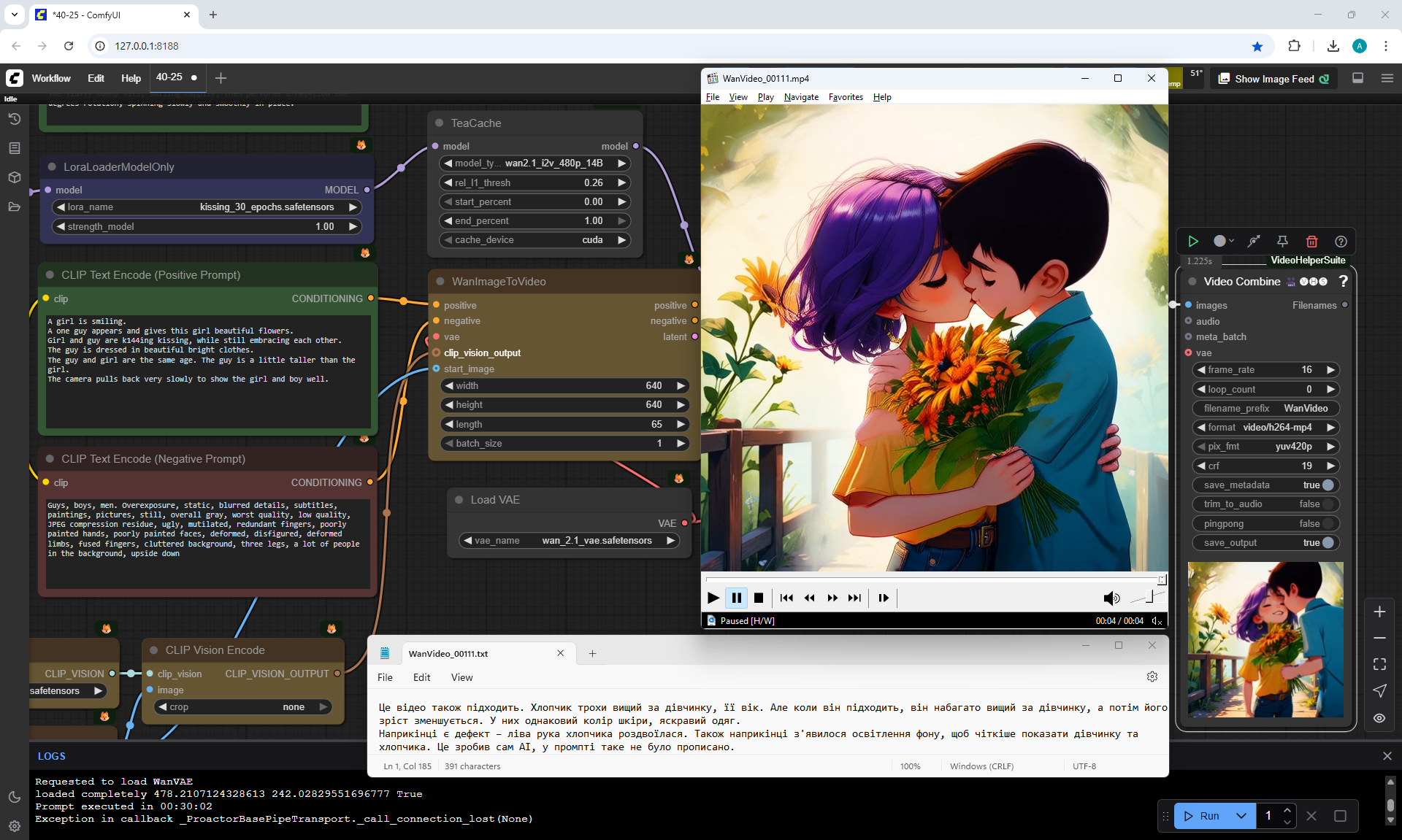
A girl is smiling.
A one guy appears and gives this girl beautiful flowers.
Girl and guy are k144ing kissing, while still embracing each other.
The guy and girl are the same age. The guy is a little taller than the girl.
The camera pulls back very slowly to show the girl and boy well.
At first I didn't specify the height and age of the boy, and a tall man appeared in one video.
Then I indicated in the prompt that it was the boy, slightly taller than the girl, of the same age.
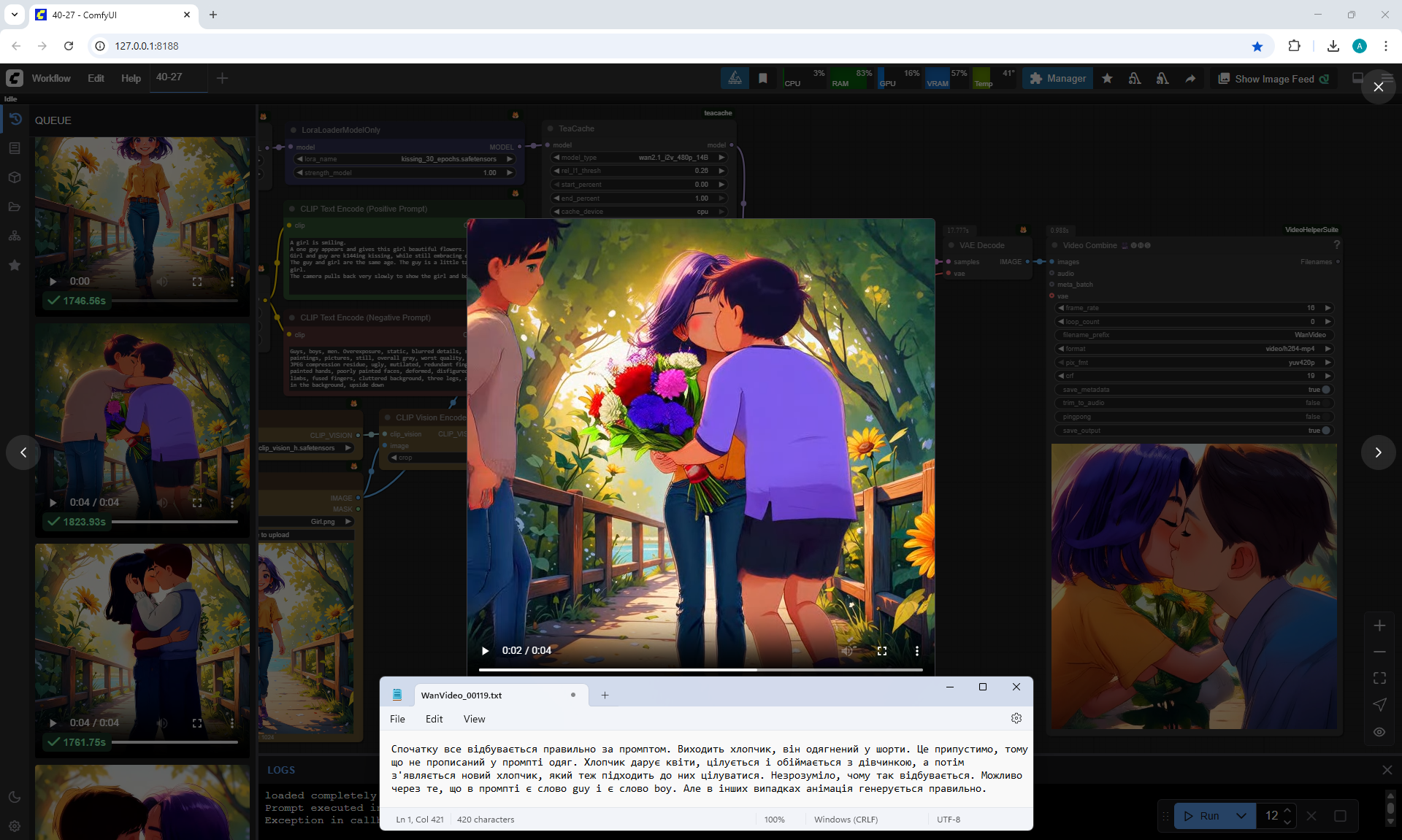
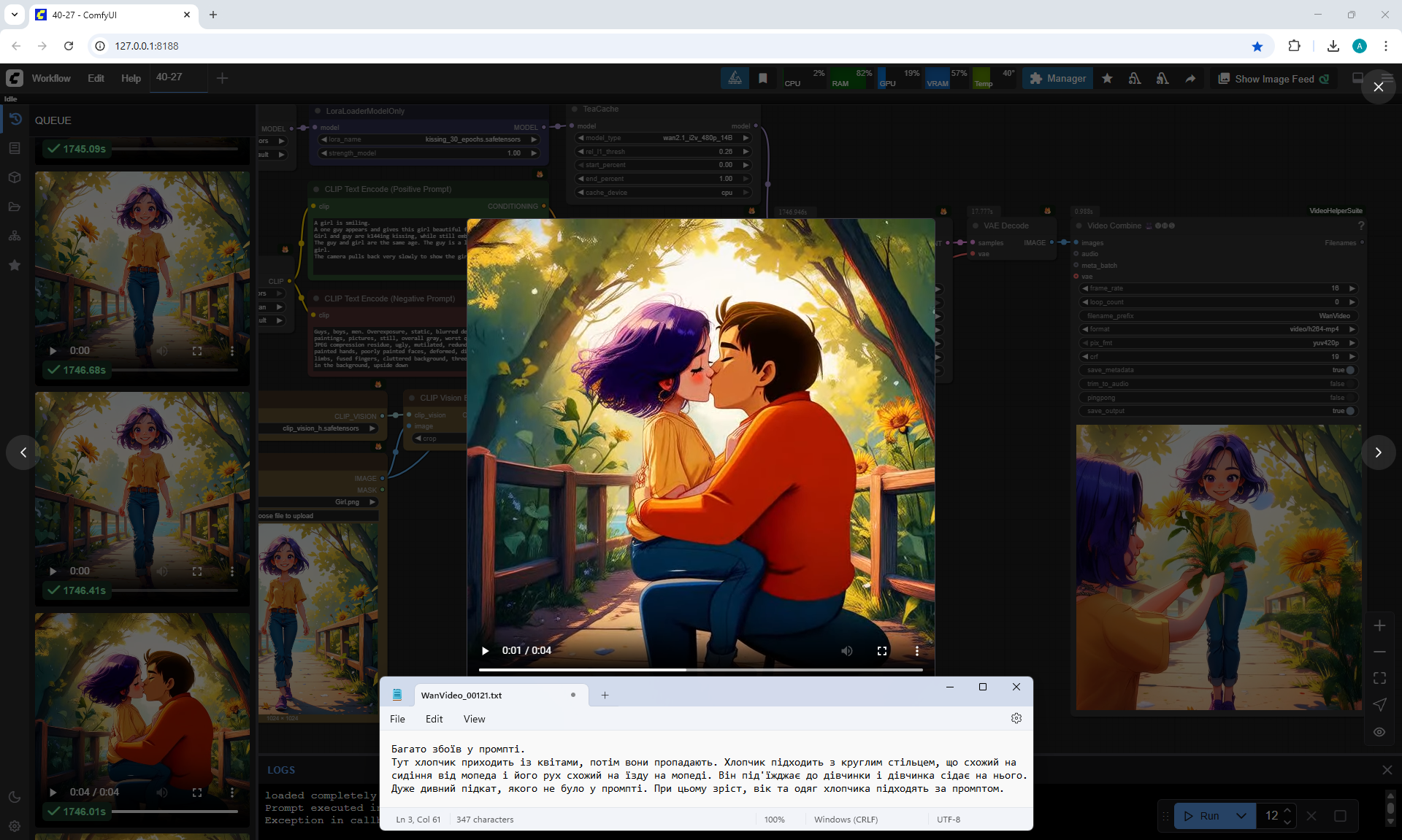
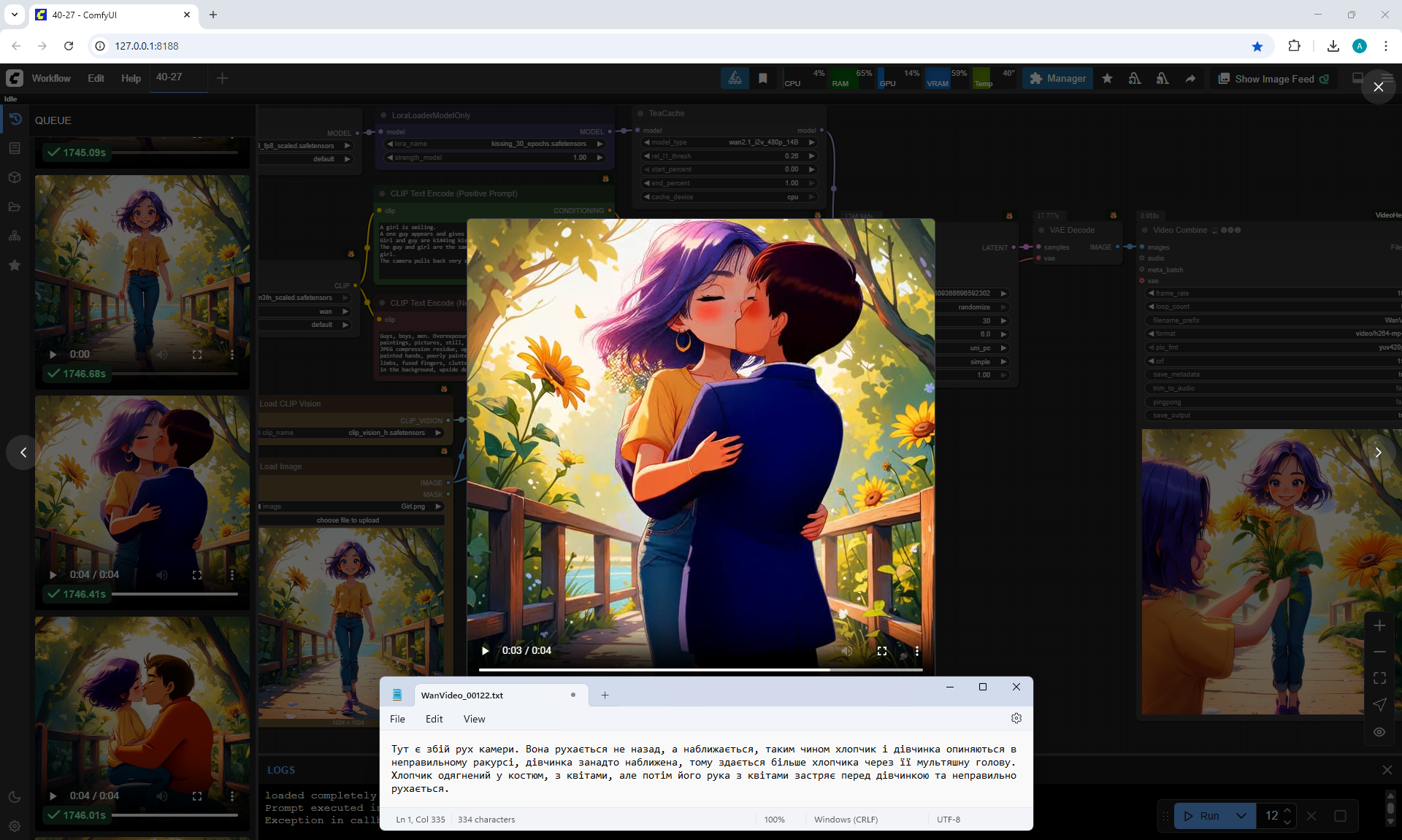
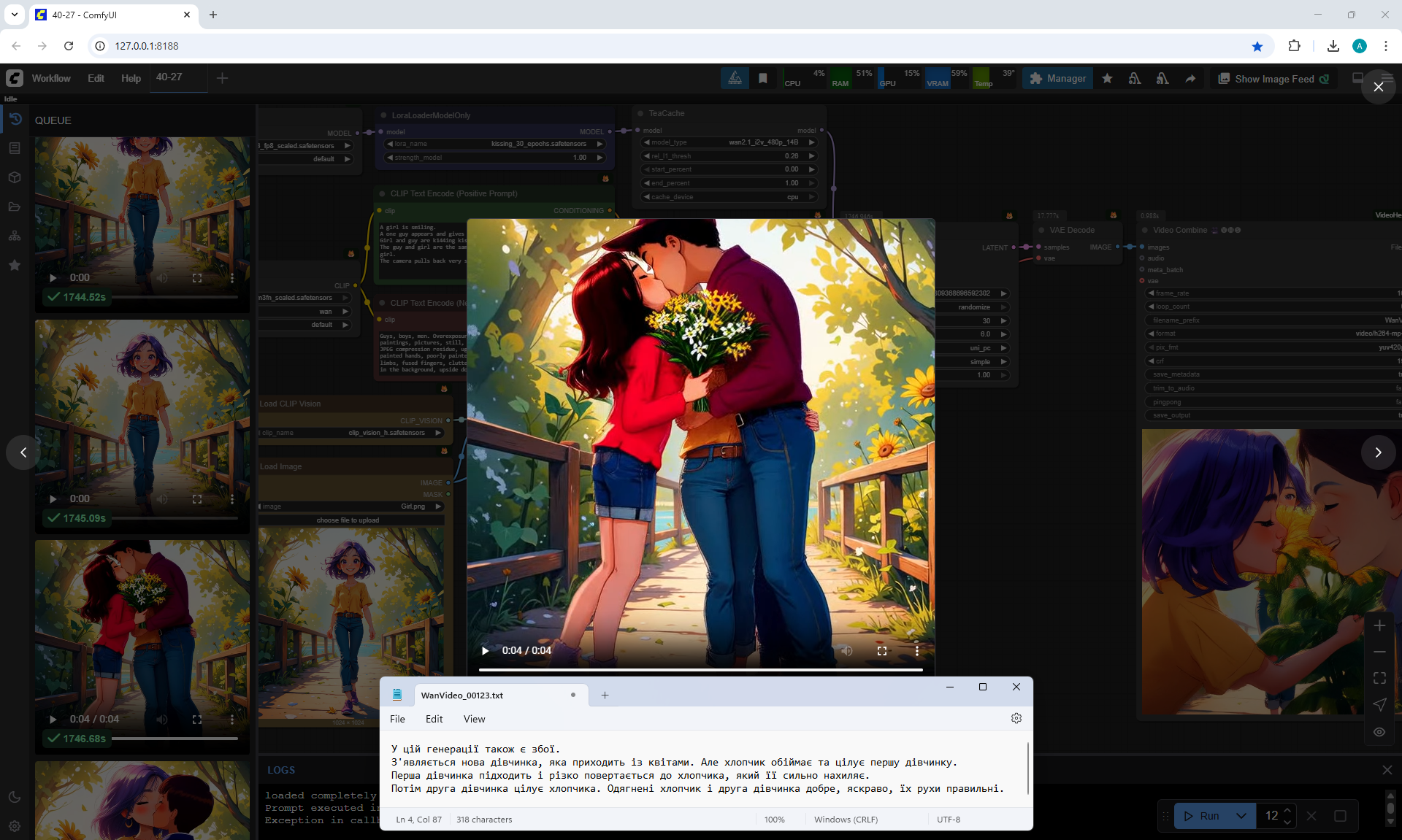
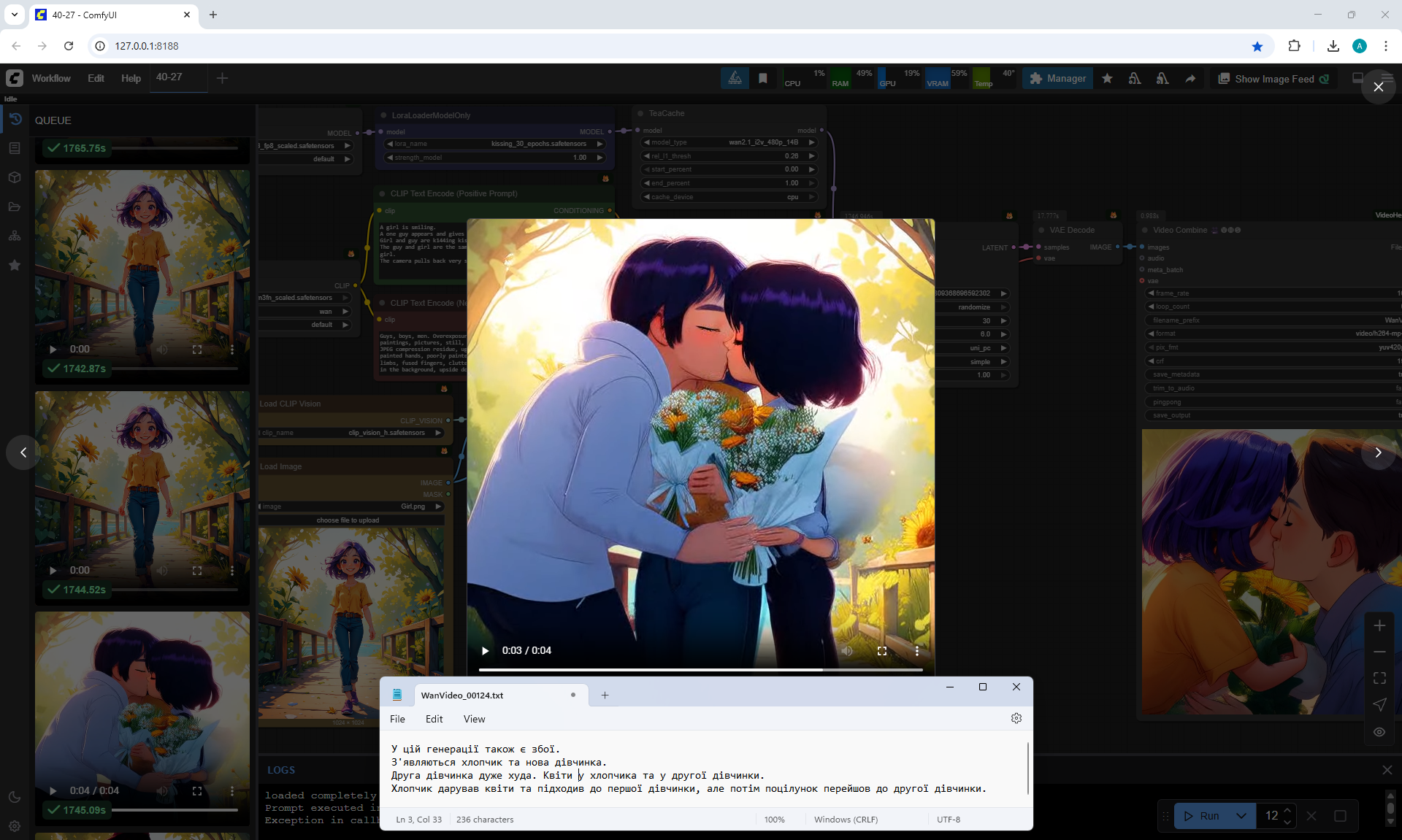
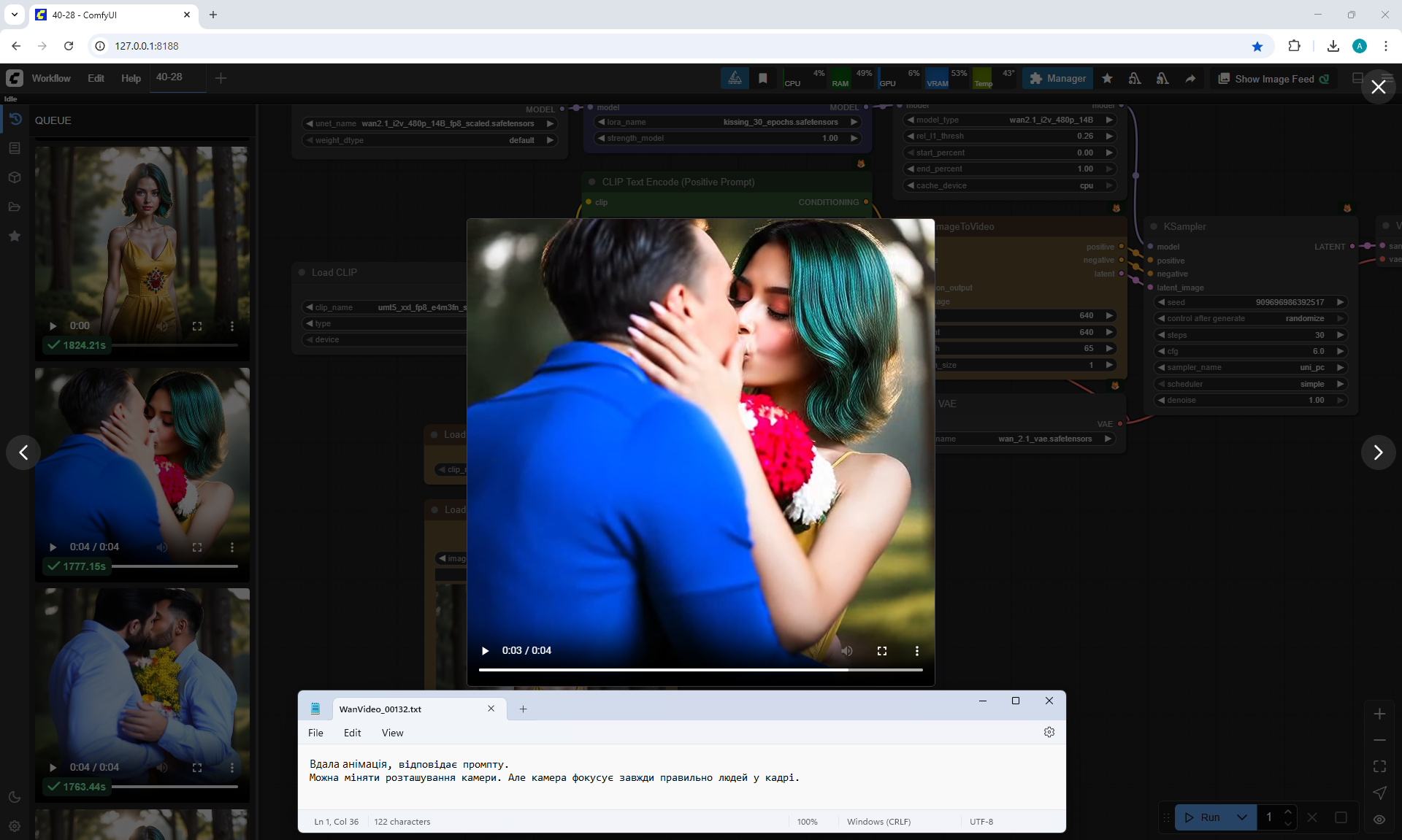
At the prompt, the girl walks, smiles, a boy approaches her, gives her flowers, they kiss and hug.
The video lasts 4 seconds.
I made 27 generations, 12 of them came up, but not completely, there are options where the boy limped.
On large images, successful videos, smaller ones with errors.
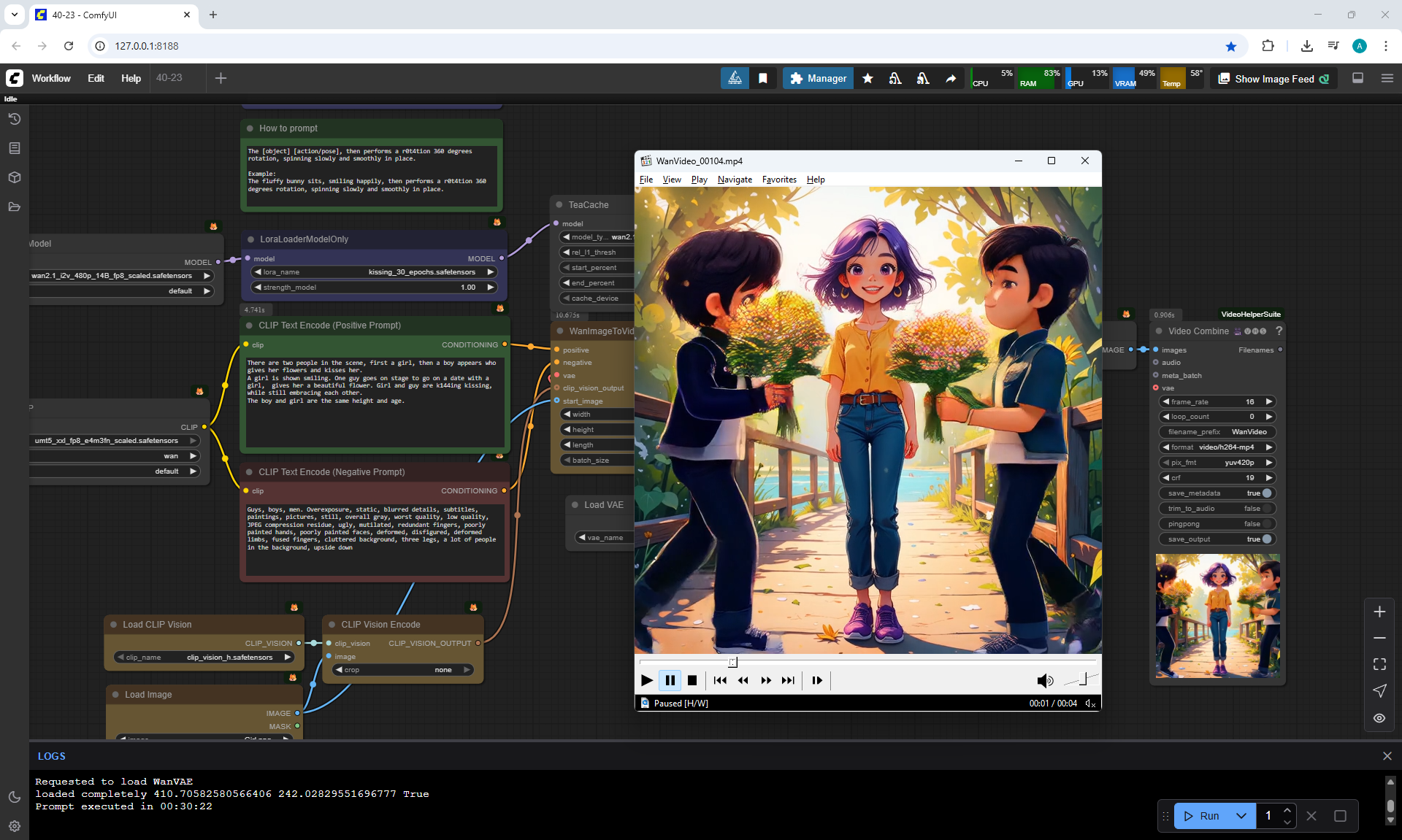
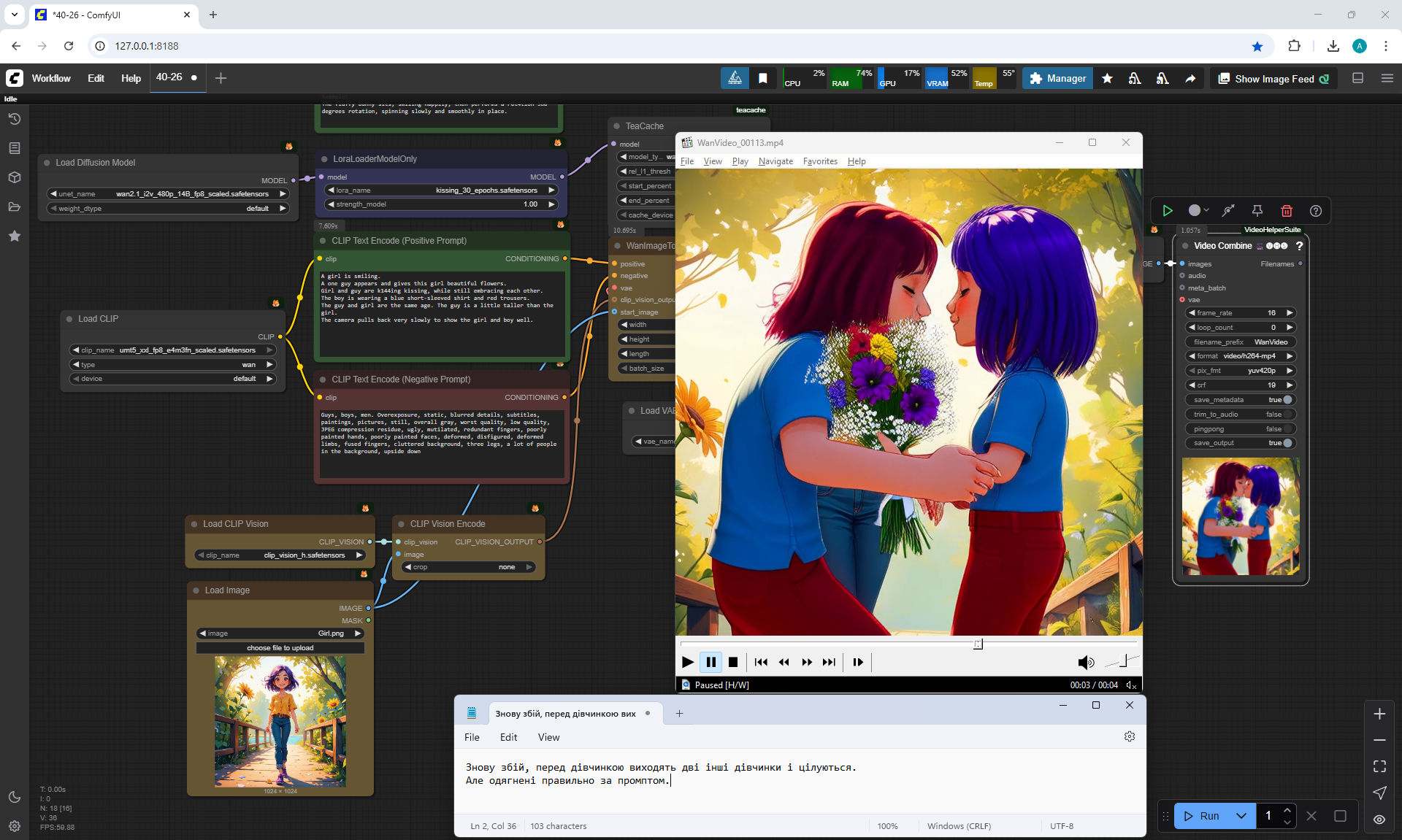
Often two other people are generated who meet in front of the girl, give flowers, kiss.




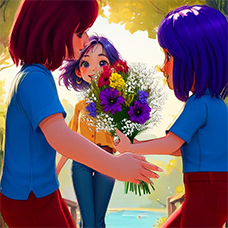
Almost successful animation,
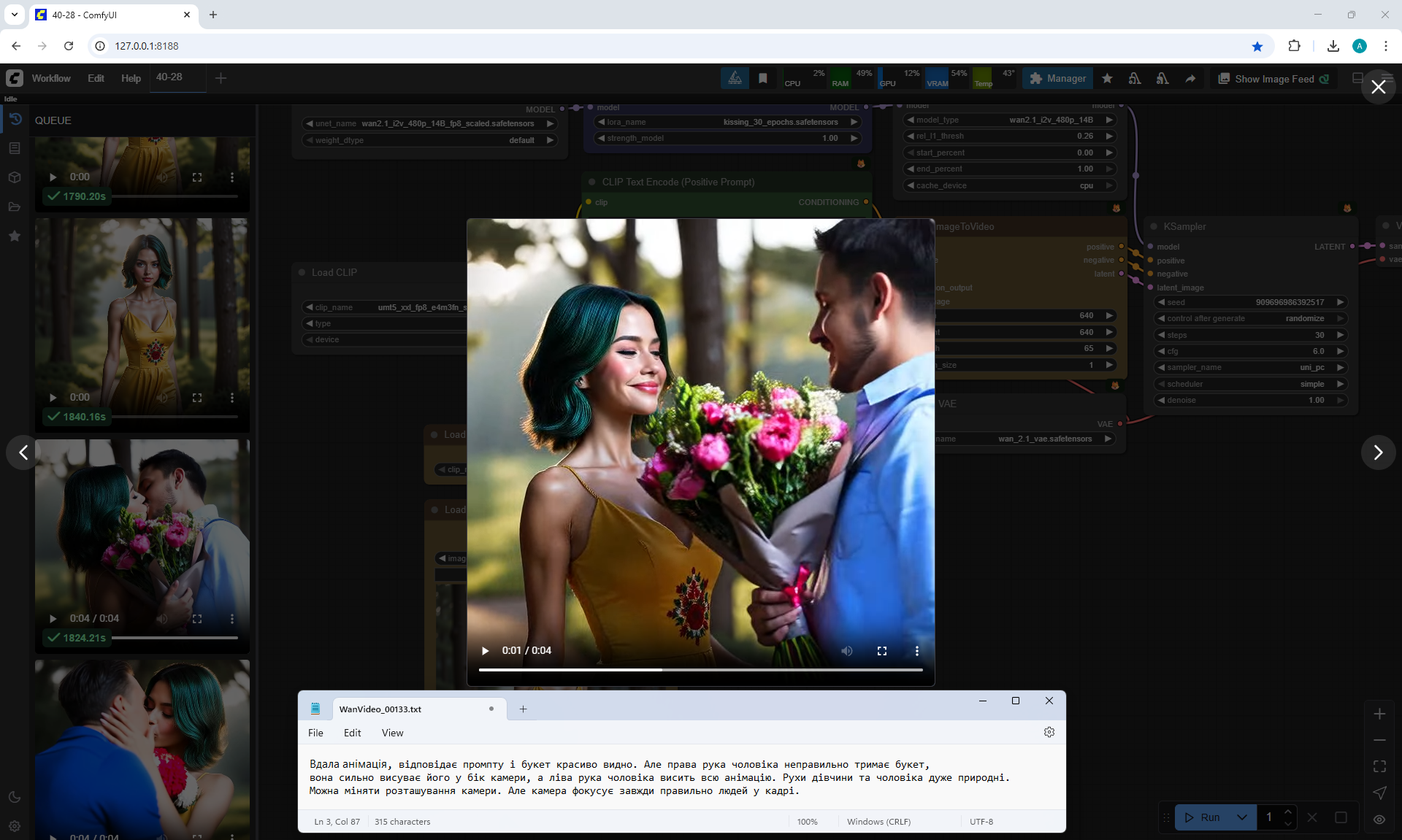
but the boy is shorter than the girl, this animation was generated before I specified in the prompt that the boy is taller than the girl.
Also the boy steps a little on the girl's foot. The boy has very large sneakers, compared to the size of the girl's foot. The boy is holding flowers - sunflowers, which grow around the surrounding background. Basically, the bouquet of colors is generated in bright.
Sometimes the second girl gives the boy flowers. Sometimes two boys appear and kiss, and the girl looks on, smiling.
Sometimes this girl approaches the two and hugs them.
The same prompt can generate a good video, and then errors.
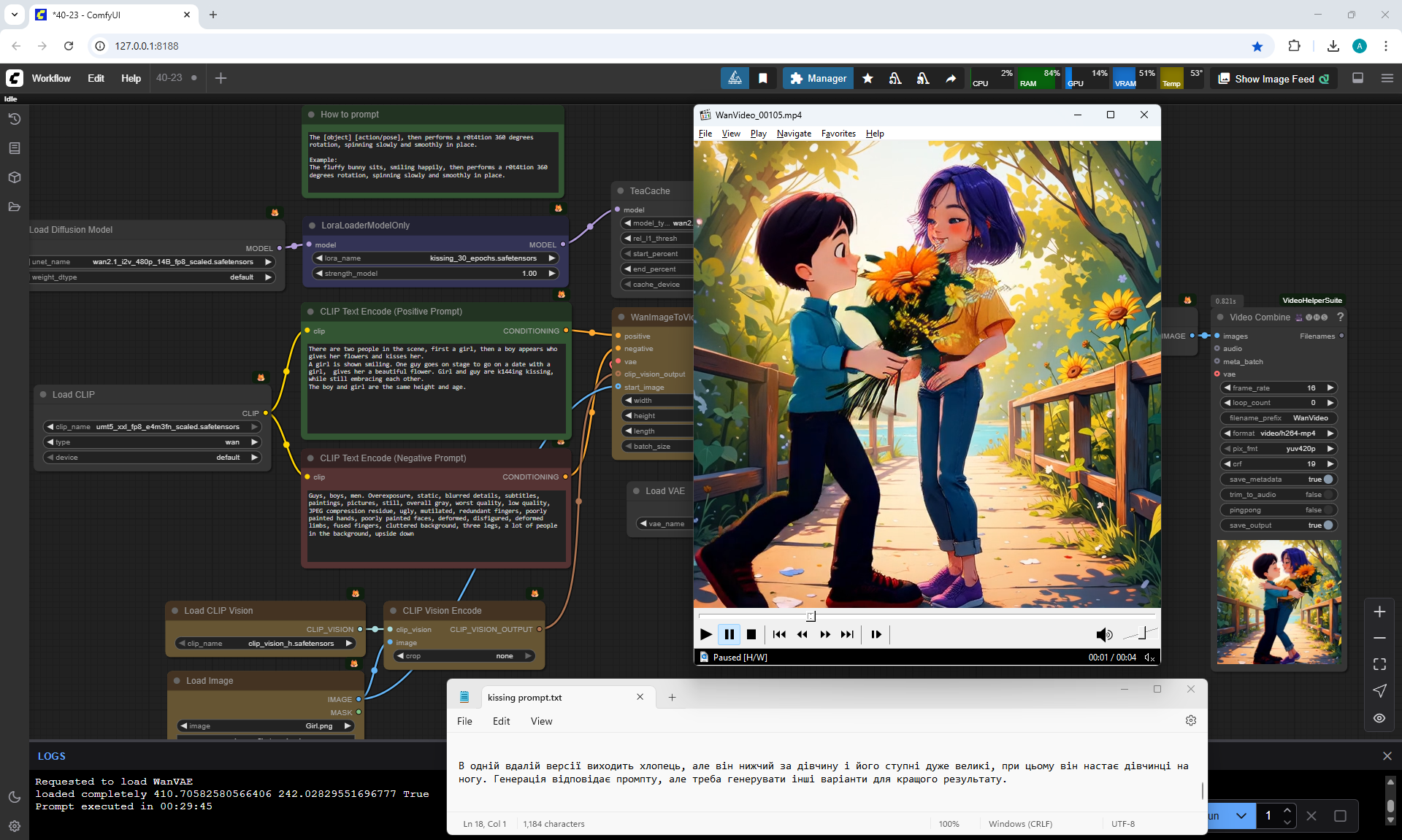
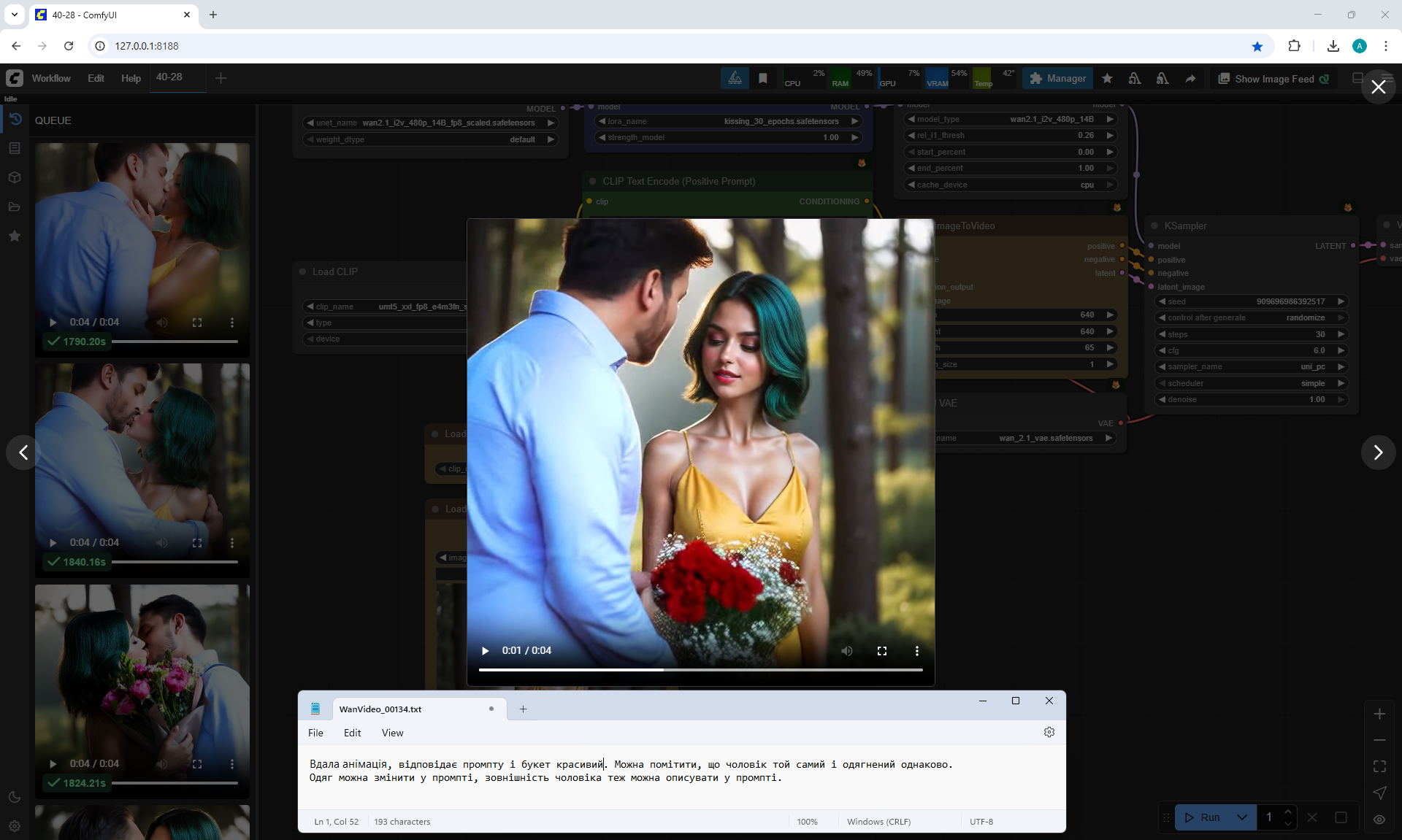
In this video In the prompt, I prescribed clothes for the guy: blue T-shirt, red jeans. Two girls appeared in these clothes.





There were errors in the boy's height, you indicate that the boy is slightly taller than the girl, but the boy appears shorter than the girl and a girl squats when kissing a boy., the boy has no flowers. The girl's jeans have turned into shorts.
I wrote in the prompt that the boy's clothes are similar to the girl's clothes, it generated exactly the same clothes for the boy.
All points need to be specified, what clothes, what color, otherwise there will be unpredictable results.
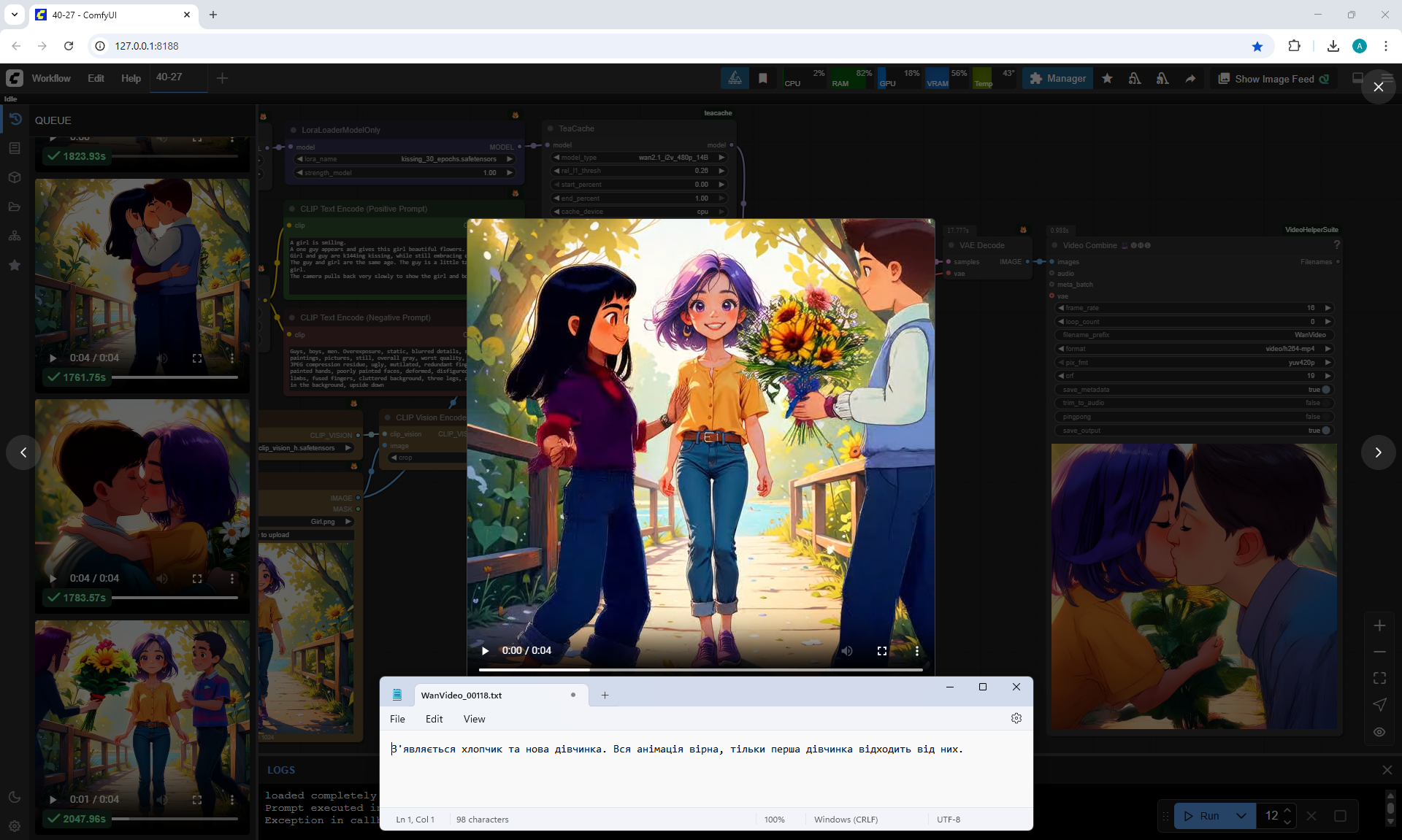
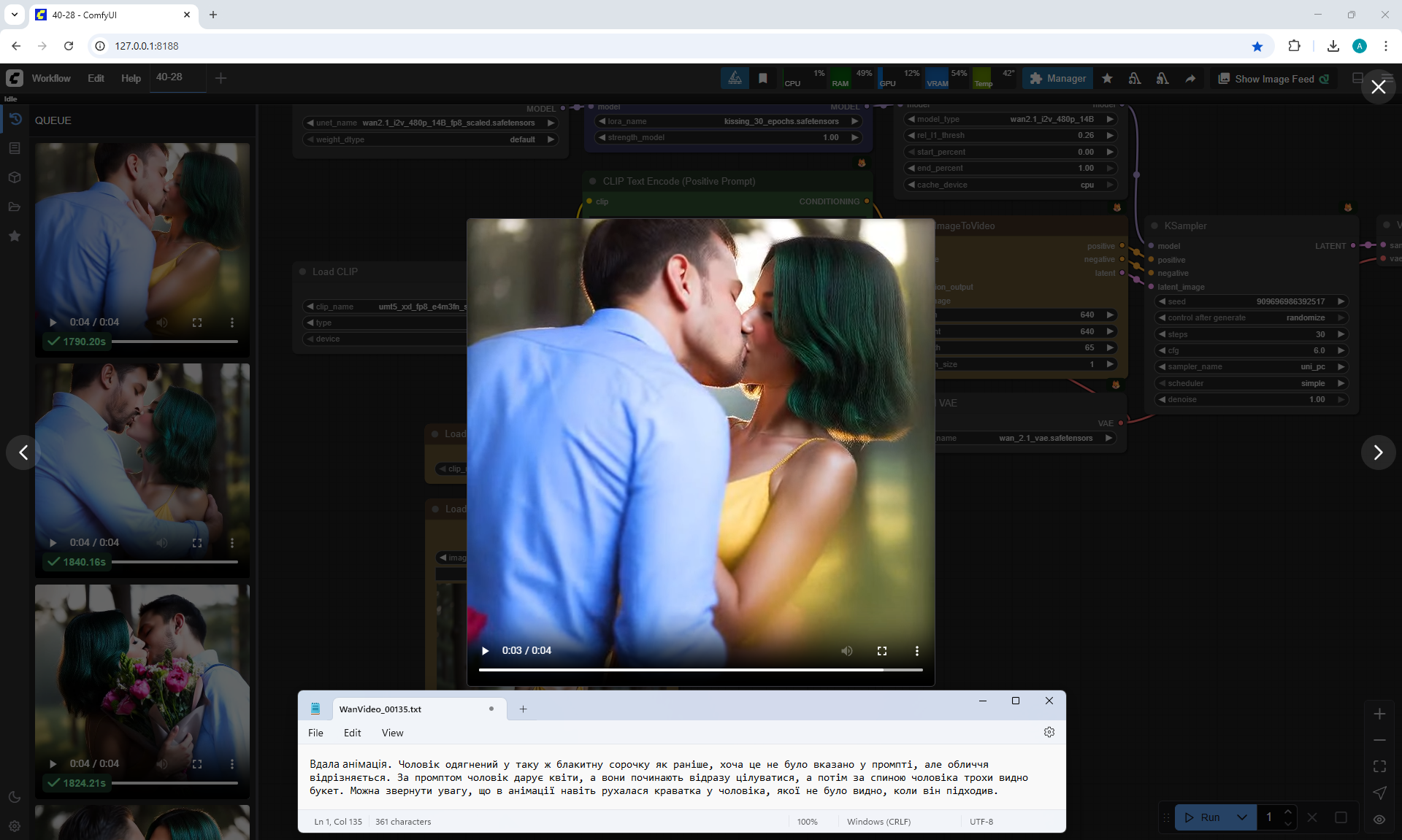
In this video prompt glitches. The boy doesn't notice the girl and encounters her for the first time in generations and keeps walking and pushing her. Another girl appears with flowers, she walks towards the boy. The first girl ends up between them.
In this video
a boy and a new girl appear. The animation is correct, but the first girl moves away from them.
In this video a guy with flowers, dressed in shorts and a t-shirt, meets a girl,
at first everything is fine, then a second boy appears above, who starts hugging and kissing them.
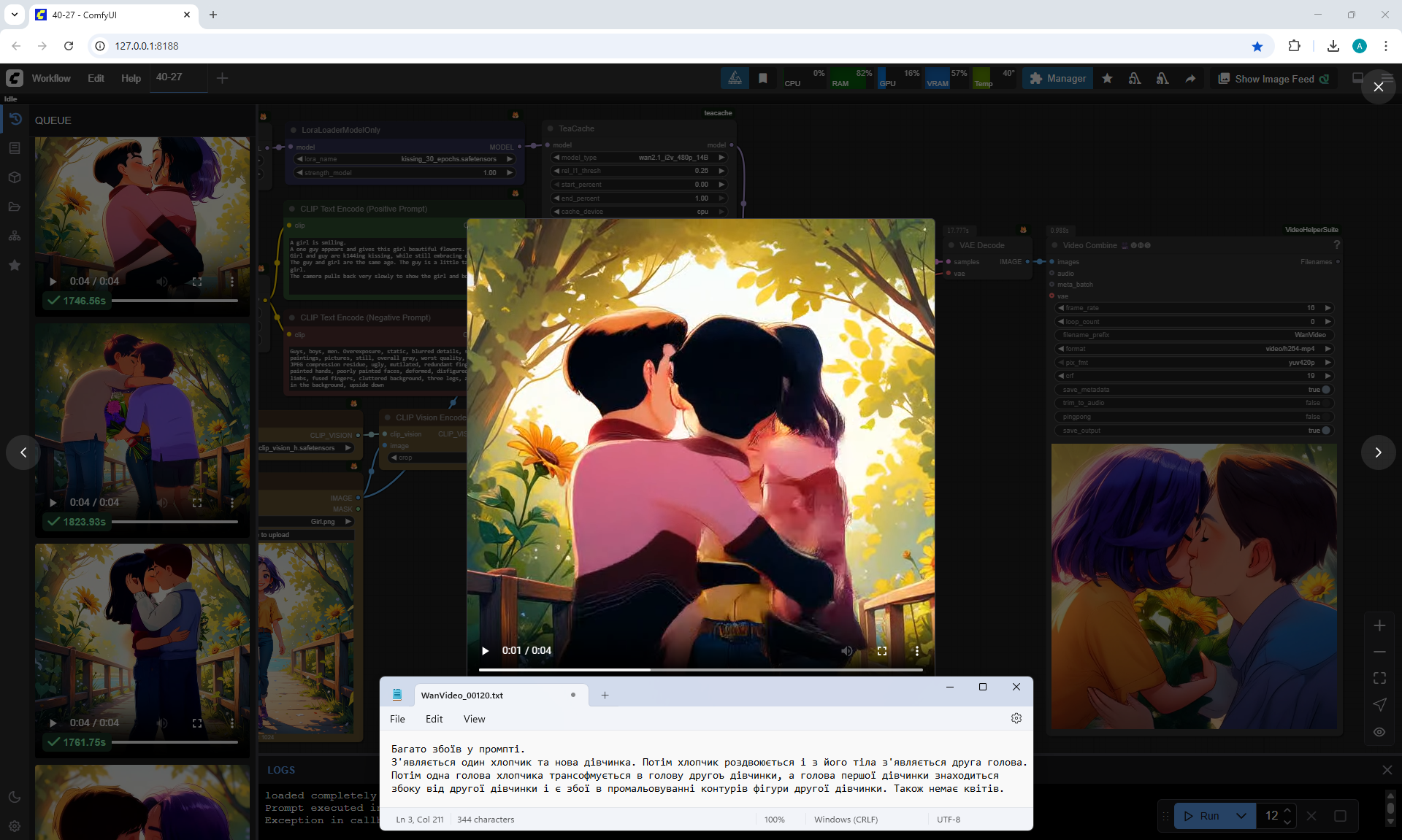
In this video many glitches in the prompt.
One boy and a new girl appear. Then the boy splits and a second head appears from his body.
Then one of the boy's heads transforms into a girl's head, and the first girl's head is on the side of the second girl and there are glitches in drawing the contours of the second girl's figure. Also, there are no flowers.





In this video many mistakes in the prompt. A boy arrives on some kind of seat that looks like part of a moped. The boy has flowers, but he doesn't give them, and immediately the girl sits on his legs and they kiss.
This video more or less corresponds to the prompt. The boy's clothes are not bright, although the prompt indicates bright, but in general it fits, and the bouquet is beautiful, not sunflower. Then there are personal preferences in what clothes the boy should wear, what race he is, etc.
You can pay attention that when I wanted to generate just the girl's gait, there were various glitches, the girl sometimes limped, sometimes her legs diverged to the sides or touched each other. Here the girl's gait was not indicated in the prompt, but in all generations the girl and other people walk and move without glitches, there are no glitches in the movement of the body, arms, head, there are even facial expressions and different reactions of the girl. For example, squeezing when the boys kissed, the girl bent down to the boy's height and kept her size, did not merge in space with another person.
In this video there are also glitches.
A new girl appears, who comes with flowers. But the boy hugs and kisses the first girl.
The first girl approaches and turns sharply to the boy, who leans her heavily.
Then the second girl kisses the boy. The boy and the second girl are dressed well, brightly, their movements are correct.
In this video there are also glitches.
A girl and a boy appear, dressed identically. The second girl is very small for some reason. They each have flowers, they give them to the first girl, they start kissing the first girl, then the first girl's head disappears, the boy's head appears.
In this video animation glitches.
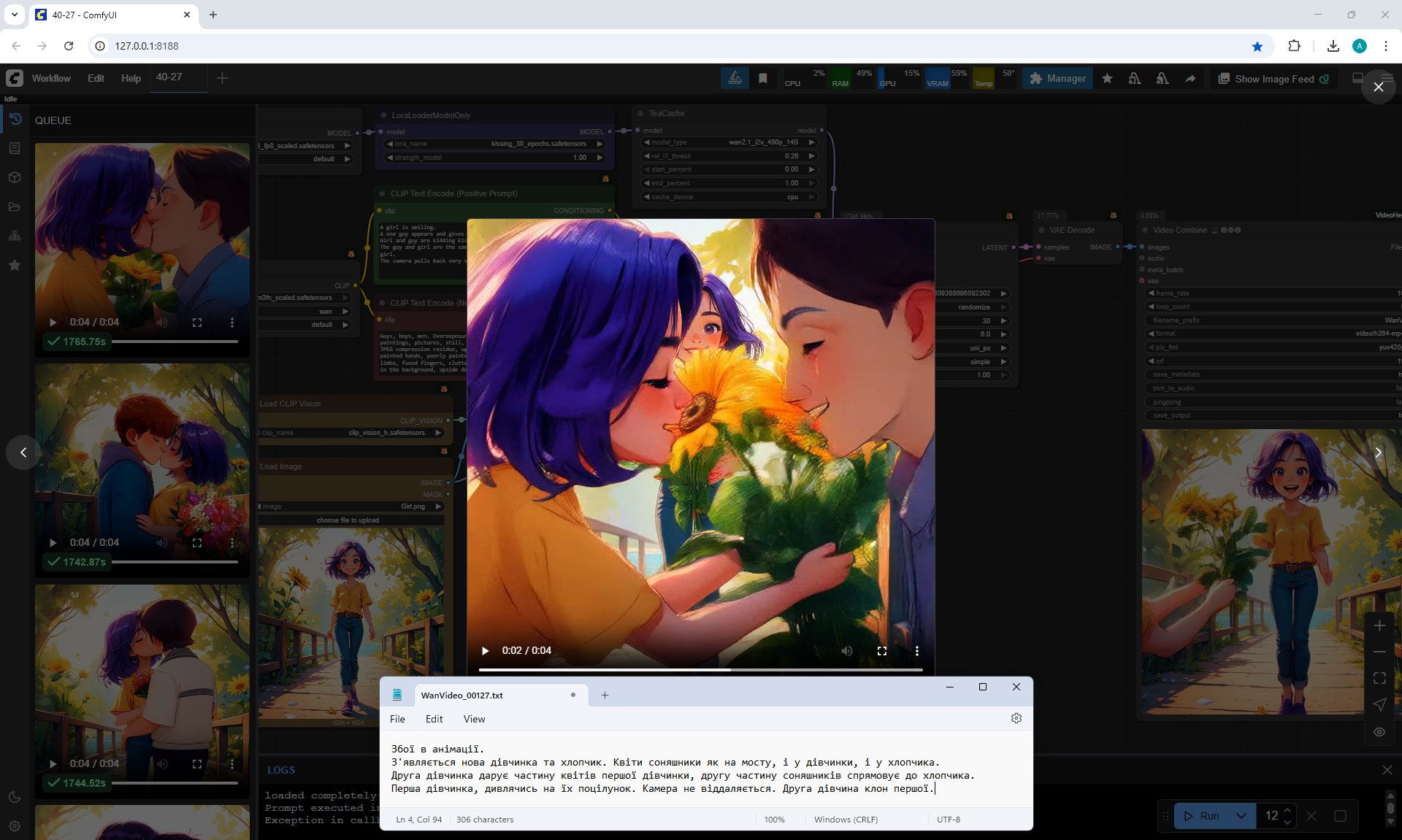
A new girl and boy appear. Sunflowers are like on a bridge, both the girl and the boy.
The second girl gives some of the flowers to the first girl, the second part of the sunflowers she directs to the boy.
The first girl is looking at their kiss. The second girl is a clone of the first.


This videoalso fits. The boy is a little taller than the girl, her age. But when he fits, he is much taller than the girl, and then his height decreases. They have the same skin color, bright clothes.
There is a defect at the end - the boy's left hand is split. Also, at the end, the background lighting appeared to show the girl and the boy more clearly. This was done by the AI itself, this was not specified in the prompt.
In this video in general, in my opinion, everything fits as expected, only the clothes of the boy and the girl are the same.
Here it is necessary to clarify in more detail what the boy is wearing.


This video
comes at the prompt, but jerks sharply during the kiss.
This video
approaches at the prompt, but the girl is limping.


Quality generation, no glitches. Everything worked out fine. Quality generation, no glitches either. Everything worked out fine.


In this video
nice animation, the only thing is, the boy didn't give the girl the flowers, they appeared in the girl's hands themselves.
The boy's left hand, which should have the flowers, hung down and didn't move, and only at the end of the animation did the hand come to life.
High-quality generation, no glitches.
The boy moved his hand a little abruptly as he approached.
The prompt had loose clothing, so the boy was wearing a hoodie. Sometimes the boy is in a suit, sometimes in a T-shirt.





I tested LoRa animation effects with rotation on Wan2.1 14B 480p I2V LoRAs
360 Degree Rotation Effect LoRA for Wan2.1 14B I2V 480p
Цю жінку I generated in lesson 28.
This is the prompt I used to generatelarge 2 second video:
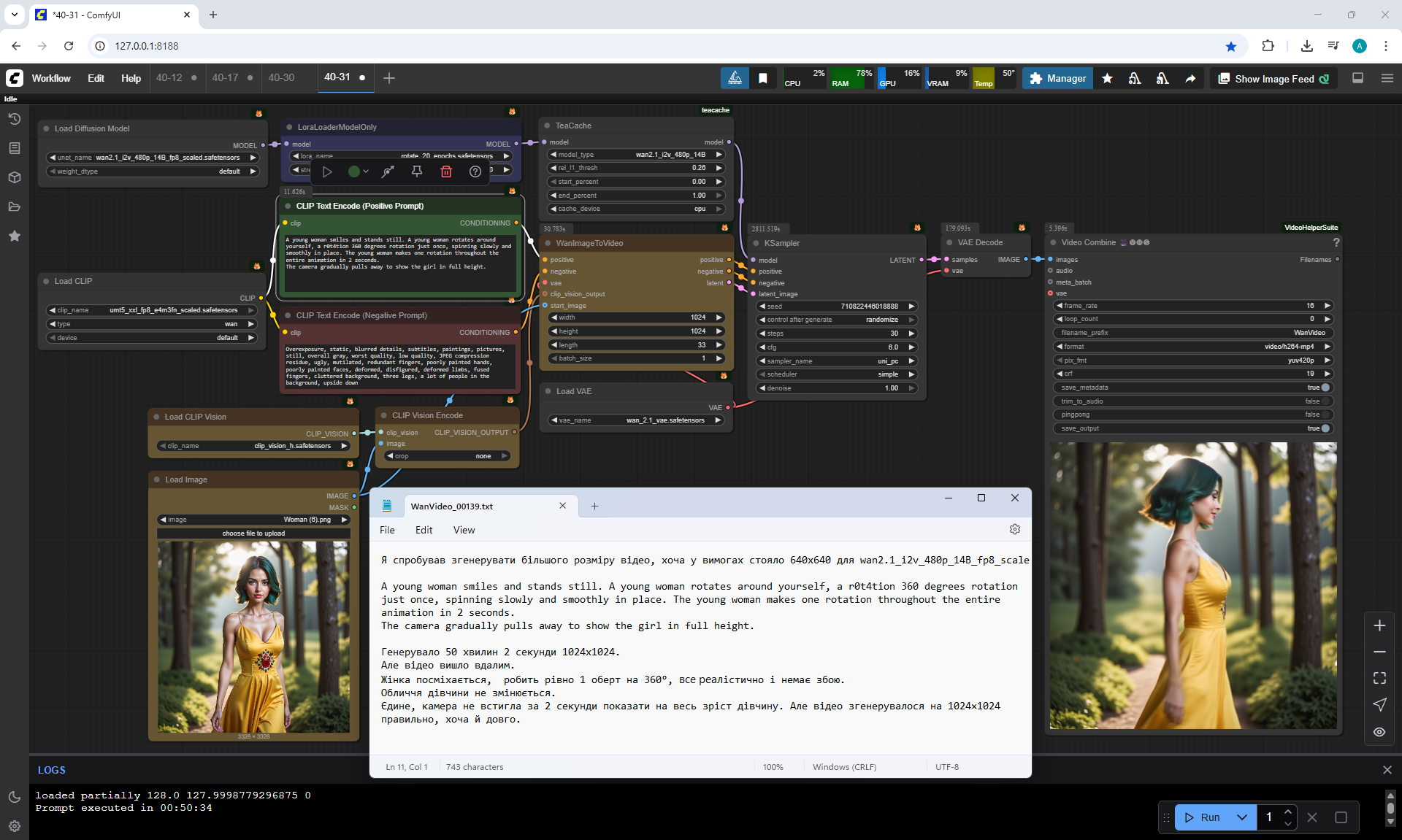
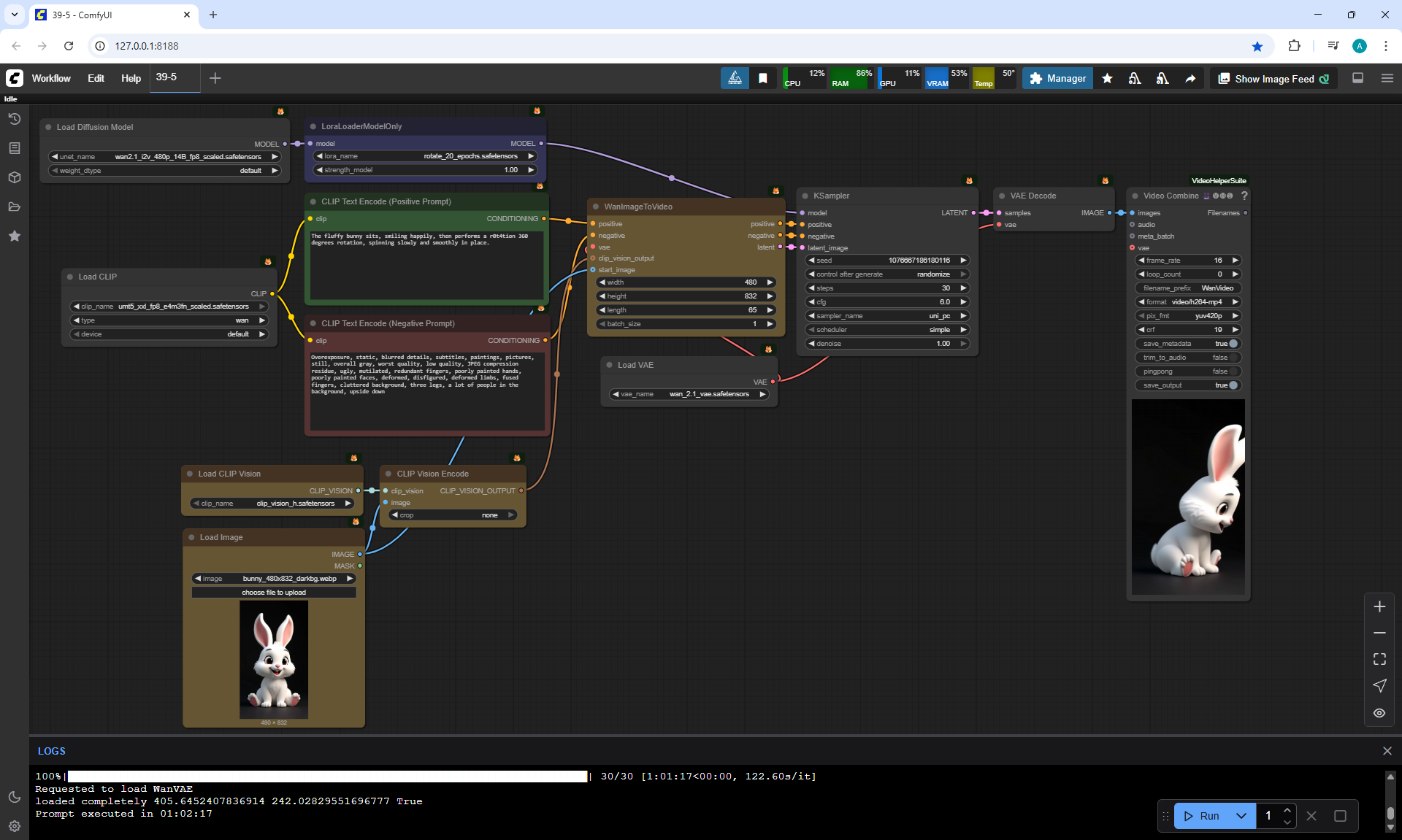
A young woman smiles and stands still. A young woman rotates around yourself, a r0t4tion 360 degrees rotation just once, spinning slowly and smoothly in place. The young woman makes one rotation throughout the entire animation in 2 seconds.
The camera gradually pulls away to show the woman in full height.
When I generated a 4 second video, the girl always spun around herself a few times.
When I generated a 2 second video, the girl correctly made one 360° rotation.
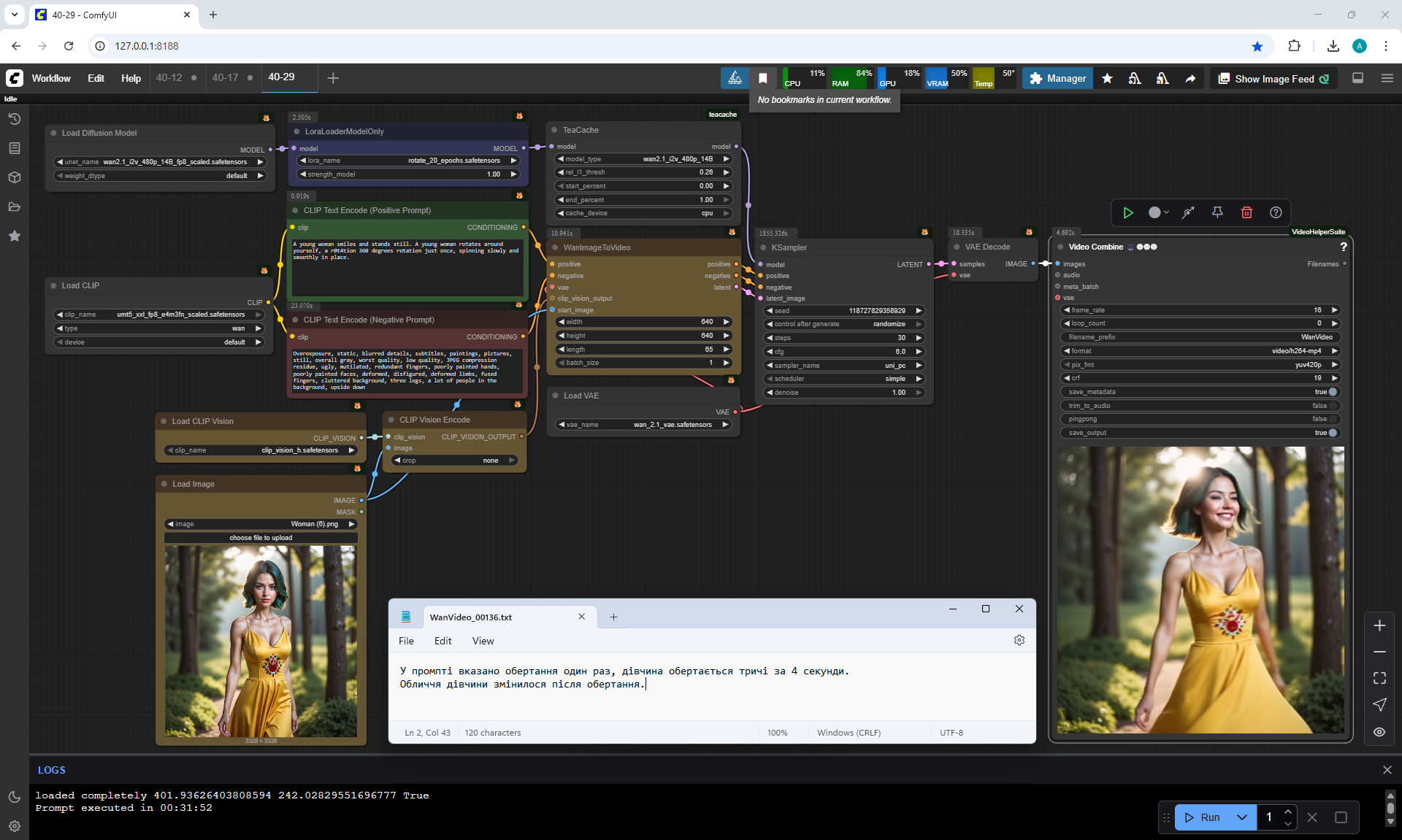
The prompt says to rotate once, The girl turns around three times in 4 seconds.
The girl's face changed after rotation. There are no obvious defects in the animation, the camera does not move away.
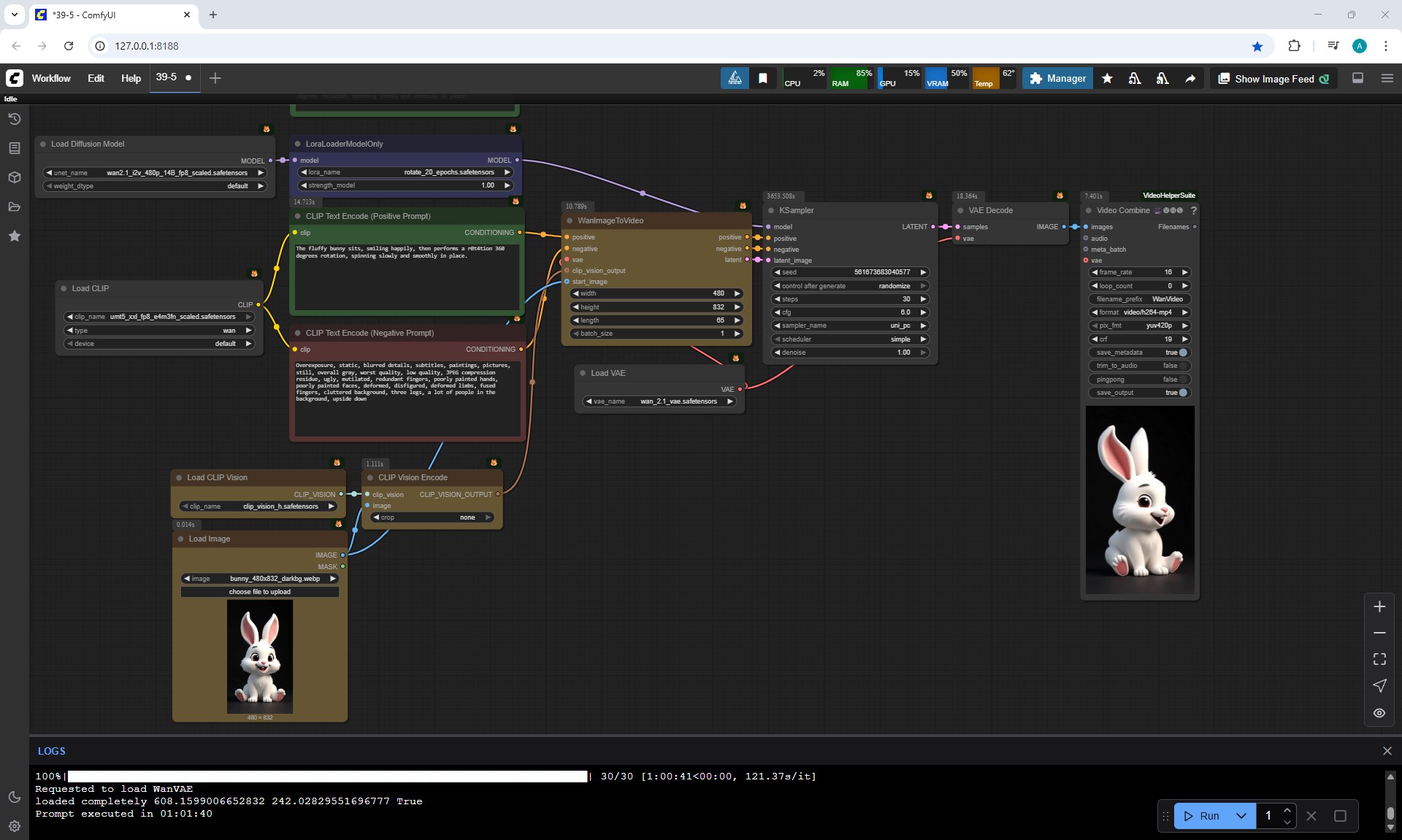
Changed the prompt:
A young woman smiles and stands still. A young woman rotates around yourself, a r0t4tion 360 degrees rotation just once, spinning slowly and smoothly in place. In four seconds the girl makes one rotation.
The camera gradually pulls away to show the girl in full height.
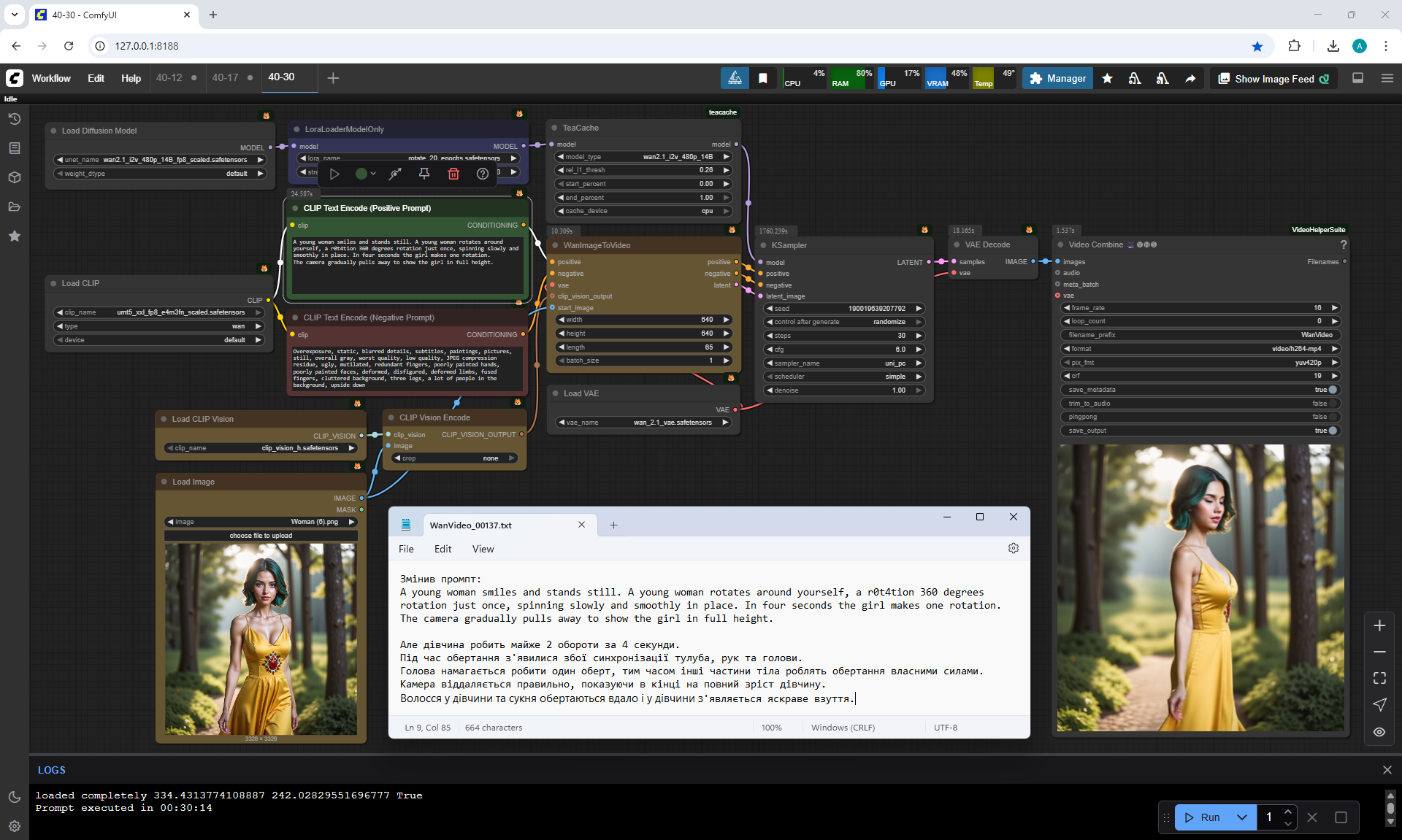
But In the video, the girl makes almost 2 revolutions in 4 seconds.
During the rotation, synchronization failures of the torso, arms and head appeared.
The head tries to make one rotation, while the other parts of the body rotate on their own.
The camera zooms out correctly, showing the girl in full growth at the end.
The girl's hair and dress rotate successfully and the girl's bright shoes appear.
But there is a failure of the rotation of the head and hair.
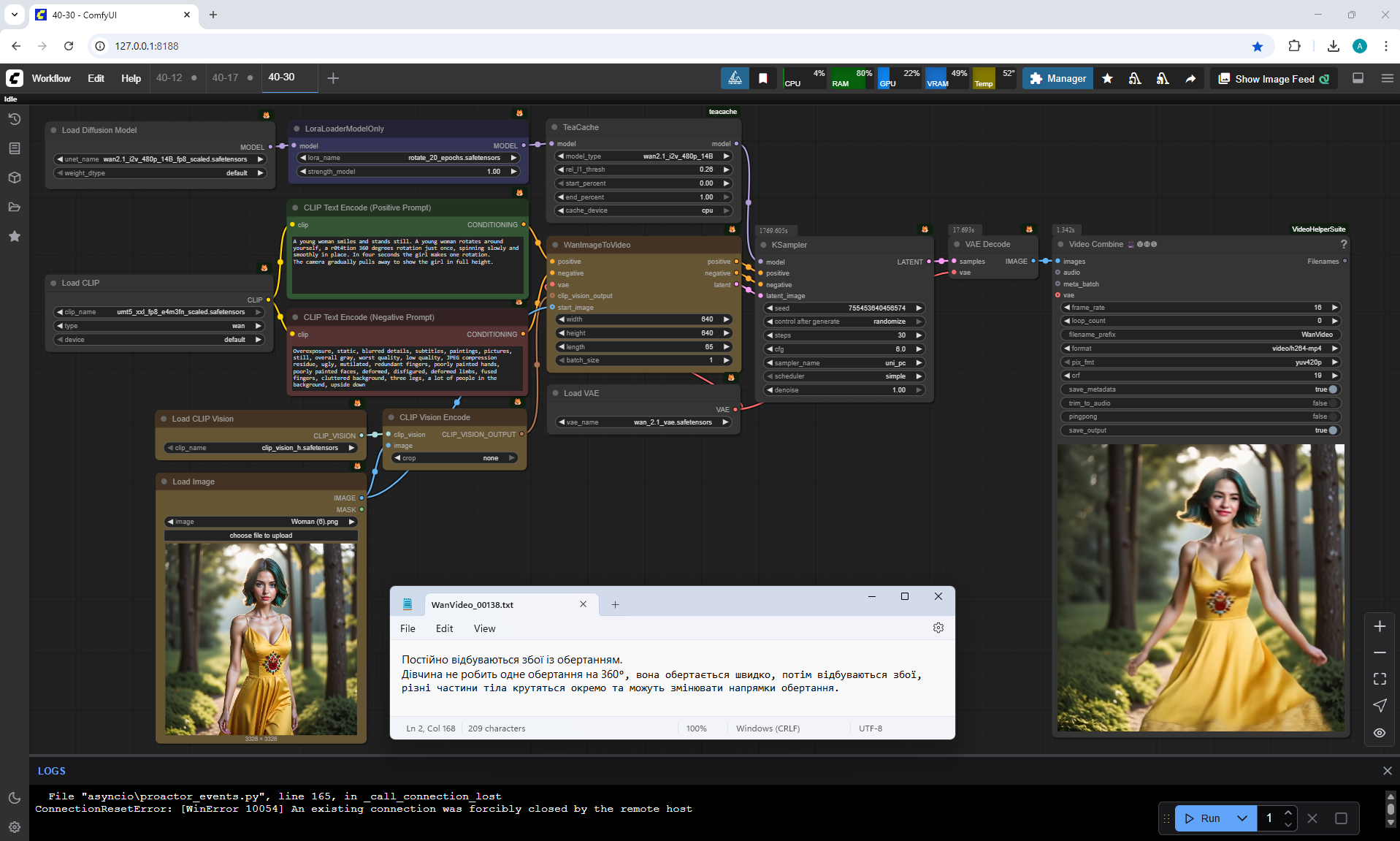
Rotation failures occur constantly.
The girl doesn't do one 360° rotation, it spins fast, then crashes, different parts of the body spin separately and can change directions of rotation.
I tried to generate a larger video, although the requirements said 640x640 for wan2.1_i2v_480p_14B_fp8_scale:
A young woman smiles and stands still. A young woman rotates around yourself, a r0t4tion 360 degrees rotation just once, spinning slowly and smoothly in place. The young woman makes one rotation throughout the entire animation in 2 seconds.
The camera gradually pulls away to show the girl in full height.
It took me 50 minutes and 2 seconds to generate a 1024x1024 video on my computer,
but the video turned out well.
The woman smiles, makes exactly 1 rotation of 360°, everything is realistic and there are no glitches.
The girl's face does not change.
The only thing is that the camera did not have time to show the girl in full growth in 2 seconds. The generated video at 1024×1024 corresponds to the prompt, there are no glitches, although it was generated for a long time.




I tested LoRa animation effects with a kiss on Wan2.1 14B 480p I2V LoRAs
Kissing LoRA for Wan2.1 14B I2V 480p
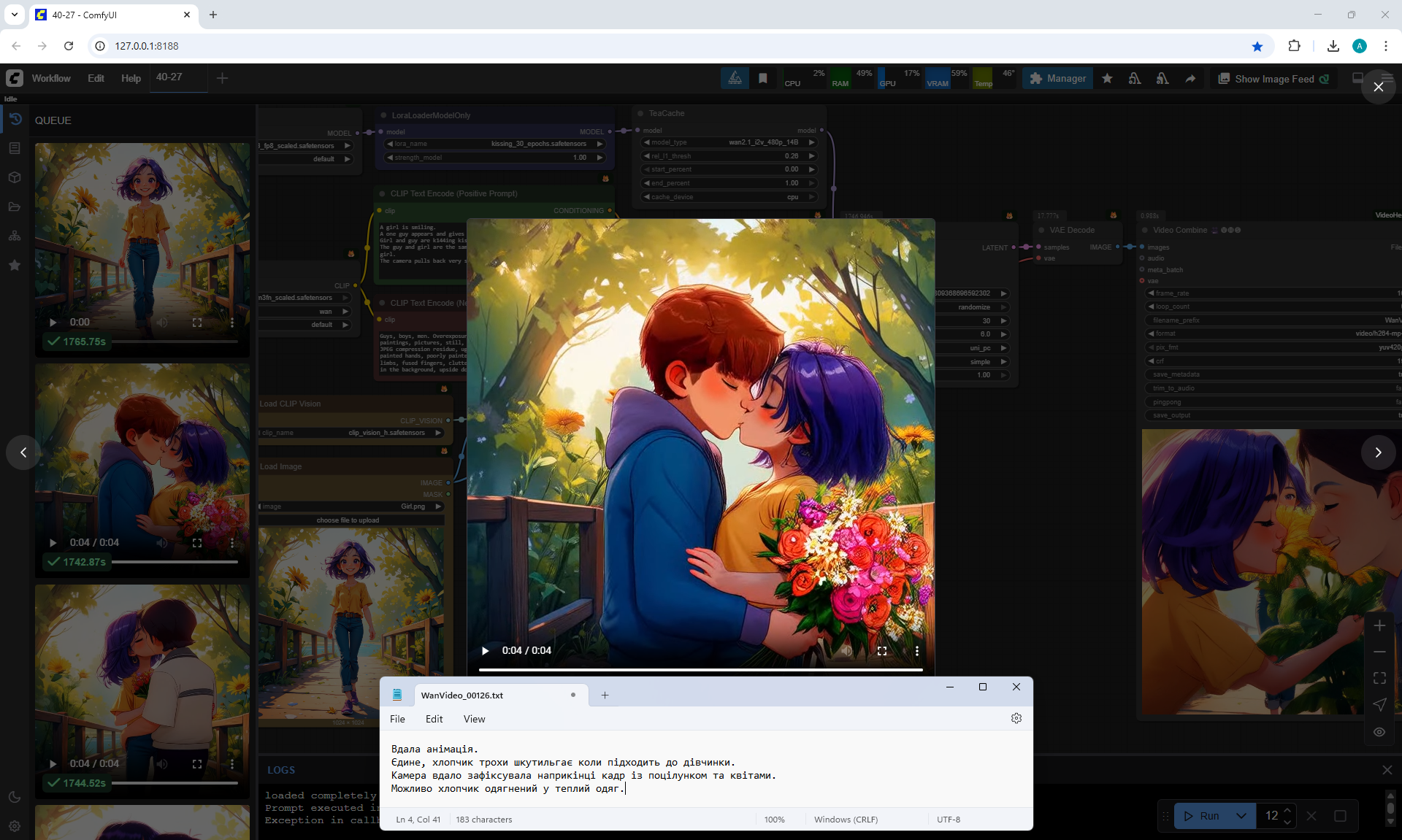
This woman I generated in lesson 28.
Prompt:
A woman is smiling.
A one man appears and gives this woman beautiful flowers.
Woman and man are k144ing kissing, while still embracing each other.
The man and woman are the same age. The man is a little taller than the woman.
The camera pulls back very slowly to show the man and woman well.
I did not prescribe men's clothing in the prompt.
All men have good clothes, a blue shirt, a suit, clothes that fit the appearance of a woman.
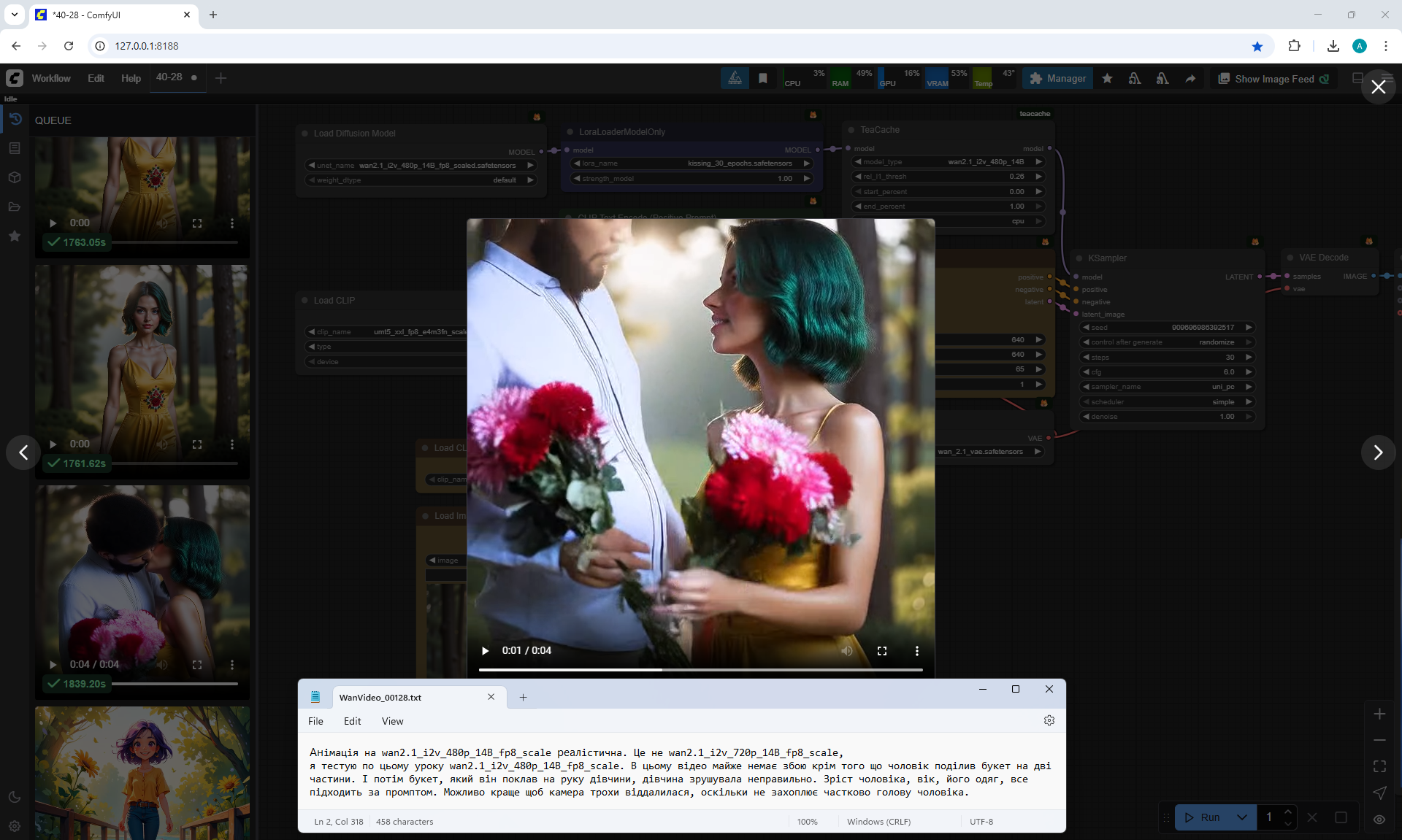
Ця анімація вдала.
Maybe it's worth moving the camera away, but the camera follows the couple's movement and keeps them in close-up.
But the prompt says that the camera is slowly moving back.
Good animation.
There is almost no glitch in the video except that the man divided the bouquet into two parts. And then the bouquet that he put on the girl's hand, the girl moved it incorrectly. The man's height, age, his clothes, everything fits the prompt. It is better if the camera moves a little further away, so as not to partially capture the man's head.
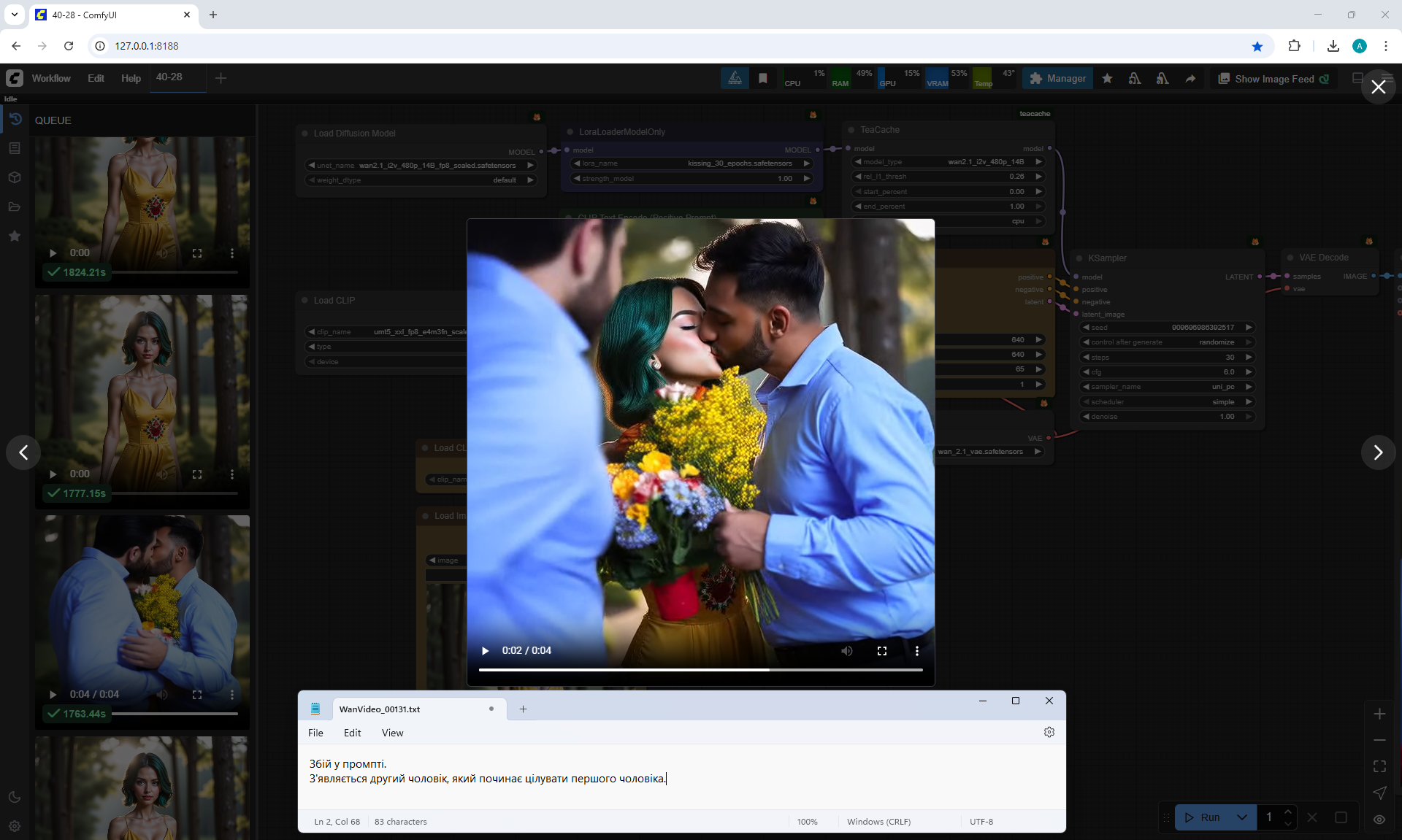
Two men appear in this video.
In the video, everything is correct at first, one man appeared, who gave flowers to a woman, they kiss and hug. But suddenly a second man appears, also with flowers and kisses the first man. When the second man gives flowers, the woman extends her hand, but does not take the bouquet and the bouquet levitates in the air. The first man hugs the second man with his hand and it is visible that he has a woman's manicure on his fingers.
Good animation.
The man is wearing the same blue shirt as before, although this was not indicated in the prompt, but the face is different. At the prompt, the man gives flowers, and they immediately start kissing, and then a bouquet is slightly visible behind the man's back. You can notice that the animation even moved the man's tie, which was not visible when he approached. Also, the pattern on the woman's dress never disappeared.


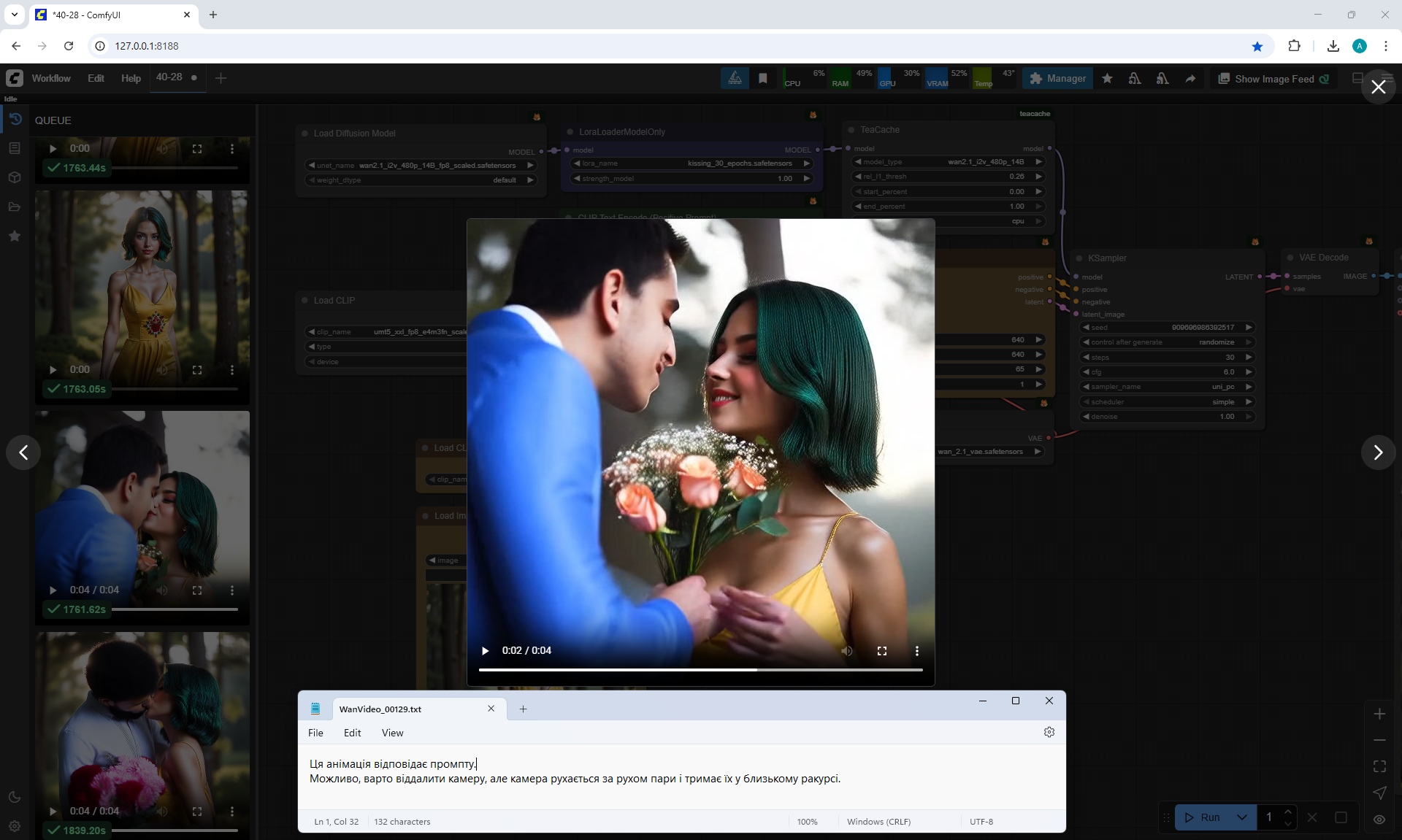
This animation corresponds to the prompt.
Good animation, due to the fast movement of the man there is a small defect with the flowers, they are not clearly visible and change shape.
In the animation the man moves from one side to the other, the movement is not natural, similar to circling in a dance.
Good animation, corresponds to the prompt.
It is possible to change the camera position.


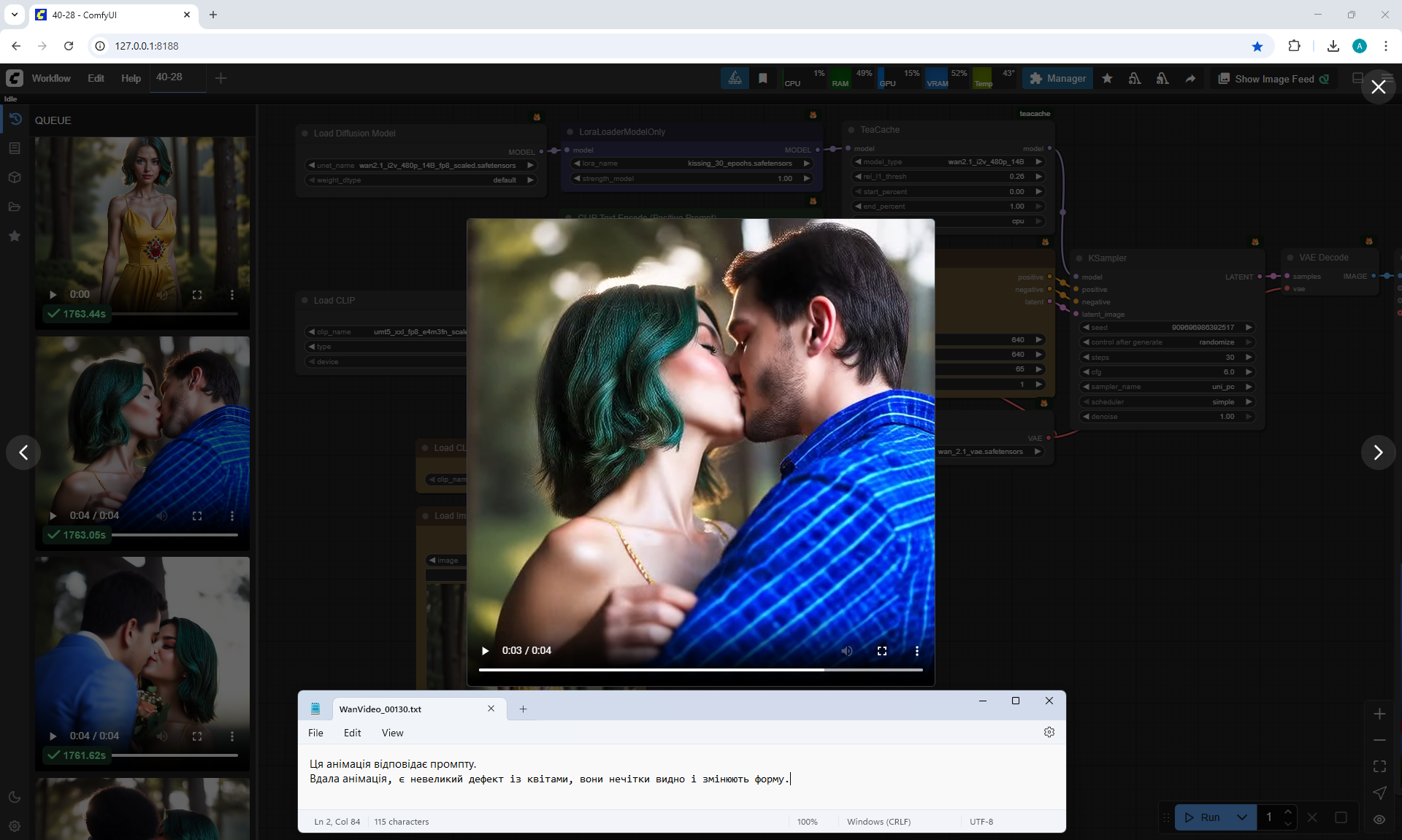
Good animation.
The animation corresponds to the prompt and the bouquet is beautifully visible. But the man's right hand is holding the bouquet incorrectly, it pushes it strongly towards the camera, and the man's left hand hangs throughout the animation.
You can change the camera position, move them away to show people in full growth. The camera almost always focuses correctly on people in the frame as indicated in the prompt.
The animation is good, it matches the prompt, and the bouquet is beautiful.
You can see that the man looks similar to the man in the previous video and is dressed the same.
The clothes can be changed in the prompt, the man's appearance can also be described in the prompt.

Good animation, corresponds to the prompt.
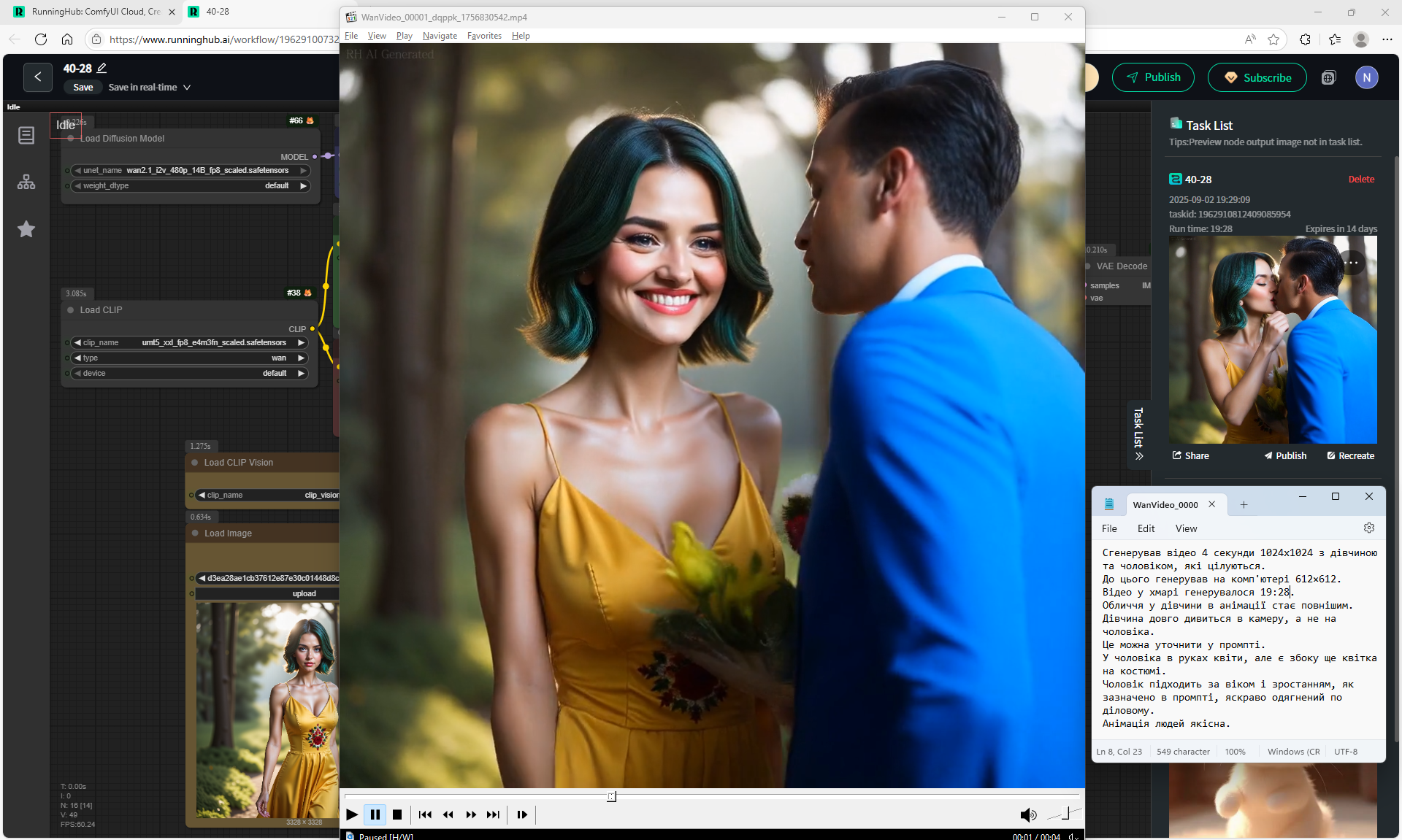
Generated a 4 second 1024x1024 video with a girl and a man kissing.
This is one video with this woman and man kissing of this size.
Before that, I generated on a 612x612 computer.
On Wan2.1 14B 480p I2V, this size 1024x1024 is not recommended, but the animation in it turns out to be of high quality.
I cannot generate a 4 second video on Wan2.1 14B 480p I2V on a computer of this size 1024x1024, a GPU load error appears, in this size 1024x1024 I was able to generate a video for only 2 seconds. The video in the cloud was generated for 19 minutes 28 seconds.
The faces in the video are realistic, the girl's eyelashes are detailed, the people's hair is better visible, the hands are well detailed, the girl's manicure is clearly visible.
The girl's face in the animation becomes fuller. The girl looks into the camera for a long time, not at the man.
This can be clarified in the prompt.
The man has flowers in his hands, but there is another flower on the side of the suit.
The man is suitable in age and height, as indicated in the prompt, dressed in bright, business clothes.
The animation of people is high-quality.




I tested LoRa animation effects with a samuraiWan2.1 14B 480p I2V LoRAs
Samurai Effect LoRA for Wan2.1 14B I2V 480p
This woman I generated in lesson 28.
Prompt:
A woman begins the 54mur41 samurai transformation, and becomes a samurai. She is wearing a traditional samurai outfit, and is holding a katana.
The woman's clothes are replaced by those of a samurai.
The colors of the girl's samurai robe are black or red or other colors, the robe has decorations like the samurai ones.
The woman doesn't walk, she stands still.
All parts of the girl's body move correctly, the girl's head and torso move synchronously.
The camera smoothly moves back and shows the girl in full height.
The animation is unsuccessful.
The girl's dress does not change.
She wears beige jeans, and holds two swords in her hands.
The girl bends her leg at the knee, but then she can't hold this position.
The animation looks like the girl's rehearsal before she learns to transform into a samurai.
The camera zooms out correctly and captures the girl's full height at the end of the animation.
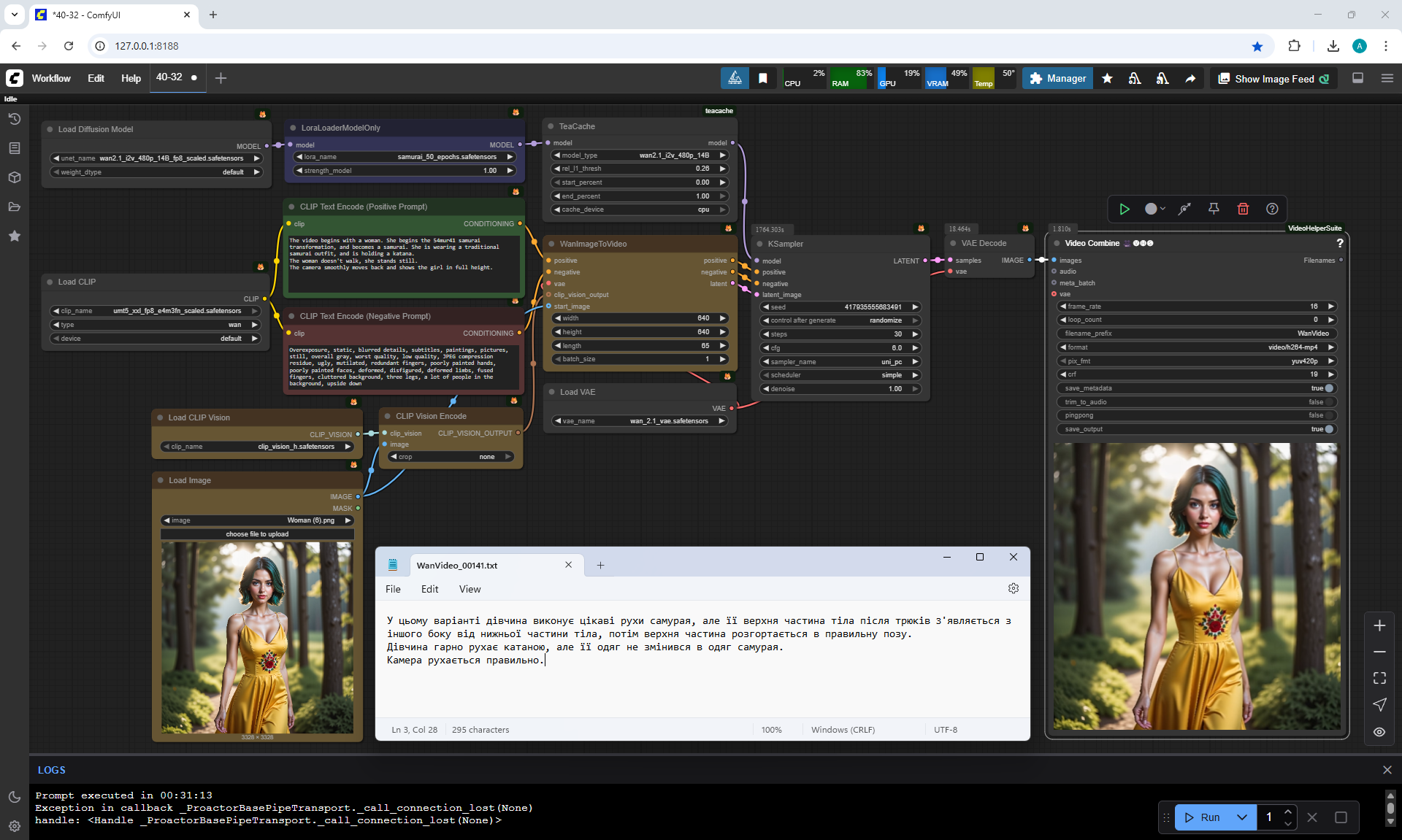
In this version, the girl performs interesting samurai movements.
But the upper part of the woman's body after the tricks appears on the other side of the lower part of the body, then the upper part unfolds into the correct pose.
The girl moves the katana beautifully, but her clothes have not changed into samurai clothes.
The camera moves correctly.
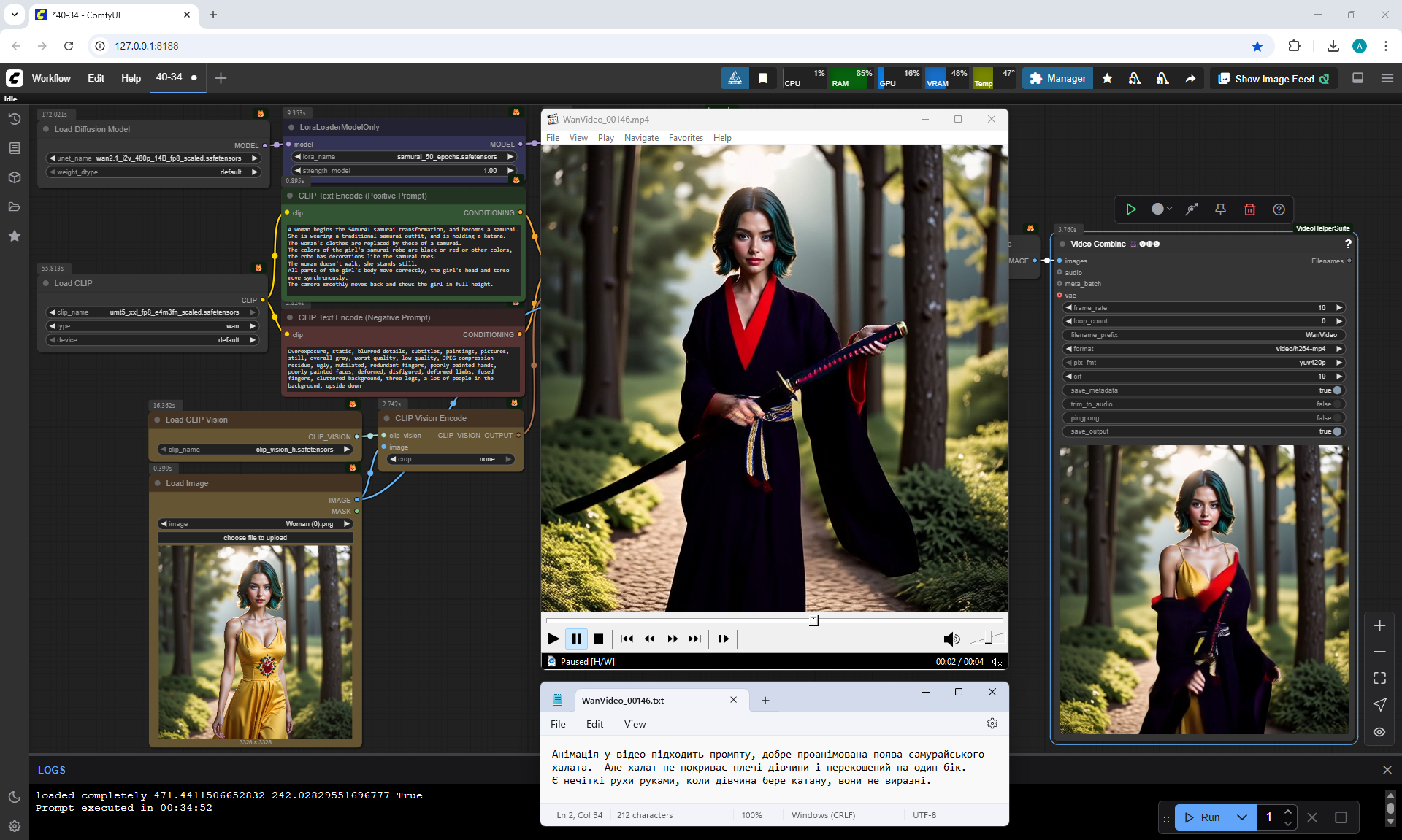
At the beginning of the animation, there is a delay of the girl on one frame, perhaps this is because at first in the prompt I indicated that the girl was smiling, then I further described the details of the animation.
A girl doesn't turn into a samurai.
For some reason, the woman's yellow dress doesn't change into samurai clothing, although it worked well with the cartoon-style girl and the girl animated well into various samurai poses.
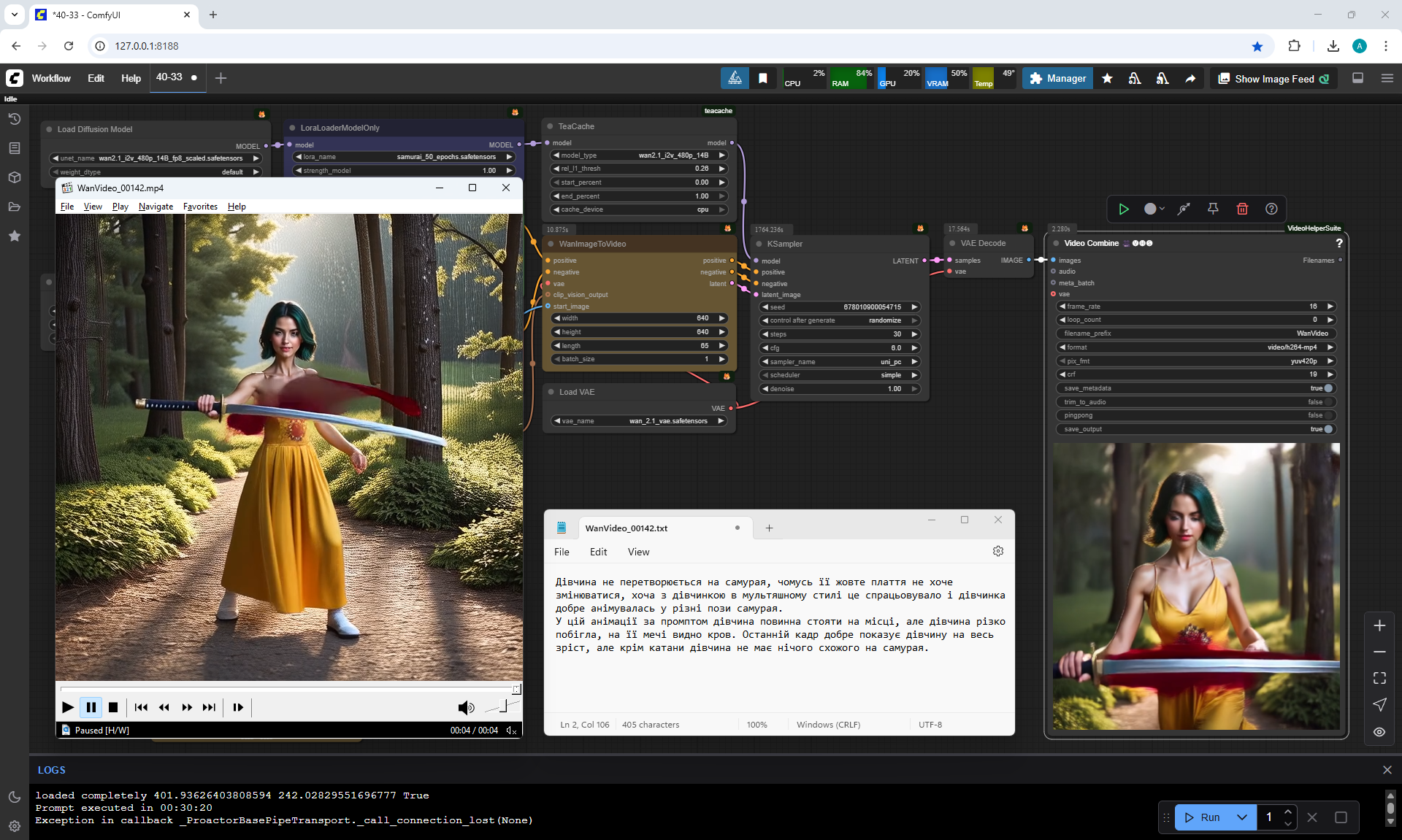
In this animation, the girl is supposed to stand still at the prompt, but the girl suddenly runs away, blood is visible on her sword. The last frame shows the girl well in full growth, but apart from the katana, the girl has nothing resembling a samurai.
Partially successful generation.
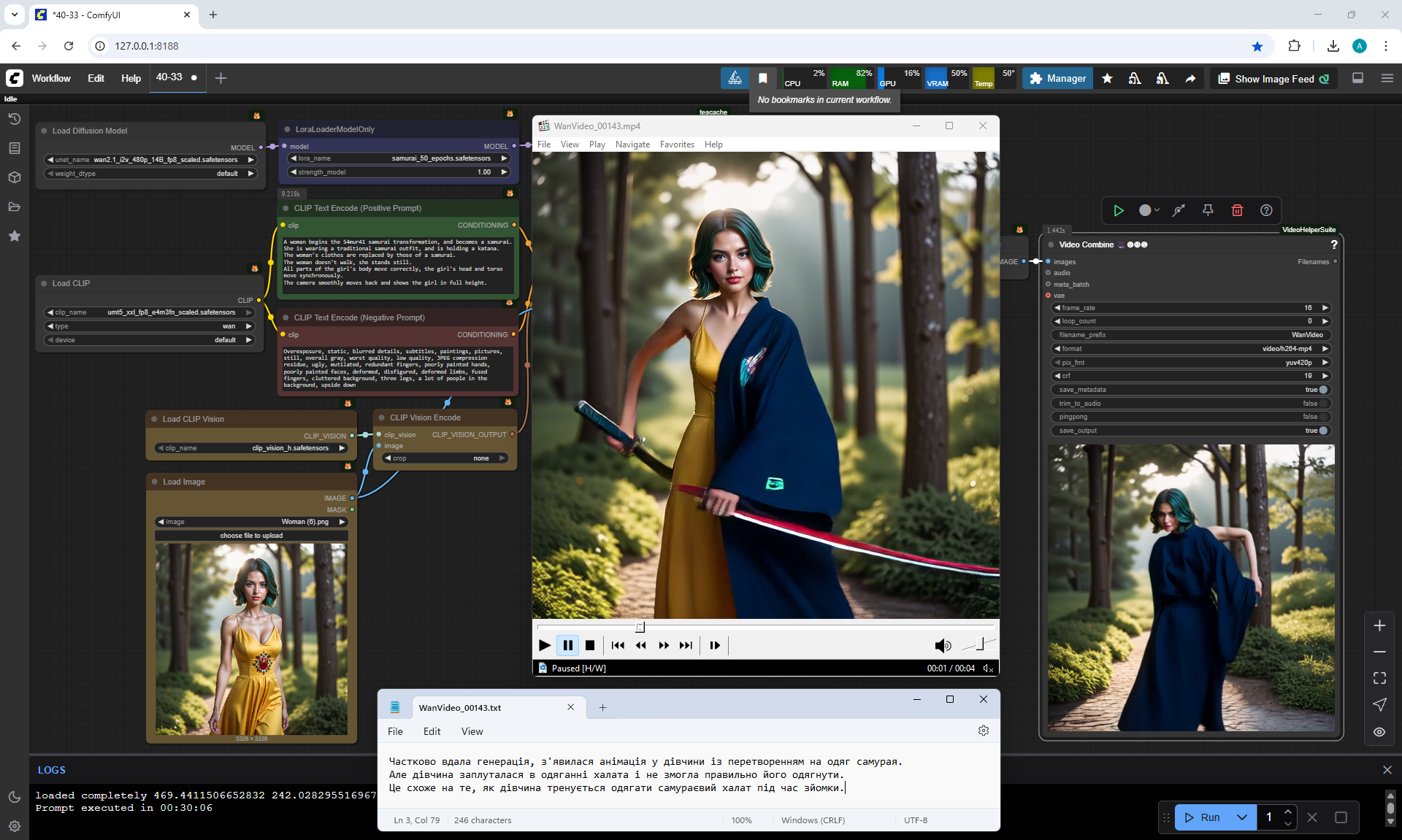
The girl had an animation of her transformation into samurai clothes.
But the girl got confused in putting on the robe and couldn't put it on properly.
It's like the girl practicing putting on a samurai robe during filming.




I like how the girl is animated and the appearance of the samurai robe,
there is a glitch in the animation with the hand when the katana appeared.
The samurai robe is always blue for some reason, I added the color of the robe to the description later.
I like the idea of this rotation animation.,
but the animation is correct from 2 seconds.
Towards the middle of the animation, a person runs out at the beginning and turns into a girl. The girl's head rotation is animated incorrectly.
The black robe with red inserts looks beautiful. At the end of the animation, the girl has a beautiful samurai gesture, a spectacular movement with a katana and smiles nicely.
The animation in the video fits the prompt,
the appearance of the samurai robe is well animated. But the robe does not cover the girl's shoulders evenly and is skewed to one side.
There are unclear hand movements when the girl takes the katana, they are not expressive.
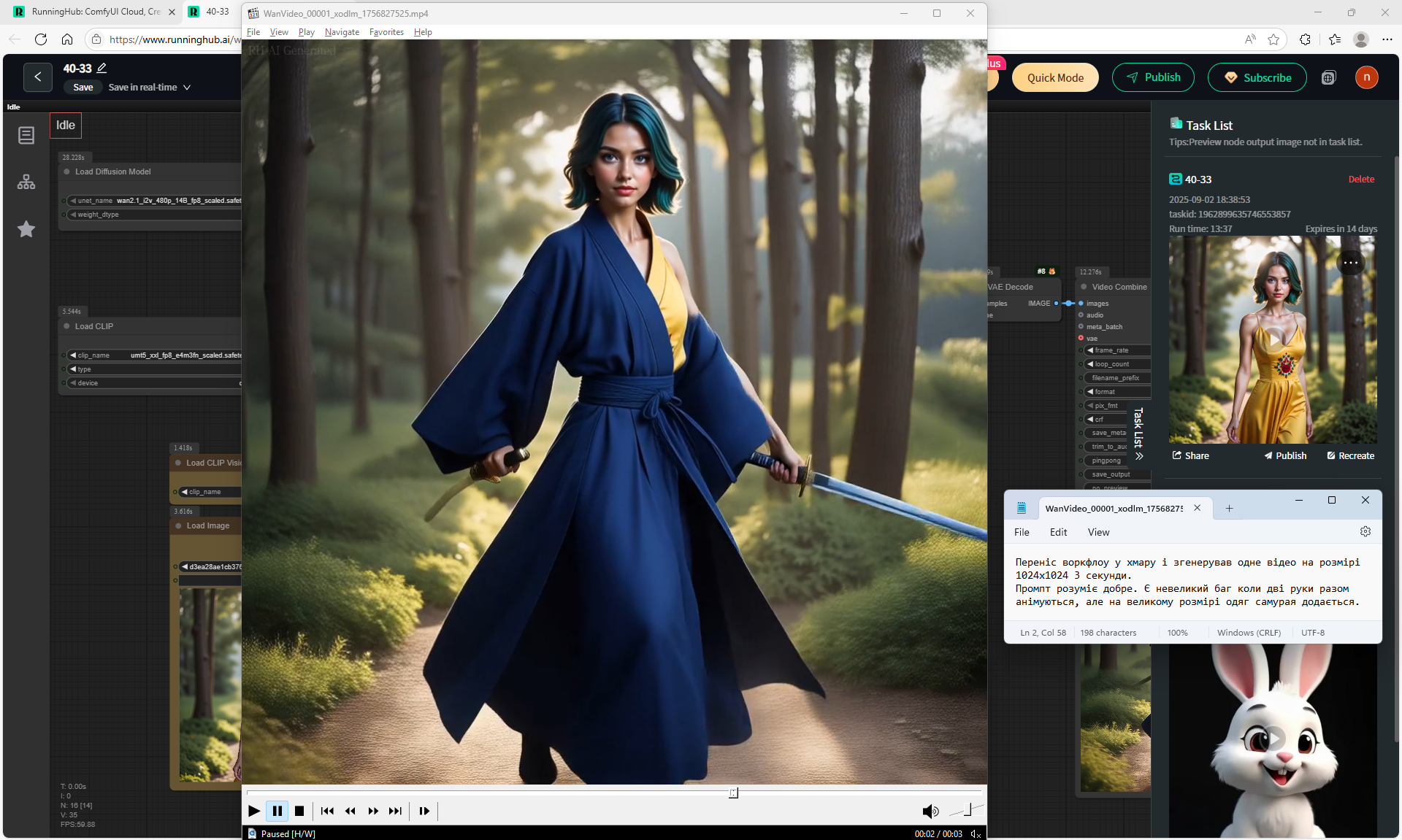
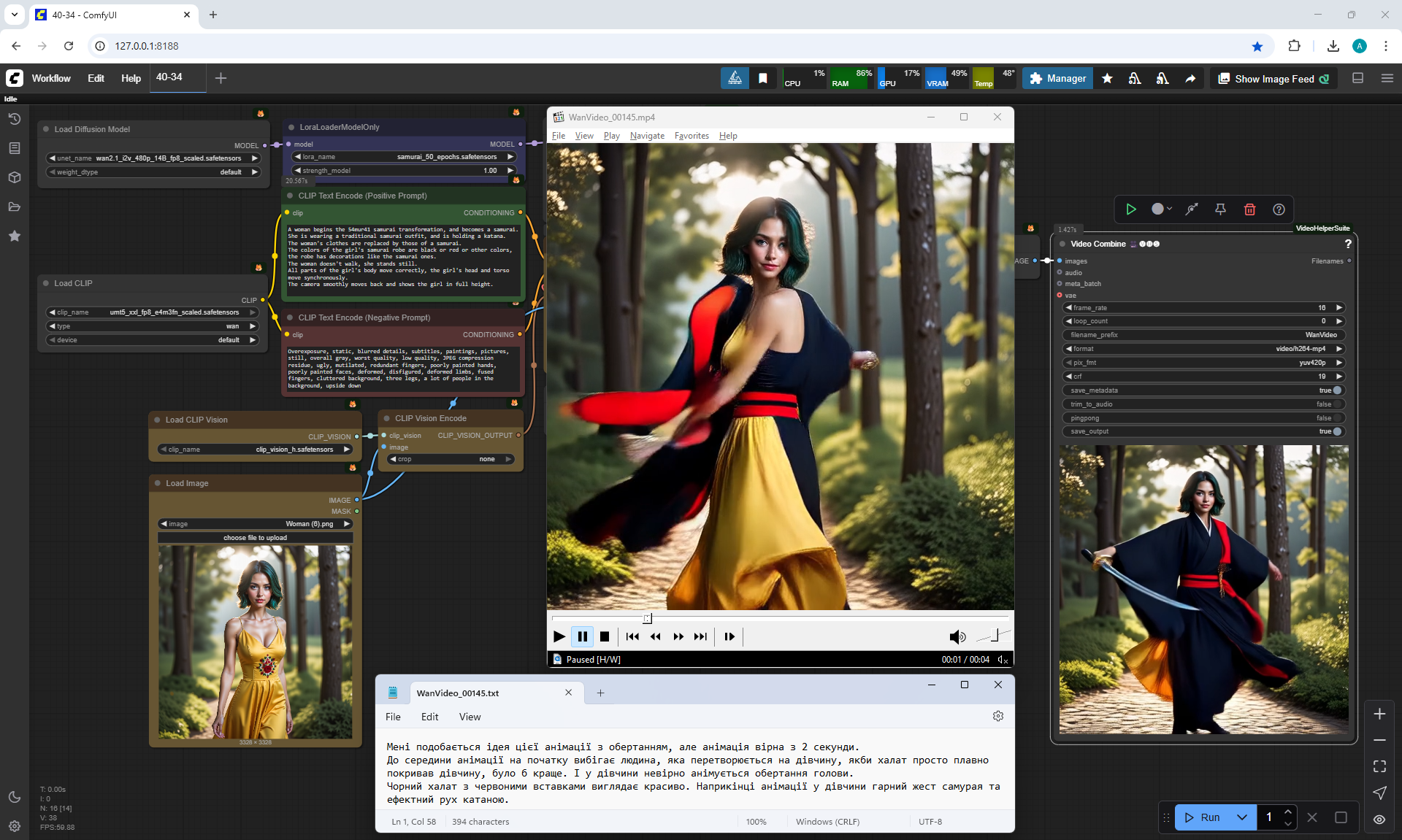
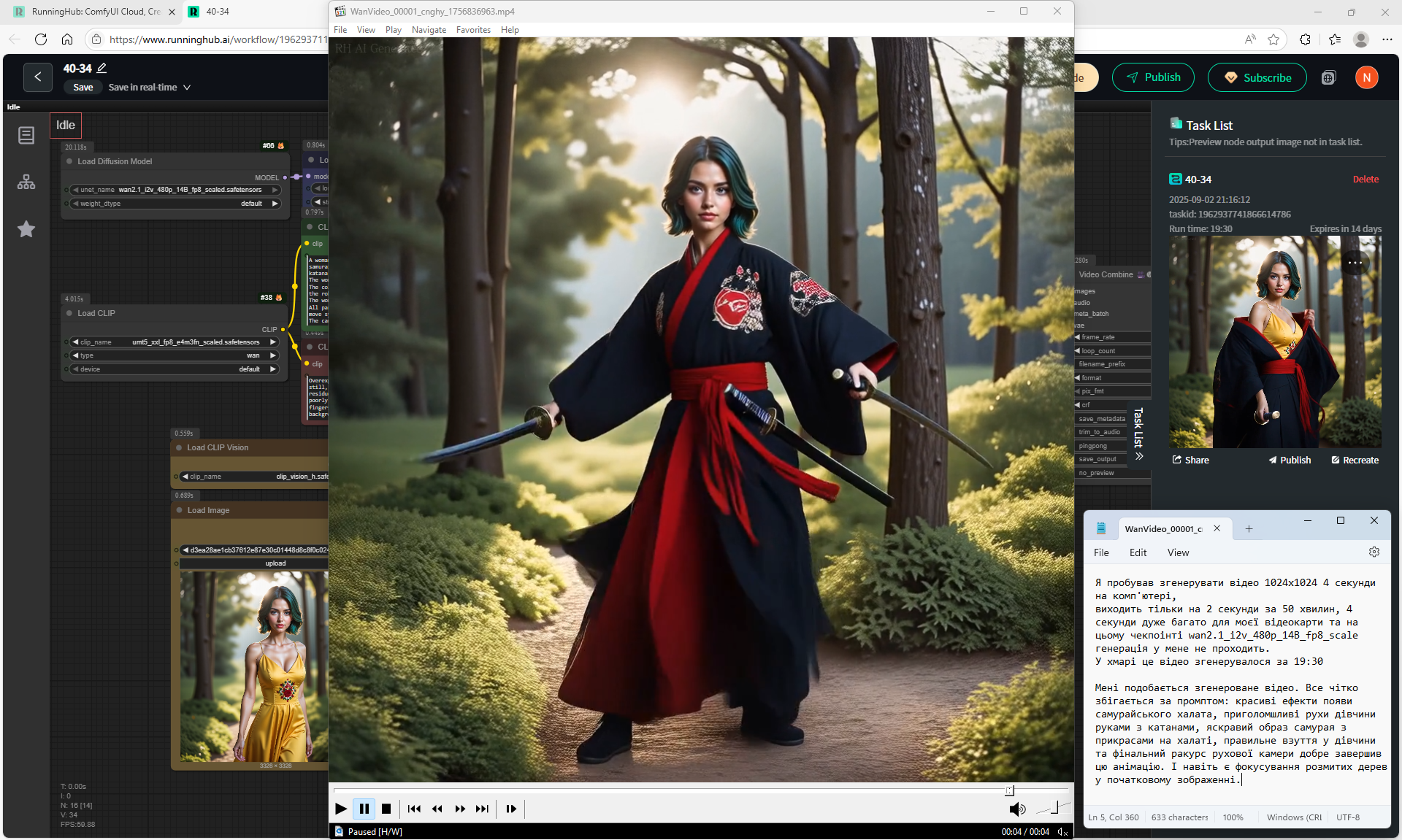
Almost successful animation of a woman transforming into a samurai. I moved the workflow to the cloud, generated this video at 1024x1024 size for 3 seconds, generated in 13:37.
The prompt understands well. There is a small bug when two hands animate together instead of one, one hand did not disappear, but the second one appeared. At a large size of 1024x1024, samurai clothes are added and animated, at a size of 640x640 there were options without changing clothes. On Wan2.1 14B 480p I2V this size of 1024x1024 is not recommended, but the animation in it turns out to be high-quality, but it takes a long time to generate and more than 2-3 seconds on my computer with such a size 1024x1024 on Wan2.1 14B 480p I2V does not generate.

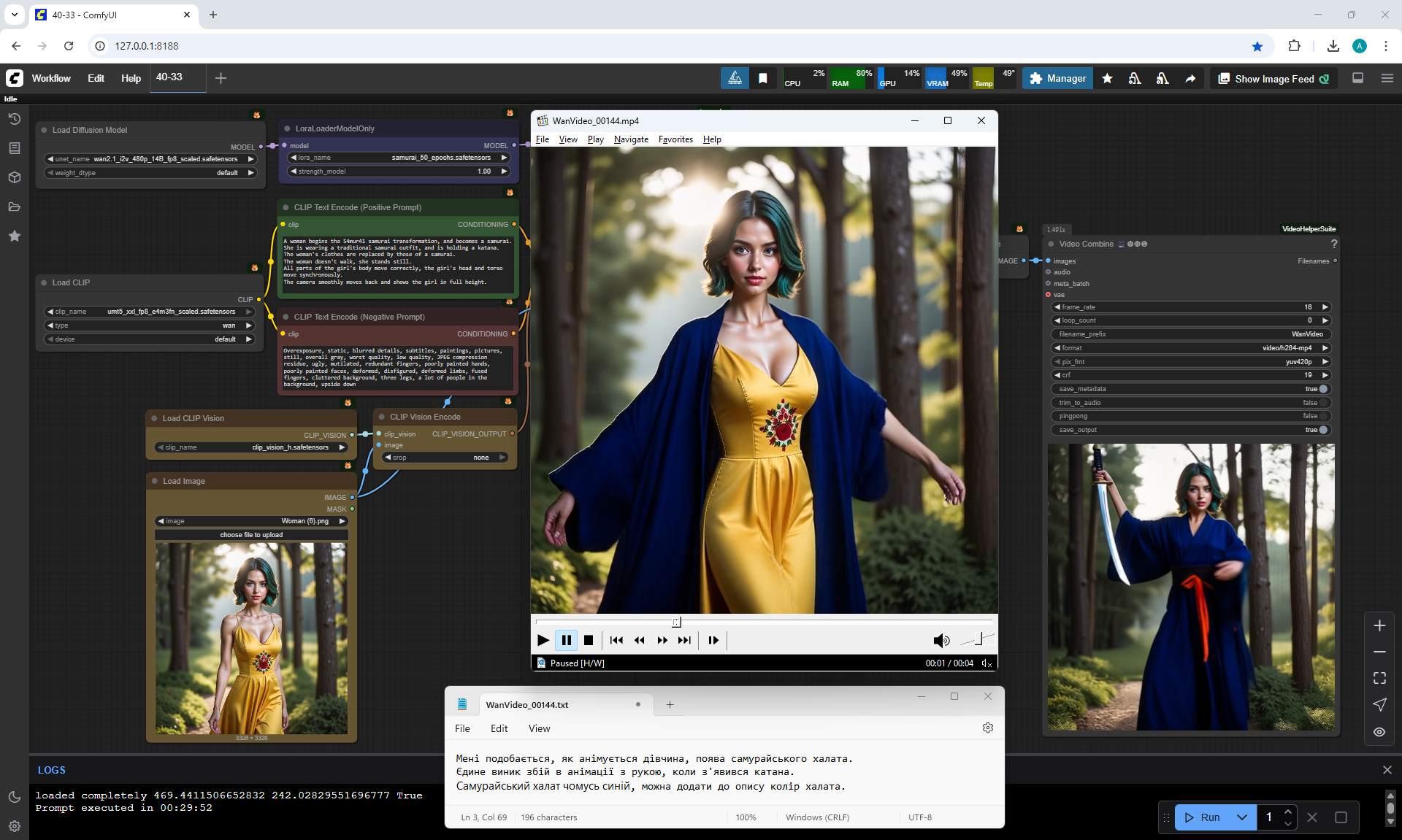
This animation is good.
I like the generated video. Everything clearly matches the prompt: beautiful effects of the appearance of the samurai robe, stunning movements of the girl's hands with katanas, a bright image of the samurai with decorations on the robe, the girl's correct shoes and the final angle of the moving camera completed this animation well. And there is even a focus on the blurred trees in the final frame.
I tried to generate a 1024x1024 4 second video on my computer,
at recommended requirements at 640x640
It only takes 2 seconds in 50 minutes, 4 seconds is too much for my video card at the wan2.1_i2v_480p_14B_fp8_scale checkpoint, the generation doesn't work for me, I need to generate in the cloud.
In the cloud, this video was generated in 19 minutes 30 seconds.
And although in the requirements Wan2.1-T2V-14B-480PIt is indicated that there is no 720P, I managed to generate successful animations at 1024x1024 for 3-4 seconds on this checkpoint in the cloud.
I have not tested the checkpoint Wan2.1-I2V-14B-720P, it is very demanding on the video card and RAM, it requires a lot, but it can be used in the cloud.